Penggunaan Metodologi Analisa Komponen
Utama (PCA) untuk Mereduksi Faktor-Faktor
yang Mempengaruhi Penyakit Jantung Koroner
Galih Hendro M.
Jurusan Teknik Elektro dan Teknologi Informasi Universitas Gadjah Mada Yogyakarta, Indonesia galih_smula@yahoo.comT. B. Adji
Jurusan Teknik Elektro dan Teknologi Informasi Universitas Gadjah Mada Yogyakarta, Indonesiaadji.tba@gmail.com
N. A. Setiawan
Jurusan Teknik Elektro dan Teknologi Informasi Universitas Gadjah Mada Yogyakarta, Indonesia noorwewe@yahoo.comAbstrak— Tujuan dari penelitian ini adalah untuk mereduksi variabel-variabel yang benar-benar mempengaruhi penyakit jantung koroner. Untuk mendapatkan informasi yang diinginkan, maka diperlukan suatu metodologi yang tepat agar dapat digunakan dalam mengolah data yang sudah ada. Ada banyak metodologi yang digunakan untuk melakukan pengurangan variabel
(feature eksraction) seperti principal component analysis (PCA), rough set theory, algoritma genetika, dan lainnya.
Metodologi yang akan digunakan untuk melakukan reduksi dalam penelitian ini adalah metodologi principal component
analisa (PCA) atau analisa komponen utama. Metodologi
PCA digunakan untuk mereduksi jumlah variabel yang ada pada dataset sehingga dari 13 variabel yang terdapat pada dataset hanya akan diketahui empat variabel yang benar-benar mempengaruhi penyakit jantung koroner dan empat variabel yang dihasilkan dengan metodologi PCA dapat mewakili 13 variabel yang ada pada dataset. Dataset yang digunakan pada penelitian ini adalah data penyakit jantung koroner yang diperoleh dari Cleveland Clinic Foundation yang merupakan koleksi database dari Universitas California, Irvine (UCI) machine learning repository.
Kata kunci-principal component analysis (pca), penyakit jantung koroner, feature ekstraction, reduksi variabel
I. PENDAHULUAN
Jantung merupakan organ yang sangat penting bagi manusia karena jantung diperlukan untuk memompa darah ke seluruh tubuh sehingga tubuh mendapatkan oksigen dari sari makanan yang diperlukan untuk metabolisme tubuh [1]. Salah satu yang perlu dihindari adalah penyakit jantung koroner yang merupakan salah satu penyakit berbahaya yang bisa menyebabkan serangan jantung. Penyakit jantung koroner disebabkan karena adanya penyempitan arteri koronaria sehingga menyebabkan jantung kekurangan oksigen. Penyakit jantung koroner tidak hanya berdampak moralitas yang dapat menyebabkan kematian pada seseorang, tetapi juga berdampak disabilitas yang menyebabkan kerugian ekonomis yang tertinggi dibandingkan dengan penyakit lain. Diperkirakan dana yang dibelanjakan tiap tahunnya untuk perawatan penyakit jantung koroner di Amerika Serikat adalah sebesar 14 milyar US$ (sekitar 42 triliun rupiah). Menurut estimasi World Health Organization
(WHO), sekitar 50% dari 17 juta penduduk dunia meninggal akibat jantung dan pembuluh darah.
Beberapa penelitian menggunakan feature ekstraction untuk mereduksi jumlah variabel terkait dengan penyakit jantung koroner, diantaranya Khempila dan boonjing. 2011. dalam [2] menggunakan algoritma genetika untuk mereduksi jumlah variabel penyakit jantung koroner. Hasil reduksi dilihat dari information gain yang dihasilkan, dari 13 variabel yang ada diperoleh delapan variabel. Setiawan, dkk. 2007. dalam [3] menggunakan metodologi rough set theory untuk melakukan reduksi variabel dengan dataset penyakit jantung koroner. Dari 13 variabel yang ada pada dataset UCI machine learning repository diperoleh hasil reduksi variabel sebanyak enam variabel. Soni, dkk. 2011. dalam makalahnya [4] merangkum beberapa papper dan jurnal terkait dengan penyakit jantung koroner. Dalam makalah ini digunakan algoritma lain seperti naïve bayes, k nearest neighbour’s, pohon keputusan, dan rough set theory. Pada makalah ini disimpulkan bahwa algoritma pohon keputusan (dessicion tree) menghasilkan nilai ketelitian yang paling tinggi dalam memprediksi penyakit jantung koroner. Pada penelitian ini akan digunakan metodologi PCA untuk mengurangi jumlah variabel yang ada dan menentukan faktor-faktor yang mempengaruhi penyakit jantung koroner.
Principal component analysis (analisa komponen utama) adalah salah satu fitur ekstraksi (reduksi) variabel yang banyak digunakan. Bisa dikatakan principal component analysis merupakan analisa tertua dan paling terkenal dari teknik statistika multivariate [5]. PCA pertama kali perkenalkan oleh Karl Pearson pada tahun 1901. Harold Hotelling melakukan analisa untuk variabel stokastik. Hotelling menggunakan pendekatan PCA yang sebelumnya telah dikemukan oleh Pearson dan memperkenalkan istilah “component” sebagai variabel yang dihasilkan dengan menggunakan metodologi PCA. Perkembangan selanjutnya dikenal dengan istilah “principal component” yang menjelaskan komponen utama atau variabel baru yang dihasilkan/direduksi. Inilah cikal bakal dari analisa PCA. Analisa PCA dikenal juga dengan dengan Transformasi Karhunen-Loeve dan Transformasi Hotelling.
Principal component analysis adalah kombinasi linear dari variabel awal yang secara geometris kombinasi linear ini merupakan sistem koordinat baru yang diperoleh dari rotasi sistem semula [6]. Metoda PCA sangat berguna digunakan jika data yang ada memiliki jumlah variabel yang besar dan memiliki korelasi antar variabelnya. Perhitungan dari principal component analysis didasarkan pada perhitungan nilai eigen dan vektor eigen yang menyatakan penyebaran data dari suatu dataset. Tujuan dari analisa PCA adalah untuk mereduksi variabel yang ada menjadi lebih sedikit tanpa harus kehilangan informasi yang termuat dalam data asli/awal. Dengan menggunakan PCA, variabel yang tadinya sebanyak n variabel akan direduksi menjadi k variabel baru (principal component) dengan jumlah k lebih sedikit dari n dan dengan hanya menggunakan k principal component akan menghasilkan nilai yang sama dengan menggunakan n variabel [7]. Variabel hasil dari reduksi tersebut dinamakan principal component (komponen utama) atau bisa juga disebut faktor. Sifat dari variabel baru yang terbentuk dengan analisa PCA nantinya selain memiliki jumlah variabel yang berjumlah lebih sedikit tetapi juga menghilangkan korelasi antar variabel yang terbentuk.
II. METODOLOGI
Pada makalah ini akan digunakan metodologi principal component analysis (PCA) untuk melakukan reduksi variabel sehingga dari 13 variabel yang ada pada dataset akan diperoleh empat variabel baru yang mewakili 13 variabel asal dan empat variabel baru yang terbentuk merupakan faktor-faktor yang menyebabkan penyakit jantung koroner. Data yang akan digunakan untuk penelitian ini adalah data UCI Machine Learning Repository [8]. UCI Machine Learning Repository adalah sebuah penyimpanan database yang berkaitan dengan bidang kesehatan dan bidang sosial. Data yang ada pada website ini telah dibuat sejak tahun 1988 dan sampai saat ini data tersebut banyak digunakan untuk penelitian berskala internasional dan bahan dalam pembuatan makalah di bidang ilmu komputer.
Pada UCI mahine learning repository, dataset untuk penyakit jantung koroner memiliki 14 variabel dan 304 responden (record). Akan tetapi, jumlah variabel yang digunakan untuk metodologi PCA adalah sebanyak 13 variabel karena variabel terakhir yaitu variabel num digunakan untuk analisa lebih lanjut seperti untuk mengklasifikasikan penyakit jantung koroner, membuat aturan dari dataset yang ada, dan pengambilan keputusan. Sebelum dilakukan analisa dengan menggunakan PCA maka perlu dilakukan pembersihan data (data cleaning) yaitu membuang data yang tidak lengkap (missing value), data yang terduplikasi, dan data yang tidak konsisten. Tujuan dari pembersihan data adalah untuk mendapatkan
component analysis (PCA). Variabel penyakit jantung koroner dapat dilihat pada Tabel 1.
TABEL 1 VARIABEL PENYAKIT JANTUNG KORONER
Variabel Keterangan
Age Age in years
Sex 1 : male, 0 : female
Cp
Chest Pain 1: typical angina; 2 : atypical angina; 3 : non anginal pain; 4 : asymptomatic
Trestbps resting blood pressure (in mm Hg on admission to the hospital)
Chol serum cholestoral in mg/dl
Fbs (fasting blood sugar > 120 mg/dl) (1 = true; 0 = false)
Restecg
resting electrocardiographic results 0:normal; 1: having ST-T wave abnormality (T wave inversions and/or ST elevation or depression of > 0.05 mV); 2: showing probable or definite left ventricular hypertrophy by Estes' criteria
Thalach maximum heart rate achieved
Exang exercise induced angina (1 = yes; 0 = no) Oldpeak ST depression induced by exercise relative
to rest
Slope the slope of the peak exercise ST segment. 1:upsloping; 2:flat; 3:downsloping Ca number of major vessels (0-3) colored by
flourosopy
Thal 3 = normal; 6 = fixed defect; 7 = reversable defect
Num diagnosis of heart disease (disease status) Perhitungan analisa dengan menggunakan metodologi PCA adalah masalah memecahkan permasalahan persamaan eigen seperti yang dilihat pada Persamaan 1 karena pada dasarnya perhitungan PCA didasarkan pada nilai eigen yang lebih dari satu. Adapun algoritma PCA secara umum sebagai berikut :
· Hitung matriks kovarian dengan menggunakan Persamaan 2. Cov (xy) =
å
-n xy ) )( (x y (2) · Hitung nilai eigen dengan menyelesaikanPersamaan 3.
(A – λI) = 0 (3) · Hitung vektor eigen dengan menyelesaikan
Persamaan 4.
[A – λI] [X] = [0] (4) · Tentukan variabel baru (principal component) dengan mengalikan variabel asli dengan matriks vektor eigen.
Sedangkan variansi yang dapat dijelaskan oleh variabel baru ke-I tergantung kontribusi pi, dari
masing-akan digunmasing-akan untuk analisa selanjutnya [7]. Pertama, dengan melihat total variansi yang dapat dijelaskan lebih dari 80%. Cara kedua adalah dengan melihat nilai eigen yang lebih dari satu. Cara ketiga adalah dengan mengamati scree plot yaitu dengan melihat patahan siku dari scree plot. Pada penelitian ini untuk menentukan jumlah komponen utama yang dihasilkan pada analisa PCA adalah dengan melihat nilai eigen lebih dari satu.
III. IMPLEMENTASI
Analisa dengan menggunakan metodologi PCA dilakukan apabila terdapat korelasi/hubungan antar variabelnya karena tujuan dari analisa dari PCA adalah membuat sejumlah variabel baru yang tidak memiliki korelasi antar variabelnya (korelasi = 0) dan jumlah variabel yang ada lebih sedikit dari jumlah variabel awal (feature ekstraction). Implementasi dari analisa PCA pada penelitian ini menggunakan software SPSS 19.
Sebelum dilakukan analisa dengan metodologi PCA, dilakukan terlebih dahulu proses pembersihan data (data cleaning) yang bertujuan untuk membuang data yang duplikat, memeriksa data yang tidak konsisten, menghilangkan data yang tidak lengkap (missing value). Hal ini dilakukan agar pada saat analisa hasil yang diperoleh adalah hasil yang sebenarnya. Ada beberapa cara yang digunakan untuk mengatasi data yang hilang/kosong yaitu dengan mengabaikan/membuangnya jika jumlah datanya besar dan dapat juga dilakukan dengan menggantikan data yang hilang dengan nilai rata-rata dari variabel jika jumlah datanya terbatas atau kecil [8]. Missing value pada dataset penelitian ini dilakukan dengan cara membuang record yang tidak memiliki nilai. Dari dataset yang digunakan dalam penelitian ini terdapat 304 responden dan setelah dilakukan pembersihan data maka diperoleh 297 responden. Data yang telah dibersihkan kemudian dihitung nilai Barlett Test of Sphericity yang digunakan untuk mengetahui apakah ada korelasi yang signifikan antar variabel dan menghitung nilai Keiser-Meyers-Oklin (KMO) Measure of Sampling Adequacy yang digunakan untuk mengukur kecukupan sampel dengan cara membandingkan besarnya korelasi yang diamati dengan korelasi parsialnya. Kedua uji ini dilakukan untuk memastikan dataset yang digunakan memenuhi persyaratan analisa PCA. Hasil hari analisa Barlett Test of Sphericity dan KMO dapat dilihat pada Gambar 1. Dari Gambar 1 diketahui nilai Barlett Test of Sphericity 671,256 pada signifikan 0,000 yang berarti pada penelitian ini ada korelasi yang sangat signifikan antar variabel dan hasil perhitungan KMO sebesar 0,695 menunjukkan kecukupan sampel termasuk kategori menengah sehingga dataset penyakit jantung yang digunakan dalam penelitian ini memenuhi syarat analisa dengan menggunakan metodologi PCA.
Gambar 1 Hasil evaluasi Barlett Test of Sphericity dan KMO
IV. HASIL DAN ANALISA
Setelah memastikan bahwa dataset yang digunakan memenuhi syarat untuk melakukan analisa PCA dengan melihat nilai Barlett Test dan nilai KMO maka analisa PCA dapat dilakukan. Analisa PCA diawali dengan menghitung nilai korelasi antar variabel karena pada dasarnya analisa PCA dapat dilakukan jika variabel yang ada memiliki korelasi. Ada dua cara yang digunakan dalam menentukan hubungan antara variabel yaitu dengan menghitung nilai korelasi (matriks korelasi ) antar variabel dan dengan menghitung kovarian (matriks kovarian) dari semua variabel yang ada [5]. Pada analisa ini dilakukan perhitungan korelasi dari setiap variabel dan di bentuk dalam sebuah matriks korelasi. Dari matriks korelasi nantinya akan dilakukan analisa PCA dengan melihat nilai eigen yang ada pada masing-masing variabel. Variabel baru (principal component) yang terbentuk didasarkan pada nilai eigen lebih dari satu. Hasil dari perhitungan nilai egen dan varian dapat dilihat pada Tabel 2.
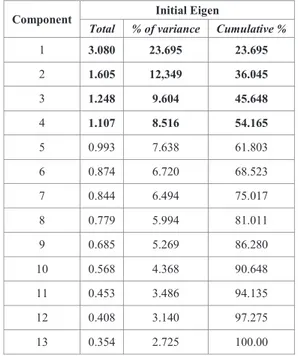
TABEL2 NILAI EIGEN HASIL ANALISA KOMPONEN UTAMA (PCA)
Component Initial Eigen
Total % of variance Cumulative %
1 3.080 23.695 23.695 2 1.605 12,349 36.045 3 1.248 9.604 45.648 4 1.107 8.516 54.165 5 0.993 7.638 61.803 6 0.874 6.720 68.523 7 0.844 6.494 75.017 8 0.779 5.994 81.011 9 0.685 5.269 86.280 10 0.568 4.368 90.648 11 0.453 3.486 94.135 12 0.408 3.140 97.275 13 0.354 2.725 100.00
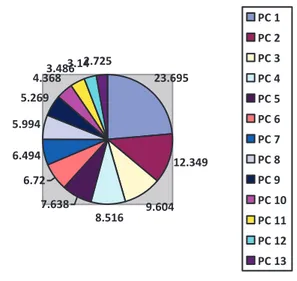
23.695 12.349 9.604 8.516 7.638 6.72 6.494 5.994 5.269 4.368 3.4863.142.725 PC 1 PC 2 PC 3 PC 4 PC 5 PC 6 PC 7 PC 8 PC 9 PC 10 PC 11 PC 12 PC 13
Gambar 2 Kontribusi Masing-Masing Variabel (% of Variance) Tabel 2 menjelaskan nilai eigen dari masing-masing variabel beserta variannya. Pada tabel 2 diperoleh empat variabel baru (principal component) yang memiliki nilai eigen lebih dari satu. Keempat variabel ini memiliki nilai eigen yang telah terurut. Principal component pertama memilki nilai eigen sebesar 3,080 (varian sebesar 23,695%), principal component kedua memiliki nilai eigen 1,605 (varian sebesar 12,349%), principal component ketiga memiliki nilai eigen 1,248 (varian sebesar 9,604%), dan principal component keempat 1,107 (varian 8,516%). Keempat variabel baru ini mampu menjelaskan keragaman data sebesar 54,165% (dilihat dari % cumulative/total varian ). Untuk menentukan variabel apa saja yang termasuk dalam empat variabel baru ini dan variabel yang benar-benar mempengaruhi penyakit jantung koroner maka dilakukan rotasi faktor (transformasi) dengan menggunakan metodologi rotasi faktor varimax.
TABEL3 ROTASI FAKTOR DENGAN MENGGUNAKAN METODOLOGI VARIMAX Component 1 2 3 4 Age 0.275 0.661 0.118 -0.156 Sex 0.090 -0.80 -0.016 0.831 Cp 0.784 -0.032 0.028 -0.022 Tresbps -0.210 0.613 0.273 -0.001 Chol 0.228 0.423 -0.152 -0.432 Fbs -0.220 0.548 -0.077 0.334 Restecg 0.044 0.409 0.109 -0.070 Thalach -0.583 -0.154 -0.420 -0.009 Exang 0.617 -0.006 0.266 0.153
Tabel 3 menjelaskan hubungan (korelasi) antara variabel asli dengan variabel baru (principal component) yang dibentuk dengan PCA yang disebut dengan nilai loading. Nilai loading yang dipilih adalah nilai loading di atas 0,5 yang dianggap mampu menjelaskan variabel yang mempengaruhi penyakit jantung koroner (diberi warna merah). Variabel lain yang memiliki nilai loading dibawah 0,5 dianggap tidak atau kurang berpengaruh dalam penyakit jantung koroener dan dengan menggunakan empat variabel baru yang terbentuk telah mewakili 13 variabel pada data asli. Tabel 4 menjelaskan secara lebih terinci variabel-variabel yang mempengaruhi penyakit jantung koroner dan varian yang dijelaskan dari masing-masing variabel.
TABEL4 RINGKASAN ANALISA KOMPONEN UTAMA (PCA) Principal Component (PC) Nama Variabel Faktor Loading Varian yang dijelaskan PC 1 : Peredaran Darah Cp Thalach Exang 0,784 -0,583 0,617 23,695 PC 2 : Tekanan Darah Age Tresbps 0,661 0,613 12,349 PC 3 : Denyut Jantung Oldpeak Slope 0,762 0,867 9,604 PC 4 : Jenis Kelamin Sex Thal 0,831 0,589 8,516
Pada Tabel 4 diketahui bahwa principal component pertama memiliki nilai persentase varian sebesar 23,695%. Berdasarkan nilai loadingnya, variabel yang membentuk principal component pertama yaitu cp (loading 0,784), thalach (loading -0,583), dan exang (loading 0,617). Principal component pertama ini lalu diberi nama peredaran darah. Principal component kedua memiliki nilai persentase 12,349% dari total variansinya. Berdasarkan nilai loadingnya, variabel yang membentuk principal component kedua yaitu age (loading 0,661) dan tresbps (0,613). Principal component kedua ini lalu diberi nama tekanan darah. Principal component ketiga memiliki nilai persentase variansi sebesar 9,604%. Berdasarkan nilai loadingnya, variabel yang membentuk principal component ketiga ini yaitu oldpeak (loading 0,762) dan slope (loading 0,867). Principal component ketiga ini diberi nama denyut jantung. Principal component keempat memiliki nilai persentase variansi sebesar 8,516%. Berdasarkan nilai loadingnya, variabel yang membentuk principal component keempat yaitu sex (loading 0,831) dan thal (loading 0,589). Principal component keempat ini diberi nama jenis kelamin. Pemberian nama pada keempat variabel baru (principal component) yang terbentuk berdasarkan karakteristik dari variabel yang membentuknya.
V. KESIMPULAN
jantung koroner ini mampu dijelaskan hanya dengan empat variabel yang terbentuk.
· Keempat variabel baru yang dibentuk dengan analisa PCA adalah peredarah darah, tekanan darah, denyut jantung, dan jenis kelamin. Keempat variabel ini merupakan faktor-faktor yang mempengaruhi penyakit jantung koroner.
REFERENCES
[1] http://kumpulan.info/sehat/artikel-kesehatan/48-artikel- kesehatan/189-mengatasi-penyakit-jantung-dan-serangan-jantung.html . diakses tanggal 19 April 2011.
[2] Khemphila, Anchana dan Boonjing, Veera. Heart disease Classification using Neural Network and Feature Selection. IEEE Computer Society. 2011.
[3] Setiawan, N.A dkk. Missing Data Estimation on Heart Disease Using Artificial Neural Network and Rough Set Theory. IEEE Computer Society. 2007.
[4] Soni, Jyoti dkk. Predictive Data Mining for Medical Diagnosis : An Overview of Heart Disease Prediction
[5] Jolliffe, I.T. Principal Component Analysis. Edisi kedua. Springer-Verlag. New York. 2002.
[6] Susetyoko, Ronny dan Purwantini, Elly. Teknik Reduksi Dimensi Menggunakan Komponen Utama Data Partisi Pada Pengklasifikasian Data Berdimensi Tinggi dengan Ukuran Sampel Kecil.
[7] Johnson dan Wichern. Applied Multivariate Statistical Analysis. Edisi keenam. Pearson Prentice Hall. 2007.
[8] http://www.ics.uci.edu/~mlearn/MLRepository.html.Irvine, CA:University of California, Department of Information and Computer Science. 1998.
[9] Santosa, B. Data Mining : Teknik Pemanfaatan Untuk Keperluan Bisnis. Graha Ilmu. Yogyakarta. 2007.