This textbook is an extremely useful asset for national as well as international students of Big Data Analytics. This book addresses the needs of undergraduate and postgraduate students in computer science and engineering, information technology and related disciplines, along with industry professionals to develop innovative Big Data Analytics solutions based on Spark ecosystem tools with Python libraries, which include the use of machine learning concepts .
Learningand Assessment Tools Learning Objectives
Salient Features
The chapter explains the methods of web mining, link analysis, analysis of web graphs, PageRank methods, web structure analysis, finding hubs and communities, social network analysis and representation of social networks as graphs. Another highlight of the chapter is the description of machine learning programs using sklearn for SVMs, Naive Bayes classifiers, linear and polynomial regression analyses, and predictive analytics.
Online LearningCenter
It describes computational methods to find the clustering in social network graphs, SimRank, to count triangles (clique) and discover the communities. The chapter explains MapReduce implementation for counting items in a dataset, creating Hive data tables from a CSV format dataset, and creating data frames from RDDs.
Acknowledgements
Contents
Introductionto Big Data Analytics
Introductionto Hadoop
NoSQLBig Data Management,MongoDB and Cassandra
MapReduce, Hive and Pig
Sparkand Big Data Analytics
Machine LearningAlgorithmsfor Big Data Analytics
Text, Web Content,Link, and Social Network Analytics
ProgrammingExamples in Analytics and Machine Learning using Hadoop, Sparkand Python
List of Acronyms
Chapter 1
Introductionto Big Data Analytics
Classification of Data-Structured, Semi-structuredand Unstructured
Multi- or semi-structured data has some semantic meaning and the data comes in structured and unstructured formats. Multi-structured data analysis tools help players design better strategies to win chess championships.
Big Data Definitions
Big Data Characteristics
This means that the type to which Big Data belongs is also an important characteristic that must be known for proper data processing. Veracity is also considered an important characteristic to take into account the quality of the recorded data, which can vary widely and affect its accurate analysis.
Big Data Types
The following examples explain the uses of big data generated from multiple types of data sources. The company uses Big Data types such as: Machine-generated data on the sale of chocolate, reports of unfilled or filled machine transaction data.
Big Data Classification
Big Data HandlingTechniques
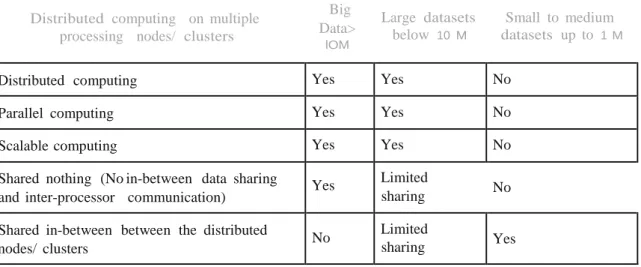
SCALABILITY AND PARALLEL PROCESSING Big Data needs to process large volumes of data, and therefore needs intensive computation. Big data processing and analytics require vertical and horizontal computing resources scaling and scaling.
Analytics Scalabilityto Big Data
When workload and complexity exceed system capacity, scale up and scale out. Alternative ways to scale up and scale out analytics software processing and Big Data analytics use the Massively Parallel Processing Platforms (MPPs), cloud, grid, clusters and distributed computing software.
Massively ParallelProcessingPlatforms
The easiest way to scale up and scale out execution of analytics software is to deploy it on a larger machine with more CPUs for greater volume, speed, variety and complexity of data. Also, if more CPUs are added to a computer, but the software doesn't take advantage of them, it won't get any performance boost from the extra CPUs.
Cloud Computing
Infrastructure as a Service (IaaS): Provides access to Olot11d servkes ofifer, la:aS, resources, such as hard drives, network connections, modalforprooassinj; a11T1a. Apache CloudStack is an open source software for deploying and managing a large network of virtual machines and offers public cloud services that provide highly scalable Infrastructure as a Service (IaaS).
Grid and Cluster Computing Grid Computing
Cloud computing depends on the sharing of resources (for example, networks, servers, storage, applications and services) to achieve coordination and coherence between resources similar to grid computing. Disadvantages of Grid Computing Grid computing is the single point, which leads to failure in case of underperformance or failure of any of the participating nodes.
VolunteerComputing
The storage capacity of a system varies depending on the number of users, instances, and the amount of data being transferred at any given time. They move processes between nodes to maintain an even load on the group of connected computers.
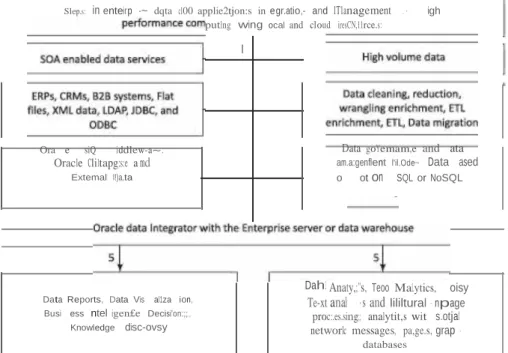
Data Architecture Design
Data management means enabling, controlling, protecting, delivering and increasing the value of data and information assets. Data management, which includes establishing processes to ensure the availability, usability, integrity, security and high quality of data.

Data Sources
Assume that Analysis_APP does not connect or directly link to the data source UG_CS_Sem_StudID_Gradedsatabase. The table stores the data source definitions for all UG and PG as well as all the students' subjects and semester grades.
Data Quality
Outlier: Consider an outlier in students' transcripts for any of the five subjects in a student's fourth semester result. The chocolate sales that are not added one day can be added to the next day's sales data.
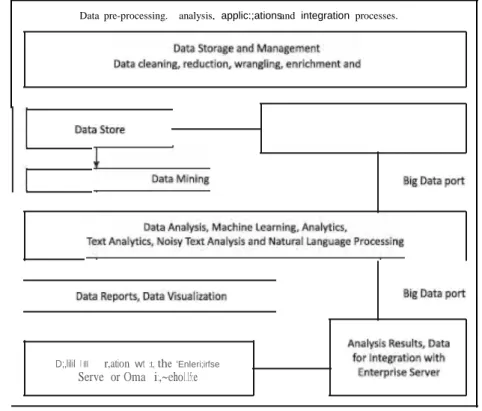
Data Pre-processing
Techopedia's definition is as follows: "Data enrichment refers to operations or processes that refine, enhance, or enhance the raw data.". A CSV file can also use tab-delimited formats with spaces, tabs, or separators for the values in the fields. The two consecutive double quotes mean that one of the double quotes is retained in the text "Theory of Computations".
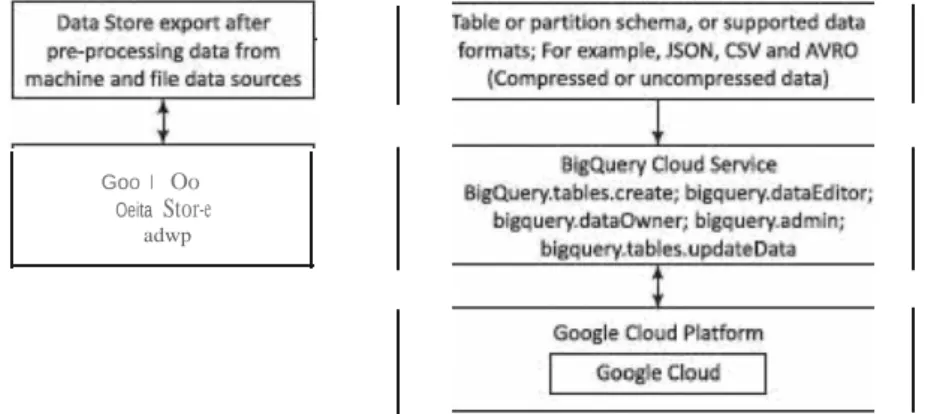
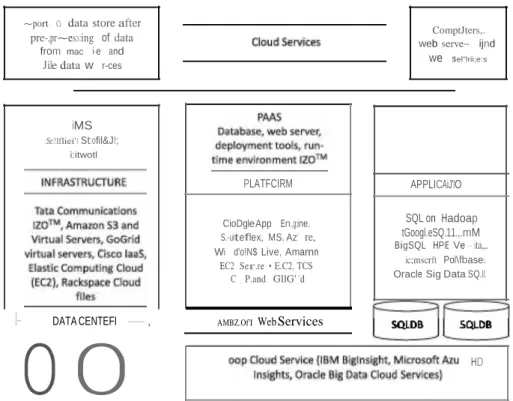
Data Store Export to Cloud
- Export of Data to AWS and Rackspace Clouds
A process preprocesses the data from data rows in the MySQL database and creates a CSV file. ii) An EC2 instance provides an AWS data pipeline. iii) The CSV file is exported to Amazon 53 via pipeline. The data is exported from a table or partition scheme, )SON, CSV or AVRO files from data sources after preprocessing. Data Store first performs preprocessing from machine and file data sources. Processing converts the data into table or partition schemes or supported data formats.
Data Storage and Management: Traditional Systems
How will the ACVM's sales be analyzed for each type of chocolate using the data source master•. The data consists of transaction records, tables, relationships and metadata that build the information about the business data. The data stores for each record order in consecutive columns, so that the 100th entry at column 1 and the 100th entry for column 2 belong to the same record.
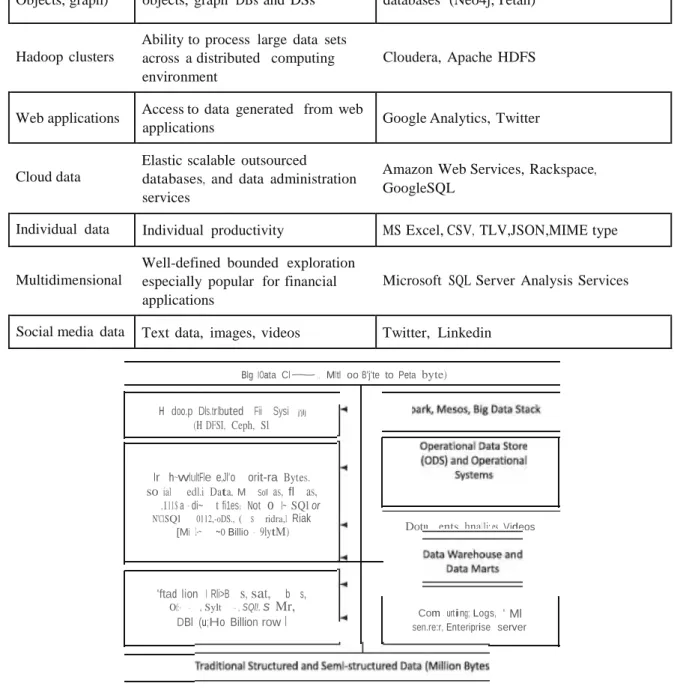
Big Data Storage
Microsoft Access, Oracle, IBM DB2, SQL Server, MySQL, PostgreSQL Composite, SQL on Hadoop [HPE (Hewlett Packard . Enterprise) Vertica, IBM BigSQL, Microsoft Polybase, Oracle Big Data SQL]. Key-value pairs, fast read/write using collections of name-value pairs to store any type of data;. Key-value pair databases: Riak DS (Data Store), OrientDB, column format databases (HBase, Cassandra), Document oriented databases: CouchDB, MongoDB; Curve.
Big Data Platform
The Big Data platform consists of Big Data storage(s), server(s), and data management and business intelligence software. Storage can implement Hadoop Distributed File System (HDFS), NoSQL data stores, such as HBase, MongoDB, Cassandra. Applications, machine learning algorithms, analysis and visualization tools use the Big Data Stack (BDS) in a cloud service, such as Amazon EC2, Azure or private cloud.

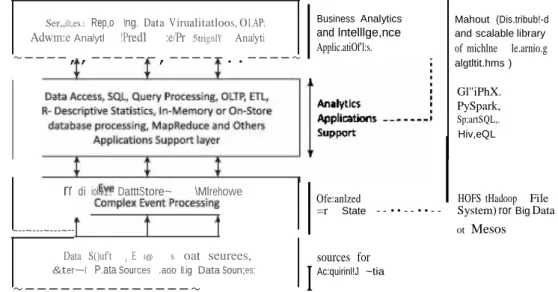
Big Data Analytics
The figure also shows on the right the Big Data file systems, machine learning algorithms and query languages and the use of the Hadoop ecosystem. When Big Data is combined with powerful data analytics, enterprises can perform valuable business-related tasks. The importance of Big Data lies in the fact that what one does ~raprocmfnq.~ra . with it rather than how big or big it is.
BIG DATA ANALYTICS APPLICATIONS AND CASE STUDIES Many applications such as social network and social media,
- Big Data in Marketingand Sales
- Big Data and Healthcare
- Big Data in Medicine
- Big Data in Advertising
Big data provides marketing insights into (i) the most effective content at each stage of a sales cycle, (ii) investing in improving customer relationship management (CRM), (iii) adding to strategies to increase customer lifetime value (CLTV), (iv) lowering customer acquisition cost (CAC). How Big Data Analytics enables the prevention of fraud, waste and abuse of the healthcare system. Big data analytics deploys a large amount of data to identify and derive intelligence using predictive models about individuals.
Fill in the fields with assumed values for two students in the same semester in the same course. 2 https:// statswiki.unece.org/ display/bigdata/Classification-of-Types-of-Big-Data 3 https://www.ibm.com/ developerworks/library /bd-archpatternsl/. 14 https://www.mckinsey.com/industries/pharmaceuticals-and-medical-products/our-insights/the-role-of-big-data-in-medicine.
Chapter 2
Introductionto Hadoop
LEARNING OBJECTIVES
Hadoop Core Components
For example, Hadoop Common provides several components and interfaces for distributed file systems and general input/output. The tasks or subtasks of the user application run in parallel on the Hadoop, using scheduling and processing the requests for the resources while executing the tasks in a distributed manner. MapReduce v2 - Hadoop 2 YARN-based system for parallel processing of large data sets and distributed processing of the application tasks.
Features of Hadoop
Hadoop Distributed File System (HDFS) - A Java-based distributed file system that can store all kinds of data on the disks in the clusters. Stream analysis and real-time processing pose problems when streams have high data throughput. YARN provides a platform for many different forms of data processing, from traditional batch processing to application processing such as interactive queries, text analysis and streaming analysis.
Hadoop Ecosystem Components
These different types of data can be moved into HDFS for analysis using interactive query processing tools of Hadoop ecosystem components such as Hive, or provided to web business processes using Apache HBase. extensible library and Ml applications. A holistic view of Hadoop architecture provides an idea of implementing Hadoop components into an ecosystem. HDFS is a Java-based distributed file system that can store various types of data across computers.

Hadoop Streaming
Hadoop Pipes
HADOOP DISTRIBUTED FILE SYSTEM Big data analytics applications are software applications that utilize large-scale data. HDFS is designed to run on a cluster of computers and servers at cloud-based utilities. HDFS provides high throughput access to data-centric applications that require large-scale data processing workloads.
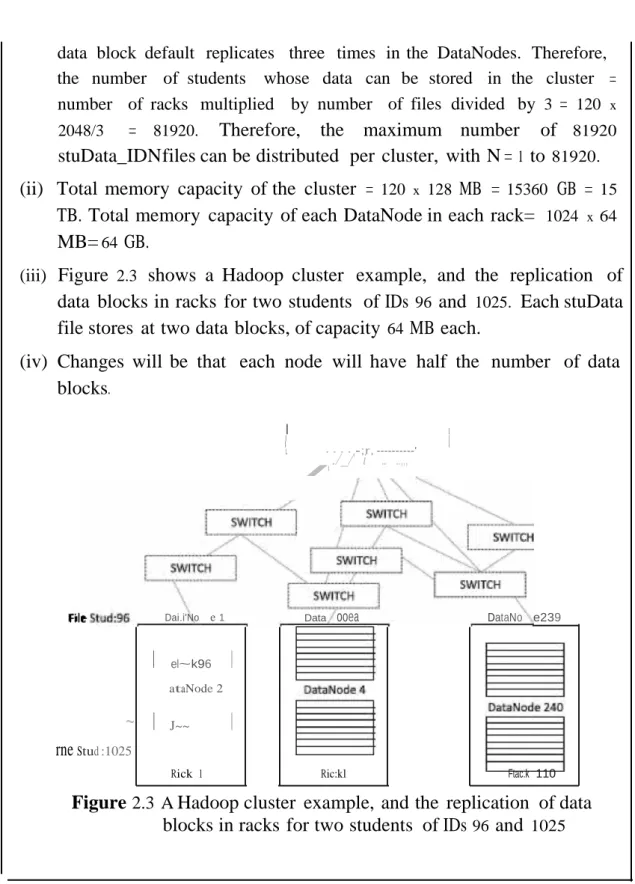
HDFS Data Storage
- Hadoop Physical Organization
For simplicity, assume that each rack has two nodes each with memory capacity = 64 GB. data block standard replicates three times in DataNodes. Therefore, the number of students whose data can be stored in the cluster = number of racks multiplied by the number of files divided by 3 = 120 x. Total memory capacity of each DataNode in each rack = 1024 x 64. iii) Figure 2.3 shows a Hadoop cluster example and the replication of data blocks in racks for two students with ID 96 and 1025.
HDFS Commands
Then $Hadoop hdfs-set stuData_id96 /user/ stu filesdir. copies the file for id96's student to the stu_filesdir directory. ls Assume that all files will be listed. Assume that stuData_id96 will be copied from stu_filesdir to new students directory newstu_filesDir. Then $Hadoop hdf s-cp stuData _ id96 /user/stu_filesdir newstu_filesDir copies the file for student ID 96 to the stu_filesdir directory.

- Hadoop MapReduce Framework
- Hadoop 2 Execution Model
- Hadoop Ecosystem
- Zookeeper
- Ambari
- Hadoop Administration
- HBase
- Hive
- Mahout
The Hadoop system sends the Map and Reduce jobs to the appropriate servers in the cluster. Each task can consist of a number of sub-tasks (threads), which run in parallel at the nodes in the cluster. By default, the data blocks replicate to at least three DataNodes in the same or remote nodes.
Chapter 3
NoSQLBig Data Management, MongoDB and Cassandra
RECALL FROM PREVIOUS CHAPTERS
NoSQL
Examples of NoSQL data architecture patterns for arrays are key-value pairs, name/value pairs, column family. A NoSQL data store based on a column family, a data store that provides BigTable-like capabilities (Sections 2.6 and 3.3.3.2); scalability, strong consistency,. A step towards NoSQL data storage; key-value distributed data store; it provides transactional semantics for data manipulation, horizontal scalability, simple administration and monitoring.
Schema-less Models
Metadata helps select an object, data specifications, and uses that design where and when. Metadata specifies access permissions, object attributes, and enables adding an attribute layer to objects.
Increasing Flexibility for Data Manipulation
NoSQL database design does not consider the need for consistency throughout the processing time. Eventual consistency means consistency requirements in NoSQL databases that will be met at some point in the future. Use database examples for students in various university courses to demonstrate the concept of increasing the flexibility of NoSQL DBs.
- Key-Value Store
- Document Store
- TabularData
- BigTable Data Store
- Object Data Store
The simplest way to implement a schemaless data store is to use key-value pairs. Thus, a row group has all the column data stored in memory for in-memory analysis. It is fast to query all the field values of a column in a family, all columns in the family, or a group of column families in memory in the column family data store.