Halaman Pengesahan iii
Halaman Pernyataan iv
Halaman Persembahan v
Halaman Motto vi
PRAKATA vii
DAFTAR ISI viii
DAFTAR TABEL xi
DAFTAR GAMBAR xii
INTISARI xiv
ABSTRACT xv
I PENDAHULUAN 1
1.1 Latar Belakang Masalah . . . 1
1.2 Perumusan Masalah . . . 3 1.3 Batasan Masalah . . . 3 1.4 Tujuan Penelitian . . . 3 1.5 Manfaat Penelitian . . . 4 1.6 Keaslian Penelitian . . . 4 1.7 Metodologi Penelitian . . . 4
1.7.1 Pengumpulan data email . . . 4
1.7.2 Pra pengolahan data . . . 5
1.7.3 Ekstraksi ciri . . . 5
1.7.4 Pengelompokan . . . 5
1.7.5 Penentuan label dan pembuatan hirarki . . . 6
1.7.6 Uji coba . . . 6
ix
1.8 Sistematika Penulisan . . . 7
II TINJAUAN PUSTAKA 8 III DASAR TEORI 12 3.1 Stemming . . . 12
3.1.1 Stemmingbahasa Indonesia . . . 13
3.2 Vector Space Model . . . 19
3.2.1 Pembobotan kata . . . 19
3.3 Latent Semantic Indexing . . . 20
3.3.1 Singular value decomposition . . . 21
3.4 Suffix Array . . . 23
3.4.1 Contoh suffix array . . . 23
3.5 Evaluasi pengelompokan hasil pencarian . . . 24
IV ANALISIS DAN RANCANGAN SISTEM 26 4.1 Gambaran Sistem . . . 26
4.2 Analisis Kebutuhan Sistem . . . 26
4.3 Analisis Masukan . . . 27
4.4 Analisis Keluaran . . . 27
4.5 Rancangan Arsitektur Sistem . . . 27
4.6 Pengumpulan data . . . 28
4.7 Rancangan Algoritma . . . 29
4.7.1 Pra pengolahan data . . . 30
4.7.2 Ekstraksi ciri . . . 31
4.7.3 Identifikasi dan pembuatan kelompok . . . 33
4.7.4 Penentuan label dan hirarki . . . 36
4.8 Rancangan Diagram Alir Data untuk Implementasi Aplikasi . . . 41
4.8.1 Diagram kontek . . . 41
4.8.2 Diagram alir data level 1 . . . 41
4.9 Rancangan Antarmuka untuk Implementasi Aplikasi . . . 42
4.9.1 Rancangan halaman pencarian . . . 42
4.9.2 Rancangan halaman hasil pencarian . . . 43
V IMPLEMENTASI 45 5.1 Implementasi Sistem . . . 45
5.2 Implementasi Pengumpulan Data . . . 45
5.3 Implementasi Pra Pengolahan Data . . . 46
5.3.1 Fungsi stemming . . . 48
5.4 Ekstraksi Ciri . . . 53
5.5 Pengelompokan Email . . . 55
5.6 Pembuatan Hirarki . . . 57
VI HASIL PENELITIAN DAN PEMBAHASAN 59 6.1 Pengujian Sistem . . . 59
6.1.1 Pengujian proses pengumpulan data . . . 59
6.1.2 Pengujian proses stemming . . . 60
6.1.3 Pengujian proses mendapatkan frase . . . 61
6.2 Analisis Pengujian Pengelompokan . . . 63
6.2.1 Pengujian parameter q . . . 63
6.2.2 Pengujian parameter t . . . 65
6.2.3 Analisis pemilihan label terhadap anggota kelompok . . . 68
6.2.4 Analisis pembuatan hirarki kelompok . . . 69
6.3 Kelebihan dan Kekurangan Sistem . . . 70
VIIKESIMPULAN DAN SARAN 71 7.1 Kesimpulan . . . 71
7.2 Saran . . . 72
DAFTAR TABEL
2.1 Ringkasan beberapa penelitian sebelumnya dan penelitian yang akan
dikerjakan . . . 9
3.1 Kombinasi awalan akhiran yang tidak diijinkan . . . 14
3.2 Cara menentukan tipe awalan untuk kata yang diawali dengan "te-" . 15 3.3 Jenis awalan berdasarkan tipe awalannya . . . 15
3.4 Aturan untuk inflectional particle . . . 17
3.5 Aturan untuk inflectional possesive pronoun . . . 17
3.6 Aturan untuk first order derivational prefix . . . 18
3.7 Aturan untuk second order derivational prefix . . . 18
3.8 Aturan untuk derivational suffix . . . 18
5.1 Tahapan pembuangan imbuhan . . . 48
6.1 Contoh hasil stemming . . . 62
6.2 Pengujian parameter q untuk menghitung k . . . 64
6.3 Pengujian parameter t untuk melihat kualitas pengelompokan . . . 66
6.4 Pengujian parameter t dengan data judul dan isi email . . . 68
6.5 Label dan kelompoknya . . . 69
6.6 Pengujian parameter t1 dan parameter t2 pada fungsi hirarki . . . 70
3.2 Contoh text dan indeknya . . . 23
3.3 Hubungan nilai indek dan akhiran . . . 23
4.1 Arsitektur sistem . . . 28
4.2 Pseudo-code algoritma pengelompokan email . . . 29
4.3 Diagram alir pra pengolahan data . . . 31
4.4 Pseudo-code ringkasan tahap ekstraksi ciri . . . 33
4.5 Diagram alir penemuan frase . . . 34
4.6 Diagram alir pembuatan matrik kata-dokumen dan dekomposisi nilai singular . . . 36
4.7 Diagram alir menghitung jumlah kelompok . . . 37
4.8 Diagram alir penentuan kelompok dan label . . . 39
4.9 Pseudo-code penentuan hirarki . . . 40
4.10 Pseudo-code penggabungan dua kelompok . . . 40
4.11 Diagram kontek . . . 41
4.12 Diagram alir data level 1 . . . 42
4.13 Rancangan halaman pencarian . . . 43
4.14 Rancangan halaman hasil pencarian . . . 44
5.1 Contoh query untuk email [email protected] . . . 46
5.2 Fungsi parse untuk text filtering dan stemming . . . 47
5.3 Fungsi buang imbuhan . . . 49
5.4 Fungsi buang akhiran . . . 50
5.5 Fungsi buang awalan . . . 52
5.6 Fungsi buang luluh . . . 53
5.7 Fungsi mendapatkan frase . . . 54
5.8 Fungsi membuat kumpulan frase . . . 55
5.9 Fungsi hitung SVD dan jumlah kelompok . . . 56
5.10 Fungsi menampilkan hasil pengelompokan . . . 57
5.11 Fungsi membuat hirarki . . . 58
xiii
6.1 Pengujian parameter q untuk menghitung k dengan jumlah dokumen
SEMANTIK, HIRARKI DAN LANGSUNG PADA BASIS DATA
ARSIP EMAIL
Oleh M. Zudha Ghofur 08/279229/PPA/2770
Untuk mengelola surat elektronik (email) yang tersimpan, saat ini diperluk-an suatu aturdiperluk-an ydiperluk-ang dibuat secara mdiperluk-anual untuk menyaring/mengkategorikdiperluk-an sesuai yang dikehendaki. Sedangkan untuk menemukan kembali email yang telah disimp-an, dapat digunakan fitur pencarian. Hasil pencarian yang ada pada email client saat ini hanyalah berupa daftar email secara rata. Untuk memudahkan pengguna mencari email yang relevan dengan mudah dan cepat, diperlukan cara untuk mengelompokkan email ke dalam suatu label/kategori yang relevan. Pengelompokan email tidak hanya berdasarkan kata saja tetapi juga berupa semantik/frase, dan juga bisa disajikan secara hirarki dan dikelompokkan secara langsung.
Penelitian dilakukan mulai dari pengumpulan data email yang disimpan seba-gai basis data arsip email, kemudian dilakukan pra pengolahan data yang terdiri dari stopingdan stemming. Tahap selanjutnya yaitu ekstraksi ciri, di sini digunakan fra-se kunci yang diekstraksi dari kumpulan email fra-sebagai ciri email. Setelah ciri email didapatkan kemudian dilakukan proses pengelompokan dengan menggunakan penge-lompokan orthogonal, yaitu digunakan Singular Value Decomposition (SVD). Pada tahap ini akan dilakukan analisa, apakah pengelompokan dengan SVD menghasilkan pengelompokan secara akurat dan persistent atau tidak. Tahap selanjutnya adalah pe-nentuan label dan hirarki, label ditentukan terhadap kata/frase kunci yang memiliki nilai terbesar dalam kelompok vektor dan hirarki dilakukan dengan membandingkan tiap pasangan kelompok untuk melihat apakah dapat dilakukan penggabungan kelom-pok atau diperlakukan sebagai relasi induk-anak. Tahap terakhir dilakukan pengujian. Melihat hasil pengujian penelitian tahapan demi tahapan, maka dapat diketa-hui bahwa sistem pengelompokan orthogonal terhadap basis data arsip email mampu mengelompokkan email secara semantik, dan juga dapat dibuat suatu hirarki yang memudahkan pengguna dalam menelusuri email yang relevan.
Kata-kata kunci : latent semantic indexing, cluster, email, arsip email, seman-tik, temu kembali.
ABSTRACT
SEMANTIC, HIERARCHICAL AND ONLINE EMAIL
CLUSTERING ON EMAIL ARCHIVE DATABASE
By
M. Zudha Ghofur 08/279229/PPA/2770
To manage the stored email, it currently takes a manually created rules to filter/ categorize as desired. Meanwhile, to rediscover the email that has been saved, it can be used search feature. Search results in the email client is currently just a flat list of email. To facilitate users easily and quickly search for relevant email, needed a way to classify emails into a relevant label/category. Email clustering not only by words but also in the form of semantic/phrases, and can also be presented in a hierarchical and online clustering.
The research was conducted start from data collection of electronic mail are stored as email database archive, then do preprocessing includes stopping and stem-ming. The next stage is feature extraction, here used key phrases which are extracted from a collection of email as a feature of the email. Having obtained the email fea-ture, then do the clustering by using orthogonal clustering, which used Singular Value Decomposition. At this stage it will be analyzed, whether clustering with SVD pro-duces accurate grouping and persistent or not. The next stage is to determine the label and hierarchy, the label specified key words/phrases that have the greatest value in the group vector, and the hierarchical done by comparing each pair of groups, to see whether the merger can be treated as a group or a parent-child relationship. The last stage of this research will be testing each stage.
Seeing the results of stage-by-stage testing research, it can be seen that the orthogonal clustering system on the email archive database capable of clustering se-mantically electronic mail, and also can be made of a hierarchy that allows users to browse the relevant email.
Keywords : latent semantic indexing, cluster, email, email archive, semantic, information retrieval.
1.1 Latar Belakang Masalah
Saat ini, surat elektronik atau email merupakan salah satu cara yang masih dipakai untuk berkomunikasi secara elektronik. Email telah digunakan sejak era AR-PANET hingga era internet saat ini. Rata-rata pengguna internet di dunia memiliki alamat email, sehingga pengguna email berbanding lurus terhadap pengguna internet. Perkembangan email saat ini semakin luas dimasyarakat. Hal ini didukung dengan hadirnya perangkat bergerak yang mendukung layanan email, seperti PDA (personal digital assistant), smartphone, dan MID (mobile internet device). Apalagi layanan push email yang ditawarkan oleh beberapa provider telekomunikasi membe-rikan posisi penting dari adanya email tersebut.
Dengan adanya kemajuan teknologi penyimpanan, saat ini kapasitas email se-makin bertambah. Layanan email yang ditawarkan secara cuma-cuma bahkan mampu memberikan kapasitas penyimpanan sampai 30 Gigabyte (contoh: gmail untuk pen-didikan). Dengan adanya kapasitas penyimpanan email yang semakin besar, maka pengguna email cenderung untuk menyimpan/mempertahankan emailnya. Meskipun demikian, pengguna email dapat menggunakan email client, dan memindahkan ema-ilnya dari server ke komputer pribadinya, sehingga semua email dapat disimpan dan dibaca secara offline. Seiring waktu, jumlah email yang dimiliki tiap pengguna akan bertambah banyak dan tidak selayaknya email-email tersebut dihapus, karena kapasi-tas yang cukup dan sebagian besar email tersebut cukup penting bagi pengguna.
Saat ini, untuk keperluan arsip email, yaitu menyimpan data-data email sela-ma mungkin, dapat dilakukan dengan menggunakan aplikasi pengarsipan esela-mail yang telah ada, antara lain: mailarchiva, mailpiler, enkive, archiveopteryx, archivemail, MHonArc. Beberapa aplikasi pengarsipan email dapat menyimpan email ke dalam suatu basis data, sehingga dapat dikelola kembali dengan mudah, Thickins (2006).
Secara teknis email terdiri dari beberapa bagian atau atribut seperti atribut mail-dari, mail-untuk, subjek, pesan, lampiran dan lain-lain. Sekumpulan email pada kotak surat dapat diperlakukan sebagai jumlah record email dengan jumlah atribut dari email. Dengan cara ini email disimpan dalam kotak surat dapat diperlakukan sebagai basis data email, Nagwani dan Bhansali (2010).
2
Salah satu aplikasi mail transfer agent (MTA) yaitu DBMail, mampu mena-ngani email yang datang dan kemudian menyimpannya pada suatu basis data. Apli-kasi DBMail ini salah satu prosesnya yaitu mengurai suatu email kedalam basis data yang terdiri dari beberapa atribut seperti judul, pesan, tanggal, dari, lampiran, dan seterusnya. Aplikasi DBMail dapat dipakai sebagai basis data arsip email yang akan dikelola lebih lanjut.
Untuk mengelola email-email yang tersimpan, saat ini diperlukan suatu aturan yang dibuat secara manual untuk menyaring/mengkategorikan sesuai yang dikehen-daki. Sedangkan untuk menemukan kembali email yang telah disimpan, dapat digu-nakan fitur pencarian. Hasil pencarian yang ada pada email client saat ini hanyalah berupa daftar email secara rata.
Untuk memudahkan pengguna mencari email yang relevan dengan mudah dan cepat, diperlukan cara untuk mengelompokkan email kedalam suatu label/kategori yang relevan. Pengelompokan email tidak hanya berdasarkan kata saja tetapi juga berupa semantik/frase. Pengelompokan email secara semantik, maksudnya algoritma mampu mengelompokkan hasil pencarian berdasarkan topik semantik. Hasil pen-carian memungkinkan memiliki beberapa topik, sehingga algoritma juga diupayak-an mampu memberikdiupayak-an label tiap kelompok ydiupayak-ang menggambarkdiupayak-an topik kelompok. Dengan demikian pengguna dapat dengan mudah menentukan secara sekilas apakah suatu kelompok sesuai atau tidak dengan keinginannya.
Sebelum dikelompokkan, algoritma harus menentukan jumlah kelompok yang ideal dan sesuai. Misalkan dalam pencarian didapatkan 100 data, berapa jumlah ke-lompok yang cocok? apakah 5, 10 atau 20? Bagaimana jika datanya hanya 5, apakah tetap dibuat 5 kelompok. Dengan mengetahui jumlah kelompok yang sesuai, diha-rapkan dapat ditampilkan hasil yang lebih representatif.
Selanjutnya, pengelompokan email disajikan secara hirarki, maksudnya ha-sil pengelompokan dijadikan seperti struktur pohon sehingga dapat dengan mudah ditelusuri oleh pengguna.
Dengan adanya DBMail, yang menyimpan suatu email ke dalam basis data, maka selanjutnya dapat dilakukan pengambilan email untuk dilakukan proses penge-lompokan secara semantik terhadap atribut email yang dikehendaki. DBMail dalam penelitian ini akan membantu mengurangi proses penguraian email dan menjadikan proses pengelompokan lebih responsif.
1.2 Perumusan Masalah
Berdasarkan uraian dari latar belakang masalah dapat dirumuskan permasa-lahan yang ada untuk diselesaikan dalam penelitian ini, yaitu:
1. Bagaimana mengembangkan metode tahapan pengelompokan email secara se-mantik?
2. Bagaimana menentukan jumlah kelompok yang ideal? 3. Bagaimana hasil pemilihan label kelompok?
4. Bagaimana mengimplementasikan metode pengelompokan email secara seman-tik dan hirarki dari basis data arsip email?
1.3 Batasan Masalah
Dalam penelitian ini, terdapat beberapa batasan masalah yaitu: 1. Pengelompokan email pada satu bahasa yaitu bahasa Indonesia. 2. Pra pemrosesan menggunakan stemmer bahasa Indonesia. 3. Email telah tersimpan pada suatu basis data arsip email. 4. Identifikasi semantik/frase menggunakan Suffix Array.
5. Dalam penelitian ini tidak mencakup pencarian semantik maupun klasifikasi semantik.
1.4 Tujuan Penelitian
Tujuan yang ingin dicapai melalui penelitian ini antara lain:
1. Mengembangkan metode yang mampu mengelompokan surat elektronik secara semantik.
2. Mengembangkan cara pengambilan/ekstraksi ciri email dari basis data arsip email.
4
4. Melakukan analisis hasil pengelompokan secara semantik. 5. Melakukan analisis hasil pemilihan label kelompok. 6. Melakukan analisis hirarki hasil pengelompokan.
7. Mengembangkan aplikasi prototipe sistem pengelompokan email secara se-mantik dan hirarki dari basis data arsip email.
1.5 Manfaat Penelitian
Dengan mengacu pada tujuan penelitian di atas, maka manfaat penelitian me-liputi hal-hal sebagai berikut:
1. Menghasilkan metode pengelompokan surat elektronik secara semantik, hirarki dan langsung untuk basis data arsip email.
2. Menghasilkan aplikasi prototipe yang dapat memudahkan pencarian email de-ngan dikelompokkan berdasarkan relevansinya.
3. Selain itu hasil dari penelitian ini juga dapat menjadi salah satu acuan tentang pengelompokan text pada email.
1.6 Keaslian Penelitian
Berdasarkan penelusuran literatur dan internet yang dilakukan penulis, sejauh ini belum ditemukan penelitian yang membahas khusus pengelompokan email secara semantik, hirarki dan langsung pada basis data arsip email. Namun demikian, ada penelitian sejenis tentang pengelompokan secara semantik, hirarki dan langsung pada hasil pencarian web yang akan dipaparkan pada tinjauan pustaka pada penelitian ini.
1.7 Metodologi Penelitian
1.7.1 Pengumpulan data email
Pengumpulan data email dilakukan melalui sebuah basis data email yang di-peroleh dari MTA (Mail Transfer Agent) yang ada. Proses ini menggunakan LMTP (Local Mail Transport Protocol) atau program mail delivery, yang akan menerus-kan email yang datang ke sebuah program. Program ini selanjutnya menginjeksi email ke
basis data. Email yang masuk ke basis data sudah dalam bentuk terurai. Dari basis data ini, kemudian akan diambil email yang sesuai untuk diproses lebih lanjut.
1.7.2 Pra pengolahan data
Tahapan dasar dari pra pengolahan data adalah text filtering dan stemming. Te-xt filteringmerupakan proses penghapusan kata yang memiliki jumlah huruf sedikit, kata yang sering muncul, dan simbol khusus. Stemming merupakan proses pencari-an akar kata ypencari-ang dapat mengurpencari-angi dimensi kata. Stemming ypencari-ang akpencari-an digunakpencari-an adalah dari Asian dkk. (2003). Pada tahap ini perlu pengumpulan kata dasar dalam bahasa Indonesia sebanyak mungkin dan dimasukkan dalam suatu kamus kata dasar. Data ini akan memberikan keakuratan lebih berdasarkan Asian dkk. (2003). Selain itu juga perlu dilakukan penentuan stop word yang ada dalam bahasa Indonesia. Pemi-lihan stop word yang tepat dan maksimal akan sangat membantu dalam mengurangi dimensi data.
1.7.3 Ekstraksi ciri
Dalam penelitian ini digunakan frase kunci yang diekstraksi dari kumpulan email sebagai ciri email. Ada dua kentungan dengan ciri ini, yaitu dapat mening-katkan kualitas pengelompokan melalui peningkatan informasi yang terdapat dalam email, dan keuntungan berikutnya adalah membantu untuk membuat label yang ring-kas dan akurat untuk kelompok yang dihasilkan. Algoritma pencarian frase untuk kumpulan email adalah sama untuk email tunggal, karena sebuah kumpulan email dapat dianggap sebagai sebuah pseudo-email. Dalam tahap ini akan diimplementa-sikan algoritma suffix array. Dengan suffix array ini akan didapatkan semantik topik yang bisa berupa kata atau kumpulan kata/frase, sehingga akan didapat suatu label suatu kelompok yang memiliki informasi ringkas dan akurat.
1.7.4 Pengelompokan
Pada tahap ini dilakukan proses pengelompokan dengan menggunakan ngelompokan orthogonal. Drineas dkk. (1999) telah memperkenalkan konsep pe-ngelompokan orthogonal dan juga membuktikan bahwa SVD dapat digunakan untuk pengelompokan orthogonal secara cepat dan efisien. Pada tahap ini akan dilakukan analisa, apakah pengelompokan dengan SVD menghasilkan pengelompokan secara
6
akurat dan persistent atau tidak. Penggunaan SVD juga dapat digunakan untuk me-nentukan label, dan pengelompokkannya menggunakan vector space model seperti pada penelitian Osinki (2003).
1.7.5 Penentuan label dan pembuatan hirarki
Tahap selanjutnya adalah penentuan label dan hirarki. Label ditentukan terha-dap kata/frase kunci yang memiliki nilai terbesar dalam kelompok vektor. Selanjut-nya dilakukan pembuatan hirarki untuk memudahkan pengaturan. Hirarki dilakukan dengan membandingkan tiap pasangan kelompok untuk melihat apakah dapat dila-kukan penggabungan kelompok atau diperladila-kukan sebagai relasi induk-anak.
1.7.6 Uji coba
Setiap tahap akan melalui proses ujicoba, dan pada proses akhir dilakukan uji-coba secara keseluruhan. Ujiuji-coba akan dilakukan dengan melakukan fungsionalitas dari setiap tahapan, apakah sesuai dengan yang diharapkan atau tidak. Diharapk-an dengDiharapk-an dilakukDiharapk-an ujicoba dapat ditentukDiharapk-an apakah tahapDiharapk-an-tahapDiharapk-an tersebut telah optimal atau belum dan apakah sesuai dengan perkiraan hasilnya.
1.8 Sistematika Penulisan
Penulisan tesis ini dibuat dalam bentuk Sistematika Penulisan sebagai berikut:
Bab I : Pendahuluan
Bab ini berisi latar belakang permasalahan, rumusan masalah dalam penelitian ini, batasan permasalahan, tujuan penelitian, manfaat pene-litian, keaslian tesis, metode penelitian dan sistematika penulisan.
Bab II : Tinjauan Pustaka
Bab ini berisi tentang uraian sistematis informasi hasil penelitian yang disajikan dalam pustaka dan menghubungkannya dengan masalah pe-nelitian yang sedang diteliti.
Bab III : Landasan Teori
Bab ini berisi tentang teori-teori dan referensi-referensi serta pengerti-an dasar ypengerti-ang berkaitpengerti-an dengpengerti-an topik penelitipengerti-an dpengerti-an pengerti-analisa data dalam penyusunan tesis ini yang berhubungan dengan judul.
Bab IV : Analisis dan Perancangan Sistem
Bab ini berisi tentang analisa kebutuhan dan desain untuk membangun sebuah sistem aplikasi yang diusulkan.
Bab V : Implementasi
Bab ini berisi langkah-langkah implementasi pengembangan sistem pengelompokan email.
Bab VI : Hasil Penelitian dan Pembahasan
Bab ini membahas analisa sistem yang telah dibangun, menganalisis validitas sistem, keuntungan dan kerugian sistem.
Bab VII : Kesimpulan dan Saran
Bab ini merupakan kesimpulan dari keseluruhan implementasi sistem yang dibuat dan saran untuk pengembangan sistem selanjutnya.
BAB II
TINJAUAN PUSTAKA
Penelitian tentang pengelompokan hasil pencarian web secara semantik, hi-rarki dan cepat pernah dilakukan oleh Zhang dan Dong (2001) dengan mengimple-mentasikan algoritma berdasarkan suffix array (Yamamoto dan Church, 2001), untuk menemukan frase. Efisiensi metode ini telah dibuktikan dengan mampu menangani berapapun besarnya kata-kata. Konsep pengelompokan secara orthogonal diusulkan untuk masalah pengelompokan secara umum. Zhang dan Dong (2001) juga membuk-tikan bahwa matrik SVD (Singular Value Decomposition) dapat memberikan solusi untuk pengelompokan orthogonal. Algoritma pengelompokan orthogonal memiliki landasan matematika yang kuat dan banyak keunggulan dibanding algoritma penge-lompokan heuristic tradisional.
Pencarian akar kata biasanya menghilangkan imbuhannya. Pencarian akar ka-ta banyak dipakai oleh banyak aplikasi seperti pencarian text, penterjemah mesin, peringkasan dokumen dan juga pengelompokan text. Sebagai contoh, pencarian kata inggris mengurangi kata "computer", "computing", "computation", dan "computabi-lity" menjadi akar kata umum "comput-". Dalam pencarian kata, akar kata terse-but memungkinkan kata "computers" untuk mencari semua dokumen berisi akar kata "comput-". Dalam bahasa Indonesia, pencarian akar kata agak rumit, karena memili-ki awalan, akhiran, sisipan, dan juga awalan dan akhiran yang menjadikan pencarian kata yang relevan lebih sulit. Asian dkk. (2003) telah melakukan investigasi terhadap performa dari lima algoritma pencarian akar kata dalam bahasa Indonesia, dan me-nunjukkan bahwa dengan ketersediaan kamus, algoritma Nazief dan Adriani berhasil mencari akar kata sekitar 93% keakuratannya. Dengan algoritma yang disempurnak-an, berhasil mencapai keakuratan 95% (Asian dkk., 2003).
Osinki (2003) membahas tentang algoritma lingo untuk pengelompokan hasil pencarian web. Dalam algoritma lingo dibahas tentang deteksi bahasa dan modifi-kasi dari algoritma yang telah dibuat oleh Zhang dan Dong (2001). Dalam lingo, pengelompokan berdasarkan label kelompok yang menggunakan SVD dan diimple-mentasikan menggunakan vector space model.
Nagwani dan Bhansali (2010) telah melakukan penelitian tentang model pe-ngelompokan email dengan pembobotan terhadap atribut email. Dengan model ini, akan didapat kelompok email berdasarkan atribut-atribut email yang ada.
pokannya sendiri menggunakan algoritma K-means. Metode kemiripan dari cluster menggunakan pembobotan dengan penjumlahan dari kemiripan atribut "dari", "ju-dul", dan "isi". Untuk normalisasi kemiripan, penjumlahan dari bobot tersebut adalah 1.
Prabhakar dan Basavaraju (2010) membahas tentang pemanfaatan pengelom-pokan text untuk mendeteksi spam. Pada penelitian ini, digunakan algoritma K-Means dan juga Algoritma BIRCH-Balanced Iterative Reducing and Clustering using Hierarchies.
Dalam penelitian lain, Kulkarni dan Pedersen (2005) menggunakan penge-lompokan email secara unsupervised dan pelabelan untuk kontek yang mirip sehing-ga didapat nama-nama yang mirip dalam satu kelompok. Densehing-gan kemiripan secara kontek, didapat observasi bahwa email dapat dianggap sebuah kontek, dan dengan pe-ngelompokan secara bersama-sama didapat pepe-ngelompokan berdasarkan pokok dari isi email daripada kemunculan string secara spesifik.
Dalam penelitian ini, meskipun banyak merujuk pada penelitian Zhang dan Dong (2001) dan Osinki (2003), namun penelitian ini memiliki beberapa perbedaan antara lain:
1. Penggunaan suffix array akan memakai perkata dan tidak perkarakter seperti pada penelitian Zhang dan Dong (2001).
2. Objek penelitian ini adalah pada email yang telah terurai pada basis data. Se-dangkan pada penelitian Zhang dan Dong (2001) dan Osinki (2003) merupakan kumpulan cuplikan dari hasil mesin pencari.
3. Pada penelitian ini mengkhususkan diri pada pra pemrosesan data dengan per-lakuan terhadap bahasa Indonesia sedang dalam Zhang dan Dong (2001) tidak dilakukan pra pemrosesan dan pada Osinki (2003) dilakukan pra pemrosesan dengan pencarian akar kata untuk bahasa inggris.
4. Tahapan dan proses pengelompokan maupun proses lain hasilnya mungkin ak-an berbeda dengak-an penelitiak-an Zhak-ang dak-an Dong (2001) maupun Osinki (2003) karena implementasi dari penelitian tersebut akan ditulis ulang dengan konsep yang ada.
Ringkasan hasil penelitian sebelumnya tentang pengelompokan email maupun hasil pencarian diperlihatkan pada Tabel 2.1.
10
Tabel 2.1: Ringkasan beberapa penelitian sebelumnya dan penelitian yang akan dikerjakan
No Peneliti Uraian Metode
1 Zhang dan
Dong (2001)
Penelitian memfokuskan pada pengelom-pokan hasil pencarian web untuk memban-tu pengguna mencari informasi web yang re-levan lebih mudah dah cepat
konsep penge-lompokan or-thogonal
2 Osinki (2003) Penelitian ini mengusulkan sebuah algoritma yang dinamakan LINGO untuk mengelom-pokkan hasil pencarian web
SVD untuk la-bel dan VSM
3 Nagwani
dan Bhansali (2010)
Dalam penelitian ini, pembobotan kemiripan atribut email berdasarkan model data mining diusulkan untuk mengelompokkan email un-tuk mengetahui kelompok email
Menggunakan K-Means dengan teknik text similiarity 4 Prabhakar dan Basavara-ju (2010)
Penelitian ini mengusulkan teknik detek-si spam menggunakan pengelompokan text berdasarkan model ruang vektor
algoritma K-Means dan Algoritma BIRCH untuk pengelompok-an. Nearest neighbor dan K-nearest ne-ighbor untuk klasifikasi
5 Kulkarni dan Pedersen (2005)
Penelitian ini menerapkan teknik unsupervi-sed word sense discrimination berdasarkan pengelompokan kontek yang sama terhadap permasalahan pembedaan nama dalam pe-ngelompokan email. Label didasarkan pada nama menggunakan sensecluster yang terdiri dari beberapa algoritma clustering 6 Penelitian yang akan dikerjakan
Penelitian ini fokus terhadap pengelompokk-an email dengpengelompokk-an menghasilkpengelompokk-an label secara semantik khususnya untuk bahasa Indonesia dan disajikan dengan hirarki, data diambil dari basis data email yang dinormalisasi se-hingga bisa diproses lebih cepat
Menggunakan pra-proses stemmer Indo-nesia, suffix array per kata, pengelompok-an orthogonal dan pelabelan menggunakan SVD
BAB III
DASAR TEORI
Untuk mendukung penelitian ini, pada bab III ini diuraikan beberapa dasar te-ori yang berkaitan dengan penelitian, antara lain stemming, vector space model, latent semantic indexing, suffix array, serta evaluasi pengelompokan hasil pencarian. Stem-ming pada penelitian ini digunakan untuk pencarian akar kata yang nantinya dapat mengurangi dimensi data. Vector space model digunakan sebagai penyajian doku-men email yang akan diolah. Kemudian latent semantic indexing digunakan untuk dasar pengelompokan dokumen penelitian. Suffix array digunakan untuk menentuk-an frase atau kata secara semmenentuk-antik. Terakhir adalah teknik evaluasi pengelompokmenentuk-an hasil pencarian yang digunakan untuk mengevaluasi hasil dari penelitian ini.
3.1 Stemming
Stemmingadalah suatu proses yang mentransformasi kata-kata yang terdapat dalam suatu dokumen ke kata-kata akarnya (root word) dengan menggunakan aturan-aturan tertentu. Sebagai contoh, kata bergabung, menggabungkan, digabung, akan di-stem ke akar katanya yaitu "gabung". Proses di-stemming pada teks berbahasa Indonesia berbeda dengan stemming pada teks berbahasa Inggris. Pada teks berbahasa Inggris, proses yang diperlukan hanya proses menghilangkan sufiks (akhiran). Sedangkan pada teks berbahasa Indonesia, selain sufiks, juga dihilangkan prefiks (awalan), dan konfiks (awalan dan akhiran).
Proses stemming setidaknya memiliki dua tujuan, yang pertama yaitu efisien-si, ukuran indeks dapat diperkecil karena beberapa kata berimbuhan yang memiliki kata dasar yang sama akan diindeks menjadi satu, sehingga akan mengurangi ke-butuhan ruang penyimpanan untuk indeks dan mempercepat proses pencarian, yang kedua yaitu meningkatkan efektifitas dokumen yang ditemukan kembali (recall) de-ngan mengurangi varian kata menjadi bentuk kata dasarnya (stem). Stemming bukan merupakan proses untuk mendapatkan bentuk baku atau tata bahasa yang benar. Oleh karena itu, algoritma stemming masih dapat ditolerir jika membuat beberapa kesalah-an dkesalah-an tidak harus menghasilkkesalah-an kata-kata ykesalah-ang bermakna (semkesalah-antik).
3.1.1 Stemming bahasa Indonesia
Algoritma stemming untuk beberapa bahasa telah dikembangkan, seperti Al-goritma Porter untuk teks berbahasa inggris, alAl-goritma Porter untuk teks berbahasa Indonesia, dan algoritma Nazief dan Adriani untuk teks berbahasa Indonesia. Imbuh-an (affixes) pada bahasa Indonesia lebih komplek bila dibImbuh-andingkImbuh-an dengImbuh-an imbuhImbuh-an pada bahasa Inggris. Pada bahasa Indonesia afiks terdiri dari awalan (prefixes), si-sipan (infixes), akhiran (suffixes), bentuk perulangan (repeated forms) dan kombinasi dari awalan dan akhiran confixes. Imbuhan-imbuhan yang melekat pada suatu kata harus dihilangkan untuk mengubah bentuk kata tersebut menjadi bentuk kata dasar-nya. Sebagai contoh kata "mengasihi", jika dihilangkan awalan dan akhiran menjadi "asih".
Struktur pembentukan kata dalam bahasa Indonesia adalah sebagai berikut: [awalan-1] + [awalan-2] + kata dasar + [akhiran] + [kepunyaan] + [sandang]
Masing-masing bagian tersebut (yang dalam kotak bisa ada atau tidak), digabungkan dengan kata dasar membentuk kata berimbuhan. Di bawah ini imbuhan yang banyak digunakan dalam bahasa Indonesia :
1. Kata sandang: -lah, -kah, -pun, -tah. 2. Kata kepunyaan: -ku, -mu, -nya. 3. Akhiran: -i, -an, -kan.
4. Awalan: me-, ber-, pe-, di-, ke-, ter-, se-.
Algoritma yang dibuat oleh Bobby Nazief dan Mirna Adriani merupakan salah satu algoritma stemmer bahasa Indonesia yang dapat bekerja dengan baik (Asian dkk., 2003). Algoritma ini memiliki tahap-tahap sebagai berikut:
1. Cari kata yang akan distem dalam kamus. Jika ditemukan maka diasumsikan bahwa kata tesebut adalah kata dasar. Maka algoritma berhenti.
2. Inflection suffixes ("-lah", "-kah", "-ku", "-mu", atau "-nya") dibuang. Jika ber-upa particles ("-lah", "-kah", "-tah" atau "-pun") maka langkah ini diulangi lagi untuk menghapus possesive pronouns ("-ku", "-mu", atau "-nya"), jika ada. 3. Hapus derivation suffixes ("-i", "-an" atau "-kan"). Jika kata ditemukan di
14
(a) Jika "-an" telah dihapus dan huruf terakhir dari kata tersebut adalah "-k", maka "-k" juga ikut dihapus. Jika kata tersebut ditemukan dalam kamus maka algoritma berhenti. Jika tidak ditemukan maka lakukan langkah 3(b).
(b) Akhiran yang dihapus ("-i", "-an" atau "-kan") dikembalikan, lanjut ke langkah 4.
4. Hapus Derivation Prefix. Jika pada langkah 3 ada sufiks yang dihapus maka lanjutkan ke langkah 4(a), jika tidak lanjutkan ke langkah 4(b).
(a) Periksa Tabel 3.1 kombinasi awalan-akhiran yang tidak diijinkan. Jika ditemukan maka algoritma berhenti, jika tidak lanjutkan ke langkah 4(b). (b) Tentukan tipe awalan, kemudian hapus awalan. Jika kata dasar belum juga ditemukan lakukan langkah 5, jika sudah maka algoritma berhenti. Catat-an: jika awalan kedua sama dengan awalan pertama algoritma berhenti. 5. Melakukan Perekaman.
6. Jika semua langkah telah selesai tetapi tidak juga berhasil maka kata awal dia-sumsikan sebagai kata dasar. Proses selesai.
Tabel 3.1: Kombinasi awalan akhiran yang tidak diijinkan
Awalan akhiran yang tidak diijinkan
be- -i
di- -an
ke- -i, -kan
me- -an
se- -i, -kan
Tipe awalan ditentukan melalui langkah-langkah berikut:
1. Jika awalannya adalah: "di-", "ke-", atau "se-" maka tipe awalannya secara berturut-turut adalah "di-", "ke-", atau "se-".
2. Jika awalannya adalah "te-", "me-", "be-", atau "pe-" maka dibutuhkan sebuah proses tambahan untuk menentukan tipe awalannya.
3. Jika dua karakter pertama bukan "di-", "ke-", "se-", "te-", "be-", "me-", atau "pe-" maka berhenti.
4. Jika tipe awalan adalah "none" maka berhenti. Jika tipe awalan adalah bukan "none" maka awalan dapat dilihat pada Tabel 3.2. Hapus awalan jika ditemu-kan.
Tabel 3.2: Cara menentukan tipe awalan untuk kata yang diawali dengan "te-"
Karakter yang mengikuti Tipe
Set 1 Set 2 Set 3 Set 4 Awalan
"-r-" "-r-" - - none
"-r-" vokal - - ter-luluh
"-r-" bukan (vokal atau "-r-") "-er-" vokal ter "-r-" bukan (vokal atau "-r-") "-er-" bukan vokal ter-"-r-" bukan (vokal atau "-r-") bukan "-er-" - ter
bukan (vokal atau "-r-") "-er-" vokal - none
bukan (vokal atau "-r-") "-er-" bukan vokal - te
Untuk mengatasi keterbatasan pada algoritma Bobby Nazief dan Mirna Adri-ani, maka ditambahkan aturan-aturan dibawah ini (Asian dkk., 2003):
1. Aturan untuk reduplikasi.
• Jika kedua kata yang dihubungkan oleh kata penghubung adalah kata yang sama maka akar kata adalah bentuk tunggalnya, contoh : "buku-buku" akar katanya adalah "buku".
• Jika kedua kata berlainan, misalnya "bolak-balik", "berbalas-balasan, dan "seolah-olah". Untuk mendapatkan akar katanya, kedua kata diartikan se-cara terpisah. Jika keduanya memiliki akar kata yang sama maka diubah
Tabel 3.3: Jenis awalan berdasarkan tipe awalannya
Tipe awalan Awalan yang harus dihapus
di- di-ke- ke-se- se-te- te-ter- ter-ter-luluh ter
16
menjadi bentuk tunggal, contoh: kata "berbalas-balasan", "berbalas" dan "balasan" memiliki akar kata yang sama yaitu "balas", maka akar kata "berbalas-balasan" adalah "balas". Sebaliknya, pada kata "bolak-balik", "bolak" dan "balik" memiliki kata dasar yang berbeda, maka kata dasar-nya adalah "bolak-balik"
2. Tambahan bentuk awalan dan akhiran serta aturannya.
• Untuk tipe awalan "mem-", kata yang diawali dengan awalan "memp-" memiliki tipe awalan "mem-".
• Tipe awalan "meng-", kata yang diawali dengan awalan "mengk-" memi-liki tipe awalan "meng-".
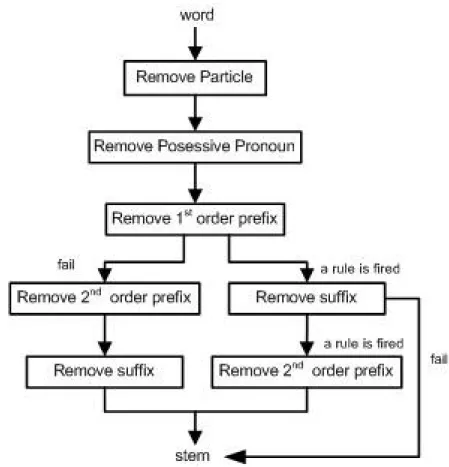
Algoritma kedua adalah algoritma Porter bahasa Indonesia (Tala, 2004). Ada-pun langkah-langkah algoritma ini adalah sebagai berikut:
1. Hapus Particle.
2. Hapus Possesive Pronoun.
3. Hapus awalan pertama. Jika tidak ada lanjutkan ke langkah 4(a), jika ada maka lanjutkan ke langkah 4(b).
4. (a) Hapus awalan kedua, lanjutkan ke langkah 5(a).
(b) Hapus akhiran, jika tidak ditemukan maka kata tersebut diasumsikan se-bagai kata dasar. Jika ditemukan maka lanjutkan ke langkah 5(b).
5. (a) Hapus akhiran. Kemudian kata akhir diasumsikan sebagai kata dasar. (b) Hapus awalan kedua. Kemudian kata akhir diasumsikan sebagai kata
da-sar.
Terdapat 5 kelompok aturan pada algoritma Porter untuk bahasa Indonesia ini. Aturan pertama yaitu aturan untuk mengubah akhiran partikel inflectional par-ticle, jika ditemukan akhiran yang memenuhi kondisi, maka akhiran dihapus, lihat tabel Tabel 3.4. Aturan kedua yaitu aturan untuk inflectional possesive pronoun se-perti terlihat pada Tabel 3.5. Aturan ketiga yaitu aturan untuk first order derivational prefixseperti terlihat pada Tabel 3.6. Aturan keempat yaitu aturan untuk second order derivational prefixseperti terlihat pada Tabel 3.7. Terakhir, aturan kelima yaitu atur-an untuk derivational suffix dapat dilihat pada Tabel 3.8. Setiap akhiratur-an atau awalatur-an
Tabel 3.4: Aturan untuk inflectional particle
Akhiran Pengganti Kondisi penilaian Kondisi tambahan Contoh
-kah NULL 2 NULL bukukah
-lah NULL 2 NULL pergilah
-pun NULL 2 NULL bukupun
Tabel 3.5: Aturan untuk inflectional possesive pronoun
Akhiran Pengganti Kondisi penilaian Kondisi tambahan Contoh
-ku NULL 2 NULL bukuku
-mu NULL 2 NULL bukumu
-nya NULL 2 NULL bukunya
yang memenuhi kondisi akan dilakukan penggantian akhiran sesuai tabel. Kata "NU-LL" dalam tabel maksudnya adalah kosong atau tidak ada.
Proses stemming menggunakan algoritma Porter dapat dilihat pada Gambar 3.1.
18
Tabel 3.6: Aturan untuk first order derivational prefix
Awalan Pengganti Kondisi penilaian Kondisi tambahan Contoh
meng- NULL 2 NULL mengukur => ukur
meny- S 2 V...* menyapu => sapu
men- NULL 2 NULL menduga => duga
mem- P 2 V... memaksa => paksa
mem- NULL 2 NULL membaca => baca
me- NULL 2 NULL merusak => rusak
peng- NULL 2 NULL pengukur => ukur
peny- S 2 V... penyapu => sapu
pen- NULL 2 NULL penduga => duga
pem- P 2 V... pemaksa => paksa
pem- NULL 2 NULL pembaca => baca
di- NULL 2 NULL diukur => ukur
ter- NULL 2 NULL tersapu => sapu
ke- NULL 2 NULL kekasih => kasih
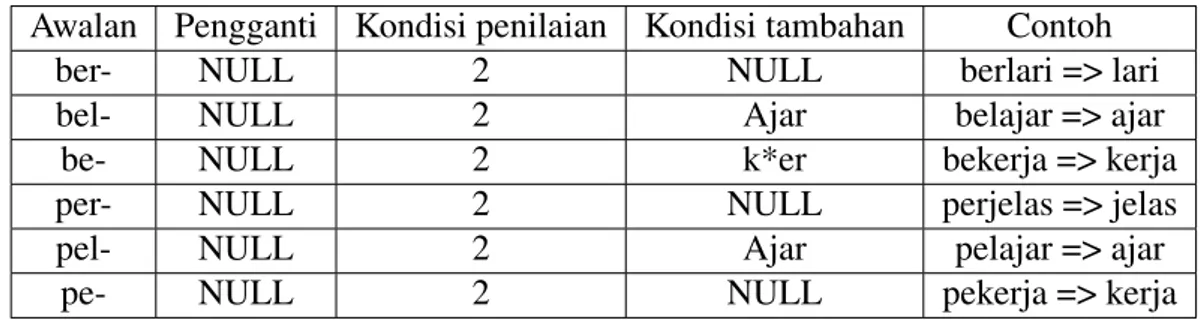
Tabel 3.7: Aturan untuk second order derivational prefix
Awalan Pengganti Kondisi penilaian Kondisi tambahan Contoh
ber- NULL 2 NULL berlari => lari
bel- NULL 2 Ajar belajar => ajar
be- NULL 2 k*er bekerja => kerja
per- NULL 2 NULL perjelas => jelas
pel- NULL 2 Ajar pelajar => ajar
pe- NULL 2 NULL pekerja => kerja
Tabel 3.8: Aturan untuk derivational suffix
Akhiran Pengganti Kondisi
pe-nilaian
Kondisi
tam-bahan
Contoh
-kan NULL 2 Prefix bukan
anggota {ke,
peng}
tarikkan => ta-rik, mengambilk-an => ambil
-an NULL 2 prefix bukan
anggota {di,
meng, ter}
makanan =>
makan, perjanji-an => jperjanji-anji
-i NULL 2 prefix bukan
anggota {ber,
ke, peng}
Tandai => tanda, mendapati => da-pat
3.2 Vector Space Model
Berbagai model matematika telah diusulkan untuk menyajikan sistem dan pro-sedur temu kembali. Model boolean membandingkan pernyataan penelusuran boo-lean dengan kumpulan kata yang digunakan untuk mengidentifikasi isi dokumen. Model probabilistik berdasarkan perhitungan probabilistik yang relevan pada kum-pulan dokumen. Terakhir, Vector Space Model (Model Ruang Vektor) menggunakan kumpulan kata untuk menyajikan penelusuran dan dokumen-dokumen, menggunakan operasi aljabar linear dasar untuk menghitung kemiripannya. Diantara model terse-but, vektor space model yang paling sederhana digunakan dan pada beberapa keper-luan yang paling produktif (Salton, 1989).
Pada Vector Space Model (VSM), setiap dokumen dalam koleksi disajikan sebagai vektor multidimensi. Tiap komponen dari vektor mencerminkan sebuah kata tertentu atau term yang terhubung dengan dokumen yang berkaitan. Nilai dari tiap komponen tergantung dari derajat hubungan diantara kata yang bersesuaian dengan dokumennya. Salah satu untuk mengukur hubungan kata dengan dokumen yaitu de-ngan pembobotan kata.
3.2.1 Pembobotan kata
Pembobotan kata yaitu proses menghitung derajat hubungan atau asosiasi di-antara kata dan dokumen. Karena model ruang vektor memerlukan keterhubungan-nya ditunjukkan oleh sebuah nilai numerik tunggal, maka aij melambangkan derajat
hubungan antara term i dan dokumen j.
Pembobotan biner, pada kasus sederhana asosiasinya menggunakan biner: aij = 1 jika kata i muncul pada dokumen j, jika tidak aij = 0. Pembobotan
bi-ner menginformasikan tentang fakta bahwa suatu term berelasi terhadap dokumen tetapi tidak memiliki informasi tentang sebera besar hubungannya.
Pembobotan frekuensi kata, pembobotan kata yang lebih bagus yaitu dengan frekuensi kata. Pada skema ini aij = tfij dengan tfij menandakan berapa banyak
kata i yang muncul pada dokumen j. Lebih jelasnya, frekuensi kata lebih informa-tif dibanding pembobotan biner yang sederhana. Meskipun demikian, pembobotan ini masih memiliki kelemahan. Untuk mengidentifikasi masalahnya, anggaplah pa-da kumpulan dokumen terpa-dapat 95% kata "komputer" yang sering muncul. Secara lokal, untuk tiap dokumen secara terpisah, kata tersebut menunjukkan isi dari doku-men. Tetapi, karena kata tersebut muncul pada hampir tiap koleksi dokumen, maka
20
tidak dapat dibedakan dokumen satu dengan lainnya. Maka, secara keseluruhan kata "komputer" bernilai sedikit. Untuk itu frekuensi kata hanya fokus pada kemunculan kata secara lokal.
Pembobotan Tf-idf , tf-idf (term frequency inverse document frequency) ditu-jukan untuk meyeimbangkan kata yang muncul secara lokal dan keseluruhan dalam dokumen-dokumen. Skema ini dituliskan sebagai berikut:
aij = tfijlog(N/dfi) (3.1)
dengan tfij adalah frekuensi kata, dfi menunjukkan jumlah dokumen yang
memiliki kata i, dan N menunjukkan jumlah total dokumen dalam koleksi. log(N/dfi),
atau seringkali diacu sebagai faktor idf (inverse document frequency), akun untuk pembobotan keseluruhan untuk kata i. Dengan demikian, ketika sebuah kata muncul pada seluruh koleksi dokumen,dfi = N maka bobot kata menjadi 0, menunjukkan
bahwa kata tersebut tidak berguna sebagai pembeda dokumen. Untuk penjelasan le-bih rinci tentang skema pembobotan kata diatas bisa dilihat Salton (1989).
3.3 Latent Semantic Indexing
Latent Semantic Indexing (LSI) adalah metode pengindeksan dan pencari-an ypencari-ang menggunakpencari-an teknik matematika ypencari-ang disebut dekomposisi nilai singular (SVD) untuk mengidentifikasi pola-pola dalam hubungan antara istilah dan konsep yang terkandung dalam koleksi terstruktur dari teks. LSI didasarkan pada prinsip bah-wa kata-kata yang digunakan dalam konteks yang sama cenderung memiliki makna yang sama. Fitur utama dari LSI adalah kemampuannya untuk mengekstrak isi kon-septual dari teks dengan membuat asosiasi antara istilah yang muncul dalam konteks yang serupa.
Dinamakan Latent Semantic Indexing karena kemampuannya untuk mengko-relasikan secara semantik istilah yang berhubungan dan laten dalam kumpulan teks, pertama kali diterapkan untuk teks di laboratorium Bell pada akhir 1980-an. Metode ini, juga dinamakan Latent Semantic Analysis (LSA), mengungkap struktur seman-tik laten yang mendasari penggunaan kata dalam teks dan bagaimana hal itu dapat digunakan untuk mengekstrak makna teks dalam menanggapi permintaan pengguna, sering disebut sebagai konsep pencarian. Pertanyaan, atau pencarian konsep, terhadap satu kumpulan dokumen yang telah mengalami LSI akan mengembalikan hasil yang
secara konseptual mirip maksudnya dengan kriteria pencarian meskipun jika hasilnya tidak mengandung suatu kata tertentu atau kata-kata dengan kriteria pencarian.
LSI mengatasi dua kendala yang paling bermasalah dari permintaan kata kun-ci Boolean: beberapa kata yang memiliki makna sama (sinonim) dan kata-kata yang memiliki lebih dari satu makna (polisemi). Sinonim dan polisemi sering menjadi penyebab dari ketidaksesuaian dalam kosa kata yang digunakan oleh penulis doku-men dan pengguna sistem temu kembali informasi. Akibatnya, permintaan kata kunci boolean sering memberikan hasil yang tidak relevan dan kehilangan informasi yang relevan.
LSI juga digunakan untuk melakukan kategorisasi dokumen secara otomatis. Bahkan, beberapa percobaan telah menunjukkan bahwa ada sejumlah korelasi an-tara cara LSI dan proses manusia dalam mengkategorikan teks (Landauer, T., dkk., 1998). Kategorisasi dokumen yaitu penetapan dokumen untuk satu atau lebih kate-gori yang telah ditentukan berdasarkan kesamaannya dengan isi konseptual dari ka-tegori (Dumais dkk., 1998). LSI menggunakan dokumen contoh untuk membangun konsep dasar untuk setiap kategori. Selama pengolahan kategorisasi, konsep-konsep yang terkandung dalam dokumen yang dikategorikan dibandingkan dengan konsep-konsep yang terkandung dalam contoh item, dan kategori ditetapkan untuk dokumen berdasarkan kesamaan antara konsep yang dikandungnya dan konsep-konsep yang terkandung dalam dokumen contoh.
Pengelompokan dinamis berdasarkan isi konseptual dokumen juga dapat di-lakukan dengan menggunakan LSI. Pengelompokan adalah cara untuk mengelom-pokkan dokumen berdasarkan kesamaan konseptual satu dengan lainnya tanpa meng-gunakan dokumen contoh untuk membangun konsep dasar untuk setiap kelompok. Hal ini sangat berguna ketika berhadapan dengan koleksi yang belum diketahui dari teks yang tidak terstruktur.
LSI menggunakan teknik aljabar linear untuk mempelajari korelasi konseptu-al dkonseptu-alam kumpulan teks. Secara umum, prosesnya meliputi pembuatan matrik kata-dokumen berbobot, melakukan dekomposisi nilai singular pada matrik, dan menggu-nakan matrik untuk mengidentifikasi konsep-konsep yang terkandung dalam teks.
3.3.1 Singular value decomposition
Dasar matematika yang membentuk LSI adalah Singular Value Decomposi-tion(SVD)/Dekomposisi Nilai Singular dari matrik kata-dokumen. Dekomposisi
me-22
misahkan sebuah matrik A t × d menjadi tiga matrik U , Σ, dan V sehingga menjadi A = U ΣVT.
U adalah matrik ortogonal t × t dengan kolom vektor disebut vektor singular kiri A, V adalah matrik ortogonal d × d dengan vektor kolom disebut vektor singular kanan dari A, dan Σ adalah matrik diagonal t × d yang memiliki nilai-nilai singular dari A dengan urutan menurun (σ1 ≥ σ2 ≥ .. ≥ σmin(t,d)) di sepanjang diagonal.
Urutan rAdari matrik A sama dengan jumlah non-nol nilai-nilai singular. Kolom rA
pertama dari U membentuk basis ortogonal untuk ruang kolom dari A. Pengambilan dokumen SVD
Pada pengambilan dokumen berbasis SVD, hanya k pertama dari vektor basis yang digunakan yaitu matrik Uk yang akan diproses lebih lanjut. Untuk menghitung
ni-lai k dipilih norma Frobenius dari matrik kata-dokumen dan perkiraan peringkat-k. Cara tersebut dipilih karena pendekatan lain memiliki parameter-parameter yang ti-dak mudah diterapkan. Cara ini juga dilakukan oleh Zhang dan Dong (2001) untuk SHOC. Dengan norma Frobenius diperlukan asumsi porsentanse ambang batas q yang menentukan sejauh mana perkiraan peringkat-k harus mempertahankan informasi as-linya. Dengan cara ini, k ditentukan untuk nilai minimal yang memenuhi kondisi berikut: q(A, k) = kAkkF kAkF = q Pk i=1(σ2i) q PrA i=1(σ2i) (1 ≤ k ≤ r) (3.2)
Pada Formula 3.2, A adalah matrik kata-dokumen asli, Ak adalah perkiraan
peringkat-k, rA adalah peringkat dari matrik A, σi adalah urutan ke-i nilai singular
(urutan ke-i dari elemen diagonal dari matrik Σ SVD) dan kAkF menyatakan norma
Frobenius dari matrik A. Sebagai contoh, diberikan ambang batas kualitas kelompok q* (misal: 80%), jumlah k kelompok ideal yaitu jumlah minimal k yang memenuhi q(A, k) ≤ q∗
Zhang dan Dong (2001) dalam penelitiannya untuk pengelompokan orthogo-nal memberikan ambang batas t untuk menentukan kekuatan pengelompokan. Doku-men ke-g pada kelompok Vgterdiri dari kumpulan dokumen yang memiliki nilai lebih
besar dari parameter t dalam vektor yg. Kata/kata kunci yang memiliki nilai terbesar
3.4 Suffix Array
Suffix Array adalah struktur data yang dirancang untuk pencarian yang efisien untuk teks yang besar. Struktur datanya hanyalah sebuah array yang berisi semua po-inter ke akhiran teks yang diurutkan berdasarkan leksikografis (abjad). Setiap akhir-an merupakakhir-an string yakhir-ang dimulai pada posisi tertentu dalam teks dakhir-an berakhir pada akhir teks. Pencarian teks dapat dilakukan dengan pencarian biner menggunakan su-ffix array.
3.4.1 Contoh suffix array
Misalkan pada teks ’abracadabra’ ingin dibuat suffix array. Pertama, yang ha-rus dilakukan adalah menentukan indek untuk teks tersebut. Nilai indek menentukan posisi tempat pencarian dapat dilakukan. Dalam contoh ini, nilai indek ditetapkan ti-ap karakter. Dengan demikian, nantinya dti-apat dicari contoh teks dengan suffix array pada setiap posisi. Hasil penentuan indek pada contoh teks ’abracadabra’ bisa dilihat pada Gambar 3.2.
Gambar 3.2: Contoh text dan indeknya
Kedua, yaitu mengurutkan nilai indek berdasarkan pada akhiran yang berse-suaian. Hubungan antara nilai indek dan akhiran seperti Gambar 3.3
24
3.5 Evaluasi pengelompokan hasil pencarian
Ada beberapa cara secara umum untuk melakukan evaluasi pengelompokan. Terdapat dua persamaan yang umum dipakai untuk evaluasi sistem temu kembali, ya-itu precision dan recall. Precision adalah perbadingan dokumen yang relevan dari seluruh dokumen yang berhasil ditemukembalikan, dapat diartikan juga sebagai rasio jumlah dokumen yang ditemukan dan dianggap relevan untuk kebutuhan pengguna. Sedangkan recall adalah perbandingan antara dokumen relevan yang berhasil dite-mukembalikan dari seluruh dokumen relevan yang ada di dalam sistem, dapat juga diartikan sebagai jumlah dokumen relevan yang ditemukan dibanding dengan jumlah semua dokumen relevan di dalam sistem.
P recission = |Ra|
|A| (3.3)
Recall = |Ra|
|R| (3.4)
|Ra| : Jumlah dokumen relevan yang ditemukembalikan |R| : Jumlah dokumen yang relevan
|A| : Jumlah hasil temu kembali
Sedangkan untuk menentukan nilai dari recall dan precission harus didapatkan jumlah dokumen yang relevan terhadap suatu topik informasi. Dengan membaca do-kumen tersebut secara keseluruhan akan dapat ditentukan suatu isi dodo-kumen tersebut relevan terhadap topik atau tidak.
Idealnya, kedua perhitungan tersebut menghasilkan nilai 1. Nilai precision 1 berarti semua hasil yang keluar adalah relevan, dan jika nilai recall 1 berarti semua dokumen relevan berhasil didapatkan. Pada prakteknya, terdapat hubungan yang ber-kebalikan antara recall dan precision yaitu bahwa nilai recall dapat dinaikan dengan cara memperbanyak dokumen yang didapat, tetapi hal ini akan mengurangi nilai pre-cission yaitu semakin bertambah juga dokumen tidak relevan yang didapatkan. Begi-tu juga sebaliknya, semakin sedikit dokumen yang didapat akan semakin bertambah dokumen yang relevan.
Berikut penjelasan singkat tiga metode yang umum dipakai untuk melakukan evaluasi terhadap hasil pengelompokan:
1. Standard IR metrics
pengu-kuran precision dan recall. Salah satu variasi metode ini yaitu isi dari kelompok terurut teratas dianggap sebagai himpunan dari dokumen yang didapat. Dengan himpunan dokumen yang relevan dan dikenal sebagai priori atau diidentifikasi terlebih dahulu, precision dan recall dapat dihitung dengan mudah.
2. Pendekatan Merge-then-cluster
yaitu sebuah metode untuk menguji algoritma pengelompokan pada sebuah kumpulan text yang telah disiapkan sebelumnya. Beberapa kumpulan text bia-sanya dibuat dengan menggabungkan sekumpulan dokumen kecil yang memi-liki kemiripan topik. Sebuah algoritma pengelompokan yang bagus harus dapat mendapatkan kelompok aslinya. Kehandalan dari pendekatan metode ini sangat ditentukan dari karakteristik koleksi masukannya. Jika sekumpulan data memi-liki kemiripan topik, pengujian algoritma mungkin tidak dapat memisahkannya dengan baik, sehingga menurunkan hasil analisis. Keunggulan dari metode ini yaitu evaluasi dapat dilakukan secara langsung dan otomatis.
3. Evaluasi pengguna
evaluasi metode ini berdasar dari opini pengguna sesungguhnya tentang kua-litas pengelompokan. Data mengenai evaluasi pengguna dapat dikumpulkan melalui beberapa pertanyaan yang disiapkan atau dapat juga dari catatan ser-ver web. Pendekatan ini dapat mengetahui apakah algoritma pengelompokan memenuhi kebutuhan pengguna atau tidak. Meskipun demikian, metode ini memiliki beberapa kekurangan, yaitu tingkat pemahaman pengguna terhadap kebutuhan dan sistem yang berbeda-beda. Untuk mendapatkan evaluasi yang berkualitas, pengguna sebaiknya memahami pengetahuan minimal tentang ba-gaimana menggunakan sistem, sehingga pengalaman pengguna mengenai wak-tu dan akurasi yang dihasilkan tidak jauh berbeda. Kekurangan lainnya dari evaluasi pengguna yaitu evaluasi ini tidak dapat dilakukan secara langsung dan otomatis. Hal ini menyebabkan tidak cocok untuk percobaan, misalnya dengan mencoba beberapa parameter, dan sebagainya.
BAB IV
ANALISIS DAN RANCANGAN SISTEM
4.1 Gambaran Sistem
Dalam bab ini akan dibahas tentang analisis dan rancangan sistem untuk me-lakukan pengelompokan email dari basis data arsip email pengguna. Pada bab ini juga dibahas tentang rancangan sistem prototipe aplikasi pengelompokan email dari basis data arsip email untuk membuktikan bahwa metode pengelompokan dapat di-implementasikan. Dengan adanya sistem pengelompokan email, email dalam basis data arsip email dapat ditelusuri oleh pengguna. Kemudian hasil penelusuran terse-but akan ditampilkan oleh aplikasi dalam sebuah hirarki, hirarki ini merupakan hasil pengelompokan email sesuai dengan label/kategori pada hirarki tersebut.
4.2 Analisis Kebutuhan Sistem
Sebelum sistem dibuat, terlebih dahulu dilakukan analisis kebutuhan sistem. Analisis kebutuhan sistem merupakan proses identifikasi dan evaluasi permasalahan-permasalahan yang ada, sehingga dapat dibangun sebuah sistem yang sesuai dengan yang diharapkan. Sistem aplikasi pengelompokan email, dibuat untuk kebutuhan se-bagai berikut:
1. Dapat melakukan proses pengumpulan data email, yaitu email masuk dan email keluar dan menyimpannya sebagai suatu arsip basis data email.
2. Dapat melakukan proses pengindeksan (indexing) termasuk didalamnya pra pemrosesan data, yaitu stemming untuk bahasa Indonesia, dan penghilangan daftar stopwords untuk setiap email yang akan diproses lebih lanjut.
3. Sistem hanya bisa diakses oleh pengguna yang terdaftar/telah memiliki email. 4. Dapat dilakukan proses penemuan kembali informasi dari basis data arsip
ema-il, sesuai dengan masukan dari pengguna, dengan penerapan pengelompokan orthogonal.
5. Dapat dilakukan penelusuran terhadap arsip email terhadap judul dan isi email.
6. Email dikelompokkan secara semantik yang dapat memberikan label sutu kata atau frase yang bermakna.
4.3 Analisis Masukan
Setelah dilakukan analisis kebutuhan sistem, maka diperlukan analisis masuk-an untuk memenuhi kebutuhmasuk-an sistem. Untuk masukmasuk-an ymasuk-ang diperlukmasuk-an adalah semua lalu-lintas dari surat elektronik pada suatu organisasi dan pada domain tertentu. Ada beberapa hal yang perlu dipertimbangkan dalam menangani surat elektronik tersebut, yaitu: alamat pengirim, almat tujuan, waktu pengiriman, judul dan isi serta bahasa yang digunakan. Isi email pun memiliki beberapa jenis, antara lain jenis plain text dan html (hyper text markup language maupun campuran (multipart). Dalam sistem ini yang diproses dan dikelompokkan adalah isi surat elektronik yang berupa text.
4.4 Analisis Keluaran
Setelah diketahui analisis kebutuhan sistem dan analisis masukan, kemudian dilakukan analisis keluaran. Analisis keluaran berguna untuk mengetahui keluaran apa saja yang akan dihasilkan dari suatu sistem serta untuk mengetahui kesesuaian antara kebutuhan dan metode yang digunakan. Keluaran dari sistem ini yaitu berupa temu kembali informasi yang telah dikelompokkan sesuai dengan relevansinya. Ke-luaran ini kemudian akan diukur apakah sesuai dengan masukan yang diberikan oleh pengguna. Pengukuran atau pengujian dilakukan dengan cara menghitung tingkat precision dan F-Masure hasil temu kembali informasi. Analisis terhadap proses pe-ngelompokan hasil temu kembali informasi dilakukan dengan cara membandingkan nilai F-Measure berdasarkan input kata kunci yang diberikan.
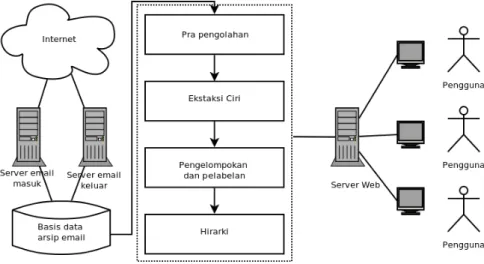
4.5 Rancangan Arsitektur Sistem
Rancangan arsitektur sistem yang akan dikembangkan tampak seperti Gambar 4.1. Sistem dimulai dari pengumpulan data, data ini berasal dari sebuah basis data ar-sip email. Setiap email dari internet yang dialamatkan untuk suatu alamat email yang akan dikelompokkan akan diterima oleh server email masuk atau server email kelu-ar yang kemudian akan disimpan pada basis data kelu-arsip email. Server email masuk maksudnya server yang bertugas menerima email dari server luar, sedangkan server email keluar maksudnya server email yang digunakan untuk mengirim email keluar
28
yang akan diterima server email lain. Email-email yang disimpan dalam basis data arsip email telah dalam bentuk terurai dalam tabel yang berelasi, sehingga memu-dahkan proses lebih lanjut. Setelah tahap pengumpulan data, selanjutnya proses pra pengolahan data. Proses pra pengolahan data dilakukan agar data yang akan diproses lebih lanjut lebih efisien. Proses selanjutnya adalah ekstraksi ciri yang akan meng-hasilkan kata/frase kunci dalam bentuk vector space model. Setelah proses ekstraksi ciri, baru kemudian dilakukan proses pengelompokan dengan menggunakan metode latent semantic indexingsekaligus menentukan pelabelan kelompok. Proses terakhir yaitu pembentukan hirarki agar email mudah ditelusuri. Proses-proses mulai dari pra pengolahan data sampai pembentukan hirarki dilakukan pada server web yang kemu-dian akan disajikan ke pengguna dengan antarmuka web.
Gambar 4.1: Arsitektur sistem
4.6 Pengumpulan data
Tahap pengumpulan data email disini dilakukan melalui sebuah server basis data email yang diperoleh dari MTA (Mail Transfer Agent) yang ada, yaitu berupa server email masuk dan server email keluar. Proses ini menggunakan LMTP (Local Mail Transport Protocol) atau program mail delivery, yang akan meneruskan email yang datang ke sebuah program. Program ini selanjutnya melakukan penguraian/par-sing email dan menyimpannya pada sebuah basis data. Dari basis data ini, kemudian akan diambil email yang sesuai dengan pencarian pengguna untuk diproses lebih lan-jut.
4.7 Rancangan Algoritma
Ketika merancang sebuah algoritma pengelompokan email, perlu diperhatikan untuk memastikan isi dan label dari hasil pengelompokan memiliki arti bagi penggu-na. Ada dua pendekatan algoritma pengelompokan text pada umumnya, yaitu: per-tama, mendapatkan isi pengelompokan terlebih dahulu kemudian berdasarkan isi pe-ngelompokan baru ditentukan labelnya. Kedua, mendapatkan label/deskripsi terlebih dahulu, kemudian berdasarkan label menentukan isi pengelompokan. Pada penelitian ini akan dilakukan pendekatan yang pertama, yaitu menentukan isi baru kemudian ditentukan labelnya.
Untuk mendapatkan algoritma pengelompokan yang lebih baik, maka proses pengelompokan diawali dengan sebuah pra pengolahan data, tahap ini meliputi text filteringdan stemming. Selanjutnya dilakukan ekstraksi ciri sekaligus dilakukan pe-ngelompokan. Kemudian dilakukan tahap pasca pengolahan data yang akan membuat suatu hirarki. Tahapan utama dari algoritma pengelompokan email seperti terlihat pa-da Gambar 4.2
/∗ ∗ Tahap 1 : Pra P e n g o l a h a n Data ∗ / f o r e a c h d o c u m e n t { do t e x t f i l t e r i n g ; a p p l y s t e m m i n g ; } /∗ ∗ Tahap 2 : E k s t r a k s i C i r i ∗ / d i s c o v e r f r e q u e n t t e r m s and p h r a s e s ; /∗ ∗ Tahap 3 : P e n g e l o m p o k a n dan l a b e l ∗ / g u n a k a n LSI u n t u k p e n g e l o m p o k a n ; f o r e a c h c l u s t e r { t e n t u k a n l a b e l ; } /∗ ∗ Tahap 4 : Tahap a k h i r p e n g e l o m p o k a n ∗ / f o r e a c h l a b e l { t e n t u k a n h i r a r k i ; }
30
4.7.1 Pra pengolahan data
Pada sistem pengelompokan email ini, sesuai analisis masukan, yang bertin-dak sebagai masukan adalah berupa isi email yang berupa text. Karena isi email terdiri dari beberapa bagian dan jenis, maka perlu dipilih bagian isi email yang beje-nis text. Meskipun sudah ada seleksi terhadap masukan yang berupa text, tahap pra pengolahan data ini masih perlu dilakukan untuk mengurangi data yang tidak perlu. Jika tahap pra pengolahan data ini tidak dilakukan, maka Latent Semantic Indexing yang akan dipakai untuk pengelompokan akan menghasilkan istilah-istilah yang tidak memiliki arti, dan akan mengakibatkan label-label kelompok yang tidak berguna. Ja-di, tujuan utama dari tahap pra pengolahan data adalah untuk menghilangkan semua karakter dan istilah pada masukan yang akan mempengaruhi kualitas pengelompokan email.
Dalam algoritma ini terdapat dua tahap pra pengolahan data, yaitu text filtering dan stemming.
Text filtering
Pada tahap text filtering, dilakukan proses penghapusan kata yang memiliki jumlah huruf sedikit, kata yang sering muncul, dan simbol khusus. Tahap ini sering juga disebut stopping. Selain untuk meningkatkan kualitas pengelompokan email, text filtering juga akan meningkatkan performa dari proses pengolahan data karena data yang diolah akan sedikit berkurang.
Stemming
Stemmingmerupakan proses pencarian akar kata yang dapat mengurangi di-mensi kata. Stemming yang akan digunakan adalah algoritma Nazief dan Adriani yang disempurnakan (Asian dkk., 2003). Pada tahap ini perlu pengumpulan kata dasar dalam bahasa Indonesia sebanyak mungkin dan dimasukkan dalam suatu ka-mus kata dasar. Data ini akan memberikan keakuratan lebih berdasarkan Asian dkk. (2003). Selain itu juga perlu dilakukan penentuan stop word yang ada dalam baha-sa Indonesia. Pemilihan stop word yang tepat dan maksimal akan baha-sangat membantu dalam mengurangi dimensi data.
Dengan proses stemming ini, karena mengurangi dimensi data, maka proses pengolahan data juga akan lebih cepat tanpa mengurangi kualitas dari hasil penge-lompokan. Alur proses yang akan diimplementasikan untuk tahap pra pengolahan data ditunjukkan dalam diagram alir Gambar 4.3.
Gambar 4.3: Diagram alir pra pengolahan data 4.7.2 Ekstraksi ciri
Tujuan dari tahap ekstraksi ciri yaitu untuk memperoleh frase atau kata tung-gal yang akan meningkatkan kualitas pengelompokan melalui peningkatan informasi yang terdapat dalam email. Selain itu, dengan ekstraksi ciri akan membantu untuk membuat label yang ringkas dan akurat untuk kelompok yang dihasilkan. Untuk me-milih frase atau kata tersebut, maka beberapa hal yang dipertimbangkan antara lain:
32
kali dalam jumlah yang ditentukan. Hal ini sesuai dengan asumsi temu kembali informasi, bahwa ciri yang sering muncul pada masukan akan memiliki penje-lasan yang lebih kuat. Sebaliknya, dengan mengabaikan kata atau frase yang jarang akan meningkatkan secara drastis efisiensi waktu untuk algoritma secara keseluruhan (Osinki, 2003).
2. frase atau kata dibatasi hanya yang terdapat dalam sebuah kalimat/dokumen. Hal ini dikarenakan batasan kalimat/dokumen biasanya mengindikasikan topik tertentu (Zhang dan Dong, 2001).
3. frase atau kata harus lengkap (Zhang dan Dong, 2001). Dibandingkan frase tidak lengkap, frase yang lengkap akan memiliki makna dan deskripsi yang lebih baik pada sebuah dokumen.
Untuk ekstraksi ciri pada tesis ini digunakan algoritma menemukan frase yang telah dimodifikasi yang diusulkan oleh Zhang dan Dong (2001). Algoritma ini menggu-nakan varian suffix array yang ditambahkan struktur data tambahan, yaitu array LCP (Longest Common Prefix). Array ini terdiri dari N +1 bilangan bulat sementara setiap elemen LCP [i] berisi panjang prefiks umum terpanjang antara akhiran yang berde-katan S [i-1] dan S [i]. Untuk menyederhanakan algoritma, array LCP ditambahkan dengan nol sehingga LCP [0] = LCP [N] = 0.
Algoritma penemuan frase bekerja dalam dua tahap. Pada tahap pertama, frase kanan dan kiri-lengkap ditemukan, dan pada tahap kedua, mereka digabungkan men-jadi satu set frase lengkap. Selanjutnya dipilih frase yang melebihi dari batas yang ditentukan untuk menjadi sebagai ciri yang akan dikelompokkan. Menurut Osinki (2003), untuk akurasi pengelompokan terbaik, nilai batas yang ditentukan berada an-tara 2 dan 5. Untuk penelitian ini diambil nilai terendah 2 yang berarti frase yang muncul 2 kali atau lebih dianggap sebagai frase yang dipakai ciri. Untuk ringkasan algoritma tahap ekstraksi ciri diperlihatkan pada Gambar 4.4.
Untuk mempermudah implementasi penemuan frase yang akan menghasilkan kata/frase yang akan menjadi ciri, maka dibuatlah diagram alir seperti ditunjukkan da-lam Gambar 4.5. Tahapan dari diagram alir penemuan frase dapat dijelaskan sebagai berikut:
1. Pertama inisiasi awal variabel alldoc dan alldocr yang akan menampung ga-bungan semua dokumen asal dan semua dokumen kebalikannya.
/∗ ∗ ∗ Tahap 2 : E k s t r a k s i C i r i ∗ / /∗ ∗ Penggabungan dokumen ∗ / g a b u n g semua dokumen ; b u a t v e r s i i n v e r s i d a r i dokumen y a n g t e l a h d i g a b u n g ; /∗ ∗ penemuan f r a s e l e n g k a p ∗ / t e m u k a n f r a s e k a n a n l e n g k a p ; t e m u k a n f r a s e k i r i l e n g k a p ; u r u t k a n f r a s e k i r i l e n g k a p s e c a r a a b j a d ; g a b u n g k a n f r a s e k i r i dan k a n a n l e n g k a p k e d a l a m s e b u a h f r a s e l e n g k a p ; /∗ ∗ S e l e k s i a k h i r ∗ / u n t u k p r o s e s s e l a n j u t n y a , p i l i h f r a s e dan k a t a y a n g f r e k u e n s i n y a m e l e b i h i b a t a s y a n g d i t e n t u k a n ;
Gambar 4.4: Pseudo-code ringkasan tahap ekstraksi ciri
2. Selanjutnya lakukan penggabungan dokumen sampai selesai dan disimpan pada variabel alldoc.
3. Setelah digabung, buat dokumen kebalikannya yang disimpan pada variabel alldocr.
4. Kemudian secara berturut-turut, cari suffix array dari alldoc dan simpan dalam variabel sa, hitung lcp dari alldoc dan simpan dalam variabel lcp, cari frase kanan lengkap atau rcs (right complete substring) dari alldoc dan simpan dalam variabel rcs.
5. Setelah rcs diketahui, kemudian rcs diurutkan.
6. Lakukan hal yang sama untuk alldocr untuk mencari lcs (left complete subs-tring).
7. Langkah terakhir untuk mendapatkan frase yaitu dengan mencari irisan antara lcsdan rcs. Hasil dari irisan rcs dan lcs ini yang akan digunakan sebagai ciri.
4.7.3 Identifikasi dan pembuatan kelompok
Pada tahap identifikasi dan pembuatan kelompok ini akan didasarkan dari de-komposisi SVD dari matrik kata-dokumen. Tahap ini terdiri dari pembuatan matrik kata-dokumen, selanjutnya yaitu menentukan latent semantic dari dokumen-dokumen
34
Gambar 4.5: Diagram alir penemuan frase
dengan menganalisa hubungan antara kata dan dokumen. Tahap ini melakukan de-komposisi nilai singular pada matrik kata-dokumen yang telah dibuat pada tahap se-belumnya untuk mendapatkan matrik U , S, dan V . Kemudian dihitung jumlah ke-lompok yang yang akan dibuat. Jumlah keke-lompok dihitung dengan menggunakan parameter q (ambang batas yang dianggap wajar) dan menggunakan matrik S hasil dari dekomposisi nilai singular. Pembuatan matrik kata-dokumen dan perhitungan dekomposisi nilai singular ditunjukkan pada diagram alir Gambar 4.6. Diagram alir pada Gambar 4.6 dapat dijelaskan sebagai berikut:
1. Pembuatan matrik kata-dokumen dibutuhkan tiga masukan yaitu jumlah doku-men dan dokudoku-men dan keyf rase atau frase kunci hasil dari proses ekstraksi ciri tahap sebelumnya.
2. Selanjutnya, lakukan perulangan sejumlah dokumen.
dan lcp.
4. Lakukan perulangan sebanyak keyf rase. Perulangan ini digunakan untuk meng-etahui apakah frase/kata kunci ada di dokumen atau tidak.
5. Lakukan pencarian frase di dokumen dengan data variabel sa dan lcp.
6. Apakah ditemukan frase didokumen? jika tidak, lanjutkan ke frase selanjutnya. 7. Jika frase ditemukan, cek apakah frase sudah ada di matrik kata-dokumen? jika tidak, tambahkan frase ke matrik-dokumen. Jika ada, tambahkan dokumen ke matrik matrik kata-dokumen yang sesuai.
8. Lanjutkan sampai frase kunci habis. 9. Lanjutkan sampai jumlah dokumen habis.
10. Setelah pembentukan matrik kata-dokumen selesai, lakukan penghitungan de-komposisi nilai singular dan simpan pada variabel U , S, V t.
11. Hasil akhir dari tahap ini yaitu matrik U , S, V t, dan matrk kata-dokumen. Untuk menghitung jumlah kelompok, berdasarkan Formula 3.2, maka dibu-atlah diagram alir seperti ditunjukkan pada Gambar 4.7. Tahapan dari diagram alir dapat dijelaskan sebagai berikut:
1. Untuk menghitung jumlah kelompok, diperlukan dua masukan, yaitu matrik S hasil dari fungsi svd dan paramater q.
2. Tentukan variabel awal i, yaitu 1.
3. Periksa apakah variabel i kurang dari atau sama dengan panjang matrik S. Jika benar lakukan langkah selanjutnya, jika salah, proses selesai.
4. Selanjutnya lakukan penghitungan formula dengan menggunakan fungsi yang sesuai dan simpan hasilnya dalam variabel qa.
5. Selanjutnya dilakukan pengecekan, apakah nilai qa lebih besar sama dengan parameter q?
6. Jika salah, lakukan penambahan variabel i, dan ulangi langkah nomor 3. 7. Jika benar, simpan nilai i. Nilai i ini yang menjadi hasil jumlah kelompok.
36
Gambar 4.6: Diagram alir pembuatan matrik kata-dokumen dan dekomposisi nilai singular
4.7.4 Penentuan label dan hirarki
Penentuan label untuk tiap kelompok dibuat berdasarkan pengelompokan or-thogonal. Label ditentukan terhadap kata/frase kunci yang memiliki nilai terbesar
Gambar 4.7: Diagram alir menghitung jumlah kelompok
dalam kelompok vektor. Penentuan kelompok dan label dapat dilihat pada diagram alir Gambar 4.8. Pada diagram alir Gambar 4.8 dapat dijelaskan sebagai berikut:
1. Penentuan kelompok dan label memiliki 5 masukan, yaitu k yang merupakan jumlah kelompok hasil dari proses penentuan jumlah kelompok. Variabel t yang merupakan variabel untuk ambang batas apakah suatu dokumen dapat dimasukkan ke kelompok tertentu atau tidak. Tiga variabel matrik U , V t hasil dari perhitungan dekomposisi nilai singular pada tahap sebelumnya dan matrik A yaitu matrik kata-dokumen. V t adalah matrik transpose dari matrik V . 2. Langkah berikutnya adalah inisiasi awal kelompok yang akan menyimpan hasil
pengelompokan dan label yang akan menyimpan label kelompok. Variabel kolomkatamengambil kolom matrik U sebanyak k, dan variabel barisdokumen yang mengambil baris matrik V t sebanyak k.
3. Lakukan perulangan sejumlah kelompok dimulai dari i=1.
4. Lakukan inisialisasi awal, yaitu kelompok ke-i kosong, max=-9999 dan index=-1