2.1 Kamus
Kamus merupakan buku rujukan yang berisi penjelasan terkait dengan makna
kata-kata. Kamus berfungsi untuk membantu seseorang mengenal perkataan baru. Selain
menerangkan makna kata, kamus juga mungkin mempunyai pedoman sebutan,
asal-usul(etimologi) suatu perkataan dan juga contoh penggunaan bagi kata tersebut.
Kamus disusun sesuai dengan abjad dari A-Z dengan tujuan memudahkan pengguna
kamus dalam mencari istilah yang diinginkannya dengan cepat dan mudah.
Berdasarkan penggunaan bahasa, kamus dibagi menjadi beberapa jenis (Pusat
Bahasa Departemen Pendidikan Nasional, 2002), yaitu :
1. Kamus Ekabahasa
Pada kamus ini, kata-kata yang dijelaskan dengan penjelasannya menggunakan
bahasa yang sama. Perbedaan jelas yang dimiliki kamus ini dengan kamus
dwibahasa adalah karena kamus ini disusun berdasarkan pembuktian data
korpus yaitu bermaksud untuk memberikan definisi atas kata-kata berdasarkan
makna kata yang diberikan dalam penggunaan kalimat yang mengandung
kata-kata tersebut.
Contoh kamus ekabahasa ini ialah Kamus Besar Bahasa Indonesia.
2. Kamus Dwibahasa
Dapat dilihat dari namanya, kamus ini menggunakan dua bahasa pada kata
masukan dan memberikan persamaan kata dari kata yang berkaitan dengan
menggunakan bahasa lain.
Contohnya adalah Kamus Inggris-Indonesia.
3. Kamus Aneka Bahasa
Selain itu terdapat pula jenis Kamus Khusus, yaitu kamus yang merujuk kepada
kamus yang mempunyai fungsi khusus (Pusat Bahasa Departemen Pendidikan
Nasional, 2002), contohnya :
1. Kamus Istilah
Kamus ini berisi istilah-istilah khusus untuk suatu bidang tertentu. Fungsinya
adalah untuk kegunaan ilmiah.
2. Kamus Etimologi
Kamus etimologi ini merupakan kamus yang menerangkan asal usul suatu
perkataan dan maksud asalnya.
3. Kamus Tesaurus
Kamus tesaurus menerangkan maksud suatu perkataan dengan memberikan
kata searti atau sinonim dan juga kata yang berlawanan arti atau antonim.
Kamus ini digunakan para penulis untuk meragamkan penggunaan diksi.
4. Kamus Peribahasa/Simpulan Bahasa
Kamus ini menerangkan maksud sesuatu peribahasa/simpulan bahasa. Kamus
ini digunakan sebagai rujukan dan pada umumnya kamus ini dibaca dengan
tujuan keindahan.
5. Kamus Kata Nama Khas
Kamus ini hanya menyimpan kata nama khas seperti nama tempat, nama
tokoh, dan juga nama bagi instusi. Biasanya kamus ini digunakan untuk
menyediakan rujukan bagi nama-nama ini.
6. Kamus Terjemahan
Kamus ini menampilkan kata searti dalam bahasa asing untuk satu bahasa
sasaran. Kegunaannya adalah untuk membantu para penerjemah
7. Kamus Kolokasi
Kamus kolokasi merupakan kamus yang menerangkan tentang padanan kata, contohnya kata ‘terdiri’ yang selalu berpadanan dengan ‘dari’ atau ‘atas’.
Secara fisik, kamus terbagi menjadi dua jenis yaitu kamus yang berbentuk
buku dan kamus elektronik(digital) (Nurhapipah, 2011). Kamus berbentuk buku
terdiri dari puluhan bahkan ratusan lembar halaman kata. Berbeda dengan kamus buku
sebuah fasilitas yang membantu pengguna mencari kata dengan cara mengetikkan kata
yang diinginkan pada kolom pencarian. Penggunaan kamus elektronik atau kamus
digital ini lebih efisien dalam hal waktu dibandingkan dengan kamus buku.
2.2 Fitur atau Layanan Autocomplete
Fitur autocomplete atau word completion merupakan fasilitas yang disediakan oleh
berbagai web browser, email-programs, search engine interface, source code editors,
database query tools, word processor, dan command line interpreters. Autocomplete
juga tersedia untuk atau sudah terintegrasi di dalam text editor. Autocomplete
melakukan prediksi terhadap sebuah kata atau frasa yang pengguna ingin tulis tanpa
harus menulis keseluruhan kata atau frasa secara lengkap (Kusuma, 2012).
Autocomplete digunakan untuk mempermudah masalah pada pengetikan,
misalnya apabila pengguna tidak dapat mengeja suatu kata dengan baik atau pengguna
bingung dan sering sulit mengingat istilah yang tepat. Autocomplete dapat membantu
untuk melengkapi kata yang diketikkan oleh pengguna menjadi kata yang mungkin
dimaksud oleh pengguna. Dengan begitu, penggunaan autocomplete ini dapat
mempersingkat waktu pengguna pada pengetikan kata tersebut (Morville & Callender,
2010).
Autocomplete bekerja ketika pengguna menulis huruf pertama atau beberapa
huruf/karakter dari sebuah kata. Program yang melakukan prediksi akan mencari
kemungkinan kata sebagai pilihan. Jika kata yang dimaksud ada dalam pilihan itu,
maka pengguna dapat memilih itu (Kusuma, 2012).
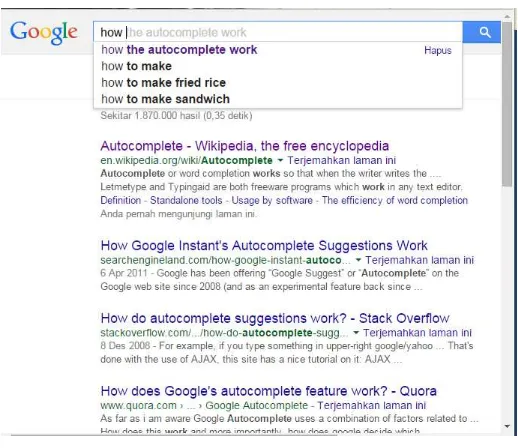
Fitur autocomplete dapat dilihat pada Facebook Search ataupun search
suggestion pada Google Search, Seacrh engine pada media sosial, pada aplikasi
katalog perpustakaan, kamus dan aplikasi pencarian lainnya. Fitur autocomplete ini
Gambar 2.1 Autocomplete pada Google Search
2.3 Algoritma Exact String Matching
Pencocokan string merupakan bagian terpenting dari sebuah proses pencarian string
dalam sebuah dokumen. Pencocokan string melakukan pencarian untuk semua
kemunculan string pendek yang disebut pattern terhadap string yang lebih panjang
atau disebut text. Hasil dari pencarian string dalam dokumen tergantung pada teknik
atau cara pencocokan string yang digunakan.
Exact string matching, yaitu pencocokan sebuah string secara sangat tepat
dengan susunan karakter dalam string yang dicocokkan baik dalam jumlah maupun
urutan karakter dalam stringnya.
Pada proses pencocokan string, digunakan sebuah window yang akan
bergeser di text. Window itu memiliki panjang yang sama dengan panjang pattern.
Pada awal proses pencocokan string, window diletakkan pada ujung kiri text, lalu
karakter-karakter pada window dibandingkan dengan karakter-karakter pada pattern,
kemudian window akan digeser ke kanan di text dengan jarak tertentu, dan pergeseran
tersebut baru akan berhenti bila window tersebut sampai pada ujung kanan text atau
sampai pattern ditemukan cocok. (Charras & Lecroq, 2001).
Algoritma brute force merupakan algoritma paling alami untuk pencocokan
string. Algoritma brute force menemukan semua kemunculan karakter dari pattern y
pengembangan dari algoritma brute force dapat diklasifikasikan berdasarkan pada
urutan pada saat algortima tersebut melakukan pencocokan antara karakter di pattern
dan karakter di text pada setiap tahap pencocokannya (Charras & Lecroq, 2001).
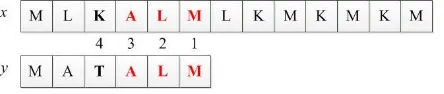
Kategori pertama, arah yang paling alami dalam pencocokan string yaitu dari
kiri ke kanan. Algoritma kategori ini melakukan pencocokan string dimulai dari
karakter paling kiri pattern seperti yang ditunjukkan pada gambar 2.2. Beberapa
algoritma yang termasuk dalam kategori ini adalah algoritma brute force, algoritma
Karb-Rabin, dan algoritma Knuth-Morris-Pratt.
Gambar 2.2 Pencocokan dari karakter paling kiri ke karakter paling kanan pattern(left to right)
Kategori kedua, algoritma yang melakukan pencocokan dari kanan ke kiri
karakter pada pattern seperti yang dapat dilihat pada gambar 2.3. Algoritma yang
termasuk dalam kategori ini umumnya dikatakan sebagai algoritma yang
menghasilkan hasil terbaik pada praktekmya, yaitu algoritma Boyer-Moore.
Gambar 2.3 Pencocokan dari karakter paling kanan ke karakter paling kiri pattern(right to left)
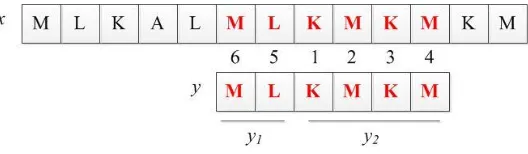
Kategori ketiga yaitu pencocokan dari dua arah yang telah ditentukan oleh
tiap algoritma tertentu. Salah satunya seperti yang diterapkan oleh Galil-Seiferas dan
Crochemore-Perrin dalam algoritma Two Way, mereka membagi pattern y menjadi
dua bagian yaitu y = y1y2. Seperti yang dapat kita lihat pada gambar 2.4, pertama kali,
pencarian terjadi pada y2 yang dilakukan dari karakter paling kiri ke kanan, apabila
text selanjutnya pada pencarian kedua algoritma akan memeriksa pada y1 yang
dilakukan dari kanan ke kiri seperti yang ditunjukkan pada gambar 2.5.
Gambar 2.4 Pencocokan pada patterny2 dimulai dari karakter paling kiri
Gambar 2.5 Pencocokan pada pattern y1 dimulai dari karakter paling kanan
2.4 Algoritma Boyer-Moore
Algoritma Boyer-Moore dipublikasikan pada tahun 1977 oleh Robert S. Boyer dan J.
Strother Moore pada tahun 1997. Algoritma Boyer-Moore dianggap sebagai algoritma
pencocokan string yang paling efisien pada aplikasi umum, karena sering
diimplementasikan pada text editors untuk perintah “search” dan “subtitute” (Charras & Lecroq, 2001).
Algoritma ini kemudian dikembangkan menjadi beberapa varian, diantaranya
Turbo Boyer-Moore, Tuned Boyer-Moore, Hoorspol dan Zhu-Takaoka. Dan dari hasil
penilitan yang dilakukan oleh Sagita (2013), disimpulkan bahwa algoritma
Boyer-Moore memiliki waktu pencarian tercepat dari varian Boyer-Boyer-Moore lainnya. Dimana
algoritma Turbo Boyer-Moore merupakan algoritma tercepat kedua dan yang paling
lambat adalah algoritma Tuned Boyer-Moore.
Algoritma Boyer-Moore melakukan pencocokan dimulai dari karakter yang
paling kanan hingga karakter paling kiri pattern. Jika terjadi ketidakcocokan antara
karakter pada pattern akan diperiksa satu persatu untuk mendeteksi apakah ada
karakter pada text tersebut yang sama dengan karakter pada pattern. Apabila terjadi
kecocokan, maka pattern akan digeser sedemikian rupa sehingga posisi karakter yang
sama antara pattern dan text terletak sejajar.
Secara sistematis, langkah-langkah yang dilakukan algoritma Boyer-Moore
pada saat mencocokkan string adalah sebagai berikut (Soleh, 2011) :
a. Algoritma mulai mencocokkan pattern pada awal text.
b. Algoritma ini akan mencocokkan karakter per karakter dari kanan ke kiri
pattern dengan karakter di text yang bersesuaian, sampai salah satu kondisi
berikut dipenuhi :
i. Karakter pada pattern dan pada text yang dibandingkan tidak cocok
(mismatch).
ii. Semua karakter di pattern cocok. Kemudian algoritma akan
memberitahukan penemuan di posisi ini.
c. Algoritma kemudian menggeser pattern dengan memaksimalkan nilai
pergeseran good-suffix dan pergeseran bad-character, lalu mengulangi langkah
2 sampai pattern berada diujung text.
Tabel pergeseran bad-character dan good-suffix dapat dihitung dengan
kompleksitas waktu dan ruang sebesar O(n + σ) dengan σ adalah besar ruang alfabet.
Sedangkan pada fase pencarian, algoritma ini menemukan semua kemunculan dari
pattern dengan panjang n di dalam text sepanjang m dengan waktu O(nm). Pada kasus
terburuk, algoritma ini akan melakukan 3m pencocokan karakter, namun pada
performa terbaiknya algortima ini hanya akan melakukan O(n/m) pencocokan
(Charras & Lecroq, 2001).
2.4.1 Pergeseran Bad-Character
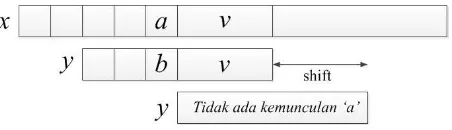
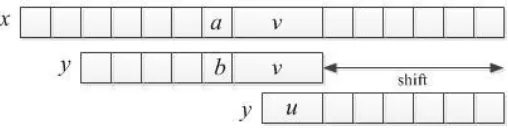
Misal, terjadi ketidakcocokan antara karakter y[i] = b pada pattern dengan karakter
x[i + j] = a pada text selama pencocokan terjadi pada posisi j. Lalu, y[i + 1 .. n– 1] = x[i + j + 1 .. j + n – 1] = v dan y[i] ≠ x[i + j]. Pergeseran bad-character terdiri dari menyejajarkan karakter x[i + j] pada text dengan kemunculan paling kanan karakter
tersebut pada pattern, proses ini dapat dilihat pada gambar 2.6. Apabila karakter a
tidak muncul pada pattern dan tidak ada kemunculan salah satu karakter pada pattern
pada pattern sejajar dengan karakter setelah x[i + j], yaitu x[i + j + 1], seperti yang
dapat dilihat pada gambar 2.7 (Charras & Lecroq, 2001).
Gambar 2.6 Pergeseran bad-character, a muncul pada y
Gambar 2.7 Pergeseran bad-character, tidak ada kemunculan a pada y
Pada tabel bad-character, setiap karakter pada pattern diberi nilai sesuai dengan
ukuran jauhnya karakter tersebut dari karakter paling kanan dari pattern dan untuk
karakter yang tidak terdapat pada pattern akan diberi nilai sejumlah karakter pada
pattern. Adapun pseudocode untuk pergeseran bad-character ini adalah sebagai
berikut :
Procedure preBmBc(
input y : array[0..n-1]of char, input n : integer,
input/output bmBc : array of integer )
Deklarasi i:integer
Algoritma
for (i=0; i<ASIZE; ++i) bmBc[i] n
2.4.2 Pergeseran Good-Suffix
Misal, terjadi ketidakcocokan antara karakter y[i] = b pada pattern dengan karakter
x[i + j] = a pada text selama pencocokan terjadi pada posisi j. Lalu, y[i + 1.. n– 1] = x[i + j + 1 .. j + n – 1] = v dan y[i] ≠ x[i + j]. Pergeseran good-suffix terdiri dari menyejajarkan potongan x[i + j + 1.. j + n– 1] = y[ i + 1..n – 1] dengan kemunculan paling kanan potongan tersebut pada y yang didahului oleh karakter yang berbeda dari
y[i], dapat dilihat pada gambar 2.8. Apabila tidak ada potongan seperti itu, pergeseran
dilakukan dengan menyejajarkan akhiran terpanjang u pada v dengan awalan dari y
yang sama dengan akhiran u tersebut, seperti pada gambar 2.9 (Charras & Lecroq,
2001).
Gambar 2.8 Pergeseran good-suffix, v muncul didahului oleh karakter c
Gambar 2.9 Pergeseran good-suffix, hanya akhiran dari v yang muncul pada y
Pada tabel pergeseran good-suffix, nilai pergeseran digunakan ketika ketidakcocokan
ditemukan berdasarkan karakter pada posisi keberapa yang menyebabkan
ketidakcocokan. Nilai dari setiap karakter yang ada pada pattern bergantung terhadap
ada atau tidaknya perulangan akhiran(suffix) v dari text pada pattern. Semakin banyak
perulangan, maka akan semakin kecil nilai pergeseran. Untuk menentukan nilai-nilai
tersebut, lebih dahulu menghitung nilai tabel suffix yang bertujuan untuk memberi
tanda adanya perulangan akhiran. Dari tabel suffix inilah tabel good-suffix akan
Pada tabel suffix, berisi nilai dari tiap karakter yang ada pada pattern yang
menunjukkan ada atau tidaknya perulangan akhiran (suffix) dan dimana posisi
perulangan tersebut sehingga ketika proses perhitungan tabel good-suffix dapat
diketahui seberapa banyak pergeseran yang akan dilakukan untuk pencocokan
selanjutnya.
Adapaun pseudocode untuk pergeseran good-suffix adalah sebagai berikut :
Procedure suffixes(
input y: array[0..n-1] of char, input n: integer,
input/output suff: array of integer )
input/output bmGs: array of integer )
Deklarasi
i, j : integer
suff : array [0..YSIZE] of integer
Algoritma
for (i=0; i < n; ++i)do
Setelah diperoleh nilai-nilai pada tabel bad-character dan tabel good-suffix,
selanjutnya algoritma Boyer-Moore akan menggunakan nilai maximum antara nilai
pergeseran bad-character dan nilai pergeseran good-suffix untuk melakukan
pergeseran window pada saat pencocokan berlangsung. Proses pencocokan string
dengan algoritma Boyer-Moore ini dapat dilihat dalam pseudocode berikut :
procedure BM(
input y: array[0..n-1] of char, input n:integer,
input x: array of[0..m-1] char, input m:integer
)
Deklarasi
i, j : integer
bmGs : array [0..YSIZE] of integer bmBc : array [0..ASIZE] of integer
Perhitungan dengan algoritma Boyer-Moore dapat dilihat pada contoh berikut ini.
Contoh :
Pattern (y) = “comp” n = 4 Text (x) = “host computer”
a. Perhitungan pergeseran bad-character
i 0 1 2 3
c c o m p *
BmBc [c] 3 2 1 0 4
Nilai pergeseran pada tabel didapat dengan perhitungan sebagai berikut :
BmBc [y[i]] = n– 1 –i BmBc [y[0]] = 4 – 1 – 0 = 3 BmBc [y[1]] = 4 – 1 – 1 = 2 BmBc [y[2]] = 4 – 1 – 2 = 1 BmBc [y[3]] = 4 – 1 – 3 = 0
Dan untuk karakter selain yang terdapat pada pattern, karakter tersebut bernilai
sejumlah karakter pattern yaitu 4.
b. Perhitungan pergeseran good suffix
Berdasarkan perhitungan sesuai pseudocode pergeserannya, didapat nilai untuk
tabel good-suffix sebagai berikut :
i 0 1 2 3
c c o m p
suff[i] 0 0 0 4 BmGs [i] 4 4 4 1
c. Pencocokan pattern dengan text
i 0 1 2 3
c c o m p *
Pencocokan 1 :
c o m p
BmBc[t] = 4
BmGs[3] = 1
Maka pergeserannya, max(1, 4) = 4
Pencocokan 2 :
c o m p
BmBc[m] = 1
BmGs[3] = 1
Maka pergeserannya, max(1, 1) = 1
Pencocokan 3 :
c o m p
Pada pencocokan ke-3, pattern ditemukan pada indeks ke-5 pada text.
2.5 Penelitian Terdahulu
Beberapa penelitian terdahulu yang berkaitan dengan autocomplete diantaranya
penelitian oleh Kusuma (2012) yang membangun fitur autocomplete pada text editor
yang menggunakan algoritma pencocokan string, yaiu algoritma brute force. Pada
penelitiannya, Kusuma (2012) memodifikasi algoritma brute force dengan mengganti
struktur data yang digunakan algoritma brute force sebelumnya. Pada penelitian h o s t c o m p u t e r
h o s t c o m p u t e r
tersebut, Kusuma (2010) menggunakan struktur data pohon/tree untuk menyimpan
reserved words, variabel, fungsi, serta daftar kata apa saja yang telah diinputkan user.
Pradhana (2012), pada penelitiannya menggunakan algoritma brute force
dalam pengecekan kata untuk menghasilkan autocorrect dan menggunakan algoritma
Boyer-Moore untuk menampilkan kata tersebut.
Sedangkan penelitian yang dilakukan oleh Primadani (2014), fitur
autocomplete dihasilkan dari perhitungan jarak levensthein distance yaitu dengan
menghitung jumlah minimum pentranformasian suatu string sumber( yang diambil
dari database) menjadi string lain yaitu sama dengan string target (yang diinput user)
yang meliputi penghapusan, penyisipan, dan penukaran. Pada penelitian ini, apabila
string sumber memiliki nilai modifikasi yang paling sedikit saat dibandingkan dengan
string sumber dianggap sebagai kata yang cocok atau paling mendekati.
Untuk keterangan lain mengenai penelitian terdahulu yang berkaitan dengan
autocomplete ini dapat dilihat pada tabel 2.1 berikut.
Tabel 2.1 Penelitian terdahulu yang berkaitan dengan autocomplete
No Nama Penelitian Penulis Keterangan
1.
Pencocokan String untuk
Fitur autocompletion pada
text editor atau integrated
Tabel 2.1 Penelitian terdahulu yang berkaitan dengan autocomplete (lanjutan)
No Nama Penelitian Penulis Keterangan
3.
Simulasi Algoritma
Levenshtein Distance untuk
Fitur Autocomplete pada
Aplikasi Katalog
Perpustakaan
Yuli Primadani
(2014)
Jika nilai jarak levenshtein
yang diperoleh terlalu besar
kemungkinan judul buku yg
dicari tidak dapat ditampilkan
Beberapa penelitian terdahulu yang menggunakan algoritma Boyer-Moore,
diantaranya penelitian oleh Minandar, et al. (2005) yang menggunakan algoritma
Boyer-Moore untuk pencocokan DNA. Pada penelitian tersebut, DNA dianggap
sebagai rangkaian string, sehingga pencocokan DNA tidak lain merupakan
pencocokan string.
Penelitian oleh Vandika & Kartawidjaja (2009), pencarian kata dilakukan
secara paralel dengan algoritma Boyer-Moore dan lingkup paralel diemulsikan dengan
menggunakan suatu perangkat lunak yang dinamakan PVM (parallel Virtual
Machine).
Soleh (2010), melakukan penelitian dengan menggunakan dua algoritma
pencocokan string yaitu algoritma KMP dan algoritma Boyer-Moore dalam
melakukan pencarian pada aplikasi Search Engine sederhana. Penggunaan dua
algoritma bertujuan untuk membandingkan algoritma mana yang melakukan
pencarian lebih cepat. Sagita & Prasetiyowati (2013) juga melakukan studi
perbandingan implementasi algoritma Boyer-Moore dan dua algortima turunannya
yaitu algoritma Turbo Boyer-Moore dan Tuned Boyer Moore dalam pencarian string.
Untuk keterangan lain mengenai penelitian terdahulu yang berkaitan dengan
Table 2.2 Penelitian terdahulu yang menggunakan Algoritma Boyer-Moore
No Nama Penelitian Penulis Keterangan
1.
yang terdiri dari satu huruf