PENENTUAN PARAMETER
PEMBANGKIT UCAPAN MODEL ARTIKULATORI
UNTUK FONEM-FONEM BAHASA INDONESIA
Aditya Arie Nugraha (13204118)
Ringkasan—Dalam ringkasan ini, dibahas mengenai penelitian yang dilakukan untuk menentukan parameter-parameter dari model artikulatori agar dapat membangkitkan ucapan yang tersusun dari fonem-fonem yang dikenal dalam bahasa Indonesia. Dalam penelitian yang dilakukan, penentuan parameter meli-batkan proses sintesis ucapan yang dilakukan dengan bantuan toolbox ARTM pada MATLAB. Proses sintesis ucapan sendiri dapat dibagi menjadi proses analisis, speech inverse filtering, penentuan eksitasi, dan sintesis. Selain keempat proses tersebut, dapat ditambahkan pula pemrosesan awal (pre-processing) dan pemrosesan akhir (post-processing). Dengan metodologi yang digunakan, parameter pembangkit ucapan model artikulatori untuk hampir seluruh fonem dalam bahasa Indonesia, kecuali kelompok fonem konsonan frikatif, berhasil diperoleh. Meskipun parameter-parameter tersebut belum mewakili model artiku-latori ideal, parameter-parameter pembangkit ucapan model artikulatori untuk fonem-fonem bahasa Indonesia yang diperoleh dalam penelitian yang dilakukan telah dapat menghasilkan sinyal yang menyerupai sinyal ucapan manusia.
Index Terms—text-to-speech, pembangkit ucapan, sintesis ar-tikulatori, model artikulatori
I. PENDAHULUAN
P
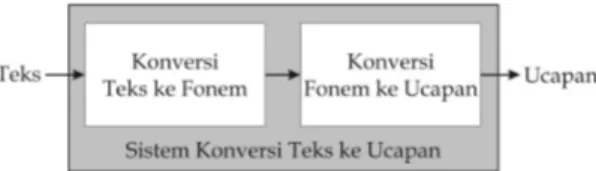
ADA dasarnya, sistem konversi teks ke ucapan (text-to-speech) terbagi dalam dua tahap, yaitu:1) Tahap konversi teks ke fonem (text-to-phoneme) 2) Tahap konversi fonem ke ucapan (phoneme-to-speech)
Gambar 1. Diagram Blok Sistem Konversi Teks ke Ucapan (text-to-speech) Tahap konversi teks ke fonem berfungsi untuk mengubah masukan yang berbentuk teks dalam suatu bahasa tertentu menjadi rangkaian kode-kode bunyi yang biasanya direpresen-tasikan dengan kode fonem, durasi, dan pitch.
Tahap konversi fonem ke ucapan berfungsi untuk meng-hasilkan sinyal ucapan berdasarkan masukan yang diterima. Masukan berupa kode fonem yang dihasilkan oleh tahap sebelumnya. Selain kode fonem, masukan berupa durasi dan pitchjuga dapat ditambahkan. Ada beberapa alternatif teknik yang dapat digunakan untuk mengimplementasikan tahap ini.
Sekolah Teknik Elekto dan Informatika, Institut Teknologi Bandung
Salah satu tekniknya adalah sintesis ucapan dengan model artikulatori.
Penilaian kualitas dari sebuah sistem konversi teks ke uca-pan (text-to-speech) diawali dengan menilai kualitas ucauca-pan yang dihasilkan. Terdapat dua kriteria penilaian yang umum dipakai, yaitu tingkat kenaturalan dan inteligibilitas. Secara teoretis, sintesis artikulatori merupakan metode pembangkit ucapan pada sistem konversi teks ke ucapan yang sangat baik untuk menghasilkan ucapan yang natural, sehingga memiliki tingkat inteligibilitas yang baik. Sampai saat ini belum ada data yang lengkap mengenai parameter-parameter dari model artikulatori untuk menghasilkan fonem-fonem bahasa Indone-sia. Padahal, data ini akan sangat diperlukan dalam pengem-bangan sistem konversi teks ke ucapan bahasa Indonesia yang menggunakan pendekatan sistem artikulatori. Oleh karena itu, perlu dilakukan penelitian untuk menemukan nilai parameter-parameter ini.
II. METODOLOGI
Secara garis besar metodologi yang digunakan dalam penyusunan Tugas Akhir ini dapat dibagi menjadi studi liter-atur, seleksi ucapan, sintesis ucapan, serta pendataan, analisis hasil, dan penarikan kesimpulan.
Seperti yang telah dikemukakan di atas, dalam penelitian ini penentuan parameter melibatkan proses sintesis ucapan yang dilakukan dengan bantuan toolbox ARTM pada MATLAB. Proses sintesis ucapan sendiri dapat dibagi menjadi proses analisis, speech inverse filtering, penentuan eksitasi, dan sin-tesis. Selain keempat proses tersebut, dapat ditambahkan pula pemrosesan awal (pre-processing) dan pemrosesan akhir (post-processing).
A. Pemrosesan Awal
Masukan dari pemrosesan awal adalah rekaman ucapan suatu kata dalam format WAV, sedangkan keluarannya adalah kontur formant dari sinyal ucapan kata tersebut.
Dengan menggunakan perangkat lunak Adobe Audition 1.5, rekaman ucapan dalam format WAV (.wav) mengalami pemrosesan awal. Pemrosesan awal meliputi reduksi derau, pengurangan silence, dan penyesuian amplitudo sinyal. Sinyal ucapan hasil pemrosesan awal kemudian disimpan dalam for-mat ASCII (.dat).
Reduksi derau dilakukan agar rekaman sinyal ucapan seda-pat mungkin mendekati sinyal ucapan sebenarnya. Penguran-gan silence dilakukan untuk memperpendek durasi rekaman,
Sinyal ucapan hasil pemrosesan di atas kemudian diolah lebih lanjut dengan menggunakan toolbox formant_track pa-da MATLAB untuk mengetahui frekuensi-frekuensi formant (frekuensi formant ke-1 sampai dengan ke-4) dari sinyal terse-but. Frekuensi-frekuensi formant tersebut direpresentasikan dalam kontur formant.
B. Analisis
Masukan dari proses analisis adalah kontur formant dari sinyal ucapan kata, sedangkan keluarannya adalah sejumlah frame dengan informasi empat frekuensi formant pertama (frekuensi formant ke-1 sampai dengan ke-4) dari bagian sinyal ucapan tertentu. Jadi, inti dari proses analisis adalah menentukan letak dan panjang frame pada sinyal ucapan sedemikian rupa sehingga didapatkan frame yang dapat merep-resentasikan suatu fonem tertentu.
C. Speech Inverse Filtering
Masukan dari proses speech inverse filtering adalah frame dengan informasi empat frekuensi formant pertama, sedangkan keluarannya adalah parameter pembangkit ucapan model ar-tikulatori dari frame yang bersangkutan.
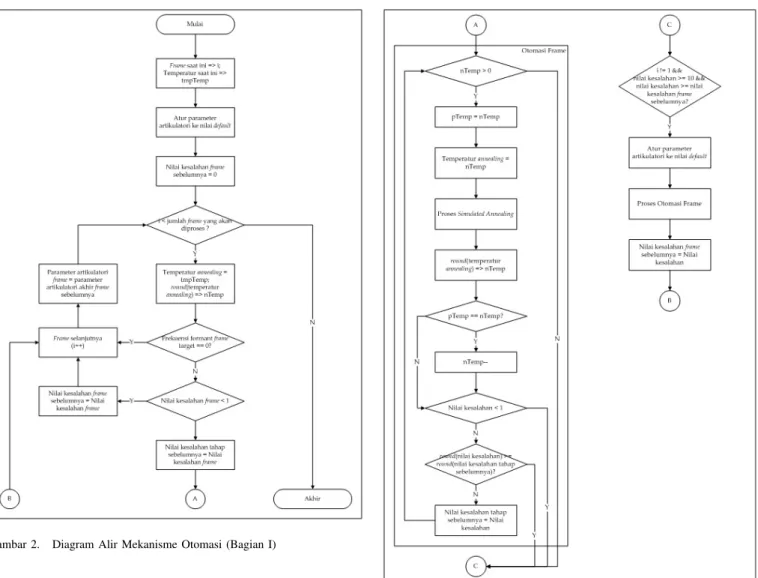
Proses speech inverse filtering dapat dilakukan dengan menentukan parameter-parameter model artikulatori secara manual. Meskipun demikian, sangat sulit untuk menentukan sembilan parameter sedemikian rupa sehingga sinyal yang nantinya dibangkitkan melalui model tersebut dapat menyamai atau setidaknya mendekati sinyal target. Oleh karena itu, dalam proses speech inverse filtering digunakanlah proses optimasi dengan algoritma simulated annealing. Selain itu, untuk men-dukung proses speech inverse filtering ini dibuatlah proses otomasi terhadap algoritma simulated annealing agar proses optimasi dapat menghasilkan nilai-nilai parameter terbaik yang dapat diraih.
Berkaitan dengan diterapkannya algoritma simulated an-nealing pada proses optimasi dari toolbox ARTM, terda-pat panduan dalam menentukan parameter annealing yang tepat.[1]
1) Tentukan konfigurasi sifat nasal fonem (nasalization extent) dan jumlah parameter dari model artikulatori yang akan dioptimasi. Jalankan proses optimasi dengan nilai default untuk parameter artikulatori dan parameter annealing. Jika nilai kesalahan (error) yang didapatkan setelah proses berakhir kurang dari 1 %, lanjutkan ke langkah 5. Jika tidak, lanjutkan ke langkah 2.
2) Periksa apakah rongga vokal yang didapatkan bentuknya wajar. Jika tidak, lanjutkan ke langkah 3. Jika seba-liknya, catat nilai kesalahan sebagai εp dan temperatur
akhir sebagai Tp. Kemudian atur parameter temperatur
awal annealing T = floor[Tp] dan jalankan proses
op-timasi lagi. Jika nilai kesalahan yang dihasilkan kurang dari εp, maka ulangi langkah ini sampai nilai
kesala-han yang diinginkan tercapai. Jika nilai kesalakesala-han yang dihasilkan tidak kurang dari εp, lanjutkan ke langkah 4.
evaluasi, dan mengubah parameter-parameter lain sesuai keinginan. Kemudian mulai proses optimasi dan lakukan langkah 2.
4) Lakukan perubahan terhadap jumlah parameter dari model artikulatori yang akan dioptimasi. Kemudian mu-lai proses optimasi dan lakukan langkah 2.
5) Periksa apakah bentuk rongga vokal mendekati bentuk rongga vokal yang tercantum dalam literatur. Jika ben-tuk keduanya mirip, maka proses optimasi selesai. Jika tidak, kembali ke langkah 1. Akan tetapi, lakukan pen-gaturan pada parameter artikulatori (tidak menggunakan nilai default) sebelum proses optimasi dilakukan. 6) Jika langkah-langkah di atas gagal untuk mengurangi
nilai kesalahan sampai batas nilai yang diinginkan, kem-bali ke fase pemilihan frame, dan pilih ulang frame yang akan dijadikan target. Kemudian lakukan proses optimasi dari langkah 1.
Mengacu pada panduan di atas, untuk memudahkan proses pengambilan data dibuatlah suatu mekanisme otomasi. Selain akan melakukan optimasi terhadap semua frame yang telah didefinisikan sebelumnya, mekanisme ini akan melakukan op-timasi sampai nilai variabel temperatur dari algoritma simulat-ed annealing bernilai mendekati nol. Sedikit berbeda dengan langkah 2 dimana temperatur awal proses optimasi selanjutnya T = floor[Tp], dalam mekanisme ini temperatur awal proses
optimasi selanjutnya T = round[Tp].
Diagram alir dari mekanisme otomasi ini dapat dilihat pada Gambar 2 dan 3.
Dari diagram alir mekanisme otomasi, dapat dilihat bahwa parameter awal artikulatori untuk proses optimasi frame su-atu frame mengambil dari parameter artikulatori hasil proses optimasi frame sebelumnya. Hal ini dilakukan dengan asum-si bahwa kondiasum-si rongga vokal tidak dapat berubah secara ekstrem, sehingga kondisi rongga vokal suatu waktu akan lebih mudah dan lebih cepat untuk dicapai dengan proses optimasi jika kondisi rongga vokal (parameter artikulatori) waktu sebelumnya digunakan sebagai acuan. Apabila usaha ini gagal untuk mencapai nilai kesalahan (error) yang diinginkan, proses optimasi terhadap suatu frame akan diulang dengan menggunakan parameter awal artikulatori default.
Perlu dicatat bahwa dalam perhitungan nilai kesalahan (er-ror) diberlakukan pembobotan sebagai berikut.
E=103(F1m-F1t)+103(F2m-F2t)+2,510(F3m-F3t)+1,510(F4m-F4t)
Dimana Fxm merupakan frekuensi formant model dan Fxt
merupakan frekuensi formant target, dengan x bernilai 1 untuk frekuensi formant pertama, 2 untuk frekuensi formant kedua, 3 untuk frekuensi formant ketiga, dan 4 untuk frekuensi formant keempat.
Pada prinsipnya, parameter-parameter pembangkit ucapan model artikulatori, yang merupakan topik dari penelitian ini, telah didapatkan dengan selesainya proses speech inverse filtering. Oleh karena itu, proses-proses berikutnya dapat di-anggap sebagai proses pendukung dalam penelitian ini.
Gambar 2. Diagram Alir Mekanisme Otomasi (Bagian I)
D. Penentuan Eksitasi
Dalam proses ini, parameter-parameter yang berkaitan den-gan eksitasi ditentukan. Dalam penelitian ini, parameter-parameter ini nilainya sama untuk semua kasus, kecuali pa-rameter frekuensi fundamental (F0) serta waktu (letak) dan durasi eksitasi. Parameter frekuensi fundamental disesuaikan dengan frekuensi fundamental sinyal ucapan dalam rekaman. Frekuensi fundamental cenderung berbeda untuk setiap orang. Frekuensi fundamental pengucap pria relatif lebih rendah dibandingkan dengan frekuensi fundamental pengucap wanita. Frekuensi ini dapat diperkirakan dengan bantuan perangkat lunak Adobe Audition 1.5. Waktu dan durasi eksitasi dis-esuaikan dengan waktu dan durasi frame pertama dari sinyal ucapan yang dimodelkan. Oleh karena itu, proses penentuan eksitasi ini berkaitan erat dengan pembagian frame terhadap sinyal dalam proses analisis yang telah diuraikan sebelumnya. Parameter-parameter selain parameter frekuensi fundamental (F0) serta waktu (letak) dan durasi eksitasi menggunakan nilai default.
E. Sintesis
Masukan dari proses sintesis ini adalah parameter model artikulatori yang dihasilkan oleh proses speech inverse filtering dan parameter eksitasi yang ditentukan pada proses penentuan eksitasi. Sedangkan, keluarannya adalah sinyal ucapan buatan
Gambar 3. Diagram Alir Mekanisme Otomasi (Bagian II)
(artificial) yang dibangkitkan berdasarkan kedua macam pa-rameter masukan.
Secara praktis, tidak ada parameter yang perlu diatur dalam proses ini. Proses sintesis dapat langsung dimulai jika kedua macam parameter masukan tersedia. Setelah proses sintesis se-lesai dilakukan, sinyal ucapan yang dihasilkan dapat disimpan dalam format ASCII (.dat).
F. Pemroresan Akhir
Masukan dari pemrosesan akhir adalah sinyal ucapan hasil proses sintesis. Sedangkan, keluarannya adalah frame yang merepresentasikan suatu fonem tertentu, beserta parameter model artikulatorinya.
Dalam menentukan apakah suatu frame cukup baik untuk merepresentasikan suatu fonem tertentu, hal pertama yang dilakukan adalah melakukan uji dengar (aural) terhadap sinyal ucapan hasil proses sintesis secara keseluruhan. Jika tingkat inteligibilitasnya cukup baik, kemudian identifikasi frame di-lakukan baik dengan mengamati frekuensi sinyal ucapan hasil sintesis maupun dengan uji dengar.
Proses pengamatan frekuensi sinyal ucapan dilakukan den-gan melakukan pengamatan terhadap spektrum sinyal.
Tampi-sinyal yang cukup merepresentasikan suatu fonem tertentu. Kemudian, dengan pengamatan terhadap spektrum sinyal, se-leksi tersebut dipersempit lagi dengan memilih bagian yang frekuensinya konsisten. Setelah proses seleksi selesai, sebuah frame yang merupakan representasi dari bagian yang dipilih dapat diperoleh. Dengan demikian, parameter model artikula-tori untuk suatu fonem tertentu berhasil diperoleh.
III. HASIL
Model artikulatori yang digunakan dalam pengerjaan Tugas Akhir ini adalah model Marmelstein yang telah dimodifikasi. Model Marmelstein dapat mencapai kesamaan antara hasil scan x-ray dengan bentuk saluran vokal midsagittal. Meskipun demikian, model ini tidak memiliki informasi yang cukup un-tuk merepresentasikan bagian bawah faring serta area di antara ujung lidah dan rahang dengan baik. Model yang digunakan telah memodifikasi bagian bawah faring serta melakukan op-timasi area di antara ujung lidah dan rahang jika dibutuhkan. Dalam model artikulatori, sekelompok variabel digu-nakan untuk mengatur bentuk dari saluran vokal. Parameter-parameter yang dapat dilihat pada Gambar 4 tersebut adalah sebagai berikut.
• Badan lidah: Badan lidah direpresentasikan oleh busur (DL-B) dari sebuah lingkaran dengan titik pusat yang dapat bergerak dan jari-jari tetap. Pusat dari badan lidah, yang disimbolkan dengan tongc, memiliki koordinat polar (sc, thetaj+thetab) yang berpusat pada titik F. Meskipun demikian, koordinat kartesian (tbodyx, tbodyy) digunakan dalam tampilan dan optimasi.
• Ujung lidah: Ujung lidah direpresentasikan oleh
koordi-nat kartesian (tipx, tipy) dari titik T. Busur B-T dan T-PFmemberi bentuk dari bagian depan lidah. Oleh karena letak titik B bervariasi tergantung pada pusat badan lidah (tongc) dan sudut rahang (JAW), pergerakan bagian depan lidah tergantung pada badan lidah dan posisi rahang.
• Rahang: Titik JAW dengan koordinat polar (sj, thetaj) digunakan untuk merepresentasikan letak rahang. Jarak sj tetap untuk sebagian besar fonem. Parameter rahang digunakan untuk menyatakan sudut dari thetaj. Perhatikan bahwa lekukan rahang didekati dengan beberapa segmen garis yang berhubungan (PF-PS-JAW-L6).
• Bibir: Bibir direpresentasikan oleh titik L5 (atas) dan
L7 (bawah). Dengan mengacu pada titik JAW, koordi-nat dari bibir bawah direpresentasikan oleh (lipp, lipo), yang memberikan keterangan mengenai protrusi bibir dan bukaan bibir. Penggunaan lipp dan lipo sebagai variabel yang terpisah memungkinkan representasi dari bibir yang terkatup, bibir yang terbuka, dan bibir yang membulat. Bibir atas L5 memiliki koordinat yang sama dengan mengacu pada titik U.
• Hyoid: Hyoid direpresentasikan oleh parameter hyoid, yaitu jarak dari titik PP ke garis H-DL. Titik PP ter-dapat pada titik tengah dari segmen garis H-DL, yang merupakan garis singgung dari busur badan lidah pada
epiglottis dan bagian atas tulang hyoid. Titik K merepre-sentasikan perkiraan dari batas bagian depan dari laring.
• Bagian atas dari saluran vokal direpresentasikan oleh letak gigi atas, U, busur langit-langit rongga mulut U-N-M (hard palate), titik tertinggi pada maxilla M, busur langit-langit rongga mulut M-V (soft palate), letak bagian belakang langit-langit rongga mulut (velum) V, letak dinding belakang faring W, dan titik tertinggi dari pe-riarytenoid G. Pada busur hard palate, titik N terletak pada segmen garis M-U sedemikian rupa sehingga jarak M-N adalah dua kali jarak N-U. Busur lingkaran M-V dan M-N memiliki pusat yang terletak pada garis vertikal melalui M. Secara umum, bentuk bagian atas dan bagian belakang dianggap tetap, kecuali untuk busur soft palate yang berada dekat dengan titik V. Untuk memberikan keterangan mengenai area bukaan velopharyngeal port, bagian belakang langit-langit rongga mulut (velum) men-jadi sebuah parameter artikulatori.
• Bagian belakang langit-langit rongga mulut (velum): Kon-disi bagian belakang langit-langit rongga mulut (velum) direpresentasikan oleh letak V dari ujung uvula yang bergerak pada segmen garis V-V’. Area bukaan velar diasumsikan proporsional terhadap jarak antara titik V dan titik tertinggi dari velum.
Gambar 4. Model Artikulatori Marmelstein[1]
Dengan mengacu model artikulatori pada Gambar 4, beserta penjelasan dari model tersebut, Tabel I memaparkan nilai-nilai parameter yang telah dihasilkan dari penelitian. Data akan ditampilkan berdasarkan kelompok fonemnya, yaitu fonem vokal dan konsonan. Kelompok fonem konsonan kemudian dibagi lagi berdasarkan cara artikulasinya menjadi konsonan
Tabel I
PARAMETERPEMBANGKITUCAPANMODELARTIKULATORIUNTUKFONEM-FONEMBAHASAINDONESIA
Fonem Parameter
Jaw Angle(rad) Tongue Tip(cm) Tongue Body(cm) Lip Open(cm) Lip Protrusion(cm) Hyoid(cm) Velum Position(cm) Kelompok Fonem Vokal
/a/ -0.400 (3.750, 4.514) (3.426, 3.886) 0.601 0.347 -0.280 (2.274, 4.668) /e/ -0.394 (3.703, 4.801) (3.433, 4.288) 0.753 0.222 -0.299 (2.291, 4.637) /@/ -0.383 (4.183, 4.736) (3.557, 4.411) 0.488 0.181 -0.142 (2.267, 4.680) /E/ -0.282 (4.267, 4.740) (3.606, 4.228) 0.345 0.041 -0.055 (2.283, 4.652) /i/ -0.305 (3.965, 5.391) (3.457, 4.658) 0.568 0.144 -0.213 (2.278, 4.662) /o/ -0.400 (3.707, 4.897) (3.081, 3.550) 0.425 0.648 -0.270 (2.088, 5.010) /O/ -0.401 (3.702, 4.799) (3.061, 3.550) 0.376 0.649 -0.298 (2.046, 5.089) /u/ -0.356 (5.064, 4.861) (3.029, 4.112) 0.113 0.422 -0.089 (2.128, 4.937)
Kelompok Fonem Konsonan Konsonan Hambat /p/ -0.401 (4.148, 4.502) (3.607, 4.528) 0.195 0.315 -0.300 (2.045, 5.090) /b/ -0.400 (4.934, 4.520) (3.340, 4.501) 0.060 0.229 0.290 (2.194, 4.815) /t/ -0.360 (4.742, 5.197) (3.762, 4.192) 0.207 0.440 -0.041 (2.047, 5.086) /d/ -0.268 (5.461, 5.132) (3.335, 4.299) 0.185 0.562 0.288 (2.268, 4.680) /k/ -0.313 (4.823, 4.836) (3.553, 4.606) 0.566 0.208 0.056 (2.244, 4.724) /g/ -0.303 (3.858, 4.543) (3.463, 4.685) 0.455 0.005 -0.300 (2.265, 4.685) Konsonan Afrikat /c/ -0.401 (5.224, 5.046) (3.592, 4.802) 0.285 0.122 -0.114 (2.214, 4.778) /j/ -0.357 (4.106, 5.628) (3.743, 4.653) 0.563 0.083 -0.026 (2.195, 4.813) Konsonan Frikatif /h/ -0.401 (3.702, 4.500) (3.417, 3.844) 0.428 0.411 -0.300 (2.246, 4.720) Konsonan Nasal /m/ -0.267 (4.093, 4.500) (3.676, 4.042) 0.466 0.000 -0.300 (2.287, 4.644) /n/ -0.396 (4.813, 5.389) (3.318, 4.063) 0.298 0.193 0.070 (2.221, 4.765) /ñ/ -0.401 (5.221, 4.971) (3.727, 4.228) 0.312 0.649 -0.298 (2.182, 4.837) /N/ -0.401 (3.702, 5.230) (3.203, 3.868) 0.372 0.649 -0.300 (2.045, 5.089) Konsonan Getar /r/ -0.401 (3.898, 4.501) (3.634, 4.476) 0.834 0.276 -0.025 (2.046, 5.088) Konsonan Lateral /l/ -0.401 (4.986, 4.760) (3.167, 3.936) 0.381 0.650 -0.296 (2.292, 4.635) Konsonan Semivokal /W/ -0.401 (3.727, 4.861) (3.016, 3.550) 0.394 0.045 -0.285 (2.045, 5.090) /y/ -0.328 (4.558, 4.845) (3.886, 4.463) 0.607 0.011 0.278 (2.265, 4.684)
hambat, afrikat, frikatif, nasal, getar, lateral, dan semivokal.[2] Sebagai tambahan, fonem juga akan ditampilkan berdasarkan letak artikulasi sesuai dengan urutan pada Tabel IPA untuk konsonan dari kiri ke kanan.
Perlu dicatat juga bahwa data yang dicantumkan merupakan data terbaik di antara data yang berhasil diperoleh, baik den-gan mempertimbangkan kesesuaian posisi artikulator secara teoretis yang mengacu pada Tabel International Phonetic Al-phabet, maupun dengan mempertimbangkan hasil uji dengar.
Berkaitan dengan sintesis fonem konsonan frikatif, pa-rameter model artikulatori tidak berhasil diperoleh dengan metodologi yang digunakan. Hal ini dikarenakan pada prak-teknya, kelompok fonem ini dibangkitkan dengan melewatkan udara pada suatu celah tertentu sehingga terbentuk turbu-lensi udara yang menimbulkan bunyi desis. Bunyi desis ini mengaburkan frekuensi formant dari fonem sehingga menye-babkan proses formant tracking untuk mendapatkan frekuensi formant tidak menghasilkan apa-apa dan proses sintesis tidak dapat dilakukan.
IV. KESIMPULAN
Selain parameter model artikulatori di atas, perlu juga dis-ampaikan bahwa parameter-parameter yang telah dicantumkan di atas belum mewakili model artikulatori ideal. Sebuah model artikulatori ideal mungkin memerlukan parameter-parameter
lain yang lebih banyak. Sampai saat ini, model seperti ini untuk bahasa Inggris pun masih belum dapat menghasilkan ucapan yang alami.
Meskipun demikian, parameter-parameter pembangkit uca-pan model artikulatori untuk fonem-fonem bahasa Indonesia yang diperoleh dalam penelitian ini telah dapat menghasilkan sinyal yang menyerupai sinyal ucapan manusia.
[2] Hasan Alwi, Soenjono Dardjowidjojo, Hans Lapoliwa, dan Anton M. Moeliono. Tata Bahasa Baku Bahasa Indonesia, Edisi Ketiga. Balai Pustaka, Jakarta, 2003.
![Gambar 4. Model Artikulatori Marmelstein[1]](https://thumb-ap.123doks.com/thumbv2/123dok/2455677.3597783/4.892.457.832.601.964/gambar-model-artikulatori-marmelstein.webp)
