PENGENALAN
SONG-TYPE
BURUNG
ORTOLAN BUNTING
MENGGUNAKAN PENDEKATAN
HIDDEN MARKOV
MODELS
SKRIPSI
Diajukan untuk Memenuhi Salah Satu Syarat
Memperoleh Gelar Sarjana Teknik
Program Studi Teknik Informatika
Oleh:
Lydia Rizcy Arimbi
NIM
: 055314072
PROGRAM STUDI TEKNIK INFORMATIKA
JURUSAN TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
HALAMAN PERSEMBAHAN
Ketika segala macam ujian dan pencobaan menekan hidup kita,
jangan menganggap semua itu seperti para penyusup,
tetapi sambutlah mereka seperti para kawan.
Skipsi ini saya persembahkan untuk :
Yesus Kristus,
keluarga, sahabat-sahabat dan kekasih.
Terima kasih untuk segalanya.
DAFTAR ISI
HALAMAN JUDUL BAHASA INDONESIA... ...I
HALAMAN JUDUL BAHASA INGGRIS ... ..II
HALAMAN PERSETUJUAN ... .III
HALAMAN PENGESAHAN... .IV
HALAMAN PERSEMBAHAN ... ..V
HALAMAN PERNYATAAN KEASLIAN KARYA ... .VI
HALAMAN PERSETUJUAN PUBLIKASI ... VII
ABSTRAK ... VIII
ABSTRACT... .IX
KATA PENGANTAR... ...X
DAFTAR ISI... XII
I. PENDAHULUAN ... …1
1.1. Latar Belakang dan Deskripsi Topik ... ....1
1.2. Rumusan Masalah ... …2
1.3. Tujuan ... …2
1.4. BatasanMasalah… ... ...3
1.5. Metodologi Penelitian ... …3
1.6. Sistematika Penulisan ... …4
II. LANDASAN TEORI ... …6
2.1. Teori
Speech Recognition
(Pengenalan suara) ... …6
2.1.1.
Feature Analysis
... …7
2.1.2.
Accoustic Modeling
... …8
2.1.3.
Language Modeling
... …8
2.2.
Feature Extraction
... …8
2.2.1.
Greenwood function cepstral coefficients
(GFCC)... …9
2.2.2.
Greenwood function cepstral coefficients
(GFCC)
Delta dan delta-delta ... ..13
2.3. Hidden Markov Models (HMM) ... ..14
2.3.1. Teori Markov Model... ..14
2.3.2. Definisi HMM... ..16
2.3.3. Algoritma
Viterbi
... ..22
2.3.4. Algoritma
Baum-Welch
... ..23
III.METODOLOGI ... ..27
3.1. Data... ..27
3.2. Skema Pengenalan Suara menggunakan HMM ... ..32
3.2.1.
Feature extraction
... ..33
3.2.2. Tahap
Training
... ..34
3.2.3. Tahap
Testing
... ..35
3.3. Kebutuhan Perangkat Lunak ... ..37
3.4. Kebutuhan Perangkat Keras ... ..37
3.5. Perancangan Antar Muka ... ..38
3.5.1. Halaman
Home
... ..38
3.5.2. Halaman Pengenalan
Song-type
... ..39
3.5.3. Halaman Pengujian Akurasi
Hidden Markov Models
... ..40
3.5.4. Halaman Bantuan... ..41
3.5.5. Halaman Tentang Program ... ..42
IV. IMPLEMENTASI DAN ANALISA ... . 43
4.1. Hasil Penelitian... ..43
4.2. Implementasi Antar Muka yang Digunakan pada Sistem ... ..48
4.2.1. Halaman Utama ... ..48
4.2.2. Halaman Pengenalan
Song-type
... ..50
4.2.3. Halaman Pengujian
Hidden Markov Models
... ..52
4.2.4. Halaman Bantuan... ..54
V. PENUTUP... ..56
5.1. Kesimpulan... ..56
5.2. Saran ... ..57
DAFTAR PUSTAKA... ..58
HALAMAN LAMPIRAN LISTING PROGRAM... ..60
HALAMAN LAMPIRAN FILE HMM... ..93
BAB I
PENDAHULUAN
1.1.
Latar Belakang dan Deskripsi Topik
Perkembangan teknologi informasi saat ini mengalami kemajuan yang
sangat pesat. Berbagai pemanfaatan teknologi informasi menghasilkan informasi
yang dapat meningkatkan kinerja manusia. Perkembangan teknologi
speech
recognition
(pengenalan suara) adalah salah satu bentuk perkembangan teknologi
di abad ke 20 yang memanfaatkan suara sebagai masukan. Komputer akan
mengenali suara sebagai perintah dan memberi terhadap perintah tersebut.
Teknologi pengenalan suara dapat diimplementasikan untuk mengenali
suara binatang. Teknik-teknik yang digunakan untuk mengenal pola suara
binatang dengan variasi vokalisasi dibagi menjadi 2 kategori yaitu kualitatif dan
kuantitatif (Mc.Gregor et al., 2000). Pendekatan kualitatif meliputi perbandingan
spectogram
yang dilakukan oleh para peneliti. Kebanyakan peneliti biologi
mengenal suara binatang dengan sonogram yaitu deskripsi dari sebuah
spectogram
. Pendekatan ini mempunyai konsep yang sederhana dan kemudahan
dalam pengoperasian (Wakita, 1976). Akan tetapi,
variable
yang dilibatkan dalam
perhitungan dengan
spectogram
tidak cukup untuk menggambarkan karakteristik
dari isi
spectrum
dan pola
signal
sehingga tingkat akurasinya rendah. Untuk itu,
diperlukan metode kuantitatif yang lebih teliti dalam pengukuran secara detail
parameter frekuensi dan parameter
temporal
dari suatu vokalisasi. Salah satu
membutuhkan waktu yang lama dalam pengoperasian, dan hasil akurasi yang
diperoleh tinggi.
Dalam penulisan tugas akhir ini, akan diterapkan pendekatan
Hidden
Markov Models
untuk mengenal
song-type
burung
Ortolon Bunting
. Burung ini
bermigrasi tersebar dari Eropa Barat ke Mongolia (Cramp, Perrins, 1994). Burung
ini mempunyai ciri khas suara yang unik. Suara yang dihasilkan mempunyai
variasi
song-type.
Burung ini mempunyai
song-type
yang berbeda untuk setiap
individu. Setiap burung mempunyai dua sampai tiga
song-type
.
1.2.
Rumusan Masalah
Dari latar belakang diatas dapat dirumuskan masalah sebagai berikut :
1. Bagaimana komputer secara otomatik dapat mengenal
song-type
burung?
2. Bagaimana mengimplementasikan pendekatan
Hidden Markov Models
(HMM) yang banyak digunakan dalam teknologi
Speech Recognation
untuk mengenali
song-type
burung?
3. Bagaimana tingkat akurasi pengenalan
song-type
burung dengan
menggunakan metode HMM?
1.3
Tujuan
Adapun tujuan dari penelitian ini adalah
1. Merancang dan mengimplementasikan metode HMM untuk mengenal
2. Menganalisa dan mengetahui keakuratan metode HMM dalam
penerapan pengenalan
song-type
burung
Ortolan Bunting
.
1.4
Batasan Masalah
Dalam pengenalan jenis nyanyian burung dilakukan beberapa batasan
sebagai berikut :
1. Suara yang dapat diproses adalah suara wav (*.WAV).
2. Ekstrak
ciri
dilakukan
dengan
menggunakan
metode
GFCC
(
Greenwood Functions Ceptral Coefficients
).
3. Pemodelan suara burung menggunakan metode HMM (
Hidden
Markov Models
).
4. Jumlah data ada lima
song-type
burung dan setiap
song-type
ada 100
song
.
5. Bahasa pemrograman yang digunakan adalah
MATLAB 6.5
.
1.5.
Metodologi Penelitian
Metodologi yang digunakan untuk penelitian sebagai berikut :
1. Studi pustaka dan literature
Tahap ini akan mempelajari teori-teori tentang pengenalan suara
(
Speech Recognition)
,
feature
extraction, metode HMM, algoritma
Baum-
Welch, algoritma
Viterbi
yang kesemuanya bersumber dari
2. Akuisisi Data
Tahap ini mengolah sampel nyanyian burung
Ortolon Bunting
dari
koleksi data yang tersedia.
3. Implementasi
Pada tahap ini akan dibuat desain
user interface
serta berbagai tombol
atau fungsi yang akan digunakan untuk membangun perangkat lunak
sebagai alat bantu untuk pengenalan
song-type
burung.
4. Pengujian dan analisa
Pada tahap ini akan dilakukan pengujian dan menganalisis hasil
akurasi dengan menggunakan pendekatan HMM.
5. Kesimpulan
Pembuatan kesimpulan dari hasil dan analisa yang dilakukan pada
tahap pengujian.
1.6.
Sistematika Penulisan
BAB I, Pendahuluan
Berisi latar belakang yang mengarah pada deskripsi topik, rumusan
masalah, batasan sistem, tujuan penelitian, metode penelitian, serta
sistematika penulisan.
BAB II, Landasan Teori
Berisi tentang teori-teori yang dipakai dalam implementasi, yaitu
Models
),
feature extraction,
algoritma
Baum-Welch
dan algoritma
Viterbi
.
BAB III, Metodologi
Berisi tentang bagaimana perancangan dan pengimplementasian
metode
Hidden Markov Models
dan desain
user interface
untuk
membangun perangkat lunak sebagai alat bantu pengenalan
song-type
burung.
BAB IV, Implementasi dan Analisa
Berisi tentang implementasi dari program yang dibuat sehingga
menghasilkan akurasi serta analisis dari sistem yang dibuat.
BAB V, Penutup
BAB II
LANDASAN TEORI
Pada bab ini akan dijelaskan beberapa teori yang menunjang perancangan
dan implementasi pengenalan
song-type
burung. Bagian ini mencakup : teknologi
Speech Recognition
,
feature extraction
dan HMM.
2.1
Teori
Speech Recognition
(Pengenalan suara)
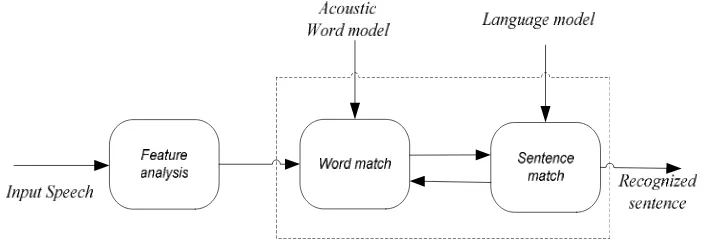
Gambar 2.1 Blok diagram sistem pengenalan suara (Rabiner,1996)
Gambar 2.1 menunjukkan blok diagram suatu sistem pengenalan suara.
Speech Recognition
(pengenalan suara) merupakan metode untuk pengembangan
dan pengimplementasian algoritma pada komputer untuk mengenal
linguistic
content
dari suatu suara. Sinyal suara merupakan sinyal yang kompleks yang tidak
mudah diuraikan. Hasil sinyal suara antara orang yang satu berbeda dengan yang
lain. Suatu sinyal suara bisa berbeda, meskipun diucapkan oleh orang yang sama
terdiri dari beberapa tahap yaitu:
feature analysis, accoustic modeling
dan
language modeling.
2.1.1.
Feature analysis
Pada
feature analysis
, suara akan diekstrak menjadi sebuah rangkaian
feature
vektor
X
yang mengandung informasi yang relevan tentang rangkaian kata
dari suatu suara.
Feature analysis
melakukan konversi sinyal suara ke dalam
bentuk rangkaian
feature
vector
yang akan digunakan pada saat klasifikasi.
Analisis suara dikerjakan pada sebuah ukuran frame tertentu pada
analysis
window
. Sebuah
window
dengan ukuran 3 ms sampai 6 ms dapat digunakan untuk
feature analysis
.
Fourier
adalah metode yang banyak digunakan untuk
mengekstrak
feature spectral
untuk pengenalan suara. Tujuan dari
feature
analysis
adalah menghitung parameter sebuah vokalisasi menjadi sebuah vektor
feature
yang berisi informasi suatu vokalisasi
. Feature analysis
pada
speech
recognition
terdiri dari tiga proses:
1. Beberapa deteksi suara digunakan untuk menghapus bagian
yang
bukan merupakan suara.
2.
Feature
diekstraksi untuk mendapatkan informasi.
3. Beberapa kompensasi sinyal diterapkan.
2.1.2.
Accoustic modeling
Accoustic modeling
digunakan untuk memodelkan secara statistik hasil
sistem harus dapat menentukan nilai
P
(
X
│
W
), kemungkinan dari observasi
X
bila
diketahui sebuah rangkaian suara tertentu
W.
2.1.3.
Language modeling
Language modeling
digunakan untuk memodelkan bentuk kata baik
berupa kata, fonem, ataupun kalimat. Awalnya sistem pengenalan suara hanya
menggunakan
informasi
akustik
untuk
mengevaluasi
kemungkinan.
Perkembangan pada sistem pengenalan suara yaitu pemisahan bahasa untuk
meningkatkan akurasi. Struktur dan
grammar
rangkaian kata meningkatkan
akurasi sistem pengenalan suara dengan menghapus rangkaian kata yang baru
yang tidak sesuai dengan
grammar
(Seneff, 1992).
Feature Extraction
Pengenalan
song-type
burung yang menggunakan data yang mempunyai
label disebut sebagai “
supervised”
. Data suara yang diambil merupakan data
signal
(audio). Namun tidak semua data audio tersebut yang digunakan, sehingga
diperlukan proses
feature extraction
untuk mengambil
feature
yang digunakan.
Feature
yang diekstrak diharapkan mempunyai kemampuan untuk membedakan
kemiripan vokalisasi serta untuk membuat model tanpa membutuhkan sebuah data
training
yang berlebihan.
Adapun tujuan dari proses
feature extraction
adalah untuk parameterisasi
suara (audio) ke dalam rangkaian
vector feature
, sehingga dapat mewakili
2.2.1.
Greenwood function cepstral coefficients (GFCC)
Greenwood function cepstral coefficients
(GFCC) merupakan salah satu
pendekatan yang digunakan untuk mengekstrak
feature
berdasarkan pada
perceptual model
dari spesies. Dalam kasus ini adalah suara spesies burung
Ortolan Bunting
.
Greenwood
(Greenwood , 1961, 1990) menjelaskan bahwa beberapa dari
spesies mamalia baik yang di darat maupun di air dapat menerima frekuensi pada
skala algoritmik dengan persamaan sebagai berikut :
= (10
−
)
(2.1)
Keterangan :
f
merupakan frekuensi (Hz)
A, a
dan
b
merupakan konstanta untuk masing-masing spesies
x
merupakan posisi dari selaput pendengaran
Untuk frekuensi
f
, maka pendefinisian frekuensi
warping
sebagai berikut :
( ) =
( + )
(2.2)
Konstanta
A
dan
a
dapat diperoleh sebagai berikut :
dimana range pende
(
LePage
, 2003).
Vocalization
waveform
Gam
Proses ekstrak
menjadi beberapa fram
data suara kemudia
didefinisikan sebagai
dimana
x(n)
adalah si
berkorespondensi den
dalam Hz dan
w(n)
hamming window
deng
ndengaran spesies tersebut
dan
Windowed FFT Greenwood filterbank Discrete cosine transform
ambar 2.2.
Blok diagram perhitungan GFCC
kstrak ciri bisa dilihat pada gambar 2.2. Siny
frame dan masing-masing frame disebut
window
udian ditransformasi menggunakan
fast fouri
ai berikut :
h sinyal dalam waktu dengan panjang
N; k=
0,1,...
dengan frekuensi
f
(
k
) =
kfs
/
N
,
f
s adalah sam
n)
adalah
time-window
.
Time-window
yang di
dengan
w(n) = 0.54 - 0.46cos(pn/N)
.
(2.4)
dan nilai
b
=0,88
Ceptral
coefficients
nyal suara dibagi
ndow
.
Window
dari
ourier transform
,
(2.5)
0,1,...
N
-1 dan
k
sampling frekuensi
Suara burung
Ortolan Bunting
mempunyai jangkuan frekuensi yang lebih
tinggi dari suara manusia.
Window-sizes
untuk suara burung adalah antara 3 ms
hingga 6 ms sehingga untuk setiap ukuran frame adalah satu-setengah dari
window-sizes
dengan
overlap
secara berturut-turut sebesar 50% dari
window-sizes
. Besarnya koefisien |
X(k)
| dikorelasikan dengan masing-masing
triangular
filter
dalam
Greenwood filterbank (k, m)
. Korelasi ini berarti koefisien magnitude
dari
fast fourier transform
dikalikan dengan
filter-gain
, didefinisikan sebagai
berikut :
( ) =
(
∑
| ( )| ( ,
))
(2.6)
untuk
m
= 1, 2, …,
M
, dimana
M
adalah jumlah dari
filterbank
dan
M<<N
.
Greenwood filterbank
merupakan kumpulan dari
triangular filter
yang
didefinisikan oleh frekuensi-frekuensi utama. Frekuensi utama pada
Greenwood
filterbank
dihitung dengan menggunakan skala
Greenwood
pada persamaan (2.2).
Triangular filter
terdapat diseluruh jangkauan frekuensi dari nol hingga frekuensi
Nyquist
.
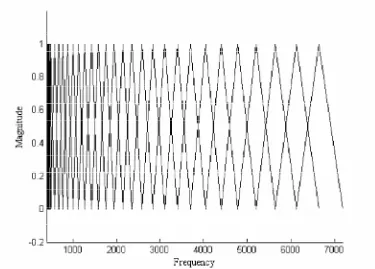
Band-limiting
menggunakan frekuensi bawah dan atas untuk me-
reject
frekuensi yang tidak diinginkan. Pada
Greenwood filterbank
, untuk suara burung
Ortolan Bunting
menggunakan jangkauan frekuensi dari 400 hz hingga 7400 Hz
(gambar 2.3) supaya sesuai dengan
−
dari
song
burung (Edwards,
Gambar 2.3.
Greenwood filterbank
Gambar 2.3 merupakan proses pada
Greenwood filterbank.
Pada proses ini
sinyal suara akan di
filter
sehingga menghasilkan
feature
yang tidak berkorelasi.
Amplitudo
filterbank
biasanya berkorelasi dan penggunaan dari sebuah
transformasi
cepstral
memberikan gambaran yang lebih baik untuk pengenalan
pola.
Discrete cosine transform
digunakan untuk menghitung koefisien
cepstral
dari log amplitudo
filterbank
sebagai berikut :
(
) =
∑
( )cos (
(
−
0,5))
(2.7)
2.2.2.
Greenwood function cepstral coefficients (GFCC) Delta dan
delta-delta
Vektor-vektor
feature
dihitung dari fungsi
Greenwood
yang memberikan
sebuah perkiraan yang terbaik dari
local spectra
. Karakteristik yang penting dari
data vokalisasi ini dinamis vokalisasi. Kinerja sistem suara dapat ditingkatkan
dengan menambah waktu turunan pada parameter statis. Banyak peneliti
memanfaatkan perkiraan daerah turunan waktu.
Delta cepstrum
(Furui, 1986)
adalah
salah
satu
bentuk
umum
dari
langkah
ini.
Delta
cepstrum
diimplementasikan sebagai turunan pertama koefisien regresi. Turunan waktu
dinyatakan sebagai berikut :
=
∑ ( )∑
(2.8)
dimana d
tadalah koefisien delta pada waktu t dihitung dalam jangka koefisien
waktu statis c
t-khingga c
t+k.
Turunan kedua, disebut sebagai delta-delta
cepstrum
atau koefisien
percepatan, sesuai dengan penerapan korelasi yang sama pada koefisien delta.
Sebagian besar sistem yang memadukan
feature
delta dan delta-delta. Kedua
feature
tersebut digunakan sebagai tambahan pada perhitungan statis seperti
2.3
Hidden Mar
2.3.1. Teori Markov
Markov mode
state (setiap transisi da
dari state-state tersebut
Dalam Markov
probabilitas observasi
dilakukan pada waktu
P
(S
n│
Untuk mempe
observasi-observasi se
menjadi :
Contoh soal :
Misalkan terda
dengan tabel probabi
berdasarkan cuaca har
Markov Models
(HMM)
kov Model
odel merupakan sistem dengan serangkaian st
si dari state mempunyai sebuah probabilitas) di
sebut disebut dengan
Markov chain.
rkov model atau
first-order-Markov
mengasum
vasi pada waktu
n
hanya tergantung pada obse
ktu
n
-1. Untuk serangkaian {S
1,S
2,...,S
n} maka
│
S
n-1,S
n-2,...,S
1) =
P
(
Sn│
Sn
-1)
(asumsi Markov)
mperoleh probabilitas gabungan (
joint probabi
si sebelumnya maupun observasi sekarang da
rdapat 3 tipe cuaca : “
sunny”, ”rainy”
dan “
abilitas
P
(
Sn+1│Sn
) cuaca yang akan terjadi
hari ini (
Sn
) yang terlihat pada tabel 2.1.
state dan transisi
dimana rangkaian
asumsikan bahwa
observasi
Sn
-1yang
Markov)
(2.9)
probability
) dari
dapat diturunkan
(2.10)
n “
foggy
”, berikut
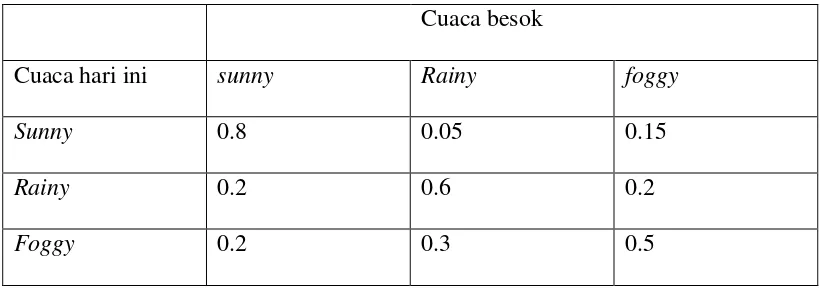
Tabel 2.1.
Probabolitas
P
(
Sn+1│
Sn
) cuaca yang akan terjadi besok berdasarkan
cuaca hari ini
Cuaca besok
Cuaca hari ini
sunny
Rainy
foggy
Sunny
0.8
0.05
0.15
Rainy
0.2
0.6
0.2
Foggy
0.2
0.3
0.5
State yang ada
q
= {“
sunny”, ”rainy”
, “
foggy
”} dan setiap hari mempunyai
kemungkinan transisi
P
(
Sn│
Sn
-1) state berdasarkan tabel probabilitas 2.1.
1.
Jika hari ini cuacanya adalah “
sunny”
berapakah probabilitas besok
bercuaca “
sunny”
dan hari berikutnya (
S3
) adalah
“rainy”
?
P(S2=sunny, S3=rainy| S1=sunny) = P(S3=rainy, S2=sunny| S1=sunny) .
P(S2=sunny| S1=sunny)= P(S3=rainy| S2=sunny) . P(S2=sunny| S1=sunny)
=
0.05 . 0.8 = 0.04
2.
Jika cuaca kemarin
S1
adalah “
rainy”
dan cuaca hari ini
S2
adalah “
foggy”,
berapakah probabilitas besok
S3
dengan cuaca “
sunny”
?
P(S3=sunny| S2=foggy, S1=rainy)= P(S3=sunny| S2=foggy)= 0.2
2.3.2
Definisi HMM
Hidden Markov Models
(HMM) adalah sebuah model statistik yang
diasumsikan dari rantai Markov dengan parameter yang tidak diketahui. Metode
probabilitas
dari model yang dimasukkan.
Hidden Markov Models
merupakan rantai markov dengan himpunan
state
terbatas yang menghasilkan suatu barisan pengamatan dan bersifat tersembunyi
(
hidden
). Perubahan atau perpindahan
state
direpresentasikan oleh suatu
himpunan peluang yang dinamakan matriks peluang transisi.
Hidden Markov
Models
dibangun oleh suatu kejadian yang tersembunyi
hidden
. HMM digunakan
untuk pembuatan model pada proses
training
dan
testing
. Bentuk model HMM
berupa state-state yang saling berhubungan. Proses
training
bertujuan untuk
membuat model untuk data suara burung. Pemodelan ini berupa model yang
bersifat kontinu untuk data suara.
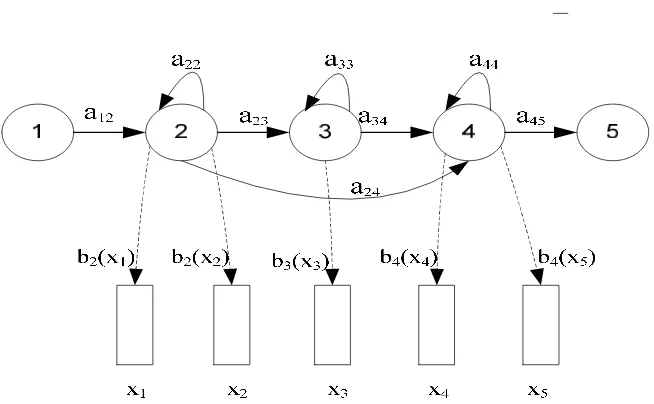
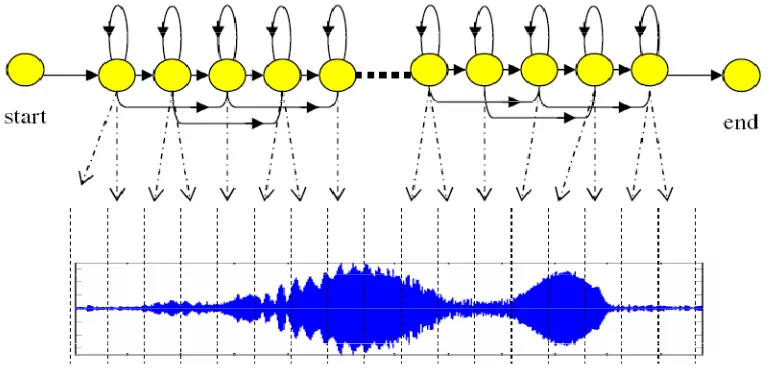
Gambar 2.4.
HMM dari kiri ke kanan (after Young et al., 2002)
Gambar 2.4 merupakan salah satu contoh rangkaian HMM dari kiri ke
kanan dimana ada sebuah lima model state yang bergerak melalui rangkaian state
3 dan 4 mempunyai
state tersebut. Matriks
berikut :
aij=
Probabilitas ke
bergerak melalui rang
transisi dan probabili
berikut :
Pendekatan ini
state
S
tersembunyi (
hi
HMM didefini
{
s
} ada
akhir
S
{
aij
} a
{
bj(k)
}
a
dan
b
memenuhi sif
ai hasil probabilitas yang saling berhubungan
riks pada model ini mempunyai 5 baris dan 5
0 1 0 0 0
0 0.3 0. 4 0. 3 0
0 0 0.3 0.7 0
0 0 0 0.3 0.7
0 0 0 0 0
keseluruhan adalah
X
yang dihasilkan oleh
angkaian state
S
adalah hanya dihitung hasil
bilitas output. Jadi rangkaian state pada gam
P ( X , S
│
M )= a
12b
2(x
1) a
22b
2(x
2) a
23b
3(x
3)...
ini, hanya rangkaian observasi
X
yang diketahui
hidden
). Pendekatan ini disebut
Hidden Mark
inisikan oleh sebuah kumpulan parameter (
adalah kumpulan state yang menyatakan state a
SF
} adalah probabilitas sebuah transisi dari state
i
} adalah probabilitas dari keluaran output
k
pa
sifat sebagai berikut :
gan dengan model
5 kolom sebagai
h model HMM
M
sil dari probabilitas
ambar 2.4 sebagai
(2.13)
ahui dan rangkaian
arkov Model
.
e awal
S1
dan state
i
sampai state
j
Ada dua asum
Markov
pada persa
independence
. Proba
observasi
xi
sehingga pr
Dengan memperhatika
maka masing-masing
probabilitas
P(xi)
yan
berikut :
Contoh soal :
Pada contoh
langsung sedangkan p
dapat kita umpamaka
hari (tidak dapat me
sumsi pada sebuah deret pertama HMM. Pertam
rsamaan (2.10). Asumsi kedua adalah a
obabilitas pada masing-masing state diperol
ngga probabilitas
P(Si|xi)
dapat dirumuskan sebaga
tikan probabilitas
P(xi)
yang tidak berubah unt
sing potensi state yang akan diuji atau diperiksa
ang sama sehingga persamaan 2.14 dapat dirum
oh Markov model, keadaan cuaca dapat diobse
n pada HMM, cuaca-cuaca dalam keadaan “
hi
akan seandainya kita dikunci disebuah kamar
elihat kondisi luar). Untuk melakukan predi
ama adalah asumsi
asumsi
output-roleh berdasarkan
bagai berikut :
(2.14)
untuk setiap state
periksa mempunyai
dirumuskan sebagai
(2.15)
diobservasi secara
hidden”
. Hal ini
ar untuk beberapa
akan terjadi, maka hanya terdapat tanda yaitu pada orang yang setiap datang ke
kamar untuk membawakan makanan, apakah orang tersebut membawa payung
atau tidak.
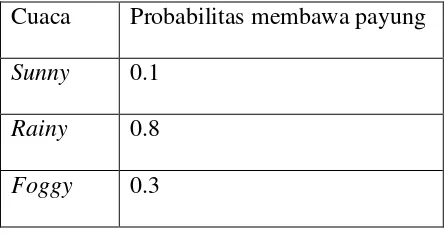
Tabel 2.2
. Probabilitas
P(xi|Si)
membawa payung berdasarkan cuaca
Si
pada hari
i
Cuaca
Probabilitas membawa payung
Sunny
0.1
Rainy
0.8
Foggy
0.3
Tabel 2.2 merupakan probabilitas membawa payung berdasarkan keadaan
cuaca. Probabilitas orang tersebut membawa payung jika cuaca pada hari itu
“
sunny”
adalah 0.1
,
jika bercuaca “
rainy
” adalah 0.8, jika bercuaca “
foggy”
adalah
0.3.
1. Seandainya hari pada saat kita terkunci bercuaca “
sunny”
. Hari
berikutnya orang yang mengantarkan makanan membawa payung.
Berapakah probabilitas masing-masing cuaca pada hari itu?
Kemungkinan hari kedua adalah “
sunny”
:
L(S2=sunny| S1=sunny, x2=membawa payung) = P(x2=membawa
payung| S2=sunny) . P(S2=sunny| S1=sunny) =
0.1 . 0.8 = 0.08
Kemungkinan hari kedua “
rainy”
:
payung| S2=rainy) . P(S2=rainy| S1=sunny) =
0.8 . 0.05 = 0.04
Kemungkinan hari kedua “
foggy”
:
L(S2=foggy| S1=sunny, x2=membawa payung) = P(x2=membawa
payung| S2=foggy) . P(S2=foggy| S1=sunny) =
0.3 . 0.15 =0.045
2. Seandainya kita tidak mengetahui cuaca pada hari kita dikunci dalam
kamar, tiga hari berturut-turut orang mengantarkan makanan tidak
membawa payung. Berapakah
likelihood
cuaca tersebut adalah
{
1=
,
2=
,
3=
}
?
L(S1=sunny| S2=foggy, S3=sunny| x1=tidak membawa payung,
x2=tidak
membawa payung, x3=tidak membawa payung) = P(x1=tidak membawa payung|
S1=sunny) . P(x2=tidak membawa payung| S2=foggy) . P(x3=tidak membawa
payung| S3=sunny) . P(S1=sunny). P(S2=foggy| S1=sunny) . P(S3=sunny|
S2=foggy) =
0.9 . 0.7 . 0.9 . 1/3 . 0.15 . 0.2 = 0.0057
Pada vokalisasi burung, state menunjukkan rangkaian waktu dari silabel,
dapat dilihat pada gambar 2.5 sebagai berikut :
Dalam kasus penge
memodelkan karakter
yang memiliki bebera
yang dihasilkan oleh sua
Struktur dasar
HMM (Rabiner, 1989
1.
Masalah evalua
Bila diketahui
menghitung p
2.
Masalah
decodi
Bila diketahui
barisan state y
3.
Masalah penge
Bagaimana menyesua
observasi?
2.3.3
Algoritma
Vit
Rangkaian obse
algoritma Viterbi. Alg
δ
dan ψ
t(i
).
δ
t(i
) adalah
semua jalur terakhir pa
genalan
song-type
burung
Ortolan Bunting,
kteristik sinyal atau suara yang secara
temporal
berapa variasi. Dalam state terdapat suatu runtun
h suara burung
Ortolan Bunting
tersebut.
sar HMM diatas memberikan tiga masalah utam
1989) sebagai berikut :
aluasi
hui suatu model HMM
dan barisan observa
probabilitas observasi jika diberikan model?
coding
hui barisan observasi dan model, bagaima
e yang optimal?
ngenalan
suaikan model parameter untuk memaksimalka
Viterbi
observasi dapat ditentukan secara rekursif
Algoritma Viterbi membuat penggunaan dari dua
δ
lah kemungkinan nilai tertinggi mendekati jalur
r pada state
i
waktu
t
.
unting,
HMM akan
poral
dan
spectrum
untun waktu sinyal
ama yang dihadapi
observasi, bagaimana
ana menentukan
lkan
probabilitas
kursif menggunakan
i dua variabel
δ
t(i
)
lur
single
diantara
ψ
t(i
) merupakan varia
pada state
i
waktu
t
.
δ
t(i
) seperti
forward re
dan perhitungannya id
HMM dengan
adalah sebagai berikut
Inisialisasi
Recursion
Terminati
Backtrack
sehingga
variabel untuk menyimpan data pada akhir jalur
ard recursion
αt
(
i
), hanya dengan mengenai rangk
a identik mendekati.
gan
N
state, cara menemukan rangkaian stat
kut :
sasi
ion
nation
racking
alur yang terbaik
(2.17)
gkaian state
single
Sebelumnya r
parameter
Φ
, algoritm
jalur yang terbaik diant
= {
S1
*,...., ST
*} dan ke
2.3.4
Algoritma
Bau
Pada
training
estimate model akan menghitung probabilitas state. Definisi γ
probabilitas pada state
sebagai berikut :
Rumus (2.16) dapat di
Selain itu juga dapat didefinisikan dengan fungsi probabilitas ξ
pada state
Si
pada wakt
rangkaian observasi
X
rangkaian observasi
X
= (
x
1,x
2, ...,x
T) adalah
oritma
Viterbi
memberikan dua hasil yang bai
diantara semua jalur yang mungkin pada model
kemungkinan jalur terbaik
P
(
X,S
*│
Φ
)=
Φ
P
(
X
│
Baum-welch
ning
akan membentuk suatu model (estimate
estimate model akan menghitung probabilitas state. Definisi γ
state
Si
pada waktu
t
, diketahui deret obeservasi
t dinyatakan dengan variabel
forward-bakward
Selain itu juga dapat didefinisikan dengan fungsi probabilitas ξ
t(aktu
t
sampai state
Sj
pada waktu
t+1
, diketah
X
sebagai berikut:
lah sebuah model
aik, yaitu pilihan
el yang dikenal,
S
*X
│
Φ
)
ate model). Pada
estimate model akan menghitung probabilitas state. Definisi γ
t(
i
) adalah
si
X
dan model
,
(2.18)
ard
seperti :
(2.19)
(i,j)
, probabilitas
tahui model
dan
Dari definisi variabel
berikut :
Hubungan antara
γ
t(
i
) dan ξ
Estimasi
awal
da
bel
forward
dan
backward
, rumus diatas didef
) dan ξ
t(i,j)sebagai berikut :
dari
parameter
model
adalah
sebaga
definsikan sebagai
(2.21)
(2.22)
agai
berikut
:
(2.23)
(2.24)
Setelah estimasi awal dari parameter model, model baru
^yang lebih mungkin
menghasilkan rangkaian observasi
X
dari model
yang dihasilkan yaitu
P(X│
^)>
P(X│
).
Algoritma
Baum-welch
yang dijelaskan diatas merupakan implementasi
secara umum dari EM algoritma. Awalnya dengan menginisialisasi parameter
HMM
=(A, B,
π
), perhitungan E (
expectation
) dan M (
maximization
) secara
bergantian. Untuk E (
expectation
) menghitung perkiraan total state
occupancy
γ
dan perkiraan total transisi state dari kemungkinan probabilitas A dan B dengan
algoritma
forward-backward
. Pada M(
maximization
), γ dan ξ digunakan untuk
menghitung probabilitas baru A, B dan
π
dengan persamaan (2.23), (2.24) dan
BAB III
METODOLOGI
Bab ini menjelaskan tahap perancangan dan pengimplementasian metode
Hidden Markov Models
untuk mengenal
song-type
burung
Ortolan Bunting
sehingga menghasilkan akurasi yang optimal.
3.1.
Data
Jenis burung yang dijadikan sampel adalah
Ortolan Bunting
(
Emberiza
hortulana)
.
Ortolan Bunting
adalah burung yang bermigrasi yang tersebar dari
Eropa Barat ke Mongolia (Cramp, Perrins, 1994). Pada musim dingin berada di
Africa. Burung ini mendiami daerah pertanian, dataran tinggi, padang pasir ,
hutan yang telah terbakar dan hutan gundul.
Ortolan Bunting
termasuk burung
monogami, diklasifikasi sebagai spesies yang langka. Burung ini mengalami
penurunan populasi yang cukup besar pada jumlah individu dan penyebarannya.
Ortolan Bunting
mempunyai
song
yang relatif sederhana dan setiap individu
mempunyai 2-3 song-type. Frekuensi
song
berada diantara 1.9 kHz dan 6.7 kHz.
Beberapa
song
dari
Ortolon Bunting
digambarkan berdasar silabel,
song-type
dan
song variants
. Jumlah keseluruhan ada 63
song type
dan 234 variasi
song
,
tersusun dari 20 silabel yang berbeda. Sebuah silabel merupakan inisial suatu
song
.
Sebuah
song
digambarkan dengan menggunakan notasi huruf seperti
song-type
mempunyai beberapa silabel yang panjang dan frekuensinya berbeda di
antara individu, tetapi mempunyai ukuran yang sama pada sonogram.
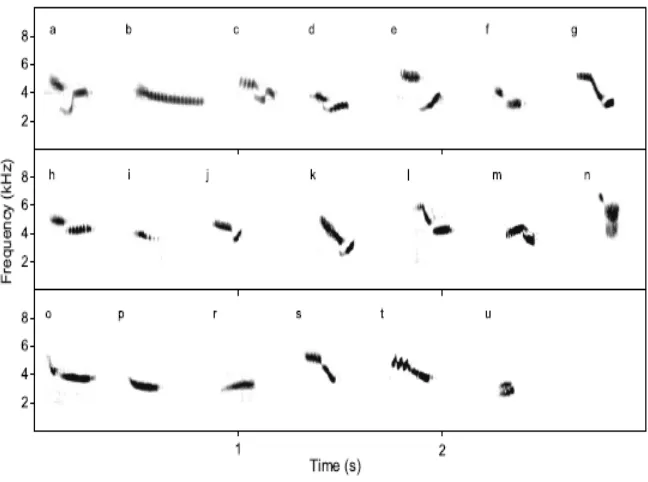
Gambar 3.1.
Syllable Ortolan Bunting
(Osiejuk, 2003)
Gambar 3.1 merupakan kumpulan silabel dari burung
Ortolan Bunting. Song-type
adalah sebuah kumpulan
song
yang terdiri dari susunan silabel yang sama pada
rangkaian yang sama. Sebagai contoh:
type
-ab(
aaabb
),
type
-cb(
cccbb
).
Setiap
song-type
mempunyai perbedaan pada jumlah silabel dalam
song
yang disebut
song variant
, misalnya :
song-type
ab mempunyai banyak
song
variant
yang mungkin yaitu
aaab,aabbbb,aaabb
. Silabel awal dan akhir
mempunyai sedikit perbedaan pada amplitudo dan frekuensi karena mekanisme
produksi suara. Contoh s
ong-type
burung
Ortolan bunting
yang diubah menjadi
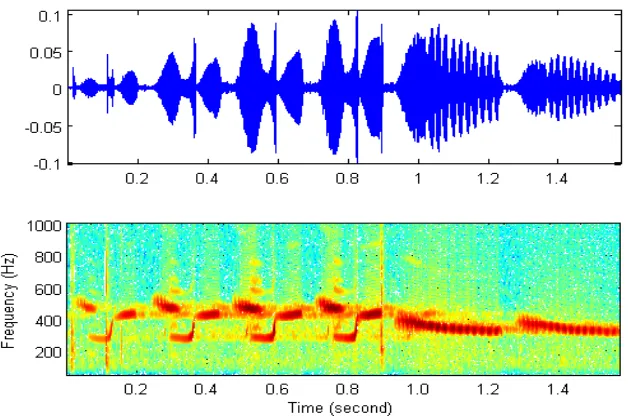
Gambar 3.2
. Specgram Song-type ab
Gambar 3.3
. Specgram Song-type cb
Perancangan dan pengimplementasian metode HMM untuk mengenal
song-type
burung
Ortolan Bunting
, menggunakan jumlah sampel lima
song-type
yaitu
song-type
ab,
song-type
cb,
song-type
cd,
song-type
eb,
song-type
ef.
(gambar 3.2 dan 3.3)
. Specgram
pada masing-masing
song-type
menggambarkan
silabelnya. Setiap
song-type
terdapat 100
song
burung
Ortolan Bunting
dan ada 8
individu burung
Ortolan Bunting
yang bernyanyi.
Tabel 3.1 menunjukkan tabel untuk pembagian data. Pembagian data
menggunakan cara
five fold cross-validation
yaitu membagi data menjadi lima
kelompok, dimana empat kelompok sebanyak 400 data digunakan untuk
pembentukan model (
training
) sedangkan yang lain sebanyak 100 data untuk
pengenalan data baru (
testing
). Proses pembentukan model (
training)
dan
pengenalan data baru (
testing
) dilakukan sebanyak lima kali sehingga data
keseluruhan yang digunakan untuk proses
training
sebanyak 2000 data dan 500
data untuk proses
testing
.
Dari hasil perhitungan diperoleh 20 feature suara untuk setiap bagian.
Tabel 3.1.
Tabel Pembagian Data
Bagian
Song-type
ab
Bagian
Song-type
cb
1
20 feature
1
20 feature
2
20 feature
2
20 feature
3
20 feature
3
20 feature
4
20 feature
4
20 feature
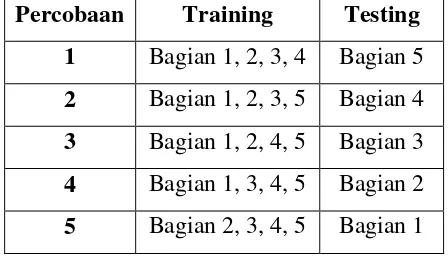
Tabel 3.2.
Tabel Percobaan Training dan Testing
Bagian
Song-type
cd
Bagian
Song-type
eb
1
20 feature
1
20 feature
2
20 feature
2
20 feature
3
20 feature
3
20 feature
4
20 feature
4
20 feature
5
20 feature
5
20 feature
Bagian
Song-type
ef
1
20 feature
2
20 feature
3
20 feature
4
20 feature
5
20 feature
Percobaan
Training
Testing
1
Bagian 1, 2, 3, 4
Bagian 5
2
Bagian 1, 2, 3, 5
Bagian 4
3
Bagian 1, 2, 4, 5
Bagian 3
4
Bagian 1, 3, 4, 5
Bagian 2
Tabel 3.2 menunjukkan tabel percobaan yang dilakukan dalam pengenalan
suara. Jika
feature
bagian 1, 2, 3, dan 4 digunakan untuk data
training
, maka
feature
bagian 5 digunakan untuk data
testing
. Hal tersebut diulang sampai setiap
kelompok digunakan sebagai
testing
.
3.2.
Skema Pengenalan Suara menggunakan HMM
Gambar 3.4
Skema sistem pengenalan suara
Gambar 3.4 menjelaskan mengenai tahapan proses yang dilakukan dalam
pengenalan suara dimulai dari suara burung yang berbentuk file .wav sebagai data
mentah diekstrak
feature
menjadi file .mfc. Suara yang telah diekstrak dijadikan
inputan dalam proses pengenalan suara untuk di
training
dan di
testing
dengan
metode HMM yang kemudian dihasilkan
song-type
yang telah dikenali sebagai
3.2.1
Feature extraction
Pada tahap
feature extraction
, data suara mentah yang berupa .wav
diekstrak menjadi data suara .mfc.
Feature extraction
menggunakan 3 jenis tipe
parameter yaitu GFCC,delta (GFCC_D) dan delta-delta (GFCC_D_A).
Masing-masing tipe parameter mempunyai parameter yang berbeda, untuk GFCC
menggunakan parameter 12, GFCC_D menggunakan parameter 24, dan
GFCC_D_A menggunakan parameter 36. Pada sistem ini, dilakukan pemilihan
ukuran window (
window-sizes
) antara 3 ms hingga 6 ms dan
overlap
antara 1,5
ms hingga 3 ms. Adapun untuk pemilihan jumlah state yaitu 5, 10 dan 15. Pada
proses
feature extraction
, mengubah informasi
time
menjadi informasi frekuensi
melalui
Fast Fourier Transform
(FFT). Kemudian, informasi frekuensi di
window
dengan ukuran window (
window-sizes
) yang dipilih. Tujuan dari proses membuat
window
agar informasi-informasi setiap bagian tidak hilang. Ukuran window
(
window-sizes
) kecil karena suara burung lebih cepat. Selanjutnya, diambil
magnitudenya setelah proses membuat
window
selesai. Kemudian, proses FFT
yang akan menghasilkan nilai besaran signal. Nilai tersebut akan dimasukkan
pada
Greenwood
. Pada
Greenwood
konstanta frekuensi
warping
dihitung dari
fmin 400 Hz hingga 7400 Hz yang tepat didengar oleh
Ortolan Bunting
. Pada
proses
Greenwoood
mengambil
gain
, kemudian dikalikan dengan nilai besaran
signal menghasilkan
output
parameter berupa koefisien parameter. Koefisien
parameter tersebut digunakan untuk observasi pada proses HMM.
Output
parameter berupa matriks dengan jumlah kolom tergantung dari jenis feature yang
GFCC_D sebanyak 24 dan GFCC_D_A sebanyak 36. Sedangkan jumlah baris
tergantung dari panjangnya sinyal suara yang dihasilkan.
3.2.2
Tahap
Training
Gambar 3.5.
Blok diagram tahap
training
Gambar 3.5 menggambarkan tahap
training
untuk pengenalan
song-type
burung. Setelah mengekstrak feature suara kemudian perancangan sistem
dilanjutkan dengan tahap
training
.
Pada tahap
training
akan membentuk model yang mewakili
masing-masing
song-type
burung
Ortolan Bunting
. Pembentukan model mencakup
perhitungan parameter menggunakan sample yang diambil dari contoh suara
masing-masing
song-type
burung
Ortolan Bunting
. Pembentukan model ini
menggunakan algoritma
Baum-Welch
. Perhitungan
Baum-Welch
untuk mean dan
varian pada masing masing state HMM.
HMM merupakan sebuah model statistik yang diasumsikan dari rantai
statistik karena metode ini mencari
means
,
varians
dan
probabilitas
dari model
yang dimasukkan. Pada proses
training
menghasilkan
output
yang tersimpan pada
file
hmmdefs
. File
hmmdefs
dapat dilihat pada halaman lampiran file HMM.
3.2.3
Tahap
Testing
Gambar 3.6.
Blok diagram tahap
testing
Gambar 3.6 menggambarkan tahap testing untuk pengenalan
song-type
burung
Ortolan Bunting
. Pada tahap
testing
akan mengenal data baru. Proses
pengenalan data baru (
testing)
menggunakan algoritma
Viterbi
. Algoritma
Viterbi
adalah algoritma
dynamic programming
untuk menemukan kemungkinan
rangkaian state yang tersembunyi (biasa disebut
Viterbi path
) yang dihasilkan
menemukan jalur terbaik dalam sebuah matrik dimana dimensi vertikal
merepresentasikan state-state hmm dan dimensi horisontal merepresentasikan
frame suara.
Pada tahap
testing
menggunakan 500 data suara yang sudah dibagi
sebelumnya. Pada awalnya tahap training untuk pembentukan model
song-type
burung
Ortolan Bunting
, yaitu “
song
ab”, “
song
cb”, “
song
cd”, “
song
eb”,
“
song
ef”. Hasil
training
adalah model yang telah diestimasi (
M
). Kemudian
HMM digunakan untuk mengenali suara baru (
O
) berdasarkan hasil
training
tersebut. P(
O
|
M
) adalah kemungkinan suatu
song-type
O dihasilkan oleh suatu
model M. Untuk mengenal suatu suara burung baru, sistem akan menghitung
berapa probabilitas data ini diturunkan oleh masing-masing model. Probabilitas
paling tinggi di antara model yang ada menunjukkan kedekatan data terhadap
model.
Perhitungan dilakukan sebanyak 5 kali percobaan yang hasilnya disajikan
dengan
confusion matrix
sebagai berikut:
Tabel 3.3.
Confusion matrix
Song-typeab
Song-type
cb
Song-type
cd
Song-type
eb
Song-type
ef
Song-type ab X
Song-type cb X
Song-type cd X
Song-type eb X
Dari hasil percobaan (tabel 3.3) kemudian dilakukan perhitungan akurasi
untuk setiap percobaan yang dilakukan. Perhitungan akurasi sebagai berikut :
=
∑
∑
× 100%
Dimana data benar adalah jumlah elemen diagonal pada
confusion matrix
, dan
data testing adalah jumlah data yang digunakan untuk testing.
3.3
Kebutuhan Perangkat Lunak
Kebutuhan perangkat lunak dalam menyelesaikan tugas akhir ini adalah
Matlab 6.5.1 MathWork yang digunakan sebagai
library
untuk menjalankan
program dan sebagai alat bantu pembangunan sistem pengenalan
song-type
burung.
3.4
Kebutuhan Perangkat Keras
Kebutuhan perangkat keras dalam menyelesaikan tugas akhir ini adalah
sebuah system computer dengan spesifikasi sebagai berikut :
1.
Prosesor
: AMD Turion64 X2 TL-60
2. Sistem Operasi
: Windows XP
3. Memory
: 1 GByte
4. Media tampilan
: VGA nVIDIA GeForce 7000M
3.5
Perancangan Antar Muka
Pada perancangan antar muka alat bantu pengenalan
song-type
ini terdiri
dari halaman
Home
, halaman pengenalan
song-type
, halaman pengujian akurasi
Hidden Markov Models
dan halaman bantuan.
3.5.1
Halaman
Home
Gambar 3.7.
Halaman
Home
sistem pengenalan
song-type
Gambar 3.7 merupakan rancangan halaman
Home
yang berisi judul
3.5.2
Halaman Pengenalan
Song-type
Gambar 3.8.
Halaman pengenalan
song-type
sistem pengenalan
song-type
Gambar 3.8 menunjukkan halaman pengenalan
song-type
. Pada halaman
ini pengguna dapat memasukkan suara dengan menekan tombol “cari”. Pada
visualisasi data input akan ditampilkan gambar
specgram
dan
signal
dari suara
yang dimasukkan. Pengguna dapat mendengar suara yang dimasukkan dengan
menekan tombol “suara” pada bawah gambar
signal
.
Pengenalan
song-type
dilakukan dengan menekan tombol “ Proses” pada
sisi kiri bawah kotak “hasil”. Hasil ekstrak
feature
dan pengenalan dapat dilihat
3.5.3
Halaman Pengujian Akurasi
Hidden Markov Models
Gambar 3.9.
Halaman pengujian akurasi dengan
Hidden Markov Models
Gambar 3.9 merupakan halaman pengujian akurasi dengan
Hidden
Markov Models
. Pada sistem ini, akan diolah 2000 model
song-type
yang
sebelumnya telah tersimpan. Pertama, pengguna memilih tipe parameter,
window-sizes
dan jumlah
state
. Setelah itu, pengguna menekan tombol “proses” untuk
menguji akurasi HMM terhadap
song-type
. Pada kotak “proses” akan
menampilkan proses dari pengujian. Pada kotak “hasil” akan menampilkan hasil
3.5.4
Halaman Bantuan
Gambar 3.10.
Halaman bantuan pengenalan
song-type
Gambar 3.10 menunjukkan halaman bantuan untuk pengenalan
song-type
.
Pada halaman ini pengguna dapat mengetahui informasi cara penggunaan sistem
3.5.5
Halaman Tentang program
Gambar 3.11.
Halaman Tentang program
BAB IV
IMPLEMENTASI DAN ANALISA
Bab ini membahas hasil implementasi sistem berupa hasil penelitian dan
analisa dari hasil penelitian yang didapatkan, serta implementasi
desain user
interface
.
Bagian pertama menganalisa hasil penelitian untuk setiap percobaan yang
dilakukan. Hasil penelitian berupa tabel hasil akurasi dengan
confusion matriks
untuk akurasi yang terbaik. Dalam penelitian ini, untuk mendapatkan akurasi
terbaik dipengaruhi oleh tipe parameter
feature
, ukuran
window
(
windows size
)
dan jumlah state. Bagian kedua menganalisa implementasi sistem dengan
penjelasaan penggunaan menu dan tombol untuk setiap halaman.
4.1
Hasil penelitian
Penelitian ini, menggunakan 5
song-type.
Setiap
song-type
mempunyai
100
song-variant.
Percobaan menggunakan data suara burung
Ortolan Bunting
sebanyak 2000
song-variant
untuk pembentukan model (
training)
dan 500
song-variant
untuk pengenalan data baru (
testing)
. Pada proses
feature extraction
, data
song-type
diekstrak menggunakan 3 jenis tipe parameter untuk mendapatkan hasil
akurasi untuk setiap percobaan yang dilakukan. Pertama, percobaan dilakukan
dengan pemilihan 3 tipe parameter yaitu GFCC, GFCC_D dan GFCC_D_A.
Kemudian, dilakukan pemilihan ukuran
window (window-sizes)
antara 3 ms
mencari tipe parameter untuk proses
feature
dan ukuran
window (window-sizes)
yang terbaik untuk pengenalan dalam bentuk akurasi secara keseluruhan. Hasil
dari tiap percobaan adalah sebagai berikut :
Tabel 4.1.
Tabel hasil akurasi pengenalan
song-type
menggunakan tipe parameter
feature
dan ukuran
window (window-sizes)
yang berubah tetapi
jumlah state tetap yaitu 15.
No.
Tipe
Parameter
Window
size
(ms)
Akurasi
1.
GFCC
3
87%
2.
GFCC_D
3
90,6%
3.
GFCC_D_A
3
91,4%
4.
GFCC
4
88,6%
5.
GFCC_D
4
90,4%
6.
GFCC_D_A
4
94,4%
7.
GFCC
5
87%
8.
GFCC_D
5
89,6%
9.
GFCC_D_A
5
92,4%
10.
GFCC
6
88%
11.
GFCC_D
6
91,2%
Gambar 4.1.
Grafik hasil akurasi pengenalan
song-type
menggunakan tipe
parameter
feature
dan ukuran
window (window-sizes)
yang berubah
tetapi jumlah state tetap yaitu 15.
Tabel 4.1 menunjukkan tabel hasil akurasi pengenalan
song-type
menggunakan tipe parameter
feature
dan ukuran
window (window-sizes)
yang
berubah. Tabel penelitian diatas, mendapatkan hasil akurasi terendah 87% untuk
feature
GFCC, sedangkan hasil akurasi tertinggi dengan
feature
GFCC_D_A
menggunakan ukuran
window (window-sizes)
4 ms dan
overlap
2 ms. Akurasi
yang dihasilkan yaitu 94,4%. GFCC dengan koefisien delta dan
acceleration
(percepatan) memberikan hasil akurasi tertinggi pada pengujian HMM, klasifikasi
benar 94,4% dari data pengujian. Apabila dibandingkan dengan penelitian yang
dilakukan oleh Trawichi, dkk (Trawichi, 2005) hasil penelitian ini lebih tinggi
karena penelitian yang dilakukan Trawichi, dkk menggunakan
feature
Mel-frequency ceptral coefficients
(MFCCs) karena MFCC merupakan jenis
feature
untuk suara manusia sehingga akurasi yang diperoleh rendah. Hasil penelitian
82,0084,00 86,00 88,00 90,00 92,00 94,00 96,00
3 4 5 6
GFCC
GFCC_D
GFCC_D_A
yang dilakukan oleh Trawichi, dkk menunjukkan akurasi terendah 63,6 % dan
akurasi tertinggi 92,4%.
Feature
menggunakan tipe parameter dan ukuran
window (window-sizes)
ini, kemudian digunakan untuk mencari hasil akurasi yang terbaik dengan jumlah
state yang berbeda yaitu 5, 10 dan 15. Hasil dari percobaan ini sebagai berikut :
Tabel 4.2.
Tabel hasil percobaan pengenalan
song-type
menggunakan tipe
parameter GFCC_D_A, ukuran
window (window-sizes)
4 ms dan
overlap
2 ms dengan jumlah state yang berubah
No.
Jumlah
State
Akurasi
1.
5
84,2%
2.
10
87%
3.
15
94,4%
Tabel 4.2 menunjukkan tabel hasil akurasi pengenalan
song-type
menggunakan tipe parameter GFCC_D_A, ukuran
window (window-sizes)
4 ms
dan
overlap
2 ms dengan jumlah state yang berubah. Hasil percobaan ini,
mendapatkan hasil akurasi tertinggi dengan jumlah state 15. Hasil akurasi
menunjukkan nilai 94,4 %.
Confusions matrix
yang dihasilkan untuk pengenalan
song-type
menggunakan tipe parameter GFCC_D_A, ukuran
window
Tabel 4.3.
C
onfusions matrix
pengenalan
song-type
menggunakan tipe
parameter GFCC_D_A, ukuran
window (window-sizes)
4 ms
dan
overlap
2 ms dengan jumlah state 15
ab
cb
cd
eb
ef
ab
98
1
0
1
0
cb
3
94
1
2
0
cd
0
2
91
0
7
eb
2
1
0
90
7
ef
2
0
0
1
99
Tabel 4.3 merupakan tabel
confusions matrix
pengenalan
song-type
menggunakan tipe parameter GFCC_D_A, ukuran
window (window-sizes)
4 ms
dan
overlap
2 ms dengan jumlah state 15. Setiap baris dari matriks di atas
mewakili label
song-type
yang dikenal, sedangkan kolom mewakili klasifikasi
yang diberikan oleh sistem untuk setiap
song-type
. Angka pada diagonal adalah
jumlah dari vokalisasi yang diklasifikasi dengan benar untuk setiap
song-type
.
Klasifikasi benar 94,4% dari data yang diuji.
Dari
confusion
matriks diatas, dapat diketahui
song-type
ef mudah dikenali
sebagai
song-type
ef, yaitu sebanyak 99. Masing-masing
song-type
mudah
dikenali dengan hasil suara yang tidak dikenal hanya sedikit yaitu kurang dari 50
sehingga memperoleh hasil akurasi yang cukup tinggi dan mampu mengenal
4.2
Implementasi Antar Muka yang Digunakan pada Sistem
4.2.1
Halaman Utama
Pada halaman utama, terdapat identitas penulis dan judul sistem yang
dibuat. Selain itu, terdapat dua pilihan menu, yaitu :
1.
Menu
Menu ini berfungsi menampilkan halaman pengenalan
song-type
dan
halaman pengujian akurasi
Hidden Markov Models
.
2.
Bantuan
Menu bantuan ini berfungsi menampilkan halaman bantuan
pengenalan
song-type
dan halaman bantuan pengujian HMM.
Halaman tersebut akan menampilkan panduan dalam menggunakan
Gambar 4.2
. Halaman utama sistem pengenalan
song-type
Gambar 4.1 menunjukkan desain antar muka dari sistem pengenalan
song-type
. Pengguna dapat menggunakan sistem ini untuk mengenal
song-type
burung
4.2.2
Halaman Pengenalan
Song-type
Gambar 4.3.
Halaman pengenalan
song-type
Gambar 4.5
Peringatan jika tidak memilih file
Gambar 4.2 menunjukkan halaman pengenalan
song-type
. Halaman ini
berfungsi mengenal suara burung yang dimasukkan lewat tombol “cari”.
Pengguna menekan tombol “cari” kemudian memasukkan suara yang dipilih
melalui jendela
file selector
seperti gambar 4.3. Jika tidak ada file suara yang
dipilih, maka akan muncul kotak peringatan “File tidak ditemukan” seperti pada
gambar 4.4.
Pada halaman pengenalan
song-type
, untuk melihat proses pengenalan
dapat dilihat pada kotak “proses”. Pada kotak ini akan menampilkan proses
feature
dan pengenalan (
testing
) dengan menggunakan algoritma
Viterbi
. Pada
proses pengenalan, sistem melakukan pencocokan suara yang dimasukkan yang
didalam file
dataTest
.
scp
dengan
hmmdefs
(file definisi HMM),
model.list
(daftar
model),
wordnet
dan
dict
. Setelah pencocokan, hasil dari proses pengenalan akan
ditampilkan pada kotak “hasil”. Pada kotak ini menampilkan suara burung dikenal
4.2.3
Halaman Pengujian
Hidden Markov Models
Gambar 4.6.
Halaman pengujian akurasi
Hidden Markov Models
Gambar 4.5 menunjukkan halaman pengujian akurasi HMM. Pada
feature
extraction
pengguna dapat memilih tipe parameter,
window-sizes
dan jumlah
state
yang akan digunakan untuk proses pengujian. Pemilihan tipe parameter ada tiga
jenis, yaitu MFCC, MFCC_D dan MFCC_D_A.
Window-sizes
terdapat empat
ukuran, yaitu 3 ms, 4 ms, 5 ms dan 6 ms. Pemilihan jumlah
state
ada tiga macam,
yaitu 5, 10 dan 15.
Proses pengujian ini ditampilkan pada kotak “proses”. Kotak ini
menampilkan proses dari mengekstrak
feature
, pembentukan prototipe model,
a.
Pengambilan
grammarSong
menggunakan fungsi HParse untuk
membuat
wordnet
.
b.
Pemrosesan seluruh
song-type
yang tersimpan dalam
allsongs.mlf
,
file
dict
, dan file
songtypephone.led
dengan fungsi HLed untuk
membuat file
songtypephone.mlf
dengan pemberian label.
c.
Pembuatan prototipe baru
proto
dengan fungsi HCompV yang
mengambil
song-type
dari
file
AllTrainData1.scp,
kemudian
disimpan dalam direktori hmm1.
d.
Pembuatan model (
training)
menggunakan fungsi HERest. Pada
proses ini menggunakan algoritma
Baum-Welch
. Pembuatan model
ini mengambil informasi
feature
dalam file
AllTrainData1.scp,
daftar
label
song-type
dalam
file
songtypephone.mlf
.
Setelah
itu,
pencocokan dengan daftar model yang disimpan dalam file
model.list
Hasil pembuatan model disimpan dalam file
hmmdefs
.
e.
Proses
testing
menggunakan fungsi HVite untuk mencocokkan
song-type
dengan mengambil daftar
testing song-type
pada file
AllTestData.scp
. File tersebut dicocokkan dengan
wordnet
,
dict
,
model.list
dan defini HMM yang tersimpan dalam
hmmdefs
.
f.
Proses
training
dan
testing
diatas dilakukan sebanyak lima kali
Pada kotak “hasil” menampilkan hasil dari pengujian jika proses
pengujian telah selesai. Hasil pengujian berupa
confusion matrix
dan prosentase
akurasi secara keseluruhan. Waktu yang dibutuhkan untuk proses pengujian ini
dapat dilihat pada bawah kotak “hasil”.
4.2.4
Halaman Bantuan
Gambar 4.7.
Halaman bantuan penggunaan sistem pengenalan
song-type
Halaman bantuan penggunaan sistem ini terlihat pada gambar seperti
penggunaan sistem ini pada halaman pengenalan
song-type
dan halaman
pengujian HMM untuk masing-masing tombol yang ada dalam kedua halaman
BAB V
PENUTUP
5.1.
Kesimpulan
1.
Langkah-langkah pengenalan dan pengujian
song-type
burung
Ortolan
Bunting
menggunakan metode HMM adalah :
1.
Ekstraksi
feature
dari suara file .wav menjadi .mfc dan
menggunakan
feature
dengan tipe parameter GFCC, GFCC_D dan
GFCC_D_A.
Window-sizes
yang digunakan antara 3 ms hingga 6
ms dan jumlah
state
sebesar 5, 10 dan 15.
2.
Proses
training
Pada
training
akan membentuk model yang mewakili
masing-masing
song-type
burung
Ortolan Bunting
. Pembentukan model
mencakup perhitungan parameter menggunakan algoritma
Baum-Welch
.
3.
Proses
testing
Pada
testing
akan mengenal data baru. Proses pengenalan data
baru
menggunakan
algoritma
Viterbi
.
Setelah
itu,
akan
menghasilkan akurasi untuk pengujian yang dilakukan.
2.
Pada penelitian ini, Hidden Markov Models merupakan metode
pengenalan suara (
speech recognition)
yang baik dalam menangani data
berupa sinyal suara dan memberi hasil akurasi yang cukup tinggi.
GFCC_D_A,
window-sizes
4 ms,
overlap
2 ms dan jumlah
state
15.
Akurasi paling tinggi sebesar 94,4 %.
3.
Penelitian ini menggunakan 500 data
song-type
dan proses evaluasi
menggunakan metode
five fold cross validation
.
4.
Penelitian ini menggunakan jenis
feature Greenwood function cepstral
coefficients
(GFCC).
5.2.
Saran
Penelitian ini sebatas mengenai pengenalan
song-type
burung
Ortolan
Bunting
, sehingga diperlukan sebuah studi lanjut untuk mengenal
song-type
burung lain atau binatang dengan mengetahui
song-type
yang dimiliki burung
maupun binatang tersebut. Selain itu, diperlukan sebuah studi lanjut untuk
mengenal
song-type