5 BAB II
TEKNIK KOMPRESI DATA
2.1 Pendahuluan
Kompresi data adalah proses pengkodean (encoding) informasi dengan menggunakan bit yang lebih sedikit dibandingkan dengan kode yang sebelumnya dipakai dengan menggunakan skema pengkodean tertentu. Kompresi data, terutama untuk proses komunikasi, dapat bekerja jika kedua pihak antara pengirim dan penerima data komunikasi memiliki skema pengkodean yang sama.
Kompresi data hanya mungkin untuk dilakukan apabila data yang direpresentasikan dalam berntuk normal mengandung informasi yang tidak dibutuhkan.
Ketika data tersebut sudah ditampilkan dalam format yang seminimal mungkin, maka data tersebut sudah tidak akan bisa dikompresi lagi. File yang demikian disebut dengan random file.
2.1.1 Kompresi Lossless
Kompresi data yang menghasilkan file data hasil kompresi yang dapat dikembalikan menjadi file data asli sebelum dikompresi secara utuh tanpa perubahan apapun. Kompresi data lossless bekerja dengan menemukan pola yang berulang di dalam pesan yang akan dikompres tersebut dan melakukan proses pengkodean pola tersebut secara efisien. Kompresi ini juga dapat berarti proses untuk mengurangi redundancy. Kompresi jenis ini ideal untuk kompresi teks.
Algoritma yang termasuk dalam metode kompresi lossless diantaranya adalah teknik dictionary coding dan huffman coding.
2.1.2 Kompresi Lossy
Kompresi data yang menghasilkan file data hasil kompresi yang tidak dapat dikembalikan menjadi file data sebelum dikompresi secara utuh. Ketika data
6 hasil kompresi di-decode kembali, data hasil decoding tersebut tidak dapat dikembalikan menjadi sama dengan data asli tetapi ada bagian data yang hilang.
Oleh karena itu kompresi jenis ini tidak baik untuk kompresi data yang kritis seperti data teks. Bentuk kompresi seperti ini sangat cocok untuk digunakan pada file-file gambar, suara, dan film. Contoh penggunaan kompresi lossless adalah pada format file JPEG, MP3, dan MPEG.
2.2 Teknik Dictionary Coding
Teknik dictionary coding adalah teknik kompresi yang dilakukan dengan cara mencari string yang sama di dalam dictionary buffer dan look-ahead buffer. Apabila ditemukan string yang sama, maka akan dikeluarkan sebuah token yang isinya mewakili informasi string tersebut. Karena ukuran token tersebut lebih kecil daripada ukuran string yang diwakilinya, maka akan terjadi kompresi.
Kompresi pada dictionary coding sangat tergantung pada data yang akan dikompresikan dan dictionary yang digunakan. Apabila pada data yang akan dikompresikan jarang ditemukan string yang sama dengan yang ada di dictionary, maka kinerja dari algoritma kompresinya terhadap data tersebut akan buruk. Sebaliknya, apabila pada data yang akan dikompresikan banyak string yang sama dengan string yang ada pada dictionary, maka kinerja algoritma kompresinya akan baik. Algoritma yang termasuk pada dictionary coding sebagian besar berasal dari keluarga algoritma Lempel-Ziv, seperti algoritma Lempel-Ziv Storer Szymanski (LZSS), algoritma Lempel-Ziv 78, dan algoritma Lempel-Ziv Welch. Ketiga algoritma tersebut akan dibahas pada subbab selanjutnya.
2.2.1 Algoritma Lempel-Ziv 77
Algoritma Lempel-Ziv 77 (LZ77) merupakan algoritma pertama dalam keluarga algoritma Lempel-Ziv. Ide utama dari algoritma ini adalah menggunakan sebagian dari input yang telah lewat sebagai dictionary, sehingga algoritma ini dapat dikatakan bekerja berdasarkan prinsip sliding window. Window bagian kiri
7 disebut dengan search buffer atau dictionary buffer, sedangkan window bagian kanan disebut dengan look-ahead buffer. Dictionary buffer menyimpan simbol- simbol yang baru saja dikodekan, sedangkan look-ahead buffer menyimpan simbol yang akan dikodekan. Pada tiap iterasi, algoritma akan mencari pada dictionary buffer substring (sepanjang mungkin) yang matching dengan prefix pada look-ahead buffer. Jika terjadi match, maka akan ditransmisikan triplet
<p,l,s>. P menujukkan posisi match pada dictionary buffer yang dihitung dari sisi kanan dictionary buffer. L menujukkan panjang match yang diperoleh, sedangkan s menunjukkan simbol pertama yang tidak match pada look-ahead buffer. Setelah token ditransmisikan, maka buffer akan digeser sebanyak jumlah match yang terjadi. Contoh operasi algoritma LZSS dapat dilihat pada gambar 2.1.
Data: “sir sid eastman easily teases sea sick seals”
Gambar 2.1. Contoh proses encoding algoritma LZ77 [1].
Gambar 2.1 dapat dijelaskan sebagai berikut:
Pertama, input mengisi look-ahead buffer sampai penuh. Karena karakter pertama dari look-ahead buffer tidak memiliki match, maka akan dikeluarkan token <0,0,”s”>. Selanjutnya, karena karakter yang dikodekan berjumlah satu buah, maka buffer akan digeser sepanjang satu karakter ke kiri.
Selanjutnya, dapat kita lihat bahwa karakter “i” juga tidak memiliki macth, sehingga akan dikeluarkan token <0,0,”i”>.
Karena input yang dikodekan berjumlah satu buah, buffer kembali digeser sebanyak satu karakter ke kiri.
8
Keadaan ketiga dan keadaan keempat masih sama seperti pada keadaan pertama dan kedua. Dengan demikian, akan dikeluarkan token <0,0,”r”> dan token <0,0,” “> untuk kedua keadaan tersebut.
Pada keadaan kelima barulah terjadi macth yaitu antara string “si”
pada dictionary buffer dengan pada look-ahead buffer, sehingga token yang dikeluarkan adalah <4,1,”e”>. Pada keadaan ini, setelah mengeluarkan token, maka input akan digeser sebanyak jumlah karakter yang macth, yaitu sebesar dua karakter.
Selanjutnya, terjadi macth antara sesama karakter spasi pada dictionary buffer dengan pada look-ahead buffer. Karena terjadi macth, maka akan dikeluarkan token <4,1,”e”>. Setelah itu, input akan digeser sebanyak jumlah karakter macth, yaitu satu buah.
Algoritma LZ77 memiliki suatu kekurangan yaitu selalu mengkodekan dengan menggunakan token yang berisi triplet. Kekurangan inilah yang menjadi salah satu hal yang diperbaiki oleh algoritma LZSS sehingga algoritma LZSS dapat menghasilkan rasio kompresi yang lebih baik daripada algoritma LZ77.
2.2.2 Algoritma Lempel Ziv Storer Szymanski
Seperti yang telah dijelaskan sebelumnya, algoritma Lempel-Ziv Storer Szymanski ini merupakan perbaikan dari algoritma LZ77. Algoritma ini dikembangkan oleh Storer dan Szymaski pada tahun1982 [3]. Pseudocode dari algoritma LZSS dapat dilihat pada gambar 2.1. Secara umum konsep dasarnya masih sama dengan algoritma LZ77, yaitu menggunakan dua buffer yang diisi oleh input berdasarkan metode sliding window. Perbedaan antara LZSS dengan LZ77 terletak pada tiga hal berikut:
Menggunakan circular queue untuk menyimpan look-ahead buffer.
Menyimpan dictionary buffer di dalam suatu pohon biner.
Menggunakan dua jenis token, yaitu yang memiliki dua field dan yang memiliki tiga field.
9
Gambar 2.2. Pseudocode algoritma LZSS [8].
2.2.2.1 Perbedaan LZSS Dengan Algoritma LZ77 2.2.1.1.1 Penggunaan Circular queue
Circular queue adalah sebuah struktur basis data. Secara fisik, circular queue adalah suatu array tetapi memiliki cara penggunaan yang khusus. Gambar 2.2 memberikan ilustrasi singkat tentang circular queue. Gambar tersebut menunjukkan sebuah array 16-byte yang dibangun dengan cara menambahkan karakter pada akhir array, dan menghapus karakter yang berada pada awal array. Posisi awal dan akhir pada circular queue selalu bergeser dari kanan ke kiri dan selalu ditunjukkan dengan s dan e.
Pada (a), terdapat 8 karakter sid_east, sisanya kosong. Pada (b), semua slot pada buffer terisi dan e menunjukkan akhir dari buffer.
Pada (c), huruf pertama (huruf s) telah dihapus dan posisinya ditempati oleh huruf sebelahnya (huruf i). Penggunaan circular queue ini sebenarnya bertujuan untuk mempercepat proses encoding, karena dengan digunakannya circular queue maka isi dari look-ahead buffer tidak perlu untuk di geser satu persatu.
10
Gambar 2.3. Circular queueI [1] .
2.2.2.1.2 Penggunaan Binary-Search Tree
Binary-search tree adalah sebuah pohon biner yang cabang sebelah kiri dari node A memiliki nilai yang lebih kecil dari node A, sedangkan cabang sebelah kanan memiliki nilai yang lebih besar daripada node A. Untuk membandingkan antara satu string dengan yang lainnya digunakan prinsip lexicographic order, yaitu berdasarkan kemunculan string tersebut pada alfabet. Sebagai contoh, string “dana” memiliki nilai lebih kecil daripada “dara”, karena huruf ketiga (“n”) dari kata dana muncul lebih dulu daripada huruf ketiga dari kata dari (“r”). Karakter spasi memiliki nilai yang lebih kecil daripada alfabet, sedangkan angka diletakkan setelah alfabet. Contoh sebuah binary-search tree dapat dilihat pada gambar 2.3.
Gambar 2.4. Gambar adalah sebuah binary-search tree [1].
2.2.2.1.3 Perbedaan Dalam Penggunaan Token
Algoritma LZSS menggunakan dua jenis token, yaitu:
11
Token yang terdiri dari pasangan byte <1,s>.
Token yang terdiri dari triplet <0,p,l>.
Variabel S adalah simbol pertama pada look-ahead buffer yang tidak match. Variabel P adalah posisi match yang ditemukan pada dictionary buffer, sedangkan variabel L adalah panjang match yang ditemukan. Bit 1 dan 0 pada awal token berfungsi layaknya sebuah flag.
Token jenis pertama akan dikeluarkan apabila tidak terjadi match antara dictionary buffer dengan look-ahead buffer, sedangkan token kedua akan dikelarkan apabila terjadi match antara dictionary buffer dengan look-ahead bufer. Token kedua akan lebih sering digunakan jika dalam proses pengkodean sering ditemukan match.
Penggunaan dua jenis token ini adalah salah satu konsep yang membuat kompresi algoritma LZSS lebih baik daripada kompresi algoritma LZ77. Hal ini terjadi karena algoritma LZSS hanya mengeluarkan token dengan 2 karakter ketika tidak terjadi match, sedangkan algoritma LZ77, seperti yang telah dijelaskan sebelumnya, tetap mengeluarkan token dengan tiga karakter ketika tidak terjadi match.
2.2.2.2 Contoh Kasus Operasi Algoritma LZSS
Contoh proses pengkodean menggunakan algoritma LZSS dapat kita lihat pada tabel II-1.
12 Data: “aababacbaacbaadaaa”
Tabel II-1. Proses pengkodean LZSS [8].
Input Buffer (search__look-ahead) Output aababacbaacbaadaaa aaaa 1a aababacbaacbaadaaa aaaa aaba 002
babacbaacbaadaaa aaaa baba 1b
abacbaacbaadaaa aaab abac 022
acbaacbaadaaa abab acba 1a
cbaacbaadaaa baba cbaa 1c
baacbaadaaa abac baac 012
acbaadaaa acba acba 004
adaaa acba adaa 1a
daaa cbaa daaa 1d
aaa baad aaa 012
a adaa a 1a
Pada contoh di atas, besarnya buffer (dictionary buffer dan look- ahead buffer) adalah 8 bit. Proses yang terjadi adalah:
Ketika awal pembacaan data, buffer diisikan dengan karakter awal yang diduplikasikan. Karena belum ada data pada dictionary buffer yang bisa dijadikan referensi, maka output dari encoder adalah karakter yang digunakan untuk inisialisasi dictionary buffer tersebut.
Selanjutnya masukkan 4 bit awal dari data, yaitu string
“aaba”, ke look-ahead buffer. Encoder akan mencari data pada dictionary buffer yang sama dengan bit awal dari string pada look-ahead buffer. Maka encoder akan mencari string terpanjang pada dictionary buffer yang bit awalnya sama dengan bit awal string pada look-ahead buffer. Maka encoder akan menemukan string “aa”. Output dari encoder adalah 022.
13
Selanjutnya, buffer akan digeser ke kiri sepanjang string yang sama. Dalam contoh, buffer digeser ke kiri sebanyak 2 bit.
Pada keadaan selanjutnya, karena pada dictionary buffer tidak ada karakter b, maka encoder akan mengeluarkan token 1b. dictionary buffer akan digeser satu bit ke kiri.
Dst.
2.2.3 Algoritma Lempel-Ziv 78
Algoritma ini merupakan algoritma ketiga yang muncul dalam keluarga algoritma Lempel-Ziv. Berbeda dengan dua algoritma Lempel-Ziv sebelumnya, algoritma ini tidak lagi menggunakan search buffer dan look-ahead buffer yang digunakan secara sliding window, melainkan menggunakan suatu dictionary yang dibangun dari string-string yang telah dokodekan sebelumnya. Output hasil encoding-nya selalu berupa token yang berisi pasangan byte. Untuk simbol yang belum ada di dictionary maka akan dikeluarkan token <0,s>. Ketika mengkodekan simbol/string yang sudah ada di dictionary , maka algoritma akan memperpanjang input yang akan dikodekan satu per satu karakter sampai menjadi string yang belum ada pada dictionary. Pada keadaan ini akan dikeluarkan token <p,s>, dengan p menunjukkan posisi suatu simbol/string tersebut dalam dictionary dan s menunjukkan simbol pertama yang membedakan string baru yang lebih panjang tersebut dengan simbol/string pada posisi p di dictionary. Contoh operasi algoritma LZ78 dapat dilihat pada gambar 2.4.
Data: “aababacbaacbaadaaa”
14
Gambar 2.5. Contoh operasi algoritma LZ78 [8].
Gambar 2.4 dapat dijelaskan sebagai berikut:
Pertama kali, karena dictionary masih kosong, maka simbol pertama yang datang akan dikode dengan token <0,s>. Karena simbol pertama adalah huruf a, maka akan dikeluarkan token <0,a>
dan encoder akan memasukkan huruf a ke dalam dictionarydengan indeks 1.
Selanjutnya, data yang akan dikodekan bergeser ke huruf a yang kedua. Karena sudah ada huruf a sebelumnya, maka akan dikeluarkan token 1. Tetapi proses tidak berlangsung sampai disana. Ketika simbol/string yang akan dikodekan sudah ada di dalam dictionary, maka algoritma akan terus memperpanjang string tersebut sampai menjadi string pertama yang belum ada di dictionary. Pada contoh di atas, karena string “ab” belum ada pada dictionary, maka algoritma akan mengkodekan input sampai bagian tersebut. Dengan demikian, token <1,b> akan dikeluarkan yang mewakili suatu string yang tersusun atas isi dari dictionary dengan indeks 1 diikuti dengan huruf b. Pada saat yang sama,
15 karena string “ab” belum ada di dictionary, maka string tersebut akan ditambahkan pada dictionary dengan indeks 2.
Pada keadaan ketiga ini encoder akan membaca simbol keempat, yaitu huruf a. Namun, karena huruf a ini sudah ada pada dictionary, maka encoder akan memperpanjang menjadi string
“ab”. Sama seperti sebelumnya, karena string “ab” merupakan salah satu entry pada dictionary, maka encoder akan kembali memerpanjang deretan string yang akan dikodekan menjadi “aba”.
Karena string ini belum ada di dictionary, maka encoder akan menambahkan string ini ke dalam dictionary dengan indeks 3.
Token yang dikeluarkan adalah <2,a>. Angka 2 pada token menujukkan string “ab”, sedangkan huruf a mewakili huruf a tambahan setelah string pada indeks 2 di dictionary.
Selanjutnya, encoder akan membaca simbol c. Karena simbol tersebut belum ada pada dictionary, maka akan dikodekan dengan token <0,c> dan huruf c akan dimasukkan ke dalam dictionary dengan indeks 4.
Pada keadaan kelima ini, encoder akan membaca huruf b. Karena huruf b belum ada pada dictionary, maka akan dikeluarkan token
<0,b> dan huruf b tersebut akan dimasukkan ke dalam dictionary dengan indeks 5.
Selanjutnya, encoder akan membaca huruf a. Karena huruf a sudah ada di dictionary, maka encoder akan terus membaca input sehingga akan terbaca string “aa”. Karena string tersebut belum ada di dictionary, maka encoder akan menambahkan string tersebut ke dalam dictionary dengan indeks 6, dan mengeluarkan token <1,a>.
Selanjutnya, encoder akan membaca huruf c. Karena huruf c sudah ada di dictionary, maka encoder akan memperpanjang string
16 sampai terbaca string “cb”. Dengan demikian, maka akan dikeluarkan token <4,b>. Angka 4 mewakili huruf c yang menempati indeks 4 pada dictionary, sedangkan huruf b pada token menujukkan adalah huruf b tambahan yang mengikuti huruf c.
Selanjutnya, encoder akan membaca huruf a. Karena huruf a sudah ada pada dicitonary, maka encoder akan memperpanjang string yang dibacanya sehingga menjadi “aa”. Namun, karena string “aa”
tersebut juga ada pada dictionary, maka encoder akan memperpanjang lagi sehingga string yang terbaca adalah “aad”.
Karena string ini belum ada pada dictionary, maka encoder akan berhenti membaca dan mengkodekan string ini dengan token
<6,d>. Angka 6 mewakili indeks tempat string “aa” pada dictionary, sedangkan huruf d merupakan huruf d yang mengikuti string “aa” sehingga string yang terbaca adalah string “aad”.
Keadaan selanjutnya sama seperti proses ini.
2.2.4 Algoritma Lempel-Ziv Welch
Algoritma ini merupakan perbaikan dari algoritma LZ78 yang diajukan oleh Terry Welch pada tahun 1984 [1]. Prinsip kerja algoritma ini sebagian besar sama dengan algoritma LZ78. Perbaikan yang dilakukan adalah mengurangi output encoder dari pasangan ke bilangan tunggal. Pseudocode algoritma LZW dapat dilihat pada gambar 2.5.
17
Gambar 2.6. Pseudocode algoritma LZW [8].
Contoh operasi algoritma LZW dapat dilihat pada tabel II-2.
Data: “aababacbaacbaadaaa”
Tabel II-2. Contoh proses encoding algoritma LZW [8].
encoder dictionary input output indeks entry
1 a
2 b
3 c
4 d
aa 1 5 aa
ab 1 6 ab
ba 2 7 ba
aba 6 8 aba
ac 1 9 ac
cb 3 10 cb
baa 7 11 baa
acb 9 12 acb
baad 11 13 baad
da 4 14 da
aaa 5 15 aaa
Proses encoding pada tabel II-2 dapat dijelaskan sebagai berikut:
18
Pertama encoder akan mengisi dictionary dengan semua simbol yang ada pada data input.
Selanjutnya, encoder akan mengkodekan huruf a. Namun, karena huruf a telah ada di dalam dictionary, maka encoder akan mencoba mengkodekan lebih banyak lagi sehingga akan terbaca string “aa”.
Karena string “aa” ini tidak ada di dalam dictionary, maka encoder akan menambahkan string tersebut, dan mengeluarkan output token 1 untuk mengkodekan huruf a.
Lalu, encoder akan mengkodekan huruf a yang kedua. Namun, karena huruf a telah ada di dalam dictionary, maka encoder akan mencoba mengkodekan lebih banyak lagi sehingga akan terbaca string “ab”. Karena string tersebut belumada di dictionary, maka encoder akan menambahkan string tersebut. Encoder akan mengeluarkan output token 1 lagi untuk huruf a yang kedua.
Selanjutnya, encoder akan mengkodekan huruf b. Namun, karena huruf b ada di dalam dictionary, maka encoder akan memperpanjang string yang akan dikodekannya menjadi string
“ba”. Karena string tersebut belum ada pada dictionary, maka encoder akan menambahkannya. Encoder juga akan mengeluarkan token 2 untuk mewakili huruf b.
Selanjutnya, encoder akan mengkodekan huruf a. Namun, karena huruf b ada di dalam dictionary, maka encoder akan memperpanjang string yang akan dikodekannya menjadi string
“ab”. Selanjutnya, karena string “ab” juga ada di dalam dictionary, maka encoder akan memperpanjang string yang akan dikodekannya menjadi string “aba”. Karena string tersebut tidak ada pada dictionary, maka encoder akan menambahkannya, dan akan mengeluarkan token 6 yang mewakili string “ab”.
19
Selanjutnya encoder akan mengkodekan huruf a. Namun, karena huruf a ada di dalam dictionary, maka encoder akan memperpanjang string yang akan dikodekannya menjadi string
“ac”. Karena string “ac” belum ada pada dictionary, maka encoder akan menambahkan string tersebut ke dalam dictionary, sekaligus mengeluarkan token 1 untuk mewakili huruf a yang dikodekannya.
Selanjutnya encoder akan mengkodekan huruf c. Karena string selanjutnya tidak ada yang sama dengan string-string pada dictionary, maka encoder akan mengeluarkan token 3 yang mewakili huruf c saja. Pada saat yang sama, encoder juga akan membaca string “cb” dan akan menambahkan string tersebut ke dalam dictionary.
Selanjutnya, encoder akan mengkodekan huruf b. Namun, karena huruf b sudah ada pada dictionary, maka encoder akan memperpanjang string yang akan dikodekan menjadi “ba”. Setelah itu, karena string “ba” tersebut ada dalam dictionary, maka encoder akan mencoba memperpanjang string yang akan dikodekannya. Namun tidak ditemukan lagi string yang sama dengan dictionary, sehingga encoder hanya akan mengkodekan string “ba” dengan token 7. Pada saat yang sama, encoder juga akan menambahkan string “baa” ke dalam dictionary.
Selanjutnya, encoder akan mengkodekan huruf a. Namun, karena huruf a ada dalam dictionary, maka encoder akan memperpanjang string yang akan dikodekannya menjadi string “ac”. Setelah itu, karena string “ac” juga ada pada dictionary, maka encoder akan membaca lebih lanjut lagi menjadi string “acb”. Karena “acb”
tidak ada di dictionar y, maka encoder akan menambahkan string tersebut dan mengeluarkan token 9 untuk mewakili string “ac”.
Dst.
20 2.3 Huffman Coding
Algoritma ini akan dibahas pada Tugas akhir ini karena algoritma ini merupakan algoritma yang digunakan oleh salah satu program kompresi untuk benchmarking algoritma LZSS. Dalam Huffman coding, panjang blok dari keluaran sumber dipetakan dalam blok biner berdasarkan panjang variabel. Cara seperti ini disebut sebagai fixed to variable-length coding. Ide dasar dari cara Huffman ini adalah memetakan mulai simbol yang paling banyak terdapat pada sebuah urutan sumber sampai dengan yang jarang muncul menjadi urutan biner. Dalam variable-length coding, sinkronisasi merupakan suatu masalah. Ini berarti harus terdapat satu cara untuk memecahkan urutan biner yang diterima kedalam suatu codeword.
Seperti yang disebutkan diatas, bahwa ide dari Huffman Coding dalam memilih panjang codeword dari yang paling besar probabilitasnya sampai dengan urutan codeword yang paling kecil probabilitasnya. Apabila kita dapat memetakan setiap keluaran sumber dari probabiltas p ke sebuah codeword dengan panjang 1/p dan pada saat yang bersamaan dapat memastikan bahwa dapat decode kembali secara unik, kita dapat mencari rata-rata panjang kode H(x). Huffman Code dapat mendekodekan secara unik dengan H(x) minimum, dan optimum pada keunikan dari kode-kode tersebut. Algoritma dari Huffman coding adalah :
1. Pengurutan keluaran sumber dimulai dari probabilitas paling tinggi.
2. Menggabungkan 2 keluaran yang sama dekat kedalam satu keluaran yang probabilitasnya merupakan jumlah dari probabilitas sebelumnya.
3. Apabila setelah dibagi masih terdapat 2 keluaran, maka lanjut kelangkah berikutnya, namun apabila masih terdapat lebih dari 2, kembali ke langkah 1.
4. Memberikan nilai 0 dan 1 untuk kedua keluaran
5. Apabila sebuah keluaran merupakan hasil dari penggabungan 2 keluaran dari langkah sebelumnya, maka berikan tanda 0 dan 1 untuk codeword-nya, ulangi sampai keluaran merupakan satu keluaran yang berdiri sendiri.
21 Contoh penggunaan algoritma Huffman coding adalah:
Jika kita memiliki kalimat: “example of huffman coding”, maka hal pertama yang harus dilakukan adalah menghitung probabilitas dari tiap-tiap simbol. Hasilnya dapat diilhat pada tabel II-3.
Tabel II-3. Hasil perhitungan peluang kemunculan simbol.
Simbol Probabilitas
e 2/25
x 1/25
a 2/25
m 2/25
p 1/25
l 1/25
"spasi" 3/25
o 2/25
f 2/25
h 1/25
u 1/25
c 1/25
d 1/25
i 1/25
n 2/25
g 1/25
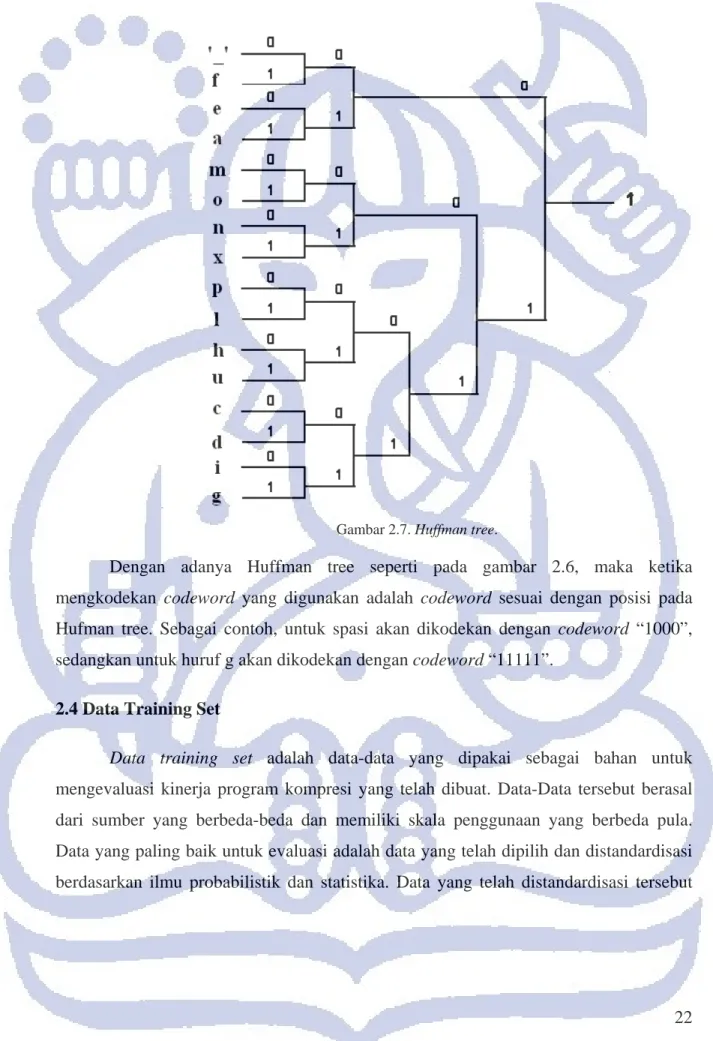
Dengan melakukan prosedur sesuai dengan algoritma Huffman, maka akan didapatkan Huffman tree sebagai berikut:
22
Gambar 2.7. Huffman tree.
Dengan adanya Huffman tree seperti pada gambar 2.6, maka ketika mengkodekan codeword yang digunakan adalah codeword sesuai dengan posisi pada Hufman tree. Sebagai contoh, untuk spasi akan dikodekan dengan codeword “1000”, sedangkan untuk huruf g akan dikodekan dengan codeword “11111”.
2.4 Data Training Set
Data training set adalah data-data yang dipakai sebagai bahan untuk mengevaluasi kinerja program kompresi yang telah dibuat. Data-Data tersebut berasal dari sumber yang berbeda-beda dan memiliki skala penggunaan yang berbeda pula.
Data yang paling baik untuk evaluasi adalah data yang telah dipilih dan distandardisasi berdasarkan ilmu probabilistik dan statistika. Data yang telah distandardisasi tersebut
23 akan menghasilkan keluaran yang lebih merepresentasikan kinerja suatu algoritma kompresi terhadap bentuk data yang banyak digunakan secara umum.
2.4.1 Corpus
Corpus adalah kumpulan data standar yang digunakan dalam melakukan evaluasi terhadap suatu kompresi lossless secara empiris. Corpus diperlukan untuk memberikan bukti secara riil terhadap hasil analitis. Sebagai contoh, secara analitis algoritma LZ78 memberikan kompresi yang sangat baik untuk input yang banyak, tetapi dalam situasi praktis, kebanyakan file terlalu kecil, sehingga ketika dikompresi menggunakan LZ78 tidak memberikan hasil yang optimal.
Menurut [4] cara terbaik untuk mengevaluasi suatu kompresi adalah dengan mengevaluasi setiap kemungkinan input dan mencatat keluaran input tersebut. Tetapi cara ini tidak mungkin untuk dilakukan karena memerlukan sistem komputasi yang banyak. Cara yang paling optimal dalam mengevaluasi suatu kompresi adalah dengan mengujikan data-data yang paling mungkin digunakan. Hal tersebutlah yang mendasari pembentukan suatu Corpus. Selain hal di atas, yang mendasari pembuatan Corpus adalah karena pada masa sebelum dibuatnya Corpus, kebanyakan orang menggunakan data milik pribadinya untuk mengevaluasi suatu algoritma kompresi. Menurut penulis hal ini memberikan hasil yang kurang objektif karena bisa saja data tersebut telah dimanipulasi untuk bekerja optimal menggunakan suatu algoritma kompresi tertentu.
2.4.1.1 Calgary Corpus
Calgary Corpus adalah Corpus pertama yang dibuat. Calgary Corpus dikembangkan pada tahun 1980an, dan menjadi standar de facto pengujian kompresi pada tahun 1990an [5].
Data yang digunakan dalam Calgary Corpus lebih terdiri dari beberapa file teks sederhana, file gambar, dan beberapa source code program. Isi dari Calgary Corpus dapat dilihat pada table II-2.
24 Calgary Corpus dianggap sudah kadaluarsa karena data yang digunakan oleh Corpus tersebut sudah tidak sesuai lagi dengan data-data yang banyak dipakai saat ini. Sebagai contoh, saat ini banyak sekali file-file html yang digunakan dalam membentuk suatu situs web, tetapi file bentuk html tersebut tidak ada dalam Calgary Corpus. Alasan inilah yang mendasari dikembangkannya Corpus baru pada awal tahun 1997 yang diberi nama Canterbury Corpus. Meskipun demikian, Calgary Corpus tetap saja masih sering digunakan sebagai tambahan data acuan untuk benchmarking kinerja suatu algoritma kompresi.
Tabel II-4. Daftar file Calgary Corpus
File Akronim Kategori Ukuran (byte)
obj1 obj1 Object code for VAX 21504
progc progc Source code in "C" 39611 progp progp Source code in PASCAL 49379
paper1 paper1 Technical paper 53161
progl progl Source code in LISP 71646
paper2 paper2 Technical paper 82199
trans trans Transcript of terminal session 93695
geo geo Geophysical data 102400
bib bib Bibliography (refer format) 111261 obj2 obj2 Object code for Apple Mac 246814
news news USENET batch file 377109
pic pic Black and white fax picture 513216 book2 book2 Non‐fiction book (troff format) 610856
book1 book1 Fiction book 768771
Total 3141622
25 2.4.1.2 Canterbury Corpus
Seperti yang telah dijelaskan sebelumnya, Canterbury Corpus merupakan pengganti dari Calgary Corpus yang dianggap sudah kadaluarsa. Data-Data yang digunakan dalam Canterbury Corpus adalah data-data kontemporer yang sering dipakai di masa sekarang. Data-Data yang digunakan dalam Canterbury Corpus dalam kita lihat pada tabel II-3.
Penjelasan tentang pemilihan data-data yang digunakan dalam Canterbury Corpus dijelaskan dalam [4].
Tabel II-5. File-File yang digunakan dalam Canterbury Corpus.
File Akronim Kategori Ukuran (byte)
alice29.txt text English text 152089
asyoulik.txt play Shakespeare 125179
cp.html html HTML source 24603
fields.c Csrc C source 11150
grammar.lsp list LISP source 3721
kennedy.xls Excl Excel Spreadsheet 1029744 lcet10.txt tech Technical writing 426754
plrabn12.txt poem Poetry 481861
ptt5 fax CCITT test set 513216
sum SPRC SPARC Executable 38240
xargs.1 man GNU manual page 4227
Total 2810784
2.4.3 Data Dari Archieve Comparison Test
Archieve Comparison Test (ACT) [6] adalah suatu situs web yang menyediakan data-data benchmarking beberapa program kompresi yang populer digunakan. Data-Data ini merupakan suatu kumpulan dari hasil riset yang dilakukan oleh seorang Doktor yang bernama Jeff Gilchrist dari Universitas Carleton, Ottawa, Kanada. Bahan-Bahan yang digunakan diantaranya adalah:
• Corpus Calgary.
• Corpus Canterbury.
26
• File teks yang telah distandardisasi menurut ACT.
• File gambar yang telah distandardisasi ACT.
Di bawah ini akan dibahas tentang data-data acuan yang digunakan yang belum dibahas sebelumnya dalam Tugas Akhir ini.
2.4.3.1 Kompresi Teks
Data ini adalah data yang dipakai untuk kompresi teks pada [6], yang terdiri dari tiga buah file teks. Atribut data tersebut dapat kita lihat selengkapnya pada tabel II-4.
Tabel II-6. File benchmarking teks yang digunakan ACT
File Akronim Isi File Ukuran (byte)
1musk10.txt musk The Three Musketeers 1344739 anne11.txt anne Anne of Green Gables 586390 world95.txt world CIA World Fact Book 2988578
Total 4919707
2.4.3.2 Kompresi TIFF
Data ini adalah data yang dipakai oleh ACT untuk benchmarking program kompresi terhadap gambar-gambar yang berekstensi .TIFF. Atribut lengkap dari file gambar yang digunakan dapat kita lihat pada tabel II-5, sedangkan isi file tersebut dapat kita lihat pada gambar 2.5-2.12.
Tabel II-7. Atribut file gambar yang digunakan oleh ACT File Ukuran Hasil Kompresi Rasio
clegg.tiff 1749650 1963137 112.2017
frymire 3706306 566383 15.2816
lena 786568 852639 108.3999
monarch 1179784 1022627 86.67917
peppers 786568 798470 101.5132
sail 1179784 1149924 97.46903
serrano 1498414 233356 15.57353
tulips 1179784 1177853 99.83633
Total 12066858 7764389 64.34474
27
Gambar 2.8. Clegg.TIFF [6].
Gambar 2.9. Frymire.TIFF [6].
Gambar 2.10 Lena.TIFF [6].
Gambar 2.11. Monarch.TIFF [6].
Gambar 2.12. Peppers.TIFF [6].
Gambar 2.13. Sail.TIFF [6].
28
Gambar 2.14. Serrano.TIFF [6]. Gambar 2.15. Tulips.TIFF [6].
2.3.4 Data Milik Penulis
Selain data-data yang telah disebutkan di atas, penulis juga menggunakan beberapa data milik penulis. Tujuannya adalah untuk mengevaluasi kinerja algoritma LZSS secara spesifik untuk melakukan kompresi data-data yang telah penulis kelompokkan.
2.3.4.1 File Teks
File teks milik penulis yang akan digunakan di dalam Tugas Akhir ini telah penulis standarkan dalam format Microsoft Word. File-File yang memiliki format selain format Word telah penulis konversikan terlebih dahulu.
Selanjutnya, file-file tersebut penulis kelompokkan berdasarkan isinya. Kelompok-Kelompok tersebut adalah:
Buku teknik.
Buku non-teknik.
Artikel bahasa Indonesia.
Kelompok buku teknik memiliki ciri-ciri sebagai berikut:
Ukuran file besar.
Frekuensi kemunculan gambar tinggi.
29
Menggunakan bahasa Inggris.
Kelompok buku non-teknik memiliki ciri-ciri sebagai berikut:
Ukuran file lebih kecil daripada buku teknik.
Frekuensi kemunculan gambar rendah.
Menggunakan bahasa Inggris.
Kelompok artikel bahasa Indonesia memiliki ciri sebagai berikut:
Ukuran file relatif sedang.
Frekuensi kemunculan gambar lebih kecil dari buku teknik tetapi lebih besar dari buku non-teknik.
Menggunakan bahasa Indonesia.
2.3.4.2 File Gambar
File gambar yang penulis gunakan dalam Tugas Akhir ini memiliki format yang sama. Hal ini penulis lakukan agar perlakuan algoritma LZSS terhadap semua file sama sehinga evaluasi untuk mengetahui jenis file gambar yang memberikan kompresi yang optimal oleh algortma LZSS dapat dilakukan.
File-File gambar yang penulis gunakan tidak penulis kelompokkan.
Melakukan pengelompokkan file gambar secara gamblang berdasarkan ciri tertentu tidak memungkinkan untuk penulis lakukan karena kesamaan karakteristik pada file gambar sangat sulit untuk ditemukan.
2.4 Program Kompresi Existing
Pada Tugas Akhir ini, benchmarking kinerja algoritma LZSS dilakukan terhadap beberapa program kompresi yang banyak digunakan secara luas di masyarakat.
Selanjutnya akan dijelaskan lebih jauh tentang program-program kompresi yang digunakan pada Tugas Akhir ini.
30 2.5.1 WinZip
WinZip adalah salah satu program kompresi yang banyak digunakan secara luas di masyarakat. Program ini dikembangkan oleh Nico Mak pada tahun 1998. Winzip dapat berkerja di lingkungan sistem operasi Microsoft Windows maupun Apple Macintosh. File-File hasil kompresi WinZip memiliki ekstensi .ZIP.
Ketika melakukan kompresi, program WinZip menggunakan empat buah algoritma yang digunakan secara kaskade. Algoritma tersebut adalah LZH, LZW, Shannon-Fano, dan Huffman Coding.
Pada Tugas Akhir ini, program WinZip bukanlah program yang dijadikan pembanding utama, melainkan hanya diikut sertakan sebagai bahan pertimbangan tambahan.
2.5.2 WinRAR
WinRAR adalah sebuah program kompresi yang dapat digunakan di lingkungan sistem operasi Microsoft Windows maupun UNIX. Program ini dibuat oleh Eugene Roshal pada tahun 1993. Untuk melakukan kompresinya, WinRAR menggunakan algoritma kompresi LZ77 dan Huffman Coding secara kascade.
Pada Tugas Akhir ini, program WinRAR bukanlah program yang dijadikan pembanding utama, melainkan hanya diikut sertakan sebagai bahan pertimbangan tambahan.
2.5.3 Compress
Compress adalah program kompresi yang menggunakan algoritma kompresi LZC, yaitu sebuah modifikasi algoritma LZW yang menggunakan pointer yang besarnya berubah-ubah. Algoritma yang digunakan dalam program ini telah dipatenkan pada tahun 1983 oleh Sperry Research Center. Program ini biasanya digunakan untuk mengopresi file-file tar pada lingkungan sistem operasi UNIX. File hasil kompresi menggunakan Compress memiliki ekstensi .Z.
31 Program Compress ini merupakan program pembanding utama karena sama-sama menggunakan satu jenis kompresi seperti program LZSS yang penulis gunakan.
2.5.4 Gzip
Gzip adalah suatu program kompresi yang dirancang untuk menggantikan program kompresi Compress. Kelebihan Gzip dibandingkan dengan Compress adalah dalam kinerja kompresinya dan tidak menggunakan algoritma yang telah dipatenkan. Gzip dikembangkan oleh duet Jean-loup Gailly dan Mark Adler pada tahun 1993. File hasil kompresi menggunakan Gzip memiliki ektensi .GZ. Gzip lebih banyak digunakan dalam lingkungan sistem operasi UNIX dan varian- variannya untuk mengopresi file-file tar.
Program Gzip menggunakan dua buah algoritma kompresi, yaitu algoritma Shannon-Fano dan Huffman Coding.
2.5.5 Prediction by Partial Matching
Prediction by Partial Matching (PPM/PPMC) adalah sebuah teknik adaptive statistical data compression yang berdasarkan pada context modelling dan teknik prediksi. Model PPM menggunakan seperangkat simbol pada deretan simbol yang belum dikompresi untuk memprediksikan deretan simbol selanjutnya yang akan dikompresi.
Algoritma PPM ditemukan dan dikembangkan oleh John Cleary dan Ian Witten. Selanjutnya, algoritma ini diimplementasikan menjadi suatu program kompresi oleh Alistair Moffat pada bulan Juli tahun1987.
2.5.6 Pack
Program pack ini adalah sebuah program kompresi yang biasa digunakan pada sistem operasi UNIX. Program ini menggunakan algoritma Huffman coding dalam melakukan kompresi. Program ini merupakan salah satu program utama
32 yang dijadikan acuan dalam benchmarking terhadap algoritma LZSS karena sama-sama menggunakan sebuah algoritma dalam proses kompresinya.
![Gambar 2.1. Contoh proses encoding algoritma LZ77 [1].](https://thumb-ap.123doks.com/thumbv2/123dok/3558031.3861930/3.918.106.822.76.1116/gambar-contoh-proses-encoding-algoritma-lz.webp)
![Gambar 2.2. Pseudocode algoritma LZSS [8].](https://thumb-ap.123doks.com/thumbv2/123dok/3558031.3861930/5.918.107.819.80.1125/gambar-pseudocode-algoritma-lzss.webp)
![Gambar 2.3. Circular queueI [1] .](https://thumb-ap.123doks.com/thumbv2/123dok/3558031.3861930/6.918.109.819.78.1120/gambar-circular-queuei.webp)
![Tabel II-1. Proses pengkodean LZSS [8].](https://thumb-ap.123doks.com/thumbv2/123dok/3558031.3861930/8.918.106.813.76.1119/tabel-ii-proses-pengkodean-lzss.webp)
![Gambar 2.5. Contoh operasi algoritma LZ78 [8].](https://thumb-ap.123doks.com/thumbv2/123dok/3558031.3861930/10.918.107.819.82.1119/gambar-contoh-operasi-algoritma-lz.webp)
![Gambar 2.6. Pseudocode algoritma LZW [8].](https://thumb-ap.123doks.com/thumbv2/123dok/3558031.3861930/13.918.109.819.75.1114/gambar-pseudocode-algoritma-lzw.webp)