Fakultas Ilmu Komputer
1526
Pengelompokan Lagu Berdasarkan Emosi Menggunakan Algoritma
Fuzzy
C-Means
Muhja Mufidah Afaf Amirah1, Agus Wahyu Widodo2, Candra Dewi3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Musik digital sudah berkembang secara dramatis dalam beberapa tahun ini. Musik-musik yang disediakan terdiri dari berbagai jenis dan emosi yang bersifat acak. Karenanya, diperlukan cara untuk mengorganisasikan lagu-lagu tersebut, untuk mengelompokan lagu-lagu tersebut berdasarkan suatu karakteristik yang spesifik. Pengorganisasian lagu memungkinkan pengguna untuk menavigasi ke musik-musik yang mereka tuju, juga untuk memberikan saran dan rekomendasi lagu baik bagi masyarakat ataupun industri yang berhubungan dengan musik. Penelitian ini akan melakukan pengelompokan lagu berdasarkan emosi menggunakan algoritma Fuzzy C-Means. Kami menggunakan atribut audio berupa valensi, energi, loudness, dan tempo sebagai fitur yang mencerminkan emosi dari lagu. Hasil cluster dari setiap data lagu ditentukan berdasarkan derajat keanggotaan yang dimilikinya. Pengujian validitas cluster dilakukan untuk menguji ketepatan dari hasil clustering yang dilakukan. Pengujian dilakukan dengan variasi data 20%, 40%, 60%, 80%, dan 100% dari total keseluruhan data yang berjumlah 150 lagu. Dari hasil pengujian, didapatkan nilai error minimum sebesar 0.00000001 (1x10-8). Hasil pengujian menunjukkan bahwa jumlah cluster yang optimal untuk digunakan dalam penelitian ini adalah sebanyak 5 cluster. Sedangkan, nilai pembobot yang optimal untuk digunakan dalam penelitian ini yaitu 2, dengan nilai validitas cluster mencapai 0.7 atau 70%.
Kata Kunci: pengelompokan, emosi, lagu, fuzzy c-means, atribut audio
Abstract
Digital music has grown dramatically in recent years. They offering musics in various type and emotion that are random. Therefore, there is a need to organize the songs, they need to somehow clusterize their files based on a specific characteristic. The purpose of such organization is to enable users to navigate to pieces of music they like, and also to give them advice and recommendation for people or music-related industries. This research proposed a clustering of songs based on their emotion using the Fuzzy c-means algorithm. Audio attributes of valence, energy, loudness, and tempo are used as features that represent the emotions of the song. The cluster of each data is determined based on their membership degree. Cluster validity index is used to evaluate the fitness of partitions produced by clustering algorithms. The algorithm is tested on different amount of data, which is 20%, 40%, 60%, 80%, and 100% data of total 150 songs. The testing result obtained a minimum error value of 0.00000001 (1x10-8). The results showed that the optimal number of clusters that are best to be used in this research is 5. While, the optimal fuzzifier value to be used in this research is 2 with the cluster validity value reaches 0.7 or 70%
Keywords: clustering, emotion, song, fuzzy c-means, audio atribut
1. PENDAHULUAN
Musik digital sudah berkembang secara dramatis dalam beberapa tahun terakhir. Berbagai website maupun aplikasi menawarkan konten musik dalam berbagai bentuk, seperti MP3, waf, dan lain sebagainya. Musik-musik
untuk menavigasi ke musik-musik yang mereka tuju, pengorganisasian tersebut juga bertujuan untuk memberikan saran dan rekomendasi lagu (Cilibrasi, et al., 2004).
Selain genre, pengelompokan musik berdasarkan emosi yang dimilikinya juga penting untuk dilakukan. Studi tentang hubungan antara musik dan emosi telah banyak diteliti dalam bidang psikologi musik. Penelitian-penelitian tersebut berusaha untuk memahami hubungan psikologis antara musik dan pengaruhnya terhadap manusia. Hal ini termasuk dengan reaksi emosional manusia terhadap musik dan komponen apa saja dari musik yang dapat mencerminkan emosi. Beberapa penelitian menyebutkan bahwa fitur suprasegmental dalam musik, seperti tempo, merupakan komponen dalam musik yang lebih membawa informasi emosional dari suatu lagu dibandingkan fitur segmental yang dimilikinya (Kappas, et al., 1991).
Keragaman struktur yang dimiliki oleh suatu lagu atau musik membuat banyak peneliti tertarik untuk mengorganisasikannya. Salah satu penelitian yang melakukan pengelompokan lagu yaitu Abhisek Sen yang mengelompokan genre lagu menggunakan algoritma K-Means (Sen, 2014). Akurasi yang dihasilkan dalam penelitian ini sebesar 75%. Namun, metode K-Means memiliki beberapa kelemahan untuk permasalahan clustering. Kegagalan untuk mencapai konvergen merupakan salah satu kelemahan yang memiliki peluang yang cukup besar pada algoritma K-Means (Agusta, 2007). Dalam metode K-Means, setiap data di dalam dataset dialoasikan secara tegas (hard) untuk menjadi bagian dari suatu kelompok (cluster) tertentu. Hal ini mengakibatkan data yang telah dipindah ke cluster baru bisa jadi justru lebih cocok dalam cluster sebelumnya. Begitu pula dengan keadaan sebaliknya (Bora & Gupta, 2014).
Untuk mengatasi kelemahan dari penggunaan algoritma K-Means, penelitian ini mengusulkan penggunaan algoritma Fuzzy c-means (FCM). FCM merupakan sebuah algoritma untuk clustering data, dimana setiap data akan digolongkan menjadi anggota sebuah cluster dengan ditentukan oleh derajat keanggotaannya. Kelebihan dari FCM adalah sebuah data diukur derajat keanggotaannya dalam rentang 0 sampai 1. Hal ini membuat peluang permasalahan konvergensi pada FCM sangatlah kecil.
Algoritma Fuzzy c-means sendiri juga merupakan perbaikan dari metode pengelompokan yang sudah ada sebelumnya (Dunn, 1973). Fitria Febrianti melakukan penelitian untuk membandingkan algoritma K-Means dengan FCM, hasil menunjukkan bahwa nilai RMSE metode FCM lebih kecil dibandingkan dengan nilai RMSE metode K-Means (Febrianti, et al., 2016).
Berdasarkan uraian permasalahan yang telah dijelaskan, maka dibuat sebuah penelitian tentang pengelompokan lagu berdasarkan emosi menggunakan algoritma Fuzzy C-Means yang diharapkan mampu memberikan hasil yang lebih baik dibandingkan penelitian – penelitian sebelumnya.
2. LANDASAN TEORI
2.1. Model Emosi Lagu
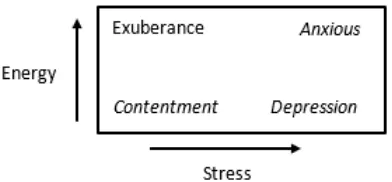
Emosi lagu menggambarkan makna emosional yang melekat pada sebuah klip lagu. Hal ini membantu dalam pemahaman lagu, pencarian lagu, dan beberapa aplikasi yang berkaitan dengan lagu (Liu, et al., 2003). Dalam pengelompokan lagu berdasarkan emosi, diperlukan pemilihan model untuk memetakan ruang dalam emosi menjadi nilai matematika yang terukur sehingga setiap lagu dapat dipisahkan sesuai emosinya (Singth, et al., 2010). Pada akhir tahun 1990-an, Thayer mengusulkan sebuah model emosi dengan dua dimensi. Pendekatan ini memberikan teori bahwa emosi membawakan dua faktor, yaitu stress (senang atau cemas), dan energi (tenang atau energik). Dalam model ini, emosi lagu terbagi ke dalam empat kelompok (Liu, et al., 2003), yaitu kepuasan atau kesenangan (contentment), depresi (depression), gembira (exuberance), dan cemas (anxious) yang digambarkan dalam Gambar 1.
Gambar 1 Model Emosi Thayer
menenangkan dan gelisah, gembira (exuberance) mengacu pada musik yang bahagia dan energik, sedangkan kecemasan (anxious) mengacu pada musik yang menggelisahkan dan energik (Liu, et al., 2003).
2.2. Fuzzy C-Means
Fuzzy c-means (FCM) merupakan teknik clustering yang pertama kali dikemukakan oleh Dunn pada tahun 1973 dan kemudian dikembangkan oleh Bezdek pada tahun 1981 (Pravitasari, 2009). FCM merupakan suatu teknik clustering dimana keberadaan dari tiap titik data dalam suatu cluster ditentukan oleh derajat keanggotaan dengan rentang 0 sampai 1 (Bora & Gupta, 2014). Tujuan dari algoritma FCM adalah untuk menemukan nilai c atau pusat cluster optimal dengan minimalisasi fungsi objektif (Nascimento, et al., 1999). Output dari Fuzzy c-means bukan berupa fuzzy inference system, melainkan berupa deretan pusat cluster dan derajat keanggotaan untuk setiap data (Kusumadewi & Purnomo, 2010 ). Algoritma FCM adalah sebagai berikut (Khoiruddin, 2007) :
Selanjutnya, hitung derajat keanggotaan awal dengan Persamaan (2).
5. Hitung fungsi objektif pada iterasi ke-t, Pt :
𝑃𝑡= ∑ ∑ ([∑(𝑋𝑖𝑗− 𝑉𝑘𝑗2)
6. Perbaiki derajat keanggotaan setiap data menggunakan Persamaan 5.
Jika kondisi belum memenuhi, maka ulangi dari langkah ke-4.
2.3. Modified Partition Coefficient
Modified Partition Coefficient (MPC) merupakan salah satu cara untuk mengukur tingkat validitas cluster yang menggunakan nilai-nilai derajat keanggotan 𝜇𝑖𝑘. Tujuan utama dari validitas cluster yaitu untuk mengevaluasi kualitas dari cluster tersebut dan menentukan seberapa baik data diwakili oleh cluster yang dipilih (Sandhir, et al., 2012). MPC merupakan perbaikan dari metode Partition Coefficient (PC). Metode PC diusulkan oleh Bezdek dalam (Maimon & Rokach, 2010) yang didefninisikan dengan Persamaan (6).
𝑃𝐶(𝑐) =1𝑛∑𝑐𝑖=1∑ (𝜇𝑛𝑗=1 𝑖𝑗)2
(6)
PC cenderung mengalami perubahan yang monoton terhadap nilai c (Xie, et al., 2011). Hal ini diperbaiki oleh metode MPC yang diusulkan oleh Dave (Wu & Yang, 2005) dan didefinisikan oleh Persamaan (7).
𝑀𝑃𝐶(𝑐) = 1 −𝐶 − 1 (1 − 𝑃𝐶(𝑐))𝐶 (7)
Nilai MPC berkisar antara 0 ≤ 𝑀𝑃𝐶(𝑐) ≤
3. DATASET
Dalam model emosi Thayer, terdapat dua sumbu utama yang berperan dalam menentukan emosi dari lagu yaitu (Han, et al., 2009):
• Stres, emosi positif atau negatif • Energi, energi tinggi atau rendah
Valensi (valence) merupakan fitur yang merepresentasi sumbu X atau dimensi stres. Sementara itu, energi merupakan fitur yang merepresentasikan sumbu Y (Liu, et al., 2003; Han, et al., 2009).
Terdapat beberapa fitur lain yang juga terkait dengan emosi lagu dan mempengaruhi ekspresi emosional dalam musik. Berbagai penelitian menunjukkan bahwa tempo dan loudness merupakan fitur yang sangat terkait dengan ekspresi dari emosi (Gabrielle & Stromboli, 2001; Jamdar, et al., 2015)..
Data atribut audio dari lagu yang digunakan dalam penelitian ini diambil dari Spotify. Spotify merupakan sebuah penyimpanan informasi musik online yang mengandung informasi lebih dari 30 juta lagu dari 1.5 juta artis (Sen, 2014). Spotify sendiri mempunyai pengembang API yang ditulis rapi dalam berbagai bahasa pemrograman, salah satunya python, dan mengijinkan pengguna untuk mengambil data atribut audio yang dibutuhkan untuk setiap lagu. Perhitungan atribut audio dari lagu yang digunakan telah dihitung langsung oleh Spotify. Kami menggunakan atribut audio berupa valensi, energi, loudness, dan tempo.
3.1. Valensi
Valensi merupakan fitur yang digunakan untuk menggambarkan positif atau negatif suatu emosi (Jamdar, et al., 2015). Dalam Spotify, valensi bernilai 0 sampai 1. Lagu dengan valensi tinggi terdengar lebih positif seperti senang, ceria, atau gembira. Sebaliknya, lagu dengan valensi yang rendah akan lebih negatif seperti sedih, tertekan, atau marah (Watson & Mandryk, 2012).
3.2. Tempo
Jumlah ketukan per menit atau biasa disebut dengan tempo menggambarkan hubungan antara kecepatan dan intensitas emosi dalam suatu lagu. Tempo yang tinggi pada umumnya memiliki energi yang lebih tinggi dan cepat jika dibandingkan dengan lagu yang memiliki tempo rendah (Jamdar, et al., 2015). Tempo yang pelan cenderung menggambarkan emosi seperti
tentram, tenang, sedih, dan lembut. Sedangkan di sisi sebaliknya, tempo yang cepat lebih mendeskirpsikan emosi gembira, senang, dan semangat (Thompson & Quinto, 2011). Pada model emosi Thayer, lagu yang berada dalam kelompok gembira (Exuberance) memiliki tempo yang cepat lebih dibandingkan dengan lagu yang berada dalam kelompok depresi (depression) (Liu, et al., 2003).
3.3. Loudness
Loudness atau intensitas kerasnya suara merupakan pengukuran terhadap intensitas gelombang audio yang dinyatakan dalam desibel. Semakin keras lagu cenderung menggambarkan lagu yang semakin energik dan agresif. Berbeda dengan lagu yang lembut, lagu tipe ini cenderung menggunakan instrumen yang lembut dan menggambarkan emosi yang lebih tenang (Jamdar, et al., 2015).
3.4. Energi
Energi pada sebuah lagu mengindikasikan intensitas emosi dalam lagu tersebut. Energi dihitung dalam skala 0 sampai 1 (Jamdar, et al., 2015). Energi dalam lagu membuat pendengarnya merasa energik, ataupun sebaliknya (Sen, 2014). Lagu dalam kelompok contentment dan depresion memiliki tingkat energi yang lebih rendah dibandingkan dengan lagu yang menggambarkan kegembiraan (exuberance).
4. METODE PENELITIAN
Dalam penelitian ini, dilakukan beberapa tahapan yaitu studi literatur, pengumpulan data, perancangan, implementasi, pengujian dan analisis, serta pengambilan kesimpulan dari penelitian. Tahapan dari pengerjaan penelitian secara umum ditunjukkan pada Gambar 2.
dilakukan proses evaluasi menggunakan MPC untuk didapatkan nilai validitas cluster. Setelah keseluruhan proses selesai, maka akan didapatkan output berupa nilai MPC serta kelompok-kelompok lagu. Alur proses pengelompokan lagu berdasarkan emosi menggunakan algoritma Fuzzy C-Means secara umum ditunjukkan pada Gambar 3.
Gambar 2 Diagram Alir Metode Penelitian
Gambar 3 Alur Proses Penelitian
5. HASIL DAN PEMBAHASAN
Pengujian dalam penelitian ini dilakukan dalam dua skenario pengujian. Pengujian pertama dilakukan untuk mendapatkan nilai error minimum (ξ) yang tepat agar didapatkan hasil yang optimal. Pengujian kedua yaitu uji validitas. Pengujian ini dilakukan dengan memasukkan nilai error minimum yang telah
didapatkan pada pengujian pertama. Pengujian validitas cluster dilakukan menggunakan MPC dan terdiri dari tiga tahap, yaitu pengujian terhadap banyaknya jumlah cluster, pengujian terhadap nilai pembobot, dan pengujian terhadap ciri. Data lagu yang digunakan untuk setiap pengujian berasal dari genre dan jumlah yang berbeda.
5.1. Hasil Pengujian Nilai Error Minimum
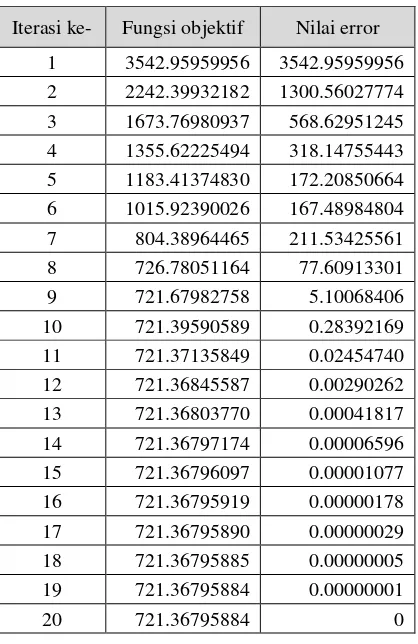
Pengujian pertama dilakukan untuk mendapatkan nilai error minimum (ξ). Pengujian dilakukan pada saat fungsi objektif telah mencapai kondisi konvergen. Nilai error diperoleh dengan menghitung selisih dari fungsi objektif yang didapatkan pada setiap iterasi. Fungsi objektif dikatakan telah konvergen apabila nilai yang dihasilkan sudah tidak mengalami perubahan lagi, sehingga kesalahan (error) yang dihasilkan bernilai 0. Pada pengujian ini, parameter jumlah cluster yang digunakan adalah sebanyak 3 dengan maksimum iterasi 100. Hasil pengujian nilai error terhadap fungsi objektif ditunjukkan pada Tabel 1.
Tabel 1 Hasil Pengujian Terhadap Fungsi Objektif
Iterasi ke- Fungsi objektif Nilai error
1 3542.95959956 3542.95959956 2 2242.39932182 1300.56027774
3 1673.76980937 568.62951245
4 1355.62225494 318.14755443
5 1183.41374830 172.20850664
6 1015.92390026 167.48984804
7 804.38964465 211.53425561
8 726.78051164 77.60913301
9 721.67982758 5.10068406
10 721.39590589 0.28392169
11 721.37135849 0.02454740
12 721.36845587 0.00290262
13 721.36803770 0.00041817
14 721.36797174 0.00006596
15 721.36796097 0.00001077
16 721.36795919 0.00000178
17 721.36795890 0.00000029
18 721.36795885 0.00000005
19 721.36795884 0.00000001
20 721.36795884 0
Berdasarkan Tabel 1, dapat diketahui bahwa nilai fungsi objektif menjadi konvergen Pengujian dan Analisis
Implementasi Sistem Perancangan Studi Literatur
Pengumpulan Data
Pengambilan Kesimpulan dan Evaluasi
Mulai
Data file lagu yang akan dikelompokkan
Nilai MPC dan kelompok-kelompok lagu
Selesai
ketika mencapai iterasi ke-20. Nilai error minimum yang diperoleh pada saat fungsi objektif telah konvergen adalah sebesar 0.00000001 (1 x 10-8). Nilai ini kemudian akan
ditetapkan sebagai masukan pada pengujian-pengujian berikutnya.
5.2. Hasil Pengujian Terhadap Jumlah Cluster
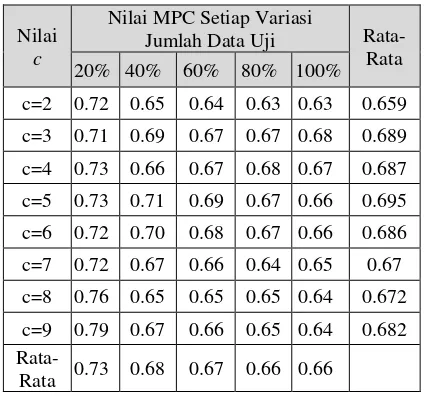
Pengujian terhadap jumlah cluster (c) dilakukan untuk mengetahui pengaruh banyaknya jumlah cluster terhadap nilai validitas MPC. Tujuan pengujian ini yaitu untuk mendapatkan nilai c terbaik yang memiliki nilai MPC paling baik untuk digunakan pada pengujian selanjutnya. Pengujian terhadap jumlah cluster dilakukan dengan membandingkan hasil nilai MPC dari banyaknya cluster yang berbeda untuk setiap variasi data uji. Pengujian dilakukan dengan variasi data sebanyak 20%, 40%, 60%, 80%, dan 100% dari total keseluruhan 150 data. Pada pengujian ini, nilai c yang digunakan yaitu c=2 sampai dengan c=9 dengan nilai pembobot w=2. Hasil uji validitas terhadap variasi jumlah cluster ditunjukkan pada Tabel 2.
Tabel 2 Hasil Pengujian MPC Terhadap Jumlah Cluster
Nilai
c
Nilai MPC Setiap Variasi
Jumlah Data Uji
Rata-Rata
Tabel 2 menunjukkan bahwa semakin besar jumlah cluster atau nilai c yang dimasukkan maka nilai validitas MPC yang dihasilkan cenderung semakin menurun. Nilai c yang semakin besar berarti bahwa semakin banyak variasi pada tingkatan emosi lagu. Persebaran data dalam kelompok yang tidak merata dan jarak data yang semakin jauh menyebabkan nilai
validitas MPC yang semakin menurun ketika nilai c yang dimasukkan semakin besar.
Pada Tabel 2 juga terlihat bahwa nilai indeks validitas MPC tertinggi didapatkan pada nilai c=5. Hal ini berarti pada jumlah c=5, masing-masing data sudah berada dalam kelompok yang memiliki satu emosi lagu yang serupa dengan tingkat ketepatan hasil clustering sebesar 0.69472. Dengan demikian, nilai c=5 merupakan jumlah cluster yang optimal untuk diterapkan dalam penelitian ini.
5.3. Hasil Pengujian Terhadap Pembobot
Pengujian validitas juga dilakukan terhadap nilai w yang merupakan bobot pangkat pada perhitungan nilai keanggotaan metode FCM. Nilai dari pembobot (w) bernilai w>1. Tujuan dari pengujian ini untuk mengetahui pengaruh nilai pembobot terhadap nilai validitas MPC serta untuk mendapatkan nilai w terbaik yang memiliki nilai MPC paling tinggi.
Pengujian terhadap nilai pembobot dilakukan dengan membandingkan hasil nilai MPC dari nilai w yang berbeda untuk setiap variasi data uji. Komposisi data lagu untuk pengujian nilai pembobot sama dengan komposisi data lagu yang digunakan pada pengujian jumlah cluster. Pada pengujian ini, nilai w yang digunakan terdiri dari w=2 sampai dengan w=9 dengan jumlah cluster 5. Hasil pengujian terhadap pembobot ditunjukkan dalam Tabel 3.
Tabel 3 menunjukkan bahwa nilai validitas tertinggi didapatkan pada saat w bernilai 2, yaitu sebesar 0.69951. terlihat bahwa semakin besar nilai w yang dimasukkan maka hasil validitas cluster akan semakin rendah. Hal ini berarti nilai w yang besar mengakibatkan hasil clustering yang semakin tidak optimal. Penyebaran partisi data yang cenderung kabur (fuzzy) menyebabkan turunnya nilai validitas cluster pada nilai w yang besar. Dengan demikian, dalam kasus ini nilai w=2 merupakan nilai pembobot yang baik untuk diterapkan dalam penelitian ini.
Tabel 3 Hasil Pengujian MPC Terhadap Jumlah Cluster
Nilai w
Nilai MPC Setiap Variasi Jumlah
Rata-w=5 0.638 0.713 0.693 0.667 0.675 0.6772
w=6 0.61 0.711 0.691 0.678 0.676 0.673
w=7 0.608 0.709 0.689 0.678 0.676 0.6721
w=8 0.598 0.661 0.688 0.678 0.677 0.6602
w=9 0.498 0.633 0.686 0.658 0.677 0.6303
5.4. Hasil Pengujian Terhadap Ciri
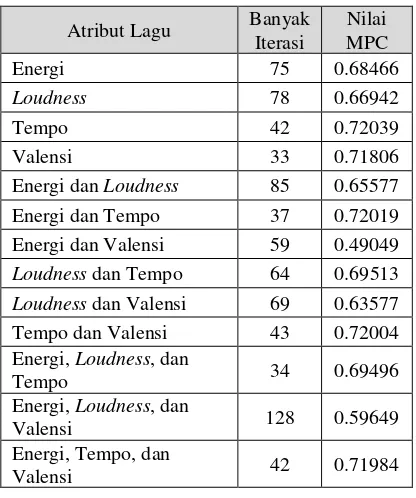
Pengujian terhadap ciri dilakukan dengan membandingkan hasil nilai MPC terhadap setiap variasi ciri yang diujikan. Ciri yang digunakan dalam penelitian ini berupa atribut audio dari lagu, yaitu valensi, energi, loudness, dan tempo. Variasi ciri yang digunakan untuk pengujian ini yaitu dengan menguji setiap ciri secara individu, menguji kombinasi ciri dengan jumlah 2 variasi dan 3 variasi, serta menguji keempat ciri secara keseluruhan. Hal ini dilakukan untuk mengetahui kombinasi ciri mana yang menghasilkan nilai MPC terbaik serta untuk untuk mengetahui efektifitas ciri yang digunakan terhadap hasil clustering. Data yang digunakan dalam pengujian ini berjumlah 75 data lagu. Pengujian ini menggunakan parameter terbaik yang telah didapatkan pada pengujian-pengujian sebelumnya, yaitu dengan memasukkan nilai error minimum ξ=1x10-8, pembobot w=2, dan
banyak clusterc=5. Hasil pengujian terhadap ciri yang telah dilakukan dapat ditunjukkan pada Tabel 4.
Tabel 4 Hasil Pengujian MPC terhadap Variasi Ciri Atribut Lagu
Atribut Lagu Banyak
Iterasi
Nilai MPC
Energi 75 0.68466
Loudness 78 0.66942
Tempo 42 0.72039
Valensi 33 0.71806
Energi dan Loudness 85 0.65577
Energi dan Tempo 37 0.72019
Energi dan Valensi 59 0.49049
Loudness dan Tempo 64 0.69513
Loudness, Tempo, dan
Valensi 39 0.6948
Energi, Loudness, Tempo,
dan Valensi 45 0.69971
Dalam Tabel 4, perpaduan ciri energi dan valensi yang merupakan atribut dalam model emosi Thayer menghasilkan nilai MPC terendah, yaitu sebesar 0.49049. Dalam penelitian ini, kami memadukan energi dan valensi dengan atribut audio lain, yaitu tempo dan loudness yang dalam berbagai literatur disebutkan bahwa kedua fitur tersebut juga berpengaruh dalam merepresentasikan emosi dari lagu. Nilai MPC yang dihasilkan oleh ciri atribut audio tempo yaitu sebesar 0.72039 yang merupakan nilai MPC tertinggi yang didapatkan dalam pengujian ini. Hal ini membuktikan teori bahwa tempo merupakan atribut audio lagu yang sangat merepresentasikan emosi dari lagu. Sementara itu, perpaduan keempat ciri atribut audio yang dipilih dalam penelitian ini berhasil mencapai nilai MPC sebesar 0.6997. Nilai yang didapatkan oleh perpaduan keempat ciri ini menunjukkan nilai yang lebih tinggi dibandingkan hanya menggunakan kedua fitur energi dan valensi. Nilai MPC yang lebih tinggi ini membuktikan bahwa penambahan fitur yang kami lakukan dapat merepresentasikan emosi lagu lebih baik dibandingkan dengan hanya menggunakan fitur energi dan valensi. Namun, nilai MPC yang didapatkan pada perpaduan keempat ciri masih lebih rendah dibandingkan dengan perpaduan tiga fitur energi, tempo, dan valensi yang mencapai 0.71984. Hal ini kemungkinan besar dikarenakan penggunaan fitur loudness yang digunakan dalam penelitian ini. Hal ini terbukti dengan rendahnya nilai MPC yang dimiliki oleh fitur loudness jika dibandingkan dengan hasil nilai MPC dari ketiga fitur lainnya.
6. KESIMPULAN
Berdasarkan hasil pengujian dan analisis hasil penelitian terhadap pengelompokan lagu berdasarkan emosi menggunakan algoritma Fuzzy C-Means, maka dapat diambil beberapa kesimpulan, yaitu :
dan tempo untuk merepresentasikan emosi lagu.
2. Berdasarkan pengujian yang telah dilakukan, nilai error minimum yang didapatkan pada saat fungsi objektif telah konvergen adalah sebesar 0.00000001 (1 x 10-8). Banyaknya cluster yang optimal
untuk digunakan dalam penelitian ini adalah sebanyak 5 cluster dengan nilai validitas cluster mencapai 0.69472 atau 69.5%. Sedangkan, nilai pembobot (w) yang optimal untuk digunakan dalam penelitian ini yaitu 2 dengan nilai validitas cluster mencapai 0.69951 atau 69.95%.
DAFTAR PUSTAKA
Agusta, Y., 2007. K-Means – Penerapan, Permasalahan dan Metode Terkait. Jurnal Sistem dan Informatika, Februari, Volume 3, pp. 47-60.
Bezdek, J., 1981. Pattern Recognition with Fuzzy Objective Function Algorithms. New York: Plenum Press.
Bora, D. . J. & Gupta, D. A. K., 2014. A Comparative study Between Fuzzy Clustering Algorithm and Hard Clustering Algorithm. International Journal of Computer Trends and Technology (IJCTT), April, 10(2), pp. 108 - 113.
Cilibrasi, R., Vit´anyi, P. & Wolf, R. d., 2004. Algorithmic Clustering of Music. Amsterdam, EDELMUSIC, pp. 110-117.
Gabrielle, A. & Stromboli, E., 2001. The influence of musical structure on emotional expression. Music and Emotion: Theory and Research, pp. 223-243.
Jamdar, A., Abraham, J., Khanna, K. & Dubey, R., 2015. Emotion Analysis of Songs Based on Lyrical and Audio Features. International Journal of Artificial Intelligence & Applications (IJAIA), May, 6(03), pp. 35-50.
Kappas, A., Hess, U. & Scherer, K. R., 1991. Voice and emotion. In: Fundamentals of nonverbal behavior. Cambridge, UK: Cambridge University Press, pp. 38-200.
Khoiruddin, A. A., 2007. Menentukan Nilai
Akhir Kuliah Dengan Fuzzy C-Means. Seminar Nasional Sistem dan Informatika, pp. 232-238.
Kusumadewi, S. & Purnomo, H., 2010 . Aplikasi Logika Fuzzy untuk Pendukung Keputusan. Jakarta: Graha Ilmu.
Liu, D., Liu, L. & Zhang, H.-J., 2003. Automatic Mood Detection from Acoustic Music Data. In Proceedings of the 4th International Symposium on Music Information Retrieval, pp. 81-87.
Maimon, O. & Rokach, L., 2010. Data Mining and Knowledge Discovery Handbook. 2nd ed. London: Springer Science+Business Media.
Nascimento, S., Mirkin, B. & Moura-Pires, F., 1999. A Fuzzy Clustering Model of Data and Fuzzy c-Means, s.l.: Department of Computer Science of FCT- Universidade Nova de Lisboa and DIMACS .
Pravitasari, A. A., 2009. Penentuan Banyak Kelompok dalam Fuzzy C-Means Cluster Berdasarkan Proporsi Eigen Value Dari Matriks Similarity dan Indeks XB (Xie dan Beni). PROSIDING, 5 Desember.pp. 623-632.
Sandhir, R. P., Muhuri , S. & Nayak, T. K., 2012. Dynamic Fuzzy c-Means (dFCM) Clustering and its Application to Calorimetric Data Reconstruction in High Energy Physics. Nuclear Instruments and Methods in Physics Research Section A: Accelerators, Spectrometers, Detectors and Associated Equipment, Volume 681, pp. 34-43.
Sen, A., 2014. Automatic Music Clustering using Audio Attributes. International Journal of Computer Science Engineering (IJCSE), November, 3(06), pp. 307-312.
Singth, P., Kapoor, A., Kaushik, V. & Maringanti, H. B., 2010. Architecture for Automated Tagging and Clustering of Song Files According to Mood. IJCSI International Journal of Computer Science, pp. 11-17.
Aesthetic Mind: Philosophy and Psychology. Oxford: Oxford University Press , pp. 357-375.
Watson , D. & Mandryk, R. L., 2012. Modeling Musical Mood From Audio Features And Listening Context On An In-Situ Data Set. International Society for Music Information Retrieval, pp. 31-36.
Wu, K.-L. & Yang, M.-S., 2005. A Cluter Validity Index for Fuzzy Clustering. Pattern Recognition Letters, 1 Juli, 26(9), pp. 1275-1291.