Fakultas Ilmu Komputer
3860
Klasifikasi Pendonor Darah Menggunakan Metode
Support Vector Machine
(SVM) Pada Dataset RFMTC
Erwin Bagus Nugroho1, Muhammad Tanzil Furqon2, Nurul Hidayat3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Donor darah adalah proses pengambilan darah dari seseorang yang dilakukan secara sukarela kemudian dipakai untuk transfusi darah bagi pasien yang membutuhkan. Darah dari pendonor tidak dapat digunakan setelah 42 hari Menurut American Red Cross. Satu-satunya cara untuk memenuhi permintaan kantong darah dengan memiliki sumbangan darah rutin dari pendonor yang sehat. Di Indonesia pada tahun 2013 mengalami kekurangan kantong darah sebanyak 2.476.389cc, dimana idealnya ketersediaan darah adalah 2,5% dari jumlah penduduk. Dalam mengatasi permasalahan tersebut dibutuhkan suatu sistem yang mampu memprediksi perilaku pendonor agar dapat mengantisipasi kekurangan kantong darah. Regency, Frequency, Monetary, Time, Churn Probability (RFMTC) merupakan modifikasi dari metode RFM yang digunakan untuk meramalkan perilaku pendonor darah untuk mendonorkan darahnya kembali atau tidak mendonor. untuk dapat mengklasifikasikan perilaku pendonor penelitian ini menggunakan metode Support Vector Machine (SVM). Data yang digunakan dalam penelitian ini adalah 748 yang di bagi menjadi data latih dan data uji. Hasil akurasi penelitian ini mendapatkan akurasi terbaik berdasarkan rasio data 50%:50%, dengan menggunakan kernel linier dan nilai parameter Lambda(λ) = 2, Gamma (γ), = 0.5, Epsilon (ε) = 0.005, dan Complexity (C) = 20. Hasil dari akurasi metode SVM pada klasifikasi pendonor darah sebesar 72.64%.
Kata kunci: pendonor darah, klasifikasi, support vector machine (SVM), kernel linier
Abstract
Blood donation is a process of taking blood from a person voluntarily to blood transfusions for patients in need. Blood from donors can’t be used after 42 days. The only way to meet the demand for blood bags are having regular blood donations from a healthy donor. In Indonesia 2013, there is 2,476,389cc shortage of blood bags, where the ideal blood availability is 2.5% of the population. These problems required a system that can predict the behavior of donors in order to anticipate the shortage of blood bags. Regency, Frequency, Monetary, Time, Churn Probability (RFMTC) is a modification of the RFM method modified that used to predict the blood donor behavior to donate or not to donate bloods. The method for classifying the behavior of donors in this research are Support Vector Machine (SVM) method. Data that was used in this research is 748 which is divided into training data and test data. The accuracy result got best accuracy based on 50%: 50% data ratio, using linear kernel and parameter value λ (lambda) = 2, Gamma (γ), = 0.5, Epsilon (ε) = 0.005, and C (complexity) = 20. The result of SVM method accuracy on blood donor classification is 72.64%.
Keywords: blood donator, classification, support vector machine (SVM), kernel linier
1. PENDAHULUAN
Darah mempunyai peranan penting dalam tubuh manusia. Fungsi dari darah antara lain mengantarkan zat-zat dan oksigen ke seluruh jaringan manusia (Kusuma, 2015). Donor darah adalah proses pengambilan darah dari seseorang sukarelawan kemudian digunakan untuk
Menurut American Red Cross, darah dari pendonor tidak dapat digunakan setelah 42 hari. Satu-satunya cara untuk memenuhi permintaan kantong darah dengan memiliki sumbangan darah rutin dari pendonor yang sehat (Darwiche, dll., 2010). Kesadaran masyarakat sangat diperlukan untuk memenuhi kebutuhan kantong darah. Pada tahun 2013 indonesia mengalami kekurangan kantong darah sejumlah 2.476.389, dimana idealnya ketersediaan darah 2,5% dari jumlah penduduk (Kementrian Kesehatan Republik Indonesia, 2014). Dalam kasus ini diperlukan sebuah metode klasifikasi untuk memprediksi perilaku pendonor darah, sehingga dapat mencukupi ketersediaan darah atau dapat mengantisipasi kekurangan ketersediaan darah yang ditetapkan yaitu 2,5% dari jumlah pendukuk.
Pada penelitian sebelumnya dengan metode C4.5 dan Naive Bayes untuk prediksi pendonor darah dengan dataset RFMTC, diperoleh hasil dengan nilai accuracy 70% untuk Naive Bayes dan 67% untuk C4.5.(Susanto & Agustina, 2016).
Regency, Frequency, Monetary, Time, Churn Probability (RFMTC) merupakan modifikasi dari metode RFM yang digunakan untuk meramalkan perilaku pendonor darah yang potensial untuk mendonorkan darahnya kembali atau tidak mendonor. Karena model RFM tidak bisa memprediksi nilai untuk kembali lagi di masa depan sedangkan RFMTC
dapat menyimpulkan rumus untuk
memperkirakan itu (I-Cheng, dll., 2009).
Penelitian selanjutnya menggunakan metode Support Vector Machine dengan judul Implementasi Metode Support Vector Machine untuk Rekomendasi Pemilihan Terapi Dehidrasi pada Anak dan menghasilkan akurasi tertinggi 87,09% dan rata-rata 84,02% (Rani, 2016).
Berdasarkan permasalahan diatas solusi untuk klasifikasi perilaku pendonor darah yang akan datang untuk mendonorkan darahnya
kembali dan yang tidak dengan
mengimplementasikan metode Support Vector Machine (SVM). Metode SVM merupakan metode klasifikasi dengan pembelajaran terbimbing (supervised learning) yang berusahan menemukan sebuah hyperplane berukuran (p-1) dimensi yang dapat memisahkan data pelatihan berdasarkan kelasnya. Dengan demikian akan dibangun sebuah sistem untuk melakukan klasifikasi perilaku pendonor darah.
Maka judul pada penelitian ini adalah lasifikasi pendonor darah menggunakan metode support vector machine (SVM) pada dataset RFMTC.
2. DATASET RFMTC
RFMTC merupakan modifikasi dari RFM. variabel RFMTC yaitu regency jumlah sejak bulan terakhir kali menyumbang darah, frequency total berapakali mendonor, monetary total sumbangan darah dari pendonor dalam c.c., Time total bulan menyumbangkan darah sejak pertama kali, Churn Probability untuk mempresentasikan pendonor akan mendonorkan darahnya kembali atau yang tidak, 1 menyatakan donor darah, 0 tidak menyubang darah (Darwiche, dll., 2010). Dataset RFMTC didapat dari UCI dataset.
3. SUPPORT VECTOR MACHINE (SVM)
Support Vector Machine (SVM) merupakan metode dari teori statistik yang hasilnya sangat menjanjikan untuk memberikan hasil yang terbaik. Metode ini juga dapat berkerja baik pada dataset berdimensi tinggi dan memetakan data asli dari dimensi asalnya ke dimensi berbeda yang lebih tinggi (Prasetyo, 2012).
3.1 Sequential Training
Metode SVM merupakan metode
pembelajaran dengan mencari sebuah hyperplane. Metode sequential learning merupakan pengembangan dari metode quadratic programming (QP) yang dapat memberikan nilai optimal dalam klasifikasi berdimensi tinggi. (Vijayakumar, 1999).
1.
Tahap pertama menghitung matriks [D]ijmenggunakan Persamaan 1.
2
,
i j i j ij yy Kx x
D (1)
Keterangan:
xi xj
K , : kernel
2.
Selanjutnya menggunakan Persamaan 2, Persamaan 3, dan Persamaan 4.a.
n
1 j
j
i= Dij
E (2)
b.
min
max
1Ei
,
i
,C
i
(3)c.
iii (4)Keterangan:
i
: digunakan dalam mengontrol kecepatan proses pembelajaran
: sebagai pembatas Lagrange multiplier. Untuk langkah ke-2 dilakukan sampai kondisi terpenuhi atau sampai iterasi maksimum (δα< ε ).3.2 Testing SVM
Tahap pertama melakukan perhitungan nilai f(x) menggunakan rumus: menggunakan rumus sebagai berikut :
x w x w
untuk mendapatkan nilai w digunakan rumus sebagai berikut :
4. PENGUJIAN DAN ANALISIS
4.1. Pengujian Rasio Data
Pada pengujian rasio data digunakan dataset sejumlah 748 data. Parameter awal yang akan
digunakan adalah λ = 0.5, C = 1, ε = 0.001, dan
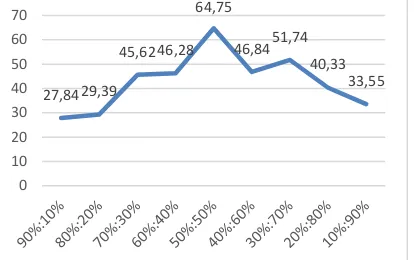
γ = 0.5. Hasil pengujian rasio perbandingan ditunjukkan pada Gambar 1.
Gambar 1 Grafik tingkat pengujian rasio
Pada Gambar 1 dapat dilihat semakin banyak data latih maka nilai akurasi tidak baik dikarenakan parameter awal belum optimal. Selain itu banyaknya jumlah data dan aktual class dapat mempengaruhi perubahan nilai akurasi. Pada Gambar 1 menunjukkan titik tertentu nilai akurasi berada pada kondisi optimal dan setelah itu mengalami penurunan. Jadi dapat disimpulkan bahwa sebaran data latih
dan data uji mempengaruhi nilai akurasi di setiap rasionya. Nilai perbandingan data yang memiliki rata-rata akurasi tertinggi akan dilanjutkan untuk proses pengujian selanjutnya.
4.2. Pengujian Parameter Lambda (λ)
Pengujian Lamda (λ) dilakukan untuk mendapatkan nilai λ terbaik. Pengujian nilai λ yang digunakan yaitu 0.1, 0.3, 0.5, 1, 1.5, 2, 2.5. Nilai parameter SVM yang digunakan adalah γ = 0.5, ε = 0.001, C = 1, rasio perbandingan 50:50. Nilai default untuk Lamda (λ) adalah 0.5. Hasil pengujian nilai Lamda (λ) dapat dilihat pada Gambar 2.
Gambar 2 Grafik tingkat akurasi hasil pengujian nilai
lambda
Pada Gambar 2 diketahui nilai rata-rata akurasi tertinggi terdapat pada nilai lamda (λ) 2 sebesar 64.17%. Hal ini menunjukkan bahwa, semakin besar nilai λ tidak membuat akurasi menjadi baik. λ hanya berpengaruh pada waktu komputasi pada perhitungan matrix Hessian karena λ dapat menjadikan sistem lambat dalam mencapai konvergensi. Nilai λ yang memiliki nilai akurasi tertinggi akan dilanjutkan untuk menguji konstanta gamma (γ).
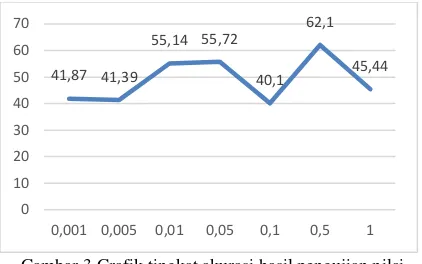
4.3. Pengujian Parameter Gamma (γ)
Pengujian parameter gamma (γ) dilakukan untuk mendapatkan nilai terbaik untuk parameter γ. Untuk pengujian nilai parameter γ yang digunakan yaitu 1.10-3, 5.10-3, 1.10-2, 5.10-2,
1.10-1, 5.10-1, dan 1. Nilai parameter SVM yang
Gambar 3 Grafik tingkat akurasi hasil pengujian nilai
gamma
Pada Gambar 3 diketahui nilai rata-rata akurasi
tertinggi untuk parameter γ terdapat pada nilai γ
0.5 dengan nilai akurasi 62.1%. Hal ini menunjukkan bahwa semakin besar atau kecil
nilai γ, tidak menjamin akurasi akan menjadi baik. Semakin besar nilai γ maka semakin besar
juga learning rate sehingga proses pembelajaran akan semakin cepat dan membuat akurasi tidak
stabil. Nilai γ dengan akurasi tertinggi akan
dilanjutkan untuk menguji parameter epsilon (ε).
4.4. Pengujian Parameter Epsilon (ε)
Pengujian parameter epsilon (ε) yang digunakan yaitu 1.10-6, 1.10-5, 1.10-4, 5.10-4, 1.10-3, 5.10-3,
dan 1.10-2. Nilai untuk parameter SVM yang
digunakan adalah λ = 2, γ = 0.5, C = 1 rasio perbandingan 50:50. Nilai default untuk ε adalah 0.001. Hasil pengujian nilai ε dapat dilihat pada Gambar 4.
Gambar 4 Grafik tingkat akurasi hasil pengujian nilai
epsilon
Pada Gambar 4 diketahui nilai rata-rata tertinggi untuk parameterε yaitu pada nilai 0.001 dengan nilai akurasi 64.05%. Hal ini diketahui bahwa nilai ε berpengaruh terhadap nilai akurasi yang dihasilkan. Semakin besar nilai ε , maka banyaknya iterasi akan semakin kecil, sedangkan semakin kecil nilai ε, maka jumlah iterasi semakin banyak. Nilai ε dengan rata-rata tertinggi akan dilanjutkan untuk menguji nilai parameter complexity (C).
4.5. Pengujian Parameter Complexity (C) Pengujian nilai parameter Complexity (C) yang digunakan yaitu 1, 10, 20, 30, 40, 50, dan 60. Nilai untuk parameter SVM yang digunakan yaitu λ = 2, γ = 0.5, ε = 0.005, rasio perbandingan 50:50. Nilai default untuk parameter C adalah 1. Hasil pengujian parameter C dapat dilihat pada Gambar 5.
Gambar 5 Grafik tingkat akurasi hasil pengujian complexity
Pada Gambar 5 diketahui nilai rata-rata tertinggi untuk C terdapat pada nilai 20 dengan nilai akurasi 62.51%. Hal ini disebabkan, jika mengurangi tingkat akurasi pada proses training, sehingga mengakibatkan data testing tidak dapat diklasifikasikan dengan baik.
Dari hasil semua pengujian parameter yang di lakukan dapat disimpulkan bahwa SVM mempunyai tingkat akurasi sebesar 76.47% dengan nilai paramater λ = 2, γ = 0.5, ε = 0.005, C = 20, rasio perbandingan 50:50.
4. KESIMPULAN
Dalam mengimplementasikan metode Support Vector Machine (SVM) pada klasifikasi pendonor darah data yang digunakan dari UCI Dataset berupa dataset RFMTC. Tahap selanjutnya adalah mencari rasio perbandingan antara data latih dan data uji. setelah itu melakukan normalisasi menggunakan kernel linier dan melakukan proses perhitungan sequential SVM. Setelah proses selasai diperoleh nilai α baru dan nilai bias (b) yang digunakan untuk memproses data testing. Hasil dari proses testing merupakan klasifikasi
masing-masing class. Hasil akhir merupakan hasil akurasi yang di dapat dengan membandingkan class actual dengan predicted class.
Untuk mengetahui hasil akurasi metode Support Vector Machine (SVM) pada klasifikasi pendonor darah menggunakan dataset RFMTC rasio data testing dan data trainging menggunakan 50% : 50% karena diperoleh hasil akurasi tertinggi sebesar 72.64%. Pemilihan nilai parameter lamda (λ), gamma (γ), epsilon (ε), dan complexity(C) berpengaruh pada nilai α dan nilai bias (b) serta nilai akurasi. Menurut hasil pengujian, parameter terbaik yang menampilkan
akurasi terbaik pada pengujian SVM ini adalah λ = 2, γ = 0.5, ε = 0.005, dan C = 20, sehingga diperoleh akurasi terbaik yaitu 72.64%.
5. DAFTAR PUSTAKA
Aviliani, Sumarwan, Sugema & Saefuddin, 2011. Segmentasi Nasabah Tabungan Mikro Berdasarkan Recency, Frequency, dan Monetary (Kasus Bank BRI). Finance and Banking, Volume 13(1), pp. 95-109. Christianini, N. & Shawe-Taylor, J., 2000. An
Introduction to Support Vector Machines. Cambridge University Press.
Darwiche, M., Feuilloy, M., Bousaleh, G. & Schang, D., 2010. Prediction of Blood Transfusion Donation. IEEE, pp. 51-56. Fais, S. N., Aditya, M. & Mulya, S., 2014.
Klasifikasi Calon Pendonor Darah Dengan Metode Naive Bayes Clasifier. Universitas Brawijaya.
Haykin, S., 1999. Neural Network: A Comprehensive Foundation. New Jersey: Prentice Hall.
I-Cheng, Y., King-Jang, Y. & Tao-Ming, T., 2009. Knowledge Discovery on RFM Model Using Bernoulli Sequence. Kementrian Kesehatan Republik Indonesia,
2014. [Online]
Available at:
http://sehatnegeriku.kemkes.go.id [Diakses 1 Maret 2017].
Kusuma, A. A., 2015. Aplikasi Penentuan Calon Pendonor Darah Menggunakan Metode Algoritma ID3 (Studi Kasus PMI Kota Kediri). UN PGRI Kediri.
Octaviani, P. A., Wilandari, Y. & Ispriyanti, D., 2014. Penerapan Metode Klasifikasi Support Vector Machine (SVM) Pada Data Akreditasi Sekolah Dasar (SD) Di Kabupaten Magelang. UNDIP.
Permana, R. A., 2016. Seleksi Atribut Pada Metode Support Vector Machine Untuk Menentukan Kelulusan Mahasiswa E-Learning. STMIK Antar Bangsa.
Prasetyo, E., 2012. Data Mining : Konsep dan
Aplikasi Menggunakan Matlab.
Indonesia: Andi Yogyakarta.
Rani, 2016. Implementasi Metode Support Vector Machine untuk Rekomendasi Pemilihan Terapi Dehidrasi Pada Anak. Santosa, B., 2011. Metode Metaheuristik Konsep
dan Implementasi. Surabaya: Guna Widya.
Saputra, K. Y., Suyadnya, I. M. A. & Swamardika, I. B. A., 2016. Rancang Bangun Aplikasi Komunitas Donor Darah Berbasis Web Dan Android Yang Dilengkapi Layanan Informasi Geografis. Universitas Udayana.
Scholkopf, B. & Smola, A., 2002. Learning with Kernels. Massachusetts: The MIT Press, Cambridge.
Susanto, W. E. & Agustina, C., 2016. Komparasi Akurasi Algoritma C4.5 dan Naive Bayes untuk Prediksi Pendonor Darah Potensial dengan Dataset RFMTC. AMIK BSI Yogyakarta.
Vapnik, V., 1997. Statistical Learning Theory. New York: John Wiley and Sons, Inc.. Vijayakumar, S. & Wu, S., 1999. Sequential