REGRESI NONLINEAR
Asumsi kelinearan tidak selalu dapat dipenuhi dalam suatu analisis regresi. Hal ini dapat juga dilihat dari letak titik-titik pada diagram pencar data (x,y) yang sangat menyimpang dari sebuah garis lurus. Banyak sekali model regresi nonlinear, dan hanya beberapa yang akan dibahas disini. Model polinommerupakan topik pertama yang kita bicarakan, sebelum membicarakan model-model lainnya, seperti model eksponen, model geometri, dan model hiperbola.
A. Model Polinom
Model polinom dinyatakan dalam bentuk umum y = c0 + c1 + c 2 x2 + . . . + c k xk
dimana ci i = 0, 1, 2, . . ., k ( yang harus bilangan bulat positif ) adalah konstanta. Untuk lebih
kongkretnya pembahasan, model derajat dua akan menjadi pusat perhatian pada bagian berikut ini.
1. Model Derajat Dua
Kita perhatikan bahwa model polinom mempunyai hanya satu peubah dasar, yaitu x. Untuk k = 1, kita peroleh model regresi linear sederhana ( garis lurus )
y = c0 + c1 x.
Polinom derajat dua, yaitu untuk k = 2 mempunyai model kuadratik ( parabola ) dengan bentuk umum
y = c0 + c 1 + c 2x2.
Dari model matematis diatas, kita dapat menulis model statistis parabola dalam bentuk μY|x = β0 + β1X + β2X2
atau
Y = β0 + β1 X + β2 X2 + ε
Dengan persamaan ini, huruf besar Y dan X menunjukkan peubah statistik ; β0, β1, dan β2
menyatakan parameter yang tidak diketahui dan disebut koefisien regresi; μY|x menyatakan
rata-rata Y dan X yang diberikan; dan ε menyatakan komponen kesalahan yang mewakili selisih antara respons teramati Y dan X respons rata-rata μY|x pada X.
Jika kita asumsikan model parabola diatas yang cocok untuk menjelaskan hubungan X dan Y, kita harus menentukan sebuah taksiran parabola tertentu yang paling sesuai dengan ditentukan dengan menggunakan metode kuadrat terkecil.
▸ Baca selengkapnya: model c adalah
(2)Taksiran untuk model parabola kuadratik dapat ditulis dengan.
Ŷ = b0 + b1 X2 + b2X2
Dengan koefisien-koefisien b0, b1, dan b2 ditentukan berdasarkan data hasil pengalaman. Jika
(xi, yi), i = 1, 2, . . ., n menyatakan data hasil pengamatan dalam sebuah sampel berukuran n, metode kuadrat terkecil memberikan nilai-nilai b0, b1, dan b2 dengan cara menyelesaikan persamaan normal berikut.
n b0 + b1 ∑ + b2 ∑ 2 = ∑
b0 ∑ + b1 ∑ 2 + b2 ∑ 3 = ∑
b0 ∑ 2 + b1 ∑ 3 + b2 ∑ 4 = ∑ 2yi
Kita akan perhatikan sebuah contoh hipotesis berikut untuk menunjukkan metode regresi polinom
Andaikan sebuah studi labolatorium untuk menentukan hubungan antara dosis (X) dari jenis obat dan tambahan berat badan (Y) dari sejenis hewan. Delapan hewan jenis kelamin, umur, dan ukuran badan yang sama dipilih secara acak dan deberikan satu diantara delapan tingkatan dosis. Rancagan studi ini dapat dipertanyakan karena tidak mempunyai lebih dari satu hewan yang menerima dosis yang sama, seperti juga kecilnya ukuran sampel. Ulangan pada setiap dosis yang akan memberikan taksiaran yang andal tentang variasi data dari hewan ke hewan. Akan tetapi, untuk beberapa studi labolatorium, mendapatkan sejumlah hewan yang cukup tidak selalu tersedia dengan mudah, juga biaya dan waktu sering menjadi faktor penghambat. Harus dicatat bahwa data untuk contoh ini diupayakan untuk menyederhanakan analisis dan menunjukkan adanya hubungan yang elas bersifat derajat dua.
Tabel 6.1 Tambahan berat badan setelah dua minggu sebagai fungsi dari tingkatan dosis.
Tingkatan Dosis (X) 1 2 3 4 5 6 7 8 Tambahan Berat
(Y) (dag) 1 1,2 1,8 2,5 3,6 4,7 6,6 9,1
Tambahan berat dalam dekagram (dag) diukur untuk setiap hewan setelah dua minggu, dimana semua hewan dalam keadaan labolatorium dan gizi yang sama. Data diberikan dalam Tabel 6.1, dan diagram pencarkan diberikan pada gambar 6.1. Dengan mata kepala dapat melihat bahwa diagram menunjukkan sebuah kurva parabola dan merupakan model yang lebih sesuai daripada sebuah garis lurus. Kita akan mengkuantitatifkan hasil pengamatan mata ini.
y 9 8 7 6 5 4 3 2 1 1 2 3 4 5 6 7 8 x
Kita memcoba mentukan regresi nonlinear dengan mengambil bentuk parabola kuandrik. Untuk itu, kita buat Tabel 6.2 dengan menambahkan X2 , X3 , XY dan X2Y pada Tabel 6.1. Dari Tabel 6.2, kita peroleh persamaan normal
8 b0 + 36 b1 + 204 b2 = 30,5
36 b0 + 204 b1 + 1296 b2 = 184,0
204 b0 + 1296 b1 + 8772 b2 = 1227,0
Tabel 6.2 Nilai-nilai yang perlu untuk regresi parabola
X Y X X X XY XY 1 1 1 1 1 1 1 2 1,2 4 8 16 2,4 4,8 3 1,8 9 27 81 5,4 16,2 4 2,5 16 64 256 10 40 5 3,6 25 125 625 18 90 6 4,7 36 216 1296 28,2 169,2 7 6,6 49 343 2401 46,2 323,4 8 9,1 64 512 4096 72,8 582,4 36 30,5 204 1296 8772 184 1227
Setelah tiga persamaan simultan ini diselesaikan, diperoleh b0 = 1,348 , b1 = -0,414,
dan b2 = 0,170, sehingga persamaan regresi parabola dapat ditulis Ŷ = 1,348 - 0,414 X + 0,170 X2
Terdapat tiga pertanyaan dasar yang berkaitan dengan inferensi regresi polinom derajat dua. 1. Apakah regresi kuadratik itu signifikan; yaitu lebih banyak variasi Y yang dapat
dijelaskan oleh model derajat dua daripada mengabaikan X sama sekali ( dan hanya menggunakan Y )?
2. Apakah model derajat dua secara signifikan memberikan daya ramal yang lebih besar daripada yang diberikan yang diberikan oleh model garis lurus?
3. Andaikan bahwa model derajat dua lebih sesuai daripada model garis lurus, apakah sebagainya) terhadap model derajat dua?
Untuk menentukan apakah regresi kuadratik signifikan, kita memerlukan uji hipotesis nol, H0: Regresi dengan suku-suku X dan X2 tidak signifikan (yaitu β1 = β2 = 0 ). Prosedur penguji
untuk hipotesis nol ini menggunakan uji F dengan menghitung RJK Regrsi RJKR
F = =
RJK Kesalahan RJKK
Dimana RJK adalah rata-rata jumlah kuadrat, atau jumlah kuadrat (JK) dibagi dengan derajat kebebasan (dk) yang bersangkutan, sehingga RJKR menyatakan rata-rata jumlah kuadrat kesalahan. Untuk membandingkan nilai statistik F dengan nilai krisis yang sesuai dari distribusi F, digunakan nilai tabel yang (dalam contoh ini) mempunyai dk pembilang 2 dan dk penyebut 5. Jika nilai statistik F lebih besar daripada nilai F tabel, maka pengujian signifikan dan H0 ditolak. Akan tetapi dengan perhitungan komputer, nilai tabel distribusi F
tidak diperlukan karena nilai statistika F yang diperoleh disertai dengan nilai peluang P(F > Fhitung ) yang bisa disebut nilai p. Jika nilai p inilebih kecil daripada nilai taraf signifikansi
yang ditentukan, maka pengujian signifikan.
Tabel analisis variasi (ANAVAR) untuk model regresi parabola dapat dibuat seperti pada model regresi garis lurus. Dengan bantuan SAS. Perhitungan akan lebih mudah dan hanya memberikan perintah
Prog GLM; Model Y = X X*X;
Apa yang telah ditunjkkan saat ini? Kita menyimpulkan bahwa model derajat satu (garis lurus) tidak sebagus model derajat dua (parabola). Kita sekarang perlu menentukan apakah menambahkan suku-suku derajat lebih tinggi terhadap model derajat dua dibutuhkan. Sebagai contoh, kita dapat menembahkan suku X3 pada model derajat dua dan kemudian menguji apakah hasil ramalan secara signifikansi ditingkatkan. Membentuk model derajat tiga dengan kuadrat terkecil menghasilkan table ANAVAR yang diberikan pada Tabel 6.5
Tabel 6.5 ANAVAR untuk model kubik dengan data berta hewan Sumber Variansi dk JK RJK F Regresi X 1 52,04 52,04 X2|X 1 4,830 4.830 X3|X,X2 1 0.140 0.140 10,00 Kesalahan 4 0,056 0.014 Total 7 57,07 R2= 0.999
Untuk menguji apakah tambahan suku derajat tiga secra signifikan meningkatkan kesesuaian model, statistic berikut di hitung:
=( ekstra tambahan X
3 /1
(model derajat tiga =
Statistik ini mempuyai distribusi F dengan dk pembilang 1 dan dk penyebut 4 pada H0: Penambahan suku X3 tidak berarti (yakni β3=0). Karena F0.95;(1,4)= 7.71 dan F0.99;(1,4) =21,20,
kita mempunyai 0.01<p<0,05. Nilai p ini membuat sedikit kesulitan untuk menentukan apakah kita memasukkan suku X3 dalam model. Hal ini menunjukkan bahwa H0 ditolak
untuk taraf signifikansi α=0,05 akan tetapi tidak untuk α=0,01. Namun demikian, beberapa pertanyaan lain harus dipertimbangkan;
a) Nilai R2 untuk model parabola sangat tinggi, yaitu 0,997
b) Nilai R2 hanya meningkat dari 0,997 ke 0,999 dalam perjalanan dari model derajat dua ke model derajat tiga,
c) Diagram pencar jelas menunjukkan kurva derajat dua, dan
d) Jika ragu, model yang paling sederhana lebih baik karena itu akan paling mudah diinterpretasi.
Semuanya dipertimbangkan, kemudian kesimpulan yang paling masuk akal adalah model derajat dua yang paling sesuai. Kesimpulan untuk data Tabel 6.1 adalah model yang paling baik adalah:
Ŷ=1,348-0,414+0,170X2 , dengan R2=0,997
Akhirnya, mengetahui simpangan baku (atau kesalahan baku) dari taksiran koefisien regresi akan bermanfaat. Sangant sulit menghitung dengan manual untuk model yang melibatkan dua atau lbeih peubah peramal. Namun, semua program regresiyang umumnya digunakan memberikan nilai-nilai numeric untuk taksiran koefisien regresi beserta taksiran simpangan bakunya. Untuk model regresi derajat dua terdapat hasil pengolahan data dalam hasil
computer, kita mendapatkan Sb1=0,141 (Std.Error of Estimate untuk X) dan Sb2=0.015
(Std.Error of Estimate untuk X*X). Sebagai contoh, interval kepercayaan 100(1-α % untuk β2 adalah:
b2 t(1-α 2⁄ );5 b2,
Di mana dk untuk nilai kritis tyang sesuai adalah dk yang sesuai dengan JKK dalam Tabel 6.3. ecara khusus, interval kepercayaan 95% untuk β2 dalam contoh kita adalah:
0,170 2,57(0,015)atau 0,13 β2 0,21,
Karena b2=0,170, t0,975;5=2,57, dan Sb2=0,015. Kita bias melihat bahwa interval ini tidak
memuat nol, yang sesuai dengan kesimpulan table ANAVAR yang menyangkut pentingnya suku X2 dalam model kuadratik. adi, tidak cukup alas an untuk menyatakan bahwa β2=0
pada taraf kepercayaan 95%. 2. Model derajat lebih tinggi
Kita sudah melihat cara ide-ide dasar regresi ganda dapat diterapkan untuk membentuk dan menguji model kuadratik dan kubik.metode yang sama digunakan untuk semua model polinon derajat lebih tinggi.namun,beberapa isu terkait perlu didiskusikan : yakni penggunaan polinom ortogonal dan strategi untuk memilih sebuah model polinom.
Beberapa derajat polinom untuk dipertimbangkan bergantung pada masalah yang dipelajari,serta banyak dan jenis data yang terkumpul.satu pertayaanan,khususnya dalam studi biologi dan ilmu sosial, perlu dijawab: apakah hubungan regresi dapat dijelaskan oleh sebuah fungsi monoton ( yakni yang selalu naik, atau selaluh turun)? Jika hanya fungsi-fungsi monoton yang menjadi perhatian , biasanya model derajat dua atau derajat tiga akan memadai ( walaupun kemonotonan tidak menjamin ,karna untuk contoh, beberapa parabola naik kemudian turun). Sejumlah besar nilai peubah paramal yang baik tepatnya dalam kesalahan variasi yang kecil diperlukan untuk membentuk model derajat lebih tinggi dari kubik secara andal.
Pertimbangan yang lebih umum adalah banyaknya lengkungan ( lebih teknis,titik-titik belok) dalam kurva polinom yang akan dibentuk.sebagai contoh,model derajat satu tidak mempunyai lengkungan ; model derajat dua tidak akan mempunyai lebih dari satu lengkungan; dan setiap tambahan suku derajat lebih tinggi menambah satu potensi lengkungan.dalam praktik, menentukan model polinom lebih dari derajat tiga biasanya membawah ke model yang tidak selalu turundan tidak juga selalu naik. Teori, substansi,dan bukti empiris harus ada untuk mendukung penggunaan model-model rumit yang tidak menoton tersebut.
Banyaknya data secara langsung membatasi derajat yang dapat digunakan.kita dapat memperhatikan data tambahan berat hewan(tabel 6.1) dengan delapan nilai yang berbeda,polinom derajat tujuh akan sesuai dengan delapan titik secara sempurna , memberikan nilai JKK=0 dan nilai R2=1. Namun , karna persamaan yang dibentuk akan mempunyai delapan taksiran parameter,tidak ada penghematan yang dibuat dengan hanya
mendaftar delapan titik.umumnya ,maksimum derajat polinom yang dapat dibentuk satu kurangnya dari banyaknya nilai X yang berbeda.
3. Uji Tuna Cocok
Andaikan bahwa sebuah model polinum sudah dibentuk dan taksiran-taksiran koefisien regresinya diuji untuk signifikansi. Bagimana seseorang dapat meyakini bawhwa sebuah model dari derajat lebih tinggi dari derajat tertinggi yang diuji tampaknya tidak diperlukan? Uji Tuna Cocok dapat digunakan untuk pertanyaan ini. Secara koseptual, uji Tuna Cocok menyangkut evaluasi dari sebuah model yang lebih rumit dari pada yang dipertimbangakansbelumnya. Secara historis, istila tersebut kadang-kadang digunakan untuk menjelaskan prosedur klasik. Uji Tuna Cocock klasik dapat digunakan hanya kalau pada pengulangan pengamatan. Dengan istila ulangan, kita maksudkan bahwasatuan eksperimen (subjek) mempunyai nilai X yang sama dengan satuna eksperimen yang lain.
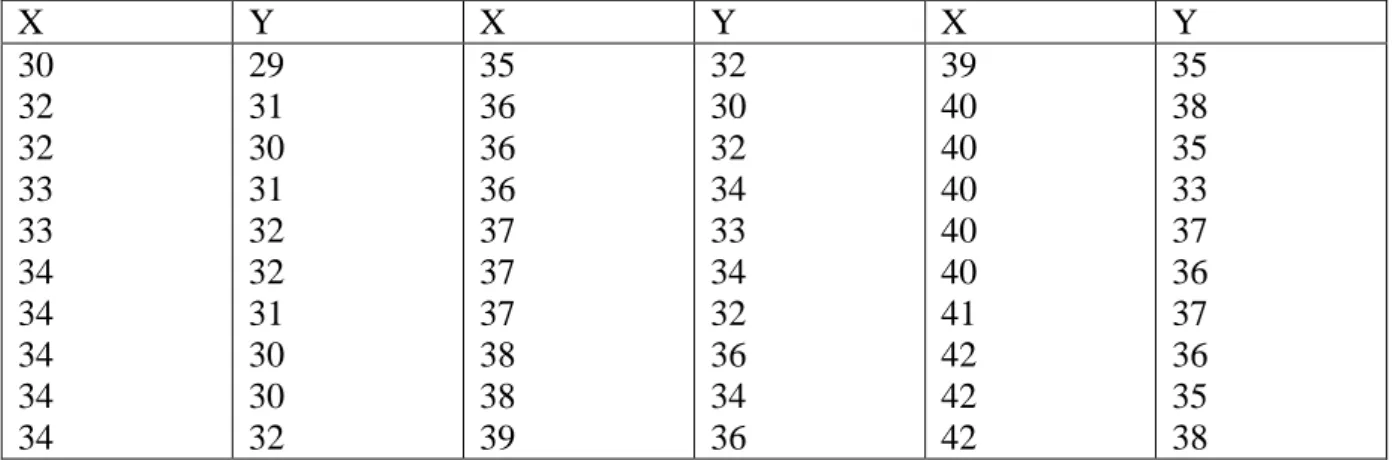
Misalnya, data dalam table 6.6 menunjukkan hasil pengamatan terhadap banyaknya pengunjung (X) dan banyaknya yang brbelanja (Y) pada sebuah tokoh selam 30 hari. Untuk mempermudahkan perhitungan, data diurutkan berdasarkan besarnya X
Tabel 6.6 Data pengunjung (X) dan pembeli (Y) sebuah Tokoh
X Y X Y X Y 30 32 32 33 33 34 34 34 34 34 29 31 30 31 32 32 31 30 30 32 35 36 36 36 37 37 37 38 38 39 32 30 32 34 33 34 32 36 34 36 39 40 40 40 40 40 41 42 42 42 35 38 35 33 37 36 37 36 35 38
Kita bias melihat adanya ulangan nilai-nilai X pada data tersebut, sehingga variasi kesalahan pengukuran dapat diperhitungkan.
Dari hasil computer, kita peroleh nilai F=92,335 dengan nilai p=0,0001. Dengan demikian, taksiran model Regeresi Y= 8,24 + 0,68X siginafikansi secara statis. Kita bias memeriksa, apakah JKK masih cukup besar. Kalau JKK masih cukup besar, kita bias meningkatakan model dengan memepertimbangakan model lain, seperti kuadratik atau model non linier lainnya. Untuk maksud ini, uji tuna cocok dapat dilakukan. Untuk melakukan itu JKK dipecah menjadi dua bagian, yaitu JKK karena pengukuaran, yaitu JKK(P), dan JKK karena tuna cocok, yaitu JKK(TC). Rumus untuk menghitung JKK(P) adalah
( )=∑ {∑ Yi2-(∑ Yi)2
ni
}
Dengan tanda jumlah yang pertama ∑ diambil untuk semua nilai X yang sama, dan ni=banyaknya nilai X yang sama tersebut untuk kelompok ke-i. JKK(TC) dapat dihitung dengan pengurangan yaitu:
JKK(TC)=JKK-JKK(P).
Selanjutnya, dk untuk JKK(TC)=k-2, dimana k=banyaknya nilai-nilai X yang berbeda, dan dk untuk JKK(P)=n-k.
Table ANAVAR (hasil komputer) memberikan nilai jumlah kuadrat kesalahan, JKK=46,29619. JKKK ini dapat dipecah menjadi dua bagian, dan JKK(P), dihitung sebagai berikut:
JKK(P)=36,9667. Dengan demikian, JKK(TC)=JKK-JKK(P)=46,29619-36,7667=9,3302. Banyaknya nilai X yang berbeda k=12, sehingga dk untuk tuna cocok adalah 12-2=10. Kemudian, kita dapat membuat table ANAVAR seperti pada Tabel 6.7
Tabel 6.7 ANAVAR untuk model uji tuna cocok
Sumber variansi dk JK RJK F
Regresi X 1 152,6705 152,6705 92,3350
Kesalahan 28 46,2962 1,6534
Tuna cocok 10 9,3302 0,9330 0,4543
Pengukuran 18 36,9667 2,0537
ika α=5%, dengan dk pembilang 10 dan dk penyebut 18, kita mendapatkan F0,05;(10,18)=2,41. Untuk uji tuna cocok, didapat F=0,4543 dan ini lebih kecil dari 2,41. Jadi, pengujian tidak signifikan, yang berarti rerata kuadrat tuna cocok tidak dapat menjadi alas an untuk mangatakan bahwa model linier ditolak. Dengan demikian, tidak ada alas an untuk mencari model nonlinier.
4. strategi penentuan model polinom
Model polinom, kadang-kadang memulai dengan model terkecil, melibatkan hanya satu satu suku linear, dan secara berurutan menambahkan suku-suku X yang pangkatnya meningkat. Prosedur ini adalah sebuah strategi pembuatan model seleksi maju.
Dengan strategi seleksi maju, seseorang biasanya menguji pentingnya sebuah calon peubah peramal(predictor) dengan membandingkan jumlah kuadrat ekstra regresi untuk tambahan peramal itu terhadap rerata kuadrat sisaan (residual mean square). Rerata kuadrat
sisaan ini berdasarkan pada penentuan sebuah model yang memuat calon peubah(peramal) dean peubah-peubah yang tidak ada di dalam model. Statistik F parsial yang sesuai dalam bentuk
( | )
( | )
( )
Pendekatan uji seleksi maju yang dijelaskan di atas dapat membawa pada pelemahan (underfitting) data, yakni algoritma seleksi maju tampaknya berhenti terlalu cepat, sehinnga memilki model dengan derjat lebih rendah daripada yang sesungguhnya diperlukan.
Bias ini dapat dihindari dengan menggunakan strategi seleksi mundur, dimana uji F pada setiap langkah mundur selalu melibatkan rata-rata kuadrat kesalahan untuk model penuh (atau terbesar) yang dibentuk. Akan tetapi, ketika menggunakan pendeketan eliminasi mundur, itu mungkin menguatkan (overfit) data, (yakni memilih sebuah model akhir yang sedikit lebih tinggi daripada yang diperlukan). Untungnya, taksiran rata-rata kuadrat sisa dari model penuh masih merupakan taksiran sahih (unbiased). Akibatnya, menggunakan taksiran ini pada penyebut uji F parsial pada setiap langkah mundurakan tetap menjadi prosedur sahih. Apa yang hilang dengan sedikit mengangkat data adalah suatu kuasa statistis (statistical power), akan tetapi kehilangan ini biasanya diabaikan.
Jadi, untuk menetapkanm model polinom, kita umumnya merekomendasikan strategi eliminasi mundur untuk memilih peubah, dan menggunakan dalam semua uji F parsial taksiran rata-rata kuadrat kesalahan berdasarkan pada model polinom derajat tertinggi. Jika mengimplementasikan startegi ini,kita rekomendasikan pertama, memilih model derajat tiga atau lebih rendah untuk menyederhanakan interpretasi dan meningkatkan kecermatan perhitungan. Kedua, lakukan seleksi mundur dalam bentuk bertahap mulai dari suku derajat tertinggi, seseorang harus secara berturut-turut menghilangkan suku-suku yang tidak signifikan, berhenti pada suku dengan derajat yang pertama signifikan. Suku ini dan semua suku dengan derajat lebih rendah harus dipertahankan dalam model akhir. Ketiga, lakukan uji F parsial-ganda untuk tuna cocok. Keempat, metode analisis sisaan harus digunakan, seperti dengan semua pendekatan regresi.
B. Model Eksponen
Model eksponen adalah salah satu model yang juga banyak digunakan apabila situasi tidak memungkinkan model linear atau polinom. Taksiran model eksponen ditulis dengan
Ŷ
Dengan a dan b konstanta, dan dapat dikembalikan kepada model linear apabila diambil logaritmanya. Dalam bentuk logaritma persamaannya menjadi
log Ŷ = log a +(log b X
Apabila diambil Ŷ * = log Ŷ, a* = log a, dan b* = log b, maka diperoleh Ŷ * = log a* + b* X
Dan ini adalah model linaer sederhana. Dengan menggunakan rumus koefisien regresi linear sederhana, a* dan b* dapat dihitung , dan selanjutnya a dan b dapat ditentukan.
Dalam bentuk logaritma, a dan b dapat dicari dengan rumus
∑ ( )∑
(∑ ) (∑ )(∑ ) ∑ (∑ )
Untuk penggunaan model ini, kita perhatikan data dalam Tabel 6.8.
Tabel 6.8 Tinggi semacam tumbuhan selama 10 minggu. Minggu ke 1 2 3 4 5 6 7 8 9 10 Tinggi Y (cm) 6 15 23 27 30 37 38 38 39 40 8 12 23 29 33 37 36 36 38 38 9 13 20 30 32 36 36 39 42 13 25 35 35
Dari rumus diatas, tampak bahwa nilai-nilai Y harus diambil logaritmanya, sedangkan X tetap sebagai mana asalnya. Jika ini dilakukan, maka hasilnya diperoleh seperti pada Tabel 6.9.
Tabel 6.9 Logaritma tinggi semacam tumbuhan selama 10 minggu.
Peubah X 1 2 3 4 5 6 7 8 9 10 Log Y 0,7782 1,1761 1,3617 1,4314 1,4771 1,5682 1,5798 1,5798 1,5911 1,6021 0,9031 1,0792 1,3617 1,4624 1,5185 1,5682 1,5563 1,5563 1,5798 1,5798 0,9542 1,1139 1,3010 1,4771 1,5051 1,5563 1,5563 1,5911 1,6232 1,1139 1,3979 1,5441 1,5441
Dari Tabel 6.9 diperoleh
∑ ∑
∑ ∑
Dengan demikian diperoleh
( ) ( )( ) ( ) ( ) , atau
log b = 0,0692 yang menghasilkan b = 1,173 ( )( ), atau
Log a = 1,051 yang menghasilkan a = 1,25 Jadi regresi model eksponen yang diperoleh adalah Ŷ = (11,25) (1,173)X
Nilai log a dan log b dapat diperoleh langsung dengan bantuan komputer. Perintah yang diberikan pada SAS adalah
Proc Reg ; Model log Y = X
Model eksponen yang kita bangun adalah log Ÿ = log a + log b X, sehingga dari hasil komputer kita peroleh log a = 1,051 dan log b = 0,0693 (cara manual memberikan hasil 0,0692). Dari hasil komputer, selain kita dapat menentukan taksiran parameter model, signifikansi model juga diberikan. Kita perhatikan bahwa nilai F =77,792 dengan nilai P = 0,0001. Nilai R2 = 0,7151 menunjukkan bahwa model signifikan dengan daya ramal sekitar 72%.
Model eksponen diatas sering pula disebut model pertumbuhan karena sering banyak digunakan dalam menganalisis data sebagai hasil pengamatan mengenai gejala yang sifatnya tumbuh. Dalam hal ini, modelnya diubah sedikit dan persamaannya menjadi
Ŷ = aebX
Dengan e = bilangan pokok logaritma alam atau logaritma Napier, yang nilainya hingga empat desimal adalah 2,7183.
Penyelesaian model terakhir dilakukan dengan mengambil logaritma alam dan bukan logaritma biasa. Hasilnya menjadi
ln Ŷ =ln a + b X
Jika daftar logaritma alam (kalkulator dengan fungsi ln atau bilang e) tidak tersedia maka dapat digunakan daftar logaritma biasa, akan tetapi persamaan regresi menjadi
log Ŷ = log a + 0,4343 b X C. Model Geometris
Persamaan umum model ini ditaksir oleh bentuk Ŷ = a Xb
Dengan a dan b konstanta. Jika model ini diambil logaritmanya diperoleh hasil log Ŷ = log a + b log X
dan ini merupakan model linear dalam log X dan log Ŷ. oefisien-koefisien a dan b dapat dicari dari
∑ ∑
(∑ ) (∑ )(∑ ) ∑ (∑ )
Untuk melihat penggunaan rumus ini, kita perhatikan data (sudjana,1992) dalam Tabel 6.10 yang grafiknya terdapat pada gambar 6.2.
Tabel 6.10 data hasil pengamatan X Y X Y 20 150 35 125 60 105 100 100 150 92 300 97 500 97 800 62 1200 58 1300 40 1500 38 1600 35 Y 1600 1200 80
40
0
40 800 1200 1600 X
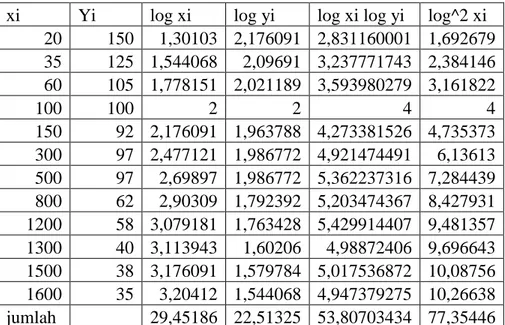
Kita akan melihat apakah model geometris cocok atau tidak dan untuk ini diperlukan tabel 6.11
Tabel 6.11 nilai-nilai yang diperlukan untuk menghitung a dan b model geometris xi Yi log xi log yi log xi log yi log^2 xi
20 150 1,30103 2,176091 2,831160001 1,692679 35 125 1,544068 2,09691 3,237771743 2,384146 60 105 1,778151 2,021189 3,593980279 3,161822 100 100 2 2 4 4 150 92 2,176091 1,963788 4,273381526 4,735373 300 97 2,477121 1,986772 4,921474491 6,13613 500 97 2,69897 1,986772 5,362237316 7,284439 800 62 2,90309 1,792392 5,203474367 8,427931 1200 58 3,079181 1,763428 5,429914407 9,481357 1300 40 3,113943 1,60206 4,98872406 9,696643 1500 38 3,176091 1,579784 5,017536872 10,08756 1600 35 3,20412 1,544068 4,947379275 10,26638 jumlah 29,45186 22,51325 53,80703434 77,35446
Dengan menggunakan rumus diatas untuk data tabel 6.11 kita peroleh :
( ) ( )( )
( ) ( )
( ) ( ) yang menghasilkan a = 377,6.
Persamaan regresinya adalah
Ŷ =(377,6) X-0,2856
Nilai log a dan log b maupun hasil uji signifikansi model dapat pula diperoleh langsung dengan bantuan komputer. Perhitungan komputer dengan model log Ŷ = log a + b log X memberikan hasil seperti berikut. Kita dapat melihat pada hasil komputer bahwa log a = 2,5770 dan b = -0,2856 yang sama dengan hasil manual. Informasi tambahan pada hasil komputer memberi tahukan bahwa model signifikan karena nila F = 47,673 dengan nila F =0,0001. Selanjutnya, daya ramal model sebesar 83% (R2 = 0,8266) diberikan juga dalam hasil komputer itu.
D.MODEL LOGISTIK
Model logistik mempunyai banyak bentuk,dan penggunaannya juga cukup luas. Bentuk model logistik yang paling sederhana dapat ditaksir oleh
Ŷ=
Dengan a dan b konstanta. Untuk Ŷ yang tidak sama dengan nol,bentuk diatas dapat pula ditulis sebagai
Ŷ= a Jika rumus diambil logaritmanya ,maka diperoleh
log(
Ŷ) =log a + (log b) X Yang merupakan model linear dalam peubah X dan log (
Ŷ).
Koefesien-koefesien a dan b dapat dicari dengan menggunakan rumus
log a =∑ - (log b ) ∑ log b = n ∑ ) (∑ ) (∑ ) ∑ (∑ )
Kita gunakan data Tabel 6.10 untuk membuat suatu model logistik log (
Ŷ) = log a + (log b) X. Hasil komputer dapat memberikan nilai – nilai log a dan log b sebagai berikut.
Dari hasil komputer kita peroleh nilai log a = -2,0864 yang memberikan nilai a = 0,0082, dan log b = 0,000334 yang memberikan b = 1,000769 dengan demikian, logistik yang diperoleh adalah
Ŷ
( )( ) Ŷ ( )( )
Model ini signifikan dan memilki daya ramal sekitar 93%. Hal ini ditunjukkan oleh nilai F =138,145 dengan nilai p =0,0001, dan nilai R2 = 0,9325.
Model logistik ini memiliki aplikasi yang cukup penting pada regresi dengan peubah terikatnya bernilai biner( 0 dan 1). Jika Y peubah bernilai 1 dan 0, sedangkan X peubah dengan skala pengukuran interval, bentuk khusus model regresi logistik adalah
( )
Dimana (x) = H (Y|x) adalah nilai harapan bersyarat Y untuk nilai tertentu X = x yang diberikan. Karena Y, peubah dikontomi, nilai harapan bersyarat ini harus lebih atau sama dengan 0 dan kurang dari atau sama dengan 1 (yakni H(Y|x 1 .
Bentuk model logistik yang secara khusus digunakan dalam Hosmer dan Stanley Lomeshow (1989) dengan mendefinisikan logit transformation adalah sebagai berikut
( ) [ ( )
( )]
Transformasi ini sangat penting karena model regresinya memilki sifat-sifat seperti sebuah model regresi linear.
E. Model Hiperbola
Perkiraan persamaan umum sederhana untuk model hiperbola ini dapat dituliskan dalam bentuk
atau jika tidak ada Ŷ yang bernilai nol dapat ditulis menjadi
dengan a dan b konstanta,yang ternyata merupakan bentuk linear dalam peubah-peubah X dan 1/Y.
Koefisien-koefisien a dan b dapat dihitung seperti pada model garis lurus dengan rumus
a = (∑ )(∑ ) (∑ )(∑ ) ∑ (∑ ) b = (∑ ) (∑ )(∑ ) ∑ (∑ )
Untuk data Tabel 6.10, kita tentukan regresinya dengan mengambil model hiperbola. Untuk ini perlu dibuat Tabel 6.12 untuk membantu proses perhitungan.
Tabel 6.12 Nilai-nilai yang diperlukan untuk menghitung koefisien model hiperbola
Xᵢ Yᵢ 1/Yᵢ Xᵢ² Xᵢ/Yᵢ
20 150 0,0067 400 0,1333
35 125 0,0080 1225 0,2800
100 100 0,0100 10000 1,0000 150 92 0,0109 22500 1,6304 300 97 0,0103 90000 3,0928 500 97 0,0103 250000 5,1546 800 62 0,0161 640000 12,9032 1200 58 0,0172 1440000 20,6897 1300 40 0,0250 1690000 32,5000 1500 38 0,0263 2250000 39,4737 1600 35 0,0286 2560000 45,7143 7565 999 0,1789 8957725 163,1435 Dengan nilai-nilai ∑ ∑ ∑ ∑
yang diperoleh dari Tabel 6.12 didapat
a = ( )( ) ( )( )
( ) ( )
=
0,0319b = ( ) ( )( )
( ) ( )
=
0,000012Persamaan regresi model hiperbila untuk soal tersebut adalah
Hasil ini memberikan taksiran regresi Ŷ = 122,262 – 0,085 X + 0,0000197 X2
. Model ini pun signifikan dengan daya ramal 87%. Hal ini ditunjukkan oleh nilai F = 31,17 dengan nilai p = 0,0001 dan nilai R2 = 0,8737.
Kita bandingkan model hiperbola = 0,0073 + 0,00012 yang mempunyai daya ramal 93% (R2 = 0,9265 dengan model kuadratik Ŷ = 122,262 – 0,085 X + 0,0000197 X2 yang mempunyai daya ramal 87% (R2 = 0,8737). Kita bisa melihat bahwa model hiperbola sedikit lebih tinggi daya ramalnya dibandingkan dengan model kuadratik. Disamping daya ramal, kesederhanaan model dan kemudahan interprestasi harus ikut dipertimbangkan sebelum memilihmodel yang akan digunakan.