APLIKASI EXTREME LEARNING MACHINE UNTUK PERAMALAN DATA
TIME SERIES
(STUDI KASUS: SAHAM BANK BRI)
Virgania Sari
1Akademi Statistika Muhammadiyah Semarang email: [email protected]
Abstract
The machine learning technique has become a hot area of reaserch over the past years, wich is attributed to the growing research activities and significant contributions made by nomerous researches around the world. Recently, Extreme Learning Machine (ELM) was proposed as a non-iterative learning algorithm for Single-Hidden Layer Feed Forward Neural Network to increse speed of learning and accuracy of network. The daily BRI closing price stocks was forecast in this research. Using ELM methodhad best accuracy in RMSE 21.5858 and 0.38309 second of training. While, using Feedforward Neural Network had best accuracy in RMSE 36.2965 and 0.630029 second of training. Based on the result of experiment, seem the ELM is capable of giving a good prediction accuracy and speed of learning.
Keywords: forecasting, extreme machine learning, feed forward neural network, single-hidden layer feed forward neural network, time series
1. PENDAHULUAN
Artificial Neural Network telah banyak diaplikasikan untuk peramalan, regresi dan klasifikasi. Beberapa dekade terakhir Artificial Neural Network telah banyak dikembangkan. Salah satunya oleh Huang (2006)[2] mengusulkan algoritma pembelajaran baru untuk pembalajaran yang disebut Extreme Learning Machine (ELM). Elm mengatasi permasalahan pada algoritma backpropagation dalam penentuan gradien. Pada algoritma ELM bobot dan bias pada input dipilih secara acak. Formulasi ELM dapat memecahkan permasalahan pada sistem persamaan linier dengan bias pada layer hidden yang tidak diketahui. Solusi dari persamaan linier ditentukan dengan Moore-Penrose generalized pseudo inverse.
ELM merupakan jaringan saraf tiruan Feed Forward dengan satu hidden layer atau lebih dikenal dengan Single Layer Feed Forward Neural Network.ELM memiliki kelebihan dalam learning speed, sertamempunyai tingkat akurasi yang lebih baik.Sehingga diharapkan dengan metode ini outputyang dihasilkan mampu mendekati kenyataan danpenyelesaian yang optimal serta waktu komputasiyang relatif singkat.
PT Bank Rakyat Indonesia (BRI) Tbk merupakan salah satu perusahan perbankan terbesar di Indonesia.Sejak 1 Agus-tus 1992 berdasarkan Undang-Undang Perban-kan No. 7 tahun 1992 dan Peraturan Pemerintah RI No. 21 tahun 1992 status BRI berubah menjadi perseroan terbatas. Kepemilikan BRI saat itu masih 100% di tangan Pemerintah Republik Indonesia. Pada tahun 2003, Pe-merintah Indonesia memutuskan untuk menjual 30% saham bank ini, sehingga menja-di perusahaan publik dengan nama resmi PT. Bank Rakyat Indonesia (Persero) Tbk., yang masih digunakan sampai dengan saat ini. Saham PT BRI Tbk merupakan saham yang memiliki kapitalisasi terbesar setelah saham Telkom di Bursa Efek Jakarta (BEJ), dan kaptalisasinya terus meningkat.
2. METODE PENELITIAN
a. Extreme Machine Learning (ELM) Metode ELM mempunyai model matematis yang berbeda dari jaringan syaraf tiruan feedforward. Modelmatematis dari ELM lebih sederhana dan efektif. Berikutmodel
matrematis dari ELM. Untuk N jumlah sampel yang berbeda( , )
= [ , ⋯ , ] ∈
= [ , ⋯ , ] ∈
Standar SLFNs dengan jumlah hidden nodes sebanyak N dan activation function ( )dapatdigambarkan secara matematis sebagai berikut :
= ∙ +
=
Dimana :
= 1,2, . . . ,
= [ , , ⋯ , ] merupakan
vektor dari weight yangmenghubungkan i thhidden nodes dan input nodes.
= [ , , ⋯ , ] merupakan
weight vector yang menghubungkan i th hidden dan output nodes.
threshold dari i th hidden nodes. ∙ merupakan inner produk dari
dan
SLFNs dengan N hidden nodes dan activation function ( ) diasumsikan dapat meng-approximate dengantingkat error 0 atau dapat dinotasikan sebagai berikut :
− = 0
Dimana terdapat , , sehingga
∙ + = , = 1,2, ⋯ ,
Persamaan diatas dapat dituliskan secara
sederhana sebagai = Dimana = ( , ⋯ , , , ⋯ , , , ⋯ , ) = ( ∙ ⋮ + ) ⋯⋯ ( ∙ ⋮ + ) ( ∙ + ) ⋯ ( ∙ + ) × = ⋮ = ⋮
H pada persamaan di atas adalah hidden layer output matriks ( ∙ +
)menunjukkan output darihidden neuron
yang berhubungan dengan input , sedangkan merupakan matrix dari output weight dan Tmatrix dari target atau output .
Pada ELM input weight dan hidden bias ditentukansecara acak, maka output weight yang berhubungandengan hidden layer dapat ditentukan
=
Dimana merupakan matriks Moore-PenroseGeneralized Invers dari matriks H sedangkanmatriks H merupakan matriks yang tersusun darioutput masing-masing Hidden Layer dan T adalahmatriks target.
Data dinormalisasi terlebih dahulu dalam rentang [0,1] jika fungsi aktifasi yang digunakan sigmoid biner. Sedangkan jika fungsi aktivasi adalah sigmoid bipolar, maka data akan dinormalisasi dalam rentang [-1,1].
Parameter yang akan diinputkan antara lain yaitu jumlah hidden, max epoch dan target error. Untuk stopping condition,
yaitu iterasi = maksimal epoch atau MSE
≤ target error. Satu epoch mewakili satu
kali perhitungan untuk semua data pada data training.
b. Feedforward Neural Network Jaringansyaraftiruandapatdiinter-pretasikansebagairegresinonlinier yang mencirikanhubunganantaravariabeldepend en (target) y dan n-vektordarivariabelpenjelas (input) x. jaringansyaraftiruandibangundenganmeng guanakanfungsi linier dasarmelaluisebuahtruktur multilayer. Ada tigajenis layer yang digunakan, yakni layer input, layer hidden dan layer output. Layer input sebagai layer penerimasinyal,
layer output
tempatsolusiterhadapmasalah-masalah yang ditemukandan layer tersembunyi(hidden) yang memisahkan layer input dan layer output.
Dalamsebuahjaringanfeedforward, variabelpenjelaspertamasecarasimultanme ngaktivasi unit hidden melalui fungsi aktivasi dan menghasilkan unit
hiddenℎ dimana = 1,2, ⋯ , ,kemudianmeng-aktifkan unit output melaluifungsiaktivasi untukmenghasilka n output jaringan . ℎ, = + ∑ , ) , dimana = 1,2, ⋯ , = 1,2, ⋯ , = + ℎ, ataudapatditulis, = + + , = ( , ) dimana , = input jaringan
= bobot pada input = bobot bias pada input
=fungsiaktivasipada layer hidden ℎ, = unit hidden
= bobot pada unit hidden = bobot bias pada unit hidden
= fungsi aktivasi pada layer output = output jaringan
= vektor yang memuat semua nilai
dan γ.
Berikutadalahskemafeedforward neural networkdengan unit neuron hiddendan unit neuron hidden.
Gambar 1. Feedforward Neural Network
AlgoritmaLavenberg-Marquardt mem-berikan solusi numerik untuk minimasi dengan pendekatan pada turunan kedua tanpa menghitung matriks Hessian. Fungsi objektif dalam bentuk error kuadrat:
( ) =12 =12 ( − ) , = 1,2, ⋯ , .
dimana adalah output pada neural network, target dan
bias pada jaringan. Padametode Newton fungsiobjektifdimi-nimumkan dengan
= − ⁻¹ ( )
ketika ( ) = dan ( ) gradien dari ( ) maka matriks Hessian dapat diaproksimasi dengan ≈ ′ dan gradient dapat dihitung dengan = ′ dimana elemen matriks Jacobi berisi turunan pertama fungsi objektif terhadap bobot yang bersesuaian, dan adalah eror jaringan.
Algoritma Lavenberg-Marquardt da-pat diaproksimasi sebagai berikut.
= − ( + ) ′
dimana adalah learning parameter.
Learning parameter
Nilai learning parameter ≠ 0, ditu-runkan setelah langkah sukses (fungsi objektif mengecil) dan ditingkatkan hanya ketika fungsi objektif meningkat. Dengan cara ini, fungsi objektif selalu diturunkan pada setiap iterasi.
Kriteria penghentian
Selama proses belajar, bobot dalam jaringan terus menerus disesuaikan. Proses belajar akan berhenti jika eror yang dihasilkan telah mencapai mini-mum yang diinginkan.
3. HASIL DAN PEMBAHASAN
Pada penelitian ini dilakukan peramalan harga saham penutupan harian Bank Rakyat Indonesia (BRI) dengan Extreme Learning Machine (ELM) dan kemudian
dibanding-kan dengan model konvensional Feed-forward Neural Network(FNN).
Datayang digunakan harga saham penu-tupan harian BRI pada 1 Januari 2016 -24 Januari 2017. Data akan dibagi menjadi dua yakni data untuk training (pembe-lajaran) 1 Januari 2016–9 Nopember 2016 dan data untuk peramalan 10 Nopember– 24 Januari 2017. Data ini digunakan sebagai input jaringan yakni historis harga saham penutupan harian Bank BRI. Selanjutnya data untuk membangun jaringan dibagi menjadi dua yakni data untuk training untuk proses belajar Data training diambil secara acak sebanyak 80% dan data validasi 20%.
Hasilperamalanbergantungpadaarsitekt urjaringan yang dibangun,sepertibanyak layer yang digunakan, banyak neuron pada layer danmetodetrainingyang digunakan. Arsitekturjaringan yang digu-nakantelahdijelaskansebelumnya. Selan-jutnyadilakukan trial danerroruntukmenentukanbanyakneuron hidden.Hasil yang diperolehtidakkonstan (berubah-ubah). Hanyahasilterbaikyang ditampilkan.
Kemudiandarihasilinidipilihbanyak
neuron hidden yang menghasilkanRMSE terkecil,
hasiliniakandigunakanuntuksimulasi trading. Berikuthasilpemilihan neuron yang telahdilakukan.
Percobaandilakukanhingga 15 neuron pada layer hidden. Mengingatuntuk neuron hidden yang lebihbesarjaringantidakdapatmenangkapke teraturanpola.
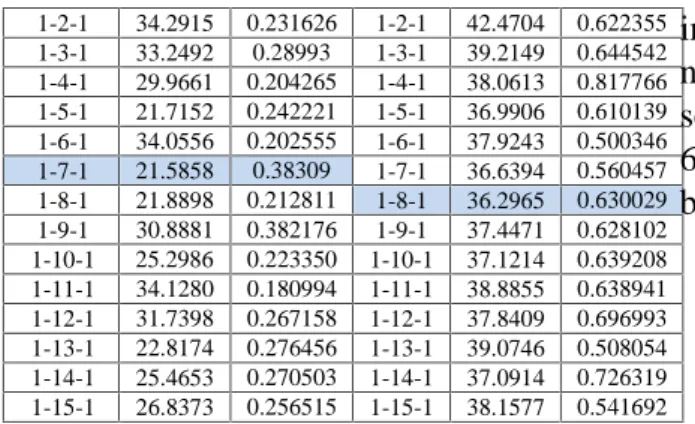
Tabel 1.Nilai Statistik Pendugaan RMSE dan time RMSE ELM CPU time RMSE FNN CPU time 1-1-1 28.5363 0.216551 1-1-1 61.1259 1.999368
1-2-1 34.2915 0.231626 1-2-1 42.4704 0.622355 1-3-1 33.2492 0.28993 1-3-1 39.2149 0.644542 1-4-1 29.9661 0.204265 1-4-1 38.0613 0.817766 1-5-1 21.7152 0.242221 1-5-1 36.9906 0.610139 1-6-1 34.0556 0.202555 1-6-1 37.9243 0.500346 1-7-1 21.5858 0.38309 1-7-1 36.6394 0.560457 1-8-1 21.8898 0.212811 1-8-1 36.2965 0.630029 1-9-1 30.8881 0.382176 1-9-1 37.4471 0.628102 1-10-1 25.2986 0.223350 1-10-1 37.1214 0.639208 1-11-1 34.1280 0.180994 1-11-1 38.8855 0.638941 1-12-1 31.7398 0.267158 1-12-1 37.8409 0.696993 1-13-1 22.8174 0.276456 1-13-1 39.0746 0.508054 1-14-1 25.4653 0.270503 1-14-1 37.0914 0.726319 1-15-1 26.8373 0.256515 1-15-1 38.1577 0.541692
Tabel diatas menunjukkan nilai RMSE dan waktu pengerjaan peramalan dengan ELM dan FNN. Dari hasil diatas dipilih yang terbaik. Arsitektur jaringan yang dipilih yakni yang menghasilkan RMSE terkecil
Hasil peramalan dengan ELM rata-rata menggunakan waktu training yang lebih cepat dibandingkan dengan FNN. Sementara untuk akurasi peramalan ELM menghasilkan RMSE lebih kecil diban-dingkan dengan FNN dengan Marquardt-Lavemberg Algorithm.
PadaarsiktekturjaringanELMjaringande nganarsitektur1 hidden nodes pada layer input, 7 nodes pada layer hidden, dan 1 node pada layer output. Nilai RMSE sebesar21.5858denganwaktupengerjaan 0.38309detik. Hasil peramalan sebagai berikut.
Gambar 2. Peramalan menggunakan ELM
PadaarsiktekturjaringanELMjaringande nganarsitektur1 hidden nodes pada layer
input, 7 nodes pada layer hidden, dan 1 node pada layer output. Nilai RMSE sebesar36.2965denganwaktupengerjaan0. 630029 detik. Hasil peramalan sebagai berikut.
Gambar 2. Peramalan menggunakan ELM
4. KESIMPULAN
ELM dapat diaplikasikan dalam memprediksi harga penutupan harian saham BRI yang diperdagangan pada Bursa Efek Jakarta. Elm memiliki keunggulan dalam akurasi peramalan dan kecepatan pemelajaran.
Pada penelitian ini ELM dibandingkan dengan model konvensional FNN dengan algoritma Marquardt-Lavenberg pada pembe-lajaran. Algoritma Marquardt-Lavenbergmemi-liki keunggulan akurasi dibanding algoritma lainnya dalam Bacpropagation.
Peramalan harga penutupan harian saham BRI dengan ELM memiliki nilai RMSE sebesar 21.5858 dan 0.38309 detik dalam proses belajar.Sedangkan, dengan menggunakan FNN memiliki nilai RMSE 36.2965 and 0.630029 detik dalam proses belajar. Rata-rata waktu belajar pada ELM lebih cepat, dengan kata lain ELM lebih akurat dan cepat dalam proses pembelajaran. 5. REFERENSI
[1] Ding, Shifei, u, Xinzheng & Nie, Ru.
“Extreme Learning Machine adn Its Application”. Springer-Verlag
London. 2013. 0 10 20 30 40 50 60 1 1.05 1.1 1.15 1.2 1.25 1.3x 10 4 waktu B B R I S to k s
Extreme Learning Machine Model
y y forecast 0 10 20 30 40 50 60 1 1.05 1.1 1.15 1.2 1.25 1.3x 10 4 waktu B B R I S to k s
ANN with Marquardt Levenberg Alghorithm
[2] Huang, Guang-Bin, Zhu, Qin-Yu & Siew, Chee-Kheing. “Extreme Learning Machine: Theory and Application”.2006
[3] Rampal, Singh & Balasundaram, S. “Application of Extreme Learning Method for Time Series Analysis”. International Journal of Intellegent Technology. [4] Sulistijanti, Wellie & Sari, Virgania.
“Perbandingan Algoritma Resilient dan Marquardt Lavenberg untuk Memprediksi Harga Kurs”. Median Jurnal, AIS-M. 2014.
[5] Vishwakarma, Virendra P. & Gupta, M. N. “A New Learning Algorithm for Single Hidden Layer Feed Forward Neural Network”. International Journal of Computer Applications (0975 – 8887) Volume 28– No.6, August 2011
[6] Wei, William W.S.”Time Series Analysis”. Second Edition. Pearson Education Inc. 2006 [7] https://finance.yahoo.com/quote/BBRI.
JK
[8] https://id.wikipedia.org/wiki/Bank_Rak yat_Indonesia