Informasi Dokumen
- Penulis:
- Siddhartha Chatterjee
- Michal Krystyanczuk
- Sekolah: Packt Publishing
- Mata Pelajaran: Social Media Analytics
- Topik: Python Social Media Analytics
- Tipe: book
- Tahun: 2017
- Kota: Birmingham
Ringkasan Dokumen
I. Introduction to the Latest Social Media Landscape and Importance
This section sets the foundation for understanding the significance of social media in today’s digital world. It discusses the evolution of social networks and the emergence of platforms like Facebook, Twitter, and YouTube, emphasizing their impact on communication, business, and society. The chapter introduces key concepts such as the social graph, which represents the relationships between users and content, and the notion of influence within social media networks. The relevance of these concepts to data analytics is highlighted, establishing a basis for exploring social data applications in later sections.
II. Harnessing Social Data - Connecting, Capturing, and Cleaning
This section delves into the technical aspects of accessing social media data through APIs. It discusses different types of APIs, including RESTful and Stream APIs, along with their advantages and limitations. The chapter also covers authentication techniques, particularly OAuth, and provides practical examples of connecting to various platforms like Twitter, Facebook, and GitHub. Additionally, it addresses the importance of data cleaning and pre-processing, setting the stage for effective data analysis by ensuring that the data is structured and usable.
III. Uncovering Brand Activity, Popularity, and Emotions on Facebook
Focusing on Facebook, this section outlines methodologies for analyzing brand presence and consumer sentiment. It introduces the Facebook API and walks through the steps of data extraction, feature extraction, and content analysis. Techniques for detecting trends and extracting emotions using tools like the Alchemy API are also discussed. This chapter emphasizes the importance of understanding consumer interactions and sentiments, which are crucial for brands aiming to enhance their marketing strategies.
IV. Analyzing Twitter Using Sentiment Analysis and Entity Recognition
This section explores the application of sentiment analysis and entity recognition on Twitter data. It explains how to obtain Twitter API keys, extract data, and perform data cleaning. The chapter introduces sentiment analysis techniques, including customized approaches using machine learning models. By integrating named entity recognition with sentiment analysis, readers learn to derive deeper insights from Twitter conversations, which can inform brand strategies and public relations efforts.
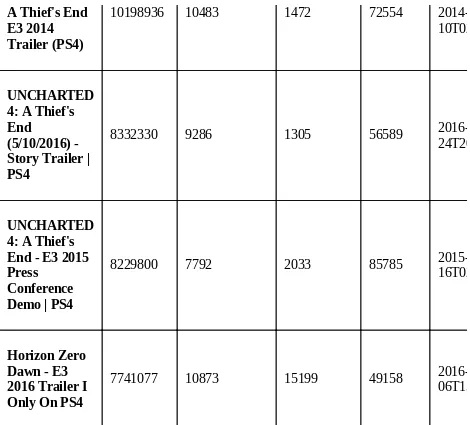
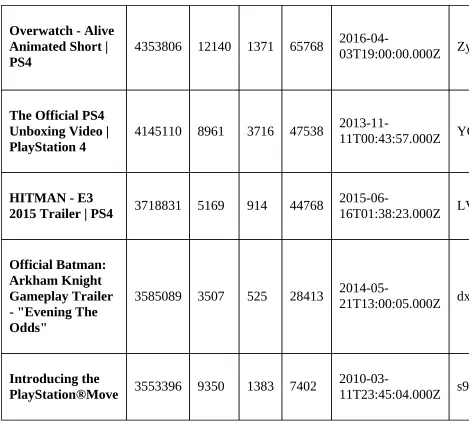
V. Campaigns and Consumer Reaction Analytics on YouTube – Structured and Unstructured
This chapter addresses the dual nature of data on YouTube, focusing on both structured and unstructured data. It details the process of obtaining YouTube API keys and extracting relevant data for analysis. The section emphasizes the analysis of consumer reactions through sentiment analysis and the timing of comments, enabling brands to gauge audience engagement and sentiment over time. This understanding is vital for optimizing marketing campaigns and content strategies on video platforms.
VI. The Next Great Technology – Trends Mining on GitHub
This section introduces GitHub as a valuable source of data for analyzing technology trends. It discusses methods for extracting data from GitHub and analyzing repositories to identify popular programming languages and technologies. By examining metrics such as forks and open issues, readers learn to uncover insights about emerging technologies and developer interests, which can inform business decisions and technology investments.
VII. Scraping and Extracting Conversational Topics on Internet Forums
This chapter covers the methodology of scraping data from online forums to extract conversational topics. It introduces the Scrapy framework and discusses the importance of forums for understanding consumer sentiments and discussions. The section emphasizes data cleaning and the application of topic modeling techniques, such as Latent Dirichlet Allocation (LDA), to analyze forum conversations. This analysis provides valuable insights into consumer behavior and preferences.
VIII. Demystifying Pinterest through Network Analysis of Users Interests
This section explores Pinterest as a unique social platform and discusses techniques for data extraction and analysis. It introduces the Pinterest API and advanced scraping methods using Selenium. The chapter emphasizes network analysis to understand user interests and relationships, enabling brands to identify influencers and trending topics. This understanding is essential for crafting targeted marketing strategies on visual platforms.
IX. Social Data Analytics at Scale – Spark and Amazon Web Services
The final chapter addresses the challenges and techniques of scaling social data analytics using distributed computing platforms like Spark and AWS. It discusses parallel computing methods and the implementation of text mining at scale. This section is crucial for data scientists looking to handle large volumes of social media data efficiently, enabling them to derive insights that can drive strategic business decisions.