36 BAB III PEMBAHASAN
Analisis cluster merupakan analisis yang bertujuan untuk mengelompokkan objek-objek pengamatan berdasarkan karakteristik yang dimiliki. Asumsi-asumsi dalam analisis cluster yaitu sampel yang diambil harus mewakili populasi dan multikolinearitas. Apabila terjadi multikolinearitas diatasi menggunakan Principal Component Analysis (PCA). Hasil dari Principal Component (PC) yang terbentuk digunakan sebagai variabel bebas baru untuk mengelompokkan kabupaten/kota berdasarkan faktor-faktor yang mempengaruhi kemiskinan di Jawa Tengah menggunakan metode Ward dan Average Linkage. Perbandingan kinerja antara metode Ward dan Average Linkage dilakukan untuk memilih metode yang menghasilkan cluster lebih baik.
A. Analisis Cluster
Telah dijelaskan sebelumnya bahwa analisis cluster merupakan analisis yang digunakan untuk mengelompokkan objek-objek pengamatan berdasarkan karakteristik yang dimiliki. Seperti teknik analisis lain, analisis
cluster menetapkan adanya asumsi-asumsi yang harus dipenuhi. Asumsi dalam analisis cluster yaitu:
1. Sampel yang diambil harus mewakili populasi yang ada
Untuk mengetahui apakah sampel yang digunakan telah mewakili populasi, dapat dilihat dari nilai Kaiser Meyer Olkin (KMO). Kaiser Meyer
37
Olkin (KMO) adalah indeks perbandingan nilai koefisien korelasi terhadap korelasi parsial (Yamin dan Kurniawan, 2014: 181).
(3. 1) (3. 2) Keterangan: = banyaknya variabel
= koefisien korelasi antara variabel dan
= koefisien korelasi parsial antara variabel dan
Menurut Yamin, Rachmach dan Kurniawan (2011: 122), jika nilai
KMO < 0,5, maka sampel tidak mewakili populasi, sedangkan jika nilai
KMO > 0,5, maka sampel mewakili populasi sehingga layak untuk dilakukan analisis cluster.
2. Multikolinearitas
Multikolinearitas adalah adanya hubungan linear atau korelasi yang tinggi antar variabel. Untuk mengetahui ada tidaknya multikolinearitas, dapat dilihat dari nilai-nilai korelasi pada matriks korelasi. Dua variabel atau lebih dikatakan multikolinearitas apabila nilai korelasinya > 0,70 (Yamin dan Kurniawan, 2014: 70). Apabila terjadi multikolinearitas diatasi menggunakan Principal Component Analysis (PCA). Kelebihan dari PCA yaitu dapat mengatasi multikolinearitas secara bersih. Artinya,
38 B. Principal Component Analysis (PCA)
Principal Component Analysis (PCA) bertujuan untuk menyederhanakan variabel yang diamati dengan cara mereduksi dimensinya. Prinsip utama dari PCA adalah terdapatnya korelasi antar variabel sehingga diduga bahwa variabel-variabel tersebut dapat direduksi. Hal ini dilakukan dengan cara menghilangkan korelasi antar variabel bebas melalui transformasi variabel bebas asal ke variabel bebas baru yang tidak berkorelasi sama sekali atau sering disebut dengan principal component (Johnson dan Wichern, 2007: 430).
Principal component (PC) merupakan suatu kombinasi linear dari variabel-variabel asal. Pembentukan PC berdasarkan dua cara yaitu matriks kovarian atau matriks korelasi (Johnson dan Wichern, 2007: 431). Pembentukan PC berdasarkan matriks kovarian digunakan apabila variabel yang diamati mempunyai satuan pengukuran yang sama, sedangkan matriks korelasi digunakan apabila variabel yang diamati mempunyai satuan berbeda. Pada skripsi ini digunakan matriks korelasi karena variabel yang digunakan memiliki satuan berbeda.
Tahapan menentukan PC berdasarkan matriks korelasi adalah sebagai berikut (Johnson dan Wichern, 2007: 436-437):
1. Membuat matriks yang berisi data dari variabel X yang telah distandarisasi.
2. Membuat matriks korelasi dari yaitu . Pereduksian PC dimulai dengan mencari nilai eigen yang diperoleh dari persamaan:
39
(3. 3)
dimana jumlahan nilai eigen merupakan trace matriks korelasi atau jumlah diagonal matriks korelasi, yaitu:
(3. 4)
Nilai eigen selalu diurutkan dari yang terbesar sampai nilai terkecil. Nilai eigen menunjukkan besarnya total varian yang dijelaskan oleh PC yang terbentuk. saling orthogonal dan dibentuk berdasarkan persamaan:
(3. 5)
Vektor eigen diperoleh dari setiap nilai eigen yang memenuhi persamaan:
(3. 6)
Beberapa ketentuan PCA dalam membentuk principal component
adalah sebagai berikut (Johnson dan Wichern, 2007: 431-432):
1. Principal Component (PC) yang terbentuk sebanyak variabel yang diamati dan setiap PC merupakan kombinasi linear dari variabel-variabel tersebut. 2. Setiap PC saling orthogonal dan saling bebas.
3. Principal Component (PC) dibentuk berdasarkan urutan total varian yang terbesar hingga paling kecil, dalam arti sebagai berikut:
a. Principal Component pertama adalah kombinasi linear dari seluruh variabel yang diamati dan memiliki varian terbesar.
b. Principal Component kedua adalah kombinasi linear dari seluruh variabel yang diamati dan bersifat orthogonal terhadap dan memiliki varian terbesar kedua.
40
c. Principal Component ketiga adalah kombinasi linear dari seluruh variabel yang diamati dan bersifat orthogonal terhadap maupun dan memiliki varian terbesar ketiga.
d. Principal Component ke- adalah kombinasi linear dari seluruh variabel yang diamati dan bersifat orthogonal terhadap , ,..., dan memiliki varian paling kecil.
Sebelum dilakukan PCA, terlebih dahulu dilakukan beberapa pengujian sebagai berikut:
1. Uji Kaiser Meyer Olkin(KMO)
Syarat yang harus dipenuhi sebelum dilakukan PCA yaitu data yang digunakan telah mencukupi untuk dianalisis. Nilai KMO dapat dicari menggunakan persamaan (3. 1) dan (3. 2).
2. Uji Bartlett
Uji Bartlett digunakan untuk mengetahui apakah matriks korelasi hubungan antara variabel adalah matriks identitas. Hal ini digunakan untuk menguji kecukupan hubungan antara variabel, dimana matriks identitas mempunyai diagonal matriks bernilai 1 dan yang lainnya adalah 0. Urutan pengujian sebagai berikut:
Hipotesis:
: matriks korelasi = matriks identitas : matriks korelasi matriks identitas Statistik uji :
41 Keterangan:
= nilai determinan matriks korelasi = banyaknya data
= banyaknya variabel Kriteria keputusan:
Tolak jika > atau
Setelah dilakukan uji KMO dan Bartlett, dilakukan pemeriksaan terhadap nilai-nilai Measure of Sampling Adequacy (MSA). Measure of Sampling Adequacy (MSA) digunakan untuk mengetahui variabel mana saja yang layak dilakukan PCA. Nilai MSA dapat dilihat pada output SPSS anti images matrices bagian correlation yang ditunjukkan oleh diagonal dari kiri atas ke kanan bawah yang bertanda huruf a dan diperoleh dari persamaan berikut:
(3. 8)
dengan = 1, 2, 3, ..., 7 , = 1, 2, 3, ..., 7 , dan
Jika nilai MSA > 0,5 maka variabel layak dilakukan PCA (Yamin dan Kurniawan, 2014: 186).
Principal component hasil dari PCA akan digunakan sebagai variabel bebas baru untuk dianalisis cluster menggunakan metode Ward dan Average Linkage. Sebelum penyusunan cluster, terlebih dahulu dilakukan pemilihan ukuran jarak. Ukuran jarak yang digunakan adalah jarak Euclid kuadrat. Adapun persamaan Euclid kuadrat adalah sebagai berikut:
42 C. Metode Ward
Metode Ward merupakan salah satu metode hirarki dalam analisis
cluster. Metode Ward bertujuan untuk memperoleh cluster yang memiliki varian dalam cluster(within cluster) sekecil mungkin. Ukuran kesamaan yang digunakan adalah jarak Euclid kuadrat (Supranto, 2010: 154). Metode Ward
mengelompokkan objek didasarkan pada kenaikan sum square error (SSE). Pada tiap tahap, dua cluster yang memiliki kenaikan SSE paling kecil digabungkan (Simamora, 2005: 218). Sum Square Error (SSE) dapat dihitung menggunakan persamaan (Gudono, 2014: 294):
(3. 10)
Keterangan:
SSE = sum square error
= jumlah anggota cluster
= nilai atau data dari objek ke-
= rata-rata (mean) nilai objek dalam sebuah cluster
Langkah-langkah pengelompokan menggunakan metode Ward adalah sebagai berikut (Johnson dan Wichern, 2007: 692-693):
1. Dimulai dari setiap objek dianggap sebagai sebuah cluster tersendiri, maka terdapat N cluster yang mempunyai satu objek. Pada tahap ini SSE bernilai nol.
2. Menghitung nilai SSE untuk setiap kombinasi dua pasang cluster dari N
cluster, lalu memilih dua pasang cluster yang memiliki nilai SSE terkecil untuk digabungkan menjadi satu cluster. Secara sistematik, N cluster akan berkurang 1 pada setiap tahap (N-1).
43
3. Membuat kombinasi dua pasang cluster baru yang terdiri dari satu cluster
yang telah terbentuk dan cluster yang lain, lalu menghitung nilai SSE lagi. Memilih dua pasang cluster yang memiliki nilai SSE terkecil untuk digabungkan menjadi satu cluster.
4. Mengulangi langkah (3) sampai semua objek bergabung menjadi satu
cluster.
D. Metode Average Linkage
Metode average linkage (pautan rata-rata) adalah metode pengelompokan yang jarak antara dua cluster didefinisikan sebagai rata-rata jarak seluruh pasangan yang berada dalam satu cluster dengan cluster yang lain. Untuk menghitung rata-rata jarak pada metode average linkage
digunakan persamaan (Johnson dan Wichern, 2007: 690):
(3. 11)
Keterangan:
= jarak antara cluster dan cluster
= jarak antara objek pada cluster dan objek pada cluster = jumlah anggota pada cluster
= jumlah anggota pada cluster
Langkah-langkah pengelompokan menggunakan metode average linkage adalah sebagai berikut (Johnson dan Wichern, 2007: 690):
1. Mencari dua objek yang memiliki kesamaan paling dekat pada matriks similaritas. Misal kedua objek itu adalah objek dan .
44
3. Penggabungan kedua merupakan penggabungan cluster dengan cluster
lain yang memiliki kesamaan paling dekat, misal cluster . Penggabungan kedua dihitung menggunakan persamaan (3. 10).
4. Mengulangi langkah (3) sebanyak N-1 kali, dimana N adalah jumlah objek.
E. Penentuan Metode Terbaik
Untuk menentukan metode yang menghasilkan cluster terbaik, digunakan nilai-nilai simpangan baku dalam cluster (within cluster) dan antar
cluster (between cluster). Persamaan-persamaan simpangan baku dalam dan antar cluster sebagai berikut:
1. Simpangan baku dalam cluster (within cluster)
(3. 12)
Keterangan:
= simpangan baku dalam cluster
= banyaknya cluster yang terbentuk = simpangan baku cluster ke-k
2. Simpangan baku antar cluster (between cluster)
(3. 13)
Keterangan:
= simpangan baku antar cluster
= banyaknya cluster yang terbentuk = rata-rata cluster ke-k
= rata-rata seluruh cluster
Metode yang mempunyai rasio terkecil merupakan metode terbaik (Bunkers dkk, 1996: 136). Semakin kecil nilai dan semakin besar nilai ,
45
maka metode yang digunakan mempunyai kinerja yang baik, artinya homogenitasnya tinggi.
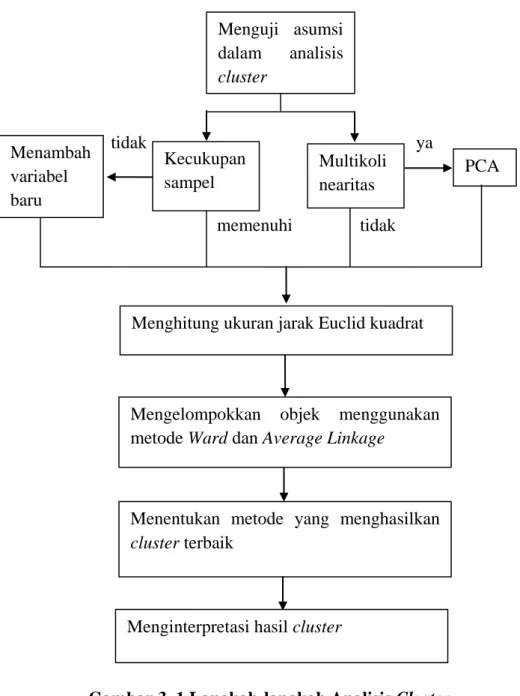
Dari uraian diatas, langkah-langkah yang dilakukan dalam analisis
cluster disajikan dalam bagan sebagai berikut:
tidak ya
memenuhi tidak
Gambar 3. 1 Langkah-langkah Analisis Cluster PCA Menguji asumsi dalam analisis cluster Kecukupan sampel Multikoli nearitas
Mengelompokkan objek menggunakan metode Ward dan Average Linkage
Menentukan metode yang menghasilkan
cluster terbaik
Menghitung ukuran jarak Euclid kuadrat
Menginterpretasi hasil cluster Menambah
variabel baru
46
F. Pengelompokan Kabupaten/Kota Berdasarkan Faktor-faktor yang Mempengaruhi Kemiskinan di Jawa Tengah Menggunakan Metode Ward dan Average Linkage
1. Deskripsi Data
Data yang digunakan merupakan data tentang faktor-faktor yang mempengaruhi kemiskinan di Jawa Tengah tahun 2014. Data diambil dari publikasi BPS berupa buku yang berjudul “Jawa Tengah Dalam Angka 2015”, “Tinjauan PDRB Kabupaten/Kota Se Jawa Tengah 2014”, dan “Data dan Informasi Kemiskinan Kabupaten/Kota Tahun 2014”. Adapun faktor-faktor yang mempengaruhi kemiskinan di Jawa Tengah tahun 2014 antara lain sebagai berikut:
a. Produk Domestik Regional Bruto (PDRB)
Menurut Sri Aditya (2010) dalam Prastyo (2010: 44) PDRB merupakan salah satu alat pengukur pertumbuhan ekonomi. Badan Pusat Statistik (BPS) menggunakan metode pendekatan produksi dalam menghitung PDRB. Dengan menggunakan metode pendekatan produksi, PDRB merupakan penjumlahan Nilai Tambah Bruto (NTB) dari barang dan jasa yang dihasilkan oleh unit-unit kegiatan ekonomi di suatu wilayah pada satu periode tertentu.
NTB dihitung dengan mengeluarkan komponen biaya dari output. Output adalah nilai seluruh barang dan jasa hasil proses produksi. Output suatu jenis komoditas adalah hasil perkalian antara kuantitas produksi dengan harga/tarif jual per unit barang, dimana harga
47
yang dimaksud merupakan harga pada tingkat produsen. Biaya antara adalah nilai seluruh barang dan jasa yang digunakan dalam proses produksi.
Secara matematis penghitungan PDRB menggunakan metode pendekatan produksi dirumuskan sebagai berikut (BPS):
(3. 14) (3. 15) (3. 16) Keterangan: = kuantitas produksi = harga produsen = biaya antara = output
= nilai tambah bruto b. Pengeluaran perkapita
Pengeluaran perkapita merupakan salah satu faktor yang mempengaruhi kemiskinan (Widiastuti, 2016: 9). Badan Pusat Statistik (BPS) menggunakan rata-rata besarnya pengeluaran perkapita sebagai pendekatan pendapatan yang mewakili capaian pembangunan untuk hidup layak. Pengukuran hidup layak menggunakan indikator kemampuan daya beli masyarakat terhadap sejumlah kebutuhan pokok makanan dan bukan makanan.
c. Upah minimum
Upah minimum mempunyai hubungan negatif dengan tingkat kemiskinan (Prastyo, 2010: 107). Hal ini menunjukkan bahwa apabila upah minimum meningkat maka tingkat kemiskinan mengalami
48
penurunan. Upah minimum merupakan suatu standar minimum yang digunakan oleh para pengusaha atau pelaku industri untuk memberikan upah kepada pekerja. Upah minimum yang digunakan dalam skripsi ini adalah upah minimum kabupaten/kota. Penetapan upah minimum kabupaten/kota harus lebih besar dari upah minimum provinsi dan ditetapkan selambat-lambatnya 40 hari sebelum tanggal berlakunya upah minimum yaitu 1 Januari (www.gajimu.com) .
d. Gizi buruk balita
Tingkat kesehatan mempunyai hubungan negatif dengan tingkat kemiskinan (Wahyudi dan Rejekingsih, 2013: 14). Hal ini menunjukkan bahwa apabila tingkat kesehatan baik maka tingkat kemiskinan mengalami penurunan. Dalam skripsi ini digunakan banyaknya balita yang mengalami gizi buruk untuk mengukur tingkat kesehatan. Semakin sedikit balita yang mengalami gizi buruk di suatu daerah, maka tingkat kesehatan masyarakat di daerah tersebut semakin baik. e. Rata-rata lama sekolah
Rata-rata lama sekolah digunakan sebagai salah satu tolak ukur tingkat pendidikan di suatu daerah. Semakin tinggi tingkat pendidikan dapat membantu menurunkan tingkat kemiskinan di suatu daerah (Wahyudi dan Rejekingsih, 2013: 14).
f. Rasio Ketergantungan
Menurut BPS, rasio ketergantungan adalah perbandingan antara jumlah penduduk umur 0-14 tahun ditambah dengan jumlah penduduk
49
65 tahun keatas dibandingkan dengan jumlah penduduk usia 15-64 tahun. Adapun persamaan rasio ketergantungan adalah sebagai berikut:
(3. 17)
Keterangan:
= rasio ketergantungan
= jumlah penduduk usia 0-14 tahun = jumlah penduduk usia 65 tahun keatas = jumlah penduduk usia 15-64 tahun
Rasio ketergantungan dapat digunakan sebagai indikator yang menunjukkan keadaan ekonomi suatu daerah. Semakin tinggi persentase rasio ketergantungan menunjukkan semakin tinggi beban yang harus ditanggung penduduk usia produktif untuk membiayai hidup penduduk usia tidak produktif (Badan Pusat Statistik).
g. Pengangguran
Pengangguran mempunyai hubungan positif dengan tingkat kemiskinan (Prastyo, 2010: 109). Semakin banyak pengangguran maka tingkat kemiskinan juga semakin meningkat. Menurut BPS, pengangguran adalah seseorang yang termasuk kelompok penduduk usia kerja yang selama periode tertentu tidak bekerja, bersedia menerima pekerjaan, dan sedang mencari pekerjaan. Dalam skripsi ini pengangguran yang dimaksud adalah pengangguran yang sedang mencari pekerjaan.
Data-data dari variabel sampai diberikan pada Lampiran 1. Ketujuh variabel tersebut digunakan untuk mengelompokkan tingkat
50
kemiskinan kabupaten/kota di Jawa Tengah menggunakan metode Ward
dan Average Linkage. 2. Uji Asumsi Analisis Cluster
Terdapat asumsi-asumsi yang harus dipenuhi dalam analisis
cluster, yaitu:
a. Sampel yang diambil harus mewakili populasi yang ada
Untuk mengetahui apakah sampel yang digunakan telah mewakili populasi, dapat dilihat dari nilai Kaiser Meyer Olkin (KMO). Berdasarkan persamaan (3.1) dan (3.2) dan perhitungan menggunakan SPSS 20, diperoleh nilai KMO sebesar 0,713. Nilai tersebut lebih dari 0,5, maka sampel telah mewakili populasi sehingga layak untuk dilakukan analisis cluster.
b. Multikolinearitas
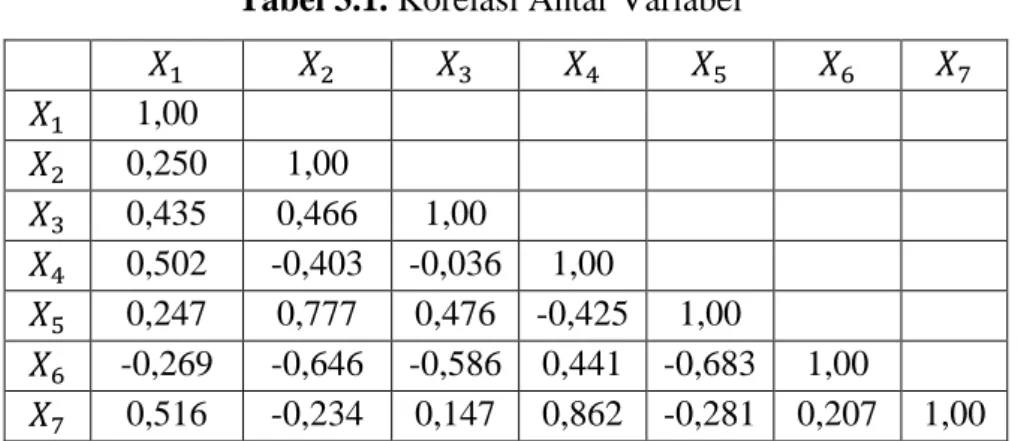
Asumsi lain analisis cluster yaitu multikolinearitas. Multikolinearitas adalah adanya korelasi atau hubungan yang sangat tinggi antar variabel. Untuk mengetahui ada tidaknya multikolinearitas, dapat dilihat dari nilai-nilai korelasi pada matriks korelasi. Dua variabel atau lebih dikatakan multikolinearitas apabila nilai korelasinya > 0,70 (Yamin dan Kurniawan, 2014: 70). Berdasarkan persamaan (2. 8) dan perhitungan menggunakan program SPSS 20 diperoleh nilai-nilai korelasi antar variabel pada Lampiran 2 dengan hasil sebagai berikut:
51
Tabel 3.1. Korelasi Antar Variabel 1,00 0,250 1,00 0,435 0,466 1,00 0,502 -0,403 -0,036 1,00 0,247 0,777 0,476 -0,425 1,00 -0,269 -0,646 -0,586 0,441 -0,683 1,00 0,516 -0,234 0,147 0,862 -0,281 0,207 1,00 Tabel 3. 1 menunjukkan bahwa variabel dan , dan mengalami multikolinearitas karena nilai korelasi lebih dari 0,7. Karena terjadi multikolinearitas antar variabel, maka perlu dilakukan penanganan multikolinearitas guna memenuhi asumsi dalam analisis
cluster. Penanganan masalah multikolinearitas menggunakan Principal Component Analysis(PCA).
3. Principal Component Analysis (PCA)
PCA bertujuan untuk menyederhanakan variabel-variabel yang diamati dengan mereduksi dimensinya tanpa kehilangan banyak informasi dari variabel asal/aslinya. Pemilihan metode PCA dikarenakan metode ini mampu mengatasi masalah multikolinearitas secara bersih. Artinya, setiap
principal component yang terbentuk dari PCA bebas dari multikolinearitas. Sebelum melakukan PCA, terlebih dahulu melakukan uji KMO dan Bartlett. Uji KMO telah dilakukan untuk memenuhi asumsi dalam analisis
cluster dan diperoleh nilai KMO sebesar 0,713. Hal ini menunjukkan bahwa data layak untuk dilakukan PCA. Uji Bartlett digunakan untuk mengetahui apakah matriks korelasi hubungan antara variabel adalah
52
matriks identitas, sehingga diketahui korelasi antar variabel. Berdasarkan persamaan (3.7) dan perhitungan menggunakan SPSS 20 diperoleh hasil (Lampiran 3) nilai = 0,000 < = 0,05. Hal ini menunjukkan bahwa terdapat korelasi antar variabel sehingga perlu dilakukan PCA.
Setelah dilakukan uji KMO dan Bartlett, dilakukan pemeriksaan terhadap nilai-nilai Measure of Sampling Adequacy (MSA). MSA
digunakan untuk mengetahui variabel mana saja yang layak dilakukan
PCA. Berdasarkan persamaan (3.8) dan perhitungan menggunakan SPSS 20 diperoleh nilai-nilai MSA yang terdapat pada output anti image matrices bagian correlation pada Lampiran 3. Nilai MSA ditunjukkan oleh diagonal dari kiri atas ke kanan bawah yang bertanda huruf a. Hasil dari
MSA ditunjukkan oleh tabel berikut:
Tabel 3.2. Nilai Measures of Sampling Adequacy(MSA)
Variabel
MSA 0,659 0,805 0,853 0,577 0,811 0,745 0,630 Variabel layak dilakukan PCA apabila mempunyai nilai MSA lebih dari 0,5. Dari tabel 3. 2 terlihat bahwa nilai-nilai MSA dari ketujuh variabel semuanya lebih dari 0,5, maka ketujuh variabel tersebut layak untuk dilakukan PCA.
Setelah uji KMO, Bartlett, dan MSA terpenuhi, maka dilakukan
PCA. Pembentukan Principal Component (PC) untuk ketujuh variabel yang digunakan berdasarkan matriks korelasi. Pemilihan penggunaan matriks korelasi dikarenakan ketujuh variabel mempunyai satuan berbeda,
53
maka harus dilakukan standarisasi data terlebih dahulu. Berdasarkan persamaan (2. 7) dan perhitungan menggunakan program Excel diperoleh data yang telah distandarisasi pada Lampiran 4, dan dapat dibuat matriks sebagai berkut: (3. 18)
Matriks korelasi adalah perkalian antara matriks dengan . Berdasarkan matriks (3. 18) diperoleh matriks sebagai berikut:
(3. 19)
Dengan mengalikan matriks (3.19) dengan (3.18) diperoleh matriks korelasi sebagai berikut:
(3. 20)
Langkah selanjutnya yaitu mencari nilai eigen dari matriks korelasi . Dengan perhitungan menggunakan SPSS 20 diperoleh output pada Lampiran 5 dengan hasil sebagai berikut:
54
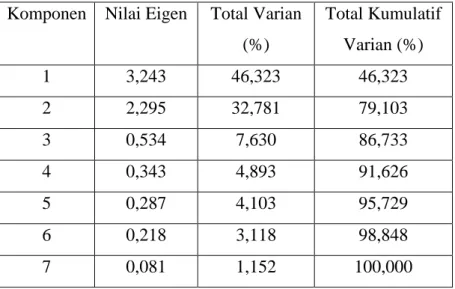
Tabel 3.3. Nilai Eigen, Total Varian, Total Kumulatif Varian Komponen Nilai Eigen Total Varian
(%) Total Kumulatif Varian (%) 1 3,243 46,323 46,323 2 2,295 32,781 79,103 3 0,534 7,630 86,733 4 0,343 4,893 91,626 5 0,287 4,103 95,729 6 0,218 3,118 98,848 7 0,081 1,152 100,000
Dari tabel 3. 3 terlihat bahwa terdapat tujuh komponen yang terbentuk dari ketujuh variabel yang digunakan. Nilai eigen diperoleh dari persamaan (3. 3) dan selalu diurutkan dari nilai yang terbesar hingga yang paling kecil. Nilai eigen menunjukkan besarnya total varian yang dijelaskan oleh komponen yang terbentuk. Kriteria minimal yang digunakan untuk menentukan Principal Component (PC) yaitu apabila nilai eigen lebih dari 1 ( >1), maka komponen tersebut terpilih sebagai PC
(Gudono, 2014: 210). Tabel 3. 3 menunjukkan bahwa terbentuk dua PC
yang mempunyai >1 yaitu dan . terdiri dari variabel pengeluaran perkapita, upah minimum, rata-rata lama sekolah, dan rasio ketergantungan, sedangkan terdiri dari variabel PDRB, gizi buruk balita, dan pengangguran. Kedua PC tersebut telah dapat menjelaskan varian dari ketujuh variabel sebesar 79,103%.
55
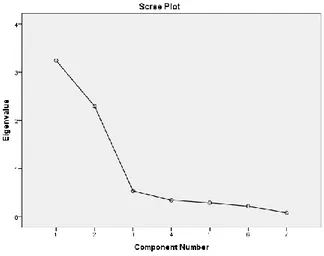
Nilai-nilai eigen yang diperoleh dapat dijelaskan secara grafik menggunakan scree plot. Scree plot menjelaskan hubungan antara banyaknya komponen yang terbentuk dengan eigenvalue.
Gambar 3. 2. Scree Plot
Untuk mengetahui nilai-nilai korelasi (loading) antara variabel dengan PC yang terbentuk dapat dilihat pada output SPSS component matrix (Lampiran 5), dengan hasil sebagai berikut:
Tabel 3.4. Komponen Matriks Variabel
0,445 0,854 0,744 -0,358 0,870 -0,867 -0,151 0,765 -0,155 0,302 0,897 -0,183 0,124 0,918
Loading merupakan nilai korelasi antara variabel dengan principal component. Dari tabel 3. 4 dapat terlihat variabel-variabel yang termasuk kedalam dan sebagai berikut:
56
Tabel 3.5. Variabel dan
Dari tabel 3.5 terlihat bahwa terdiri dari variabel pengeluaran perkapita ( ), upah minimum ( ), rata-rata lama sekolah ( ), dan rasio ketergantungan ( ). Sedangkan terdiri dari variabel PDRB ( ), gizi buruk balita ( ), dan pengangguran ( ). Nilai-nilai loading pada tabel 3.4 digunakan untuk memperoleh nilai-nilai communalities dengan mensubstitusikannya ke dalam persamaan sebagai berikut:
(3. 21)
Keterangan: = nilai korelasi (loading) variabel ke- pada PC 1
= nilai korelasi (loading) variabel ke- pada PC 2
Communalities digunakan untuk menunjukkan berapa varian yang dapat dijelaskan oleh principal component (PC) yang terbentuk. Berikut hasil subtitusi nilai loading tabel 3. 4 ke dalam persamaan (3. 21):
Tabel 3.6. Communalities
Variabel
Extraction 0,784 0,753 0,645 0,934 0,790 0,767 0,865 Hasil dari tabel 3. 6 menunjukkan nilai sebesar 0,784 yang berarti sebesar 78,4% varian dapat dijelaskan oleh PC yang terbentuk, sebesar 0,753 yang berarti bahwa sebesar 75,3% varian dapat
57
dijelaskan oleh PC yang terbentuk, sebesar 0,645 yang berarti bahwa sebesar 64,5% varian dapat dijelaskan oleh PC yang terbentuk, sebesar 0,934 yang berarti bahwa sebesar 93,4% varian dapat dijelaskan oleh PC yang terbentuk, sebesar 0,790 yang berarti bahwa sebesar 79,0% varian dapat dijelaskan oleh PC yang terbentuk, sebesar 0,767 yang berarti bahwa sebesar 76,7% varian dapat dijelaskan oleh PC yang terbentuk, dan sebesar 0,865 yang berarti bahwa sebesar 86,5% varian dapat dijelaskan oleh PC yang terbentuk.
Setelah diperoleh dua principal component hasil dari reduksi variabel, akan ditentukan koefisien dari principal component yang akan digunakan untuk membentuk persamaan PC. Berikut hasil yang diperoleh:
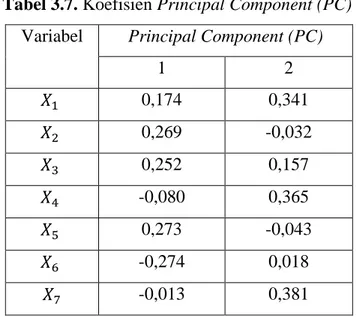
Tabel 3.7. Koefisien Principal Component(PC)
Variabel Principal Component(PC)
1 2 0,174 0,341 0,269 -0,032 0,252 0,157 -0,080 0,365 0,273 -0,043 -0,274 0,018 -0,013 0,381
Dengan mensubtitusikan hasil tabel 3.7 dengan persamaan (3.5) diperoleh persamaan berikut:
58
(3. 23)
Persamaan (3. 22) dan (3. 23) akan digunakan untuk mencari nilai-nilai dari principal component (PC) dengan hasil pada Lampiran 6. Skor
principal component inilah yang akan digunakan untuk mengelompokkan kabupaten/kota di Jawa Tengah menggunakan metode Ward dan Average Linkage, karena kedua komponen yang terbentuk sudah bebas dari multikolinearitas.
4. Pemilihan Ukuran Jarak
Sebelum melakukan pengelompokan kabupaten/kota di Jawa Tengah menggunakan metode Ward dan Average Linkage, terlebih dahulu dilakukan penghitungan jarak antar objek. Jarak inilah yang digunakan sebagai ukuran kesamaan antar objek. Ukuran kesamaan antar objek yang digunakan adalah jarak Euclid kuadrat. Semakin besar jarak menunjukkan ketaksamaan antar objek, sebaliknya semakin kecil jarak menunjukkan kesamaan antar objek.
Diberikan contoh perhitungan jarak antara Kab. Cilacap dan Kab. Banyumas, Kab. Cilacap dan Kab. Purbalingga, serta Kab. Banyumas dan Kab. Purbalingga menggunakan persamaan(3.9). Sepasang objek dihitung jaraknya menggunakan nilai-nilai dari principal component (PC) yang diperoleh dari analisis PCA. Hasil perhitungan jarak antar objek yang lain terlampir pada Lampiran 7.
59
Tabel 3.8. Perhitungan Kedekatan Kab. Cilacap dan Kab. Banyumas
Objek Total
Kab. Cilacap -0,30701 1,91600 Kab. Banyumas -0,39474 0,87607
0,08773 1,03993
0,00769 1,08145 1,089
Dari perhitungan tabel 3. 8 diperoleh nilai jarak Kab. Cilacap dengan Kab. Banyumas sebesar 1,089.
Tabel 3.9. Perhitungan Kedekatan Kab. Cilacap dan Kab. Purbalingga
Objek Total
Kab. Cilacap -0,30701 1,91600 Kab. Purbalingga -0,74843 -0,33454
0,44142 2,25054
0,19485 5,06493 5,260
Dari perhitungan tabel 3. 9 diperoleh nilai jarak Kab. Cilacap dengan Kab. Purbalingga sebesar 5,260.
Tabel 3.10. Perhitungan Kedekatan Kab. Banyumas dan Kab. Purbalingga
Objek Total
Kab. Banyumas -0,39474 0,87607 Kab. Purbalingga -0,74843 -0,33454
0,35369 1,21061
60
Dari perhitungan tabel 3. 10 diperoleh nilai jarak Kab. Banyumas dan Kab. Purbalingga sebesar 1,591.
5. Metode Ward
Metode Ward adalah salah satu metode pengelompokan hirarki yang pengelompokannya berdasarkan pada sum square error (SSE). Langkah-langkah pengelompokan menggunakan metode Ward adalah sebagai berikut:
Dimulai dari setiap objek dianggap sebagai sebuah cluster
tersendiri, maka terdapat 35 cluster (karena terdapat 35 kabupaten/kota di Provinsi Jawa Tengah) yang mempunyai satu objek. Pada tahap ini SSE
bernilai nol.
Menghitung nilai SSE untuk setiap kombinasi dua pasang cluster
dari 35 cluster, lalu memilih dua pasang cluster yang memiliki nilai SSE
terkecil untuk digabungkan menjadi satu cluster. Secara sistematik, 35
cluster akan berkurang 1 pada setiap tahap. Diberikan contoh perhitungan
SSE untuk Kab. Cilacap dan Kab. Banyumas. Data yang digunakan adalah nilai-nilai dari principal component (Lampiran 6).
Nilai rata-rata Kab. Cilacap dan Kab. Banyumas sebagai berikut: (-0,30701 + 1,91600 -0,39474 + 0,87607) / 4 = 0,52258. Rata-rata yang diperoleh digunakan untuk menghitung SSE Kab. Cilacap dan Kab. Banyumas. Berdasarkan persamaan (3.10) diperoleh nilai SSE Kab. Cilacap dan Kab. Banyumas sebagai berikut:
61
. Dua objek yang mempunyai nilai SSE paling kecil akan bergabung menjadi satu cluster.
Setelah terbentuk satu cluster yang terdiri dari dua objek pada tahap pertama, kemudian membuat kombinasi dua pasang cluster baru lagi. Dua pasang cluster baru tersebut terdiri dari satu cluster yang telah terbentuk pada tahap pertama dan cluster yang lain, kemudian menghitung nilai SSE lagi. Memilih dua pasang cluster yang memiliki nilai SSE
terkecil untuk digabungkan menjadi satu cluster. Demikian seterusnya sampai semua objek bergabung menjadi satu cluster.
Untuk mempermudah proses pengelompokkan kabupaten/kota di Jawa Tengah menggunakan metode Ward, digunakan program SPSS 20. Tahapan pembentukan cluster dapat dilihat dari output SPSS bagian
agglomeration schedule (Lampiran 9).
Pada tahap pertama, terlihat bahwa objek nomor 21 (Kab. Demak) dan nomor 24 (Kab. Kendal) bergabung menjadi satu cluster, karena memiliki jarak (pada kolom coefficients) paling kecil yaitu 0,006. Hal ini menunjukkan bahwa jarak antara kedua kabupaten tersebut merupakan jarak yang paling dekat dari banyaknya kombinasi jarak 35 kabupaten/kota. Dengan kata lain, Kab. Demak dan Kab. Kendal merupakan dua pasang objek yang memiliki nilai SSE paling kecil dari banyaknya kombinasi SSE 35 kabupaten/kota. Kemudian pada kolom next stage, menunjukkan angka 14 yang menjelaskan bahwa pada stage ke-14 proses pengelompokan dilanjutkan.
62
Tahap kedua yaitu pada stage ke-14 terlihat objek nomor 21 (Kab. Demak) bergabung dengan objek nomor 22 (Kab. Semarang) dengan jarak 0,504. Jarak tersebut merupakan jarak minimal objek terakhir yang bergabung (Kab. Semarang) dengan dua objek sebelumnya yaitu Kab. Demak dan Kab. Kendal. Pada kolom next stage, menunjukkan angka 24 yang menjelaskan bahwa pada stage ke-24 proses pengelompokan dilanjutkan.
Tahap ketiga yaitu pada stage ke-24 terlihat objek nomor 19 (Kab. Kudus) bergabung dengan objek nomor 21 (Kab. Demak) dengan jarak 3,134. Jarak tersebut merupakan jarak minimal objek terakhir yang bergabung (Kab. Kudus) dengan tiga objek sebelumnya yaitu Kab. Demak, Kab. Kendal, dan Kab. Semarang. Pada kolom next stage, menunjukkan angka 25 yang menjelaskan bahwa pada stage ke-25 proses pengelompokan dilanjutkan. Demikian seterusnya dari stage 25 dilanjutkan ke stage 29 sampai ke stage terakhir, sehingga semua objek bergabung menjadi satu cluster.
Banyaknya cluster dapat ditentukan dengan melihat dendogram (Lampiran 10). Dendogram dibaca dari kiri ke kanan. Garis vertikal menunjukkan cluster yang digabung, sedangkan garis horizontal menunjukkan jarak cluster yang digabung. Tiga tahap terakhir penggabungan terlihat bahwa cluster digabung dengan jarak yang tinggi. Penggabungan ini menyebabkan kesamaan (homogenitas) yang rendah antar anggota dalam suatu cluster. Oleh karena itu, ditetapkan banyaknya
63
cluster yang terbentuk sebanyak empat cluster. Anggota-anggota tiap
cluster dapat dilihat pada output cluster membership (Lampiran 11) dan dapat ditunjukkan pada tabel di bawah ini:
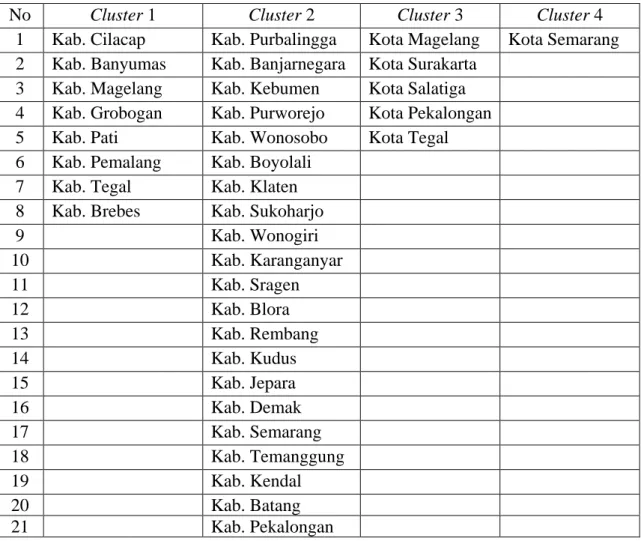
Tabel 3.11. Cluster Membership Metode Ward
No Cluster 1 Cluster 2 Cluster 3 Cluster 4
1 Kab. Cilacap Kab. Purbalingga Kota Magelang Kota Semarang 2 Kab. Banyumas Kab. Banjarnegara Kota Surakarta
3 Kab. Magelang Kab. Kebumen Kota Salatiga 4 Kab. Grobogan Kab. Purworejo Kota Pekalongan 5 Kab. Pati Kab. Wonosobo Kota Tegal
6 Kab. Pemalang Kab. Boyolali 7 Kab. Tegal Kab. Klaten 8 Kab. Brebes Kab. Sukoharjo
9 Kab. Wonogiri 10 Kab. Karanganyar 11 Kab. Sragen 12 Kab. Blora 13 Kab. Rembang 14 Kab. Kudus 15 Kab. Jepara 16 Kab. Demak 17 Kab. Semarang 18 Kab. Temanggung 19 Kab. Kendal 20 Kab. Batang 21 Kab. Pekalongan
Dari tabel 3. 11 terlihat bahwa cluster 1 terdiri dari 8 kabupaten,
cluster 2 terdiri dari 21 kabupaten, cluster 3 terdiri dari 5 kota, dan cluster
64 6. Metode Average Linkage
Metode Average Linkage adalah metode pengelompokan yang jarak antara dua cluster didefinisikan sebagai rata-rata jarak seluruh pasangan yang berada dalam satu cluster dengan cluster yang lain. Langkah-langkah pengelompokan menggunakan metode average linkage
adalah sebagai berikut:
Menghitung jarak dua objek berdasarkan persamaan (3.9), kemudian memilih dua pasang objek yang memiliki jarak paling dekat. Dari Lampiran 12 terlihat bahwa objek nomor 21 (Kab. Demak) dan nomor 24 (Kab. Kendal) bergabung menjadi satu cluster dengan jarak 0,011. Selanjutnya, menghitung jarak antara cluster yang telah terbentuk pada tahap pertama (Kab. Demak & Kab. Kendal) dengan cluster yang lain menggunakan persamaan (3.11). Dari Lampiran 12 terlihat bahwa objek yang bergabung selanjutnya adalah objek nomor 22 (Kab. Semarang). Kab. Semarang inilah yang mempunyai jarak paling dekat dengan (Kab. Demak & Kab. Kendal) daripada kabupaten/kota yang lainnya. Adapun jarak antara (Kab. Demak & Kab. Kendal) dan Kab. Semarang adalah sebagai berikut:
(3. 24) Begitu seterusnya sampai semua kabupaten/kota bergabung menjadi satu
cluster.
Untuk mempermudah proses pengelompokkan kabupaten/kota di Jawa Tengah menggunakan metode Average Linkage, digunakan program
65
SPSS 20. Tahapan pembentukan cluster dapat dilihat dari output SPSS bagian agglomeration schedule (Lampiran 12).
Pada tahap pertama, terlihat bahwa objek nomor 21 (Kab. Demak) dan nomor 24 (Kab. Kendal) bergabung menjadi satu cluster, karena memiliki jarak (pada kolom coefficients) paling kecil yaitu 0,011. Hal ini menunjukkan bahwa jarak antara kedua kabupaten tersebut merupakan jarak yang paling dekat dari banyaknya kombinasi jarak 35 kabupaten/kota. Kemudian pada kolom next stage, menunjukkan angka 14 yang menjelaskan bahwa pada stage ke-14 proses pengelompokan dilanjutkan.
Tahap kedua yaitu pada stage ke-14 terlihat objek nomor 21 (Kab. Demak) bergabung dengan objek nomor 22 (Kab. Semarang) dengan jarak 0,165. Jarak tersebut merupakan jarak minimal objek terakhir yang bergabung (Kab. Semarang) dengan dua objek sebelumnya yaitu (Kab. Demak dan Kab. Kendal). Perolehan jarak tersebut sama seperti persamaan (3. 24). Pada kolom next stage, menunjukkan angka 22 yang menjelaskan bahwa pada stage ke-22 proses pengelompokan dilanjutkan.
Tahap ketiga yaitu pada stage ke-22 terlihat objek nomor 11 (Kab. Sukoharjo) bergabung dengan objek nomor 21 (Kab. Demak) dengan jarak 0,516. Jarak tersebut merupakan jarak minimal objek terakhir yang bergabung (Kab. Sukoharjo) dengan tiga objek sebelumnya yaitu (Kab. Demak, Kab. Kendal, dan Kab. Semarang). Pada kolom next stage,
66
pengelompokan dilanjutkan. Demikian seterusnya dari stage 27 dilanjutkan ke stage 31 sampai ke stage terakhir, sehingga semua objek bergabung menjadi satu cluster.
Banyaknya cluster dapat ditentukan dengan melihat dendogram (Lampiran 13). Tahap terakhir penggabungan terlihat bahwa cluster
digabung dengan jarak yang tinggi. Penggabungan ini menyebabkan kesamaan (homogenitas) yang rendah antar anggota dalam suatu cluster. Karena akan dilakukan perbandingan hasil cluster dengan metode Ward, maka ditetapkan banyaknya cluster yang terbentuk sebanyak empat
cluster. Anggota-anggota tiap cluster dapat dilihat pada output cluster membership (Lampiran 14) dan dapat ditunjukkan pada tabel di bawah ini:
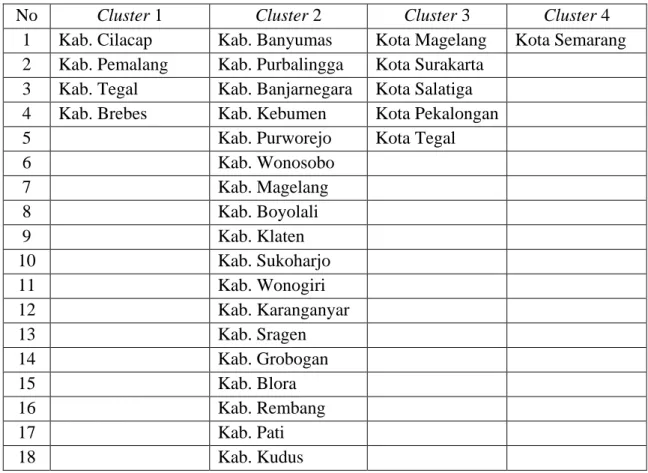
Tabel 3.12. Cluster Membership Metode Average Linkage
No Cluster 1 Cluster 2 Cluster 3 Cluster 4
1 Kab. Cilacap Kab. Banyumas Kota Magelang Kota Semarang 2 Kab. Pemalang Kab. Purbalingga Kota Surakarta
3 Kab. Tegal Kab. Banjarnegara Kota Salatiga 4 Kab. Brebes Kab. Kebumen Kota Pekalongan
5 Kab. Purworejo Kota Tegal
6 Kab. Wonosobo 7 Kab. Magelang 8 Kab. Boyolali 9 Kab. Klaten 10 Kab. Sukoharjo 11 Kab. Wonogiri 12 Kab. Karanganyar 13 Kab. Sragen 14 Kab. Grobogan 15 Kab. Blora 16 Kab. Rembang 17 Kab. Pati 18 Kab. Kudus
67
No Cluster 1 Cluster 2 Cluster 3 Cluster 4
19 Kab. Jepara 20 Kab. Demak 21 Kab. Semarang 22 Kab. Temanggung 23 Kab. Kendal 24 Kab. Batang 25 Kab. Pekalongan
Dari tabel 3.12 terlihat bahwa cluster 1 terdiri dari 4 kabupaten,
cluster 2 terdiri dari 25 kabupaten, cluster 3 terdiri dari 5 kota, dan cluster
4 terdiri dari 1 kota.
7. Penentuan Metode Terbaik
Setelah terbentuk 4 cluster dari masing-masing metode, dilakukan penentuan metode yang menghasilkan hasil cluster terbaik. Pengecekkan dilakukan menggunakan simpangan baku dalam cluster (within cluster) dan antar cluster (between cluster). Adapun perhitungannya sebagai berikut:
a. Metode Ward
1. Simpangan baku dalam cluster ( )
Diketahui cluster yang terbentuk sebanyak 4 buah (K = 4).
Simpangan baku cluster 1, rata-rata nilai principal component tiap kabupaten/kota dapat dilihat pada Lampiran 15 (tabel 1) dengan rata-rata nilai principal component cluster 1 = 0,160444. Berdasarkan persamaan (2. 6) diberikan perhitungan sebagai berikut:
68
Simpangan baku cluster 2, rata-rata nilai principal component tiap kabupaten/kota dapat dilihat pada Lampiran 15 (tabel 2) dengan rata-rata nilai principal component cluster 2 = -0,21369.
Simpangan baku cluster 3, rata-rata nilai principal component tiap kabupaten/kota dapat dilihat pada Lampiran 15 (tabel 3) dengan rata-rata nilai principal component cluster 3 = 0,01779.
69
Simpangan baku cluster 4 bernilai 0, karena cluster 4 hanya terdiri dari satu kota saja.
Berdasarkan persamaan (3.12) diperoleh nilai simpangan baku dalam
cluster ( ) sebagi berikut:
2. Simpangan baku antar cluster ( )
Telah diketahui bahwa rata-rata nilai principal component cluster 1 = 0,160444, cluster 2 = -0,21369, cluster 3 = 0,01779, cluster 4 = 3,115045. Diberikan perhitungan rata-rata seluruh cluster sebagai berikut:
=
Berdasarkan persamaan (3.13) diperoleh nilai simpangan baku antar
cluster ( ) sebagi berikut:
70 b. Metode Average Linkage
1. Simpangan baku dalam cluster ( )
Diketahui cluster yang terbentuk sebanyak 4 buah (K = 4).
Simpangan baku cluster 1, rata-rata nilai principal component tiap kabupaten/kota dapat dilihat pada Lampiran 16 (tabel 1) dengan rata-rata nilai principal component cluster 1 = 0,277563. Berdasarkan persamaan (2. 6) diberikan perhitungan sebagai berikut:
Simpangan baku cluster 2, rata-rata nilai principal component tiap kabupaten/kota dapat dilihat pada Lampiran 16 (tabel 2) dengan rata-rata nilai principal component cluster 2 = -0,17257.
71
Simpangan baku cluster 3, rata-rata nilai principal component tiap kabupaten/kota dapat dilihat pada Lampiran 16 (tabel 3) dengan rata-rata nilai principal component cluster 3 = 0,01779.
Simpangan baku cluster 4 bernilai 0, karena cluster 4 hanya terdiri dari satu kota saja.
Dengan menggunakan persamaan (3.12) diperoleh nilai simpangan baku dalam cluster ( ) sebagi berikut:
72 2. Simpangan baku antar cluster ( )
Telah diketahui bahwa rata-rata nilai principal component cluster 1 = 0,277563, cluster 2 = -0,17257, cluster 3 = 0,01779, cluster 4 = 3,115045. Diberikan perhitungan rata-rata seluruh cluster sebagai berikut:
=
Berdasarkan persamaan (3.13) diperoleh nilai simpangan baku antar
cluster ( ) sebagi berikut:
Dari hasil perhitungan nilai simpangan baku dalam cluster ( ) dan simpangan baku antar cluster ( ) kedua metode, dicari perbandingan (rasio) dari kedua simpangan baku tersebut. Untuk lebih jelasnya, berikut disajikan tabel nilai simpangan baku dalam dan antar cluster:
73
Tabel 3.13. Simpangan baku dalam dan antar cluster
Simpangan Baku Metode Ward Metode Average Linkage
simpangan baku
dalam cluster ( ) simpangan baku
antar cluster ( )
Simpangan baku dalam cluster ( ) metode Ward lebih kecil daripada metode average linkage, sedangkan simpangan baku antar cluster
( ) metode Ward lebih besar daripada metode average linkage. Perbandingan (rasio) antara dan kedua metode sebagai berikut:
. Tabel 3.14. Perbandingan (rasio) dan
Rasio Metode Ward Metode Average Linkage
Dari tabel 3.14 terlihat bahwa rasio metode Ward sebesar lebih kecil daripada rasio metode average linkage sebesar . Metode yang mempunyai rasio terkecil merupakan metode dengan kinerja terbaik. Dengan kata lain, untuk mengelompokkan kabupaten/kota Provinsi Jawa Tengah berdasarkan faktor-faktor yang mempengaruhi kemiskinan tahum 2014 lebih baik menggunakan metode
Ward.
8. Penginterpretasian Hasil Cluster
Untuk menginterpretasi dan memprofilkan hasil cluster digunakan nilai-nilai centroid tiap cluster. Centroid adalah rata-rata nilai objek yang
74
terdapat dalam cluster pada tiap variabel. Berdasarkan persamaan (2. 22) diperoleh nilai-nilai centroid tiap cluster untuk masing-masing metode sebagai berikut:
a. Metode Ward
Tabel 3.15. Rata-rata variabel pada setiap cluster Metode Ward
Variabel Cluster 1 Cluster 2 Cluster 3 Cluster 4 (PDRB) 4,01327 (PP) 1,443998 (UP) 3,20597 (GB) (RLS) 1,58368 (RK) (PG)
Dari tabel 3. 15 dapat diinterpretasikan masing-masing cluster
sebagai berikut:
1) Cluster 1 mempunyai nilai centroid tinggi untuk variabel (pengangguran). Hal ini berarti bahwa pada cluster 1, penduduk yang tidak bekerja cukup banyak. Oleh karena itu, pemerintah dapat memprioritaskan bantuan tambahan lapangan pekerjaan pada daerah di cluster 1.
2) Cluster 2 mempunyai nilai centroid tinggi untuk variabel (rasio ketergantungan). Hal ini berarti bahwa pada cluster 2, penduduk usia tidak produktif yang harus ditanggung penduduk usia produktif cukup banyak. Oleh karena itu, pemerintah dapat memberikan bantuan dengan membuat program-program usaha
75
mandiri untuk penduduk usia tidak produktif pada daerah di cluster
2.
3) Cluster 3 mempunyai nilai centroid tinggi untuk variabel (rata-rata lama sekolah). Hal ini berarti bahwa pada cluster 3, tingkat pendidikan penduduknya cukup baik.
4) Cluster 4 mempunyai nilai centroid tinggi untuk variabel (PDRB). Hal ini berarti bahwa pada cluster 4, pendapatan daerahnya sangat tinggi. Cluster 4 hanya terdiri dari satu kota, yaitu Kota Semarang.
b. Metode Average Linkage
Tabel 3.16. Rata-rata variabel pada setiap cluster
Metode Average Linkage
Variabel Cluster 1 Cluster 2 Cluster 3 Cluster 4 (PDRB) 4,01327 (PP) 1,443998 (UP) 3,20597 (GB) (RLS) 1,58368 (RK) (PG)
Dari tabel 3. 16 dapat diinterpretasikan masing-masing cluster
sebagai berikut:
1) Cluster 1 mempunyai nilai centroid tinggi untuk variabel (pengangguran). Hal ini berarti bahwa pada cluster 1, penduduk yang tidak bekerja cukup banyak. Oleh karena itu, pemerintah
76
dapat memprioritaskan bantuan tambahan lapangan pekerjaan pada daerah di cluster 1.
2) Cluster 2 mempunyai nilai centroid tinggi untuk variabel (rasio ketergantungan). Hal ini berarti bahwa pada cluster 2, penduduk usia tidak produktif yang harus ditanggung penduduk usia produktif cukup banyak. Oleh karena itu, pemerintah dapat memberikan bantuan dengan membuat program-program usaha mandiri untuk penduduk usia tidak produktif pada daerah di cluster
2.
3) Cluster 3 mempunyai nilai centroid tinggi untuk variabel (rata-rata lama sekolah). Hal ini berarti bahwa pada cluster 3, tingkat pendidikan penduduknya cukup baik.
4) Cluster 4 mempunyai nilai centroid tinggi untuk variabel (PDRB). Hal ini berarti bahwa pada cluster 4, pendapatan daerahnya sangat tinggi. Cluster 4 hanya terdiri dari satu kota, yaitu Kota Semarang.