5
2 BAB II
TINJAUAN PUSTAKA
Bab ini berisi dasar teori kecerdasan buatan dan sistem pakar untuk melandasi pemecahan masalah serta teori-teori sehubungan dengan teknologi yang digunakan dalam pembuatan sitem pakar ini.
2.1 State of the Art
The Analysis of Comparison of Expert System of Diagnosing Dog Disease by Certainty Factor Method and Dempster-Shafer Method (Setyarini, et al., 2013),
menyajikan perbandingan antara dua metode, Metode Certainty Factor dan Metode Dempster-Shafer untuk mengidentifikasi penyakit anjing. User diberikan lima macam pilihan untuk menjawab pertanyaan dari perhitungan pada setiap metode: tidak, sedikit yakin, cukup yakin, yakin, atau sangat yakin. Keakuratan analisis masing-masing metode diuji dengan menilai hasil setiap analisis metode yang didasarkan pada jawaban yang dimasukkan pengguna. Metode Certainty Factor memiliki perhitungan yang lebih sederhana daripada Metode Dempster-Shafer. Metode Dempster-Shafer lebih baik daripada Certainty Factor karena dalam menentukan hasil persentase keyakinan mempertimbangkan nilai dari semua variabel yang digunakan dalam kombinasi serta nilai perhitungan yang dihasilkan lebih bervariasi dan lebih akurat.
Sistem Pakar untuk Mendiagnosa Penyakit Gagal Ginjal dengan Menggunakan Metode Bayes (Rahayu, 2013), dimana aplikasi sistem pakar ini memudahkan user dalam proses melakukan konsultasi, karena dalam rekam medis rumah sakit cocok dengan perhitungan sistem. Pengembangan sistem pakar untuk mendiagnosa penyakit gagal ginjal dapat behasil dengan baik, yaitu mampu menghasilkan jawaban yang dibutuhkan oleh pengguna umum (pasien). Sistem dapat mengeluarkan hasil perhitungan valid yang sama dengan perhitungan manual, sehingga proses diagnosa penyakit gagal ginjal dapat dilakukan dengan cepat dan akurat.
African Trypanosomiasis Detection Using Dempster-Shafer Theory
(Maseleno & Hasan, 2012) menggambarkan bagaimana Teori Dempster-Shafer dapat digunakan untuk deteksi Trypanosomiasis Afrika. Dijelaskan sebelas gejala seperti gejala utama yang meliputi demam, urin berwarna merah, ruam kulit, kelumpuhan, sakit kepala, pendarahan di sekitar gigitan, nyeri sendi, pembengkakan kelenjar getah bening, gangguan tidur, meningitis, dan arthritis. Metode yang paling sederhana untuk menggunakan probabilitas untuk mengukur ketidakpastian dalam database adalah dengan melampirkan probabilitas untuk setiap anggota relasi, dan menggunakan nilai-nilai ini untuk memberikan probabilitas bahwa nilai tertentu adalah jawaban yang benar untuk query tertentu. Basis pengetahuan digunakan untuk menarik kesimpulan, itu berasal dari pengetahuan pasti. Penalaran di bawah ketidakpastian menggunakan beberapa hitungan matematika yang memberi interpretasi yang berbeda dan mendukung beberapa hipotesis.
The Development of Online Children Skin Diseases Diagnosis System
(Yusof, et al., 2013) dikembangkan berdasarkan aturan yang membantu mendiagnosa penyakit kulit pada anak-anak dan memberikan solusi pengobatan dengan cara yang lebih cepat dan nyaman melalui sistem online. Sistem ini juga membantu dalam mencegah penyakit kulit anak menjadi memburuk serta memberikan informasi perawatan yang tepat kepada orang tua ketika mereka menggunakan sistem ini. Meskipun sistem ini telah berhasil dikembangkan, masih dapat ditingkatkan dengan lebih banyak penyakit, gejala, dan gambar penyakit kulit atau untuk kelompok usia lainnya.
2.2 Sistem Pakar
Sistem pakar adalah sistem berbasis komputer yang menggunakan pengetahuan, fakta, dan teknik penalaran dalam memecahkan masalah, yang biasanya hanya dapat diselesaikan oleh seorang pakar dalam bidang tertentu (Martin & Oxman, 1988).
Secara umum, sistem pakar adalah sistem yang berusaha mengadopsi pengetahuan manusia ke komputer yang dirancang untuk memodelkan kemampuan
menyelesaikan masalah seperti layaknya seorang pakar. Sistem pakar ini memungkinkan orang awam dapat menyelesaikan masalahnya atau mencari informasi berkualitas yang sebenarnya hanya dapat diperoleh dengan bantuan para ahli di bidangnya. Sistem pakar ini juga dapat membantu aktivitas para pakar sebagai asisten yang berpengalaman dan mempunyai pengetahuan yang dibutuhkan. Sistem pakar mengkombinasikan kaidah-kaidah penarikan kesimpulan (inference rules) dengan basis pengetahuan tertentu yang diberikan oleh satu atau lebih pakar dalam bidang tertentu. Kombinasi dari kedua hal tersebut disimpan dalam komputer, yang selanjutnya digunakan dalam proses pengambilan keputusan untuk penyelesaian masalah tertentu. Sistem pakar memiki ciri-ciri sebagai berikut: 1. Terbatas pada bidang yang spesifik.
2. Dapat memberikan penalaran untuk data yang tidak lengkap atau tidak pasti. 3. Mengemukakan rangkaian alasan yang diberikannya dengan cara yang
dapat dipahami.
4. Berdasarkan rule atau kaidah tertentu.
5. Dirancang untuk dapat dikembangkan secara bertahap. 6. Output bersifat nasehat atau anjuran.
7. Output tergantung dari dialog dengan user.
8. Knowledge base dan inference engine terpisah.
Secara garis besar, banyak manfaat yang dapat diperoleh dengan mengembangkan sistem pakar, antara lain:
1. Masyarakat awam dapat memanfaatkan keahlian di dalam bidang tertentu tanpa kehadiran langsung seorang pakar.
2. Meningkatkan produktivitas kerja, yaitu bertambah efisiensi pekerjaan tertentu serta hasil solusi kerja.
3. Penghematan waktu dalam menyelesaikan masalah yang kompleks. 4. Memberikan penyederhanaan solusi untuk kasus yang kompleks dan
berulang-ulang.
Sistem pakar tidak hanya memiliki keuntungan, namun juga memiliki beberapa kelemahan, antara lain:
1. Daya kerja dan produktivitas manusia menjadi berkurang karena semuanya dilakukan secara otomatis oleh sistem.
2. Pengembangan perangkat lunak sistem pakar lebih sulit dibandingkan dengan sistem konvensional.
3. Sistem pakar tidak 100% bernilai benar. Modul Sistem Pakar
Menurut Staugaard (1987) suatu sistem pakar disusun oleh tiga modul utama yaitu:
1. Modul Penerimaan Pengetahuan (Knowledge Acquisition Mode)
Sistem berada pada modul ini, pada saat ia menerima pengetahuan dari pakar. Proses mengumpulkan pengetahuan yang digunakan untuk pengembangan sistem, dilakukan dengan bantuan knowledge engineer. Peran knowledge engineer adalah sebagai penghubung antara suatu sistem pakar dengan pakarnya.
2. Modul Konsultasi (Consultation Mode)
Sistem yang berada pada posisi memberikan jawaban atas permasalahan yang diajukan oleh user, sistem pakar berada dalam modul konsultasi. User berinteraksi dengan sistem dengan menjawab pertanyaan-pertanyaan yang diajukan oleh sistem.
3. Modul Penjelasan (Explanation Mode)
Modul ini menjelaskan proses pengambilan keputusan oleh sistem (bagaimana suatu keputusan dapat diperoleh).
Komponen Utama Sistem Pakar
Sistem pakar terdiri dari 2 bagian pokok, yaitu lingkungan pengembangan
(development environment) dan lingkungan konsultasi (consultation environment).
Lingkungan pengembangan digunakan sebagai pembangun sistem pakar baik dari segi pembangun komponen maupun basis pengetahuan. Lingkungan konsultasi digunakan oleh seseorang yang bukan ahli untuk berkonsultasi. Secara umum komponen sistem pakar adalah sebagai berikut (Giarratano & Riley, 1993):
1. Basis Pengetahuan (Knowledge Base)
Basis pengetahuan berisi pengetahuan-pengetahuan dalam penyelesaian masalah. Basis pengetahuan ini juga berisi tentang aturan-aturan yang berkaitan dengan pengetahuan tersebut. Pengetahuan direpresentasikan menjadi basis pengetahuan dan basis aturan selanjutnya dikodekan, dikumpulkan, dan dibentuk secara sistematis. Ada beberapa cara merepresentasikan data menjadi basis pengetahuan yaitu dalam bentuk atribut, aturan-aturan, jaringan semanik, frame, dan logika. Ada dua elemen utama basis pengetahuan yaitu:
a. Fakta, merupakan situasi (teori) informasi yang terkait.
b. Heuristic khusus atau rule, yang secara langsung menggunakan pengetahuan untuk menyelesaikan masalah tertentu.
Pengetahuan direpresentasikan dengan menggunakan aturan berbentuk
IF-THEN pada penalaran berbasis aturan. Bentuk ini digunakan apabila memiliki
sejumlah pengetahuan pakar pada suatu permasalahan tertentu dan si pakar dapat menyelesaikan masalah tersebut secara berurutan. Pengetahuan baru yang ditemukan harus di-input-kan atau diedit, maka keseluruhan program harus diubah dan memerlukan banyak waktu untuk penelusuran kembali listing program. Maka pembuatan sistem pakar dengan beberapa knowledge base perlu memperhatikan bagaimana penyimpanan yang tepat sehingga tabel data untuk menyimpan
knowledge tersebut dapat terorganisasi dengan baik bagi beberapa knowledge.
2. Mesin Inferensi (Inference Engine)
Inferensi merupakan proses yang digunakan sistem pakar untuk menghasilkan informasi baru dari informasi yang telah diketahui. Proses inferensi dilakukan dalam suatu modul yang disebut dengan Mesin Inferensi (Inference
Engine). Fungsi Inferensi Engine adalah sebagai berikut:
a. Memberikan pertanyaan kepada user.
b. Menambah jawaban pada working memory (balckboard). c. Menambahkan fakta baru dari suatu rule (hasil inferensi). d. Menambahkan fakta baru tersebut pada working memory. e. Mencocokkan fakta pada working memory dengan rule.
Secara umum dalam inferensi penalaran maju (forward chaining) aturan (rule) diuji satu persatu dalam urutan tertentu. Saat tiap aturan diuji, sistem mengevaluasi apakah kondisi benar atau salah, penalaran dimulai dari fakta terlebih dahulu untuk menguji hipotesis. Forward chaining adalah data driven karena inferensi dimulai dengan informasi yang tersedia dan kemudian konklusi diperoleh.
Metode penalaran atau mesin inferensi sistem pakar diimplementasikan dalam bentuk baris-baris coding dalam bahasa pemrograman tertentu. Maka sudah dapat diperkirakan bahwa sistem pakar dengan beberapa knowledge hanya dapat diisi beberapa kepakaran yang memiliki teknik inferensi yang sama dan memiliki struktur knowledge base yang sama.
3. Working Memory
Working memory merupakan bagian dari sistem pakar yang digunakan
untuk merekam kejadian yang sedang berlangsung termasuk keputusan sementara. Bagian ini berisi fakta-fakta masalah yang ditemukan dalam suatu proses. Fakta-fakta ini berasal dari konsultasi. Struktur working memory akan mengikuti alur inferensi sistem pakar tersebut.
4. User Interface
Bagian ini merupakan suatu mekanisme atau media komunikasi antar pemakai (user) dengan program. Bagian ini juga menyediakan dan memberikan fasilitas informasi dan beberapa keterangan yang mengarah pada penelusuran masalah sampai ditemukan solusi.
2.3 Kaidah Produksi
Pengetahuan yang berupa prosedural, maka metode representasi pengetahuan yang cocok dalam kaidah produksi. Pengetahuan dalam kaidah produksi direpresentasikan dalam bentuk:
JIKA [antecedent] MAKA [konsekuen] JIKA [kondisi] MAKA [aksi]
JIKA [premis] MAKA [konklusi]
Aturan dalam kaidah produksi diklasifikasikan menjadi Kaidah Derajat Pertama dan Kaidah Meta. Kaidah Derajat Pertama adalah aturan yang bagian
konklusinya tidak menjadi premis bagi kaidah yang lain, sebaliknya Kaidah Meta adalah aturan yang bagian konklusinya menjadi premis bagi kaidah yang lain. Kaidah Meta merupakan kaidah yang berisi penjelasan bagi kaidah yang lain.
2.4 Forward Chaining dan Backward Chaining
Metode Forward Chaining dan Backward Chaining merupakan dua teknik penalaran yang biasa digunakan dalam sistem pakar. Metode Backward Chaining adalah pelacakan kebelakang yang memulai penalarannya dari kesimpulan (goal), dengan mencari sekumpulan hipotesa-hipotesa yang mendukung menuju fakta-fakta yang mendukung sekumpulan hipotesa-hipotesa tersebut, sedangkan metode
Forward Chaining adalah pelacakan ke depan yang memulai dari sekumpulan
fakta-fakta dengan mencari kaidah yang cocok dengan dugaan/hipotesa yang ada menuju kesimpulan.
Backward Chaining
Backward Chaining atau Backward Reasoning merupakan salah satu dari
metode inferensia yang dilakukan untuk di bidang kecerdasan buatan. Backward
Chaining dimulai dangan pendekatan tujuan atau goal oriented atau
hipotesa. Backward Chaining akan bekerja dari konsekuen ke antesendent untuk melihat apakah terdapat data yang mendukung konsekuen tersebut. Metode inferensi dengan Backward Chaining akan mencari aturan atau rule yang memiliki konsekuen (Then klausa...) yang mengarah kepada tujuan yang diskenariokan/diinginkan.
Forward Chaining
Forward Chaining adalah metode inferensia yang merupakan lawan
dari Backward Chaining. Forward Chaining dimulai dengan data atau data driven, artinya pada Forward Chaining semua data dan aturan akan ditelusuri untuk mencapai tujuan atau goal yang diinginkan. Mesin Inferensia yang menggunakan Forward Chaining akan mencari antesendent (IF klausa...) sampai kondisinya benar. Forward Chaining semua pertanyaan dalam sistem pakar akan disampaikan semuanya kepada pengguna.
2.5 Teori Dempster-Shafer
Metode Dempster-Shafer pertama kali diperkenalkan oleh Dempster, yang melakukan percobaan untuk model ketidakpastian dengan berbagai kemungkinan sebagai probabilitas tunggal. Tahun 1976, Shafer menerbitkan teori Dempster dalam sebuah buku berjudul Mathematical Theory of Evident (Setyarini, et al., 2013). Secara umum Teori Dempster-Shafer ditulis dalam suatu interval:
[𝐵𝑒𝑙𝑖𝑒𝑓, 𝑃𝑙𝑎𝑢𝑠𝑖𝑏𝑖𝑙𝑖𝑡𝑦] (2.1) Belief
Belief (Bel) adalah ukuran kekuatan evidence (gejala) dalam mendukung
suatu himpunan bagian. Jika bernilai 0 maka mengindikasikan bahwa tidak ada
evidence, dan jika bernilai 1 menunjukan adanya kepastian.
Plausibility
Plausibility (Pl) dinotasikan sebagai:
𝑃𝑙(𝑠) = 1 − 𝐵𝑒𝑙(−𝑠) (2.2)
Plausibility juga bernilai 0 sampai 1, jika kita yakin akan –s, maka dapat dikatakan
bahwa Bel(¬s)=1, dan Pl(¬s)=0. Plausibility akan mengurangi tingkat kepercayaan dari evidence. Teori Dempster-Shafer kita mengenal adanya frame of discernment yang dinotasikan dengan θ dan mass function yang dinotasikan dengan m. Frame ini merupakan semesta pembicaraan dari sekumpulan hipotesis sehingga disebut dengan environtment.
Misalkan: θ = {A, B, C, D, E, F, G, H, I, J} Keterangan:
A = Gagal Ginjal Kronik B = Kanker Ginjal C = Pielonefritis D = Sindroma Nefrotik E = Hidronefrosis
F = Kanker Kandung Kemih G = Ginjal Polikista
I = Sistitis
J = Infeksi Saluran Kemih
Mass Function
Mass function (m) dalam Teori Dempster-Shafer adalah tingkat
kepercayaan dari suatu evidence measure sehingga dinotasikan dengan (m). Untuk mengatasi sejumlah evidence pada Teori Dempster-Shafer menggunakan aturan yang lebih dikenal dengan Dempster’s Rule of Combination.
𝑚3(𝑍) = ∑𝑥∩𝑦=𝑧𝑚1(𝑋). 𝑚2(𝑌) 1 − 𝐾 (2.3) Dimana, 𝐾 = ∑ 𝑚1(𝑋). 𝑚2(𝑌) 𝑥∩𝑦=∅ (2.4) Keterangan:
m1(X) adalah mass function dari evidence X.
m2(Y) adalah mass function dari evidence Y.
m3(Z) adalah mass function dari evidence Z.
Κ adalah jumlah conflict evidence.
Perhitungan Dempster-Shafer
Perhitungan Dempster-Shafer ini digunakan untuk memahami lebih dalam mengenai teori yang digunakan dalam membangun sistem pakar ini. Kasus diagnosa, pengguna menjawab lima pertanyaan yang meliputi terlihat lesu atau lemah, nafsu makan berkurang, selaput lendir (kekuningan), dehidrasi (haus meningkat), dan urin berdarah.
Aturan:
JIKA terliaht lesu / lemah DAN nafsu makan berkurang DAN selaput lendir (kekuningan) DAN dehidrasi (haus meningkat) DAN urin berdarah
Diketahui:
θ = {P1, P2, P3, P4, P5, P6, P7, P8, P9, P10, P11, P12, P13, P14, P15, P16, P17}
Evidence pertama (e1) yang mendukung hipotesis P1, P2, P3, P4, P5, P6, P7, P8, P10 dengan m = 0.60, sehingga dapat ditulis sebagai berikut:
m1{P1, P2, P3, P4, P5, P6, P7, P8, P10} = 0,60 m1{θ} = 1-0.60 = 0.40
Evidence kedua (e2) yang mendukung hipotesis P1, P2, P3, P4, P5 dengan m = 0.60, sehingga dapat ditulis sebagai berikut:
m2{P1, P2, P3, P4, P5} = 0,60
m2 {θ} = 1-0.60 = 0.40
Lakukan perhitungan untuk evidence pertama (e1) dan evidence kedua (e2) untuk mendapatkan nilai m yang baru.
Tabel 2.1 Ilustrasi Nilai Keyakinan Terhadap Dua Gejala
m2{P1,P2,P3,P4,P5} 0.60 m2{θ} 0.40 m1{P1,P2,P3,P4,P5,P6,P7, P8,P10} 0.60 {P1,P2,P3, P4,P5} 0.36 {P1,P2,P3,P4,P5,P6,P7, P8,P10} 0.24 m1{θ} 0.40 {P1,P2,P3,P4,P5} 0.24 Θ 0.16
Hitung tingkat keyakinan atau mass function (m) combine dengan Rumus (2.3) sebagai berikut:
m3 {P1,P2,P3,P4,P5} = (0.36+0.24)/(1-0) = 0.60
m3 {P1,P2,P3,P4,P5,P6,P7,P8,P10} = (0.24)/(1-0) = 0.24
m3 {θ} = (0.16)/(1-0) = 0.16
Evidence ketiga (e3) yang mendukung P1 dengan m = 0.70, sehingga dapat
ditulis sebagai berikut:
m4 {P1} = 0.70
m4 {θ} = 1-0.70 = 0.30
Tabel 2.2 Ilustrasi Nilai Keyakinan Terhadap Tiga Gejala
m4{P1} 0.70 m4{θ} 0.30 m3{P1,P2,P3, P4,P5} 0.60 {P1} 0.42 {P1,P2,P3, P4,P5} 0.18 m3{P1,P2,P3,P4, P5,P6,P7, P8,P10} 0.24 {P1} 0.17 {P1,P2,P3,P4, P5,P6,P7, P8,P10} 0.072 m3{θ} 0.16 {P1} 0.112 Θ 0.05
Hitung tingkat keyakinan atau mass function (m) combine dengan Rumus (2.3) sebagai berikut: m5{P1} = (0.42+0.17+0.112)/(1-0) = 0.702 m5{P1,P2,P3,P4,P5} = (0.18)/(1-0) = 0.18 m5{P1,P2,P3,P4,P5,P6,P7,P8,P10} = (0.072)/(1-0) = 0.072 m5{θ} = (0.05)/(1-0) = 0.05
Evidence keempat (e4) yang mendukung P1 dengan m = 0.60, sehingga
dapat ditulis sebagai berikut:
m6{P1} = 0.60
m6{θ} = 1-0.60 = 0.40
Tabel 2.3 Ilustrasi Nilai Keyakinan Terhadap Empat Gejala
m6{P1} 0.60 m6{θ} 0.40 m5{P1} 0.702 {P1} 0.42 {P1} 0.28 m5{P1,P2,P3,P4,P5} 0.18 {P1} 0.108 {P1,P2,P3,P4,P5} 0.072 m5{P1,P2,P3,P4,P5,P6,P7,P8,P10} 0.072 {P1} 0.043 {P1,P2,P3,P4,P5,P6,P7,P8,P10} 0.029 m5{θ} 0.05 {P1} 0.024 Θ 0.016
Hitung tingkat keyakinan atau mass function (m) combine dengan Rumus (2.3) sebagai berikut: m7{P1} =(0.42+0.108+0.043+0.024+0.28)/(1-0) = 0.875 m7{P1,P2,P3,P4,P5} = (0.072)/(1-0) = 0.072 m7{P1,P2,P3,P4,P5,P6,P7,P8,P10} =(0.029)/(1-0) = 0.029 m7{θ} = (0.016)/(1-0) = 0.016
Evidence selanjutnya muncul adalah e5 yang mendukung P1 dengan m =
0.70, sehingga dapat ditulis sebagai berikut:
m8{P1} = 0.70
m8{θ} = 1-0.70 = 0.30
Tabel 2.4 Ilustrasi Nilai Keyakinan Terhadap Lima Gejala
m8{P1} 0.70 m8{θ} 0.30 m7{P1} 0.875 {P1} 0.62 {P1} 0.26 m7{P1,P2,P3,P4,P5} 0.072 {P1} 0.0504 {P1,P2,P3,P4,P5} 0.0216 m7{P1,P2,P3,P4,P5,P6,P7,P8,P10} 0.029 {P1} 0.0203 {P1,P2,P3,P4,P5,P6,P7,P8,P10} 0.0087 m7{θ} 0.016 {P1} 0.0112 Θ 0.0048
Hitung tingkat keyakinan atau mass function (m) combine dengan Rumus (2.3) sebagai berikut: m9{P1} = (0.62+0.26+0.0504+0.0203+0.0112) /(1-0) = 0.962 m9{P1,P2,P3,P4,P5} = (0.0216)/(1-0) =0.0216 m9{P1,P2,P3,P4,P5,P6,P7,P8,P10} =(0.0087)/(1-0) =0.0087 m9{θ} = (0.0048)/(1-0) = 0.0048
Hasil perhitungan nilai probabilitas di atas, diperoleh keyakinan terbesar adalah m9{P1} sebesar 0.962. Dengan demikian, dapat disimpulkan bahwa
pengguna kemungkinan besar menderita P1 yang Leptospirosis dengan persentase kepercayaan adalah 0.962 * 100% = 96.2% sesuai dengan jawaban yang diberikan oleh pengguna.
2.6 Probabilitas Bayes
Probabilitas Bayes merupakan salah satu cara yang baik untuk mengatasi ketidakpastian data dengan menggunakan Formula Bayes yang dinyatakan dengan rumus sebagai berikut (Rahayu, 2013).
𝑃(𝐻|𝐸) = 𝑃(𝐸|𝐻). 𝑃(𝐻)
𝑃(𝐸) (2.5) Keterangan:
P(H|E) : probabilitas hipotesis H jika diberikan evidence E. P(E|H) : probabilitas munculnya evidence apapun.
P(E) : probabilitas evidence E.
Teori Bayes sudah dikenal dalam bidang kedokteran tetapi teori ini lebih banyak diterapkan dalam logika kedokteran modern (Cutler, 1991). Teori ini lebih banyak diterapkan pada hal-hal yang berkenaan dengan probabilitas serta kemungkinan dari penyakit dan gejala-gejala yang berkaitan. Secara umum Teori Bayes dengan E kejadian dan hipotesis H dapat dituliskan dalam bentuk:
𝑃(𝐻𝑖|𝐸) = 𝑃(𝐸 ∩ 𝐻𝑖) ∑ 𝑃(𝐸 ∩ 𝐻𝑗)𝑗 𝑃(𝐻𝑖|𝐸) = 𝑃(𝐸|𝐻𝑖)𝑃(𝐻𝑖) ∑ 𝑃(𝐸|𝐻𝑗)𝑃(𝐻𝑗)𝑗 𝑃(𝐻𝑖|𝐸) =𝑃(𝐸|𝐻𝑖)𝑃(𝐻𝑖) ∑ 𝑃(𝐸)𝑗 (2.6)
Teori Bayes dapat dikembangkan jika setelah dilakukan pengujian terhadap hipotesis yang lebih dari satu evidence. Dalam hal ini maka persamaannya menjadi:
𝑃(𝐻|𝐸, 𝑒) = 𝑃(𝐻|𝐸)𝑃(𝑒|𝐸, 𝐻)
𝑃(𝑒|𝐸) (2.7) Keterangan :
e : evidence lama.
E : evidence baru.
P(H|E,e) : probabilitas hipotesis H benar jika muncul evidence baru E dari
evidence baru E dari evidence lama e.
P(H|E) : probabilitas hipotesis H benar jika diberikan evidence E.
P(e|E,H) : kaitan antara e dan E jika hipotesis H benar.
P(e|E) : kaitan antara e dan E tanpa memandang hipotesis apapun.
Penghitungan menggunakan Probabilitas Bayes dapat dilihat pada contoh berikut ini.
Probabilitas terkena Penyakit Bronkhitis Khronika apabila mengalami batuk lebih dari 4 minggu. P(Bronchitis Khronika | batuk lebih dari 4 minggu) = 0,13. Adanya gejala baru yaitu batuk berdarah dalam 3 bulan terkahir, probabilitas terkena Penyakit Bronchitis Khronika apabila mengalami batuk berdarah dalam 3 bulan terakhir. P(Bronchitis Khronika | batuk darahdalam 3 bulan terakhir) = 0,4.
Keterkaitan antara adanya gejala batuk lebih dari 4 minggu dan batuk darah dalam 3 bulan terkahir apabila seseorang menderita Bronchitis Khronika adalah 0,33. Keterkaitan antara adanya gejala batuk lebih dari 3 minggu dan batuk darah dalam 3 bulan terakhir tanpa memperhatikan penyakit yang diderita adalah 0,15, maka:
A = batuk darah dalam 3 bulan terakhir B = batuk lebih dari 4 minggu
H = bronchitis khronika P(H |A,B) = P(H | A) x𝑃(𝐵|𝐴,𝐻) 𝑃(𝐵,𝐴) = 0.4 x 0.33 0.15 =0.88
Contoh kasus penyakit gagal ginjal akut, dimana user melakukan diagnosa dengan menjawab pertanyaan sesuai dengan gejala berikut:
G1 = 0.4 = P(E|H1) G2 = 0.2 = P(E|H2) G3 = 0.4 = P(E|H3) G4 = 0.6 = P(E|H4) G5 = 0.2 = P(E|H5) G6 = 0.2 = P(E|H6) G7 = 0.2 = P(E|H7) G8 = 0.4 = P(E|H8) G9 = 0.4 = P(E|H9)
Nilai semesta kemudian dicari dengan menjumlahkan nilai dari hipotesis di atas.
∑9
𝑘=1 = G1 + G2 + G3 + G4 + G5 + G6 + G7 + G8 + G9 = 0.4+ 0.2 + 0.6 + 0.8 + 0.2 + 0.4 + 0.2 + 0.6 + 0.4 = 3.8
Hasil penjumlahan di atas adalah 3.8, maka didapatkanlah rumus untuk menghitung nilai P(Hi) adalah sabagai berikut:
𝑃(𝐻1) = 𝐻1 ∑9 𝑘=1 = 0.4 3.8= 0.10526 𝑃(𝐻2) = 𝐻2 ∑9 𝑘=1 = 0.2 3.8= 0.05263 𝑃(𝐻3) = 𝐻3 ∑9 𝑘=1 = 0.6 3.8= 0.15789 𝑃(𝐻4) = 𝐻4 ∑9 𝑘=1 = 0.8 3.8= 0.21052
𝑃(𝐻5) = 𝐻5 ∑9 𝑘=1 = 0.2 3.8= 0.05263 𝑃(𝐻6) = 𝐻6 ∑9 𝑘=1 = 0.4 3.8= 0.10526 𝑃(𝐻7) = 𝐻7 ∑9 𝑘=1 = 0.2 3.8= 0.05263 𝑃(𝐻8) = 𝐻8 ∑9 𝑘=1 = 0.6 3.8= 0.15789 𝑃(𝐻9) = 𝐻9 ∑9𝑘=1 = 0.4 3.8= 0.10526
Nilai P(Hi) diketahui, selanjutnya probabilitas hipotesis H tanpa memandang evidence apapun adalah:
∑9𝑘=1 = P(Hi) * P(E|Hi-n)
= P(H1) * P(E|H1) + P(H2) * P(E|H2) + P(H3) * P(E|H3) + P(H4) *
P(E|H4) + P(H5) * P(E|H5) + P(H6) * P(E|H6) + P(H7) * P(E|H7) + P(H8) * P(E|H8) + P(H9) * P(E|H9) = (0.10526 * 0.4) + (0.05263 * 0.2) + (0.15789 * 0.4) + (0.21052 * 0.6) + (0.05263 * 0.2) + (0.10526 * 0.2) + (0.05263 * 0.2) + (0.15789 * 0.4) + (0.10526 * 0.4) = 0.04210 + 0.01052 + 0.06315 + 0.12631 + 0.01052 + 0.02105 + 0.01052 +0.06315 + 0.04210 = 0.38942
Langkah selanjutnya ialah mencari nilai P(Hi|E) atau probabilitas hipotesis Hi benar jika diberikan evidence E.
𝑃(𝐻1|𝐸) =0.4 ∗ 0.10526 0.38942 = 0.10811 𝑃(𝐻2|𝐸) =0.2 ∗ 0.05263 0.38942 = 0.02702 𝑃(𝐻3|𝐸) =0.4 ∗ 0.15789 0.38942 = 0.16217 𝑃(𝐻4|𝐸) =0.6 ∗ 0.21052 0.38942 = 0.32435
𝑃(𝐻5|𝐸) =0.2 ∗ 0.05263 0.38942 = 0.02702 𝑃(𝐻6|𝐸) =0.2 ∗ 0.10526 0.38942 = 0.05405 𝑃(𝐻7|𝐸) =0.2 ∗ 0.05263 0.38942 = 0.02702 𝑃(𝐻8|𝐸) =0.4 ∗ 0.15789 0.38942 = 0.16217 𝑃(𝐻9|𝐸) =0.4 ∗ 0.10526 0.38942 = 0.10811
Seluruh nilai P(Hi|E) diketahui, maka jumlahkan seluruh Nilai Bayes
dengan rumus sebagai berikut: ∑𝑛
𝑘=1 Bayes = Bayes1 + Bayes2 + Bayes3 + Bayes4 + Bayes5 + Bayes6 +
Bayes7 + Bayes8 + Bayes9
= (0.4 * 0.10811) + (0.2 * 0.02702) + (0.6 * 0.16217) + (0.8 * 0.32435) + (0.2 * 0.02702) + (0.4 * 0.05405) + (0.2 * 0.02702) + (0.4 * 0.16217) + (0.6 * 0.10811) = 0.04324 + 0. 00544 + 0.09730 + 0.25948 + 0.00544 + 0.02162 + 0.00544 + 0.06486 + 0.06486 = 0.56768
Simpulan dari perhitungan di atas adalah pengguna kemungkinan menderita gagal ginjal akut dengan persentase kepercayaan adalah 0.56768 * 100% = 56.768% sesuai dengan jawaban yang diberikan oleh pengguna.
2.7 MySQL
MySQL merupakan bahasa pemrograman open-source yang paling popular dan banyak digunakan di lingkungan Linux (Allen & Hornberger, 2002). Kepopuleran ini karena ditunjang oleh performance query dari basis datanya yang jarang bermasalah. MySQL merupakan database server yang mampu untuk memanajemen database dengan baik. MySQL dijadikan sebagai sebuah database yang paling banyak digunakan selain database yang bersifat shareware seperti Ms
Access, penggunaan MySQL biasanya dipadukan dengan menggunakan program
aplikasi PHP, karena dengan menggunakan kedua program tersebut di atas telah terbukti akan kehandalan dalam menangani permintaan data. Kemampuan lain yang dimiliki MySQL adalah mampu mendukung Relasional Database Manajemen
Sistem (RDBMS), sehingga dengan kemampuan ini MySQL akan mampu
menangani data berukuran sangat besar hingga Giga Byte.
2.8 Bahasa Pemrograman
Bahasa pemograman yang digunakan dalam pembuatan sistem pakar antara lain PHP dan HTML berikut adalah penjelasan dari masing-masing bahasa pemograman:
1. PHP
PHP: Hypertext Prepocessor adalah sebuah bahasa pemograman yang
berbentuk scripting (Nugroho, 2004). Sistem kerja ini adalah interpreter bukan sebagai compiler. Bahasa interpreter adalah bahasa yang script program tidak harus diubah kedalam bentuk source code, sedangkan bahasa
compiler adalah bahasa yang akan mengubah script program kedalam source code, selanjutnya dari bentuk source code akan diubah menjadi object code, bentuk dari obyek code akan menghasilkan file yang lebih kecil
dari file mentah sebelumnya.
2. HTML
HTML (Hypertext Markup Language) yaitu salah satu bahasa scripting yang dapat menghasilkan halaman website sehingga halaman tersebut dapat diakses pada setiap komputer pengakses (client). Dokumen HTML merupakan dokumen yang disajikan dalam browser web surfer. Dokumen ini umumnya berisi informasi ataupun interface aplikasi dalam internet.
2.9 Basis Data (Database)
Basis data merupakan komponen terpenting dalam pembangunan sistem informasi, karena menjadi tempat untuk menampung dan mengorganisasikan seluruh data yang ada dalam sistem, sehingga dapat dieksplorasi untuk menyusun
informasi-informasi dalam berbagai bentuk. Basis data merupakan himpunan kelompok data yang saling berkaitan (Kristanto, 2003). Dibutuhkan beberapa alat bantu dalam perancangan suatu database yang salah satunya adalah Data Flow
Diagram.
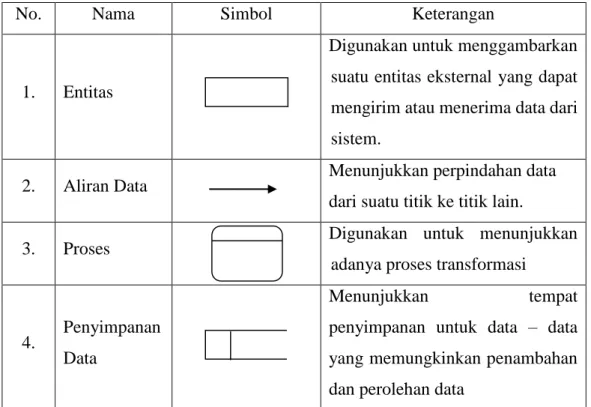
Tabel 2.5 Tabel Simbol Data Flow Diagram
No. Nama Simbol Keterangan
1. Entitas
Digunakan untuk menggambarkan suatu entitas eksternal yang dapat mengirim atau menerima data dari sistem.
2. Aliran Data Menunjukkan perpindahan data
dari suatu titik ke titik lain.
3. Proses Digunakan untuk menunjukkan
adanya proses transformasi
4. Penyimpanan Data
Menunjukkan tempat
penyimpanan untuk data – data yang memungkinkan penambahan dan perolehan data
Data Flow Diagram (DFD) adalah suatu model logika data atau proses yang
dibuat untuk menggambarkan darimana asal data dan kemana tujuan data yang keluar dari sistem, dimana data disimpan, proses apa yang menghasilkan data tersebut dan interaksi antara data yang tersimpan dan proses yang dikenakan pada data tersebut. DFD menggambarkan penyimpanan data dan proses yang mentransformasikan data. DFD menunjukkan hubungan antara data pada sistem dan proses pada sistem (Kristanto, 2003).