IDENTIFIKASI SUARA MANUSIA BERDASARKAN JENIS
KELAMIN MENGGUNAKAN EKSTRAKSI FITUR SHORT TIME
FOURIER TRANSFORM
Joseph Masarani Tandiallo 1) Susijanto Tri Rasmana2) Ira Puspasari3)
Program Studi/Jurusan Sistem Komputer Institut Bisnis dan Informatika Stikom Surabaya
Jl. Raya Kedung Baruk 98 Surabaya, 60298
Email: 1) [email protected]., 2) [email protected], 3) [email protected]
Abstract: Human voice is one of the many kind of signals. Technology development these days has made a tools or computer able to identify human voice. one of the calculation method that commonly used to analyze the signal is Fourier Transform. Short Time Fourier Transform (STFT), is a development from the Fourier transform, which adding the window function, so the signal can be represented in time domain and frequency domain. In this research, STFT method is used to extract features in human voice such as amplitude/magnitude, frequency and time. These features will be trained, and then will be tested to identify the gender/sex using one of neural network model, backpropagation. The result of this research is system has able to identify 6 voices from 7 male voices with 86% successful percentage, and also able to identify 6 out of 7 female voices with 86% successful percentage.
Keywords: Short Time Fourier Transform, Backpropagation, Voice Recognition, Suara Manusia,
Neural-Network, Matlab
Suara adalah suatu alat komunikasi paling utama yang dimiliki oleh manusia. Dengan suara, manusia dapat berkomunikasi dengan manusia lainnya. Melalui suara, manusia juga dapat melakukan banyak hal. Suara manusia pun dapat berkembang atau berubah seiring pertumbuhan usia. Suara manusia satu dengan manusia lainnya berbeda-beda intonasi dan nadanya, maka melalui suara dapat diketahui usia maupun jenis kelamin seseorang.
Suara yang diucapkan manusia berbentuk gelombang sinyal. Oleh karena berbentuk sinyal, maka suara tersebut dapat diolah secara digital, dan juga sering digunakan pada dunia teknologi maupun dunia hiburan. Seperti merekam suara bernyanyi, merekam pidato, atau dapat digunakan untuk membuat aplikasi pengenal suara.
LANDASAN TEORI
Short Time Fourier Transform
Salah satu metode yang digunakan untuk mengolah sinyal suara adalah short time fourier
transform (STFT) yang juga digunakan dalam
penelitan ini. Menurut Tulus Hayadi (2013), STFT merupakan metode transformasi yang
mengembangkan metode Fourier Transform dengan kelebihan pada kemampuan untuk mentransformasi non-stationary signal. Adapun ide dibalik metode ini adalah membuat
non-stationary signal menjadi suatu representasi stationary sinyal dengan memasukkan suatu window function. Dalam hal ini, sinyal yang ada
dibagi menjadi beberapa segmen dimana segmen yang didapatkan, diasumsikan terdiri dari
stationary signal.
Adapun rumus yang digunakan dapat dilihat pada persamaan :
(1) Keterangan: [n]= sinyal masukan 𝑛 = waktu w [𝑛] = windows 𝜔 = kecepatan sudut (2πƒ) 𝑚 = panjang windows
JCONES Vol. 5, No. 1 (2016) 177-183
Journal of Control and Network Systems
Dari rumus di atas, dapat diketahui bahwa x[n], merupakan sinyal masukan dalam domain waktu, dan STFT adalah sinyal dengan domain waktu dan frekuensi sehingga akan merepresentasikan sinyal dalam waktu-frekuensi. Dari rumus di atas, w[n] adalah suatu fungsi window. Penelitian ini menggunakan fungsi window Hann dengan rumus: (2)
Keterangan: 𝑛 = waktu
N = panjang windows
Hann window atau juga disebut jendela kosinus
yang ditinggikan biasanya dipakai sebagai fungsi
window dalam pemrosesan sinyal digital untuk
menjalankan transformasi fourier dimana ujung dari kosinus menyentuh nilai nol, sehingga
side-lobe berada pada 18 dB per oktaf.. Adapun
keunggulan dari hann window adalah sangat rendahnya artifak distorsi atau aliasing dan lebarnya main-lobe.
Permasalahan yang muncul di sini adalah bahwa STFT menggunakan kernel window pada suatu interval waktu tertentu. Berbeda dengan
Fourier Transform, sehingga tidak ada permasalahan dalam hal resolusi frekuensi. Dari ulasan yang singkat ini dapat diambil kesimpulan seperti ditunjukkan pada gambar 1:
• Window sempit (gambar 1, kiri): mempunyai resolusi waktu yang bagus, tetapi resolusi frekuensi yang tidak bagus
• Window lebar (gambar 1, kanan): mempunyai resolusi frekuensi yang bagus, tetapi resolusi waktu yang tidak bagus
Sumber: Tulus Hayadi, 2013 Gambar 1. Window sempit (kiri) dan Window
lebar (kanan) Backpropagation
Agar sebuah sistem dapat mengenali suatu jenis atau pola tertentu, maka digunakan metode jaringan saraf tiruan (JST). Salah satu metode JST yang sering dipakai adalah perambatan galat-mundur atau backpropagation. Backpropagation
menurut Kiki (2004) adalah sebuah metode sistematik untuk pelatihan multilayer jaringan saraf tiruan. Metode ini memiliki dasar matematis yang kuat, obyektif dan algoritma ini mendapatkan bentuk persamaan dan nilai koefisien dalam formula dengan meminimalkan jumlah kuadrat galat error melalui model yang dikembangkan (training set).
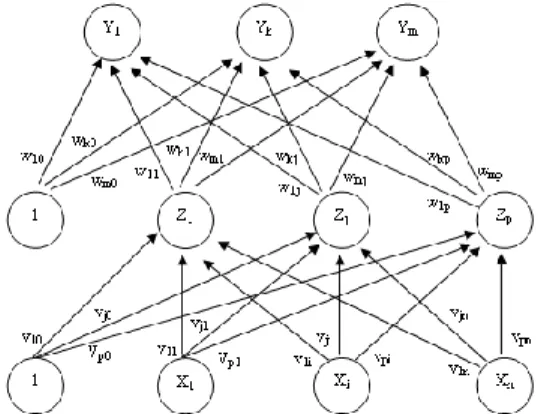
Backpropagation menurut Wirda Ayu
Utari (2010), memiliki beberapa unit yang ada dalam satu atau lebih layar tersembunyi. Gambar 2 adalah arsitektur backpropagation dengan n buah masukan (ditambah sebuah bias), sebuah layar tersembunyi yang terdiri dari p unit (ditambah sebuah bias), serta m buah keluaran.
Gambar 2. Arsitektur Model Backpropagation Pada gambar 2, Vji merupakan bobot garis dari
unit masukan Xi ke unit layar tersembunyi Zj (Vj0
merupakan bobot garis yang menghubungkan bias di unit masukan ke unit layar tersembunyi zj). Wkj merupakan bobot dari unit layar
tersembunyi Zj ke unit keluaran Vk (wk0
merupakan bobot dari bias di layar tersembunyi ke unit keluaran Zk).
Pada saat perambatan maju, neuron-neuron diaktifkan dengan menggunakan fungsi aktivasi yang dapat dideferensiasikan, seperti sigmoid, tansig atau purelin.
Salah satu jenis fungsi aktivasi yang dipakai adalah sigmoid biner yang memiliki range (0,1) Grafik fungsinya seperti gambar 3:
f(x)=1/(1+e-x) dengan turunan f’(x)=f(x) (1-f(x))
Adapun pelatihan standar backpropagation
menurut Jong, J.S., (2005) adalah:
- Meliputi 3 fase, maju, mundur, dan modifikasi bobot
- Fase I Propagasi maju, sinyal masukan (xi) dipropagasikan ke layar tersembunyi
menggunakan fungsi aktivasi yang ditentukan. Keluaran dari setiap unit tersembunyi (zj)
kemudian dipropagasikan maju lagi ke layar tersembunyi berikutnya menggunakan fungsi aktivasi yang ditentukan, demikian seterusnya hingga menghasilkan keluaran jaringan (yk).
Berikutnya, keluaran jaringan dibandingkan dengan target yang harus dicapai (tk). Selisih tk - yk
adalah kesalahan atau error yang terjadi. Iterasi dihentikan jika kesalahan ini lebih kecil dari batas toleransi, tetapi bila kesalahan lebih besar maka bobot setiap garis dalam jaringan akan dimodifikasi untuk mengurangi kesalahan yang terjadi
- Fase II Propagasi mundur, Berdasarkan kesalahan tk - yk, dihitung faktor δk (k=1,2,3,..,m)
yang dipakai untuk mendistribusikan kesalahan di unit yk ke semua unit hidden yang terhubung
langsung dengan yk. δk juga dipakai untuk
mengubah bobot garis yang berhubungan langsung dengan unit keluaran. Dengan cara yang sama, dihitung faktor δj di setiap unit di hidden
layer sebagai dasar perubahan bobot semua garis
yang berasal dari unit tersembunyi di layar di bawahnya. Demikian seterusnya hingga semua faktor δ di unit hidden yang berhubungan langsung dengan unit masukan dihitung
- Fase III Perubahan bobot, bobot semua garis dimodifikasi bersamaan. Perubahan bobot suatu garis didasarkan atas faktor δ neuron di layar atasnya. Sebagai contoh, perubahan bobot garis yang menuju ke layar keluaran didasarkan atas δk
yang ada di unit keluaran. Fase tersebut diulang hingga penghentian terpenuhi. Umumnya kondisi penghentian yang dipakai adalah jumlah iterasi atau kesalahan (Jong, J.S., 2005).
METODE
Blok Diagram
Tujuan dari penelitian ini adalah menganalisa sinyal suara manusia dan mengidentifikasi jenis kelamin dari suara tersebut, saat mengucapkan huruf vokal (a, e, i, o, u) dengan kondisi suara manusia sehat (tidak serak) dan suara dari manusia yang berusia 17-30 tahun. Penelitian yang dilakukan dijelaskan pada blok diagram gambar 4..
Gambar 4. Blok Diagram Penelitian
Suara Manusia
Pada blok ini, suara manusia (laki-laki dan perempuan) yang direkam adalah saat pengucapan huruf vokal (a, e, i, o, u) dan individu tersebut berusia 17-30 tahun. Kondisi pita suara manusia harus dalam keadaan sehat dan tidak serak pada saat pengucapan sehingga suara dapat terdengar dengan jelas. Huruf vokal diucapkan dengan nada datar atau tanpa nada, yaitu nada normal pada saat manusia berbicara, ini untuk memudahkan proses analisa suara tersebut. Begitu juga intonasi dan volume pengucapan huruf harus seragam dari awal perekaman sampai akhir, atau tidak boleh berubah-ubah.
Perekaman Suara
Suara direkam menggunakan smartphone berbasis Android. Supaya kualitas suara lebih baik maka smartphone dapat dikoneksikan dengan
earphone, headset, ataupun microphone yang
menggunakan 3.5mm 4-conductor TRRS phone
connector. Situasi perekaman adalah di ruangan sepi dan bebas noise untuk menghindari adanya suara-suara yang tidak diinginkan. Waktu maksimal untuk merekam suara adalah 3 detik. Hasil Rekaman
Suara yang direkam adalah saat pengucapan 5 huruf vokal (a, e, i, o, u) dimana satu huruf adalah satu file rekaman. File rekaman menggunakan format (.wav) dan sample rate 44100 Hz Mono 16-bit. Masing masing huruf direkam dengan waktu maksimal 3 detik. File tersebut kemudian diubah atau dipotong secara manual menggunakan perangkat lunak pada komputer (PC) untuk menghilangkan rekaman kosong seperti terlihat pada gambar 5.
Gambar 5. Bagian sinyal yang dipotong/dihilangkan
Terkadang pada saat rekaman, seseorang baru mulai berbicara pada waktu tertentu sehingga terdapat waktu jeda. Untuk mendapatkan sinyal yang diinginkan, maka perlu dilakukan cropping atau menghilangkan waktu jeda tersebut atau bagian sinyal yang tidak perlu (dalam hal ini suara hembusan nafas maupun noise lainnya) seperti terlihat pada gambar 5.
Panjang waktu rekaman setelah crop hanya dibatasi sampai 1 detik. Sehingga untuk satu orang memiliki 5 file berformat (.wav).
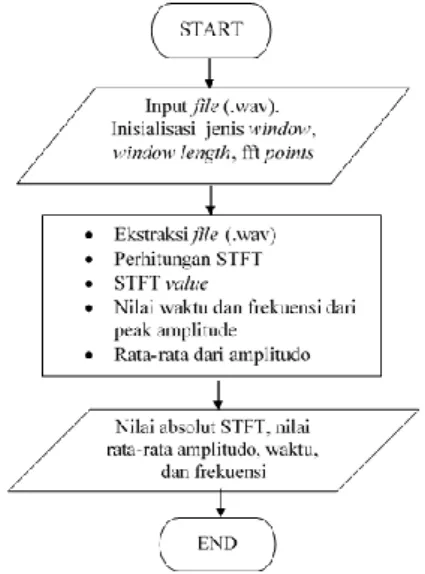
Ekstraksi Ciri
Pada bagian ini, file suara yang telah di potong dan di ubah akan dianalisa menggunakan perangkat lunak Matlab untuk mendapatkan nilai STFT. Adapun alur proses dari STFT digambarkan pada diagram alur di gambar 6.
Gambar 6. Diagram alir proses STFT Pada gambar 6, file yang diinputkan akan dibaca oleh Matlab dan di ekstraksi karakteristik dari file
(.wav). kemudian nilai karakteristik dari file tersebut di-input-kan ke dalam perhitungan STFT untuk mendapatkan nilai rata-rata STFT, nilai waktu – frekuensi saat amplitudo maksimal, dan rata-rata dari nilai amplitudo. Kemudian nilai-nilai tersebut digunakan untuk perhitungan pada jaringan saraf tiruan, maupun dapat ditampilkan sebagai spektrogram.
Pengujian Sistem
Pengujian yang dilakukan adalah menggunakan metode jaringan saraf tiruan backpropagation dengan input nilai STFT, nilai frekuensi dan waktu saat amplitude tertinggi, dan nilai rata-rata amplitudo pada sebuah sinyal suara. Neuron input berjumlah sebanyak 20 untuk satu data pelatihan, dan banyaknya responden adalah sebanyak 30 (laki-laki 15, perempuan 15) seperti terlihat pada gambar 7:
Gambar 7. Arsitektur backpropagation Pada gambar 7. Nilai X1, X2, X3, X4, adalah nilai untuk fitur suara “a” pada data responden pertama, kemudian X5, X6, X7, X8, adalah nilai fitur suara “e” pada data responden pertama demikian seterusnya untuk huruf vokal i, o, dan u. Variabel j adalah banyaknya data pelatihan pada backpropagation. Nilai awal bobot B1, B2, B3, dan nilai W pada masing masing layer adalah nilai random dari -1 sampai 1. Nilai target adalah nilai 1 sebanyak 15 (untuk input perempuan), dan nilai 0 sebanyak 15 (untuk input laki-laki).
Output dari gambar 7 adalah sebuah nilai antara 0 sampai 1. Nilai tersebut kemudian di threshold untuk membatasi data pelatihan suara perempuan atau data pelatihan suara laki-laki. Nilai yang lebih besar atau sama dengan 0.5 (>=0.5) akan dianggap sebagai perempuan, dan nilai yang lebih kecil dari 0.5 akan dianggap sebagai laki-laki (<0.5). setiap input Xnj dan bias B1 akan dikalikan dengan Wi pada layer input, dan kemudian hasilnya akan menjadi input bagi masing-masing neuron Zi, begitu juga dengan bias; dan diulang sebanyak jumlah data pelatihan
(30). Kemudian hasil inputan pada Zi akan diaktivasi dengan fungsi sigmoid biner untuk menghasilkan nilai antara 0 sampai 1.
Setelah masing-masing neuron diaktivasi, maka output dari Zi akan menjadi input ZZi. Untuk melanjutkan perhitungan ke hidden layer 2, dan output, maka output dari Zi dan juga bias B2 dikalikan pada W pada hidden layer 1 untuk dimasukkan pada hidden layer 2 (ZZi). Masukkan dari Hidden layer 1 (Zi) nantinya akan diaktivasi dahulu sebelum menjadi input ZZi. Input pada ZZi nantinya akan digunakan untuk menghitung nilai keluaran pada alur maju dengan cara mengalikan ZZi dan bias B3 dengan bobot Wi pada hidden layer 2. Hasil dari perkalian ini akan menghasilkan nilai output Y yang nilainya akan diaktivasi untuk perhitungan alur mundur.
Setelah menghasilkan keluaran Y yang telah diaktivasi, maka akan dicari selisih (error) dari target awal dengan Y, dan kemudian menghitung koreksi bobot dan bobot bias dan mengubah bobot garis yang berhubungan langsung dengan unit keluaran. Dengan cara yang sama, dihitung faktor error di setiap unit di hidden layer sebagai dasar perubahan bobot semua garis yang berasal dari unit tersembunyi di layer di bawahnya. Demikian seterusnya hingga semua faktor error di unit hidden yang berhubungan langsung dengan unit masukan dihitung. Umumnya kondisi penghentian yang dipakai adalah jumlah iterasi atau kesalahan. Toleransi kesalahan yang digunakan di penelitian ini adalah 0.01.
Nilai learning rate (α) adalah adalah laju pembelajaran, semakin besar learning rate akan berpengaruh pada semakin besarnya langkah pembelajaran. Sehingga dalam penelitian ini, learning rate yang digunakan adalah 0.1
HASIL DAN PEMBAHASAN
Data rekaman suara akan diinputkan ke dalam
Matlab untuk kemudian di ekstraksi ciri-cirinya.
Yaitu nilai STFT, nilai waktu dan frekuensi saat amplitudo terbesar / tertinggi, dan nilai rata-rata amplitudo pada satu file. Data-data tersebut dinormalisasi terlebih dahulu sebelum dilakukan pengujian.
Tabel 1 dan 2 adalah hasil nilai ekstraksi STFT, yang diambil dari 1 responden laki-laki dan perempuan.
Tabel 1. Hasil Ekstraksi Ciri STFT dari satu responden laki-laki Huruf Vokal STFT Value Amplitudo tertinggi (dB) Saat amplitudo tertinggi Time (s) Frequency (Hz) A 193.01 -8.4734 0.255 678.295 E 211.73 -7.6694 0.116 882.861 I 152.85 -10.4998 0.290 678.295 O 195.34 -8.3693 0.185 732.128 U 142.95 -11.0811 0.116 785.961
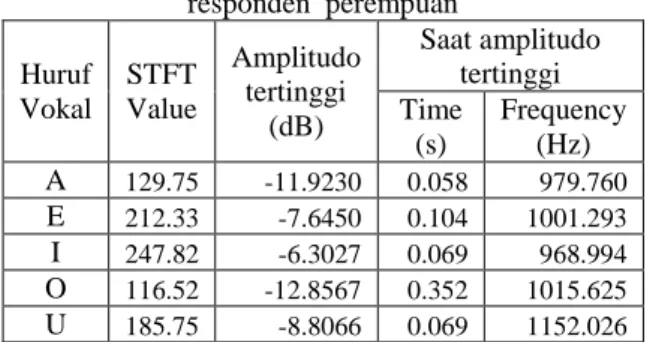
Tabel 2. Hasil Ekstraksi Ciri STFT dari satu responden perempuan Huruf Vokal STFT Value Amplitudo tertinggi (dB) Saat amplitudo tertinggi Time (s) Frequency (Hz) A 129.75 -11.9230 0.058 979.760 E 212.33 -7.6450 0.104 1001.293 I 247.82 -6.3027 0.069 968.994 O 116.52 -12.8567 0.352 1015.625 U 185.75 -8.8066 0.069 1152.026
Pada tabel 1 dan 2 dapat dilihat hasil ekstraksi fitur suara menggunakan STFT. Terdapat nilai STFT value saat amplitudo tertinggi, kemudian nilai amplitudo tertinggi dalam desibel, dan nilai waktu dan frekuensi saat amplitudo tertinggi. Dapat dilihat bahwa nilai-nilai tersebut tidak seragam, sehingga tidak dapat dijadikan masukan untuk backprogagation. Cara untuk menseragamkan nilai tersebut adalah menormalisasikan menjadi sebuah bilangan antara 0 sampai 1 dengan cara membagi bilangan tersebut dengan bilangan terbesarnya.
Adapun nilai terbesar dari hasil normalisasi selalu menunjukkan angka 1, dan nilai terkecil adalah nilai 0, hal ini dikarenakan data dinormalisasi menjadi nilai antara 0 sampai 1. Dalam hal ini, penggunaan nilai maksimal atau nilai terbesar tidak berlaku untuk nilai STFT dan nilai amplitudo, karena pada perhitungan sebelumnya nilai yang digunakan adalah nilai terbesar dari matriks STFT, dan nilai terbesar dari nilai amplitudo. Sehingga untuk alternatifnya adalah merata-rata nilai yang sudah dinormalisasi untuk mendapatkan nilai yang berbeda setiap rekaman sinyal suara.
Hasil normalisasi tabel 1 dan 2 ditunjukkan pada tabel 3 dan 4
Tabel 3. Hasil Ekstraksi Ciri STFT dari satu responden laki-laki Huruf Vokal STFT Value Average amplitude Saat amplitudo tertinggi Time Frequency A 0.0061 0.4819 0.2985 0.0308 E 0.0074 0.5181 0.6000 0.0205 I 0.0068 0.5519 0.6324 0.0127 O 0.0042 0.4419 0.5541 0.0210 U 0.0035 0.4521 0.6290 0.0146
Tabel 4. Hasil Ekstraksi Ciri STFT dari satu responden perempuan Huruf Vokal STFT Value Average amplitude Saat amplitudo tertinggi Time Frequency A 0.0068 0.5473 0.2857 0.0522 E 0.0075 0.5562 0.4872 0.0313 I 0.0084 0.5143 0.4286 0.1416 O 0.0043 0.4676 0.3077 0.0317 U 0.0045 0.5172 0.4889 0.0327
Data pada tabel 3 dan 4 sudah seragam atau tidak terdapat nilai yang selisihnya terlalu besar dengan nilai yang lainnya. Data tersebut kemudian dapat ditampilkan kedalam bentuk spektrogram seperti dibawah berikut
Gambar 7. Spektrogram huruf “a” pada salah seorang responden laki-laki.
Gambar 8. Spektrogram huruf “a” pada salah seorang responden perempuan.
Setelah didapat nilai-nilai STFT tersebut, kemudian akan dilakukan pengujian dengan
backpropagation, dengan jumlah neuron input
sebanyak 20, yaitu banyaknya fitur suara pada kelima huruf vokal, dengan nilai target adalah 0 untuk laki-laki dan 1 untuk perempuan. Hasil dari pengujian data yang digunakan sebagai training adalah sebagai berikut:
Gambar 9. Grafik error pada setiap iterasi Pada gambar 9, dapat terlihat bahwa sistem akan berusaha meminimalkan nilai mean square error yang dihasilkan pada setiap iterasi. Error sudah mencapai dibawah 0.1 saat iterasi ke 1000 dan seterusnya. Saat error sudah sama dengan nilai threshold, dalam hal ini dibatasi sampai 0.01, atau jumlah iterasi sudah terpenuhi, maka bobot terakhir yang dipakai untuk pelatihan akan disimpan kedalam file (.mat) untuk nantinya akan digunakan dalam pengujian.
Tabel 5 adalah hasil persentase keberhasilan pengenalan 30 data training dimana n adalah banyak data training, dan z adalah data training yang berhasil dikenali, dengan nilai MSE = 0.0107, dengan iterasi sebanyak 10000.
Tabel 5. Persentase keberhasilan pengenalan pada data training
Jenis kelamin n z error (%)
Laki-laki 15 15 0 100%
Perempuan 15 15 0 100%
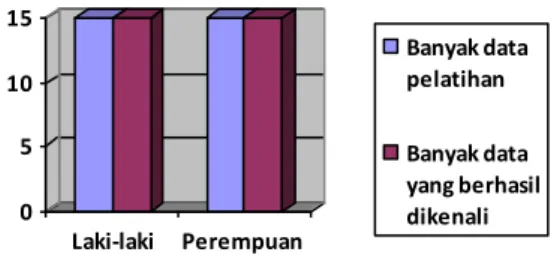
0 5 10 15 Laki-laki Perempuan Banyak data pelatihan Banyak data yang berhasil dikenali
Gambar 10. Grafik keberhasilan pengenalan pada data training
Saat proses pengujian atau identifikasi, sistem sudah dapat mengenali data yang dilatihkan dengan baik dengan persentase keberhasilan total 100% seperti ditunjukkan pada table 5 dan gambar 10.
Dengan nilai bobot optimal yang sudah tersimpan tadi, maka akan diuji sebuah data baru dengan harapannya, data tersebut dapat langsung diidentifikasi jenis kelaminnya. Perlu diketahui bahwa pada pengujian, algoritma backpropagation cukup hanya dilakukan proses feed forward, sehingga nilai yang dikeluarkan langsung diidentifikasi.
Saat pengujian pada data baru, sistem juga dapat mengidentifikasi suara laki-laki dan perempuan, namun terjadi kesalahan pada masing masing suara seperti terlihat pada tabel 6. Hal ini dapat terjadi karena ada kemiripan suara laki-laki pada perempuan saat perekaman suara, sehingga akan menghasilkan fitur-fitur suara hampir sama dengan laki-laki, maupun kemiripan suara perempuan pada suara laki-laki. Hal ini juga dapat dipengaruhi dari kurang banyaknya data pelatihan, sehingga untuk bisa mengenali, sistem perlu banyak mengenali banyak data untuk memahami berbagai macam pola. Dari tabel 4. dapat dibuat dalam bentuk grafik seperti pada gambar 11
Tabel 6. Persentase keberhasilan pengenalan pada data baru
Jenis kelamin n z error (%)
Laki-laki 7 6 1 86%
Perempuan 7 6 1 86%
Jumlah persentase total 86%
5.5 6 6.5 7
Laki-laki Perempuan
Banyak data baru Berhasil dikenali
Gambar 11. Grafik keberhasilan pengenalan pada data baru
Gambar 11. dan tabel 6. menunjukkan bahwa presentase pengujian 14 data baru yang belum pernah dilatih, yaitu sebanyak 7 data laki-laki dan 7 data perempuan. Terjadi kesalahan pengenalan satu data training pada masing-masing data uji laki-laki dan perempuan, sehingga yang berhasil dikenali adalah 6 data laki-laki dan 6 data perempuan dengan tingkat keberhasilan masing-masing adalah 86%.
SIMPULAN
Berdasarkan penelitian diatas, dapat diambil kesimpulan sebagai berikut:
1. Penelitian ini berhasil mengekstraksi fitur-fitur pada suara manusia saat mengucapkan huruf vokal dengan menggunakan metode short time
fourier transform.
2. Dari hasil identifikasi yang telah dilakukan, persentase keberhasilan pengenalan data suara pada laki-laki adalah sebesar 86% dan pada perempuan 86%.
DAFTAR PUSTAKA
Hayadi, Tulus., Suprapto, Yoyon K., Sumpeno, Surya. 2012. Estimasi Sinyal Gamelan
Menggunakan Kalman Filter untuk transkripsi. Jurusan Teknik Elektro FTI –
ITS.
Jong, J.S., 2005. Jaringan Syaraf Tiruan dan
Pemrogramannya Menggunakan Matlab.
Yogyakarta, Andi
Kiki., Kusumadewi, Sri. 2004. Analisis Jaringan
Saraf Tiruan dengan Metode Backpropagation Untuk Mendeteksi Gangguan Psikologi. Universitas Islam
Indonesia.
Utari, Wirda Ayu. 2010. Pengenalan Pola Dengan
Menggunakan MetodeBackpropagation Menggunakan Matlab. Universitas Gunadarma.