Fakultas Ilmu Komputer
Universitas Brawijaya
6694
Analisis Sentimen Pada Ulasan Aplikasi Mobile Banking Menggunakan
Metode Support Vector Machine dan Lexicon Based Features
Katherine Ivana Ruslim1, Putra Pandu Adikara2, Indriati3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Analisis sentimen adalah bidang penelitian dalam text mining yang sangat populer. Ide dasar dari analisis sentimen adalah menemukan polaritas dari dokumen dan mengklasifikasikannya menjadi positif atau negatif. Dokumen teks yang digunakan dalam penelitian yaitu ulasan pada Google Play Store mengenai aplikasi mobile banking. Support Vector Machine merupakan metode yang digunakan serta menambahkan Lexicon Based Features sebagai pembaruan fitur selain menerapkan fitur Bag of Words. Data penelitian sebanyak 500 data dengan pembagian 90% data latih dan 10% data uji. Hasil evaluasi sistem yang didapatkan dengan gabungan fitur Bag of Words dan Lexicon Based Features lebih tinggi dibandingkan dengan hasil evaluasi sistem yang hanya menerapkan fitur Bag of Words maupun sistem yang hanya menerapkan Lexicon Based Features. Hasil evaluasi yang didapatkan oleh gabungan kedua fitur dengan pengujian menerapkan 10 fold cross validation yaitu accuracy = 0,846, recall = 0,846,
precision = 0,864, dan f-measure = 0,855 dengan nilai parameter Support Vector Machine yang
digunakan merupakan nilai parameter yang terbaik yaitu sigma kernel RBF = 3, lambda = 0,1, gamma = 0,001, complexity = 0,1, epsilon = 0,001, dan iterasi = 50.
Kata kunci: lexicon based features, support vector machine, analisis sentimen, mobile banking, bag of words Abstract
Sentiment analysis is a very popular field of research in text mining. The basic idea of sentiment analysis is finding the polarity of the document and classifying it into positive or negative. The text documents used in the research are reviews on the Google Play Store regarding the mobile banking application. Support Vector Machine is a method used and added Lexicon Based Features as additional feature besides using the Bag of Words. The research data is 500 data by dividing 90% training data and 10% test data. The system evaluation results obtained with a combination of Bag of Words and Lexicon Based Features are higher than the results of system evaluations that only use the Bag of Words and systems that only use Lexicon Based Features. The evaluation results obtained by the combination of the two features with testing using 10 fold cross validation are accuracy = 0,846, recall = 0,846, precision = 0,864, and f-measure = 0,855 with the Support Vector Machine parameter value used is the best parameter value of sigma kernel RBF = 3, lambda = 0,1, gamma = 0,001, complexity = 0,1, epsilon = 0,001, and iteration = 50.
Keywords: lexicon based features, support vector machine, sentiment analysis, mobile banking, bag of words
1. PENDAHULUAN
Saat ini industri perbankan melakukan berbagai inovasi keuangan yaitu mengalihkan focus mereka dari perbankan tradisional ke perbankan berbasis teknologi untuk memenuhi kebutuhan nasabah serta untuk meningkatkan daya saing. Mobile banking adalah salah satu dari inovasi tersebut. Mobile banking dapat didefinisikan sebagai melakukan berbagai
transaksi perbankan seperti transfer dana, pengecekan saldo, investasi, pembayaran tagihan yang dilakukan melalui penggunaan ponsel. Fasilitas ini menghilangkan batasan ruang dan waktu dari berbagai transaksi perbankan (Singh dan Sinha, 2016).
Berdasarkan inovasi dan fasilitas yang ditawarkan tersebut, banyak nasabah yang telah menggunakan aplikasi mobile banking dalam proses transaksi perbankan. Salah satu yang
populer dari beberapa aplikasi mobile banking yang tersedia dalam Google Play Store yaitu aplikasi mobile banking yang dimiliki oleh bank BCA yakni BCA Mobile. Total unduhan pengguna aplikasi BCA Mobile ini terhitung sampai dengan bulan Februari 2019 yaitu sebanyak 10 juta unduhan. Dalam penggunaannya, aplikasi tersebut tentu mendapatkan tanggapan berupa kritik serta saran dari pengguna aplikasi. Tanggapan terhadap penggunaan aplikasi ini dituliskan oleh pengguna aplikasi salah satunya pada kolom komentar pada laman Google Play Store. Tanggapan pengguna tersebut dapat digunakan oleh pengembang aplikasi untuk mengembangkan aplikasinya menjadi lebih baik.
Tanggapan dalam penggunaan pada aplikasi mobile banking ini masuk setiap harinya dengan jumlah tanggapan sebanyak ratusan sehingga tanggapan tersebut sulit untuk dipilah menjadi tanggapan yang termasuk positif atau termasuk tanggapan yang negatif. Dengan demikian untuk memecahkan perihal tersebut memerlukan sebuah sistem yang sanggup memilah tanggapan positif atau negatif untuk memudahkan pengembang aplikasi mengetahui tanggapan dari pengunaan aplikasi termasuk ke dalam tanggapan positif atau tanggapan yang negatif. Analisis sentimen merupakan bidang penelitian yang sangat populer dalam text mining dapat dijadikan sebagai cara untuk mengatasi hal tersebut. Ide dasar pada analisis sentimen ini yaitu menemukan polaritas dari dokumen dan mengklasifikasikannya menjadi positif atau negatif (Kaur, Mangat, dan Nidhi, 2017).
Metode dalam penelitian ini yang digunakan yaitu metode Support Vector
Machine sebagai metode pengklasifikasian
analisis sentimen menjadi positif atau negatif. Metode ini digunakan sebab pada penelitian Ilmawan dan Winarko (2015) mengenai analisis sentimen dengan objek aplikasi mobile dengan menggunakan data yang diambil dari komentar-komentar yang ada pada Google Play Store. Penelitian ini membuktikan bahwa metode
Support Vector Machine memiliki akurasi yang
lebih tinggi dibandingkan dengan akurasi yang diperoleh dari metode Naïve Bayes. Akurasi yang didapatkan dari metode Naïve Bayes adalah 83,87% sedangkan akurasi mengalami peningkatan dengan penggunaan metode
Support Vector Machine yaitu menjadi 89,49%.
Selain penelitian tersebut terdapat pula penelitian sebelumnya dengan objek analisis
sentimen yang menerapkan metode Support
Vector Machine yaitu penelitian oleh Windasari,
Uzzi, dan Satoto (2018) untuk analisis sentimen positif atau negatif terhadap transportasi online terutama GoJek. Metode ekstraksi fitur pada penelitian ini adalah unigram dan TF-IDF. Penelitian tersebut menghasilkan akurasi sebesar 86%.
Sementara itu untuk pembaruan fitur selain menerapkan fitur Bag of Words juga dapat menambahkan fitur lain yakni Lexicon Based
Features. Lexicon Based Features ini terbukti
menjadi fitur yang memiliki peranan paling penting pada analisis sentimen. Hal tersebut dibuktikan oleh Siddiqua, Ahsan, dan Chy (2016) dengan melakukan pemeringkatan pada tiap fitur dalam penelitian yang dilakukan. Pemeringkatan tiap fitur ini dilakukan dengan menerapkan metode seleksi fitur yaitu
information gain serta metode chi-square.
Penelitian ini diharapkan dapat melakukan analisis sentimen tentang ulasan aplikasi mobile
banking terutama aplikasi BCA Mobile sehingga
dapat diketahui akurasi serta pengaruh dari penerapan dari Lexicon Based Features di dalam analisis sentimen dengan menerapkan metode untuk klasifikasi yaitu Support Vector Machine. 2. METODE PENELITIAN
2.1. Data
Data ulasan aplikasi mobile banking yaitu aplikasi BCA Mobile adalah data yang berasal dari penelitian Onantya, Indriati, dan Adikara, 2019 (data sekunder). Data sebanyak 500 data dengan pembagian 90% data latih dan 10% data uji. Kamus yang digunakan terdiri dari kamus kata positif dan kata negatif, kamus kata sifat, kamus kata keterangan, kamus kata kerja, dan kamus kata penegasan. Kamus kata positif dan kata negatif serta kamus kata penegadasan merupakan kamus yang berasa dari penelitian Wahid dan Azhari, 2017. Kamus kata sifat, kamus kata keterangan, dan kamus kata kerja menggunakan API dari Kateglo (Kamus, Tesaurus, Glosarium).
2.2. Deskripsi Umum Sistem
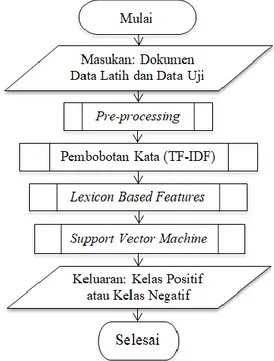
Pada Gambar 1. data latih dan data uji akan dijadikan masukan pada sistem yang selanjutnya akan melalui proses yaitu proses pre-processing dan proses pemberian bobot (pembobotan kata). Pada pemberian bobot ini terdiri dari dua proses pembobotan yaitu yang pertama adalah TF-IDF
dan berikutnya atau yang kedua adalah pemberian bobot dengan bantuan lexicon/kamus yaitu pada proses Lexicon Based Features. Berikutnya proses yang akan dilakukan yaitu menghitung berdasarkan metode yang diterapkan untuk klasifikasi yaitu metode
Support Vector Machine untuk mendapatkan
keluaran yang meliputi dua kelas yakni kelas yang positif atau kelas yang negatif.
Gambar 1.Diagram Alir Algoritme 2.3. Pre-processing
Pre-processing digunakan dalam
mempersiapkan data atau dokumen sebelum dilakukan proses yang lain. Proses
pre-processing mempunyai tujuan untuk
menghasilkan data yang sesuai dengan cara mendapatkan data yang memiliki isi yang lebih mudah untuk diproses dalam sistem. Penting melakukan proses ini di dalam analisis sentimen karena kata-kata atau kalimat memiliki noise yang tinggi dan berisi kata-kata yang tidak terstruktur (Mujilahwati, 2016). Pre-processing yang dilakukan meliputi empat sub-proses yakni
processing sub-proses case folding, pre-processing sub-proses cleaning, pre-pre-processing
proses stemming, dan pre-processing sub-proses tokenisasi.
2.4. Pembobotan Kata
Pembobotan kata yaitu tahap dalam pemberian bobot atau nilai untuk setiap kata yang berasal dari data latih. Metode pemberian bobot atau nilai yang dipilih dalam penelitian ini
yakni TF-IDF. Metode pemberian bobot ini dilakukan dengan cara melakukan pembobotan yang didasarkan pada banyaknya kata yang muncul di dalam dokumen (Windasari, Uzzi, dan Satoto, 2018). Metode ini terdiri dari lima sub-proses perhitungan bobot yakni perhitungan bobot TF, perhitungan bobot Wtf, perhitungan
bobot DF, perhitungan bobot IDF, dan perhitungan bobot terakhir yakni TF-IDF. 2.5. Lexicon Based Features
Lexicon Based Features merupakan tipe
dari fitur dengan didasari oleh knowledge atau pengetahuan yang memiliki focus pada memperoleh lexicon berdasarkan opini dari teks dan kemudian mengidentifikasi polaritas lexicon tersebut. Lexicon merupakan kumpulan istilah yang diketahui (Desai dan Mehta, 2017). Fitur ini memberikan bobot dengan membutuhkan bantuan lexicon/kamus untuk mengklasifikasikan dokumen menjadi sentimen yang positif atau sentimen yang negatif (Tiara, Sabariah, dan Effendy, 2015). Pembobotan kata dengan Lexicon Based Features terdiri dari perhitungan 15 fitur yaitu F1-F15 yang dapat dilihat rincian atau deskripsi dari 15 fitur tersebut dalam Tabel 1 (Siddiqua, Ahsan, dan Chy, 2016).
Tabel 1. Deskripsi Fitur Tipe Lexicon Based Features
Tipe Kode
Fitur Deskripsi Fitur
Lexicon Based Features
F1 Banyak kata positif yang terdapat di dalam dokumen.
F2 Banyak kata negatif yang terdapat di dalam dokumen.
F3 Banyak kata positif di dalam
adjective (kata sifat).
F4 Banyak kata negatif di dalam
adjective (kata sifat).
F5 Banyak kata positif di dalam verb (kata kerja).
F6 Banyak kata negatif di dalam
verb (kata kerja).
F7 Banyak kata positif di dalam
adverb (kata keterangan)
F8 Banyak kata negatif di dalam
adverb (kata keterangan)
F9 Persentase kata positif di dalam
adjective (kata sifat).
F10 Persentase kata negatif di dalam
F11 Persentase kata positif di dalam
verb (kata kerja).
F12 Persentase kata negatif di dalam
verb (kata kerja).
F13 Persentase kata positif di dalam
adverb (kata keterangan).
F14 Persentase kata negatif di dalam
adverb (kata keterangan).
F15 Banyak kata penegasan yang terdapat di dalam dokumen.
2.6. Support Vector Machine (SVM)
Support Vector Machine di dalam analisis
sentimen merupakan metode yang melatih pengelompokkan sentimen yang diambil berdasarkan banyaknya kemunculan berbagai kata yang terkandung di dalam dokumen atau dapat disebut juga metode ini termasuk dalam
supervised learning. Metode ini memiliki tujuan
yakni menentukan hyperplane optimal yang mempunyai margin maksimum. Margin dapat didefinisikan sebagai jarak antara titik terdekat dari setiap kelas atau support vector dengan
hyperplane (Croft, Metzler, dan Strohman,
2015).
Secara umum, kasus-kasus di dunia nyata bersifat non-linier sehingga hyperplane belum mampu melakukan pemisahan antara dua kelas dengan sempurna. Solusi untuk permasalan tersebut yaitu fungsi kernel (Nugroho, Witarto, dan Handoko, 2003). Kernel pada Support
Vector Machine terdiri dari Kernel Radial Basis Function (RBF), Kernel Linier, Kernel Sigmoid,
dan Kernel Polynomial. Pada penelitian ini, kernel yang akan dipilih dalam proses pembelajaran menerapkan metode Support
Vector Machine adalah RBF karena kernel RBF
ini menghasilkan persentase akurasi yang lebih tinggi dibandingkan Kernel Polynomial
berdasarkan penelitian yang dilakukan Darma, Perdana, dan Indriati (2018).
2.7. Sequential Training
Penelitian yang dilakukan Vijayakumar dan Wu (1999) mengenai metode pembelajaran pada
Support Vector Machine yakni sequential training memberikan hasil penelitian bahwa
metode pembelajaran tersebut dalam menemukan hyperplane memberi solusi yang optimal dalam klasifikasi yang memiliki dimensi yang tinggi. Metode ini memiliki algoritme yang sederhana sehingga waktu yang dibutuhkan tidak lama. Algoritme sequential training yakni:
1. Inisialisasi parameter yaitu σ (sigma) kernel
RBF, λ (lambda), iterasi maksimum, γ (gamma), 𝜀 (epsilon), dan C (complexity). 2. Inisialisasi nilai awal pada alpha dengan 0. 3. Lakukan perhitungan sesuai dengan
Persamaan (1) untuk mendapatkan nilai matriks Hessian.
𝐷𝑖𝑗=𝑦𝑖𝑦𝑗(𝐾(𝑥𝑖, 𝑥𝑗) + 𝜆2) (1)
4. Lakukan perhitungan sesuai dengan yang ditunjukkan pada Persamaan (2), Persamaan (3), dan Persamaan (4) untuk memperbarui nilai E (error) dan 𝛼 (alpha).
1. Ei = ∑𝑁𝑖 𝛼𝑗 𝐷𝑖𝑗 (2)
2. 𝛿𝛼𝑖 = 𝑚𝑖𝑛(𝑚𝑎𝑥[𝛾(1 − 𝐸𝑖), −𝛼𝑖], 𝐶 − 𝛼𝑖) (3)
3. 𝛼𝑖= 𝛼𝑖+ 𝛿𝛼𝑖 (4)
4. Melakukan langkah nomor 4 sampai nilai dari Max(δα)<ε atau sampai memenuhi kondisi iterasi maksimum.
5. Kemudian diperoleh nilai Support Vector (SV).
6. Selanjutnya melakukan perhitungan sesuai dengan Persamaan (5) untuk mendapatkan nilai bias. 𝑏 = −1 2(∑ 𝛼𝑖𝑦𝑖𝐾( 𝑁 𝑖=0 𝑥𝑖, 𝑥−) + ∑𝑁 𝛼𝑖𝑦𝑖𝐾(𝑥𝑖, 𝑥+ 𝑖=0 )) (5)
7. Hitung sesuai dengan Persamaan (6) untuk mendapatkan nilai fungsi f(x).
𝑓(𝑥) = ∑𝑁𝑖=0𝛼𝑖𝑦𝑖𝐾(𝑥𝑖, 𝑥) + 𝑏 (6)
3. PENGUJIAN DAN ANALISIS
Terdapat dua macam pengujian dalam sistem pada penelitian ini yakni pengujian parameter Support Vector Machine dan pengujian pengaruh Lexicon Based Features. Dilakukan pengujian pada parameter Support
Vector Machine dengan tujuan memperoleh nilai
dari parameter Support Vector Machine terbaik guna mencapai hasil evaluasi yakni accuracy yang memiliki nilai tinggi. Nilai dari parameter
Support Vector Machine yang akan dilakukan
pengujian terdiri dari nilai parameter σ (sigma)
kernel RBF, nilai parameter λ (lambda), nilai
parameter 𝜸 (gamma), nilai parameter C (complexity), nilai parameter ε (epsilon), dan
nilai parameter iterasi.
Pengaruh pada Lexicon Based Features diuji untuk melihat apakah penggunaan dari fitur ini memperoleh accuracy yang baik ataupun sebaliknya. Pengujian ini terdiri dari tiga pengujian yaitu pengujian Bag of Words, pengujian Lexicon Based Features, pengujian gabungan dari Bag of Words dan Lexicon Based
Features yang ketiga pengujian tersebut
klasifikasi Support Vector Machine dan menerapkan 10 fold cross validation.
3.1. Pengujian Nilai Parameter σ (Sigma) Kernel RBF
Pengujian nilai parameter sigma ini dilakukan untuk mengetahui nilai dari parameter
sigma yang terbaik. Pengujian ini menggunakan
nilai parameter lambda = 0,5, gamma = 0,001,
complexity = 1, epsilon = 0,0001, dan iterasi =
50. Pengujian menghasilkan grafik sesuai dengan yang ditampilkan pada Gambar 2.
Gambar 2. Grafik Hasil Evaluasi Nilai σ (Sigma) Seperti yang ditampilkan pada Gambar 2 dalam pengujian untuk mengetahui nilai sigma yang memperoleh hasil terbaik ditunjukkan pada saat nilai sigma = 3 yaitu memperoleh hasil
accuracy = 0,860, recall = 0,860, precision =
0,875, dan f-measure = 0,867. Hasil accuracy mengalami penurunan yaitu menjadi 0,460 pada saat nilai sigma = 4 atau saat nilai sigma semakin besar. Semakin besar nilai dari parameter sigma dapat merubah hasil accuracy menjadi menurun dan tidak stabil. Ini dibuktikan pada saat nilai parameter sigma = 10 menghasilkan nilai
accuracy = 0,520.
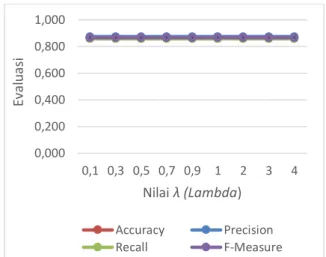
3.2. Pengujian Nilai Parameter λ (Lambda) Pengujian nilai parameter lambda ini dilakukan untuk mengetahui nilai dari parameter
lambda yang terbaik. Pengujian ini menggunakan nilai parameter sigma = 3, gamma = 0,001, complexity = 1, epsilon = 0,0001, dan iterasi = 50. Pengujian menghasilkan grafik sesuai dengan yang ditampilkan pada Gambar 3.
Gambar 3. Grafik Hasil Evaluasi Nilai λ (Lambda) Seperti yang ditampilkan pada Gambar 3 dalam pengujian untuk mengetahui nilai lambda yang memperoleh hasil terbaik menunjukkan hasil accuracy = 0,860, recall = 0,860, precision
= 0,875, dan f-measure = 0,867 terhadap seluruh
nilai lambda yang diujikan. Hal ini menunjukkan bahwa accuracy yang diperoleh tidak mengalami perubahan apabila nilai lambda yang diterapkan semakin kecil maupun semakin besar.
3.3. Pengujian Nilai Parameter ϒ (Gamma) Pengujian nilai parameter gamma ini dilakukan untuk mengetahui nilai dari parameter
gamma yang terbaik. Pengujian ini
menggunakan nilai parameter sigma = 3, lambda = 0,1, complexity = 1, epsilon = 0,0001, dan iterasi = 50. Pengujian menghasilkan grafik sesuai dengan yang ditampilkan pada Gambar 4.
Gambar 4. Grafik Hasil Evaluasi Nilai ϒ (Gamma) 0,000 0,200 0,400 0,600 0,800 1,000 Ev al u as i Nilai σ (Sigma) Accuracy Precision Recall F-Measure 0,000 0,200 0,400 0,600 0,800 1,000 0,1 0,3 0,5 0,7 0,9 1 2 3 4 Ev al u as i Nilai λ (Lambda) Accuracy Precision Recall F-Measure 0,000 0,200 0,400 0,600 0,800 1,000 0 ,0 0 00 0 0 1 0, 00 000 1 0 ,0 0 00 1 0 ,0 0 01 0 ,0 0 1 0 ,0 1 0 ,1 1 10 20 50 100 1000 Ev al u as i Nilai ϒ (Gamma) Accuracy Precision Recall F-Measure
Seperti yang ditampilkan pada Gambar 4 terhadap pengujian agar mengetahui nilai
gamma yang memperoleh hasil terbaik menunjukkan hasil accuracy = 0,860, recall = 0,860, precision = 0,875, dan f-measure = 0,867 pada saat nilai gamma = 0,001. Nilai gamma memiliki pengaruh pada kecepatan pembelajaran. Nilai gamma apabila semakin besar maka kecepatan pembelajaran pada sistem juga akan semakin besar untuk mencapai konvergensi. Apabila nilai gamma semakin besar akan mengurangi ketelitian yang ada pada sistem namun sebaliknya apabila nilai gamma kecil maka akan meningkatkan ketelitian yang dimiliki oleh sistem.
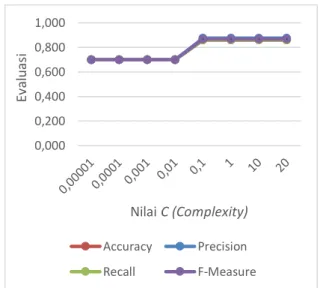
3.4. Pengujian Nilai Parameter C (Complexity)
Pengujian nilai parameter complexity ini dilakukan guna mengetahui nilai dari parameter
complexity yang terbaik. Pengujian ini menggunakan nilai parameter sigma = 3, lambda = 0,1, gamma = 0,001, epsilon = 0,0001, dan iterasi = 50. Pengujian menghasilkan grafik sesuai dengan yang ditampilkan pada Gambar 5.
Gambar 5. Grafik Hasil Evaluasi Nilai C (Complexity)
Seperti yang ditampilkan pada Gambar 5 dalam pengujian untuk mengetahui nilai
complexity yang memperoleh hasil terbaik
menunjukkan hasil accuracy = 0,860, recall = 0,860, precision = 0,875, dan f-measure = 0,867 pada saat nilai complexity = 0,1. Nilai
complexity berguna untuk mengontrol kesalahan
klasifikasi. Nilai complexity yang semakin besar dapat menyebabkan hasil accuracy yang
diperoleh menjadi meningkat. Hal tersebut dikarenakan nilai complexity yang diperbesar akan membuat penalti terhadap kesalahan pada klasifikasi semakin besar sehingga hanya sedikit data yang dapat melanggar batas pemisah antar dua kelas atau hyperplane.
3.5. Pengujian Nilai Parameter ε (Epsilon) Pengujian nilai parameter epsilon ini dilakukan guna mengetahui nilai dari parameter
epsilon yang terbaik. Pengujian ini menggunakan nilai parameter sigma = 3, lambda = 0,1, gamma = 0,001, complexity = 0,1, dan iterasi = 50. Pengujian menghasilkan grafik sesuai dengan yang ditampilkan pada Gambar 6.
Gambar 6. Grafik Hasil Evaluasi Nilai ε (Epsilon) Seperti yang ditampilkan pada Gambar 6 dalam pengujian untuk mengetahui nilai epsilon yang memperoleh hasil terbaik menunjukkan hasil accuracy = 0,860, recall = 0,860, precision
= 0,875, dan f-measure = 0,867 pada saat nilai epsilon = 0,001. Nilai epsilon berguna untuk
mengontrol perubahan yang terjadi dalam nilai
alpha. Konvergensi dini akan terjadi apabila
nilai epsilon yang diterapkan semakin besar dan akan mengakibatkan diperolehnya hasil
accuracy yang rendah.
3.6. Pengujian Nilai Parameter Iterasi
Pengujian nilai parameter iterasi ini dilakukan guna mengetahui nilai dari parameter iterasi yang terbaik. Pengujian ini menggunakan nilai parameter sigma = 3, lambda = 0,1, gamma = 0,001, complexity = 0,1, dan epsilon = 0,001. Pengujian menghasilkan grafik sesuai dengan yang ditampilkan pada Gambar 7.
0,000 0,200 0,400 0,600 0,800 1,000 Ev al u as i Nilai C (Complexity) Accuracy Precision Recall F-Measure 0,000 0,200 0,400 0,600 0,800 1,000 Ev al u as i Nilai ε (Epsilon) Accuracy Precision Recall F-Measure
Gambar 7. Grafik Hasil Evaluasi Nilai Iterasi Seperti yang ditampilkan pada Gambar 7 dalam pengujian untuk mengetahui nilai iterasi yang memperoleh hasil terbaik menunjukkan hasil accuracy = 0,860, recall = 0,860, precision
= 0,875, dan f-measure = 0,867 pada saat nilai
iterasi = 50. Nilai iterasi berguna untuk merubah nilai dari alpha. Hasil accuracy yang didapatkan apabila rendah disebabkan oleh nilai alpha masih belum mencapai konvergen sedangkan hasil accuracy yang didapatkan tersebut tinggi disebabkan alpha telah konvergen karena nilai iterasi memberi waktu bagi alpha sampai alpha tersebut mencapai konvergen.
3.7. Pengujian Pengaruh Lexicon Based Features
Pengujian ini akan melakukan perbandingan terhadap hasil evaluasi dari sistem yang hanya menggunakan fitur Bag of Words, sistem yang menerapkan Lexicon Based
Features, dan sistem yang menerapkan gabungan dari kedua fitur tersebut. Pengujian ini akan dilakukan dengan menerapkan 10 fold
cross validation. Nilai dari parameter Support Vector Machine yang akan digunakan pada
pengujian ini yakni nilai terbaik yang diperoleh dalam pengujian nilai parameter sebelumnya. Nilai-nilai tersebut yakni sigma = 3, lambda = 0,1, gamma = 0,001, complexity = 0,1, epsilon
= 0,001, dan iterasi = 50. Pengujian
menghasilkan grafik sesuai dengan yang ditampilkan pada Gambar 8.
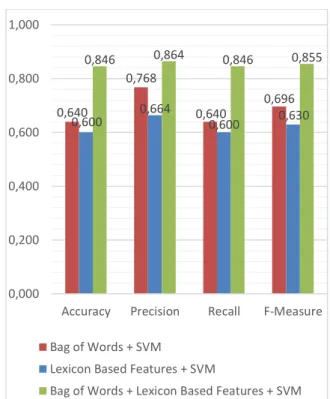
Gambar 8. Grafik Hasil Evaluasi Pengaruh Lexicon Based Features
Seperti yang ditampilkan pada Gambar 8 memberikan hasil yang menunjukkan bahwa hasil evaluasi sistem dengan gabungan fitur (Bag
of Words dan Lexicon Based Features)
memberikan hasil evaluasi sistem yang lebih tinggi dibandingkan hasil evaluasi sistem yang menerapkan fitur Bag of Words maupun hasil evaluasi sistem yang menerapkan Lexicon Based
Features.
Pada kata-kata tunggal yang didapatkan pada sistem yang menerapkan fitur Bag of Words hampir sama dalam tiap kelas sehingga tidak banyak kata yang bisa dijadikan pembeda. Hal ini bisa dibuktikan pada salah satu data uji yaitu “Sering bgt error, mobile banking bukannya
memudahkan malah menyulitkan nasabah kalo begini kejadiannya, bca sbg bank yg terkemuka hrsnya bs mengatasi masalah aplikasi kayak gini”. Data uji tersebut
diklasifikasikan salah oleh sistem karena pada data uji tersebut kata-kata tunggal yang didapatkan sama antara kedua kelas lebih banyak dibandingkan dengan kata-kata tunggal yang berbeda antara kedua kelas tersebut sehingga klasifikasi mendapatkan hasil pengklasifikasian yang salah. Hasil evaluasi yang didapatkan oleh sistem yang menerapkan fitur Bag of Words adalah accuracy = 0,640,
recall = 0,640, precision = 0,768, dan f-measure
= 0,696. 0,000 0,200 0,400 0,600 0,800 1,000 10 25 50 75 100 250 500 1000 Ev al u as i Iterasi Accuracy Precision Recall F-Measure 0,640 0,768 0,640 0,696 0,600 0,664 0,600 0,630 0,846 0,864 0,846 0,855 0,000 0,200 0,400 0,600 0,800 1,000
Accuracy Precision Recall F-Measure
Bag of Words + SVM
Lexicon Based Features + SVM
Beberapa kata yang digunakan pada sistem yang menerapkan Lexicon Based Features tidak terdapat di dalam kamus/lexicon. Hal ini dibuktikan pada salah satu data uji yaitu “Good
aplication Sangat membantu dan mempermudah transaksi dimana saja dan kapan saja..” yang mana hasil sistem ini
mendapatkan klasifikasi yang salah. Setelah data uji tersebut melalui proses pre-procesing mendapatkan kata-kata tunggal yaitu “good”,
“application”, “sangat”, “bantu”, “dan”, “mudah”, “transaksi”, “mana”, “saja”, “dan”, “kapan”, dan “saja”. Beberapa
kata-kata tunggal tersebut yaitu “good”,
“application”, “bantu”, “dan”, “transaksi”, “saja”, dan ”kapan” tidak terdapat di dalam lexicon/kamus sehingga pada saat pembobotan
kata berdasarkan lexicon menghasilkan nilai 0 dan dapat menurunkan accuracy. Hasil evaluasi yang didapatkan oleh sistem yang menerapkan
Lexicon Based Features adalah accuracy =
0,600, recall = 0,600, precision = 0,664, dan
f-measure = 0,630.
Penggabungan Lexicon Based Features dengan fitur Bag of Words menyebabkan sistem lebih bisa mengklasifikasikan data uji secara benar. Hal ini dibuktikan pada salah satu data uji yaitu “Buruk Mau masuk aja sulit banget...
Tolong dibenahi aplkasiny... Jangan mengecewakan konsumen, aplikasi ini sangat BURUK!!!!”. Pengujian data uji tersebut pada
sistem yang menerapkan fitur Bag of Words diklasifikasikan salah, pada sistem yang menerapkan Lexicon Based Features juga diklasifikasikan dengan salah sedangkan ketika digabungkan kedua fitur sistem dapat mengklasifikasikan dengan benar. Hal ini disebabkan penggabungan kedua fitur akan menutupi kelemahan dari tiap fitur. Selain itu kata-kata yang tidak masuk dalam kamus/lexicon, pada fitur Bag of Words kata-kata tersebut akan tetap dicatat sehingga fitur yang diperoleh akan menjadi lebih banyak dan
accuracy dari sistem dapat meningkat. Hasil
evaluasi yang didapatkan dengan gabungan kedua fitur adalah accuracy = 0,846, recall = 0,846, precision = 0,864, dan f-measure = 0,855. 4. KESIMPULAN
Berdasarkan hasil dari pengujian dan analisis dapat disimpulkan yaitu hasil accuracy tertinggi terhadap analisis sentimen pada ulasan aplikasi mobile banking dengan menerapkan metode Support Vector Machine adalah 0,860
dengan nilai-nilai dari parameter Support Vector
Machine terbaik yang digunakan meliputi nilai σ (sigma) Kernel RBF = 3, lambda = 0,1, gamma
= 0,001, complexity = 0,1, epsilon = 0,001, dan iterasi = 50.
Penambahan fitur selain Bag of Words yaitu
Lexicon Based Features mempunyai pengaruh
terhadap analisis sentimen pada ulasan aplikasi
mobile banking dengan penerapan Support Vector Machine apabila kedua fitur tersebut
digabungkan. Hasil evaluasi sistem dengan gabungan kedua fitur tersebut lebih tinggi dibandingkan dengan hasil evaluasi sistem yang menerapkan salah satu fitur yaitu sistem dengan penerapan fitur Bag of Words maupun sistem dengan penerapan Lexicon Based Features. Hasil evaluasi sistem yang didapatkan dengan gabungan kedua fitur yaitu accuracy = 0,846,
recall = 0,846, precision = 0,864, dan f-measure = 0,855. Penggabungan kedua fitur akan
menutupi kelamahan dari tiap fitur. Selain itu kata-kata yang tidak masuk dalam kamus/lexicon, pada fitur Bag of Words kata-kata tersebut akan tetap dicatat sehingga fitur yang diperoleh akan menjadi lebih banyak dan
accuracy dari sistem dapat meningkat.
Penerapan dari Lexicon Based Features akan menjadi lebih optimal apabila daftar kata-kata yang ada lebih lengkap. Hal ini dapat dilakukan dengan cara menambahkan kata-kata positif maupun kata-kata negatif ke dalam kamus/lexicon.
5. DAFTAR PUSTAKA
Croft, W.B., Metzler, D. and Strohman, T., 2015.
Search Engines: Information Retrieval in Practice. Pearson Education, Inc.
Darma, I.M.B.S., Perdana, R.S. and Indriati, 2018. Penerapan Sentimen Analisis Acara Televisi Pada Twitter Menggunakan Support Vector Machine dan Algoritma Genetika sebagai Metode Seleksi Fitur. Jurnal Pengembangan
Teknologi Informasi dan Ilmu
Komputer, pp.998–1007.
Desai, M. and Mehta, M.A., 2017. Techniques for Sentiment Analysis of Twitter data: A Comprehensive Survey. Proceeding -
IEEE International Conference on
Computing, Communication and
Automation, ICCCA 2016, pp.149–154.
Ilmawan, L.B. and Winarko, E.W., 2015. Aplikasi Mobile untuk Analisis Sentimen pada Google Play. IJCCS,
9(1), pp.53–64.
Kaur, H., Mangat, V. and Nidhi, 2017. A Survey of Sentiment Analysis Techniques.
Proceedings of the International Conference on IoT in Social, Mobile, Analytics and Cloud, I-SMAC 2017,
pp.921–925.
Mujilahwati, S., 2016. Pre-Processing Text Mining Pada Data Twitter. Seminar
Nasional Teknologi Informasi dan Komunikasi, 2016 (Sentika), pp.2089–
9815.
Nugroho, A.S., Witarto, A.B. and Handoko, D., 2003. Support Vector Machine - Teori dan Aplikasinya dalam Bioinformatika.
Proceeding of Indonesian Scientific Meeting in Central Japan, pp.842–847.
Onantya, I.D., Indriati and Adikara, P.P., 2019. Analisis Sentimen Pada Ulasan Aplikasi BCA Mobile Menggunakan BM25 dan Improved K-Nearest Neighbor. Jurnal
Pengembangan Teknologi Informasi dan Ilmu Komputer, pp.2575–2580.
Siddiqua, U.A., Ahsan, T. and Chy, A.N., 2016.
Combining a Rule-based Classifier with Ensemble of Feature Sets and Machine Learning Techniques for Sentiment
Analysis on Microblog. 19th
International Conference on Computer and Information Technology, pp.304 -
309.
Singh, N. and Sinha, N., 2016. Comparative Analysis of Public and Private A Study on Mobile Banking and its Impact on Customer’s Banking Transactions: A Comparative Analysis of Public and Private Sector Banks in India. Journal of
Business & Change Management,
pp.98–105.
Tiara, Sabariah, M.K. and Effendy, V., 2015. Sentiment Analysis on Twitter Using The Combination of Lexicon-based and Support Vector Machine for Assessing The Performance of A Television Program. 2015 3rd International Conference on Information and Communication Technology, ICoICT 2015, pp.386–390.
Vijayakumar, S. and Wu, S., 1999. Sequential
Support Vector Classifiers and Regression. Proc. International
Conference on Soft Computing
(SOCO'99), Genoa, Italy, [e-journal]
610(10).
Wahid, D.H. and SN, A., 2016. Peringkasan Sentimen Esktraktif di Twitter Menggunakan Hybrid TF-IDF dan Cosine Similarity. Ijccs, pp.207–218. Windasari, I.P., Uzzi, F.N. and Satoto, K.I.,
2018. Sentiment Analysis on Twitter Posts: An Analysis of Positive or Negative Opinion on GoJek.
Proceedings - 2017 4th International Conference on Information Technology, Computer, and Electrical Engineering, ICITACEE 2017, pp.266–269.