BAB 2
TINJAUAN PUSTAKA
2.1. Algoritma String Matching
Algoritma string matching merupakan komponen dasar dalam pengimplementasian berbagai perangkat lunak praktis yang sudah ada. String matching digunakan untuk menemukan satu atau lebih string yang disebut dengan pattern (string yang akan dicocokkan ke dalam text) dalam string yang disebut dengan text (string yang diinput) (Charras & Lecroq 2004).
Pengertian string menurut Dictionary of Algorithms and Data Structures, National
Institute of Standards and Technology (NIST) adalah susunan dari karakter-karakter
(angka, alfabet atau karakter yang lain) dan biasanya direpresentasikan sebagai struktur data array. String dapat berupa kata, frase, atau kalimat. Pencocokan string merupakan bagian penting dari sebuah proses pencarian string (string searching) dalam sebuah dokumen. Hasil dari pencarian sebuah string dalam dokumen tergantung dari teknik atau cara pencocokan string yang digunakan. Pencocokan string (string matching) menurut
Dictionary of Algorithms and Data Structures, National Institute of Standards and
Technology (NIST), diartikan sebagai sebuah permasalahan untuk menemukan pola
2.2. Algoritma Reverse Colussi
Algoritma merupakan urutan langkah-langkah untuk menyelesaikan masalah yang disusun secara sistematis. Algoritma Reverse Colussi merupakan satu dari sekian banyak algoritma string matching atau sering disebut pencocokan string. Algoritma Reverse
Colussi merupakan perbaikan dari algoritma Boyer – Moore dan idenya berasal dari
Colussi. Proses pencocokan tiap-tiap karakter pada algoritma Reverse Collusi
menggunakan sepasang karakter yang telah didefinisikan pada tabel rcBc dan rcGs. Algoritma Reverse Colussi mempunyai posisi ke dalam dua kategori yakni special
position dan non-special position. Dimana special position akan diproses terlebih dahulu.
Algoritma Reverse Colussi terdiri dari dua fase, yaitu fase pemrosesan awal dan fase pencarian. Pada fase pemrosesan awal dilakukan pencarian sepasang karakter, special
position, dan non-special position untuk menentukan pergeseran pattern. Pada fase
pencarian, dilakukan operasi pencocokan pattern terhadap teks.
Reverse Colussi mempunyai 2 tabel untuk menentukan dan menemukan dalam
pencocokan string, yakni tabel rcBc, dan rcGs (Admizan, 2014). Perbandingan dilakukan dalam urutan tertentu yang diberikan oleh fase pemrosesan awal .Waktu dari algoritma
Reverse Colussi pada fase preprocessing adalah O(m2) dan fase pencarian adalah O(n) (Hussain, et al. 2013).
Proses inti pencarian Algoritma Reverse Colussi yaitu dilakukan dengan teknik
random dimana teknik ini memungkinankan pengecekan karakter selalu dari ujung kanan
karakter dan pengecekan selanjutnya ditentukan oleh nilai tabel h yang sudah didefinisikan (Charras & Lecroq 2004).
Langkah pertama yang dilakukan adalah tahapan preprocessing yaitu meciptakan dua buah tabel shif / pergesaran rcBc (Reverse Colussi Bad Character) & rcGs (Reverse
Colussi Good Suffixes). Kedua tabel ini diciptakan merujuk kepada pattern yang akan
dicari oleh karena itu jika pattern berubah maka tabel juga akan berubah. Hasil
preprocessing untuk pattern TAMAT dari teks TATOMATAMATANGGA terlihat
2.2.1. Fase Pemrosesan Awal
Fase ini bertujuan untuk menetukan special positition dan juga non-special position menggunakan tabel rcGs (Reverse Colussi Get suffix), pencarian sepasang karakter menggunakan tabel rcBc (Reverse Colussi Bad character). Untuk melakukan pencarian sepasang karakter , langkah yang harus dilakukan pertama kali adalah membuat tabel
loccated.
2.2.1.1. Tabel loccated
Tabel ini berfungsi untuk melakukan perwakilan karakter dari setiap pattern yang dimasukkan , setelah itu karakter yang di dapat akan menjadikan karakter tersebut ke dalam tabel rcBc. Syarat menentukan tabel loccated adalah sebagai berikut :
1. Mengambil perwakilan karakter dari pattern , dan dimulai dari kiri tabel. 2. Nilai awal dari tiap-tiap karakter adalah (-1) , sebelum angka tersebut
digantikan oleh index, index dimulai dari 0.
3. Menentukan tabel loccated dimulai dari panjang pattern (m) dikurangi 1
Tabel 2.1 Nilai loccated
indeks 0 1 2 3 4 char A M T *
pattern T A M A T locc 3 2 0 -1
2.2.1.2. Tabel rcBc
Dalam membuat tabel rcBc, tabel ini berfungsi untuk menampung pencarian sepasang karakter, dengan syarat :
1. Karakter (present matched charcter) yang digunakan adalah perwakilan dari pattern yang sudah didapat dari tabel loccated
3. Bila ditemukan sepasang karakter , ambil jumlah sisa karakter dari pattern tersebut untuk mengisi nilai .
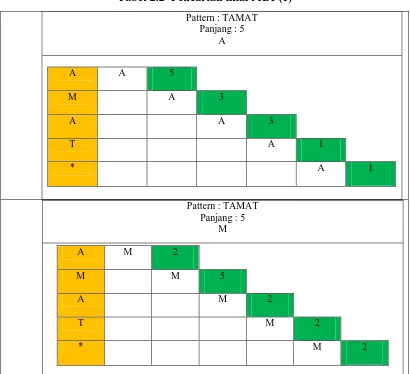
4. Dimulai dari m-1( 5-1), berarti dimulai dari karakter ke 4 Tabel 2.2 Pencarian nilai rcBc (1)
Pattern : TAMAT Panjang : 5
A
A A 5
M A 3
A A 3
T A 1
* A 1
Pattern : TAMAT Panjang : 5
M
A M 2
M M 5
A M 2
T M 2
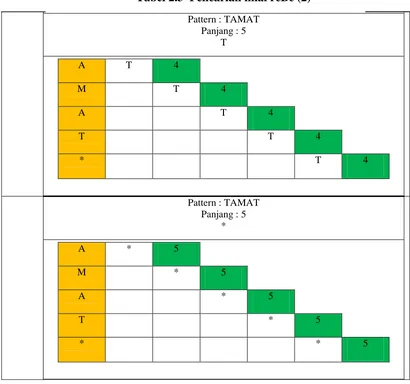
Pattern : TAMAT Panjang : 5
T
A T 4
M T 4
A T 4
T T 4
* T 4
Pattern : TAMAT Panjang : 5
*
A * 5
M * 5
A * 5
T * 5
* * 5
Ketika proses pencarian sepasang karakter selesai , langkah selanjutnya adalah melakukan pengisian dari nilai tabel diatas ke dalam tabel rcBc.
Tabel 2.4 Nilai tabel rcBc
1 2 3 4 5
A 5 3 3 1 2
M 2 5 2 2 2
T 4 4 4 4 4
* 5 5 5 5 5
Character
Length
Setelah tabel rcBc terbentuk proses selanjutnya adalah membuat tabel rcGs. Sebelum tabel rcGs terbentuk ada beberapa tabel yang harus dibuat, yakni tabel link, hmin , kmin,
rmin, dan terakhir adalah rcGs beserta tabel h, dimana tabel h berfungsi untuk
menentukan atau melakukan pengecekan karakter pertama kali yang harus di cek pada saat fase pencocokan pattern (Haryadi, 2011).
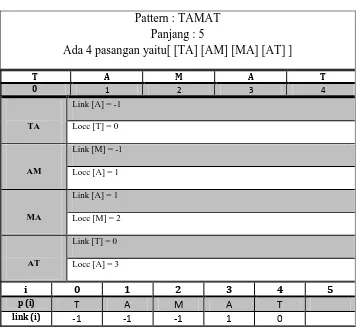
2.2.1.3. Tabel link
Untuk mengisi tabel link ada bebrapa point yang harus diperhatikan adalah sebagai berikut:
1. link dari 0 adalah (-1)
2. Bila belum pernah jumpa ,nilai link diberi nilai (-1) 3. link(n) adalah loccated dari nilai terakhir .
4. located awal proses dimulai dari 0
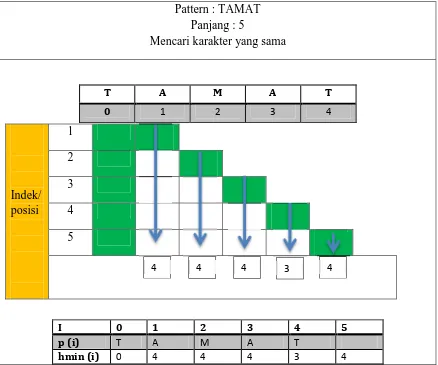
2.2.1.4. Tabel hmin
Tabel hmin berfungsi untuk menampung atau menyimpan jumlah pergeseran untuk setiap special position, berikut persyaratannya :
1. Nilai indeks 0 adalah 0
2. Proses ini bertujuan mencari karakter yang tidak sama , lalu nilai diambil dari indek karakter tersebut.
3. Apabila karakter yang dicari selalu sama atau tidak dapat maka nilai akan diberikan dari panjang pattern, yakni 4.
Tabel 2.6 Pencarian nilai tabel hmin Pattern : TAMAT
Panjang : 5
Mencari karakter yang sama
T A M A T
0 1 2 3 4
I 0 1 2 3 4 5
p (i) T A M A T
hmin (i) 0 4 4 4 3 4
Indek/ posisi
1 2 3 4 5
4
2.2.1.5. Tabel kmin
Fungsi dari tabel kmin untuk membantu mengambil nilai dari rmin nanti , dimana syarat dari tabel ini adalah :
1. Proses dari kanan ke kiri , dan isi semua nilai dengan nilai 0, 2. Panjang pattern (m) = 5 , k (kmin) , 5 1,
3. kmin[hmin[k]] = k ,
4. Ambil kmin dari terakhir kali dieksekusi.
Tabel 2.7 Pencarian nilai tabel kmin Pattern : TAMAT
Panjang : 5 Mencari nilai kmin
K=5 kmin[hmin[k]] = k
kmin[hmin[5]] = 5 kmin [4] = 5
K=4 kmin[hmin[k]] = k
kmin[hmin[4]] = 4 kmin [3] = 4
K=3 kmin[hmin[k]] = k
kmin[hmin[3]] = 3 kmin [4] = 3
K=2 kmin[hmin[k]] = k
kmin[hmin[2]] = 2 kmin [4] = 2
K=1 kmin[hmin[k]] = k
kmin[hmin[1]] = 1 kmin [4] = 1
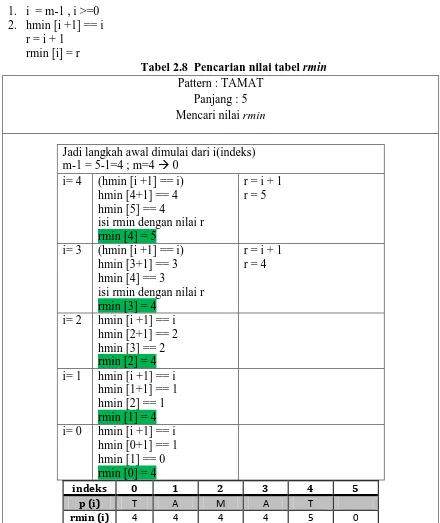
2.2.1.6. Tabel rmin
Tabel rmin berfungsi untuk menampung nilai pergeseran dari non-special position, dimana proses ini dilakukan dari kiri ke kanan dengan syarat :
1. i = m-1 , i >=0 2. hmin [i +1] == i
r = i + 1 rmin [i] = r
Tabel 2.8 Pencarian nilai tabel rmin Pattern : TAMAT
Jadi langkah awal dimulai dari i(indeks) m-1 = 5-1=4 ; m=4 0
i= 4 (hmin [i +1] == i) hmin [4+1] == 4 hmin [5] == 4
isi rmin dengan nilai r rmin [4] = 5
2.2.1.7 Tabel rcGs dan h
Tabel rcGs ini berfungsi untuk menampung nilai pergeseran atupun pencocokan karakter. Nilai rcGs didapat bersamaan dengan nilai h, tabel h bertujuan untuk melakukan pengecekan Special karakter yang harus pertama kali dicek pada saat melakukan pencocokan string (Haryadi, 2011). Berikut persyaratan komputasi dari tabel rcGs dan h.
Tabel 2.9 Pencarian nilai tabel rcGs dan h
Komputasi untuk mengambil nilai tabel rcGs (Charras & Lecroq 2004) i = 1
Proses Dimulai dari indeks =1 K = 1 5
K=1 hmin [k] != m-1 hmin [1] != 4 4 != 4
FALSE , lanjut ke langkah selanjutnya
K=2 hmin [k] != m-1 hmin [2] != 4 4 != 4
FALSE , lanjut ke langkah selanjutnya
K=3 hmin [k] != m-1 hmin [3] != 4 4 != 4
FALSE , lanjut ke langkah selanjutnya
Kmin [hmin[k]]== k Kmin[3]==4
4 == 4
True , masuk ke langkah pemberian nilai rcgs dan h
False,Lanjut ke kondisi selanjutnya
Lanjut ke kondisi selanjutnya Proses i =m-1 i = 4 m =5 j== m-2
--j = 3 0 J=3 Kmin [j]==0
Kmin[3] == 0 4 == 0
False, lanjut kelangkah selanjutnya
J=2 Kmin [j]==0 Kmin[2] == 0 0 == 0
True, lanjut kelangkah selanjutnya
h[i] = j
True, lanjut kelangkah selanjutnya
h[i] = j
True, lanjut kelangkah selanjutnya
h[i] = j
Setelah proses fase pemrosesan awal selesai maka didapat tabel rcGs beserta tabel h seperti tabel 2.8 berikut :
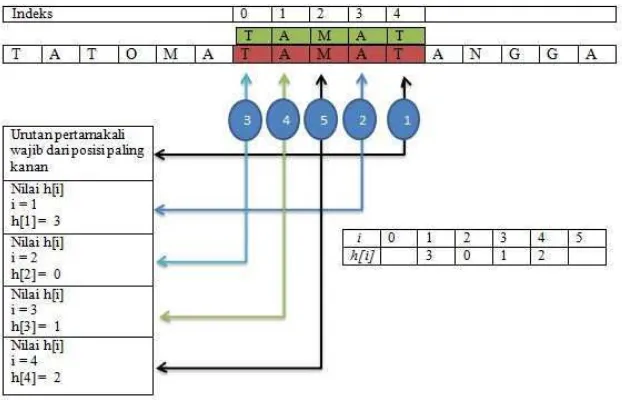
Tabel 2.10 Tabel rcGs
i 0 1 2 3 4 5
p(i) T A M A T
link(i) -1 -1 -1 1 0
hmin(i) 0 4 4 4 3 4
kmin(i) 0 0 0 4 1 0
rmin(i) 4 4 4 4 5 0
rcGs(i) 0 4 4 4 4 4
h(i) 3 0 1 2
2.2.2 Fase pencocokan pattern
Setelah tabel rcBc dan rcGs selesai terbentuk , pencocokan pattern dilakukan berdasarkan nilai dari kedua tabel tersebut. Pada algoritma Reverse Colussi , perbandingan karakter dilakukan dengan menggunakan urutan tertentu yang didapat dari tabel h. Untuk menentukan pengecekan pada lompatan pada saat melakukan pencocokan string membutuhkan tabel h, gambaran pengecekan karakter dapat dilihat pada gambar 2.2 berikut.
Persyaratan dalam menentukan pencocokan pattern ada 2 metode ,yakni:
1. Jika belum pernah menjumpai karakter yang sama maka gunakan nilai dari tabel
rcBc .
2. Jika sudah pernah menjumpai karakter yang sama,minimal 1 karakter metode eksekusi maka gunakan nilai dari tabel rcGs.
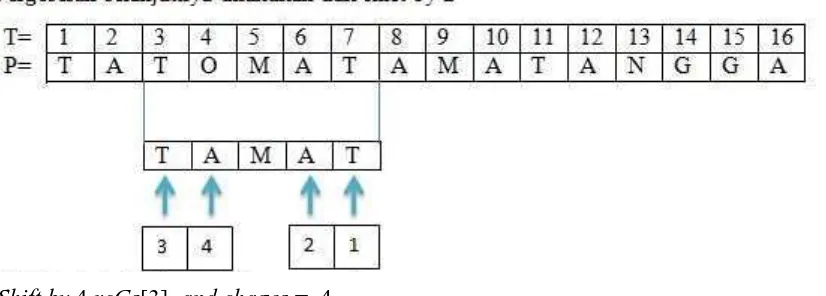
Gambar 2.2 Percobaan pencocokan karakter (1)
Gambar 2.3 Percobaan pencocokan karakter (2)
Shift by 4 rcGs[3], and chages = 4
Karena pada pertama kali tidak cocok maka digunakan tabel rcBc
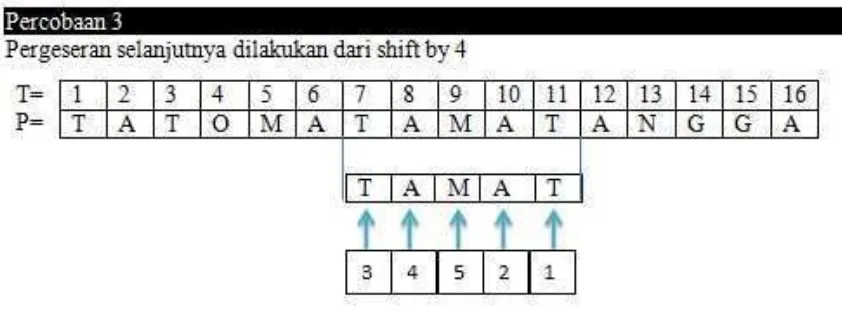
Gambar 2.4 Percobaan pencocokan karakter (3)
Gambar 2.5 Percobaan pencocokan karakter (4)
Karena pergeseran selanjutnya adalah 4 dan teks yang akan dieksekusi hanya tersisa 1, maka pencarian selesai. Dari hasil diatas untuk melakukan pencocokan pattern TAMAT pada teks TATOMATAMATAANGGA memerlukan percobaan sebanyak 4 kali dengan jumlah perbandingan komparasi sebanyak 11.
2.3 Penelitian yang Relevan
Berikut beberapa penelitian yang relevan dengan penelitian ini:
1. Rizki Primandar Admizan (2014) dalam skripsi yang berjudul Perbandingan Algoritma Reverse Colussi dengan Algoritma Karp-Rabin Dalam Mencari Dan Mencocokkan String Pada Word Game . Dengan melakukan perbandingan performansi dari algoritma Reverse Colussi dan algoritma Karp-Rabin maka akan dapat diketahui cara kerja dan performansi dalam kecepatan dan ketepatan dari kedua algoritma tersebut. Agar selanjutnya algoritma yang lebih bagus dapat digunakan pada perangkat lunak pencocokan kata.