INTISARI
Penempatan atau pengelompokan lagu sesuai dengan tema, sangat diperlukan dalam suatu siaran radio. Penempatan tema lagu yang tepat akan memudahkan penyiar radio memilihkan lagu sesuai permintaan pendengar. Cara pengelompokan tema secara otomatis dapat dipergunakan, salah satunya dengan K-means clustering. Pada penelitian ini tema lagu diambil dari teks lirik lagu. Tujuan dari penelitian ini adalah membangun sistem yang secara otomatis mampu mengelompokkan tema lirik lagu, dan mengetahui tingkat akurasi pengelompokan.
Tahapan proses dimulai dari pengolahan kata atau pengolahan teks disebut dengan text mining. Dalam text mining terdapat beberapa proses yaitu text operation yang terdiri dari tokenizing, stopword, stemming serta pembobotan kata, selanjutnya dapat diolah menggunakan K-Means clustering. Proses clustering terdiri dari, inisialisasi centroid awal menggunakan Variance Initialization, selanjutnya menghitung jarak centroid pada data menggunakan Euclidean distance, hingga dapat pengelompokkan yang sesuai dengan akurasi. Penghitungan akurasi menggunakan confusion matrix. Selanjutnya untuk melihat kesesuaian sistem yang dibuat, maka dimasukkan data baru yang diproses dengan sistem, lalu dapat menentukan data baru tergolong salah satu jenis tema.
Dari penelitian yang dilakukan pada studi kasus Radio Masdha Yogyakarta, didapatkan total data lirik lagu sebanyak 400 serta jumlah cluster terbagi menjadi empat. Cluster tersebut terdiri dari, cluster percintaan, persahabatan, religi dan perjuangan. Hasil penelitian pengelompokkan lirik lagu berdasarkan tema dapat berjalan baik dengan akurasi 93,25% untuk jumlah frekuensi kata unik maksimal 121 (batas atas) dan kata unik minimal 0 (batas bawah).
ABSTRACT
The song placement or grouping based on the theme is really needed in a radiobroadcast. The accurate song theme placement will ease the broadcaster to choose the song in accordance with the listeners’ requests. One of the automatic way of theme grouping that can be used is K-Means Clustering. In this research, the song theme is taken from the text of song lyrics. The aim of this study is developing a system that can automatically group the song lyric theme and know the accuracy level of the grouping.
The process stage is started with the data processing or text processing called as text mining. In text mining, there are some processes. First, the text operation. The text operation consists of tokenizing, stopword, steeming, and word weighting then can be processed using K-Means clustering. In clustering process, it consists of initial centroid initialization uses Variance Initialization, next counts the centroid distance on the data using Euclidean distance until get the proper grouping accurately. The accuracy counting uses confusion matrix. The next step to see the suitability system that has been made, new data is added which then is processed by a system. After that, it can decide the new data is classified into one specific theme.
From the research that has been conducted as case study in Masdha Radio Yogyakarta, total data available 400 and divided into four clusters. The clusters consist of love cluster, friendship cluster, religion cluster, and fighting cluster. The result of research song lyric grouping based on the theme works well with 93.25% accuracy for the unique word frequency numbers 121 maximum and unique word 0 minimum.
i
PENGELOMPOKAN TEMA LIRIK LAGU
MENGGUNAKAN METODE K-MEANS CLUSTERING
(Studi Kasus : Radio Masdha Yogyakarta)SKRIPSI
Diajukan Untuk Memenuhi Salah Satu Syarat
Memperoleh Gelar Sarjana Komputer
Program Studi Teknik Informatika
Disusun Oleh :
Dionisia Bhisetya Rarasati
115314045
PROGRAM STUDI TEKNIK INFORMATIKA
JURUSAN TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
ii
A GROUPING OF SONG-LYRIC THEMES
USING K-MEANS CLUSTERING
(Case Study : Radio Masdha of Yogyakarta)FINAL PROJECT
Presented as Partial Fulfillment of Requirements
To Obtain Sarjana Komputer Degree
In Informatics Engineering Study Program
Written By :
Dionisia Bhisetya Rarasati
115314045
INFORMATICS ENGINEERING STUDY PROGRAM
DEPARTMENT OF INFORMATICS ENGINEERING
FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY
YOGYAKARTA
HALAMAN
PENGESAIIAN
SKRIPSI
PENGELOMPOKAN TEMA
LIRIK
LAGU
MENGGUNAKAN
METODN K-MEANS CLUSTERING
(Studi Kasus : Radio Masdha Yogyakarta)
Dipersiapkan dan ditulis oleh :
Dionisia Bhisetya Rarasati
115314045
Telah dipertahankan di depan Panitia Penguji
Pada tanggal 27 Agustus 2015
Dan dinyatakan memenuhi syarat
Susunan Panitia Penguji
Nama Lengkap
Ketua
: Dr. Anastasia Rita Widiarti, M.Kom Sekretaris : Robertus Adi Nugroho S.T., M.Eng.Anggota
: Dr. C. Kuntoro Adi, S.J., M.A, M.Sc.Tanda Tangan
ffilqr?-r
ruL-Yogyakarta,.{J...fu-Y*g
20lE
Fakultas Sains dan TeknologiUniversitas Sanata Dharma
Dekan,
Prima Rosa, S.Si., M.Sc.
iv
d.e
&'
iit
v
HALAMAN PERSEMBAHAN
“The
key for a happiness is when
you thankful for the grace that
God has
given.”
This final project belongs to:
My Parents and my family thank you so much for guiding me
My Best Partner thank you so much for all support
vi
PERNYATAAN KEASLIAN KARYA
Saya menyatakan dengan sesungguhnya bahwa di dalam skripsi yang saya
tulis ini tidak memuat karya atau bagian karya orang lain, kecuali yang telah
disebutkan dalam kutipan dan daftar pustaka, sebagaimana layaknya karya ilmiah.
Yogyakarta, 27 Agustus 2015
Penulis
vii
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI KARYA
ILMIAH UNTUK KEPENTINGAN AKADEMIS
Yang bertanda tangan di bawah ini, saya mahasiswa Universitas Sanata Dharma:
Nama : Dionisia Bhisetya Rarasati
NIM : 115314045
Demi pengembangan ilmu pengetahuan, saya memberikan kepada Perpustakaan
Universitas Sanata Dharma karya ilmiah yang berjudul:
PENGELOMPOKAN TEMA LIRIK LAGU
MENGGUNAKAN METODE K-MEANS CLUSTERING
Beserta perangkat yang diperlukan (bila ada). Dengan demikian saya memberikan kepada
perpustakaan Universitas Sanata Dharma hak untuk menyimpan, mengalihkan dalam
bentuk media lain, mengelolanya dalam bentuk pangkalan data mendistribusikan secara
terbatas, dan mempublikasikannya di Internet atau media lain untuk kepentingan
akademis tanpa perlu meminta ijin dari saya maupun memberikan royalti kepada saya
selama tetap mencantumkan nama saya sebagai penulis.
Demikian pernyataan ini saya buat dengan sebenarnya.
Yogyakarta, 27 Agustus 2015
Yang menyatakan,
viii
INTISARI
Penempatan atau pengelompokan lagu sesuai dengan tema, sangat diperlukan dalam suatu siaran radio. Penempatan tema lagu yang tepat akan memudahkan penyiar radio memilihkan lagu sesuai permintaan pendengar. Cara pengelompokan tema secara otomatis dapat dipergunakan, salah satunya dengan K-means clustering. Pada penelitian ini tema lagu diambil dari teks lirik lagu. Tujuan dari penelitian ini adalah membangun sistem yang secara otomatis mampu mengelompokkan tema lirik lagu, dan mengetahui tingkat akurasi pengelompokan.
Tahapan proses dimulai dari pengolahan kata atau pengolahan teks disebut dengan text mining. Dalam text mining terdapat beberapa proses yaitu text operation yang terdiri dari tokenizing, stopword, stemming serta pembobotan kata, selanjutnya dapat diolah menggunakan K-Means clustering. Proses clustering terdiri dari, inisialisasi centroid awal menggunakan Variance Initialization, selanjutnya menghitung jarak centroid pada data menggunakan Euclidean distance, hingga dapat pengelompokkan yang sesuai dengan akurasi. Penghitungan akurasi menggunakan confusion matrix. Selanjutnya untuk melihat kesesuaian sistem yang dibuat, maka dimasukkan data baru yang diproses dengan sistem, lalu dapat menentukan data baru tergolong salah satu jenis tema.
Dari penelitian yang dilakukan pada studi kasus Radio Masdha Yogyakarta, didapatkan total data lirik lagu sebanyak 400 serta jumlah cluster terbagi menjadi empat. Cluster tersebut terdiri dari, cluster percintaan, persahabatan, religi dan perjuangan. Hasil penelitian pengelompokkan lirik lagu berdasarkan tema dapat berjalan baik dengan akurasi 93,25% untuk jumlah frekuensi kata unik maksimal 121 (batas atas) dan kata unik minimal 0 (batas bawah).
ix ABSTRACT
The song placement or grouping based on the theme is really needed in a radiobroadcast. The accurate song theme placement will ease the broadcaster to
choose the song in accordance with the listeners’ requests. One of the automatic
way of theme grouping that can be used is K-Means Clustering. In this research, the song theme is taken from the text of song lyrics. The aim of this study is developing a system that can automatically group the song lyric theme and know the accuracy level of the grouping.
The process stage is started with the data processing or text processing called as text mining. In text mining, there are some processes. First, the text operation. The text operation consists of tokenizing, stopword, steeming, and word weighting then can be processed using K-Means clustering. In clustering process, it consists of initial centroid initialization uses Variance Initialization, next counts the centroid distance on the data using Euclidean distance until get the proper grouping accurately. The accuracy counting uses confusion matrix. The next step to see the suitability system that has been made, new data is added which then is processed by a system. After that, it can decide the new data is classified into one specific theme.
From the research that has been conducted as case study in Masdha Radio Yogyakarta, total data available 400 and divided into four clusters. The clusters consist of love cluster, friendship cluster, religion cluster, and fighting cluster. The result of research song lyric grouping based on the theme works well with 93.25% accuracy for the unique word frequency numbers 121 maximum and unique word 0 minimum.
x
KATA PENGANTAR
Puji dan syukur penulis panjatkan kepada Tuhan Yesus Kristus atas
berkat yang diberikan dalam penyusunan Skripsi ini sehingga semuanya
dapat berjalan dengan baik dan lancar.
Skripsi ini merupakan salah satu syarat mahasiswa untuk
mendapatkan gelar sarjana S-1 pada Prodi Teknik Informatika, Fakultas
Sains dan Teknologi, Universitas Sanata Dharma Yogyakarta.
Berkat bimbingan dan dukungan dari berbagai pihak, Skripsi ini
dapat terselesaikan. Pada kesempatan ini dengan segenap kerendahan hati
penulis menyampaikan rasa terimakasih kepada :
1. Paulina Heruningsih Prima Rosa, S.Si., M.Sc., selaku Dekan Fakultas
Sains dan Teknologi Universitas Sanata Dharma Yogyakarta.
2. Dr. C. Kuntoro Adi, S.J.,M.A.,M.Sc. selaku Dosen Pembimbing Skripsi,
yang dengan sabar memberi arahan serta bimbingan kepada penulis
dalam pembuatan skripsi.
3. Drs. Ignatius Pratomo, Anastasia Sri Sumarni, Maria Sukarsih, Bernardus
Grawiradhika, Caroline Pundyaresmi selaku keluarga penulis yang
senantiasa telah mendukung dan memberi semangat penulis dalam
menyelesaikan skripsi.
4. Timotius Slamet Putro Cahyono yang selalu mendukung, memberikan
semangat serta menjadi pendengar setiap cerita suka-duka yang penulis
hadapi dalam proses pembuatan skripsi hingga dapat menyelesaikan
xi
5. Romo Poldo, Eric, Dio, Bee, Priska serta teman-teman Teknik
Informatika Universitas Sanata Dharma khususnya Angkatan 2011 dan
teman penulis lain yang tidak dapat disebutkan satu-persatu yang telah
mendukung penulis dalam menyelesaikan Skripsi ini.
Penulis menyadari dalam penulisan Skripsi ini masih jauh dari sempurna.
Segala kritik dan saran yang membangun sangat diharapkan oleh penulis
demi penyempurnaan dikemudian hari. Akhir kata, semoga Skripsi ini dapat
berguna bagi kita semua.
Yogyakarta, 27 Agustus 2015
Penulis,
xii
DAFTAR ISI
HALAMAN JUDUL ... i
TITLE PAGE ... ii
HALAMAN PERSETUJUAN ... iii
PENGELOMPOKAN TEMA LIRIK LAGU ... iii
HALAMAN PENGESAHAN ... iv
PENGELOMPOKAN TEMA LIRIK LAGU ... iv
HALAMAN PERSEMBAHAN ... v
PERNYATAAN KEASLIAN KARYA ... vi
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ... vii
PENGELOMPOKAN TEMA LIRIK LAGU ... vii
INTISARI ... viii
ABSTRACT ... ix
KATA PENGANTAR ... x
BAB I ... 1
1.1. Latar Belakang ... 1
1.2. Rumusan Masalah ... 3
1.3. Tujuan Penelitian ... 3
1.4. Batasan Masalah ... 3
1.5. Sistematika Penulisan ... 3
BAB II ... 5
2.1. Information Retrieval ... 5
2.1.1. Proses Information Retrieval ... 5
2.1.1.1. Text Operation ... 6
2.1.1.1.1. Tokenizing ... 6
2.1.1.1.2. Stopwords Removal / Filtering ... 7
2.1.1.1.3. Stemming ... 7
2.1.1.1.3.1. Aturan / Rule Stemming ... 8
2.1.1.1.4. Penggabungan Kata Berdasarkan Sinonim ... 12
2.1.1.1.5. Pembobotan Kata ... 12
xiii
2.1.1.1.7. Variance Initialization ... 16
2.2. K-Means Clustering ... 17
2.2.1. Langkah Algoritma K-Means clustering ... 19
2.2.2. Flowchart K-Means Clustering ... 21
2.3. Confusion Matrix ... 22
BAB III ... 24
3.1. Data ... 24
3.2. Deskripsi Sistem ... 24
3.3. Model Analisis ... 25
3.3.1. Diagram Block ... 25
3.3.1.1. Text Operation ... 27
3.3.1.1.1. Tokenizing ... 27
3.3.1.1.2. Stopword removal / filtering ... 29
3.3.1.1.3. Stemming ... 32
3.3.1.1.4. Pembobotan Kata ... 34
3.3.1.1.5. Penggabungan Kata (Sinonim) ... 40
3.3.1.1.6. Normalisasi Z-Score ... 41
3.3.1.2. K-Means Clustering ... 43
3.3.1.3. Pengujian Akurasi ... 46
3.4. Desain Interface ... 47
3.5. Spesifikasi Software dan Hardware ... 48
BAB IV ... 49
4.1. Implementasi ... 49
4.1.1. User Interface ... 49
4.1.2. Data ... 57
4.1.2.1. Text Operation ... 58
4.1.2.1.1. Tokenizing ... 58
4.1.2.1.2. Stopword ... 58
4.1.2.1.3. Stemming ... 59
4.1.2.1.4. Sinonim ... 60
4.1.2.1.5. Pembobotan Kata ... 61
xiv
4.1.2.2. K-Means Clustering ... 62
4.1.2.3. Output Centroid ... 63
4.1.2.4. Akurasi ... 63
4.2. Analisa Hasil ... 63
BAB V ... 68
5.1. Kesimpulan ... 68
5.2. Saran ... 69
DAFTAR PUSTAKA ... 70
xv
DAFTAR GAMBAR
Gambar 2.1 Proses Information Retrieval (Manning C. D., 2008) ... 5
Gambar 2.2 Ilustrasi Penentuan Keanggotaan Kelompok Berdasarkan Jarak (Turban dkk, 2005)... 18
Gambar 2.3 Flowchart Algoritma KMeans ... 21
Gambar 3.1 Diagram Block ... 25
Gambar 3.2 Tokenizing dokumen pertama ... 27
Gambar 3.3 Tokenizing dokumen kedua ... 28
Gambar 3.4 Tokenizing dokumen ketiga ... 28
Gambar 3.5 Tokenizing dokumen keempat ... 29
Gambar 3.6 Stopword dokumen pertama... 30
Gambar 3.7 Stopword dokumen kedua ... 30
Gambar 3.8 Stopword dokumen ketiga ... 31
Gambar 3.9 Stopword dokumen keempat ... 31
Gambar 3.10 Stemming dokumen pertama ... 32
Gambar 3.11 Stemming dokumen kedua ... 32
Gambar 3.12 Stemming dokumen ketiga ... 33
Gambar 3.13 Stemming dokumen keempat ... 33
Gambar 3.14 Pembobotan kata dokumen pertama ... 34
Gambar 3.15 Pembobotan kata dokumen kedua ... 34
Gambar 3.16 Pembobotan kata dokumen ketiga ... 35
Gambar 3.17 Pembobotan kata dokumen keempat ... 35
Gambar 3.18 Desain Interface ... 48
Gambar 4.1 Implementasi user interface sebelum proses dilakukan ... 50
Gambar 4.2 Implementasi user interface setelah proses dilakukan ... 50
Gambar 4.3 Jumlah data dan button Preprocessing... 51
Gambar 4.4 Batas bawah dan batas atas ... 52
Gambar 4.5 Button Proses Clustering ... 52
xvi
Gambar 4.7 Hasil Cluster ... 54
Gambar 4.8 Hasil Akurasi ... 55
Gambar 4.9 Hasil Input Data Baru ... 55
Gambar 4.10 Tampil Teks Lagu ... 56
Gambar 4.11 Hasil message informasi ... 56
Gambar 4.12 Kumpulan data ... 57
Gambar 4.13 Salah satu contoh data lirik lagu ... 57
Gambar 4.14 Implementasi Program Tokenizing ... 58
Gambar 4.15 Implementasi Program Stopword ... 59
Gambar 4.16 Implementasi Program Stemming ... 59
Gambar 4.17 Kamus Sinonim ... 60
Gambar 4.18 Implementasi Program Sinonim ... 60
Gambar 4.19 Hasil akurasi ... 63
Gambar 4.20 Hasil akurasi Batas Atas 121 dan Batas Bawah 0-5... 66
xvii
DAFTAR TABEL
Tabel 2.1 Kombinasi Awal dan Akhir ... 10
Tabel 2.2 Cara Menentukan Tipe Awalan Untuk awalan "te-" ... 10
Tabel 2.3 Jenis Awalan Berdasarkan Tipe ... 11
Tabel 2.4 Tabel Confusion Matrix ... 22
Tabel 3.1 Tabel menghitung DF ... 36
Tabel 3.2 Tabel menghitung IDF ... 36
Tabel 3.3 Tabel menghitung bobot pertama ... 38
Tabel 3.4 Tabel menghitung bobot kedua ... 38
Tabel 3.5 Tabel menghitung bobot ketiga ... 39
Tabel 3.6 Tabel menghitung bobot keempat ... 39
Tabel 3.7 Tabel contoh data belum mengalami penggabungan kata ... 40
Tabel 3.8 Tabel contoh data telah mengalami penggabungan kata ... 40
Tabel 3.9 Tabel Pembobotan... 41
Tabel 3.10 Tabel Standar Deviasi Per Lirik ... 42
Tabel 3.11 Tabel Mean ... 42
Tabel 3.12 Tabel Normalisasi ... 43
Tabel 3.13 Tabel Variance ... 44
Tabel 3.14 Tabel Sort Lirik ... 45
Tabel 3.15 Tabel Centroid ... 45
Tabel 3.16 Tabel Jarak Terdekat (Euclidean Distance) ... 46
Tabel 3.17 Tabel hasil cluster ... 46
Tabel 4.1 Tabel kata unik hasil preprocessing ... 53
Tabel 4.2 Tabel Hasil Centroid ... 54
Tabel 4.3 Tabel Confusion Matrix ... 55
Tabel 4.4 Tabel Pembobotan Kata ... 61
Tabel 4.5 Normalisasi Z-Score ... 62
Tabel 4.6 Hasil pengelompokkan cluster ... 62
xviii
1
BAB I
PENDAHULUAN
1.1. Latar Belakang
Radio Masdha FM adalah radio kampus dengan segala dinamika
kemahasiswaan yang dimiliki oleh Universitas Katholik yaitu Universitas
Sanata Dharma dan telah resmi berbentuk badan hukum dengan nama PT.
Radio Swara Mahasiswa Sanata Dharma. Radio Masdha FM menawarkan
program acara yang mengerti dunia kaum muda dimana tema sangat
diperlukan untuk menjelaskan perasaan atau emosi yang dapat dirangkai
melalui lirik lagu. Terdapat banyak tema lagu yang dikenal masyarakat yaitu
seperti percintaan, persahabatan, perjuangan, religi serta jenis tema lainnya.
Maka untuk menghindari penempatan tema lagu yang tidak sesuai dengan
lirik lagu diperlukan suatu metode untuk menentukan tema lagu sesuai
dengan lirik lagu. Kata-kata pada lirik lagu diolah sehingga nantinya dapat
untuk menggolongkan berdasarkan kesesuaian tema. Pengolahan kata atau
pengolahan teks disebut dengan text mining. Setelah proses pengolahan kata
selesai selanjutnya diperlukan penggolongan atau clustering tema pada lirik
lagu, salah satunya menggunakan metode K-Means.
K-Means clustering merupakan salah satu metode yang sering digunakan, karena memiliki akurasi yang tinggi serta pengolahannya yang
mudah dimengerti sehingga dinilai cukup efisien, yang ditunjukkan dengan
kompleksitasnya O(tkn), dengan catatan n adalah banyaknya obyek data, k
2 k dan t jauh lebih kecil daripada nilai n. Selain itu, dalam iterasinya metode
ini akan berhenti dalam kondisi optimum lokal (Williams, 2006).
Penelitian yang sudah pernah dilakukan berkaitan dengan tema pada lirik
lagu adalah menggunakan metode Transformed Weight-Normalized Complement Naive Bayes (TWCNB). Evaluasi sistem yang dilakukan terhadap 29 data uji dan 224 data latih dengan perubahan jumlah data latih
yang berbeda-beda pada 4 skenario menghasilkan nilai terbaik pada
precision senilai 0,89, recall senilai 0,856 dan nilai F-measure senilai 0,857.
(Pratiwi, 2014).
Melalui penjelasan metode K-Means diatas, maka pada penelitian ini menggunakan metode K-Means untuk clustering tema pada lirik lagu. Salah
satu contoh kasus yang telah dipecahkan dengan menggunakan metode K-Means Clustering adalah untuk pengelompokkan posisi pemain sepakbola (Nugroho, 2012), dimana pada penelitian ini hasil pengujian akurasi
program dengan menggunakan 5 cross validation yaitu 53,49%, 46,52%, 54,72%, 66,50%, 50,83% (rata-rata akurasi 54,41%). Sehingga dengan
melakukan penelitian ini dapat mengetahui tingkat akurasi serta efisien
untuk menyelesaikan masalah clustering tema pada lirik lagu menggunakan
metode ini.
Maka masalah pokok yang ingin dijawab pada penelitian ini ialah
dengan menggunakan metode K-Means clustering, mampukah sistem secara
otomatis mengelompokkan tema lirik lagu dengan baik, sehingga dapat
3
1.2. Rumusan Masalah
Berdasarkan Latar Belakang yang ada dapat di rumuskan masalah yaitu :
Berapakah tingkat akurasi pengelompokan lirik lagu berdasarkan tema
dengan menggunakan metode K-Means clustering ?
1.3. Tujuan Penelitian
Tujuan dari penelitian ini adalah membangun sistem yang secara
otomatis mampu mengelompokan tema lirik lagu, dan mengetahui tingkat
akurasi pengelompokkan.
1.4. Batasan Masalah
Dalam batasan masalah ini, penulis membatasi permasalahan yang perlu,
yaitu :
1. Data pada lirik lagu adalah lirik lagu yang berbahasa Indonesia.
2. Clustering yang digunakan sebanyak empat cluster yaitu percintaan, persahabatan, religi, dan perjuangan.
3. Data lirik lagu yang diambil adalah Refrain.
1.5. Sistematika Penulisan
BAB I : Pendahuluan
Berisi penjelasan mengenai masalah yang akan diteliti,
berisi latar belakang, rumusan masalah, tujuan penelitian,
4 BAB II : Landasan Teori
Berisi mengenai penjelasan dan uraian mengenai teori-teori
yang berkaitan dengan topik dari clustering tema pada lirik
lagu menggunakan metode K-Means.
BAB III : Metodologi
Berisi analisis dan desain yang merupakan detil teknis
sistem yang akan dibangun.
BAB IV : Implementasi dan Analisis Hasil
Berisi implementasi dan perancangan sistem yang telah
dibuat sebelumnya serta analisis hasil dari program yang
telah dibuat.
BAB V : Penutup
Berisi kesimpulan dan saran dari sistem yang telah dibuat,
5
BAB II
LANDASAN TEORI
Pada bab ini membahas tentang penjelasan serta uraian mengenai
teori-teori yang berkaitan dengan topik dari clustering tema pada lirik lagu menggunakan metode K-Means. Berikut ini teori-teori yang akan dibahas:
2.1. Information Retrieval
Information Retrieval merupakan sekumpulan algoritma dan teknologi untuk melakukan pemrosesan, penyimpanan, dan menemukan kembali
informasi (terstruktur) pada suatu koleksi data yang besar (Manning dkk.,
2008). Data yang digunakan dapat berupa teks, tabel, gambar maupun video.
Sistem IR yang baik memungkinkan pengguna menentukan secara cepat dan
akurat apakah isi dari dokumen yang diterima memenuhi kebutuhannya.
2.1.1. Proses Information Retrieval
Proses information retrieval secara garis besar digambarkan dalam Gambar 2.1 dibawah ini:
6 2.1.1.1. Text Operation
Text mining memiliki definisi menambang data yang berupa teks di mana sumber data biasanya didapatkan dari dokumen, dan tujuannya adalah
mencari kata - kata yang dapat mewakili isi dari dokumen sehingga dapat
dilakukan analisa keterhubungan antar dokumen. (Harlian, 2006).
Proses kerja dari text mining terdapat beberapa tahapan, yaitu:
Dalam text mining melalui proses text preprocessing, yaitu proses yang diterapkan terhadap data teks yang bertujuan untuk menghasilkan data
numerik. Tahapan dalam proses ini, yaitu :
2.1.1.1.1. Tokenizing
Tokenizing : tahap pemotongan string input berdasarkan tiap kata yang menyusunnya. Sehingga mengubah semua huruf dalam dokumen menjadi
huruf kecil dan karakter selain huruf dihilangkan.
Contoh proses tokenizing :
Kalimat asal :
Kuketuk pintuMu dan Kau bukakan.
Hasil dari text preprocessing:
Kuketuk kau
Pintumu bukakan
7 2.1.1.1.2. Stopwords Removal / Filtering
Tahap stopword adalah tahap penyaringan kata-kata penting dari hasil tokenizing, dimana kata yang tidak relevan dibuang. Proses ini menggunakan pendekatan stoplist atau stopword. Contoh stopword yaitu
“ada”, “kita”, “kamu”, dan lain lain.
Contoh proses stopword:
Hasil dari text preprocessing :
Kuketuk Kau
Pintumu bukakan
Dan
Hasil dari stopword:
Ketuk
Pintu
Bukakan
2.1.1.1.3.Stemming
Stemming merupakan tahap mencari root kata dari tiap kata hasil stopword.
Hasil dari stopword:
Ketuk
Pintu
8 Hasil dari stemming:
Ketuk
Pintu
Buka
2.1.1.1.3.1.Aturan / Rule Stemming
Algoritma Stemming untuk menghilangkan kata berimbuhan memiliki tahap-tahap sebagai berikut (Nazief dan Adriani, 2007):
1. Pertama cari kata yang akan distem dalam kamus kata dasar. Jika ditemukan
maka diasumsikan kata adalah root word. Maka algoritma berhenti.
2. Inflection Suffixes (“-lah”, “-kah”, “-ku”, “-mu”, atau “-nya”) dibuang. Jika berupa particles (“-lah”, “-kah”, “-tah” atau “-pun”) maka langkah ini
diulangi lagi untuk menghapus Possesive Pronouns(“-ku”, “-mu”, atau “
-nya”), jika ada.
3. Hapus Derivation Suffixes (“-i”, “-an” atau “-kan”). Jika kata ditemukan di
kamus, maka algoritma berhenti. Jika tidak maka ke langkah 3a
a. Jika “-an” telah dihapus dan huruf terakhir dari kata tersebut adalah “-k”,
maka “-k” juga ikut dihapus. Jika kata tersebut ditemukan dalam kamus
maka algoritma berhenti. Jika tidak ditemukan maka lakukan langkah
3b.
b. Akhiran yang dihapus (“-i”, “-an” atau “-kan”) dikembalikan, lanjut ke
langkah 4.
4. Hapus Derivation Prefix. Jika pada langkah 3 ada sufiks yang dihapus maka
9 a. Periksa tabel kombinasi awalan-akhiran yang tidak diijinkan. Jika
ditemukan maka algoritma berhenti, jika tidak
b. pergi ke langkah 4b.
c. For i = 1 to 3, tentukan tipe awalan kemudian hapus awalan. Jika root
word belum juga ditemukan lakukan langkah 5, jika sudah maka
algoritma berhenti. Catatan: jika awalan kedua sama dengan awalan
pertama algoritma berhenti.
5. Melakukan Recoding.
6. Jika semua langkah telah selesai tetapi tidak juga berhasil maka kata awal
diasumsikan sebagai root word. Proses selesai.
Tipe awalan ditentukan melalui langkah-langkah berikut:
1. Jika awalannya adalah: “di-”, “ke-”, atau “se-” maka tipe awalannya secara
berturut-turut adalah “di-”, “ke-”, atau “se-”.
2. Jika awalannya adalah “te-”, “me-”, “be-”, atau “pe-” maka dibutuhkan
sebuah proses tambahan untuk menentukan tipe awalannya.
3. Jika dua karakter pertama bukan “di-”, “ke-”, “se-”, “te-”, “be-”, “me-”, atau
“pe-” maka berhenti.
4. Jika tipe awalan adalah “none” maka berhenti. Jika tipe awalan adalah bukan
“none” maka awalan dapat dilihat pada Tabel 2.2 Hapus awalan jika
10 Tabel 2.1 Kombinasi Awal dan Akhir
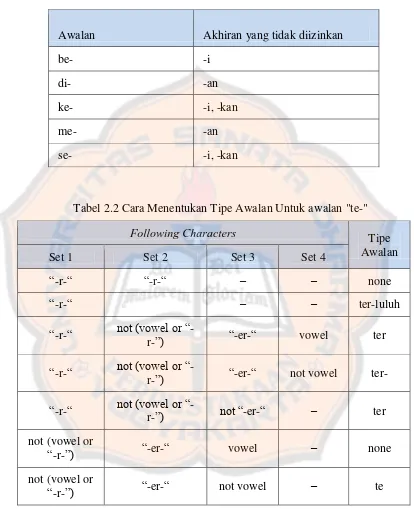
Tabel 2.2 Cara Menentukan Tipe Awalan Untuk awalan "te-"
Following Characters Tipe
Awalan Set 1 Set 2 Set 3 Set 4
“-r-“ “-r-“ – – none
“-r-“ – – ter-luluh
“-r-“ not (vowel or “
-r-”) “-er-“ vowel ter
“-r-“ not (vowel or “
-r-”) “-er-“ not vowel ter-
“-r-“ not (vowel or “
-r-”) not “-er-“ – ter
not (vowel or
“-r-”) “-er-“ vowel – none
not (vowel or
“-r-”) “-er-“ not vowel – te Awalan Akhiran yang tidak diizinkan
be- -i
di- -an
ke- -i, -kan
me- -an
11 Tabel 2.3. Jenis Awalan Berdasarkan Tipe
Tipe Awalan Awalan yang harus dihapus
di- di-
ke- ke-
se- se-
te- te-
ter- ter-
ter-luluh Ter
Untuk mengatasi keterbatasan pada algoritma di atas, maka ditambahkan
aturan-aturan dibawah ini:
1. Aturan untuk reduplikasi.
Jika kedua kata yang dihubungkan oleh kata penghubung adalah kata yang
sama maka root word adalah bentuk tunggalnya, contoh : “buku
-buku” root word-nya adalah “buku”.
Kata lain, misalnya “bolak-balik”, “berbalas-balasan, dan ”seolah-olah”.
Untuk mendapatkan root word-nya, kedua kata diartikan secara terpisah.
Jika keduanya memiliki root word yang sama maka diubah menjadi
bentuk tunggal, contoh: kata “berbalas-balasan”, “berbalas” dan “balasan”
memiliki root word yang sama yaitu “balas”, maka root word “berbalas
-balasan” adalah “balas”. Sebaliknya, pada kata “bolak-balik”, “bolak” dan
“balik” memilikiroot word yang berbeda, maka root word-nya adalah
12 2. Tambahan bentuk awalan dan akhiran serta aturannya.
Untuk tipe awalan “mem-“, kata yang diawali dengan awalan “memp-”
memiliki tipe awalan “mem-”.
Tipe awalan “meng-“, kata yang diawali dengan awalan “mengk-”
memiliki tipe awalan “meng-”.
2.1.1.1.4. Penggabungan Kata Berdasarkan Sinonim
Menurut Kamus Besar Bahasa Indonesia (KBBI) sinonim adalah bentuk
bahasa yg maknanya mirip atau sama dengan bentuk bahasa lain. Proses
sinonim akan dilakukan ketika ada kata berbeda namun memiliki makna
yang sama, untuk me-minimal-kan jumlah kata yang terdapat pada sistem,
tanpa menghilangkan jumlah frekuensi.
2.1.1.1.5. Pembobotan Kata
Pemberian bobot terhadap suatu kata dilakukan dengan memberikan
nilai frekuensi suatu kata sebagai bobot. Apabila kemunculan suatu kata
dalam dokumen semakin besar maka nilai kesesuaian semakin besar pula.
Pembobotan kata dipengaruhi oleh hal-hal berikut ini (Mandala dan
Setiawan, 2004):
1. Term Frequency (tf) factor, yaitu faktor yang menentukan bobot term pada suatu dokumen berdasarkan jumlah kemunculannya dalam dokumen
13 diperhitungkan dalam pemberian bobot terhadap suatu kata. Semakin besar
jumlah kemunculan suatu term (tf tinggi) dalam dokumen, semakin besar pula bobotnya dalam dokumen atau akan memberikan nilai kesesuian yang
semakin besar.
2. Inverse Document Frequency (idf) factor, yaitu pengurangan dominansi term yang sering muncul di berbagai dokumen. Hal ini diperlukan karena term yang banyak muncul di berbagai dokumen, dapat dianggap sebagai term umum (common term) sehingga tidak penting nilainya. Sebaliknya faktor kejarangmunculan kata (term scarcity) dalam koleksi dokumen harus
diperhatikan dalam pemberian bobot. Kata yang muncul pada sedikit
dokumen harus dipandang sebagai kata yang lebih penting (uncommon tems)
daripada kata yang muncul pada banyak dokumen (Mandala dan Setiawan,
2004). Pembobotan akan memperhitungkan faktor kebalikan frekuensi
dokumen yang mengandung suatu kata (inverse document frequency).
Pada metode ini, perhitungan bobot term t dalam dokumen dilakukan dengan mengalikan nilai Term Frequency dengan Inverse Document Frequency.
Pada Term Frequency (tf) terdapat beberapa perhitungan yang dapat digunakan yaitu (Mandala dan Setiawan, 2004):
1. tf biner (binery tf), hanya memperhatikan apakah suatu kata ada atau tidak
14 2. tf murni (raw tf), nilai tf diberikan berdasarkan jumlah kemunculan suatu
kata di dokumen.
3. tf logaritmik, hal ini untuk menghindari dominansi dokumen yang
mengandung sedikit kata dalam query, namun mempunyai frekuensi yang
tinggi.
tf = 1 + log (tf) (2.1)
4. tf normalisasi, menggunakan perbandingan antara frekuensi sebuah kata
dengan jumlah keseluruhan kata pada dokumen.
(2.2)
Pada Inverse Document Frequency (idf) perhitungannya adalah :
idf
j = log (D /df j ) (2.3)
Keterangan :
D : jumlah semua dokumen dalam koleksi
df
j : jumlah dokumen yang mengandung term t j
15
(2.4)
Keterangan :
w
ij : bobot term tj terhadap dokumen di
tf
ij : jumlah kemunculan term tj dalam dokumen di
D : jumlah semua dokumen yang ada dalam database
df
j : jumlah dokumen yang mengandung term tj
(minimal ada satu kata yaitu term t
j)
Berdasarkan Persamaan (2.4) berapapun besarnya nilai tf
ij , jika D = dfj
didapatkan hasil 0 (nol) untuk perhitungan idf. Maka dapat ditambahkan nilai 1 pada sisi idf, sehingga perhitungan bobot menjadi sebagai berikut :
(2.5)
2.1.1.1.6. Normalisasi ZScore
Z-score merupakan metode normalisasi yang berdasarkan mean (nilai rata-rata) dan standar deviasi dari data. Metode ini sangat berguna jika kita
tidak mengetahui nilai aktual minimum dan maksimum dari data. (Martiana,
2013). Lihat Persamaan (2.6)
newdata = (data-mean)/std (2.6)
Pada persamaan (2.6)
new data = data baru
mean = rata-rata
16 2.1.1.1.7. Variance Initialization
Variance Initialization merupakan salah satu teknik analisis multivariate yang berfungsi untuk membedakan rerata lebih dari dua kelompok data
dengan cara membandingkan variansinya. Analisis varian termasuk dalam
kategori statistik parametric. (Ghozali, 2009).
Untuk membandingkan variansinya, maka digunakan rumus variance yang terdapat pada persamaan (2.7)
(2.7)
Pada persamaan (2.7)
xi = nilai x ke-i
= rata-rata
n = ukuran sampel s2 = varian
Untuk menghitung standar deviasi (simpangan baku) maka digunakan
rumus standar deviasi seperti yang terdapat pada persamaan (2.8)
(2.8)
Pada persamaan (2.8)
s2 = varian
17 2.2. K-Means Clustering
K Means clustering merupakan metode yang populer digunakan untuk mendapatkan deskripsi dari sekumpulan data dengan cara mengungkapkan
kecenderungan setiap individu data untuk berkelompok dengan
individu-individu data lainnya. Kecenderungan pengelompokan tersebut didasarkan
pada kemiripan karakteristik tiap individu data yang ada. Ide dasar dari
metode ini adalah menemukan pusat dari setiap kelompok data yang
mungkin ada untuk kemudian mengelompokkan setiap data individu
kedalam salah satu dari kelompok-kelompok tersebut berdasarkan jaraknya
(Turban dkk., 2005). Semakin dekat jarak data individual, sebut saja X1
dengan salah satu pusat dari kelompok yang ada , sebut saja A, maka
semakin jelas bahwa X1 tersebut merupakan anggota dari kelompok yang
berpusat di A dan semakin jelas pula bahwa X1 bukan anggota dari
kelompok-kelompok yang lainnya (ilustrasi dapat dilihat pada gambar 2.2).
Secara kuantitatif hal ini ditunjukkan melalui fakta bahwa d1A yaitu jarak
dari X1 ke A mempunyai nilai yang paling kecil jika dibandingankan
18 Gambar 2.2 Ilustrasi Penentuan Keanggotaan Kelompok Berdasarkan
Jarak (Turban dkk., 2005)
Cara untuk menemukan pusat yang paling sesuai sebagai upaya
merepresentasikan posisi dari sebuah kelompok data terhadap kelompok
data yang lainnya dilakukan sebuah proses perulangan. Proses perulangan
ini dimulai dengan menentukan secara sembarang posisi dari pusat-pusat
kelompok yang telah ditetapkan. Selanjutnya ditentukan keanggotaan setiap
individu data berdasarkan jarak terpendek terhadap pusat-pusat tersebut.
Pada iterasi kedua dan seterusnya dilakukan pembaharuan posisi pusat untuk
semua kelompok. Langkah selanjutnya dilakukan pembaharuan keanggotaan
19 2.2.1. Langkah Algoritma K-Means clustering
Langkah-langkah dalam algoritma K-means clustering adalah (Agusta, 2007) :
1. Tentukan k sebagai jumlah cluster yang di bentuk.
Untuk menentukan banyaknya cluster k dilakukan dengan beberapa pertimbangan seperti pertimbangan teoritis dan konseptual yang mungkin
diusulkan untuk menentukan berapa banyak cluster.
2. Bangkitkan k Centroid (titik pusat cluster) awal secara random.
Penentuan centroid awal dilakukan secara random/acak dari objek-objek yang tersedia sebanyak k cluster, kemudian untuk menghitung centroid cluster ke-i berikutnya,digunakan rumus sebagai berikut :
(2.9)
dimana; : centroid pada cluster
: objek ke-i
n : banyaknya objek/jumlah objek yang menjadi anggota cluster
3. Hitung jarak setiap objek ke masing-masing centroid dari masing-masing
cluster. Untuk menghitung jarak antara objek dengan centroid penulis menggunakan Euclidian Distance.
(2.10)
20 yi : daya y ke-i
n : banyaknya objek
4. Alokasikan masing-masing objek ke dalam centroid yang paling terdekat.
Untuk melakukan pengalokasian objek kedalam masing-masing cluster pada
saat iterasi secara umum dapat dilakukan dengan cara hard k-means, dimana
secara tegas setiap objek dinyatakan sebagai anggota cluster dengan mengukur jarak kedekatan sifatnya terhadap titik pusat cluster tersebut.
5.Lakukan iterasi, kemudian tentukan posisi centroid baru dengan menggunakan persamaan (2.9).
6. Ulangi langkah 3 jika posisi centroid baru tidak sama.
21 2.2.2. Flowchart K-Means Clustering
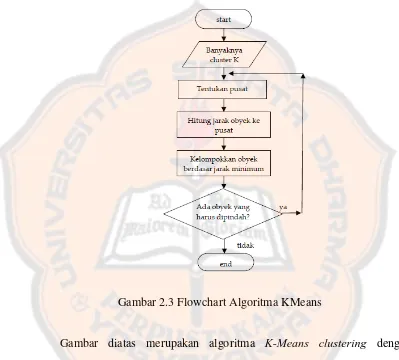
[image:41.595.99.498.190.550.2]Berikut penggambaran algoritma k-means clustering menggunakan flowchart:
Gambar 2.3 Flowchart Algoritma KMeans
Gambar diatas merupakan algoritma K-Means clustering dengan menggunakan flowchart. Langkah pertama adalah menentukan banyaknya
jumlah cluster K, selanjutnya menentukan titik pusat, penentuan titik pusat
dapat ditentukan secara random atau menggunakan salah satu cara yaitu
22 pengulangan pada tahap penentuan titik pusat, ketika tidak ada lagi obyek
yang harus dipindah maka selesai.
2.3. Confusion Matrix
Pada tahapan pengujian akurasi suatu clustering maka hal yang diproses
adalah pemberian label pada masing-masing cluster. Pemberian label di
dapat dari studi kasus, dimana pada label satu ialah percintaan, label dua
ialah perjuangan, label ketiga ialah religi dan label empat ialah persahabatan.
Setelah didapat empat label pada masing-masing cluster maka diproses menggunakan pengujian Confusion Matrix.
Confusion Matrix berisi informasi yang aktual dan dapat diprediksi (Kohavi dan Provost, 1998), dimana kinerja sistem dapat di evaluasi
menggunakan data dalam matriks.
Tabel dibawah ini menunjukkan confusion matrix untuk dua class (Kohavi dan Provost, 1998) :
Tabel 2.4 . Tabel Confusion Matrix
Keterangan :
a adalah jumlah prediksi yang benar bahwa contoh bersifat negatif.
b adalah jumlah prediksi yang salah bahwa contoh bersifat positif.
c adalah jumlah prediksi yang salah bahwa contoh bersifat positif
[image:42.595.98.516.270.621.2]23 Beberapa macam cara untuk menghitung akurasi, antara lain dengan
menggunakan :
Akurasi (AD)
Recall atau true positive rate (TP)
False positive rate (FP)
True negative rate (TN)
False negative rate (FN)
Tahap terakhir yaitu precision (P)
Dalam penelitian ini, untuk menghitung tingkat akurasi penulis
menggunakan perhitungan Akurasi (AD), dengan penjelasan:
Akurasi adalah jumlah prediksi yang benar, yang ditentukan dengan
persamaan (2.11):
24
BAB III
METODOLOGI
Bab ini menjelaskan tentang perancangan penelitian yang akan dibuat
oleh penulis, yang berisi data, deskripsi sistem, model analisis serta desain
interface. Penjelasannya sebagai berikut:
3.1. Data
Data yang digunakan adalah data lagu yang bersumber dari Radio
Masdha Yogyakarta, langkah selanjutnya mencari lirik lagu berdasarkan
data lagu yang diperoleh dari Radio Masdha Yogyakarta, selanjutnya data
lirik lagu untuk diolah hanya diambil pada bagian refrain.
3.2. Deskripsi Sistem
Sistem ini digunakan untuk mengetahui tingkat akurasi penggolongan
tema berdasarkan lirik lagu dengan menggunakan metode K-Means clustering. Langkahnya adalah melalui data lirik lagu yang berekstensi .txt, teks akan mengalami tahapan preprocessing yang terdiri dari (tokenizing, stopword dan stemming). Tahap kedua yaitu tahapan pembobotan kata menggunakan TF-IDF untuk menentukan nilai frekuensi dari dokumen, serta
melakukan penggabungan kata (sinonim), apabila terdapat kata yang
berbeda namun makna sama, maka gabungkan menjadi satu kata, setelah
mendapatkan bobot, maka hasil pembobotan di normalisasi menggunakan
25 menemukan centroid awal yang akan diproses pada tahapan K-Means clustering. Tahap selanjutnya yaitu menentukan kedekatan atau kemiripan data pada centroid yaitu tema (percintaan, perjuangan, religi dan
persahabatan) dengan metode K-Means Clustering menggunakan Euclidean
Distance. Tahap terakhir adalah proses penghitungan akurasi menggunakan Confusion Matrix.
Setelah menemukan hasil akurasi serta pengelompokkan selanjutnya
sistem melakukan proses input data baru, yang berfungsi untuk mengetahui
data baru termasuk dalam tema yang mana. Maka data baru dapat
dikategorikan termasuk salah satu dari tema yang ada.
3.3. Model Analisis
Pada bagian model analisis berisi diagram block yang terdiri dari text operation, K-means clustering, pengujian akurasi serta input data baru. Penjelasannya sebagai berikut:
3.3.1. Diagram Block
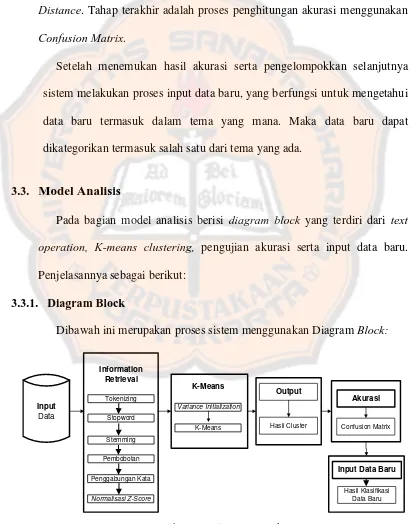
Dibawah ini merupakan proses sistem menggunakan Diagram Block:
Input
Data
Information Retrieval
Tokenizing
Stopword
Pembobotan Stemming
K-Means
Variance Initialization
K-Means
Output
Hasil Cluster
Akurasi
Confusion Matrix
Penggabungan Kata
Normalisasi Z-Score
Input Data Baru
[image:45.595.102.513.220.744.2]Hasil Klasifikasi Data Baru
26 Pada gambar 3.1. proses clustering dimulai dari input data yang berupa lirik lagu, kemudian dilanjutkan dengan text operation, pada proses ini terdapat beberapa tahapan yaitu tokenizing untuk pemisahan kata, stopword
untuk menghilangkan kata-kata yang tidak mengandung makna, stemming untuk menghilangkan kata berimbuhan, dan pembobotan untuk proses
memberi index atau frekuensi yang terdapat pada kata hasil akhir dari proses
stemming, selanjutnya masuk ke proses penggabungan kata (sinonim), apabila terdapat kata berbeda tetapi memiliki makna yang sama, maka
sistem dapat menggabungkan bersama dengan frekuensinya, lalu kata hasil
pembobotan melakukan proses normalisasi menggunakan Z-Score membandingkan kata yang satu dengan lainnya. Tahapan selanjutnya yaitu
tahapan K-Means yang terdiri dari Variance Initialization proses ini digunakan untuk mencari variance terbesar sehingga penentuan nilai awal centroid, selanjutnya proses K-Means, dicari kedekatan antara centroid yang
telah didapat dengan data menggunakan kedekatan Euclidean Distance. Selanjutnya untuk output terdiri dari hasil cluster, dimana terdapat pembagian data dalam empat cluster berdasarkan centroid terdekat. Untuk pengujian menggunakan Confusion Matrix, dimana jumlah prediksi yang benar dibagi dengan total seluruh data. Setelah menemukan hasil akurasi,
maka sistem menambahkan data baru untuk menemukan hasil klasifikasi
27 3.3.1.1. Text Operation
Langkah kerja serta penjelasan mengenai Text Operation adalah
sebagai berikut:
3.3.1.1.1.Tokenizing
Pada proses tokenizing proses yang terjadi adalah pemenggalan kalimat menjadi tiap-tiap kata, kata diubah menjadi huruf kecil dan menghilangkan
karakter yang bukan termasuk kata. Maka dibawah ini merupakan contoh
lirik lagu dari tema perjuangan, religi, percintaan dan persahabatan yang
mengalami proses tokenizing.
Dokumen pertama (perjuangan) :
Garuda pancasila Akulah pendukungmu Patriot proklamasi Sedia berkorban untukmu Pancasila dasar negara Rakyat adil makmur sentosa Pribadi bangsaku
Ayo maju maju Ayo maju maju Ayo maju maju
garuda rakyat
pancasila adil
akulah makmur
pendukungmu sentosa patriot pribadi
proklamasi bangsaku
sedia ayo
berkorban maju
untukmu maju
pancasila ayo
dasar maju
negara maju
ayo maju maju
Gambar 3.2 Tokenizing dokumen pertama
Pada gambar 3.2 merupakan contoh lirik lagu yang mengalami proses
28 Dokumen kedua (religi) :
Kau b’ri yang kupinta
Saat kumencari kumendapatkan Kuketuk pintuMu dan Kau bukakan
S’bab Kau Bapaku, Bapa yang
kekal
kau dan bri kau yang bukakan kupinta sbab saat kau kumencari bapaku kumendapatkan bapa kuketuk yang pintumu kekal
Gambar 3.3. Tokenizing dokumen kedua
Pada gambar 3.3 merupakan contoh lirik lagu yang mengalami proses
tokenizing, lirik lagu yang digunakan pada gambar diatas adalah contoh lirik lagu dengan tema religi.
Dokumen ketiga (percintaan) :
(Mencoba) mengerti, arti hadirmu,
Mengerti, sinar diwajahmu Mengerti, tenangnya jiwaku, Akhirnya ku mengerti, diriku memang untuk kau miliki
[image:48.595.98.512.104.556.2]mencoba jiwaku mengerti akhirnya arti ku hadirmu mengerti mengerti diriku sinar memang diwajahmu untuk mengerti kau tenangnya miliki
Gambar 3.4. Tokenizing dokumen ketiga
Pada gambar 3.4 merupakan contoh lirik lagu yang mengalami proses
29 Dokumen keempat (persahabatan) :
kau teman sejati kita teman sejati hadapilan dunia genggam tanganku
[image:49.595.100.515.101.654.2]kau sejati teman hadapilah sejati dunia kita genggam teman tanganku
Gambar 3.5. Tokenizing dokumen keempat
Pada gambar 3.5 merupakan contoh lirik lagu yang mengalami proses
tokenizing, lirik lagu yang digunakan pada gambar diatas adalah contoh lirik lagu dengan tema persahabatan.
3.3.1.1.2. Stopword removal / filtering
Setelah mengalami proses tokenizing, langkah selanjutnya adalah proses stopword. Stopword merupakan tahap penyaringan kata-kata yang penting, sehingga kata yang tidak relevan dapat dibuang. Kata-kata yang tidak
relevan memiliki kamus kata tersendiri, sehingga sistem mengecek kata
yang muncul di dokumen lirik lagu terhadap kamus kata stopword. Jika kata
pada data lirik lagu ada dengan kamus kata stopword maka kata tersebut dibuang. Maka dibawah ini merupakan contoh lirik lagu dari tema
perjuangan, religi, percintaan dan persahabatan yang mengalami proses
30 Dokumen pertama (perjuangan) :
garuda rakyat pancasila adil akulah makmur pendukungmu sentosa patriot pribadi proklamasi bangsaku
sedia ayo
berkorban maju untukmu maju pancasila ayo dasar maju negara maju ayo maju maju
garuda rakyat pancasila adil
makmur pendukung sentosa patriot pribadi proklamasi bangsa
sedia ayo
berkorban maju maju pancasila ayo dasar maju negara maju ayo maju maju
Gambar 3.6. Stopword dokumen pertama
Pada gambar 3.6 merupakan contoh lirik lagu yang mengalami proses
stopword, lirik lagu yang digunakan pada gambar diatas adalah contoh lirik lagu dengan tema perjuangan.
Dokumen kedua (religi) :
bukakan pinta
mencari bapa bapa ketuk
pintu kekal kau dan
bri kau yang bukakan kupinta sbab saat kau kumencari bapaku kumendapatkan bapa kuketuk yang pintumu kekal
Gambar 3.7. Stopword dokumen kedua
Pada gambar 3.7 merupakan contoh lirik lagu yang mengalami proses
31 Dokumen ketiga (percintaan) :
mencoba jiwaku mengerti
arti ku hadirmu mengerti mengerti diriku sinar memang diwajahmu untuk mengerti kau tenangnya miliki
mencoba jiwa mengerti
hadir mengerti mengerti
sinar diwajah mengerti
tenangnya miliki
Gambar 3.8. Stopword dokumen ketiga
Pada gambar 3.8 merupakan contoh lirik lagu yang mengalami proses
stopword, lirik lagu yang digunakan pada gambar diatas adalah contoh lirik lagu dengan tema percintaan.
Dokumen keempat (persahabatan) :
kau teman sejati kita teman sejati hadapilan dunia genggam tanganku
sejati teman hadapilah sejati dunia
[image:51.595.98.508.113.567.2]genggam teman tangan
Gambar 3.9. Stopword dokumen keempat
Pada gambar 3.9 merupakan contoh lirik lagu yang mengalami proses
32 3.3.1.1.3.Stemming
Pada proses selanjutnya ialah proses stemming dimana mencari kata dasar dari data lirik lagu yang diperoleh. Dibawah ini merupakan contoh
data lirik lagu yang mengalami proses stemming:
Dokumen pertama (perjuangan) :
garuda rakyat pancasila adil
makmur pendukung sentosa patriot pribadi proklamasi bangsa
sedia ayo
berkorban maju maju pancasila ayo dasar maju negara maju ayo maju maju
garuda rakyat pancasila adil
makmur dukung sentosa patriot pribadi proklamasi bangsa
sedia ayo
korban maju maju pancasila ayo dasar maju negara maju ayo maju maju
Gambar 3.10. Stemming dokumen pertama
Pada gambar 3.10 merupakan contoh lirik lagu yang mengalami proses
stemming, lirik lagu yang digunakan pada gambar diatas adalah contoh lirik lagu dengan tema perjuangan.
Dokumen kedua (religi) :
bukakan pinta
mencari bapa bapa ketuk
pintu kekal
buka pinta
cari bapa bapa ketuk
pintu kekal
33 Pada gambar 3.11 merupakan contoh lirik lagu yang mengalami proses
stemming, lirik lagu yang digunakan pada gambar diatas adalah contoh lirik lagu dengan tema religi.
Dokumen ketiga (percintaan) :
mencoba jiwa mengerti
hadir mengerti mengerti
sinar diwajah mengerti
tenangnya miliki
coba jiwa mengerti
hadir mengerti mengerti
sinar wajah mengerti
tenang milik
Gambar 3.12. Stemming dokumen ketiga
Pada gambar 3.12 merupakan contoh lirik lagu yang mengalami proses
stemming, lirik lagu yang digunakan pada gambar diatas adalah contoh lirik lagu dengan tema percintaan.
Dokumen keempat (persahabatan) :
sejati teman hadapilah sejati dunia
genggam teman tangan
sejati teman hadapi sejati dunia
genggam teman tangan
Gambar 3.13. Stemming dokumen keempat
Pada gambar 3.13 merupakan contoh lirik lagu yang mengalami proses
34 3.3.1.1.4.Pembobotan Kata
Pada proses pembobotan kata, tahapan yang dilakukan adalah
memberikan nilai frekuensi suatu kata sebagai bobot, yang nantinya dapat
diproses pada K-means clustering. Dibawah ini merupakan contoh proses pembobotan kata:
Menghitung TF (Term Frequency)
garuda rakyat pancasila adil
makmur dukung sentosa patriot pribadi proklamasi bangsa
sedia ayo
korban maju maju pancasila ayo
dasar maju
negara maju ayo maju maju
D
1 [image:54.595.99.496.210.555.2]TF garuda = 1 pancasila = 2 dukung = 1 patriot = 1 proklamasi = 1 sedia=1 korban=1 dasar=1 negara=1 rakyat=1 adil=1 makmur=1 sentosa=1 pribadi=1 bangsa=1 ayo=3 maju=6
Gambar 3.14. Pembobotan kata dokumen pertama
Pada gambar 3.14 merupakan contoh lirik lagu yang mengalami proses
penghitungan term frequency, lirik lagu yang digunakan pada gambar diatas
adalah contoh lirik lagu dengan tema perjuangan.
buka pinta
cari bapa bapa ketuk
pintu kekal
D
2 TF pinta=1 cari=1 ketuk=1 pintu=1 buka=1 bapa=2 kekal=135 Pada gambar 3.15 merupakan contoh lirik lagu yang mengalami proses
penghitungan term frequency, lirik lagu yang digunakan pada gambar diatas
adalah contoh lirik lagu dengan tema religi.
coba jiwa mengerti
hadir mengerti mengerti
sinar wajah mengerti
tenang milik
[image:55.595.99.506.192.583.2]D
3 TF coba=1 mengerti=4 hadir=1 sinar=1 wajah=1 tenang=1 jiwa=1 milik=1Gambar 3.16. Pembobotan kata dokumen ketiga
Pada gambar 3.16 merupakan contoh lirik lagu yang mengalami proses
penghitungan term frequency, lirik lagu yang digunakan pada gambar diatas
adalah contoh lirik lagu dengan tema percintaan.
sejati teman hadapi sejati dunia
genggam teman tangan
D
4 TF teman=2 sejati=2 hadapi=1 dunia=1 genggam=1 tangan=1Gambar 3.17. Pembobotan kata dokumen keempat
Pada gambar 3.17 merupakan contoh lirik lagu yang mengalami proses
penghitungan term frequency, lirik lagu yang digunakan pada gambar diatas
36 Menghitung DF (Document Frequency)
Tabel 3.1. Tabel menghitung DF ID word DF
1 Garuda 1 21 pintu 1 2 pancasila 2 22 buka 1 3 dukung 1 23 bapa 2 4 Patriot 1 24 kekal 1 5 proklamasi 1 25 coba 1 6 Sedia 1 26 mengerti 4 7 Korban 1 27 hadir 1 8 Dasar 1 28 sinar 1 9 Negara 1 29 wajah 1 10 Rakyat 1 30 tenang 1 11 Adil 1 31 jiwa 1 12 makmur 1 32 milik 1 13 sentosa 1 33 teman 2 14 pribadi 1 34 sejati 2 15 Bangsa 1 35 hadapi 1 16 Ayo 3 36 dunia 1 17 Maju 6 37 genggam 1 18 Pinta 1 38 tangan 1 19 Cari 1
20 Ketuk 1
Pada Tabel 3.1 merupakan contoh penghitungan document frequency, document frequency merupakan banyaknya bobot (term frequency) yang terkandung dalam seluruh data lirik.
Menghitung IDF (Inverse Document Frequency)
Tabel 3.2. Tabel menghitung IDF ID word DF IDF
1 garuda 1 1.7243
2 pancasila 2 1.4232
3 dukung 1 1.7243
4 patriot 1 1.7243
5 proklamasi 1 1.7243
6 sedia 1 1.7243
7 korban 1 1.7243
8 dasar 1 1.7243
9 negara 1 1.7243
37 Tabel 3.2. Tabel menghitung IDF (Lanjutan)
ID word DF IDF
11 adil 1 1.7243
12 makmur 1 1.7243
13 sentosa 1 1.7243
14 pribadi 1 1.7243
15 bangsa 1 1.7243
16 ayo 3 1.2472
17 maju 6 0.9461
18 pinta 1 1.7243
19 cari 1 1.7243
20 ketuk 1 1.7243
21 pintu 1 1.7243
22 buka 1 1.7243
23 bapa 2 1.4232
24 kekal 2 1.4232
25 coba 1 1.7243
26 mengerti 4 1.1222
27 hadir 1 1.7243
28 sinar 1 1.7243
29 wajah 1 1.7243
30 tenang 1 1.7243
31 jiwa 1 1.7243
32 milik 1 1.7243
33 teman 2 1.4232
34 sejati 2 1.4232
35 hadapi 1 1.7243
36 dunia 1 1.7243
37 genggam 1 1.7243
38 tangan 1 1.7243
Pada Tabel 3.2 merupakan contoh penghitungan inverse document frequency.
Menghitung Wij
Langkah selanjutnya ialah menghitung bobot (Wij) yang terdapat pada
38 term frequency dengan inverse document frequency. Dibawah ini merupakan contoh data lagu yang melakukan proses penghitungan Wij.
Menghitung bobot pertama
Tabel 3.3. Tabel menghitung bobot pertama
ID word DF IDF Wij
1 garuda 1 1.72427587 1.7242759 2 pancasila 2 1.423245874 2.8464917 3 dukung 1 1.72427587 1.7242759 4 patriot 1 1.72427587 1.7242759 5 proklamasi 1 1.72427587 1.7242759 6 sedia 1 1.72427587 1.7242759 7 korban 1 1.72427587 1.7242759 8 dasar 1 1.72427587 1.7242759 9 negara 1 1.72427587 1.7242759 10 rakyat 1 1.72427587 1.7242759 11 adil 1 1.72427587 1.7242759 12 makmur 1 1.72427587 1.7242759 13 sentosa 1 1.72427587 1.7242759 14 pribadi 1 1.72427587 1.7242759 15 bangsa 1 1.72427587 1.7242759 16 ayo 3 1.247154615 3.7414638 17 maju=6 6 0.946124619 5.6767477 Total Wij 36.404565
Pada Tabel 3.3 merupakan contoh penghitungan Wij yang terkandung dalam setiap data lirik. Lirik lagu yang digunakan pada gambar diatas adalah
contoh lirik lagu dengan tema perjuangan.
Menghitung bobot kedua
39 Pada Tabel 3.4 merupakan contoh penghitungan Wij yang terkandung dalam setiap data lirik. Lirik lagu yang digunakan pada gambar diatas adalah
contoh lirik lagu dengan tema religi.
Menghitung bobot ketiga
Tabel 3.5. Tabel menghitung bobot ketiga
ID word DF IDF Wij
25 coba 1 1.72427587 1.7242759 26 mengerti 4 1.122215878 4.4888635 27 hadir 1 1.72427587 1.7242759 28 sinar 1 1.72427587 1.7242759 29 wajah 1 1.72427587 1.7242759 30 tenang 1 1.72427587 1.7242759 31 jiwa 1 1.72427587 1.7242759 32 milik 1 1.72427587 1.7242759 Total Wij 16.558795
Pada Tabel 3.5 merupakan contoh penghitungan Wij yang terkandung dalam setiap data lirik. Lirik lagu yang digunakan pada gambar diatas adalah
contoh lirik lagu dengan tema percintaan.
Menghitung bobot keempat
Tabel 3.6. Tabel menghitung bobot keempat
ID word DF IDF Wij
40 Pada Tabel 3.6 merupakan contoh penghitungan Wij yang terkandung dalam setiap data lirik. Lirik lagu yang digunakan pada gambar diatas adalah
contoh lirik lagu dengan tema persahabatan.
3.3.1.1.5.Penggabungan Kata (Sinonim)
Penggabungan Kata dilihat dari sinonim yang bersumber dari Kamus
Besar Bahasa Indonesia (KBBI). Menurut Kamus Besar Bahasa Indonesia
(KBBI) sinonim adalah bentuk bahasa yang maknanya mirip atau sama
dengan bentuk bahasa lain, maka pada proses penggabungan kata dapat
dilakukan ketika terdapat kata berbeda namun memiliki arti sama, maka
dapat digabungkan menjadi satu kata, tanpa mengubah nilai frekuensi.
Dibawah ini adalah contoh kata yang mengalami proses penggabungan kata
Lihat tabel 3.7 dan 3.8:
Tabel 3.7. Tabel contoh data belum mengalami penggabungan kata kata tf
kangen 1 kawan 1 rindu 1 sahabat 1 teman 1
Tabel 3.8. Tabel contoh data telah mengalami penggabungan kata kata tf
rindu 2 teman 3
Berdasarkan contoh data diatas, terdapat lima kata yang masing-masing
41 kata yang memiliki makna berbeda, sedangkan kata lainnya masuk kedalam
dua kata tersebut.
3.3.1.1.6.Normalisasi Z-Score
Setelah menemukan pembobotan, langkah selanjutnya adalah proses
normalisasi menggunakan z-score, yang berfungsi supaya kata hasil pembobotan yang satu dengan yang lainnya dapat dibandingkan. Dibawah
ini merupakan langkah-langkah untuk mendapatkan hasil normalisasi:
1. Hasil Pembobotan yang telah mengalami proses tokenizing, stopword dan
stemming. Lihat tabel 3.9.
Tabel 3.9. Tabel Pembobotan
cinta bendera tuhan teman Dokumen 1 0.60206 0 0 0 Dokumen 2 0.60206 0 0 0 Dokumen 3 0 0.823909 0 0 Dokumen 4 0 5.20412 0 0 Dokumen 5 0.60206 0 1.124939 0 Dokumen 6 0 0 1.124939 0 Dokumen 7 0 0 0 2.40824 Dokumen 8 0 0 0 0.60206
Berdasarkan Tabel 3.9 telah mengalami proses pembobotan. Sebagai
contoh pada kata cinta di Dokumen 1, Bobot (Wij) sebesar 0.60206 yang
42 2. Mencari nilai standar deviasi dari masing-masing data lirik. Lihat tabel
3.10.
Tabel 3.10. Tabel Standar Deviasi Per Lirik STD
Dokumen 1 0.30103 Dokumen 2 0.30103 Dokumen 3 0.411954 Dokumen 4 2.60206 Dokumen 5 0.54232 Dokumen 6 0.562469 Dokumen 7 1.20412 Dokumen 8 0.30103
Pada Tabel 3.10 masing-masing dokumen dicari nilai standar deviasi,
untuk dapat diproses pada tahapan normalisasi.
3. Mencari nilai mean dari masing-masing data lirik. Lihat Tabel 3.11.
Tabel 3.11. Tabel Mean
MEAN
Dokumen 1 0.150515 Dokumen 2 0.150515 Dokumen 3 0.205977 Dokumen 4 1.30103 Dokumen 5 0.43175 Dokumen 6 0.281235 Dokumen 7 0.60206 Dokumen 8 0.150515
Pada Tabel 3.11 masing-masing dokumen dicari nilai mean, untuk dapat
diproses pada tahapan normalisasi.
4. Hasil normalisasi, berdasarkan perhitungan rumus yang telah dipaparkan
43 Tabel 3.12. Tabel Normalisasi
cinta bendera tuhan teman Dokumen 1 1.5 -0.5 -0.5 -0.5 Dokumen 2 1.5 -0.5 -0.5 -0.5 Dokumen 3 -0.5 1.5 -0.5 -0.5 Dokumen 4 -0.5 1.5 -0.5 -0.5 Dokumen 5 0.31404 -0.79612 1.278192 -0.79612 Dokumen 6 -0.5 -0.5 1.5 -0.5 Dokumen 7 -0.5 -0.5 -0.5 1.5 Dokumen 8 -0.5 -0.5 -0.5 1.5
Berdasarkan Tabel 3.12 mengalami proses normalisasi dengan
menggunakan Z-Score, nilai yang diperoleh pada tabel diatas adalah data dikurangi dengan rata-rata (mean) lalu dibagi dengan standar deviasi, maka
diperoleh nilai masing-masing normalisasi pada setiap dokumen.
3.3.1.2. K-Means Clustering
Setelah melakukan proses text operation selanjutnya langkah pengelompokkan menggunakan K-Means Clustering. Centroid awal=4 centroid, dipilih empat centroid dikarenakan sudah dibatasi dengan pengelompokan topik yang diasumsikan menjadi empat kelompok/cluster
yaitu percintaan, perjuangan, persahabatan dan religi, selanjutnya untuk
penentuan centroid menggunakan variance initialization, dicari variance terbesar, kemudian lirik di sort menggunakan hasil variance terbesar dan lirik yang sudah di sort dibagi menjadi empat bagian, setiap bagian pada kelompok/cluster dicari rata-rata/mean, maka itulah centroid awal. Setelah
44 antara centroid dengan masing-masing dokumen menggunakan Euclidean distance.
Penjelasan dari langkah kerja Metode K-Means :
1. Menentukan banyaknya cluster k
2. Menentukan centroid menggunakan Variance Initialization.
3. Menghitung centroid cluster ke-i
4. Menghitung jarak objek ke masing-masing centroid pada
tiap-tiap cluster menggunakan Euclidean Distance.
5. Pengalokasian objek ke dalam tiap-tiap cluster.
Pada tabel 3.12 menunjukkan contoh dokumen lagu yang telah
mengalami proses normalisasi, kemudian dicari variance menggunakan persamaan(2.7):
Berikut ini contoh dokumen yang telah mengalami proses variance. Lihat tabel 3.13.
Tabel 3.13. Tabel Variance
cinta bendera tuhan teman Dokumen 1 1.5 -0.5 -0.5 -0.5 Dokumen 2 1.5 -0.5 -0.5 -0.5 Dokumen 3 -0.5 1.5 -0.5 -0.5 Dokumen 4 -0.5 1.5 -0.5 -0.5 Dokumen 5 0.31404 -0.79612 1.278192 -0.79612 Dokumen 6 -0.5 -0.5 1.5 -0.5 Dokumen 7 -0.5 -0.5 -0.5 1.5 Dokumen 8 -0.5 -0.5 -0.5 1.5
45 Setelah mendapatkan nilai dari variance, maka mencari variance terbesar, lalu sort dokumen berdasarkan variance terbesar. Pada data diatas,
variance terbesar berada pada kata : bendera didokumen 3 dan 4, serta teman didokumen 7 dan 8, sebagai acuan diambil pada kata bendera
[image:65.595.98.505.239.763.2]didokumen 3, maka sort dokumen 3 yang memiliki variance terbesar. Lihat
tabel 3.14.
Tabel 3.14. Tabel Sort Lirik
Cinta bendera tuhan teman Dokumen 3 -0.5 1.5 -0.5 -0.5 Dokumen 4 -0.5 1.5 -0.5 -0.5 Dokumen 1 1.5 -0.5 -0.5 -0.5 Dokumen 2 1.5 -0.5 -0.5 -0.5 Dokumen 6 -0.5 -0.5 1.5 -0.5 Dokumen 7 -0.5 -0.5 -0.5 1.5 Dokumen 8 -0.5 -0.5 -0.5 1.5 Dokumen 5 0.31404 -0.79612 1.278192 -0.79612
Selanjutnya untuk mencari centroid langkahnya adalah bagi jumlah data
dokumen menjadi empat bagian, lalu cari rata-rata (mean) pada tiap-tiap
bagian, maka itulah centroid awal yang didapat. Lihat Tabel 3.15.
Tabel 3.15. Tabel Centroid
cinta bendera tuhan teman Dokumen 3 -0.5 1.5 -0.5 -0.5 Dokumen 4 -0.5 1.5 -0.5 -0.5 Do