Darmanta Sukrianto
Akademi Manajemen Informatika dan Komputer “Mahaputra Riau” [email protected]
Abstract. Lecturer is a professional educator who has duties and responsibilities and play an important role in educating the nation . Therefore , lecturer profession needs to be improved and developed continuously according to the functional position of lecturers in order to avoid mistakes of the students. In relation to student satisfaction , it certainly must be addressed so that lecturers can provide excellent instruction to students in a more professional . With the implementation of Data Mining using k - means clustering will produce clustering performance assessment lecturers to see the extent to which faculty provide instruction in accordance with the expectations of students and a reference unruk development and improve the quality of lecturers in teaching and learning.
Keywords : Data Mining , k -means clustering , performance.
Abstrak. Dosen merupakan pendidik profesional yang mempunyai tugas dan tanggung jawab serta
berperan penting dalammencerdaskan kehidupan bangsa. Oleh sebab itu, profesi dosen perlu ditingkatkan dan dikembangkan secara terus menerusmenurut jabatan fungsional dosen agar tidak menimbulkankesalahan terhadap anak didiknya.Dalam kaitannya dengan kepuasan mahasiswa, hal tersebut tentunyaharus segera dibenahi agar dosen dapat memberikan pengajaran yang primakepada mahasiswa secara lebih profesional.Dengan penerapan Data Mining menggunakan metode k – means
clustering akan menghasilkan klasterisasi penilaian kinerja dosen untuk melihat sejauh mana dosen
memberikan pengajaran sesuai dengan harapan mahasiswa/wi dan menjadi acuan unruk pengembangan mutu dan meningkatkan kemampuan dosen dalam proses belajar mengajar.
Kata Kunci : Data Mining, k-means clustering, kinerja.
PENDAHULUAN
Untuk mencapai keberhasilan dalam
sebuah usaha bidang pendidikan, kepuasan mahasiswa harus menjadi dasar dari keputusan manajemen, sehingga perguruan tinggi harus menjadikan peningkatan kepuasan mahasiswa sebagai suatu sasaran yang mendasar. Dalam rangka untuk memberikan pelayanan yang berkualitas suatu institusi pendidikan secara
continue harus mengadakan pembinaan
kelembagaan. Langkah ini penting untuk
memperbaiki pelayanan dari waktu ke waktu. Langkah pembinaan tersebut diperlukan oleh suatu lembaga/institusi dikarenakan tingkat kepuasan yang diterima oleh pengguna layanan jasa tentunya akan terus berubah seiring dengan baiknya tingkat pendidikan. Dosen merupakan pendidik professional yang mempunyai tugas dan tanggung jawab serta berperan penting dalam mencerdaskan kehidupan bangsa. Oleh sebab itu,
profesi dosen perlu ditingkatkan dan
dikembangkan secara terus menerus menurut jabatan fungsional dosen agar tidak menimbulkan kesalahan terhadap anak didiknya. Dalam
kaitannya dengan kepuasan mahasiswa, hal tersebut tentunya harus segera dibenahi agar dosen dapat memberikan pengajaran yang prima kepada mahasiswa secara lebih professional.
Pelaksanaan penilaian kinerja dosen yang dilakukan oleh penulis akan menghasilkan klasterisasi dosen yaitu klaster buruk, klaster kurang, klaster cukup, klaster baik, dan klaster sangat baik dimana data-datanya diperoleh dari penilaian mahasiswa terhadap dosen secara objektif dan transparan melalui kuisioner.
TINJAUAN PUSTAKA
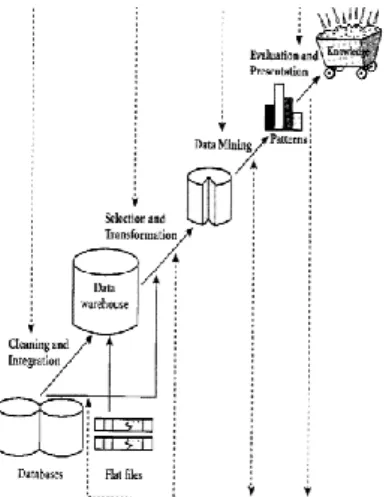
Knowledge Discovery in Database (KDD) Knowledge Discovery in Database (KDD) yaitu
merupakan kegiatan yang meliputi pengumpulan, pemakaian data historis untuk menemukan keteraturan, pola atau hubungan dalam set data berukuran besar (Deka et al, 2014).
Data Mining
Data Mining (DM) adalah serangkaian proses
untuk menggali nilai tambah dari suatu kumpulan data berupa pengetahuan yang selama ini tidak diketahui secara manual. Beberapa teknik yang
sering disebut-sebut dalam literatur DM antara lain : clustering, classification, association rule
mining, neural network, dan genetic algorithm
(Linda wati , 2008). Tahapan Data Mining menurut Budanis dan Nofi (2014), Data Mining memiliki tahapan – tahapan antara lain:
1. Pembersihan data (data cleaning)
Pembersihan data merupakan proses
menghilangkan noise dan data yang tidak konsisten atau data tidak relevan.
2. Integrasi data (data integration)
Integrasi data merupakan penggabungan data dari berbagai database ke dalam satu database baru.
3. Seleksi Data (Data Selection)
Data yang ada pada database sering kali tidak semuanya dipakai, oleh karena itu hanya data yang sesuai untuk dianalisis yang akan diambil dari database.
4. Transformasi data (Data Transformation) Data diubah atau digabung ke dalam format yang sesuai untuk diproses dalam Data
Mining.
5. Proses mining,
Merupakan suatu proses utama saat metode diterapkan untuk menemukan pengetahuan berharga dan tersembunyi dari data.
6. Evaluasi pola (pattern evaluation)
Untuk mengidentifikasi pola-pola menarik kedalam knowledge based yang ditemukan.
7. Presentasi pengetahuan (knowledge
presentation)
Merupakan visualisasi dan penyajian
pengetahuan mengenai metode yang
digunakan untuk memperoleh pengetahuan yang diperoleh pengguna.
Gambar 1 : Tahapan Data Mining
Clustering
Clustering adalah salah satu sub - kategori data
mining dan merupakan proses di mana sampel yang sama dibagi menjadi kelompok-kelompok yang disebut cluster . Setiap cluster termasuk sampel di mana anggota yang mirip satu sama lain dan berbeda dengan sampel yang tersedia dari kelompok lain (Gharehchopogh et al 2014). Pada dasarnya clustering merupakan suatu metode untuk mencari dan mengelompokkan data yang memiliki kemiripan karakteriktik
(similarity) antara satu data dengan data yang
lain. Clustering merupakan salah satu metode
data mining yang bersifat tanpa arahan (unsupervised), maksudnya metode ini diterapkan
tanpa adanya latihan (training) dan tanpa ada guru (teacher) serta tidak memerlukan target output. Dalam data mining ada dua jenis metode
clustering yang digunakan dalam pengelompokan
data, yaitu hierarchical clustering dan
non-hierarchical clustering (Ong , 2013). K-Means Clustering
K-means clustering merupakan salah satu metode
data clustering non-hirarki yang mengelompokan
data dalam bentuk satu atau lebih
cluster/kelompok. Data-data yang memiliki
karakteristik yang sama dikelompokan dalam satu
cluster/kelompok dan data yang memiliki
karakteristik yang berbeda Menurut Ong (2013), langkah-langkah melakukan clustering dengan metode K-Means adalah sebagai berikut:
1. Pilih jumlah cluster k.
2. Inisialisasi k pusat cluster ini bisa dilakukan dengan berbagai cara. Namun yang paling sering dilakukan adalah dengan cara random. Pusat-pusat cluster diberi nilai awal dengan angka-angka random,
3. Alokasikan semua data/ objek ke cluster terdekat. Kedekatan dua objek ditentukan berdasarkan jarak kedua objek tersebut. Demikian juga kedekatan suatu data ke cluster tertentu ditentukan jarak antara data dengan pusat cluster. Dalam tahap ini perlu dihitung jarak tiap data ke tiap pusat cluster. Jarak paling antara satu data dengan satu cluster tertentu akan menentukan suatu data masuk dalam cluster mana. Untuk menghiutng jarak semua data ke setiap tiitk pusat cluster dapat menggunakan teori jarak Euclidean yang dirumuskan sebagai berikut:
Keterangan:
D (i,j) = Jarak data ke i ke pusat cluster j
Xki = Data ke i pada atribut data ke k Xkj= Titik pusat ke j pada atribut ke k
4. Hitung kembali pusat cluster dengan keanggotaan cluster yang sekarang. Pusat
cluster adalah rata-rata dari semua data/ objek
dalam cluster tertentu. Jika dikehendaki bisa juga menggunakan median dari cluster tersebut. Jadi rata-rata (mean) bukan satu-satunya ukuran yang bisa dipakai.
5. Tugaskan lagi setiap objek memakai pusat
cluster yang baru. Jika pusat cluster tidak
berubah lagi maka proses clustering selesai. Atau, kembali ke langkah nomor 3 sampai pusat cluster tidak berubah lagi
METODOLOGI PENELITIAN
Metodologi penelitian yang digunakan yaitu langkah – langkah yang dilaksanakan dalam penelitian ini. Langkah – langkah tersebut digambarkan dalam bentuk kerangka kerja (frame
work) yang disusun tersetruktur dan terarah,
mulai dari merumuskan masalah sampai
menghasilkan suatu kesimpulan yang dapat dijadikan dasar dalam pengambilan keputusan, seperti kesimpulan tentang kriteria yang tepat untuk menentukan kinerja dosen berdasarkan penilaian yang diberikan oleh mahasiswa di Amik Mahaputra Riau yang menjadi objek penelitian ini.
Kerangka Kerja Penelitian
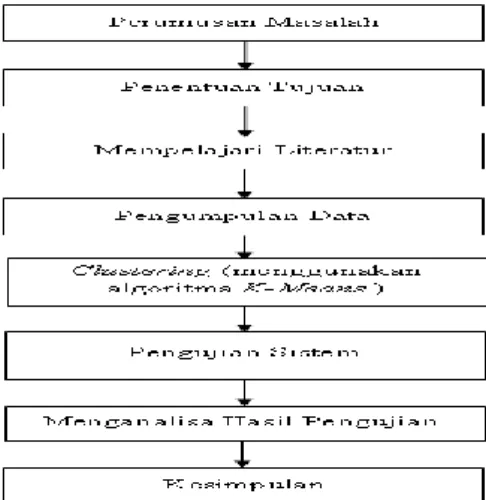
Untuk memberikan panduan dalam penyusunan penelitian ini, maka perlu disusun sebuah kerangka kerja yang terdiri dari langkah – langkah yang dapat dilihat dari gambar 2.
Gambar 2 : Kerangka Kerja
Dari kerangka kerja pada gambar 2 maka dapat diuraikan pembahasan dari masing – masing kegiatan yang dilakukan, sebagai berikut :
1. Perumusan Masalah
Tahap perumusan masalah merupakan
langkah awal dari penelitian, karena pada tahapan ini dilakukan proses pengamatan, pendefinisian dan explorasi lebih dalam terhadap permasalahan yang ada.
2. Penentuan Tujuan
Berdasarkan perumusan masalah yang ada, maka tahap penentuan tujuan berguna untuk memperjelas langkah – langkah tentang apa saja yang menjadi sasaran penelitian ini. Pada tahap ini juga ditentukan tujuan dari
penelitian ini yaitu bagaimana
mengimplementasikan teknik data
mining untuk memudahkan dalam proses pengambilan keputusan dengan melakukan pengklasifikasian kriteria kinerja dosen terhadap prestasi akademik yang dicapai. 3. Mempelajari literature
Dilakukan dengan tujuan untuk mengetahui
metode apa yang digunakan dalam
menyelesaikan permasalahan yang akan diteliti, serta mendapatkan dasar-dasar referensi yang kuat bagi peneliti dalam
menerapkan suatu metode yang
digunakannya. 4. Pengumpulan Data
Pada tahap ini dilakukan pengumpulan data
dan informasi untuk memahami
permasalahan yang ada. Data yang
diperlukan dalam penelitian ini adalah data dosen pada Amik Mahaputra Riau dan kegiatan yang dilakukan adalah sebagai berikut :
a. Mengambil sampel dosen mulai dari dosen tetap dan dosen tidak tetap.
b. Mengambil data berdasarkan angket yang disebarkan pada sampel penelitian yang memuat variabel – variabel antara lain
menyangkut kompetensi kompetensi
kepribadian, kompetensi profesional dan kompetensi sosial.
5. Clustering menggunakan algoritma K-Means Tahapan proses dimana data yang sudah
dipraproses di cluster dengan menggunakan algoritma K-Means
6. Pengujian Sistem
Tahapan ini yaitu mengimplementasikan dengan menggunakan tools (aplikasi) dalam hal ini penulis menggunakan Aplikasi Rapid
perbandingan dengan proses yang dibuat
secara manual.
Mekanisme pengujian yang dilakukan adalah melakukan pengujian secara manual dengan menggunakan rumus, untuk mengelompokkan dosen menggunakan metode K – Means
Clustering. Adapun tahapan pengujian adalah
sebagai berikut :
a. Menentukan k sebagai jumlah cluster yang ingin dibentuk. Kemudian menentukan titik pusat cluster awal secara random. Setelah itu menghitung jarak setiap data masing – masing centroid. Yang mana setiap data memilih centroid yang terdekat. Adapun data yang digunakan berupa data dosen tetap dan dosen tidak tetap pada Amik Mahaputra Riau. Selanjutnya data tersebut diproses berdasarkan metode K – Means Clustering. b. Kembali kelangkah 3 jika posisi centroid
baru dengan centroid yang lama tidak sama. c. Selanjutnya, dari cluster yang telah
didapatkan maka pencarian cluster baru dengan algoritma K-Means dapat dilakukan dengan menentukan nilai centroid baru secara manual dengan menggunakan data
cluster yang diambil dari proses cluster
pertama. Kemudian lakukan perhitungan untuk menentukan jarak setiap data dan centroid yang telah di bentuk dengan menggunakan rumus Euclidean Distance. Proses akan berlanjut jika anggota cluster 1 pada iterasi 1 dan iterasi 2 berbeda . Proses akan berhenti jika perbadingan iterasi 1dan iterasi 2 sama. Setelah cluster terbentuk, tahap selanjutnya yaitu memberi nama spesifik untuk menggambarkan isi cluster tersebut.
7. Menganalisa Hasil Pengujian
Pada tahapan ini akan dilakukan analisa
terhadap hasil dari implementasi
menggunakan metode K – Means Clustering untuk menentukan kinerja dari setiap dosen. 8. Kesimpulan
Tahap ini merupakan tahapan akhir yaitu membuat suatu kesimpulan dari pengujian hasil yang dibuat dengan metode K-Means
Clustering dengan tools yang digunakan yaitu Rapid Miner sehingga dapat melakukan komparasi dari data yang ada.
HASIL DAN PEMBAHASAN
Deskriptif Sistem
Data yang digunakan peneliti untuk tesis ini diperoleh dari hasil kusioner yang dilakukan oleh
mahasiswa/wi terhadap dosen tetap dan tidak tetap di Amik Mahaputra Riau. Hasil kusioner tersebut digunakan untuk menentukan kinerja dari dosen yang nantinya terbentuk beberapa kelompok dosen sangat baik, baik, cukup, tidak baik dan sangat tidak baik. Semua data akan
diolah kemudian dilanjutkan dengan
menggunakan metode k-means clustering. Analisa Sistem
Analisa sistem ini menjelaskan mengenai cara menentukan kinerja dosen terhadap mahasiswa dalam proses belajar mengajar dengan melihat kriteria seperti pengajaran dan personal.
Masukan Sistem
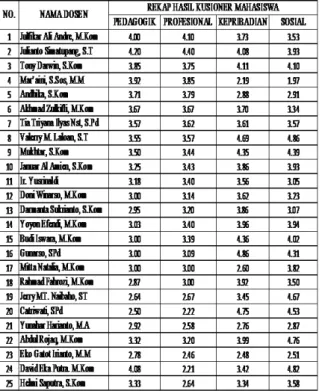
Pada penelitian ini data diperoleh melalui kusioner kepada mahasiswa/wi Amik Mahaputra Riau. Hasil dari proses kusioner yang dsebarkan kepada mahasiswa yaitu berupa angka dari penilaian mahasiswa/wi yang dibagi menjadi 4 penilaian terhadap dosen dalam proses belajar mengajar dan personal dosen tersebut diantaranya kopetensi pedagogik, kopetensi profesional, kopetensi kepribadian, kopetensi sosial. Adapun data rekap penilaian hasil kusioner yang diberikan oleh mahasiswa/wi yang didapat dari kusioner dapat dilihat pada tabel 1.
Tabel 1: Data Rekap Kusioner Dosen Oleh Mahasiswa
Keluaran Sistem
Keluaran yang dihasilkan oleh sistem ini adalah
cluster dari setiap kelompok dosen dengan 5
kriteria yang telah ditentukan yaitu cluster sangat baik, cluster baik, cluster biasa/cukup, cluster tidak baik dan cluster sangat tidak baik. Setiap
cluster nantinya berisi data dosen yang
dikelompokkan berdasarkan kriteria yang telah ditentukan tersebut.
Implementasi Metode K – Means Clustering Tahapan pegujian yang dilakukan adalah sebagai berikut :
1.
Menentukan jumlah cluster K.Pada tahap ini jumlah cluster ditentukan berdasarkan kelompok cluster yang akan dibentuk yaitu 5 cluster.
2.
Tentukan K titik pusat cluster secara acak (random).Pada percobaan ini ditentukan 5 data secara acak sebagai titik pusat awal untuk
memperhitungkan jarak dari seluruh
kelompok cluster yang akan dibentuk. Data acak tersebut dapat dilihat pada tabel 2. Tabel 2 : Data Titik Pusat Awal Cluster
3.
Hitung jarak tiap data dengan masing – masing pusat cluster.Setelah titik pusat awal ditentukan, langkah selanjutnya adalah menghitung jarak setiap
data dengan pusat cluster dengan
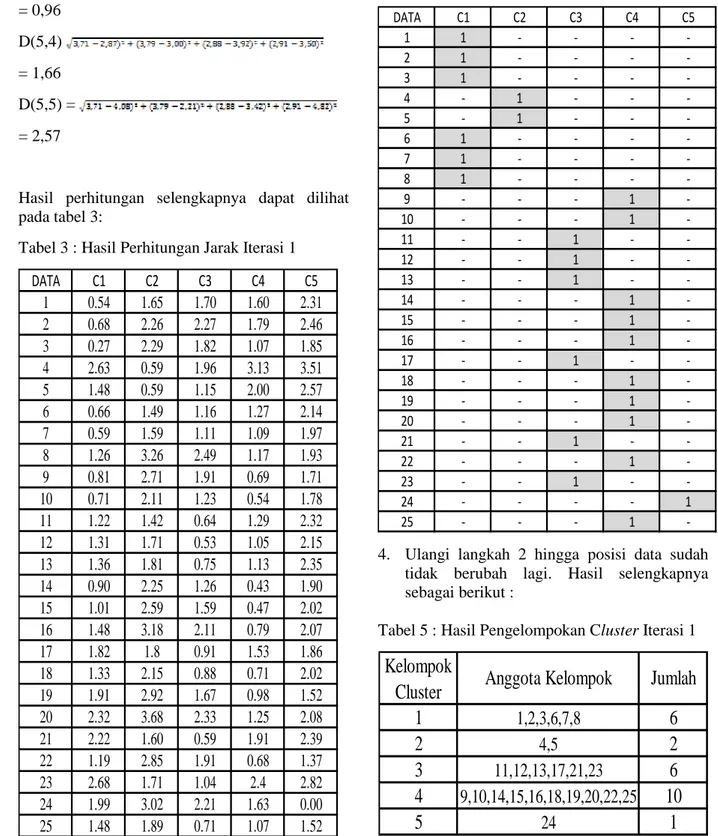
menggunakan persamaan Eucliden Distance. Perhitungan jarak dari data – data terhadap masing – masing pusat cluster adalah sebagai berikut: D(1,1)= = 0,00 D(1,2) = = 1,13 D(1,3) = = 1,19 D(1,4) = 1,59 D(1,5) = = 2,31 Data 2 D(2,1) = = 0,64 D(2,2) = = 1,76 D(2,3) = = 1,76 D(2,4) = 1,98 D(2,5) = = 2,46 Data 3 D(3,1) = = 0,78 D(3,2) = = 1,72 D(3,3) = = 1,40 D(3,4) = 1,38 D(3,5) = = 1,85 Data 4 D(4,1) = = 2,20 D(4,2) = = 1,18 D(4,3) = = 1,95 D(4,4) = 2,67 D(4,5) = = 3,51
Data 5 D(5,1) = = 1,13 D(5,2) = = 0,00 D(5,3) = = 0,96 D(5,4) = 1,66 D(5,5) = = 2,57
Hasil perhitungan selengkapnya dapat dilihat pada tabel 3:
Tabel 3 : Hasil Perhitungan Jarak Iterasi 1
DATA C1 C2 C3 C4 C5 1 0.54 1.65 1.70 1.60 2.31 2 0.68 2.26 2.27 1.79 2.46 3 0.27 2.29 1.82 1.07 1.85 4 2.63 0.59 1.96 3.13 3.51 5 1.48 0.59 1.15 2.00 2.57 6 0.66 1.49 1.16 1.27 2.14 7 0.59 1.59 1.11 1.09 1.97 8 1.26 3.26 2.49 1.17 1.93 9 0.81 2.71 1.91 0.69 1.71 10 0.71 2.11 1.23 0.54 1.78 11 1.22 1.42 0.64 1.29 2.32 12 1.31 1.71 0.53 1.05 2.15 13 1.36 1.81 0.75 1.13 2.35 14 0.90 2.25 1.26 0.43 1.90 15 1.01 2.59 1.59 0.47 2.02 16 1.48 3.18 2.11 0.79 2.07 17 1.82 1.8 0.91 1.53 1.86 18 1.33 2.15 0.88 0.71 2.02 19 1.91 2.92 1.67 0.98 1.52 20 2.32 3.68 2.33 1.25 2.08 21 2.22 1.60 0.59 1.91 2.39 22 1.19 2.85 1.91 0.68 1.37 23 2.68 1.71 1.04 2.4 2.82 24 1.99 3.02 2.21 1.63 0.00 25 1.48 1.89 0.71 1.07 1.52
Setiap kolom pada tabel 3 menunjukkan nilai jarak terhadap pusat cluster. Data 1 merupakan jarak terkecil diperoleh pada kelompok 2, sehingga data 1 akan menjadi anggota dari kelompok 2. Demikian juga pada data ke 2, jarak terkecil ada pada kelompok 3, maka data tersebut masuk pada kelompok 3. Posisi dari cluster dapat dilihat pada tabel 4 sebagai berikut :
Tabel 4 : Posisi Cluster Iterasi 1
DATA C1 C2 C3 C4 C5 1 1 - - - -2 1 - - - -3 1 - - - -4 - 1 - - -5 - 1 - - -6 1 - - - -7 1 - - - -8 1 - - - -9 - - - 1 -10 - - - 1 -11 - - 1 - -12 - - 1 - -13 - - 1 - -14 - - - 1 -15 - - - 1 -16 - - - 1 -17 - - 1 - -18 - - - 1 -19 - - - 1 -20 - - - 1 -21 - - 1 - -22 - - - 1 -23 - - 1 - -24 - - - - 1 25 - - - 1
-4. Ulangi langkah 2 hingga posisi data sudah tidak berubah lagi. Hasil selengkapnya sebagai berikut :
Tabel 5 : Hasil Pengelompokan Cluster Iterasi 1
1
1,2,3,6,7,8
6
2
4,5
2
3
11,12,13,17,21,23
6
4
9,10,14,15,16,18,19,20,22,25
10
5
24
1
Kelompok
Cluster
Anggota Kelompok
Jumlah
Tabel 6 : Hasil Perhitungan Jarak Iterasi 2 DATA C1 C2 C3 C4 C5 1 0.54 1.65 1.70 1.60 2.31 2 0.68 2.26 2.27 1.79 2.46 3 0.27 2.29 1.82 1.07 1.85 4 2.63 0.59 1.96 3.13 3.51 5 1.48 0.59 1.15 2.00 2.57 6 0.66 1.49 1.16 1.27 2.14 7 0.59 1.59 1.11 1.09 1.97 8 1.26 3.26 2.49 1.17 1.93 9 0.81 2.71 1.91 0.69 1.71 10 0.71 2.11 1.23 0.54 1.78 11 1.22 1.42 0.64 1.29 2.32 12 1.31 1.71 0.53 1.05 2.15 13 1.36 1.81 0.75 1.13 2.35 14 0.90 2.25 1.26 0.43 1.90 15 1.01 2.59 1.59 0.47 2.02 16 1.48 3.18 2.11 0.79 2.07 17 1.82 1.80 0.91 1.53 1.86 18 1.33 2.15 0.88 0.71 2.02 19 1.91 2.92 1.67 0.98 1.52 20 2.32 3.68 2.33 1.25 2.08 21 2.22 1.60 0.59 1.91 2.39 22 1.19 2.85 1.91 0.68 1.37 23 2.68 1.71 1.04 2.40 2.82 24 1.99 3.02 2.21 1.63 0.00 25 1.48 1.89 0.71 1.07 1.52
Tabel 7 : Posisi Cluster Iterasi 2
DATA C1 C2 C3 C4 C5 1 1 - - - -2 1 - - - -3 1 - - - -4 - 1 - - -5 - 1 - - -6 1 - - - -7 1 - - - -8 - - - 1 -9 - - - 1 -10 - - - 1 -11 - - 1 0 -12 - - 1 0 -13 - - 1 0 -14 - - - 1 -15 - - - 1 -16 - - - 1 -17 - - 1 - -18 - - - 1 -19 - - - 1 -20 - - - 1 -21 - - 1 - -22 - - - 1 -23 - - 1 - -24 - - - - 1 25 - - 1 -
-Tabel 8 : Hasil Pengelompokan Cluster Iterasi 2
1 1,2,3,6,7 5 2 4,5 2 3 11,12,13,17,21,23,25 7 4 8,9,10,14,15,16,18,19,20,22 10 5 24 1 Kelompok
Cluster Anggota Kelompok Jumlah
Tabel 9 : Hasil Perhitungan Jarak Iterasi 3
DATA C1 C2 C3 C4 C5 1 0.31 1.65 1.67 1.62 2.31 2 0.69 2.26 2.24 1.74 2.46 3 0.51 2.29 1.77 1.02 1.85 4 2.39 0.59 2.01 3.27 3.51 5 1.26 0.59 1.18 2.13 2.57 6 0.49 1.49 1.14 1.35 2.14 7 0.49 1.59 1.07 1.17 1.97 8 1.51 3.26 2.42 0.98 1.93 9 1.04 2.71 1.84 0.55 1.71 10 0.81 2.11 1.17 0.61 1.78 11 1.10 1.42 0.65 1.43 2.32 12 1.26 1.71 0.50 1.22 2.15 13 1.31 1.81 0.75 1.28 2.35 14 1.01 2.25 1.21 0.51 1.90 15 1.17 2.59 1.54 0.40 2.02 16 1.68 3.18 2.05 0.65 2.07 17 1.77 1.80 0.88 1.69 1.86 18 1.36 2.15 0.84 0.88 2.02 19 2.03 2.92 1.60 1.07 1.52 20 2.49 3.68 2.26 1.23 2.08 21 2.12 1.60 0.61 2.11 2.39 22 1.40 2.85 1.84 0.59 1.37 23 2.56 1.71 1.09 2.60 2.82 24 2.10 3.02 2.11 1.68 0.00 25 1.46 1.89 0.61 1.26 1.52
Tabel 10 : Posisi Cluster Iterasi 3
DATA C1 C2 C3 C4 C5 1 1 - - - -2 1 - - - -3 1 - - - -4 - 1 - - -5 - 1 - - -6 1 - - - -7 1 - - - -8 - - - 1 -9 - - - 1 -10 - - - 1 -11 - - 1 - -12 - - 1 - -13 - - 1 - -14 - - - 1 -15 - - - 1 -16 - - - 1 -17 - - 1 - -18 - - 1 - -19 - - - 1 -20 - - - 1 -21 - - 1 - -22 - - - 1 -23 - - 1 - -24 - - - - 1 25 - - 1 -
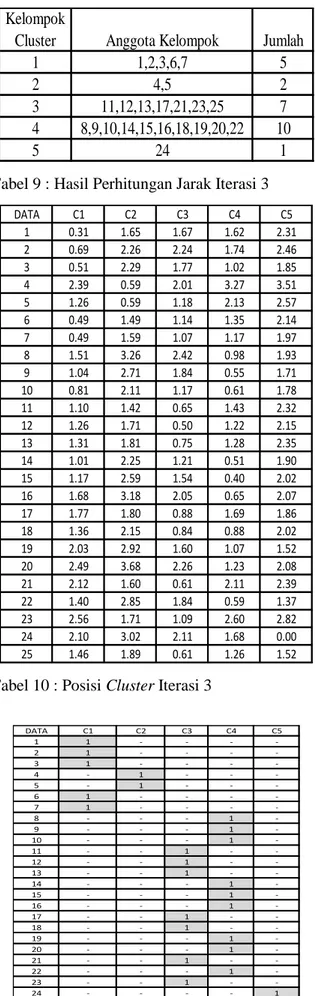
-Tabel 11 : Hasil Pengelompokan Cluster Iterasi 3 1 1,2,3,6,7 5 2 4,5 2 3 11,12,13,17,18,21,23,25 8 4 8,9,10,14,15,16,19,22,24 9 5 20 1 Kelompok
Cluster Anggota Kelompok Jumlah
Tabel 12 : Hasil Pengelompokan Cluster Iterasi 4 1 1,2,3,6,7 5 2 4,5 2 3 11,12,13,17,18,21,23,25 8 4 8,9,10,14,15,16,19,22,24 9 5 20 1 Kelompok
Cluster Anggota Kelompok Jumlah
Pada pengujian iterasi ke 3 dan 4
centroid tidak mengalami perubahan (sama
dengan centroid sebelumnya) maka proses iterasi selesai dan diperoleh 3 cluster dengan 4 iterasi. Dari hasil nilai perhitungan cluster dengan 4 iterasi bahwa cluster 1 adalah dengan nilai tertinggi dimasukkan pada kriteria sangat baik,
cluster 4 baik, cluster 5 cukup, cluster 2 kurang
dan cluster 3 kurang baik.
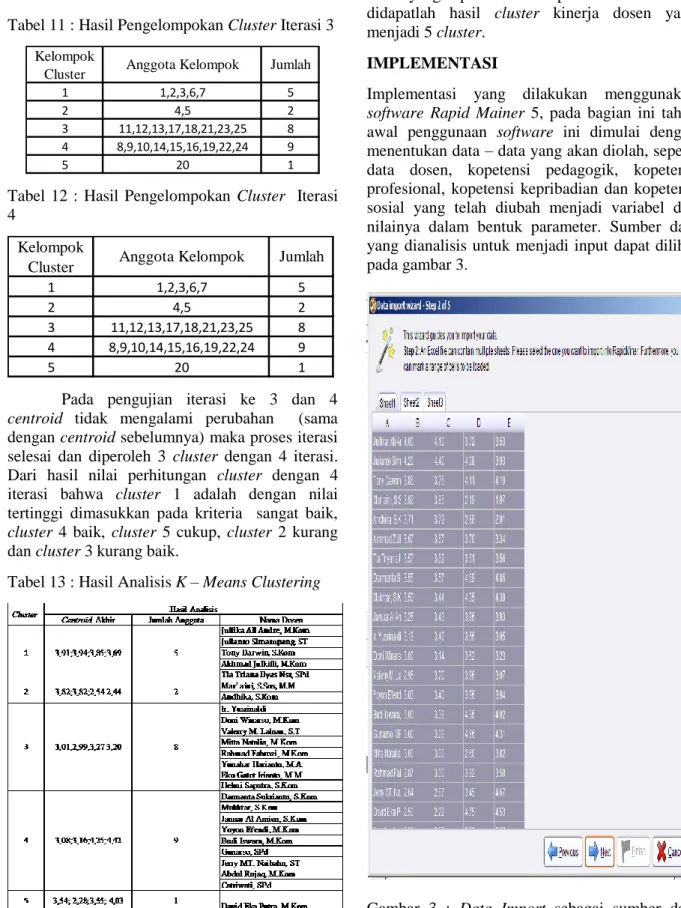
Tabel 13 : Hasil Analisis K – Means Clustering
Kesimpulan dari hasil pengujian tersebut adalah nilai pusat cluster yang ditentukan sangat mempengaruhi hasil dan perhitungan cluster yang dilakukan, oleh karena itu pemilihan nilai pusat
cluster harus tersebar / acak agar menghasilkan
hasil yang optimal. Dari penelitian ini maka didapatlah hasil cluster kinerja dosen yang menjadi 5 cluster.
IMPLEMENTASI
Implementasi yang dilakukan menggunakan
software Rapid Mainer 5, pada bagian ini tahap
awal penggunaan software ini dimulai dengan menentukan data – data yang akan diolah, seperti data dosen, kopetensi pedagogik, kopetensi profesional, kopetensi kepribadian dan kopetensi sosial yang telah diubah menjadi variabel dan nilainya dalam bentuk parameter. Sumber data yang dianalisis untuk menjadi input dapat dilihat pada gambar 3.
Gambar 3 : Data Import sebagai sumber data dianalisis
Selanjutnya tentukan jumlah cluster atau pengelompokan yang kita inginkan, untuk jumlah
cluster jangan sampai melebihi jumlah data.
Gambar 4 : Parameter menentukan jumlah cluster Setelah ditentukan jumlah “k” dan “max run” kemudian proses analisis menggunakan k-means
clustering yang menghasilkan jumlah anggota
pada cluster yang dihasilkan dalam bentuk
Cluster Model sepeti gambar 3 berikut :
Gambar 5 : Cluster Model (Clustering) jumlah anggota pada cluster
Terlihat hasil pengelompokan data kinerja dosen amik mahaputra yang menghasilkan 5 cluster,
yakni cluster 0 dengan 1 items, cluster 1 dengan 5 items, cluster 2 dengan 2 items, cluster 3 dengan 9 items dan cluster 4 dengan 8 items. Setiap cluster berisikan anggota yang termasuk hanya dalam anggota cluster tersebut, untuk melihat anggota masing – masing setiap cluster pilih Folder View seperti pada gambar 6.
Gambar 6 : Pengelompokan kinerja dosen Hasil dari gambar 4 dalam bentuk grafik bubble menjelaskan pada sumbu x batas maksimal nilai predikat yang diperoleh oleh setiap dosen dan pada sumbu y cluster secara keseluruhan. Bulatan – bulatan yang disebut bubble pada grafik adalah penelompokan data di mana yang bulatan yang berwarna biru adalah pengelompokan yang temasuk dalam cluster 1 yang bejumlah 5 anggota, warna biru langit menunjukkan anggota dari cluster 2, warna hijau menunjukkan anggota
cluster 3, warna kuning menunjukkan anggota cluster 4 dan warna merah menunjukkan anggota cluster 1 seperti pada gambar 7.
Gambar 7 : Pengelompokan data bentuk grafik bubble
SIMPULAN
Berdasarkan penelitian yang telah dilakukan, maka dapat ditarik kesimpulan sebagai berikut : 1. Mengelompokkan data dengan metode
k-means clustering dilakukan dengan cara
menentukan jumlah cluster, hitung jarak terdekat dengan pusat cluster. Data dengan jarak terdekat menyatakan anggota dari
cluster tersebut, dilakukan perhitungan kembali sampai data tidak berpindah pada
cluster lain.
2. Data kelompok dosen yang sangat baik, baik, cukup, kurang, kurang baik didapatkan setelah perhitungan dengan menggunakan metode k-means clustering selesai, data dengan pusat centroid terbesar adalah kelompok dosen yang mempunyai kinerja sangat baik pada proses belajar mengajar terhadap mahasiswa/wi dan data dengan pusat centroid terendah adalah kelompok dosen yang mempunyai kinerja sangat kurang baik oleh mahasiswa/wi.
3. Dengan menggunakan software Rapid
Mainer metode k – means clustering sangat
membantu dalam melakukan
pengelompokan, sehingga memudahkan
pengguna dalam melakukan penggalian informasi siapa saja yang masuk kedalam anggota kelompok tertentu.
4. Hasil penelitian ini bisa dijadikan sebagai acuan bagi pihak akademik dan dosen dalam
proses pengembangan mutu dan
meningkatkan kemampuan dosen dalam proses belajar mengajar.
DAFTAR RUJUKAN
[1] Deka Dwinavinta Candra Nugraha, Zumrotun Naimah, Makhfuzi Fahmi, Novi Setiani (2014). Klasterisasi Judul Buku Dengan Menggunakan Metode K-Means, Seminar Nasional Aplikasi Teknologi Informasi (SNATI), ISSN: 1907 - 5022.
[2] Farhad Soleimanian Gharechopogh, Yasin Rahimpur, Seyyed Reza Khaze (2014), Combining Clustering Algorithhms For Provide Marketing Policy in Electronic
Stores, International Journal of
Programmning Languages and Applications (IJPLA), Volume : 4,Nomor: 1.
[3] Goldie Gunadi, Dana Indra Sensuse (2012). Penerapan Data Mining Market Basket Analysis Terhadap Data Penjualan Produk Buku Dengan Menggunakan Algoritma Apriori dan Frequent Pattern Grownth
(FP-GROWNTH), Jurnal Informatika MKOM, Volume : 4, No. 1,Nomor: ISSN: 2085-725X.
[4] Johan Oscar Ong (2013), Implementasi
Algoritma K-Means Clustering Untuk
Menentukan Strategi Marketing President University, Jurnal Ilmiah Teknik Industri, Volume 12, No. 1, ISSN :1412- 6869. [5] Shaker H. El – Sappagh, Samir El-Masri,
A.M.Riad, Mohammed Elmogy (2013), Data
Mining and Knowledge Discovery :
Aplications, Techniques, Challenges ans Process Models in Healtcare, International Journal of Engineering Researc and Aplications (IJERA), Volume : 3, Issue 3, ,Nomor: ISSN: 2248-9622.
[6] Aprisawati (2013), Implementasi Data Mining
Pemilihan Pelanggan Potensial
Menggunakan Algoritma K-Means, Pelita Informatika Budi Darma, Volume : 5, No. 3,Nomor: ISSN: 2301-9425.
[7] Lindawati (2008), Data Mining Dengan Teknik Clustering Dalam Pengklasifikasian Data Mahasiswa Studi Kasus Prediksi Lama
Studi Mahasiswa Universitas Bina
Nusantara, Seminar Nasional Informatika (semnasIF 2008), ISSN :1979-2328.
[8] Tahta Alfina, Budi Santosa, Ali Ridho Barakbah (2012). Analisa Perbandingan Metode Hierarchical Clustering, K-Means dan Gabungan Keduanya dalam Cluster Data, Jurnal Teknik ITS, Volume : 1,Nomor: ISSN: 2301-9271.