Pengenalan Identitas Manusia Melalui Iris Mata Menggunakan Gray Level
Co-occurence Matrix
Muh. Aswan Abidin1 , Kurniawan Nur Ramadhani2 , Anditya Arifianto3
1,2,3 Fakultas Informatika, Universitas Telkom, Bandung
1 [email protected], 2 [email protected], 3 [email protected]
Abstrak
Pada tugas akhir ini penulis menerapkan metode Gray Level Co-occurence Matrix sebagai ekstraksi ciri pada iris mata dan untuk mengklasifikasikan data menggunakan K-Nearest Neighbors serta Support Ve- ctor Machine. Dalam sistem ini menggunakan dataset UBIRIS Version 1 yang berjumlah 2000 gambar iris dari 100 individu. Hasil yang didapatkan dari pengujian ini menggunakan ekstraksi ciri Gray Level Co- occurence Matrix mampu menghasilkan F1 Score sebesar 71.10%
Kata Kunci : Biometrics, Gray Level Co-occurence Matrix, K-Nearest Neighbors, Support Vector Machine
Abstract
In this final project the writer applies Gray Level Co-occurence Matrix method as feature extraction on iris and to classify data using K-Nearest Neighbors and Support Vector Machine. In this system using UBIRIS Version 1 dataset which amounts to 2000 iris images of 100 individuals. The results obtained from this test using feature extraction Gray Level Co-occurence Matrix capable of producing F1 Score of 71.10%
Keywords: Biometrics, Gray Co-occurrence Matrix, K-Nearest Neighbor, Support Vector Machine
1. Pendahuluan
Latar Belakang
Biometrik merupakan cara untuk mengidentifikasi seseorang berdasarkan kelakuan manusia dan berbagai ka- rakteristik biologi yang terukur, misalnya pola iris mata, sidik jari, pengenalan wajah, telapak tangan dan karak- teristik perilaku seseorang seperti ritme mengetik, suara dan tanda tangan. Penggunaan sistem biometrik salah satunya adalah iris mata. Iris mata merupakan daerah unik yang terdapat pada manusia yang dibatasi oleh pupil dan sklera. Iris mata memiliki banyak keuntungan yaitu memiliki tekstur yang unik, memiliki pengenalan tingkat akurasi yang tinggi, sehingga setiap orang mampu dibedakan melalui iris mata. Oleh karena itu iris mata menjadi salah satu sistem biometrik untuk mengidentifikasi secara baik dan sulit untuk digandakan.[4]
Saat ini sistem identitas menggunakan metode konvensional misalnya kartu identitas yang digunakan untuk absensi atau password yang digunakan untuk masuk ke dalam sistem. Metode konvensional ini masih mempunyai kelemahan didalam verifikator.[4]
Oleh karena itu penggunaan biometrik iris merupakan mekanisme yang lebih aman daripada menggunakan mekanisme konvensional, karena mengurangi resiko kesalahan didalam identifikasi data. Jika biometrik iris diban- dingkan dengan biometrik sidik jari, maka biometrik iris lebih tinggi tingkat identifikasinya, karena pada biometrik sidik jari dapat meninggalkan jejak di beberapa lokasi, sehingga jejak tersebut bisa di duplikat dan disalahgunakan, sedangkan pada biometrik iris tidak meninggalkan jejak di lokasi, karena iris mata merupakan organ internal pada manusia yang secara tidak langsung bersentuhan dengan objek.[4]
Pada penelitian ini penulis menggunakan Gray Level Co-occurence Matrix (GLCM) sebagai ekstraksi fitur untuk menganalisa tekstur, parameter yang digunakan adalah Contrast, Entropy, Energy, Homogenity dan Cor- relation. Klasifikasi citra iris yang digunakan adalah metode K-Nearest Neigbors (KNN) dan Support Vector Machine (SVM), metode ini paling baik untuk mendeteksi citra iris mata[5].
Topik dan Batasannya
Berdasarkan latar belakang yang telah diuraikan, dapat dirumuskan permasalahan pada penelitian ini adalah bagaimana cara menerapkan metode Gray Level Co-occurence Matrix pada sistem pengenalan citra iris dan per- formansi dari sistem ini.
Adapun batasan masalah pada penelitian ini adalah penelitian ini difokuskan pada implementasi algoritma Gray Level Co-occurence Matrix sebagai ekstraksi ciri, dan dataset yang digunakan yaitu UBIRIS Version 1 yang berjumlah 2000 gambar iris dari 100 individu, tetapi pada dataset UBIRIS ini terdapat mata yang mempunyai ben- tuk lingkaran iris sekitar 70% atau tidak sepenuhnya terlihat, dikarenakan tertutup oleh kelopak mata.
Tujuan
Tujuan dari penelitian ini adalah untuk mengidentifikasi seseorang dengan menerapkan sistem pengenalan citra iris menggunakan Gray Level Co-occurence Matrix dan menganalisis performansi kinerja dari sistem pengenalan citra iris.
Organisasi Tulisan
Penulisan tugas akhir ini disusun dalam beberapa bagian yang setiap bagian, berisi data-data berikut : Bagian 1 - Pendahuluan, Bagian 2 - Studi Terkait, Bagian 3 - Sistem yang dibangun, Bagian 4 - Evaluasi, dan Bagian 5 - Kesimpulan.
2. Studi Terkait
Sailesh Conjeti dan Dhiraj Puroshottam Jetwani, Patient Identification Using High-Confidence Wavelet based Iris Pattern Recognition. Sistem ini mengenai identifikasi pasien untuk keselamatan dan perencanaan kesehatan dengan menggunakan teknik Iris Pattern Recognition. Teknik yang diusulkan terdiri dari segmentasi iris meng- gunakan Non-orthogonal Wavelets diikuti oleh rekonstruksi selektif. Setelah proses rekonstruksi dilakukan nor- malisasi dengan menggunakan Daugman Rubber Sheet. Sistem ini mendapatkan akurasi 95.49% untuk predictive ability dan 99.82% untuk sensitivity[3].
Muhammad Faisal Zafar, Zaigham Zaheer dan Javid Khurshid, Novel Iris Segmentation and Recognition Sys- tem for Human Identification. Sistem ini mengenai identifikasi manusia menggunakan pendekatan G. Daugman dan Wildes. Prosedur di dalam pengenalan iris terdiri dari empat tahap yaitu normalisasi, segmentasi, ekstraksi fitur dan klasifikasi. Metode segmentasi memberikan keuntungan beberapa aspek dari pendekatan tersebut. Kla- sifikasi yang digunakan yaitu Support Vector Machine yang menghasilkan tingkat identifikasi lebih tepat dengan akurasi mencapai 100%[6].
P. Steffi Vanthana dan A. Muthukumar, Iris Authentication Using Gray Level Co-occurence Matrix And Hau- sdorff Dimension. Sistem ini mengenai keamanan sistem. Penggunaan dan penyalahgunaan kata kunci (password) yang salah. Salah satu hal yang menjadi solusi dari permasalahan tersebut yaitu menggunakan biometrik seba- gai cara untuk mengidentifikasi dan memverifikasi sistem pengenalan iris. Ekstraksi fitur yang digunakan yaitu GLCM (Gray Level Co-occurence Matrix) dan HD Hausdorff Dimensi[2].
Ruchi Luhadiya dan Prof. Dr. Anagha Khedkar, Iris Detection for Person Identification using Multiclass SVM. Sistem ini mengenai keamanan sistem. Berbagai macam perilaku yang buruk di dalam menggunakan sistem, sehingga untuk mendapatkan sistem yang lebih aman. Sistem otentikasi di perkenalkan untuk menyelesaikan masalah tersebut. Dengan menggunakan GLCM (Gray Level Co-occurence Matrix) sebagai ekstraksi fitur dan multiclass SVM (Support Vector Machine). Sistem ini menghasilkan tingkat akurasi sebesar 94.23% [4].
Abdul Matin, Firoz Mahmud, Syed Tauhid Zuhori, dan Barshon Sen, Human Iris as a Biometric for Identity Verification. Sistem ini mengenai perbandingan metode ekstraksi fitur dalam segmentasi citra iris yaitu Bole, Da- ugman, Masek, dan Proposed Method. Dari hasil segmentasi menggunakan Hough Transform sebesar 91.56%[1].
3. Sistem yang Dibangun
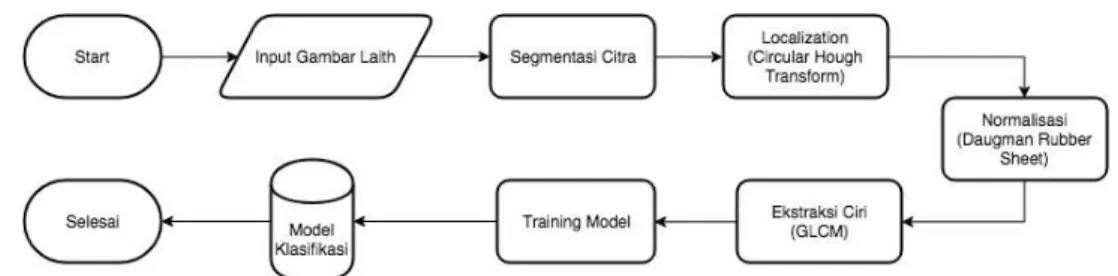
Secara umum sistem yang dibangun yaitu pendeteksian iris mata dengan maghasilkan klasifikasi iris mata, se- hingga dapat menentukan datanya teridentifikasi atau tidak teridentifikasi. Pada tahap pertama, sistem mendeteksi bagian dari mata saja. Setelah mata terdeteksi maka langkah selanjutnya dilakukan proses segmentasi citra yaitu mendeteksi garis tepi untuk mengetahui garis batas luar dan batas dalam suatu objek pada citra. Setelah garis tepi ditemukan dari iris mata maka proses localization dilanjutkan yaitu memisahkan objek sklera dan iris. Objek yang diambil untuk di deteksi hanyalah iris saja. Untuk menentukan radius lingkaran dari iris digunakan algoritma Circular Hough Transform, sehingga citra iris telah di dapatkan. Proses selanjutnya yaitu menghilangkan noise yang terdapat pada permukaan citra iris seperti kelopak mata dan bulu mata. Selanjutnya tahap normalisasi yaitu mengubah bentuk lingkaran iris menjadi bentuk persegi panjang menggunakan Daugman’s Rubber Sheet sehingga objek yang dihasilkan dilanjutkan untuk melakukan ekstraksi fitur pada citra menggunakan GLCM (Gray Level Co-occurence Matrix) sehingga diperoleh nilai piksel matriks.
3.1 Diagram Pembangunan Model Klasifikasi
Gambar 1. Flowchart Diagram pembangunan model klasifikasi
3.2 Diagram Proses Pengujian
Gambar 2. Flowchart Diagram proses pengujian
4. Evaluasi
Pada bagian studi terkait telah dijelaskan beberapa penelitian yang telah dilakukan. Dari penelitian tersebut bertujuan untuk mengidentifikasi manusia dengan menggunakan berbagai jenis metode seperti GLCM (Gray Level Co-occurence Matrix), HD Hausdorff Dimensi yang digunakan sebagai ekstraksi fitur. Dari beberapa penelitian tersebut, salah satunya yang menggunakan ekstraksi fitur GLCM (Gray Level Co-occurence Matrix) pengukuran yang dilakukan lebih diutamakan pada setiap derajat keabuan atau sudut GLCM . Oleh karena itu pada penelitian tugas akhir ini dilakukan pengukuran GLCM (Gray Level Co-occurence Matrix) dari berbagai objek seperti derajat keabuan atau sudut, dan jarak piksel ketetanggan.
4.1 Pengujian Sistem
Pengujian sistem dilakukan untuk mencari parameter yang terbaik, sehingga dapat menghasilkan pemodelan yang optimal. Terdapat skenario yang dilakukan untuk mencapai tujuan, dimana hasil dari skenario pengujian akan di analisis.
4.2 Skenario Pengujian
Dalam pengerjaan tugas akhir ini terdapat satu skenario pengujian. Skenario yang dibangun akan digunakan untuk mengetahui performansi dari sistem pengenalan iris mata.
Pengujian pada skenario ini berfokus terhadap beberapa parameter GLCM dan algoritma klasifikasi seperti KNN dan SVM, beserta parameter klasifikasi yang memiliki performansi optimal dalam mengklasifikasikan indi- vidu terhadap iris mata. Parameter yang diuji meliputi nilai pada setiap sudut atau derajat keabuan dan jarak piksel ketetanggan. Pada metode klasifikasi, diuji dua algoritma klasifikasi yaitu algoritma KNN dan SVM. Setiap algo- ritma mempunyai beberapa parameter seperti KNN dengan parameter jumlah tetangga (k) dan pada SVM dengan
parameter kernel.
Tabel 1. Tabel Skenario Pengujian.
Skenario Pengujian Tujuan Penelitian Parameter yang diuji
Skenario Penentuan Prame- ter GLCM
Tujuan dilakukan pengujian ini adalah untuk mencari ni- lai dari parameter GLCM yaitu derajat keabuan atau sudtu dan jarak piksel ke- tetanggan, serta parameter yang dibutuhkan oleh algo- ritma klasifikasi yaitu jum- lah K pada KNN dan jenis kernel SVM yang mengha- silkan performansi optimal.
Sudut = 0o , 45o , 90o , dan 135o
Jarak piksel = 1, 2, dan 3 Nilai K = 1, 3, dan 5 Kernel = Linear, Polynomi- al, dan RBF.
4.3 Analisis Pengujian Skenario
Pada skenario ini merupakan pengujian setiap nilai parameter dari metode Gray Level Co-occurence Matrix yang bertujuan untuk mendapatkan parameter yang menghasilkan performansi terbaik. Parameter yang diuji antara lain sebagai berikut :
1. Jumlah sudut yaitu 0o , 45o , 90o dan 135o .
2. Jarak piksel ketetanggan yaitu 1,2 dan 3.
3. Algoritma klasifikasi yang digunakan yaitu KNN dan SVM. Pada algoritma KNN digunakan jumlah K sebesar 1, 3, dan 5. Sedangkan pada SVM digunakan kernel linear, polynomial dan rbf(gaussian).
Teknik pengujian ini dilakukan dengan menggunakan teknik K-Fold Cross Validation dengan membagi jumlah data sejumlah parmeter K. Nilai K yang digunakan pada pengujian dengan menggunakan teknik K-Fold Cross Validation adalah 5.
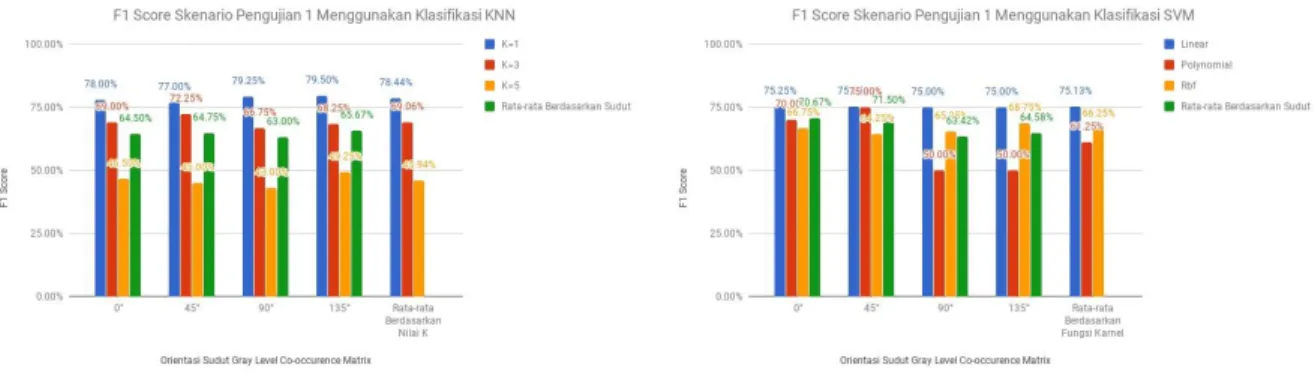
Pengujian pada skenario ini dibagi kedalam 3 bagian. Bagian pertama yaitu pengujian dengan menggunakan jarak piksel d=1. Bagian kedua yaitu pengujian dengan menggunakan jarak piksel d=2. Bagian ketiga yaitu pe- ngujian dengan menggunakan jarak piksel d=3. Hasil yang didapatkan pada ketiga tahap yang dijalankan akan dibandingkan yang mana menghasilkan performansi yang paling optimal dengan membandingkan hasil klasifikasi menggunakan KNN dan SVM. Hasil dari pengujian pada bagian ini dijabarkan pada lampiran 1 dan 2. Berikut adalah hasil terbaik pada pengujian bagian pertama yaitu pengujian skenario dengan menggunakan jarak 1 piksel.
Gambar 3. Perbandingan F1 Score dari setiap sudut menggunakan klasifikasi KNN dan SVM pada jarak 1 piksel. Dari grafik pengujian skenario dengan algoritma KNN, dapat dilihat bahwa f1-score tertinggi hasil rata-rata ber- dasarkan sudut dengan jarak 1 piksel terdapat pada sudut 135o dengan nilai f1-score 65.67%, kemudian berturut-
yaitu pada sudut 90o sebesar 63.00%. Sedangkan pengujian skenario dengan algoritma SVM, dapat dilihat bah-
wa f1-score tertinggi hasil rata-rata berdasarkan sudut dengan jarak 1 piksel terdapat pada sudut 45o dengan nilai
f1-score 71.50%, kemudian berturut-turut untuk sudut 0o sebesar 70.67%, sudut 135o sebesar 64.58%, dan yang
paling rendah pada jarak 1 piksel yaitu pada sudut 90o sebesar 63.42%. Untuk sudut yang menghasilkan nilai f1-
score tertinggi, hal ini dikarenakan banyaknya pasangan dua piksel yang muncul dengan intensitas tertentu pada jarak 1 piksel yang lebih dominan pada orientasi arah piksel dengan sudut 135o dan 45o .
Dari hasil pengujian bagian kedua telah dijabarkan pada lampiran 3 dan 4. Berikut adalah hasil terbaik pada pengujian bagian kedua yaitu pengujian skenario dengan menggunakan jarak 2 piksel.
Gambar 4. Perbandingan F1 Score dari setiap sudut menggunakan klasifikasi KNN dan SVM pada jarak 2 piksel. Dari grafik pengujian skenario dengan algoritma KNN, dapat dilihat bahwa f1-score tertinggi hasil rata-rata berdasarkan sudut dengan jarak 2 piksel terdapat pada sudut 135o dengan nilai f1-score 62.33%, kemudian berturut-turut untuk sudut 0o sebesar 62.08%, sudut 90o sebesar 61.58%, dan yang paling rendah pada jarak 2 piksel yaitu pada sudut 45o sebesar 61.33%. Sedangkan pengujian skenario dengan algoritma SVM, dapat dilihat bahwa f1-score tertinggi hasil rata-rata berdasarkan sudut dengan jarak 2 piksel terdapat pada sudut 45o dengan nilai f1-score 70.58%, kemudian berturut-turut untuk sudut 0o sebesar 63.83%, sudut 135o sebesar 62.17%, dan yang paling rendah pada jarak 2 piksel yaitu pada sudut 90o sebesar 55.42%. Untuk sudut yang menghasilkan nilai f1-score tertinggi, hal ini dikarenakan banyaknya pasangan dua piksel yang muncul dengan intensitas tertentu pada jarak 2 piksel yang lebih dominan pada orientasi arah piksel dengan sudut 135o dan 45o .
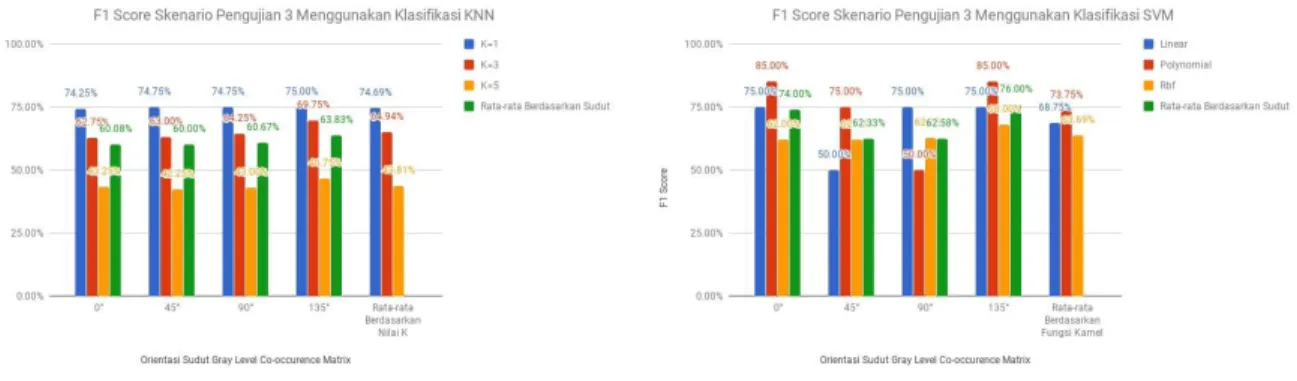
Dari hasil pengujian bagian kedua telah dijabarkan pada lampiran 5 dan 6. Berikut adalah hasil terbaik pada pengujian bagian kedua yaitu pengujian skenario dengan menggunakan jarak 3 piksel.
Gambar 5. Perbandingan F1 Score dari setiap sudut menggunakan klasifikasi KNN dan SVM pada jarak 3 piksel. Dari grafik pengujian skenario dengan algoritma KNN, dapat dilihat bahwa f1-score tertinggi hasil rata-rata berdasarkan sudut dengan jarak 3 piksel terdapat pada sudut 135o dengan nilai f1-score 63.83%, kemudian
berturut-turut untuk sudut 90o sebesar 60.67%, sudut 0o sebesar 60.08%, dan yang paling rendah pada ja-
rak 3 piksel yaitu pada sudut 45o sebesar 60.00%. Sedangkan pengujian skenario dengan algoritma SVM,
dapat dilihat bahwa f1-score tertinggi hasil rata-rata berdasarkan sudut dengan jarak 3 piksel terdapat pada sudut 135o dengan nilai f1-score 76.00%, kemudian berturut-turut untuk sudut 0o sebesar 74.00%, sudut 90o
sebesar 62.58%, dan yang paling rendah pada jarak 3 piksel yaitu pada sudut 45o sebesar 62.33%. Untuk
mun-cul dengan intensitas tertentu pada jarak 3 piksel yang lebih dominan pada orientasi arah piksel dengan sudut 135o .
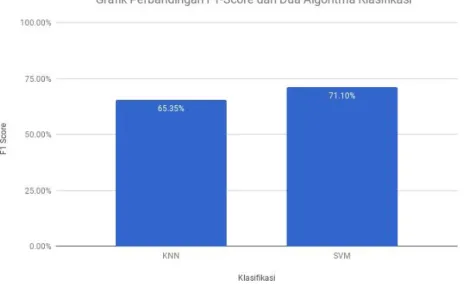
Berikut ini adalah grafik perbandingan akurasi yang didapatkan pada dua algoritma klasifikasi, perbandingan tersebut telah dijabarkan pada lampiran 7.
Gambar 6. Grafik Perbandingan Akurasi dari Dua Algoritma Klasifikasi
Dari grafik perbandingan akurasi menggunakan dua algoritma klasifikasi, dapat dilihat bahwa algoritma kla- sifikasi SVM dapat menghasilkan tingkat f1-score terbesar yaitu 71.10% dimana hasil klasifikasi ini didapatkan dominan pada karnel linear.
Dari pengujian yang dilakukan pada skenario pengujian, dapat dianalisis parameter GLCM yang menghasilkan performansi paling optimal.Yang pertama yaitu derajat keabuan atau sudut 135o dengan menghasilkan performansi
paling optimal dari ketiga jarak piksel. Hal ini membuktikan bahwa banyaknya pasangan dua piksel yang muncul dengan intensitas tertentu pada ketiga jarak piksel GLCM.
Parameter kedua yaitu jarak piksel GLCM yang menghasilkan performansi paling optimal. Jarak 1 piksel yang menghasilkan tingkat performansi paling optimal sebesar 70.37% (dapat dilihat pada lampiran 7). Hal ini dika- renakan penggunaan jarak GLCM yang berbeda, menghasilkan matriks GLCM yang berbeda sehingga ciri yang diekstraksi akan menghasilkan nilai yang berbeda satu dengan yang lainnya.
Parameter ketiga yaitu algoritma klasifikasi yang digunakan untuk melakukan klasifikasi pengenalan identitas manusia. Algoritma klasifikasi yang menghasilkan performansi paling optimal adalah algoritma SVM dengan kernel linear. Hal ini dikarenakan fitur iris yang telah diproses menggunakan GLCM lebih cocok diklasifikasi dengan menggunakan algoritma SVM pada kernel linear.
Dari hasil percobaan yang telah dilakukan pada skenario ini, menghasilkan nilai parameter GLCM dan jenis algoritma klasifikasi yang menghasilkan performansi paling optimal yaitu :
1. Derajat keabuan atau sudut 135o menghasilkan performansi rata-rata 64.00%.
2. Jarak 1 piksel menghasilkan performansi rata-rata 70.37% 3. Algoritma klasifikasi SVM pada kernel linear.
5. Kesimpulan
5.1 Kesimpulan
Berdasarkan hasil pengujian dan analisis yang telah dilakukan, maka dapat disimpulkan bahwa : 1. Sistem klasifikasi pengenalan identitas manusia mendapatkan f1-score tertinggi sebesar 71.10%.
2. Jarak 1 piksel pada parameter ekstraksi ciri Gray Level Co-occurence Matrix dapat mempengaruhi f1-score sehingga menghasilkan performansi tertinggi.
3. Algoritma ekstraksi ciri Gray Level Co-occurence Matrix menghasilkan f1-score tertinggi dengan menggu- nakan algoritma klasifikasi SVM (Support Vector Machine).
5.2 Saran
Berdasarkan pengujian pengenalan identitas manusia melalui iris mata dengan menggunakan GLCM atau ma- triks kookurensi aras keabuan, dapat diberikan beberapa saran sebagai berikut :
1. Perlu dilakukan penelitian lebih lanjut yang bertujuan untuk mengurangi kesalahan dalam proses segmentasi citra iris mata yang disebabkan oleh deteksi lingkaran iris yang tidak sesuai dengan region dari iris. 2. Diharapkan penelitian selanjutnya memperhatikan jumlah citra yang terdapat pada setiap individu, semakin
banyak citra dalam satu individu semakin baik dalam proses pelatihan datasetnya.
Daftar Pustaka
[1] S. T. Z. d. B. S. Abdul Matin, Firoz Mahmud. Human Iris as a Biometric for Identity Verification. 2nd Inter- national Conference on Electrical, Computer & Telecommunication Engineering (ICECTE) 8-10 December 2016, Rajshahi-6204, Bangladesh, 2016.
[2] P. V. dan A. Muthukumar. Iris Authentication Using Gray Level Co-occurence Matrix and Hausdorff Dimen- sion. International Conference on Computer Communication and Informatics, pages 1–5, 2015.
[3] S. C. dan Dhiraj Puroshottam Jetwani. Patient Identification using High-confidence Wavelet based Iris Pattern Recognition. Proceedings of the IEEE-EMBS International Conference on Biomedical and Health Informatics (BHI 2012), Hongkong and Shenzhen, China, 2-7 Jan 2012, pages 628–631, 2012.
[4] R. L. dan Prof. Dr. Anagha Khedkar. Iris Detection for Person Identification using Multiclass SVM. 2016 IEEE International Conference on Advances in Electronics, Communication and Computer Technology (ICAECCT) Rajarshi Shahu College of Engineering, Pune India, Dec 2-3, 2016, pages 387–392, 2016.
[5] S. P. d. D. W. J.R. Lyle, P.E. Miller. Soft Biometrics Classification Using Local Appearance Pariocular Region Features,. The Journal of The Pattern Recognition Society, 4, 2012.
[6] d. J. K. Muhammad Faisal Zafar, Zaigham Zaheer. Novel Iris Segmentation and Recognition System for Human Identification. Proceedings of 2013 10th International Bhurban Conference on Applied Sciences & Technology (IBCAST), Islamabad, Pakistan, 15th - 18th January, 2013, pages 128–131, 2013.