Geographically Weighted Regression For Prediction of Underdeveloped Regions in
East Java Province Based On Poverty Indicators
Dr. Rusdi Hidayat N
1, Dr. Bambang Widjanarko Otok, M.Si
2, Zumarsiyah Mahsyari
3, Siti Halimah
Sa’diyah
4and Dimas Achmad Fadhila
51Business Administration Study Program, FISIP, UPN “Veteran” East Java, Surabaya 2,3,4,5Department of Statistics, FMKSD, Institut Teknologi Sepuluh Nopember, Surabaya 1[email protected],2,3,4,5{dr.otok.bw, zm.mahsyari, diyahshs, dafdimas23}@gmail.com
Keywords: GWR, Kernel Function. Adaptive Bisquare, Underdeveloped regions, poverty.
Abstract: Underdevelopment problem of a region can be seen from the dimensions of the economy, human resources, financial capability, infrastructure, accessibility, and regional characteristics. One way to see a region is underdeveloped or not is by looking the percentage of people living in poverty in a region in the publication data of underdeveloped regional indicators issued by the Central Bureau of Statistics (BPS). The results showed that the percentage of people in East Java Province who are living in poverty using linear regression is not yet appropriate. The percentage of people living in poverty spread spatially because there is heterogeneity between the observation sites which means that the observation of a location depends on the observation in another location that the distance is adjacent so that the spatial regression modeling is done with Adaptive BiSquare Kernel function. The grouping results with GWR resulted in five groups based on significant variables. Each group is characterized by life expectancy, mean years of schooling, expenditure and literacy rate.
1 INTRODUCTION
Daerah tertinggal merupakan suatu daerah dengan kabupaten yang masyarakat dan wilayahnya relatif kurang berkembang dibandingkan daerah lain dalam skala nasional. Ketertinggalan daerah tersebut dapat diukur berdasarkan enam kriteria utama yaitu ekonomi, sumber daya manusia, infrastruktur, kapasitas keuangan daerah, aksesibilitas dan
karakteristik daerah (Direktorat Jenderal
Pembangunan Daerah Tertinggal, 2016). Untuk mengidentifikasi suatu kabupaten mengalami ketertinggalan dapat diukur dengan menggunakan standar yang telah ditetapkan sebelumnya mengacu pada Peraturan Menteri Desa, Pembangunan Daerah Tertinggal dan Transmigrasi No. 3 Tahun 2016 tentang Petunjuk Teknis Penentuan Indikator Daerah Tertinggal Secara Nasional. Identifikasi masalah ketertinggalan suatu wilayah dalam makalah ini didasarkan pada indikator persentase penduduk miskin.
Suatu penelitian dipengaruhi oleh aspek kewilayahan (spasial) maka perlu dipertimbangkan
data spasial pada model. Data spasial merupakan data yang memuat informasi lokasi. Pada data spasial, seringkali pengamatan di suatu lokasi bergantung pada pengamatan di lokasi lain yang
berdekatan (neighboring) (Anselin, 1988). Hukum
tersebut merupakan dasar pengkajian permasalahan berdasarkan efek lokasi atau metode spasial. Dalam permodelan, apabila model regresi klasik digunakan sebagai alat analisis pada data spasial, maka dapat menyebabkan kesimpulan yang kurang tepat karena asumsi error saling bebas dan asumsi homogenitas
tidak terpenuhi
.
2 LITERATURE RIVIEW
Model Geographically Weighted Regression
model regresi global dimana ide dasarnya diambil dari regresi non parametrik (Mei, 2006). Variabel
respon y dalam model GWR diprediksi dengan
variabel prediktor dan masing-masing koefisien regresinya bergantung pada lokasi dimana data tersebut diamati. Model GWR dinyatakan sebagai berikut (Fotheringham dkk, 2002):
Estimasi parameter model GWR dilakukan dengan
metode Weighted Least Squares (WLS) yaitu
dengan memberikan pembobot yang berbeda untuk setiap lokasi dimana data diamati. Misalkan
pembobot untuk setiap lokasi
u vi, i
adalah
,
j i i
w u v ,j= 1, 2,…,nmaka parameter pada lokasi
pengamatan
u
i,
v
i
diestimasi denganmenambahkan unsur pembobot w u vj
i, i
padapersamaan (1) dan kemudian meminimumkan jumlah kuadrat residual, atau dalam bentuk matriks jumlah kuadrat residualnya adalah:
Jika persamaan (2) diturunkan terhadap
,
T
i i
u v
β
dan hasilnya disamakan dengan nolmaka diperoleh estimator parameter model GWR:
1
x adalah elemen
baris ke-idari matriks X. Maka nilai prediksi untuk
y pada lokasi pengamatan
u vi, i
dapat diperolehdengan cara berikut:
1
ˆ
ˆ T , T T , T ,
i i i i i i i i i
y x β u v x X W u v X X W u v y
Sehingga untuk seluruh pengamatan dapat dituliskan sebagai berikut:
denganIadalah matriks identitas berukuran nxn dan
Peran pembobot pada model GWR sangat penting karena nilai pembobot ini mewakili letak data observasi satu dengan lainnya. Skema pembobotan pada GWR dapat menggunakan beberapa metode yang berbeda. Ada beberapa literatur yang bisa digunakan untuk menentukan besarnya pembobot untuk masing-masing lokasi yang berbeda pada model GWR, diantaranya dengan
menggunakan fungsi kernel (kernel function).
Fungsi kernel digunakan untuk mengestimasi
paramater dalam model GWR jika fungsi jarak
wjadalah fungsi yang kontinu dan monoton turun (Chasco, Garcia dan Vicens, 2007). Pembobot yang terbentuk dengan menggunakan fungsi kernel ini
adalah fungsi jarak Gaussian (Gaussian Distance
Function), fungsiExponential, fungsi Bisquare, dan
fungsi kernel Tricube dan melibatkan parameter
penghalus (bandwidth) (Lesage, 2001). Metode
Cross Validation (CV) untuk memilih bandwidth
optimum, yang secara matematis didefinisikan sebagai berikut:
pengamatan di lokasi
u vi, i
dihilangkan dariproses estimasi. Untuk mendapatkan nilai
h
yangoptimal maka diperoleh dari
h
yang menghasilkannilai CV yang minimum.
Pengujian hipotesis pada model GWR terdiri dari pengujian kesesuaian model GWR dan pengujian parameter model. Pengujian kesesuaian
model GWR (goodness of fit) dilakukan dengan
hipotesis sebagai berikut :
0
H :
k u vi, i
k (tidak ada perbedaan yangsignifikan antara model regresi global dan GWR)
1
H :
Paling sedikit ada satu
k
u vi i,
k untuksetiap k0,1,2, , , dan 1,2, , p i n
(ada perbedaan yang signifikan antara model
Penentuan statistik uji berdasarkan pada
Residual Sum of Square (RSS) yang diperoleh
masing-masing dibawah H0 dan H1. Dibawah
kondisi H0, dengan menggunakan metode OLS
diperoleh nilai RSS berikut:
0 ˆ ˆ
ˆ
ˆ
RSS H ε εT y y T y y y I H yT dengan H X X X X
T
1 T yang bersifat idempotent.Dibawah kondisi H1, koefisien regresi yang
bervariasi secara spasial pada persamaan (1) ditentukan dengan metode GWR, sehingga diperoleh nilai RSS berikut:
sehingga diperoleh statistik uji sebagai berikut (Leung dkk., 2000a):
Dibawah H0 ,
F
1 akan mengikuti distribusi Fdengan derajat bebas 12
1
maka tolak H0jika
1 2
Alternatif lain sebagai statistik uji adalah dengan menggunakan selisih jumlah kuadrat residual
dibawah H0 dan dibawah H1 (Leung dkk, 2000a),
yaitu:
Dibawah H0
F
2 akan mengikuti distribusi F denganderajat bebas 1 12
2
diambil taraf signifikansi
maka tolak H0 jika1 2
Jika disimpulkan bahwa model GWR berbeda nyata dengan model regresi global, maka langkah selanjutnya adalah melakukan uji parsial untuk mengetahui apakah ada perbedaan pengaruh yang
signifikan dari variabel prediktor
x
k antara satulokasi dengan lokasi lainnya (Mei, He dan Fang, 2004).
Pengujian ini dapat dilakukan dengan hipotesis: H0 :
k
u v1 1,
k
u v2, 2
k
u vn, n
(tidak ada perbedaan pengaruh yang signifikan darivariabel prediktor
x
k antara satu lokasi denganlokasi lainnya)
H1 : Minimal ada satu,
, , untuk 1,2,...,
k u vi i i n
k0,1,2, , p
yang berbeda. (ada perbedaan pengaruh yang
signifikan dari variabel prediktor
x
k antara satulokasi dengan lokasi lainnya)
Untuk melakukan pengujian di atas maka ditentukan terlebih dahulu varians
ˆ
k
u
i,
v
i
(i= 1, 2, ..., n) yang dinotasikan dengan:
Sedangkan statistik uji yang digunakan adalah:
k
e
adalah vektor kolom berukuran
p
1
yangbernilai satu untuk elemen ke-k dan nol untuk
lainnya. Matriks L seperti pada persamaan (4) dan
RSS(H1) seperti pada persamaan (5).
Dibawah H0, statistik uji
F
3 akanberdistribusi F dengan derajat bebas 12
1
pada persamaan (6). Tolak H0 jika
1 2
3 , ,df df
F F
(Leung dkk., 2000a).
Adapun pengujian signifikansi parameter model pada setiap lokasi dilakukan dengan menguji parameter secara parsial. Pengujian ini dilakukan untuk mengetahui parameter mana saja yang signifikan mempengaruhi variabel responnya. Bentuk hipotesisnya adalah sebagai berikut:
distribusi normal multivariat dengan rata-rata
dengan
c
kk adalah elemen diagonal ke-kdari matrikT i i
C C
. Sehingga statistik uji yang digunakan adalah:ˆ ( , )
Dibawah H0 T akan mengikuti distribusi t dengan
derajat bebas 12
2
sementara itu
ˆ
diperolehdengan mengakarkan 2 1
1
signifikansi yang diberikan sebesar
, makadiambil keputusan tolak H0 atau dengan kata lain
parameter k
u vi, i
signifikan terhadap modelAkaike Information Criterion Correction (AICc) metode yang digunakan untuk memilih model terbaik yang didefinisikan sebagai berikut :
ˆ
( )
: Nilai estimator standar deviasi dari error hasilestimasi maksimum likelihood, yaitu ˆ2 RSS
n
S : Matriks proyeksi dimana ˆy Sy
Pemilihan model terbaik dilakukan dengan menentukan model dengan nilai AICc terkecil (Fotheringham dkk, 2002).
3. METHODOLOGY
Data yang digunakan adalah data sekunder yang diperoleh dari Publikasi BPS 2014. Variabel penelitian disajikan pada Tabel 1 berikut.
Tabel 1. Variabel Penelitian Variabel. Indikator
Y Persentase penduduk miskin X1 Angka Harapan Hidup X2 Rata-Rata Lama Sekolah X3 Pengeluaran Per Kapita Penduduk X4 Angka Melek Huruf
Tahapan yang dilakukan dalam penelitian. 1. Deskripsi karakteristik dan pola persebaran
persentase penduduk miskin di Jawa Timur. 2. Pemodelan persentase penduduk miskin di Jawa
Timur dengan Regresi Linier dan GWR dengan kriteria AIC. Langkah-langkahnya sebagai berikut.
i. Deteksi kasus mutikolinieritas.
ii. Pemodelan persentase penduduk miskin di Jawa Timur dengan Regresi Linier:
a. Menghitung nilai penaksir parameter model Regresi Linier
b. Melakukan peengujian paramaeter secara serentak dan parsial.
iii. Melakukan pemodelan GWR pada persentase penduduk miskin di Jawa Timur:
a. Menghitung jarak euclidian antar lokasi
pengamatan berdasarkan posisi geografis.
Jarak euclidean antara lokasi i yang
terletak pada koordinat (ui, vi) terhadap
lokasijpada koordinat (uj,vj)
b. Menentukan bandwidth optimum dengan
kriteria CV
c. Menentukan pembobot yang optimum dengan fungsi pembobot kernel gauss. d. Menghitung nilai penaksir parameter
model GWR
e. Menguji parameter GWR (uji kesesuaian dan uji parsial)
Membandingkan nilai AICc Model Regresi Global / Linier dengan model GWR, nilai AICc yang minimum merupakan model yang terbaik.
4. RESULT AND DISCUSSION
Deskripsi penelitian ini meliputi mean dan standar deviasi dari masing-masing variabel disajikan pada Tabel berikut.
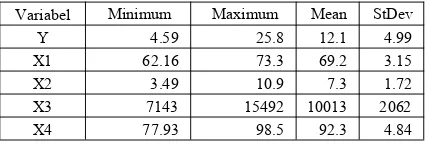
Tabel 2. Deskripsi Variabel Penelitian
Variabel Minimum Maximum Mean StDev Y 4.59 25.8 12.1 4.99 X1 62.16 73.3 69.2 3.15 X2 3.49 10.9 7.3 1.72 X3 7143 15492 10013 2062 X4 77.93 98.5 92.3 4.84
Deteksi Multikolinearitas
Salah satu syarat dalam analisis regresi dengan beberapa variabel prediktor adalah tidak ada kasus multikolinieritas atau tidak terdapat variabel prediktor yang memiliki korelasi dengan variabel prediktor lainnya. Pendeteksian mutikolinieritas dilakukan berdasarkan nilai Variance Inflation Factor (VIF). Berikut ini nilai VIF pada masing-masing variabel prediktor.
Tabel 3.Nilai VIF Variabel Prediktor
Variabel X1 X2 X3 X4 VIF 2.085 9.066 4.698 4.526
Tabel 2., diperoleh informasi bahwa semua variabel prediktor memiliki nilai VIF yang kurang 10. Hal ini
mendeteksi bahwa tidak terdapat kasus
multikolinieritas atau tidak terdapat variabel
prediktor yang memiliki korelasi dengan variabel prediktor lainnya.
Uji Signifikansi Parameter Regresi Linier Prevalensi Hipertensi
Berikut ini uji signifikansi parameter regresi linier baik secara serentak maupun parsial untuk mengetahui pengaruh dari variabel prediktor yang digunakan. Hipotesis untuk uji signifikansi parameter secara serentak pada regresi linier adalah sebagai berikut.
H0 : β1 = β2 =…= β4 = 0 (parameter tidak
berpengaruh signifikan terhadap model)
H1: minimal ada satuβk≠ 0 ;k= 1,2,…,4 (minimal
ada satu parameter yang berpengaruh signifikan terhadap model)
Tabel 4. Tabel ANOVA Regresi Linear
Sumber
Variasi SquaresSum of df SquareMean F p Regression 598.32 9 66.48 2.14 0.030
Residual 4418.32 142 31.11
Total 5016.64 151
Tabel 4., menghasilkan nilai Fhitungsebesar 2,14 dan
p-value sebesar 0,030. Berdasarkan taraf signifikansi
( ) sebesar 5% dan F(0,05;9;142) sebesar 1,946,
diperoleh keputusan Tolak H0karena nilai Fhitung >
F(0,05;9;142)atau p-value < 0,05. Hal ini dapat diartikan bahwa terdapat minimal ada satu parameter yang
berpengaruh signifikan terhadap prevalensi
hipertensi.
Selanjutnya untuk mengetahui variabel prediktor mana saja yang memberikan pengaruh secara signifikan, maka dilakukan pengujian signifikansi parameter secara parsial yang disajikan pada Tabel 5. Berikut ini hipotesis uji signifikansi parameter secara spasial terhadap model regresi linier (global).
H0:βk= 0,
H1:βk≠ 0, k= 1,2,3,4
Tabel 5. Uji Parameter Koefisien Regresi Secara Parsial
Parameter Koefisien SE
Koefisien Thitung Sig.
0 59.720 16.410 3.640 0.001
1 0.076 0.187 0.410 0.687
2 -1.422 0.789 -1.800 0.081
3 -0.000 0.000 -0.140 0.891
4 -0.454 0.179 -2.530 0.016
Berdasarkan hasil pengujian pada Tabel 5,
2;n p1 0.025,33 2.035
t t , diperoleh informasi
bahwa semua nilai T hitung lebih kecil dari t table,
kecuali parameter 4. Hal ini menunjukkan bahwa
variabel angka melek huruf berpengaruh secara signifikan terhadap persentase penduduk miskin.
Pengujian Asumsi Residual
Pengujian asumsi residual identik, independen, dan berdistribusi normal (IIDN).
Uji Asumsi Residual Identik
Salah satu uji asumsi dalam regresi OLS
adalah varians residual harus bersifat
homoskedastisitas (bersifat identik) atau terjadi kasus heteroskedastisitas. Cara mengidentifikasi adanya kasus heteroskedastisitas adalah dengan membuat model regresi antara residual dan variabel prediktornya. Apabila terdapat variabel prediktor yang berpengaruh secara signifikan terhadap model, maka dapat dikatakan bahwa residual tersebut tidak identik atau terjadi kasus heteroskedastisitas. Pengujian asumsi residual identik memberikan
informasi bahwa tidak terdapat kasus
heteroskedastisitas atau residual telah identik dengan
taraf signifikan ( ) sebesar 0,05 dan
; ,p n p1 0,05;4,33 2.659
F F . Hal ini dikarenakan
oleh nilai P-Value yaitu sebesar 0.119 lebih besar
dari dan Fhitung sebesar 1.99 lebih kecil dari 2.659
maka tidak terjadi heteroskedastisitas.
Uji Asumsi Residual Independen
Uji asumsi residual independen digunakan untuk mengetahui ada atau tidaknya hubungan antar
residual. Statistik uji yang digunakan adalah
Durbin-Watson. Nilai DW = 1.099 diperoleh nilai
07875
d
. Sehingga keputusan yang dapatdiambil adalah Tolak H0 karena
0802
tersebut menunjukkan bahwa ada hubungan antar residual, sehingga asumsi residual independen tidak terpenuhi.
Uji Asumsi Berdistribusi Normal
Uji asumsi berdistribusi normal dilakukan
dengan ujiKolmogorov-Smirnovberikut ini.
H0: Data berdistribusi normal
H1: Data tidak berdistribusi normal
5.0
Probability Plot of Residual Normal
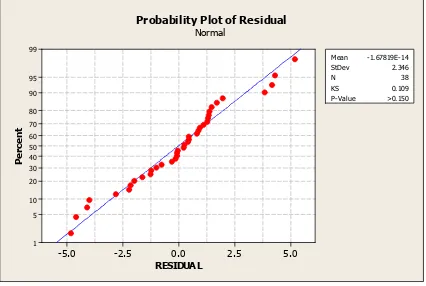
Gambar 1. Probability Plot Normal Residual
Berdasarkan Gambar 2 diperoleh informasi bahwa titik-titik merah menyebar mendekati garis linier (normal) yang berarti bahwa data telah berdistribusi normal. Selain itu, juga dapat dilihat
dari nilai P-Value yaitu lebih besar 0,15. Sehingga
keputusan yang dapat diambil adalah Gagal Tolak
H0 pada taraf signifikan () sebesar 5%, artinya,
data telah memenuhi asumsi berdistribusi normal. Berdasarkan hasil pengujian asumi tersebut, dapat disimpulkan bahwa residual pada model regresi linier (global) data telah berdistribusi normal, tetapi asumsi identik dan independen tidak terpenuhi.
Sehingga dilakukan regresi spasial dengan
pendekatan GWR.
Pemodelan Regresi Spasial Persentase
Penduduk Miskin
Analisis menggunakan metode GWR
bertujuan untuk mengetahui variabel yang
berpengaruh terhadap persentase penduduk miskin pada masing-masing lokasi pengamatan yaitu kabupaten/kota di provinsi Jawa Timur. Langkah awal yang dilakukan untuk mendapatkan model GWR adalah menentukan titik koordinat lintang dan
bujur pada tiap lokasi, menghitung jarak euclidean
dan menentukan nilai bandwidth optimum
berdasarkan kriteria Cross Validation (CV).
Langkah selanjutnya adalah menentukan matriks
pembobot dengan fungsi kernel: Fixed Gaussian,
fixed bi-square, Adaptive Gaussian, Adaptive Bi-Square dan menaksir parameter model GWR. Matriks pembobot yang diperoleh untuk tiap lokasi kemudian digunakan untuk membentuk model, sehingga diperoleh model yang berbeda-beda pada tiap lokasi pengamatan.
H0: k(ui,vi)k ;
(Tidak ada perbedaan signifikan antara model regresi linier (global) dan model GWR)
H1: minimal ada satu k(ui,vi)k k= 1,
2, ….,9
(Ada perbedaan signifikan antara model regresi linier (global) dan model GWR)
Tabel 6.Estimasi GWR pada Bobot Fungsi Kernel
Statistik Fixed Bobot Fungsi
Gaussian Bi-SquareFixed AdaptiveGaussian Bisquare*Adaptive
MSE 5.560 5.049 5.989 1.995
R2 0.829 0.852 0.797 0.998 AICc 185.676 184.839 186.017 -14185
Tabel 6 menunjukkan perbandingan estimasi model GWR dengan pembobot yang berbeda-beda. Pengujian kesesuaian model GWR dilakukan dengan menggunakan selisih jumlah kuadrat residual model GWR dan model regresi global. Model GWR akan berbeda signifikan dengan model regresi global jika dapat menurunkan jumlah kuadrat residual secara signifikan. Tabel 6 menunjukkan bahwa nilai AICc terkecil adalah model GWR dengan pembobot kernel adaptive Bisquare yaitu sebesar -14185. Sehingga dengan menggunakan tingkat signifikansi α sebesar 5% maka dapat disimpulkan bahwa model GWR berbeda signifikan dengan model regresi global. Artinya model GWR dengan pembobot kernel adaptive Bisquare lebih layak untuk menggambarkan persentase penduduk miskin di Provinsi Jawa Timur.
Selanjutnya adalah pengujian signifikansi parameter model GWR dengan pembobot kernel adaptive Bisquare secara parsial untuk mengetahui parameter mana saja yang berpengaruh secara signifikan terhadap persentase penduduk miskin di
tiap lokasi pengamatan. Pengelompokkan
kabupaten/kota yang memiliki kesamaan variabel yang berpengaruh signifikan terhadap persentase penduduk miskin disajikan pada Tabel 7.
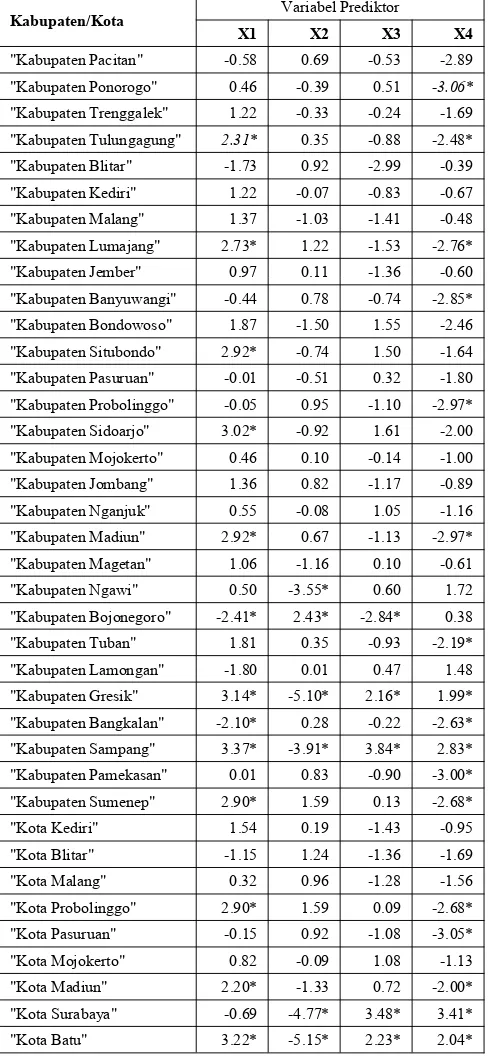
Tabel 7.Nilai T-hitung Pada Variabel di Tiap Kabupaten/Kota Menggunakan Adaptive Bi-Square
Kabupaten/Kota Variabel Prediktor
X1 X2 X3 X4
"Kabupaten Pacitan" -0.58 0.69 -0.53 -2.89 "Kabupaten Ponorogo" 0.46 -0.39 0.51 -3.06*
5
CONCLUSIONS
Hasil pemodelan persentase penduduk miskin di Provinsi Jawa Timur berdasarkan kabupaten/kota menggunakan regresi linier hanya 1 variabel yang mempengaruhi persentase penduduk miskin, yaitu angka melek huruf. persentase penduduk miskin di Provinsi Jawa Timur menyebar secara spasial karena terdapat heterogenitas antar lokasi pengamatan yang berarti bahwa pengamatan suatu lokasi bergantung pada pengamatan di lokasi lain yang jaraknya berdekatan sehingga dilakukan pemodelan regresi
spasial dengan fungsi kernel Adaptive Bisquare,
yang meghasilkan 5 kelompok.
REFERENCES
Anselin, L, (1988), Spatial Econometrics: Method and Models, Kluwer Academic Publishers, the Netherlands
Chasco, C., Garcia, I., & Vicens, J. (2007), Modeling Spatial Variations in Household Disposible Income with Geographically Weighted Regression, Munich Personal RePEc Arkhive (MPRA) Working Papper No. 1682.
Draper, N., & Smith, H. (1992),Analisis Regresi Terapan, PT Gramedia Pustaka Utama, Jakarta
Fotheringham, A.S., Brunsdon, C., & Charlton, M. (2002), Geographically Weighted Regression, Jhon Wiley & Sons, Chichester, UK
LeSage, J.P. (2001), A Family of Geographically Weighted Regression, Departement of Economics University of Toledo.
Leung, Y., Mei, C.L., & Zhang, W.X. (2000a), Statistic Tests for Spatial Non-Stationarity Based on the Geographically Weighted Regression Model, Environment and PlanningA, 32 9-32.
Leung, Y., Mei, C.L., & Zhang, W.X., (2000b), Testing for spatial autocorrelation among the residuals of the geographically weighted regression" Environment and Planning A,32, 871-890.