by Judith Hurwitz, Alan Nugent, Dr. Fern Halper,
and Marcia Kaufman
111 River Street Hoboken, NJ 07030-5774
www.wiley.com
Copyright © 2013 by John Wiley & Sons, Inc., Hoboken, New Jersey Published simultaneously in Canada
No part of this publication may be reproduced, stored in a retrieval system or transmitted in any form or by any means, electronic, mechanical, photocopying, recording, scanning or otherwise, except as permit-ted under Sections 107 or 108 of the 1976 Unipermit-ted States Copyright Act, without either the prior written permission of the Publisher, or authorization through payment of the appropriate per-copy fee to the Copyright Clearance Center, 222 Rosewood Drive, Danvers, MA 01923, (978) 750-8400, fax (978) 646-8600. Requests to the Publisher for permission should be addressed to the Permissions Department, John Wiley & Sons, Inc., 111 River Street, Hoboken, NJ 07030, (201) 748-6011, fax (201) 748-6008, or online at http:// www.wiley.com/go/permissions.
Trademarks: Wiley, the Wiley logo, For Dummies, the Dummies Man logo, A Reference for the Rest of Us!, The Dummies Way, Dummies Daily, The Fun and Easy Way, Dummies.com, Making Everything Easier, and related trade dress are trademarks or registered trademarks of John Wiley & Sons, Inc. and/or its affili-ates in the United Staffili-ates and other countries, and may not be used without written permission. All other trademarks are the property of their respective owners. John Wiley & Sons, Inc. is not associated with any product or vendor mentioned in this book.
LIMIT OF LIABILITY/DISCLAIMER OF WARRANTY: THE PUBLISHER AND THE AUTHOR MAKE NO REPRESENTATIONS OR WARRANTIES WITH RESPECT TO THE ACCURACY OR COMPLETENESS OF THE CONTENTS OF THIS WORK AND SPECIFICALLY DISCLAIM ALL WARRANTIES, INCLUDING WITH-OUT LIMITATION WARRANTIES OF FITNESS FOR A PARTICULAR PURPOSE. NO WARRANTY MAY BE CREATED OR EXTENDED BY SALES OR PROMOTIONAL MATERIALS. THE ADVICE AND STRATEGIES CONTAINED HEREIN MAY NOT BE SUITABLE FOR EVERY SITUATION. THIS WORK IS SOLD WITH THE UNDERSTANDING THAT THE PUBLISHER IS NOT ENGAGED IN RENDERING LEGAL, ACCOUNTING, OR OTHER PROFESSIONAL SERVICES. IF PROFESSIONAL ASSISTANCE IS REQUIRED, THE SERVICES OF A COMPETENT PROFESSIONAL PERSON SHOULD BE SOUGHT. NEITHER THE PUBLISHER NOR THE AUTHOR SHALL BE LIABLE FOR DAMAGES ARISING HEREFROM. THE FACT THAT AN ORGANIZATION OR WEBSITE IS REFERRED TO IN THIS WORK AS A CITATION AND/OR A POTENTIAL SOURCE OF FUR-THER INFORMATION DOES NOT MEAN THAT THE AUTHOR OR THE PUBLISHER ENDORSES THE INFOR-MATION THE ORGANIZATION OR WEBSITE MAY PROVIDE OR RECOMMENDATIONS IT MAY MAKE. FURTHER, READERS SHOULD BE AWARE THAT INTERNET WEBSITES LISTED IN THIS WORK MAY HAVE CHANGED OR DISAPPEARED BETWEEN WHEN THIS WORK WAS WRITTEN AND WHEN IT IS READ.
For general information on our other products and services, please contact our Customer Care Department within the U.S. at 877-762-2974, outside the U.S. at 317-572-3993, or fax 317-572-4002. For technical support, please visit www.wiley.com/techsupport.
Wiley publishes in a variety of print and electronic formats and by print-on-demand. Some material included with standard print versions of this book may not be included in e-books or in print-on-demand. If this book refers to media such as a CD or DVD that is not included in the version you purchased, you may download this material at http://booksupport.wiley.com. For more information about Wiley products, visit www.wiley.com.
Library of Congress Control Number: 2013933950
ISBN: 978-1-118-50422-2 (pbk); ISBN 978-1-118-64417-1 (ebk); ISBN 978-1-118-64396-9 (ebk); ISBN 978-1-118-64401-0 (ebk)
Judith S. Hurwitz is President and CEO of Hurwitz & Associates, a research and consulting firm focused on emerging technology, including cloud comput-ing, big data, analytics, software development, service management, and secu-rity and governance. She is a technology strategist, thought leader, and author. A pioneer in anticipating technology innovation and adoption, she has served as a trusted advisor to many industry leaders over the years. Judith has helped these companies make the transition to a new business model focused on the business value of emerging platforms. She was the founder of Hurwitz Group. She has worked in various corporations, including Apollo Computer and John Hancock. She has written extensively about all aspects of distributed software. In 2011 she authored Smart or Lucky? How Technology Leaders Turn Chance into Success (Jossey Bass, 2011). Judith is a co-author on five retail For Dummies titles including Hybrid Cloud For Dummies (John Wiley & Sons, Inc., 2012), Cloud Computing For Dummies (John Wiley & Sons, Inc., 2010), Service Management For Dummies, and Service Oriented Architecture For Dummies, 2nd Edition (both John Wiley & Sons, Inc., 2009). She is also a co-author on many custom published For Dummies titles including Platform as a Service For Dummies, CloudBees Special Edition (John Wiley & Sons, Inc., 2012), Cloud For Dummies, IBM Midsize Company Limited Edition (John Wiley & Sons, Inc., 2011), Private Cloud For Dummies, IBM Limited Edition (2011), and Information on Demand For Dummies, IBM Limited Edition (2008) (both John Wiley & Sons, Inc.).
Judith holds BS and MS degrees from Boston University, serves on several advisory boards of emerging companies, and was named a distinguished alumnus of Boston University’s College of Arts & Sciences in 2005. She serves on Boston University’s Alumni Council. She is also a recipient of the 2005 Massachusetts Technology Leadership Council award.
Alan F. Nugent is a Principal Consultant with Hurwitz & Associates. Al is an experienced technology leader and industry veteran of more than three decades. Most recently, he was the Chief Executive and Chief Technology Officer at Mzinga, Inc., a leader in the development and delivery of cloud-based solutions for big data, real-time analytics, social intelligence, and community management. Prior to Mzinga, he was executive vice president and Chief Technology Officer at CA, Inc. where he was responsible for setting the strategic technology direction for the company. He joined CA as senior vice president and general manager of CA’s Enterprise Systems Management (ESM) business unit and managed the product portfolio for infrastructure and data management. Prior to joining CA in April of 2005, Al was senior vice president and CTO of Novell, where he was the innovator behind the company’s moves into open source and identity-driven solutions. As consulting CTO for BellSouth he led the corporate initiative to consolidate and transform all of BellSouth’s disparate customer and operational data into a single data instance.
rean cooking, and has passion for cellaring American and Italian wines.
Fern Halper, PhD, is a Fellow with Hurwitz & Associates and Director of TDWI Research for Advanced Analytics. She has more than 20 years of experience in data analysis, business analysis, and strategy development. Fern has published numerous articles on data analysis and advanced ana-lytics. She has done extensive research, writing, and speaking on the topic of predictive analytics and text analytics. Fern publishes a regular technol-ogy blog. She has held key positions at AT&T Bell Laboratories and Lucent Technologies, where she was responsible for developing innovative data analysis systems as well as developing strategy and product-line plans for Internet businesses. Fern has taught courses in information technology at several universities. She received her BA from Colgate University and her PhD from Texas A&M University.
Fern is a co-author on four retail For Dummies titles including Hybrid Cloud For Dummies (John Wiley & Sons, Inc., 2012), Cloud Computing For Dummies (John Wiley & Sons, Inc., 2010), Service Oriented Architecture For Dummies, 2nd Edition, and Service Management For Dummies (both John Wiley & Sons, Inc., 2009). She is also a co-author on many custom published For Dummies titles including Cloud For Dummies, IBM Midsize Company Limited Edition (John Wiley & Sons, Inc., 2011), Platform as a Service For Dummies, CloudBees Special Edition (John Wiley & Sons, Inc., 2012), and Information on Demand For Dummies, IBM Limited Edition (John Wiley & Sons, Inc., 2008).
Marcia A. Kaufman is a founding Partner and COO of Hurwitz & Associates, a research and consulting firm focused on emerging technology, including cloud computing, big data, analytics, software development, service management, and security and governance. She has written extensively on the business value of virtualization and cloud computing, with an emphasis on evolving cloud infrastructure and business models, data-encryption and end-point security, and online transaction processing in cloud environments. Marcia has more than 20 years of experience in business strategy, industry research, distributed software, software quality, information management, and analytics. Marcia has worked within the financial services, manufacturing, and services industries. During her tenure at Data Resources, Inc. (DRI), she developed sophisticated industry models and forecasts. She holds an AB from Connecticut College in mathematics and economics and an MBA from Boston University.
Judith dedicates this book to her husband, Warren, her children, Sara and David, and her mother, Elaine. She also dedicates this book in memory of her father, David.
Alan dedicates this book to his wife Jane for all her love and support; his three children Chris, Jeff, and Greg; and the memory of his parents who started him on this journey.
Fern dedicates this book to her husband, Clay, daughters, Katie and Lindsay, and her sister Adrienne.
We heartily thank our friends at Wiley, most especially our editor, Nicole Sholly. In addition, we would like to thank our technical editor, Brenda Michelson, for her insightful contributions.
The authors would like to acknowledge the contribution of the following technology industry thought leaders who graciously offered their time to share their technical and business knowledge on a wide range of issues related to hybrid cloud. Their assistance was provided in many ways,
including technology briefings, sharing of research, case study examples, and reviewing content. We thank the following people and their organizations for their valuable assistance:
Context Relevant: Forrest Carman
Dell: Matt Walken
Epsilon: Bob Zurek
IBM: Rick Clements, David Corrigan, Phil Francisco, Stephen Gold, Glen Hintze, Jeff Jones, Nancy Kop, Dave Lindquist, Angel Luis Diaz, Bill Mathews, Kim Minor, Tracey Mustacchio, Bob Palmer, Craig Rhinehart, Jan Shauer, Brian Vile, Glen Zimmerman
Kognitio: Michael Hiskey, Steve Millard
Opera Solutions: Jacob Spoelstra
RainStor: Ramon Chen, Deidre Mahon
SAS Institute: Malcom Alexander, Michael Ames
VMware: Chris Keene
side the U.S. at 317-572-3993, or fax 317-572-4002.
Some of the people who helped bring this book to market include the following:
Acquisitions, Editorial
Senior Project Editor: Nicole Sholly
Project Editor: Dean Miller
Acquisitions Editor: Constance Santisteban
Copy Editor: John Edwards
Technical Editor: Brenda Michelson
Editorial Manager: Kevin Kirschner
Editorial Assistant: Anne Sullivan
Sr. Editorial Assistant: Cherie Case
Cover Photo: © Baris Simsek / iStockphoto
Composition Services
Project Coordinator: Sheree Montgomery
Layout and Graphics: Jennifer Creasey, Joyce Haughey
Proofreaders: Debbye Butler, Lauren Mandelbaum
Indexer: Valerie Haynes Perry
Publishing and Editorial for Technology Dummies
Richard Swadley, Vice President and Executive Group Publisher
Andy Cummings, Vice President and Publisher
Mary Bednarek, Executive Acquisitions Director
Mary C. Corder, Editorial Director
Publishing for Consumer Dummies
Kathleen Nebenhaus, Vice President and Executive Publisher
Composition Services
Introduction ... 1
Part I: Getting Started with Big Data . ... 7
Chapter 1: Grasping the Fundamentals of Big Data . ...9
Chapter 2: Examining Big Data Types . ...25
Chapter 3: Old Meets New: Distributed Computing . ...37
Part II: Technology Foundations for Big Data ... 45
Chapter 4: Digging into Big Data Technology Components . ...47
Chapter 5: Virtualization and How It Supports Distributed Computing . ...61
Chapter 6: Examining the Cloud and Big Data . ...71
Part III: Big Data Management ... 83
Chapter 7: Operational Databases . ...85
Chapter 8: MapReduce Fundamentals . ...101
Chapter 9: Exploring the World of Hadoop . ...111
Chapter 10: The Hadoop Foundation and Ecosystem . ...121
Chapter 11: Appliances and Big Data Warehouses . ...129
Part IV: Analytics and Big Data ... 139
Chapter 12: Defining Big Data Analytics . ...141
Chapter 13: Understanding Text Analytics and Big Data. ...153
Chapter 14: Customized Approaches for Analysis of Big Data . ...167
Part V: Big Data Implementation ... 179
Chapter 15: Integrating Data Sources . ...181
Chapter 16: Dealing with Real-Time Data Streams and Complex Event Processing . ...193
Chapter 17: Operationalizing Big Data . ...201
Chapter 18: Applying Big Data within Your Organization . ...211
Chapter 21: Analyzing Data in Motion: A Real-World View . ...245
Chapter 22: Improving Business Processes with Big Data Analytics: A Real-World View . ...255
Part VII: The Part of Tens ... 263
Chapter 23: Ten Big Data Best Practices . ...265
Chapter 24: Ten Great Big Data Resources . ...271
Chapter 25: Ten Big Data Do’s and Don’ts . ...275
Glossary ... 279
Introduction .
1
About This Book . ...2
Foolish Assumptions . ...2
How This Book Is Organized . ...3
Part I: Getting Started with Big Data ...3
Part II: Technology Foundations for Big Data ...3
Part III: Big Data Management ...3
Part IV: Analytics and Big Data ...4
Part V: Big Data Implementation ...4
Part VI: Big Data Solutions in the Real World ...4
Part VII: The Part of Tens ...4
Glossary ...4
Icons Used in This Book . ...5
Where to Go from Here . ...5
Part I: Getting Started with Big Data .
7
Chapter 1: Grasping the Fundamentals of Big Data . . . .9
The Evolution of Data Management . ...10
Understanding the Waves of Managing Data . ...11
Wave 1: Creating manageable data structures...11
Wave 2: Web and content management ...13
Wave 3: Managing big data ...14
Defining Big Data . ...15
Building a Successful Big Data Management Architecture . ...16
Beginning with capture, organize, integrate, analyze, and act ...16
Setting the architectural foundation ...17
Performance matters ...20
Traditional and advanced analytics ...22
The Big Data Journey . ...23
Chapter 2: Examining Big Data Types . . . .
25
Defining Structured Data . ...26Exploring sources of big structured data ...26
Understanding the role of relational databases in big data ...27
Defining Unstructured Data . ...29
Looking at Real-Time and Non-Real-Time Requirements . ...32
Putting Big Data Together . ...33
Managing different data types . ...33
Integrating data types into a big data environment . ...34
Chapter 3: Old Meets New: Distributed Computing . . . .37
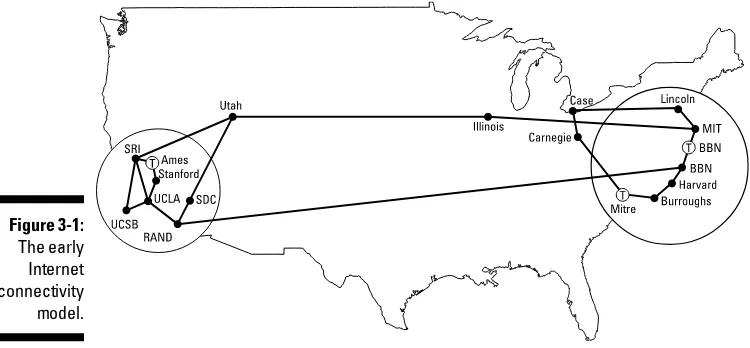
A Brief History of Distributed Computing . ...37
Giving thanks to DARPA ...38
The value of a consistent model ...39
Understanding the Basics of Distributed Computing . ...40
Why we need distributed computing for big data ...40
The changing economics of computing ...40
The problem with latency ...41
Demand meets solutions...41
Getting Performance Right . ...42
Part II: Technology Foundations for Big Data ... 45
Chapter 4: Digging into Big Data Technology Components . . . .47
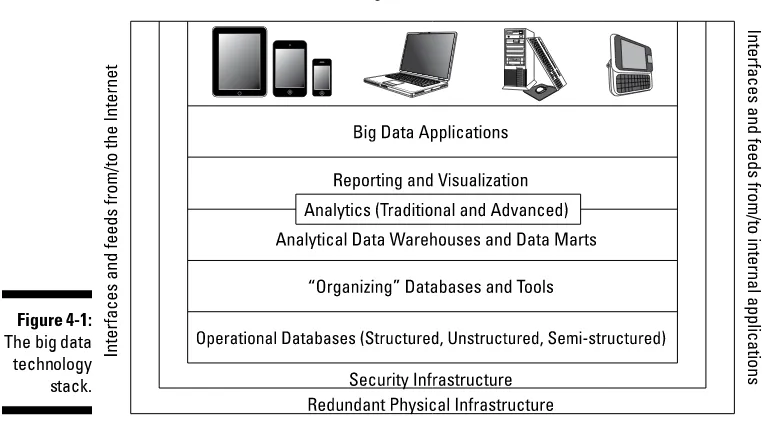
Exploring the Big Data Stack . ...48
Layer 0: Redundant Physical Infrastructure . ...49
Physical redundant networks ...51
Managing hardware: Storage and servers ...51
Infrastructure operations ...51
Layer 1: Security Infrastructure . ...52
Interfaces and Feeds to and from Applications and the Internet . ...53
Layer 2: Operational Databases . ...54
Layer 3: Organizing Data Services and Tools . ...56
Layer 4: Analytical Data Warehouses . ...56
Big Data Analytics . ...58
Big Data Applications . ...58
Chapter 5: Virtualization and How It Supports
Distributed Computing . . . .61
Understanding the Basics of Virtualization . ...61
The importance of virtualization to big data ...63
Server virtualization ...64
Application virtualization ...65
Network virtualization...66
Processor and memory virtualization ...66
Data and storage virtualization ...67
Managing Virtualization with the Hypervisor . ...68
Abstraction and Virtualization . ...69
Chapter 6: Examining the Cloud and Big Data . . . .
71
Defining the Cloud in the Context of Big Data . ...71
Understanding Cloud Deployment and Delivery Models . ...72
Cloud deployment models ...73
Cloud delivery models ...74
The Cloud as an Imperative for Big Data . ...75
Making Use of the Cloud for Big Data . ...77
Providers in the Big Data Cloud Market . ...78
Amazon’s Public Elastic Compute Cloud . ...78
Google big data services . ...79
Part III: Big Data Management .
83
Chapter 7: Operational Databases . . . .
85
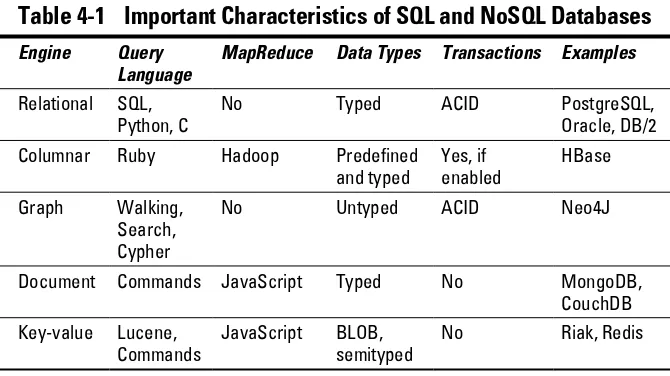
RDBMSs Are Important in a Big Data Environment . ...87PostgreSQL relational database . ...87
Nonrelational Databases . ...88
Key-Value Pair Databases . ...89
Riak key-value database . ...90
Document Databases . ...91
MongoDB ...92
CouchDB ...93
Columnar Databases . ...94
HBase columnar database . ...94
Graph Databases . ...95
Neo4J graph database . ...96
Spatial Databases . ...97
PostGIS/OpenGEO Suite . ...98
Polyglot Persistence . ...99
Chapter 8: MapReduce Fundamentals . . . .
101
Tracing the Origins of MapReduce . ...101Understanding the map Function . ...103
Adding the reduce Function . ...104
Putting map and reduce Together . ...105
Chapter 9: Exploring the World of Hadoop . . . .
111
Explaining Hadoop . ...111
Understanding the Hadoop Distributed File System (HDFS) . ...112
NameNodes ...113
Data nodes ...114
Under the covers of HDFS ...115
Hadoop MapReduce . ...116
Getting the data ready . ...117
Let the mapping begin . ...118
Reduce and combine . ...118
Chapter 10: The Hadoop Foundation and Ecosystem . . . .121
Building a Big Data Foundation with the Hadoop Ecosystem . ...121
Managing Resources and Applications with Hadoop YARN . ...122
Storing Big Data with HBase . ...123
Mining Big Data with Hive . ...124
Interacting with the Hadoop Ecosystem . ...125
Pig and Pig Latin. ...125
Sqoop . ...126
Zookeeper . ...127
Chapter 11: Appliances and Big Data Warehouses . . . .129
Integrating Big Data with the Traditional Data Warehouse . ...129
Optimizing the data warehouse ...130
Differentiating big data structures from data warehouse data .... 130
Examining a hybrid process case study ...131
Big Data Analysis and the Data Warehouse . ...133
The integration lynchpin ...134
Rethinking extraction, transformation, and loading ...134
Changing the Role of the Data Warehouse . ...135
Changing Deployment Models in the Big Data Era . ...136
The appliance model ...136
The cloud model ...137
Part IV: Analytics and Big Data .
139
Chapter 12: Defining Big Data Analytics . . . .
141
Using Big Data to Get Results . ...142Basic analytics . ...142
Advanced analytics. ...143
Modifying Business Intelligence Products to Handle Big Data . ...147
Data ...147
Analytical algorithms ...148
Infrastructure support ...148
Studying Big Data Analytics Examples . ...149
Orbitz ...149
Nokia ...150
NASA ...150
Big Data Analytics Solutions . ...151
Chapter 13: Understanding Text Analytics and Big Data . . . .
153
Exploring Unstructured Data . ...154Understanding Text Analytics . ...155
The difference between text analytics and search . ...156
Analysis and Extraction Techniques . ...157
Understanding the extracted information ...159
Taxonomies ...160
Putting Your Results Together with Structured Data . ...160
Putting Big Data to Use . ...161
Voice of the customer ...161
Social media analytics ...162
Text Analytics Tools for Big Data . ...164
Attensity . ...164
Clarabridge . ...165
IBM . ...165
OpenText . ...165
SAS . ...166
Chapter 14: Customized Approaches for Analysis of Big Data . . . . .
167
Building New Models and Approaches to Support Big Data . ...168Characteristics of big data analysis . ...168
Understanding Different Approaches to Big Data Analysis . ...170
Custom applications for big data analysis ...171
Part V: Big Data Implementation .
179
Chapter 15: Integrating Data Sources . . . .181
Identifying the Data You Need . ...181
Exploratory stage . ...182
Codifying stage . ...184
Understanding the Fundamentals of Big Data Integration . ...186
Defining Traditional ETL . ...187
Data transformation . ...188
Understanding ELT — Extract, Load, and Transform . ...189
Prioritizing Big Data Quality . ...189
Using Hadoop as ETL . ...191
Best Practices for Data Integration in a Big Data World . ...191
Chapter 16: Dealing with Real-Time Data Streams and
Complex Event Processing . . . .193
Explaining Streaming Data and Complex Event Processing . ...194
Using Streaming Data . ...194
Data streaming ...195
The need for metadata in streams ...196
Using Complex Event Processing . ...198
Differentiating CEP from Streams . ...199
Understanding the Impact of Streaming Data and CEP on Business .... 200
Chapter 17: Operationalizing Big Data . . . .201
Making Big Data a Part of Your Operational Process . ...201
Integrating big data ...202
Incorporating big data into the diagnosis of diseases ...203
Understanding Big Data Workflows . ...205
Workload in context to the business problem . ...206
Ensuring the Validity, Veracity, and Volatility of Big Data . ...207
Data validity . ...207
Data volatility . ...208
Chapter 18: Applying Big Data within Your Organization . . . .211
Figuring the Economics of Big Data . ...212
Identification of data types and sources. ...212
Business process modifications or new process creation . ...215
The technology impact of big data workflows . ...215
Finding the talent to support big data projects . ...216
Calculating the return on investment (ROI) from big data investments . ...216
Enterprise Data Management and Big Data . ...217
Defining Enterprise Data Management . ...217
Creating a Big Data Implementation Road Map . ...218
Understanding business urgency ...218
Projecting the right amount of capacity ...219
Selecting the right software development methodology ...219
Balancing budgets and skill sets ...219
Determining your appetite for risk ...220
Chapter 19: Security and Governance for Big Data Environments . . .
225
Security in Context with Big Data . ...225
Assessing the risk for the business ...226
Risks lurking inside big data ...226
Understanding Data Protection Options . ...227
The Data Governance Challenge . ...228
Auditing your big data process ...230
Identifying the key stakeholders ...231
Putting the Right Organizational Structure in Place . ...231
Part VI: Big Data Solutions in the Real World .
235
Chapter 20: The Importance of Big Data to Business . . . .
237
Big Data as a Business Planning Tool . ...238Stage 1: Planning with data ...238
Stage 2: Doing the analysis ...239
Stage 3: Checking the results...239
Stage 4: Acting on the plan ...240
Adding New Dimensions to the Planning Cycle . ...240
Stage 5: Monitoring in real time ...240
Stage 6: Adjusting the impact ...241
Stage 7: Enabling experimentation ...241
Keeping Data Analytics in Perspective . ...241
Getting Started with the Right Foundation . ...242
Getting your big data strategy started . ...242
Planning for Big Data . ...243
Transforming Business Processes with Big Data . ...244
Chapter 21: Analyzing Data in Motion: A Real-World View . . . .245
Understanding Companies’ Needs for Data in Motion . ...246
The value of streaming data . ...247
Streaming Data with an Environmental Impact . ...247
Using sensors to provide real-time information about rivers and oceans . ...248
The benefits of real-time data . ...249
Streaming Data with a Public Policy Impact . ...249
Streaming Data in the Energy Industry . ...252
Using streaming data to increase energy efficiency . ...252
Using streaming data to advance the production of alternative sources of energy . ...252
Connecting Streaming Data to Historical and Other Real-Time Data Sources . ...253
Chapter 22: Improving Business Processes with Big
Data Analytics: A Real-World View . . . .255
Understanding Companies’ Needs for Big Data Analytics . ...256
Improving the Customer Experience with Text Analytics . ...256
The business value to the big data analytics implementation .... 257
Using Big Data Analytics to Determine Next Best Action . ...257
Preventing Fraud with Big Data Analytics . ...260
The Business Benefit of Integrating New Sources of Data . ...262
Part VII: The Part of Tens ... 263
Chapter 23: Ten Big Data Best Practices . . . .265
Understand Your Goals . ...265
Establish a Road Map . ...266
Discover Your Data . ...266
Figure Out What Data You Don’t Have . ...267
Understand the Technology Options . ...267
Plan for Security in Context with Big Data . ...268
Plan a Data Governance Strategy . ...268
Plan for Data Stewardship . ...268
Continually Test Your Assumptions . ...269
Study Best Practices and Leverage Patterns . ...269
Chapter 24: Ten Great Big Data Resources . . . .271
Hurwitz & Associates . ...271
Standards Organizations . ...271
The Open Data Foundation ...272
The Cloud Security Alliance ...272
National Institute of Standards and Technology ...272
Apache Software Foundation ...273
OASIS ...273
Vendor Sites . ...273
Online Collaborative Sites . ...274
Chapter 25: Ten Big Data Do’s and Don’ts . . . .275
Do Involve All Business Units in Your Big Data Strategy . ...275
Do Evaluate All Delivery Models for Big Data . ...276
Do Think about Your Traditional Data Sources as Part of Your Big Data Strategy . ...276
Do Plan for Consistent Metadata . ...276
Do Distribute Your Data . ...277
Don’t Rely on a Single Approach to Big Data Analytics . ...277
Don’t Go Big Before You Are Ready . ...277
Don’t Overlook the Need to Integrate Data . ...277
Don’t Forget to Manage Data Securely . ...278
Don’t Overlook the Need to Manage the Performance of Your Data .... 278
Glossary ... 279
W
elcome to Big Data For Dummies. Big data is becoming one of the most important technology trends that has the potential for dramati-cally changing the way organizations use information to enhance the cus-tomer experience and transform their business models. How does a company go about using data to the best advantage? What does it mean to transform massive amounts of data into knowledge? In this book, we provide you with insights into how technology transitions in software, hardware, and delivery models are changing the way that data can be used in new ways.Big data is not a single market. Rather, it is a combination of data-manage-ment technologies that have evolved over time. Big data enables organiza-tions to store, manage, and manipulate vast amounts of data at the right speed and at the right time to gain the right insights. The key to understand-ing big data is that data has to be managed so that it can meet the business requirement a given solution is designed to support. Most companies are at an early stage with their big data journey. Many companies are experiment-ing with techniques that allow them to collect massive amounts of data to determine whether hidden patterns exist within that data that might be an early indication of an important change. Some data may indicate that cus-tomer buying patterns are changing or that new elements are in the business that need to be addressed before it is too late.
As companies begin to evaluate new types of big data solutions, many new opportunities will unfold. For example, manufacturing companies may be able to monitor data coming from machine sensors to determine how pro-cesses need to be modified before a catastrophic event happens. It will be possible for retailers to monitor data in real time to upsell customers related products as they are executing a transaction. Big data solutions can be used in healthcare to determine the cause of an illness and provide a physician with guidance on treatment options.
Big data is not an isolated solution, however. Implementing a big data solu-tion requires that the infrastructure be in place to support the scalability, distribution, and management of that data. Therefore, it is important to put both a business and technical strategy in place to make use of this important technology trend.
engines to transform the value of their data. We wrote this book to provide a perspective on what big data is and how it’s changing the way that organiza-tions can leverage more data than was possible in the past. We think that this book will give you the context to make informed decisions.
About This Book
Big data is new to many people, so it requires some investigation and under-standing of both the technical and business requirements. Many different people need knowledge about big data. Some of you want to delve into the technical details, while others want to understand the economic implica-tions of making use of big data technologies. Other executives need to know enough to be able to understand how big data can affect business decisions. Implementing a big data environment requires both an architectural and a business approach — and lots of planning.
No matter what your goal is in reading this book, we address the following issues to help you understand big data and the impact it can have on your business:
✓ What is the architecture for big data? How can you manage huge vol-umes of data without causing major disruptions in your data center?
✓ When should you integrate the outcome of your big data analysis with your data warehouse?
✓ What are the implications of security and governance on the use of big data? How can you keep your company safe?
✓ What is the value of different data technologies, and when should you consider them as part of your big data strategy?
✓ What types of data sources can you take advantage of with big data analytics? How can you apply different types of analytics to business problems?
Foolish Assumptions
Try as we might to be all things to all people, when it came to writing this book, we had to pick who we thought would be most interested in Big Data For Dummies. Here’s who we think you are:
✓ You’re a businessperson who wants little or nothing to do with tech-nology. But you live in the 21st century, so you can’t escape it. People are saying, “It’s all about big data,” so you think that you better find out what they’re talking about.
✓ You’re an IT person who knows a heck of a lot about technology. The thing is, you’re new to big data. Everybody says it’s something different. Once and for all, you want the whole picture.
Whoever you are, welcome. We’re here to help.
How This Book Is Organized
We divided our book into seven parts for easy reading. Feel free to skip about.
Part I: Getting Started with Big Data
In this part, we explain the basic concepts you need for a full understanding of big data, from both a technical and a business perspective. We also intro-duce you to the major concepts and components so that you can hold your own in any meaningful conversation about big data.
Part II: Technology Foundations
for Big Data
Part II is for both technical and business professionals who need to under-stand the different types of big data components and the underlying tech-nology concepts that support big data. In this section, we give you an understanding about the type of infrastructure that will make big data more practical.
Part III: Big Data Management
Part IV: Analytics and Big Data
How do you analyze the massive amounts of data that become part of your big data infrastructure? In this part of the book, we go deeper into the differ-ent types of analytics that are helpful in getting real meaning from your data. This part helps you think about ways that you can turn big data into action for your business.
Part V: Big Data Implementation
This part gets to the details of what it means to actually manage data, includ-ing issues such as operationalizinclud-ing your data and protectinclud-ing the security and privacy of that data. This section gives you plenty to think about in this criti-cal area.
Part VI: Big Data Solutions
in the Real World
In this section, you get an understanding of how companies are beginning to use big data to transform their business operations. If you want to get a peek into the future at what you might be able to do with data, this section is for you.
Part VII: The Part of Tens
If you’re new to the For Dummies treasure-trove, you’re no doubt unfamiliar with The Part of Tens. In this section, Wiley editors torture For Dummies authors into creating useful bits of information that are easily accessible in lists containing ten (or so) elucidating elements. We started these chapters kicking and screaming but are ultimately very glad that they’re here. After you read through the big data best practices, and the do’s and don’ts we pro-vide in The Part of Tens, we think you’ll be glad, too.
Glossary
Icons Used in This Book
Pay attention. The bother you save may be your own.
You may be sorry if this little tidbit slips your mind.
With this icon, we mark particularly useful points to pay attention to.
Here you find tidbits for the more technically inclined.
Where to Go from Here
We’ve created an overview of big data and introduced you to all its signifi-cant components. We recommend that you read the first four chapters to give you the context for what big data is about and what technologies are in place to make implementations a reality. The next two chapters introduce you to some of the underlying infrastructure issues that are important to understand. The following eight chapters get into a lot more detail about the different types of data structures that are foundational to big data.
You can read the book from cover to cover, but if you’re not that kind of person, we’ve tried to adhere to the For Dummies style of keeping chapters self-contained so that you can go straight to the topics that interest you most. Wherever you start, we wish you well.
Many of these chapters could be expanded into full-length books of their own. Big data and the emerging technology landscape are a big focus for us at Hurwitz & Associates, and we invite you to visit our website and read our blogs and insights at www.hurwitz.com.
Big
Data
getting started
with
✓ Trace the evolution of data management.
✓ Define big data and its technology components.
✓ Understand the different types of big data.
✓ Integrate structured and unstructured data.
✓ Understand the difference between real-time and non-real-time data.
Grasping the Fundamentals of
Big Data
In This Chapter
▶ Looking at a history of data management ▶ Understanding why big data matters to business ▶ Applying big data to business effectiveness ▶ Defining the foundational elements of big data ▶ Examining big data’s role in the future
M
anaging and analyzing data have always offered the greatest benefits and the greatest challenges for organizations of all sizes and across all industries. Businesses have long struggled with finding a pragmatic approach to capturing information about their customers, products, and services. When a company only had a handful of customers who all bought the same product in the same way, things were pretty straightforward and simple. But over time, companies and the markets they participate in have grown more complicated. To survive or gain a competitive advantage with customers, these companies added more product lines and diversified how they deliver their product. Data struggles are not limited to business. Research and devel-opment (R&D) organizations, for example, have struggled to get enough com-puting power to run sophisticated models or to process images and other sources of scientific data.Although each data source can be independently managed and searched, the challenge today is how companies can make sense of the intersection of all these different types of data. When you are dealing with so much information in so many different forms, it is impossible to think about data management in traditional ways. Although we have always had a lot of data, the difference today is that significantly more of it exists, and it varies in type and timeli-ness. Organizations are also finding more ways to make use of this informa-tion than ever before. Therefore, you have to think about managing data differently. That is the opportunity and challenge of big data. In this chapter, we provide you a context for what the evolution of the movement to big data is all about and what it means to your organization.
The Evolution of Data Management
It would be nice to think that each new innovation in data management is a fresh start and disconnected from the past. However, whether revolution-ary or incremental, most new stages or waves of data management build on their predecessors. Although data management is typically viewed through a software lens, it actually has to be viewed from a holistic perspective. Data management has to include technology advances in hardware, storage, net-working, and computing models such as virtualization and cloud computing. The convergence of emerging technologies and reduction in costs for every-thing from storage to compute cycles have transformed the data landscape and made new opportunities possible.
As all these technology factors converge, it is transforming the way we manage and leverage data. Big data is the latest trend to emerge because of these factors. So, what is big data and why is it so important? Later in the book, we provide a more comprehensive definition. To get you started, big data is defined as any kind of data source that has at least three shared char-acteristics:
✓ Extremely large Volumes of data
✓ Extremely high Velocity of data
✓ Extremely wide Variety of data
Organizations today are at a tipping point in data management. We have moved from the era where the technology was designed to support a specific business need, such as determining how many items were sold to how many customers, to a time when organizations have more data from more sources than ever before. All this data looks like a potential gold mine, but like a gold mine, you only have a little gold and lot more of everything else. The tech-nology challenges are “How do you make sense of that data when you can’t easily recognize the patterns that are the most meaningful for your business decisions? How does your organization deal with massive amounts of data in a meaningful way?” Before we get into the options, we take a look at the evo-lution of data management and see how these waves are connected.
Understanding the Waves
of Managing Data
Each data management wave is born out of the necessity to try and solve a specific type of data management problem. Each of these waves or phases evolved because of cause and effect. When a new technology solution came to market, it required the discovery of new approaches. When the relational database came to market, it needed a set of tools to allow managers to study the relationship between data elements. When companies started storing unstructured data, analysts needed new capabilities such as natural lan-guage–based analysis tools to gain insights that would be useful to business. If you were a search engine company leader, you began to realize that you had access to immense amounts of data that could be monetized. To gain value from that data required new innovative tools and approaches.
The data management waves over the past five decades have culminated in where we are today: the initiation of the big data era. So, to understand big data, you have to understand the underpinning of these previous waves. You also need to understand that as we move from one wave to another, we don’t throw away the tools and technology and practices that we have been using to address a different set of problems.
Wave 1: Creating manageable
data structures
brute-force methods, including very detailed programming models to create some value. Later in the 1970s, things changed with the invention of the rela-tional data model and the relarela-tional database management system (RDBMS) that imposed structure and a method for improving performance. Most importantly, the relational model added a level of abstraction (the structured query language [SQL], report generators, and data management tools) so that it was easier for programmers to satisfy the growing business demands to extract value from data.
The relational model offered an ecosystem of tools from a large number of emerging software companies. It filled a growing need to help compa-nies better organize their data and be able to compare transactions from one geography to another. In addition, it helped business managers who wanted to be able to examine information such as inventory and compare it to customer order information for decision-making purposes. But a prob-lem emerged from this exploding demand for answers: Storing this growing volume of data was expensive and accessing it was slow. Making matters worse, lots of data duplication existed, and the actual business value of that data was hard to measure.
At this stage, an urgent need existed to find a new set of technologies to support the relational model. The Entity-Relationship (ER) model emerged, which added additional abstraction to increase the usability of the data. In this model, each item was defined independently of its use. Therefore, devel-opers could create new relationships between data sources without complex programming. It was a huge advance at the time, and it enabled developers to push the boundaries of the technology and create more complex models requiring complex techniques for joining entities together. The market for relational databases exploded and remains vibrant today. It is especially important for transactional data management of highly structured data.
Sometimes these data warehouses themselves were too complex and large and didn’t offer the speed and agility that the business required. The answer was a further refinement of the data being managed through data marts. These data marts were focused on specific business issues and were much more streamlined and supported the business need for speedy queries than the more massive data warehouses. Like any wave of data management, the warehouse has evolved to support emerging technologies such as integrated systems and data appliances.
Data warehouses and data marts solved many problems for companies need-ing a consistent way to manage massive transactional data. But when it came to managing huge volumes of unstructured or semi-structured data, the ware-house was not able to evolve enough to meet changing demands. To com-plicate matters, data warehouses are typically fed in batch intervals, usually weekly or daily. This is fine for planning, financial reporting, and traditional marketing campaigns, but is too slow for increasingly real-time business and consumer environments.
How would companies be able to transform their traditional data manage-ment approaches to handle the expanding volume of unstructured data elements? The solution did not emerge overnight. As companies began to store unstructured data, vendors began to add capabilities such as BLOBs (binary large objects). In essence, an unstructured data element would be stored in a relational database as one contiguous chunk of data. This object could be labeled (that is, a customer inquiry) but you couldn’t see what was inside that object. Clearly, this wasn’t going to solve changing customer or business needs.
Enter the object database management system (ODBMS). The object data-base stored the BLOB as an addressable set of pieces so that we could see what was in there. Unlike the BLOB, which was an independent unit appended to a traditional relational database, the object database provided a unified approach for dealing with unstructured data. Object databases include a programming language and a structure for the data elements so that it is easier to manipulate various data objects without programming and complex joins. The object databases introduced a new level of innovation that helped lead to the second wave of data management.
manage unstructured data, mostly documents. In the 1990s with the rise of the web, organizations wanted to move beyond documents and store and manage web content, images, audio, and video.
The market evolved from a set of disconnected solutions to a more unified model that brought together these elements into a platform that incorporated business process management, version control, information recognition, text management, and collaboration. This new generation of systems added meta-data (information about the organization and characteristics of the stored information). These solutions remain incredibly important for companies needing to manage all this data in a logical manner. But at the same time, a new generation of requirements has begun to emerge that drive us to the next wave. These new requirements have been driven, in large part, by a conver-gence of factors including the web, virtualization, and cloud computing. In this new wave, organizations are beginning to understand that they need to manage a new generation of data sources with an unprecedented amount and variety of data that needs to be processed at an unheard-of speed.
Wave 3: Managing big data
Is big data really new or is it an evolution in the data management journey? The answer is yes — it is actually both. As with other waves in data manage-ment, big data is built on top of the evolution of data management practices over the past five decades. What is new is that for the first time, the cost of computing cycles and storage has reached a tipping point. Why is this important? Only a few years ago, organizations typically would compromise by storing snapshots or subsets of important information because the cost of storage and processing limitations prohibited them from storing everything they wanted to analyze.
In many situations, this compromise worked fine. For example, a manufactur-ing company might have collected machine data every two minutes to deter-mine the health of systems. However, there could be situations where the snapshot would not contain information about a new type of defect and that might go unnoticed for months.
But no technology transition happens in isolation; it happens when an impor-tant need exists that can be met by the availability and maturation of technol-ogy. Many of the technologies at the heart of big data, such as virtualization, parallel processing, distributed file systems, and in-memory databases, have been around for decades. Advanced analytics have also been around for decades, although they have not always been practical. Other technologies such as Hadoop and MapReduce have been on the scene for only a few years. This combination of technology advances can now address significant busi-ness problems. Busibusi-nesses want to be able to gain insights and actionable results from many different kinds of data at the right speed — no matter how much data is involved.
If companies can analyze petabytes of data (equivalent to 20 million four-drawer file cabinets filled with text files or 13.3 years of HDTV content) with acceptable performance to discern patterns and anomalies, businesses can begin to make sense of data in new ways. The move to big data is not just about businesses. Science, research, and government activities have also helped to drive it forward. Just think about analyzing the human genome or dealing with all the astronomical data collected at observatories to advance our understanding of the world around us. Consider the amount of data the government collects in its antiterrorist activities as well, and you get the idea that big data is not just about business.
Different approaches to handling data exist based on whether it is data in motion or data at rest. Here’s a quick example of each. Data in motion would be used if a company is able to analyze the quality of its products during the manufacturing process to avoid costly errors. Data at rest would be used by a business analyst to better understand customers’ current buying patterns based on all aspects of the customer relationship, including sales, social media data, and customer service interactions.
Keep in mind that we are still at an early stage of leveraging huge volumes of data to gain a 360-degree view of the business and anticipate shifts and changes in customer expectations. The technologies required to get the answers the business needs are still isolated from each other. To get to the desired end state, the technologies from all three waves will have to come together. As you will see as you read this book, big data is not simply about one tool or one technology. It is about how all these technologies come together to give the right insights, at the right time, based on the right data — whether it is generated by people, machines, or the web.
Defining Big Data
the capability to manage a huge volume of disparate data, at the right speed, and within the right time frame to allow real-time analysis and reaction. As we note earlier in this chapter, big data is typically broken down by three characteristics:
✓ Volume: How much data
✓ Velocity: How fast that data is processed
✓ Variety: The various types of data
Although it’s convenient to simplify big data into the three Vs, it can be mis-leading and overly simplistic. For example, you may be managing a relatively small amount of very disparate, complex data or you may be processing a huge volume of very simple data. That simple data may be all structured or all unstructured. Even more important is the fourth V: veracity. How accurate is that data in predicting business value? Do the results of a big data analysis actually make sense?
It is critical that you don’t underestimate the task at hand. Data must be able to be verified based on both accuracy and context. An innovative business may want to be able to analyze massive amounts of data in real time to quickly assess the value of that customer and the potential to provide additional offers to that customer. It is necessary to identify the right amount and types of data that can be analyzed to impact business outcomes. Big data incorpo-rates all data, including structured data and unstructured data from e-mail, social media, text streams, and more. This kind of data management requires that companies leverage both their structured and unstructured data.
Building a Successful Big Data
Management Architecture
We have moved from an era where an organization could implement a data-base to meet a specific project need and be done. But as data has become the fuel of growth and innovation, it is more important than ever to have an underlying architecture to support growing requirements.
Beginning with capture, organize,
integrate, analyze, and act
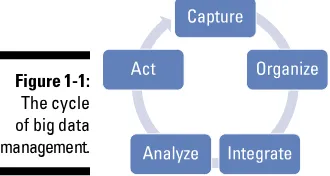
successfully implemented, data can be analyzed based on the problem being addressed. Finally, management takes action based on the outcome of that analysis. For example, Amazon.com might recommend a book based on a past purchase or a customer might receive a coupon for a discount for a future purchase of a related product to one that was just purchased.
Figure 1-1:
The cycle of big data management.
Although this sounds straightforward, certain nuances of these functions are complicated. Validation is a particularly important issue. If your organization is combining data sources, it is critical that you have the ability to validate that these sources make sense when combined. Also, certain data sources may con-tain sensitive information, so you must implement sufficient levels of security and governance. We cover data management in more detail in Chapter 7.
Of course, any foray into big data first needs to start with the problem you’re trying to solve. That will dictate the kind of data that you need and what the architecture might look like.
Setting the architectural foundation
In addition to supporting the functional requirements, it is important to sup-port the required performance. Your needs will depend on the nature of the analysis you are supporting. You will need the right amount of computational power and speed. While some of the analysis you will do will be performed in real time, you will inevitably be storing some amount of data as well. Your architecture also has to have the right amount of redundancy so that you are protected from unanticipated latency and downtime.
Your organization and its needs will determine how much attention you have to pay to these performance issues. So, start out by asking yourself the fol-lowing questions:
✓ How much data will my organization need to manage today and in the future?
✓ How much risk can my organization afford? Is my industry subject to strict security, compliance, and governance requirements?
✓ How important is speed to my need to manage data?
✓ How certain or precise does the data need to be?
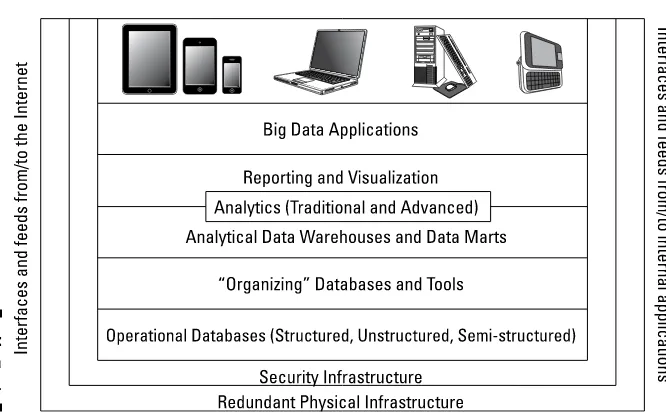
To understand big data, it helps to lay out the components of the architec-ture. A big data management architecture must include a variety of services that enable companies to make use of myriad data sources in a fast and effec-tive manner. To help you make sense of this, we put the components into a diagram (see Figure 1-2) that will help you see what’s there and the relation-ship between the components. In the next section, we explain each compo-nent and describe how these compocompo-nents are related to each other.
Figure 1-2:
The big data architecture.
Interfaces and feeds
Redundant physical infrastructure
The supporting physical infrastructure is fundamental to the operation and scalability of a big data architecture. In fact, without the availability of robust physical infrastructures, big data would probably not have emerged as such an important trend. To support an unanticipated or unpredictable volume of data, a physical infrastructure for big data has to be different than that for traditional data. The physical infrastructure is based on a distributed computing model. This means that data may be physically stored in many different locations and can be linked together through networks, the use of a distributed file system, and various big data analytic tools and applications.
Redundancy is important because we are dealing with so much data from so many different sources. Redundancy comes in many forms. If your com-pany has created a private cloud, you will want to have redundancy built within the private environment so that it can scale out to support changing workloads. If your company wants to contain internal IT growth, it may use external cloud services to augment its internal resources. In some cases, this redundancy may come in the form of a Software as a Service (SaaS) offering that allows companies to do sophisticated data analysis as a service. The SaaS approach offers lower costs, quicker startup, and seamless evolution of the underlying technology.
Security infrastructure
The more important big data analysis becomes to companies, the more important it will be to secure that data. For example, if you are a healthcare company, you will probably want to use big data applications to determine changes in demographics or shifts in patient needs. This data about your constituents needs to be protected both to meet compliance requirements and to protect the patients’ privacy. You will need to take into account who is allowed to see the data and under what circumstances they are allowed to do so. You will need to be able to verify the identity of users as well as pro-tect the identity of patients. These types of security requirements need to be part of the big data fabric from the outset and not an afterthought.
Operational data sources
When you think about big data, it is important to understand that you have to incorporate all the data sources that will give you a complete picture of your business and see how the data impacts the way you operate your busi-ness. Traditionally, an operational data source consisted of highly structured data managed by the line of business in a relational database. But as the world changes, it is important to understand that operational data now has to encompass a broader set of data sources, including unstructured sources such as customer and social media data in all its forms.
databases. In essence, you need to map the data architectures to the types of transactions. Doing so will help to ensure the right data is available when you need it. You also need data architectures that support complex unstructured content. You need to include both relational databases and nonrelational databases in your approach to harnessing big data. It is also necessary to include unstructured data sources, such as content management systems, so that you can get closer to that 360-degree business view.
All these operational data sources have several characteristics in common:
✓ They represent systems of record that keep track of the critical data required for real-time, day-to-day operation of the business.
✓ They are continually updated based on transactions happening within business units and from the web.
✓ For these sources to provide an accurate representation of the business, they must blend structured and unstructured data.
✓ These systems also must be able to scale to support thousands of users on a consistent basis. These might include transactional e-commerce systems, customer relationship management systems, or call center applications.
Performance matters
Your data architecture also needs to perform in concert with your organiza-tion’s supporting infrastructure. For example, you might be interested in running models to determine whether it is safe to drill for oil in an offshore area given real-time data of temperature, salinity, sediment resuspension, and a host of other biological, chemical, and physical properties of the water column. It might take days to run this model using a traditional server con-figuration. However, using a distributed computing model, what took days might now take minutes.
Other important operational database approaches include columnar data-bases that store information efficiently in columns rather than rows. This approach leads to faster performance because input/output is extremely fast. When geographic data storage is part of the equation, a spatial database is optimized to store and query data based on how objects are related in space.
Organizing data services and tools
Not all the data that organizations use is operational. A growing amount of data comes from a variety of sources that aren’t quite as organized or straightforward, including data that comes from machines or sensors, and massive public and private data sources. In the past, most companies weren’t able to either capture or store this vast amount of data. It was simply too expensive or too overwhelming. Even if companies were able to capture the data, they did not have the tools to do anything about it. Very few tools could make sense of these vast amounts of data. The tools that did exist were complex to use and did not produce results in a reasonable time frame. In the end, those who really wanted to go to the enormous effort of analyzing this data were forced to work with snapshots of data. This has the undesir-able effect of missing important events because they were not in a particular snapshot.
MapReduce, Hadoop, and Big Table
With the evolution of computing technology, it is now possible to manage immense volumes of data that previously could have only been handled by supercomputers at great expense. Prices of systems have dropped, and as a result, new techniques for distributed computing are mainstream. The real breakthrough in big data happened as companies like Yahoo!, Google, and Facebook came to the realization that they needed help in monetizing the massive amounts of data their offerings were creating.
These emerging companies needed to find new technologies that would allow them to store, access, and analyze huge amounts of data in near real time so that they could monetize the benefits of owning this much data about participants in their networks. Their resulting solutions are transforming the data management market. In particular, the innovations MapReduce, Hadoop, and Big Table proved to be the sparks that led to a new generation of data management. These technologies address one of the most fundamental prob-lems — the capability to process massive amounts of data efficiently, cost-effectively, and in a timely fashion.
MapReduce
systems and handles the placement of the tasks in a way that balances the load and manages recovery from failures. After the distributed computation is completed, another function called “reduce” aggregates all the elements back together to provide a result. An example of MapReduce usage would be to determine how many pages of a book are written in each of 50 different languages.
Big Table
Big Table was developed by Google to be a distributed storage system intended to manage highly scalable structured data. Data is organized into tables with rows and columns. Unlike a traditional relational database model, Big Table is a sparse, distributed, persistent multidimensional sorted map. It is intended to store huge volumes of data across commodity servers.
Hadoop
Hadoop is an Apache-managed software framework derived from MapReduce and Big Table. Hadoop allows applications based on MapReduce to run on large clusters of commodity hardware. The project is the foundation for the computing architecture supporting Yahoo!’s business. Hadoop is designed to parallelize data processing across computing nodes to speed computations and hide latency. Two major components of Hadoop exist: a massively scal-able distributed file system that can support petabytes of data and a mas-sively scalable MapReduce engine that computes results in batch.
Traditional and advanced analytics
What does your business now do with all the data in all its forms to try to make sense of it for the business? It requires many different approaches to analysis, depending on the problem being solved. Some analyses will use a traditional data warehouse, while other analyses will take advantage of advanced predictive analytics. Managing big data holistically requires many different approaches to help the business to successfully plan for the future.
Analytical data warehouses and data marts
After a company sorts through the massive amounts of data available, it is often pragmatic to take the subset of data that reveals patterns and put it into a form that’s available to the business. These warehouses and marts pro-vide compression, multilevel partitioning, and a massively parallel process-ing architecture.
Big data analytics
data and provide results that can be optimized to solve a business problem. Analytics can get quite complex with big data. For example, some organiza-tions are using predictive models that couple structured and unstructured data together to predict fraud. Social media analytics, text analytics, and new kinds of analytics are being utilized by organizations looking to gain insight into big data. Big data analytics are described in more detail in chapters 12, 13, and 14.
Reporting and visualization
Organizations have always relied on the capability to create reports to give them an understanding of what the data tells them about everything from monthly sales figures to projections of growth. Big data changes the way that data is managed and used. If a company can collect, manage, and ana-lyze enough data, it can use a new generation of tools to help management truly understand the impact not just of a collection of data elements but also how these data elements offer context based on the business problem being addressed. With big data, reporting and data visualization become tools for looking at the context of how data is related and the impact of those relation-ships on the future.
Big data applications
Traditionally, the business expected that data would be used to answer ques-tions about what to do and when to do it. Data was often integrated as fields into general-purpose business applications. With the advent of big data, this is changing. Now, we are seeing the development of applications that are designed specifically to take advantage of the unique characteristics of big data.
Some of the emerging applications are in areas such as healthcare, manu-facturing management, traffic management, and so on. What do all these big data applications have in common? They rely on huge volumes, velocities, and varieties of data to transform the behavior of a market. In healthcare, a big data application might be able to monitor premature infants to deter-mine when data indicates when intervention is needed. In manufacturing, a big data application can be used to prevent a machine from shutting down during a production run. A big data traffic management application can reduce the number of traffic jams on busy city highways to decrease acci-dents, save fuel, and reduce pollution.
The Big Data Journey
Examining Big Data Types
In This Chapter
▶ Identifying structured and unstructured data
▶ Recognizing real-time and non-real-time requirements for data types ▶ Integrating data types into a big data environment
V
ariety is the spice of life, and variety is one of the principles of big data. In Chapter 1, we discuss the importance of being able to manage the variety of data types. Clearly, big data encompasses everything from dollar transactions to tweets to images to audio. Therefore, taking advantage of big data requires that all this information be integrated for analysis and data management. Doing this type of activity is harder than it sounds. In this chapter, we examine the two main types of data that make up big data — structured and unstructured — and provide you with definitions and examples of each.Although data management has been around for a long time, two factors are new in the big data world:
✓ Some sources of big data are actually new like the data generated from sensors, smartphone, and tablets.
✓ Previously produced data hadn’t been captured or stored and analyzed in a usable way. The main reason for this is that the technology wasn’t there to do so. In other words, we didn’t have a cost-effective way to deal with all that data.