THE LANGUAGE KINSHIP OF TEOCHEW, HAKKA, AND CANTONESE
TESIS
Oleh
SHERLY NOVITA 177009023/LNG
FAKULTAS ILMU BUDAYA UNIVERSITAS SUMATERA UTARA
MEDAN 2021
THE LANGUAGE KINSHIP OF TEOCHEW, HAKKA, AND CANTONESE
TESIS
Diajukan Sebagai Salah Satu Syarat untuk Memperoleh Gelar Magister Sains dalam Program Studi Linguistik pada Program Pascasarjana
Fakultas Ilmu Budaya Universitas Sumatera Utara
Oleh
SHERLY NOVITA 177009023/LNG
FAKULTAS ILMU BUDAYA UNIVERSITAS SUMATERA UTARA
MEDAN 2021
Universitas Sumatera Utara
Universitas Sumatera Utara
i
TINGKAT KEKERABATAN ANTARA DIALEK TEOCHEW, HAKKA, DAN KANTON
ABSTRAK
Tesis ini berjudul "Tingkat Kekerabatan antara Teochew, Hakka, dan Kanton". Penelitian ini bertujuan untuk mengidentifikasi persamaan dan perbedaan bunyi pada dialek Teochew (TC), Hakka (HK), dan Kanton (CO). Perbandingan antara ketiga dialek ini dapat dikatakan sama usianya dengan timbulnya ilmu bahasa itu sendiri. Pemahaman tentang bahasa selalu menarik perhatian orang untuk mengetahui sejauh mana terdapat kemiripan aspek bahasa tersebut.
Menghitung persentase kognat dan menemukan kapan ketiga dialek dalam tesis ini termasuk ke dalam satu keluarga bahasa sebelum akhirnya berpisah menjadi dialek yang berbeda atau waktu pisah didasarkan pada teori Linguistik Historis Komparatif. Metode penelitian yang diterapkan adalah metode kuantitatif-kualitatif dengan menggunakan daftar Swadesh proto Sino-Tibet. Metode dan teknik pengumpulan data yang digunakan mengacu pada metode cakap dengan teknik rekam – catat. Data dianalisis dengan menggunakan metode korespondensi kualitatif dan metode kuantitatif dengan teknik glotokronologi dan leksikostatistik. Hasil penelitian menunjukkan bahwa dialek TC, HK, dan CO memiliki pasangan identik, korespondensi fonemis, satu fonem yang berbeda, dan satu suku yang serupa. Dialek TC~HK dan TC~CO memiliki 60 dan 75 kata berkerabat dengan tingkat kekerabatan atau persentase kognat sebesar 29 % dan 36 %, yang keduanya dikategorikan ke dalam subkelompok stok. Di sisi lain, HK~CO memiliki 121 kata berkerabat dengan tingkat kekerabatan atau persentase kognat sebesar 58 % dan dikategorikan dalam subkelompok famili. Simpulan penelitian ini adalah bahwa dialek HK dan CO merupakan dialek yang paling dekat dan berkerabat di antara ketiga dialek yang dibandingkan. Dialek HK dan CO merupakan dua bahasa yang berkerabat pada tahun 765 sesudah Masehi (2,020 – 1,255) sebelum akhirnya berpisah.
Kata kunci — korespondensi fonemis, tingkat kekerabatan, persentase kognat, waktu pisah, dialek
Universitas Sumatera Utara
THE LANGUAGE KINSHIP OF TEOCHEW, HAKKA, AND CANTONESE
ABSTRACT
This thesis is entitled "The Language Kinship of Teochew, Hakka, and Cantonese". This research is aimed to identify the similarities and differences in terms of sounds of Teochew (TC), Hakka (HK), and Cantonese (CO). The comparison of these three dialects can be said to be the same lineage by seeing the linguistics itself. The understanding about languages is always attractive to some people to know the language aspect similarities further. To calculate the cognate percentages of relationship of them, and to discover when they were separated before they were considered to be a language family or the lineages are based on the theory of Historical Comparative Linguistics. The research method used is quantitative- qualitative method through Sino-Tibetan Swadesh List. The data collection method and technique used refer to interview method, recording and note-taking technique or rekam - catat. The data were analyzed by using qualitative method of correspondences and quantitative methods of glottochronology and lexicostatistics.
The result of the research shows that TC, HK, and CO are having identical pairs, phonemic correspondences, different one phoneme, and one syllable similarity.
TC~HK and TC~CO are having 60 and 75 related words at the percentage levels of 29 % and 36 %, both are categorized into the subgroup of clump or stock. On the other hand, HK~CO is having 121 related words at the percentage level of 58 % in the subgroup of family. The conclusion of this research is that HK and CO are the closest dialects of the three compared dialects. They were together and considered as family in 765 AD (2,020 - 1,255) before diverging.
Keywords — sound correspondences, language kinship, cognate percentages, lineages, dialects
iii
ACKNOWLEDGMENT
The writer is grateful to The Almighty God for establishing her in completing this thesis.
In compiling this thesis, the writer has received a lot of moral and material supports from some people. Therefore, the writer would like to express her sincere gratitude to:
1. Dr. Muryanto Amin, S.Sos., M.Si, as the rector in Universitas Sumatera Utara.
2. Dr. Budi Agustono, M.S., as the Dean of the Faculty of Sciences in Universitas Sumatera Utara.
3. Dr. Eddy Setia, M.Ed., TESP., as the Head of the Linguistic Program in Universitas Sumatera Utara, and the examiner of the thesis, who has been giving inputs and suggestions for this thesis.
4. Dr. T. Thyrhaya Zein, M.A., as the Secretary of Linguistic Program in Universitas Sumatera Utara, who has been very supporting and motivating the writer during her study.
5. Dr. Dwi Widayati, M.Hum., as the advisor of the thesis, who has been guiding, motivating, supporting, and being considerate, as well as welcoming and providing free time for the writer to have a discussion during the counselling and study.
6. Dr. Bahagia Tarigan, M.A., as the advisor of the thesis, who has been guiding, motivating, supporting, and being considerate, as well as welcoming and providing free time for the writer to have a discussion during the counselling and study.
7. Prof. T. Silvana Sinar, M.A., Ph.D., as the examiner of the thesis, who has been giving inputs and suggestions for this thesis.
8. Dr. Dardanila, M.Hum., as the examiner of the thesis, who has been giving inputs and suggestions for this thesis.
The writer also thanks board of lecturers in Department of Linguistics, all the
Universitas Sumatera Utara
encouragement; as well as her parents, friends, and informants for their unceasing encouragement and support.
The writer realizes that this thesis is not perfect, yet the writer wishes that this thesis may be beneficial for the readers and the scientific purposes.
Medan, 5th June 2020 The Writer,
Sherly Novita
v
BIOGRAPHY
I. Personal Information
Name : Sherly Novita
Place / Date of Birth : Medan / 27 November 1991
Sex : Female
Religion : Buddhist
Status : Divorced
Address : Jln. Pukat VII Gg. Indah No. 10 e-mail : [email protected]
II. Educational Background
1. TK Perguruan Jenderal Sudirman 2. SD Perguruan Jenderal Sudirman 3. SMP Perguruan Swasta Wiyata Dharma 4. SMA Perguruan Swasta Wiyata Dharma 5. S-1 Methodist University of Indonesia (UMI)
III. Working Experience
1. English teacher at Leo English Course
2. English teacher at Winfield (Y.P. Karya Anugerah) 3. Kindergarten Principal at TK Karya Anugerah IV. Article Publication
1. A Semantic Analysis of Experiencer Construction in Hokkien (Macrothink Institute International Journal of Linguistics, 2019, Vol. 11, No. 1. P-ISSN 1948-5425)
2. Pembentukan Verba Ergatif dalam Bahasa Hokkien: Kajian Morfosintaksis (Jurnal Linguistika, 2019, Vol. 26. No. 1, P-ISSN 0854-9613 / E-ISSN 2656-6419)
Universitas Sumatera Utara
Simalungun di Kota Medan: Kajian Linguistik Historis Komparatif (Jurnal Linguistika, 2019, Vol. 26 No. 3, P-ISSN 0854-9613 / E- ISSN 2656-6419)
4. The Degree of Relationship among Teochew, Hakka, and Cantonese (Talenta Conference Series: Local Wisdom, Social, and Arts (LWSA), 2020, Vol. 3 No. 3, P-ISSN 2654-7058 / E-ISSN 2654- 7066)
5. The Sound Correspondence of Teochew, Hakka, and Cantonese (Jurnal Humanika, 2020, Vol. 27. No. 2, P-ISSN 1412-9418 / E- ISSN 2502-5783)
6. Multilingualism as The Cause of Teochew Dialect Extinction in Medan (The 1st International Virtual Seminar on Endangered Language and Linguistics 2020 / IVSoELL)
vii
TABLE OF CONTENTS
Page
ABSTRAK ………i
ABSTRACT ...ii
ACKNOWLEDGMENT ... iii
BIOGRAPHY ... .v
TABLE OF CONTENTS ...vii
LIST OF ABBREVIATIONS ... ix
LIST OF SYMBOLS ... x
LIST OF FIGURES ... xi
LIST OF TABLES ...xii
LIST OF APPENDIX ... xiii
CHAPTER I INTRODUCTION ... 1
1.1 Background of the Study ... 1
1.2 The Problems of the Study ... 9
1.3 The Objectives of the Study ... 10
1.4 The Scope of the Study ... 10
1.5 The Significances of the Study ... ……….11
CHAPTER II LITERATURE REVIEW ... 12
2.1 Kinship ... 12
2.2 Historical Comparative Linguistics ………...12
2.3 Phonology in Teochew ... 15
2.4 Phonology in Hakka ... 17
2.5 Phonology in Cantonese ... 19
2.6 Review of Preview Research ... 20
CHAPTER III RESEARCH METHODOLOGY ...24
3.1 The Research Design ... 24
3.2 The Data ... 24
3.3 The Source of the Data ... 25
3.4 The Technique of Data Collection ... 26
3.5 Data Analysis Technique ... 26
CHAPTER IV ANALYSIS, FINDINGS, AND DISCUSSION ... 34
4.1 Analysis ...34
4.1.1 The Sound Correspondence between TC ~ HK... 34
4.1.2 The Sound Correspondence between TC ~ CO ... 40
4.1.3 The Sound Correspondence between HK ~ CO ... 46
4.2 Findings ... 55
4.2.1 Kinship of TC ~ HK ... 56
4.2.2 Kinship of TC ~ CO ... 59
Universitas Sumatera Utara
4.3 Discussion ... 65
CHAPTER V CONCLUSION AND SUGGESTION ... 67
5.1 Conclusion ... 67
5.2 Suggestion ... 70
REFERENCES ... 71
ix
LIST OF ABBREVIATIONS
STEDT : Sino-Tibetan Etymological Dictionary and Thesaurus
ST : Sino-Tibetan
TC : Teochew
HK : Hakka
CO : Cantonese
Universitas Sumatera Utara
LIST OF SYMBOLS
~ : correspondency
– : variation
[ … ] : phonetic sign
xi
LIST OF FIGURES
No. Name of Figures Page
1.1 1.2
The Map of Medan City ……….
Sino-Tibetan Family ………..………
4 7
2.5 Cantonese Vowels ……….… 19
2.6. Cantonese Consonants ………..…. 19
Universitas Sumatera Utara
No. Name of Tables Page
2.1 Teochew Consonants ………..…… 16
2.2 Teochew Vowel Nucleus ……….…..……. 17
2.3 Hakka Consonants ……….….…… 17
2.4 Hakka Final Vowels ………..…………. 18
3.1 Language Subgroups ………. 30
3.2 Glottochronology ……….……….. 32
4.1 Identical Pair of TC ~ HK ……….…..……….. 35
4.2 Phonemic Correspondence of TC ~ HK ……….………….. 36
4.3 Different One Phoneme Ø – ŋ of TC ~ HK ……….. 38
4.4 One Syllable Similarity of TC ~ HK ………..………….. 39
4.5 Phonemic Correspondence of TC ~ CO ……….…….…….. 40
4.6 Different One Phoneme ŋ – n of TC ~ CO ……….….…….. 44
4.7 One Syllable Similarity of TC ~ CO ………..….…….. 46
4.8 Identical Pair of HK ~ CO ……….………..…….. 47
4.9 Phonemic Correspondence of HK ~ CO ……….….………. 49
4.10 Different One Phoneme of HK ~ CO ……….….…….. 52
4.11 One Syllable Similarity of HK ~ CO ……….….…….. 54
xiii
LIST OF APPENDIX
No. Name of Appendix Page
1 Teochew Word Transcription …..………..…… 75
2 Hakka Word Transcription …..………..…… 80
3 Cantonese Word Transcription …..….………..…… 85
4 Informants …..………..…… 90
Universitas Sumatera Utara
CHAPTER I INTRODUCTION
1.1 Background of the Study
This study discusses kinship of three different languages. The languages raised in this study are Teochew, Hakka, and Cantonese in Medan, North Sumatra, Indonesia. Medan, as the capital of the province of North Sumatra Indonesia, particularly Medan is a multicultural city consisting of various kinds of ethnicities with various regional languages. The regional languages in Indonesia have similarities in the pronunciation of several vocabulary words. Similarities of regional languages can occur due to language interactions.
Based on archive of Pemko Medan (2015), the term “Tionghoa” / “təŋ laŋ” /
“hua ren” or so-called “Chinese” means the Chinese from China in Indonesian pers in 1950s. The Chinese in Indonesia are the Indonesian who came from China, precisely from Guangdong and since the first or second generation have been living in Indonesia, and socializing with local people, as well as mastering one or more languages used in Indonesia. The Chinese in Indonesia are considered as the minor group in Indonesia. In 1961, they were considered to be around 2,45 million people or 2.5% of the entire citizens in Indonesia that time. The Chinese started moving to Indonesia in the 9th century during Tang Dinasty for trading and living a better life.
The migration of Chinese to Medan vary and in different periods of time. The
2
Sumatra harbor and had trading through the system of barter. This trading system lasted for quite long resulting some of the traders stayed in East Sumatera. The second wave started in 1863 when the Dutch needed more workers for their farm as they did not get along with the native in Medan. Therefore, they brought in the workers from China. In the 19th century, with the assistance of the Dutch East Indies and the businessmen from Deli, the Chinese were able to monopoly all of the transportation sectors in Deli. Even most of the farm owners gave the opportunities to the Chinese to subsidize food and work as contractors in the farm. This happened due to the hard work of the Chinese. Since then, the Chinese started to bring their families from China by ship and causing them to live in groups, make their own villages, and use their own languages. This is the beginning of the Chinese exclusivism. This exclusivity was given by the Dutch colony by building ethnicity blocks, such as “Kampung Cina”,
“Kampung Arab”, “Kampung Keling”, “Tuan Kebon” for Europeans, and
“Pemukiman Rakyat Sultan” for the natives. Each of these ethnics started to have their own life styles and acted exclusively towards one another.
The Chinese in Medan came from many ethnics, yet the most ethnic living in Medan is Hokkien as 82.11%. Although the Chinese have many ethnicities, the ethnic varieties in their daily life are not obviously seen as they only show one ethnic unit as Chinese. They succeed in mastering industry, shops, hotels, banks, and general commerce as well as distribution. The Chinese in Medan are considered by other community groups as groups which have a lot of money. They are often targeted extortion by local thugs where they live and run their businesses. They tend to reside
Universitas Sumatera Utara
in the city center or trade center. They prefer living in their business area which is quite crowded and close to their family. It is thought that their living place functions as their cocoons and considered as ethnic fortress. The Chinese schools and recreation centres are mostly built in the middle of their living place in Medan.
The Chinese in Medan are normally not fluent in speaking Bahasa, as since their childhood, they have been living and going to school around the ethnics. They speak their mother tongue, either at home or outside their house with their Chinese friends. People always assume that Chinese language or mother tongue used by the Chinese is Mandarin rather than Hokkien. Moreover, specifically in Medan, not all Chinese people can pronounce Mandarin. Mandarin is usually learnt at schools (Rini, 2013: 195). Thus, the dialect that is used by the Chinese in Medan is Hokkien.
However, Hokkien is not the only ethnic group of Chinese. Chinese itself, especially in Medan, is categorized into many ethnic groups, such as Teochew, Hakka, Cantonese, Hokkien, Hokchiu, Henghua, Hainan, and Hailufeng. Due to Medan as the same place where these three languages (TC, HK, and CO) are concentrated in, therefore the writer puts Medan as the area of this study.
4
Figure 1.1 The Map of Medan City [based on Arsip Daerah Pemerintah Kota Medan, archive of Pemko Medan]
Universitas Sumatera Utara
Based on the population survey on Chinese residents in Medan (Waspada, 2015), it was reported that in 2010 there were 23.794 Chinese living in Medan Area, 20.379 in Medan Timur, 16.207 in Medan Kota, 14.731 Medan Barat, 14.215 Medan Petisah, 13.079 Medan Tembung, 11.425 Medan Johor, 11.116 Medan Sunggal, 11.021 Medan Perjuangan, 8.040 Medan Maimun, 7.563 Medan Deli, 6.985 Medan Polonia, 5.727 Medan Marelan, 5.579 Medan Denai, 2.116 Medan Belawan, 762 Medan Amplas, and 230 Medan Tuntungan.
Seeing from the numbers of the Chinese spread in Medan, the writer decided to take Medan Area. Medan Timur, and Medan Tembung as the fields of the study.
However, Medan Kota, Medan Barat, and Medan Petisah are business areas such as offices or work places and schools, which makes the research difficult to be accomplished as most of the ethnics will gather there and use Hokkien as daily conversation with colleagues and peers.
Teochew is a Southern Min dialect spoken mainly by the Teochew in the Chaoshan region eastern Guangdong and by their diaspora around the world. It is a language dialect included as the Sino-Tibetan language family. This dialect is similar to Hokkien. Teochew can be regarded as a Hokkien dialect influenced by the Cantonese dialect. Because its geographical location is in the north of Guangdong province, near the border with Fujian province. It is estimated that the number of Chiosu speakers is 10-15 million people and spread throughout the world. Teochew people in Indonesia mainly live in Medan, Riau, Jambi, South Sumatra, and Pontianak (Dawis, 2009: 76-83).
Sagart (2002) describes Hakka as an ethnic group from China, originally from
6 North China which migrated to South China. Migration of Hakka people to Indonesia
happened in several waves. The first wave landed in Riau Islands such as in Bangka Island and Belitung as tin miners in the 18th century. The second group of colonies were established along the Kapuas River in Borneo in the 19th century, predecessor to early Singapore residents. In the early 20th century, new arrivals joined their compatriots as traders, merchants and labourers in major cities such as Jakarta, Surabaya, Bandung, Medan, etc. In Indonesia, Malaysia and Singapore, Hakka people are sometimes known as Khek, from the Hokkien pronunciation. However, the use of the word 'Khek' is limited mainly to areas where the local Chinese population is mainly of Hokkien origin. In places where other Chinese subgroups predominate, the term 'Hakka' is still more commonly used.
Hence, Cantonese according to Bauer and Wakefield (2019) is a language dialect used by the residents from Guangzhou, the capital of Guangdong Province and are the largest city in southern China. Many of the residents are highly educated, and are known for their effective traditional medicine techniques. Cantonese in Indonesia is often called as Konghu language, which is one of the Chinese dialects spoken in the southwestern regions of China (Guangdong), Hong Kong, Macau, and Chinese descent communities in Southeast Asia. Cantonese is spoken by nearly 70 million people worldwide. According to research from Han linguists in China, the Cantonese dialect is one of the oldest Han dialects that remains today. Cantonese dialects were used extensively during the Tang Dynasty. Cantonese in Indonesia are concentrated in Jakarta, Medan, Makassar and Manado.
Universitas Sumatera Utara
Sino-Tibetan Language family can be drawn as follows:
Mandarin (Putonghua) Beijing, Kyrgyzstan, Kazakhstan Wu (Suzhou dialect) Shanghai, Zhejiang, Jiangsu, Anhui Gan (Nanchang dialect) Jiangxi and neighbouring areas
Xiang (Changsha & Shuangfeng) Hunan, southern Hubei
Min (Hokkien)
Fujian, eastern Guangdong, Xiamen, Hainan, Leizhou Peninsula
Hakka (Meixian)- Han (Teochew) Southern China, Shanghai, Taiwan, Singapore, Malaysia
Yue (Cantonese) Guangdong, Guangxi, Hongkong Guangdong, Guang
Figure 1.2 Sino-Tibetan Family [based on Sino-Tibetan Etymological Dictionary and Thesaurus (2016), Matisoff – Principal Investigator of STEDT]
Sino-Tibetan (ST) is one of the largest language families in the world, with more first-language speakers than even Indo-European. The more than 1.1 billion speakers of Sinitic (the Chinese dialects) constitute the world's largest speech community. ST includes both the Sinitic and the Tibeto-Burman languages. Most
8 scholars in China today take an even broader view of ST (called Hàn-Zàng in
Mandarin), including not only these two branches, but Tai (= "Daic") and Hmong- Mien (= Miao-Yao) as well. According to STEDT (Sino-Tibetan Etymological Dictionary and Thesaurus), Chinese is considered as Sino-Tibetan language family;
moreover, Chinese itself has many dialects spread and spoken within China and around the world. The identity of Chinese is Mandarin which is spoken by most of the Chinese as their national language in China. In other parts of China, people speak other dialects; for example, Hokkien (Min) is spoken around Fujian province, eastern Guangdong, Xiamen, Hainan, and Leizhou Peninsula, Cantonese is spoken in Guangdong, Guangxi and Hongkong.
Dialects especially Teochew (TC), Hakka (HK), and Cantonese (CO) are chosen as the languages to be analyzed in order to build and develop dialects, a study towards dialects is a mandatory point to be taken. It is fundamentally based on awareness that dialects have essential function and position for Indonesians.
Dialects in Indonesia are mostly analyzed synchronically. Analysing dialects in a diachronic way is rare. It also happens on comparing a language with the other languages in terms of finding the kinship especially in Sino-Tibetan languages. The writer also would like to clarify that the Chinese living in Indonesia especially in the districts of Medan, Medan city, is not merely Hokkien as there are Teochew, Hakka, and Cantonese people who mostly resides in Medan compared to other ethnic groups.
Some examples below illustrate the similarities and differences of three languages that become the object of research: (24) three, (44) animal, (125) stand,
Universitas Sumatera Utara
(143) float, and (144) flow.
TC HK CO
three (24) [sa] [sam] [sam]
animal (44) [khim siu] [khim siu] [kham sau]
stand (125) [khia] [khi] [khei]
flow (144) [lau] [liu] [lau]
The above data shows that all three languages have equal kinship and also have the distinction of vocabulary. From the words above, there are consonant initials of /s/
(TC) = /s/ (HK) = /s/ (CO). It also happens for the other consonants such as /l/ and /kh/. For consonant phoneme /l/, it can be proven as TC, HK, and CO have phoneme /l/ in their consonant list which is considered as lateral alveolar. Meanwhile for /s/ is categorized as fricative sound and /kh/ is plosive velar sound. In vowels, it is clear that
/i/ is changed to /a/ for CO. Example (144), the sounds after the consonants are not vowels, but vocalic clusters.
1.2 The Problems of the Study
The problems of this study are related to Teochew (TC), Hakka (HK), and Cantonese (CO) words. The problems of the study can be formulated as follows.
1. What are the sound correspondences of TC, HK, and CO?
2. How are the percentage levels of TC, HK, and CO if they are considered a
10 language family?
3. How are TC, HK, and CO exactly considered as family before diverging?
1.3 The Objectives of the Study
Objectives are the goals to be achieved in conducting the research. In this case, the objectives are related to the findings of answers based on the questions raised in the problems of the study. Therefore, the objectives of the study are as follows.
1. to analyze the vowel and consonant correspondences of TC, HK, and CO.
2. to calculate the subgroup percentage levels of kinship for TC, HK, and CO.
3. to discover approximately how long the lineages of TC, HK, and CO were diverged.
Furthermore, the wider objective of this thesis is to contribute something to human knowledge.
1.4 The Scope of the Study
To discover the kinship of languages can be done through phonological, morphological, syntactical, and semantical reconstructions. This research is restricted on the sound correspondences of three Sino-Tibetan dialects in Medan. The scope is done because the syntactical, semantical, and morphological reconstructions have been done by some authors which the authors did not discuss phonologically.
Phonological language reconstruction is beneficial to predict the language proto either in linguistics, evolutionary, and history.
Universitas Sumatera Utara
1.5 The Significances of the Study
In this research, there are two significances of the study, namely:
1. Theoretically, this study deals with TC, HK, and CO native speakers in pronouncing the Sino-Tibetan Swadesh lists. So, it is aimed to give information to the readers about the glossaries and sound changes in these three languages and the kinship of them especially to discover the lineages of their diverging.
It can also be used as a contribution to scientific study for further research.
2. Practically, this thesis is significant for the readers to be aware of their mother tongue so the dialects in Indonesia can still be preserved and maintained by the speakers and the young generations.
12 CHAPTER II LITERATURE REVIEW
2.1 Kinship
Kinship in linguistic terms is interpreted as a relationship between two or more languages derived from the same source (KBBI, 2018). Whereas, related languages are interpreted as languages that have genealogical relationships with other languages.
Thus, related languages are languages that have a relationship between one another.
The relationship may have to do with the same origin at the ancestors. This may bring about similarities between the languages. The similarity is mainly seen in terms of phonology, or perhaps morphology, even syntax. Kridalaksana (2008: 116) explains in the Linguistic Dictionary that genetic relationships are relations between two or more languages which are derived from the same parent language source, called ancestor language.
2.2 Historical Comparative Linguistics
This research is based on the theory in Historical Comparative Linguistics (Comparative Linguistic History) (Lehman 1972; Hock 1988; Bynon 1979). This theory is also called diachronic theory, which involves the analysis of the form and regularity of changes in common languages such as those accompanied by sound changes, to reconstruct the language of the past, the ancient language (proto) that lived on thousands of years before that. This ancient language (proto) is changed and broken
Universitas Sumatera Utara
into several derivative languages due to the place and time factor (Bynon, 1979: 54).
These derived languages inherit the rules of the original language and will be different because of the development (innovation) that occurred later after the language is different (Bynon, 1979: 61).
One of the goals in Comparative Linguistic History is to question cognate languages by making comparisons of the elements that show kinship (Crowley, 2010;
Keraf, 1990; Widayati, 2016). This research is aimed to identify the similarities and differences in terms of sounds of Teochew, Hakka, and Cantonese, to calculate the cognate percentages of relationship of them, and to discover when they were separated before they were considered to be a language family.
Langacker (1972: 329-330) states that the tool is a comparative method is systematic sound correspondence in related languages. For him, differences in phonetic form in correspondence devices systematic. Corresponding sounds do not have to be the same but appear regularly in the same position in words that are similar to both of in terms of form and meaning. In this explanation, he does not use the term device phonemic correspondence, but uses the term sound correspondence which the data is phonetic data.
Haugen (1972) calls the “comparative” approach, i.e., the deliberate reconstruction of a hypothetical mother tongue on the basis of current dialects, such as is the case for Nynorsk (as discussed by Jahr, this volume; cf. also Hoekstra, ibid., for a discussion of a similar attempt in the history of Frisian).
14
According to Crowley (1992: 93), sound correspondence is sound devices in related words reflected by a single language. Crowley (1992: 106) explains that sound correspondence devices involving sounds that are phonetically similar. Therefore, in this study, aspects of language were used as the basis for phonological comparisons to count the calculation of kinship.
Keraf (1984: 22) states that historical comparative linguistics (comparative historical linguistics) is a branch of Language Science that questions language in the field of time and changes in language elements that occur in that time field. As for one of the goals and interests of comparative historical linguistics is to organize (sub- grouping) languages in a language family. Languages in the same family do not necessarily have the same level of kinship or the same level of similarity with each other. Keraf (1984: 34) states that kin languages from the same proto will always show the following similarities: 1. the similarity of the sound system (phonetics) and sound arrangement (phonology); 2. morphological similarities, namely similarities in word forms and similarities in grammatical forms; 3. syntactic similarities, namely the similarity of the relationship between words in a sentence.
In comparing two or more languages can use the lexicostatistics and glottochronology techniques. Keraf (1984: 121) states that lexicostatistics is a technique in grouping languages that is more likely to prioritize the observation of words (words) statistically, then to determine the groupings based on the percentage of similarities and differences in a language with other languages. Keraf (1984: 128) states that a word pair will be expressed as a relative if it satisfies one of the
Universitas Sumatera Utara
provisions (a) the pair is identical, (b) the pair has phonemic correspondence, (c) phonetic similarity, or (d) one different phoneme. Meanwhile, Crowley (2010: 148) claims glottochronology as a technique to count the time depth of languages which share approximately 80 percent of their vocabulary by comparing the genetic differences using the mathematical formula.
For instance, the word „four‟ in Teochew is [si], Hakka [si], and Cantonese [se], considering from the sound correspondences, it means we find each set of sounds that appears to be descended from the same original sound as follows:
TC s i
HK s i
CO s e
It can be seen that there is a final correspondence vowel of /i/ in TC to /i/ in HK and to /e/ in CO. The initial correspondence consonant of /s/ remains in all three languages.
2.3 Phonology in Teochew
Syllables in Teochew contain an onset consonant, a medial glide, a nucleus, usually in the form of a vowel, but can also be occupied by a syllabic consonant like [ŋ], and a final consonant. All the elements of the syllable except for the nucleus are optional, which means a vowel or a syllabic consonant alone can stand as a fully- fledged syllable. Teochew finals consist maximally of a medial, nucleus and coda. The medial can be i or u, the nucleus can be a monophthong or diphthong, and the coda
16 can be a nasal or a stop. A syllable must consist minimally of a vowel nucleus or
syllabic nasal.
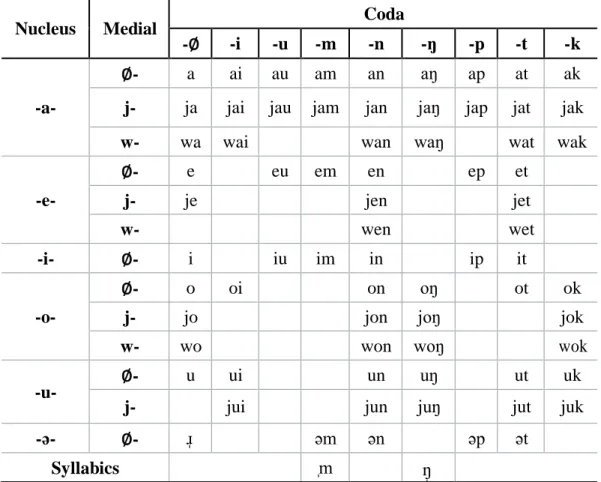
Consonants (Kitikanan, 2013: 111) and vowels in Teochew can be seen as follows:
Table 2.1 Teochew Consonants
Bilabial Dental Alveolar Palatal Velar Uvular Nasal
voiceless m n ŋ
voiced m n ŋ ɴ
Stop
aspirated pʰ tʰ cʰ kʰ
voiceless p t c k ʔ
voiced b ɟ ɡ ɢ
Affricate aspirated t
s ʰ
voiceless ts kx
voiceless dz
Fricative
central
voiceless f θ s ç x h
voiced v ð z ʝ ɣ ʁ
lateral
voiceless ɬ ʎ ˔ ʟ
voiced ɮ ʎ ʟ
Approxi mant
central ʋ ɹ ɰ
lateral l ʟ ʟ
Trill ʙ r ʀ
Flap
central ⱱ ɾ ɢ
lateral ɺ ʟ ʟ
Universitas Sumatera Utara
Table 2.2 Teochew Vowel Nucleus
2.4 Phonology in Hakka
Cheung (2011) states that there are two series of stops and affricates in Hakka, both voiceless: tenuis /p, t, ts, k/ and aspirated /pʰ, tʰ, tsʰ, kʰ/.
Table 2.3 Hakka Consonants
Labial Dental Palatal Velar Glottal
Nasal /m/ ⟨m⟩ /n/ ⟨n⟩ [ɲ] ⟨ng(i)⟩* /ŋ/ ⟨ng⟩
Plosive
tenuis /p/ ⟨b⟩ /t/ ⟨d⟩ [c] ⟨g(i)⟩* /k/ ⟨g⟩ (ʔ)
aspirated /pʰ/ ⟨p⟩ /tʰ/ ⟨t⟩ [cʰ] ⟨k(i)⟩* /kʰ/ ⟨k⟩
Affricate
tenuis /ts/ ⟨z⟩
aspirated /tsʰ/ ⟨c⟩
Fricative /f/ ⟨f⟩ /s/ ⟨s⟩ [ç] ⟨h(i)⟩* /h/ ⟨h⟩
Approximant /ʋ/ ⟨v⟩ /l/ ⟨l⟩ /j/ ⟨y⟩
18 When the initials /k/ ⟨g⟩, /kʰ/ ⟨k⟩, /h/ ⟨h⟩, and /ŋ/ ⟨ng⟩ are followed by
a palatal medial /j/ ⟨i⟩, they become [c] ⟨g(i)⟩, [cʰ] ⟨k(i)⟩, [ç] ⟨h(i)⟩, and [ɲ] ⟨ng(i)⟩, respectively. Hakka has six vowels, [i e a ə o u], that are romanised as i, ê, a, e, o and u, respectively. Moreover, Hakka finals exhibit the final consonants found in Middle Chinese, namely [m, n, ŋ, p, t, k] which are romanised as m, n, ng, b, d, and g respectively in the official romanization.
Table 2.4 Hakka Final Vowels
Nucleus Medial Coda
-∅ -i -u -m -n -ŋ -p -t -k
-a-
∅- a ai au am an aŋ ap at ak
j- ja jai jau jam jan jaŋ jap jat jak
w- wa wai wan waŋ wat wak
-e-
∅- e eu em en ep et
j- je jen jet
w- wen wet
-i- ∅- i iu im in ip it
-o-
∅- o oi on oŋ ot ok
j- jo jon joŋ jok
w- wo won woŋ wok
-u-
∅- u ui un uŋ ut uk
j- jui jun juŋ jut juk
-ə- ∅- ɹ əm ən əp ət
Syllabics m ŋ
Universitas Sumatera Utara
2.5 Phonology in Cantonese
The phonology in Cantonese can be described as follows:
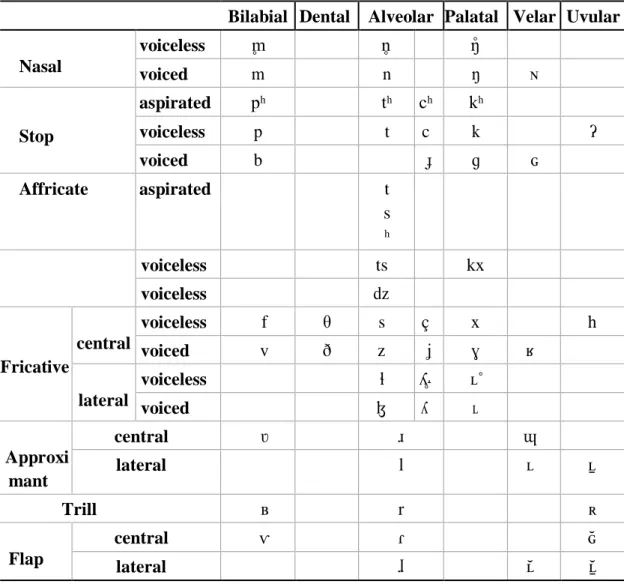
Figure 2.5 Cantonese Vowels [based on Modern Cantonese Phonology – Bauer and Benedict (2011: 33)]
Figure 2.6 Cantonese Consonants [based on Modern Cantonese Phonology – Bauer and Benedict (2011: 16)]
Vocalic cluster or vowel nucleus is a term which is not often encountered in
20 clusters” which he specifically introduced as the English equivalent of Chinese fùhé
yuányīn. When used in the descriptions of non-sinitic languages, the term “vowel cluster” is normally synonymous with “diphthong” and/or “triphthong”.
2.6 Review of Previous Research
There are several researches that are used as references or literature reviews in this paper. From those researches, there are four research articles which are relevant to this research. Firstly, Veniranda's article (2016) which showed the vowels in Teochew Pontianak dialect in terms of oral and nasal. The writer uses Praat program to obtain the values of the fundamental frequencies, the intensities, the first three bandwidths and the first three formant values. This article contributed in showing the writer on how the vowels in Teochew is pronounced by the speakers.
S econdly, Meng‟s article (2007) which described further on the comparison of both Cantonese and English which makes an interference for a Cantonese speaker to pronounce English. In this article, Meng showed that there are some vowels in English which disappear in Cantonese, such as /e, æ, o, ə, ˄, a/. Then, for the consonants, some of the disappeared English consonants in Cantonese are /b, d, g, tʃ, ʤ, v, θ, ʒ, ð, z, ʃ/. The research article by Meng provided a vivid explanation and figures of the vowels and consonants in Cantonese which really helped the writer in
discovering the consonants and vowels.
Universitas Sumatera Utara
Then, there is an article by Sagart (2019) which analyzed further about the syllabic structure of Sino-Tibetan languages. Some languages only allow consonant- vowel-type syllables, while others have complex clusters and final consonants. In this article, the writer mentions that Sino-Bodic (grouping together Chinese, Tibetan, and Kiranti, excluding Lolo-Burmese; Post and Blench‟s hypothesis that subgroups in northeastern India such as Tani (Bokar) and Mishmi (Yidu and Deng) are among the first branches of the family, while Sinitic is closer to Lolo-Burmese and Tibetan, according to morphology-rich subgroups. This article displayed a tree model which enables the writer to comprehend on the subfamilies of Sino-Tibetan languages.
There are three models of cognate change along a tree to reconstruct the tree topology and internal node ages in a Bayesian framework.
Next, there is Zang‟s article (2019) which also contributed in displaying Sino-Tibetan languages using the quantitative method of glottochronology. It performed a Bayesian phylogenetic analysis to examine two competing hypotheses of the origin of the Sino-Tibetan language family: the „northern-origin hypothesis‟ and the „southwestern-origin hypothesis. This article was using Bayesian phylogenetic approach that provided alternative opportunities methods to circumvent the limitation from glottochronology method (uses lexical data to estimate absolute divergence times). These approaches permit flexible evolutionary models, and are a powerful tool for inferring evolutionary tempo and mode of change in language families worldwide. However, this article discusses Sino-Tibetan languages in general, not particularly Chinese dialects.
22 Other writing related to the Comparative Historical Linguistic Study is found
in Widayati and Lubis‟ research article (2018) that focused on the inherited Proto- Austronesian vowel phonemes in Karo language and (2016) that discussed about vocal and consonant PAN features in Nias and Sigulai languages. These research articles are both analyzing the sound correspondences in vowel and consonant phonemes of the languages. It is stated that the sound was inherited linearly *i is a vowel and * u * l * g consonant in Nias and Sigulai. The sound experience is fading
*s/*S, *c, *y, *k, *q, and *h; the sound inherited linearly once- fading and change was * e> ǝ, o, and u; * A> a, o; * P> f, b; * B> f, w / v; * M> m, Ø; *> W, b; * T> t, d; * D> d, l, n; * N> g, k; * R / * R> r, l, Ø; * Ɲ> ɲ, n; * Z> j, l; and * ŋ> ŋ, Ø. The changes are varied in point three took place on the third syllable and a different position. All types of changing, it turned out all the words PAN closed syllable, experiencing consonant deletion at any syllable in Nias language and particularly Sigulai language. Compared to Karo language, it is found out that PAN‟s vowels *a,
*i, and *u do not only inherit linearity and regularity, but also inherit sporadic innovative vowels; the vowel *ǝ inherits linearity in Karo. The writer was inspired by these articles because they showed further on how the languages corresponded each other in terms of the phonemes and are in the same boat with what the writer was writing, as in using the same techniques and methods.
Polili, Sinar, Widayati, and Syahputra (2018) also contributed in applying the similar theory, method, and approach to this research. The article is about the status of Nias language (2018) which discussed three parts of Nias language in certain districts as the research objects. It is also applying the techniques of
Universitas Sumatera Utara
glottochronology and lexicostatistics in historical linguistics to discover the kinship and to estimate the age of North Nias, South Nias, and West Nias. The method used in the article is also qualitative-quantitative method; for addition, the data collection used is as by Sudaryanto (1988). It is found that the three Nias languages are categorized into the group of language by the percentage of 86.5 – 91%. The reflection lexical PAN in Nias language is related linearly or in innovation. Lexical reflection linearly does not change, in a word (PAN). Therefore, by reading this article, the writer might reflect clearly on what he was writing in different protos (Austronesian and Sino-Tibetan).
Lastly is Dardanila‟s article (2015) about the cognates among the Karo, Alas, and Gayo languages. This article contributed in helping the writer to find the cognates of languages in terms of the related lexicostatistics theory. This article is also identifying the subgroup family of the languages yet in Austronesian protos.
24
CHAPTER III
RESEARCH METHODOLOGY
3.1 The Research Design
This study was conducted with qualitative and quantitative researches through Sino-Tibetan Swadesh List pronounced by the informants. Qualitative research according to Earl (2014) refers to the meanings, concepts, definitions, characteristics, metaphors, symbols, and descriptions of the object of the study and not to their counts or measures. Hence, quantitative research according to List and Moran (2013) which refers to the module for the evaluation of basic tasks in historical linguistics, such as phonetic alignment and cognate detection. There are many Teochew, Hakka, and Cantonese speakers in Medan and this population is too large for the flexibility of the research. Therefore, samples of Medan Tembung, Medan Area, and Medan Timur districts have been taken since there are more percentages of Chinese people living by there.
3.2 The Data
The data are the key to have a research on a particular topic. The data for this research is the spoken language of some informants in Medan Area, Medan Tembung, and Medan Timur districts. Medan Area is an area where most Hakkas do their activities such as running business, socializing, having education, and living nearby their relatives or their ethnic groups, Medan Tembung is an area where most the
24
Universitas Sumatera Utara
Teochew live, and Medan Timur is an area where most the Cantonese live. The Chinese use their living areas of their ethnics as cocoons and those who are leaving the cocoons will be considered as Chinese Quarter (those who leave the Chinese social network). Data which were collected are the spoken data of the individuals pronouncing on the Sino-Tibetan Swadesh List which consists of 207 words. The writer has a field research on the informants‟ utterances.
3.3 The Source of the Data
The object of this study is the kinship of Teochew, Hakka, and Cantonese, so the data for the thesis were acquired from the utterances of the Teochew informants in Medan Tembung, Hakka informants in Medan Area, and Cantonese informants in Medan Timur pronouncing the lists. Sino-Tibetan Swadesh list is a list of the most widely used as a reference for the study of language kinship in the world. Swadesh vocabulary becomes the referenced study of amounted 207 vocabularies, a vocabulary that is used universally in the world. It implies that this vocabulary is on the world's population and is unlikely to change in a long time (e.g. parts of body – tongue, head;
colours – black, yellow; personal pronoun – you, he; verbs – see, hear, etc.) Hence, the informants are the Chinese ethnic groups reside in Medan, particularly those who are from the ethnic groups of Teochew, Hakka, and Cantonese and are at the age of 25-60 years old and know their ethnic languages pretty well.
25
26
3.4 The Technique of Data Collection
In order to collect the data in this proposal, the writer used the method of by Sudaryanto (2015) called interview method or cakap (conversation) which enables the writer to bait into a conversation with the informants face to face with the techniques of recording and note-taking or rekam dan catat by asking the informants to pronounce their ethnic group dialects based on the glossaries provided from Sino- Tibetan Swadesh List. Then she asked them to pronounce each of the words and their pronunciation was recorded by using a recorder as soon as it was uttered. After that the recording voices were transcribed into phonetic transcriptions or phonetic symbols, so that the phonemes could be analyzed easily.
3.5 Data Analysis Technique
Any study that uses sound change theories of comparative historical linguistics should know the terminology of correspondence and the terminology of variations.
Mahsun (1995:29) and Keraf (1996:79) report that correspondence terminology is used to explain the sound changes that occur regularly in a particular position on any appearance of that sound whereas a variation is of sound changes that are not regular occurrences (sporadic). Crowley (1992:385), Mahsun (1995:34), and Keraf (1996:90) express that sound changes are characterized by a variation of sound changes which can be classified into several types, such as assimilation, dissimilation, metathesis, contraction, and syncope. The sound changed carry on the nature and the character of each. According to Hock (1988:63) and the three experts mentioned above, the most
Universitas Sumatera Utara
common kind of sound changes is assimilation and it happens in most common languages in the world. Further, Crowley (1992:49) says that assimilation sound changed occur, when one sound causes another sound to change so that the two sounds end up more similar or identical to each other in some way and it is focused on the concept of phonetic similarities. Therefore, two sounds can be regarded as similar or identical if both carry the same phonetic features in general or about the same before the change occurs, such as a combination of sound [np] in a language. Both of these sounds have the same phonetic features, such as the following:
/n/ /p/
voiced voiceless
bilabial alveolar
nasal stop
Assimilation is a sound change where some phonemes (typically consonants or vowels) change to be more similar to other nearby sounds. Dissimilation is a phenomenon where similar consonants or vowels in a word become less similar, especially the sound of /r/. Metathesis is the transposition of sounds or syllables in a word or of words in a sentence and it refers to the interchange of two or more contiguous sounds. A contraction is a shortened version of the written and spoken forms of a word, syllable, or word group, created by omission of internal letters and sounds. Syncope is the loss of unstressed vowel.
28 After setting the words of relatives with the procedure as stated above, the
similarities, the differences, and the percentage of three languages can be determined.
The similarities and differences in the three languages could be determined by using the correspondence table to answer the first problem of study.
To answer the second of study, the technique used is lexicostatistics.
Lexicostatistics technique in a quantitative approach can be considered equal and sometimes distinguished by some linguists with glottochronology. But when viewed of the stage with the use of lexicostatistics glottochronology, both has connectivity directly. Glottochronology technique follows lexicostatistics technique.
Lexicostatistics technique is used to determine the percentage of the kinship several languages compared. After the percentage of the kinship several languages determined new technique glottochronology followed by the research is used just one term enclosing procedure is lexicostatistics analysis. The technique of lexicostatistics is a method of language grouping in a study of historical linguistics comparative which is already used by lot of researchers of language in the world. The most famous used by Dyen in his work in grouping the Austronesian languages based on 250 famous languages.
This study uses a comparison method to compile a set of traits that correspond to Teochew (TC), Hakka (HK), and Cantonese (CO) using a basic vocabulary list of three languages, compiled by Sino-Tibetan Swadesh List. The list of vocabularies brings advantages in research because they consist of non-cultural words and retention of basic words that have been tested in languages that have written texts.
Universitas Sumatera Utara
![Figure 1.1 The Map of Medan City [based on Arsip Daerah Pemerintah Kota Medan, archive of Pemko Medan]](https://thumb-ap.123doks.com/thumbv2/123dok/3318463.3798253/22.918.211.773.183.906/figure-medan-arsip-daerah-pemerintah-medan-archive-pemko.webp)
![Figure 1.2 Sino-Tibetan Family [based on Sino-Tibetan Etymological Dictionary and Thesaurus (2016), Matisoff – Principal Investigator of STEDT]](https://thumb-ap.123doks.com/thumbv2/123dok/3318463.3798253/25.918.170.858.164.1021/tibetan-tibetan-etymological-dictionary-thesaurus-matisoff-principal-investigator.webp)
![Figure 2.6 Cantonese Consonants [based on Modern Cantonese Phonology – Bauer and Benedict (2011: 16)]](https://thumb-ap.123doks.com/thumbv2/123dok/3318463.3798253/37.918.168.790.577.865/figure-cantonese-consonants-modern-cantonese-phonology-bauer-benedict.webp)




