SISTEM PENENTUAN PENERIMA BEASISWA MENGGUNAKAN METODE K-MEANS CLUSTERING DAN VIŠEKRITERIJUMSKO
KOMPROMISNO RANGIRANJE (VIKOR)
SKRIPSI
VARUNA DEWI 141402089
PROGRAM STUDI S1 TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
MEDAN 2018
SISTEM PENENTUAN PENERIMA BEASISWA MENGGUNAKAN METODE K-MEANS CLUSTERING DAN VIŠEKRITERIJUMSKO KOMPROMISNO
RANGIRANJE (VIKOR)
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat memperoleh ijazah Sarjana Teknologi Informasi
VARUNA DEWI 141402089
PROGRAM STUDI S1 TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
MEDAN 2018
iii
PERNYATAAN
SISTEM PENENTUAN PENERIMA BEASISWA MENGGUNAKAN METODE K-MEANS CLUSTERING DAN VIŠEKRITERIJUMSKO KOMPROMISNO
RANGIRANJE (VIKOR)
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil karya saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing telah disebutkan sumbernya.
Medan, Juli 2018
Varuna Dewi 141402089
UCAPAN TERIMAKASIH
Puji dan syukur kehadirat Tuhan yang Maha Esa, karena rahmat dan izin-Nya Penulis dapat menyelesaikan penyusunan skripsi ini, sebagai syarat untuk memperoleh gelar Sarjana Komputer, pada Program Studi S1 Teknologi Informasi Fakultas Ilmu Komputer dan Teknologi Informasi Universitas Sumatera Utara.
Skripsi ini penulis persembahkan kepada kedua orangtua penulis, Ibu Wanitha Dewi dan Ayah Wamanen yang selalu memberikan doa, dukungan dan kasih sayang kepada penulis. Terima kasih penulis ucapkan kepada kakak penulis Laxhmi Mahesvary Sharojini Naidu, ST dan adik penulis Maharani Fatmawathy Naidu yang selalu memberikan doa dan dukungan semangat dalam pengerjaan skripsi ini.
Penulis menyadari bahwa penelitian ini tidak akan terwujud tanpa bantuan banyak pihak. Dengan kerendahan hati, penulis ingin menyampaikan ucapan terima kasih kepada:
1. Bapak Prof. Dr. Opim Salim Sitompul, M.Sc selaku Dekan Fasilkom-TI Universitas Sumatera Utara.
2. Bapak Romi Fadillah Rahmat, B.Comp.Sc., M.Sc selaku Ketua Program Studi S1 Teknologi Informasi Universitas Sumatera Utara.
3. Bapak Baihaqi Siregar, S.Si, MT. selaku Dosen Pembimbing I yang telah memberikan bimbingan dan saran kepada penulis.
4. Bapak Seniman, S.Kom, M.Kom selaku Dosen Pembimbing II yang telah memberikan bimbingan dan saran kepada penulis.
5. Ibu Sarah Purnamawati, ST., M.Sc selaku Dosen Pembanding I yang telah memberikan kritik dan saran dalam penyempurnaan skripsi ini.
6. Bapak Indra Aulia, S.TI., M.Kom selaku Dosen Pembanding II yang telah memberikan kritik dan saran dalam penyempurnaan skripsi ini.
7. Sahabat tersayang Sity Ayu Novarina Suyanto, Victoria Tambunan, Hetly Saint Kartika, Afzalurrahmah, Aggie Wicita Riny Riady, Zurwatus Saniyah, dan Cindy Pakpahan yang selalu memberikan dukungan dan motivasi.
v
8. Sahabat seperjuangan pengerjaan skripsi Santa C. Hutabarat yang selalu memberikan motivasi dan Kakak Novira Naili Ulya Siregar yang sudah banyak membantu dalam proses pengerjaan skripsi.
9. Teman-teman seperjuangan dari Teknologi Informasi USU angkatan 2014 yang selalu memberikan dukungan dan motivasi.
10. Teman-teman pengurus HIMATIF periode 2016/2017 dan periode 2017/2018.
11. Teman-teman seperjuangan dari Paguyuban Karya Salemba Empat USU periode 2016/2017 dan periode 2017/2018.
12. Yayasan Karya Salemba Empat dan donatur beasiswa penulis, PT. Perusahaan Gas Negara.
13. Semua pihak-pihak yang telah membantu penulis secara langsung dan tidak langsung, yang tidak dapat penulis sebutkan satu persatu yang telah membantu penyelesaian skripsi ini.
Semoga Tuhan yang Maha Esa melimpahkan nikmat dan karunia kepada semua pihak yang telah memberikan bantuan, perhatian serta dukungan kepada penulis dalam menyelesaikan skripsi ini.
Medan, Juli 2018
Penulis
ABSTRAK
Setiap warga negara berhak mendapat pendidikan, namun banyak warga negara yang tidak dapat melanjutkan pendidikan karena keterbatasan yang mereka miliki. Salah satu cara untuk mengurangi masalah tersebut adalah diberikannya beasiswa. Terdapat beberapa jenis program beasiswa kepada mahasiswa berprestasi dan memerlukan bantuan ekonomi dalam menyelesaikan kuliahnya, oleh sebab itu dibutuhkan suatu sistem yang mampu mengelompokkan keadaan pendaftar beasiswa lalu dirangkingkan untuk prioritas dalam mendapatkan program beasiswa. Untuk pengelompokkan digunakan metode k-means clustering yang mempunyai beberapa kriteria yaitu jumlah penghasilan orangtua, tagihan PLN dan tagihan PDAM. Lalu pada perengkingan digunakan salah satu dari metode multi attribute decision making yaitu VIšekriterijumsko KOmpromisno Rangiranje (VIKOR).
Kriteria yang digunakan dalam perangkingan adalah jumlah penghasilan orangtua. Dari hasil pengujian terhadap 21.614 data pendaftar beasiswa, dihasilkan 3 cluster yaitu 13.423 pendaftar pada cluster 1 yang artinya tidak layak mendapatkan beasiswa, 7.030 pendaftar pada cluster 2 yang artinya direkomendasi mendapatkan beasiswa, dan 1.161 pendaftar pada cluster 3 yang artinya layak mendapatkan beasiswa.
Kata kunci: beasiswa, multi attribute decision making, k-means clustering, VIšekriterijumsko KOmpromisno Rangiranje.
vii
DETERMINATION SYSTEM FOR SCHOLARSHIP FELLOW BY USING K-MEANS CLUSTERING METHOD AND
VIŠEKRITERIJUMSKO KOMPROMISNO RANGIRANJE (VIKOR).
ABSTRACT
Every citizen has the right to get education, nevertheless many of the citizen cannot continue their education to the higher level because of their financial inability. One of the ways to overcome this problem is by giving scholarship. There are many kind of scholarship given to the prestigious students and in need of financial aid to finish their education, so that a system is needed for clustering the scholarship applicants condition and then ranked for priority to get scholarship. For clustering the k-means clustering method is used which has some criterias they are parent income, electricity bill and water bill. And then in ranking one of the multi attribute decision making method is used that is VIKOR.
The criteria used in ranking is parent income. From the result of 21.614 scholarship applicant data testing, 3 clusters come out they are 13.423 applicants in cluster 1 which means cannot get scholarship, 7.030 applicants in second cluster which means recommended to get scholarship, and 1.161 applicants from cluster 3 which means are fit to get scholarship.
Keyword: scholarship, multi attribute decision making, k-means clustering, VIšekriterijumsko KOmpromisno Rangiranje.
DAFTAR ISI
PERSETUJUAN iii
PERNYATAAN iv
UCAPAN TERIMA KASIH v
ABSTRAK vii
ABSTRACT viii
DAFTAR ISI ix
DAFTAR TABEL xii
DAFTAR GAMBAR xiii
BAB 1 PENDAHULUAN
1.1 Latar Belakang 1
1.2 Rumusan Masalah 3
1.3 Batasan Masalah 3
1.4 Tujuan Penelitian 3
1.5 Manfaat Penelitian 4
1.6 Metodologi Penelitian 4
1.7 Sistematika Penulisan 5
BAB 2 LANDASAN TEORI
2.1 Beasiswa 7
2.2 Data Mining 8
2.3 Clustering 10
2.4 Algoritma K-Means 10
2.5 Multi Criteria Decision Making (MCDM) 12
ix
2.7 Penelitian Terdahulu 15
BAB 3 ANALISIS DAN PERANCANGAN
3.1 Data yang Digunakan 18
3.2 Arsitektur Umum 18
3.3 Analisis Clustering K-Means 21
3.3.1 Menentukan Jumlah Cluster 21
3.3.2 Menentukan Pusat Cluster (centroid) 21 3.3.3 Hitung Jarak Data dengan Rumus Euclidean Distance 21 3.3.4 Kelompokkan Data pada Cluster Terdekat 23
3.3.5 Hasil Clustering 23
3.4 Analisis VIKOR 25
3.4.1 Membuat Matriks Keputusan Ternormalisasi 25 3.4.2 Menentukan Solusi Ideal & Ideal Negatif 27
3.4.3 Menghitung Utility Measures 27
3.4.4 Menghitung Indeks VIKOR 29
3.4.5 Perangkingan Alternatif 30
3.4.6 Usulan Solusi Kompromi 31
3.5 Perancangan Sistem 33
3.5.1 Perancangan flowchart 33
3.5.1.1 Flowchart Clustering K-Means 33
3.5.1.2 Flowchart VIKOR 34
3.5.1.3 Diagram Aktivitas 35
3.5.1.4 Diagram Use Case 36
3.5.1.5 Sequence Diagram 37
3.5.2 Rancangan tampilan antarmuka pengguna 38 BAB 4 IMPLEMENTASI DAN PENGUJIAN
4.1 Implementasi Sistem 41
4.1.1 Spesifikasi Perangkat Keras & Lunak 41 4.1.2 Implementasi Coding Program 42
4.1.2.1 Main.java 42
4.1.2.2 Const.java 42
4.1.2.3 Cluster.java 43
4.1.3 Implementasi Perancangan Antarmuka 43 4.1.3.1 Halaman Specification 43
4.1.3.2 Halaman About 44
4.1.3.3 Halaman Performance 45
4.1.3.4 Halaman Data 45
4.1.3.5 Proses VIKOR 46
4.2 Pengujian Sistem 46
4.2.1 Ilustrasi Data 47 4.2.2 Hasil Clustering 47
4.2.3 Hasil VIKOR 49
4.2.4 Validasi Hasil Akhir 51
BAB 5 KESIMPULAN DAN SARAN
5.1 Kesimpulan 52
5.2 Saran 53
DAFTAR PUSTAKA 54
xi
DAFTAR TABEL
Halaman
Tabel 2.1. Penelitian Terdahulu 17
Tabel 3.1. Pusat Cluster Iterasi 1 22
Tabel 3.2. Hasil Cluster iterasi 1 23
Table 3.3. Hasil Cluster Pertama 23
Table 3.4. Hasil Cluster Kedua 24
Tabel 3.5. Hasil Cluster Ketiga 24
Tabel 3.6. Data Kriteria Cluster 3 25
Tabel 3.7. Hasil Normalisasi Matriks 27
Tabel 3.8. Hasil Si, dan Ri 29
Tabel 3.9. Hasil Qi 30
Tabel 3.10. Hasil Pengurutan Si, Ri dan Qi 31
Tabel 3.11. Hasil Akhir Perengkingan Cluster Layak 32
Tabel 3.12. Diagram Aktivitas 35
Tabel 4.1 Hasil Perankingan VIKOR 49
Tabel 4.2 Perbandingan Hasil Akhir 51
DAFTAR GAMBAR
Halaman
Gambar 2.1. Bidang Ilmu Data Mining 8
Gambar 2.2. Tahapan Data Mining 10
Gambar 3.1. Arsitektur Umum 20
Gambar 3.2. Flowchart Clustering K-Means 33
Gambar 3.3. Flowchart VIKOR 34
Gambar 3.4. Use Case Diagram 36
Gambar 3.5. Sequence Diagram 37
Gambar 3.6. Rancangan Halaman Specification 38
Gambar 3.7. Rancangan Halaman Performance 39
Gambar 3.8. Rancangan Halaman About 39
Gambar 3.9. Rancangan Halaman Data 40
Gambar 3.10. Rancangan Halaman VIKOR Analyze 40
Gambar 4.1. Coding Main.java 42
Gambar 4.2. Coding Const.java 42
Gambar 4.3. Coding Cluster.java 43
Gambar 4.4. Tampilan Spesification 44
Gambar 4.5. Tampilan About 44
Gambar 4.6. Tampilan Performance 45
xiii
Gambar 4.7. Tampilan Data 45
Gambar 4.8. Proses VIKOR 46
Gambar 4.9. Data numerik .arff 47
Gambar 4.10. Cluster 1 48
Gambar 4.11. Cluster 2 48
Gambar 4.12. Cluster 3 49
Gambar 4.13. Hasil Akhir Penerima Beasiswa 50
BAB 1
PENDAHULUAN
1.1. Latar Belakang
Pendidikan bagi manusia merupakan kebutuhan mutlak yang harus dipenuhi sepanjang hayat. Pendidikan merupakan usaha agar manusia dapat mengembangkan potensi dirinya melalui proses pembelajaran dan/ cara lain yang dikenal dan diakui oleh masyarakat. Undang-Undang Dasar Negara Republik Indonesia Tahun 1945 pasal 31 ayat (1) menyebutkan bahwa setiap warga negara berhak mendapatkan pendidikan.
Namun pada kenyataannya, masih terdapat berbagai persoalan yang ada di dunia pendidikan di Indonesia. Mulai dari kurangnya tenaga pengajar, fasilitas yang kurang memadai, sampai kesulitan pembiayaan dan sudah lama menjadi wacana yang mewarnai dunia pendidikan. Adanya beasiswa merupakan salah satu jalan keluar dari permasalahan tersebut.
Menurut Kamus Besar Bahasa Indonesia, beasiswa adalah tunjangan yang diberikan kepada pelajar atau mahasiswa sebagai bantuan biaya belajar. Ada berbagai jenis beasiswa yang saat ini ditawarkan untuk mahasiswa. Kementrian Riset, Teknologi, Pendidikan Tinggi mencatat sedikitnya ada 23 beasiswa yang rutin ditawarkan tiap tahunnya kepada mahasiswa S1 dalam negeri.
Kriteria yang dibutuhkan untuk mendapatkan beasiswa pun bermacam-macam, seperti alasan kebutuhan beasiswa, keaktifan di organisasi dalam maupun luar kampus, prestasi serta IP dan IPK selama berkuliah.
Dalam melakukan seleksi beasiswa tentu akan mengalami kesulitan karena banyaknya yang mendaftar beasiswa dan banyaknya kriteria yang digunakan untuk menentukan keputusan penerima beasiswa yang sesuai dengan yang diharapkan. Untuk itu diperlukan suatu aplikasi sistem pendukung keputusan (SPK) yang dapat memperhitungkan segala kriteria yang mendukung pengambilan keputusan guna membantu, mempercepat dan mempermudah proses pengambilan keputusan dalam penentuan penerima beasiswa. Dari pengamatan masalah diatas, peneliti berkeinginan untuk membangun sistem yang mampu mengelompokkan yang mana menjadi prioritas untuk mendapatkan program beasiswa lalu merangkingnya, sehingga program beasiswa ini menyasar mahasiswa yang tepat mendapatkan beasiswa dengan cepat dan sesuai dengan anggaran.
Clustering adalah suatu metode pengelompokan berdasarkan ukuran kedekatan (kemiripan). Clustering berbeda dengan group, group berarti kelompok yang sama.
Cluster tidak harus selalu sama akan tetapi pengelompokannya berdasarkan pada kedekatan dari suatu karakteristik sample yang ada, salah satunya dengan menggunakan rumus jarak euclidean (Satriyanto, 2011).
Pada penelitian kali ini, penulis mengajukan metode K-Means Clustering yang telah digunakan pada beberapa penelitian seperti penentuan penerima beasiswa dengan kriteria berupa Indeks Prestasi Kumulatif (IPK), jumlah tanggungan keluarga, dan penghasilan total orang tua yang menghasilkan 3 cluster yaitu menerima, dipertimbangkan, dan tidak berhak menerima beasiswa (Hastuti, 2013). Selain itu penelitian lain yang dilakukan ialah untuk menilai kedisiplinan siswa di SMPN 21 Medan dengan clustering K-Means dan Analytical Hierarchy Process yang menghasilkan 4 cluster yaitu sangat disiplin, disiplin, cukup disiplin dan tidak disiplin (Bancin,2014).
Metode MADM digunakan untuk menyeleksi agar mendapatkan alternatif dari sejumlah alternatif. Metode MADM yang akan digunakan adalah VIšekriterijumsko KOmpromisno Rangiranje (VIKOR). VIKOR dapat digunakan untuk menyeleksi lebih
untuk seleksi penerima beasiswa dengan 4 kriteria yaitu indeks prestasi, semester, daya listrik dan jumlah tagihan listrik (Lengkong et al, 2015). Berdasarkan latar belakang di atas, maka penulis mengajukan proposal penelitian dengan judul “SISTEM
PENENTUAN PENERIMA BEASISWA MENGGUNAKAN METODE
CLUSTERING K-MEANS DAN VIŠEKRITERIJUMSKO KOMPROMISNO RANGIRANJE (VIKOR)”.
1.2. Rumusan Masalah
Permasalahan yang dihadapi adalah penentuan penerima beasiswa di Indonesia masih menggunakan cara manual sehingga perlu adanya sebuah aplikasi dengan mengimplementasikan metode K-Means Clustering dan VIKOR untuk menentukan kelulusan penerimaan beasiswa.
1.3. Batasan Masalah
Batasan masalah yang diberikan dalam penelitian ini adalah:
1. Data yang digunakan adalah data pendaftar Beasiswa Karya Salemba Empat tahun 2017.
2. Kriteria yang digunakan adalah:
A. Penghasilan Ayah
B. Penghasilan Ibu (jika ada) C. Tagihan PLN
D. Tagihan PDAM
3. Tidak mencakup syarat pendaftar beasiswa.
1.4. Tujuan Penelitian
Tujuan dari penelitian ini adalah untuk membantu pemerintah atau yayasan beasiswa dalam mengelompokkan serta meranking data mahasiswa yang mendaftar beasiswa dengan menggunakan clustering K-Means dan VIKOR.
3
1.5. Manfaat Penelitian
Adapun manfaat penelitian ini diantara lain yaitu:
1. Membantu pemerintah dan yayasan beasiswa untuk menyalurkan bantuan beasiswa tepat sasaran serta memprioritaskan yang paling membutuhkan.
2. Memberi masukan untuk penelitian lain dalam bidang K-Means Clustering dan Multi Attribute Decision Making VIKOR
1.6. Metodologi Penelitian
Beberapa tahapan yang akan dilakukan pada penelitian ini adalah sebagai berikut:
1. Studi Literatur
Pada tahap ini dilakukan proses mengumpulkan bahan referensi mengenai program beasiswa, multi attribute decision making, K-Means clustering, dan VIKOR dari berbagai buku, jurnal, artikel, dan beberapa sumber referensi lainnya.
2. Analisis Permasalahan
Pada tahap ini dilakukan analisis terhadap berbagai referensi yang telah dikumpulkan untuk mendapatkan pemahaman mengenai K-Means clustering dan VIKOR untuk menyelesaikan masalah menentukan penerima beasiswa.
3. Perancangan
Pada tahap ini dilakukan perancangan arsitektur yang akan digunakan untuk pengumpulan data dan perancangan antar muka. Proses perancangan dilakukan berdasarkan hasil analisis terhadap studi literatur yang telah didapatkan dan dipahami.
4. Implementasi
Pada tahap ini dilakukan implementasi dari hasil analisis dan perancangan yang telah dilakukan ke dalam pembangunan kode program menggunakan Bahasa pemrograman Java.
5. Pengujian
Pada tahap ini dilakukan pengujian terhadap hasil yang didapatkan melalui impelementasi K-Means clustering dan VIKOR untuk menentukan penerima beasiswa serta memastikan sistem telah berjalan sesuai dengan yang diharapkan.
6. Penyusunan Laporan
Pada tahap ini dilakukan penyusunan laporan mengenai hasil analisis dan implementasi K-Means clustering dan VIKOR untuk menentukan beasiswa.
1.7. Sistematika Penulisan
Sitematika penulisan dari skripsi ini terdiri dari lima bagian utama sebagai berikut:
Bab 1: Pendahuluan
Bab ini berisi latar belakang, rumusan masalah, batasan masalah, tujuan penelitian, manfaat penelitian, metodologi dan sistematika penulisan.
Bab 2: Landasan Teori
Bab ini berisi teori-teori yang digunakan untuk memahami permasalahan yang dibahas pada penelitian ini. Teori-teori yang berhubungan dengan beasiswa, data mining, clustering, k-means, multi attribute decision making, VIKOR.
Bab 3: Analisis dan Perancangan
Bab ini berisi tentang analisis dan penerapan K-Means clustering untuk pengelompokkan dan VIKOR untuk perangkingan penerima beasiswa serta perancangan seperti flowchart dan tampilan.
Bab 4: Implementasi dan Pengujian
Bab ini berisi pembahasan tentang implementasi dari analisis dan perancangan yang telah disusun pada Bab 3. Selain itu, pada bab ini juga dipaparkan hasil dari pengujian sistem yang telah dibangun.
5
Bab 5: Kesimpulan dan Saran
Bab ini berisi kesimpulan dari seluruh pembahasan pada bab-bab sebelumnya dan saran-saran yang disampaikan untuk pengembangan pada penelitian selanjutnya.
BAB 2
LANDASAN TEORI 2.1. Beasiswa
Beasiswa adalah pemberian berupa bantuan keuangan yang diberikan kepada perorangan, mahasiswa atau pelajar yang digunakan demi keberlangsungan pendidikan yang ditempuh. Beasiswa diartikan sebagai bentuk penghargaan yang diberikan kepada individu agar dapat melanjutkan pendidikan ke jenjang yang lebih tinggi (Murniasih, 2009).
Penghargaan itu dapat berupa akses tertentu pada suatu institusi atau penghargaan berupa bantuan keuangan. Pada dasarnya, beasiswa adalah penghasilan bagi yang menerimanya. Hal ini sesuai dengan ketentuan pasal 4 ayat (1) Undang-undang PPh/2000. Disebutkan pengertian penghasilan adalah tambahan kemampuan ekonomis dengan nama dan dalam bentuk apapun yang diterima atau diperoleh dari sumber Indonesia atau luar Indonesia yang dapat digunakan untuk konsumsi atau menambah kekayaan wajib pajak. Karena beasiswa bisa diartikan menambah kemampuan ekonomis bagi penerimanya, berarti beasiswa merupakan penghasilan.
Beasiswa dapat diberikan oleh Lembaga pemerintah, perusaahaan ataupun yayasan. Pemberian beasiswa dapat dikategorikan pada pemberian cuma-cuma ataupun pemberian dengan ikatan kerja (biasa disebut ikatan dinas) setelah selesainya pendidikan. Lama ikatan dinas ini berbeda-beda, tergantung pada lembaga yang memberikan beasiswa tersebut.
2.2. Data Mining
Data Mining adalah analisis meninjau sekumpulan data untuk menemukan suatu hubungan yang tidak diduga dan meringkas data secara berbeda dengan sebelumnya yang bermanfaat dan dipahami oleh pemilik data (Larose, 2005).
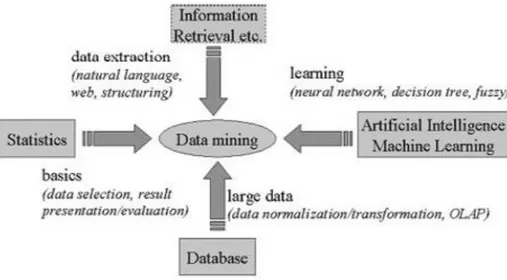
Data Mining mewarisi banyak aspek dan teknik dari berbagai bidang ilmu. Dari Gambar 2.1 menunjukkan bahwa data mining memiliki akar yang panjang dari bidang.
Gambar 2.1 Bidang Ilmu Data Mining (Pramudiono, 2006) Data Mining adalah bagian dari Knowledge Discovery in Database (KDD).
Knowledge Discovery in Database (KDD) adalah keseluruhan proses untuk mencari dan mengidentifikasi pola atau informasi data, dimana pola yang ditemukan bersifat sah, baru, dapat bermanfaat dan dapat dimengerti. Secara garis besar proses KDD terdiri atas beberapa tahap (Fayyad, 1996).
1. Data Selection
Pemilihan (seleksi) data dilakukan dari suatu kumpulan data operasional, sebelum tahap penggalian informasi dalam KDD dimulai proses ini perlu
dilakukan. Data hasil seleksi disimpan dalam suatu berkas, terpisah dari basis data operasional.
2. Pre-processing
Proses cleaning perlu dilakukan pada data yang menjadi fokus KDD sebelum proses data mining dapat dilakukan. Proses cleaning melingkupi antara lain membuang data yang memiliki duplikasi, data yang tidak konsisten diperiksa, dan memperbaiki kesalahan pada data, seperti kesalahan cetak (typo), juga dilakukan proses enrichment, yaitu proses
“memperkaya” data yang sudah ada dengan data atau informasi lain yang relevan dan diperlukan untuk KDD, seperti data atau informasi eksternal.
3. Transformation
Proses transformasi pada data yang telah dipilih adalah coding, sehingga sesuai untuk proses data mining. Proses coding dalam KDD merupakan proses kreatif dan sangat tergantung pada jenis atau pola informasi yang akan dicari dalam basis data.
4. Data mining
Data mining merupakan proses untuk mencari suatu pola atau informasi yang menarik dalam data yang terpilih dengan teknik atau metode tertentu.
Data mining memiliki teknik, metode, atau algoritma dalam sangat bervariasi. Pemilihan metode dan algoritma yang tepat sangat bergantung pada tujuan dan proses KDD secara keseluruhan.
5. Interpretation/Evalution
Interpretation merupakan proses untuk menampilkan pola informasi yang dihasilkan dari proses data mining oleh pihak yang berkepentingan. Tahap ini meliputi pemeriksaan terhadap pola atau informasi yang ditemukan agar tidak bertentangan dengan fakta atau hipotesis yang ada sebelumnya.
9
2.3. Clustering
Clustering adalah metode penganalisaan data untuk menemukan suatu kelompok- kelompok dari sekumpulan objek atau individu yang memiliki karakteristik yang sama. Clustering merupakan salah satu metode dalam data mining. Di dalam clustering terdapat dua pendekatan. Dua pendekatan utama adalah clustering dengan pendekatan partisi dan clustering dengan pendekatan hirarki (Oliveira et al, 2007). Clustering dengan pendekatan partisi (partition-based clustering) adalah mengelompokkan data dengan memilah-milah data yang dianalisa ke dalam cluster yang ada. Clustering dengan pendekatan hirarki (hierarchical clustering) adalah mengelompokkan data dengan membuat hirarki berupa dendogram yaitu data yang mirip ditempatkan pada hirarki yang berdekatan sedangkan yang tidak diletakkan para hirarki yang berjauhan.
3.4. Algoritma K-Means
K-Means merupakan salah satu metode data clustering non hirarki yang mempartisi
dikelompokkan ke dalam satu cluster yang sama dan data yang mempunyai karakteristik yang berbeda dikelompokkan ke dalam kelompok lain sehingga data yang berada dalam satu cluster/kelompok memiliki tingkat variasi yang kecil (Agusta, 2007).
Menurut Sarwono (2011), algoritma k-means adalah sebagai berikut:
1. Menentukan k sebagai jumlah cluster yang ingin dibentuk.
2. Membangkitkan nilai random untuk pusat cluster awal (centroid) sebanyak k.
3. Menghitung jarak setiap data input terhadap masing-masing centroid menggunakan rumus jarak Eucledian (Eucledian Distance) hingga ditemukan jarak yang paling dekat dari setiap data dengan centroid.
Berikut adalah persamaan Eucledian Distance:
(𝑥𝑖, 𝜇𝑗) = √(xi − μj)2… (2.1) dimana:
𝑥𝑖 : data kriteria
𝜇𝑗 : centroid pada cluster ke-j
4. Mengklasifikasikan setiap data berdasarkan kedekatannya dengan centroid (jarak terkecil).
5. Memperbaharui nilai centroid. Nilai centroid baru diperoleh dari rata- rata cluster yang bersangkutan dengan rumus:
𝜇(t+1)= 1
𝑁𝑠𝑗∑𝑗=𝑠𝑗𝑋j… (2.2) dimana:
𝜇(t+1) : centroid baru pada iterasi ke (t+1) Nsj : banyak data pada cluster Sj
11
6. Melakukan perulangan dari langkah 2 hingga 5 hingga anggota tiap cluster tidak ada yang berubah.
7. Jika langkah 6 telah terpenuhi, maka nilai pusat cluster (µj) pada iterasi terakhir akan digunakan sebagai parameter untuk menentukan klasifikasi data.
2.5. Multi Criteria Decision Making (MCDM)
Multi criteria decision making (MCDM) merupakan teknik pengambilan keputusan dari beberapa pilihan alternatif yang ada. Di dalam MCDM ini mengandung unsur atribut, obyektif, dan tujuan (Rahardjo et al, 2000).
Atribut menerangkan, memberi ciri kepada suatu obyek.
Misalnya tinggi, panjang dan sebagainya.
Obyektif menyatakan arah perbaikan atau kesukaan terhadap atribut, misalnya memaksimalkan umur, meminimalkan harga, dan sebagainya. Obyektif dapat pula berasal dari attribute yang menjadi suatu obyektif jika pada atribut tersebut diberi arah tertentu.
Tujuan ditentukan terlebih dahulu. Misalnya suatu proyek mempunyai obyektif memaksimumkan profit, maka proyek tersebut mempunyai tujuan mencapai profit 10 juta/bulan.
Kriteria merupakan ukuran, aturan-aturan ataupun standar-standar yang memandu suatu pengambilan keputusan. Pengambilan keputusan dilakukan melalui pemilihan atau memformulasikan atribut-atribut, obyektif-obyektif, maupun tujuan-tujuan yang berbeda, maka atribut, obyektif maupun tujuan dianggap sebagai kriteria. Kriteria dibangun dari kebutuhan-kebutuhan dasar manusia serta nilai-nilai yang diinginkannya. Ada dua macam kategori dari multi criteria decision making (MCDM), yaitu:
1. Multiple Objective Decision Making (MODM) 2. Multiple Attribute Decision Making (MADM)
Multiple Objective Decision Making (MODM) menyangkut masalah perancangan (design), di mana teknik-teknik matematik optimasi digunakan, untuk jumlah alternatif yang sangat besar (sampai dengan tak berhingga) dan untuk menjawab pertanyaan apa (what) dan berapa banyak (how much).
Multiple Attribute Decision Making (MADM), menyangkut masalah pemilihan, di mana analisa matematis tidak terlalu banyak dibutuhkan atau dapat digunakan untuk pemilihan hanya terhadap sejumlah kecil alternatif saja. Metode Analytical Hierarchy Process (AHP), Simple Additive Weighting Method (SAW), Technique for Order by Similarity to Ideal Solution Method (TOPSIS), VIšekriterijumsko KOmpromisno Rangiranje (VIKOR) merupakan bagian dari teknik MADM.
2.6. VIšekriterijumsko KOmpromisno Rangiranje (VIKOR)
Metode VIšekriterijumsko KOmpromisno Rangiranje (VIKOR) dikembangkan untuk optimasi multikriteria dari sistem yang kompleks. VIKOR digunakan untuk menentukan daftar peringkat, solusi kompromi, dan bobot interval stabilitas. Untuk kestabilan preferensi solusi kompromi diperoleh dengan initial bobot. Metode VIKOR memiliki kelebihan pada proses pemeringkatan dengan memiliki nilai preferensi untuk pemeringkatan dan dapat mengatasi pemeringkatan banyak alternatif dengan lebih mudah. Serta memperkenalkan indeks berbasis indeks multikriteria pada ukuran khusus "kedekatan" dengan solusi "ideal" (Opricovic, 1998).
Prosedur perhitungan metode VIKOR menurut (Opricovic & Tzeng, 2004) dan (Zhang, et al., 2016) mengikuti tahap-tahap di bawah ini:
1. Menghitung normalisasi matrik keputusan
Perhitungan normalisasi matrik keputusan terhadap setiap data L mengikuti persamaan:
13
f
ij=
𝐿𝑖𝑗√∑𝑚𝑖=1𝐿2𝐼𝐽
…
(2.3)
Dimana i merupakan alternatif ke 1,2,3 hingga m, j merupakan alternatif ke 1,2,3 hingga n. Xij adalah nilai elemen dari setiap kriteria dan fij merupakan nilai hasil normalisasi. Akan diperoleh matrik F yang mengandung keseluruhan nilai elemen hasil normalisasi, ditunjukkan melalui persamaan
F = 𝐴1 𝐴2
⋮ 𝐴𝑚
[
𝐶𝑥1 𝐶𝑥2 … 𝐶𝑥𝑛 𝑥11 𝑥12 … 𝑥1𝑛 𝑥21 𝑥22 … 𝑥2𝑛
⋮ ⋮ ⋮ ⋮
𝑥𝑚1 𝑥𝑚2 … 𝑥𝑚𝑛]
(2.4)
2. Menentukan solusi ideal dan ideal negative
Menentukan alternative dengan nilai tertinggi yang berarti sebagai solusi positif (f j*). Sedangkan yang mempunyai nilai terendah akan menjadi ideal negative (f j-). Cara menentukan nilai f j* dan f j- melalui persamaan:
f j * = maxifij
f j - = minifij (2.5)
3. Menghitung Utility Measures
Untuk mendapatkan nilai Si dan Ri, diperlukan nilai bobot kriteria. Bobot kriteria (wj) bertujuan untuk merepresentasikan kepentingan relatif. Nilai Si dan Ri dihitung secara berturut-turut melalui persamaan
Si = ∑ 𝑤𝑗 𝑓 𝑗∗ −𝑓 𝑖 𝑗 (𝑓 𝑗∗ −𝑓 𝑗−)
𝑛𝑗=1 (2.6)
Ri = Maxj [𝑤𝑗 (𝑓 𝑗∗ −𝑓 𝑖 𝑗)
(𝑓 𝑗∗ −𝑓 𝑗−)] (2.7)
4. Menghitung indeks VIKOR (Qi)
Perhitungan indeks VIKOR menggunakan persamaan
𝑆𝑖−𝑆∗ 𝑅𝑖−𝑅∗
dengan ketentuan:
S* = Mini(Si) R* = Mini(Ri) S- = Maxi(Si) R- = Maxi(Ri),
Untuk menghitung nilai VIKOR diperlukan variabel v yang dikenal dengan istilah bobot strategis dari mayoritas kriteria, dimana nilai v default ditetapkan sebesar 0,5.
5. Melakukan perangkingan alternatif dengan nilai Si, Ri, dan Qi.
6. Mengajukan solusi kompromi
Solusi kompromi berupa alternatif (A′) diajukan ketika kondisi C1 dan C2 terpenuhi di mana alternatif A′ merupakan alternatif yang menempati peringkat pertama dalam pemeringkatan nilai VIKOR (𝑄𝑖). Adapun kondisi C1 dan C2 sebagai berikut:
A. Kondisi C1: Acceptable Advantage
Kondisi C1 diterima apabila Q(A2) – Q(A1) ≥ DQ, dengan DQ = 1/(n-1). A1 adalah alternatif urutan pertama dalam perankingan 𝑄𝑖, A2 adalah alternatif urutan kedua dalam perankingan 𝑄𝑖.
B. Kondisi C2: Acceptable Stability
Untuk memenuhi kondisi C2, alternatif A′ harus pula menduduki peringkat pertama dalam pemeringkatan nilai 𝑆𝑖 dan/atau 𝑅𝑖. Apabila kondisi C2 terpenuhi, maka solusi kompromi lain bisa diusulkan, yaitu alternatif A1, A2, … An dimana An ditentukan dari relasi Q(An) – Q(A1) < DQ untuk n yaitu posisi alternatif yang terdekat.
2.7. Penelitian Terdahulu
Beberapa penelitian yang telah dilakukan sebelumnya, diantaranya yaitu: penelitian yang dilakukan oleh (Anindya Khrisna Wardhani, 2016), yaitu Implementasi Algoritma K-Means untuk Pengelompokkan Penyakit Pasien pada Puskesmas Kajen Pekalongan.
15
Penelitian ini berhasil dilakukan dengan melakukan inisialisasi jumlah cluster sebanyak 2 buah.
Penelitian selanjutnya yang dilakukan oleh (Noor Fitriana Hastuti, 2013) yaitu Pemanfaatan Metode K-Means Clustering dalam Penentuan Penerima Beasiswa. Pada penelitian ini pengujian dilakukan sebanyak 40 kali percobaan untuk mendapatkan nilai presisi hasil implementasi metode K-Means. Nilai error presisi pada hasil klasifikasi berdasarkan IPK adalah 0,118.
Penelitian selanjutnya yang dilakukan oleh (Fitriani, 2016) yaitu Penerapan Metode Clustering Data dengan C-Means untuk Rekomendasi Penerima Beasiswa pada Universitas Sumatera Utara. Penelitian ini berhasil dilakukan dan menyarankan penggunaan algoritma lain. Hasil penelitian menunjukkan bahwa penggunaan gabungan metode AHP dan VIKOR dapat membantu proses seleksi dengan menyediakan urutan penerima beasiswa berdasarkan kriteria yang telah ditetapkan dan diberi bobot oleh pimpinan.
Penelitian terdahulu yang telah dipaparkan akan diuraikan secara singkat pada Tabel 2.1.
Tabel 2.1. Penelitian Terdahulu
No Peneliti Judul Metode
1 Anindya Khrisna Wardhani, et al
2016
Implementasi Algoritma K-Means untuk Pengelompokkan Penyakit Pasien pada Puskesmas Kajen Pekalongan
K-Means
2 Hastuti, 2013
Pemanfaatan Metode K-Means Clustering dalam Penentuan Penerima Beasiswa
Clustering dan K- means
3 Lengkong, et al, 2015
Implementasi Metode VIKOR untuk Seleksi Penerima Beasiswa.
Multi Atributte Decision Making (MADM) dan VIKOR
4 F. Nasari, S.
Darma 2015
Penerapan K-Means Clustering pada Data Penerima Mahasiswa Baru
K-Means
5 Fitriani, Desi 2016
Penerapan Metode Clustering Data Dengan C-Means Untuk Rekomendasi Penerima Beasiswa Pada Universitas Sumatera Utara
C-Means
Pada penelitian ini penulis mengimplementasikan metode K-Means Clustering untuk pengelompokkan dan VIKOR digunakan untuk melakukan perangkingan agar dapat menentukan penerima beasiswa.
17
BAB 3
ANALISIS DAN PERANCANGAN
Pada bab ini akan dibahas mengenai analisis dan perancangan sistem. Pada tahap analisis akan dilakukan analisis terhadap algoritma K-Means Clustering dan VIKOR. Pada tahap perancangan akan dibahas mengenai diagram aktivitas, diagram use case, diagram sequence, flowchart dan tampilan antarmuka pada aplikasi yang akan dibangun.
3.1. Data yang Digunakan
Data yang digunakan dalam penelitian berasal data pendaftar beasiswa Karya Salemba Empat tahun 2017. Dari data tersebut diambil data pendaftar beasiswa dari 33 Universitas di seluruh Indonesia. Setelah pengumpulan data dilakukan analisis data sesuai dengan kebutuhan sistem. Analisis data dilakukan menggunakan K-Means Clustering dan VIKOR.
Total data yang digunakan 21.614 data pendaftar beasiswa.
Dari data tersebut terdapat 3 kriteria yang digunakan dalam penelitian. Dimana 3 kriteria digunakan untuk K-Means clustering dan 1 kriteria untuk VIKOR. Adapun 3 kriteria untuk pengelompokkan adalah jumlah penghasilan orangtua pendaftar, tagihan PLN, dan tagihan PDAM. Sedangkan 1 kriteria untuk VIKOR adalah jumlah penghasilan orangtua. Data yang digunakan adalah dalam format csv yang di export ke format arff menggunkana software Weka Explorer.
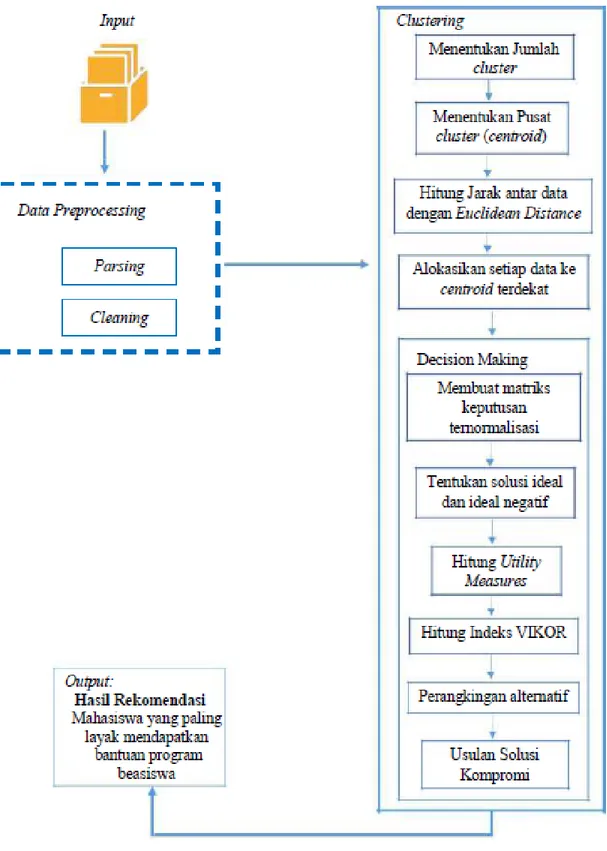
3.2. Arsitektur Umum
Metode yang diajukan untuk menentukan penerima beasiswa terdiri dari beberapa tahapan.
Tahapan-tahapan tersebut dimulai dari data preprocessing berupa parsing untuk
memeriksa data yang inkonsisten dan kesalahan cetak (tipografi) serta mengisi missing value. Tahapan selanjutnya yaitu clustering, di dalam tahap pengelompokkan ini diawali dengan menentukan jumlah cluster setelah itu tentukan titik pusat cluster (centroid) lalu hitung jarak antar data ke titik pusat cluster dengan persamaan euclidean distance.
Kemudian alokasikan data-data tersebut ke cluster terdekat sehingga diketahui di kelompok mana data tersebut berada. Tahap selanjutnya yaitu decision making, dimana data yang telah dikelompokkan akan dirangkingkan. Dari data tersebut dibuat matriks keputusan berdasarkan kriteria dan alternatif yang dimiliki yang setelah itu dinormalisasikan.
Selanjutnya tentukanlah solusi ideal positif dan negatifnya yang diikuti dengan menghitung utility measures. Lalu hitunglah indeks VIKOR berdasarkan nilai utility measures tersebut.
Kemudian rangkingkan semua alternatif sehingga didapatilah hasil perangkingan untuk hasil rekomendasi yang berhak menerima beasiswa. Adapun tahapan-tahapan diatas dapat dilihat dalam bentuk arsitektur umum pada Gambar 3.1.
19
Gambar 3.1 Arsitektur Umum
3.3. Analisis K-Means Clustering
Pada tahap ini dilakukan analisis dengan K-Means Clustering. Tahapan analisis yang akan dilakukan yaitu:
3.3.1. Menentukan Jumlah Cluster
Tahap awal dalam proses clustering adalah menentukan berapa jumlah cluster yang diinginkan. Pada sistem penentuan penerima beasiswa akan digunakan 3 cluster yaitu cluster pertama (C1), cluster kedua (C2) dan cluster ketiga (C3).
3.3.2. Menentukan Pusat Cluster (centroid)
Pada tahap ini ditentukan nilai pusat cluster (centroid) awal secara random dari data yang telah diinputkan. Centroid kriteria 1 jumlah penghasilan orangtua, centroid 2 tagihan PLN, centroid 3 tagihan PDAM. Maka diperoleh:
C1= (6.885.571; 50.118; 40.064) C2= (1.315.133; 47.680; 40.768) C3= (1.294.884; 64.976; 34.801)
3.3.3. Hitung Jarak Data dengan Euclidean Distance
Kemudian akan dihitung jarak dari setiap data ke setiap pusat cluster yang ada dengan euclidean distance sehingga ditemukan jarak terdekat dari tiap data ke centroid. Perhitungan dengan euclidean distance dapat digunakan dengan persamaan 3.1:
𝑑(𝑥𝑖, 𝜇𝑗) = √(𝑥𝑖𝑎 − 𝜇𝑗𝑎)2 + (𝑥𝑖𝑏 − 𝜇𝑗𝑏)2 (3.1) Dengan ketentuan sebagai berikut:
xi : data kriteria
µj : centroid pada cluster ke-j
Jarak data pertama ke pusat cluster pertama
d11=√(2.603.310– 6.885.571)2 + (60.791– 50.118)2 + (46.490 – 40.064)2
21
Jarak data pertama ke pusat cluster kedua
d12=√(2.603.310– 1.315.133)2+ (60.791– 47.680)2+ (46.490– 40.768)2
= 1.28825643
Jarak data pertama ke pusat cluster ketiga
d13= √(2.603.310– 1.294.884)2+ (60.791– 64.976)2+ (46.490– 34.801)2
= 1.3084849
Jarak data kedua ke pusat cluster pertama
d21= √(2.000.000– 6.885.571)2 + (60.973– 50.118)2 + (43.189– 40.064)2
= 1.54495733
Jarak data kedua ke pusat cluster kedua
d22= √(2.000.000– 1.315.133)2 + (60.973– 47.680)2 + (43.189– 40.768)2
= 2.16616106
Jarak data kedua ke pusat cluster ketiga
d23= √(2.000.000 −1.294.884)2+ (60.973−64.976)2+ (43.189−34.801)2
= 2.22996627
Jarak data ketiga ke pusat cluster pertama
d31=√(2.000.000 − 6.885.571)2+ (68.267 − 50.118)2+ (35.516 − 40.064)2
= 1.54496453
Jarak data ketiga ke pusat cluster kedua
d32= √(2.000.000 −1.315.133)2+ (68.267−47.680)2+ (35.516−40.768)2
= 2.16678152
Jarak data ketiga ke pusat cluster ketiga
d32= √(2.000.000 −1.294.884)2+ (68.267−64.976)2+ (35.516− 34.801)2
= 1.04193435
Hasil perhitungan jarak awal pada iterasi-1 dapat dilihat pada Tabel 3.10.
Tabel 3.1. Pusat cluster iterasi 1
Nama Cluster 1 Cluster 2 Cluster 3
Pendaftar 1 1.35417556 1.28825643 1.3084849
Pendaftar 2 1.54495733 2.16616106 2.22996627
Pendaftar 3 1.54496453 2.16678152 1.04193435
⋮ ⋮ ⋮ ⋮
Pendaftar 21.614 1.61278855 1.0499382 2.9001268
3.3.4. Kelompokkan Data pada Cluster Terdekat
Dari hasil hitungan pada Tabel 3.10, setiap data akan dialokasikan ke suatu cluster berdasarkan jarak terdekat dari pusat clusternya. Pada data pertama diperoleh jarak terdekat dengan pusat cluster kedua, maka data tersebut akan menjadi anggota cluster kedua. Hasil cluster pada iterasi 1 dapat dilihat pada Tabel 3.11:
Tabel 3.2. Hasil cluster iterasi 1
Nama Cluster 1 Cluster 2 Cluster 3
Pendaftar 1 *
Pendaftar 2 *
Pendaftar 3 *
⋮ ⋮ ⋮ ⋮
Pendaftar 21.614 *
3.3.5. Hasil Clustering
Proses iterasi berakhir pada iterasi ke 1 dan menghasilkan 13.423 data untuk cluster pertama, 7.030 data pada cluster kedua dan 1.161 data pada cluster ketiga yang dapat dilihat di Tabel 3.14, Tabel 3.15 dan Tabel 3.16.
Tabel 3.3. Hasil Cluster Pertama
No Nama Cluster
1 Pendaftar 2 Cluster 1
2 Pendaftar 6 Cluster 1
3 Pendaftar 10 Cluster 1
23
4 Pendaftar 11 Cluster 1
5 Pendaftar 12 Cluster 1
⋮ ⋮ ⋮
13.423 Pendaftar 21.240 Cluster 1
Tabel 3.4. Hasil Cluster Kedua
No Nama Cluster
1 Pendaftar 1 Cluster 2
2 Pendaftar 5 Cluster 2
3 Pendaftar 8 Cluster 2
4 Pendafta 13 Cluster 2
5 Pendaftar 17 Cluster 2
⋮ ⋮ ⋮
7.030 Pendaftar 21.614 Cluster 2
Tabel 3.5. Hasil Cluster Ketiga
No Nama Cluster
1 Pendaftar 3 Cluster 3
2 Pendaftar 4 Cluster 3
3 Pendaftar 7 Cluster 3
4 Pendaftar 9 Cluster 3
5 Pendaftar 14 Cluster 3
⋮ ⋮ ⋮
1.161 Pendaftar 17.832 Cluster 3
Dari hasil pusat cluster didapatkan informasi sebagai berikut:
1. Cluster 1 adalah kondisi dimana pendaftar beasiswa memiliki jumlah penghasilan orangtua yang relatif tinggi tetapi tagihan PLN dan tagihan PDAM yang rendah.
2. Cluster 2 adalah kondisi dimana pendaftar beasiswa memiliki jumlah penghasilan orangtua yang relatif rendah tetapi tagihan PLN dan tagihan PDAM yang tinggi.
3. Cluster 3 adalah kondisi dimana pendaftar beasiswa memiliki jumlah penghasilan orangtua, tagihan PLN dan tagihan PDAM yang tidak rendah maupun tinggi.
Oleh karena itu, hasil cluster untuk pengelompokkan keadaaan rumah yang berhak mendapatkan bantuan dikelompokkan menjadi 3 cluster yaitu:
1. Cluster tidak layak, dimana keadaan pendaftar beasiswa sangat tidak layak dan tidak berhak mendapatkan beasiswa.
2. Cluster rekomendasi, dimana keadaan pendaftar beasiswa sangat membutuhkan beasiswa.
3. Cluster layak, dimana keadaan pendaftar beasiswa layak mendapatkan beasiswa namun diperlukan perangkingan.
3.4. Analisis VIKOR
Setelah melewati proses clustering, maka dilanjutkan ke proses perangkingan dengan VIKOR dengan 6 tahapan. Tahapan analisis VIKOR yang akan dilakukan yaitu:
3.4.1. Membuat matriks keputusan ternormalisasi
Tahap pertama dalam proses perangkingan VIKOR adalah membuat matriks keputusan ternormalisasi. Pada Tabel 3.17 menunjukan data alternatif dan kriteria dari cluster layak. Kriteria-kriterianya adalah jumlah penghasilan orangtua.
Kemudian terdapat alternatif A1 sampai A1161, yaitu 1.161 pendaftar yang layak mendapatkan beasiswa yang terdapat di cluster 3.
Tabel 3.6. Data Kriteria Cluster 3
No Alternatif C3
1 Pendaftar 3 2.000.000
25
2 Pendaftar 4 750.000
3 Pendaftar 7 1.500.000
4 Pendaftar 9 1.500.000
5 Pendaftar 14 2.000.000
⋮ ⋮ ⋮
1.161 Pendaftar 17.832 750.000
Untuk melakukan matriks keputusan ternormalisasi digunakan persamaan
𝑓
ij=
𝐿𝑖𝑗√∑𝑚𝑖=1𝐿2𝑖𝑗
(3.2)
Dimana:
Lij adalah nilai dari Alternative Ai.
Perhitungan normalisasi dapat dilihat dibawah ini:
f13= 2.000.000
√(2.000.0002+750.0002+1.500.0002+1.500.0002+2.000.0002+⋯+750.0002)
= 2.000.000
√2.302.870.798.017.970
= 2.000.000
47.988.236
= 0.041
f23= 750.000
√(2.000.0002+750.0002+1.500.0002+1.500.0002+2.000.0002+⋯+750.0002)
= 750.000
√2.302.870.798.017.970
= 750.000
47.988.236
= 0.015
f33= 1.500.000
√(2.000.0002+750.0002+1.500.0002+1.500.0002+2.000.0002+⋯+750.0002)
= 1.500.000
√2.302.870.798.017.970
= 1.500.000
47.988.236
= 0.031
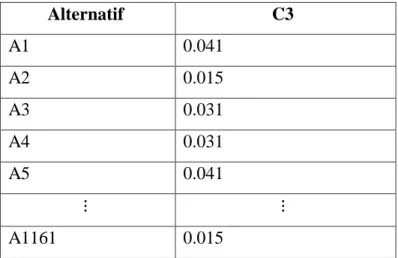
Hasil normalisasi matriks dapat dilihat pada Tabel 3.7.
Tabel 3.7. Hasil Normalisasi Matriks
Alternatif C3
A1 0.041
A2 0.015
A3 0.031
A4 0.031
A5 0.041
⋮ ⋮
A1161 0.015
3.4.2. Menentukan solusi ideal dan ideal negatif
Solusi ideal adalah nilai maksimum hasil normalisasi dari tiap kriteria. Sedangkan nilai ideal negatif adalah nilai minimum normalisasi dari masing – masing kriteria.
Solusi ideal dan ideal negatif diperoleh dengan persamaan sebagai berikut:
A* = {max fij |i=1,2, …, m}
= {𝑓1∗,𝑓2∗ , …, 𝑓𝑛∗} (3.3) A- = {min fij |i=1,2, …, m}
= {𝑓1−, 𝑓2−, …, 𝑓𝑛−} (3.4) Solusi idealnya
A* = {𝑓3∗} = {0,041}
Ideal negatif A- = {𝑓3−}
= {0,015}
3.4.3. Menghitung Utility Measures
Utility measures dihitung berdasarkan 𝑆𝑖 (maximum group utility) dan 𝑅𝑖 (minimum individual regret of the opponent). 𝑆𝑖 (maximum group utility) adalah titik terjauh dari solusi ideal sedangkan dan 𝑅𝑖 (minimum individual regret of the
27
opponent) adalah titik terdekat dari solusi ideal. Adapun cara menghitung utility measures dapat dilihat pada persamaan 3.5 dan 3.6.
Si = ∑ 𝑤𝑗 𝑓𝑗∗−𝑓𝑖𝑗
(𝑓𝑗∗−𝑓𝑗−)
𝑛𝑗=1 (3.5)
Ri = Maxj[𝑤𝑗 (𝑓𝑗∗−𝑓𝑖𝑗)
(𝑓𝑗∗−𝑓𝑗−)] (3.6) Dengan ketentuan:
𝑆𝑖 : maximum group utility
𝑅𝑖 : minimum individual regret of the opponent 𝑓𝑗∗ : nilai tertinggi dari kriteria
𝑓𝑗− : nilai terkecil dari kriteria
𝑤𝑗 : bobot yang diberikan pada setiap kriteria
Kemudian nilai 𝑤 atau bobot yang telah ditentukan untuk setiap kriteria sebagai berikut:
Jumlah penghasilan orang tua: 0,4 Adapun perhitungan untuk Si yaitu:
S1 = w1
𝑓𝑗∗−𝑓𝑖𝑗 (𝑓𝑗∗−𝑓𝑗−)
S1 = 0,4 0,041−0,041 (0,041−0,015)
S1 = 0,4 0
0,026
S1 = 0
S2 = w1 𝑓𝑗∗−𝑓𝑖𝑗 (𝑓𝑗∗−𝑓𝑗−)
S2 = 0,4 0,041−0,015 (0,041−0,015)
S2 = 0,4
Sedangkan untuk nilai Ri adalah R1 = Max[𝑤1 (𝑓𝑗𝑓𝑗∗∗−𝑓𝑗−𝑓𝑖𝑗−)]
R1 = 0
R2 = Max[𝑤1 𝑓𝑗∗−𝑓𝑖𝑗
(𝑓𝑗∗−𝑓𝑗−)] R2 = 0,4
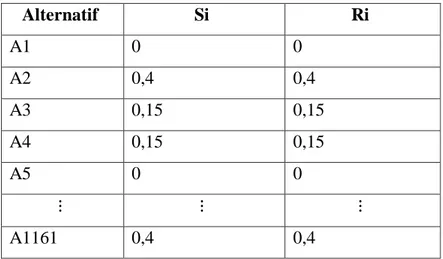
Hasil perhitungan Si dan Ri dapat dilihat pada Tabel 3.8.
Tabel 3.8. Hasil Si dan Ri
Alternatif Si Ri
A1 0 0
A2 0,4 0,4
A3 0,15 0,15
A4 0,15 0,15
A5 0 0
⋮ ⋮ ⋮
A1161 0,4 0,4
3.4.4. Menghitung Indeks VIKOR
Menghitung indeks VIKOR adalah menghitung nilai perangkingan 𝑄𝑖 menggunakan nilai 𝑆𝑖 dan 𝑅𝑖 dari perhitungan Utility Measures. Perhitungan indeks VIKOR menggunakan persamaan 3.8
𝑄𝑖 = v[𝑆𝑖− 𝑆∗
𝑆−−𝑆∗]+ (1-v) [𝑅𝑖− 𝑅∗
𝑅−−𝑅∗] (3.7)
Dengan ketentuan:
S* = Mini (Si) R* = Mini(R), S- = Maxi (Si) R- = Maxi(R), v = bobot (biasanya bernilai 0,5)
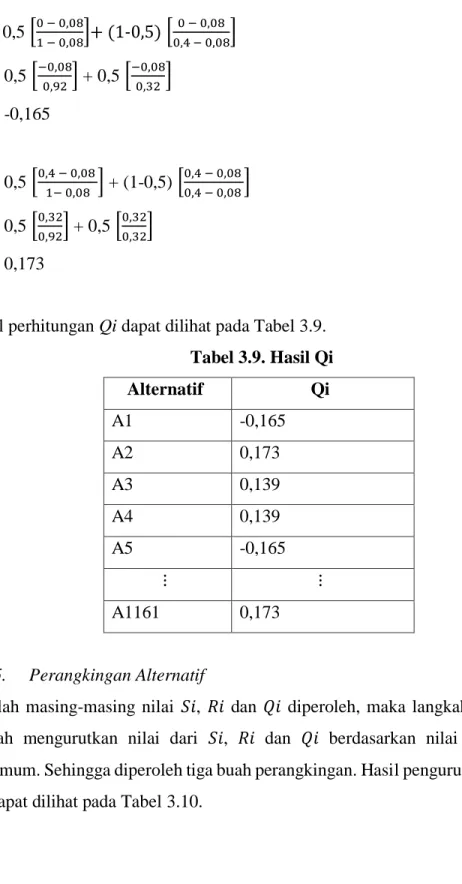
Nilai indeks VIKOR yang terpilih menjadi solusi terbaik adalah dengan nilai terkecil.
29
Q1 = 0,5 [0 − 0,08
1 − 0,08]+ (1-0,5) [0 − 0,08
0,4 − 0,08] Q1 = 0,5 [−0,08
0,92] + 0,5 [−0,08
0,32] Q1 = -0,165
Q2 = 0,5 [0,4 − 0,08
1− 0,08 ] + (1-0,5) [0,4 − 0,08 0,4 − 0,08 ] Q2 = 0,5 [0,32
0,92] + 0,5 [0,32
0,32] Q2 = 0,173
Hasil perhitungan Qi dapat dilihat pada Tabel 3.9.
Tabel 3.9. Hasil Qi
Alternatif Qi
A1 -0,165
A2 0,173
A3 0,139
A4 0,139
A5 -0,165
⋮ ⋮
A1161 0,173
3.4.5. Perangkingan Alternatif
Setelah masing-masing nilai 𝑆𝑖, 𝑅𝑖 dan 𝑄𝑖 diperoleh, maka langkah selanjutnya adalah mengurutkan nilai dari 𝑆𝑖, 𝑅𝑖 dan 𝑄𝑖 berdasarkan nilai yang paling minimum. Sehingga diperoleh tiga buah perangkingan. Hasil pengurutan 𝑆𝑖, 𝑅𝑖 dan 𝑄𝑖 dapat dilihat pada Tabel 3.10.
Tabel 3.10. Hasil Pengurutan Si, Ri, dan Qi Alternatif Si Ranking
Si
Ri Ranking Ri
Qi Ranking Qi
A1 0 1 0 1 -0,165 1
A2 0,4 1056 0,4 1056 0,173 1160
A3 0,15 698 0,15 698 0,139 453
A4 0,15 690 0,15 690 0,139 454
A5 0 2 0 2 -0,165 2
⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮
A1161 0,4 1057 0,4 1057 0,173 1161
Setelah mendapatkan 3 macam perangkingan seperti yang ditunjukkan oleh Tabel 3.10 perangkingan 𝑆𝑖 merupakan perangkingan berdasarkan pendekatan dengan titik solusi terjauh dengan solusi ideal, perangkingan 𝑅𝑖 adalah perangkingan berdasarkan pendekatan dengan titik solusi terdekat dengan solusi ideal, sedangkan perangkingan 𝑄𝑖 merupakan perangkingan kompromi dengan menghitung indeks VIKOR.
3.4.6. Usulan Solusi Kompromi
Usulan solusi kompromi adalah langkah terakhir dalam menentukan rangking setiap alternatif. Untuk melakukan solusi kompromi dilihat berdasarkan rangking terbaik dengan nilai 𝑄𝑖 minimum dengan 2 kondisi berikut.
A. Acceptable Advantage
Kondisi ini terpenuhi dengan cara menghitung selisih dari nilai alternatif peringkat kedua dengan peringkat pertama harus lebih besar atau sama dengan nilai DQ.
Q(A2) – Q(A1) ≥ DQ (3.8) DQ = 1
(𝑛−1) (3.9)
Dimana n adalah jumlah alternatif.
31
B. Acceptable Stability
Jika kondisi pertama tidak terpenuhi, maka nilai A1 harus menjadi rangking terbaik pada 𝑆𝑖 dan/atau 𝑅𝑖. Solusi kompromi lain bisa diusulkan yaitu alternatif A1, A2, … An dengan persamaan 3.10.
Q(An) – Q(A1) < DQ (3.10) Dimana n yaitu posisi alternatif yang berada pada kondisi saling berdekatan.
Maka usulan kompromi untuk hitungan cluster tidak layak menggunakan acceptable advantage adalah.
Q(A2) – Q(A1) ≥ DQ 0.0271– 0 ≥ 1
(1161−1)
0.0271 ≥ 0.0008 (diterima)
Solusi kompromi telah terpenuhi dan perangkingan alternatif terbaik adalah berdasarkan nilai Q minimum. Maka hasil perangkingan cluster tidak layak dapat dilihat pada Tabel 3.11.
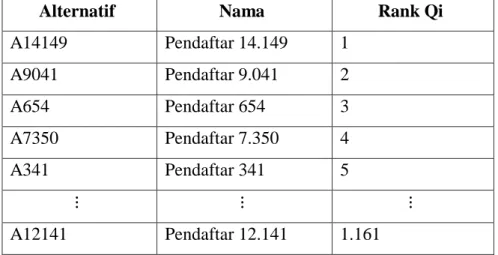
Tabel 3.11. Hasil Akhir Perangkingan Cluster Layak
Alternatif Nama Rank Qi
A14149 Pendaftar 14.149 1
A9041 Pendaftar 9.041 2
A654 Pendaftar 654 3
A7350 Pendaftar 7.350 4
A341 Pendaftar 341 5
⋮ ⋮ ⋮
A12141 Pendaftar 12.141 1.161
Dari hasil perangkingan cluster layak menggunakan VIKOR didapatkan A14149 pada urutan pertama, A9041 pada urutan kedua, A654 pada urutan ketiga, A7350 berada pada urutan keempat, A341 berada pada urutan kelima hingga A12141 berada pada urutan terakhir atau urutan ke
3.5. Perancangan Sistem 3.5.1. Perancangan flowchart
Flowchart merupakan gambaran dalam bentuk diagram alir dari algoritma dalam suatu program yang menyatakan arah alur program dalam menyelesaikan suatu masalah.
3.5.1.1. Flowchart K-Means Clustering
33
Pada flowchart k-means clustering, proses awal dimulai dari menentukan jumlah cluster yang akan dibentuk. Kemudian tentukan nilai centroid pada masing-masing cluster. Setelah itu hitung jarak data ke masing-masing pusat cluster menggunakan persamaan euclidean distance. Kelompokkan data ke dalam cluster berdasarkan hasil perhitungan dengan jarak terdekat. Lalu hitung rata-rata dari tiap pusat cluster untuk mendapatkan pusat cluster yang baru. Setelah didapatkan pusat cluster yang baru, bandingkan titik pusat cluster yang baru dengan lama jika posisi anggota tiap cluster berubah maka ulangi menghitung jarak data ke masing-masing pusat cluster, jika tidak berubah maka nilai pusat cluster terakhir akan digunakan untuk menampilkan hasil clustering.
3.5.1.2. Flowchart VIKOR
Pada flowchart VIKOR proses awal dimulai dengan membuat matriks keputusan ternormalisasi dari alternatif dan kriteria. Lalu tentukan solusi ideal yaitu nilai maksimum dari hasil normalisasi dan ideal negatif adalah nilai minimum dari hasil normalisasi. Setelah itu hitung utility measures dan regret measures. Lalu hitung indeks VIKOR. Setelah mendapatkan hasil utility measures, regret measures dan indeks VIKOR dilakukan perangkingan, maka didapatkan tiga buah perangkingan. Lalu diajukanlah solusi kompromi untuk mendapatkan hasil perangkingan terbaik. Kemudian ditampilkan hasil akhir perangkingan.
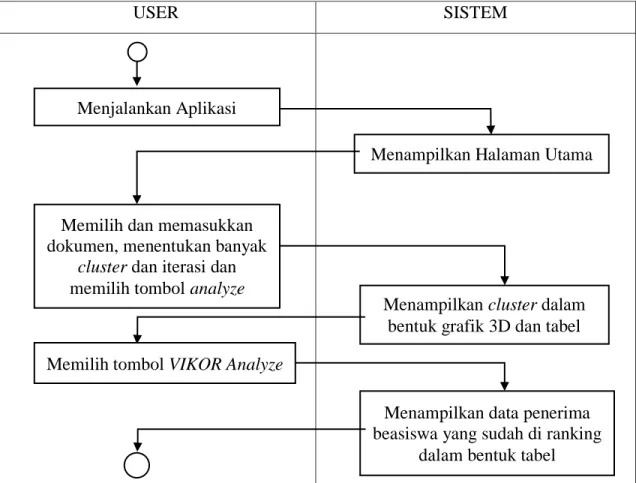
3.5.1.3 Diagram Aktivitas
Diagram aktivitas menggambarkan alur proses berupa urutan- urutan kegiatan yang terjadi di dalam sistem yang dirancang. Kegiatan user di dalam sistem antara lain upload file data yang akan di cluster dan menentukan berapa banyak cluster yang akan dibuat oleh sistem. Urutan- urutan kegiatan tersebut dapat dilihat pada tabel 3.12.
Tabel 3.12 Diagram Aktivitas
USER SISTEM
Menjalankan Aplikasi
Menampilkan Halaman Utama
Memilih dan memasukkan dokumen, menentukan banyak
cluster dan iterasi dan memilih tombol analyze
Menampilkan cluster dalam bentuk grafik 3D dan tabel Memilih tombol VIKOR Analyze
Menampilkan data penerima beasiswa yang sudah di ranking
dalam bentuk tabel
35
3.5.1.4 Diagram Use Case
Diagram Use Case menjelaskan interaksi yang terjadi antara user dengan sistem yang ada. Interaksi antara user dengan sistem ini dapat dilihat pada Gambar 3.4.
User
Memasukkan file data pendaftar beasiswa
Menentukan jumlah cluster dan
iterasi
Mendapatkan hasil data yang sudah di
rengking
k-means clustering Mendapatkan
hasil clustering data
pendaftar beasiswa
VIKOR
<<include>>
Input file Sistem Penerimaan Beasiswa
Gambar 3.4. Use Case Diagram
3.5.1.5. Sequence Diagram
Diagram Sequence memperlihatkan interkasi-interaksi antar objek didalam sistem dari setiap event yang ditampilkan secara bertahap, seperti pada Gambar 3.5.
User
Halaman utama
Halaman Performance
Data clustering
Rengking
VIKOR Hasil akhir
Memasukkan file data penerima beasiswa
Menentukan jumlah clustering dan iterasi
Meng-cluster data
Mengklik button Vikor Analyze
Merengking data
Mengklik button hasil akhir
Menampilkan data hasil akhir penerima beasiswa
Gambar 3.5. Sequence Diagram
37
3.5.2. Rancangan tampilan antarmuka pengguna
Tampilan antarmuka pengguna merupakan sebuah desain tampilan yang akan dibangun pada aplikasi ini. Antarmuka yang dibangun diharapkan dapat memudahkan pengguna untuk memahami dan menjalankan program aplikasi dengan baik. Perancangan antarmuka program aplikasi ini terdiri dari menu Specification, Performance, about, data dan VIKOR Analyze.
Rancangan antar muka menu Specification dapat dilihat pada Gambar 3.6.
Gambar 3.6. Rancangan Halaman Specification
Rancangan antar muka Performance dapat dilihat pada Gambar 3.7.
Gambar 3.7. Rancangan halaman Performance Rancangan antar muka menu about dapat dilihat pada Gambar 3.8.
Gambar 3.8. Rancangan halaman about
39
Rancangan antar muka menu data dapat dilihat pada Gambar 3.9.
Gambar 3.9. Rancangan halaman data
Rancangan antar muka menu VIKOR Analyze dapat dilihat pada Gambar 3.10.
Gambar 3.10. Rancangan halaman VIKOR Analyze
BAB 4
IMPLEMENTASI DAN PENGUJIAN
Pada bab ini akan dijelaskan tentang proses pengimplementasian K-Means Clustering dan VIKOR pada sistem, sesuai perancangan sistem yang telah dibahas pada Bab 3 serta melakukan pengujian sistem yang telah dibangun.
4.1. Implementasi Sistem
Pada tahap implementasi sistem, K-Means dan VIKOR akan diimplementasikan ke dalam sistem dengan menggunakan bahasa pemrograman Java sesuai perancangan yang telah dilakukan.
4.1.1 Spesifikasi Perangkat Keras dan Lunak yang Digunakan
Adapun spesifikasi perangkat keras dan lunak yang digunakan untuk membangun sistem ini adalah sebagai berikut:
1. Processor Intel® Core™ i3-4030U CPU 1.90GHz.
2. Memory (RAM): 4.00 GB.
3. Kapasitas hardisk 1 TB.
4. Sistem Operasi yang digunakan adalah Microsoft Windows 10 Pro.
5. NetBeans IDE 8.2 6. Software Weka Explorer
4.1.2 Implementasi coding program
Adapun implementasi dari coding program yang telah dibuat pada sistem ini adalah:
4.1.2.1 Main.java
Halaman Main.java merupakan halaman java yang berfungsi untuk menampung halaman- halaman lainnya.
Gambar 4.1. Coding Main.java 4.1.2.2 Const.java
Halaman Const.java merupakan halaman java yang berfungsi untuk meletakkan algoritme menghitung jarak Euclidian.
Gambar 4.2. Coding Const.java