AUTOMATIC SPEECH
RECOGNITION
Disusun Oleh
KELOMPOK 9Nama : NADIA MIFTAHUL I. (151611513012) DAVID MUAMAR (151611513014) EMIR SYAIFULLAH (151611513021) AZHAR SYAMRIDHA N. (151611513023) BIGSON NOER A. (151611513031) RIZAL BUDIMAN (151611513053) Pengajar : HALIMATUS
Program Studi D3 Sistem Informasi
Fakultas Vokasi
Universitas Airlangga
Surabaya
KATA PENGANTAR
Puji syukur kami panjatkan kehadirat Allah SWT yang telah memberikan rahmat serta karunia-NYA kepada kami sehingga kami berhasil menyelesaikan Tugas Makalah ini dengan tepat waktunya yang berjudul “AUTOMATIC SPEECH RECOGNITION “. Makalah ini berisi tentang pembahasan judul di atas sehingga dapat menambah wawasasan ilmu pengetahuan untuk pembaca. Kami menyadari bahwa makalah ini masih jauh dari sempurna, Oleh karna itu kritik dan saran dari semua pihak yang bersifat membangun selalu kami harapkan demi kesempurnaan makalahini.Akhir kata, saya mengucapkan terima kasih.
Surabaya, 11 November 2016
DAFTAR ISI
KATA PENGANTAR... ii
DAFTAR ISI... iii
DAFTAR GAMBAR... iv
BAB I... 1
PENDAHULUAN... 1
1.1 Latar belakang... 1
1.2 Rumusan Masalah...2
1.3 Tujuan Pembuatan Makalah...2
1.3 Manfaat... 2
BAB II... 3
ISI... 3
2.1 Pengertian Automatic Speech Recognition...3
2.3 Skema utama Automatic Speech Recognition...5
2.4 Jenis-jenis Speech Recognition...7
2.5 Kelebihan dan kekurangan Speech Recognition...7
2.6 Proses Kerja Alat Speech Recognition...8
2.7 Implementasi Speech Recognition...9
2.8 Penerapan Speech Recognition...10
BAB III... 12
KESIMPULAN... 12
DAFTAR GAMBAR
gambar 1 Speech Recognition...2
gambar 2 Alur Speech Recognition...3
gambar 3 Sejarah Speech Recognition...4
gambar 4 Skema Utama Speech Recognition...5
gambar 5 Penerapan Speech Recognition bidang komunikasi...10
BAB I
PENDAHULUAN
1.1 Latar belakang
Pengenalan suara (voice recognition) dibagi menjadi dua jenis, yaitu Speech Recognition dan speaker recognition. Namun pada kali ini konsen kita hanya kepada
Speech Recognition yang berarti proses identifikasi yang dilakukan komputer untuk mengenali kata yang diucapkan oleh seseorang tanpa mempedulikan identitas orang terkait dengan melakukan konversi sebuah sinyal akustik, yang ditangkap oleh audio device (perangkat input suara). Pola kerja Pengenalan Ujaran (Speech Recognition) adalah mencocokkan sinyal akustik yang diterima dengan data yang tersimpan dalam template ataupun database. Proses pencocokan memiliki dua model utama yaitu Model Akustik yang terdiri dari fonem yang memiliki nilai tertentu yang diambil dari sinyal akustik dan Model Bahasa berupa metode yang mengestimasikan satu kata diikuti oleh serangkaian kata lainnya.
Speech Recognition juga merupakan sistem yang digunakan untuk mengenali perintah kata dari suara manusia dan kemudian diterjemahkan menjadi suatu data yang dimengerti oleh komputer. Pada saat ini, sistem ini digunakan untuk menggantikan peranan input dari keyboard dan mouse. Keuntungan dari sistem ini adalah pada kecepatan dan kemudahan dalam penggunaannya. Kata – kata yang ditangkap dan dikenali bisa jadi sebagai hasil akhir, untuk sebuah aplikasi seperti command and control, penginputan data, dan persiapan dokumen. Parameter yang dibandingkan ialah tingkat penekanan suara yang kemudian akan dicocokkan dengan template database
yang tersedia. Sedangkan sistem pengenalan suara berdasarkan orang yang berbicara dinamakan speaker recognition. Kompleksitas algoritma pada Speech Recognition yang diimplementasikan lebih sederhana daripada speaker recognition. Algoritma yang akan diimplementasikan pada bahasan mengenai proses Speech Recognition ini adalah algoritma FFT (Fast Fourier Transform), yaitu algoritma yang cukup efisien dalam pemrosesan sinyal digital (dalam hal ini suara) dalam bentuk diskrit. Algoritma ini mengimplementasikan algoritma Divide and Conquer untuk pemrosesannya. Konsep utama algoritma ini adalah mengubah sinyal suara yang berbasis waktu menjadi berbasis frekuensi dengan membagi masalah menjadi beberapa masalah yang lebih kecil. Kemudian setiap masalah diselesaikan dengan cara melakukan pencocokan pola digital suara.
1.2 Rumusan Masalah
1. Apa yang dimaksud Automatic Speech Recognition..? 2. Apa saja kelebihan Automatic Speech Recognition..? 3. Bagaimana Cara kerja Automatic Speech Recognition..?
4. Apa tujuan dibuatnya Automatic Speech Recognition..?
5. Bidang apa saja yang dapat menerapkan Automatic Speech Recognition..?
1.2 Tujuan Pembuatan Makalah
1. Mengetahui apa itu Automatic Speech Recognition..
2. Mengetahui tujuan dibuatnya Automatic Speech Recognition.. 3. Mengetahui cara kerja Atomatic Speech Recognition.
4. Mengetahui apa saja kelebihan Automatic Speech Recognition.
5. Mengetahui bidang apa saja yang dapat menerapkan Automatic Speech Recognition.
1.3 Manfaat
1. Memberikan informasi bagi pembaca tentang Automatic Speech Recognition dan kelebihannya.
2. Memberikan informasi bagi pembaca tentang tujuan dibuatnya Automatic Speech Recognition
3. Memberikan informasi bagi pembaca bagaimana cara kerja Automatic Speech Recognition.
4. Memberikan informasi bagi pembaca Bidang apa saja yang dapat menerapkan
BAB II
ISI
2.1 Pengertian Automatic Speech Recognition
“Speech Recognition atau Automatic Speech Recognition (ASR) atau pengenalan suara adalah sebuah proses konversi sinyal suara menjadi kata atau perintah. Dalam hal ini diperlukan sebuah algoritma yang diinmplementasikan menjadi sebuah program komputer untuk menjalankan perintah tersebut. Aplikasi pengenalan suara yang telah diimplementasikan hingga saat ini antara lain untuk melakukan panggilan (Misalnya, "Panggil Ayah"), Melakukan input data sederhana (Misalnya, memasukkan nomor kartu kredit), Pengolahan kata menjadi teks (Misal, windows speech recognition), sistem pesawat (Misal, pengatur lalu-lintas udara atau yang dikenal dengan
Air Traffic Controllers ).” ( Faizin, 2014. Automatic Speech Recognition, http://www.slideshare.net/faizin2q1/paper-tentang-speech-recognition, 9 Nov 2016)
Speech Recognition atau pengenalan pembicaraan (juga dikenal sebagai pengenalan suara otomatis atau pengakuan komputer pidato) mengkonversi diucapkan kata-kata untuk teks. Istilah "pengenalan suara" digunakan untuk merujuk kepada sistem pengakuan yang harus dilatih untuk kasus-speaker tertentu seperti untuk perangkat lunak pengenal yang paling desktop.Menyadari pembicara dapat menyederhanakan tugas menerjemahkan pidato. Pengenalan pembicaraan adalah solusi yang lebih luas yang mengacu pada teknologi yang dapat mengenali pidato tanpa
ditargetkan pada pembicara tunggal seperti sistem call center yang dapat mengenali suarasewenang-wenang.
Speech Recognition adalah solusi yang lebih luas yang mengacu pada teknologi yang dapat mengenali pembicaraan tanpa ditargetkan pada pembicara tunggal seperti sistem call center yang dapat mengenali suara dengan sendirinya.
Alat pengenal ucapan, yang sering disebut dengan speech recognizer, membutuhkan sampel kata sebenarnya yang diucapkan dari pengguna. Sampel kata akan didigitalisasi, disimpan dalam komputer, dan kemudian digunakan sebagai basis data dalam mencocokkan kata yang diucapkan selanjutnya. Sebagian besar alat pengenal ucapan sifatnya masih tergantung kepada pembicara. Alat ini hanya dapat mengenal kata yang diucapkan dari satu atau dua orang saja dan hanya bisa mengenal kata-kata terpisah, yaitu kata-kata yang dalam penyampaiannya terdapat jeda antar kata. Hanya sebagian kecil dari peralatan yang menggunakan teknologi ini yang sifatnya tidak tergantung pada pembicara. Alat ini sudah dapat mengenal kata yang diucapkan oleh banyak orang dan juga dapat mengenal kata-kata continue, atau kata-kata yang dalam penyampaiannya tidak terdapat jeda antar kata.
Secara umum, speech recognizer memproses sinyal suara yang masuk dan menyimpannya dalam bentuk digital. Hasil proses digitalisasi tersebut kemudian dikonversi dalam bentuk spektrum suara yang akan dianalisa dengan membandingkan dengan template suara pada database sistem. Sebelumnya, data suara masukan dipilah-pilah dan diproses satu per satu berdasarkan urutannya. Pemilahan ini dilakukan agar proses analisis dapat dilakukan secara paralel.
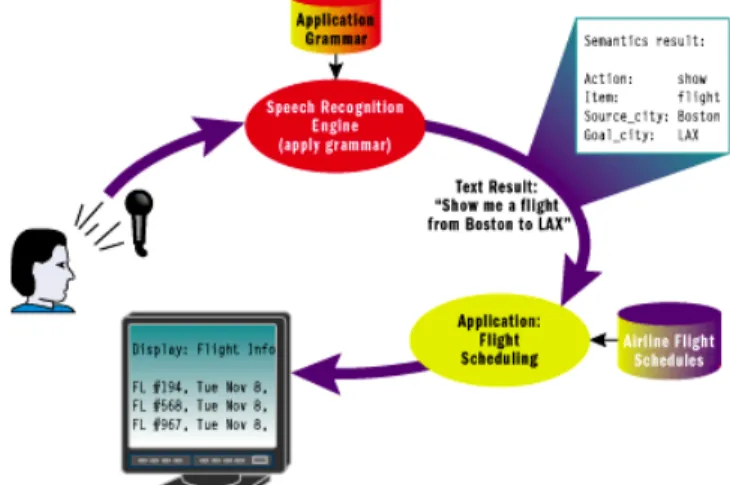
2.2 Skema utama Automatic Speech Recognition
Terdapat 4 langkah utama dalam sistem pengenalan suara: 1 Penerimaan data input
2 Ekstraksi, yaitu penyimpanan data masukan sekaligus pembuatan database untuk template.
3 Pembandingan / pencocokan, yaitu tahap pencocokan data baru dengan data suara (pencocokan tata bahasa) pada template.
4 Validasi identitas pengguna.
Sebelumnya, data suara masukan dipilah-pilah dan diproses satu per satu berdasarkan urutannya. Pemilahan ini dilakukan agar proses analisis dapat dilakukan secara paralel. Proses yang pertama kali dilakukan ialah memproses gelombang kontinu spektrum suara ke dalam bentuk diskrit. Langkah berikutnya ialah proses kalkulasi yang dibagi menjadi dua bagian :
A. Transformasi gelombang diskrit menjadi array data.
B. Untuk masing-masing elemen pada data, hitung "ketinggian" gelombang (frekuensi). Objek permasaiahan yang akan dibagi adalah masukan berukuran n, berupa data diskrit gelombang suara.
Ketika mengkonversi gelombang suara ke dalam bentuk diskrit, gelombang diperlebar dengan cara memperinci berdasarkan waktu. Hal ini dilakukan agar proses algoritma selanjutnya lebih mudah dilakukan. Namun, efek buruknya ialah array data yang terbentuk akan lebih banyak.
Dari tiap elemen array data tersebut, dikonversi ke dalam bentuk bilangan biner. Data biner tersebut yang nantinya akan dibandingkan dengan template data suara. Proses divide and conquer:
A. Pilih sebuah angka N, dimana N merupakan bilangan bulat kelipatan 2.Bilangan ini berfungsi untuk menghitung jumlah elemen transformasi FFT.
B. Bagi dua data diskrit secara (dengan menerapkan algoritma divide and conquer) menjadi data diskrit yang lebih kecii berukuran N = N,.N2.
C. Objek data dimasukkan ke dalam table (sebagai elemen tabel).
D. Untuk setiap eiemen data, dicocokkan dengan data pada template (pada data template juga dilakukan pemrosesan digitaiisasi menjadi data diskrit, dengan cara yang sama dengan proses digitaiisasi data masukan bam yang ingin dicocokkan).
E. Setiap masalah disatukan kembali dan dianalisis secara keseluruhan, kecocokan dari segi tata bahasa dan apakah data yang diucapkan sesuai dengan kata yang tersedia pada template data.
F. Verifikasi data. Jika sesuai, proses iebih lanjut, sesuai dengan aplikasi yang mengimplementasikan algoritma ini.
2.3 Jenis-jenis Speech Recognition
Berdasarkan kemampuan dalam mengenal kata yang diucapkan, terdapat 5 jenis pengenalan kata, yaitu :
1 Kata-kata yang terisolasi : Proses pengidentifikasian kata yang hanya dapat mengenal kata yang diucapkan jika kata tersebut memiliki jeda waktu pengucapan antar kata
2 Kata-kata yang berhubungan : Proses pengidentifikasian kata yang mirip dengan kata-kata terisolasi, namun membutuhkan jeda waktu pengucapan antar kata yang lebih singkat
3 Kata-kata yang berkelanjutan : Proses pengidentifikasian kata yang sudah lebih maju karena dapat mengenal kata-kata yang diucapkan secara berkesinambungan dengan jeda waktu yang sangat sedikit atau tanpa jeda waktu. Proses pengenalan suara ini sangat rumit karena membutuhkan metode khusus untuk membedakan kata-kata yang diucapkan tanpa jeda waktu. Pengguna perangkat ini dapat mengucapkan kata-kata secara natural
4 Kata-kata spontan : Proses pengidentifikasian kata yang dapat mengenal kata-kata yang diucapkan secara spontan tanpa jeda waktu antar kata-kata
Verifikasi atau identifikasi suara : Proses pengidentifikasian kata yang tidak hanya mampu mengenal kata, namun juga mengidentifikasi siapa yang berbicara.
2.4 Kelebihan dan kekurangan Speech Recognition
Kelebihan: 1 Cepat
Teknologi ini mempercepat transmisi informasi dan umpan balik dari transmisi tersebut. Contohnya pada komando suara. Hanya dalam selang waktu sekitar satu atau dua detik setelah kita mengkomandokan perintah melalui suara, komputer sudah memberi umpan balik atas komando kita.
2 Mudah digunakan
Kemudahan teknologi ini juga dapat dilihat dalam aplikasi komando suara. Komando yang biasanya kita masukkan ke dalam komputer dengan menggunakan tetikus atau papan ketik kini dapat dengan mudahnya kita lakukan tanpa perangkat keras, yakni dengan komando suara.
Kekurangan:
1 Rawan terhadap gangguan. Hal ini disebabkan oleh proses sinyal suara yang masih berbasis frekuensi. Ketika sebuah informasi dalam sinyal suara mempunyai komponen frekuensi yang sama banyaknya dengan komponen frekuensi gangguannya, akan sulit untuk memisahkan gangguan dari sinyal suara.
2 Jumlah kata yang dapat dikenal terbatas. Hal ini disebabkan pengenal ucapan bekerja dengan cara mencari kemiripan dengan basis data yang dimiliki.
2.5 Proses Kerja Alat Speech Recognition
Alat pengenal ucapan memiliki empat tahapan dalam prosesnya, yaitu :
1. Tahap penerimaan masukan : Masukan berupa kata-kata yang diucapkan lewat pengeras suara.
2. Tahap ekstraksi : Tahap ini adalah tahap penyimpanaan masukan yang berupa suara sekaligus pembuatan basis data sebagai pola. Proses ekstraksi dilakukan berdasarkan metode Model Markov Tersembunyi atau Hidden Markov Model (HMM), yang merupakan model statistik dari sebuah sistem yang diasumsikan oleh Markov sebagai suatu proses dengan parameter yang tidak diketahui.
Tantangan dalam model statistik ini adalah menentukan parameter-parameter tersembunyi dari parameter yang dapat diamati. Parameter-parameter yang telah kita tentukan kemudian digunakan untuk analisis yang lebih jauh pada proses pengenalan kata yang diucapkan. Berdasarkan HMM, proses pengenalan ucapan secara umum menghasilkan keluaran yang dapat dikarakterisasikan sebagai sinyal. Sinyal dapat bersifat diskrit (karakter dalam abjad) maupun kontinu (pengukuran temperatur, alunan musik). Sinyal dapat pula bersifat stabil (nilai statistiknya tidak berubah terhadap waktu) maupun nonstabil (nilai sinyal berubah-ubah terhadap waktu).
Dengan melakukan pemodelan terhadap sinyal secara benar, dapat dilakukan simulasi terhadap masukan dan pelatihan sebanyak mungkin melalui proses simulasi tersebut sehingga model dapat diterapkan dalam sistem prediksi, sistem pengenalan, maupun sistem identifikasi. Secara garis besar model sinyal dapat dikategorikan menjadi dua golongan, yaitu: model deterministik dan model statistikal. Model deterministik menggunakannilai-nilai properti dari sebuah sinyal seperti: amplitudo, frekuensi, danfase dari gelombang sinus. Model statistika menggunakan nilai- nilai statistik dari sebuah sinyal seperti: proses Gaussian, proses Poisson, proses Markov, danproses Markov Tersembunyi. Suatu model HMM secara umum memiliki unsur-unsur sebagai berikut:
A. N, yaitu jumlah bagian dalam model. Secara umum bagian tersebut saling terhubung satu dengan yang lain, dan suatu bagian bisa mencapai semua bagian yang lain, serta sebaliknya (disebut dengan model
ergodik). Namun hal tersebut tidak mutlak karena terdapat kondisi lain dimana suatu bagian hanya bisa berputar ke diri sendiri dan berpindah ke satu bagian berikutnya. Hal ini bergantung pada implementasi dari model.
B. M, yaitu jumlah simbol observasi secara unik pada tiap bagiannya, misalnya: karakter dalam abjad, dimana bagian diartikan sebagai huruf dalam kata.
C. Probabilita Perpindahan Bagian { } = ij A a
E. Inisial Distribusi Bagian i p p . Dengan memberikan nilai pada N, M, A, B, dan p , HMM dapat digunakan sebagai generator untuk menghasilkan urutan observasi. dimana tiap observasi t o adalah salah satu simbol dari V, dan T adalah jumlah observasi dalam suatu sequence.
F. Setelah memberikan nilai N, M, A, B, dan p , maka proses ekstraksi dapat diurutkan. Berikut adalah tahapan ekstraksi pengenalan ucapan berdasarkan HMM :
a. Tahap ekstraksi tampilan : Penyaringan sinyal suara dan pengubahan sinyal suara analog ke digital
b. Tahap tugas pemodelan : Pembuatan suatu model HMM dari data-data yang berupa sampel ucapan sebuah kata yang sudah berupa data digital
c. Tahap sistem pengenalan HMM : Penemuan parameter-parameter yang dapat merepresentasikan sinyal suara untuk analisis lebih lanjut.
3. Tahap pembandingan : Tahap ini merupakan tahap pencocokan data baru dengan data suara (pencocokan tata bahasa) pada pola. Tahap ini dimulai dengan proses konversi sinyal suara digital hasil dari proses ekstraksi ke dalam bentuk spektrum suara yang akan dianalisa dengan membandingkannya dengan pola suara pada basis data. Sebelumnya, data suara masukan dipilah-pilah dan diproses satu per satu berdasarkan urutannya. Pemilihan ini dilakukan agar proses analisis dapat dilakukan secara paralel. Proses yang pertama kali dilakukan ialah memproses gelombang kontinu spektrum suara ke dalam bentuk diskrit. Langkah berikutnya ialah proses kalkulasi yang dibagi menjadi dua bagian :
A. Transformasi gelombang diskrit menjadi data yang terurut : Gelombang diskrit berbentuk masukan berukuran yang menjadi objek yang akan dibagi pada proses konversi dengan cara pembagian rincian waktu
B. Menghitung frekuensi pada tiap elemen data yang terurut
C. Selanjutnya tiap elemen dari data yang terurut tersebut dikonversi ke dalam bentuk bilangan biner. Data biner tersebut nantinya akan dibandingkan dengan pola data suara dan kemudian diterjemahkan sebagai keluaran yang dapat berbentuk tulisan ataupun perintah pada perangkat.
4. Tahap validasi identitas pengguna: Alat pengenal ucapan yang sudah memiliki sistem verifikasi/identifikasi suara akan melakukan identifikasi orang yang berbicara berdasarkan kata yang diucapkan setelah menerjemahkan suara tersebut menjadi tulisan atau komando.
2.6 Implementasi Speech Recognition
Hardware yang dibutuhkan dalam implementasi Speech Recognition :
1. Sound card : Merupakan perangkat yang ditambahkan dalam suatu Komputer yang fungsinya sebagai perangkat input dan output suara untuk mengubah sinyal elektrik, menjadi analog maupun menjadi digital.
2. Microphone : Perangkat input suara yang berfungsi untuk mengubah suara yang melewati udara, air dari benda orang menjadi sinyal elektrik.
3. Komputer Server : Dalam proses suara digital menterjemahkan gelombang suara menjadi suatu simbol biasanya menjadi suatu nomor biner yang dapat diproses lagi kemudian diidentifikasikan dan dicocokan dengan database yang berisi berkas suara agar dapat dikenali.
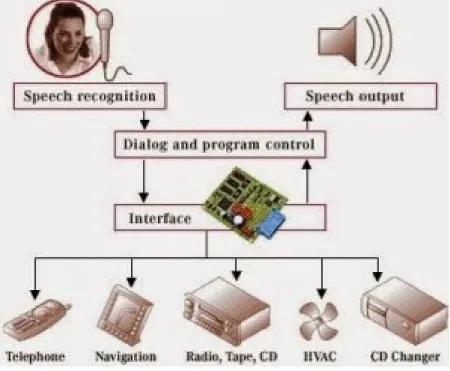
2.7 Penerapan Speech Recognition 1. Bidang Komunikasi
A. Komando Suara: Komando Suara adalah suatu program pada komputer yang melakukan perintah berdasarkan komando suara dari pengguna. Contohnya pada aplikasi Microsoft Voice yang berbasis bahasa Inggris. Ketika pengguna mengatakan “Mulai kalkulator” dengan intonasi dan tata bahasa yang sesuai, komputer akan segera membuka aplikasi kalkulator. Jika komando suara yang diberikan sesuai dengan daftar perintah yang tersedia, aplikasi akan memastikan komando suara dengan menampilkan tulisan “Apakah Anda meminta saya untuk mulai kalkulator.?”. Untuk melakukan verifikasi, pengguna cukup mengatakan “Lakukan” dan komputer akan langsung beroperasi.
gambar 4 Penerapan Speech Recognition bidang komunikasi
B. Pendiktean : Pendiktean adalah sebuah proses mendikte yang sekarang ini banyak dimanfaatkan dalam pembuatan laporan atau penelitian. Contohnya pada aplikasi Microsoft Dictation yang merupakan aplikasi yang dapat menuliskan apa yang diucapkan oleh pengguna secara otomatis.
C. Telepon : Pada telepon, teknologi pengenal ucapan digunakan pada proses penekanan tombol otomatis yang dapat menelpon nomor tujuan dengan komando suara.
2. Bidang Kesehatan
A. Alat pengenal ucapan banyak digunakan dalam bidang kesehatan untuk membantu para penyandang cacat dalam beraktivitas. Contohnya pada aplikasi Antarmuka Suara Pengguna atau Voice User Interface (VUI) yang menggunakan teknologi pengenal ucapan dimana pengendalian saklar lampu misalnya, tidak perlu dilakukan secara manual dengan menggerakkan saklar tetapi cukup dengan mengeluarkan perintah dalam bentuk ucapan sebagai saklarnya. Metode ini membantu manusia yang secara fisik tidak dapat menggerakkan saklar karena cacat pada tangan misalnya. Penerapan VUI ini tidak hanya untuk lampu saja tapi bisa juga untuk aplikasi-aplikasi kontrol yang lain.
B. Peralatan elektronik yang menyimpan riwayat kesehatan atau Electronic Medical Records (EMR) dapat digunakan secara lebih efektif bila menggunakan teknologi Speech Recognition. Proses pencarian, pertanyaan dan pencarian akan lebih mudah bila menggunakan suara daripada menggunakan keyboard.
3. Bidang Militer
A. Pelatihan Penerbangan : Aplikasi alat pengenal ucapan dalam bidang militer adalah pada pengatur lalu lintas udara atau yang dikenal dengan Air Traffic Controllers (ATC) yang dipakai oleh para pilot untuk mendapatkan keterangan mengenai keadaan lalu-lintas udara seperti radar, cuaca, dan navigasi. Alat pengenal ucapan digunakan sebagai pengganti operator yang memberikan informasi kepada pilot dengan cara berdialog.
B. Helikopter : Aplikasi alat pengenal ucapan pada helikopter digunakan untuk berkomunikasi lewat radio dan menyesuaikan sistem navigasi. Alat ini sangat diperlukan pada helikopter karena ketika terbang, sangat banyak gangguan yang akan menyulitkan pilot bila harus berkomunikasi dan menyesuaikan navigasi dengan terlebih dahulu memencet tombol tertentu.
C. Lain-Lain : Teknologi ini digunakan pada pengoperasian berbagai peralatan pesawat tempur seperti penentuan frekuensi radio, pengaktifan sistem autopilot, penentuan koordinat tuas kendali, parameter peluncuran senjata, pengaktifan sistem navigasi, dan pengaturan tampilan status penerbangan.
4. Entertainment
A. Pada beberapa games komputer,voice recognition digunakan untuk menyelesaikan misi-misi tertentu seperti pada game Tom Clancy’s End
War and Lifeline. Selain itu teknologi ini juga dapat digunakan untuk membantu proses pengetikan pada orang yang memiliki cacat pada bagian tangan.
B. Beberapa software yang menggunakan sistem teknologi Speech Recognition antara lain Microsoft Voice Command, Nuance Voice Control, VITO Voice2Go, Speereo Voice translator dan SVOX.
BAB III
KESIMPULAN
Suatu pengembangan sistem yang memungkinkan komputer untuk menerima masukan berupa kata yang diucapkan. Alat pengenal ucapan atau yang sering disebut dengan Speech Recognizer, membutuhkan sampel kata sebenarnya yang diucapkan dari pengguna. Penggunaan speech recognicition telah berkembang di berbagai sistem
device seperti pada OS Windows dengan Speech Recognition, smartphone Android, dan yang paling terkenal adalah aplikasi Siri pada iPhone.
DAFTAR PUSTAKA
“Pengertian Automatic Speech Recognition“http://rikyta.blogspot.com/2016/03/pengertian-automatic-speech-recognition.html Diunduh pada tanggal 9 November 2016. Pukul 12.30 WIB
“Speech Recognition” http://princessglad.blogspot.co.id/2014/11/speech-recognition.html diunduh pada tanggal 10 November 2016. Pukul 13.50 WIB “Speech Recognition” https://praptoprasojo.wordpress.com/2015/11/13/speech-recognition/. diunduh pada tanggal 10 november 2016. Pukul 14.50 WIB
“Automatic Speech Recognition”, http://www.slideshare.net/faizin2q1/paper-tentang-speech-recognition, diakses pada 9 November 2016. Pukul 12.45 WIB