Ujian nasional(UN) merupakan salah satu contoh sistem evaluasi standar pendidikan yang ada di Indonesia. UN ini dilaksanakan dengan tujuan untuk memetakan mutu pendidikan di Indonesia. Kegiatan evaluasi memang penting untuk dilakukan demi meningkatnya mutu pendidikan karena kegiatan ini evaluasi dapat memperlihatkan sampai sejauh mana siswa memahami materi yang diberikan. Setiap tahunnya Kementrian Pendidikan dan Kebudayaan (kemendikbud) selalu mengeluarkan nilai hasil UN dengan harapan dari data tesebut dapat ditemukan sebuah informasi yang bermanfaat untuk peningkatan mutu pendidikan di Indonesia. Salah satu bidang ilmu yang dapat digunakan untuk mendapatkan informasi dari kumpulan data tersebut adalah dengan data mining.
Salah satu penerapan data mining pada tugas akhir ini menggunakan teknik association rule dengan algoritma FP-Growth. Teknik ini dapat digunakan untuk mencari frequent itemset dalam kumpulan data. Penelitian ini bertujuan untuk menerapkan algoritma FP-Growth pada data nilai daya serap UN SMA di Yogyakarta untuk mata pelajaran Bahasa Indonesia.
Metodologi penelitian yang digunakan dalam penelitian ini adalah penelitian pustaka, KDD (Knowledge Discovery in Database) dan pembuatan laporan. Pada tahap awal KDD akan dilakukan pembersihan data dan integrasi data secara manual melalui Ms.Excel. Selanjutnya dilakukan seleksi data dan transformasi data di dalam perangkat lunak yang dibuat. Setelah itu dilakukanlah proses data mining dan terakhir adalah proses pattern evaluation dan knowledge presentation yang dikenakan pada hasil aturan asosiasi yang terbentuk. Pengujian terhadap sistem ini terdiri dari pengujian black box, pengujian validitas dan pengujian running time.
Berdasarkan semua pengujian, disimpulkan bahwa algoritma FP-Growth dapat diterapkan dan dapat menemukan aturan asosiasi yang menarik dari data nilai daya serap. Sistem yang dibuat dengan melakukan penerapan metode FP-Growth ini menghasilkan 5 aturan asosiasi yang menarik berdasarkan nilai lift ratio tertinggi untuk tahun akademik 2012/2013-2013/2014 ada 3 aturan asosiasi dan untuk tahun 2014/2015 ada 2 aturan asosiasi. Secara subyektif kompetensi-kompetensi dalam aturan-aturan asosiasi tersebut memang saling berkaitan.
The national examination (UN) is one example of a standard evaluation system of education in Indonesia. UN carried out in order to map the quality of education in Indonesia. Evaluation is the important things to do for improving the quality of education. this activity can reveal the extent to which students understand the material provided. Each year, Kementrian Pendidikan dan Kebudayaan (Kemendikbud) always display the results of the UN with the propose can be founded a useful information for improving the quality of education in Indonesia. One area of science that can be used to obtain information from the dataset is with data mining.
This thesis using one technic of data mining association rule with FP-Growth algorithm. This technique can be used to find frequent itemset in the data set. This research aims to implement the algorithm FP-Growth in the value data absorption UN High School in Yogyakarta's for Indonesian subjects.
The methodology for this research used in this study is a research library, KDD (Knowledge Discovery in Databases) and make a report. In the early stages of KDD will do data cleansing and data integration manually at Ms.Excel. Furthermore, the data selection and transformation of data will be do at the software that was created. After that perform the data mining process and the last is a process of pattern evaluation, and knowledge presentation imposed on the results of the association rules formed. Testing of the system consists of a black box testing, testing the validity and running time testing.
Based on all the tests, it was concluded that FP-Growth algorithm can be applied and can find an interesting association rules from the data value of absorption. The system that was created with FP-Growth method produces 5 interesting association rules based on the value of the highest lift ratio for the academic year 2012 / 2013-2013 / 2014 there are three rules of the association and for the year 2014/2015 there are two rules of association. Subjectively competencies in the rules of the association are correlated.
i
PENERAPAN ALGORITMA FP-GROWTH UNTUK ANALISIS POLA ASOSIASI DAYA SERAP HASIL JIAN NASIONAL MATA PELAJARAN BAHASA
INDONESIA SMA DI YOGYAKARTA
SKRIPSI
Diajukan untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Komputer
Program Studi Teknik Informatika
Disusun Oleh: Brigita Cynthia Dewi
125314016
PROGRAM STUDI TEKNIK INFORMATIKA JURUSAN TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA
ii
FP GROWTH ALGORITHM IMPLEMENTATION FOR ABSORTIVE CAPACITY ASSOCIATION RULE ANALYSIS ON INDONESIAN LANGUAGE
SUBJECT AT SENIOR HIGH SCHOOL NATIONAL EXAMINATION IN YOGYAKARTA
A THESIS
Presented as Partial Fulfillment of The Requirement To Obtain The Sarjana Komputer Degree In Informatics Engineering Study Program
By:
Brigita Cynthia Dewi 125314016
INFORMATICS ENGINEERING STUDY PROGRAM DEPARTMENT OF INFORMATICS ENGINEERING
FACULTY OF SCIENCE AND TECHNOLOGY SANATA DHARMA UNIVERSITY
v
vii ABSTRAK
Ujian nasional(UN) merupakan salah satu contoh sistem evaluasi standar pendidikan yang ada di Indonesia. UN ini dilaksanakan dengan tujuan untuk memetakan mutu pendidikan di Indonesia. Kegiatan evaluasi memang penting untuk dilakukan demi meningkatnya mutu pendidikan karena kegiatan ini evaluasi dapat memperlihatkan sampai sejauh mana siswa memahami materi yang diberikan. Setiap tahunnya Kementrian Pendidikan dan Kebudayaan (kemendikbud) selalu mengeluarkan nilai hasil UN dengan harapan dari data tesebut dapat ditemukan sebuah informasi yang bermanfaat untuk peningkatan mutu pendidikan di Indonesia. Salah satu bidang ilmu yang dapat digunakan untuk mendapatkan informasi dari kumpulan data tersebut adalah dengan data mining.
Salah satu penerapan data mining pada tugas akhir ini menggunakan teknik association rule dengan algoritma FP-Growth. Teknik ini dapat digunakan untuk mencari frequent itemset dalam kumpulan data. Penelitian ini bertujuan untuk menerapkan algoritma FP-Growth pada data nilai daya serap UN SMA di Yogyakarta untuk mata pelajaran Bahasa Indonesia.
Metodologi penelitian yang digunakan dalam penelitian ini adalah penelitian pustaka, KDD (Knowledge Discovery in Database) dan pembuatan laporan. Pada tahap awal KDD akan dilakukan pembersihan data dan integrasi data secara manual melalui Ms.Excel. Selanjutnya dilakukan seleksi data dan transformasi data di dalam perangkat lunak yang dibuat. Setelah itu dilakukanlah proses data mining dan terakhir adalah proses pattern evaluation dan knowledge presentation yang dikenakan pada hasil aturan asosiasi yang terbentuk. Pengujian terhadap sistem ini terdiri dari pengujian black box, pengujian validitas dan pengujian running time.
Berdasarkan semua pengujian, disimpulkan bahwa algoritma FP-Growth dapat diterapkan dan dapat menemukan aturan asosiasi yang menarik dari data nilai daya serap. Sistem yang dibuat dengan melakukan penerapan metode FP-Growth ini menghasilkan 5 aturan asosiasi yang menarik berdasarkan nilai lift ratio tertinggi untuk tahun akademik 2012/2013-2013/2014 ada 3 aturan asosiasi dan untuk tahun 2014/2015 ada 2 aturan asosiasi. Secara subyektif kompetensi-kompetensi dalam aturan-aturan asosiasi tersebut memang saling berkaitan.
viii ABSTRACT
The national examination (UN) is one example of a standard evaluation system of education in Indonesia. UN carried out in order to map the quality of education in Indonesia. Evaluation is the important things to do for improving the quality of education. this activity can reveal the extent to which students understand the material provided. Each year, Kementrian Pendidikan dan Kebudayaan (Kemendikbud) always display the results of the UN with the propose can be founded a useful information for improving the quality of education in Indonesia. One area of science that can be used to obtain information from the dataset is with data mining.
This thesis using one technic of data mining association rule with FP-Growth algorithm. This technique can be used to find frequent itemset in the data set. This research aims to implement the algorithm FP-Growth in the value data absorption UN High School in Yogyakarta's for Indonesian subjects.
The methodology for this research used in this study is a research library, KDD (Knowledge Discovery in Databases) and make a report. In the early stages of KDD will do data cleansing and data integration manually at Ms.Excel. Furthermore, the data selection and transformation of data will be do at the software that was created. After that perform the data mining process and the last is a process of pattern evaluation, and knowledge presentation imposed on the results of the association rules formed. Testing of the system consists of a black box testing, testing the validity and running time testing.
Based on all the tests, it was concluded that FP-Growth algorithm can be applied and can find an interesting association rules from the data value of absorption. The system that was created with FP-Growth method produces 5 interesting association rules based on the value of the highest lift ratio for the academic year 2012 / 2013-2013 / 2014 there are three rules of the association and for the year 2014/2015 there are two rules of association. Subjectively competencies in the rules of the association are correlated.
ix
KATA PENGANTAR
Puji dan syukur penulis panjatkan kepada Tuhan Yang Maha Esa karena atas rahmat dan karunia-Nya, penulis dapat menyelesaikan Tugas Akhir yang berjudul
“PENERAPAN ALGORITMA FP-GROWTH UNTUK ANALISIS POLA ASOSIASI
DAYA SERAP HASIL UJIAN NASIONAL MATA PELAJARAN BAHASA
INDONESIA SMA DI YOGYAKARTA” ini dengan baik.
Dalam proses penulisan tugas akhir ini penulis menyadari bahwa ada begitu banyak pihak yang turut membantu memberikan motivasi semangat dan juga bantuan dalam menyelesaikan tugas akhir ini. Oleh karena itu saya ingin mengucapkan terima kasih antara lain kepada :
1. Bapak Sudi Mungkasi, S.Si., M.Math.Sc.,Ph.D. selaku Dekan Fakultas Sains
dan Teknologi.
2. Ibu Dr. Anastasia Rita Widiarti, selaku Kepla Prodi Teknik Informatika.
3. Bapak Puspaningtyas Sanjoyo Adi, S.T., M.T sebagai dosen pembimbing
akademik, yang telah memberikan bimbingan dan saran selama penulis menempuh studi.
4. Ibu P.H Prima Rosa, S.Si., M.Sc selaku dosem pembimbing skripsi yang telah
memberikan kesabaran, waktu dan saran sehingga dapat diselesaikannya tugas akhir ini.
5. Seluruh dosen yang telah mendidik dan memberikan pengetahuan dan
pengalaman berharga selama penulis belajar di Universitas Sanata Dharma Yogyakarta.
6. Orang tua dan adik yang telah memberikan kasih sayang, perhatian, doa dan
dukungan sehingga penulis dapat menyelesaik tugas akhir.
7. Teman-teman bimbingan bu Rosa yang selalu dapat memberikan motivasi dan
semangat.
xi
DAFTAR ISI
A THESIS...ii
HALAMAN PERSETUJUAN ... Error! Bookmark not defined. HALAMAN PENGESEHAN ... iv
PERNYATAAN KEASLIAN KARYA ...v
LEMBAR PERNYATAAN PERSETUJUAN ... vi
ABSTRAK ... vii
ABSTRACT ... viii
KATA PENGANTAR... ix
DAFTAR ISI ... xi
1.6 Metodologi Penelitian ... 5
1.7 Sistematika Penulisan ... 6
BAB II ... 7
LANDASAN TEORI ... 7
2.1 Pengertian Penambangan Data ... 7
2.2 Tujuan Penambangan Data ... 7
2.3 Teknik Data Mining ... 8
2.4 Knowledge Discovery in Database (KDD) ... 9
xii
BAB III ... 20
METODE PENELITIAN ... 20
3.1 Sumber Data ... 20
3.2 Spesifikasi Alat ... 24
3.3 Tahap – Tahap Penelitian ... 24
BAB IV ... 28
PEMROSESAN AWAL DAN PERANCANGAN PERANGKAT LUNAK PENAMBANGAN DATA ... 28
4.1 Perancangan Awal Sumber Data ... 28
4.2 Pengembangan Perangkat Lunak Penambangan Data ... 29
BAB V ... 49
IMPLEMENTASI PENAMBANGAN DATA... 49
DAN EVALUASI HASIL ... 49
5.1 Implementasi Rancangan Perangkat Lunak Penambangan Data ... 49
5.2.1 Implementasi Kelas Model ... 49
5.2.2 Implementasi Kelas View ... 49
5.2.3 Implementasi Kelas Controller... 50
5.2 Evaluasi Hasil ... 50
5.2.1 Uji Coba Perangkat Lunak (Black Box Testing)... 50
xiii
DAFTAR GAMBAR
Gambar 2. 1 Diagram Model Klasifikasi ... 8
Gambar 2. 2 Penambangan data sebagai tahapan dalam proses KDD ... 10
Gambar 2. 3 Tabel data transaksi ... 13
Gambar 2. 4 Tabel daftar support count tiap item ... 13
Gambar 2. 5 Pembuatan FP Tree ... 14
Gambar 2. 6 Sub-database node I3 ... 15
Gambar 4. 1 Diagram Konteks ... 30
Gambar 4. 2 Diagram Usecase ... 31
Gambar 4. 3 Ilustrasi FPTree ... 34
Gambar 4. 4 Susunan arraylist untuk kode sekolah 01-010 ... 35
Gambar 4. 5 Susunan arraylist untuk kode sekolah 01-019 ... 35
Gambar 4. 6 Data arraylist dalam arraylist ... 35
Gambar 4. 7 Diagram Kelas Desain ... 36
Gambar 4. 8 Halaman Awal ... 43
Gambar 4. 9 Halaman About ... 44
Gambar 4. 10 Halaman Help ... 45
Gambar 4. 11 Halaman Preprocessing ... 46
Gambar 4. 12 Halaman Asosiasi ... 47
Gambar 4. 13 Halaman Database ... 48
Gambar 4. 14 Diagram Kelas Analisis ... 85
Gambar 5. 1 (a)Kotak Dialog “Pilih File” (b)Tabel Dataset ... 51
Gambar 5. 2 Kotak Dialog Salah Pilih File ... 51
Gambar 5. 3 Tampilan Setelah Menekan Tombol “Tandai Semua” ... 52
Gambar 5. 4 Tampilan Setelah Menekan Tombol “Hapus Atribut” ... 52
Gambar 5. 5 Tampilan Setelah Menekan Tombol “Batal” ... 52
Gambar 5. 6 Hasil Pencarian Aturan asosiasi ... 55
Gambar 5. 7 Tampilan Ketika Min Support dan Minimum confidence Tidak Diisi .. 55
Gambar 5. 8 Kotak Dialog Simpan Hasil... 56
Gambar 5. 9 Kotak Dialog Jika Berhasil Menyimpan Data ... 56
Gambar 5. 10 Dataset Supermarket.arff ... 59
Gambar 5. 11 Dataset Setelah di Preprocessing ... 60
Gambar 5. 12 Uji Running Time Min Confidence=60% ... 67
Gambar 5. 13 Uji Running Time Min Confidence=90% ... 68
Gambar 5. 14 Uji Running Time Min Confidence=60% ... 68
xiv
DAFTAR TABEL
Tabel 2. 1 Interval Daya Serap Siswa ... 18
Tabel 3. 1 Tabel Atribut Data Mata Pelajaran Bahasa Indonesia 2012/2013 & 2013/2014 ... 20
Tabel 3. 2 Tabel Atribut Data Mata Pelajaran Bahasa Indonesia 2014/2015 ... 22
Tabel 4. 1 Daftar Kelas Untuk Tiap Usecase ... 32
Tabel 5. 1 Tabel Implementasi Kelas Model ... 49
Tabel 5. 2Tabel Implementasi Kelas View ... 49
Tabel 5. 3 Tabel Implementasi Kelas Controller ... 50
Tabel 5. 4 Tabel Hasil Uji Pada Halaman Preprocessing ... 52
Tabel 5. 5 Tabel Pengujian Halaman Preprocessing ... 54
Tabel 5. 6 Tabel Pengujian dengan Hitungan Manual ... 57
Tabel 5. 7 Tabel Hasil Pengujian dengan WEKA ... 60
Tabel 5. 8 Tabel Hasil Pengujian Tahun 2012/2013 & 2013/2014, Min Conf=60% . 63 Tabel 5. 9 Tabel Hasil Pengujian Tahun 2012/2013 & 2013/2014, Min Conf = 90% 63 Tabel 5. 10 Tabel Hasil Pengujian Tahun 2014/2015, Min Conf = 60% ... 65
Tabel 5. 11 Tabel Hasil Pengujian Tahun 2014/2015, Min Conf = 90% ... 66
Tabel 5. 12 Daftar aturan asosiasi data tahun 2012/2013-2013/2014... 71
Tabel 5. 13 Daftar aturan asosiasi data tahun 2014/2015 ... 74
xv
DAFTAR LAMPIRAN
Lampiran 1 : Diagram Aktivitas ... 82
Lampiran 2 : Diagram Kelas Analisis ... 85
Lampiran 3 : Diagram Sequence ... 86
Lampiran 4 : Diagram Kelas Desain ... 89
Lampiran 5 : Penghitungan Manual... 95
1
BAB I
PENDAHULUAN
1.1. Latar Belakang
2
daftar dan juga daya serap. Dalam penelitian ini, bentuk informasi yang akan digunakan adalah informasi daya serap. Informasi daya serap ini berisi informasi laporan daya serap Ujian Nasional siswa SMA dari program IPA dengan mata pelajaran Bahasa Indonesia yang memiliki 21 kompetensi. Dari data tersebut diharapkan dapat digali informasi keterkaitan antara kompetensi yang satu dengan kompetensi lainnya dari sekolah-sekolah yang memiliki nilai daya serap yang memenuhi standar yang ditentukan. Informasi tersebut dapat dimanfaatkan oleh dinas pendidikan untuk membantu dinas pendidikan memberikan langkah-langkah perbaikan mengenai metode pembelajaran ada saat ini guna meningkatkan mutu pendidikan di Yogyakarta. Penelitian ini juga dapat dimanfaatkan oleh para peneliti di bidang pendidikan sebagai rekomendasi analisa agar dapat dikaji lebih mendalam lagi. Salah satu teknik yang dapat dipergunakan untuk menggali informasi tersebut adalah data mining.
Data mining adalah suatu istilah yang digunakan untuk menguraikan penemuan
pengetahuan didalam database. Data mining adalah proses yang menggunakan teknik statistik, matematika, kecerdasan buatan dan machine learning untuk mengekstraksi dan mengidentifikasi informasi yang bermanfaat dan pengetahuan yang terkait dari berbagai database besar (Turban, dkk.2005). Data mining sendiri memiliki berbagai macam teknik, salah satunya adalah teknik asosiasi. Analisis asosiasi atau association rule mining adalah teknik data mining untuk menemukan aturan asosiatif antara suatu
kombinasi item. Dalam kasus ini peneliti melakukan penelitian dari data nilai daya serap siswa SMA Yogyakarta untuk mencari tahu pola keterkaitan antara kompetensi yang satu dengan yang lainnya yang mempengaruhi keberhasilan siswa menggunakan algoritma FP-Growth.
Algoritma FP-Growth merupakan salah satu alternatif algoritma yang dapat digunakan untuk menentukan himpunan data yang paling sering muncul (frequent itemset) dalam sebuah kumpulan data. Menurut Octaviani, (2010) algoritma
3
algoritma ini juga dapat menghasilkan aturan yang sama baiknya dengan algoritma Apriori setelah diujikan pada data transaksi penjulan untuk melakukan market base analysis. Pada penelitian tugas akhir ini nantinya akan dibuat sebuah sistem yang
menerapkan algoritma FP-Growth pada data nilai daya serap siswa yang diharapkan dapat menemukan pola asosiasi antar kompetensi. Pada penelitian ini, peneliti hanya akan berfokus pada mata pelajaran Bahasa Indonesia. Mata pelajaran ini dipilih karena peneliti berpendapat bahwa Bahasa Indonesia itu merupakan salah satu identitas Bangsa Indonesia. Bahasa Indonesia mempunyai kedudukan yang sangat penting dalam kehidupan berbangsa dan bernegara maka Bahasa Indonesia juga merupakan salah satu mata pelajaran yang selalu diberikan semenjak siswa masih berada di tingkat Taman Kanak-Kanak. Tujuan pembelajaran dari mata pelajaran ini bukan hanya untuk sekedar siswa lulus dalam ujian melainkan mereka dapat menggunakan Bahasa Indonesia yang baik dan benar di kehidupan sehari-harinya. Karena kebutuhan itulah, penting bagi tenaga pendidik untuk mengetahui sejauh mana kemampuan berbahasa Indonesia anak didiknya. Hasil keluaran dari sistem diharapkan dapat digunakan untuk mengetahui kompetensi apa saja yang ternyata memiliki keterkaitan berdasarkan nilai lift ratio sebagai analisa secara obyektif dan juga berdasarkan pendapat dari seorang
praktisi pendidikan di bidang Bahasa Indonesia sebagai analisa secara subyektif. Aturan asosiasi yang didapatkan tersebut dapat digunakan oleh dinas pendidikan untuk mengambil langkah-langkah perbaikan kepada sekolah-sekolah yang memiliki nilai daya serap kurang dari standar yang ditentukan pada kompetensi-kompetensi yang ada di dalam aturan asosiasi tersebut. Salah satu perbaikan yang dilakukan adalah dengan memperbaiki metode pembelajaran di masa yang akan datang yang berfokus pada kompetensi-kompetensi di dalam aturan asosiasi yang didapatkan.
1.2. Rumusan Masalah
4
1. Bagaimana menerapkan algoritma FP-Growth untuk menemukan aturan
asosiasi antar kompetensi dari nilai daya serap Ujian Nasional?
2. Apakah algoritma FP-Growth dapat menemukan aturan asosiasi yang
menarik berdasarkan ukuran lift ratio aturan asosiasi yang dihasilkan dari data nilai daya serap ujian nasional SMA di Yogyakarta?
1.3. Batasan Masalah
Batasan masalah yang dibahas dalam penulisan tugas akhir ini adalah sebagai berikut:
b. Sistem menggunakan data nilai daya serap UN SMA di Yogyakarta jurusan
IPA dengan mata pelajaran Bahasa Indonesia tahun ajaran 2012/2013, 2013/2014, 2014/2015.
c. Data yang digunakan merupakan data yang diambil dari situs
www.litbang.kemendikbud.go.id.
1.4. Tujuan Penelitian
Tujuan dari penelitian ini adalah menerapkan algoritma FP-Growth pada data nilai daya serap untuk menenemukan pola asosiasi antara kompetensi yang satu dengan yang lainnya pada suatu mata pelajaran.
1.5. Manfaat Penelitian
5
1.6 Metodologi Penelitian
1.6.1 Penelitian Pustaka
Pada tahap ini, dilakukan penelitian pustaka untuk memperoleh informasi dan menggali teori-teori tentang teknik data mining. Dalam penelitian ini penulis mempelajari literatur yang berkaitan dengan teknik data mining asosiasi khususnya algoritma FP-Growth dan literatur lainnya yang berguna bagi sistem yang akan dibangun.
1.6.2 Knowledge Discovery in Database (KDD)
KDD ini merupakan tahap-tahap yang perlu dilakukan dalam penelitian di bidang penambangan data (data mining). Proses KDD ini pula terdiri dari data cleaning, data integration, data selection, data transformation, data mining,
pattern evaluation dan knowledge presentation. Tujuan dari proses ini adalah
untuk mendapatkan informasi dari data nilai daya serap SMA di Yogyakarta. Pada salah satu tahap yang akan dilalui pada proses KDD ini adalah pembuatan perangkat lunak sebagai alat uji yang menggunakan metodologi waterfall. Metodologi tersebut terdiri dari analisa terhadap kebutuhan sistem, desain perangkat lunak dan yang terakhir adalah pengujian. Hasil yang didapatkan, kemudian akan dianalisa apakah hasil tersebut menghasilkan sebuah informasi yang bermanfaat.
1.6.3 Pembuatan Laporan
6
1.7 Sistematika Penulisan
BAB I. Pendahuluan
Bab ini berisi latar belakang, rumusan masalah, tujuan, manfaat, batasan masalah, metodologi penelitian, dan sistematika penulisan.
BAB II. Landasan Teori
Bab ini akan menjelaskan mengenai teori yang berkaitan dengan judul/masalah di tugas akhir.
BAB III. Metode Penelitian
Bab ini akan menjelaskan tentang penelitian pustaka yang berisikan data dan sumber data yang digunakan dan juga ada proses KDD yang menjelaskan tentang langkah-langkah yang digunakan dalam penelitian ini. Dan yang terakhir dijelaskan pula tentang pembuatan laporan.
BAB IV Pemrosesan Awal dan Perancangan Perangkat Lunak Penambangan Data
Bab ini berisikan langkah awal perancangan penelitian dan perancangan pembuatan perangkat lunak.
BAB V Implementasi Penambangan Data dan Evaluasi Hasil
Bab ini akan menjelaskan mengenai proses pengujian sistem dan juga beserta analisis dari hasil pengujian tersebut.
BAB VI Penutup
Bab ini akan menjelaskan mengenai kesimpulan beserta kelebihan dan kelemahan sistem yang dibuat.
7
BAB II
LANDASAN TEORI
2.1 Pengertian Penambangan Data
Penambangan data adalah proses yang menggunakan teknik statistik, matematika, kecerdasan buatan, dan machine learning untuk mengekstraksi dan mengidentifikasi informasi yang bermanfaat dan pengetahuan yang terakit dari berbagai database besar (Turban et al, 2005). Sedangkan menurut Pramudiono (2006) data mining adalah serangkaian proses untuk menggali nilai tambah dari suatu kumpulan data berupa pengetahuan yang selama ini tidak diketahui secara manual. Terkadang penambangan data biasa juga dikenal dengan KDD (Knowledge Discovery in Database), padahal sebenarnya penambangan data
merupakan salah satu tahapan pada proses KDD. Pemanfaatan penambangan data ini juga sudah banyak diterapkan dalam banyak bidang. Salah satu contoh pemanfaatan penambangan data yaitu untuk menganalisa pasar sehingga sebuah pelaku bisnis bisa lebih mengetahui pola pembelian para konsumennya.
2.2 Tujuan Penambangan Data
Tujuan dari penambangan data (Hoffer et al, 2005) adalah: 1. Explanatory
Untuk menjelaskan beberapa kondisi penelitian, seperti mengapa penjualan truk pick-up meningkat di Colorado.
2. Confirmatory
8
Untuk menganalisa data yang memiliki hubungan yang baru. Misalnya, pola apa yang cocok untuk kasus penggelapan kartu kredit.
2.3 Teknik Data Mining
2.3.1 Classification
Klasifikasi merupakan proses pembelajaran suatu fungsi tujuan (target) yang memetakan tiap himpunan atribut x sebagai input ke satu dari label kelas y yang didefinisikan sebelumnya sebagai output. Fungsi target disebut juga model klasifikasi (Hermawati, 2013).
Beberapa algoritma klasifikasi antara lain pohon keputusan, nearest neighbor, naïve bayes, neural networks dan support vector machines.
2.3.2 Clustering
Analisa cluster yaitu menemukan kumpulan objek hingga objek-objek dalam satu kelompok sama (atau punya hubungan) dengan yang lain dan berbeda
(atau tidak berhubungan) dengan objek – objek dalam kelompok lain. Tujuan dari
analisa cluster adalah meminimalkan jarak di dalam cluster dan memaksimalkan jarak antar cluster (Hermawati, 2013).
Classification model
9
2.3.3 Association Rules
Association juga disebut sebagai Market Basket Analysis. Sebuah problem
bisnis yang khas adalah menganalisa tabel transaksi penjualan dan mengidentifikasi produk-produk yang seringkali dibeli bersamaan oleh customer, misalnya apabila orang membeli sambal, biasanya juga dia membeli kecap. Kesamaan yang ada dari data pembelian digunakan untuk mengidentifikasi kelompok kesamaan dari produk dan kebiasaan apa yang terjadi guna kepentingan cross-selling.
2.3.4 Regresi
Regresi ini biasanya digunakan untuk memprediksi nilai dari suatu variabel kontinyu yang diberikan berdasarkan nilai dari variabel yang lain, dengan mengasumsikan sebuah model ketergantungan linier atau nonlinier. Teknik ini banyak dipelajari dalam statistika, bidang jaringan syaraf tiruan (neural network). Contoh aplikasi untuk teknik regresi adalah (Hermawati, 2013).
a. Memprediksi jumlah penjualan produk baru berdasarkan pada belanja
promosi/iklan
b. Memprediksi kecepatan angina sebagai suatu fungsi suhu, kelembaban, tekanan
udara, dsb.
c. Time series prediction dari indeks stock market.
2.4 Knowledge Discovery in Database (KDD)
10
Gambar 2. 2 Penambangan data sebagai tahapan dalam proses KDD (Sumber : Fayyad, 1996)
a. Data Cleaning
Sebelum proses penambangan data dapat dilaksanakan, perlu dilakukan proses cleaning pada data yang menjadi fokus KDD. Proses cleaning mencakup antara lain membuang duplikasi data, memeriksa data yang inkonsisten dan memperbaiki kesalahan pada data, seperti kesalahan cetak (tipografi). Lalu dilakukan juga proses enrichment, yaitu proses
“memperkaya” data yang sudah ada dengan data atau informasi lain
yang relevan dan diperlukan untuk KDD, seperti data atau informasi eksternal.
b. Data Integration
11 c. Data Selection
Pemilihan (seleksi) data dari sekumpulan data operasional perlu dilakukan sebelum tahap penggalian informasi dalam KDD dimulai. Data hasil seleksi yang akan digunakan untuk proses penambangan data, disimpan dalam suatu berkas, terpisah dari basis data operasional. d. Data Transformation
Coding adalah proses transformasi pada data yang telah dipilih,
sehingga data tersebut sesuai untuk proses penambangan data. Proses coding dalam KDD merupakan proses kreatif dan sangat tergantung
pada jenis atau pola informasi yang akan dicari dalam basis data.
e. Penambangan Data
Penambangan data adalah proses mencari pola atau informasi menarik dalam data terpilih dengan menggunakan teknik atau metode tertentu. Teknik, metode atau algoritma dalam penambangan data sangat bervariasi. Pemilihan metode atau algoritma yang tepat sangat bergantung pada tujuan dan proses KDD secara keseluruhan.
f. Pattern Evaluation
Pola informasi yang dihasilkan dari proses penambangan data perlu ditampilkan dalam bentuk yang mudah dimengerti oleh pihak yang berkepentingan. Tahap ini merupakan bagian dari proses KDD yang disebut interpretation. Tahap ini mencakup pemeriksaan apakah pola atau informasi yang ditemukan bertentangan dengan fakta atau hipotesis yang ada sebelumnya.
g. Knowledge Presentation
12
……… .
……… . 2.5Association Rules
2.5.1 Pengertian Association Rules
Association rules merupakan sebuah ekspresi implikasi yang berbentuk X Y, dimana X dan Y merupakan disjoint itemset (X∩Y) = ø. Contoh: {Pena,Tinta} {Jus}. Dalam association rule, kita dapat menghitung support dan confidence. Confidence menyatakan seberapa sering item-item dalam Y muncul dalam transaksi
yang berisi X. Sedangkan support menyatakan seberapa sering item-item dalam X dan Y muncul dalam transaksi secara bersamaan. Secara formal dapat dinyatakan dengan persamaan berikut ini:
s(XY) =∑ �
�
c(XY) =∑ �
∑
Dimana s adalah support dan c adalah confidence (Hermawati, 2013).
2.5.2 Frequent Pattern
Frequent Patterns adalah pola yang sering terjadi di dalam data. Ada banyak jenis dari
frequent patterns, termasuk di dalamnya pola, sekelompok item set, sub-sequence, dan
sub-struktur. Sebuah frequent patterns biasanya mengacu pada satu set item yang sering muncul bersama-sama dalam suatu kumpulan data transaksional, misalnya seperti susu dan roti.
2.6Frequent Pattern Growth (FP-Growth)
13
2.3 hanya saja item-item dari tiap transaksi tersebut harus diurutkan kembali berdasarkan jumlah count-nya (Gambar 2.4).
Gambar 2. 3 Tabel data transaksi (Sumber : Han et al. 2006 )
Gambar 2. 4 Tabel daftar support count tiap item (Sumber : Han et al. 2006 )
14
Gambar 2. 5 Pembuatan FP Tree
(Sumber : Han et al. 2006 )
Cara pembuatan FPTree dilakukan dengan cara membaca satu persatu dari transaksi pertama. Misalnya untuk TID T100 daftar item-nya adalah {I2,I1,I5}, maka untuk dibuat kedalam FP Tree buatlah 3 node untuk I2, I1 dan I5 beserta path sehinga menjadi null I2 I1 I5 dengan count untuk I2, I1 dan I5 adalah 1. Selanjutnya untuk TID T200 dengan daftar item {I2,I4}, maka dibuat 2 node untuk I2 dan I4 beserta path-nya null I2 I4. TID T100 dan T200 memiliki prefix yang sama yaitu I2. Maka count I2 bertambah menjadi 2.
Metode FPGrowth dapat dibagi menjadi 3 tahapan utama (Han et al. 2006). Ketiga tahapan ini akan dilakukan secara berulang-ulang untuk setiap item di header table yang diurutkan berdasarkan frekuensinya:
a. Tahap pembangkitan conditional pattern base
Conditional Pattern base merupakan subdatabase yang berisi prefix path
(lintasan prefix) dan suffix pattern (pola akhiran). Pembangkitan conditional pattern base didapatkan melalui FPtree yang telah dibangun sebelumnya.
15
Setelah menemukan node tersebut, maka dapat ditelusuri node-node apa saja yang dilalui dari I3 sampai ke root. Node-node yang dilewati tersebut akan menjadi sebuah lintasan. Lintasan-lintasan yang terbentuk untuk node I3 adalah {I2,I1: 2},{I2:2} dan {I1:2}. Lintasan-lintasan tersebutlah yang akan menjadi conditional pattern base.
Gambar 2. 6 Sub-database node I3
b. Tahap pembangkitan conditional FPTree
Pada tahap ini, support count dari setiap item pada setiap conditional pattern base dijumlahkan, lalu setiap item yang memiliki jumlah support count lebih
besar sama dengan minimum support count yang akan dibangkitkan dengan conditional FPtree. Berdasarkan hasil conditional pattern base untuk node
I3 yang telah dijelaskan pada tahap sebelumnya, dapat dihitung support count dari setiap itemnya adalah {I2:4, I1:2} dan {I1:2}
c. Tahap pencarian frequent itemset
16
… .
..… . … . merupakan single path melainkan bercabang. Untuk setiap single path akan dikombinasikan dan hasil frequent pattern-nya adalah {{I2, I3: 4},{I1, I3: 4},{I2, I1, I3: 2}}.
2.7Lift ratio
Salah satu cara yang lebih baik untuk melihat kuat tidaknya aturan asosiasi adalah dengan menghitung lift ratio. Cara kerja metode ini adalah membagi confidence dengan expected confidence. Confidence dapat dihitung dengan rumus 2.3. Anteseden merupakan sebab yang menjadikan item konsekuen. Sedangkan
konsekuen adalah sebuah akibat atau juga item yang akan dibeli setelah membeli
anteseden. Jika didapatkan aturan asosiasi A B maka A sebagai anteseden dan B sebagai konsekuen. Nilai dari expected confidence dapat dihitung dengan rumus 2.4.
� = jumlah transaksi yang mengandung anteseden dan konsekuen
jumlah transaksi yang mengandung anteseden
�� � � = jumlah transaksi yang mengandung konsekuen
jumlah transaksi dalam database
Lift ratio dapat dihitung dengan cara membandingkan antara confidence untuk
suatu aturan dibagi dengan expected confidence. Berikut rumus dari lift ratio:
�� � ���� = expected � �
17
nilai lift ratio < 1 maka kemunculan A berkorelasi negative dengan kemunculan B, artinya kemunculan salah satu item mempengaruhi hal yang sebaliknya pada kemunculan item lainnya. Contoh dari korelasi negative adalah jika penjualan item A naik maka mempengaruhi jumlah penjualan B menjadi menurun. Jika didapatkan lift ratio > 1 maka kemunculan A berkorelasi positive dengan kemunculan B,
artinya kemunculan A ini berhubungan dengan kemunculan B. Contoh dari korelasi positive adalah jika item A dibeli maka item B juga akan dibeli. Sedangkan jika lift
ratio = 1 maka kemuncul item A dan B independent dan tidak ada korelasi diantara
kedua item tersebut (Han et al. 2006).
2.8Evaluasi Pengajaran
2.8.1 Pengertian Evaluasi
Dalam dunia pendidikan kita sering mendengar kata evaluasi. Tidak banyak orang yang mengetahui bahwa hakikat dari dari evaluasi dan bahkan apa itu itu evaluasi terkadang disalah artikan oleh seorang guru. Padahal seorang guru memiliki salah satu kewajiban yakni melakukan evaluasi kepada program pembelajaran yang telah dilakukan. Evaluasi sering disalah artikan oleh seorang guru dengan kata ujian, padahal ujian hanya salah satu bentuk evaluasi. Jika ujian tidak dilaksanakan dengan baik dari segi penyusunan Intsrumennya, bahkan ujian pun yang dibuat asal-asal tidak dapat dikategorikan sebagai bentuk evaluasi.
Bloom (1971) mendefinisikan evaluasi, sebagaimana kita lihat, adalah pengumpulan kenyataan secara sistematis untuk menetapkan apakah dalam kenyataannya terjadi perubahan dalam diri siswa dan menetapkan sejauh mana tingkat perubahan dalam pribadi siswa. Sejalan dengan itu, Stufflebeam (1985), mengatakan bahwa evaluasi merupakan proses menggambarkan, memperoleh, dan menyajikan informasi yang berguna untuk menilai alternatif keputusan.
18
data yang diambil dari suatu atau sekelompok objek. Sedangkan ujian dapat dilakukan tanpa ada tujuan untuk memeperbaiki nilai. Ujian juga dapat dilakukan hanya untuk menyaring dan menentukan kelas dari kumpulan objek.
Salah satu cara untuk melihat pemetaan hasil evaluasi adalah dengan melihat nilai daya serap. Untuk mengetahui daya serap siswa dari hasil belajarnya digunakan analisis dengan menggunakan interval daya serap siswa pada tabel 2.1.
Tabel 2. 1 Interval Daya Serap Siswa
No. Interval Kategori
1 0% - 39% Sangat Rendah
2 40% - 59% Rendah
3 60% - 74% Sedang
4 75% - 84% Tinggi
5 85% - 100% Sangat Tinggi
2.8.2 Manfaat Pelaksanaan Evaluasi
Manfaat pelaksanaan evaluasi dalam dunia pendidikan, khususnya dunia persekolahan, evaluasi mempunyai makna ditinjau dari berbagi segi (Dahlan,2014):
a. Makna bagi siswa
Dengan diadakannya evaluasi, maka siswa dapat mengetahui sejauh mana telah berhasil mengikuti pelajaran yang diberikan oleh guru. Hasil yang diperoleh siswa dari pekerjaan menilai ini ada kemungkinan:
19
b. Makna bagi guru
Dengan hasil penilaian yang diperoleh guru akan dapat mengetahui siswa-siswa mana yang sudah berhasil menguasai bahan, maupun mengetahui siswa-siswa yang belum berhasil menguasai bahan. Guru akan mengetahui apakah materi yang diajarkan sudah tepat bagi siswa sehingga untuk memberikan pengajaran di waktu yang akan datang tidak perlu diakan perubahan.
c. Makna bagi sekolah
20 www.litbang.kemdikbud.go.id. Data yang didapat tersebut berekstensi .xls dan berisikan nilai daya serap siswa SMA pada saat ujian nasional pada tahun akademik 2012/2013, 2013/2014 dan 2014/2015 yang terbagi ke dalam tiap-tiap kompetensi. Data yang dipakai merupakan data siswa program IPA dengan mata pelajaran Bahasa Indonesia yang memiliki 21 kompetensi. Untuk masukan sistem, pengguna akan memilih 1 dari beberapa mata pelajaran yang ada. Mata pelajaran Bahasa Indonesia memiliki 21 kompetensi yang diujikan pada Ujian Nasional SMA tahun akademik 2012/2013 & 2013/2014. Kompetensi-kompetensi yang diujikan tersebut adalah:
Tabel 3. 1 Tabel Atribut Data Mata Pelajaran Bahasa Indonesia 2012/2013 & 2013/2014
Kode Atribut Keterangan
KODE_SEKOLAH Kode Sekolah
NAMA_SEKOLAH Nama Sekolah
JNS_SEK Jenis Sekolah (SMA/NA)
STS_SEK Status Sekolah (Negeri/Swasta)
BIND1 Melengkapi berbagai bentuk dan jenis paragraf dengan
kalimat yang padu
21
BIND3 Melengkapi larik puisi lama/baru (dengan kata
kias/berlambang/ berima/bermajas
BIND4 Melengkapi paragraf dengan kata baku, kata serapan, kata
berimbuhan, kata ulang, ungkapan, peribahasa
BIND5 Melengkapi teks pidato
BIND6 Menentukan isi dan simpulan grafik, diagram atau tabel
BIND7 Menentukan isi paragraf: fakta, opini, pernyataan/ jawaban
pertanyaan sesuai isi, tujuan penulis, arti kata/istilah, isi biografi
BIND8 Menentukan isi puisi lama, pantun, gurindam
BIND9 Menentukan kalimat resensi
BIND10 Menentukan kalimat kritik
BIND11 Menentukan opini penulis dan pihak yang dituju dalam tajuk
rencana/editorial
BIND12 Menentukan unsur-unsur intrinsik dan ekstrinsik sastra
Melayu klasik/hikayat
BIND13 Menentukan unsur-unsur intrinsik puisi
BIND14 Menentukan unsur-unsur intrinsik puisi
BIND15 Menentukan unsur-unsur intrinsik/ ekstrinsik
novel/cerpen/drama
BIND16 Menentukan unsur-unsur paragraf, ide pokok, kalimat
utama, kalimat penjelas
BIND17 Menulis judul sesuai EYD
BIND18 Menulis karya ilmiah (latar belakang dan rumusan masalah)
22
BIND20 Menyunting kalimat dalam surat resmi
BIND21 Menyunting penggunaan kalimat/frasa/kata
penghubung/istilah dalam paragraf
Sedangkan pada tahun 2014/2015 ada sedikit perubahan pada kompetensi yang diujikan. Ada satu kompetensi yang dibedakan dengan tahun-tahun sebelumnya. Perbedaan tersebut terletak pada munculnya kompetensi baru yaitu BIND18
“Menulis paragraf padu”. Daftar kompetensi yang diujikan adalah sebagai berikut:
Tabel 3. 2 Tabel Atribut Data Mata Pelajaran Bahasa Indonesia 2014/2015
Kode Atribut Keterangan
KODE_SEKOLAH Kode Sekolah
NAMA_SEKOLAH Nama Sekolah
JNS_SEK Jenis Sekolah (SMA/NA)
STS_SEK Status Sekolah (Negeri/Swasta)
BIND1 Melengkapi berbagai bentuk dan jenis paragraf dengan
kalimat yang padu
BIND2 Melengkapi dialog drama
BIND3 Melengkapi larik puisi lama/baru (dengan kata
kias/berlambang/ berima/bermajas
BIND4 Melengkapi paragraf dg kata baku, kata serapan, kata
berimbuhan, kata ulang, ungkapan, peribahasa
BIND5 Melengkapi teks pidato
BIND6 Menentukan isi dan simpulan grafik, diagram atau tabel
BIND7 Menentukan isi paragraf: fakta, opini, pernyataan/jawaban
23
BIND8 Menentukan isi puisi lama, pantun, gurindam
BIND9 Menentukan kalimar resensi
BIND10 Menentukan kalimat kritik
BIND11 Menentukan opini penulis dan pihak yang dituju dalam tajuk
rencana/editorial
BIND12 Menentukan unsur-unsur intrinsik dan ekstrinsik sastra
Melayu klasik/hikayat
BIND13 Menentukan unsur-unsur intrinsik puisi
BIND14 Menentukan unsur-unsur intrinsik/ ekstrinsik
novel/cerpen/drama
BIND15 Menentukan unsur-unsur paragraf, ide pokok, kalimat
utama, kalimat penjelas
BIND16 Menulis judul sesuai EYD
BIND17 Menulis karya ilmiah (latar belakang dan rumusan masalah)
BIND18 Menulis paragraf padu
BIND19 Menulis surat resmi
BIND20 Menyunting kalimat dalam surat resmi
BIND21 Menyunting penggunaan kalimat/frasa/kata
penghubung/istilah dalam paragraf
24 3.2Spesifikasi Alat
Sistem dibuat dengan menggunakan hardware dan software sebagai berikut :
a. Spesifikasi hardware
a. Proses Intel Pentium Core i3 2.30GHz
b. RAM 2 GB
c. Harddisk 500 GB
b. Spesifikasi Software
a. Sistem Operasi Microsoft Windows 10
b. Compiler IDE NetBeans 8.0
Software ini akan digunakan untuk membuat tampilan interface dan sekaligus membuat source code.
3.3Tahap – Tahap Penelitian
a. Studi Kasus
Ujian nasional adalah salah satu sistem evaluasi standar pendidikan yang ada di Indonesia. Ujian ini diadakan dengan tujuan untuk pengendalian mutu pendidikan secara nasional. Demi meningkatnya mutu pendidikan nasional, maka ada baiknya jika para pengajar dapat selalu mengevaluasi hasil dari ujian nasional sekolahnya masing-masing. Untuk mendapatkan evaluasi yang lebih mendalam, maka digunakanlah nilai daya serap yang terdiri dari beberapa kompetensi dari setiap mata pelajaran. Penelitian ini diharapkan dapat menemukan pola keterkaitan antara satu kompetensi dengan kompetensi lainnya yang mempengaruhi sebuah sekolah mendapatkan nilai lebih dari standar nilai daya serap yang ditentukan pada kompetensi-kompetensi tertentu.
b. Penelitian Pustaka
25
penulis mempelajari literatur yang berkaitan dengan teknik penambangan data asosiasi khususnya algoritma FP-Growth dan literatur lainnya yang berguna bagi sistem yang akan dibangun.
c. Knowledge Discovery in Database (KDD)
Setelah tahap-tahap sebelumnya dilakukan, maka tahap ini sangat diperlukan karena penelitian ini berada di bidang penambangan data. Proses KDD pula terdiri dari data cleaning, data integration, data selection, data transformation, data mining, pattern evaluation dan knowledge presentation. Pada tahap awal
akan dilakukan data cleaning dan data integration pada data nilai daya serap sehingga data tersebut dapat digunakan untuk mencari pola asosiasinya. Proses awal ini dilakukan secara manual menggunakan tool Microsoft Excel. Lalu untuk proses selanjutnya seperti data selection, data transformation dan data mining akan dilakukan di dalam perangkat lunak yang akan dibuat. Sedangkan
proses pattern evaluation dan knowledge presentation baru dapat dilakukan setelah perangkat lunak selesai dibangun karena proses ini membutuhkan hasil dari alat uji tersebut.
d. Pengembangan Perangkat Lunak
1. Metode Pengembangan Sistem
26
a. Analisa
Langkah ini merupakan analisa terhadap kebutuhan sistem. Pengumpulan data dalam tahap ini bisa melakukan sebuah penelitian, wawancara atau studi literatur. Seorang sistem analis bertugas dalam mencari informasi sebanyak mungkin dari pengguna sehingga sistem yang dibuat dapat sesuai dengan keinginan pengguna. Tahapan ini biasanya akan menghasilkan dokumen user requirement yang dapat digunakan sistem analis untuk menerjemahkan ke dalam bahasa pemrograman.
b. Design
Proses desain akan menerjemahkan syarat kebutuhan ke sebuah perancangan perangkat lunak yang dapat diperkirakan sebelum di ubah ke dalam bahasa pemrograman. Proses ini berfokus pada struktur data, arsitektur perangkat lunak, representasi interface, dan detail algoritma. Tahapan ini akan menghasilkan dokumen yang disebut software requirement. Dokumen ini yang digunakan seorang programmer untuk
membangun sistemnya.
c. Code dan Testing
Coding merupakan penerjemahan design ke dalam bahasa
27
2. Pengujian
Pengujian dilakukan dengan alat uji yang sudah dibuat pada tahap sebelumnya. Metode untuk pengujian sistem ini adalah metode pengujian black box, pengujian dataset dan uji validasi. Pengujian black box ini berisi
pengujian dengan pengisian data secara benar dan tidak benar. Untuk
pengujian dataset, pengujian dilakukan dengan mencoba
mengkombinasikan nilai min support dan min confidence untuk melihat nilai lift ratio yang dihasilkan. Selain itu, dari hasil kombinasi tersebut juga dapat dilihat nilai running time. Kemudian untuk pengujian validasi, hasil dari perangkat lunak yang dibuat akan dibandingkan dengan hasil dari aplikasi WEKA yang telah terpercaya hasilnya.
e. Analisis dan Pembuatan Laporan
28
BAB IV
PEMROSESAN AWAL DAN PERANCANGAN PERANGKAT
LUNAK PENAMBANGAN DATA
4.1 Perancangan Awal Sumber Data
4.1.1 Pembersihan Data
Proses pembersihan data yang dilakukan dalam penelitian ini adalah dengan membuang data yang tidak lengkap. Pada penelitian ini ada 2 sekolah yang harus dihapus karena tidak memiliki nilai. Dua sekolah tersebut adalah SMA Piri 2
Yogyakarta dengan id 01-032 dan SMA Proklamasi’45 dengan id 04-071.
4.1.2 Integrasi Data
Tahap ini berisikan penggabungan dari bermacam- macam data dari berbagai sumber. Dalam penelitian ini peneliti menggunakan 3 data yaitu data tahun akademik 2012/2013 dan 2013/2014 dan 2014/2015. Data pada tiap tahun tersebut memiliki 21 kompetensi. Data pada tahun 2012/2013 & 2013/2014 memiliki kompetensi-kompetensi yang sama. Sedangkan pada tahun 2014/2015 ada satu kompetensi-kompetensi yang berbeda. Data tahun 2012/2013 & 2013/2014 tersebut akhirnya digabungkan menjadi satu karena memiliki kompetensi yan g sama. Penggabungan ini bertujuan untuk memperbanyak data yang akan digunakan sebagai dataset karena walaupun nama sekolah sama tetapi tetap berbeda siswanya. Sedangkan data tahun 2014/2015 tetap menjadi satu dataset tanpa digabung dengan data lainnya.
4.1.3 Seleksi Data
29
pelajaran Bahasa Indonesia. Dari semua atribut tersebut yang dipakai hanya atribut nama kompetensi tiap mata pelajaran. Daftar atribut yang digunakan dapat dilihat pada tabel 3.1 dan tabel 3.2 di bab 3. Sedangkan contoh data yang akan digunakan dapat dilihat pada Lampiran 6.
4.1.4 Transformasi Data
Proses transformasi dilakukan pada data yang telah dipilih, sehingga data tersebut sesuai untuk proses penambangan data. Pada tahap ini dilakukan proses preprocessing dengan cara hanya mengambil nilai yang memenuhi standar nilai yang
dimasukkan oleh pengguna. Dari Gambar 3.1 dapat dilihat nilai yang block warna berarti memenuhi nilai standar yakni lebih dari 75. Nilai 75 itu adalah nilai yang diisikan oleh pengguna. Berdasarkan tabel 2.1 di bab 2, nilai 75 masuk kedalam kategori tinggi. Nilai-nilai kompetensi yang di block tersebut kemudian diambil dimasukkan kedalam array. Misalnya untuk kode sekolah 01-001 maka kompetensi yang digunakan adalah BIND1, BIND2, BIND3, BIND4, BIND5, BIND6, BIND7, BIND8, BIND9, BIND10, BIND11, BIND14, BIND15, BIND17, BIND18, BIND19, BIND20, BIND21.
Gambar 3. 1 Data Nilai Daya Serap
Setelah itu kompetensi juga diurutkan berdasarkan kompetensi yang memiliki jumlah frekuensi dari yang tertinggi ke terendah. Setelah itu data siap digunakan untuk masuk ke proses penambangan data.
4.2 Pengembangan Perangkat Lunak Penambangan Data
4.2.1 Perancangan Umum
4.2.1.1Input
30
memasukkan nilai minimum support, minimum confidence dan nilai standar daya serap terlebih dahulu. Data yang dipakai adalah data nilai daya serap siswa SMA yang terdiri dari beberapa kolom kompetensi.
Pengguna
Gambar 4. 1Diagram Konteks
4.2.1.2Proses
Proses sistem terdiri dari beberapa langkah untuk dapat menemukan aturan asosiasi yang berfungsi untuk menemukan pola keterkaitan antar kompetensi yaitu:
1 Pengambilan data yang sudah melalui tahap preprocessing untuk digunakan
saat proses penambangan data.
2 Penentuan minimum support dan minimum confidence yang berfungsi
dalam menentukan aturan asosiasi.
3 Proses asosiasi untuk mencari pola keterkaitan kompetensi dijalankan.
4 Analisis hasil asosiasi terhadap proses penambangan data yang telah
dijalankan.
4.2.1.3Output
31
4.2.2 Diagram Use Case
Diagram usecase merupakan sebuah gambaran sistem yang dilihat dari sudut pandang pengguna sistem (user). Pengguna sistem dalam diagram usecase dapat juga disebut actor. Actor pada sistem ini hanya akan ada satu actor saja dan dapat melakukan 3
aktivitas seperti memilih data, mencari aturan dan menyimpan hasil. Ketiga aktivitas tersebut merupakan aktivitas yang saling berhubungan, sehingga tiap aktivitas harus dijalankan berurutan.
Pengguna
Memilih Data
Mencari aturan asosiasi
Menyimpan Hasil
<<include>>
<<include>>
32
4.2.3 Diagram Aktivitas
Diagram aktivitas sistem yang akan dibuat terlampir pada Lampiran 1. Diagram aktivitas yang dipakai sebanyak 3 buah menyesuaikan dengan jumlah aktivitas dari usecase yang ada. Diagram aktivitas tersebut terdiri dari:
1. Memilih data
2. Mencari aturan
3. Menyimpan hasil
4. Mencari aturan
4.2.4 Diagram Kelas Analisis
Fungsi dari pembuatan diagram kelas tahap analisis ini berguna untuk mempermudah dalam penyusunan sequence diagram. Diagram kelas analisis dapat dilihat pada Lampiran 2.
Tabel 4. 1 Daftar Kelas Untuk Tiap Usecase
Usecase Boundary Control Class Model Class (Entity)
Memilih
view_asosiasi Control_algorithm comparitorHeaderTable
TreeNode
33
pengguna, boundary, controller dan model berupa pesan/message. Diagram sequence pada sistem ini terdiri dari 3 diagram sesuai dengan usecase. Diagram dapat dilihat pada Lampiran 3.
4.2.6 Struktur Data
Sistem pencarian aturan asosiasi ini membutuhkan suatu tempat penyimpanan data yang tidak membutuhkan memori yang terlalu banyak dan tidak menghabiskan waktu yang cukup banyak ketika sistem dijalankan karena dapat mengolah data dengan efisien. Berdasarkan kebutuhan diatas maka penelitian ini akan menggunakan konsep penyimpanan data menggunakan struktur data karena penyimpanan dengan struktur data tidak membutuhkan memori yang besar dan lebih efisien dalam mengolah data. Struktur data yang digunakan pada sistem ini adalah Tree dan Arraylist. Tree pada sistem ini dapat memiliki jumlah anak yang tidak sama jumlahnya untuk setiap node dan juga tidak bisa ditetapkan di awal. Maka struktur data Tree ini ditambahkan struktur data yang dinamis seperti List untuk menyimpan jumlah anaknya.
a. Tree
34
Gambar 4. 3 Ilustrasi FPTree
b. Arraylist
Arraylist memiliki sifat seperti array, tetapi perbedaan utamanya adalah Arraylist
bersifat dinamis dalam arti dapat memperbesar kapasitasnya secara otomatis apabila diperlukan (Rickyanto,2003).
Pada penelitian ini penulis menggunakan arraylist dalam arraylist
(ArrayList<ArrayList<String>>) untuk membuat matriks. Penulis memilih
35
BIND6 BIND12 BIND16
Gambar 4. 4 Susunan arraylist untuk kode sekolah 01-010
BIND3 BIND4
Gambar 4. 5 Susunan arraylist untuk kode sekolah 01-019
Objek arraylist baru akan selalu dibuat untuk setiap kode sekolah yang berbeda. Setelah membuat objek arraylist untuk tiap sekolah maka akan dibuat objek arraylist untuk menjadikan satu semua objek arraylist sebelumnya. Gambaran datanya akan berubah menjadi seperti di gambar 4.6.
BIND6 BIND12 BIND16
BIND3 BIND4
BIND6 BIND4 BIND15 BIND17
Gambar 4. 6 Data arraylist dalam arraylist
c. TreeNode
4.2.7 Diagram Kelas Desain
36
Gambar 4. 7 Diagram Kelas Desain
4.2.8 Rincian Algoritma untuk Setiap Metode
4.2.8.1 Metode-metode di dalam kelas control_algorithm
Nama Metode FPTree(ArrayList<LinkedList<String>> array1,
37
Fungsi Metode Mengubah data yang sudah dikenai preprocessing menjadi
bentuk Tree Algoritma :
1 Method ini memiliki masukkan berupa arraylist yang berisi data nilai daya serap.
2 Satu persatu persatu nilai dalam array akan dibuat pohon dengan memanggil
method insertNode().
3 Setelah pohon FPTree selesai dibuat maka headerTable yang sudah terisi akan
diurutkan dari yang terkecil ke terbesar count-nya.
Nama Metode insertNode(LinkedList<String> array1, TreeNode treenode,
ArrayList<TreeNode> headerTable)
Fungsi Metode Menambah node pada pohon
Algoritma:
1. Pertama kali yang dilakukan adalah mengecek apakah array yang sebagai
inputan kosong atau tidak. Jika kosong maka akan langsung me-return.
2. Jika array tidak kosong, maka akan dicek apakah root pada treenode sudah ada
isinya atau belum.
3. Jika root belum memiliki anak, maka akan dibuat node baru yang lalu akan
dibuat menjadi anak dari root. Node tersebut juga akan di link-an dengan headerTable.
4. Sedangkan jika root memiliki anak maka akan dicek apakah item pertama pada
array tersebut sudah ada pada pohon atau belum. Jika sudah maka akan ditambahkan countnya.
5. Setelah itu, item petama pada array tersebut dihapus.
6. Array tadi lalu dimasukkan kembali menjadi parameter saat memanggil method
38
Nama Metode FPGrowth(ArrayList<LinkedList<String>> array1, double
batas, int totalTransaction, double minConfidence)
Fungsi Metode Memanggil method FPGrowth dan menghitung nilai
confidence dan lift ratio
Algoritma:
1 Method ini pertama tama akan memanggil method FPgowth() untuk membuat
conditional pattern base, conditional fp tree dan frequent itemset.
2 Setelah mendapatkan frequent-k itemset, lalu frequent-k itemset tersebut dicari
yang k-nya paling tinggi.
3 Frequent itemset yang paling tinggi tersebut akan digunakan untuk membuat
kombinasi aturan asosiasi dengan memanggil method CountConfAndLift yang ada di kelas model_combination
Nama Metode FPgrowth(TreeNode treeNode, String base, double
threshold, ArrayList<TreeNode> headerTable, Map<String, Integer> frequentPatterns)
Fungsi Metode Mencari conditional pattern base, conditional fp tree dan
frequent itemset Algoritma:
1. Lakukan perulangan dari data pada headerTable yang memiliki nilai count paling
kecil.
2. Lalu akan dilakukan perulangan juga untuk mencari letak item tadi pada pohon.
Setelah diketahui letaknya maka akan diruntut ke parentnya hingga sampai ke root. Proses tersebut dicatat sebagai conditional pattern base.
3. Jika item pada headerTable memiliki conditional pattern base yang count-nya
39
4. Setelah itu maka akan dipanggil method conditional_fp_tree_constructor untuk
mencari conditional fp tree
5. Selama conditional fptree memiliki anak maka proses selanjutnya adalah
memanggil method dirinya sendiri sampai conditional fptree tidak memiliki anak.
Nama Metode conditional_fptree_constructor(Map<String, Integer>
conditionalPatternBase, Map<String, Integer>
conditionalItemsMaptoFrequencies, double threshold, ArrayList<TreeNode> conditional_headerTable)
Fungsi Metode Membuat pohon yang akan digunakan untuk mencari
conditional fp tree Algoritma:
1. Masukan dari method ini adalah conditional pattern base yang sudah didapatkan
sebelumnya.
2. Setelah itu conditional pattern base tersebut dicek apakah countnya lebih besar
atau sama dengan minimum support.
3. Jika iya maka pattern base tersebut akan disimpan pada array baru.
4. Setelah pattern base dicek maka akan dibuat pohonnya dari pattern base yang memenuhi minimum support
5. Method akan mengembalikan nilai berupa TreeNode
Nama Metode insert(LinkedList<String> pattern_vector, int
count_of_pattern, TreeNode conditional_fptree,
ArrayList<TreeNode> conditional_headerTable)
Fungsi Metode Membuat pohon untuk mencari conditional fp tree
Algoritma:
1. Pertama kali yang dilakukan adalah mengecek apakah array yang sebagai inputan
40
2. Jika array tidak kosong, maka akan dicek apakah root pada treenode sudah ada
isinya atau belum.
3. Jika root belum memiliki anak, maka akan dibuat node baru yang lalu akan dibuat
menjadi anak dari root. Node tersebut juga akan di link-an dengan headerTable.
4. Sedangkan jika root memiliki anak maka akan dicek apakah item pertama pada
array tersebut sudah ada pada pohon atau belum. Jika sudah maka akan ditambahkan countnya.
5. Setelah itu, item petama pada array tersebut dihapus.
6. Array tadi lalu dimasukkan kembali menjadi parameter saat memanggil method
dirinya sendiri.
4.2.8.2 Algoritma Kelas model_combination
Nama Metode Combine(int start, HashMap temp, Map freqmap)
Fungsi Metode Membuat kombinasi dari string yang menjadi inputan
Algoritma:
1. Lakukan perulangan dari iterasi=1 sampai jumlah karakter dari string yang diinputkan
2. Satu persatu karakter diambil di gabungkan
3. Gabungan karakter tersebut lalu dicek, selama jumlahnya masih kurang dari jumlah string maka akan disimpan didalam arraylist antecendent
4. Langkah selanjutnya adalah memanggil dirinya sendiri untuk rekursif
Nama Metode CountConfAndLift(Map freqmap, HashMap map, int max,
int total, double minCon)
Fungsi Metode Menghitung nilai confidence dan lift ratio dari aturan yang
41 Algoritma:
1. Lakukan nested-loop untuk membuat kombinasi dari anteseden dan konsekuen
2. Setelah ditemukan kombinasinya, tiap kombinasi dihitung nilai confidence dan
lift rationya
3. Jika nilai confidence memenuhi nilai minimum confidence yang ditentukan maka
kombinasi tersebut akan dijadikan aturan asosiasi dan disimpan didalam arraylist
4.2.8.3 Algoritma Kelas View_Asosiasi
Nama Metode BubbleSortODesc(LinkedList<String> data, HashMap
map)
Fungsi Metode Mengurutkan data bertipe LinkedList dari besar ke kecil
Algoritma:
1. Lakukan perulangan dari iterasi=1 sampai data.size()-1
2. Lakukan perulangan kembali dari elemen=0 sampai data.size()-1-elemen
3. Lalu bandingkan count dari data sekarang dengan yang data setelahnya. Jumlah count dapat diambil dari hashmap.
4. Jika count data sekarang lebih kecil maka indeks data akan ditukar dengan indeks
data setelahnya.
Nama Metode BubbleSortODescArrayList(ArrayList
<TreeNode> data)
Fungsi Metode Mengurutkan data bertipe ArrayList<TreeNode> dari besar
ke kecil Algoritma:
d. Lakukan perulangan dari iterasi=1 sampai data.size()-1
e. Lakukan perulangan kembali dari elemen=0 sampai
42
f. Lalu bandingkan count dari data sekarang dengan yang data setelahnya.
Jumlah count dapat diambil dari object TreeNode.
g. Jika count data sekarang lebih kecil maka indeks data akan ditukar dengan indeks data setelahnya.
Nama Metode RemoveNoFequentItem()
Fungsi Metode Menghapus data yang memiliki count lebih kecil dari
minimum support
Algoritma:
1. Lakukan nested-loop untuk mengambil data ArrayList
2. Cek count dari tiap data
3. Jika count lebih besar atau sama dengan minimum support maka data akan
43
4.2.9 Antarmuka
1. Halaman Awal
Gambar 4. 8 Halaman Awal
Halaman ini merupakan halaman utama yang akan ditampilkan pertama kali saat sistem dijalankan. Halaman ini berisi 4 tombol yaitu BERANDA, BANTUAN, TENTANG dan MASUK SISTEM. Tombol BERANDA akan menghubungkan dengan halaman view_home. Sedangkan tombol BANTUAN ia akan menghubungkan dengan view_help, tombol TENTANG akan menghubungkan dengan view_about. Dan yang terakhir yaitu tombol MASUK SISTEM yang akan menghubungkan dengan halaman view_preprocessing untuk memulai memilih data yang akan digunakan.
44
2. Halaman About
Gambar 4. 9 Halaman About
45
3. Halaman Help
Gambar 4. 10 Halaman Help
46
4. Halaman Preprocessing
Gambar 4. 11 Halaman Preprocessing
47
5. Halaman Asosisasi
Gambar 4. 12 Halaman Asosiasi
Halaman ini akan berisikan tabel dengan data yang sudah melalui proses preprocessing. Setelah itu pengguna dapat memasukkan nilai minimal support dan
minimal confidence yang dapat digunakan untuk proses pencarian aturan asosiasi dengan algoritma FPGrowth dengan menekan tombol PROSES.
48
6. Halaman Database
Gambar 4. 13 Halaman Database
49 BAB V
IMPLEMENTASI PENAMBANGAN DATA DAN EVALUASI HASIL
5.1Implementasi Rancangan Perangkat Lunak Penambangan Data
Sistem pencarian aturan asosiasi ini menggunakan beberapa kelas yang mendukung jalannya sistem. Kelas yang digunakan totalnya berjumlah 11 yang dibagi menjadi 3 package. Package – package tersebut bernama model, view dan controller. Berikut
adalah daftar kelas-kelas yang digunakan:
5.2.1 Implementasi Kelas Model
Berikut ini adalah tabel yang berisikan daftar kelas yang ada di package model. Pada tabel tersebut disertakan juga nama file fisik dan nama file executable.
Tabel 5. 1 Tabel Implementasi Kelas Model
No Nama Kelas Nama File Fisik Nama File Executable
1 TreeNode TreeNode.java TreeNode.class
2 model_atributSelection model_atributSelection.java model_atributSelection.class
3 model_combination model_combination.java model_combination.class
4 comparatorHeaderTable comparatorHeaderTable.java comparatorHeaderTable.class
5.2.2 Implementasi Kelas View
Berikut ini adalah tabel yang berisikan daftar kelas yang ada di package view. Pada tabel tersebut disertakan juga nama file fisik dan nama file executable.
Tabel 5. 2Tabel Implementasi Kelas View
No Nama Kelas Nama File Fisik Nama File Executable
1 view_about view_about.java view_about.class
50
3 view_help view_help.java view_help.class
4 view_home view_home.java view_home.class
5 view_preprocessing view_preprocessing.java view_preprocessing.class
5.2.3 Implementasi Kelas Controller
Berikut ini adalah tabel yang berisikan daftar kelas yang ada di package controller. Pada tabel tersebut disertakan juga nama file fisik dan nama file
executable.
Tabel 5. 3 Tabel Implementasi Kelas Controller
No Nama Kelas Nama File Fisik Nama File Executable
1 Control_algorithm Control_algorithm.java Control_algorithm.class
2 Control_atributSelection Control_atributSelection
.java
Control_atribut Selection.class
5.2Evaluasi Hasil
5.2.1 Uji Coba Perangkat Lunak (Black Box Testing)
a. Pengujian Pada Halaman Preprocessing
51
Gambar 5. 1 (a)Kotak Dialog “Pilih File” (b)Tabel Dataset
Gambar 5. 2 Kotak Dialog Salah Pilih File
Selanjutnya ketika pengguna melakukan seleksi atribut, pengguna diberikan 3
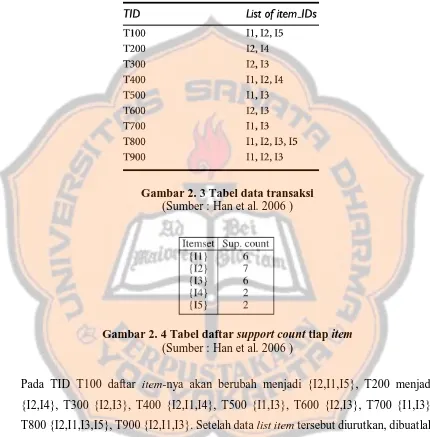
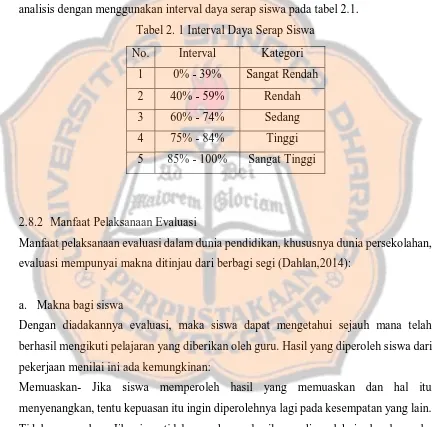
fasilitas tombol. Tombol pertama yaitu tombol “Tandai Semua” untuk
menandai semua checkbox pada tabel sekaligus (Gambar 5.3). Tombol kedua
52
Gambar 5. 3 Tampilan Setelah Menekan Tombol “Tandai Semua”
Gambar 5. 4 Tampilan Setelah Menekan Tombol “Hapus Atribut”
Gambar 5. 5 Tampilan Setelah Menekan Tombol “Batal”
Berikut ini adalah tabel yang mencatat hasil dari pengujian blackbox pada aktivitas-aktivitas yang dapat dilakukan pada Halaman Preprocessing
Tabel 5. 4 Tabel Hasil Uji Pada Halaman Preprocessing
Kasus dan Hasil Uji Pada Halaman Preprocessing
Require Skenario Uji Hasil yang diharapkan Hasil
Pengujian