HALAMAN JUDUL
LAPORAN PROJECT BASED
TRAVEL COST METHOD (TCM) KARYAWAN WIRASWASTA DI KOTA SEMARANG
(Disusun untuk memenuhi tugas mata kuliah Penilaian Tanah)
Disusun Oleh:
Kelompok IV-A
Novika Ita Cahyanti 21110120120006
William Gozali 21110120130105
Dara Jati Septiningdiah 21110120140059
Fadillah Eka Putri 21110120140158
DEPARTEMEN TEKNIK GEODESI FAKULTAS TEKNIK
UNIVERSITAS DIPONEGORO
OKTOBER 2023
ii
KATA PENGANTAR
Puji syukur kami panjatkan kepada Tuhan Yang Maha Esa yang telah memberikan rahmat dan karunianya, sehingga kami dapat menyelesaikan laporan project based ini dengan baik. Laporan ini penyusun buat untuk memenuhi tugas mata kuliah Penilaian Tanah. Selama mengerjakan laporan ini, penyusun telah dibantu oleh beberapa pihak. Oleh karena itu, ucapan terima penyusun ucapkan kepada:
1. Bapak Dr. L.M. Sabri, S.T., M.T., selaku ketua Departemen Teknik Geodesi Fakultas Teknik Universitas Diponegoro.
2. Bapak Fauzi Janu Amarrohman, S.T., M.Eng., selaku dosen pengampu mata kuliah Penilaian Tanah.
3. Bapak Arwan Putra Wijaya, S.T., M.T., selaku dosen pengampu mata kuliah Penilaian Tanah yang telah membimbing kami dalam penyusunan laporan ini.
4. Seluruh pihak yang telah membantu kami dalam menyusun laporan project based Penilaian Tanah.
Penyusun menyadari bahwa masih banyak kekurangan dalam laporan ini, baik dari materi maupun teknik penyajiannya, mengingat kurangnya pengetahuan dan pengalaman penyusun. Oleh karena itu, kritik dan saran yang membangun sangat penyusun harapkan untuk hasil yang lebih baik. Semoga tugas ini dapat bermanfaat, khususnya bagi mahasiswa Program Studi Teknik Geodesi Fakultas Teknik Universitas Diponegoro dan masyarakat pada umumnya.
Semarang, Oktober 2023
Penyusun
iii
DAFTAR ISI
HALAMAN JUDUL ... i
KATA PENGANTAR ... ii
DAFTAR ISI ... iii
DAFTAR GAMBAR ... vi
DAFTAR TABEL ... ix
DAFTAR LAMPIRAN ... x
BAB I PENDAHULUAN ... 1
I.1 Latar Belakang ... 1
I.2 Rumusan Masalah ... 2
I.3 Tujuan dan Manfaat Penelitian ... 2
I.3.1 Tujuan ... 2
I.3.2 Manfaat ... 3
I.4 Batasan Masalah ... 3
I.5 Sistematika Penulisan ... 4
BAB II TINJAUAN PUSTAKA ... 5
II.1 Konsep Travel Cost Method (TCM) ... 5
II.1.1 Konsep Zonal Travel Cost Method (ZTCM) ... 6
II.1.2 Konsep Individual Travel Cost Method (ITCM) ... 7
II.2 Teknik Pengambilan Sampel (Sampling) ... 8
II.3 Analisis Regresi Linear Berganda ... 10
II.4 Uji Asumsi Klasik ... 11
II.4.1 Uji Normalitas ... 11
II.4.2 Uji Autokorelasi ... 12
II.4.3 Uji Multikolinearitas ... 13
II.4.4 Uji Heterokedastisitas ... 14
iv
II.5 Software SPSS ... 14
II.6 ArcGIS ... 15
II.7 Deskripsi Lokasi Penelitian ... 16
BAB III METODOLOGI PENELITIAN ... 18
III.1 Alat dan Data ... 18
III.1.1 Alat ... 18
III.1.2 Data ... 18
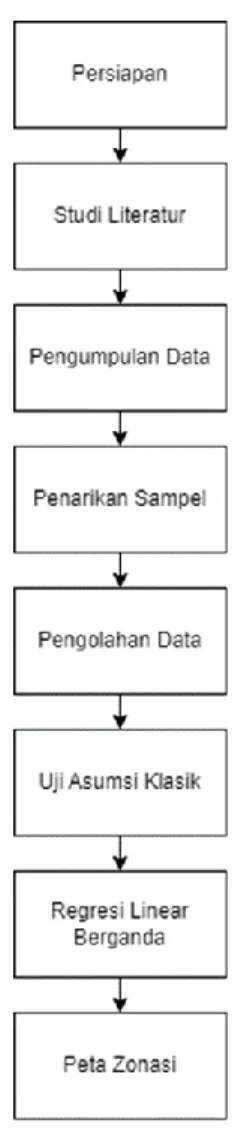
III.2 Persiapan ... 19
III.2.1 Diagram Alir Penelitian ... 19
III.2.2 Studi Literatur ... 20
III.3 Pengumpulan Data Kuesioner ... 20
III.3.1 Pengumpulan Data ... 20
III.3.2 Tahapan Penarikan Sampel (Sampling) ... 20
III.4 Tahapan Pelaksanaan Pengolahan Data... 20
III.4.1 Tahapan Pengolahan Uji Asumsi Klasik ... 21
III.4.2 Tahapan Pengolahan Regresi Linear Berganda ... 26
III.4.3 Tahapan Pembuatan Peta Zonasi ... 28
BAB IV HASIL DAN ANALISIS ... 31
IV.1 Hasil dan Analisis Uji Asumsi Klasik TCM... 31
IV.1.1 Hasil dan Analisis Uji Normalitas ... 31
IV.1.2 Hasil dan Analisis Uji Autokorelasi... 37
IV.1.3 Hasil dan Analisis Uji Multikolinearitas ... 40
IV.1.4 Hasil dan Analisis Uji Heterokedastisitas ... 42
IV.2 Hasil dan Analisis Regresi TCM ... 46
IV.3 Hasil dan Analisis Peta Zonasi ... 51
BAB V PENUTUP ... 53
v
V.1 Simpulan ... 53
V.2 Saran ... 54
DAFTAR PUSTAKA ... xi
LAMPIRAN ... xii
vi
DAFTAR GAMBAR
Gambar II-1 Software IMB SPSS Statistic 25 ... 14
Gambar II-2 Tampilan Awal Software ArcMap 10.8 ... 15
Gambar II-3 Kota Semarang ... 16
Gambar III-1 Laptop Asus Vivobook 14 ... 18
Gambar III-2 Diagram Alir Penelitian ... 19
Gambar III-3 Sub Menu Import Data ... 21
Gambar III-4 Data Setelah Import ... 21
Gambar III-5 Jendela Linear Regression ... 22
Gambar III-6 Parameter Regresi Linear ... 22
Gambar III-7 Sub Menu 1-Sample K-S ... 22
Gambar III-8 Hasil Uji Normalitas ... 23
Gambar III-9 Jendela One-Sample Kolmogorov-Smirnov Test ... 23
Gambar III-10 Menu Transform ... 24
Gambar III-11 Penulisan Target Variabel ... 24
Gambar III-12 Tampilan ABRES ... 25
Gambar III-13 Hasil Regresi Linear Kedua ... 25
Gambar III-14 Hasil Residual Statistics ... 25
Gambar III-15 Data Penelitian ... 26
Gambar III-16 Regression pada Data Analysis ... 26
Gambar III-17 Jendela Regression ... 27
Gambar III-18 Hasil Regresi Linear Berganda ... 27
Gambar III-19 Hasil Multiple R, Adjusted R Square, Significance F ... 27
Gambar III-20 Persamaan TCM ... 28
Gambar III-21 Tampilan Awal ArcGIS ... 28
Gambar III-22 Add Data SHP Titik UNDIP dan SHP Kota Semarang ... 29
Gambar III-23 Multiple Ring Buffer ... 29
Gambar III-24 Setting Parameter Multiple Ring Buffer ... 29
Gambar III-25 Hasil Multiple Ring Buffer ... 30
Gambar IV-1 Hasil Uji Normalitas Zona 1 ... 31
Gambar IV-2 Hasil Uji Normalitas Zona 2 ... 32
Gambar IV-3 Hasil Uji Normalitas Zona 3 ... 32
vii
Gambar IV-4 Hasil Uji Normalitas Zona 4 ... 32
Gambar IV-5 Hasil Uji Normalitas Zona 5 ... 33
Gambar IV-6 Histogram Uji Normalitas Zona 1 ... 34
Gambar IV-7 Histogram Uji Normalitas Zona 2 ... 34
Gambar IV-8 Histogram Uji Normalitas Zona 3 ... 34
Gambar IV-9 Histogram Uji Normalitas Zona 4 ... 35
Gambar IV-10 Histogram Uji Normalitas Zona 5 ... 35
Gambar IV-11 Hasil P-Plot Uji Normalitas Zona 1 ... 36
Gambar IV-12 Hasil P-Plot Uji Normalitas Zona 2 ... 36
Gambar IV-13 Hasil P-Plot Uji Normalitas Zona 3 ... 36
Gambar IV-14 Hasil P-Plot Uji Normalitas Zona 4 ... 37
Gambar IV-15 Hasil P-Plot Uji Normalitas Zona 5 ... 37
Gambar IV-16 Hasil Uji Autokorelasi Durbin Watson Zona 1 ... 38
Gambar IV-17 Hasil Uji Autokorelasi Durbin Watson Zona 2 ... 38
Gambar IV-18 Hasil Uji Autokorelasi Durbin Watson Zona 3 ... 38
Gambar IV-19 Hasil Uji Autokorelasi Durbin Watson Zona 4 ... 38
Gambar IV-20 Hasil Uji Autokorelasi Durbin Watson Zona 5 ... 38
Gambar IV-21 Hasil Uji Multikolinearitas Zona 1 ... 40
Gambar IV-22 Hasil Uji Multikolinearitas Zona 2 ... 40
Gambar IV-23 Hasil Uji Multikolinearitas Zona 3 ... 41
Gambar IV-24 Hasil Uji Multikolinearitas Zona 4 ... 41
Gambar IV-25 Hasil Uji Multikolinearitas Zona 5 ... 41
Gambar IV-26 Hasil Uji Heteroskedastisitas Zona 1 ... 42
Gambar IV-27 Hasil Uji Heteroskedastisitas Zona 2 ... 42
Gambar IV-28 Hasil Uji Heteroskedastisitas Zona 3 ... 43
Gambar IV-29 Hasil Uji Heteroskedastisitas Zona 4 ... 43
Gambar IV-30 Hasil Uji Heteroskedastisitas Zona 5 ... 43
Gambar IV-31 Scatter Plotter Uji Heterokedastisitas Zona 1 ... 44
Gambar IV-32 Scatter Plotter Uji Heterokedastisitas Zona 2 ... 44
Gambar IV-33 Scatter Plotter Uji Heterokedastisitas Zona 3 ... 45
Gambar IV-34 Scatter Plotter Uji Heterokedastisitas Zona 4 ... 45
Gambar IV-35 Scatter Plotter Uji Heterokedastisitas Zona 5 ... 45
viii
Gambar IV-36 Hasil Regresi Zona 1 ... 46
Gambar IV-37 Hasil Regresi Zona 2 ... 47
Gambar IV-38 Hasil Regresi Zona 3 ... 48
Gambar IV-39 Hasil Regresi Zona 4 ... 49
Gambar IV-40 Hasil Regresi Zona 5 ... 50
ix
DAFTAR TABEL
Tabel II-1 Hipotesis Uji Autokorelasi ... 13
Tabel IV-1 Hasil Uji Normalitas Setiap Zona ... 33
Tabel IV-2 Hasil Uji Autokorelasi Durbin Watson Masing-Masing Zona ... 38
Tabel IV-3 Hasil Uji Syarat Autokorelasi ... 39
Tabel IV-4 Nilai Tolerance dan VIF Setiap Zona ... 41
Tabel IV-5 Hasil Signifikansi Uji Heteroskedastisitas Setiap Zona ... 43
Tabel IV-6 Kategori Korelasi... 46
Tabel IV-7 Hasil TCM Zona 1 ... 47
Tabel IV-8 Hasil TCM Zona 2 ... 48
Tabel IV-9 Hasil TCM Zona 3 ... 49
Tabel IV-10 Hasil TCM Zona 4 ... 50
Tabel IV-11 Hasil TCM Zona 5 ... 51
x
DAFTAR LAMPIRAN
Lampiran 1. Data Karyawan Wiraswata di Kota Semarang ... xiii Lampiran 2. Layout Peta Zonasi Nilai Ekonomi Kawasan Kota Semarang ... xviii
1
BAB I
PENDAHULUAN
I.1 Latar Belakang
Pada tahun 2023, berdasarkan Laporan Wakil Rektor Akademik dan Kemahasiswaan Universitas Diponegoro menyatakan bahwa jumlah mahasiswa baru Universitas Diponegoro tahun akademik 2023/2024 adalah sebanyak 14.445 orang. Peningkatan jumlah mahasiswa akan sejalan dengan meningkatnya jumlah populasi, kebutuhan hidup, dan sektor ekonomi yang ada di kawasan UNDIP dan sekitarnya. Hal ini tentu saja membawa manfaat ekonomis dalam meningkatkan kesejahteraan masyarakat yang ada di sekitarnya, seperti munculnya usaha-usaha dalam bentuk barang dan jasa. Manfaat ekonomi tersebut dapat dioptimalkan dengan melakukan berbagai kebijakan pengembangan potensi kawasan di sekitar UNDIP. Sebagai dasar untuk perumusan kebijakan tersebut dapat digunakan hasil perhitungan nilai ekonomi kawasan di sekitar UNDIP, khususnya dari aspek profesi (karyawan swasta). Komponen-komponen profesi karyawan swasta yang dinilai dapat menjadi referensi bagi pihak-pihak terkait guna pengambilan keputusan dan kebijakan dalam mengembangkan berbagai ragam jenis usaha sebagai sumber pendapatan potensial yang dapat dihasilkan untuk keberlangsungan dan kelestarian kawasan di sekitar UNDIP.
Nilai ekonomi didefinisikan sebagai pengukuran jumlah maksimum seseorang untuk mengorbankan barang atau jasa guna memperoleh barang atau jasa lainnya. Secara formal, konsep ini disebut sebagai keinginan membayar (willingness to pay) seseorang terhadap barang atau jasa yang dihasilkan oleh sumberdaya alam dan lingkungan. Dalam perhitungan kelayakan ekonomi pada suatu pengembangan dapat dilihat dari dua sisi, yakni dilihat dari potensi sumberdaya dan potensi pasarnya. Berdasarkan pengertian tersebut, yang dimaksudkan sebagai nilai ekonomi kawasan UNDIP adalah agregasi besar kemampuan membayar karyawan terhadap manfaat yang diperolehnya dari kawasan UNDIP. Sebagai proxy dari ukuran besar kemampuan membayar karyawan swasta atas hasil usaha barang dan jasa yang dibangun tersebut adalah biaya kunjungan karyawan (travel cost).
2 Proxy tersebut dalam metode valuasi ekonomi sumberdaya alam dan lingkungan, termasuk kawasan ekonomi UNDIP, dirumuskan dalam suatu metode valuasi ekonomi yaitu Travel Cost Method (TCM). Metode ini berguna untuk mengestimasi nilai daerah yang menyediakan berbagai sumber kegiatan perputaran roda ekonomi. Penilaian dengan metode ini pada umumnya digunakan untuk menghitung nilai guna langsung suatu kawasan tertentu yang mempunyai keunikan ataupun daya tarik pengunjung, seperti kawasan ekonomi di sekitar UNDIP.
Pendekatan dengan metode ini menganggap bahwa biaya perjalanan serta waktu yang dikorbankan para karyawan swasta untuk menuju kawasan UNDIP itu dianggap sebagai nilai lingkungan yang karyawan bersedia untuk membayar.
I.2 Rumusan Masalah
Rumusan masalah yang muncul akibat dari latar belakang yang telah dijabarkan sebelumnya sebagai berikut:
1. Apa pendekatan perhitungan yang digunakan dalam perhitungan zona nilai ekonomi kawasan UNDIP?
2. Bagaimana korelasi antara perhitungan uji asumsi klasik yang digunakan pada perhitungan sampel data terhadap perhitungan zona nilai ekonomi kawasan UNDIP?
3. Apa faktor yang mempengaruhi peningkatan ataupun penurunan besarnya total biaya perjalanan (total travel cost) karyawan swasta ke kawasan UNDIP?
I.3 Tujuan dan Manfaat Penelitian
Berikut ini tujuan dan manfaat yang dapat diperoleh dari penelitian yang dilakukan oleh kelompok IV-A.
I.3.1 Tujuan
Tujuan dalam penyusunan laporan ini sebagai berikut:
1. Untuk mengetahui dan memahami pendekatan perhitungan yang digunakan dalam perhitungan zona nilai ekonomi kawasan UNDIP.
2. Untuk mengetahui dan memahami korelasi antara perhitungan uji asumsi klasik yang digunakan pada perhitungan sampel data terhadap perhitungan zona nilai ekonomi kawasan UNDIP.
3 3. Untuk mengetahui dan memahami faktor yang mempengaruhi peningkatan ataupun penurunan besarnya total biaya perjalanan (total travel cost) karyawan swasta ke kawasan UNDIP.
I.3.2 Manfaat
Manfaat yang didapat pada pelaksanaan kegiatan penelitian yang dilakukan oleh kelompok IV-A sebagai berikut:
1. Bagi Mahasiswa
Hasil penelitian ini diharapkan mampu memberikan gambaran jelas bagi mahasiswa mengenai teknik perhitungan metode TCM (Travel Cost Method) dalam menghitung zona nilai ekonomi kawasan di sekitar UNDIP.
2. Bagi Pihak Kampus
Hasil penelitian ini diharapkan dapat berkontribusi dalam memenuhi tugas mata kuliah Penilaian Tanah dalam mengaplikasikan data penilaian tanah berupa data survei transaksi atau penawaran dengan menggunakan metode Travel Cost Method (TCM) sebagai bentuk dalam pemahaman terhadap capaian Rencana Pembelajaran Semester (RPS).
3. Bagi Karyawan Swasta dan Kawasan Universitas Diponegoro
Hasil penelitian ini diharapkan dapat menjadi referensi bagi pihak-pihak terkait guna pengambilan keputusan dan kebijakan dalam mengembangkan berbagai ragam jenis usaha sebagai sumber pendapatan potensial yang dapat dihasilkan untuk keberlangsungan dan kelestarian kawasan di sekitar UNDIP.
I.4 Batasan Masalah
Pembatasan suatu masalah digunakan untuk menghindari adanya penyimpangan maupun pelebaran pokok masalah agar penelitian tersebut lebih terarah dan memudahkan dalam pembahasan sehingga tujuan penelitian akan tercapai. Beberapa batasan masalah dalam penelitian ini sebagai berikut:
1. Lokasi kegiatan penelitian ini hanya dilaksanakan di kawasan sekitar UNDIP.
2. Objek penelitian yang digunakan dalam kegiatan ini hanya kepada karyawan swasta yang berasal dari Kota Semarang.
4 3. Parameter yang digunakan dalam penelitian ini meliputi data biaya perjalanan karyawan swasta dari rumah menuju kawasan UNDIP, biaya akomodasi dan living cost, usia, pendidikan, penghasilan, pekerjaan, dan frekuensi kunjungan ke kawasan di sekitar UNDIP.
4. Metode yang digunakan dalam perhitungan sampel data menggunakan perhitungan uji asumsi klasik yang meliputi uji normalitas, uji multikolinearitas, uji heteroskedatisitas, dan uji otokorelasi. Dalam perhitungan zona nilai ekonomi kawasan menggunakan metode Travel Cost Method (TCM), sedangkan dalam pembobotannya menggunakan analisis regresi TCM.
I.5 Sistematika Penulisan
Sistematika disusun untuk dapat memberikan gambaran yang jelas dan terarah, serta lebih memudahkan dalam menangkap keseluruhan laporan ini maka digunakan sistematika penulisan penelitian sebagai berikut:
BAB I PENDAHULUAN
Pada bab ini berisi mengenai latar belakang, rumusan masalah, tujuan dan manfaat, batasan masalah dan sistematika penulisan dari penelitian.
BAB II TINJAUAN PUSTAKA
Pada bab ini berisi mengenai dasar teori yang digunakan sebagai acuan serta pendukung dari penelitian.
BAB III METODOLOGI PENELITIAN
Pada bab ini membahas mengenai tahapan-tahapan dalam pelaksanaan penelitian, seperti alat dan data, diagram alir dan pelaksanaan pengolahan data.
BAB IV HASIL DAN ANALISIS
Bab ini membahas mengenai hasil dan analisis penelitian dari pengolahan yang dilakukan.
BAB V PENUTUP
Pada bab ini berisi mengenai simpulan dan saran dari penelitian yang telah dilakukan berdasarkan rumusan masalah yang telah dibuat dan saran yang dapat digunakan untuk penelitian selanjutnya.
5
BAB II
TINJAUAN PUSTAKA
II.1 Konsep Travel Cost Method (TCM)
Metode Travel Cost Method (TCM) digunakan untuk mengestimasi nilai guna ekonomi yang berhubungan dengan ekosistem atau lokasi-lokasi yang dimanfaatkan untuk rekreasi. TCM dapat digunakan untuk mengestimasi manfaat atau biaya ekonomi yang dihasilkan dari beberapa hal berikut ini (Cristiany, 2013):
1. Perubahan biaya akses untuk suatu lokasi wisata 2. Eliminasi lokasi wisata yang ada
3. Penambahan lokasi wisata baru
4. Perubahan kualitas lingkungan pada suatu lokasi wisata
Premis dasar dari TCM adalah bahwa waktu dan biaya perjalanan yang dibelanjakan oleh individu untuk mengunjungi suatu lokasi mencerminkan ‘harga’
bagi akses ke lokasi itu. Dengan demikian, kesediaan membayar (willingness to pay) orang-orang untuk mengunjungi lokasi itu dapat diestimasi berdasarkan banyaknya perjalanan yang mereka lakukan dengan beragam biaya perjalanan. Hal ini analog dengan estimasi kesediaan-membayar (WTP) orang-orang itu untuk suatu barang yang dipasarkan berdasarkan kuantitas barang yang diminta pada beragam harga. TCM dipilih untuk valuasi ini berdasarkan dua alasan utama sebagai berikut:
1. Lokasi sangat bernilai bagi orang-orang sebagai lokasi wisata. Di lokasi ini tidak ada spesies langka atau keunikan lain yang akan membuat “non-use values” di lokasi ini signifikan.
2. Anggaran bagi proyek untuk melindungi lokasi ini relatif murah, sehingga penggunaan metode yang relatif murah seperti TCM menjadi sangat menarik.
Prinsip yang mendasari pendekatan TCM ada-lah teori permintaan konsumen yang men-jelaskan bahwa nilai yang ditempatkan seseorang pada lingkungan dapat dijelaskan oleh biaya yang dikeluarkan individu menuju tempat yang dikunjungi. Tujuan TCM adalah untuk menentukan nilai guna SDA dengan metode tidak langsung atau pendekatan proxy biaya yang dikeluarkan untuk menggunakan layanan SDA digunakan sebagai perkiraan (proxy) untuk
6 menentukan harga SDA yang diteliti. Terdapat 2 (dua) tipe pendekatan yang dapat dilakukan dalam TCM, yaitu Zonal Travel Cost Method (ZTCM) dan Individual Travel Cost Method (ITCM) (Sianturi, 2022).
II.1.1 Konsep Zonal Travel Cost Method (ZTCM)
Zonal Travel Cost Method (ZTCM) adalah estimasi TCM berdasarkan data yang berhubungan dengan zona asal pengunjung (pengelompokan zona asal).
Pendekatan ZTCM termasuk yang relatif mudah dan murah karena data yang diperlukan relatif banyak mengandalkan data sekunder dan beberapa data sederhana dari responden saat survei. Pendekatan ini mengestimasi bahwa jumlah kunjungan merupakan biaya perjalanan yang didasarkan pada zona asal pengunjung (Sianturi, 2022). Tempat rekreasi dibagi ke dalam beberapa zona kunjungan dan diperlukan data jumlah pengunjung per tahun. Lalu diperoleh data jumlah kunjungan per 1.000 penduduk (data jarak, waktu perjalanan, serta biaya setiap perjalanan per satuan jarak). Biaya perjalanan diperoleh secara keseluruhan dan kurva permintaan untuk kunjungan ke tempat wisata. Berikut ini tahapan pelaksanaan ZTCM:
1. Mengidentifikasi lokasi dan mengumpulkan data pengunjung yang berhubungan dengan daerah asal mereka serta jumlah kunjungan ke lokasi dalam jangka waktu tertentu, misalnya satu tahun.
2. Mendefinisikan zona asal, kemudian mengalokasikan pengunjung berdasarkan zona yang lebih sesuai.
3. Mengkalkulasikan zona kunjungan per keluarga ke lokasi (wisata) dan menghitung rata-rata biaya perjalanan dari setiap zona ke lokasi wisata.
4. Menggunakan data sensus untuk memperoleh variabel yang berhubungan dengan karakteristik sosial ekonomi tiap zona.
5. Menggunakan data (3) dan (4) untuk mengestimasi fungsi (persamaan) perjalanan.
6. Menggambarkan kurva permintaan (demand curve) dan menentukan surplus konsumen berdasarkan kurva tersebut.
7. Mengkalkulasikan total surplus konsumen berdasarkan zona.
8. Estimasi dari total surplus konsumen tiap zona digunakan untuk mendapatkan total surplus konsumen secara keseluruhan.
7 Persamaan dari pendekatan ZTCM sebagai berikut.
𝑉ℎ𝑗/𝑁ℎ = 𝑓(𝑃ℎ𝑗, 𝑆𝑂𝐶ℎ, 𝑆𝑈𝐵ℎ) ...(II-1) Dimana:
𝑉ℎ𝑗/𝑁ℎ = Tingkat partisipasi zona h (kunjungan perkapita ke lokasi (wisata) j)
𝑃ℎ𝑗 = Biaya perjalanan dari zona h ke lokasi j
𝑆𝑂𝐶ℎ = Vektor dari karakteristik sosial ekonomi zona h
𝑆𝑈𝐵ℎ = Vektor dari karakteristik lokasi rekreasi substitusi untuk individu di zona h
II.1.2 Konsep Individual Travel Cost Method (ITCM)
Individual Travel Cost Method (ITCM) merupakan perhitungan TCM yang digunakan untuk menghitung tingkat kunjungan per individu pada satu periode waktu. Metode ini adalah mengestimasi CVM berdasarkan data survei dari setiap individu (pengunjung), bukan berdasarkan pengelompokan zona (ITCM lebih sering digunakan). Oleh karena itu, metode ITCM didasarkan pada data primer yang diperoleh melalui survei lapangan atau wawancara individu pengunjung serta pengaplikasian teknik statistika. Metode ini memiliki kelebihan dimana hasil yang didapat lebih akurat dibandingkan metode ZTCM karena data diperoleh secara langsung dari pengunjung. ITCM memiliki hipotesis dimana kunjungan ke objek wisata sangat dipengaruhi oleh besarnya biaya perjalanan yang dikeluarkan, sehingga metode ini menghasilkan kurva yang memiliki kemiringan negatif karena adanya hubungan negatif antara jumlah kunjungan dan biaya perjalanan.
Sederhananya, ketika terjadi kenaikan pada biaya perjalanan ke suatu objek wisata maka pengunjung tersebut akan mulai mengurangi kunjungan ke objek wisata tersebut dan lebih memilih untuk pergi ke objek wisata lain yang memiliki biaya perjalanan yang lebih rendah (Lasmana, 2022).
Tahapan metode ITCM sebagai berikut:
1. Mengidentifikasi lokasi (wisata) survei kuisioner untuk mengumpulkan data penggunjung yang berhubungan dengan biaya perjalanan mereka ke lokasi, jumlah kunjungan, pilihan-pilihan rekreasi, karakteristik sosial ekonomi, dan sebagainya.
8 2. Menetapkan fungsi (persamaan) perjalanan dan mengestimasi model travel cost (regresi hubungan jumlah kunjungan dengan biaya perjalanan dan variabel lainnya).
3. Menggambarkan kurva permintaan (demand curve) dan menentukan surplus konsumen berdasarkan kurva tersebut.
4. Menghitung total surplus konsumen untuk lokasi wisata.
Persamaan dari pendekatan ITCM sebagai berikut.
𝑉𝑖𝑗 = 𝑓(𝐶𝑖𝑗, 𝑇𝑖𝑗, 𝑄𝑖𝑗, 𝑆𝑖𝑗, 𝑀𝑖𝑗) ...(II-2) Dimana:
𝑉𝑖𝑗 = Jumlah kunjungan oleh individu i ke objek wisata j
𝐶𝑖𝑗 = Biaya perjalanan yang dikeluarkan oleh individu i untuk mengunjungi objek wisata j
𝑇𝑖𝑗 = Biaya waktu yang dikeluarkan oleh individu i untuk mengunjungi objek wisata j
𝑄𝑖𝑗 = Persepsi responden terhadap kualitas lingkungan dari tempat yang dikunjungi
𝑆𝑖𝑗 = Karakteristik objek wisata substitusi yang mungkin ada di tempat lain
𝑀𝑖𝑗 = Pendapatan dari individu i II.2 Teknik Pengambilan Sampel (Sampling)
Teknik sampling adalah sebuah metode yang dilakukan untuk menentukan jumlah dan anggota sampel. Setiap anggota tentu saja menjadi wakil dari populasi yang dipilih setelah dikelompokkan berdasarkan kesamaan karakter. Teknik sampling yang digunakan juga harus disesuaikan dengan tujuan dari penelitian. Hal yang perlu diperhatikan dalam pengambilan sampel adalah seluruh variabel yang berkaitan dengan penelitian. Unsur-unsur khusus yang melekat pada pribadi tertentu saja perlu diperhatikan karena individu dengan kemampuan khusus dalam sampel akan membawa bias data dan tentu mempengaruhi distribusi data yang ada.
Kesesuaian karakteristik daerah, tingkatan, dan kecenderungan khusus juga perlu dipertimbangkan dalam memilih teknik sampling yang sesuai (Sugiyono, 2011).
Teknik sampling secara garis besar dikelompokkan menjadi dua sebagai berikut:
9 1. Probability Sampling
Probability sampling merupakan teknik sampling yang memberikan peluang yang sama bagi setiap unsur (anggota) populasi untuk dipilih menjadi anggota sampel. Probability sampling juga menuntut agar peneliti sudah mengetahui besarnya sampel yang diinginkan, sehingga peneliti wajib bersikap bahwa setiap unsur atau kelompok unsur harus memiliki peluang yang sama untuk dijadikan sampel. Berikut ini jenis probability sampling:
a. Simple Random Sampling
Teknik ini adalah pengambilan sampel dari populasi yang dilakukan secara acak tanpa memperhatikan strata yang ada dalam populasi itu.
Cara ini dilakukan jika anggota populasi bersifat homogen.
b. Proportionate Stratified Random Sampling
Teknik ini adalah teknik pengampilan sampel yang digunakan jika populasi memiliki anggota atau unsur yang tidak homogen dan berstrata secara proporsional.
c. Disproportionate Stratified Random Sampling
Teknik ini digunakan untuk menentukan jumlah sampel jika populasi berstrata tetapi kurang proporsional.
d. Sampling Area
Teknik ini digunakan untuk menentukan sampel bila objek yang diteliti atau sumber data sangat luas, seperti penduduk dari suatu negara, provinsi, atau kabupaten. Penentuan penduduk mana yang akan dijadikan sumber data, maka pengambilan sampelnya berdasarkan daerah populasi yang telah ditetapkan.
2. Non Probability Sampling
Non Probability Sampling merupakan teknik yang tidak memberi peluang atau kesempatan yang sama bagi setiap unsur atau anggota populasi untuk dipilih menjadi sampel. Jenis-jenis non probability sampling sebagai berikut:
a. Sampling Sistematis
10 Teknik ini adalah pengambilan sampel berdasarkan urutan dari anggota populasi uang telah diberikan nomor urut. Pengambilan sampel dapat dilakukan dengan nomor ganjil saja atau kelipatan dari bilangan tertentu.
b. Sampling Kuota
Teknik ini adalah teknik sampling yang berfungsi untuk menentukan sampel dari populasi yang mempunyai ciri-ciri tertentu sampai jumlah (kuota) yang diinginkan.
c. Sampling Insidental
Teknik ini adalah teknik penentuan sampel berdasarkan kebetulan, yaitu siapa saja yang secara kebetulan atau insidental bertemu dengan peneliti dapat digunakan sebagai sampel jika orang tersebut dipandang cocok sebagai sumber data.
d. Purposive Sampling
Teknik ini adalah teknik untuk menentukan sampel dengan pertimbangan tertentu sesuai dengan tujuan yang dikehendaki. Sampel ini cocok digunakan untuk penelitian kualitatif atau penelitian yang tidak melakukan generalisasi.
e. Sampling Jenuh
Sampling jenuh adalah menentukan sampel bila semua anggota populasi digunakan sebagai sampel. Hal ini sering dilakukan jika jumlah populasi relatif kecil yakni kurang dari 30 orang.
f. Snowball Sampling
Teknik ini adalah teknik penentuan sampel yang mula-mula jumlahnya kecil, kemudian membesar.
II.3 Analisis Regresi Linear Berganda
Menurut (Hasan, 2008), regresi merupakan suatu alat ukur yang digunakan untuk mengukur ada tidaknya korelasi antar variabel. Analisis regresi lebih akurat dalam melakukan analisis korelasi karena pada analisis tersebut terdapat kesulitan dalam menunjukkan slop (tingkat perubahan suatu variabel terhadap variabel lainnya dapat ditentukan). Analisis regresi dapat meramal atau memperkirakan nilai
11 variabel bebas lebih akurat. Regresi linier dibagi menjadi dua, yaitu regresi linier dan regresi linier berganda.
Analisis regresi linier merupakan alat perhitungan dalam statistika yang di gunakan untuk mengetahui apakah terdapat hubungan dari variabel bebas dengan variabel terikat. Sementara analisis regresi linier berganda memiliki tujuan untuk mengetahui signifikansi pengaruh variabel independen yaitu variabel yang tidak dipengaruhi oleh variabel lain terhadap variabel dependen yaitu keberadaan dari suatu variabel yang dipengaruhi oleh variabel lain sehingga dapat diperoleh prediksi yang tepat (Pramesti, 2017). Rumus yang digunakan untuk melakukan perhitungan sebagai berikut:
𝑌 = 𝑏0+ 𝑏1𝑋1 + 𝑏2𝑋2+ ⋯ + 𝑏𝑛𝑋𝑛 ...(II-3) Dimana:
Y = Variabel terikat
𝑏0, 𝑏1, 𝑏2, … , 𝑏𝑛 = Koefisien regresi 𝑋1, 𝑋2, 𝑋3, … , 𝑋𝑛 = Variabel independen II.4 Uji Asumsi Klasik
Uji asumsi klasik digunakan untuk memperoleh hasil regresi yang baik dan efisien.
Uji asumsi klasik dalam penelitian ini meliputi uji normalitas, uji autokorelasi, uji autokorelasi, uji multikolinearitas, dan uji heterokedastisitas.
II.4.1 Uji Normalitas
Uji normalitas memiliki tujuan untuk mengetahui apakah distribusi data penelitian yang digunakan mendekati atau terdistribusi secara normal, yaitu distribusi dengan pola lonceng. Data penelitian dikatakan baik jika pola datanya seperti distribusi normal atau mendekati distribusi normal (Santoso, 2017).
Pendekatan analisis menggunakan grafik normal probability plot digunakan sebagai salah satu pendekatan yang digunakan untuk melakukan uji normalitas suatu data. Pendekatan ini akan menggambarkan data berupa titik-titik yang tersebar mengikuti atau merapat pada garis diagonalnya jika nilai residual terdistribusi secara normal. Namun, apabila datanya tidak mengikuti arah garis diagonal dan menyebar jauh dari garis diagonal atau grafik histogram, maka nilai residual tidak menunjukan terjadinya pola distribusi normal dan model regresinya tidak memenuhi asumsi normalitas.
12 II.4.2 Uji Autokorelasi
Uji autokorelasi digunakan untuk menguji apakah pada model terjadi adanya korelasi atau hubungan antara kesalahan variabel pengganggu pada suatu periode t ke periode t-1 atau satu periode sebelumnya (Yudiaatmaja, 2013).
Masalah ini akan timbul jika residual atau kesalahan pengganggu tidak bebas dari suatu pengamatan ke pengamatan lainnya. Kesalahan ini banyak ditemukan pada data runtutan waktu karena gangguan pada individu atau kelompok akan memengaruhi gangguan pada individu atau kelompok yang sama pada periode waktu selanjutnya. Untuk mengetahui adanya kesalahan autokorelasi dapat dilakukan dengan menggunakan cara berikut ini (Janie, 2012):
1. Uji Durbin Watson
Uji Durbin Watson merupakan salah satu cara yang umum dilakukan dalam pengujian autokorelasi yang memiliki syarat adanya intercept (konstanta) dalam model regresi dan tidak ada variabel lagi di antara variabel independen. Metode ini merupakan metode yang sering digunakan.
Ketentuan-ketentuan pada metode Uji Durbin Watson sebagai berikut:
a. Apabila nilai DW kurang dari 0 –1,5 maka dapat dikatakan bahwa data tersebut terjadi gejala autokorelasi.
b. Apabila nilai DW berada diantara 1,5 – 2,5 maka dapat dikatakan bahwa data tersebut tidak terjadi gejala autokorelasi.
c. Apabila nilai DW berada diantara 2,5 – 4 maka dapat dikatakan bahwa data tersebut terjadi keambiguan data, sehingga tidak diketahui dengan jelas apakah data tersebut terjadi gejala autokorelasi atau tidak.
Uji autokorelasi dilakukan untuk menguji apakah dalam model regresi linier terdapat korelasi kesalahan pengganggu pada periode t dengan kesalahan pada periode sebelumnya. Dasar pengambilan keputusan pada uji autokorelasi sebagai berikut:
a. Jika dw < dl atau d > 4 - dl maka terdapat autokorelasi.
b. Jika du < dw < 4 - du maka tidak terdapat autokorelasi.
c. Jika dl < dw < du atau 4-du < dw < 4-dl maka tidak menghasilkan kesimpulan yang pasti.
13 Penentuan keputusan juga dapat dilakukan dengan pengambilan keputusan sesuai dengan tabel keputusan dengan membandingkan DW hasil dengan DW tabel.
Tabel II-1 Hipotesis Uji Autokorelasi
H0 Keputusan Jika HA
Tidak ada autokorelasi positif
Tolak 0<d<dl Terdapat autokorelatif positif Tidak ada autokorelasi
positif
No Decision
dl≤d≤du Tidak diketahui Tidak ada autokorelasi
negatif
Tolak 4-dl<d<4 Terdapat autokorelatif negatif Tidak ada autokorelasi
negatif
No Decision
4-du≤d≤4-dl Tidak diketahui Tidak ada autokorelasi
positif atau negatif
Tidak ditolak
du<d<4-du Tidak terdapat autokorelasi Dimana:
H0 = tidak terdapat autokorelasi HA = terdapat autokorelasi 2. Run Test
Run test merupakan salah satu cara yang digunakan untuk menguji apakah terdapat korelasi yang tinggi antar residual. Jika tidak ada korelasi antar residual maka residual dikatakan acak atau random. Suatu data residual dapat dikatakan tidak terjadi autokorelasi atau memiliki data yang acak apabila nilai Asymp. Sig (2-tailed) memiliki signifikasi di atas 0,05.
II.4.3 Uji Multikolinearitas
Uji multikolinearitas merupakan pengujian yang digunakan untuk melihat apakah pada model regresi ditemukan adanya korelasi antar variabel bebas.
Multikolinearitas dapat terjadi apabila terdapat dua variabel bebas dimana keduanya berkorelasi dengan sangat kuat. Untuk melihat apakah terjadi
14 multikolinearitas pada model regresi dapat diketahui dengan cara sebagai berikut (Yudiaatmaja, 2013):
1. Jika antar variabel terjadi korelasi yang sangat kuat dengan r > 0,90 maka terindikasi adanya multikolinearitas. Begitu juga sebaliknya jika r < 0,90 maka dapat dikatakan tidak terjadi multikolinearitas.
2. Jika nilai Variance Inflation Factor (VIF) ≤ 10 maka tidak terjadi multikolinaeritas, tetapi jika VIF > 10 maka dapat diindikasikan adanya multikolinearitas.
II.4.4 Uji Heterokedastisitas
Uji heterokedastisitas adalah uji yang dilakukan untuk menguji apakah pada model regresi memiliki ketidaksamaan varian dari residual diantara anggota grup yang lain. Jika terjadi ketidaksamaan pada variansi dari residual maka dapat dikatakan terjadinya heteroskedasitas. Namun, jika terjadi kesamaan pada variansi dari residual maka dikatakan adanya homoskedasitas. Model regresi yang baik jika tidak terjadi heteroskedasitas (Santoso, 2017).
II.5 Software SPSS
Gambar II-1 Software IMB SPSS Statistic 25
Statistical Package for the Social Sciences (SPSS) adalah program aplikasi bisnis yang berguna untuk menganalisa data statistik. Versi terbaru program ini adalah SPSS 20, yang dirilis pada tanggal 16 Agustus 2011. Software SPSS dibuat dan dikembangkan oleh SPSS Inc. yang kemudian diakuisisi oleh IBM Corporation. Perangkat lunak komputer ini memiliki kelebihan pada kemudahan penggunaannya dalam mengolah dan menganalisis data statistik. Program SPSS banyak diaplikasikan dan digunakan oleh kalangan pengguna komputer di bidang bisnis, perkantoran, pendidikan, dan penelitian. Fungsi utama aplikasi SPSS adalah untuk analisis data, selain itu SPSS juga dapat digunakan sebagai berikut ini:
15 1. Pengolahan dan mendokumentasikan data
2. Representasi data statistik 3. Analisis statistik
4. Survei
5. Pembuatan data turunan 6. Analisis data
7. Data mining
8. Melakukan riset pemasaran
Beberapa kemudahan lain yang dimiliki SPSS dalam pengoperasiannya adalah karena SPSS menyediakan beberapa fasilitas. Fasilitas yang di miliki SPSS, yaitu Data Editor, Viewer, Multidimensional Pivot Tables, High-Resolution Graphics, Database Access, Data Transformations, Electronic Distribution, Online Help, Akses Data Tanpa Tempat Penyimpanan Sementara, Interface dengan Database Relasional, Analisis Distribusi, Multiple Sesi, Mapping (dqlab, 2021).
II.6 ArcGIS
Gambar II-2 Tampilan Awal Software ArcMap 10.8
ArcGIS merupakan software berbayar berbasis Geographic Information System (GIS) yang dikembangkan oleh ESRI (Environment Science & Research Institue). Pada versi terbarunya, ArcGis Deskstop memiliki beberapa fitur diantaranya (Geosriwijaya, 2016):
1. ArcMap, memiliki kemampuan untuk visualisasi, editing, pembuatan peta tematik, pengelolaan dari data tabular (excel), memilih (query), menggunakan fitur Geoprocessing untuk menganalisa dan customize data ataupun melakukan output berupa tampilan peta.
16 2. ArcGlobe, merupakan salah satu aplikasi yang memiliki tampilan seperti Google Earth yang memiliki fungsi sebagai tampilan datum permukaan bumi dengan menggunakan citra satelit.
3. ArcCatalog, yaitu aplikasi yang memiliki fitur untuk membuat data vektor dan mengelompokannya sesuai dengan fungsi yang diinginkan.
4. ArcScene, merupakan aplikasi yang memiliki kelebiha yaitu terdapat fitur 3D dimana worksheet-nya dapat diolah dengan tampilan X, Y, dan Z.
II.7 Deskripsi Lokasi Penelitian
Gambar II-3 Kota Semarang
Kota Semarang adalah ibu kota provinsi Jawa Tengah, Indonesia. Kota ini adalah kota metropolitan terbesar kelima di Indonesia setelah Jakarta, Surabaya, Bandung, dan Medan. Sebagai salah satu kota yang berkembang di Pulau Jawa, kota Semarang mempunyai jumlah penduduk sekitar 1.693.035 jiwa, pada pertengahan tahun 2023. Kawasan mega-urban Semarang yang tergabung dalam wilayah metropolitan Kedungsepur (Kabupaten Kendal, Kabupaten Demak, Ungaran Kabupaten Semarang, Kota Salatiga, Kota Semarang, dan Purwodadi Kabupaten Grobogan) berpenduduk mencapai 7,3 juta jiwa, sekaligus sebagai wilayah metropolitan berpenduduk terbanyak keempat di Indonesia, setelah Jabodetabek (Jakarta), Gerbangkertosusilo (Surabaya), dan Bandung Raya (Bandung). Dalam beberapa tahun terakhir, perkembangan Semarang yang signifikan ditandai pula dengan munculnya beberapa gedung pencakar langit yang tersebar di penjuru kota dan penataan kota dengan dibangunnya tempat-tempat ramah pejalan kaki. Perkembangan regional ini menunjukan peran strategis Kota Semarang terhadap roda perekonomian nasional.
17 Kota Semarang mengenal sistem pembagian wilayah kota yang terdiri atas Semarang Tengah atau Semarang Pusat, Semarang Timur, Semarang Selatan, Semarang Barat, dan Semarang Utara. Pembagian wilayah kota ini bermula dari pembagian wilayah sub-residen oleh Pemerintah Hindia Belanda yang setingkat dengan kecamatan. Namun saat ini, pembagian wilayah kota ini berbeda dengan pembagian administratif wilayah kecamatan. Meskipun pembagian kota ini jarang dipergunakan dalam lingkungan Pemerintahan Kota Semarang. Namun pembagian kota ini digunakan untuk mempermudah dalam menerangkan suatu lokasi menurut letaknya terhadap pusat kota Semarang. Pembagian kota ini juga digunakan oleh beberapa instansi di lingkungan Kota Semarang untuk mempermudah jangkauan pelayanan, seperti PLN dan PDAM (semarangkota.go.id, 2018).
18
BAB III
METODOLOGI PENELITIAN
III.1 Alat dan Data
Alat dan data yang digunakan pada penelitian ini sebagai berikut.
III.1.1 Alat
Alat yang digunakan dalam pelaksanaan dan pengolahan data penelitian ini sebagai berikut:
Gambar III-1 Laptop Asus Vivobook 14
Display : 14” FHD IPS
Processor : Intel Corei5-1135G7
Grafis : Intel Iris Xe 80EU Graphics
Memory : 8 GB DDR4
Storage : SSD 512 GB
Sistem operasi : Windows 10 Home
1. Laptop Asus Vivobook 14 dengan spesifikasi sebagai berikut.
2. Microsoft Excel 2019 untuk perhitungan data dan pengolahan data.
3. Microsoft Word 2019 untuk pembuatan laporan.
4. Software SPSS untuk pengolahan uji asumsi klasik.
5. ArcGIS 10.8 untuk pembuatan peta zonasi dan penyajian peta.
III.1.2 Data
Data yang diperlukan untuk penelitian ini meliputi dua jenis data, sebagai berikut:
1. Data Spasial
19 Data spasial yang digunakan dalam penelitian ini yaitu peta atau shapefile administrasi Kota Semarang.
2. Data Non Spasial
Data non spasial yang digunakan dalam penelitian ini yaitu data kuesioner TCM dari karyawan swasta di Universitas Diponegoro.
III.2 Persiapan
Persiapan merupakan kegiatan yang sangat penting dilakukan sebelum pelaksanaan penelitian dimulai. Semakin baik dalam melaksanakan persiapan maka pelaksanaan penelitian akan berjalan sesuai dengan rencana pelaksanaan penelitian.
Kegiatan persiapan yang dilaksanakan dalam penelitian ini berupa studi literatur.
III.2.1 Diagram Alir Penelitian
Tahapan yang dilakukan pada penelitian ini digambarkan pada diagram alir sebagai berikut:
Gambar III-2 Diagram Alir Penelitian
20 III.2.2 Studi Literatur
Studi literatur yang dilakukan adalah serangkaian kegiatan yang berkenaan dengan metode pengumpulan data pustaka, membaca dan mencatat, serta mengelolah bahan penelitian.
III.3 Pengumpulan Data Kuesioner
Tahapan pengumpulan data kuesioner terdiri dari pengumpulan data, tahapan penarikan sampel (sampling), tahapan pelaksanaan pengolahan data, tahapan pengolahan uji asumsi klasik, tahapan pengolahan regresi linear berganda, dan tahapan pembuatan peta zonasi.
III.3.1 Pengumpulan Data
Tahapan pengumpulan data dimulai dari melakukan pengambilan data yang dibutuhkan terkait jenis profesi karyawan swasta seperti Karyawan Warteg, Karyawan Fotocopy, Karyawan Bengkel, Karyawan Laundry, dan sebagainya yang berada di kawasan sekitaran UNDIP. Pengambilan data dilakukan dengan melakukan survei dan wawancara secara langsung ke lokasi-lokasi usaha yang dijalani.
III.3.2 Tahapan Penarikan Sampel (Sampling)
Tahapan penarikan sampel yang dilakukan dalam penelitian ini menggunakan metode Sampel Acak Berdasarkan Area (Cluster Random Sampling). Penggunaan metode ini didasarkan pada kelompok wilayah dari anggota karyawan swasta yang digunakan sebagai objek dalam penelitian. Pada penelitian ini, objek penelitian dikelompokkan berdasarkan tempat domisili asal karyawan swasta yakni yang berasal dari Kota Semarang dengan jumlah sampel data sebanyak 66 responden. Penggunaan metode ini ditujukan untuk melihat bagaimana tingkat partisipasi masyarakat asli Kota Semarang dalam kegiatan perekonomian di kawasan sekitar UNDIP.
III.4 Tahapan Pelaksanaan Pengolahan Data
Tahapan pelaksanaan pengolahan data pada penelitian ini meliputi tahapan uji asumsi klasik menggunakan software SPSS, tahapan regresi linear berganda, dan tahapan pembuatan peta zonasi menggunakan software ArcMap.
21 III.4.1 Tahapan Pengolahan Uji Asumsi Klasik
Pengolahan uji asumsi klasik dilakukan menggunakan software SPSS Statistics. Tahapan pengolahan uji asumsi klasik pada penelitian ini sebagai berikut:
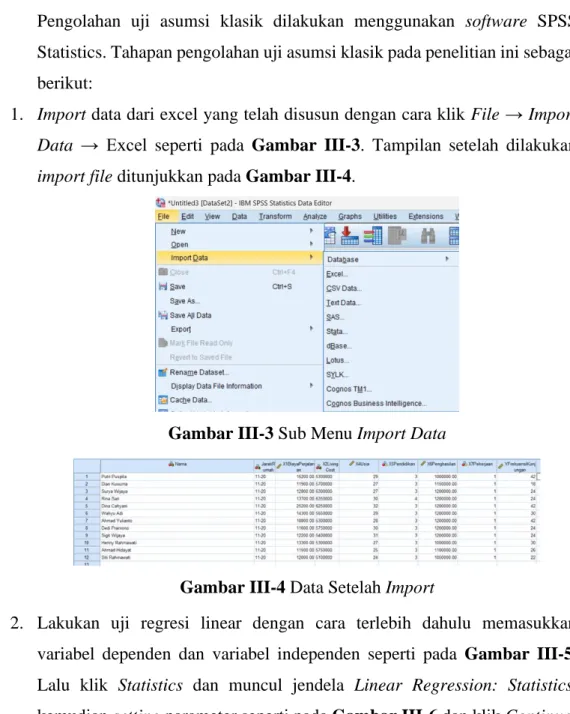
1. Import data dari excel yang telah disusun dengan cara klik File → Import Data → Excel seperti pada Gambar III-3. Tampilan setelah dilakukan import file ditunjukkan pada Gambar III-4.
Gambar III-3 Sub Menu Import Data
Gambar III-4 Data Setelah Import
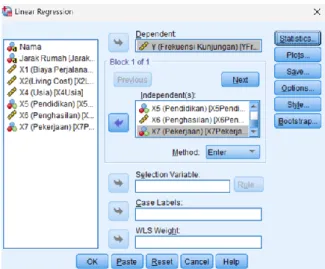
2. Lakukan uji regresi linear dengan cara terlebih dahulu memasukkan variabel dependen dan variabel independen seperti pada Gambar III-5.
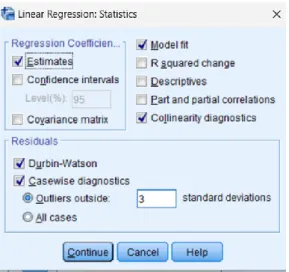
Lalu klik Statistics dan muncul jendela Linear Regression: Statistics, kemudian setting parameter seperti pada Gambar III-6 dan klik Continue.
22 Gambar III-5 Jendela Linear Regression
Gambar III-6 Parameter Regresi Linear
3. Lakukan uji normalitas dengan cara klik Nonparametric Tests → Legacy Dialogs → 1-Sample K-S seperti pada Gambar III-7 Hasil uji normalitas ditunjukkan pada Gambar III-8.
Gambar III-7 Sub Menu 1-Sample K-S
23 Gambar III-8 Hasil Uji Normalitas
4. Input variabel ZRE pada Test Variabel List seperti pada Gambar III-9.
Gambar III-9 Jendela One-Sample Kolmogorov-Smirnov Test 5. Klik Transform, kemudian klik Compute Variabel seperti pada Gambar
III-10, kemudian muncul jendela Compute Variabel.
24 Gambar III-10 Menu Transform
6. Beri perintah ABRES pada Target Variabel agar nilai ZRE menjadi positif seperti pada Gambar III-11 Tampilan ABRES ditunjukkan pada Gambar III-12.
Gambar III-11 Penulisan Target Variabel
25 Gambar III-12 Tampilan ABRES
7. Lakukan regresi linear kedua dengan memasukkan variabel ABRES hingga menghasilkan output seperti pada Gambar III-13.
Gambar III-13 Hasil Regresi Linear Kedua
8. Tampilan output Residuals Statistics ditunjukkan pada Gambar III-14.
Gambar III-14 Hasil Residual Statistics
26 III.4.2 Tahapan Pengolahan Regresi Linear Berganda
Pengolahan regresi linear berganda dilakukan menggunakan Microsoft Excel. Tahapan pengolahan regresi linear berganda sebagai berikut:
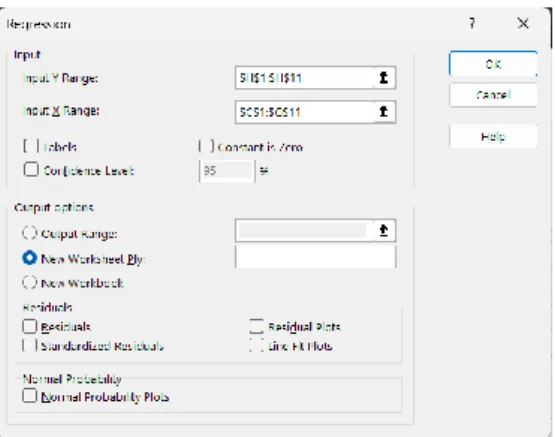
1. Buka file Excel yang berisi data penelitian yang akan diolah seperti contoh pada Gambar III-15. Lalu klik Data → Data Analysis → Regression seperti pada Gambar III-16.
Gambar III-15 Data Penelitian
Gambar III-16 Regression pada Data Analysis
2. Input variabel X dan Y serta centang bagian Labels seperti pada Gambar III-17, kemudian klik OK.
27 Gambar III-17 Jendela Regression
3. Excel akan memunculkan sheets baru berisi hasil regresi linear berganda yang telah dilakukan, kemudian salin dan tempelkan hasil tersebut pada sheet tiap zona seperti pada Gambar ….
Gambar III-18 Hasil Regresi Linear Berganda
4. Lakukan analisis terhadap Multiple R, Adjusted R Square, dan Significance F dengan hasil seperti ditunjukkan pada Gambar III-19.
Gambar III-19 Hasil Multiple R, Adjusted R Square, Significance F 5. Lakukan perhitungan TCM menggunakan persamaan II-3 hingga diperoleh
hasil seperti pada Gambar III-20.
28 Gambar III-20 Persamaan TCM
III.4.3 Tahapan Pembuatan Peta Zonasi
Pembuatan peta zonasi dilakukan menggunakan software ArcGIS 10.8.
Penelitian ini terbagi menjadi menjadi 5 zona dimana masing-masing zona berjarak 0-4 km, 5-8 km, 9-12 km, 13-16 km, dan 17-20 km. tahapan pembuatan peta zonasi sebagai berikut:
1. Buka software ArcGIS hingga muncul tampilan seperti pada Gambar III- 21, Lalu masukkan data SHP titik Universitas Diponegoro dan SHP Kota Semarang pada jendela Add Data seperti pada Gambar III-22.
Gambar III-21 Tampilan Awal ArcGIS
29 Gambar III-22 Add Data SHP Titik UNDIP dan SHP Kota Semarang 2. Lakukan proses multiple ring buffer menggunakan ArcToolBox, kemudian
klik Multiple Ring Buffer (Analysis) seperti pada Gambar III-23.
Gambar III-23 Multiple Ring Buffer
3. Input feature titik Universitas Diponegoro, kemudian atur jarak setiap zona dengan interval 4 km untuk wilayah Kota Semarang. Setting parameter ditunjukkan pada Gambar III-24.
Gambar III-24 Setting Parameter Multiple Ring Buffer
30 4. Hasil pengolahan multiple ring buffer ditunjukkan pada Gambar III-25.
Gambar III-25 Hasil Multiple Ring Buffer
31
BAB IV
HASIL DAN ANALISIS
IV.1 Hasil dan Analisis Uji Asumsi Klasik TCM
Analisis uji asumsi klasik digunakan untuk mengetahui kesesuaian data penelitian dengan masing-masing uji asumsi klasik. Uji ini dilakukan menggunakan software SPSS Statistics. Uji asumsi klasik terdiri dari uji normalitas, uji autokorelasi, uji multikolinearitas, dan uji heterokedastisitas.
IV.1.1 Hasil dan Analisis Uji Normalitas
Uji normalitas digunakan untuk menguji apakah dalam model regresi variabel pengganggu atau residual memiliki distribusi normal atau tidak, dimana residual tersebut harus terdistribusi normal. Residual yang terdistribusi normal akan menyebar di daerah garis diagonal dan searah dengan garis diagonal pada hasil scatter plotter. Selain itu, grafik histogram akan membentuk lonceng atau gunung.
Data yang tidak terdistribusi normal ditunjukkan dengan sebaran data jauh dari garis diagonal dan tidak mengikuti arah garis diagonal. Berikut ini nilai hasil, histogram, dan sebaran titik atau P-plot dari masing-masing zona TCM karyawan wiraswasta di Kota Semarang menggunakan software SPSS:
1. Nilai Hasil Uji Normalitas
Nilai hasil uji normalitas ditunjukkan pada Gambar IV-1 hingga IV-5.
Gambar IV-1 Hasil Uji Normalitas Zona 1
32 Gambar IV-2 Hasil Uji Normalitas Zona 2
Gambar IV-3 Hasil Uji Normalitas Zona 3
Gambar IV-4 Hasil Uji Normalitas Zona 4
33 Gambar IV-5 Hasil Uji Normalitas Zona 5
Hasil uji normalitas masing-masing zona pada Gambar IV-1 hingga IV-5 dituliskan pada Tabel IV-1.
Tabel IV-1 Hasil Uji Normalitas Setiap Zona
Zona Asymp. Sig
(2-tailed) Uji Normal (>0,05)
Zona 1 (0-4 km) 0,098 Memenuhi
Zona 2 (5-8 km) 0,200 Memenuhi
Zona 3 (9-12 km) 0,200 Memenuhi
Zona 4 (13-16 km) 0,106 Memenuhi
Zona 5 (17-20 km) 0,200 Memenuhi
Berdasarkan hasil uji normalitas pada Tabel IV-1 dapat diketahui bahwa masing-masing zona dari zona 1 hingga zona 5 telah memenuhi syarat uji normalitas, yaitu nilai residual variabel independen dan variabel dependen masing-masing zona lebih dari 0,05.
2. Histogram Uji Normalitas
Grafik histogram hasil uji normalitas masing-masing zona ditunjukkan pada Gambar IV-6 hingga Gambar IV-10.
34 Gambar IV-6 Histogram Uji Normalitas Zona 1
Gambar IV-7 Histogram Uji Normalitas Zona 2
Gambar IV-8 Histogram Uji Normalitas Zona 3
35 Gambar IV-9 Histogram Uji Normalitas Zona 4
Gambar IV-10 Histogram Uji Normalitas Zona 5
Berdasarkan grafik histogram menunjukkan masing-masing zona membentuk lonceng sempurna. Hal tersebut berkaitan dengan nilai signifikansi uji normalitas, dimana lonceng akan berbentuk sempurna jika nilai residual semakin tinggi (>0,05). Apabila nilai residual tidak memenuhi uji normalitas atau nilai signifikansinya berada di dekat 0,05 atau <0,05, maka grafik histogram tidak membentuk lonceng yang sempurna.
3. P-Plot Uji Normalitas
Hasil P-Plot masing-masing zona ditunjukkan pada Gambar IV-11 hingga IV-15.
36 Gambar IV-11 Hasil P-Plot Uji Normalitas Zona 1
Gambar IV-12 Hasil P-Plot Uji Normalitas Zona 2
Gambar IV-13 Hasil P-Plot Uji Normalitas Zona 3
37 Gambar IV-14 Hasil P-Plot Uji Normalitas Zona 4
Gambar IV-15 Hasil P-Plot Uji Normalitas Zona 5
Berdasarkan hasil P-Plot diketahui bahwa data pada masing-masing zona menyebar di sekitar garis diagonal dan mengikuti arah garis diagonal. Oleh karena itu, grafik probability normal pada masing-masing zona memenuhi syarat uji normalitas. Hal tersebut berhubungan dengan nilai signifikan yang dihasilkan, dimana nilai yang semakin besar (>0,05) akan menunjukkan sebaran yang linear mengikuti garis dan searah dengan garis diagonal.
IV.1.2 Hasil dan Analisis Uji Autokorelasi
Uji autokorelasi pada penelitian ini menggunakan metode Durbin Watson karena metode ini merupakan metode yang sering digunakan. Uji Durbin Watson adalah uji autokorelasi yang menilai adanya autokorelasi pada residual. Hasil uji autokorelasi menggunakan metode Durbin Watson pada masing-masing zona ditunjukkan pada Gambar IV-16 hingga IV-20.
38 Gambar IV-16 Hasil Uji Autokorelasi Durbin Watson Zona 1
Gambar IV-17 Hasil Uji Autokorelasi Durbin Watson Zona 2
Gambar IV-18 Hasil Uji Autokorelasi Durbin Watson Zona 3
Gambar IV-19 Hasil Uji Autokorelasi Durbin Watson Zona 4
Gambar IV-20 Hasil Uji Autokorelasi Durbin Watson Zona 5 Hasil perhitungan uji autokorelasi Durbin Watson pada masing-masing zona ditunjukkan pada Tabel IV-2.
Tabel IV-2 Hasil Uji Autokorelasi Durbin Watson Masing-Masing Zona
Zona α k n du 4-du dl 4-dl d DW
Zona 1 0,05 6 16 2,3881 1,6119 0,5022 3,4978 2,8903 1,476 Zona 2 0,05 6 12 2,832 1,168 0,2681 3,7319 3,1001 2,309 Zona 3 0,05 6 13 2,692 1,308 0,3278 3,6722 3,0198 1,466
39
Zona α k n du 4-du dl 4-dl d DW
Zona 4 0,05 6 13 2,692 1,308 0,3278 3,6722 3,0198 1,428 Zona 5 0,05 6 12 2,832 1,168 0,2681 3,7319 3,1001 2,548 Berdasarkan uji autokorelasi menggunakan metode Durbin Watson, hanya zona 2 dengan nilai DW berada pada rentang 1,5 – 2,5 maka dapat dikatakan bahwa data tersebut tidak terjadi gejala autokorelasi dari variabel-variabel pengamatnya. Hal tersebut menandakan bahwa antar responden satu dengan responden lainnya tidak saling memberikan pengaruh yang menyimpang pada jawaban yang melenceng atau tidak sesuai. Nilai DW pada zona 5 berada pada diantara 2,5 – 4 maka dapat dikatakan bahwa data tersebut terjadi keambiguan data, sehingga tidak diketahui dengan jelas apakah data tersebut terjadi gejala autokorelasi atau tidak. Untuk zona 1, 3, dan 4 berada pada rentang 0 – 1,5 maka dapat dikatakan bahwa data tersebut terjadi gejala autokorelasi. Apabila menggunakan ketentuan perhitungan didapatkan kesimpulan pada Tabel IV-3 sebagai berikut:
Tabel IV-3 Hasil Uji Syarat Autokorelasi
Zona dw<dl d>4-dl du<dw<4-
du dl<dw<du
4- du<dw<4-
dl
Simpulan
Zona 1 Tidak memenuhi
Tidak memenuhi
Tidak memenuhi
Memenuhi Tidak memenuhi
Tidak menghasilkan
simpulan yang pasti Zona 2 Tidak
memenuhi
Tidak memenuhi
Tidak memenuhi
Tidak memenuhi
Memenuhi Tidak menghasilkan
simpulan yang pasti Zona 3 Tidak
memenuhi
Tidak memenuhi
Tidak memenuhi
Memenuhi Memenuhi Tidak menghasilkan
simpulan yang pasti Zona 4 Tidak
memenuhi
Tidak memenuhi
Tidak memenuhi
Memenuhi Memenuhi Tidak menghasilkan
simpulan yang pasti
40
Zona 5 Tidak memenuhi
Tidak memenuhi
Tidak memenuhi
Memenuhi Memenuhi Tidak menghasilkan
simpulan yang pasti
Berdasarkan hasil pada Tabel IV-3 dengan menggunakan taraf signifikansi 0,05 dapat dilihat bahwa apabila hasilnya dimasukkan sesuai persamaan ketentuan maka semua zona tidak menghasilkan simpulan yang pasti karena pada zona 1 memenuhi dl<dw<du, zona 2 memenuhi 4-du<dw<4-dl, sedangkan zona 3, 4, dan 5 memenuhi dl<dw<du atau 4-du<dw<4-dl.
IV.1.3 Hasil dan Analisis Uji Multikolinearitas
Uji multikolineritas digunakan untuk mengetahui ada atau tidaknya penyimpangan asumsi klasik multikolinearitas, yaitu adanya hubungan linear antar variabel independent (bebas) dalam model regresi. Pengujian ini dilakukan menggunakan nilai VIF (Variance Inflation Factor). Apabila nilai VIF<10 dan nilai tolerance>0,1, maka data tersebut memenuhi syarat uji dan tidak terdapat gejala multikolinearitas. Apabila ditemukan hubungan korelasi yang tinggi antar variabel bebas maka data dapat dikatakan terjadi gejala multikolinearitas. Hasil uji multikolinearitas masing-masing zona ditunjukkan pada Gambar IV-21 hingga Gambar IV-25.
Gambar IV-21 Hasil Uji Multikolinearitas Zona 1
Gambar IV-22 Hasil Uji Multikolinearitas Zona 2
41 Gambar IV-23 Hasil Uji Multikolinearitas Zona 3
Gambar IV-24 Hasil Uji Multikolinearitas Zona 4
Gambar IV-25 Hasil Uji Multikolinearitas Zona 5
Nilai tolerance dan VIF pada masing-masing zona ditunjukkan pada Tabel IV-4.
Tabel IV-4 Nilai Tolerance dan VIF Setiap Zona
Variabel
Nilai VIF Zona 1
Nilai VIF Zona 2
Nilai VIF Zona 3
Nilai VIF Zona 4
Nilai VIF Zona 5
Tol VIF Tol VIF Tol VIF Tol VIF Tol VIF
X1 0,789 1,268 0,384 2,602 0,766 1,305 0,365 2,743 0,693 1,444 X2 0,631 1,585 0,310 3,228 0,969 1,032 0,387 2,583 0,601 1,663 X3 0,805 1,243 0,384 2,605 0,714 1,400 0,673 1,486 0,660 1,514 X4 0,768 1,302 0,587 1,703 - - 0,444 2,254 0,506 1,975 X5 0,669 1,495 0,363 2,757 0,779 1,283 0,944 1,059 0,829 1,206
Berdasarkan hasil pengujian pada Tabel IV-4, menunjukan bahwa data TCM pada masing-masing zona memiliki nilai VIF < 10 dan nilai tolerance > 0,1 maka data penelitian dinyatakan baik dan tidak terdapat gejala multikolinearitas. Jadi, variabel
42 bebas (X1 hingga X5) untuk data TCM tidak ditemukan korelasi yang tinggi antar variabel bebas satu dengan yang lainnya. Apabila terjadi gejala multikolinearitas maka koefisien korelasi menjadi tidak menentu dan standart error menjadi sangat besar atau tidak diketahui jumlah kesalahannya. Pada variabel X4 di zona 3, tidak ditemukan nilai tolerance dan VIF karena variabel X4 (pendidikan) di zona 3 memiliki bobot yang sama, yaitu sebesar 3.
IV.1.4 Hasil dan Analisis Uji Heterokedastisitas
Uji heterokesdasitas digunakan untuk menguji apakah dalam model regresi terjadi ketidaksamaan variansi dari residual satu dengan yang lain. Dasar pengambilan keputusan dalam uji ini adalah nilai signifikansi > 0,05. Syarat yang harus terpenuhi dalam model regresi adalah tidak adanya gejala heteroskedastisitas.
Heteroskedastisitas akan mengakibatkan penaksiran koefisien-koefisien regresi menjadi tidak efisien. Data dinyatakan homoskedastisitas apabila penyebaran nilai- nilai residual terhadap nilai-nilai prediksi tidak membentuk suatu pola tertentu pada scatter plotter, jika nilai-nilai membentuk pola tertentu maka mengalami gejala heteroskedastisitas.
1. Hasil P-Value Setiap Zona
Hasil uji heterokesdasitas ditunjukkan pada Gambar IV-26 hingga Gambar IV-30.
Gambar IV-26 Hasil Uji Heteroskedastisitas Zona 1
Gambar IV-27 Hasil Uji Heteroskedastisitas Zona 2
43 Gambar IV-28 Hasil Uji Heteroskedastisitas Zona 3
Gambar IV-29 Hasil Uji Heteroskedastisitas Zona 4
Gambar IV-30 Hasil Uji Heteroskedastisitas Zona 5
Hasil signifikansi uji heteroskedastisitas pada masing-masing zona ditunjukkan juga pada Tabel IV-5.
Tabel IV-5 Hasil Signifikansi Uji Heteroskedastisitas Setiap Zona
Parameter
Sig p- value Zona 1
Sig p- value Zona 2
Sig p- value Zona 3
Sig p- value Zona 4
Sig p- value Zona 5
Konstan (Y) 0,047 0,209 0,858 0,350 0,139
Biaya Perjalanan (X1) 0,016 0,831 0,699 0,100 0,089
Living Cost (X2) 0,691 0,147 0,396 0,538 0,736
Usia (X3) 0,458 0,810 0,923 0,694 0,536
Pendidikan (X4) 0,991 0,960 - 0,858 0,762
Penghasilan (X5) 0,230 0,296 0,600 0,187 0,432
Berdasarkan Tabel IV-5 menunjukkan p-value pada seluruh zona bernilai
>0,05, sehingga seluruh zona tersebut tidak terjadi gejala
44 heteroskedastisitas. Pada variabel pendidikan (X4) di zona 3 tidak ditemukan nilai p-value karena bobot pada variabel tersebut bernilai sama, yaitu berbobot 3.
2. Scatter Plotter Uji Heterokedastisitas
Hasil sebaran titik pada scatter plotter uji heteroskedastisitas masing- masing zona ditunjukkan pada Gambar IV-31 hingga Gambar IV-35.
Gambar IV-31 Scatter Plotter Uji Heterokedastisitas Zona 1
Gambar IV-32 Scatter Plotter Uji Heterokedastisitas Zona 2
45 Gambar IV-33 Scatter Plotter Uji Heterokedastisitas Zona 3
Gambar IV-34 Scatter Plotter Uji Heterokedastisitas Zona 4
Gambar IV-35 Scatter Plotter Uji Heterokedastisitas Zona 5 Berdasarkan hasil scatter plotter sebaran data pada seluruh zona menunjukan bahwa data titik plot tersebar dan tidak membentuk pola
46 tertentu. Hal tersebut menunjukkan bahwa scatter plot menunjukan penyebaran nilai-nilai residual terhadap nilai-nilai prediksi adalah homokesdatisitas atau datanya homogen, sehingga tidak terjadi heteroskesdastisitas. Oleh karena itu, data pada model regresi yang digunakan tidak terjadi ketidaksamaan variansi dari residual satu dengan yang lain atau tidak mengalami gejala heterokesdasitas.
IV.2 Hasil dan Analisis Regresi TCM
Pada perhitungan menggunakan metode TCM, terlebih dahulu mengetahui kategori korelasi. Kategori korelasi dapat ditentukan berdasarkan dari hasil nilai multiple R. Tabel IV-6 merupakan kategori korelasi.
Tabel IV-6 Kategori Korelasi Kategori Korelasi
0,00 – 0,199 Sangat Rendah
0,20 – 0,399 Rendah
0,40 – 0,599 Sedang
0,60 – 0,799 Kuat
0,80 – 1,00 Sangat Kuat
Apabila nilai signifikansi alfa < 0,05, maka terdapat pengaruh yang signifikan antara variabel X1 hingga X5 dengan variabel Y. Berikut ini hasil dari perhitungan Travel Cost Method (TCM) pada masing-masing zona.
1. Zona 1
Hasil yang diperoleh menggunakan metode regresi ditunjukkan pada Gambar IV-36.
Gambar IV-36 Hasil Regresi Zona 1
Nilai Multiple R sebesar 0,773423188, sehingga hubungan antara variabel X1, X2, X3, X4 dan X5 termasuk dalam kategori kuat. Nilai koefisien determinasi yang diambil dari data Adjusted R Square yaitu sebesar
47 0,095912698 atau 9,59%. Angka tersebut menunjukkan bahwa variabel X1, X2, X3, X4 dan X5 menjelaskan variabel Y sebesar 9,59% dan sisanya dipengaruhi oleh faktor lain. Zona 1 memiliki nilai signifikansi alfa lebih dari sama dengan 0,05, tidak terdapat pengaruh yang signifikan antara variabel X dengan variabel Y. Hasil perhitungan TCM untuk zona 1 ditunjukkan pada Tabel IV-7.
Tabel IV-7 Hasil TCM Zona 1 TCM
21,82511325 21,158355 32,43458683 43.31909995 41.0123756 26.50642158 26.83753775 37.07165143 31.83485859
42 324 2. Zona 2
Hasil yang diperoleh menggunakan metode regresi ditunjukkan pada Gambar IV-37.
Gambar IV-37 Hasil Regresi Zona 2
Nilai Multiple R sebesar 0,7688799, sehingga hubungan antara variabel X1, X2, X3, X4 dan X5 termasuk dalam kategori kuat. Nilai koefisien determinasi yang diambil dari data Adjusted R Square yaitu sebesar