Fakultas Ilmu Komputer
Universitas Brawijaya
3366
Implementasi Metode Support Vector Machine (SVM) Untuk Klasifikasi
Rumah Layak Huni (Studi Kasus: Desa Kidal Kecamatan Tumpang
Kabupaten Malang)
Weni Agustina1, Muh. Tanzil Furqon2, Bayu Rahayudi3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Rumah merupakan bagian penting dalam aspek kehidupan. Rumah yang layak digunakan tempat tinggal yaitu rumah yang bersih, aman, dan nyaman. Kurangnya pengetahuan tentang fungsi rumah pada masyarakat, semakin susah terwujudnya rumah yang layak huni. Pemerintah kesulitan dalam menilai rumah layak huni, pada kenyataanya rumah yang tidak bagus namun penghasilan tinggi. Bantuan yang diberikan pemerintah seringkali salah sasaran, banyak masyarakat yang protes karena hal seperti ini. Untuk mengatasi masalah tidak salah sasaran, maka pemerintah membutuhkan sistem yang mengklasifikasikan rumah layak huni dan rumah tidak layak huni. Sistem untuk klasifikasi rumah layak huni dibuat menggunakan metode Support Vector Machine (SVM). Dalam penelitian ini menggunakan 160 data yang terbagi menjadi dua jenis yaitu layak dan tidak layak. Metode yang digunakan yaitu metode Support Vector Machine (SVM) merupakan metode klasifikasi yang baik. Metode Support Vector Machine (SVM) ini bersifat linier, namun metode SVM juga bisa digunakan untuk menyelesaikan masalah non-linier. Hasil pengujian menghasilkan rata-rata akurasi sebesar 98,75% dengan menggunakan metode pengujian K-fold Cross Validation dengan nilai k = 10, serta parameter metode SVM antara lain yaitu 𝜆 = 0,5, 𝛾 = 0,001, 𝐶 = 1, 𝑑 = 2, iterasi maksimum = 10 iterasi dan menggunakan kernel Polynomial of degree.
Kata kunci: klasifikasi, rumah, layak huni, support vector machine
Abstract
House is an important part in the aspect of life. A habitable house that is good to be used is clean, safe, and comfortable. Lack of knowledge about the function of house in the society, more difficult to imply the realization of a habitable house. Government gets difficulty in assessing the habitable house. In fact, the unpreety house has high income. Government's assistance often misplaced, many people complain because of this. To overcome the problem, then the government needs a system that classifies habitable house and inhabitable house. The system for classification of habitable house was made using the Support Vector Machine (SVM) method. this study uses 160 data that is divided into two types that are habitable and inhabitable. The method used is Support Vector Machine (SVM) method is a good classification method. Support Vector Machine (SVM) method is linear, but SVM method can also be used to solve non-linear problem. The experiment result shows an average accuracy of 98,75% using K-fold Cross Validation test method with k = 10, and SVM method parameters are 𝜆 = 0,5, 𝛾 = 0,001, 𝐶 = 1, 𝑑 = 2, maximum iteration = 10 iteration and using the Polynomial of degree kernel.
Keyword: classification, house, uninhabitable, support vector machine
1. PENDAHULUAN
Kebutuhan manusia yang paling dasar yaitu rumah. Rumah harus bersih, nyaman, aman serta layak huni. Rumah layak huni susah diwujudkan oleh masyarakat yang
miskin karena keterbatasan ekonomi (Hendi, 2016).
Kenyataan yang ada di masyarakat yaitu masih banyak rumah yang tidak layak huni. Keterbatasan pengetahuan tentang fungsi rumah dan sarana prasarana dapat menyebabkan semakin sulit terwujudnya
rumah layak huni (Kementrian Sosial Republik Indonesia, 2017).
Pemerintah kesulitan dalam menilai rumah yang layak atau tidak layak. Pada kenyatannya rumah yang tidak layak, akan tetapi mempunyai penghasilan yang cukup lumayan untuk membangun rumah yang layak. Oleh karena itu, diperlukan suatu sistem untuk mengklasifikasikan rumah layak huni dan rumah tidak layak huni berdasarkan kriteria-kriteria seperti penghasilan, keadaan fisik bangunan, dan fasilitas yang ada di dalam rumah agar dapat membantu pemerintah dalam pemberian bantuan supaya tidak salah sasaran.
Pada penelitian yang dilakukan sebelumnya tentang klasifikasi rumah layak huni yang dilakukan oleh (Simatupang, Wuryandari, & Suparti, 2016). Penelitian ini mempunyai akurasi 71,43% dan tingkat error sebesar 28,57%. Sedangkan penelitian menggunakan metode Naive Bayes Classifier mempunyai tingkat akurasi 95,24% dan tingkat error 4,76%.
Penelitian selanjutnya tentang metode Support Vector Machine (SVM) yang dilakukan oleh (Ogunlana, Olabode, Oluwadare, & Iwasokun, 2015). Penelitian ini membahas tentang klasifikasi jenis ikan menunjukkan bahwa metode Support Vector Machine (SVM) mempunyai tingkat akurasi sebesar 78,59%. Penelitian selanjutnya yang dilakukan oleh (Ustuner, Samli, & Dixon, 2015) ini membahas tentang citra RapidEye untuk wilayah studi di Turki menggunakan metode Support Vector Machine (SVM) dan menunjukkan tingakat akurasi sebesar 85,63%. Sedangkan pada penelitian yang yang dilakukan oleh (Vanitha, Devaraj, & Venkatesulu, 2015) membahas klasifikasi data gen microarray. Dengan menggunakan metode SVM linier mempunyai tingkat akurasi 0,9777. Dari penelitian yang dilakukan sebelumnya, metode Support Vector Machine (SVM) mempunyai akurasi yang tinggi dalam proses klasifikasi data.
Berdasarkan uraian dari penelitian-penelitian di atas, maka penuliskmengambil judul “Implementasi Metode Support Vector Machine untuk Klasifikasi Rumah Layak Huni Studi Kasus: Desa Kidal Kecamatan Tumpang Kabupaten Malang”. Kriteria-kriteria yang digunakan yaitu tentang fisik bangunan rumah dan fasilitas yang ada di dalam rumah, metode Support Vector
Machine dianggap mempunyai tingkat akurasi yang baik dalam masalah klasifikasi data.
2. KAJIAN PUSTAKA 2.1 Rumah Layak Huni
Rumah adalah salah satu kebutuhan yang wajib dipenuhi. Rumah merupakan tempat tinggal, tempat berkumpul keluarga. Oleh karena itu, rumah harus dalam keadaan layak huni demi terbentuknya kesejahteraan masyarakat. Namun, saat ini dengan meningkatnya kemiskinan serta ekonomi yang lemah akan mempersulit untuk mewujudkan rumah yang layak huni (Hendi, 2016).
Pekerjaan masyarakat desa yang mayoritas adalah petani serta kurangnya pengetahuan terhadap masyarakat akan pentingnya rumah yang tidak membahayakan penghuninya juga menjadi penyebab sulitnya menciptakan rumah yang layak huni.
Untuk mengatasi masalah tersebut pemerintah mengadakan program dengan cara memberikan bantuan kepada rumah yang tidak layak huni yang disebut dengan Rehabilitas Sosial Rumah Tidak Layak Huni (RS-RTLH). Bantuan yang diberikan kepada masyarakat yaitu berupa bantuan dana untuk memperbaiki rumah yang rusak dan tidak layak huni (Fauzi, 2016).
Kriteria-kriteria yang harus dipenuhi untuk mendapatkan bantuan dana dari pemerintah antara lain (Kementrian Sosial Republik Indonesia, 2017):
1. Mempunyai kartu identitas diri yang masih berlaku (KTP/Identitas lain)
2. Kepala keluarga atau anggota keluarga tidak mempunyai pekerjaan atau mempunyai pekerjaan tetapi penghasilannya tidak dapat kmemenuhi kebutuhan keluarga sehari-hari.
3. Kebutuhan pokok tidak dapat terpenuhi sehingga masih membutuhkan bantuan seperti zakat dan raskin
4. Hanya rumah dan tanah barang berharga yang dimiliki
5. Rumah yang ditempati merupakan rumah tidak layak huni, dengan kondisi rumah:
a. Tidak permanen dan/atau rusak b. Dinding dan atap terbuat dari bahan
c. Dinding dan atap sudah rusak sehingga bahaya bagi keselamatan penghuni
d. Lantai rumah sudah rusak
6. Tidak mempunyai fasilitas kamar mandi, cuci, dan kakus.
2.2 Klasifikasi
Klasifikasi adalah proses mengelompokkan data menjadi kelas tertentu berdasarkan kelas yang sudah ada (Simatupang, Wuryandari, & Suparti, 2016). Klasifikasi merupakan teknik yang memudahkan karena dengan melakukan klasifikasi data akan lebih mudah dalam proses pencarian karena data sudah berkelompok. Klasifikasi dapat mempermudah mengidentifikasi data dalam jenis dan kelompok, sehingga klasifikasi bisa memprediksi anggota kelompok dari masing-masing data (Bhavsar & Panchal, 2012).
Teknik yang digunakan dalam proses klasifikasi antara lain Decision Tree Induction, Rule Base classifier, Bayesian classifier, Artifical Neural Network, Nearest Neighbor classifier, Support Vector Machine, dan Ensamble classifier (Bhavsar & Panchal, 2012).
2.3 Support Vector Machine (SVM)
Support Vector Machine (SVM) adalah salah satu metode yang bisa digunakan dalam proses klasifikasi atau regresi. Metode SVM dapat mengklasifikasikan masalah secara linier, namun saat ini SVM sudah berkembang bisa menyelesaikan masalah secara non-linier dengan mencari hyperplane yang digunakan untuk jarak maksimal antar kelas data (Oktaviani, Wulandari, & Ispriyanti, 2014).
Support Vector Machine (SVM) merupakan metode yang bersifat non-parametric dan biasanya digunakan dalam klasifikasi data serta pengolahan citra. Tingkat akurasi pada metode ini diambil dari parameter dan kernel, pengguna dapat menetukan parameter dan pada kernel setiap parameter akan memiliki dampak yang berbeda (Ustuner, Samli, & Dixon, 2015).
Metode Support Vector Machine (SVM) terdapat dua cara dalam penyelesainnya, yaitu linier dan non-linier.
1. Normalisasi
Normalisasi yaitu proses menyederhanakan rentang data dengan jangkauan nilai tertentu. Normalisasi digunakan untuk data yang bernilai
sangat besar dan sangat kecil agar mendapatkan rentang nilai yang seimbang (Haryati, et al., 2016). Berikut adalah rumus persamaan normalisasi data yang akan dijelaskan pada Persamaan 2.1
𝑵𝒐𝒓𝒎𝒂𝒍𝒊𝒔𝒂𝒔𝒊 = 𝒙−𝒎𝒊𝒏
𝒎𝒂𝒙−𝒎𝒊𝒏 (2.1) Pada Persamaan 2.1 yaitu untuk menghitung normalisasi data. Nilai normalisasi dapat diperoleh dari nilai x data dikurangi nilai nimimal dari keseluruhan data, selanjutnya dibagi nilai maksimal data yang dikurangi nilai minimal.
2. Squential Training
Metode Support Vector Machine (SVM) mempunyai beberapa jenis proses training antara lain Quadratic Programming, Sequential Minimal Optimization, dan Sequential Training. Quadratic Programming memerlukan waktu yang cukup lama serta algoritmanya kompleks. Sequential Minimal Optimization sebagai pengembangan Quadratic Programming yang digunakan unrtuk menyelesaikan optimasi yang kecil serta algoritmanya juga kompleks. Sedangkan Sequential Training, algoritmanya lebih sederhana serta tidak butuh waktu yang lama. Berikut adalah Algoritma Sequential Training (Vanitha, Devaraj, & Venkatesulu, 2015).
Melakukan inisialisasi terhadap 𝛼1= 1, kemudian parameter lainnya seperti 𝜆 = 0.5, 𝛾 = 2, 𝐶 = 1, 𝜀 = 0.0001.
Menghitung matriks hessian dengan persamaan 2.2.
𝐷𝑖𝑗= 𝑦𝑖𝑦𝑗(𝐾(𝑥𝑖, 𝑥𝑗) + 𝜆2 (2.2) Mulai dari data ke i sampai dengan j, dapat dihitung nilai error menggunakan persamaan berikut: a. Menghitung 𝐸𝑖 𝐸𝑖 = ∑𝑛𝑗=1𝛼𝑗𝐷𝑖𝑗 (2.3) b. Menghitung 𝛿𝛼𝑖 𝛿𝛼𝑖 = min(max[𝛾(1 − 𝐸𝑖), 𝛼𝑖] , 𝐶 − 𝛼𝑖 (2.4) c. Menghitung 𝛼𝑖 d. 𝛼𝑖 = 𝛼𝑖+ 𝛿𝛼𝑖 (2.5) Langkah ketiga dilakukan secara berulang-ulang sampai mendapatkan iterasi maksimum. Kemudian akan didapatkan nilai support vector.
3. Testing Support Vector Machine
Testing merupakan tahap pengujian dari metode Support Vestor Machine. Tahap testing dilakukan untuk mencari nilai 𝑓(𝑥) yang ditunjukkan pada persamaan 2.6.
𝑓(𝑥) = ∑𝑛𝑖=1𝛼𝑖𝑦𝑗𝐾(𝑥𝑖, 𝑥) + 𝑏 (2.6) Untuk mencari nilai 𝑏 dapat menggunakan persamaan 2.7. 𝑏 = −1 2[∑ 𝛼𝑖𝑦𝑖𝐾(𝑥𝑖, 𝑥 +) + 𝑛 𝑖=1 ∑𝑛𝑖=1𝛼𝑖𝑦𝑖𝐾(𝑥𝑖, 𝑥−)] (2.7) 4. Akurasi
Dalam teknik klasifikasi akan ada teknik untuk menguji tingkat akurasi. Pengujian akurasi digunakan untuk mengecek hasil dari sistem dengan data yang ada sebenarnya. Proses perhitungan akurasi dan tingkat error adalah sebagai berikut (Simatupang, Wuryandari, & Suparti, 2016):
𝐴𝑘𝑢𝑟𝑎𝑠𝑖 =𝑗𝑢𝑚𝑙𝑎ℎ𝑑𝑎𝑡𝑎𝑢𝑗𝑖𝑦𝑎𝑛𝑔𝑏𝑒𝑛𝑎𝑟 𝑗𝑢𝑚𝑙𝑎ℎ𝑡𝑜𝑡𝑎𝑙𝑑𝑎𝑡𝑎𝑢𝑗𝑖 (2.8) 𝐸𝑟𝑟𝑜𝑟 =𝑗𝑢𝑚𝑙𝑎ℎ𝑑𝑎𝑡𝑎𝑢𝑗𝑖𝑦𝑎𝑛𝑔𝑠𝑎𝑙𝑎ℎ
𝑗𝑢𝑚𝑙𝑎ℎ𝑡𝑜𝑡𝑎𝑙𝑑𝑎𝑡𝑎𝑢𝑗𝑖 (2.9)
5. K-fold Cross Validation
K-fold Cross Validation merupakan metode pengujian yang digunakan untuk optimasi nilai parameter. Terdapat nilai k yang digunakan untuk membagi data dan melakukan proses perulangan pada pengujian (Athoillah, Irawan, & Imah, 2015).
3. PERANCANGAN DAN IMPLEMENTASI
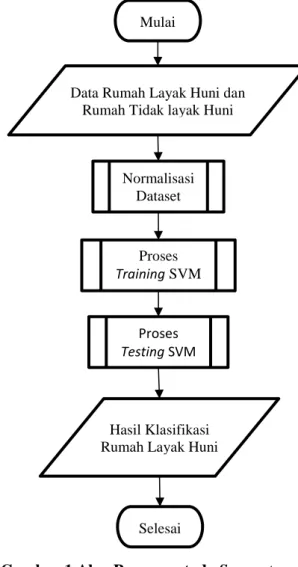
Proses klasifikasi rumah layak huni dengan metode support vector machine ditunjukkan pada Gambar 1.
Gambar 1 menjelaskan tentang proses klasifikasi rumah layak huni menggunakan metode Support Vector Machine (SVM). Proses awal yaitu memberikan input berupa data parameter rumah layak huni sebagai acuan proses seleksi penerima bantuan. Data berjumlah 160 data dengan parameter antara lain jumlah penghasilan per bulan, pekerjaan, jumlah anggota, jumlah KK dalam rumah, status kepemilikan tanah, kondisi rumah, luas bangunan, luas tanah, jenis lantai rumah, bahan dinding rumah, kondisi dinding rumah, bahan atap rumah, kamar MCK, air bersih, dan listrik
Data parameter tersebut akan dihitung mengunakan metode Support Vector Machine (SVM). Selanjutnya dilakukan proses nomalisasi pada dataset serta membagi dataset tersebut menjadi data training dan data testing. Metode Support Vector Machine (SVM) dimulai dari proses training dengan menggunakan metode sequential training untuk mendapatkan parameter SVM. Proses testing akan dilakukan
setelah proses training selesai. Output yang dihasilkan berupa hasil klasifikasi rumah layak huni yang akan digunakan untuk proses evaluasi mengukur nilai akurasi yang dihasilkan oleh sistem.
Gambar 1 Alur Proses metode Support Vector Machice
4. PENGUJIAN DAN ANALISIS
Penelitian ini dilakukan pengujian dan analisis terhadap sistem klasifikasi rumah layak huni meggunakan metode support vector machine (SVM). Pengujian yang dilakukan yaitu pengujian parameter-parameter yaitu parameter lambda (ʎ), parameter gamma (𝛾), parameter complexity (C), pengujian iterasi serta pengujian menggunakan metode k-fold cross validation.
4.1. Pengujian Gamma (𝜸)
Pada pengujian gamma (𝛾) nilai parameter Sequential Training SVM yang digunakan yaitu 𝜆 = 0,5, 𝐶 = 1, 𝑑 = 2, iterasi maksimum = 2 iterasi, nilai k = 10, dan menggunakan data sebanyak 160 data. Hasil Pengujian gamma (𝛾)
Data Rumah Layak Huni dan Rumah Tidak layak Huni
Normalisasi Dataset Proses Training SVM Proses Testing SVM Mulai Hasil Klasifikasi Rumah Layak Huni
dapat dilihat pada Gambar 2.
Gambar 2 Pengujian Nilai gamma (𝜸) Analisis hasil Gambar 2 yaitu tingkat akurasi tertinggi terdapat pada nilai 𝛾 = 0,001 dengan akurasi sebesar 100%. Nilai akurasi cenderung naik dan stabil ketika nilai 𝛾 diatas 0,001. Hal ini karena nilai 𝛾 (gamma) berpengaruh pada proses pembelajaran. Dapat disimpulkan bahwa ketika nilai 𝛾 (gamma) semakin tinggi maka nilai learning rate akan semakin cepat. Begitu sebaliknya jika nilai 𝛾 (gamma) semakin kecil akan menyebabkan ketelitian sistem semakin lambat sehingga memperoleh akurasi rendah.
4.2. Pengujian lambda (𝝀)
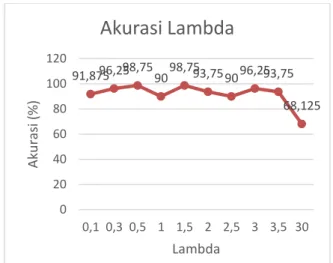
Pada pengujian 𝜆 (lambda) nilai parameter Sequential Training SVM yang digunakan dalam pengujian ini yaitu 𝛾 = 0,001, 𝐶 = 1, 𝑑 = 2, iterasi maksimum = 2 iterasi, nilai k = 10, dan menggunakan data sebanyak 160 data. Hasil pengujian dapat dilihat pada Gambar 3.
Analisis hasil Gambar 3 yaitu akurasi cenderung stabil. Nilai akurasi terbaik terdapat ketika nilai 𝜆 (lambda) yaitu 0,5 dan 1,5 dengan akurasi sebesar 98,75%. Dapat disimpulkan bahwa nilai 𝜆 (lambda) yang semakin tinggi maka akan memperoleh nilai akurasi yang baik. Namun, ketika nilai 𝜆 (lambda) terlalu besar dapat mengakibatkan waktu komputasi perhitungan matriks Hessian yang lama dan mengakibatkan sistem berjalan lebih lambat. Hal tersebut bisa dilihat ketika nilai 𝜆 (lambda) = 30 yang menghasilkan nilai akurasi turun menjadi 68,125%.
Gambar 3 Pengujian Lambda 4.3. Pengujian Complexity (C)
Pada pengujian 𝐶 (complexity) nilai parameter Sequential Training SVM yang digunakan dalam pengujian ini yaitu 𝛾 = 0,001, 𝜆 = 0,5, 𝑑 = 2, iterasi maksimum = 2 iterasi, nilai k = 10, dan menggunakan data sebanyak 160 data. Hasil pengujian bisa dilihat pada Gambar 4.
Gambar 4 Pengujian Complexity
Analisis hasil Gambar 4 yaitu tingkat akurasi tinggi ketika nilai 𝐶 yaitu 1. Namun, akurasi turun ketika nilai 𝐶 terlalu besar. Hal ini disebabkan karena parameter 𝐶 berpengaruh terhadap kesalahan yang terjadi ketika melakukan klasifikasi. Tujuan parameter 𝐶 adalah untuk meminimalkan nilai error. Berdasarkan pengujian dapat dilihat ketika nilai 𝐶 semakin kecil maka akan menunjukkan kesalahan yang kecil juga dan begitu sebaliknya.
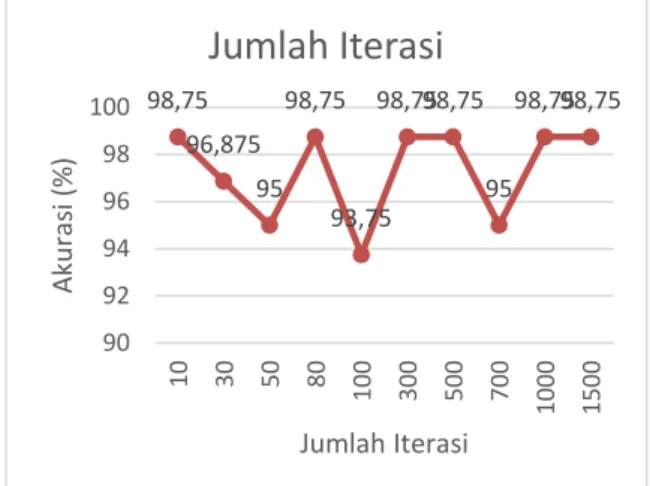
4.4. Pengujian Jumlah Iterasi
Pada pengujian jumlah iterasi nilai parameter Sequential Training SVM yang digunakan dalam pengujian ini yaitu 𝛾 = 0,001, 90 95 100 9597,598,7593,7598,12595,625 98,75 85 90 95 100 105 0,00001 0,0001 0,001 0,1 0,5 1 1,5 2,5 5 10 Aku ras i (% ) Gamma
Akurasi Gamma
91,87596,2598,759098,7593,759096,2593,75 68,125 0 20 40 60 80 100 120 0,1 0,3 0,5 1 1,5 2 2,5 3 3,5 30 Aku ra si (% ) LambdaAkurasi Lambda
95 95 90 93,75 96,87598,75 95 93,7593,75 91,25 84 86 88 90 92 94 96 98 100 Aku ra si (% ) CAkurasi C
𝐶 = 1, 𝑑 = 2, 𝜆 = 0,5, nilai k = 10, dan menggunakan data sebanyak 160 data. Hasil pengujian dapat dilihat pada Gambar 5.
Gambar 5 Pengujian Jumlah Iterasi
Analisis hasil Gambar 5 yaitu nilai optimal pada pengujian ini yaitu 98,75%. Hasil akurasi cenderung naik dan turun karena data yang digunakan random.
4.5. Pengujian K-fold Cross Validation
Pada pengujian pembagian data menggunakan metode k-fold Cross Validation nilai parameter Sequential Training SVM yang digunakan dalam pengujian ini yaitu 𝛾 = 0,001, 𝐶 = 1, 𝑑 = 2, 𝜆 = 0.5, nilai k=10, iterasi maksimum = 10 iterasi, dan menggunakan data sebanyak 160 data. Hasil pengujian dapat dilihat pada Gambar 6.
Gambar 6 K-fold Cross Validation
Analisis hasil dari Gambar 6 yaitu akurasi yang dihasilkan cenderung stabil yaitu diatas 90% Dapat disimpulkan bahwa data yang digunakan adalah valid.
5. PENUTUP
Hasil pengujian yang sudah dilakukan sistem klasifikasi rumah layak huni
menggunakan metode Support Vector Machine (SVM) menghasilkan akurasi yang baik dengan parameter yaitu 𝛾 = 0,001, 𝐶 = 1, 𝑑 = 2, 𝜆 = 0,5, nilai k = 10 dan jumlah iterasi maksimum 10 iterasi. Berdasarkan hasil dari pengujian metode Support Vector Machine (SVM) sangat cocok untuk klasifikasi rumah layak huni dengan nilai akurasi rata-rata yaitu 98,75%.
6. DAFTAR PUSTAKA
Athoillah, M., Irawan, M., & Imah, E. (2015). Study Comparison of SVM, K-NN, and Backpropagation-Based, Classifier for Image Retrieval. Journal of Computer Science and Information.
Bhavsar, H., & Panchal, M. H. (2012). A Review on Support Vector Machine for Data Classification. International Journal of Advanced Research in Computer Engineering & Technology(IJARCET). Fauzi, W. (2016). Sistem Pendukung Keputusan
Penerima Bantuan Dana Rutilahu dengan Menggunakan Metode Electre. Sentika.
Haryati, Febby, D., Abdillah, Gunawan, Hadiana, & Asep. (2016). Klasifikasi Jenis Batubara menggunakan JST dengan Algoritma Backpropagation. Hendi, R. (2016). Implementasi Program
Rehabilitasi Sosial Terhadap Rumah Tidak Layak Huni di Desa Seleman Kecamatan Bunguran Timur Laut Kabupaten Natuna. Ilmu Administrasi Negara.
Kementrian Sosial Republik Indonesia. (2017). Kriteria Rumah Layak Huni.
Ogunlana, S., Olabode, O., Oluwadare, S., & Iwasokun, G. B. (2015). Fish Classification using Support Vector Machine. African Journal of Computng & ICT.
Oktaviani, P. A., Wulandari, Y., & Ispriyanti, D. (2014). Penerapan Metode Klasifikasi Support Vector Machine (SVM) Pada Data Akreditasi Sekolah Dasar (SD) di Kabupaten Magelang. Gaussian. Prasetyo, E. (2014). DATA MINING Mengolah
Data menjadi Informasi menggunakan MATLAB. Yogyakarta: CV. ANDI OFFSET (Penertib Andi).
98,75 96,875 95 98,75 93,75 98,7598,75 95 98,7598,75 90 92 94 96 98 100 10 30 50 80 100 300 500 700 1000 1500 Aku ras i (% ) Jumlah Iterasi
Jumlah Iterasi
95 96,25 97 95,3795 98,75 95 98,75 95 97 93 94 95 96 97 98 99 100 1 2 3 4 5 6 7 8 9 10 Aku ras i( % ) Nilai kSimatupang, F. J., Wuryandari, T., & Suparti. (2016). Klasifikasi Rumah Layak Huni di Kabupaten Brebes dengan Menggunakan Metode Learning Vector Quantization dan Naive Bayes. Gaussian.
Ustuner, M., Samli, F. B., & Dixon, B. (2015). Application of Support Vector Machines for Landuse Classification Using High-Resolution RapidEye Images: A Sensitivity Analysis. European Journal of Remote Sensing. Vanitha, D., Devaraj, & Venkatesulu. (2015).
Gene Expression Data Classification using Support Vector Machine and Mutual Information-based Gene Selection. Procedia Computer Science.