BAB 3
ANALISIS HIPOTESIS
Pada bagian ini dibahas mengenai analisis hipotesis “sequential pattern dapat
dimanfaatkan sebagai node ordering dalam mengkonstruksi struktur BN”. Analisis
dimulai dengan melakukan kajian terhadap karakteristik dan manfaat dari node ordering dan sequence pattern untuk menemukan prinsip yang ada pada keduanya. Hasil yang diperoleh akan digunakan sebagai acuan dasar untuk menganalisis hipotesis, kemudian dari hasil analisis tersebut akan dapat disimpulkan kebenaran hipotesis yang diajukan.
Pada bagian akhir dilakukan analisis lebih lanjut adanya kemungkinan pemanfaatan sequential pattern sebagai informasi node ordering yang digunakan oleh algoritma apapun dalam mengkonstruksi struktur BN. Bab ini ditutup dengan pemaparan hubungan sequential pattern dan node ordering dalam konteks konstruksi struktur BN.
3.1. Node
Ordering
Sesuai dengan definisi II.16, bahwa stuktur causal Bayesian network adalah struktur yang dibangun dari model DAG. Jika model DAG dikonstruksi dengan memanfaatkan informasi node ordering, maka model DAG tersebut menyatakan bukan hanya kebebasan (independency) saja, tetapi juga kebebasan bersyarat (conditional independency) [PEA01]. Hal ini terjadi karena node ordering yang dimanfaatkan merepresentasikan kausalitas. Pernyataan tersebut diperkuat oleh definisi II.17, bahwa node ordering adalah urutan simpul-sumpul pada graf yang merepresentasikan hubungan sebab-akibat (causal) yang artinya adalah simpul yang muncul lebih awal adalah simpul yang merupakan penyebab dari simpul yang muncul berikutnya [CHE01[a]]. Sebagai contoh, seorang yang telah menderita penyakit paru akan mengakibatkan orang tersebut sering mengalami keletihan (penyakit paru-paru sebagai sebab, dan keletihan sebagai akibat). Dengan demikian, node ordering itu menyatakan suatu hubungan kausalitas yang kuat yang akan dimanfaatkan oleh algoritma konstruksi struktur BN pada saat melakukan CI test, karena node ordering
tersebut membantu untuk menemukan bukan hanya kebebasan saja, tetapi juga kebebasan bersyarat.
Informasi node ordering biasanya didefinisikan oleh pakar berdasarkan pengalamannya dengan tetap menjamin hubungan kausalitas pada seluruh simpul. Informasi node ordering dapat juga merupakan hasil uji statistik yang dilakukan pada penelitian. Pada algoritma TPDA ∏ node ordering merupakan sebuah masukan yang menjadi prasyarat mutlak ada yang harus dipenuhi.
Pada saat mengkonstruksi struktur BN, algoritma TPDA ∏ memanfaatkan informasi mengenai node ordering untuk meminimalkan jumlah CI test. Jumlah CI test dapat direduksi karena dengan diketahuinya informasi node ordering tersebut maka pemeriksaan terhadap aliran informasi yang terdapat pada pasangan simpul tidak harus berulang kali. Sebagai akibatnya, algoritma TPDA ∏ yang memanfaatkan informasi node ordering akan memiliki kompleksitas yang relatif lebih baik jika dibanding dengan algoritma lain dengan tanpa diketahui informasi node ordering.
Untuk memberi penjelasan yang lebih detil, berikut diberikan sebuah contoh yang diambil dari sub bab 2.2.1 yaitu contoh yang digunakan pada algoritma TPDA ∏. Pada saat pembahasan contoh tersebut, manfaat dari node ordering pada setiap fase konstruksi stuktur BN juga akan diidentifikasi.
Diasumsikan bahwa diberikan informasi node ordering adalah (A,B,C,D,E). Pada fase 1, dilakukan penghitungan nilai mutual information pasangan simpul yang lebih besar dari ε, dan dihasilkan urutan pasangan simpul adalah I(B,D) ≥ I(C,E) ≥ I(B,E) ≥ I(A,B) ≥ I(B,C) ≥ I(C,D) ≥ I(D,E) ≥ I(A,D) ≥ I(A,E) ≥ I(A,C). Selanjutnya pasangan simpul diambil satu demi satu untuk diperiksa, dimulai pada pasangan yang memiliki nilai mutual information terbesar. Jika hasil pemeriksaan memberikan hasil bahwa pasangan simpul yang diambil tersebut tidak memiliki lintasan terbuka (open path) pada graf terkini, maka sebuah busur dibuat untuk menghubungkan pasangan simpul tersebut. Proses pemeriksaan tersebut terus dilakukan hingga seluruh pasangan simpul telah selesai diperiksa.
Ada atau tidak ada lintasan terbuka pada graf dapat diperiksa dengan memanfaatkan informasi node ordering yang diberikan. Menurut definisi II.1, lintasan terbuka hanya dapat terjadi pada dua jenis chain yang non collider, yaitu head-to-tail dan tail-to-tail. Kedua jenis chain ini sangat mudah diidentifikasi dengan memanfaatkan node ordering. Pada gambar II.6.b simpul C dan D tidak dihubungkan oleh sebuah busur karena hasil pemeriksaan menunjukkan bahwa pasangan simpul (C,D) telah memiliki lintasan terbuka yaitu C←B→D (tail-to-tail).
Pada fase 2, graf terkini kembali diperiksa untuk menghubungkan simpul-simpul yang seharusnya terhubung, namun pada graf tersebut masih belum terhubung. Caranya adalah dengan menemukan cut set yang dapat membuat dua buah simpul d-separated pada graf. Berdasarkan definisi II.2, d-separation dapat terjadi jika setiap chain antara dua simpul diblok oleh cut set. Selanjutnya cut-set yang ditemukan akan digunakan dalam CI test untuk memeriksa apakah dua simpul tersebut adalah bebas kondisional jika diketahui cut set. Jika ternyata bebas kondisional maka pasangan simpul tersebut dihubungan dengan sebuah busur. Tanpa informasi node ordering pengujian CI test harus dilakukan berulang kali antar simpul (untuk menemukan menentukan cut-set yang minimal), sehingga dapat ditemukan arah panah dari busur yang menghubungan kedua simpul tersebut. Dengan memanfaatkan node ordering, CI test yang dilakukan tidak perlu bolak-balik antara simpul, namun cukup sekali saja sehingga kompleksitas algoritma bisa berkurang. Pada gambar II. 6.c simpul C dan D tidak dihubungkan oleh sebuah busur karena hasil CI test menunjukkan bahwa I(C,D|{B}) < ε yang artinya bebas kondisional.
Pada fase 3, graf terkini kembali diperiksa untuk membuang busur yang berlebih. Prinsip yang sama seperti pada fase 2 digunakan yaitu menemukan cut set dan melakukan CI test untuk memeriksa kebebasan kondisionalnya. Informasi node ordering juga dimanfaatkan untuk menemukan minimum cut set.
Dengan contoh yang telah diberikan, terlihat jelas bahwa informasi node ordering yang digunakan pada algoritma TPDA ∏ bermanfaat untuk mengurangi jumlah CI test yang harus dilakukan. Dengan diketahuinya node ordering, maka CI test tidak perlu lagi dilakukan berulang kali pada pasangan simpul, karena sebelum CI test
dilakukan, sumber (penyebab) dan tujuan (akibat) dari aliran informasi sudah diketahui secara pasti.
Melalui pemaparan yang telah diberikan tersebut, terlihat jelas bahwa node ordering yang digunakan oleh algoritma TPDA ∏ sangat bermanfaat untuk mengurangi banyaknya pemeriksaan lintasan dan arah yang terdapat pada pasangan simpul saat melakukan CI test. Pada satu pasang simpul, pemeriksaan dilakukan cukup satu kali saja, karena prinsip kausalitas yang melekat pada informasi node ordering menjadi sebuah syarat cukup untuk menetapkan cut set yang tepat, sehingga CI test dapat dilakukan satu kali saja dengan mengkondisikan cut set sebagai himpunan simpul yang diketahui nilainya (memiliki evident). Sebagai contoh, jika diketahui informasi node ordering adalah (A,B,C), maka pemeriksaan yang perlu dilakukan pada pasangan simpul (A,C) adalah I(A,C|B) karena {B} adalah cut set yang tepat.
3.2. Sequential
Pattern
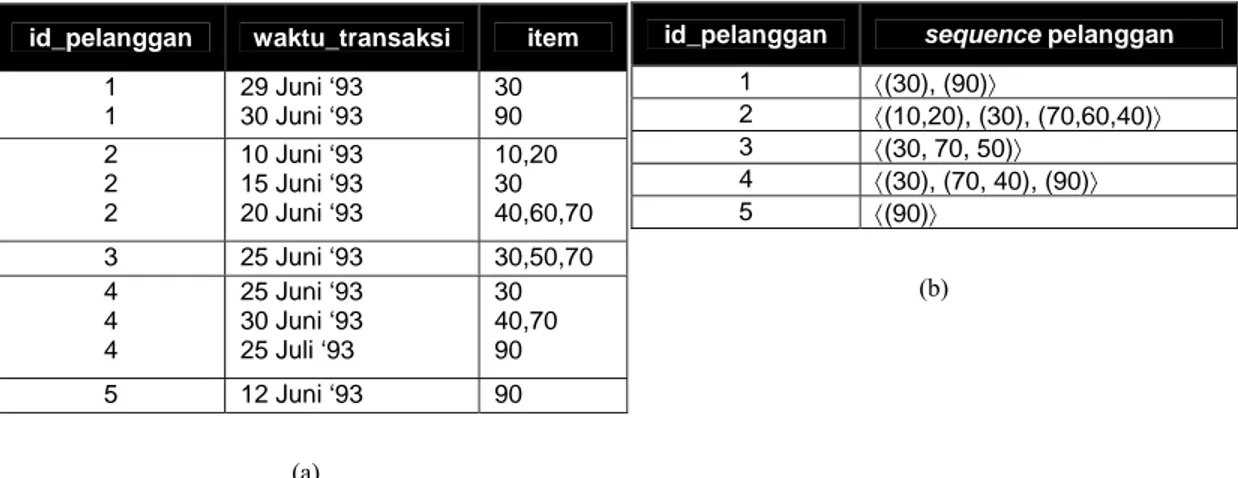
Sequential pattern adalah pola yang merepresentasikan urutan waktu terjadinya peristiwa-peristiwa (sesuai definisi II.18), yang merupakan hasil proses mining terhadap suatu himpunan data transaksi berukuran relatif besar. Sequential pattern pada dasarnya disusun oleh himpunan frequent itemset yang memenuhi min_sup, yaitu himpunan itemset yang memiliki frekuensi kemunculan melebihi threshold (sesuai definisi II.20).
Berikut diberikan sebuah contoh, yang diambil dari gambar III.1. Seluruh data transaksi telah dikelompokkan ke dalam id_pelanggan dan diurutkan menaik berdasarkan
waktu_transaksi pada gambar III.1(a) dan sequence pelanggan yang terbentuk terdapat pada gambar III.1(b)
(a)
id_pelanggan waktu_transaksi item
1 1 29 Juni ‘93 30 Juni ‘93 30 90 2 2 2 10 Juni ‘93 15 Juni ‘93 20 Juni ‘93 10,20 30 40,60,70 3 25 Juni ‘93 30,50,70 4 4 4 25 Juni ‘93 30 Juni ‘93 25 Juli ‘93 30 40,70 90 5 12 Juni ‘93 90 (b)
id_pelanggan sequence pelanggan
1 〈(30), (90)〉
2 〈(10,20), (30), (70,60,40)〉 3 〈(30, 70, 50)〉
4 〈(30), (70, 40), (90)〉
5 〈(90)〉
Gambar III.1. Cuplikan proses pembentukan sequential pattern: (a) Data seluruh transaksi dikelompokkan dan diurutkan (b) Sequence pelanggan
Sequence pelanggan yang terdapat pada gambar III.1(b) berisikan himpunan itemset. Untuk pelanggan pertama, sequence yang terbentuk adalah 〈(30), (90)〉 dengan itemset pertama berisikan sebuah item dengan nomor 30, dan itemset kedua berisikan sebuah item dengan nomor 90. Kedua itemset tersebut dituliskan terurut sesuai tanggal transaksi, yang dalam hal ini item 30 lebih dahulu dibeli kemudian item 90. Hal yang sama juga berlaku untuk pelanggan lainnya.
Dari seluruh sequence pelanggan yang terbentuk, akan ditentukan frequent itemset dengan menggunakan aturan support yang ada pada association rule. Sebagai contoh, jika didefinisikan min_sup adalah 25% maka akan dihasilkan dua buah maksimal sequence yaitu 〈(30), (90)〉 dan 〈(30), (40, 70). (definisi maksimal sequence ada pada definisi II.21).
Kedua sequence yang terbentuk akan menjadi sequential pattern. Terlihat bahwa sequential pattern tetap merepresentasikan adanya informasi temporal. Pada sequential pattern 〈(30), (40, 70)〉 itemset pertama yang berisi sebuah item dengan nomor 30, dan pada itemset kedua berisi dua buah item bernomor 40 dan 70. Hal ini menunjukkan pola transaksi yang dilakukan oleh pelanggan adalah: pertama sekali membeli item 30, dan suatu saat nanti akan membeli item 40 saja atau 70 saja atau keduanya. Pola sequence yang dihasilkan adalah akibat dari proses pengurutan
seluruh transaksi berdasarkan atribut waktu_transaksi yang dilakukan oleh masing-masing pelanggan.
Proses yang dilalui hingga dapat menemukan sequential pattern disebut sequential pattern mining, dan telah diaplikasikan dalam algoritma yang dikembangkan dengan konsep dasar sequential pattern. Sebagai catatan, dalam tulisan ini tidak dibahas tentang algoritmanya, namun sebuah algoritma AprioriAll telah diberikan pada bagian lampiran C. Pada proses tersebut, aturan support digunakan berulang kali dalam melakukan seleksi untuk menemukan seluruh frequent itemset. Aturan support tersebut adalah alat bantu uji statistik untuk menemukan seluruh sequence yang memenuhi syarat minimum support.
Dengan melihat karakteristik sequential pattern tersebut, maka dapat disimpulkan bahwa sequential pattern adalah mengandung informasi urutan waktu kejadian atau disebut dengan informasi temporal.
3.3. Analisis Hipotesis
Untuk menyegarkan ingatan, kembali dituliskan hipotesis pada penelitian ini yaitu: sequential pattern dapat dimanfaatkan sebagai informasi node ordering dalam mengkonstruksi struktur BN. Hipotesis ini berdasar pada adanya kesamaan yang terdapat pada node ordering dan sequential pattern. Yang pertama, kesamaan dalam notasi penulisan, yaitu notasi (n1,n2,n3,n4,...ni) pada node ordering dan notasi
〈s1,s2,s3,s4,...sj〉 pada sequential pattern. Yang kedua, kesamaan dalam urutan
kemunculan simpul pada node ordering dan urutan kemunculan himpunan itemset pada sequential pattern (dalam hal urutan simpul n1 muncul mendahului n2, dan dalam
hal urutan himpunan elemen s1 muncul mendahului s2). Berdasarkan kesamaan tersebut, timbul suatu dugaan bahwa pada dasarnya informasi node ordering dapat disediakan oleh sequential pattern, sehingga sequential pattern dapat dimanfaatkan sebagai node ordering dan selanjutnya digunakan sebagai paramater masukan pada algoritma konstruksi struktur BN.
Seperti telah dijelaskan terlebih dahulu, pada sequential pattern, pola sequence yang dihasilkan menyatakan urutan kejadian peristiwa-peristiwa. Dalam suatu kumpulan
data transaksi belanja atau yang lebih dikenal dengan market basket data, sequence tersebut menyatakan urutan waktu pembelian himpunan item yang dilakukan oleh pelanggan, berdasarkan waktu kunjungan belanja yang terjadi. Suatu sequential pattern dinotasikan dengan 〈 is1, is2, ... , isk〉 yang dalam hal ini ik adalah itemset dan k
merepresentasikan waktu terjadinya transaksi dengan nilai k yang lebih kecil menyatakan waktu terjadinya transaksi lebih dahulu dibandingkan dengan nilai k yang lebih besar (sesuai definisi II.21). Jadi penulisan sebuah sequential pettern 〈(30), (40, 70)〉 yang dapat juga ditulis dengan 〈(30), (70, 40)〉 (urutan item pada suatu itemset tidak diperhatikan sesuai definisi II.20), menunjukkan bahwa peristiwa terjadinya transaksi terhadap itemset (30) mendahului terjadinya transaksi terhadap itemset (40, 70). Melaui notasi penulisan tersebut ditarik kesimpulan bahwa dari seluruh transaksi yang dianalisis, peristiwa transaksi belanja terhadap item dengan nomor 30 mendahului transaksi belanja item dengan nomor 40 saja, atau 70 saja, atau 40 dan 70 bersamaan, telah memenuhi syarat tertentu untuk dapat dijadikan sebagai sebuah informasi pola belanja yang umum dilakukan oleh pelanggan. Sebagai akibatnya, jika kemudian hari seorang pelanggan melakukan transaksi pembelian terhadap item dengan nomor 30, maka probabilitas pelanggan yang sama akan membeli item dengan nomor 40 saja, atau 70 saja, atau keduanya bersamaan, lebih besar dibanding probabilitas membeli item lainnya. Pada proses menemukan pola sequence tersebut, seluruh transaksi yang terjadi dibentuk menjadi customer sequence yang disusun terurut menaik berdasarkan waktu transaksi (sesuai definisi II.20), kemudian digunakan aturan support untuk menemukan seluruh frequent itemset. Sebagai akibatnya pola sequence yang dihasilkan secara implisit menyatakan hubungan kemunculan itemset dalam urutan waktu (temporal).
Untuk lebih jelas, berikut diberikan sebuah contoh. Andaikan seorang pelanggan pada transaksi pertama melakukan pembelian terhadap sebuah item, misalkan item tersebut adalah komputer, maka biasanya pelanggan tersebut juga pada suatu saat nanti akan melakukan pembelian terhadap printer. Suatu saat di sini artinya bisa saja pada transaksi yang sama atau pada transaksi berikutnya. Namun secara intuisi, hampir dapat dipastikan bahwa seseorang tidak akan membeli printer terlebih dahulu pada suatu transaksi, lalu kemudian membeli komputer pada transaksi berikutnya. Hal ini adalah wajar, karena printer tidak dapat digunakan tanpa ada komputer, namun
sebaliknya komputer dapat digunakan meskipun tidak ada printer. Dalam contoh tersebut, printer adalah item pelengkap, sehingga printer dibeli setelah komputer. Lalu jika diasumsikan pelanggan tersebut melakukan pembelian terhadap komputer pada suatu transaksi, maka data transaksi pembelian komputer oleh pelanggan tersebut akan disimpan, dengan atribut id_pelanggan, item, dan waktu_transaksi. Seiring berjalannya waktu, pelanggan tersebut memiliki kebutuhan untuk mencetak hasil pekerjaannya dengan menggunakan printer. Kemudian pelanggan tersebut kembali ke toko yang sama untuk membeli printer. Data transaksi pembelian printer oleh pelanggan tersebut akan disimpan dengan atribut transaksi yang sama dengan transaksi sebelumnya. Sebagi akibatnya akan tercatat bahwa pelanggan tersebut telah melakukan dua transaksi terhadap item yang berbeda, yaitu transaksi pertama terhadap komputer dan kemudian transaksi kedua terhadap printer, dan kedua transaksi memiliki waktu_transaksi yang berbeda. Seluruh data transaksi yang terjadi termasuk data transaksi yang dilakukan oleh pelanggan lainnya, akan membentuk sebuah market basket data. Untuk mempersingkat penjelasan, setelah melalui proses-proses yang mengaplikasikan min_sup untuk menemukan frequent itemset, diasumsikan bahwa sequential pattern yang dihasilkan adalah 〈(komputer), (printer)〉. Sequential pattern ini merepresentasikan suatu urutan transaksi, yaitu transaksi komputer dilakukan mendahului transaksi printer.
Dari contoh tersebut terlihat bahwa pada dunia nyata sesungguhnya sudah ada hubungan kausalitas antara komputer dan printer. Hubungan kausalitas ini juga yang membentuk suatu pola sequence yang ditemukan dari basis data. Namun pola sequence yang dihasilkan dari basis data, tidak merepresentasikan adanya hubungan kausalitas antara komputer dan printer. Hal ini dapat disimpulkan karena hasil uji statistik dengan aturan support hanya akan memberikan hasil perhitungan kemunculan bersama himpunan item yang memenuhi threshold. Dengan mengambil contoh yang diberikan pada kasus pembelian komputer dan printer, sequential pattern yang ditemukan pada market basket data akan menghasilkan pola sequence yang memenuhi minimum support. Pola sequence yang dihasilkan menyatakan urutan terjadinya transaksi pembelian itemset. Pengujian statistik yang dilakukan secara ilmiah dalam menghasilkan sequential pattern yang hanya merepresentasikan informasi temporal (urutan waktu terjadinya peristiwa).
Pada node ordering, penulisan notasi dinyatakan dengan (n1,n2,n3,n4,...,ni) yang
merepresentasikan hubungan kausalitas yang ada pada seluruh simpul tersebut. Sebuah informasi node ordering berupa (A,B,C,D,E) merepresentasikan bahwa simpul A adalah penyebab dari simpul B, C, D, dan E sehingga pasangan simpul yang dihubungkan oleh busur berarah yang mungkin dibentuk adalah: AÆB, AÆC, AÆD, AÆE, BÆC, BÆD, BÆE, CÆD, CÆE, dan DÆE (sesuai definisi II.7).
Dalam proses membangun struktur BN, algoritma TPDA ∏ memanfaatkan informasi node ordering tersebut dalam melakukan pengujian statistik yang disebut dengan CI test untuk memeriksa apakah dua buah simpul bebas kondisional atau tidak, sehingga jumlah CI test dapat dikurangi. Pemeriksaan dengan mudah dilakukan pada saat menemukan cut-set yang tepat yang dapat membuat simpul A dan simpul B menjadi d-seperated. Sebagai contoh, untuk melakukan d-seperation terhadap simpul A dan simpul B, dengan informasi node ordering adalah (A,B,C,D,E) yang menunjukkan bahwa A mendahului B, maka sebuat cut set dapat ditentukan sebagai orangtua dari B.
Berdasarkan definisi II.11, sesuai konteks berpikir manusia, informasi node ordering akan diterjemahkan ke dalam dua aspek yaitu temporal dan statistik. Secara temporal, jika diberikan informasi node ordering adalah (A,B,C) maka dapat dinyatakan bahwa simpul A adalah penyebab dari simpul B, atau simpul C, atau kedua simpul B dan C, yang berarti A terjadi lebih dahulu kemudian B dan kemudian C. Tetapi aspek temporal saja tidak cukup, sehingga seharusnya perlu penjelasan ilmiah secara statistik untuk menterjemahkan node ordering. Namun karena informasi node ordering didefinisikan secara langsung oleh pakar dan merupakan hasil penelitian atau pengalamannya, maka penjelasan statistik tidak diperlukan lagi, karena hubungan kausalitas pada node ordering sudah dijamin.
Pada lain pihak, sequential pattern merepresentasikan informasi temporal. Informasi temporal yang ada pada sequential pattern cocok dengan informasi node ordering namun terbatas hanya pada aspek temporal saja. Jika seandainya sequential pattern merepresentasikan hubungan kausalitas maka sudah pasti sequential pattern cocok dengan node ordering. Namun karena penjelasan ilmiah secara statistik pada
sequential pattern yang dilakukan dengan mengaplikasikan hanya prinsip frequent itemset, maka sequential pattern sama sekali tidak merepresentasikan hubungan kausalitas, namun hanya merepresentasikan informasi temporal. Pada lain pihak, node ordering yang dihasilkan oleh pakar, didefinisikan berdasarkan suatu uji statistik atau pengalamannya dan telah dijamin hubungan kausalitas simpul penyusunnya (dituliskan pada bab 3). Pengujian statistik yang dilakukan pada node ordering semata-mata hanya menentukan hubungan kausalitas yang terkandung pada kumpulan data, dan tidak ada hubungannya dengan informasi temporal (sesuai definisi II.13)
Secara notasi penulisan, memang sequential pattern dengan notasi 〈is1, is2, ... , isk〉 dan
node ordering dengan notasi (n1,n2,n3,n4,...,ni) memiliki persamaan ditinjau dari
struktur penulisannya. Namun meskipun dari sisi notasi keduanya dituliskan relatif sama, namun kedua notasi penulisan tersebut tidak merepresentasikan satu prinsip yang sama, masing-masing merepresentasikan prinsip yang berbeda, yaitu prinsip informasi temporal pada sequential pattern dan prinsip hubungan kausalitas pada node ordering. Demikian juga urutan kemunculan simpul yang ada pada node ordering, meskipun pada sequential pattern notasi 〈is1, is2, ... , isk〉 menyatakan bahwa
is dengan indeks k yang lebih kecil lebih dahulu terjadi dibanding is dengan indeks k yang lebih besar, sama seperti pada node ordering notasi (n1,n2,n3,n4,...,ni) yang
menyatakan bahwa simpul n dengan indeks i yang lebih kecil lebih dahulu terjadi dibanding n dengan indeks i yang lebih besar, namun pada node ordering urutan simpul tidak semata-mata hanya merepresentasikan urutan kejadian. Pada node ordering, selain merepresentasikan urutan kejadian, juga merepresentasikan hubungan kausalitas. Lebih lanjut lagi, pada algoritma konstruksi struktur BN, informasi node ordering yang dimanfaatkan adalah informasi node ordering yang merepresentasikan adanya hubungan kausalitas.
3.1.1. Kesimpulan Analisis Hipotesis
Sesuai dengan pembahasan yang diberikan, maka meskipun aspek temporal memberi peluang kepada sequential pattern untuk dapat dimanfaatkan sebagai informasi node ordering, namun karena informasi node ordering yang dibutuhkan oleh algoritma konstruksi struktur BN adalah informasi yang merepresentasikan adanya hubungan kausalitas, akibatnya hipotesis dipatahkan. Sesuai dengan definisi II.13 bahwa hanya
hubungan kausalitas yang dapat ditemukan lewat pengujian statistik, dan tidak ada hubungannya dengan informasi temporal.
Untuk dapat menyimpulkan keterkaitan antara sequential pattern dan node ordering, maka kembali digunakan definisi II.11. Menurut definisi II.11 dalam konteks berpikir manusia, hubungan kausalitas harus memenuhi dua aspek yaitu: temporal dan statistik. Aspek temporal menyatakan bahwa sebab harus mendahului akibat. Sedangkan aspek statistik adalah untuk menyatakan suatu ‘penjelasan ilmiah’ akan kausalitas untuk memastikan bahwa hanya hal yang bersifat ilmiah yang akan dihasilkan [PEA01]. Artinya adalah bahwa dengan melakukan pengujian statistik, hubungan kausalitas dapat dinyatakan secara ilmiah, dan pada setiap hubungan kausalitas tentu mengandung informasi temporal.
Pada sub bab sebelumnya, node ordering secara ilmiah berdasarkan pemeriksaan statistik sudah terbukti merepresentasikan hubungan kausalitas. Berdasarkan definisi tersebut, maka node ordering juga pasti merepresentasikan informasi temporal. Pada lain pihak, sequential pattern secara ilmiah berdasarkan pemeriksaan statistik hanya merepresentasikan informasi temporal. Maka disimpulkan bahwa secara matematis,
sequential pattern adalah himpunan bagian dari node ordering.
Sudah jelas bahwa sequential pattern tidak memiliki unsur kausalitas untuk dijadikan sebagai node ordering. Pertanyaan yang kemudian muncul adalah: apakah dengan menambahkan uji statistik kausalitas pada sequential pattern yang sudah ditemukan tersebut (atau diformulasikan dengan SP + uji statistik kausalitas), akan membuat hasil baru tersebut dapat dimanfaatkan sebagai node ordering sehingga dapat dimanfaatkan oleh algoritma konstruksi struktur BN?
Sesungguhnya hasil baru tersebut (SP + uji statistik kausalitas) dapat dimanfaatkan sebagai node ordering. Namun jika hal ini dilakukan, akan terjadi tumpang tindih (over lap) antara SP + uji kausalitas dan algoritma konstruksi struktur BN itu sendiri. Hasil analisis pada peran node ordering pada sub bab III.1 menunjukan bahwa pemeriksaan kebebasan kondisional (CI test) pada pasangan simpul dapat dikurangi bila informasi node ordering sudah diketahui, dan dalam hal ini pengujian CI test tersebut adalah pengujian statistik kausalitas. Dari kenyataan ini jelas terlihat bahwa
pada saat mengkonstruksi struktur BN, algoritma melakukan sejumlah uji statistik untuk memeriksa kebergantungan dan kebebasan kondisional pada pasangan simpul, dan uji statistik tersebut sesungguhnya telah menemukan kausalitas yang ada pada simpul-simpul yang diperiksanya (definisi konsep CI test dan d-separation). Sebagai akibatnya, jika uji statistik kausalitas dilakukan juga pada SP, maka uji statistik kualitas akan dilakukan dua kali sehingga tidak efektif dan tidak efisien. Jadi disimpulkan bahwa uji statistik kausalitas yang dilakukan pada SP (SP + uji statistik kausalitas) dianggap tidak efektif dan tidak efisien.
Sebenarnya SP yang dihasilkan dapat dimanfaatkan untuk mempersempit ruang pencarian terhadap NO. Penjelasannya adalah sebagai berikut. Pada saat menentukan NO, tersedia sejumlah variabel yang menjadi atribut data. Pada awalnya, seluruh variabel ini akan dijadikan sebagai NO. Namun pada pembentukan NO tersebut, SP yang sudah dihasilkan dapat dimanfaatkan sehingga jumlah variabel yang membentuk NO dapat direduksi, karena informasi temporal yang direpresentasikan oleh SP dapat dimanfaatkan untuk mempersempit ruang pencarian pada saat menentukan NO.
Karena informasi SP tidak memadai untuk dapat menjadi NO, maka hipotesis yang menyatakan bahwa: “sequential pattern dapat dimanfaatkan sebagai informasi node
ordering dalam mengkonstruksi struktur Bayesian network” secara ilmiah
dinyatakan tidak sepenuhnya benar. Sequential pattern masih dapat dimanfaatkan sebagai informasi node ordering namun tidak secara langsung, karena pada sequential pattern yang telah dihasilkan perlu ditambahkan uji statistik kausalitas sehingga sequential pattern tersebut akan merepresentasikan informasi kausalitas, dan selanjutnya dapat dimanfaatkan sebagai node ordering.