HIERARCHIAL CLUSTERING ANALYSIS
DALAM PEMERATAAN PEMBANGUNAN INDONESIA
Anantamurti Purwa Hapsari 1, Emielda Rizqiah 1, Handy Febri Satoto 1, M. Afifuddin 1, M. Imron Mas’ud1, Seta Wiriawan 1, dan Yudha Prasetyo 2
1
Program Magister Teknik Industri, FTI-Institut Teknologi Sepuluh Nopember (ITS),
E-mail : [email protected], [email protected], [email protected], [email protected], [email protected], [email protected]
2
Jurusan Teknik Industri, FTI-Institut Teknologi Sepuluh Nopember (ITS), E-mail : [email protected]
ABSTRAK
Kunci dari pembangunan adalah kemakmuran bersama. Pemerataan hasil pembangunan dan
pertumbuhan ekonomi yang tinggi merupakan tujuan pembangunan yang ingin dicapai. Oleh karena itu
perlu dilakukan kajian terhadap pemerataan pembangunan semua provinsi di Indonesia, sehingga dapat
meningkatkan kesejahteraan dan kemakmuran bagi semua masyarakat Indonesia. Penelitian ini
melibatkan 33 provinsi di Indonesia dengan empat variabel interdependensi yaitu Indeks Pendidikan (IP),
Indeks Harapan Hidup (IHH), Indeks Pembangunan Manusia (IPM) dan Gini Ratio. Metode yang
digunakan adalah metode
Hierarchial Clustering. Hasil penelitian ini diperoleh 8 cluster. Untuk
variabel Indeks Pendidikan (IP), cluster terendah adalah provinsi Papua. Variabel Indeks Harapan Hidup
(IHH) cluster terendah adalah provinsi Nusa Tenggara Barat, variabel Indeks Pembangunan Manusia
(IPM) cluster terendah yaitu provinsi Papua, sedangkan berdasarkan Gini Ratio cluster terendah adalah
provinsi Papua dan D.I. Yogyakarta.
Kata kunci : Hierarchial Clustering, Pemerataan Pembangunan Indonesia, Indeks Pendidikan, Indeks
Harapan Hidup, Indeks Pembangunan Manusia dan Gini Ratio.
PENDAHULUAN
Pembangunan pada hakekatnya bertujuan
untuk meningkatkan kesejahteraan hajat hidup
orang banyak serta perbaikan kualitas berbagai
aspek kehidupan manusia.
Pembangunan merupakan agenda sentral
bagi semua negara, pembangunan dapat diartikan
sebagai upaya terencana dan terprogram yang
dilakukan secara terus menerus oleh suatu Negara
untuk menciptakan masyarakat yang lebih baik,
dan merupakan proses dinamis untuk mencapai
kesejahtraan masyaraka.
Pemerataaan pembangunan bagi bangsa
Indonesia sudah lama dinantikan serta diinginkan
oleh rakyat Indonesia. Harapan dan cita-cita yang
diinginkan
dapat
diimpementasikan
melalui
pembangunan nasional untuk dapat meningkatkan
kesejahtraan
dan
kemakmuran
masyrakat.
Menurut Badan Pusat Statistik, pertumbuhan
ekonomi,
merupakan
indikator
yang
biasa
digunakan untuk menilai sampai seberapa jauh
pembangunan suatu daerah dalam periode tertentu.
Mudarajat kuncoro (2004) melihat dan
mendefenisikan pembangunan sebagai suatu
proses yang berisifat multidimensional. Perubahan
yang mencakup berbagai aspek kehidupan
manusia seperti dalam hal struktur sosial, sikap
mental, dan lembaga-lembaga sosial termasuk
akselerasi
pertumbuhan
ekonomi,
perbaikan
distribusi
pendapatan,
dan
pemberantasan
kemiskinan absolut.
METODOLOGI PENELITIAN
a.
Sumber dan Metode Pengumpulan Data
Data yang digunakan dalam penelitian ini
adalah data sekunder yang diperoleh dari data BPS
pada tahun 2010.
b.
Variabel dan Objek Penelitian
Dalam penelitian ini ditetapkan sebanyak
empat variabel interdependensi yang terkait
dengan aspek-aspek pemerataan pembangunan.
Empat variabel tersebut adalah Indeks Harapan
Hidup, Indeks Pembangunan Manusia, Gini Ratio
dan
Indeks
Pendidikan.
Dimana
Indeks
Pendidikan terdiri dari 2 variabel yaitu variabel
Angka Melek Huruf dan Angka Partisipasi
Sekolah. Objek dalam penelitian ini adalah 33
provinsi di seluruh Indonesia.
Indeks harapan hidup sangat dipengaruhi
oleh kualitas kesehatan, diantara pola hidup sehat,
pola konsumsi makanan, dan kualitas lingkungan
pemukiman. Angka harapan hidup juga digunakan
sebagai indikator untuk menilai taraf kesehatan
masyakarat. Angka harapan hidup ini diperoleh
dari SUSENAS 2012 (BPS, 2012) dengan
dengan membandingkan jumlah kematian bayi
dengan jumlah kelahiran bayi pada waktu
tertentu.
IHH = Rata-rata anak yang dilahirkan hidup / ALH
IHH = Indeks Harapan Hidup
ALH = Rata-rata anak yang masih hidup usia 3-4
tahun
Indeks pendidikan di dapat memiliki dua
indikator khusus yakni angka melek huruf (LIT)
dan rata-rata lamanya sekolah (MYS). Kedua
indikator ini dapat mencerminkan pengetahuan
dan
keterampilan,
sehingga
membentuk
persamaan seperti berikut:
IP
L
IT
MYS
dengan:
IP = Indeks Pendidikan
L
IT= Angka melek huruf
MYS = Rata-rata lamanya sekolah (tahun)
Gini Ratio merupakan ukuran kemerataan
pendapatan yang dihitung berdasarkan kelas
pendapatan. Angka koefisien Gini terletak
antara 0 (nol) dan 1 (satu). Nol mencerminkan
kemerataan sempurna dan satu menggambarkan
ketidakmerataan sempurna.
Indeks
Pembangunan
Manusia
(IPM)
merupakan suatu indikator yang dapat digunakan
untuk melihat kegiatan pembangunan yang telah
dilakukan di suatu wilayah. Kriteria IPM
berdasar UNDP dapat dilihat pada tabel di bawah.
Tabel Kriteria UNDP
Tingkat status
Kriteria
Rendah
IPM < 50
Menengah kebawah 50
≤
IPM < 66
Menengah keatas
66
≤
IPM < 80
Tinggi
IPM
≥80
c.
Tahapan Awal Analisa Data
Tahap awal sebelum dilakukan
peng-clusteran adalah data yang telah ada dianalisa
deskriptif untuk mengetahui nilai minimum,
maksimum, mean dan varian variabel-variabel di
tiap provinsi. Jika varian terlalubanyak berarti hal
ini
menunjukkan
terdapat
ketidakmerataan
pembangunan antar provinsi.
Setelah
analisa
deksriptif,
kemudian
dilakukan uji normalitas data untuk mengetahui
apakah data sudah signifikan dan layak untuk
diteliti lebih lanjut atau belum. Adapun uji
normalitas data yang dilakukan adalah dengan
menggunakan uji Kolmogorov- Smirnov.
d.
Tahap Analisa Cluster
Pada analisa ini menggunakan software
SPSS versi 18. Tahap pengclusteran menggunakan
metode yang digunakan adalah
Hierarchial
Clustering untuk menentukan jumlah cluster yang
terbentuk dari 33 provinsi di Indonesia dengan 4
variabel interdependensi yaitu Indeks Harapan
Hidup, Indeks Pendidikan, Gini Ratio dan Indeks
Pembangunan Manusia.
Algoritma yang digunakan yaitu algoritma
single linkage dan complete linkage.
1.
Case Proximity Summary
Menunjukkan jumlah
cases apakah terdapat
missing value, outlier,
data yang tidak valid atau
tidak.
2.
Proximity Matrik
Proximity
matrix
menunjukkan
nilai
kedekatan (similarity) antar 2
case berbeda yang
direpresentasikan dengan jarak. Semakin kecil nila
jarak antara 2 case menunjukkan semakin dekat
jaraknya sehingga semakin mirip kedua data
tersebut dan semakin besar kemungkinan bagi
kedua case tersebut untuk tergabung ke dalam 1
cluster yang sama. Proximity matrix menunjukkan
asal mula agglomeration schedule.
3.
Aglomeration Schedule
Merepresentasikan
detail
urutan
pem-bentukan cluster (dimana cluster-cluster baru yang
lebih besar dibentuk dengan menggabungkan
cluster-cluster sebelumnya yang telah ada).
Kolom
cluster
1 dan
cluster
menunjukkan
cluster
pertama yang akan digabungkan dengan
cluster
kedua
pada
stage
tertentu.
Coefficient
menunjukkan nilai kedekatan hasil penggabungan
cluster, bergantung metode yang digunakan.
4.
Dendogram
Dendogram merupakan diagram garpu.
Diagram ini lebih sering digunakan karena lebih
interpretative dalam
cluster analysis.
Lebih
jelasnya, dendogram
menunjukkan hubungan
antar cases
dan struktur dari
dendogram
memberikan petunjuk cases-cases
yang mana
yang berasal dari cluster
tertentu.
Dalam hal ini
akan dipilih
dendogram agar bisa diperoleh
penggambaran yang jelas mengenai bagaimana
cluster yang menjadi hasil dari cluster analysis ini
terbentuk. Dalam dendogram bisa diketahui
berapa cluster yang terbentuk dari 33 provinsi di
Indonesia dilihat dari 4 variabel interdependensi
yang ada.
e.
Analisa Akhir
Setelah diperoleh jumlah cluster dari 33
provinsi,
kemudian
masing-masing
cluster
dilakukan analisis deskriptif untuk mengetahui
cluster mana yang mempunyai rata-rata indeks
harapan hidup, indeks pendidikan, gini ratio dan
indeks pembangunan manusia yang terendah.
Sehingga bisa diketahui provinsi mana saja yang
masih belum merata pembangunannya.
HASIL DAN PEMBAHASAN
a.
Deskripsi Data
Menurut UNDP (United Nation
Deve-lopment Programme) Provinsi di Indonesia
memiliki rata-rata Indeks Harapan Hidup (IHH)
sebesar 71,2237. angka ini dapat di katakan
bahwa indeks harapan hidup manusia di tiap-tiap
provinsi di Indonesia tergolong ke dalam
golongan angka harapan hidup menengah keatas.
Hal ini berarti angka harapan hidup penduduk
Indonesia sudah baik. Sedangkan variansi dari
IHH ini adalah sebesar 4,056 dengan angka ini
dapat dikatakan perbedaan anatara setiap objek
pada variabel ini sebesar 4,056%, dengan
demikian dapat pula di katakan bahwa IHH
Provinsi di Indonesia sudah hampir homogen.
Hal ini menunjukkan bahwa IHH provinsi di
Indonesia hampir merata.
Indeks Pendidikan (IP) Indonesia memiliki
rata-rata 64,94, indeks
ini termasuk dalam indeks
menengah ke atas. Hal ini berarti bahwa IP
provinsi di Indonesia sudah baik. Meskipun
demikian, masih ada pula IP provinsi di Indonesia
yang masih kurang, dengan IP
47,61, yakni
Provinsi Papua. Variansi data IP ini cukup besar,
yakni 18,639, dari variansi ini dapat disimpulkan
bahwa IP Indonesia kurang homogen. Dengan
demikian bukan berarti data ini tidak layak untuk
diteliti, karena ketidak homogenan yang terjadi.
Hal ini adalah murni menunjukkan keadaan IP
semua provinsi di Indonesia.
Indeks Pembangunan Manusia tersusun
atas rata-rata dari Indeks Pendidikan (IP), Indeks
Harapan Hidup (IHH), dan Gini Ratio. Rata-rata
IPM provinsi di Indonesia adalah 71,8567.
Menurut standart UNDP, indeks ini merupakan
indeks dengan kriteria menengah keatas.
Sedangkan variansi dari IPM ini adalah 8,851.
Sebagai inti dari peneltian ini variansi dari IPM
ini dapat dikatakan cukup baik karena berada jauh
di bawah 50.00.
Gini Ratio merupakan ukuran kemerataan
pendapatan yang dihitung berdasarkan kelas
pendapatan. Angka koefisien Gini terletak
antara 0 (nol) dan 1 (satu). Nol mencerminkan
kemerataan sempurna dan satu menggambarkan
ketidakmerataan
sempurna.
Indeks
Gini
menunjukkan
tingkat
ketimpangan
atau
kemerataan distribusi pendapatan. Nilai koefisien
gini (G) antara 0 dan 1 (0<g<1). Rata-rata gini
ratio provinsi di Indonesia sebesar 0,3957 yang
berarti bahwa masih terdapat ketimpangan
distribusi pendapatan, dimana varian yang terjadi
sebesar 0,001 yang menunjukkan bahwa gini ratio
masing-masing provinsi nilainya cenderung sama.
Descriptive Statistics
N Min Max Mean Std.
Deviation Variance Indeks_ Pendidikan 33 47.61 69.55 64.9421 4.31734 18.639 Indeks_Harapan _Hidup 33 67.00 76.20 71.2273 2.01390 4.056 Indeks_Pemban gunan_Manusia 33 64.94 77.60 71.8567 2.97506 8.851 Gini_Ratio 33 .29 .43 .3597 .03771 .001 Valid N (listwise) 33
b.
Analisis Data
Setelah data dideskripsikan, langkah
selanjutnya adalah analisis data. Adapun tujuan
dari
analisis
data
ini
adalah
untuk
mengaplikasikan analisis
cluster pada data IHH,
IP, IPM dan Gini Ratio semua provinsi di
Indonesia
guna
mengetahui
pemerataan
pembangunan yang dilakukan oleh pemerintah
pusat. Dalam analisis data, yang dilakukan
pertama kali adalah Uji Normalitas Data.
c.
Uji Normalitas Data
Uji normalitas data ini dilakukan untuk
mengetahui apakah data sudah signifikan dan
layak untuk diteliti lebih lanjut atau belum.
Adapun uji normalitas data yang dilakukan
adalah dengan menggunakan uji Kolmogorov-
Smirnov.
One-Sample Kolmogorov-Smirnov Test
Indeks_ pendidikan Indeks_ Harapan_ Hidup Indeks_ Pembangu nan Gini_ Ratio N 33 33 33 33 Normal Parametersa Mean 64.9421 71.2273 71.8567 .3597 Std. Deviation 4.31734 2.01390 2.97506 .03771 Most Extreme Differences Absolute .243 .131 .084 .120 Positive .149 .131 .084 .120 Negative -.243 -.096 -.080 -.109 Kolmogorov-Smirnov Z 1.396 .754 .482 .687
Asymp. Sig. (2-tailed) .041 .620 .974 .733
a. Test distribution is Normal.
Uji normalitas data di atas memakai
∝
= 5%.
∝
ini ditentukan sebagai kriteria signifikansi data.
Dari hasil uji normalitas data pada tabel di atas
dapat diketahui signifikansi dari masing-masing
variabel dengan deskripsi sebagai berikut.
IHH, IP, IPM, Gini Ratio masing-masing
memiliki nilai signifikansi sebesar 0.041, 0.620,
0.974 dan 0.733 dimana signifikansinya lebih besar
dari alfa (α) yaitu > 0.05, sehingga dapat dikatakan
bahwa data berdistribusi normal.
d.
Analisa Cluster
Analisis
cluster
merupakan
teknik
multivariat yang mempunyai tujuan utama untuk
mengelompokkan
objek-objek
berdasarkan
karakteristik yang dimilikinya. Analisis cluster
mengklasifikasi objek sehingga setiap objek yang
paling dekat kesamaannya dengan objek lain
berada dalam cluster yang sama. Dalam penelitian
ini dilakukan pengelompokkan data dengan
menggunakan analisis cluster heirarki. Tipe dasar
dalam metode ini adalah aglomerasi dan
pemecahan. Dalam metode aglomerasi tiap
observasi pada mulanya dianggap sebagai cluster
tersendiri sehingga terdapat cluster sebanyak
jumlah observasi. Kemudian dua cluster yang
terdekat kesamaannya digabung menjadi suatu
cluster baru, sehingga jumlah cluster berkurang
satu pada tiap tahap. Berikut hasil
running
pengolahan data cluster pemerataan pembangunan
dengan menggunakan SPSS.
1.
Case Proximity Summary:
Menunjukkan jumlah
cases apakah terdapat
missing value, outlier,
data yang tidak valid atau
tidak. Berikut Tabel Case Processing Summary.
Tabel Case Processing Summary
Cases
Valid Missing Total
N Percent N Percent N Percent
33 100.0 0 .0 33 100.0
Hasil
Case
Processing
Summary
menunjukkan terdapat 3 kolom yang terdiri dari
kolom Valid, Missing, dan Total. Angka-angka di
atas menunjukkan bahwa dari 33
respondents
tidak ada missing value ditunjukkan dengan nilai 0
percent missing dan 100% data valid.
2.
Proximity Matrik
Proximity
matrix
menunjukkan
nilai
kedekatan (similarity) antar 2 case berbeda yang
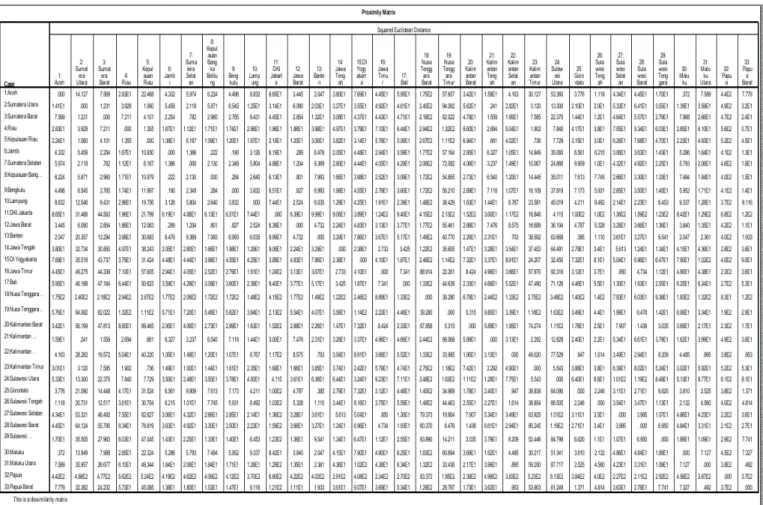
direpresentasikan dengan jarak. Tabel Proximity
Matrik dapat dilihat pada Lampiran 1.
Hasil proximity yang sudah ada dapat dilihat
bahwa pada Aceh bernilai 0,000 dan untuk
Sumatra
Utara
bernilai
14,127.
Hal
ini
mengindikasikan bahwa jarak/distance antara
Aceh dan Sumatra Utara adalah bernilai 14,127.
Jika dibandingkan dengan Sumatra Barat yang
bernilai
7,509
yang
menunjukkan
bahwa
kedekatan jarak/distance antara Aceh dengan
Sumatra Barat adalah lebih dekat. Dapat diartikan
pula kemungkinan Aceh tergabung menjadi 1
cluster dengan Sumatra Barat lebih besar
dibandingkan
dengan
kemungkinan
Aceh
tergabung 1 cluster dengan Sumatra Utara.
3.
Aglomeration Schedule
Merepresentasikan
detail
urutan
pem-bentukan cluster (dimana cluster-cluster baru yang
lebih besar dibentuk dengan menggabungkan
cluster-cluster sebelumnya yang telah ada).
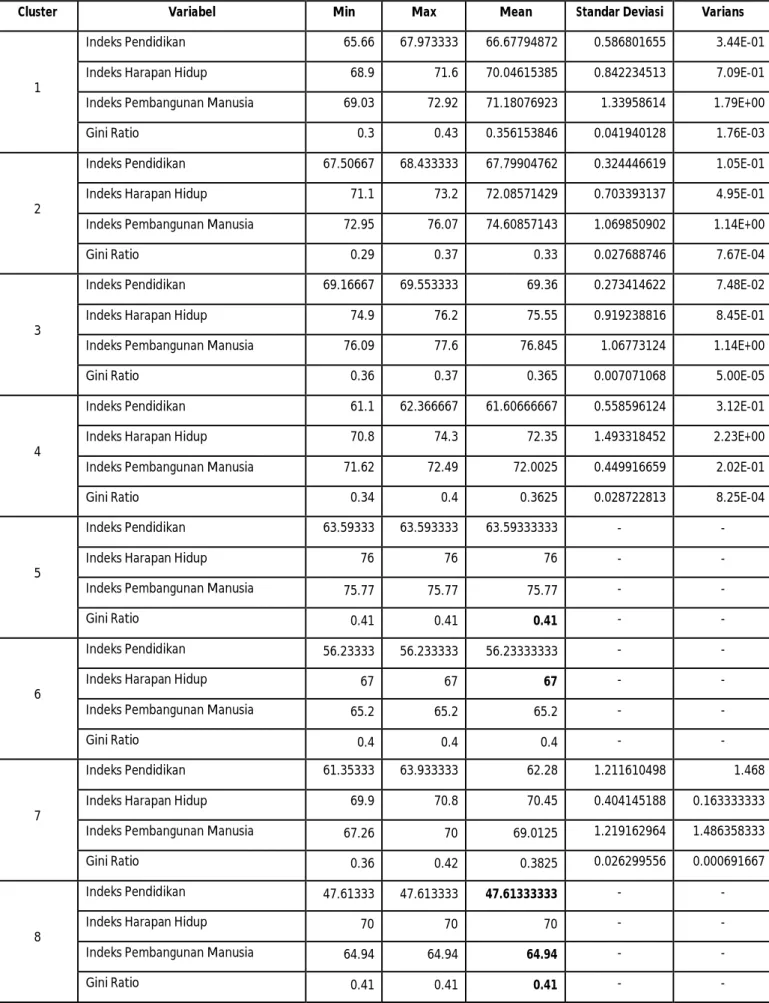
Berikut Tabel Aglomeration Schedule.
Agglomeration Schedule Stage Cluster Combined Coeffi cients Stage Cluster First Appears Next Stage Cluster 1 Cluster 2 Cluster 1 Cluster 2
1 6 9 .190 0 0 3 2 2 21 .241 0 0 16 3 6 8 .253 1 0 7 4 1 30 .372 0 0 13 5 13 25 .385 0 0 10 6 31 33 .492 0 0 15 7 6 12 .639 3 0 17 8 5 23 .736 0 0 14 9 3 7 .782 0 0 16 10 13 22 .825 5 0 15 11 16 27 .850 0 0 23 12 20 28 1.438 0 0 21 13 1 26 1.625 4 0 20 14 4 5 1.628 0 8 22 15 13 31 1.673 10 6 20 16 2 3 2.036 2 9 22 17 6 10 3.030 7 0 25 18 14 17 3.425 0 0 23 19 11 24 4.115 0 0 28 20 1 13 4.300 13 15 25 21 20 29 4.992 12 0 24 22 2 4 5.009 16 14 27 23 14 16 7.175 18 11 26 24 19 20 8.667 0 21 26 25 1 6 8.724 20 17 27 26 14 19 17.399 23 24 29 27 1 2 21.286 25 22 29 28 11 15 35.682 19 0 30 29 1 14 41.796 27 26 30 30 1 11 68.020 29 28 32 31 18 32 83.372 0 0 32 32 1 18 289.530 30 31 0
Metode yang digunakan disini adalah
Between Group-Linkage, maka nilai kedekatan
hasil penggabungan tersebut berdasarkan nilai
rata-rata. Semakin kecil nilai
Coefficient berarti
semakin baik karena menunjukkan kemiripan
case-nya. Sedangkan untuk kolom
Next stage
menunjukkan
stage berikutnya yang merupakan
kelanjutan dari stage sebelumnya.
Pada data diatas, dapat dilihat bahwa case 6
dan case 9 pada kolom cluster combined memiliki
coefficients terendah yaitu 0,190 yang berarti
memiliki hubungan yang dekat.
Hasil tabel diatas diperoleh bahwa lonjakan
paling tinggi di
cluster
paling kecil terjadi pada
stage 25 ke
stage 26. Pada
stage 25 ke
stage
26
memiliki perbedaan sekitar 8,675. Ini merupakan
lonjakan yang cukup tinggi bila dibandingkan
dengan
stage 24 ke
stage
25 yang memiliki
perbedaan sekitar 0,057. Sehingga hasil yang
mungkin diambil adalah stage 25 dengan hasil 8
cluster. Dalam hal ini menunjukkan bahwa untuk
cara
stopping rule ini masih terdapat unsur
subjektivitas mengenai keputusan jumlah
cluster
yang diambil dengan nilai kedekatan dalam cluster
tersebut.
4.
Dendogram
Dendogram digunakan karena lebih
inter
pretative
dalam
cluster
analysis
karena
menunjukkan hubungan antar cases
dan struktur
dari dendogram
memberikan petunjuk cases-cases
yang
berasal
dari
cluster
tertentu.
Hasil
Dendogram dengan SPSS dapat dilihat pada
Lampiran 1.
Bila diingikan 8 cluster yang terbentuk maka
akan didapatkan nilai
Rescaled Distance Cluster
Combine (jarak kedakatan) sekitar ± 2. Hal ini
menjukkan bahwa anggota dalam 1 cluster
memiliki nilai jarak kedekatan yang hampir mirip.
5.
Cluster Membership
Fungsi utamanya untuk menentukan jumlah
cluster. Jika peneliti memiliki hipotesis tentang
berapa banyak cluster yang harus dihasilkan, maka
peneliti dapat
memerintahkan SPSS untuk
membuat beberapa cluster, baik itu dalam jumlah
cluster yang pasti maupun dalam bentuk range
(kisaran jumlah cluster yang diperkirakan akan
dihasilkan). Hasil Cluster Membership dari
penelitian ini adalah sebagai berikut:
Cluster Membership
Case 8 Clusters 1:Aceh 1 2:Sumatera Utara 2 3:Sumatera Barat 2 4:Riau 2 5:Kepulauan Riau 2 6:Jambi 1 7:Sumatera Selatan 28:Kepulauan Bangka Belitung 1
9:Bengkulu 1 10:Lampung 1 11:DKI Jakarta 3 12:Jawa Barat 1 13:Banten 1 14:Jawa Tengah 4 15:DI Yogyakarta 5 16:Jawa Timur 4 17:Bali 4
18:Nusa Tenggara Barat 6
19:Nusa Tenggara Timur 7
20:Kalimantan Barat 7 21:Kalimantan Tengah 2 22:Kalimantan Selatan 1 23:Kalimantan Timur 2 24:Sulawesi Utara 3 25:Gorontalo 1 26:Sulawesi Tengah 1 27:Sulawesi Selatan 4 28:Sulawesi Barat 7 29:Sulawesi Tenggara 7 30:Maluku 1 31:Maluku Utara 1 32:Papua 8 33:Papua Barat 1
Dalam hasil di atas tampak bahwa Provinsi
Aceh merupakan anggota cluster 1, Sumatera
Utara dan Sumatera Barat merupakan anggota
cluster 2, dan seterusnya. Ringkasan tabel hasil
cluster secara keseluruhan dapat dilihat pada tabel
berikut:
Tabel Hasil Clustering Provinsi di Indonesia
Provinsi Cluster IP IHP IPM Gini
Ratio Aceh
1
67.52 69.3 71.7 0.3
Jambi 66.52 70.8 72.74 0.3
Kep. Bangka Belitung 66.11 71 72.86 0.3
Bengkulu 66.27 70.5 72.92 0.37 Lampung 65.66 71.6 71.42 0.36 Jawa Barat 66.79 70.9 72.29 0.36 Banten 66.90 69.7 70.48 0.42 Kalimantan Selatan 66.53 69.2 69.92 0.37 Gorontalo 66.47 70.1 70.28 0.43 Sulawesi Tengah 66.72 68.9 71.14 0.37 Maluku 67.97 69.6 71.42 0.33 Maluku Utara 66.85 69.2 69.03 0.34 Papua Barat 66.51 69.8 69.15 0.38 Sumatera Utara 2 67.81 72.1 74.19 0.35 Sumatera Barat 67.56 71.1 73.78 0.33 Riau 68.43 72.2 76.07 0.33 Kepulauan Riau 67.99 72.6 75.07 0.29 Sumatera Selatan 67.51 71.4 72.95 0.34 Kalimantan Tengah 67.65 72 74.64 0.3 Kalimantan Timur 67.63 73.2 75.56 0.37 DKI Jakarta 3 69.55 76.2 77.6 0.36 Sulawesi Utara 69.17 74.9 76.09 0.37 Jawa Tengah 4 62.37 72.6 72.49 0.34 Jawa Timur 61.29 71.7 71.62 0.34 Bali 61.67 74.3 72.28 0.37 Sulawesi Selatan 61.10 70.8 71.62 0.4 DI Yogyakarta 5 63.59 76 75.77 0.41
Nusa Tenggara Barat 6 56.23 67 65.2 0.4
Nusa Tenggara Timur
7 61.39 69.9 67.26 0.38 Kalimantan Barat 62.44 70.7 69.15 0.37 Sulawesi Barat 61.35 70.8 69.64 0.36 Sulawesi Tenggara 63.93 70.4 70 0.42 Papua 8 47.61 70 64.94 0.41
Setelah diketahui jumlah cluster yang terjadi
dan pengelompokan masing-masing provinsi ke
dalam cluster tersebut maka dilakukan analisis
deskriptif pada masing-masing cluster. Hal ini
untuk mengetahui gambaran karakteristik dari
masing-masing
cluster
dan
penanganan
selanjutnya untuk masalah ketenagakerjaan dari
cluster-cluster yang terbentuk. Hasil analisa
deskriptif pada masing-masing cluster dapat
dilihat pada Lampiran 2.
Hasil analisis deskriptif hasil cluster dari
semua provinsi yang ada di Indonesia, dapat
diketahui
bahwa
untuk
Indeks
Pendidikan
terendah adalah cluster 8 dengan nilai rata-rata
sebesar 46,613 yaitu Provinsi Papua. Indeks
Pendidikan ini tergolong rendah, dimana indeks
pendidikan terdiri dari Angka Melek Huruf dan
Angka Partispasi Sekolah. Jadi bisa disimpulkan
bahwa penduduk di Papua masih banyak yang
buta huruf dan angka partisipasi sekolahnya juga
rendah/sedikit. Provinsi Papua juga memiliki
Indeks Pembangunan Manusia (IPM) dan Gini
Ratio yang paling rendah dibandingkan cluster
lainnya. Nilai IPM Provinsi Papua sebesar 64,94
dan Gini Ratio sebesar 0,41. IPM dapat digunakan
untuk memperoleh gambaran secara menyeluruh
tentang kondisi hasil pembangunan suatu negara
atau daerah. Tiga unsur pembangun IPM tersebut
adalah indeks harapan hidup, indeks pendidikan,
dan indeks pembelanjaan perkapita. Indeks Gini
merupakan ukuran kemerataan pendapatan yang
dihitung berdasarkan kelas pendapatan. Angka
koefisien Gini terletak antara 0 (nol) dan 1 (satu).
Nol mencerminkan kemerataan sempurna dan
satu menggambarkan ketidakmerataan sempurna.
Jadi Provinsi Papua perlu mendapatkan prioritas
utama dalam pembangunan di segala sektor
kehidupan terutama hal-hal yang meliputi Indeks
Pendidikan, (IP) Indeks Pembangunan Manusia
(IPM), dan Gini ratio. IP, IPM, dan Gini Ratio
yang rendah mencerminkan sektor pendidikan,
kemerataan
pembangunan,
dan
kemerataan
pendapatan yang rendah.
Indeks Harapan Hidup (IHH) terendah
terjadi di cluster 6 yaitu Provinsi Nusa Tenggara
Barat dengan nilai 67. Hal ini mengindikasikan
sektor kesehatan masyarakat di Nusa Tenggara
Barat kurang memadai . Angka harapan hidup
sangat dipengaruhi oleh kualitas kesehatan,
diantara pola hidup sehat, pola konsumsi
makanan, dan kualitas lingkungan pemukiman.
Sektor kesehatan menjadi prioritas utama dalam
pembangunan di Provinsi Nusa Tenggara Barat.
Provinsi Nusa Tenggara Barat perlu juga
mendapat
perhatian
khusus
untuk
Indeks
Pendidikan (IP), Indeks Pembangunan Manusia
(IPM) karena memiliki nilai yang relatif rendah
dibandingkan dengan cluster-cluster lainnya yaitu
masing-masing sebesar 56,23 dan 65,3. Serta
memiliki Indeks Gini ratio yang tinggi yaitu
sebesar 0,4. Hal ini menunjukkan perlunya
pembangunan di seluruh sektor. Provinsi Nusa
Tenggara Barat memiliki prioritas pembangunan
IP, IPM, dan Gini Ratio kedua setelah cluster 8
yaitu Provinsi Papua.
Pada Cluster 6 dan 8 memiliki Gini Ratio
yang paling rendah dibandingkan dengan
cluster-cluster lainnya dengan nilai sebesar 0,41. Nilai ini
menunjukkan bahwa pemerataan pendapatan di
cluster ini tidak merata. Anggota cluster 6 adalah
Provinsi D.I. Yogyakarta, dan cluster 8 adalah
Provinsi Papua.
Dari data didapatkan bahwa Provinsi Papua,
Nusa Tenggara Barat, dan D.I. Yogyakarta
memiliki Gini Ratio yang relatif tinggi yaitu
sekitar 0,4 - 0,41sehingga menjadi prioritas dalam
pemerataan pendapatan. Berikut tabel mengenai
pembangunan berdasarkan 4 kriteria tersebut.
Kriteria Pembangunan Berdasarkan Provinsi Prioritas 1 Prioritas 2 IP Papua NTB IHH NTB IPM Papua NTB
Gini Ratio Papua dan DIY NTB
KESIMPULAN
Adapun kesimpulan dari penelitian ini
didapat bahwa:
1.
Analisa cluster dapat mengelompokkan 33
provinsi ke dalam beberapa cluster dengan
menggunakan kedekatan Rescaled Distance
Cluster Combine berdasarkan 4 variabel yang
ditetapkan yaitu IP, IHH, IPM dan Gini Ratio.
2.
Prioritas pembangunan berdasarkan Indeks
Pendidikan (IP) adalah provinsi Papua dan
Nusa Tenggara Barat
3.
Prioritas pembangunan berdasarkan Indeks
Harapan Hidup (IHH) yaitu provinsi Nusa
Tenggara Barat
4.
Prioritas pembangunan berdasarkan Indeks
Pembangunan Manusia (IPM) adalah provinsi
Papua dan Nusa Tenggara Barat
5.
Prioritas pembangunan berdasarkan Gini Ratio
yaitu provinsi Papua, Di. Yogyakarta dan Nusa
Tenggara Barat.
DAFTAR PUSTAKA
BPS. 2006. Survei Angkatan Kerja Nasional.
Jakarta
BPS. 2007. Survei Angkatan Kerja Nasional.
Jakarta
BPS. 2009. Data Strategis BPS. Jakarta
BPS. 2012. Perkembangan Beberapa Indikator
Utama Sosial-Ekonomi Indonesia. Jakarta
Djamaluddin, Arief. 2009. Bahan Kuliah Ekonomi
Pembangunan.
Universitas
Borobudur.
Jakarta
Dumairi. 1996. Matematika Terapan Untuk
Bisnis dan Ekonomi. Edisi ke-2.
Yogyakarta: BFE.
Kuncoro,
Mudrajad.
2006.
Ekonomika
Pembangunan
:
Teori,
Masalah
dan
Kebijakan. UPP edisi ke-4. UPP STIM
YKPN. Yogyakarta.
Santoso, Singgih. 2012. Aplikasi SPSS pada
Statistik Multivariat. Kompas Gramedia.
Jakarta
Sharma, S.1996. Applied Multivariate Techniques.
New York: John Wiley & Sons, Inc.
Siswadi
dan
B.
Suharjo.
1998.
Analisis
Eksplorasi Data Peubah Ganda.
Tugas
Akhir
Tidak diterbitkan. Bogor: Jurusan
Matematika Fakultas MIPA IPB, Bogor.
Yudha,
Aditya
Ananta.
2012.
Pemerataan
Lampiran 1.
Tabel Proximity Matrix
Lampiran 2.
Tabel Hasil Analisis Deskriptif Masing-masing Cluster
Cluster Variabel Min Max Mean Standar Deviasi Varians
1
Indeks Pendidikan 65.66 67.973333 66.67794872 0.586801655 3.44E-01
Indeks Harapan Hidup 68.9 71.6 70.04615385 0.842234513 7.09E-01
Indeks Pembangunan Manusia 69.03 72.92 71.18076923 1.33958614 1.79E+00
Gini Ratio 0.3 0.43 0.356153846 0.041940128 1.76E-03
2
Indeks Pendidikan 67.50667 68.433333 67.79904762 0.324446619 1.05E-01
Indeks Harapan Hidup 71.1 73.2 72.08571429 0.703393137 4.95E-01
Indeks Pembangunan Manusia 72.95 76.07 74.60857143 1.069850902 1.14E+00
Gini Ratio 0.29 0.37 0.33 0.027688746 7.67E-04
3
Indeks Pendidikan 69.16667 69.553333 69.36 0.273414622 7.48E-02
Indeks Harapan Hidup 74.9 76.2 75.55 0.919238816 8.45E-01
Indeks Pembangunan Manusia 76.09 77.6 76.845 1.06773124 1.14E+00
Gini Ratio 0.36 0.37 0.365 0.007071068 5.00E-05
4
Indeks Pendidikan 61.1 62.366667 61.60666667 0.558596124 3.12E-01
Indeks Harapan Hidup 70.8 74.3 72.35 1.493318452 2.23E+00
Indeks Pembangunan Manusia 71.62 72.49 72.0025 0.449916659 2.02E-01
Gini Ratio 0.34 0.4 0.3625 0.028722813 8.25E-04
5
Indeks Pendidikan 63.59333 63.593333 63.59333333 - -
Indeks Harapan Hidup 76 76 76 - -
Indeks Pembangunan Manusia 75.77 75.77 75.77 - -
Gini Ratio 0.41 0.41 0.41 - -
6
Indeks Pendidikan 56.23333 56.233333 56.23333333 - -
Indeks Harapan Hidup 67 67 67 - -
Indeks Pembangunan Manusia 65.2 65.2 65.2 - -
Gini Ratio 0.4 0.4 0.4 - -
7
Indeks Pendidikan 61.35333 63.933333 62.28 1.211610498 1.468
Indeks Harapan Hidup 69.9 70.8 70.45 0.404145188 0.163333333
Indeks Pembangunan Manusia 67.26 70 69.0125 1.219162964 1.486358333
Gini Ratio 0.36 0.42 0.3825 0.026299556 0.000691667
8
Indeks Pendidikan 47.61333 47.613333 47.61333333 - -
Indeks Harapan Hidup 70 70 70 - -
Indeks Pembangunan Manusia 64.94 64.94 64.94 - -