Fakultas Ilmu Komputer
5009
Peramalan Harga Saham Menggunakan Metode Extreme Learning
Machine (ELM) Studi Kasus Saham Bank Mandiri
Muhammad Iqbal Pratama1, Putra Pandu Adikara2, Sigit Adinugroho3 Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Saham adalah salah satu jenis investasi yang dapat menghasilkan keuntungan terbesar. Salah satu masalah yang ada pada investasi saham adalah sulitnya meramal harga saham sehingga menimbulkan keraguan untuk membeli atau menjual suatu saham. Metode ELM diimplementasikan untuk peramalan harga saham dengan studi kasus saham harian Bank Mandiri. Metode ini memiliki keunggulan berupa waktu pelatihan yang cepat dan nilai error yang rendah. Proses yang dilakukan adalah melakukan normalisasi terhadap data saham harian Bank Mandiri, membangkitkan bobot input dan bobot bias, melakukan tahap pelatihan, melakukan tahap pengujian, melakukan denormalisasi terhadap data hasil peramalan, dan melakukan evaluasi model menggunakan Mean Absolute Percentage Error (MAPE). Fitur berupa harga Open, High dan Low akan digunakan untuk meramal harga saham harian Bank Mandiri. Dari hasil pengujian, didapatkan nilai MAPE terendah sebesar 1,012% dengan menggunakan fungsi aktivasi sigmoid, jumlah neuron pada hidden layer sebanyak empat buah neuron dan data yang digunakan adalah data satu tahun terakhir.
Kata kunci: Extreme Learning Machine, Saham, MAPE Abstract
Stock investment is one of the most profitable type of investment. One of the biggest problem in stock investing is the difficultness to predict a stock price and it led to doubt whether to buy or sell a stock.
Extreme Learning Machine is implemented to predict a stock price using Bank Mandiri’s stock as a case
study. This algorithm has some advantages such as fast training time and small error value. Extreme
Learning Machine’s processes involve normalizing Bank Mandiri daily stock data, generating input weight and bias weight, training the model, testing the model, denormalizing predicted value and evaluating the model using Mean Absolute Percentage Error (MAPE). The features used to predict Bank
Mandiri’s stock price are Open, High and Low price. The smallest MAPE value obtained from the
testing phase is 1,012% using sigmoid activation function, four neurons in hidden layer and the data used is the last one year.
Keywords: Extreme Learning Machine, Stock, MAPE
1. PENDAHULUAN
Investasi saham adalah salah satu bentuk investasi yang dapat memberikan keuntungan yang tinggi. Apabila seseorang memiliki uang simpanan yang tidak berisiko untuk diinvestasikan, maka investasi saham adalah pilihan terbaik untuk meningkatkan uang yang dimilikinya. Selain itu, investasi saham juga berguna untuk melawan laju inflasi pada saat harga kebutuhan terus meningkat sehingga melemahkan nilai mata uang.
Dua tipe investasi saham yang sering dilakukan oleh seorang investor adalah investasi
jangka pendek dan investasi jangka panjang. Investasi jangka pendek melibatkan transaksi jual beli suatu saham dalam kurun waktu kurang dari satu tahun, sedangkan investasi jangka panjang berada dalam kurun waktu lebih dari satu tahun. Kedua tipe investasi ini memiliki permasalahan yang sama, yaitu sulitnya meramal harga saham suatu perusahaan (Zeng-min, Chong, 2010). Apabila seorang investor baru tidak cermat dalam mengamati pergerakan harga saham, investasi saham justru akan menimbulkan kerugian.
Regression (SVR) untuk meramal index saham Nikkei 225. Nilai MAPE yang dihasilkan dari penelitian tersebut adalah 1.4676%. Namun metode ini masih memiliki kelemahan, yaitu kecepatan waktu pelatihan.
Beberapa algoritme peramalan sudah banyak diteliti, salah satu yang memiliki waktu pelatihan cepat dan nilai error
yang rendah
adalah
Extreme Learning Machine (ELM) yang merupakan salah satu algoritme jaringan saraf tiruan. Pada sebuah penelitian yang dilakukan oleh Huang (2012), performa ELM dibandingkan dengan SVR. Hasilnya nilai RMSE yang dihasilkan oleh ELM mengungguli SVR pada beberapa studi kasus dan ELM memiliki waktu pelatihan yang lebih cepat dibandingkan SVR.Dalam penelitian lainnya mengenai peramalan tingkat penyerapan sumur yang dilakukan oleh Cheng, Cai dan Pan pada tahun 2009 ELM kembali dibandingkan dengan SVR. Hasilnya, ELM mengungguli SVR dalam kecepatan waktu pelatihan, nilai error pada tahap pelatihan dan kecepatan waktu pengujian. Nilai error pada tahap pengujian ELM juga hanya memiliki selisih sebesar 0.0011 lebih rendah dibanding SVR.
ELM diimplementasikan pada data berbentuk time-series dalam penelitian lainnya mengenai peramalan harga listrik dan performa ELM dibandingkan dengan algoritme Simple Moving Average (SMA). Hasilnya, nilai MAPE yang dihasilkan ELM lebih baik dibanding SMA (Tee, et al., 2017).
Berdasarkan paparan di atas, ELM akan diimplementasikan untuk peramalan harga saham harian karena ELM dapat menghasilkan nilai error yang rendah dan memiliki kecepatan waktu pelatihan yang baik sehingga apabila data saham harus diolah secara real-time hasil yang diberikan tetap baik.
2. Saham
Saham merupakan sebuah tanda bukti kepemilikan seseorang pada suatu perusahaan (Barus, Christina, 2014). Apabila seseorang memiliki banyak saham pada sebuah perusahaan, maka orang tersebut memiliki persentase kepemilikan yang tinggi di perusahaan yang bersangkutan.
Beberapa parameter yang biasanya ada dalam data saham harian adalah Open, High, Low dan Price.Open adalah harga saham pada saat perdagangan dibuka, High adalah harga
tertinggi sebuah saham pada satu hari perdagangan, Low adalah harga terendah sebuah saham pada satu hari perdagangan, sedangkan
Price adalah harga saham pada saat perdagangan ditutup.
3. Extreme Learning Machine
ELM termasuk dalam single layer feedforward neural network (SLFNs) dimana nilai bobot input dan bias dibangkitkan secara acak (Huang, et al., 2012). Kelebihan dari ELM adalah waktu pelatihan yang cepat dibanding algoritme lain seperti SVR dan Backpropagation. Tahap yang ada pada ELM meliputi normalisasi, pelatihan, pengujian, denormalisasi dan evaluasi.
Normalisasi dilakukan menggunakan Min-Max Normalization menggunakan rumus:
𝑍 = 𝑥𝑖−min(𝑥)
max(𝑥)−min(𝑥) (1)
Keterangan:
Z = Nilai hasil normalisasi
Xi = Nilai data index ke-i pada setiap fitur
Min(x) = Nilai terkecil dalam satu fitur
Max(x) = Nilai terbesar dalam satu fitur
Tahap pelatihan dilakukan dengan langkah-langkah sebagai berikut:
1. Membangkitkan nilai bobot input W dan bias dimana matriks W adalah hubungan antara neuron i input layer dan neuron ke-j hidden layer (Li, 2016), sedangkan matriks bias berukuran [1 x j]. Nilai bobot input berada dalam rentang -1 hingga 1 sedangkan nilai bobot bias berada dalam rentang 0 hingga 1.
2. Menghitung matriks inisialisasi dengan persamaan:
𝐻𝑖𝑛𝑖𝑡= (𝑋 ∗ 𝑊𝑇) + 𝑏 (2)
Keterangan:
X = matriks input layer WT = matriks transpose W Hinit = matriks inisialisasi b = nilai bias
3. Mengaktivasi matriks inisialisasi dengan persamaan:
𝐻 = 1/(1 + exp(−𝐻𝑖𝑛𝑖𝑡)) (3)
Keterangan:
4. Menghitung matriks Moore-Penrose Generalized Inverse dengan rumus:
𝐻+= (𝐻𝑇∗ 𝐻)−1∗ 𝐻𝑇 (4)
5. Menghitung nilai β dengan rumus:
𝛽 = 𝐻+∗ 𝑌 (5)
Keterangan:
β = nilai beta estimasi
H+ = matriks Moore-Penrose Generalized Inverse
Y = vektor output layer
Kemudian tahap pengujian dilakukan dengan langkah-langkah sebagai berikut:
1. Menghitung hasil peramalan dengan rumus:
𝑌𝑝𝑟𝑒𝑑 = 𝛽 ∗ 𝐻 (6)
Keterangan:
Ypred = vektor hasil peramalan β = nilai beta estimasi
H = matriks data uji hasil aktivasi
2. Melakukan denormalisasi dengan rumus:
𝐷 = (𝑚𝑎𝑥 − 𝑚𝑖𝑛) + 𝑚𝑖𝑛 (7)
Keterangan:
D = hasil denormalisasi
Max = nilai maksimum fitur yang bersangkutan
Min = nilai minimum fitur yang bersangkutan
Hasil peramalan yang sudah didenormalisasi kemudian dievaluasi menggunakan rumus berikut:
𝑀𝐴𝑃𝐸 = 𝑁1 ∑𝑛 |𝑌−𝑌𝑝𝑟𝑒𝑑|𝑌
𝑖=1 (8)
Keterangan: N = banyaknya data Y = nilai asli
Ypred = nilai hasil peramalan
4. Cross Validation
Cross
Validation
dilakukan untuk
menguji kemampuan prediksi suatu model
(Fonseca-Delgado, Gomez-Gil, 2013). Salah
satu metode
cross validation
yang sering
digunakan adalah
k-Fold.
Pada metode ini,
data yang digunakan dibagi menjadi
beberapa bagian (
fold
) yang berukuran
kurang lebih sama. Gambar 1 menunjukkan
proses
k-Fold
pada data berbentuk
time
series
.
Gambar 1. k-Fold pada data time-series
Sumber: (Fonseca-Delgado, Gomez-Gil, 2013)
5. Metodologi Penelitian 5.1. Pengumpulan Data
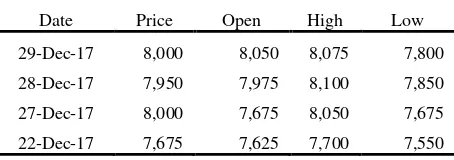
Data yang digunakan pada penelitian ini adalah data saham harian Bank Mandiri dari tanggal 16 Maret 2012 – 29 Desember 2017. Data tersebut didapatkan melalui website investing.com.
Tabel 1 menunjukkan contoh data saham harian Bank Mandiri yang akan digunakan.
Tabel 1. Contoh data saham harian Bank Mandiri
Date Price Open High Low
29-Dec-17 8,000 8,050 8,075 7,800
28-Dec-17 7,950 7,975 8,100 7,850
27-Dec-17 8,000 7,675 8,050 7,675
22-Dec-17 7,675 7,625 7,700 7,550
5.2. Alur Metode
6. PENGUJIAN DAN ANALISIS 6.1 Pengujian Fungsi Aktivasi
Tabel 2 menunjukkan perbandingan nilai MAPE yang dihasilkan menggunakan fungsi aktivasi sigmoid, sin dan tanh.
Tabel 2. Tabel pengujian fungsi aktivasi
Fungsi Aktivasi Rata-rata MAPE
Sigmoid 1,28%
Sin 1,316%
Tanh 1,322%
Menurut penelitian yang dilakukan oleh Cao (2017), fungsi aktivasi sigmoid adalah fungsi aktivasi terbaik untuk diimplementasikan pada permasalahan regresi. Hasil pengujian fungsi aktivasi pada penelitian ini menunjukkan bahwa performa fungsi aktivasi sigmoid mengungguli performa fungsi aktivasi sin dan tanh.
Hasil rata-rata MAPE dari fungsi aktivasi sigmoid hanya memiliki selisih sebesar 0.036% dengan fungsi aktivasi sin dan 0.042% dengan fungsi aktivasi tanh. Hal ini dapat disebabkan karena rentang nilai pemetaan ketiga fungsi aktivasi tersebut mirip. Nilai pemetaan dari fungsi aktivasi sigmoid berada di antara 0 sampai 1, sedangkan nilai pemetaan fungsi aktivasi sin dan tanh berada di antara -1 sampai 1.
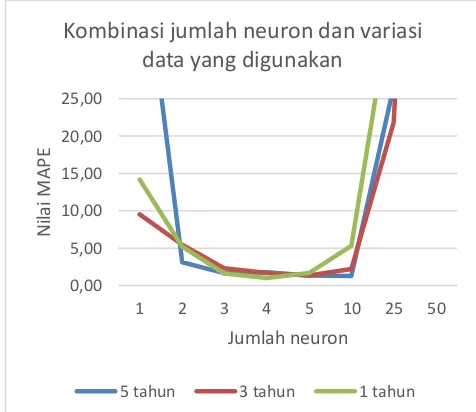
6.2 Pengujian Kombinasi Jumlah Neuron dan Variasi Jumlah Data
Berdasarkan grafik yang ditunjukkan pada Gambar 3, dapat dilihat bahwa penggunaan neuron sebanyak empat buah dan penggunaan data satu tahun terakhir menghasilkan performa terbaik. Grafik tersebut juga menunjukkan bahwa penggunaan neuron yang lebih sedikit ataupun lebih banyak tidak berarti akan menghasilkan performa yang lebih baik. Penggunaan jumlah neuron yang terlalu banyak dapat menyebabkan permasalahan overfitting
dan performa generalisasi yang buruk (Ke, Liu, 2008).
Pada penelitian ini, kasus overfitting dapat timbul lebih cepat karena jarak antar data yang digunakan berdekatan.
Gambar 2. Diagram alir metode ELM
Gambar 3. Grafik nilai MAPE kombinasi jumlah neuron dan variasi jumlah data
0,00 5,00 10,00 15,00 20,00 25,00
1 2 3 4 5 10 25 50
N
il
ai
MAP
E
Jumlah neuron
Kombinasi jumlah neuron dan variasi
data yang digunakan
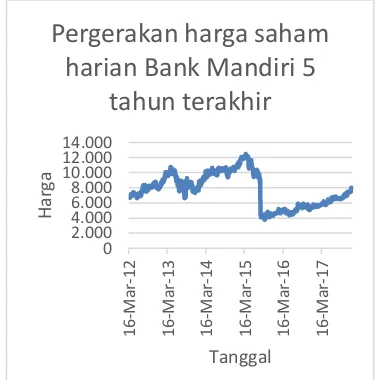
Penggunaan data latih satu tahun terakhir juga menghasilkan performa yang lebih baik. Hal ini dapat terjadi karena pergerakan data saham harian Bank Mandiri selama satu tahun terakhir lebih stabil dibandingkan data tiga tahun dan lima tahun terakhir seperti yang terlihat pada Gambar 4, Gambar 5 dan Gambar 6.
6.3 Pengujian Dengan Data Uji yang Sama Pada Setiap Skenario
Pengujian ini dilakukan untuk mengetahui jumlah data latih seperti apa yang menghasilkan rata-rata MAPE terendah. Jumlah data uji yang digunakan pada setiap skenario sama, yaitu data satu bulan terakhir.
Tabel 3. Tabel pengujian dengan data uji yang sama pada setiap skenario
Banyak data latih
Rata-rata MAPE
1 Tahun
1,012%
3 Tahun
1,495%
5 Tahun
1,22%
Dari Tabel 3 dapat dilihat bahwa penggunaan data latih selama satu tahun terakhir tetap menghasilkan nilai MAPE yang terendah.
6.4 Cross Validation Data Time Series
Cross Validation digunakan untuk mengevaluasi performa model ELM yang sudah dibuat. Tabel 4 menunjukkan hasil cross validation menggunakan 11-fold yang sudah dilakukan. Fold train menyatakan bulan yang digunakan sebagai data latih, sedangkan fold test
menyatakan bulan yang digunakan sebagai data uji.
Hasil yang didapatkan menunjukkan performa model ELM yang sudah dibuat menggunakan data satu tahun terakhir. Setiap
fold tidak menunjukkan adanya tanda-tanda
underfitting maupun overfitting. Rata-rata nilai MAPE dari cross validation ini adalah sebesar 1,128%.
7. PENUTUP
Berdasarkan hasil pengujian dan analisis, didapatkan kesimpulan
nilai MAPE terbaik
yang dihasilkan dari penelitian ini adalah
sebesar 1,012% dengan menggunakan
fungsi aktivasi sigmoid, jumlah neuron
sebanyak empat buah, data yang digunakan
adalah data satu tahun terakhir dan data uji
Gambar 4. Grafik pergerakan saham harian Bank Mandiri 5 tahun terakhir
Gambar 5. Grafik pergerakan saham harian Bank Mandiri 3 tahun terakhir
Gambar 6. Grafik pergerakan saham harian Bank Mandiri 1 tahun terakhir
harian Bank Mandiri 5
tahun terakhir
harian Bank Mandiri 3
tahun terakhir
harian Bank Mandiri 1
Tabel 4. Tabel cross validation
Fold train
Fold test
Rata-rata MAPE
1
2
1,014%
1-2
3
1,174%
1-3
4
1,356%
1-4
5
1,556%
1-5
6
1,346%
1-6
7
1,348%
1-7
8
0,834%
1-8
9
0,586%
1-9
10
0,992%
1-10
11
1,096%
1-11
12
1,116%
yang digunakan adalah data satu bulan
terakhir.
Jika neuron yang digunakan berjumlah
kurang dari empat buah, maka model yang
dibuat kemungkinan akan mengalami
underfitting,
sedangkan apabila neuron yang
digunakan berjumlah lebih dari sepuluh
buah, maka akan ada kemungkinan model
mengalami
overfitting
.
Hasil
cross
validation
yang telah dilakukan juga tidak
menunjukkan
adanya
tanda-tanda
underfitting
ataupun
overfitting
pada model
terbaik yang didapatkan.
8. DAFTAR PUSTAKA
Barus. A. C, Christina, 2014. Pengaruh Reaksi Pasar Terhadap Harga Saham Perusahaan yang Terdaftar di Bursa Efek Indonesia. Jurnal Wira Ekonomi Mikroskil, Vol. 4, No. 1.
Cao, W., et al. 2017. Some Trick in Parameter Selection for Extreme Learning Machine. IOP Conference Series: Materials Science and Engineering.
Cheng, G. J., Cai, L. and Pan, H. X. 2009. Comparison of Extreme Learning Machine with Support Vector Regression for Reservoir Permeability Prediction.2009 International Conference on Computational Intelligence and Security, Beijing, pp. 173-176.
Fonseca-Delgado, R., Gomez-GIl, P. 2013. An Assessment of Ten-Fold and Monte Carlo Cross Validations for Time Series Forecasting. 2013 10th International
Conference on Electrical Engineering,
Computer Science and Automatic Control (CCE), Mexico City, pp. 215-220.
Huang, G., Zhou, H., Ding, X. & Zhang, R., 2012. Extreme Learning Machine for Regression and Multiclass Classification.
IEEE Transactions on systems, man, and cybernetics—PART B: CYBERNETICS, VOL. 42, NO. 2..
Ke, J., Liu, X. 2008. Empirical Analysis of Optimal Hidden Neurons in Neural Network Modeling for Stock Prediction. 2008 IEEE Pacific-Asia Workshop on Computational Intelligence and Industrial Application, Wuhan, pp. 828-832.
Li, G. X. 2016. Application of Extreme Learning Machine Algorithm in the Regression Fitting. 2016 International Conference on Information System and Artificial Intelligence (ISAI), Hong Kong, pp. 419-422.