ANT COLONY OPTIMIZATION
Maulani KapiudinKepala Bagian Perencanaan System.
STEIJl.Kayu jati No 11 A Rawamangun Jakarta Timur e-mail: [email protected] atau [email protected]
ABSTRAK: Pada penelitian untuk sistem klasifikasi potensial customer ini didesain dengan melakukan
ekstrak rule berdasarkan klasifikasi dari data mentah dengan kriteria tertentu. Proses pencarian menggunakan database pelanggan dari suatu bank dengan teknik data mining dengan ant colony optimization. Dilakukan percobaan dengan min_case_per_rule variety dan phenomene updating pada periode waktu tertentu. Hasilnya adalah sekelompok class pelanggan yang didasarkan dari rules yang dibangun dengan ant dan dengan dimodifikasi dengan pheromone updating, area permasalahan menjadi lebih melebar. Prototype dari software ini menggunakan C++ versi 6. Database pelanggan dibangun dengan Microsoft Access. Paper ini memberikan informasi mengenai potensi pelanggan dari bank, sehingga dapat diklasifikasikan dengan prototype dari software.
Kata kunci: ant colony optimization, classification, min_case_per_rule, term, pheromone updating
ABSTRACT: In this research the system for potentially customer classification is designed by extracting
rule based classification from raw data with certain criteria. The searching process uses customer database from a bank with data mining technic by using ant colony optimization. A test based on min_case_per_rule variety and phenomene updating were done on a certain period of time. The result are group of customer class which base on rules built by ant and by modifying the pheromone updating, the area of the case is getting bigger. Prototype of the software is coded with C++ 6 version. The customer database master is created by using Microsoft Access. This paper gives information about potential customer of bank that can be classified by prototype of the software.
Keywords: ant colony optimization, classification, min_case_per_rule, term, pheromone updating
PENDAHULUAN
Perkembangan dunia bisnis yang sangat pesat, mendorong terbentuknya suatu timbunan data-data yang berukuran sangat besar. Data-data tersebut pada umumnya berasal dari data entry dan customer service, kemudian oleh komputer data tersebut disimpan ke dalam server. Di dalam server data di ubah menjadi informasi yang disimpan dalam bentuk tabel-tabel. Informasi yang didapat dari data dalam bentuk tabel-tabel tersebut sangat sedikit yang dapat dimanfaatkan oleh pihak manajemen perusahaan dalam pengambilan keputusan untuk kemajuan perusahaan, oleh karena itu perlu adanya aktivitas penggalian (ekstraksi) data yang masih tersembunyi untuk selanjutnya diolah menjadi pengetahuan yang bermanfaat dalam pengambilan keputusan. Proses ekstraksi informasi dari kumpulan data-data yang tersimpan di server disebut dengan data mining
Data mining merupakan bidang penelitian inter disiplin yang intinya adalah interseksi antara machine learning, statistic dan database. Pada dasarnya data mining bertujuan untuk mengekstraksi pengetahuan yang masih tersembunyi dari data yang sangat besar yang hasilnya tidak hanya akurat tetapi harus dapat
dipahami oleh pengguna. Sifat mudah dapat dipahami sangat penting bilamana pencarian pengetahuan akan digunakan untuk mendukung sebuah keputusan yang di buat oleh pengguna, dalam hal ini biasanya pihak manajemen suatu perusahaan. Bagaimanapun pen-carian pengetahuan yang tidak dapat dipahami oleh pengguna, tidak akan dapat diinterpretasikan secara benar. Dalam kasus ini kemungkinan pengguna tidak akan cukup yakin dengan pencarian pengetahuan yang digunakan untuk pengambilan keputusan, karena akan menyebabkan keputusan yang salah.
Ada beberapa model task yang termasuk data mining, classification, regression, clustering, depen-dence modeling dan lain-lain. Masing-masing task dapat dianggap sebagai sebuah algoritma data mining yang dapat memecahkan satu jenis masalah, oleh karena itu langkah pertama dalam desain sebuah algoritma data mining adalah mendefinisikan kemana algoritma ini akan dipakai.
Dalam penelitian ini akan diajukan algoritma Ant Colony Optimization untuk klasifikasi kaidah-kaidah (rules) dalam data mining. Tujuan dari kaidah-kaidah ini adalah membuat masing-masing kasus (object, record, instance) ke dalam satu kelas, di luar kelas yang telah didefinisikan sebelumnya, berdasarkan
nilai dari beberapa atribut prediksi (predictor attribute) dari kasus tersebut.
Dalam kontek klasifikasi untuk kaidah-kaidah dalam data mining, pencarian pengetahuan sering digambarkan dalam bentuk IF-THEN rules, sebagai berikut:
IF < conditions > THEN < kelas > Bagian rule antecedent (IF) mengandung sebuah himpunan dari kondisi-kondisi, biasanya dihubungkan dengan operator penghubung logika (AND). Dalam tesis ini semua kaidah (rule) yang berfungsi sebagai antecedent, mempunyai term logika dalam bentuk:
IF term1 AND term2 AND…
Masing-masing term adalah sebuah triple < attribute, operator, value > seperti: <Gender = Female>
Bagian rule consequent (THEN) menspesi-fikasikan kelas prediksi untuk kasus yang atribut prediktornya memenuhi seluruh term yang dispesi-fikasikan dalam rule antecedent. Dari sebuah tinjauan data mining, jenis representasi pengetahuan ini mempunyai keuntungan untuk dimengerti secara intuitif oleh pengguna sepanjang jumlah kaidah pencarian dan jumlah term dalam rule antecedent tidak besar.
Pada saat ini penggunaan algoritma Ant Colony Optimization (ACO) untuk klasifikasi kaidah-kaidah dalam kontek data mining adalah merupakan daerah penelitian yang belum dieksplorasi, yang sesung-guhnya pengembangan ant algorithm untuk data mining merupakan algoritma untuk pengelompokan yang mana task-task data mining sangat berbeda dari klasifikasi yang dimaksud oleh penelitian ini.
Penggunaan algoritma ACO untuk data mining menjanjikan suatu daerah penelitian baru karena mengandung agen-agen sederhana yang mewakili sekelompok semut yang masing-masing saling be-kerja sama antara satu dengan yang lainnya untuk mencapai munculnya tingkah laku bersama pada sistem keseluruhan menghasilkan sebuah sistem robust yang mampu menemukan solusi yang ber-kualitas tinggi untuk problem dengan daerah pen-carian yang besar
Dalam kontek pencarian kaidah, sebuah algoritma ACO mempunyai kemampuan untuk membentuk secara fleksibel, pencarian robust untuk sebuah kombinasi term-term (kondisi logika) yang mengan-dung nilai dari atribut prediktor
Jika pada customer service sebuah perusahaan keuangan (bank) melakukan questioner terhadap customer (customer biasa maupun yang sudah menjadi pelanggan) untuk mendapatkan berbagai atribut mengenai pelanggan dan hubungannya dengan
perusahaan, maka dari data hasil questioner tersebut dapat dikelompokkan berbagai tipe dan kelas dari pelanggan dengan range tertentu sebagai pelanggan potensial. Dengan menggunakan data penghasilan dan kemampuan untuk menyimpan (saving) dari pelang-gan pada perioda tertentu maka akan didapatkan suatu klasifikasi dari pelanggan menurut kelas-kelas tertentu yang dapat dijadikan acuan untuk pengambilan keputusan dari perusahaan yang bersangkutan.
TINJAUAN PUSTAKA
Knowledge Discovery In Databases
Knowledge Discovery in databases (KDD) adalah keseluruhan proses non trivial untuk mencari dan mengidentifikasi pola (patern) dalam data, di-mana pola yang ditemukan bersifat sah (valid), baru (novel), dapat bermanfaat (potentially usefull), dapat dimengerti (ultimately understandable).
Istilah data mining dan knowledge discovery in databases (KDD) sering kali digunakan secara ber-gantian untuk menjelaskan proses penggalian informasi tersembunyi dalam suatu basis data yang besar. Sebenarnya kedua istilah tersebut memiliki konsep yang berbeda akan tetapi berkaitan satu sama lain. Salah satu tahapan dalam keseluruhan proses KDD adalah data mining.
Data Mining
Data mining adalah proses mencari pola atau informasi menarik dalam data terpilihdengan meng-gunakan teknik atau metoda tertentu. Teknik, metoda, atau algoritma dalam data mining sangat bervariasi. Pemilihan metoda atau algoritma yang tepat sangat bergantung pada tujuan dan proses KDD secara keseluruhan. Karakteristik Data Mining [6]:
- Jumlah data yang begitu besar dan harus dianalisa dengan teknik yang otomatis, contoh data transaksi - Noisy, incomplete data
Data yang bersifat heterogenous Metoda Data Mining
Berikut ini beberapa metoda data mining yang umum digunakan: Decision trees dan kaidah, Meto-dologi Klasifikasi & Regresi Non-Linear, ACO. Ant Colony Optimization (ACO)
ACO adalah sistem agen yang mensimulasikan tingkah laku natural dari kelompok semut (ants) yang mengandung mekanisma kerjasama dan adaptasi. Tingkah laku kelompok semut (ants) yaitu fakta bahwa kemampuan menemukan jalan terpendek antara sumber makanan dan sarang. Beradaptasi
terhadap perubahan lingkungan tanpa menggunakan informasi visual. Kemampuan yang membangkitkan minat dari kelompok semut lain Sebagai hasil, pada akhirnya semut-semut akan konvergen ke jalur yang lebih pendek, yang diharapkan optimum atau mendekati solusi optimum untuk target problem. Ide dasar dari proses ini dapat dilihat pada Gambar 1.
Gambar 1. Ants Menemukan Jalur Terpendek Disekeliling Obstacle [4]
Algoritma ACO
Algoritma ACO didasarkan pada ide-ide berikut: - Masing-masing jalur (path) yang diikuti oleh
semut diasosiasikan sebagai kandidat solusi. Ketika seekor semut melalui sebuah jalur, sejumlah pheromone dijatuhkan pada jalur sesuai dengan kualitas term (hubungan) kandidat solusi untuk “Target problem”
Kaidah yang terbaik yang dibangun oleh seluruh semut dianggap sebagai kaidah yang dicari. Kaidah yang lain dibuang. Hal ini melengkapi sebuah iterasi dari sistem itu.
Gambar 2. Tinjauan Algoritma Ant-Miner [4]
Algoritma ini menggunakan kontruksi kaidah dan Peningkatan Pheromone .
Kontruksi Kaidah:
Misalkan termij kondisi kaidah (rule) dalam
format Ait = Vij, di mana Ai adalah atribut ke-i dan Vij
adalah nilai ke-j dari domain Ai. Probabilitas termij
terpilih untuk ditambahkan ke current partial rule diberikan oleh persamaan (1).
∑∑
∀
∈
=
a i b j ij ij ij ij ij iI
i
,
(t).η
τ
(t).η
τ
(t)
P
(1) dimana:ηij adalah nilai dari problem-dependent heuristic
function untuk termij;
τij(t) adalah jumlah pheromone yang tersedia saat itu
(at time t) dalam posisi i,j dari trail yang diikuti oleh semut;
a adalah jumlah total atribut;
bi adalah jumlah total nilai pada domain atribut I; I adalah atribut yang belum digunakan oleh semut.
ARSITEKTUR SISTEM
Aplikasi ini terdiri dari dua bagian utama yaitu database sebagai sumber data yang akan diolah, dan perangkat lunak aplikasi data mining. SQL server digunakan untuk membuat database dan untuk melakukan koneksi dengan aplikasi menggunakan ODBC:SQL sebagai drivernya, sehingga aplikasi dapat melakukan query terhadap database, seperti yang digambarkan seperti Gambar 3.
DATABASE ODBC APLIKASI DATA MINING Query SQL ResultSet Row
Gambar 3. Arsitektur Sistem
Proses pada aplikasi data mining dapat dilihat pada Gambar 4.
Fungsi Heuristik User
Mencari kaidah-kaidah Database Pelanggan Probability Transition Rule
Pemutakhiran Pheromone Input / Inisialisasi Parameter
Deskripsi use case diagram dari Gambar 4:
1. User mengaktifkan sistem dan memasukkan nilai No_of_Ant, Min_case_per_rule, Max_unco-vered_case, No_rule_converg, dan variasi pemu-takhiran pheromone (original atau modified) sebagai parameter sitem.
2. Sistem yang diwakili oleh semut akan mem-bangun kaidah untuk pertama kalinya dengan mengambil satu kasus untuk dijadikan kaidah dari training set (database pelanggan yang sudah di simpan dalam query).
3. Sistem akan membandingkan kaidah yang dibangun dengan semua elemen dari training set sampai jumlah training set memenuhi min_case_ per_rule atau kaidah sama dengan kaidah yang dibangun sebelumnya (No_rule_converg-1) 4. Jika sistem memenuhi kriteria pada (3), maka
semut lain akan memulai pembangunan kaidah dengan sebelumnya menghitung fungsi heuristik dan pemutakhiran pheromone dari kaidah yang terpilih.
5. Sistem akan mengulang proses sampai maksimal sebanyak No_of_Ant
6. Kaidah yang terbaik yang dibangun oleh seluruh semut akan dipindahkan ke dicovered rule sebagai kaidah yang dicari. Kaidah yang terbaik dipilih berdasarkan jumlah konvergensi yang terjadi.
7. Selanjutnya sistem akan memulai pencarian kembali kaidah sampai No_of uncovered_cases lebih kecil dari Max_uncovered_Cases.
Implementasi Database
Database ini dirancang berdasarkan kebutuhan pengujian sistem dan disusun berdasarkan Field dan record. Field merupakan atribut dan record diaso-siasikan dengan nilai dari atribut tersebut dalam bentuk Ai = Vij dengan Ai adalah atribut yang ke i dan Vij adalah nilai dari atribut ke-i pada record ke-j dari database.
Implementasi Graphical User Interface
Untuk memudahkan pengguna berinteraksi dengan sistem diperlukan 2 buah Graphical User Interface (GUI) yaitu:
1. GUI Menu: yang berfungsi sebagai form awal masuk ke sistem Ant Colony dan hasil proses pencarian kaidah (rule discovery) untuk data mining.
2. GUI Input: yang berfungsi sebagai form untuk memasukkan nilai-nilai parameter yang diperlukan untuk proses pencarian kaidah untuk data mining.
Kedua Graphical User Interface (GUI) dipakai untuk berbagai variasi perubahan setting internal algoritma ACO maupun untuk modifikasi pemu-takhiran pheromone.
Gambar 5. GUI Menu dari Ant Colony Optimiza-tion
Gambar 6. GUI Setting Input Ant Colony
Optimiza-tion
Pengujian
Pengujian sistem dilakukan pada prototipe perangkat lunak yaitu untuk klasifikasi pelanggan potensial dengan melakukan variasi pada parameter min_case_per_rule, jumlah term dan modifikasi pada
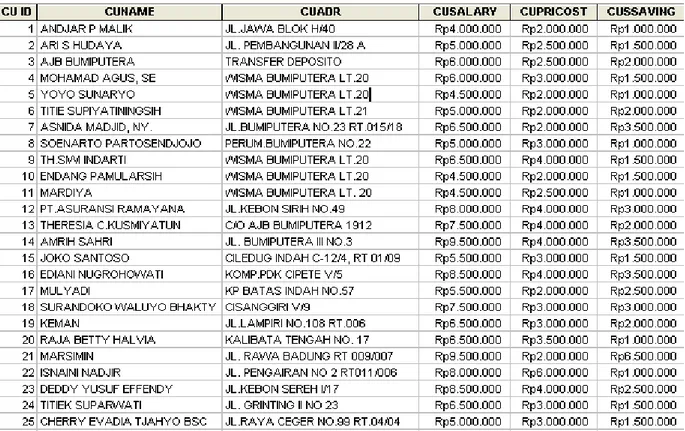
pemutakhiran pheromone. Sumber data untuk pengu-jian berasal dari tabel data pelanggan sebuah bank dengan melakukan penambahan pada field SALARY, CUPRICOST, dan CUSAVING sebanyak 500 pelanggan.Kelas-kelas prediktor yang dipakai dalam pengujian sebanyak 10 kelas yaitu:
o CUSAVING > 90 % CUSALARY
o CUSAVING > 80 % CUSALARY AND CUSAVING
< 90 % CUSALARY
o CUSAVING > 70 % CUSALARY AND CUSAVING
< 80 % CUSALARY
o CUSAVING > 60 % CUSALARY AND CUSAVING
< 70 % CUSALARY
o CUSAVING > 50 % CUSALARY AND CUSAVING
< 60 % CUSALARY
o CUSAVING > 40 % CUSALARY AND CUSAVING
< 50 % CUSALARY
o CUSAVING > 30 % CUSALARY AND CUSAVING
< 40 % CUSALARY
o CUSAVING > 20 % CUSALARY AND CUSAVING
< 30 % CUSALARY
o CUSAVING > 10 % CUSALARY AND CUSAVING
< 20 % CUSALARY
o CUSAVING < 10 % CUSALARY
HASIL PENGUJIAN Hasil Pengujian
Berikut ini diperlihatkan hasil pengujian, dalam bentuk tabel, tampilan program serta output yang dihasilkan oleh sistem dengan melakukan variasi pada min_case_per_rule, jumlah term, dan modifikasi pemutakhiran pheromone (modified pheromone updating).
Tabel 2. Tabel Kelas Berdasarkan Variasi Phero-mone, min_case_per_rule, dan Jumlah
Term
PHEROMONE Min_Case_per_rule Jumlah Term Banyaknya Kelas
Original 5 1 4 Original 10 1 3 Original 30 1 1 Original 5 2 10 Original 10 2 5 Original 30 2 1 Original 5 3 14 Original 10 3 2 Original 30 3 1 Modified 5 1 4 Modified 10 1 3 Modified 30 1 1 Modified 5 2 9 Modified 10 2 6 Modified 30 2 3 Modified 5 3 11 Modified 10 3 6 Modified 30 3 3
Berdasarkan Tabel 2 dapat disimpulkan sebagai berikut:
1. Dengan bertambahnya min_case_per_rule maka bertambah sedikit pelanggan dari tabel data pelanggan yang terlingkupi oleh kaidah-kaidah yang dibangun algoritma ACO.
2. Dengan bertambahnya jumlah term, maka bertambah banyak pelanggan dari tabel database pelanggan yang terlingkupi oleh kaidah-kaidah yang dibangun algoritma ACO.
3. Daerah yang terlingkupi oleh kaidah-kaidah bertambah banyak ketika pemutakhiran phero-mone dimodifikasi
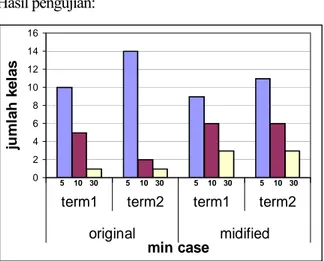
Hasil pengujian dalam bentuk grafik Hasil pengujian: 0 2 4 6 8 10 12 14 16
term1 term2 term1 term2
original midified min case ju ml ah kel as 5 10 30 5 10 30 5 10 30 5 10 30
Gambar 7. Term 1, Trem 2 Kumpulan Data Nasa-bah Bank yang Terdiri dari Nama
Customer, Address, Customer Saving
dan Salary
Dari Gambar 7 terlihat adanya perbaikan dari jumlah kasus yang terlingkupi, dengan dilakukannya modifikasi pemutakhiran pheromone. Modifikasi pheromone updating menyebabkan banyaknya pelanggan yang terlingkupi dari tabel database pelanggan menjadi lebih banyak
KESIMPULAN DAN SARAN Kesimpulan
1. Dengan bertambahnya min_case_per_rule maka bertambah sedikit pelanggan dari tabel data pelanggan yang terlingkupi oleh kaidah-kaidah yang dibangun algoritma ACO.
2. Dengan bertambahnya jumlah term, maka bertambah banyak pelanggan dari tabel database pelanggan yang terlingkupi oleh kaidah-kaidah yang dibangun algoritma ACO.
3. Daerah yang terlingkupi oleh kaidah-kaidah bertambah banyak ketika pheromone updating dimodifikasi
4. Kaidah-kaidah yang terbentuk ada mengalami perubahan dengan adanya modifikasi dari phero-mone updating
5. Modifikasi pheromone updating menyebabkan banyaknya pelanggan yang terlingkupi dari tabel database pelanggan menjadi lebih banyak
6. Rule dengan jumlah anggota paling banyak (the best rule) tidak berubah dengan variasi min_case_per_rule dan modifikasi dari pheromone updating,
Pengembangan Sistem dan Saran
Pengembangan sistem dari Algoritma Ant colony Optimization sangat dimungkinkan karena merupakan daerah penelitian yang masih baru. Di sini ada bebe-rapa usulan untuk pengembangan sistem dari algoritma ACO sebagai berikut:
1. Penelitian lebih lanjut dengan jumlah data yang lebih banyak
2. Untuk menilai keakuratan dari algoritma ACO perlu adanya algoritma pembanding.
3. Perlu diadakan penelitian dengan pengukuran entropy pada nilai informasi dengan banyak term. DAFTAR PUSTAKA
1. Parepinelli, R.S. Lopes, H.S, and Freitas, A, Data Mining with an Ant Colony Optimization Algo-rithm, 2001.
2. Bonabeau, E, Dorigo, M, and Theraulaz, G., Swarm Intelligence From Natural to Artificial System, Oxford University Press, New York., 1999.
3 Dhewangga, Puja, Nikula, Data Mining Untuk Menentukan Tata Letak Produk Supermarket, 2003.
4. Kadir, Abdul, Pemerograman C++, Andi Offset Press, Yogyakarta, 1995.
5 Nugroho, Adi Paulus, Desain dan Implementasi Business Intelligence Untuk Mendukung Pem-buatan Keputusan, Tesis Magister, Institut Tekno-logi Bandung, 2003.
6 V. Christanto, Karakteristik Data Mining, Infor-matika Press, Bandung, 2002.
7 Hendriana, Riki, Pemerograman Visual C++ Microsoft Foundation Class, Dinastindo Press, Jakarta. 2003.
![Gambar 1. Ants Menemukan Jalur Terpendek Disekeliling Obstacle [4]](https://thumb-ap.123doks.com/thumbv2/123dok/4536888.3292857/3.892.87.412.291.457/gambar-ants-menemukan-jalur-terpendek-disekeliling-obstacle.webp)