Perbandingan Metode Klasifikasi Regresi Logistik Dengan Jaringan Saraf Tiruan (Studi Kasus: Pemilihan Jurusan Bahasa dan IPS pada SMAN 2 Samarinda Tahun Ajaran
2011/2012)
Comparison of Classification Methods Between Logistic Regression and Artificial Neural Network
(Case Study: Selection of Language and Social Studies Depertement at SMAN 2 Samarinda academic year 2011/2012)
Ramli1, Desi Yuniarti2 dan Rito Goejantoro3
1
Mahasiswa Program Studi Statistika FMIPA Universitas Mulawarman
2,3
Dosen Program Studi Statistika FMIPA Universitas Mulawarman
Email: [email protected]; [email protected]; [email protected] Abstract
Classification problems can be solved by using logistic regression and classification method of artificial neural network or artificial neural network (ANN). Classification with logistic regression method performed by transforming the dependent variable into a logit variable is the natural log of the odds ratio. In the ANN classification done by accepting a vector of input and then calculates a response or output by processing through the process elements are interrelated. The elements are arranged in several layers (layer) and the input data flow from one layer to the next in sequence. Output values can be scalar values or vectors, calculated at the output layer. The purpose of this study was to determine the results of the classification by using logistic regression and neural network analysis then compared with the classification accuracy. The data used in this study is the data the average value of report cards in the 1st half and the 2nd half of the class X for English and social studies subjects at SMAN 2 Samarinda academic year 2011/2012. The amount of data is 314 students with 2 to 4 response variables explanatory variables. Based on these results, the obtained results for the logistic regression classification accuracy of 78.34% and 80.89% for ANN analysis. From the comparison of artificial neural network classification method is a better classification method in solving the classification of English and social studies majors elections in SMAN 2 Samarinda academic year 2011/2012.
Keywords: Logistic Regression, Neural Networks, Classification, Classification Accuracy. Pendahuluan
Pengklasifikasian merupakan salah satu metode untuk mengelompokkan atau mengklasifikasikan suatu data yang disusun secara sistematis. Masalah klasifikasi sering dijumpai dalam kehidupan sehari-hari. Baik itu pengklasifikasian data pada bidang akademik, sosial, pemerintah, maupun pada bidang lainnya. Masalah klasifikasi ini muncul ketika terdapat sejumlah ukuran yang terdiri dari satu atau beberapa kategori yang tidak dapat diidentifikasikan secara langsung tetapi harus menggunakan suatu ukuran.
Regresi logistik merupakan salah satu metode klasifikasi yang sering digunakan, regresi logistik merupakan suatu teknik analisis data dalam statistika yang bertujuan untuk mengetahui hubungan antara beberapa variabel dimana variabel responnya adalah bersifat kategorik, baik nominal maupun ordinal dengan variabel penjelasnya dapat bersifat kategorik atau kontinu. Regresi logistik biner digunakan saat variabel respon merupakan variabel dikotomus (kategorik dengan 2 macam kategori), sedangkan regresi logistik multinomial digunakan saat variabel respon adalah variabel kategorik dengan lebih
dari 2 kategori. Regresi logistik tidak memodelkan secara langsung variabel respon (Y) dengan variabel penjelas (X), melainkan melalui transformasi variabel respon ke variabel logit yang merupakan natural log dari odds rasio (Fractal, 2003).
Jaringan Saraf Tiruan (JST) adalah suatu sistem pemrosesan informasi yang mencoba meniru otak manusia. Kelebihan dari JST adalah mampu mengakuisisi pengetahuan walau tidak ada kepastian, mampu melakukan generalisasi dan ekstraksi dari suatu pola data tertentu dan dapat menciptakan suatu pola pengetahuan melalui pengaturan diri kemampuan belajar. Dan kelemahan pada JST kurang mampu melakukan operasi numerik dengan presisi tinggi, kurang mampu melakukan operasi algoritma aritmatik dan lamanya proses training yang mungkin terjadi dalam waktu yang sangat lama untuk jumlah data yang besar.
Pada berbagai permasalahan, dibutuhkan analisis yang melibatkan proses klasifikasi. Tujuan klasifikasi adalah mengelompokkan objek pengamatan berdasarkan serangkaian variabel-variabel yang disebut sebagai variabel-variabel penjelas. Dua metode klasifikasi yang diterapkan dan akan
dievaluasi dalam penelitian ini adalah klasifikasi melalui Regresi Logistik dan Jaringan Saraf Tiruan.
Dari beberapa penelitian sebelumnya telah dilakukan penelitian membandingkan metode pengklasifikasian, yaitu Perbandingan Analisis Diskriminan Mahalanobis dan Analisis Jaringan Saraf Tiruan oleh Firmansyah (2010), perbandingan Metode Klasifikasi Analisis Diskriminan, Regresi Logistik dan Jaringan Saraf Tiruan pada kasus pengelompokan bunga oleh Suhermin (2002).
Pada penelitian ini dibahas perbandingan metode klasifikasi regresi logistik dengan jaringan saraf tiruan pada studi kasus: pemilihan jurusan Bahasa dan IPS pada SMAN 2 Samarinda tahun ajaran 2011/2012.
Tujuan yang ingin dicapai dari penelitian ini adalah untuk mengetahui model pengklasifikasian yang terbaik antara regresi logistik dan jaringan saraf tiruan.
Regresi Logistik
Regresi logistik merupakan suatu teknik analisis data dalam statistika yang bertujuan untuk mengetahui hubungan antara beberapa variabel dimana variabel responnya adalah bersifat kategorik, baik nominal maupun ordinal dengan variabel penjelasnya dapat bersifat kategorik atau kontinu. Regresi logistik biner merupakan salah satu pendekatan model matematis yang digunakan untuk menganalisis hubungan beberapa faktor dengan sebuah variabel yang bersifat biner. Pada regresi logistik jika variabel responnya terdiri dari dua kategori misalnya Y=1 menyatakan hasil yang diperoleh ”sukses” dan Y=0 menyatakan hasil yang diperoleh “gagal” maka regresi logistik tersebut menggunakan regresi logistik biner (Fractal, 2003).
Metode regresi logistik memiliki teknik dan prosedur yang tidak jauh berbeda dengan metode regresi linear. Jika prosedur linear dalam mengestimasi nilai parameter sering menggunakan metode Ordinary Least Squares (OLS), maka untuk mengestimasi nilai parameter dalam regresi logistik adalah dengan menggunakan metode Maximum Likelihood Estimation (MLE). Untuk mencari persamaan logistiknya maka model yang dipakai adalah: 𝜋 𝑥 = 𝑒 𝛽 0+ 𝑝𝑗 =1𝛽 𝑗 𝑥𝑗 1+𝑒𝛽 0+ 𝛽 𝑗 𝑥𝑗 𝑝 𝑗 =1 (1) Dari persamaan (1) diperoleh 1 – π(x) sebagai berikut: 1 − 𝜋 𝑥 = 1 − 𝑒 𝛽0+ 𝑝𝑗 =1𝛽𝑗𝑥𝑗 1 + 𝑒𝛽0+ 𝑝𝑗 =1𝛽𝑗𝑥𝑗 1 − 𝜋 𝑥 =1 + 𝑒 𝛽0+ 𝑝𝑗 =1𝛽𝑗𝑥𝑗 − 𝑒𝛽0 𝑝𝑗 =1𝛽𝑗𝑥𝑗 1 + 𝑒𝛽0 𝑝𝑗 =1𝛽𝑗𝑥𝑗 = 1 1 + 𝑒𝛽0 𝑝𝑗 =1𝛽𝑗𝑥𝑗 Sehingga 𝜋(𝑥) 1−𝜋(𝑥) sebagai berikut: 𝜋(𝑥) 1 − 𝜋(𝑥)= 𝑒 𝛽0 𝑝𝑗 =1𝛽𝑗𝑥𝑗
Jadi, persamaan logistiknya adalah: 𝑔 𝑥 = 𝑙𝑛 𝜋 𝑥
1 − 𝜋 𝑥 = 𝑙𝑛 𝑒𝛽0 𝑝𝑗 =1𝛽𝑗𝑥𝑗
= 𝛽0+ 𝑝𝑗 =1𝛽𝑗𝑥𝑗 (2) Estimasi Parameter Regresi Logistik
Pengujian parameter pada regresi logistik sangat penting untuk dilakukan. Hal ini dikarenakan pengujian tersebut digunakan untuk menentukan apakah variabel bebas dalam model signifikan terhadap variebel terikat. Pengujian dapat dilakukan secara:
1. Uji Goodness Of Fit
Dalam mencocokkan sebuah model logistik, perlu dipilih sebuah model dengan fungsi penghubung dan variabel penjelas yang hasilnya paling cocok. Untuk itu digunakan uji statistik Goodness Of Fit untuk membandingkan kecocokan dalam model-model yang berbeda. Untuk pengujian ini dapat digunakan uji Hosmer dan Lemeshow. 𝐶 = (𝑂𝑘−𝑛′𝑘𝜋𝑘)2 𝑛′ 𝑘𝜋𝑘(1−𝜋𝑘) 𝑔 𝑘 =1 (3) 2. Uji Serentak (simultan)
Bertujuan untuk mengetahui pengaruh variabel bebas secara serentak terhadap variabel terikat.
3. Uji Parsial
Dalam uji parsial ini, pengujian dilakukan dengan menguji setiap βj secara individual. Hasil
pengujian secara individual akan menunjukkan apakah suatu variabel prediktor layak untuk masuk dalam model atau tidak.
Pada model regresi logistik, β1 menunjukkan
besar perbedaan antara nilai variabel terikat ketika variabel bebas (x+1) dan nilai variabel terikat ketika variabel bebas x untuk setiap nilai x. Untuk variabel bebas yang bersifat dikotomi, diasumsikan nilai x adalah 0 dan 1, Selanjutnya dibentuk suatu Tabel klasifikasi 2x2 sebagai mana dinyatakan pada Tabel 1.
Tabel 1. Nilai Model Regresi Logistik untuk Variabel Bebas Bersifat Biner (0,1)
Varibel Penjelas (x) x = 1 x = 0 Variabel Respon (y) y =1 𝜋 1 = 𝑒 𝛽0+𝛽1 1 + 𝑒𝛽0+𝛽1 𝜋 0 = 𝑒 𝛽0 1 + 𝑒𝛽0 y =0 1 − 𝜋 1 = 1 1 + 𝑒𝛽0+𝛽1 1 − 𝜋 0 = 1 1 + 𝑒𝛽0
Sumber : Hosmer dan Lemeshow (2000)
Nilai odds untuk terjadinya variabel respon di antara variabel penjelas yang mempunyai x=1 adalah:
𝑃(𝑦= 1 𝑥=1) 𝑃(𝑦= 0 𝑥=1)=
𝜋 (1)
1−𝜋 (1) (4)
Sedangkan nilai odds untuk terjadinya variabel respon di antara variabel penjelas yang mempunyai x = 0 adalah:
𝑃(𝑦= 1 𝑥=0) 𝑃(𝑦= 0 𝑥=0)=
𝜋 (0)
1−𝜋 (0) (5)
Bila nilai odds tersebut ditransformasikan ke dalam bentuk log dengan bilangan dasar akan diperoleh:
𝑙𝑛 𝑜𝑑𝑑𝑠 = 𝑔 𝑥 = 𝑙𝑛 𝜋(𝑥)
1−𝜋(1) (6)
Sehingga untuk x=1, maka: 𝑔 1 = 𝑙𝑛 𝜋(1)
1−𝜋(1) (7)
dan untuk x =0, maka: 𝑔 0 = 𝑙𝑛 𝜋(0)
1−𝜋(0) (8)
Log odds ratio merupakan perbedaan atau selisih nilai logit. Dengan mensubstitusikan model logistik pada Tabel 1. Nilai Model Regresi Logistik untuk variabel penjelas, maka didapatkan:
𝜓 =𝜋(1)/ 1 − 𝜋(1) 𝜋(0)/ 1 − 𝜋(0)
𝜓 = 𝑒𝛽1 (9)
Sehingga log odds ratio menjadi : ln(ψ) = β1
Jaringan Saraf Tiruan
Jaringan Saraf Tiruan (JST) bisa dibayangkan seperti otak buatan didalam cerita-cerita fiksi ilmiah. Otak buatan ini dapat berpikir seperti manusia dan juga sepandai manusia dalam menyimpulkan sesuatu potongan-potongan informasi yang diterima. Komputer diusahakan agar bisa berpikir sama seperti cara berpikir manusia, caranya adalah dengan melakukan peniruan terhadap aktivitas-aktivitas yang terjadi di dalam sebuah jaringan saraf biologi. Itulah sebabnya mengapa JST dikatakan hanya
mengambil ide dari cara kerja jaringan saraf biologis.
Salah satu contoh pengambilan ide dari jaringan saraf biologis adalah adanya elemen-elemen pemrosesan pada JST yang saling terhubung dari beroperasi secara paralel. Ini meniru jaringan saraf biologis yang tersusun dari sel-sel saraf (neuron). Cara kerja dari elemen-elemen pemrosesan JST juga sama seperti cara neuron meng-encode informasi yang diterimanya,seperti Gambar 1 (Puspitaningrum, 2006).
Gambar 1. Contoh sel saraf biologis
Jaringan saraf biologis merupakan kumpulan dari sel-sel saraf (neuron). Neuron mempunyai tugas mengolah informasi. Komponen-komponen utama dari sebuah neuron dapat dikelompokkan menjadi 3 bagian yaitu:
1. Dendrite bertugas untuk menerima informasi. 2. Badan sel (soma) berfungsi sebagai tempat
pengolahan informasi.
3. Akson (neurit) mengirimkan implus-implus ke sel saraf lainnya.
Fungsi Sigmoid Biner
Fungsi ini digunakan untuk jaringan saraf yang dilatih dengan menggunakan metode backpropagation. Fungsi sigmoid biner memiliki nilai pada range 0 sampai 1. Oleh karena itu, fungsi ini sering digunakan untuk jaringan saraf yang membutuhkan nilai output yang terletak pada interval 0 sampai 1. Namun, fungsi ini bisa juga digunakan oleh jaringan saraf yang nilai outputnya 0 sampai 1 atau yang bukan 0 sampai 1 sesuai dengan keperluan. Persamaan fungsi sigmoid biner ditunjukkan pada persamaan (10) dan grafiknya ditunjukkan pada Gambar 2.
𝑓 𝑥 = 1
1+𝑒−𝑥 (10)
Gambar 2. Grafik Keanggotaan Fungsi Aktivasi
Sigmoid Biner
-1 1
Arsitektur Backpropagation
Backpropagation memiliki beberapa unit yang ada dalam satu atau lebih layar tersembunyi. Gambar 3 adalah arsitektur backpropagation dengan n buah masukan (ditambah sebuah bias), sebuah layer tersembunyi yang terdiri dari p unit (ditambah sebuah bias), serta m buah unit keluaran. 𝑣𝑗𝑖 merupakan bobot garis dari unit masukan 𝑥𝑖 ke unit layer tersembunyi 𝑧𝑖 (𝑣𝑗0 merupakan bobot garis yang menghubungkan bias di unit masukan ke unit layer tersembunyi 𝑧𝑗) 𝑤𝑘𝑗merupakan bobot dari unit layer tersembunyi
𝑧𝑗 ke unit keluaran 𝑦𝑘 (𝑤𝑘0 merupakan bobot dari bias di layer tersembunyi ke unit keluaran 𝑧𝑘) (Jong, 2005).
Gambar 3. Arsitektur Backpropagation
Pelatihan Backpropagation
Pelatihan backpropagation menggunakan metode pencarian titik minimum untuk mencari bobot dengan error minimum. Untuk melatih jaringan digunakan perintah train pada matlab. Pelatihan dilakukan untuk meminimumkan kuadrat kesalahan rata – rata (MSE). Metode paling sederhana untuk merubah bobot adalah metode penurunan gradien (gradient descent). Bobot dan bias diubah pada arah dimana unjuk kerja fungsi menurun paling cepat.
Perangkat Matlab menyediakan beberapa metode pencarian titik minimumnya. Pencarian titik minimum dengan metode penurunan gradien dilakukan dengan memberikan parameter ’traingd’ dalam parameter pelatihan setelah fungsi aktivasi pada perintah newff.
net.trainParam.show : dipakai untuk menampilkan frekuensi perubahan MSE (biasanya setiap 25 epoch)
net.trainParam.epochs : dipakai untuk menentukan jumlah epoch (iterasi) maksimum (biasanya 500 epoch)
net.trainParam.goal : dipakai untuk menentukan batas nilai MSE agar iterasi dihentikan. Iterasi akan berhenti jika MSE < batas yang ditentukan dalam net.trainParam.goal atau jumlah epoch mencapai batas yang ditentukan dalam net.trainParam.epochs (biasanya 0.1)
net.trainParam.lr : dipakai untuk menentukan laju pemahaman (
= learning rate). Semakin besar nilai
, semakin cepat pula proses pelatihan. Akan tetapi jika
terlalu besar, maka algoritma menjadi tidak stabil dan mencapai titik minimum lokal (biasanya α=0.5) ( Jong, 2005).Metodologi Penelitian
Metode pengklasifikasian yang digunakan dalam penelitian ini adalah analisis regresi logistik dan analisis jaringan saraf tiruan. Hasil analisis regresi logistik dengan bantuan software SPSS 16.0 dan hasil analisis jaringan saraf tiruan dengan bantuan software Matlab 7.1. Adapun langkah-langkah yang dilakukan dalam analisis regresi logistik adalah:
1. Estimasi parameter model regresi logistik. 2. Pemlihan model yang cocok/uji goodness of
fit.
3. Pengujian parameter.
4. Interprestasi model koefisien regresi logistik. 5. Perhitungan persentase ketepatan klasifikasi. Langkah-langkah yang dilakukan dalam analisis jaringan saraf tiruan adalah:
1. Inisialisasi jaringan saraf. 2. Membangun jaringan saraf tiruan. 3. Pelatihan jaringan.
4. Evaluasi output jaringan (MAPE).
5. Perhitungan persentase ketetapan klasifikasi. Dan membandingkan hasil klasifikasi regresi logistik dengan jaringan saraf tiruan.
Hasil dan Pembahasan
Data yang digunakan adalah nilai rata-rata raport siswa/siswi SMAN 2 Samarinda kelas X semester 1 dan semester 2 tahun ajaran 2011/2012. Menggunakan regresi logistik dan jaringan saraf tiruan.
1. Analisis Regresi Logistik
Metode pengklasifikasian yang digunakan dalam penelitian ini adalah Analisis Regresi Logistik. Hasil Analisis Regresi Logistik diperoleh dengan bantuan software SPSS 16.0. Uji Likelihood Ratio atau Uji Simultan
Pengujian ini dilakukan untuk mengetahui apakah variabel respon mempunyai pengaruh yang signifikan terhadap variabel penjelas. Pada pengklasifikasian jurusan Bahasa dan IPS dengan menggunakan Analisis Regresi Logistik.
Tabel 2. Log-Likelihood Regresi Logistik
Step -2 Log likelihood
1 287,997
Pada Tabel 2. nilai G adalah 287,997 dimana nilai G > χ2(0.05,4) yaitu 287,997 > 9,49 maka H0
ditolak, dan dapat disimpulkan bahwa minimal ada satu variabel penjelas yang berpengaruh terhadap variabel respon.
Uji Parsial Menggunakan Uji Wald
Pengujian ini dilakukan untuk mengetahui pengaruh dari masing-masing variabel X1, X2, X3
dan X4 terhadap Jurusan. Pada Tabel 3 diperoleh
keempat variabel penjelas mempunyai pengaruh terhadap variabel respon
Tabel 3. Uji Parsial
Variabel Wald p-value
𝑋1 50,788 0,000
𝑋2 39,756 0,000
𝑋3 8,708 0,003
𝑋4 53,434 0,000
Berdasarkan Tabel 3 dengan α (0,05) dapat diambil kesimpulan bahwa semua variabel penjelas berpengaruh terhadap variabel respon. Model Persamaan Regresi Logistik
Berdasarkan nilai koefisien β diketahui bahwa Keempat variabel penjelas mempunyai pengaruh yang signifikan terhadap variabel respon sehingga empat variabel ini dimasukkan dalam regresi logistik, seperti pada Tabel 4.
Tabel 4. Nilai β Model Regresi Logistik
Parameter Estimasi p-value
𝛽0 -4,089 0,678
𝛽1 0,398 0,000
𝛽2 -0,324 0,000
𝛽3 0,362 0,003
𝛽4 -0,380 0,000
Pada Tabel 4. didapatkan model regresi logistik yang diperoleh dengan variabel respon Y = π(x) adalah Jurusan dengan variabel penjelas X1, X2, X3
dan X4. Sehingga di dapat model regresi logistik
yaitu:
𝑔 𝑥 = −4,089 + 0,398𝑋1− 0,324𝑋2+ 0,362𝑋3−
0,380𝑋4
Uji Kesesuaian Model
Pengujian ini dilakukan untuk menilai kesesuaian model regresi logistik dengan cara membandingkan hasil pengamatan dengan nilai dugaan.
Tabel 5. Hosmer dan Lemeshow Test
Step Chi-square Df p-value
1 9,222 8 0,324
Pada Tabel 5. diketahui bahwa nilai p-value Hosmer and Lemeshow Test adalah sebesar 0,324 > α (0,05) atau 𝐶 = 9,222 < 𝑋2
(0,05;8) =
15,51 maka H0 diterima. Sehingga dapat
disimpulkan bahwa tidak ada perbedaan antara hasil pengamatan dengan nilai dugaan atau model regresi logistik tersebut layak untuk digunakan. Interprestasi Model Koefisien Regresi Logistik
Nilai kecenderungan antara satu kategori
dengan kategori lain pada variabel penjelas yang kualitatif dinyatakan dengan Odds Ratio. Rasio kecenderungan dapat dilihat, kolom Exp (β) dan dapat disederhanakan seperti Tabel 6.
Tabel 6. Nilai Odds Ratio
Estimasi Parameter Odds Ratio
X 1 1,488
X 2 0,724
X 3 1,437
X 4 0,684
Pada Tabel 6. dapat disimpulkan sebagai berikut: 1. Odds Ratio nilai rata-rata pelajaran Bahasa
Indonesia pada rapot semester 1 dan 2 kelas X (X1)
Diperoleh nilai odds ratio sebesar 1,488, ini berarti bahwa peluang pengklasifikasian variabel X1 cenderung berada pada pemilihan
jurusan Bahasa 1,488 kalinya terhadap pemilihan jurusan IPS.
2. Odds Ratio nilai rata-rata pelajaran Bahasa Inggris pada rapot semester 1 dan 2 kelas X (X2)
Diperoleh nilai odds ratio sebesar 0,724, ini berarti bahwa peluang pengklasifikasian variabel X2 cenderung berada pada pemilihan
jurusan Bahasa 0,724 kalinya terhadap pemilihan jurusan IPS.
3. Odds Ratio nilai rata-rata pelajaran Ekonomi pada rapot semester 1 dan 2 kelas X (X3)
Diperoleh nilai odds ratio sebesar 1,437, ini berarti bahwa peluang pengklasifikasian variabel X3 cenderung berada pada pemilihan
jurusan Bahasa 1,437 kalinya terhadap pemilihan jurusan IPS.
4. Odds Ratio nilai rata-rata pelajaran Geografi pada rapot semester 1 dan 2 kelas X (X4)
Diperoleh nilai odds ratio sebesar 0,684, ini berarti bahwa peluang pengklasifikasian variabel X4 cenderung berada pada pemilihan
jurusan Bahasa 0,684 kalinya terhadap pemilihan jurusan IPS.
Pengklasifikasi dengan Menggunakan Regresi Logistik
Persentase ketepatan klasifikasi adalah rasio antara jumlah observasi-observasi yang diklasifikasikan secara tepat oleh model (sesuai dengan kelompok yang sebenarnya) dengan jumlah seluruh observasi. Evaluasi klasifikasi dilakukan dengan cara membuat tabulasi perhitungan masing-masing |εi|. Dikatakan tepat
klasifikasi jika ; 0 ≤ |εi| < 0,5.
Tabel 7. Prediksi Keanggotaan Suatu Observasi Berdasarkan Suatu Model
Jurusan yang diprediksi oleh model
Bahasa IPS
Jurusan Bahasa 115 35
Persentase ketepatan klasifikasi =115+131
314 x100%
= 78,34%
2. Analisis Jaringan Saraf Tiruan
Analisis jaringan saraf tiruan yang digunakan untuk masalah pengelompokkan adalah jaringan saraf tiruan metode backpropagation. Untuk perhitungan dan pemprograman jaringan saraf tiruan backpropagation, digunakan bantuan program Matlab 7.01.
Inisialisasi Jaringan Saraf Tiruan Backpropagation
a. Menentukan Variabel
Berdasarkan data penelitian ini, maka variabel, X 1, X 2 , X 2 dan X 4, adalah input
penelitian ini serta pemilihan jurusan adalah target pada penelitian ini. Output yang dihasilkan akan dinotasikan dengan 𝑌 seperti pada Tabel 8.
Tabel 8. Deskripsi Variabel
Variabel Ukuran Sampel
Input 𝑋1 314 𝑋2 314 𝑋3 314 𝑋4 314 Output 𝑌 314
b. Menentukan parameter dalam pelatihan (learning)
Sebelum jaringan yang telah dibentuk melakukan pelatihan terhadap data input dinotasikan P dan matriks target dinotasikan T, maka akan ditentukan parameter pelatihan. Adapun nilai parameter tersebut adalah sebagai berikut:
1. Banyaknya Epochs (iterasi) : 100000 2. Error minimum : 0,05 3. Learning rate (
) : 0,05 4. Iterasi untuk update grafik error : 1000 c. Inisialisasi bobot awal penghubung tiap lapisanPada penelitian ini, jaringan yang dibentuk terdiri dari 4 lapisan input, 4 lapisan tersembunyi dan 1 lapisan output, maka bobot penghubung tiap lapisan dalam bentuk matriks dapat ditentukan sebagai berikut:
1. Bobot awal lapisan input ke lapisan tersembunyi 0,7862 −0,8364 0,4108 −0.0342 0,6581 0,7852 −0,1612 −1,1317 0,2987 −0,0195 0,2361 0,3791 0,7930 0,7976 −1,3397 −0,2477 2. Bobot awal bias pada lapisan input ke lapisan tersembunyi −5,2691 0,8555 2,1646 −3,3568
3.Bobot awal lapisan tersembunyi ke lapisan output
3,3610 3,2177 −0,6925 3,0385 4. Bobot awal bias pada lapisan tersembunyi ke lapisan output
−4,4622
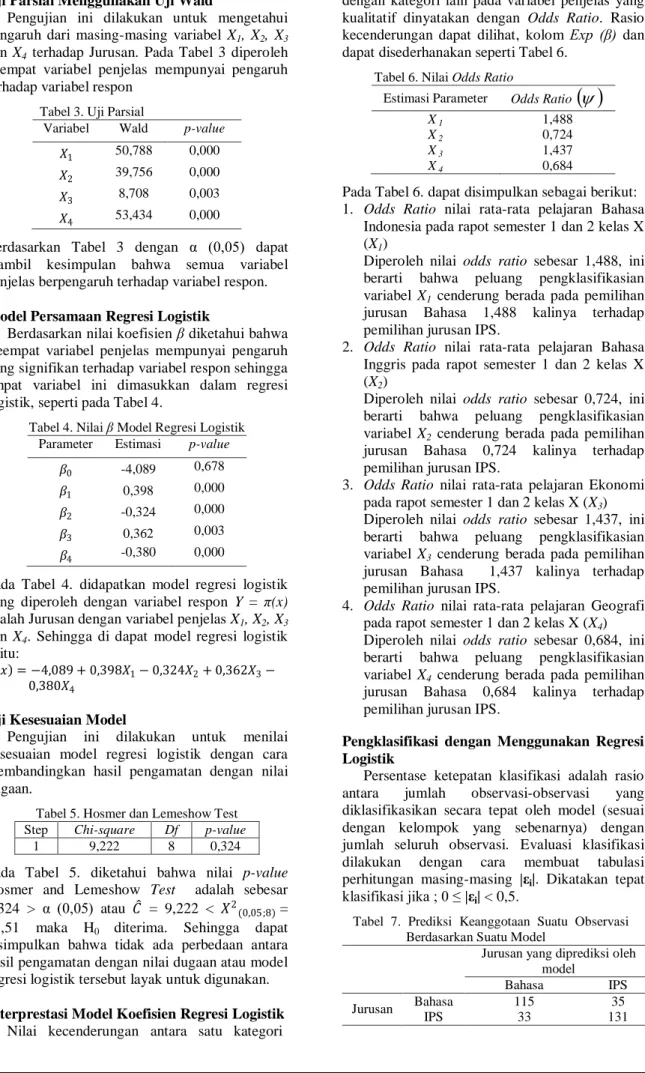
Bobot awal lapisan input berfungsi untuk memperkuat sinyal dari neuron-neuron pada lapisan input. Bobot awal lapisan tersembunyi berfungsi untuk memperkuat sinyal pada lapisan tersembunyi. Demikian juga halnya dengan bobot awal bias pada lapisan input dan lapisan tersembunyi. Dari output program matlab diperoleh bahwa jaringan melakukan pelatihan sebanyak 100000 epochs, jaringan belum mampu untuk mencapai nilai error minimum yang telah ditetapkan yaitu 0,05. Tetapi, dari grafik nilai MSE seperti pada Gambar 4, terlihat bahw selama proses pelatihan nilai MSE terus turun untuk mencapai nilai minimum yang ditetapkan yaitu 0,05.
Gambar 4. Grafik nilai MSE
Setelah jaringan melakukan pelatihan sebanyak 100000 epochs, diperoleh nilai bobot akhir jaringan untuk setiap lapisan. Bobot-bobot inilah yang merupakan bobot terbaik dalam fungsinya memperkuat input sehingga dihasilkan nilai output jaringan untuk mencapai target yang ditetapkan.
1.Bobot akhir lapisan input ke lapisan tersembunyi 0,7027 0,4357 0,1132 0,6735 0,3310 −0,5197 0,1205 −1,5186 0,1622 0,1116 0,0313 0,6828 0,5621 −0,9096 −0,6814 −2,0956 2.Bobot akhir bias pada lapisan input ke lapisan tersembunyi −5,4019 0,9121 2,5947 −2,1025
3.Bobot akhir lapisan tersembunyi ke lapisan output
3,3115 2,8944 −0,3268 3,8487 4.Bobot akhir bias pada lapisan tersembunyi ke lapisan output
−4,6727
Berdasarkan hasil output matlab untuk program jaringan saraf tiruan, diperoleh hasil output. Dari output jaringan, terlihat bahwa semua output memiliki nilai di bawah nilai error yang
ditetapkan yaitu 0,05. Nilai error yang ditetapkan, merupakan batasan dalam menentukan hasil pengelompokkan. Sehingga dapat disimpulkan bahwa hasil output jaringan yang dihasilkan sesuai dengan target (kelompok) yang ditetapkan. Hal ini juga terlihat dari hasil grafik pemetaan output dan target seperti terlihat pada Gambar 5 berikut ini :
Gambar 5. Grafik Pemetaan Output dan Target
Dari Gambar 5 terlihat bahwa output jaringan menyebar mendekati target yang ditetapkan (kelompok). Karena jaringan saraf tiruan hanya dapat mendekati atau mengestimasi target, maka output yang dihasilkan tidak bisa sesuai dengan nilai target (kelompok).
Menghitung nilai MAPE Jaringan Saraf Tiruan
Untuk menilai kinerja jaringan saraf tiruan backpropagation yang telah dibangun, diperlukan perhitungan nilai Mean Absolute Percentage Error (MAPE). Jika output jaringan dinotasikan dengan 𝑌 dan target jaringan dinotasikan dengan 𝑌 maka nilai MAPE dapat dihitung.
𝑀𝐴𝑃𝐸 = 𝑌𝑖−𝑌 𝑖 𝑌𝑖 𝑛 𝑖=1 𝑛 𝑥100% = 𝑌𝑖+𝑌 𝑖 𝑌𝑖 314 314 𝑖=1 𝑥100% = 23,70%
Dari perhitungan MAPE diatas, diperoleh nilai MAPE jaringan saraf tiruan backpropagation sebesar 23,70%. Dari nilai yang diperoleh ini, dapat dinilai kinerja jaringan saraf tiruan backpropagation dalam mendekati atau mengestimasi hasil pengelompokkan adalah baik, karena memberikan nilai rata-rata persen error yang kecil yaitu 23,70%.
Pengklasifikasi dengan Jaringan Saraf Tiruan Evaluasi klasifikasi dilakukan dengan cara membuat tabulasi perhitungan masing-masing 𝑌𝑖− 𝑌 𝑖 = absolute error. Diharapkan absolute
error tersebut bisa sekecil mungkin sehingga pengamatan tepat diklasifikasikan. Dikatakan tepat klasifikasi jika : 0 ≤ 𝑌𝑖− 𝑌 𝑖 ≤ 0,05.
Berdasarkan Tabel 9, dapat ditentukan ketepatan klasifikasi Jaringan Syaraf Tiruan.
Persentase ketepatan klasifikasi =115+139
342 × 100%
= 80,89%
Tabel 9. Prediksi Keanggotaan Jaringan Saraf Tiruan Jurusan yang diprediksi oleh
model
Bahasa IPS
Jurusan Bahasa 115 35
IPS 25 139
Perbandingan Hasil Pengelompokkan Dengan Teknik Analisis Regresi Logistik Dan Teknik Analisis Jaringan Saraf Tiruan
Dari hasil pengelompokkan dengan metode analisis regresi logistik dan analisis jaringan saraf tiruan akan dibandingkan dengan melihat ketepatan klasifikasi.
Tabel 10. Hasil pengelompokkan dengan metode analisis regresi logistik dan analisis jaringan saraf tiruan
Berdasarkan Tabel 10, diketahui dengan menggunakan teknik analisis regresi logistik, diperoleh :
Dari 150 siswa yang diklasifikasikan ke Jurusan Bahasa, 115 siswa tepat diklasifikasikan ke jurusan Bahasa dan sisanya 35 siswa tidak tepat diklasifikasikan ke Jurusan Bahasa.
Dari 164 siswa yang diklasifikasikan ke Jurusan IPS, 131 siswa tepat diklasifikasikan ke jurusan IPS dan sisanya 33 siswa tidak tepat diklasifikasikan ke Jurusan IPS.
Sedangkan untuk analisis jaringan saraf tiruan, diperoleh :
Dari 150 siswa yang diklasifikasikan ke Jurusan Bahasa, 115 siswa tepat diklasifikasikan ke jurusan Bahasa dan sisanya 33 siswa tidak tepat diklasifikasikan ke Jurusan Bahasa.
Dari 164 siswa yang diklasifikasikan ke Jurusan IPS, 139 siswa tepat diklasifikasikan ke jurusan IPS dan sisanya 25 siswa tidak tepat diklasifikasikan ke Jurusan IPS.
Dari perhitungan persentase ketepatan klasifikasi, diperoleh nilai persentase ketepatan klasifikasi analisis regresi logistik sebesar 78,34% dan nilai persentase ketepatan klasifikasi analisis jaringan saraf tiruan sebesar 80,89%.
Kesimpulan
Berdasarkan hasil dan pembahasan tersebut, maka dapat disimpulkan bahwa dalam penyelesaian pengklasifikasian pemilihan jurusan Bahasa dan IPS pada SMAN 2 Samarinda tahun ajaran 2011/2012 lebih tepat menggunakan jaringan saraf tiruan karena ketepatan klasifikasi yaitu sebesar 80,89%.
Jurusan Regresi Logistik Jaringan Saraf Tiruan
Bahasa IPS Bahasa IPS
Bahasa 115 35 115 35
Daftar Pustaka
Hosmer, D. W. and Lemeshow, S. (2000). Applied Logistic Regression. John Wiley and Sons, Inc. USA.
Firmansyah, Yudhi. 2010. Perbandingan Analisis Diskriminan Mahalanobis dan Analisis Jaringan Saraf Tiruan Dalam MenyelesaikanMasalah Pengelompokkan. Jurusan S1 Statistika Fakultas FMIPA Universitas Mulawarman: Samarinda.
Fractal (2003), Comparative Analysis of Classification Techniques, A Fractal White Paper.
Puspitaningrum, Diyah. 2006. Pengantar Jaringan Saraf Tiruan. Yogyakarta: Andi. Siang, J. Jek. 2005. Jaringan Saraf Tiruan dan
Pemogramannya menggunakan Matlab. Yogyakarta : Andi.
Suhermin Ari Pujianti. 2002. Perbandingan Metode Klasifikasi Analisis Deskrriminan, Regresi Logistik dan Jaringan Saraf Tiruan Pada Kasus Pengelompokan Bunga. Pasca Sarjana Jurusan