No. Dok.: FM-GKM-S1TI-FT-6-06-07; Tgl. Efektif : 09 Juli 2018; Rev : 01; Halaman : 1 dari 1
TUGAS SARJANA
Diajukan Untuk Memenuhi Sebagian Dari
Syarat-syarat Memperoleh Gelar Sarjana Teknik Industri
Oleh
ADINDA KARINA RENGGALI NIM : 170403105
D E P A R T E M E N T E K N I K I N D U S T R I F A K U L T A S T E K N I K
UNIVERSITAS SUMATERA UTARA MEDAN
2021
No. Dok.: FM-GKM-S1TI-FT-6-06-07; Tgl. Efektif : 09 Juli 2018; Rev : 01; Halaman : 1 dari 1
TUGAS SARJANA
Diajukan Untuk Memenuhi Sebagian Dari Syarat-Syarat Memperoleh Gelar Sarjana Teknik
Oleh
ADINDA KARINA RENGGALI NIM. 170403105
Disetujui Oleh : Dosen Pembimbing,
(Ir. Nurhayati Sembiring, MT)
D E P A R T E M E N T E K N I K I N D U S T R I F A K U L T A S T E K N I K
UNIVERSITAS SUMATERA UTARA M E D A N
2 0 2 1
JUDUL :
ANALISIS SENTIMEN DATA REVIEW APLIKASI FEMALE DAILY PADA WEBSITE GOOGLE PLAY MENGGUNAKAN ALGORITMA NAÏVE BAYES
Saya menyatakan bahwa Tugas Akhir ini adalah hasil karya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing disebutkan sumbernya.
Medan, 13 Juli 2021
Adinda Karina Renggali
NIM : 170403105
Mengetahui akan hal itu, maka perusahaan dapat memanfaatkan opini-opini tersebut untuk meningkatkan pelayanan dan kualitas perusahaan. Masyarakat Indonesia mulai tertarik akan kecantikan. Hal ini dibuktikan oleh penjualan kosmetik yang terus meningkat setiap tahunnya. Karena hal tersebut, masyarakat membutuhkan sebuah wadah tentang kecantikan. Female Daily merupakan salah satu wadah kecantikan di Indonesia. Aplikasi Female Daily telah diunduh sebanyak lebih dari 100.000 pengguna. Beberapa pengguna telah menyampaikan pendapatnya mengenai aplikasi Female Daily melalui situs Google Play. Machine learning adalah salah satu aplikasi dari kecerdasan buatan. Machine learning memiliki alat yang bisa digunakan untuk klasifikasi, yaitu algoritma Naive Bayes.
Algoritma Naive Bayes dapat mengklasifikasikan opini pengguna mengenai aplikasi Female Daily. Algoritma ini mengklasifikasikannya menjadi positif dan negatif. Dari hasil analisis sentimen ulasan pengguna aplikasi Female Daily, didapatkan keakuratan dalam menggunakan algoritma Naive Bayes adalah sebesar 82,5%. Dari hasil keakuratan tersebut, maka algoritma Naive Bayes efektif dalam melakukan klasifikasi ulasan pengguna mengenai aplikasi Female Daily.
Penelitian ini diharapkan dapat berguna dalam melakukan analisis sentimen yang selanjutnya.
Kata kunci: Analisis Sentimen, Machine Learning, Naive Bayes, Female Daily, Google Colab
can take advantage of these opinions to improve the service and quality of the company. Indonesian people began to be interested in beauty. This is evidenced by the sales of cosmetics that continue to increase every year. Because of this, society needs a platform about beauty. Female Daily is one of the beauty forums in Indonesia. Female Daily application has been downloaded by more than 100,000 users. Several users have expressed their opinion about the Female Daily application through the Google Play site. Machine learning is one of the applications of artificial intelligence. Machine learning has a tool that can be used for classification, namely the Naive Bayes algorithm. The Naive Bayes algorithm can classify user opinions about the Female Daily application. This algorithm classifies them into positive and negative. From the sentiment analysis of the Female Daily application user reviews, the accuracy in using the Naive Bayes algorithm is 82.5%. From the results of this accuracy, the Naive Bayes algorithm is effective in classifying user reviews regarding the Female Daily application. This research is expected to be useful in conducting further sentiment analysis.
Keywords: Sentiment Analysis, Machine Learning, Naive Bayes, Female Daily, Google Colab
rahmat kepada penulis sehingga penulis dapat menyelesaikan tugas sarjana penulis dengan baik.
Laporan tugas sarjana ini merupakan salah satu syarat dari Departemen Teknik Industri Universitas Sumatera Utara (USU) dalam memperoleh gelar sarjana. Adapun tugas sarjana ini berjudul “Analisis Sentimen Data Review Aplikasi Female Daily pada Website Google Play Menggunakan Algoritma Naïve Bayes”.
Penulis menyadari bahwa laporan tugas sarjana ini masih jauh dari kata sempurna. Oleh karena itu, penulis mengharapkan kritik dan saran yang dapat membantu penulis dalam menyempurnakan tugas sarjana ini. Semoga tugas sarjana ini dapat memberikan manfaat kepada kita semua.
UNIVERSITAS SUMATERA UTARA PENULIS,
MEDAN, NOVEMBER 2020 ADINDA KARINA RENGGALI
dan rahmat-Nya, penulis dapat mengikuti pendidikan di Departemen Teknik Industri Universitas Sumatera Utara (USU) dengan baik dan dapat menyelesaikan penulisan laporan Tugas Sarjana ini. Banyak pihak yang telah membantu penulis dalam menyelesaikan Laporan Tugas Sarjana ini, baik bantuan secara spiritual, materil, informasi maupun administrasi. Maka pada kesempatan ini penulis mengucapkan terima kasih kepada:
1. Allah SWT yang telah memberikan rahmat dan karunia-Nya dalam membuat penulis dapat menyelesaikan tugas sarjana ini
2. Orang tua penulis, Ir. Armia Zuhri dan Dr. Puspitawati M.Si atas doa, perhatian, bimbingan dan dukungan moril dan materil, yang menjadi motivasi penulis untuk menyelesaikan perkuliahan dan penulisan tugas sarjana ini.
3. Kedua kakak penulis, Adinda Ayu Temashiera dan Adinda Melati Luthfishara yang selalu memberikan dukungan, hiburan, dan motivasi sehingga penulis dapat menyelesaikan laporan tugas sarjana ini.
4. Ibu Dr. Ir. Meilita Tryana Sembiring, MT, IPM selaku Ketua Departemen Teknik Industri, Fakultas Teknik, Universitas Sumatera Utara dan Bapak Buchari, ST, M.Kes selaku Sekretaris Departemen Teknik Industri, Fakultas Teknik, Universitas Sumatera Utara.
menyelesaikan Tugas Sarjana ini.
6. Ibu Ir. Dini Wahyuni, M.T selaku Dosen Pembimbing Akademik penulis yang telah memberikan arahan, ilmu dan saran kepada penulis dalam menjalani kegiatan perkuliahan dari semester 1 hingga akhir.
7. Seluruh dosen Departemen Teknik Industri, Fakultas Teknik, Universitas Sumatera Utara yang telah memberikan pengajaran selama perkuliahan yang menjadi bekal penulis dalam menyelesaikan tugas sarjana ini.
8. Sahabat-sahabat penulis tersayang di Departemen Teknik Industri, yang juga merupakan teman seperjuangan skripsi, yaitu Suci, Dea, Yence, Rini, Ardi, Stefry, Cindy, Nita, Inggi, Christ dan Ira dalam membantu, menghibur dan mewarnai kehidupan penulis selama di perkuliahan.
9. Tim Eo-dong, Laras, Thalita, dan Azoura yang telah berbagi pengalaman dan cerita serta menghibur penulis.
10. Teman-teman kelas Cenayang, yang telah menghabiskan waktu bersama dan menghibur penulis selama kuliah.
11. Seluruh pihak yang tidak dapat disebutkan satu-satu yang telah membantu penulis baik dalam menyelesaikan tugas sarjana ini ataupun hal lainnya.
ADINDA KARINA RENGGALI
LEMBAR JUDUL ... i
LEMBAR PENGESAHAN ... ii
PERNYATAAN ORISINALITAS ... iii
SERTIFIKAT EVALUASI TUGAS SARJANA ... iv
ABSTRAK ... v
KATA PENGANTAR ... vii
UCAPAN TERIMA KASIH... viii
DAFTAR ISI ... x
DAFTAR TABEL ... xv
DAFTAR GAMBAR ... xvi
DAFTAR LAMPIRAN ... xviii
I PENDAHULUAN ... I-1 1.1. Latar Belakang ... I-1 1.2. Perumusan Masalah ... I-5 1.3. Tujuan Penelitian ... I-6 1.4. Manfaat Penelitian ... I-6 1.5. Batasan dan Asumsi Penelitian ... I-7
DAFTAR ISI (LANJUTAN)
BAB HALAMAN
II TINJAUAN PUSTAKA ... II-1 2.1. Female Daily ... II-1 2.2. Google Play ... II-2 2.3. Analisa Sentimen ... II-3 2.4. Kecerdasan Buatan ... II-4 2.5. Machine Learning ... II-5 2.6. Data Mining ... II-6 2.7. Metode Pelatihan ... II-6 2.8. Teknik Data Mining ... II-7 2.9. Text Mining ... II-9 2.10. Web Scraping ... II-10 2.11. Google Colab ... II-10 2.12. Preprocessing Data ... II-11 2.12.1. Case Folding ... II-12 2.12.2. Tokenizing ... II-12 2.12.3. Spelling Normalization ... II-12 2.12.4. Filtering... II-12 2.12.5. Stemming ... II-13 2.13. Term Frequency (TF) ... II-13 2.14. Algoritma Naïve Bayes ... II-14 2.15. Evaluasi Klasifikasi ... II-16
DAFTAR ISI (LANJUTAN)
BAB HALAMAN
2.16. Review Hasil Penelitian ... II-17 2.17. Kerangka Konseptual ... II-21
III METODOLOGI PENELITIAN ... III-1 3.1. Jenis Penelitian ... III-1 3.2. Lokasi dan Waktu Penelitian ... III-1 3.3. Objek Penelitian ... III-1 3.4. Metodologi Pengumpulan Data... III-2 3.5. Metode Analisis Data ... III-2 3.6. Kerangka Penelitian ... III-3
IV PENGUMPULAN DAN PENGOLAHAN DATA... IV-1 4.1. Pengumpulan Data ... IV-1
4.1.1. Web Scraping ... IV-1 4.2. Pengolahan Data... IV-4 4.2.1. Labelling ... IV-4 4.2.2. Preprocessing Data ... IV-5 4.2.2.1. Case Folding ... IV-6 4.2.2.2. Tokenizing ... IV-7 4.2.2.3. Spelling Normalization ... IV-7 4.2.2.4. Filtering ... IV-8
DAFTAR ISI (LANJUTAN)
BAB HALAMAN
4.2.2.5. Stemming ... IV-8 4.2.3. Data Split ... IV-9 4.2.3.1 Data Training ... IV-9 4.2.3.2. Data Testing ... IV-9 4.2.4. Term Frequency ... IV-9 4.2.5. Algoritma Naïve Bayes ... IV-12 4.3. Implementasi pada Google Colab ... IV-14 4.3.1. Upload File ... IV-14 4.3.2 Preprocessing Data ... IV-14 4.3.2.1. Case Folding... IV-14 4.3.2.2. Tokenizing ... IV-15 4.3.2.3. Speliing Normalization ... IV-17 4.3.2.4. Filtering ... IV-17 4.3.2.5. Stemming ... IV-18 4.3.3. Data Split ... IV-27 4.3.3.1. Data Training ... IV-28 4.3.3.2. Data Testing ... IV-35 4.3.4. Term Frequency (TF) dan Inverse Document
Frequency (IDF)... IV-37 4.3.4.1. Term Frequency (TF) dan Inverse Document
Frequency (IDF) pada Data Training ... IV-37
DAFTAR ISI (LANJUTAN)
BAB HALAMAN
4.3.4.2. Term Frequency (TF) dan Inverse Document Frequency (IDF) pada Data Testing ... IV-37 4.3.5. Algoritma Naïve Bayes ... IV-38 4.3.5.1. Pengujian Algoritma Naïve Bayes... IV-38
V ANALISIS DAN PEMBAHASAN ... VI-1 5.1. Analisis Data ... V-1 5.2. Analisis Implementasi Algoritma Naïve Bayes ... V-1 5.3. Analisis Tingkat Akurasi Algoritma Naïve Bayes ... V-4 5.4. Visualisasi Kata ... V-7 5.4.1. Ulasan Positif ... V-9 5.4.2. Ulasan Negatif ... V-12 5.5. Keilmuan Teknik Industri yang Digunakan pada Penelitian .... V-14
VI KESIMPULAN DAN SARAN ... VI-1 6.1. Kesimpulan ... VI-1 6.2. Saran ... VI-2
DAFTAR PUSTAKA LAMPIRAN
DAFTAR TABEL
TABEL HALAMAN
4.1. Contoh Data Hasil Labelling ... IV-5 4.2. Contoh Kalimat ... IV-10 4.3. Kata-kata dalam Kalimat ... IV-10 4.4. Perhitungan Nilai TF... IV-10 4.5. Perhitungan Nilai IDF ... IV-11 4.6. Contoh Klasifikasi Algoritma Naïve Bayes ... IV-12 4.7. Hasil Preprocessing ... IV-19 4.8. Data Training... IV-28 4.9. Data Testing ... IV-35 4.10. Hasil Pengujian Algoritma Naïve Bayes ... IV-39 5.1. Hasil Analisis Sentimen dengan Algoritma Naïve Bayes... V-1 5.2. Perbandingan Klasifikasi Secara Manual dan Menggunakan
Algoritma Naïve Bayes (Prediksi) ... V-3
1.1. Pertumbuhan Pengguna Internet ... I-1 1.2. Jumlah Populasi Perempuan di Indonesia ... I-2 1.3. Penjualan Kosmetik di Indonesia ... I-3 2.1. Logo Female Daily ... II-2 2.2. Bagian Utama dalam Kecerdasan Buatan ... II-5 2.3. Teknik Data Mining ... II-9 2.4. Kerangka Konseptual ... II-21 3.1. Kerangka Penelitian ... III-3 4.1. Situs Google Play ... IV-1 4.2. Pengambilan Data Review ... IV-2 4.3. Data Preview ... IV-3 4.4. Tampilan Excel... IV-3 4.5. Case Folding ... IV-6 4.6. Tokenizing ... IV-7 4.7. Spelling Normalization... IV-7 4.8. Filtering... IV-8 4.9. Stemming ... IV-8 4.10. Upload File ... IV-14 4.11. Case Folding pada Google Colab ... IV-15
DAFTAR GAMBAR (LANJUTAN)
GAMBAR HALAMAN
4.12. Penghapusan Karakter Spesial pada Google Colab ... IV-15 4.13. Penghapusan Tanda Baca pada Google Colab ... IV-16 4.14. Tokenizing pada Google Colab ... IV-16 4.15. Spelling Normalization pada Google Colab ... IV-17 4.16. Filtering pada Google Colab ... IV-18 4.17. Stemming pada Google Colab ... IV-18 4.18. Data Split pada Google Colab... IV-27 4.19. Term Frequency (TF) dan Inverse Document Frequency
(IDF) Data Training pada Google Colab ... IV-37 4.20. Term Frequency (TF) dan Inverse Document Frequency
(IDF) Data Testing pada Google Colab ... IV-38 4.21. Algoritma Naïve Bayes pada Google Colab ... IV-38 4.22. Hasil Pengujian Algoritma Naïve Bayes... IV-39 5.1. Persentase Analisis Sentimen dengan Algoritma Naïve
Bayes ... V-4
5.2. Tingkat Akurasi Algoritma Naïve Bayes ... V-7 IV-3 5.3. Frekuensi Kata pada Ulasan Aplikasi Female Daily ... V-8
5.4. WordCloud ulasan aplikasi Female Daily... V-9 5.5. Frekuensi Kata pada Ulasan Positif ... V-10 5.6. WordCloud Ulasan Positif... V-11
DAFTAR GAMBAR (LANJUTAN)
GAMBAR HALAMAN
5.7 Frekuensi Kata pada Ulasan Negatif ... V-12 5.8. WordCloud Ulasan Negatif ... V-13
1. Data Set ... L-1 2. Surat Permohonan Tugas Sarjana ... L-2 3. Surat Keputusan Tugas Sarjana ... L-3 4. Lembar Asistensi Laporan Tugas Sarjana... L-4
I-1 1.1. Latar Belakang
Seiring dengan berjalannya waktu, manusia tidak bisa lepas dari smartphone.
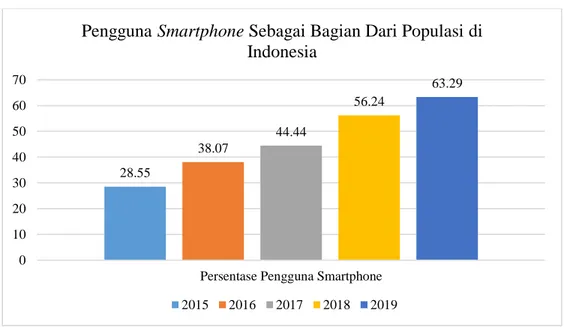
Hal tersebut dibuktikan dengan tingkat banyaknya pengguna smartphone sebagai bagian dari populasi di Indonesia yang meningkat setiap tahunnya seperti pada gambar 1.1. yang didapat dari statista.
Gambar 1.1. Pengguna Smartphone Sebagai Bagian Dari Populasi di Indonesia
Berdasarkan gambar 1.1., pengguna smartphone di Indonesia pada tahun 2015 adalah sebesar 28,55% dari populasi manusia di Indonesia. Kemudian pada tahun 2017 ada sebanyak 44,44%. Dan pada tahun 2019 ada sebanyak 63,29%.
28.55
38.07
44.44
56.24
63.29
0 10 20 30 40 50 60 70
Persentase Pengguna Smartphone
Pengguna Smartphone Sebagai Bagian Dari Populasi di Indonesia
2015 2016 2017 2018 2019
Terdapat beberapa sistem operasi smartphone yang ada di Indonesia, yaitu Android, iOS, Blackberry OS, Windows Phone, Symbian OS, Maemo OS, Meego OS, Open WebOS, dan Palm OS. Berdasarkan statista, pada Agustus 2020, Android menguasai lebih dari 90 persen pasar sistem operasi seluler di Indonesia. Pada Android, pengguna melakukan pengunduhan aplikasi melalui Google Play.
Google Play adalah suatu layanan digital yang berisi berbagai macam aplikasi.
Menurut statista, pada tahun 2021 banyaknya aplikasi yang ada pada Google Play adalah sebanyak 2,89 juta aplikasi. Pada Google Play terdapat beberapa kategori aplikasi, yaitu games, edukasi, bisnis, keuangan, kecantikan, makanan & minuman, fotografi, dll.
Masyarakat Indonesia mulai sadar akan kecantikan. Hal ini dibuktikan dengan data populasi perempuan menurut Badan Pusat Statistik (BPS) dan penjualan produk kosmetik di Indonesia menurut tirto.id yang didapat dari Statista. Gambar 1.2.
merupakan data jumlah populasi perempuan di Indonesia.
Gambar 1.2. Jumlah Populasi Perempuan di Indonesia
131,879.20
133,416.90 133,542.00
131,000.00 131,500.00 132,000.00 132,500.00 133,000.00 133,500.00 134,000.00
Ribu Jiwa
Tahun
Jumlah Populasi Perempuan di Indonesia
2018 2019 2020
Berdasarkan gambar 1.2., didapat bahwa jumlah populasi perempuan terus meningkat. Pada tahun 2018 ada sebanyak 131.879.200 jiwa perempuan di Indonesia.
Pada tahun 2019, terdapat 133.416.900 jiwa perempuan di Indonesia. Pada tahun 2020 terdapat 133.542.000 jiwa perempuan di Indonesia.
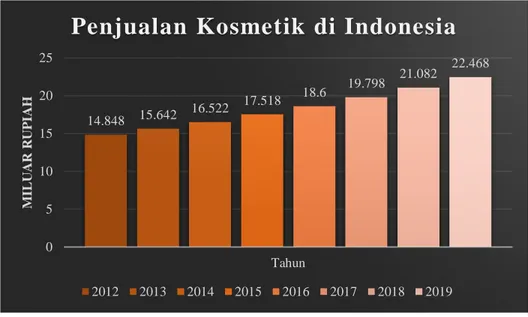
Gambar 1.3. Penjualan Kosmetik di Indonesia
Berdasarkan gambar 1.3., penjualan kosmetik di Indonesia terus meningkat di setiap tahunnya. Tirto.id menyebutkan pada tahun 2012, penjualan produk kecantikan adalah sebesar 14,848 Miliar Rupiah pada tahun 2015 naik menjadi sebesar 17,518 Miliar Rupiah, pada tahun 2017 naik menjadi sebesar 19,798 Miliar Rupiah, dan pada tahun 2019 naik menjadi sebesar 22,468 Miliar Rupiah (Gumiwang,2019).
Menurut survei ZAP beauty index pada tahun 2018, didapatkan bahwa 73,2%
wanita mencari review produk terlebih dahulu sebelum membeli sebuah produk kecantikan secara online maupun offline. Karena hal tersebut, masyarakat membutuhkan wadah yang menyediakan review mengenai produk.
14.848 15.642 16.522 17.518 18.6 19.798 21.082 22.468
0 5 10 15 20 25
Tahun
MILUAR RUPIAH
Penjualan Kosmetik di Indonesia
2012 2013 2014 2015 2016 2017 2018 2019
Menurut similarweb, aplikasi mengenai kecantikan peringkat pertama yang ada di Indonesia adalah aplikasi Female Daily. Aplikasi Female Daily menyediakan editorial, forum diskusi, dan review produk sehingga para pengguna dapat mengetahui informasi dan berdiskusi mengenai suatu produk kecantikan tersebut. Berdasarkan ulasan setahun terakhir, aplikasi Female Daily mendapatkan rating rata-rata sebesar 3,27 dari 5 pada situs Google Play. Angka tersebut tergolong rendah, sehingga Female Daily ingin memperbaiki performansi dari aplikasinya. Hal yang dapat dilakukan adalah dengan mengetahui alasan para pengguna memberikan ulasan positif dan negatif.
Untuk mengetahui alasan para pengguna memberikan ulasan positif dan negatif, perlu dilakukan analisis sentimen dan proses klasifikasi. Analisis sentimen adalah mendapatkan pendapat seseorang mengenai suatu entitas tertentu. Entitas tersebut bisa berupa produk, masalah, individu, layanan, peristiwa, topik, dan atribut lainnya. Analisis sentimen dapat digunakan perusahaan untuk menganalisis pemikiran konsumen mengenai produk ataupun layanan perusahaan tersebut. Proses klasifikasi ulasan mengenai aplikasi Female Daily dapat dilakukan dengan menggunakan machine learning.
Machine learning adalah aplikasi dari artificial intelligence (AI) yang membangun sistem yang belajar secara otomatis dan mampu untuk meningkatkan kemampuannya berlandaskan pengalaman yang ada pada masa lalu. Pada machine learning, terdapat beberapa algoritma yang dapat melakukan proses klasifikasi, salah satunya adalah Naïve Bayes. Klasifikasi dengan Algoritma Naïve Bayes pada umumnya menggunakan metode pendekatan peluang dan statistik.
Algoritma Naïve Bayes memiliki beberapa kelebihan, yaitu mudah untuk dimengerti, tidak membutuhkan data latih dalam jumlah besar, cepat dan efisien (Pane et al., 2020). Berdasarkan beberapa penelitian sebelumnya, algoritma Naïve Bayes memiliki nilai akurasi yang lebih tinggi dibanding algoritma lainnya. Salah satunya adalah penelitian yang dilakukan oleh Waliansyah dan Fitriyah pada tahun 2019 terbukti algoritma Naïve Bayes memiliki tingkat akurasi paling tinggi, yaitu 82,7%
dibandingkan algoritma k-Nearest Neighbor (k-NN) sebesar 70%. Contoh penelitian lainnya dilakukan oleh Lasulika pada tahun 2019 terbukti bahwa Algoritma Naïve Bayes mempunyai akurasi paling tinggi sebesar 96% dibandingkan algoritma lainnya seperti k-NN sebesar 92% dan Support Vector Machine (SVM) sebesar 66%.
Melalui penelitian Analisis Sentimen Data Review Aplikasi Female Daily pada Website Google Play menggunakan Algoritma Naïve Bayes diharapkan mampu mengklasifikasikan teks mengenai aplikasi Female Daily sehingga dapat mengekstrak informasi yang ada di dalamnya dan penyampaian informasi dari penelitian ini dapat berguna bagi pihak-pihak yang membutuhkannya.
1.2. Rumusan Masalah
Berdasarkan latar belakang yang telah dijabarkan, berikut merupakan rumusan masalah dari penelitian ini, yaitu :
1. Bagaimana gambaran umum tentang aplikasi Female Daily pada situs Google Play dengan menggunakan algoritma Naïve Bayes?
2. Bagaimana pengklasifikasian data opini para pengguna mengenai aplikasi Female Daily dengan menggunakan metode Naïve Bayes?
3. Mengapa pengguna dapat memberikan ulasan positif atau negatif?
1.3. Tujuan Penelitian
Tujuan umum dari penelitian ini adalah untuk mengidentifikasi alasan para pengguna memberikan ulasan positif dan negatif.
Adapun tujuan khusus dari penelitian ini adalah :
1. Mengidentifikasi persepsi pengguna aplikasi Female Daily pada situs Google Play menurut algoritma Naïve Bayes
2. Menghitung tingkat keakuratan dari hasil analisis sentimen menggunakan algoritma Naïve Bayes
3. Mengidentifikasi apa saja yang membuat para pengguna memberikan ulasan positif dan negatif
1.4. Manfaat Penelitian
Manfaat yang didapat dalam melakukan penelitian ini adalah sebagai berikut : 1. Penelitian ini bermanfaat sebagai tambahan referensi di Departemen Teknik
Industri bagi yang ingin melakukan penelitian mengenai analisis sentimen dengan menggunakan algoritma Naïve Bayes.
2. Hasil penelitian ini bisa dijadikan sebagai bahan pertimbangan bagi perusahaan dalam pengambilan keputusan tentang analisis sentimen yang dapat digunakan untuk memperbaiki performasi secara keseluruhan.
3. Meningkatkan pengetahuan dan wawasan mahasiswa dalam mengimplementasikan teori yang diperoleh dalam perkuliahan, terutama mengenai algoritma Naïve Bayes.
1.5. Batasan Masalah dan Asumsi
Berikut merupakan batasan masalah yang ditentukan dalam penelitian ini : 1. Data yang digunakan adalah data ulasan aplikasi Female Daily pada website
Google Play pada tanggal 1 April 2020 – 1 April 2021.
2. Variabel yang diambil antara lain nama pengguna, rating yang diberikan, tanggal pengguna mengunggah ulasan, dan ulasan.
3. Dalam pengklasifikasian data, digunakan algoritma Naïve Bayes
Berikut merupakan asumsi-asumsi yang digunakan dalam penelitian ini : 1. Data diperoleh dari sumber yang valid.
2. Hubungan antar variabel memiliki hubungan yang positif.
II-1 2.1. Female Daily
Aplikasi Female Daily adalah platform kecantikan yang menyediakan fitur yang membuat para penggunanya dapat berinteraksi satu sama lain. Aplikasi Female Daily menyediakan blog atau editorial, forum diskusi, serta ulasan produk sehingga para pengguna dapat mengetahui informasi dan berdiskusi mengenai suatu produk kecantikan tersebut. Female Daily adalah salah satu wadah kecantikan yang paling populer di Indonesia. Hanifa Ambadar merupakan founder sekaligus Chief Executive Officer (CEO) dari Female Daily. Female Daily juga merupakan salah satu perusahaan berbasis komunitas yang terkemuka untuk perempuan mengenai kecantikan.
Female Daily pada awalnya merupakan blog pribadi milik Hanifa Ambadar yang bertopik fashion dan kecantikan. Alasan Hanifa membuat blog dengan tema tersebut adalah karena banyaknya teman dan kerabat Hanifa yang berada di Jakarta bertanya mengenai fashion trend yang sedang terjadi di Amerika Serikat. Hanifa sendiri memang sedang melakukan studi S2 di Marville University yang berada di St. Louis, Amerika Serikat. Pada tahun 2006, Hanifa kemudian bergabung dengan temannya, Affi Asegaf yang juga menulis di blog pribadinya. Mereka berdua membentuk satu blog bernama fashionesedaily.com. Karena banyaknya peminat dari blog tersebut, Hanifa dan Affi memutuskan untuk membentuk sebuah
komunitas pada tanggal 27 Mei 2007. Komunitas tersebut bernama Female Daily.
Female Daily dapat diakses pada www.femaledaily.com. Pada hari pertama komunitas dibentuk, terdapat kurang lebih 50 orang yang mendaftar.
sumber : femaledaily.com
Gambar 2.1. Logo Female Daily
Aplikasi Female Daily diluncurkan pada tahun 2016. Pada aplikasi Female Daily, para pengguna dapat memperoleh dan mencari berbagai informasi mengenai kecantikan. Dengan memperoleh informasi tersebut, para pengguna dapat mengambil keputusan dalam menentukan produk mana yang ingin dibeli atau digunakan oleh pengguna (Ekaputri, et al., 2020). Produk kecantikan tersebut berupa make up, perawatan kulit (skincare), perawatan rambut (haircare), dan perawatan tubuh (bodycare).
2.2. Google Play
Google Play merupakan suatu digital service yang didalamnya meliputi toko online berupa games, film, buku, dan aplikasi lainnya. Google Play bisa diakses melalui berbagai cara, yaitu situas, Google television (TV), dan aplikasi andoid berupa Play Store. Pada tanggal 22 Oktorber 2018 pertama kali Google Play diluncurkan. Terdapat kurang lebih 700.000 aplikasi yang terdapat pada Google Play (Setiawan, 2021).
Google Play juga bisa digunakan sebagai sarana untuk timbal balik, misalkan aplikasi atau software yang kita buat dipublikasikan di Google Play, kemudian kita bisa melihat ulasan-ulasan dari para pengguna yang telah memakai aplikasi, seberapa efisien, apakah ada bug, ataupun kekurangan dan kelebihan dari aplikasi tersebut (Sulistiowati, 2019). Pada penelitian ini, akan diambil data ulasan para pengguna mengenai aplikasi Female Daily.
2.3. Analisa Sentimen
Pada era sekarang ini, banyak orang yang menyampaikan pendapat ataupun pikirannya kepada orang lain yang bahkan tidak dikenalnya melalui internet.
Pencarian informasi dilakukan dengan mengetahui pendapat orang lain mengenai suatu hal. Dengan teknologi informasi terkini kita dapat mengembangkan sistem yang dapat mengerti tentang pikiran orang lain secara otomatis dan memberikan penilaian mood pada pendapat seseorang yang ada di internet. Analisis mood pada pendapat disebut dengan Analisis Sentimen, yaitu analisis pada klasifikasi teks tentang teks yang dinilai secara otomatis berdasarkan sifatnya (Simanjuntak,2018).
Analisis sentimen juga mendapatkan pendapat seseorang mengenai suatu entitas tertentu. Entitas tersebut bisa berupa produk, masalah, individu, layanan, peristiwa, topik, dan atribut lainnya (Misprajiko, 2018).
Besarnya manfaat dan pengaruh dari analisis sentimen menyebabkan penelitian mengenai analisis sentimen berkembang pesat, bahkan di Amerika terdapat kurang lebih 30 perusahaan yang memanfaatkan analisis sentimen dalam
mendapatkan informasi mengenai opini masyarakat terhadap suatu produk ataupun service perusahaan (Simanjuntak,2018).
2.4. Kecerdasan Buatan (Artificial Intelligence)
Komputer pada awalnya digunakan hanya untuk membantu manusia yang dapat dilakukan lebih baik oleh manusia. Namun seiring berjalannya waktu, komputer memilki peran lebih pada kehidupan manusia. Komputer tidak lagi hanya digunakan sebagai alat hitung.
Kecerdasan buatan adalah salah satu ilmu komputer mengenai cara membuat komputer (mesin) mampu untuk melakukan pekerjaan seperti manusia ataupun lebih baik. Menurut John McCarthy, kecerdasan buatan mempunyai tujuan agar dapat membuat model proses berpikir manusia dan merancang mesin yang mampu menyerupai perilaku manusia.
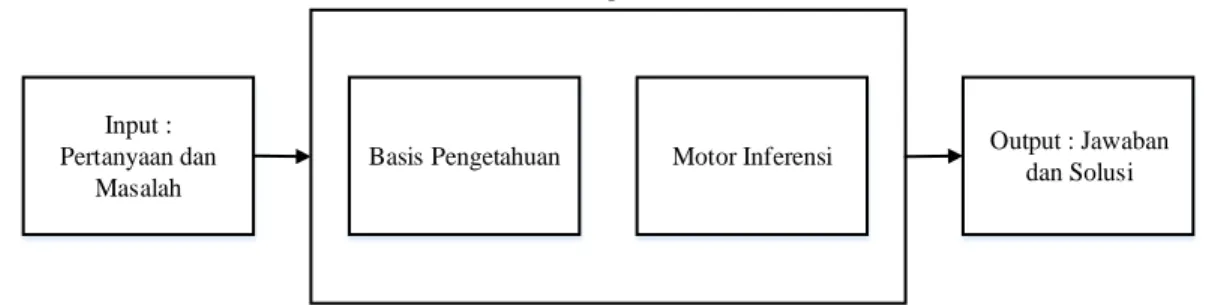
Terdapat 2 hal yang dibutuhkan untuk menjadi bagian utama dalam perancangan aplikasi artificial intelligence (AI), yaitu :
1. Basis Pengetahuan (Knowledge Based), merupakan bagian yang berisi data, hubungan antara satu dan yang lainnya, fakta, dan teori.
2. Motor Infrensi (Inference Engine), merupakan kapabilitas dalam menarik kesimpulan berdasarkan pengalaman.
Input : Pertanyaan dan
Masalah
Basis Pengetahuan Motor Inferensi Output : Jawaban dan Solusi Komputer
Gambar 2.2. Bagian Utama dalam Kecerdasan Buatan
Berdasarkan gambar 2.2. dapat dilihat bahwa kecerdasan buatan diawali dari input berupa pertanyaan dan masalah yang ada, kemudian diproses menggunakan komputer dengan basis pengetahuan dan motor inferensi. Kemudian akan membuahkan hasil menjadi output berupa jawaban dan solusi (Nurhikmat, 2018).
2.5. Machine Learning
Machine learning diawali oleh Warren Mc Culloch yang menjelaskan konsep dari jaringan saraf. Machine learning merupakan aplikasi dari artificial intelligence (AI) yang membangun sistem yang mampu belajar secara otomatis dan mampu untuk meningkatkan kemampuannya berlandaskan pengalaman tanpa harus diprogram secara eksplisit. Machine learning memiliki fokus pada perkembangan sebuah program komputer yang memiliki kemampuan dalam mengakses dan mempelajari data tersebut.
Machine learning juga merupakan algoritma yang mempunyai maksud untuk menemukan dan melaksanakan model-model di dalam data. Teknik statistik
digunakan dalam menemukan model-model tersebut. Secara sederhana machine learning membuat komputer berperilaku seperti manusia. Kinerja tersebut bisa didapat dengan menganalisis data yang ada secara terus-menerus (Kusuma, 2020).
2.6. Data Mining
Data mining adalah proses mengekstrak atau mengumpulkan data-data yang dibutuhkan dari berbagai perspektif, yang kemudian disatukan ke dalam suatu basis data yang berguna. Pada prosesnya informasi tersebut akan dianalisa apakah ada hubungan ataupun pola-pola tertentu dari suatu data (Siregar dan Puspabhuana, 2017).
Berikut adalah karakteristik data mining, yaitu :
1. Data mining adalah hubungan keterkaitan dalam invensi suatu pola yang tersembunyi.
2. Data mining biasanya memanfaatkan data dalam jumlah besar.
3. Data mining berperan dalam pembuatan keputusan.
2.7. Metode Pelatihan
Pada umumnya, metode pelatihan dalam data mining dibedakan menjadi 2, yaitu :
1. Unsupervised learning
Unsupervised learning adalah metode yang dilakukankan tanpa menggunakan guru (teacher) dan latihan (training). Maksud dari guru adalah kelas dari data yang ada.
2. Supervised learning
Supervised learning adalah metode yang dilakukan dengan menggunakan guru (teacher) dan latihan (training). Di dalam pendekatan ini digunakan beberapa contoh data yang memiliki akhiran selama terjadinya latihan untuk mendapatkan fungsi regresi, fungsi pemisah, atau fungsi keputusan (Ridwan, et al., 2013).
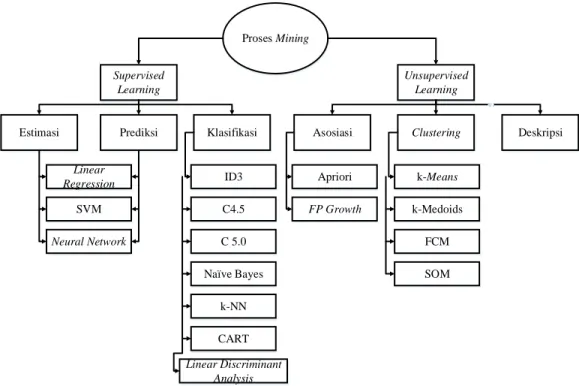
2.8. Teknik Data Mining
Berikut merupakan teknik-teknik dari data mining berdasarkan pekerjaan yang dapat dilakukan, yaitu :
1. Estimasi
Pada estimasi, variabel tujuan estimasi umumnya lebih kearah numerik dibanding kategori.
2. Prediksi
Prediksi adalah teknik yang dilakukan untuk mengetahui hal yang akan terjadi di kemudian hari. Prediksi mempunyai kesamaan dengan klasifikasi dan estimasi.
3. Klasifikasi
Pada klasifikasi variabel, tujuan bersifat kategorik. Contohnya, sebuah perusahaan ingin mengklasifikasikan besar tanah ke dalam tiga kelas, yaitu, luas, lumayan luas, dan sempit (Ridwan et al., 2013). Klasifikasi juga merupakan teknik yang berfungsi untuk memprediksi variabel target berdasarkan variabel input. Prediksi dari klasifikasi didasarkan pada model
yang dibangun dari kumpulan data yang sebelumnya telah ada (dikenal).
Klasifikasi memprediksi variabel output dengan tipe data kategorikal ataupun polinominal (misalnya, prediksi keputusan ya atau tidak dalam menyetujui pinjaman) (Misprajiko, 2018).
4. Clustering
Pada clustering dilakukan pengamatan, pengelompokan record, ataupun kasus dalam kelas/label yang memiliki kesamaan.
5. Asosiasi
Asosiasi dilakukan dengan menemukan hubungan antara kasus-kasus berbeda yang terjadi di satu waktu.
6. Deskripsi
Maksud dari deskripsi adalah mendapatkan cara untuk memaparkan trend dan pola yang tersembunyi di dalam data.
Proses Mining
Supervised Learning
Unsupervised Learning
Estimasi Prediksi Klasifikasi Asosiasi Clustering Deskripsi
Linear Regression
SVM Neural Network
ID3 C4.5 C 5.0 Naïve Bayes
k-NN
CART Linear Discriminant
Analysis
Apriori FP Growth
k-Means k-Medoids
FCM SOM
U J
Gambar 2.3. Teknik Data Mining
2.9. Text Mining
Ada beberapa teknik yang dilakukan dalam klasifikasi, salah satunya adalah text mining. Text mining merupakan jenis dari data mining yang berguna untuk mengidentifikasi pola-pola yang tersembunyi dan menarik yang diambil dari gabungan data dalam bentuk teks yang berjumlah besar (Ratniasih, et al., 2017).
Umumnya, ada dua pekerjaan pada text mining, yaitu penggalian prediktif (predictive mining) dan penggalian deskriptif (descriptive mining).
Ada beberapa perkerjaan yang dilakukan pada penggalian prediktif, yaitu pengklasifikasian data ke dalam beberapa bagian, yang kemudian akan digunakan dalam membuat keputusan. Contohnya, pembelian pelanggan akan suatu produk bisa diprediksi melalui data ulasan pembelian mengenai kepuasan pelanggan akan
produk atau layanan yang diberikan. Kemudian dilakukan penggalian deskriptif yang berguna untuk mengelompokkan data berdasarkan bagian atau konsep yang sudah ditentukan (Simanjuntak, 2018).
2.10. Web Scraping
Dalam mengambil data yang ada di internet, dilakukanlah web scraping.
Biasanya data yang diambil berbentuk halaman-halaman web dalam bahasa markup seperti Extensible HyperText Markup Language (XHTML) atau HyperText Markup Language (HTML). Data yang ada di internet umumnya adalah data semi- terstruktur. Kemudian data yang telah dilakukan web scraping digunakan untuk keperluan lain. Tools scraping banyak digunakan di dalam penelitian untuk mengumpulkan data dari web tertentu (Ayani et al., 2019). Dalam penelitian ini, dilakukan web scraping pada situs Google Play.
2.11. Google Colab
Google Colab merupakan sebuah alat yang diciptakan oleh Google Internal Research. Google Colab merupakan alat berbasis cloud yang dapat digunakan secara gratis. Google Colab diciptakan khusus agar programmer ataupun peneliti yang sulit yang tidak memiliki akses ke perangkat dengan spesifikasi yang tinggi.
Bahasa pemrograman Phyton dengan menggunakan format notebook adalah coding environment dari Google Colab.
Ada beberapa manfaat dari menggunakan Google Colab, yaitu :
1. Mudah untuk Berintegrasi
Dengan menggunakan Google Colab, peneliti dapat dengan mudah mempertautkan dengan Jupyter Notebook di perangkat dengan local runtime. Google Colab juga dapat dihubungkan dengan Google Drive.
2. Fleksibel
Google Colab dapat melakukan run sebuah program melalui telepon genggam dengan mudah. Google Colab bisa diakses melalui browser, sehingga para programmer dapat melakukan running pada telepon genggam selama telepon genggam tersebut terhubung dengan Google Drive yang sama.
3. Kolaborasi
Dengan menggunakan Google Colab, seorang programmer dapat melakukan kolaborasi dengan orang ataupun programmer lain. Hal tersebut bisa dilakukan dilakukan bahkan secara online (Rahcmadani, 2020).
2.12. Preprocessing
Preprocessing adalah tahapan yang menghilangkan error (noise), menghapus data duplikat, dan memperbaiki kesalahan pada data, dan memeriksa data yang tidak konsisten seperti salah ketik (Dan, et al., 2015). Tahapan yang dilakukan pada preprocessing adalah case folding, tokenizing, spelling normalization, filtering dan stemming.
2.12.1. Case folding
Case folding adalah tahap yang dilakukan untuk mengganti semua huruf
yang ada di dalam data menjadi huruf kecil (Fatmawati dan Affandes, 2017). Semua karakter dihapuskan, kecuali huruf.
2.12.2. Tokenizing
Tokenizing adalah tahapan dilakukannya pemisahan terhadap kalimat data ulasan menjadi sebuah kata tunggal. Pada tahapan tokenizing juga menghapus beberapa karakter pada kalimat, yaitu angka, tanda baca, dan lainnya. (Fatmawati dan Affandes, 2017).
2.12.3. Spelling Normalization
Spelling normalization merupakan tahapan untuk membenahi kata yang tidak sesuai dengan penulisan kata yang seharusnya, contohnya “yg” diganti menjadi “yang” (Fatmawati dan Affandes, 2017).
2.12.4. Filtering
Filtering adalah tahap pengambilan kata-kata penting dari hasil proses penghapusan stopwords. Stopwords adalah kata umum yang dianggap tidak mempunyai arti (unik) dari suatu data. Filtering bisa dilakukan dengan menggunakan algoritma stop list atau word list (Ratniasih, et al., 2017).
2.12.5. Stemming
Stemming adalah tahap dimana kata-kata yang berimbuhan diganti menjadi ke bentuk kata dasar (Fatmawati dan Affandes, 2017). Contohnya, kata
“tergantikan” diubah menjadi “ganti”.
2.13. Term Frequency (TF)
Term frequency adalah frekuensi munculnya sebuah kata pada data yang bersangkutan. Semakin besar jumlah munculnya sebuah kata tersebut (TF tinggi) di dalam data, maka semakin besar pula bobot dan nilai kesesuaian yang akan diberikan (Simanjuntak, 2018).
Berikut merupakan beberapa macam formula dalam Term frequency (TF) yang dapat digunakan, yaitu :
1. Binary TF (TF biner), pada TF ini, dilakukan pemeriksaan terhadap apakah suatu kata ada atau tidak di dalam data, bila tidak ada maka diberi nilai nol (0), namun bila ada maka diberi nilai satu (1).
2. Raw TF (TF murni), nilai TF diberikan berdasarkan jumlah munculnya suatu kata di dalam data. Misalnya, jika sebuah kata muncul empat (4) kali, maka kata tersebut bernilai empat (4).
3. TF logaritmik, TF ini digunakan untuk menghindari dominansi data yang mempunyai sedikit kata dalam query, tetapi memiliki frekuensi yang tinggi.
4. TF normalisasi, digunakan dengan membandingkan frekuensi suatu kata dengan nilai maksimum yang ada dengan keseluruhan frekuensi kata yang ada pada data tersebut.
2.14. Algoritma Naïve Bayes
Algoritma Naïve Bayes adalah salah satu metode klasifikasi dari artifical intelligence (AI) dan data mining. Naïve Bayes menggunakan metode statistik dan peluang. Naïve Bayes juga merupakan suatu kelas keputusan, memanfaatkan kalkulasi probabilitas matematika dengan kondisi bahwa berdasarkan informasi obyek, nilai keputusan adalah benar (Putri, 2017).
Naïve Bayes classification didasari pada teori Bayes yang mempunyai kapabilitas klasifikasi yang sama dengan decision tree dan neural network.
Klasifikasi dengan Algoritma Naïve Bayes umumnya menggunakan metode pendekatan peluang dan statistik. Algoritma Naïve Bayes ditemukan oleh seorang ilmuwan yang berasal dari inggris, yaitu Thomas Bayes. Kecepatan dan akurasi yang tinggi terbukti dapat diperoleh dengan metode Naïve Bayes bahkan pada data yang berjumlah besar. Berdasarkan hal yang sudah terjadi di masa lalu, algoritma Naïve Bayes dapat meramalkan pendekatan peluang yang akan terjadi di masa depan (Balya, 2019).
Berikut merupakan tahapan algoritma Naïve Bayes, yaitu:
1. Menghitung jumlah class/label.
2. Menghitung jumlah kasus yang sama dengan class/label yang sama.
3. Mengalikan semua variabel class/label.
4. Membandingkan hasil dari semua variabel.
Terdapat persamaan pada Algoritma Naïve Bayes classification yang bisa dijadikan rujukan dalam menghitung nilai probabilitas untuk pengambilan suatu keputusan (Balya, 2019). Berikut merupakan persamaannya :
P(X|H)= P(H|X),P(X) P(H) Keterangan :
X : Data dengan label yang belum diketahui
H : Hipotesis data X adalah suatu class/label spesifik P(H|X) : Probabilitas hipotesis H berdasarkan kondisi X P(H) : Probabilitas hipotesis H
P(X|H) : Probabilitas X berdasarkan kondisi pada hipotesis H P(X) : Probabilitas X
Algoritma Naïve Bayes memiliki beberapa kelebihan, yaitu : 1. Tidak membutuhkan data latih yang banyak
2. Mudah untuk dimengerti
3. Dalam melakukan perhitungan lebih cepat 4. Pengkodean yang digunakan sederhana
Selain memiliki kelebihan, algoritma Naïve Bayes juga memiliki kekurangan, yaitu jika probabilitasnya adalah 0, maka algoritma tidak dapat memprediksi data tersebut (Pane, 2020).
2.15. Evaluasi Klasifikasi
Evaluasi klasifikasi algoritma Naive Bayes dilakukan dengan menggunakan nilai akurasi, precision, recall, dan F1-score. Akurasi adalah jumlah banyaknya prediksi yang benar dibandingkan dengan prediksi yang salah. Berikut merupakan rumusnya.
Accuracy = (TP+TN)/(TP+FN+FP+TN)
Precision adalah perbandingan antara yang diprediksi benar positif dengan keseluruhan hasil yang diprediksi positif.
Precision = (TP)/(TP+FP)
Recall adalah perbandingan antara hasil prediksi benar positif dengan keseluruhan data yang benar-benar positif.
Recall = (TP)/(TP+FN)
F1-score adalah perbandingan antara rata-rata precision dan recall yang dibobotkan (Suprayogi, 2021).
F1-score = 2*(Recall*Precission)/(Recall + Precission) Dimana :
True Positive (TP) : kasus dimana ulasan diprediksi positif, memang benar positif.
True Negative (TN) : kasus dimana ulasan diprediksi negatif dan sebenarnya ulasan tersebut memang negatif.
False Positive (FP) : kasus dimana ulasan yang diprediksi positif, ternyata tidak, prediksinya salah (negatif).
False Negative (FN): kasus dimana ulasan yang diprediksi tidak negatif, tetapi ternyata sebenarnya positif.
2.16. Review Hasil Penelitian
Berikut ini merupakan penelitian-penelitian yang memiliki kaitan dengan Analisis Sentimen Data Review Aplikasi Female Daily pada Website Google Play Menggunakan Algoritma Naïve Bayes :
1. Simanjuntak melakukan penelitian pada tahun 2018 mengenai Analisis Sentimen pada Layanan Gojek Indonesia Menggunakan Multinomial Naïve Bayes. Tujuan penelitian ini adalah untuk mendapatkan opini masyarakat mengenai kualitas dari beberapa layanan gojek Indonesia apakah positif, negatif atau netral dengan menggunakan algoritma Multinomial Naïve Bayes Classifier. Perusahaan Gojek ingin mengetahui apa saja yang perlu diperbaiki dari kualitas dan pelayanannya. Pengujian dengan Multinomial Naïve Bayes yang dilakukan pada layanan Gojek mendapatkan akurasi sebesar 92,30%.
2. Putri melakukan penelitian pada tahun 2017 mengenai Penerapan Naïve Bayesian untuk Perankingan Kegiatan di Fakultas TIK Universitas Semarang. Tujuan penelitian ini adalah suatu perankingan berdasarkan favorit mana yang mempunyai peminat yang paling banyak. Hal ini dapat memacu program studi lain untuk lebih semangat dalam meningkatkan ilmu pengetahuan baru bagi mahasiswa, dan menyelenggarakan kegiatan yang menarik mahasiswa.
3. Rozi, Hamdana, dan Alfahmi melakukan penelitian pada tahun 2018 mengenai Pengembangan Aplikasi Analisis Sentimen Twitter Menggunakan Metode Naïve Bayes Classifier (Studi Kasus SAMSAT Kota
Malang). Tujuan penelitian ini adalah membangun aplikasi sentimen yang menerapkan metode Naïve Bayes classifier untuk mengklasifikasikannya.
Hasil akurasi tertinggi yang didapat yaitu kategori positif terdapat 82%, negatif terdapat 92%, dan netral terdapat 80%.
4. Misprajiko melakukan penelitian pada tahun 2018 mengenai Implementasi Metode Naïve Bayes untuk Analisis Sentimen Data Evaluasi Kinerja Dosen pada Sistem Kuesioner Berbasis Web. Tujuan penelitian ini adalah untuk membuat sistem kuesioner berbasis web yang dilengkapi dengan analisis sentimen menggunakan metode Naïve Bayes. Hasil dari keakuratan algoritma Naïve Bayes dalam melakukan penelitian ini adalah sebesar 83,50%.
5. Flores, Jasa, dan Linawati melakukan penelitian mengenai Analisis Sentimen untuk Mengetahui Kelemahan dan Kelebihan Pesaing Bisnis Rumah Makan Berdasarkan Komentar Positif dan Negatif di Instagram.
Tujuan penelitian ini adalah untuk mengidentifikasi kelemahan dan kelebihan dapat dilakukan dengan mengumpulkan data dari komentar- komentar yang ada pada akun Instagram pesaing, dengan menggunakan teknik Text Preprocessing. Hasil dari penelitian adalah keakuratan dari teknik tersebut adalah sebesar 85%.
6. Devita, Herwanto dan Wibawa melakukan penelitian pada tahun 2018 mengenai Perbandingan Kinerja Metode Naïve Bayes dan k-Nearest Neighbor untuk Klasifikasi Artikel Berbahasa Indonesia. Tujuan penelitian ini adalah untuk melakukan klasifikasi, yaitu mengelompokkan artikel-
artikel jurnal berdasarkan judul dan isi dengan akurat dan otomatis. Artikel- artikel tersebut dibagi menjadi beberapa klasifikasi, yaitu pendidikan ekonomi, pendidikan bisnis manajemen, akuntasi aktual, dan ekonomi bisnis. Dalam menyelesaikan masalah tersebut, digunakan algoritma k- Nearest Neighbor dan Naïve Bayes pada penelitian ini. Terbukti bahwa Naïve Bayes tingkat akurasinya lebih tinggi dengan bernilai 70%, yaitu sebanyak 28 artikel yang benar dari 40 artikel. Sedangkan nilai akurasi yang didapat dari k-Nearest Neighbor adalah sebesar 40%, yaitu sebanyak 16 artikel dari 40 artikel.
7. Nurdiana dan Algifari melakukan penelitian pada tahun 2020 mengenai Studi Komparasi Algoritma ID3 dan Algoritma Naïve Bayes untuk Klasifikasi Penyakit Diabetes Mellitus. Tujuan dari penelitian ini adalah untuk mengklasifikasikan prediksi akan terjadinya penyakit diabetes mellitus. Penelitian ini menggunakan algoritma Naïve Bayes dan Iterative Dichotomiser 3 (ID3). Penelitian ini menggunakan aplikasi Jupyter Notebook dengan bahasa pemrograman Phyton . Pada penelitian ini didapat Algoritma Naïve Bayes yang memiliki nilai akurasi paling tinggi, yaitu sebesar 76%. Sedangkan dengan algoritma ID3, didapat nilai akurasi sebesar 74%.
8. Waliansyah dan Firtriyah melakukan penelitian pada tahun 2019 mengenai Perbandingan Akurasi Klasifikasi Citra Kayu Jati Menggunakan Metode Naïve Bayes dan k-Nearest Neighbor (k-NN). Jenis kayu ada banyak sekali di Indonesia, pada penelitian ini, akan dilakukan pengelompokkan kayu jati
dengan menggunakan algoritma Naïve Bayes dan k-Nearest Neighbor (k- NN). Kayu jati tersebut dikelompokkan menjadi 3, yaitu sulawesi, semarangan dan blora. Terbukti bahwa algoritma Naïve Bayes memiliki tingkat akurasi yang lebih tinggi dibandingkan k-NN. Dengan k-NN, didapat tingkat akurasi sebesar 70% sedangkan Naïve Bayes sebesar 82,7%
9. Lasulika melakukan penelitian pada tahun 2019 mengenai Komparasi Naïve Bayes, Support Vector Machine (SVM) dan k-Nearest Neighbor untuk Mengetahui Akurasi Tertinggi pada Prediksi Kelancaran Pembayaran TV Kabel. Tujuan dari penelitian ini adalah agar dapat memprediksi seberapa lancar pembayaran nasabah dari perusahaan. Penelitian ini menggunakan tiga jenis klasifikasi, yaitu Naïve Bayes, SVM dan k-NN.
Berdasarkan penelitian didapat bahwa algoritma Naïve Bayes memiliki tingkat akurasi paling tinggi, yaitu sebesar 96%, yang diikuti dengan k-NN sebesar 92%, dan yang terakhir dengan SVM sebesar 66%.
10. Kadafi melakukan penelitian pada tahun 2018 mengenai Perbandingan Algoritma untuk Klasifikasi Nilai pada Penjurusan Siswa SMA. Tujuan penelitian ini adalah untuk mengetahui pelajaran apa yang paling mempengaruhi siswa dalam menentukan penjurusan. Metode yang digunakan adalah dengan menggunakan algoritma Naïve Bayes, k-NN, C4.5, Rule Induction, dll. Berdasarkan penelitian ini, terbukti bahwa algoritma Naïve Bayes yang memiliki tingkat akurasi paling tinggi, yaitu sebesar 79,51%. Sedangkan dengan algoritma k-NN, didapat tingkat akurasi sebesar 77,86%, algoritma C4.5 tingkat akurasi sebesar 77,09%, dan
algoritma Rule Induction sebesar 75,57%. Didapatkan juga bahwa mata pelajaran yang paling berpengaruh dalam penjurusan siswa SMA adalah mata pelajaran fisika.
2.17. Kerangka Konseptual
Kerangka konseptual adalah bentuk kerangka berpikir yang digunakan untuk pendekatan ilmiah dan memperlihatkan hubungan antar variabel-variabel yang ada pada penelitian. Gambar 2.4. merupakan kerangka konseptual pada penelitian ini.
Data Training
Data Testing
Akurasi Klasifikator Algoritma Naïve
Bayes
Hasil Prediksi
Alasan Pengguna memberikan Ulasan
Positif dan Negatif
Gambar 2.4. Kerangka Konseptual
Variabel adalah segala sesuatu yang dapat memiliki nilai yang berbeda- beda (variasi). Variabel terbagi menjadi beberapa jenis, yaitu variabel independen, variabel dependen, variabel moderator, variabel intervening, dan variabel kontrol.
Variabel independen adalah variabel yang keberadaannya tidak dipengaruhi oleh variabel lainnya, tetapi mempengaruhi variabel dependen. Variabel dependen adalah variabel yang nilainya dipengaruhi oleh variabel lain. Variabel moderator adalah variabel yang mempengaruhi hubungan antara variabel dependen dan independen. Variabel intervening adalah variabel yang mempengaruhi kejadian yang diamati tetapi tidak dapat diukur ataupun dimanipulasi. Variabel kontrol adalah variabel yangdapat dikendalikan dengan tujuan untuk mengetahui pengaruh dari variabel independen terhadap variabel dependen (Sinulingga, 2011).
Berdasarkan gambar 2.4. dapat dilihat bahwa hasil prediksi, akurasi klasifikator, dan alasan pengguna memberikan ulasan positif atau negatif dipengaruhi oleh data yang ada, yaitu data training dan data testing. Maka dengan demikian diketahuilah bahwa variabel data training dan data testing merupakan variabel independen. Data training dan data testing sendiri terdiri dari nama pengguna, rating yang diberikan pengguna, tanggal pengguna mengunggah ulasan, dan ulasan yang diberikan pengguna mengenai aplikasi Female Daily. Sedangkan variabel hasil prediksi, akurasi klasifikator, dan alasan pengguna memberikan ulasan positif atau negatif merupakan variabel dependen.
Hasil prediksi adalah hasil yang didapat mengenai prediksi dari algoritma Naïve Bayes tentang ulasan pengguna berupa positif atau negatif. Akurasi klasifikator adalah tingkat keakuratan dari algoritma Naïve Bayes dalam mengklasifikasikan ulasan pengguna menjadi positif dan negatif. Pada penelitian ini juga terdapat variabel lainnya yang dapat dikendalikan oleh peneliti, yaitu
variabel algoritma Naïve Bayes. Oleh karena itu, algoritma Naïve Bayes adalah variabel kontrol.
III-1
BAB III
METODOLOGI PENELITIAN
3.1. Jenis Penelitian
Penelitian ini menggunakan jenis penelitian deskriptif. Penelitian deskriptif merupakan penelitian yang berupaya untuk menginterpretasi dan menggambarkan objek sesuai dengan yang ada. Penelitian deskriptif juga disebut penelitian survei, yaitu penelitian yang mengumpulkan data untuk mengumpulkan informasi berupa pendapat dari sejumlah orang mengenai suatu topik tertentu (Mustafa, et al., 2020). Penelitian ini menggambarkan secara umum ulasan terhadap aplikasi Female Daily yang terdapat pada website Google Play.
3.2. Lokasi dan Waktu Penelitian
Penelitian ini dilakukan pada website Google Play. Waktu penelitian dilakukan pada bulan April 2021 s/d sekarang.
3.3. Objek Penelitian
Objek dari penelitian ini ulasan mengenai aplikasi Female Daily yang terdapat pada situs Google Play.
3.4. Metodologi Pengumpulan Data
Data primer adalah data yang digunakan dalam penelitian ini. Data primer adalah data yang didapat tidak dari perantara dan diperoleh secara langsung dari sumber. Data primer dapat berbentuk pendapat subjek secara individu ataupun secara kelompok (Mustafa, et al., 2020). Data yang digunakan adalah data yang terdapat di situs Google Play. Data tersebut diperoleh dengan melakukan web scraping pada website Google Play. Data yang diambil dengan cara web scraping adalah data mengenai nama pengguna, tanggal pengguna mengunggah ulasan, rating yang diberikan pengguna, dan ulasan pengguna mengenai aplikasi Female Daily. Data ulasan yang digunakan adalah ulasan pengguna aplikasi Female Daily yang diunggah sejak tanggal 1 April 2020 sampai dengan 1 April 2021, yaitu sebanyak 200 data.
3.5. Metode Analisis Data
Berikut merupakan metode analisis data yang digunakan dalam penelitian ini, yaitu :
1. Analisis deskriptif, digunakan untuk menggambarkan secara umum persepsi pengguna aplikasi Female Daily melalui ulasan yang ada di situs Google Play.
2. Metode Machine learning yaitu Naïve Bayes yang berguna untuk mengklasifikasikan ulasan ke dalam bentuk positif dan negatif.
3. Analisis keakuratan algoritma Naïve Bayes dalam mengklasifikasikan data ulasan aplikasi Female Daily.
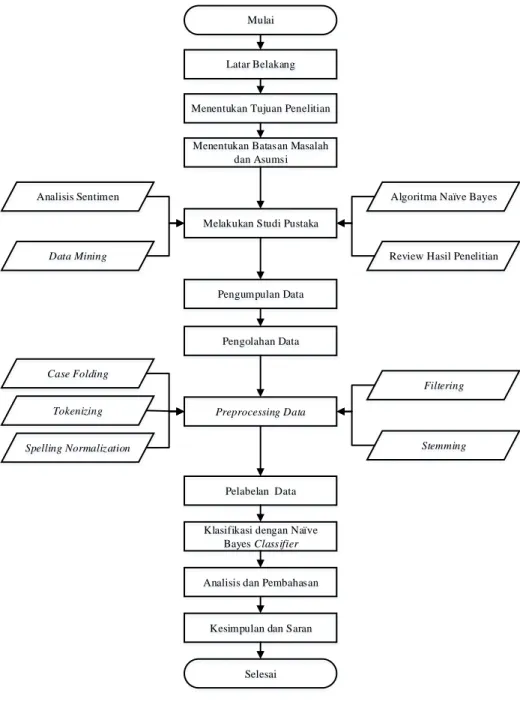
3.6. Kerangka Penelitian
Berikut merupakan kerangka dari penelitian ini :
Mulai
Latar Belakang
Menentukan Tujuan Penelitian
Menentukan Batasan Masalah dan Asumsi
Melakukan Studi Pustaka
Algoritma Naïve Bayes
Review Hasil Penelitian Analisis Sentimen
Data Mining
Pengumpulan Data
Pengolahan Data
Preprocessing Data
Pelabelan Data
Klasifikasi dengan Naïve Bayes Classifier
Analisis dan Pembahasan
Kesimpulan dan Saran
Selesai
Filtering
Stemming Case Folding
Tokenizing
Spelling Normalization
Gambar 3.1. Kerangka Penelitian
Berdasarkan gambar 3.1., dapat dilihat bahwa penelitian dimulai dengan latar belakang, yang kemudian dilanjutkan dengan tujuan penelitian, lalu batasan masalah dan asumsinya. Kemudian dilanjutkan dengan studi pustaka mengenai analisis sentimen, data mining, dan algoritma Naïve Bayes. Setelah itu dilakukan pengumpulan data, yang kemudian diolah. Pengolahan dimulai dari preprocessing data, kemudian pelabelan data, klasifikasi data dengan algoritma Naïve Bayes.
Kemudian dilakukan analisis dan pembahasan, dan ditutup dengan kesimpulan dan saran.
IV-1 4.1. Pengumpulan Data
4.1.1. Web Scraping
Pengambilan data pada penelitian ini adalah dengan mengambil data yang ada di situs Google Play mengenai ulasan para pengguna aplikasi Female Daily. Alamat dari situs tersebut adalah https://play.google.com/store/apps/details?id=
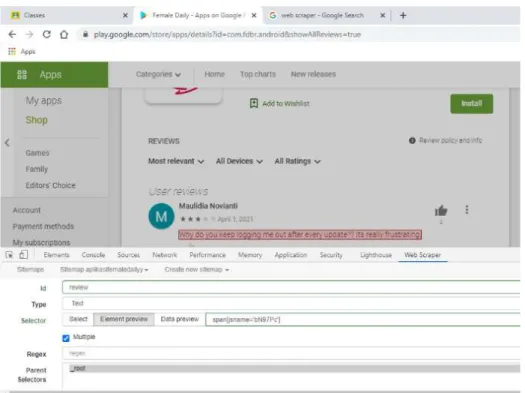
com.fdbr.android&showAllReviews=true. Dari situs tersebut, akan dilakukan web scraping dengan menggunakan web scraper. Data yang diambil dari situs tersebut adalah nama pengguna, tanggal pengguna menulis ulasan, rating yang diberikan, serta ulasan mengenai aplikasi Female Daily. Pada website tersebut, diklik inspect seperti yang bisa dilihat pada gambar 4.1.
Gambar 4.1. Situs Google Play
Selanjutnya, dibuat sitemap bernama aplikasi femaledailyy, kemudian membuat beberapa selector baru, yaitu nama, rating, tanggal, dan review. Gambar 4.2.
merupakan salah satu contoh dari pengambilan data review dari situs tersebut.
Gambar 4.2. Pengambilan Data Review
Gambar 4.3. merupakan data preview dari review.
Gambar 4.3. Data Preview
Dari data yang telah diambil, data tersebut disalin ke dalam aplikasi excel, seperti pada gambar 4.4.
Gambar 4.4. Tampilan Excel
4.2. Pengolahan Data 4.2.1. Labelling
Berdasarkan data yang didapat, lalu dilakukan proses labelling. Labelling digunakan untuk mengetahui pandangan mengenai ulasan yang ada. Proses labelling dilakukan secara manual oleh peneliti. Pada penelitian ini, labelling dibagi menjadi 2 kelas sentimen, yaitu kelas positif dan kelas negatif. Kemudian dibuat label score, yaitu kelas negatif dilabelkan dengan angka 0, sedangkan kelas positif dilabelkan dengan angka 1. Tabel 4.1. adalah contoh dari data yang telah dilakukan proses labelling :
Tabel 4.1. Contoh Data Hasil Labelling
No Nama Rating Tanggal Review Sentimen Label Score
1 Maulidia
Novianti 3 01 April 2021 Mengapa Anda ?? Ini benar-benar
membuat frustrasi. Negatif 0
2 Nadhirah
Seraphine 5 01 April 2021
Platform informasi terkait wanita terbaik yang pernah saya gunakan, saya kehilangan akun pertama saya karena saya menghapus email saya, tetapi masih menikmati aplikasi menggunakan akun baru saya, pengembang pekerjaan yang hebat!
Positif 1
3 Relya Galuh 4 01 April 2021
Please be better .... tolong ya, kenapa tiap buka aplikasi ini handphone suka
"freeze" sendiri. Otomatis stop sendiri.
Dan suka out sendiri dari aplikasi.
Padahal memori HP sudah termasuk besar dong.Tolong di perbaiki lagi kedepannya. Biar aksesnya semakin lancar 😎😎😎
Negatif 0
4 Saluran
DSW 2 01 April 2021 Gak bisa² loading terus Negatif 0
5 DWINDA
FARADITA 4 28 Maret 2021
update mulu sis . huhu tp sekarang semakin bagus dan mudah
penggunaannya
Positif 1
Tabel 4.1. Contoh Data Hasil Labelling (Lanjutan)
No Nama Rating Tanggal Review Sentimen Label Score
6 Mutia Rosa
Maharani 5 26 Maret 2021 seperti buku. semua skincare body
care bisa kupelajari dari sini Positif 1 7 Ersilia
Cesaria 5 22 Maret 2021 Terima kasih perempuan setiap hari ... Positif 1
8 Lailinr fdh 5 20 Maret 2021
Bisa belajar banyak tentang dunia perempuan dan membahas banyak topik mulai dari skincare, haircare, kosmetik lengkap. Bener-bener ngasi pengalaman yang berharga makasih female daily
Positif 1
9 Veraws 99 3 16 Maret 2021
Gak ngerti deh udh berkali2 Update aplikasinya tapi tetep aja gambar yang aku upload sering gak muncul-_-' tolong dong FD diperbaiki.
Negatif 0
10 Dewi Diah 5 13 Maret 2021 Sangat membantu ... Kerja Bagus Positif 1
4.2.2. Preprocessing Data
Data yang diperoleh dari website Google Play dengan cara web scraping belum bisa digunakan karena data tersebut masih mengandung unsur noise atau kesalahan.
Untuk memperbaiki hal tersebut maka wajib dilakukan preprocessing pada data tersebut. Berikut langkah langkah yang dilakukan dalam preprocessing data :
1. Case Folding 2. Tokenizing
3. Spelling Normalization 4. Filtering
5. Stemming
4.2.2.1.Case Folding
Pada tahap case folding, data review yang memiliki karakter huruf kapital akan diganti menjadi huruf kecil, dan semua tanda baca selain huruf dihilangkan. Contohnya
“AplikAsi” diubah menjadi “aplikasi”. Contoh lainnya adalah “baGus” diubah menjadi
“bagus”. Gambar 4.5. merupakan contoh perlakuan case folding pada salah satu review pengguna.
Bisa belajar banyak tentang dunia perempuan dan membahas banyak
topik mulai dari skincare, haircare, kosmetik lengkap deh.
Bener-bener ngasi pengalaman yang berharga makasih female
daily
bisa belajar banyak tentang dunia perempuan dan membahas banyak
topik mulai dari skincare, haircare, kosmetik lengkap deh.
bener-bener ngasi pengalaman yang berharga makasih female
daily menjadi
Gambar 4.5. Case Folding
4.2.2.2.Tokenizing
Pada tahap tokenizing, pada data review dilakukan pemisahan terhadap kalimat menjadi kata per kata yang menyusun kalimat tersebut. Pada tahap tokenizing juga dilakukan penghapusan tanda baca, double spasi, emoji, dan lainnya. Gambar 4.6.
merupakan contoh perlakuan tokenizing pada salah satu review pengguna :
mengapa anda terus mengeluarkan saya setelah setiap pembaruan ??
ini benar-benar membuat frustrasi.
mengapa anda terus mengeluarkan
saya setelah
setiap pembaruan
ini benar benar membuat frustrasi menjadi
Gambar 4.6. Tokenizing
4.2.2.3.Spelling Normalization
Pada tahap ini, data review yang ada akan diperbaiki kata-kata yang memiliki ejaan yang salah dan disingkat. Contohnya pada kata “bagus” dengan penulisan yang salah, seperti “bgs”. Contoh kata lain adalah “tidak”, dengan penulisan yang salah seperti “gk”. Gambar 4.7. merupakan contoh perlakuan spelling normalization pada salah satu review pengguna:
aplikasi bagus gak lambat aplikasi bagus tidak lambat
Gambar 4.7. Spelling Normalization
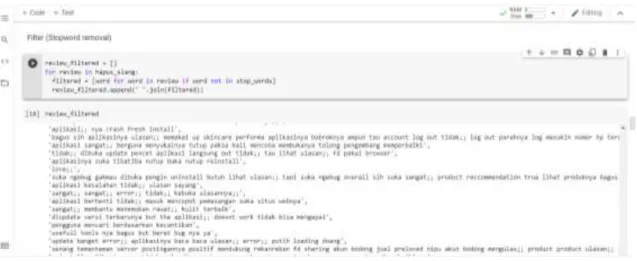
4.2.2.4.Filtering
Pada tahap filtering, pada data review dilakukan stopword, yaitu dihilangkannya kata-kata yang tidak penting. Contohnya adalah kata “yang”, “saya”,
“aku”, “dia” dan lainnya. Gambar 4.8. merupakan contoh perlakuan filtering pada salah satu review pengguna :
sangat bantu saya dalam pilih produk kosmetik dan rawat wajah
bantu pilih produk kosmetik rawat wajah
Gambar 4.8. Filtering
4.2.2.5.Stemming
Pada tahap stemming, pada data review, imbuhan pada kata-kata akan dihilangkan. Contohnya adalah kata “dihilangkan” diubah menjadi “hilang”. Gambar 4.9. adalah contoh perlakuan stemming pada salah satu review pengguna :
sangat membantu saya dalam memilih produk kosmetik dan
perawatan wajah
sangat bantu saya dalam pilih produk kosmetik dan rawat wajah
Gambar 4.9. Stemming