TUGAS AKHIR – SS141501
PENGELOMPOKAN PROVINSI
DI INDONESIA BERDASARKAN INDIKATOR
KESEJAHTERAAN RAKYAT MENGGUNAKAN METODE
C-MEANS
DAN
FUZZY C-MEANS CLUSTERING
ANNISA SAJIDAH NRP 1311 100 135
Dosen Pembimbing Dr. Dra. Ismaini Zain, M.Si
Program Studi S1 Statistika
Fakultas Matematika dan Ilmu Pengetahuan Alam Institut Teknologi Sepuluh Nopember
TUGAS AKHIR –SS141501
PENGELOMPOKAN PROVINSI
DI INDONESIA BERDASARKAN INDIKATOR
KESEJAHTERAAN RAKYAT MENGGUNAKAN METODE
C-MEANS
DAN
FUZZY C-MEANS CLUSTERING
ANNISA SAJIDAH NRP 1311 100 135
Dosen Pembimbing Dr. Dra. Ismaini Zain, M.Si
Program Studi S1 Statistika
Fakultas Matematika dan Ilmu Pengetahuan Alam Institut Teknologi Sepuluh Nopember
FINAL PROJECT –SS141501
GROUPING PROVINCES IN INDONESIA
BASED ON WELFARE INDICATORS
USING
C-MEANS
AND
FUZZY C-MEANS
ANNISA SAJIDAH NRP 1311 100 135
Supervisor
Dr. Dra. Ismaini Zain, M.Si
Undergraduate Program of Statistics
Faculty of Mathematics and Natural Sciences Institut Teknologi Sepuluh Nopember
v
Pengelompokan Provinsi di Indonesia Berdasarkan
Indikator Kesejahteraan Rakyat dengan Metode
c-means
dan
fuzzy c-means clustering
Nama Mahasiswa : Annisa Sajidah NRP : 1311 100 135
Jurusan : Statistika FMIPA-ITS Pembimbing : Dr. Dra. Ismaini Zain, M.Si
ABSTRAK
Permasalahan sosial yang terjadi di Indonesia memberikan dampak yang cukup serius kepada kesejahteraan rakyat di suatu daerah. Kesejahteraan rakyat berkaitan dengan tujuan pembangunan nasional namun permasalahan yang ada adalah tidak mampunya pemerintah dalam memilah permasalahan di setiap daerah sehingga pembangunan yang dilakukan dapat merata. Penelitian ini bertujuan memberikan informasi kepada pihak terkait dalam pembangunan nasional agar memberikan penanganan yang sesuai kepada provinsi yang dianggap kurang sejahtera berdasarkan tingkat homogenitasnya dengan metode pengelompokan c-means dan fuzzy c-means. Pengelompokan tersebut memberikan hasil bahwa dengan c-means memberikan hasil lebih baik dibandingkan dengan fuzzy c-means clustering berdasarkan nilai icd rate terendah nya dimana cluster optimum yang terbentuk ada sebanyak 2 cluster yang dilihat dari nilai pseudo f-statistics tertinggi. Hasil c-means memberikan hasil karakteristik provinsi papua membutuhkan perhatian lebih dibandingkan provinsi lainnya dari segala dimensi. Sedangkan dengan fuzzy c-means kedua kelompok mampu meberikan karakteristik tersendiri sesuai dengan komponen utama yang membentuknya.
Kata Kunci – C-Means Clustering, Fuzzy C-Means Clusering,
vii
Grouping Provinces in Indonesia Based On Welfare
Indicators Using
c-means
and
fuzzy c-means clustering
Name of Student : Annisa Sajidah NRP : 1311 100 135 Department : Statistics
Advisor : Dr. Dra. Ismaini Zain, M.Si
ABSTRACT
Social problems that occur in Indonesia provide a fairly serious impact to the welfare of people in that area. Welfare indicators concerned with national development goals but the problem is the inability of the government for sorting out the problems in each area so that development can be done evenly. This study aims to provide information to stakeholders in national development in order to provide appropriate treatment to provinces that are considered less prosperous based on the level of homogenity by the method of grouping c-means and fuzzy c-means. Grouping by fuzzy c-means providing better results than with c-means clustering based on the value icd-rate cause it is the lowest rate in which the optimum cluster is formed there were two clusters are seen from the pseudo highest f-statistics. The result by c-means provide the characteristics of Papua province needs more attention compared the other provinces from all dimensions. While the fuzzy c-means two groups that gave the distinct characteristics in accordance with the principal components of dimensions that make it up.
Kata Kunci – C-Means Clustering, Fuzzy C-Means Clusering,
viii
ix
KATA PENGANTAR
Puji syukur kehadirat Allah SWT, atas limpahan rahmat yang tidak pernah berhenti sehingga terselesaikannya Tugas Akhir yang berjudul
“
Pengelompokan Provinsi di Indonesia Berdasarkan
Indikator Kesejahteraan Rakyat Dengan Metode
C-Means
dan
Fuzzy C-Means Clustering
”
dengan baik. Penyusunan Tugas Akhir ini tidak terlepas dari bantuan dan dukungan dari berbagai pihak. Oleh karena itu, pada kesempatan ini ucapan terima kasih yang sebesar-besarnya kepada:
1. Allah SWT yang telah melimpahkan segala rahmat dan kasih sayangNya sehingga terselesaikan Tugas Akhir ini dengan baik.
2. Bapak Dr. Suhartono M.Sc selaku Ketua Jurusan Statistika yang telah memberikan banyak fasilitas untuk kelancaran penyelesaian Tugas Akhir ini.
3. Ibu Dr. Dra Ismaini Zain M.Si selaku dosen pembimbing yang telah sabar dalam memberikan bimbingan dan saran atas bantuan dan semua informasi yang diberikan. Meluangkan segala kesempatan dan waktu yang ada untuk memberikan bimbingan terhadap Tugas Akhir ini.
4. Ibu Dr. Vita Ratnasari, S.Si, M.Si dan Dra. Ibu Madu Ratna, M.Si selaku dosen penguji atas saran dan kritiknya yang sangat membangun.
5. Ibu Santi Putri selaku dosen wali atas dukungan, semangat yang diberikan, nasehat setiap semester, dan saran-saran yang berguna pada saat perwalian.
x
7. Indi Yasinta dan Ummu Habibah saudara selama masa kuliah.Terimakasih banyak buat dukungan yang tak berhenti mengalir dan bersedia menyediakan tempat umtuk berkeluh kesah saat kesulitan datang saat menyelesaikan Tugas Akhir ini.
8. Fiscy Aprilia, Aprilia Tri Wahyu, Anggraeni Rahma Dewi, Fatkhiyatur Rizki dan Ilafi Andalita telah menjadi teman senasib sepenganggungan dan memberikan dukungan banyak hal dan akhirnya Tugas Akhir ini terselesikan dengan baik. 9. Teman-teman seperjuangan statistika great 2011 sigma 22
yang selalu bersama dalam dekapan hangatnya sebuah keluarga.
10. Teman-teman AIESEC Surabaya yang selalu membantu selama berada disini dan bersama untuk giving impact to the society based on Global Issues.
11. Keluarga BEM FMIPA ITS 12-13 dan BEM FMIPA ITS 13-14 yang selalu menyemangati sehingga Tugas Akhir ini terselesikan dengan baik.
12. Keluarga Karate ITS yang selalu menjadi keluarga dan menjadi teman seperjuangan mengharumkan nama ITS dengan menjadi atlit pertandingan untuk ITS.
13. Keluarga Gudang Ilmu Indonesia yang menjadi keluarga dalam berbagi ilmu kepada adik-adik yang membutuhkan. 14. Serta semua pihak yang telah mendukung dan tidak dapat
penulis sebutkan satu persatu.
Harapannya Tugas Akhir ini dapat bermanfaat bagi kita semua serta saran dan kritik yang bersifat membangun guna perbaikan di masa mendatang.
xi
KATA PENGANTAR... ... ix
DAFTAR ISI ... xi
DAFTAR GAMBAR ... xiii
DAFTAR TABEL ... xv
DAFTAR LAMPIRAN ... xvii
BAB I PENDAHULUAN 1.1 Latar Belakang ... 1
1.2 Perumusan Masalah... .. 3
1.3 Tujuan ... 3
1.4 Manfaat Penelitian ... 3
1.5 Batasan Masalah ... 4
BAB II TINJAUAN PUSTAKA 2.1 Distribusi Normal Multivariat ... 5
2.2 Uji KMO.... ... 5
2.3 Uji Barlett... 6
2.4 Analisis Cluster ... 6
2.5 C-means Clustering ... 7
2.6 Fuzzy C-means Clustering ... 9
2.7 Fungsi Keanggotaan ... 11
2.7.1 Representasi Linear ... 11
2.7.2 Representasi Segitiga ... 13
2.8 Principal Compenent Anaysis (PCA) ... 14
2.9 Pseudo f-statistics ... 15
2.10Internal Cluster Dispertion Rate (icd-rate) ... 16
2.11 One-way ANOVA ... 17
BAB III METODOLOGI PENELITIAN 3.1 Sumber Data... 19
3.2 Variabel Penelitian ... 19
xii
3.4 Definisi Operasional... 20
3.5 Langkah-langkah Penelitian ... 22
3.6 Diagram Alir... ... 24
BAB IV ANALISIS DAN PEMBAHASAN 4.1 Deskripsi Indikator Kesejahteraan Rakyat ... 25
4.2 Pengelompokan Provinsi di Indonesia dengan C-Means dan Fuzzy C-Means Clustering ... 32
4.3 Perbandingan Hasil Pengelompokan dengan C-Means dan Fuzzy C-Means Clustering ... 41
BAB V KESIMPULAN DAN SARAN 5.1 Kesimpulan ... 43
5.2 Saran ... 44
DAFTAR PUSTAKA ... 45
xiii
DAFTAR GAMBAR
Halaman
Gambar 2.1 Representasi Linear Naik ... 12
Gambar 2.2 Representasi Linear Turun ... 13
Gambar 2.3 Representasi Kurva Segitiga ... 14
Gambar 3.1 Diagram Alir Penelitian ... 24
Gambar 4.1 Indeks Gini Provinsi di Indonesia ... 28
Gambar 4.2 Persentase Penduduk Miskin di Indonesia ... 29
Gambar 4.3 Tingkat Pengangguran Terbuka ... 30
Gambar 4.4 Plot Distribusi Normal Multivariat ... 31
Gambar 4.5 Scree plot ... 33
Gambar 4.6 Peta Pengelompokan dengan C-means clustering .. 36
xiv
xv
DAFTAR TABEL
Halaman
Tabel 2.1 Uji One-way ANOVA ... 18
Tabel 3.1 Variabel Indikator Kesehatan ... 27
Tabel 3.2 Variabel Indikator Pendidikan ... 19
Tabel 3.3 Variabel Indikator Ekonomi ... 20
Tabel 3.4 Struktur Data ... 20
Tabel 4.1 Statistika Deskriptif Berdasarkan Indikator Kesehatan ... 25
Tabel 4.2 Statistika Deskriptif Berdasarkan Indikator Pendidikan ... 29
Tabel 4.3 Uji Barlett dan Uji KMO Indikator Kesejahteraan Rakyat Indonesia ... 32
Tabel 4.4 Eigenvalues dan percentage of variance ... 33
Tabel 4.5 Nilai Pseudo f-statistics Metode C-means ... 35
Tabel 4.6 Anggota Cluster Dengan C-means ... 35
Tabel 4.7 Nilai Pseudo f-statistics Metode Fuzzy c-means ... 38
Tabel 4.8 Pengelompokan Optimum Dengan Fuzzy C-Means Clustering Fungsi Keangotaan Linear Naik ... 40
Tabel 4.9 Pengelompokan Optimum Dengan Fuzzy C-Means Clustering Fungsi Keangotaan Linear Turun dan Se-gitiga ... 40
xvi
xvii
DAFTAR LAMPIRAN
Halaman
Lampiran A Data Penelitian ... 47
Lampiran B Data Penelitian Standarisasi ... 48
Lampiran C Principal Component Analysis... 49
Lampiran D Principal Component Analysis & Derajat Keanggotaan Linear Naik ... 50
Lampiran E Principal Component Analysis & Derajat Keanggotaan Linear Turun ... 51
Lampiran F Principal Component Analysis & Derajat Keanggotaan Segitiga ... 52
Lampiran G Matriks U Linear Naik ... 53
Lampiran H Matriks U Linear Turun ... 54
Lampiran I Matriks U Segitiga ... 55
Lampiran J Macro Minitab Normal Multivariat ... 56
Lampiran K Syntax Matab Fuzzy C-Means ... 57
Lampiran L Syntax Matlab Pseudo F Statistics ... 59
Lampiran M Hasil Cluster Dengan C-Means... 60
Lampiran N Hasil Cluster Dengan Fuzzy C-Means Linear naik ... 61
Lampiran O Hasil Cluster Dengan Fuzzy C-Means Linear Turun ... 62
xviii
1
BAB I
PENDAHULUAN
1.1
Latar Belakang
Indonesia merupakan negara berkembang dengan tingkat pertumbuhan penduduk setiap tahunnya cukup tinggi dimana persebaran peduduk serta lahan untuk tinggal di Indonesia tidak merata. Hal ini mengakibatkan banyak masalah sosial terjadi di Indonesia sehingga perlu dilakukan perencanaan pembangunan agar terlepas dari permasalahan sosial. Pembangunan adalah rangkaian upaya mewujudkan tujuan nasional bangsa Indonesia yang maju, mandiri, sejahtera dan berkeadilan sesuai dengan UUD 1945 alinea keempat yang menyebutkan bahwa tujuan pembangunan nasional adalah mencerdaskan kehidupan bangsa dan memajukan kesejahteraan umum yang mana hal ini mengandung makna pemberdayaan penduduk.
Sejalan dengan adanya pembangunan nasional, United Nation
atau Perserikatan Bangsa-Bangsa pada tahun 2000 mendeklarasikan kesepakatan Tujuan Pembangunan Milenium (Millenium Development Goal/ MDG’s). Terdapat delapan poin tujuan MDG’s yaitu menanggulangi kemiskinan dan kelaparan, upaya mencapai pendidikan dasar untuk semua, mendorong kesetaraan gender dan pemberdayaan perempuan, menurunkan angka kematian anak dan balita, meningkatkan angka kesehatan ibu, memerangi HIV/AIDS, malaria dan penyakit menular lainnya, memastikan kelestarian lingkungan hidup dan mengembangkan kemitraan global untuk pembangunan. Sehingga pada intinya pembangunan adalah menciptakan lingkungan yang memungkinkan masyarakat menikmati umur panjang, sehat, dan menjalankan kehidupan produktif yang mana pada intinya adalah untuk meningkatkan kesejahteraan rakyat.
dan juga kompleks sehingga suatu taraf kesejahteraan rakyat hanya dapat dinilai melalui indikator-indikator terukur dari berbagai aspek pembangunan..
Indikator kesejahteraan rakyat terdiri dari indikator pendidikan, indikator ketenagakerjaan, indikator demografi, indikator kesehatan, dan indikator sosial lainnya. (Badan Pusat Statistik,2014). Penelitian ini mengambil indikator ekonomi, pendidikan, dan kesehatan. Ketiga indikator ini diambil berdasarkan pemilihan poin pada tujuan MDG’s dari United Nation dikarenakan indikator ini merupakan dimensi yang cukup dekat dengan kesejahteraan masyarakat dimana metode yang digunakan adalah pengelompokan dengan c-means dan fuzzy c-means clustering.
Analisis kelompok (cluster analysis) merupakan salah satu teknik dalam analisis multivariat yang mempunyai tujuan utama untuk mengelompokkan objek-objek sehingga objek paling dekat kesamaannya dengan objek yang paling dekat kesamaannya berada dalam kelompok yang sama dan yang memiliki karakteristik berbeda berada pada kelompok lainnya. (Johnson, 2002).Metode
c-means clustering adalah suatu metode pengelompokan non hirarki yang mencoba mempartisi data menjadi suatu kelompok sehingga data yang memiliki karakteristik yang sama akan berada dalam satu kelompok yang sama dan memiliki karakteristik berbeda dengan data yang berada pada kelompok lain sedangkan metode fuzzy c-means adalah suatu metode pengelompokan objek yang memanfatkan dasar pembobotan dengan teori himpunan
fuzzy. Pengelompokan dengan fuzzy sering digunakan karena memberikan hasil yang cukup baik dalam hal meningkatn homogenitas tiap kelompok yang dihasilkan. (Shihab, 2000).
Penelitian terdahulu pada Ririn, 2015 dalam menentukan kelompok kota dan kabupaten di Jawa Timur berdasarkan indikator kemiskinan menggunakan metode c-means clustering
3
Penelitian ini diharapkan mampu memberikan saran kepada BAPPENAS mengenai aspek aspek pembangunan yang harus difokuskan di tiap-tiap provinsi agar mencapai tujuan pembangunan nasional yang diharapkan.
1.2 Rumusan Masalah
Pembangunan nasional yang dilakukan oleh pemerintah kurang efisien dikarenakan kurang mampunya pemerintah dalam mengidentifikasi permasalahan yang terjadi di Indonesia maka rumusan masalah dari penelitian tersebut adalah sebagai berikut. 1. Bagaimana gambaran umum indikator kesejahteraan rakyat di
Indonesia?
2. Bagaimana pengelompokan provinsi di Indonesia berdasarkan indikator kesejahteraan rakyat dengan analisa klaster c-means dan fuzzy c-means dengan cluster optimum? 3. Manakah metode yang lebih baik diantara keduanya
berdasarkan nilai icd rate terkecil dan SSW terbesar? 1.3 Tujuan
Berdasarkan rumusan masalah yang telah dijabarkan, maka tujuan yang ingin dicapai pada penelitian ini adalah sebagai berikut.
1. Mendeskripsikan gambaran kesejahteraan rakyat tiap-tiap provinsi di Indonesia.
2. Mengelompokkan provinsi di Indonesia berdasarkan indikator kesejahteraan rakyat dengan metode c-means dan
fuzzy c-means.
3. Membandingkan hasil pengelompokkan provinsi di Indonesia dengan metode c-mean dan fuzzy c-means berdasarkan nilai
1.4 Manfaat Penelitian
Berdasarkan latar belakang alinea-7 yang telah dipaparkan, rumusan masalah dan tujuan penelitian maka penelitian ini diharapkan memberikan manfaat agar mampu memberikan informasi kepada instansi terkait mengenai pengelompokan provinsi di Indonesia berdasarkan indikator kesejahteraan rakyat terutama pada indikator kesehatan, pendidikan dan ekonomi sehingga dapat menunjang keberhasilan pembangunan nasional.
1.5 Batasan Masalah
5 BAB II
TINJAUAN PUSTAKA 2.1 Distribusi Normal Multivariat
Untuk mengetahui apakah data mengikuti distribusi normal, maka dilakukan uji distribusi normal multivariat. Pengujian distribusi normal multivariat dilakukan untuk memperkuat dugaan bahwa data telah berdistribusi normal multivariat dan sebagai asumsi dasar yang harus dipenuhi sebelum pengujian lainnya (Johnson & Wichern, 2007). Untuk melakukan pengujian distribusi normal multivariat maka hipotesis yang diberikan adalah sebagai berikut.
Data berdistribusi normal multivariat Data tidak berdistribusi normal multivariat.
Pemeriksaan distribusi normal multivariat dapat dilakukan dengan melihat q-q plot atau scatter plot dari nilai square
:Nilai invers matriks varians-kovarians
Jika plot cenderung membentuk garis lurus lebih dari 0,5 dan nilai maka data disimpulkan tidak berdistribusi normal multivariat.
2.2 Uji KMO
Uji KMO adalah suatu pengujian yang digunakan untuk mengukur kecukupan sampling secara menyeluruh dan mengukur kecukupan sampling untuk setiap indikator dengan menggunakan nilai korelasi antar variabel. Hipotesis yang diberikan untuk pengujian ini adalah sebagai berikut.
Statistik Uji yang digunakan dalam pengujian ini adalah untuk dilakukan analisis faktor apabila nilai KMO > 0.5.
2.3 Uji Barlett
Uji Barlett merupakan pengujian statistik untuk menguji persamaan korelasi antara dua atau lebih variabel independen untuk dilihat nilai korelasinya (Johnson & Wichern, 2007). Hipotesis yang diberikan dalam pengujian ini adalah sebagai berikut
Statistik Uji yang digunakan dalam pengujian ini adalah sebagai berikut.
7
cluster ini, objek akan dikelompokkan sehingga setiap objek yang paling kesamaannya dengan objek lain yang berada dalam kelompok yang sama.
Metode pengelompokan dibedakan menjadi dua yaitu metode hierarki (hierarchical clustering) dan metode non-hierarki (non-hierarchical clustering) (Johnson & Wichern, 2007) dimana metode hierarki dengan berbagai pendekatan single-linkage,complete linkage dan minimum-varians. Metode non hierarki atau disebut juga metode partisi juga tekah dikembangkan dengan berbagai pendekatan algoritma. Perbedaan yang terlihat jelas adalah pada permulaan prosedurnya dimana metode hierarki mengelompokkan suatu pengamatan secara bertahap, sedangkan pada metode non hierarki dilakukan dengan melakukan partisi pada ruang sampel.
2.5 C-means Cluster
C-means merupakan salah satu metode data clustering non hierarki yang berusaha mempartisi data yang ada kedalam bentuk satu cluster/kelompok sehingga data yang memiliki karakteristik yang sama akan dikelompokkan pada satu kelompok dan yang memiliki karateristik yang berbeda akan dikelompokkan dalam kelompok yang lainnya. Dalam Mac Queen (1967) dan Johnson (2002) algoritma dasar untuk c-means cluster adalah sebagai berikut.
1. Menentukan jumlah cluster/kelompok initial, misal C.
2. Mengalokasikan data kedalam cluster/kelompok secara random.
3. Menghitung centroid rata-rata dari data yang ada di masing masing cluster/kelompok. Rumus untuk menghitung nilai
centroid adalah sebagai berikut.
∑ (2.4)
dimana :
: centroid/rata rata cluster ke-i untuk variabel ke-j
: indeks cluster
: indeks dari variabel
: nilai data ke-k yang ada di dalam cluster tersebut untuk variabel ke-j
4. Mengalokasikan masing-masing data ke centroid/rata-rata terdekat (jarak yang digunakan adalah jarak Euclidean)
dengan rumus sebagai berikut.
√(∑( )
) (2.5)
dimana :
: jarak Euclidean ke- objek : indeks objek
: indeks variabel variabel : Koordinat objek
: centroid/rata rata cluster ke-i untuk variabel ke-j
5. Kembali ke step-3, apabila masih ada data yang berpindah
cluster atau apabila perubahan nilai centroid ada yang diatas nilai threshold yang ditentukan atau apabila perubahan nilai pada objective function yang digunakan diatas nilai threshold
yang ditentukan. Objective function yang digunakan dalam c-means cluster adalah sebagai berikut.
( ) ∑ ∑( ) ( )
(2.6)
dimana :
: Banyaknya data : Banyaknya cluster
: Keanggotaan data ke-k kedalam cluster ke-i : Nilai centroid (rata-rata) cluster ke-i
( ) : square Euclidean distance space antara data ke-k
9
2.6 Fuzzy c-means clustering
Fuzzy c-means merupakan suatu teknik pengelompokan yang dikembangkan dari c-means dengan mempertimbangkankan himpunan keanggotaan fuzzy (samar) sebagai dasar pembobotan yang ditemukan pertama kali oleh Jim Bezdek pada tahun 1981 dan digunakan dalam bidang pengenalan pola (patern recognition), dan masih terus dikembangkan sampai saat ini. Dalam metode FCM Cluster ini dipergunakan variabel
membership function uik, yang merujuk pada seberapa besar probabilitas suatu data bisa menjadi anggota ke dalam suatu kelompok (cluster) dan variabel m yang merupakan weigthing exponent dari membership function uik. Metode ini merupakan pengembangan dari C-Means Cluster dengan pembobotan fuzzy
Konsep dasar fuzzy c-means adalah pertama kali menentukan pusat cluster yang akan menandai lokasi rata-rata untuk setiap
cluster. Dalam konsep fuzzy c-meansclustering, setiap objek bisa menjadi anggota dari beberapa cluster. Oleh karena itu batas-batas dalam c-meansclustering bersifat tegas (hard) dan fuzzy c-meansclustering bersifat lembut (soft) (Santosa, 2007).
Metode fuzzy c-means clustering pertama kali dengan menentukan pusat cluster yang akan menandai lokasi rata rata untuk setiap cluster. Pada konsisi awal, pusat cluster ini dikatakan belum akurat. Tiap data memiliki derajat keanggotaan untuk tiap
cluster. Dengan cara memperbaiki pusat cluster dan nilai keanggotaan data secara berulang, maka dapat dilihat bahwa pusat
cluster akan menuju lokasi yang tepat. Perulangan ini didasarkan pada minimasi fungsi objektif yang menggambarkan jarak dari titik data yang diberikan ke pusat cluster yang terbobot oleh derajat jarak keanggotaan titik data tersebut. Berikut ini merupakan langkah-langkah dalam fuzzy c-meansclustering.
1 Menentukan
a.Matriks berukuran = Jumlah objek
= Jumlah variabel
c.Pangkat (pembobot eksponen/ >1). Akan tetapi yang sering digunakan sebanyak 2.
d.Maksimum iterasi yang umum digunakan sebanyak 100 e.Kriteria penghentian (threshold/ = nilai positif yang sangat kecil). Akan tetapi yang sering digunakan sebanyak
2 Membentuk matriks partisi awal (derajat keanggotaan dalam cluster) yang merupakan matriks partisi awal.
: jumlah objek yang menjadi anggota cluster : indeks cluster
: indeks variabel : indeks objek
: pembobot eksponen
4 Perbaiki derajat keanggotaan setiap data pada setiap
cluster (perbaiki matriks partisi).
11
dengan
√(∑( )
) (2.9)
: jarak euclidean cluster ke- objek ke- : jarak euclidean variabel ke- objek : indeks variabel
: indeks cluster : indeks objek
:nilai objek ke- yang ada dalam cluster tersebut untuk variabel ke-
:titik pusat (centroid/rata-rata) cluster ke-variabel ke-
5 Menentukan kriteria penghentian iterasi, yaitu perubahan matriks partisi pada iterasi sekarang dan iterasi sebelumnya.
| | (2.10)
dimana : iterasi
: derajat keanggotaan
Apabila maka iterasi diberhentikan. Tetapi, jika tidak maka kembali ke langkah-3 (Bezdek, Ehrlich, & Full, 1984).
2.7 Fungsi Keanggotaan
Fungsi keanggotaan adalah suatu kurva yang menunjukkan pemetaan titik-titik input data kedalam nilai keanggotaannya. Salah satu cara yang dapat digunakan untuk mendapatkan nilai keanggotaan adalah dengan melalui pendekatan fungsi (Kusumadewi & Hartati, 2006)
2.6.1 Representasi Linear
1. Representasi Linear Naik
Terdapat 2 keadaan himpunan fuzzy yang linear yaitu kenaikan himpunan dimulai pada nilai domain yang memiliki derajat keanggotaan nol (0) bergerak ke kanan menuju domain yang memiliki derajat keanggotan lebih tinggi. Rumus fungsi keanggotaan linear naik dipaparkan pada rumus 2.7.
( ) {
a : nilai minimum dari domain b : nilai maksimum dari domain
Gambar 2.1 merupakan gambar representasi fungsi keanggotan fuzzy kurva linear naik.
Gambar 2.1 Representasi Linear Naik
2. Representasi Linear Turun
Fungsi keanggotaan linear yang kedua merupakan kebalikan dari yang pertama, yakni representasi linear turun. Garis lurus dimulai dari nilai domain dengan derajat keanggotaan tertinggi pada sisi kiri, kemudian bergerak menurun pada domain yang lebih rendah. Rumus fungsi keanggotaan linear turun dipaparkan pada rumus 2.8.
13
dimana:
a : nilai minimum dari domain b : nilai maksimum dari domain
Gambar 2.2 merupakan gambar representasi fungsi keanggotan
fuzzy kurva linear turun.
Gambar 2.2 Representasi Linear Turun
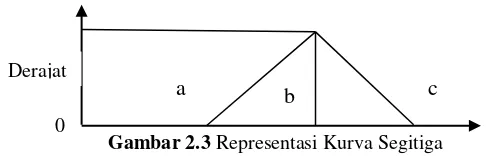
2.6.2 Representasi Kurva Segitiga
Fungsi keanggotaan segitiga pada dasarnya seperti bentuk segitiga hanya saja ada beberapa titik yang memiliki nilai keanggotaan 1. Rumus fungsi keanggotaan linear naik dipaparkan pada rumus 2.9.
Derajat Keanggotaan :
( )
{
( )
( ) ( )
( )
(2.13)
dimana:
a : nilai minimum dari domain b : nilai median dari domain
c : nilai maksimum dari suatu domain
Gambar 2.3 merupakan gambar representasi fungsi keanggotan
fuzzy kurva segitiga.
Domain b
Gambar 2.3 Representasi Kurva Segitiga
2.8 Principle Component Analysis (PCA)
Principle component analysis (PCA/analisis komponen utama) digunakan untuk menjelaskan struktur matriks varians kovarians dari suatu set variabel melalui kombinasi linier dari variabel-variabel. Secara umum, komponen utama berguna untuk mereduksi dan menginterpretasi variabel-variabel. Misalkan, terdapat buah variabel yang terdiri atas buah objek dan buah variabel tersebut dibuat sebanyak buah komponen utama (dengan ) yang merupakan kombinasi linier atas buah variabel. komponen utama tersebut dapat menggantikan buah variabel yang membentuk tanpa kehilangan banyak informasi mengenai keseluruhan variabel. Secara umum analisis komponen utama merupakan analisis intermediate yang berarti hasil komponen utama dapat digunakan untuk analisis lebih lanjut.
Komponen utama tergantung kepada matrik varian kovarian dan matrik korelasi dari seluruh variabel x x x1, 2, 3,, xj dimana pada analisis tidak memerlukan asumsi populasi harus berdistribusi Multivariate Normal. Apabila komponen utama diturunkan dari populasi Multivariate Normal interpretasi dan inferensi dapat dibuat dari komponen sampel. Penyusutan variabel dimensi dengan cara mengambil sejumlah kecil komponen yang mampu menerangkan bagian terbesar keragaman data. Apabila komponen utama yang diambil sebanyak buah, dimana , maka proporsi keragaman yang bisa diterangkan sebagai berikut.
Derajat
0
15
Sehingga nilai proporsi dari varian total populasi dapat diterangkan oleh komponen pertama, kedua atau sampai sejumlah komponen utama secara bersama-sama adalah semaksimal mungkin. Tidak ada ketetapan berapa besar proporsi keragaman data yang dianggap cukup mewakili keragaman total. Meskipun jumlah komponen utama berkurang dari variabel asal tetapi ini merupakan gabungan dari variabel-variabel asal sehingga informasi yang diberikan tidak berubah.
Pemilihan komponen utama yang digunakan didasarkan pada eigen value () yang bernilai lebih besar dari 1 ( ). Hal ini dikarenakan eigen value berasal dari matrik varian kovarian dan matrik korelasi yang merupakan standardized
dari matriks varian kovarian dengan rata-rata sebesar 1 (Rencher, 2002). Secara Ideal, banyak komponen utama yang secara kumulatif telah dapat menerangkan sekitar 60% atau lebih variasi dalam data. Nilai adalah akan mengandung nilai eigen vector ( ). Masing-masing nilai dari eigen vector ( ) dikalikan dengan masing-masing variabel asli. Sehingga menghasilkan persamaan analisis komponen utama sesuai dengan nilai dengan keragaman total telah terpenuhi (Johnson & Wichern, 2007).
2.9 PseudoF-Statistics
Penentuan jumlah cluster optimum yang pembentukan cluster
Pseudo F-statistics (
2.10 Internal Cluster Dispertion Rate (Icdrate)
Internal Cluster Dispertion Rate (Icd rate) merupakan metode yang digunakan untuk membandingkan metode klaster yang terbaik dengan mengevaluasi performansi algoritma dengan menggunakan prosentase rata-rata dari klasifikasi yang benar
(recovery rate). Nilai persebaran data-data dalam cluster (Icd rate) dari hasil akhir pengelompokan.
17
dengan
( )
(2.20)
(2.21)
:total jumlah dari kuadrat jarak terhadap rata-rata keseluruhan :total jumlah dari kuadrat jarak objek terhadap rata-rata
kelompoknya.
:Recovery Rate
2.11 One-way ANOVA
Tabel 2.1 Uji One-way ANOVA
Sumber
Variasi Jumlah Kuadrat
Derajat
19
BAB III
METODOLOGI PENELITIAN
3.1 Sumber Data
Data yang digunakan dalam penelitian Tugas Akhir ini adalah data indikator kesehatan, pendidikan dan ekonomi pada tahun 2014 yang diambil pada data Survey Ekonomi Nasional (SUSENAS) , Survey Angkatan Kerja (SAKERNAS), Profil Kesehatan Indonesia dari Badan Pusat Statistik (BPS) Indonesia. Unit penelitian yang digunakan adalah sebanyak 33 provinsi yang ada di Indonesia.
3.2 Variabel Penelitian
Berdasarkan tinjauan pustaka yang telah dijabarkan, variabel yang digunakan dalam penelitian ini adalah
1. Indikator Kesehatan
Indikator kesehatan merupakan salah satu indikator kesejahteraan rakyat yang mengukur kesejahteraan rakyat dari derajat kesehatan.
Tabel 3.1 Variabel Indikator Kesehatan Variabel Keterangan Skala
X1 ASI Eksklusif Rasio
X2 Angka Kesakitan malaria Rasio
X3 Imunisasi Anak Sekolah Rasio
X4 Rumah Tangga Air Minum Layak Rasio X5 Rumah Tangga Sanitasi Layak Rasio
2. Indikator Pendidikan
Indikator pendidikan merupakan salah satu indikator kesejahteraan rakyat yang mengukur kesejahteraan rakyat dari mutu pendidikan.
Tabel 3.2 Variabel Indikator Pendidikan Variabel Keterangan Skala
X6 Angka Melek Huruf Rasio
X7 Angka Partisipasi Sekolah Rasio
3. Indikator Ekonomi
Indikator ekonomi dalam penelitian ini merupakan salah satu indikator kesejahteraan rakyat yang mengukur kesejahteraan rakyat dari mutu demografi dan ketenagakerjaan.
Tabel 3.3 Variabel Indikator Ekonomi
Variabel Keterangan Skala
X9 Indeks Gini Rasio
X10 Penduduk Miskin Rasio
X11 Tingkat Pengangguran Terbuka Rasio
3.3 Struktur Data
Struktur data yang digunakan dalam peneltian ini adalah sebagai berikut.
Berikut adalah definisi operasional masing-masing indikator untuk masing-masing variabel indikator kesehatan, pendidikan, dan ekonomi.
1. Konsep Indikator Kesehatan
Konsep kesehatan merupakan variabel yang mampu mengukur indikator kesejahteraan rakyat berdasarkan tingkat mutu kesehatan/ pembangunan kesehatan masing-masing provinsi di Indonesia.
a. ASI Eksklusif adalah persentase bayi usia 0-6 bulan yang yang diberi air susu ibu tanpa tambahan dan minuman lain kepada bayi sejak lahir sampai usia 6 bulan.
21
jumlah penderita malaria dengan jumlah penduduk pada tempat dan waktu yang sama per 100.000 penduduk. c. Imunisasi Anak Sekolah persentase anak sekolah yang
diimunisasi setiap provinsi. Dalam penelitian ini variabel imunisasi anak sekolah diambil untuk anak sekolah di kelas 2 dan 3 SD.
d. Rumah Tangga Dengan Akses Air Bersih persentase rumah tinggal dengan bersanitasi air bersih. Air bersih meliputi air yang dibeli, PAM/PDAM, mata air dan sumur terlindungi.
e. Rumah Tangga Dengan Sanitasi Layak adalah persentase rumah tinggal dengan ketersediaan fasilitas buang air, ketersediaan tangki pembungan tinja dan sanitasi layak lainnya.
2. Konsep Indikator Pendidikan
Konsep pendidikan adalah variabel yang menjelaskan indikator kesejahteraan rakyat berdasarkan tingkat mutu pendidikan masing-masing provinsi di Indonesia.
a. Angka Melek Huruf adalah persentase penduduk usia 15 tahun keatas yang bisa membaca dan menulis serta mengerti kalimat sederhana di kehidupan sehari-hari b. Angka Partisipasi Sekolah adalah proporsi dari semua
anak yang masih sekolah pada suatu keolompok umur tertentu terhadap jumlah penduduk dengan kelompok umur sesuai. Penelitian ini khusus mengambil proporsi anak berusia 16-18 tahun keatas yang merupakan usia diluar wajib belajar 9 tahun yang dicanangkan pemerintah yang dinyatakan dalam persen.
3. Konsep Indikator Ekonomi
Konsep ekonomi merupakan variabel yang menjelaskan kesejahteraan rakyat yang dikaitkan dengan tingkat pengeluaran dan pendapatan.
a. Indeks Gini adalah adalah ukuran kemerataan pendapatan yang dihitung berdasarkan kelas pendapatan. Nilai koefisien Gini terletak antara nol yang mencerminkan kemerataan sempurna dan satu yang menggambarkan ketidakmerataan sempurna.
b. Penduduk Miskin adalah persentase penduduk yang memiliki rata-rata pengeluaran perkapita dibawah garis kemiskinan.
c. Tingkat Pengangguran Terbuka adalah indikasi tentang penduduk usia kerja yang termasuk dalam kelompok pengangguran dan dapat diukur sebagai persentase jumlah pengangguran terhadap jumlah angkatan kerja.
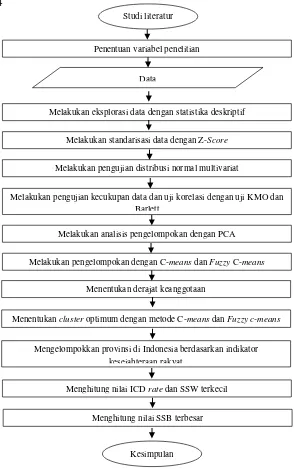
3.5 Langkah-langkah Penelitian
Berdasarkan sumber data dan variabel penelitian yang telah dipaparkan sebelumnya, langkah analisis yang akan dilakukan dalam penelitian Tugas akhir ini adalah sebagai berikut.
1. Menggambarkan indikator kesejahteraan rakyat Indonesia di tiap-tiap provinsi. Langkah langkah yang dilakukan adalah sebagai berikut.
a. Mengumpulkan data yang berisi variabel penelitian Tugas akhir
b. Analisa Statisika Deskriptif
2. Pengelompokan provinsi di Indonesia berdasarkan indikator kesejahteraan rakyat menggunakan c-means dan
fuzzy c-means dengan cluster optimum. Langkah langkah yang dilakukan adalah sebagai berikut.
a. Standarisasi data dengan Z-score
23
c. Melakukan pengujian kecukupan data dan uji korelasi antar variabel penelitian dengan uji KMO dan uji barlett.
d. Melakukan Analisis Pengelompokan dengan
Principal Component Analysis.
e. Melakukan Pengelompokan dengan C-means dan
Fuzzy c-means.
f. Menentukan derajat keanggotaan melalui fungsi keanggotaan linier naik, linier turun, dan segitiga sebagai inputasi dari metode fuzzy c-means clustering
dengan pereduksian variabel menggunakan principle component analysis.
g. Menentukan jumlah cluster optimum dengan metode
c-means dan fuzzy c-means clustering melalui nilai
pseudo-f statistics terbesar. Dalam fuzzy c-means clustering digunakan fungsi keanggotaan linier naik, linier turun dan segitiga.
h. Mengelompokkan provinsi di Indonesia berdasarkan indikator kesejahteraan rakyat sesuai dengan jumlah
cluster optimum dan menentukan karakteristik masing-masing cluster.
3. Membandingkan metode c-means clustering dan fuzzy c-means clustering dilakukan dengan langkah-langkah sebagai berikut.
a. Menghitung nilai icd rate dan SSW terkecil b. Menghitung nilai SSB terbesar.
c. Menentukan perbedaan karakteristik
Penentuan variabel penelitian
Data
Melakukan standarisasi data dengan Z-Score
Melakukan pengujian distribusi normal multivariat
Melakukan pengujian kecukupan data dan uji korelasi dengan uji KMO dan Barlett
Melakukan eksplorasi data dengan statistika deskriptif
Melakukan analisis pengelompokan dengan PCA
Melakukan pengelompokan dengan C-means dan Fuzzy C-means
Menentukan derajat keanggotaan
Menentukan cluster optimum dengan metode C-means dan Fuzzy c-means
Mengelompokkan provinsi di Indonesia berdasarkan indikator kesejahteraan rakyat
Menghitung nilai ICD rate dan SSW terkecil Menghitung nilai SSB terbesar
Kesimpulan
25
BAB IV
ANALISIS DAN PEMBAHASAN
Pada bab ini akan dilakukan analisis dan pembahasan tentang pengelompokan indikator kesejahteraan rakyat di Indonesia di tahun 2014 dengan menggunakan metode c-means clustering dan
fuzzy c-means clustering dimana data yang digunakan adalah data sekunder yang diperoleh dari hasil Survey Badan Pusat Statistika Nasional.
4.1 Deskripsi Indikator Kesejahteraan Rakyat
Deskripsi kondisi indikator kesejahteraan rakyat tiap provinsi dapat digambarkan dengan analisis statistika deskripif. Deskripsi mengenai kondisi kesejahteraan rakyat dapat diketahui dengan ukuran pemusatan dan penyebaran. Ukuran pemusatan menggunakan nilai rata-rata (mean), minimum dan maksimum. Ukuran penyebaran menggunakan nilai standard deviasi dan varians.
4.1.1 Deskripsi Bidang Kesehatan
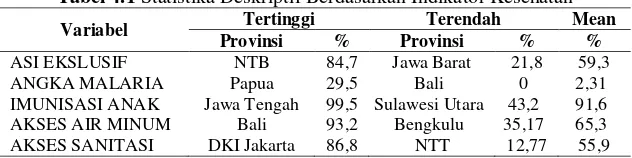
Sub-bab ini merupakan deskripsi mengenai kondisi kesejahteraan rakyat bidang kesehatan yang dilihat dari beberapa variabel yaitu Pemberian ASI Ekslusif, Angka Kesakitan Malaria, Imunisasi Anak Sekolah, Rumah Tangga Akses Air Minum Layak dan Rumah Tangga Akses Sanitasi Layak. Analisa statistika deskripif untuk indikator kesejahteraan rakyat bidang kesehatan yang mengacu pada data Lampiran A dapat digambarkan dengan Tabel 4.1.
Tabel 4.1 Statistika Deskriptif Berdasarkan Indikator Kesehatan
Variabel Tertinggi Terendah Mean Provinsi % Provinsi % %
ASI EKSLUSIF NTB 84,7 Jawa Barat 21,8 59,3
ANGKA MALARIA Papua 29,5 Bali 0 2,31
IMUNISASI ANAK Jawa Tengah 99,5 Sulawesi Utara 43,2 91,6
AKSES AIR MINUM Bali 93,2 Bengkulu 35,17 65,3
Berdasarkan Tabel 4.1 didapatkan bahwa ada beberapa provinsi menduduki peringkat tertinggi dan terendah untuk beberapa indikator kesehatan. Nusa tenggara Barat (NTB) merupakan provinsi yang memiliki persentase ASI Ekslusif tertinggi nasional dan Jawa Barat merupakan yang terendah dan ternyata NTB merupakan provinsi yang mengeluarkan peraturan pemerintah daerah tentang pemberian air susu ekslusif dimana dalam peraturan tersebut mengatur mengenai tugas dan tanggung jawab pemerintah dalam pengembangan program ASI Ekslusif.
Means sebesar 59,3% dan terdapat 13 provinsi berada dibawah rata-rata ASI Ekslusif nasional.
Peringkat tertinggi Angka Kesakitan Malaria adalah Papua dan terendah berada di Bali. Papua memiliki daerah pesisir pantai dan dataran rendah dan wilayah pegunungan tengah merupakan wilayah endemik malaria sehingga hal ini menyebabkan angka malaria di Papua masih tinggi. Terdapat 8 provinsi berada diatas rata-rata Angka Malaria nasional dan butuh perhatian lebih dari pemangku kepentingan masyarakat. Persentase Imunisasi Anak juga merupakan indikator kesehatan rakyat yang perlu diperhatikan karena terdapat 9 provinsi yang memiliki persentase dibawah rata-rata sebesar 91,67% terutama Sulawesi utara karena hal ini menunjukkan kurangnya kesadaran masyarakat untuk memberikan vaksin kepada anak agar terhindar dari penyakit.
27
4.1.2 Deskripsi Bidang Pendidikan
Indikator Kesejahteraan Rakyat yang mampu mengindikasikan rakyat tersebut sejahtera adalah dengan melihat mutu pendidikan rakyat nya. Terdapat beberapa variabel yang merupakan indikator mutu pendidikan suatu daerah yaitu Angka Melek Huruf (AMH), Angka Partisipasi Sekolah (APS) dan Angka Lama Sekolah (ALS). Berikut merupakan statistika deskriptif yang berupa peringkat di masing masing variable yang mengacu pada data Lampiran A dipaparkan dalam Tabel 4.2.
Tabel 4.2 Statistika Deskriptif Berdasarkan Indikator Pendidikan
Variabel Tertinggi Terendah Means Provinsi Nilai Provinsi Nilai Nilai
AMH Sulawesi utara 99,6 Papua 70,78 95,4
APS DI Yogyakarta 86,44 Papua 61,63 72,7
ALS DKI Jakarta 10,98 Papua 6,32 8,59
Tabel 4.2 memberikan informasi bahwa provinsi Papua merupakan provinsi dengan mutu pendidikan yang dari segala aspek cukup tertinggal baik dari kemampuan membaca yang diindikasikan dengan AMH, kesadaran akan pentingnya pendidikan formal yang dapat dilihat dari APS dan ALS. Ternyata hal ini dikarenakan kurangnya tenaga pengajar dan infrastruktur yang kurang memadai. Maka, berdasarkan fakta ini sebaiknya pemerintah memberikan perhatian lebih di bidang pendidikan kepada provinsi Papua agar memiliki mutu pendidikan yang lebih baik.
provinsi yang memiliki Angka Partisipasi Sekolah SMA yang berada di bawah rata-rata dan membutuhkan perhatian dari pemerintah setempat. Angka Lama Sekolah terlama adalah DKI Jakarta dimana provinsi ini merupakan provinsi terbesar di Indonesia dan merupakan ibukota negara Indonesia sehingga pemerintah daerah provinsi ini memang serius dalam melakukan pembangunan karna merupakan role model untuk provinsi lainnya.
4.1.3 Deskripsi Bidang Ekonomi
Indikator ekonomi memberikan gambaran ketimpangan pendapatan, penduduk miskin dan pengangguran terbuka yang ada pada suatu daerah dimana indikator tersebut mampu merepresentasikan keadaaan kesejahteraan rakyat yang ada pada daerah tersebut (BPS,2012)
Gambar 4.1 Indeks Gini Provinsi di Indonesia
Tabel 4.1 mengacu pada data Lampiran A merupakan tabel yang menunjukkan Indeks Gini provinsi di Indonesia. Indeks Gini merupakan indikasi ketimpangan pendapatan di suatu daerah dan digagas oleh Bank Dunia. Variabel yang diambil adalah gabungan pendapatan seluruh golongan yaitu golongan 40 persen
29
berpendapatan rendah, 40 persen pendapatan sedang, 20 persen golongan tinggi. Provinsi Kepulauan Bangka Belitung merupakan provinsi yang memiliki ketimpangan pendapatan terendah di Indonesia dan ini mengindikasikan bahwa tingkat ketimpangan antar kelompok cukup rendah. Indikator lain yang mampu menggambarkan kesejahteraan rakyat adalah banyak nya penduduk miskin yang ada pada suatu daerah. Berikut merupakan grafik persentase penduduk miskin setiap provinsi di Indonesia yang mengacu pada data Lampiran A.
Gambar 4.2 Persentase Penduduk Miskin di Indonesia
Indikator lain yang menggambarkan kesejahteraan rakyat suatu daerah adalah banyaknya penduduk usia kerja yang tidak memiliki pekerjaan yang digambarkan dengan tingkat pengangguran terbuka yang mengacu pada data Lampiran A.
Gambar 4.3 Tingkat Pengangguran terbuka di Indonesia Gambar 4.3 menunjukkan gambar grafik Tingkat Pengangguran Terbuka yang merupakan salah satu indikator ketenagakerjaan yang pada penelitian ini masuk dalam indikator ekonomi yang mampu mengindikasikan capaian hasil pembangunan nasional. Maluku merupakan provinsi di Indonesia yang memiliki tingkat pengangguran terbuka tertinggi di Indonesia dan ini mencerminkan besarnya jumlah penduduk di Maluku yang masuk dalam kategori usia kerja dan pengangguran.
4.2 Pengelompokan Provinsi di Indonesia Dengan C-mean
Clustering dan Fuzzy C-means Clustering
Pemaparan dengan statistika deskriptif memberikan gambaran kondisi kesejahteraan rakyat di tiap provinsi Indonesia maka selanjutnya perlu dilakukan pengelompokan dengan metode
c-means dan fuzzy c-means berdasarkan indikator kesejahteraan rakyat agar tujuan dalam penelitian dapat dicapai. Pengelompokan memerlukan asumsi yang harus dipenuhi yaitu normal multivariate
31
dan multikolinearitas sehingga perlu dilakukan pengujian asumsi terlebih dahulu.
4.2.1 Uji Asumsi Multivariat
Pengujian ini dilakukan secara serentak seluruh variabel indikator kesejahteraan rakyat di Indonesia tahun 2014. Pengujian ini diperlukan untuk memenuhi asumsi dalam analisis multivariat. 4.2.1.1 Asumsi Multivariat Normal
Dalam melakukan analisis data multivariat, perlu dilakukan pengujian asumsi distribusi normal untuk mengetahui apakah data telah berdistribusi normal multivariat sehingga layak untuk dilakukan analisis multivariat selanjutnya. Hipotesis dan statistik uji mengacu pada persamaan 2.1. Berikut adalah hasil dari pengujian normal multivariat untuk semua indikator kesejahteraan rakyat yang mengacu pada Lampiran J merupakan output dari
software macro minitab.
Gambar 4.4 Plot Distribusi Normal Multivariat
Gambar 4.4 menunjukkan bahwa jika dilihat dari visual plot QQ cenderung membentuk garis lurus dan ini diperkuat dengan nilai t yang bernilai 0,5152 yang berarti lebih dari 0,5 dan memberikan keputusan gagal tolak . Sehingga dapat disimpulkan bahwa data indikator kesejahteraan rakyat di
30
Indonesia pada tahun 2014 memenuhi asumsi distribusi normal multivariat.
4.2.1.2 Asumsi Korelasi dan Kecukupan Data
Pengujian ini dilakukan untuk mengetahui apakah data indikator kesejahteraan rakyat di Indonesia memiliki korelasi dan untuk menguji apakah data telah cukup untuk dilanjutkan ke analisis selanjutnya. Uji korelasi dilakukan dengan Barlett-test dan uji kecukupan data dilakukan dengan KMO-test. Hipotesis dan statistik uji mengacu pada persamaan 2.2 dan 2.3. Berikut merupakan hasil dari Uji Barlettdan Uji KMO.
Tabel 4.3 Uji Barlett dan Uji KMO Indikator Kesejahteraan Rakyat Indonesia
Approx. Chi Square 157,14
Df 55
Tabel 4.3 menunjukkan bahwa nilai chi-square untuk indikator kesejahteraan rakyat di Indonesia tahun 2014 sebesar 157,14 dan p-value sebesar sebesar 0,000 yang mana nilai ini memberikan keputusan tolak karena p-value kurang dari (0,05) sehingga dapat disimpulkan bahwa antar variabel memiliki korelasi yang signifikan.nilai KMO adalah sebesar 0,583 dan nilai ini lebih besar dari (0,05) sehingga memberikan keputusan tolak yang artinya data Indikator Kesejahteraan Rakyat Indonesia tahun 2014 telah cukup sehingga dapat dilanjutkan dengan analisis multivariat selanjutnya.
4.2.2 Principal Component Analysis (PCA)
33
dapat diketahui melalui output total variance explained pada Tabel 4.4 berikut ini.
Tabel 4.4 Eigenvalues dan Persentage of Variance
Component Initial Eigenvalues
Total % of Variance Cumulative% keragaman yang dapat dijelaskan sebesar 73,955%. Berikut ini merupakan gambar scree plot scree plot yang mampu menjelaskan komponen yang terbentuk secara visual.
Gambar 4.5 Scree Plot
Gambar 4.5 menunjukkan bahwa pada komponen 1 sampai 2 grafik turun secara drastis. Hal ini dikarenakan range terbesar antara komponen 1 dan 2, namun dari titik 2 ke 3 dan titik 3 ke 4 juga mengalami penurunan namun tidak cukup drastis sehingga komponen utama yang diduga terbentuk ada sebanyak 4 komponen utama yang dapat mewakili variabel-variabel pada data Indikator Kesejahteraan Rakyat Indonesia tahun 2014. Berikut ini merupakan persamaan berdasarkan 4 komponen utama yang mengacu pad Lampiran C telah terbentuk.
-0,072 -0,382 -0,101 + 0,355 + 0,330 +0,406 +0,239 +0,439 + 0,016 - 0,332 +0,280
0,490 -0,358 +0,398 -0,073 -0,118 +0,133 -0,054 -0,135 -0,426 -0,360 -0,323
0,403 +0,095 +0,3 +0,401 -+0,355 -0,362 +0,305 +0,019 + 0,402 -+0,126 - 0,224
0,189 +0,155 +0,038 - 0,180 --0,358 + 0,126 +0,675 +0,340 - 0,248 +0,353 +0,064
Berdasarkan persamaan tersebut, selanjutnya akan diperoleh nilai
score component yang pada pengelompokan menggunakan metode ini, nilai tersebut digunakan sebagai faktor yang mengelompokkan provinsi di Indonesia dan dilampirkan pada Lampiran C.
4.2.3 Pengelompokan Provinsi dengan C-means Clustering
Analisis yang dilakukan selanjutnya adalah melakukan pengelompokan dengan metode c-means clustering. Berikut ini merupakan pemaparan hasil dari analisis pengelompokan dengan 4
principal component yang telah terbentuk berdasarkan variabel indikator kesejahteraan rakyat (Lampiran C) Sehingga pengelompokan yang didapatkan berdasarkan kombinasi linear dari variabel masing-masing dimensi.
4.2.3.1 Penentuan Cluster Optimum
35
dilakukan dengan membentuk cluster yang berjumlah 2-4 cluster
terlebih dahulu kemudian menentukan nilai pseudo f-statistics
pada masing masing cluster untuk melihat cluster optimum yang terbentuk dan dijelaskan pada Tabel 4.5.
Tabel 4.5 Nilai Pseudo F-statistics metode C-Means Jumlah Cluster Pseudo F-statistics
2 7,560
3 7,018
4 5,734
Tabel 4.5 diatas merujuk pada Lampiran M yang menunjukkan bahwa nilai pseudo f-statistics untuk metode c-means clustering dengan jumlah 2 sampai 4 cluster. Nilai pseudo f-statistics terbesar merupakan jumlah pengelompokkan yang optimum, sehingga memberikan kesimpulan bahwa jumlah cluster
optimum untuk metode c-means clustering adalah 2 cluster karna nilai pseudo f-statistics nya paling tinggi dibandingkan dengan
cluster lain yaitu sebesar 7,560.
4.2.3.2 Pengelompokan Dengan Cluster Optimum
Pada pemaparan sebelumnya telah diketahui bahwa
cluster yang terbentuk adalah sebanyak 2 cluster dan berikut ini merupakan hasil dari Tabel 4.5 merupakan hasil dari analisis pengklasteran dengan c-means clustering.
Tabel 4.6 Anggota Cluster Dengan C-Means
Klaster 1 Klaster 2
Aceh Gorontalo Papua
Sumatera Utara Maluku
Sumatera Barat Maluku Utara
Riau Papua Barat
Jambi Sulawesi Barat
Sumatera Selatan Sulawesi Tengah
Bengkulu Sulawesi Selatan
Lampung Sulawesi Tenggara
Kep. Bangka Belitung Nusa Tenggara Timur
Kep. Riau Sulawesi Utara
DKI Jakarta Kalimantan Timur
Banten Kalimantan Selatan
Bali Kalimantan Barat
Nusa Tenggara Barat Jawa Barat
Jawa Timur Jawa Tengah
Tabel 4.6 diatas merupakan hasil analisis pengelompokan dengan c-means clustering dengan jumlah cluster optimum sebanyak 2 cluster. Anggota pada cluster ada sebayak 32 provinsi dan hanya 1 provinsi yang berada pada cluster 2. Berikut hasil pengelompokan dengan c-meansclustering secara visual.
Gambar 4.6 Peta Pengelompokan Dengan C-Means Clustering
37
4.2.4 Pengelompokan Provinsi dengan Fuzzy C-means Clustering
Dalam keseharian kondisi ketidakpastian lebih sering ditemui dalam mengklasifikasikan suatu kondisi. Misalnya usia tua atau muda adalah sesuatu yang tidak dapat dinyatakan dengan pasti, seperti usia berapa yang memisahkan antara tua dan muda. Lain halnya dengan jenis kelamin laki-laki atau perempuan yang sudah pasti. Demikian juga dengan kondisi temperatur dingin, normal atau panas, tidak ada batasan suhu yang pasti untuk membedakan kondisi tersebut. Dalam kasus-kasus dimana mendefinisikan keanggotaan suatu kelompok tidak jelas batasannya atau menjadi tidak pasti sehingga dalam menggunakan metode c-means clustering metode ini menjadi kurang sesuai .
Variabel yang digunakan dalam penelitian ini adalah indikator kesejahteraan rakyat dari berbagai dimensi namun masing-masing variabel tidak memiliki batasan yang jelas sehingga perlu dilakukan pengelompokan dengan fuzzy c-means
yang memiliki sifat lebih fleksibel dan diharapkan memberikan hasil pengelompokan yang lebih homogen untuk masing-masing anggota dalam satu kelompok.
Sebelum dilakukan analisis pengelompokan, variabel direduksi menggunakan komponen utama atau principal component analysis yang mana hasil analisis komponen utama menghasilkan 4 komponen dan score component yang dihasilkan dilampirkan pada lampiran C. Pengelompokan dengan fuzzy c-means dengan analisis komponen utama akan dileburkan dengan merata-ratakan score component yang dihasilkan (Vijayarajan & Muttan, 2014) . Hasil rata-rata dari score component yang dihasilkan dilampirkan pada Lampiran C.
keanggotaan yang digunakan dan dilampirkan pada Lampiran G-Lampiran I.
4.2.3.1Penentuan Cluster Optimum
Pengelompokan Indikator Kesejahteraan Rakyat di Indonesia tahun 2014 dengan metode fuzzy c-means clustering
adalah dengan membentuk cluster yang berjumlah 2-4 cluster lalu kemudian menentukan nilai pseudo f-statistics pada masing masing cluster untuk melihat cluster optimum namun pengelompokan menggunakan metode fuzzy c-means clustering, memerlukan derajat keanggotaan sesuai dengan fungsi keanggotaan yang telah dipilih. Sehingga diperlukan fungsi keanggotaan (membership function) yaitu suatu kurva yang menunjukkan pemetaan titik-titik input data ke dalam nilai keanggotaan dimana penelitian ini menggunakan fungsi keanggotaan linier naik, linier turun dan segitiga. Fungsi keanggotaan ini akan membentuk matriks derajat keanggotaan yang berukuran cluster x obyek sebagai input saat melakukan pengelompokan menggunakan fuzzy c-means clustering.
Pengelompokan dengan metode FCM clustering akan dibentuk berdasarkan 3 fungsi keanggotaaan, yaitu representasi linier naik, linier turun dan kurva segitiga dengan kelompok awal sama yaitu 2 hingga 4 cluster. Berikut ini merupakan nilai pseudo f-statistics untuk masing-masing fungsi keanggotan untuk mendapatkan cluster optimum yang dipaparkan dalam Tabel 4.7
Tabel 4.7 Nilai Pseudo F-statistics metode Fuzzy C-Means Jumlah
Cluster
Fungsi Keanggotaan
Linear Naik Linear Turun Segitiga
2 5,493 5,493 5,493
3 3,616 3,616 3,616
4 2,372 2,372 2,372
Berdasarkan Tabel 4.7 tersebut diketahui bahwa nilai pseudo f-statistics tertinggi ada pada cluster 2 untuk masing masing fungsi keanggotaan dan ini memberikan informasi bahwa cluster
39
yang digunakan berbeda, cluster optimum yang terbentuk menghasilkan hasil yang sama yaitu 2 cluster. Jadi, kesimpulannya dengan menggunakan metode fuzzy c-means clustering kelompok optimum yang digunakan adalah 2 cluster.
4.2.3.2Pengelompokan Dengan Cluster Optimum
Berdasarkan nilai pseudo f-statistics untuk metode fuzzy c-means clustering, cluster optimum yang dihasilkan adalah sama dengan metode c-means clustering yaitu sebesar 2 cluster. Hasil pengelompokan provinsi di Indonesia berdasarkan indikator kesejahteraan rakyat dengan jumlah cluster optimum dengan masing-masing fungsi keanggotaan dipaparkan pada Tabel 4.8 berikut.
Tabel 4.8 Pengelompokan Optimum Dengan Fuzzy C-Means Clustering Fungsi Keangotaan Linear Naik
Klaster 1 Klaster 2
Aceh Jambi Sulawesi Tengah
Sumatera Utara Sumatera Selatan Sulawesi Selatan
Sumatera Barat Bengkulu Sulawesi Tenggara
Riau Lampung Gorontalo
Kepulauan Riau Kep. Bangka Belitung Sulawesi Barat
DKI Jakarta DI Yogyakarta Papua Barat
Jawa Barat Jawa Timur Papua
Jawa Tengah Bali
Banten Nusa Tenggara Barat
Kalimantan Timur Nusa Tenggara Timur
Sulawesi Utara Kalimantan Barat
Maluku Kalimantan Tengah
Maluku Utara Kalimantan Selatan
Tabel 4.9 Pengelompokan Optimum Dengan Fuzzy C-Means Clustering Fungsi Keanggotaan Linear Turun dan Segitiga
Klaster 1 Klaster 2
Jambi Sulawesi Tengah Aceh
Sumatera Selatan Sulawesi Selatan Sumatera Utara
Bengkulu Sulawesi Tenggara Sumatera Barat
Lampung Gorontalo Riau
Kep. Bangka Belitung Sulawesi Barat Kepulauan Riau
DI Yogyakarta Papua Barat DKI Jakarta
Jawa Timur Papua Jawa Barat
Bali Jawa Tengah
Nusa Tenggara Barat Banten
Nusa Tenggara Timur Kalimantan Timur
Kalimantan Barat Sulawesi Utara
Kalimantan Tengah Maluku
Kalimantan Selatan Maluku Utara
Berdasarkan pemaparan tersebut, didapatkan bahwa dengan representatif segitiga, linear naik dan linear turun menghasilkan hasil yang sama. pengelompokan dengan fuzzy c-means clustering
dengan visualisasi gambar digambarkan pada gambar berikut ini.
Gambar 4.7 Peta Pengelompokan Dengan C-Means Clustering
41
menganalisis karakteristik masing-masing cluster dan diketahui bahwa cluster 1 adalah cluster dengan provinsi yang memiliki karakteristik kesejahteraan rakyat yang kurang layak pada indikator kesehatan Imunisasi Anak, Sanitasi Layak dan Air Bersih dan Angka Kesakitan Malaria. Sedangkan cluster 2 memiliki karakteristik indikator kesejahteraan rakyat yang kurang layak pada indikator kesehatan di Pemberian ASI Ekslusif. Pada Indikator kesejahteraan rakyat Indikator pendidikan di seluruh dimensi baik AMH, APS dan TPT, anggota provinsi di cluster 1 memiliki kesejahteraan yang kurang layak namun pada cluster 2, derajat mutu pendidikan tersebut dapat dikatakan cukup baik dan memenuhi target pemerintah dalam tujuan pembangunan nasional. Pada indikator kesejahteraan rakyat dimensi ekonomi, anggota di
cluster 2 merupakan anggota provinsi yang membutuhkan perhatian pada tingkat pengangguran terbuka karena cukup tinggi pada provinsi tersebut sedangkan pada cluster 1, anggota provinsi tersebut merupakan provinsi dengan indikator kesejahteraan rakyat dimenasi ekonomi yang bermasalah pada jumlah penduduk miskin yang cukup tinggi.
4.3 Perbandingan Hasil Pengelompokan dengan C-means
Clustering dan Fuzzy C-means Clustering
Metode yang digunakan dalam penelitian ini adalah menggunakan metode pengelompokan dengan c-means dan fuzzy c-means. Dalam menentukan cluster optimum, digunakan nilai
Selain itu perlu menentukan nilai dari SSW (Sum Square Within) yang merupakan nilai jarak total antar anggota dalam satu
cluster dengan pusat claster dan SSB (Sum Square Between) yang merupakan nilai jarak total antar pusat cluster. Berikut merupakan nilai icdrate dengan pengelompokkan sebanyak 2 cluster untuk metode CM dan FCM clustering menggunakan 3 fungsi keanggotaan yakni representatif linear naik, linear turun, dan segitiga. Namun, berdasarkan pemaran diatas, nilai pseudo f-statistics dan anggota cluster yang dihasilkan ketiga kurva adalah sama sehingga dapat dipastikan nilai icd-rate yang akan bernilai sama untuk metode fuzzy c-means clustering.
Tabel 4.10 Icd RateC-Means dan Fuzzy C-means Clustering
Nilai C-Means Fuzzy C-means
SSW 282,988 299,014
SSB 69,011 52,985
Icd-Rate 0,803 0,849
Tabel diatas menunjukkan bahwa metode dengan Fuzzy c-means clustering memiliki nilai icdrate yang paling rendah walau tidak berbeda dengan nilai icd-rate fuzzy c-means dan ini menunjukkan bahwa dispersi yang terjadi dengan metode pengelompokan c-means clustering cukup kecil dan metode ini merupakan metode yang lebih baik dibandingkan dengan metode
43
BAB V
KESIMPULAN DAN SARAN
5.1 Kesimpulan
Hasil dari analisis dan pembahasan mengenai pengelompokan provinsi di di Indonesia berdasarkan indikator kesejahteraan rakyat dapat dirangkum dalam kesimpulan berikut ini.
1. Gambaran umum kesejahteraan rakyat Indonesia pada masing masing provinsi di Indonesia melalui analisis statistika deskriptif didapatkan hasil untuk dimensi kesehatan terdapat 13 provinsi yang berada dibawah rata-rata nasional untuk ASI Ekslusif dan NTB merupakan provinsi dengan ASI Ekslusif tertinggi. 8 provinsi diatas rata-rata untuk Angka Kesakitan Malaria dan Papua adalah provinsi dengan Angka Kesakitan Malaria tertinggi di Indonesia. Sulawesi Utara adalah provinsi dengan Angka Imunisasi Anak tertinggi dan terdapat 9 provinsi dibawah rata-rata national untuk Angka Imunisasai Anak. Variabel Persentase Rumah Tangga Akses Air Minum Layak dan Sanitasi Layak terdapat 9 provinsi yang berada dibawah rata-rata nasional dan NTT merupakan akses sanitasi terendah di Indonesia. Dimensi pendidikan memberikan gambaran bahwa Papua merupakan provinsi dengan indikator pensisikan terburuk di Indonesia dikarenakan kurangnya tenaga pengajar di provinsi tersebut. Dimensi bidang ekonomi memberikan gambaran Bangka Belitung adalah provinsi dengan tingkat ketimpangan terbesar di Indonesia, Penduduk miskin di Indonesia terbesar berada di Papua dan Maluku merupakan provinsi dengan Tingkat Pengangguran Tertinggi di Indonesia.
2. Pengelompokan dengan c-means dan fuzzy c-means
cluster yang dilihat dari nilai pseudo f-statitics sebesar 7,560 dengan 32 provinsi berada pada cluster 1 dan hanya Papua yang berada di cluster 2 serta karakteristik yang terbentuk adalah provinsi Papua merupakan provinsi yang kesejahteraan rakyat nya kurang layak dari segala dimensi. Dengan fuzzy c-means clustering diketahui bahwa nilai
pseudo f-statistics untuk semua kurva representatif adalah sama yaitu sebesar 5,493. Anggota cluster yang terbentuk dari pengklasteran tersebut terdapat 13 provinsi yang berada pada cluster 1 dan 20 lainnya pada cluster 2.
3. Perbandingan kedua metode c-means dan fuzzy c-means
memberikan hasil bahwa c-means memberikan hasil lebih baik dibandingkan dengan c-means yang dilihat dari nilai icd rate sebesar 0,803 untuk metode c-means yang menunjukkan tingkat dispersi yang rendah.
5.2 Saran