OLEH
MAULIA HARODIAN SANI 07351911053
PROGRAM STUDI TEKNIK INFORMATIKA FAKULTAS TEKNIK
UNIVERSITAS KHAIRUN TERNATE
2023
KATA PENGANTAR
Puji syukur saya panjatkan kepada Allah Subhanahu Wa ta’ala yang telah melimpahkan rahmat, taufik, hidayah-Nya.
Sehingga penulis dapat menyusun proposal ini dengan judul
“Klasifikasi Komentar Di Twitter menggunakan Metode Decision Tree C4.5 Untuk Memprediksi, ini dapat diselesaikan untuk memenuhi salah satu persyaratan penyelesaian pendidikan sarjana Teknik Informatika Strata Satu (S1) pada Program Studi Informatika Fakultas Teknik Universitas Unkhair.
Untuk menyelesaikan proposal ini penulis sepenuhnya mendapat dukungan dari banyak pihak, oleh karena itu dengan rendah hati penulis mengucapkan terimakasih kepada:
1. Bapak Dr., M.Ridha Ajam, M.Hum., selaku Rektor Universitas Khairun.
2. Bapak Endah Harisun, S.T,.M.T., selaku dekan Fakultas Teknik Universitas Khairun
3. Bapak Rosihan, S.T., M.Cs., selaku Kordinator Program Studi Informatika Fakultas Teknik Universitas Khairun dan Selaku Penguji I yang telah memberikan masukan, kritikan dan saran demi perbaikan Skripsi ini.
4. Bapak Saiful Do Abdullah, S.T., M.T, sebagai Pembimbing I, terima kasih atas bimbingannya, serta dukungan dalam penyelesaian proposal ini.
5. Bapak Dr., Assaf Arief, S.T., M.Eng., sebagai Pembimbing II, terima kasih atas bimbingannya, serta dukungan dalam penyelesaian proposal ini.
6. Bapak Munazat Salmin, S.Pd., M.Cs., selaku Penguji II yang telah memberikan masukan, kritikan dan saran demi perbaikan Skripsi ini.
i
dilimpahkan kepada penulis hingga saat ini.
9. Teman-teman Angkatan 19 Informatika penulis mengucapkan terima kasih atas dukungannya.
Akhir kata, dengan penuh kesadaran diri dan segala kerendahan hati penulis menyadari hanya Allah yang memiliki segala kesempurnaan, sehingga masih banyak lagi rahasia-Nya yang belum tergali dan penulis ketahui. Semoga Allah Subhanahu wa Ta’ala selalu memberikan yang terbaik kepada semua pihak yang selalu membantu penulis. Aamiin.
Ternate, 16, Juni 2023
Penulis
ii
DAFTAR ISI
Halaman
KATA PENGANTAR...i
DAFTAR ISI...ii
DAFTAR TABEL...iv
BAB I PENDAHULUAN 1.1. Latar Belakang...1
1.2. Rumusan Masalah...4
1.3. Tujuan...4
1.4. Batasan Masalah...4
1.5. Manfaat...4
1.6. Sistematika penulisan...5
BAB II TINJAUAN PUSTAKA 2.1. Penelitian Terkait...6
2.2. Teori Pendukung...9
2.2.1. klasifikasi...9
2.2.2. Instagram...10
2.2.3. Twitter...11
2.2.4. hate comment...12
2.2.5. Komentar...13
2.2.6. Text mining...14
2.2.7. Pohon Keputusan...15
2.2.8. Algoritma C4.5...15
2.2.9. Text Prosesing...15
2.2.10.Indihome...17
BAB III METODE PENELITIAN 3.1. Tahapan Penelitian...18
3.2. Lokasi dan waktu penelitian...20
3.3. Alat dan Bahan Penelitian...20
3.4. Teknik Pengumpulan Data...21
ii
DAFTAR PUSTAKA...27
iii
DAFTAR TAB
Tabel 2. 1 Penelitian Terkait...6
YTabel 3. 1 Detail Spesifikasi Hardware ………..….20
Tabel 3. 2 Detail spesifikasi Software...20
Tabel 3. 3 komentar hate comment diTwitter...21
Tabel 3. 4 Contoh Penerapan Case Folding...22
Tabel 3. 5 Contoh Penerapan Tokenizing...22
Tabel 3. 6 Contoh Penerapan Stopword...23
Tabel 3. 7 Contoh Penerapan Stemming...23
Tabel 3. 8 waktu penelitian...26
media sosial tertinggi di dunia. Jumlah pengguna aktif media sosial di Indonesia adalah 167 juta orang pada Januari 2023.
Angka ini setara dengan 60,4% dari populasi negara. Jumlah pengguna aktif jejaring sosial menurun 12,57% pada Januari 2023 dibandingkan tahun sebelumnya, yakni 191 juta orang (Widi, 2023). Media sosial adalah tempat untuk mengekspresikan pendapat perihal topik tertentu. Media sosial yang paling banyak digunakan di Indonesia adalah WhattsApp, Instagram, fecebook, Twitter dan lain lain. Media sosial mengajak seluruh pihak yang berkepentingan untuk berpartisipasi dengan secara terbuka berkontribusi dan memberikan saran, berkomentar dan berbagi informasi secara cepat dan tanpa batasan (Fatmawati, 2021).
Media sosial kini banyak digunakan oleh orang tua dan anak-anak dalam menyampaikan sebuah opini yang baik tetapi juga ada opini kurang baik (Hidayatullah, 2021). Salah satunya adalah adanya komentar negatif (hate comment). hate comment sering merujuk pada komentar negatif yang dimaksudkan untuk mempermalukan atau merendahkan orang atau kelompok lain.
Komentar semacam itu biasanya menyerang korban tentang
2
masalah pribadi seperti ras, agama dan warna kulit (Zahrin Nur Azizah, 2022). Komentar negatif yang mengandung kata-kata kasar terkadang dapat memicu konfik atau perdebatan.
Salah satu platform media sosial tempat pengguna Indonesia dapat mengirim pesan singkat, komentar positif dan negatif adalah Instagram dan Twitter. Menurut Country Industry Head, mengklaim bahwa Indonesia adalah negara terbesar untuk jumlah pengguna aktif yang terus bertambah harian Instagram dan Twitter (Fadli & Hidayatullah, 2021).
Instagram merupakan media digital berupa aplikasi untuk smartphone dan salah satu media sosial yang ada.
Pengoperasiannya hampir sama dengan media sosial Twitter, hanya saja terdapat perbedaan pada saat mengambil foto (gambar) atau berbagi dengan pengguna lain. Instagram juga dapat memberikan inspirasi dan memacu kreativitas kepada penggunanya karena Instagram memiliki fitur-fitur yang membuat foto Anda menjadi lebih indah, artistik, dan lebih baik (Sanjulya et al., 2020).
Twitter didirikan oleh Jack Dorsey pada Maret 2006 dan diluncurkan pada bulan Juli. Sejak diluncurkan, Twitter telah menjadi salah satu dari sepuluh situs yang paling banyak dikunjungi di Internet dan mendapat julukan Internet Short Message (Zukhrufillah, 2018). Twitter sendiri memiliki beberapa
fungsi seperti kicauan, following, followers, biografi, profil.
Twitter juga memiliki fitur paling populer, yang digunakan untuk memudahkan melihat tweet terpopuler dan paling banyak di- retweet dari pengguna Twitter lainnya (Al Khadafi et al., 2022).
Twitter adalah berita online dan jejaring sosial tempat orang berkomunikasi melalui pesan singkat yang disebut tweet Karena banyak tweet dipublikasikan melalui Twitter, Komentar di Twitter dapat disampaikan dengan cara komunikasi secara lisan atau tulisan yang berisi kiasan (Rheza & Metandi, 2020). Namun tidak semua pengguna Twitter berkomentar dengan bijak, terdapat berbagai tindakan negatif dari salah satu pengguna yang merugikan pengguna lainnya (Fadli & Hidayatullah, 2021). Salah satu bentuk komentar yang tidak digunakan secara bijak adalah hate comment atau komentar jahat. Pada kolom komentar media sosial sering terdapat hate comment kepada akun ataupun situs media sosial terkait (Almujaddedi & Hayati, 2022)
Twitter ini mungkin berisi opini pengguna Dalam kaitannya dengan suatu objek, objek dapat berupa kejadian yang melingkupi masyarakat seperti produk atau layanan. Salah satu pelayanan operator yang digunakan oleh masyarakat adalah Indihome (Tineges et al., 2020). Seperti salah satu dari platform media sosial paling populer, perusahaan dapat menggunakan tweet di Twitter sebagai alat untuk mengetahui penerimaan atau
4
kesan masyarakat pengguna terhadap produk yang diluncurkan, misalnya yang dilakukan terhadap perusahaaan Penyedia Layanan Internet (ISP) Indihome.
Indihome adalah operator penyedia Internet Service Provider (ISP) yang presentase penggunannya paling banyak hingga mencapai 8,7% oleh masyarakat Indonesia sebagai operator penyedia ISP dibandingkan dengan operator penyedia ISP lainnya (asosiasi). Masyarakat yang menggunakan Indihome dapat memberikan kritik, saran ataupun kepuasan terkait pelayanan dapat disampaikan melalui Twitter (Tineges et al., 2020). Adapun contoh cuitan masyarakat yang terkait pada layanan Indihome diantara Akun openptheskyee mengatakan internet Indihome yang digunalan selalu mengalami penurunan kecepatan setiap pagi.
Berdasarkan paparan di atas ada beberapa permasalahan yang harus diteliti seperti banyaknya hate coment yang ada di Twitter pada layanan indihome. Solusi dari permasalahan ini adalah dengan menerapkan salah satu algoritma c4.5 (decision tree) pada klasifikasi teks komentar negatif (hate comment).
Untuk mencari data tersebut, bukan hal yang mudah karena jumlah text atau kalimat pada hate coment di Twitter sangat banyak.oleh karena itu, dibutuhkan suatu metode yang dapat mengklasifikasikan komentar atau ulasan tersebut. Untuk
klasifikasi dan menghitung tingkat akurasi terhadap ulasan atau komentar tersebut, maka digunakan teknik klasifikasi menggunakan metode C4.5. C4.5 dapat menangani atribut kontinyu dan diskrit, kemudian mengolah data training dengan missing value dan menggunakan gain ratio untuk meningkatkan gain data (Kustiyahningsih & Rahmanita, 2016). Kemampuan metode C4.5 diharapkan mampu menjawab pertanyaan pada masalah penelitian tersebut.
1.2. Rumusan Masalah
Berdasarkan latar belakang diatas, maka dapat dirumuskan masalah penelitian ini adalah alur klasifikasi pada text sehingga dapat diketahui apakah teks tersebut termasuk dalam komentar negatif (hate comment) atau bukan, pada pengguna Twitter layanan indihome menggunakan metode C4.5.
1.3. Tujuan
Adapun tujuan dari penelitian ini yaitu Dapat Menggunakan Metode C4.5 Untuk Menganalisis Terkait Klasifikasi Hate coment DiTwitter Pada Layanan Indihome.
1.4. Batasan Masalah
Batasan masalah dari penelitian sebagai berikut : 1. Data yang diperoleh melalui Aplikasi Twitter.
2. Data yang digunakan menggunakan bahasa Indonesia.
3. Implementasi metode c4.5.
6
4. Tweet yang digunakan hanya tweet yang berupa teks, tidak mengandung gambar.
1.5. Manfaat
Hasil penelitian ini secara umum diharapkan dapat memberikan manfaat sebagai berikut
1. Dapat memperoleh hasil dari klasifikasi hate comment pada Twitter dengan menggunakan metode C4.5 (decision tree).
2. Bagi pihak peneliti untuk dapat mengimplementasikan ilmu yang telah diperoleh di bangku perkuliahan.
1.6. Sistematika penulisan
Sistematika penulisan laporan ini merupakan pembahasan singkat dari setiap bab yang menjelaskan hubungan antara bab yang satu dengan bab yang lainnya, yaitu sebagai berikut:
BAB I PENDAHULUAN
Bab ini berisi pengantar dalam memahami dan mengenal materi pokok secara garis besar, yang terdiri dari latar belakang masalah/alasan, memilih judul, rumusan masalah, batasan masalah tujuan penelitian, manfaat penelitian, serta sistematika penelitian.
BAB II TINJAUAN PUSTAKA
Bab ini menguraikan teori-teori yang berkaitan dengan judul penulisan. Hala ini dimaksudkan untuk memberikan landasan
teoritis dalam menganalisis permasalahan selanjutnya sesuai dengan data-data yang diperoleh.
BAB III METODE PENELITIAN
Bab ini menguraikan tentang metode dan teknik yang digunakan untuk mengumpulkan data sehingga dapat menjawab atau menjelaskan masalah penelitian.
BAB II
TINJAUAN PUSTAKA 2.1. Penelitian Terkait
Penelitian terkait mengenai klasifikasi hate comment diTwitter. Pada bab ini akan dipaparkan beberapa landasan teori yang berkaitan dengan penelitian yang akan dilakukan oleh penulis. Berikut beberapa penelitian terkait dapat dilihat pada tabel 2.1
Tabel 2. 1 Penelitian Terkait N
o Nama
penelitian
dan Tahun Judul Hasil
1 (Yan et al.,
2022) Analisis sentiment komentar netizen Twitter terhadap kesehatan mental masyarakat Indonesia
1. Kata yang paling sering muncul adalah kata health dengan frekuensi
kemunculan kata
sebanyak 2087 kali.
2. Akurasi naïve bayes didapatkan sebesar 79%, akurasi ini
termasuk tinggi
dibandingkan dengan akurasi menggunakan metode klasifikasi biasa.
3. Hasil analisis sentimen yang telah dilakukan
diketahui bahwa
komentar pengguna
8
terhadap kesehatan mental adalah negatif dengan klasifikasi negatif sebesar 50.8%.
2. (Ihsan et al.,
2021) Algoritme decision tree untuk
mendeteksi ujaran
kebencian dan bahasa kasar multilabel pada Twitter berbahasa Indonesia
Penerapan seleksi dan rekayasa fitur dapat
diterapkan untuk
meningkatkan hasil akurasi klasifikasi algoritme Decision Tree
dalam melakukan
klasifikasi teks Twitter untuk deteksi multi kelas yang berbeda. Model yang terbentuk pada penelitian ini dapat digunakan dalam kasus klasifikasi Twitter untuk mendeteksi twit yang mengandung ujaran
kebencian (kelas
HateSpeech), bahasa kasar (kelas Abusive) dan mengukur level dari ujaran kebencian (kelas Level).
3. (Tineges et
al., 2020) Analisis Sentimen Terhadap Layanan Indihome Berdasarkan Twitter
Dengan Metode Klasifikasi Support Vector Machine (SVM)
Dengan menerapkan
metode Support Vector Machine untuk analisis
sentimen terhadap
layanan Indihome
berdasarkan data tweet berdasarkan Tabel 12 hasil evaluasi menggunakan Confussion Matrix, didapat akurasi sebesar 87%
dengan ketepatan antara hasil prediksi dengan data sebenarnya (precision) sebesar 86%, tingkat keberhasilan sistem dalam
10
memprediksi sebuah data (recall) sebesar 95%, tingkat kesalahan semua data yang diprediksi (error rate) sebesar 13%, sedangkan untuk nilai perbandingan rata-rata precision dan recall adalah sebesar 90%.
b. Hasil sentimen layanan Indihome berdasarkan data baru, dengan metode Support Vector Machine mendapatkan hasil nilai positif sebesar 18,4 % dan hasil nilai negatif sebasar 81,6%. Berdasarkan hasil
tersebut dapat
disimpulakan bahwa
tingkat kepuasan
pengguna layanan
Indihome cukup rendah.
4 (Irfani et al.,
2018) Klasifikasi Berita pada Twitter
Menggunakan Metode Naive Bayes dan Query Expansion Hipernim- Hiponim
Akurasi yang dihasilkan adalah 72% untuk klasifikasi tanpa ekstensi pertanyaan, 65.75D
dengan penambahan
hiponim dan dengan hipernim, 66,3% untuk
dengan penambahan
hiponim saja, dan 67,5%
dengan penambahan
hipernim saja. yang dilakukan oleh kurang
efektif dalam
meningkatkan akurasi dari proses klasifikasi
5. (Trihapsari,
2016) Klasifikasi cyber bulling pada media social Twitter dengan
menggunakan algoritma Naïve bayes
Akurasi tertinggi
klasifikasi tweet ke dalam dua kelas (tweet bullying, bukan tweet bullying) yang bisa dicapai dalam penelitian ini adalah sebesar 87,67 % dengan menggunakan algoritma
yang digunakan adalah TF-IDF dengan minimal term frequency=3, tanpa
melakukan proses
stopword, tokenizer yang dipakai adalah= word tokenizer dengan percentage split sebesar 70%.
2.2. Teori Pendukung
Berikut adalah teori yang digunakan sebagai pendukung dalam penelitian ini:
2.2.1. klasifikasi
Klasifikasi berasal dari bahasa latin yaitu classis yang artinya pengelompokan benda yang sama serta memisahkan benda yang tidak sama. Secara harfiah arti klasifikasi adalah penggolongan, pengelompokan. Menurut istilah klasifikasi adalah proses membagi objek atau konsep secara logika kedalam klas- klas hirarki,subklas,dan sub-subklas berdasarkan kesamaan yang mereka miliki secara umum dan yang membedakannya.
Klasifikasi secara umum juga diartikan sebagai kegiatan penataan pengetahuan secara universal kedalam beberapa susunan sistematis (Ansori, 2015).
Klasifikasi merupakan pengelompokkan secara sistematis pada suatu objek atau benda ke dalam golongan atau pola-pola tertentu berdasarkan kesamaan ciri. Masalah klasifikasi sering
12
dijumpai dalam kehidupan sehari-hari, baik pada bidang industri, sosial, kesehatan, maupun pendidikan. Penyelesaian masalah klasifikasi dapat dilakukan dengan metode klasifikasi (Aderibigbe, 2018). Sistem pengelompokan/klasifikasi koleksi dapat berdasarkan pada jenis, ukuran (tinggi, pendek, besar, kecil, dll), warna, abjad judul, dan abjad pengarang. Namun sebagian besar perpustakaan menggunakan sistem pengelompokan koleksi berdasarkan subjek bahan pustaka (Saputro, 2017).
2.2.2. Instagram
Instagram merupakan sebuah media social yang memungkinkan pengguna berinteraksi, bekerja sama, berbagi, berkomunikasi dengan pengguna lain dan membentuk komunikasi social secara social secara virtual. Media social yang semakin diminati masyarakat mulai dari muda hingga tua, khususnya kalangan kaum milenial saat ini. Media sosial yang semakin diminati masyarakat khususnya kalangan kaum milenial saat ini adalah Instagram. Instagram mempunyai suatu alat penyampaian pesan (aplikasi) untuk bisa berkomunikasi dengan khalayak secara luas dengan saling berbagi foto atau video, yang di dalamnya juga terdapat fitur-fitur lain seperti DM (Direct Message), comment, love, dan lain-lain (Akhir, 2019).
Twitter adalah komunitas online dan layanan microblogging yang memungkinkan penggunanya untuk mengirim dan membaca pesan berbasis teks hingga 140 karakter, di antaranya dikenal sebagai tweet (Putu et al., 2023). Kelahiran Twitter sendiri tidak lepas dari penemuan teknologi komunikasi sebelumnya seperti radio, televisi dan internet. Setelah James Clerk Maxwell pada tahun 1986 yang secara mengejutkan mampu menunjukkan kecepatan cahaya yang disadari oleh hubungan antara dua gaya, Heinrich Rudolf Hertz berturut-turut bereksperimen dengan gelombang radio di laboratorium pada tahun 1887 dan berdasarkan penelitiannya. ia mampu membuktikan adanya gelombang elektromagnetik dengan berhasil menciptakan alat untuk membangkitkan dan mendeteksi gelombang radio UHF, Kemudian ilmuwan lainnya seperti Quqliermo Marconi, Reginald Fessenden, Lee De Forest, David Samoff dan masih banyak lagi yang memiliki penemuan yang masih disempurnakan (Zukhrufillah, 2018). Kunci utama implementasi rencana tersebut adalah penggunaan sistem ramah, atau yang disebut pengikut. Kemudian promosikan teman dari pengikut ke pengikut. Twitter juga melihat seberapa besar pengaruh akun seseorang terhadap pengikutnya. Twitter juga memiliki halaman papan peringkat di mana sebagai
14
pengguna dapat melihat seberapa aktif pengguna akun di Twitter mereka survei pengguna Twitter indonesia.
Twitter memiliki banyak pengguna yang menggunakan platform ini untuk berbagi berita, informasi, pemikiran, dan pandangan tentang berbagai topik. Selain itu, Twitter juga digunakan oleh perusahaan, organisasi, dan individu untuk mengiklankan, mempromosikan merek mereka, dan terhubung dengan pelanggan mereka. Twitter memiliki beberapa fitur seperti retweet, like, mention, hashtag dan lain lain. Yang memungkinkan pengguna berinteraksi satu sama lain dan meningkatkan visibilitas postingan mereka di platform. Selain itu, Twitter juga memiliki API yang memungkinkan pengembang dan peneliti mengambil dan menganalisis data Twitter.
Twitter adalah platform media sosial yang dapat digunakan untuk atau intimidasi dan pelecehan online. dapat terjadi dalam bentuk apa pun, termasuk mengirim pesan yang mengancam, mengirim pesan yang melecehkan atau diskriminatif, mengirim foto atau video yang menghina, dan menggunakan kata atau frasa yang menghina atau menyinggung dalam tweet di Twitter dapat memiliki efek psikologis yang signifikan pada korban, termasuk harga diri yang rendah, rasa tidak aman, depresi, dan kecemasan.
dan mengatasi di platformnya. Misalnya, Twitter telah menerapkan fitur yang melaporkan tweet yang dianggap mencurigakan, mengancam, atau tidak pantas. Selain itu, Twitter juga memiliki kebijakan yang melarang perundungan dan pelecehan serta dapat memberikan hukuman kepada pengguna yang melanggar kebijakan tersebut. Oleh karena itu, penting bagi pengguna untuk berhati-hati saat menggunakan platform media sosial dan melaporkan intimidasi dan pelecehan yang mereka alami atau saksikan. Selain itu, setiap pengguna Twitter juga harus bertanggung jawab atas penggunaan platform yang benar dan menghormati hak dan keamanan.
2.2.4. hate comment
Hate comment berasal dari bahasa Inggris yang terdiri dari dua kata, yaitu hate dan comment. Hate berarti jahat dan comment yang artinya komentar. Secara umum, konsep komentar kebencian adalah tindakan komunikatif individu atau kelompok sebagai bentuk provokasi (hasutan), hinaan, kritik, pelecehan dan hinaan berat yang ditujukan kepada individu atau kelompok lain yang menyinggung berbagai aspek, seperti ras. , warna kulit, kebangsaan, agama. , kebangsaan dan komentar fisik di media social (Almujaddedi & Hayati, 2022). Dari segi hukum, hate comment dapat diartikan sebagai suatu bentuk
16
ujaran dan tulisan yang melanggar norma dan bertujuan untuk menghina ras, suku, agama atau struktur fisik seseorang atau kelompok dalam komentar di media social (Muwafiq et al., 2019).
Pengaturan Hukum Terhadap Pelaku Ujaran Kebencian di Media Sosial Diatur Dalam Ketentuan Pasal 28 Ayat (1) Dan (2) Jo.
Pasal 45 Ayat (2) Undang-Undang Nomor 11 Tahun 2008 Sebagaimana Diubah Dengan Undang-Undang Nomor 16 Tahun 2019 Tentang Perubahan Atas Undang-Undang Nomor 11 Tahun 2008 Tentang Informasi Dan Transaksi Elektronik (Parulia, 2022).
2.2.5. Komentar
komentar adalah cara seseorang untuk mengungkapkan pendapatnya. Ekspresi juga bisa menjadi masalah besar terkadang karena terlalu banyak ekspresi dan hanya fokus pada faktor kebencian yang tidak rasional, ekspresi yang fokus pada hal-hal yang penuh kebencian dan tidak konstruktif. Komentar adalah respons atau tanggapan yang diberikan seseorang terhadap suatu topik, postingan, artikel, atau konten lainnya.
Komentar biasanya diberikan dalam bentuk tulisan dan digunakan untuk berbagi pendapat, memperluas diskusi, memberikan umpan balik, atau menyampaikan pemikiran terkait topik yang sedang dibahas. Komentar dapat berupa pendapat
pada konteksnya.
2.2.6. Text mining
Text mining kenal sebagai penambangan data teks, adalah proses penggalian informasi berkualitas tinggi dari teks yang tidak terstruktur. Text mining adalah sebuah proses untuk mengekstraksi informasi penting dari dokumen atau teks dengan menggunakan metode statistik, machine learning, dan pengolahan bahasa alami (NLP) (Trihapsari, 2016). Text mining adalah teknik yang digunakan terlibat dalam klasifikasi, pengelompokan, penyajian informasi dan pencarian informasi (Saifuddin, 2018).
Tujuan utama dari Text mining adalah mengubah data yang tidak terstruktur menjadi data terstruktur sehingga dapat dengan mudah dianalisis menggunakan metode statistik dan pembelajaran mesin. Penambangan teks melibatkan beberapa langkah termasuk akuisisi data, preprocessing teks, ekstraksi fitur, dan analisis data. Analisis frekuensi kata adalah proses menghitung frekuensi kemunculan setiap kata dalam dokumen atau korpus teks. Topic modeling adalah teknik untuk mengidentifikasi topik-topik atau subjek yang terkandung dalam dokumen atau korpus teks. Clustering adalah proses pengelompokan dokumen atau kata berdasarkan kesamaan
18
karakteristik. Classification adalah proses mengklasifikasikan teks ke dalam kategori yang sudah ditentukan sebelumnya, seperti kategori spam atau non-spam.
Text mining digunakan untuk menganalisis teks dalam skala besar, seperti analisis sentimen pada data sosial media, klasifikasi dokumen, clustering dokumen, topic modeling, analisis asosiasi, dan lain-lain. Teknik ini dapat digunakan pada berbagai macam jenis teks, seperti email, laporan, buku, artikel, dan data sosial media.
2.2.7. Pohon Keputusan
Metode pohon keputusan merupakan sebuah metode yang dapat mengubah kenyataan yang sangat besar menjadi sebuah pohon keputusan yang merepresentasikan aturan.Aturan dapat dengan mudah dipahami dengan bahasa alami (Mardi, 2017).
Pohon keputusan memiliki node pohon yang merepresentasikan atribut yang telah diuji dan setiap cabangnya merupakan suatu pembagian hasil uji serta nodedaun (leaf) merepresentasikan kelompok kelas tertentu.
Konsep dasar dari pohon keputusan adalah mengubah data menjadi model pohon keputusan, kemudian mengubah model pohon menjadi ruledan menyederhanakan rule (Setio et al., 2020). Banyak algortima yang bisa digunakan
dan C4.5. Algoritma C4.5 merupakan pengembangan dari algoritmaID (Mardi, 2017).
2.2.8. Algoritma C4.5
Pada akhir 1970-an hingga awal 1980-an, peneliti pembelajaran mesin J. Ross Quinlan menciptakan algoritma pohon keputusan yang dikenal sebagai ID3 (Iterative Dichotomizer). Quinlan kemudian menciptakan algoritma C4.5 (sering disebut pohon keputusan), yang merupakan perluasan dari algoritma ID3. Algoritma ini memiliki kelebihan yaitu mudah dipahami, fleksibel dan menarik karena dapat divisualisasikan sebagai gambar (pohon keputusan) (Nasrullah, 2018).
2.2.9. Text Prosesing
Text Processing adalah proses mengolah, mengedit, dan menganalisis teks digital untuk mendapatkan informasi yang berguna dan membuat data teks lebih mudah diterima dan diproses oleh sistem atau mesin. Text Processing memiliki berbagai aplikasi seperti analisis sentimen, klasifikasi dokumen, pengenalan entitas, dan pencarian informasi (Sihite et al., 2018)
Pada umumnya, tahapan-tahapan dalam text processing meliputi:
a. Preprocessing: tahapan ini meliputi pembacaan data mentah, konversi ke format teks, menghilangkan karakter
20
atau simbol yang tidak diperlukan, serta mengubah teks menjadi lowercase.
b. Preprocessing: tahapan ini meliputi pembacaan data mentah, konversi ke format teks, menghilangkan karakter atau simbol yang tidak diperlukan, serta mengubah teks menjadi lowercase.
c. Tokenisasi: pemisahan teks menjadi bagian-bagian yang lebih kecil yang disebut token, seperti kata, frasa, atau kalimat.
d. Stopwords removal: menghapus kata-kata yang umum dan tidak memiliki makna dalam bahasa tertentu, seperti "a",
"the", "and".
e. Stemming atau lemmatization: mengubah kata-kata dalam teks menjadi bentuk dasarnya untuk menghindari duplikasi.
f. Feature extraction: mengekstrak fitur-fitur penting dalam teks, seperti frekuensi kata, nilai TF-IDF, atau n-gram.
g. Klasifikasi: mengklasifikasikan teks ke dalam kelompok- kelompok berdasarkan kategori yang telah ditentukan sebelumnya, seperti positif/negatif, atau spam/non-spam.
Teknik text processing banyak digunakan dalam bidang pemrosesan bahasa alami (Natural Language Processing / NLP),
pada berbagai jenis teks, seperti email, media sosial, dokumen, dan lain sebagainya.
2.2.10. Indihome
IndiHome adalah merek layanan internet, telepon, dan televisi kabel yang disediakan oleh PT Telekomunikasi Indonesia Tbk (Telkom). IndiHome menawarkan paket komunikasi terpadu yang mencakup layanan internet berkecepatan tinggi, telepon rumah, televisi kabel dan aplikasi mobile untuk mengontrol dan mengakses layanan-layanan IndiHome. IndiHome telah menjadi salah satu penyedia layanan internet terbesar di Indonesia, dengan jangkauan yang luas di berbagai kota dan wilayah di seluruh negara.
22
METODE PENELITIAN 3.1 Tahapan Penelitian
Dalam penelitian ini diperlukan beberapa tahapan dalam mencapai tujuan yang telah ditetapkan. Adapun tahapan- tahapan penelitian yang dilakukan oleh penulis dapat dilihat pada gambar dibawah ini:
24
Gambar 3.1. Alur Penelitian
Berikut adalah uraian rencana tahapan penelitian, yaitu:
1. Mengidentifikasi dan rumusan masalah
Identifikasi masalah penelitian adalah proses menemukan permasalahan yang ada dalam penelitian sedangkan rumusan masalah adalah proses penyelesaian masalah, membantu memfokuskan upaya dan memprioritaskan solusi yang tepat.
2. Tujuan penelitian
Tujuan penelitian adalah membantu menentukan apa yang akan dicapai setelah penelitian selesai dilakukan.
3. Studi pustaka
Studi pustaka adalah tahap penelitian yang melibatkan pengumpulan dan analisis informasi dari sumber-sumber terpercaya seperti jurnal, buku, dan database.
4. Pengumpulan data
Pengumpulan data di Twitter dapat dilakukan dengan menggunakan rapidminer . Ekstensi ini memungkinkan untuk menghubungkan dan mengakses data dari Twitter menggunakan kredensial API Twitter Anda..
5. Pengolahan dan pelabelan data
Digunakan untuk mengelola dan melabeli data untuk melihat apakah data ulasan komentar tersebut bersifat hate comment atau tidak.
Pada tahap ini data yang diperoleh dan yang telah dilabeli kemudian dianalisis dan diolah sesuai dengan alur metode C4.5.
7. Pembuatan laporan
Setelah selesai mengumpulkan data dan mengimplementasikan kemetode C4.5 dan
selanjutnya membuat laporan yang menceritakan hasil informasi yang didapatkan.
8. Kesimpulan dan saran
Pada tahap ini melakukan analisis yang lebih detail terhadap data yang valid dan reliable untuk mendapatkan hasil yang akurat dan juga menarik kesimpulan dan memberikan saran.
3.2 Lokasi dan waktu penelitian
Objek dalam penelitian mengenai klasifikasi komentar hate cmment dengan objek penelitian adalah pengguna Twitter, penelitian dilakukan pada semester genap tahun ajaran 2022- 2023.
3.3 Alat dan Bahan Penelitian
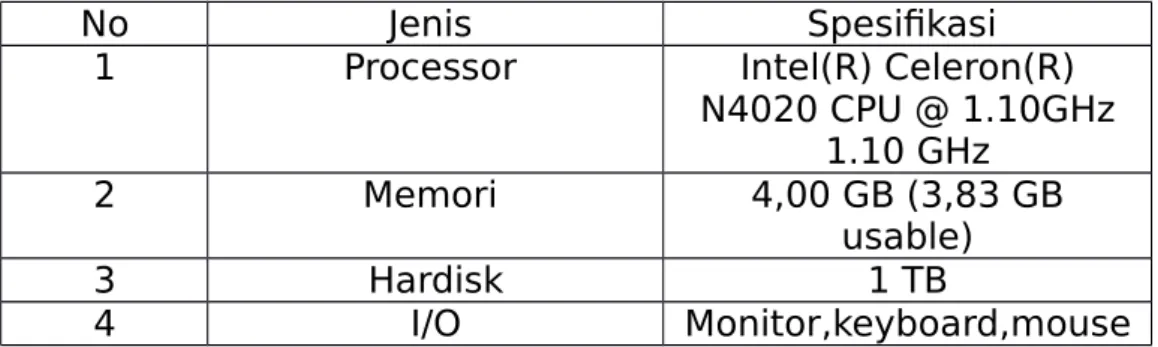
Penelitian ini menggunakan alat penelitian berupa perangkat lunak dan perangkat keras pada computer dengan spesifikasi sebagai berikut, penjelasan dapat dilihat pada table 3.1 dibawah ini:
Tabel 3. 1 Detail Spesifikasi Hardware
26
No Jenis Spesifikasi
1 Processor Intel(R) Celeron(R)
N4020 CPU @ 1.10GHz 1.10 GHz
2 Memori 4,00 GB (3,83 GB
usable)
3 Hardisk 1 TB
4 I/O Monitor,keyboard,mouse
Tabel 3. 2 Detail spesifikasi Software
No Jenis Tipe Keterangan
1 System operasi Windows
10 64 bit Digunakan untuk membuat laporan
2 Aplikasi
pengambilan data Twitter Digunakan untuk mendapatkan data
3 Aplikasi
pengolahan data Excel Digunakan untuk mengelolah data
4 Text editor Rapid
Miner Digunakan untuk
menuliskan dan
mengedit script
program.
3.4 Teknik Pengumpulan Data
Pada penelitian ini peneliti menggunakan jenis data sekunder. Pengumpulan data dilakukan yaitu melakukan Crawling data ulasan diTwitter pada layanan indihome. Proses Crawling data dilakukan dengan memanfaatkan Twitter API rapidminer sebagai akses untuk mengumpulkan data. Data ulasan kemudian disimpan dalam bentuk format file csv.
1. Studi Literatur
Teknik pengumpulan data ini dilakukan dengan mencari melalui data-data penting yang berkaitan dengan gejala yang akan diteliti. Tahap teknik pengumpulan data ini merupakan
indihome.
3.5 Input data Twitter
Pada tahap ini peneliti menyiapkan data Twitter untuk melakukan penginputan. Adapun contoh data dari Twitter pada penelitian ini dapat dilihat pada tabel 3.3.
Tabel 3. 3 komentar hate comment diTwitter
No Nama Ulasan atau komentar
1. Yoko Saputra Kenapa sih indihome kalo di chat gak pernah dibalas
2. kemenkes poy emg kau paling kontol indihome
3. IndiHomeCare Indihome parah, sinyal full tapi ketika dipake main game sinyal naik turun parah banget. Saya udah laporan beberapa kali tapi tetep sinyal naik turun
4. Lorenzo
lamaar saya seneng pake Indihome di tempat saya, lalu saya mau pindah kontrakan, bisa diatur min ?
Setelah pengambilan data selesai, maka masuk pada tahap Preprocessing, tahap ini diperlukan untuk membersihkan data dari hal yang tidak diperlukan, dengan tujuan pada tahap masuk kedalam metode C4.5 lebih optimal dalam perhitungnya, pada tahap ini melibatkan rekognisi dari isi struktur teksnya.
3.6 Text Preprocessing
Text preprocessing merupakan tahapan proses awal mempersiapkan agar teks dapat diubah menjadi lebih terstruktur dan menjadi data yang akan diolah selanjutnya
28
(Hermawan & Bellaniar Ismiati, 2020). text preprocessing merupakan langkah yang sangat penting sebelum memulai penelitian, Karena penelitian dikatakan berhasil dan lancar jika terdapat sedikit sekali kesalahan dalam text preprocessing . Text preprocessing terjadi sedemikian rupa sehingga data mentah diproses melalui beberapa langkah hingga data benar-benar siap untuk digunakan (Albab et al., 2023).
Tahapan Tahapan Text preprocessing terdiri dari proses Case Folding, Tokenizing, Stopword, dan Stemming
1. Case Folding adalah tahapan untuk mengubah semua huruf dalam dalam data menjadi huruf kecil.
Tabel 3. 4 Contoh Penerapan Case Folding Teks Tidak ada kata terlambat
untuk memulai Case folding tidak ada kata terlambat
untuk memulai
2. Tokenizing yaitu proses mengidentifikasi kata-kata dalam teks menjadi beberapa urutan yang terpotong oleh spasi atau karakter spesial.
Tabel 3. 5 Contoh Penerapan Tokenizing.
Teks Tidak ada kata terlambat untuk memulai
Tokenizing [‘tidak’,’ ada’,’ kata’,’ terlambat’,’
untuk’,’memulai’]
3. Stopword adalah sebuah kata penghubung yang tidak begitu penting,membuang kata-kata yang sering muncul, kurang
dibuang tersebut didefinisikan dalam stopword list. Contoh beberapa kata yang sering masuk ke dalam stopword list adalah ‘untuk”, “yang”, dan “itu”.
Tabel 3. 6 Contoh Penerapan Stopword Teks Tidak ada kata terlambat
untuk memulai
Stopword Tidak ada kata terlambat memulai
4. Stemming adalah proses untuk membuat kata yang berimbuhan kembali ke bentuk asalnya. Contohnya kata
“memberikan” setelah melewati tahap ini maka akan menjadi “beri”.
Tabel 3. 7 Contoh Penerapan Stemming.
Input Output
Menginsipiras
i Inspirasi
3.7 Implementasi C4.5
Pada akhir 1970-an hingga awal 1980-an, peneliti pembelajaran mesin J. Ross Quinlan menciptakan algoritma pohon keputusan yang dikenal sebagai ID3 (Iterative Dichotomizer). Quinlan kemudian menciptakan algoritma C4.5 (sering disebut pohon keputusan), yang merupakan perluasan dari algoritma ID3. Algoritma ini memiliki kelebihan yaitu mudah dipahami, fleksibel dan menarik karena dapat divisualisasikan sebagai gambar (pohon keputusan) (Nasrullah, 2018).
Pada tahapannya algoritma C4.5 memiliki 2 prinsip kerja,
30
yaitu: Membuat pohon keputusan, dan membuat aturan-aturan (rule model). Aturan aturan yang terbentuk dari pohon keputusan akan membentuk suatu kondisi dalam bentuk if then (Arifin &
Fitrianah, 2018).
Secara umum algoritma C4.5 untuk membangun pohon keputusan adalah sebagai berikut
1. Memilih atribut sebagai akar, didasarkan pada nilai gain tertinggi dari atribut-atribut yang ada
2. Membuat cabang untuk masing-masing nilai, artinya membuat cabang sesuai dengan jumlah nilai variabel gain tertinggi.
3. Membagi setiap kasus dalam cabang, berdasarkan perhitungan nilai gain tertinggi dan perhitungan dilakukan setelah perhitungan nilai gain tertinggi awal dan kemudian dilakukan proses perhitungan gain tertinggi kembali tanpa meyertakan nilai variabel gain awal.
4. Mengulangi proses dalam setiap cabang sehingga semua kasus dalam cabang memiliki kelas yang sama, mengulangi semua proses perhitungan gain tertinggi untuk masing- masing cabang kasus sampai tidak bisa lagi dilakukan proses perhitungan.
Adapun implementasi dalam algoritma Decision Tree C4.5 adalah sebagai berikut (Swastina, 2018) :
2. Hitung nilai entropy. Entropy merupakan ukuran ketidakpastian, yakni perbedaan keputusan terhadap nilai atribut tertentu. Semakin tinggi nilai entropy, semakin tinggi perbedaan keputusan (ketidakpastian).
Mencari nilai entropy dengan menggunakan rumus dalam persamaan
entropy(S) =
∑
i=0 n
−pi∗log2pi ………..
(1)
Keterangan:
S : Himpunan kasus A : fitur
n : Jumlah partisi dalam atribut Pi : Proposi dari Si terhadap S
3. Menghitung nilai gain. Gain merupakan salah satu langkah pemilihan atribut yang digunakan untuk memilih tes atribut setiap simpul pada pohon keputusan atau dengan kata lain gain merupakan tingkat pengaruh suatu atribut terhadap keputusan atau ukuran efektifitas suatu variabel dalam mengklasifikasikan data. Gain dihitung dengan rumus yang ditulis sebagai
32
gain(S,A)=Entropy(S) -
∑
i=0 n |Si|
|S|xEntropy(Si) ……….
(2)
Keterangan:
S : Himpunan kasus A : Atribut
N : Jumlah partisi dalam atribut A
|Si| : jumlah kasus pada partisi ke-i |S| : jumlah kasus dalam
Pada algoritma C4.5, nilai gain digunakan untuk menentukan variabel mana yang menjadi node dari suatu pohon keputusan. Suatu variabel yang memiliki gain tertinggi akan dijadikan node di pohon keputusan.
3.8 Jadwal penelitian
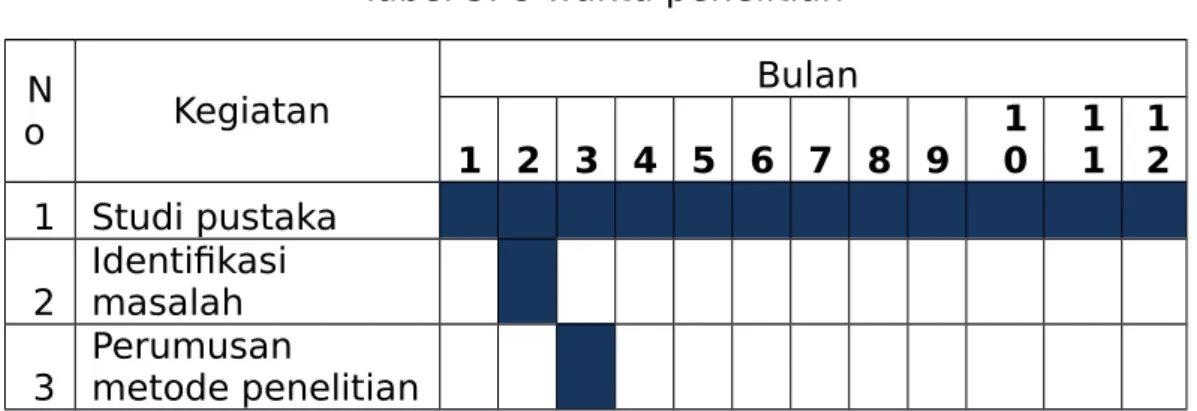
Adapun jadwal penelitian yang dilakukan oleh penelis untuk pembuatan laporan ini dapat dilihat pada tabel tabel 3.8 berikut.
Tabel 3. 8 waktu penelitian N
o Kegiatan Bulan
1 2 3 4 5 6 7 8 9 1
0 1
1 1 2 1 Studi pustaka
2 Identifikasi masalah 3 Perumusan
metode penelitian
4 data
5 Pengolahan data 6 Analisis data 7 Input dan
pengujian 8 Evaluasi dan
pembahasan 9 Pembuatan
laporan 1
0 Seminar
DAFTAR PUSTAKA
Aderibigbe. (2018). KLASIFIKASI DATA SCIMAGO JOURNAL DAN COUNTRY RANK MENGGUNAKAN ALGORITMA C4.5 TUGAS.
Energies, 6(1), 1–8.
http://journals.sagepub.com/doi/10.1177/1120700020921110
%0Ahttps://doi.org/10.1016/j.reuma.2018.06.001%0Ahttps://
doi.org/10.1016/j.arth.2018.03.044%0Ahttps://reader.elsevier .com/reader/sd/pii/S1063458420300078?
token=C039B8B13922A2079230DC9AF11A333E295FCD8 Akhir, T. (2019). MENGGUNAKAN METODE ’ K-NEAREST ’
NEIGHBOR ”.
Al Khadafi, M., Kurnia Paranitha Kartika, & Filda Febrinita. (2022).
Penerapan Metode Naïve Bayes Classifier Dan Lexicon Based Untuk Analisis Sentimen Cyberbullying Pada Bpjs. JATI (Jurnal Mahasiswa Teknik Informatika), 6(2), 725–733.
https://doi.org/10.36040/jati.v6i2.5633
Albab, M. U., P, Y. K., & Fawaiq, M. N. (2023). Optimization of the Stemming Technique on Text preprocessing President 3 Periods Topic. 20(2), 1–10.
Almujaddedi, M. S., & Hayati, R. (2022). Perspective of Islamic Law on Hate Comments in Social Media Tinjauan Hukum Islam Terhadap Hate Comment Di Media Sosial. Jurnal
Cendekia Hukum: Vol, 7, 243–256.
https://doi.org/10.3376/jch.v7i2.466
Ansori. (2015). Pembahasan Klasifikasi. Paper Knowledge . Toward a Media History of Documents, 3(April), 49–58.
Arifin, M. F., & Fitrianah, D. (2018). Rekomendasi Penerimaan Mitra Penjualan Studi Kasus : PT Atria Artha Persada.
IncomTech, 8(2), 87–102.
https://doi.org/10.22441/incomtech.v8i1.2198
34
artikel/14366/Pengaruh-Positif-dan-Negatif-Media-Sosial- Terhadap-Masyarakat.html
Hermawan, L., & Bellaniar Ismiati, M. (2020). Pembelajaran Text Preprocessing berbasis Simulator Untuk Mata Kuliah Information Retrieval. Jurnal Transformatika, 17(2), 188.
https://doi.org/10.26623/transformatika.v17i2.1705
Ihsan, F., Iskandar, I., Harahap, N. S., & Agustian, S. (2021).
Decision tree algorithm for multi-label hate speech and abusive language detection in Indonesian Twitter. Jurnal Teknologi Dan Sistem Komputer, 9(4), 199–204.
https://doi.org/10.14710/jtsiskom.2021.13907
Irfani, F. F., Fauzi, M. A., & Sari, Y. A. (2018). Klasifikasi Berita pada Twitter Menggunakan Metode Naive Bayes dan Query Expansion Hipernim-Hiponim. Jurnal Pengembangan Teknologi Informasi Dan Ilmu Komputer (J-PTIIK) Universitas Brawijaya, 2(12), 6093–6099.
Kustiyahningsih, Y., & Rahmanita, E. (2016). Aplikasi Sistem Pendukung Keputusan Menggunakan Algoritma C4.5. untuk Penjurusan SMA. Jurnal Semantec, 5(2), 101–108.
Mardi, Y. (2017). Data Mining : Klasifikasi Menggunakan Algoritma
C4.5. Edik Informatika, 2(2), 213–219.
https://doi.org/10.22202/ei.2016.v2i2.1465
Muwafiq, A. Z., Sumarlam, S., & Kristina, D. (2019). Discursive Strategies of Verbal Violence in the Users Comments on Facebook News Updates. Jurnal Ilmiah Peuradeun, 7(3), 413.
https://doi.org/10.26811/peuradeun.v7i3.297 35
Nasrullah, A. H. (2018). Penerapan Metode C4.5 untuk Klasifikasi Mahasiswa Berpotensi Drop Out. ILKOM Jurnal Ilmiah, 10(2), 244–250. https://doi.org/10.33096/ilkom.v10i2.300.244-250 Parulian, H., & Putranto, R. D. (2022). Pidana Ujaran Kebencian
Melalui Media Sosial Ditinjau dalam Perspektif Undang- Undang Nomor 19 Tahun 2016 tentang Perubahan Atas Undang Undang Nomor 11 Tahun 2008 tentang Informasi dan Transaksi Elektronik (UU ITE). Jurnal Pendidikan Dan Konseling (JPDK), 4(4), 4909–4919.
Putu, N., Saraswati, V. D., Yudistira, N., & Adikara, P. P. (2023).
Analisis Sentimen terhadap Perundungan Siber pada Twitter menggunakan Algoritma Bidirectional Encoder Representations from Transformer (BERT). 7(2), 6980–6987.
http://j-ptiik.ub.ac.id
Rheza, M. A., & Metandi, F. (2020). IMPLEMENTASI METODE K- MEANS CLUSTERING UNTUK PENENTUAN JENIS KOMENTAR PADA TWEET PSSI. 2, 73–78.
Saifuddin, L. H. (2018). Pendekatan Text mining Sebagai Sistem Pendeteksi. 1–6.
Sanjulya, L., Vidyarini, T. N., Prodi, V. M., Komunikasi, I., Kristen, U., & Surabaya, P. (2020). JURNAL E-KOMUNIKASI PROGRAM STUDI ILMU KOMUNIKASI UNIVERSITAS KRISTEN PETRA, SURABAYA Studi Komparatif: Analisis Isi Pesan Komunikasi Pemasaran Melalui Instagram (Indihome vs First Media). 1–
12.
Saputro, B. I. (2017). Penerapan Sistem Klasifikasi Perpustakaan Arkeologi di Perpustakaan Balai Arkeologi Daerah Istimewa Yogyakarta. Berkala Ilmu Perpustakaan Dan Informasi, 13(2), 107. https://doi.org/10.22146/bip.23453
Setio, P. B. N., Saputro, D. R. S., & Bowo Winarno. (2020).
Klasifikasi Dengan Pohon Keputusan Berbasis Algoritme C4.5.
36
Creative Media, 11–2018.
Swastina, L. (2018). Penerapan Algoritma C4 . 5 Untuk Penentuan Jurusan Mahasiswa. Gema Aktualita, 2(1), 93–98.
Tineges, R., Triayudi, A., & Sholihati, I. D. (2020). Analisis Sentimen Terhadap Layanan Indihome Berdasarkan Twitter Dengan Metode Klasifikasi Support Vector Machine (SVM).
Jurnal Media Informatika Budidarma, 4(3), 650.
https://doi.org/10.30865/mib.v4i3.2181
Trihapsari, E. (2016). SKRIPSI Klasifikasi Cyber Bullying Pada Media Sosial Twitter Dengan Menggunakan Cyber Bullying Classification on Twitter Social Media Using Naïve Bayes Algorithm. Klasifikasi Cyber Bullying Pada Media Sosial Twitter Dengan Menggunakan Algoritma Naïve Bayes.
Widi, S. (2023). No Title. Dataindonesia.
https://dataindonesia.id/internet/detail/pengguna-media- sosial-di-indonesia-sebanyak-167-juta-pada-2023
Yan, K., Arisandi, D., & Tony, T. (2022). Analisis Sentimen Komentar Netizen Twitter Terhadap Kesehatan Mental Masyarakat Indonesia. Jurnal Ilmu Komputer Dan Sistem Informasi, 10(1). https://doi.org/10.24912/jiksi.v10i1.17865 Zahrin Nur Azizah. (2022). No Title. Yoursay.
https://yoursay.suara.com/kolom/2022/03/28/141951/hate- comment-cara-keliru-masyarakat-dalam-menyampaikan- sebuah-kritik#:~:text=Hate comment adalah salah satunya,warna kulit%2C dan lain sebagainya.
Zukhrufillah, I. (2018). Gejala Media Sosial Twitter Sebagai Media 37
Sosial Alternatif. Al-I’lam: Jurnal Komunikasi Dan Penyiaran Islam, 1(2), 102. https://doi.org/10.31764/jail.v1i2.235
38