HOAX COVID-19
OPTIMIZATION OF SUPPORT VECTOR MACHINE PARAMETERS USING GRID SEARCH FOR COVID-19 HOAX NEWS CLASSIFICATION
SKRIPSI
Disusun Oleh : Aldo Abdullah Murad
17312217
PROGRAM STUDI S1 INFORMATIKA FAKULTAS TEKNIK DAN ILMU KOMPUTER
UNIVERSITAS TEKNOKRAT INDONESIA BANDAR LAMPUNG
2023
ii
HALAMAN PENGESAHAN SKRIPSI
OPTIMASI PARAMETER SUPPORT VECTOR MACHINE MENGGUNAKAN GRID SEARCH UNTUK KLASIFIKASI BERITA
HOAX COVID-19
Dipersiapkan dan Disusun oleh :
ALDO ABDULLAH MURAD 17312217
Telah dipertahankan di depan Dewan Penguji Pada Tanggal 2 September 2023
Dewan Penguji,
Pembimbing, Penguji,
Auliya Rahman Isnain, S.Kom., M.Cs. Yusra Fernando, S.Kom., M.Kom.
NIK. 022 16 02 02 NIK. 022 10 01 04
Skripsi ini telah diterima sebagai salah satu persyaratan untuk memperoleh gelar sarjana
Tanggal 28 November 2023
Fakultas Teknik dan Ilmu Komputer Program Studi Informatika
Dekan, Ketua,
Dr. H. Mahathir Muhammad, S.E., M.M. Dyah Ayu Megawaty, M.Kom.
NIK. 023 05 00 09 NIK. 022 09 03 05
iii
LEMBAR PERNYATAAN KEASLIAN PENELITIAN
Yang bertanda tangan di bawah ini :
Nama : Aldo Abdullah Murad
NPM : 17312217
Program Studi : Informatika
Dengan ini menyatakan bahwa laporan skripsi:
Judul : Optimasi Parameter Support Vector Machine
Menggunakan Grid Search Untuk Klasifikasi Berita Hoax Covid-19
Pembimbing : Auliya Rahman Isnain, S.Kom., M.Cs.
Belum Pernah diajukan untuk diuji sebagai persyaratan untuk memperoleh gelar akademik pada berbagai tingkat di Universitas/Perguruan Tinggi manapun. Tidak ada bagian dalam skripsi ini yang pernah dipublikasikan oleh pihak lain, kecuali bagian yang digunakan sebagai referensi, berdasarkan kaidah penulisan ilmiah yang benar.
Apabila dikemudian hari ternyata laporan tugas akhir yang saya tulis terbukti hasil saduran/plagiat, maka saya akan bersedia menanggung segala resiko yang akan saya terima.
Demikian pernyataan ini dibuat dengan sebenar-benarnya.
Bandar Lampung, Yang menyatakan,
Aldo Abdullah Murad NPM 17312217
iv
LEMBAR PERNYATAAN PUBLIKASI SKRIPSI UNTUK KEPENTINGAN AKADEMIS
Sebagai sivitas akademik Program Studi S1 Informatika Fakultas Teknik dan Ilmu Komputer Universitas Teknokrat Indonesia, saya yang bertanda tangan di bawah ini :
Nama : Aldo Abdullah Murad
NPM : 17132217
Program Studi : Informatika Jenis Karya : Skripsi
Demi pengembangan ilmu pengetahuan, menyetujui untuk memberikan kepada Program Studi S1 Informatika Fakultas Teknik dan Ilmu Komputer Universitas Indonesia Hak Bebas Royalti Noneklusif (Non-exclusive Royati-Free Right) atas karya ilmiah saya yang berjudul :
“Optimasi Parameter Support Vector Machine Menggunakan Grid Search Untuk Klasifikasi Berita Hoax Covid-19”
Beserta perangkat yang ada (jika diperlukan). Dengan Hak Bebas Royalti Noneklusif ini Program Studi S1 Informatika Fakultas Teknik dan Ilmu komputer Universitas Teknokrat Indonesia berhak menyimpan, mengalih media/formatkan, mengelola dalam bentuk pangkalan data (database), merawat, dan mempublikasikan tugas akhir saya selama tetap mencantumkan nama saya sebagai penulis/pencipta dan sebagai pemilih Hak Cipta.
Demikian pernyataan ini saya buat dengan sebenarnya.
Dibuat di : Bandar Lampung Pada Tanggal :
Yang menyatakan,
Aldo Abdullah Murad NPM. 17312217
v
KATA PENGANTAR
Puji syukur kami panjatkan kepada Allah SWT, karena atas berkat dan rahmat-nya, saya dapat menyelesaikan penelitian ini. Penulisan penelitian ini dilakukan dalam rangka menyelesaikan studi program S1 Informatika Fakultas Teknik & Ilmu Komputer Universitas Teknokrat Indonesia.
Saya menyadari bahwa, tanpa bantuan dan bimbingan dari berbagai pihak sangatlah sulit bagi penulis untuk menyelesaikan penelitian ini. Oleh karena itu, saya mengucapkan terima kasih kepada :
1. Dr. H.M. Nasrullah Yusuf, S.E., M.B.A. selaku Rektor Universitas Teknokrat Indonesia
2. Dr. H. Mahathir Muhammad, S.E., M.M. selaku Dekan Fakultas Teknik dan Ilmu komputer
3. Dyah Ayu Megawaty, M.Kom. selaku Ketua Program Studi Informatika 4. Auliya Rahman Isnain, S.Kom., M.Cs. selaku dosen pembimbing 5. Yusra Fernando, S.Kom., M.Kom. selaku dosen penguji
Akhir kata, saya berharap semoga Allah SWT berkenan membalas segala kebaikan semua pihak yang telah membantu dan semoga hasil dari penelitian ini membawa manfaat.
Bandar Lampung,
Penulis
vi DAFTAR ISI
LEMBAR JUDUL ... Error! Bookmark not defined.
HALAMAN PENGESAHAN ... ii
LEMBAR PERNYATAAN KEASLIAN PENELITIAN ... iii
LEMBAR PERNYATAAN PUBLIKASI ... iv
KATA PENGANTAR ... v
DAFTAR ISI ... vi
DAFTAR TABEL ... viii
DAFTAR GAMBAR ... ix
ABSTRAK ... x
BAB I PENDAHULUAN ... 1
1.1 Latar Belakang ... 1
1.2 Rumusan Masalah ... 3
1.3 Batasan Masalah ... 4
1.4 Tujuan Penelitian ... 4
1.5 Manfaat Penelitian ... 4
BAB II LANDASAN TEORI ... 6
2.1 Tinjauan Pustaka ... 6
2.2 Text Mining ... 11
2.3 Data Mining ... 13
2.4 Support Vector Machine ... 14
2.5 Grid Search ... 16
2.6 K-fold Cross Validation ... 16
BAB III METODE PENELITIAN... 17
3.1 Studi Literatur ... 17
3.2 Analisa dan Perancangan Sistem ... 17
3.3 Pengumpulan Data ... 18
3.2.1 Preprocessing ... 19
3.2.2 Penerapan Metode SVM ... 21
3.4 Pengujian ... 22
BAB IV IMPLEMENTASI ... 23
4.1 Deskripsi Implementasi ... 23
vii
4.2 Implementasi Pengumpulan Data ... 23
4.3 Implementasi Preprocessing ... 25
4.4 Implementasi TF-IDF ... 28
4.5 Implementasi SVM ... 30
4.6 Implementasi SVM yang Dioptimasi Grid Search ... 30
4.7 Implementasi Confusion Matrix ... 31
BAB V HASIL DAN PEMBAHASAN ... 32
5.1 Data ... 32
5.2 Pengujian SVM-Grid Search dan SVM kernel linear ... 32
5.3 Perbandingan Hasil Pengujian ... 38
BAB VI KESIMPULAN DAN SARAN ... 41
6.1 Kesimpulan ... 41
6.2 Saran ... 41
DAFTAR PUSTAKA ... 42
LAMPIRAN ... 46
viii
DAFTAR TABEL
Tabel 2.1 Tinjauan Literatur ... 6
Tabel 3.1 Contoh hasil data di Detik dan Turnbackhoax ... 18
Tabel 3.2 Contoh hasil yang diharapkan setelah tahap preprocessing ... 18
Tabel 3.3 Contoh proses case folding ... 19
Tabel 3.4 Contoh proses normalisasi fitur ... 19
Tabel 3.5 Contoh proses tokenisasi ... 20
Tabel 3.6 Contoh proses slangword ... 20
Tabel 3.7 Contoh proses stopword ... 20
Tabel 5.1 Skenario Pembagian Data Training dan Data Testing ... 33
Tabel 5.2 Hasil Prediksi SVM-Grid Search ... 33
Tabel 5.3 Hasil Prediksi SVM kernel linear ... 34
Tabel 5.4 Hasil Prediksi SVM-Grid Search ... 35
Tabel 5.5 Hasil Prediksi SVM kernel linear ... 35
Tabel 5.6 Hasil Prediksi SVM-Grid Search ... 36
Tabel 5.7 Hasil Prediksi SVM kernel linear ... 36
Tabel 5.8 Hasil Prediksi SVM-Grid Search ... 37
Tabel 5. 9 Hasil Prediksi SVM kernel linear ... 37
Tabel 5.10 Perbandingan Evaluasi Model ... 38
Tabel 5.11 Hasil Prediksi SVM-Grid Search dan SVM kernel linear Pada 4 Skenario... 39
ix
DAFTAR GAMBAR
Gambar 1.1 Digital Indonesia ... 1
Gambar 1.2 Data Hoax terkait Covid-19 ... 2
Gambar 2.1 Tahapan Text Mining ... 12
Gambar 2.2 Alur Data Mining ... 14
Gambar 2.3 SVM berusaha untuk menemukan hyperplane terbaik yang memisahkan kedua kelas ... 15
Gambar 2. 4 Hyperplane terbentuk diantara kedua kelas ... 15
Gambar 3.1 Rancangan Sistem ... 17
Gambar 3.2 Proses Penerapan SVM-Grid Search... 21
Gambar 4.1 Implementasi kode pada crawling data portal Detik.com ... 24
Gambar 4.2 Implementasi kode pada crawling data portal turnbackhoax ... 25
Gambar 4.3 Implementasi Case Folding ... 26
Gambar 4.4 Implementasi Normalisasi Fitur ... 26
Gambar 4.5 Implementasi Case Folding ... 27
Gambar 4.6 Implementasi Slangword ... 27
Gambar 4.7 Implementasi Stopword ... 28
Gambar 4.8 Implementasi pembacaan data csv ... 28
Gambar 4.9 Implementasi pengubahan data string ... 29
Gambar 4.10 Implementasi TF-IDF ... 29
Gambar 4.11 Implementasi pembagian data training dan data set ... 29
Gambar 4.12 Implementasi SVM kernel Linear ... 30
Gambar 4.13 Implementasi SVM-Grid Search ... 30
Gambar 4.14 Implementasi Confusion Matrix... 31
Gambar 5.1 Hasil Pengujian dengan SVM-Grid Search Skenario 1 ... 33
Gambar 5.2 Hasil Pengujian dengan SVM kernel linear Skenario 1 ... 34
Gambar 5.3 Hasil Pengujian dengan SVM-Grid Search Skenario 2 ... 34
Gambar 5.4 Hasil Pengujian dengan SVM kernel linear Skenario 2 ... 35
Gambar 5.5 Hasil Pengujian dengan SVM-Grid Search Skenario 3 ... 35
Gambar 5.6 Hasil Pengujian dengan SVM kernel linear Skenario 3 ... 36
Gambar 5.7 Hasil Pengujian dengan SVM-Grid Search Skenario 4 ... 37
Gambar 5.8 Hasil Pengujian dengan SVM kernel linear Skenario 4 ... 37
x ABSTRAK
OPTIMASI PARAMETER SVM MENGGUNAKAN GRID SEARCH UNTUK KLASIFIKASI BERITA HOAX COVID-19
OPTIMIZATION OF SUPPORT VECTOR MACHINE PARAMETERS USING GRID SEARCH FOR COVID-19 HOAX NEWS CLASSIFICATION
Oleh
Aldo Abdullah Murad 17312217
Berita merupakan suatu informasi yang menunjukan tempat atau keterangan waktu dan biasanya terjadi di masyarakat. Pengguna internet di Indonesia tidaklah sedikit serta internet juga merupakan salah satu media yang digunakan untuk menyebarkan informasi. Faktor yang mempengaruhi penyebaran informasi menjadi tidak terkendali karena berbagai informasi dapat diakses oleh masyarakat melalui internet tanpa validasi, dimana informasi itu dapat berupa berita palsu atau hoax.
Hoaks tentang kesehatan sangat berbahaya apabila informasi yang tidak benar dipraktikkan oleh masyarakat, seperti penyeberan informasi virus covid.
Diperlukan proses pengklasifikasian terhadap teks yang didapat pada portal berita.
Metode klasifikasi Support Vector Machine (SVM) dengan Optimasi oleh metode Grid Search memiliki 5 tahapan yaitu Data Selection, Prepocessing, Transformation, Data Mining, dan Evaluation. Penerapan metode SVM yang dioptimasi oleh Grid Search dilakukan pada situs portal berita yang dimana berita fakta dan berita bohong dijadikan sebagai data sampel. Analisis ini dilakukan untuk mengetahui tingkat akurasi dari metode yang digunakan. Metode SVM dioptimasi oleh Grid Search dibandingkan dengan metode SVM menggunakan kernel Linear.
Hasil yang diperoleh dari penelitian ini menghasilkan tingkat akurasi SVM yang dioptimasi Grid Search sebesar 90%. Pada SVM dengan kernel Linear dihasilkan akurasi sebesar 82%. Dapat disimpulkan bahwa metode SVM yang dioptimasi oleh Grid Search lebih baik dibandingkan dengan metode SVM dengan kernel Linear dalam klasifikasi berita hoax pada portal berita online.
Kata Kunci : Covid, Grid Search, Klasifikasi, Optimasi, SVM
1.1 Latar Belakang
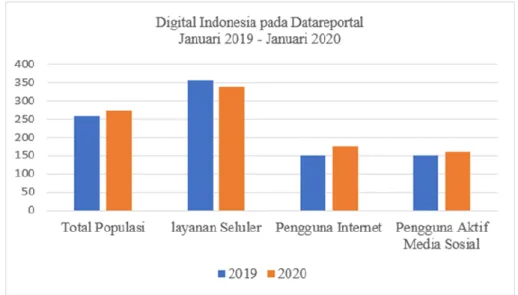
Berdasarkan Kamus Besar Bahasa Indonesia (KBBI) 2021, dijelaskan bahwa informasi tidak benar atau palsu yang didapat tanpa sumber yang jelas merupakan pengertian dari hoaks (Kemdikbud, 2016). Sedangkan dalam Oxford English Dictionary (Oxford University, 2022), hoaks didefinisikan sebagai suatu tindakan atau perbuatan yang dibuat dengan tujuan untuk membuat orang lain mempercayai sesuatu yang tidak benar. Berdasarkan data dari situs datareportal, pengguna internet dari januari tahun 2019 (Kemp, 2019) sampai januari 2020 (Kemp, 2020) mengalami peningkatan sekitar 25 juta pengguna. Hal ini merupakan salah satu faktor yang mempengaruhi penyebaran informasi menjadi tidak terkendali, sehingga berbagai informasi dapat diakses oleh masyarakat melalui internet tanpa validasi, dimana informasi itu dapat berupa berita palsu atau hoax. Peningkatan jumlah pengguna internet dapat dilihat pada Gambar 1.1 berikut.
Gambar 1.1 Digital Indonesia
Kata berita sendiri menurut Kamus Besar Bahasa Indonesia (KBBI), 2021 merupakan suatu informasi yang menunjukan tempat atau keterangan waktu dan biasanya terjadi di masyarakat (Kemdikbud, 2016). Seperti telah disinggung sebelumnya, penyebaran berita dapat berupa informasi palsu atau kebohongan yang akan dulit dikendalikan apalagi dengan kondisi yang belum dapat dipastikan. Hoaks yang menyangkut kesehatan memang marak beredar di
2
kalangan masyarakat. Hasil survei yang dilakukan oleh Surveyor Persatuan Wartawan Indonesia (PWI) menemukan bahwa hoaks kesehatan terbanyak beredar di masyarakat (Juditha, 2019). Dapat diketahui bahwa berita hoax kesehatan adalah hoax yang populer jika dibandingkan dengan berita lainnya.
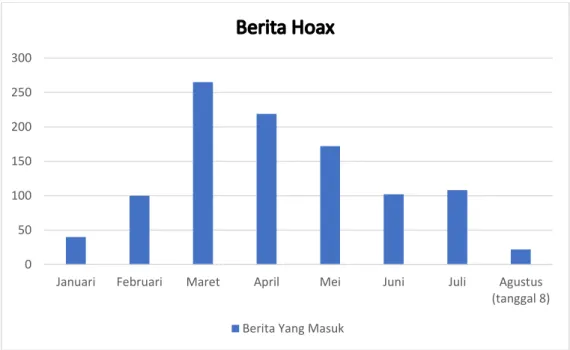
Berdasarkan data yang dirilis oleh Kominfo melalui website resminya telah mencatat dari bulan Januari – Agustus 2020 bahwa sebanyak 1028 hoaks tersebar terkait berita Covid-19 (Kominfo, 2020). Dalam hal ini, berita hoaks covid merupakan salah satu berita hoaks kesehatan yang paling banyak penyebarannya seperti ditampilkan pada table berikut.
Gambar 1.2 Data Hoax terkait Covid-19
Hoaks kesehatan sangat berbahaya apabila informasi yang tidak benar dipraktikkan oleh masyarakat, seperti mengonsumsi jenis obat-obat tertentu akan membahayakan jiwa manusia. Hoaks jenis ini juga dapat menciptakan keresahan serta kepanikan bagi masyarakat yang membacanya (Juditha, 2019).
Oleh karena itu cara untuk tidak terjerumus pada berita hoax adalah dengan membaca berita atau infomasi dari media terpercaya. Di Indonesia sendiri menurut Ketua Komisi Penelitian, Pendataan dan Ratifikasi Dewan Pers Indonesia, Ratna Komala memaparkan bahwa terdapat sekitar 43 ribu portal media berita online yang terdata. Namun, dari jumlah tersebut hanya 500 yang resmi terdaftar oleh Dewan Pers. Kemudian dari 500 media online tersebut sudah tercatat ada 78 media yang terverifikasi faktual dan administrasi serta hanya ada tujuh media online yang lolos semua verifikasi tersebut, salah satunya adalah Detik.com (Dewan Pers, 2019). Berita mengenai hoax dapat diakses melalui situs Turnbackhoax. Turnbackhoax merupakan situs pengaduan berbagai jenis hoax. Situs ini dibuat oleh KOMINFO & MASTEL (Aji and Sarmini, 2019).
0 50 100 150 200 250 300
Januari Februari Maret April Mei Juni Juli Agustus
(tanggal 8) Berita Yang Masuk
Text mining merupakan proses untuk memperoleh informasi berkualitas tinggi dari teks. Diantara proses yang dapat dilakukan dalam text mining adalah klasifikasi teks. Klasifikasi teks merupakan proses untuk menentukan suatu dokumen teks ke dalam suatu kelas tertentu (Deolika, Kusrini and Luthfi, 2019). Dalam prosesnya, klasifikasi dapat dilakukan dengan banyak cara baik secara manual ataupun dengan bantuan teknologi (Wibawa et al., 2018). Klasifikasi yang dilakukan dengan bantuan teknologi, memiliki beberapa algoritma, diantaranya Decission Tree, K-Nearest Neighbor (KNN), Naive Bayes, Neural Network (NN), Random Forest (RF) dan Support Vektor Machine (SVM).
Penulis akan berfokus pada metode Support Vector Machine (SVM).
SVM memiliki kelebihan diantara metode yang lainnya, dimana akurasi SVM lebih unggul dengan nilai akurasi pada proses k-fold validation sebesar 88,76%
dibandingkan dengan Algoritma KNN dengan akurasi 88,1% (Maulina and Sagara, 2018). Kemudian perbandingan SVM dengan Multinominal Naive Bayes (MNB) mendapatan hasil SVM lebih unggul dengan akurasi sebbesar 82%, presisi 84% dan recall 82%. Sedangkan MNB memperoleh akurasi sebesar 62%, presisi 68% dan recall 62% (Nasution and Hayaty, 2019). Untuk memaksimalkan penggunaan metode SVM, penulis akan menggunakan hyperparameter tuning serta teknik optimasi Grid Search agar akurasi prediksi dapat lebih akurat. Hyperparameter tuning merupakan arsitektur dari deep learning untuk meningkatkan performa dari model prediksi (Hutter, Kotthoff and Vanschoren, 2019). Metode yang paling banyak digunakan dalam optimasi hyperparameter yaitu Grid Search (Nugraha and Sasongko, 2022). Grid search dianggap tidak efesien bahkan tidak layak untuk digunakan (Moreno et al., 2018). Namun metode Grid Search masih menjadi solusi umum daripada harus mengubah satu hyperparameter pada satu waktu dan mengukur pengaruhnya terhadap kinerja model, justru hal tersebut akan menjadi tidak efisien dan tidak menjamin hasil yang optimal karena mengabaikan interaksi antara hyperparameter (Moreno et al., 2018). Berdasarkan latar belakang tersebut, penelitian ini perlu mengembangkan dan menganalisis model klasifikasi berita hoax covid-19 untuk mendapatkan data prediksi antara berita faktual dan berita hoax tentang covid-19. Oleh karena itu penulis mengangkat judul “Optimasi Parameter SVM Menggunakan Grid Search Untuk Klasifikasi Berita Hoax Covid-19”. Agar dapat mengetahui apakah akurasi dari Metode SVM yang dioptimasi oleh grid search lebih baik dari metode SVM yang hanya menggunakan kernel linear. Metode SVM dengan kernel linear dipilih karena akurasi kernel linear dianggap cukup tinggi dalam kasus ini dibandingkan kernel lainnya (Ropikoh et al., 2021).
1.2 Rumusan Masalah
Berdasarkan latar belakang masalah yang telah diuraikan diatas, maka rumusan masalah pada peneliatian ini adalah :
4
1. Bagaimana menerapkan metode Support Vector Machine yang dioptimasi oleh Grid Search untuk klasifikasi berita hoax?
2. Bagaimana tingkat akurasi metode Support Vector Machine yang dioptimasi oleh Grid Search terhadap metode Support Vector Machine kernel linear?
1.3 Batasan Masalah
Pembatasan masalah sangat diperlukan untuk memfokuskan suatu penelitian agar hasil yang didapat lebih maksimal. Batasan masalah pada penelitian ini diantaranya :
1. Klasifikasi berita dilakukan pada portal berita Detik dan Turnbackhoax.
2. Metode yang digunakan dalam penelitian ini adalah Support Vector Machine yang dioptimasi oleh Grid Search dengan metode pembanding adalah metode Support Vector Machine dengan kernel linear.
3. Data yang digunakan adalah data yang diambil dari portal berita Detik.com dan Turnbackhoax, sejak 1 januari 2021 sampai 30 juni 2021.
1.4 Tujuan Penelitian
Dalam sebuah penelitian ilmiah, tentu diperlukan tujuan penelitian yang jelas. Oleh karena itu tujuan dari penelitian ini diantaranya :
1. Menerapkan metode Support Vector Machine yang dioptimasi oleh Grid Search pada proses klasifikasi.
2. Menganalisa tingkat akurasi, presisi, recall, dan FI Score dari Support Vector Machine yang dioptimasi oleh Grid Search dan dibandingkan dengan metode Support Vector Machine dengan kernel linear.
3. Untuk menganalisa tingkat penyebaran berita hoax covid-19 pada situs berita online.
1.5 Manfaat Penelitian
Manfaat yang diharapkan dari penelitian ini, yaitu :
Penggunaan metode Support Vector Machine yang dioptimasi oleh Grid Search diharapkan dapat menjadi rujukan untuk pengembangan metode klasifikasi selanjutnya.
BAB II
LANDASAN TEORI
2.1 Tinjauan Pustaka
Tinjauan pustaka merupakan kumpulan dari penelitian-penelitian sebelumnya yang dapat digunakan untuk mendukung penelitian yang sedang dilakukan. Berikut adalah tinjauan literatur yang ditampilkan dalam Tabel 2.1.
Tabel 2.1 Tinjauan Literatur
No Peneliti Judul Metode Hasil
1 Isnin
Apriyatin Ropikoh,
Rijal Abdulhakim,
Ultach Enri, Nina Sulistiyowati
(2021)
Penerapan Algoritma Support Vector Machine (SVM) untuk Klasifikasi Berita Hoax Covid-19
Support Vector Machine (SVM) dan Knowledge Discovery in Database (KDD)
Hasil prediksi dengan kernel linear pada skenario 3 (80:20) sangat baik, dengan hasil 111 data hoax yang diprediksi hoax, ada 61 data hoax yang diprediksi bukan hoax.
Sedangkan data bukan hoax yang diprediksi hoax ada 55 dan data bukan hoax diprediksi bukan hoax ada 1408.
Akurasi tertinggi terdapat pada skenario 80:20 sebesar 92,90%.
Akurasi terendah didapat oleh kernel RBF pada skenario (90:10) yaitu 90,46% dan model
kurang baik
menghasilkan data hoax yang diprediksi hoax ada 28 & data hoax yang diprediksi bukan hoax ada 75. Data bukan hoax yang diprediksi hoax ada 3 & data bukan hoax yang diprediksi bukan hoax ada 712.
Tabel 2.1 Tinjauan Literatur (Lanjutan)
No Peneliti Judul Metode Hasil
2 D. Maulina and R.
Sagara (2018)
Klasifikasi Artikel Hoax Menggunakan Support Vector Machine Linear Dengan
Pembobotan Term
Frequency- Inverse Document Frequency
Support Vector Machine dengan kernel Linear
Akurasi artikel hoax dan tidak hoax dengan data 108 artikel hoax dan 132 artikel tidak hoax adalah 95.8333%, dengan Cross Validation dengan Fold 10. Kernel linear sangat cocok digunakan untuk melakukan klasifikasi
text dengan
menggunakan
pembobotan TF-IDF.
SVM Linear memiliki kecepatan training 1.37 detik untuk 240 vector data.
3 M. R. A.
Nasution and M.
Hayaty (2019)
Perbandingan Akurasi dan Waktu Proses Algoritma K- NN dan SVM dalam Analisis Sentimen Twitter
Support Vector Machine (SVM) dan K-Nearest Neighbor (K-NN)
SVM memiliki akurasi
lebih tinggi
dibandingkanK-NN, yaitu sebesar 89,70%
tanpa validasi K-Fold Cross Validation dan sebesar 88,76% dengan validasi K-Fold Cross Validation. K-NN memiliki waktu proses yang lebih cepat daripada SVM, yaitu sebesar 0.0160s tanpa validasi K-Fold Cross Validation dan sebesar 0.1505s dengan validasi
K-Fold Cross
Validation.
8
Tabel 2.1 Tinjauan Literatur (Lanjutan)
No Peneliti Judul Metode Hasil
4 C. Juditha (2019)
Literasi Informasi Melawan Hoaks Bidang
Kesehatan di Komunitas Online
Analisis Isi Kualitatif
Terbangunnya tujuh pilar literasi informasi dalam komunitas Indonesia Hoaxes.
Literasi informasi setiap anggota terbentuk dengan sendirinya dengan bergabung di dalamnya, mulai dari proses identifikasi informasi, cakupan, perencanaan,
pengumpulan informasi, evaluasi, pengelolaan, serta penyajian informasi. Admin memiliki tanggung
jawab dalam
penyebaran informasi yang benar dan meluruskan hoaks.
5 C. Juditha (2020)
Perilaku Masyarakat Terkait Penyebaran Hoaks Covid-19
Survei Dengan Pendekatan Kuantitatif.
Hasil penelitian menggambarkan bahwa pengetahuan responden tentang Covid-19, hoaks secara umum, dan hoaks tentang Covid-19 sangat
memadai, dan
dikategorikan sebagai pengetahuan level dua, yaitu memahami. Hal ini dibuktikan dengan kemampuan responden dalam mendefenisi kanapa itu virus Corona dan juga hoaks.
Informasi terkait Covid- 19 banyak diperoleh responden dari situs berita, media sosial, televisi, pesan instan, serta website resmi pemerintah.
Tabel 2.1 Tinjauan Literatur (Lanjutan)
No Peneliti Judul Metode Hasil
6 Wahyu
Nugraha, Agung Sasongko
(2022)
Hyperparameter Tuning pada Algoritma Klasifikasi dengan Grid Search
Supervised learning atau klasifikasi dan Tuning Hyperparam eter dengan Grid Search
Grid Search
menggunakan Cross Validation memberikan kemudahan dalam menguji coba setiap parameter model tanpa harus melakukan validasi manual satu
persatu. Hasil
eksperimen
menunjukkan bahwa
model XGBoost
memperoleh nilai terbaik yaitu sebesar 0,772 sedangkan Decision tree memiliki nilai terendah yaitu 0,701.
7 Ranggi Praharaning
tyas Aji , Sarmini
(2019)
Pelatihan Identifikasi dan Pelaporan Berita Hoax melalui portal ‘
turnbackhoax.id
’ kepada Masyarakat Desa
Kedungwringin
Metode Pendidikan Masyarakat
Kegiatan ini diikuti oleh 40 orang perwakilan
warga desa
Kedungwringin.
Kegiatan pengabdian
masyarakat ini
dilakukan dengan penyuluhan mengenai hoax. Materi yang
diberikan pada
penyuluhan ini meliputi :
1. Prinsip bersosial media dan internet 2. Dampak bersosial media dan internet 3. Hal yang boleh dan tidak boleh pada sosial media dan internet 4. Contoh berita hoax pada media sosial dan internet.
10
Tabel 2.1 Tinjauan Literatur (Lanjutan)
No Peneliti Judul Metode Hasil
8 Agatha Deolika ,
Kusrini , Emha Taufiq
Luthf (2019)
ANALISIS PEMBOBOTA N KATA PADA KLASIFIKASI TEXT MINING
Naïve bayes Pembobotan TF.RF dengan klasifikasi Naïve bayes lebih baik dari pembobotan TF.IDF dan WIDF dengan nilai Accuracy 98,67%, Precision 93,81%, dan Recall 96,67%. Klasifikasi naïve bayes dapat digunakan untuk mengelompokan atau klasifikasi text mining dengan baik.
9 Aji Prasetya Wibawa, Muhammad
Guntur Aji Purnama, Muhammad
Fathony Akbar,
Felix Andika Dwiyanto
(2018)
Metode-metode Klasifikasi
Jaringan Saraf Tiruan, Naïve Bayes, Support Vector Machine, Decission Tree, dan Fuzzy
Setiap metode
mempunyai
karakteristik tertentu termasuk kelemahan dan kelebihan masing- masing pendekatan.
Berdasarkan kelemahan dan kelebihan tersebut dapat dijadikan pertimbangan untuk memilih metode yang sesuai dengan macam data yang akan diolah.
10 Iwan Syarif , Adam Prugel- Bennett, Gary Wills
(2016)
SVM Parameter Optimization Using Grid Search and Genetic Algorithm to Improve Classification Performance
Support Vector Machine (SVM) dengan optimasi Grid Search dan Genetic Algorithm (GA)
Dalam 1 dataset (spambase), pencarian grid memiliki akurasi yang lebih baik dari GA.
Namun, pada dataset madelon dan intrusi GA tidak dapat menjamin hasil yang baik untuk semua kernel karena kinerja klasifikasi yang tidak begitu baik (pada dataset madelon F- measure hanya 66,67%
dan pada dataset intrusi F-measure hanya 61,31% ).
2.2 Text Mining
Text mining adalah teknik yang digunakan untuk melakukan klasifikasi untuk menemukan pola-pola menarik dari kumpulan data tekstual yang banyak (Feldman and Sanger, 2007). Text mining merupakan salah satu dari bentuk variasi data mining. Mirip dengan data mining, kecuali teknik yang dirancang untuk bekerja pada data terstuktur dalam database di data mining. Text mining dapat bekerja pada data yang tidak dan semi-terstruktur seperti dokumen teks yang lengkap, kode halaman web, dan lainnya (Pratama and Atmi, 2020).
Text mining diartikan sebagai penemuan informasi baru yang sebelumnya tidak diketahui komputer yang secara otomatis mengekstraksi informasi dari berbagai sumber. Menggabungkan informasi yang berhasil diekstrak dari berbagai sumber merupakan kunci dari proses ini (Rahmawati et al., 2020). Tujuan dari text mining adalah untuk menemukan katakata yang dapat merepresentasikan isi dokumen yang nantinya dapat dianalisis.
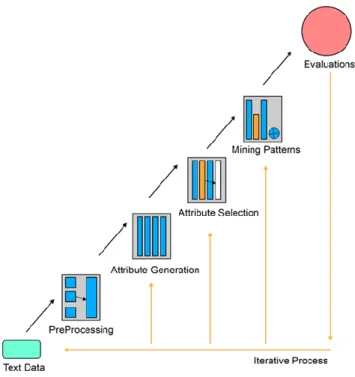
Terdapat beberapa proses yang dapat dilakukan dalam melakukan text mining untuk mendapatkan informasi yang terdapat dalam data teks (Purba and Situmorang, 2017), diantaranya :
1. Preprocessing
Tahap ini adalah tahapan dimana teks yang disiapkan untuk data harus dibersihkan terlebih dahulu dan disisakan kalimat pentingnya saja.
2. Transformation
Merupakan tahapan dimana kata diubah menjadi bentuk dasarnya dan dimensi kata yang ada dalam dokumen dikurangi.
3. Feature Selection
Adalah proses penghapusan kata yang dianggap tidak deskriptif dan pemilahan kata-kata yang dianggap penting. Ide dasarnya adalah menghapus kata-kata yang terlalu sedikit atau terlalu banyak muncul.
4. Pattern Discovery
Tahapan penting untuk menemukan pola dalam keseluruhan teks. Input awal berupa data teks akan menghasilkan output berupa pola yang akan
12
menjadi hasil dari interpretasi. Jika output tidak sesuai, maka evaluasi dilanjutkan dengan melakukan iterasi ke tahapan sebelumnya.
5. Evaluation
Tahapan dimana hasil dievaluasi apakah dapat digunakan atau harus dibuang.
Gambar 2.1 Tahapan Text Mining
Pada tahap Preprocessing, text mining dapat menghasilkan banyak fitur untuk merepresentasikan dokumen. Terdapat empat fitur yang sering digunakan pada tahap ini, yaitu :
a) Karakter
Merupakan fitur yang paling sederhana diantara fitur lainnya. Fitur ini jarang digunakan dalam text mining dikarenakan keterbatasan jumlah dari karakter itu sendiri. Terdiri dari huruf (a,b,c,….,z), angka (0,1,2,….,9), tanda baca (!,?, dan lain sebagainya), serta simbol khusus (@,#,$,%, dan lain sebagainya).
b) Words (Kata)
Merupakan kumpulan dari beberapa karakter yang mengandung suatu makna. Fitur ini lebih banyak digunakan dibandingkan karakter karena
memiliki variasi yang lebih banyak sebagai pembeda. Contohnya adalah kata “aku” yang terdiri dari gabungan karakter a, k, dan u.
c) Terms
Dapat diartikan mirip seperti words, namun pembedanya lebih signifikan dibanding words. Terdiri dari satu atau lebih words phrase yang memiliki arti yang baru.
2.3 Data Mining
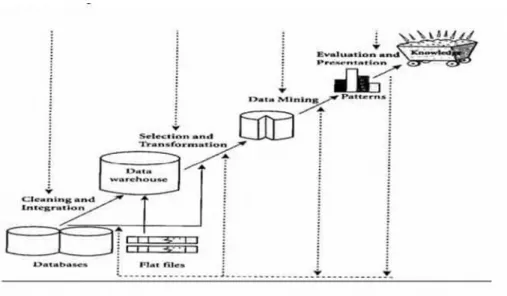
Data mining atau penambangan data adalah proses untuk mengumpulkan data yang nantinya akan diolah dengan beberapa metode. Data mining juga sering disebut penemuan pengetahuan dalam database. Tujuannya adalah untuk memanfaatkan data dan mengolahnya menjadi sesuatu atau informasi yang baru dan berguna (Fitrani and Novarika, 2019). Data mining dapat diartikan sebagai proses menemukan pola dan pengetahuan menarik dari suatu data dalam jumlah besar.
Proses data mining terbagi menjadi beberapa tahap (Rahmawati et al., 2020), yaitu :
1. Data Cleaning
Proses pembersihan noice dan data yang tidak penting.
2. Data Integration
Penggabungan data dari berbagai sumber yang masih terkait.
3. Data Selection
Pengambilan data yang relevan untuk digunakan yang ada di database.
4. Data Transformation
Data diubah dan dikonsolidasikan menjadi bentuk yang sesuai untuk melakukan operasi ringkasan dan agregasi.
5. Data Mining
Proses dimana metode cerdas dipakai untuk mengekstraksi pola data.
6. Pattern Evaluation
14
Mengidentifikasi pola yang merepresentasikan pengetahuan berdasarkan ukuran ketertarikan.
7. Knowledge Presentation
Proses visualisasi dan representasi pengetahuan untuk menyajikan pengetahuan yang telah diproses kepada pengguna.
Gambar 2.2 Alur Data Mining
2.4 Support Vector Machine
SVM adalah metode learning machine yang bekerja atas prinsip Structural Risk Minimization (SRM) dengan tujuan menemukan hyperplane terbaik yang memisahkan dua buah class pada input space. Support Vector Machine (SVM) pertama kali diperkenalkan oleh Vapnik pada tahun 1992 sebagai rangkaian harmonis konsep-konsep unggulan dalam bidang pattern recognition. Sebagai salah satu metode pattern recognition, usia SVM terbilang masih relatif muda. Walaupun demikian, evaluasi kemampuannya dalam berbagai aplikasinya menempatkannya sebagai state of the art dalam pattern recognition (Cortes and Vapnik, 1995).
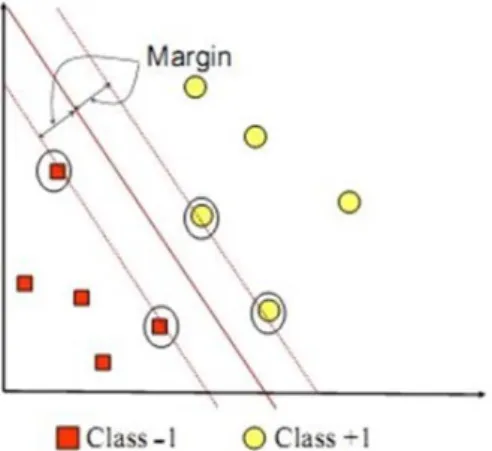
Gambar 2.3 memperlihatkan beberapa pattern yang merupakan anggota dari dua buah class: +1 dan –1. Pattern yang tergabung pada class –1 disimbolkan dengan warna merah (kotak), sedangkan pattern pada class +1, disimbolkan dengan warna kuning (lingkaran). Problem klasifikasi dapat
diterjemahkan dengan usaha menemukan garis (hyperplane) yang memisahkan antara kedua kelompok tersebut (Susilowati, Sabariah and Gozali, 2015).
Hyperplane pemisah terbaik antara kedua class dapat ditemukan dengan mengukur margin hyperplane tsb. dan mencari titik maksimalnya. Margin adalah jarak antara hyperplane tersebut dengan pattern terdekat dari masing- masing class. Pattern yang paling dekat ini disebut sebagai support vector. Garis solid pada gambar menunjukkan hyperplane yang terbaik, yaitu yang terletak tepat pada tengah -tengah kedua class, sedangkan titik merah dan kuning yang berada dalam lingkaran hitam adalah support vector. Usaha untuk mencari lokasi hyperplane ini merupakan inti dari proses pembelajaran pada SVM (Feriyawan and Danoedoro, 2012).
Gambar 2.3 SVM berusaha untuk menemukan hyperplane terbaik yang memisahkan kedua kelas
Gambar 2. 4 Hyperplane terbentuk diantara kedua kelas
16
2.5 Grid Search
Algoritma Grid Search membagi jangkauan parameter yang akan dioptimalkan kedalam grid dan melintasi semua titik untuk mendapatkan parameter yang optimal. Dalam aplikasinya, algoritma grid search harus dipandu oleh beberapa metrik kinerja, biasanya diukur dengan cross-validation pada data training. Data training adalah data latih yang digunakan untuk melatih beberapa pasangan model, sedangkan data testing adalah data uji yang digunakan untuk menguji model terbaik yang diperoleh dari data training. Oleh karena itu disarankan untuk mencoba beberapa variasi pasangan parameter pada hyperplane SVM. Pasangan parameter yang menghasilkan akurasi terbaik yang didapatkan dari uji cross-validation merupakan parameter yang optimal.
Parameter optimal tersebut yang selanjutnya digunakan untuk model SVM terbaik. Setelah itu, model SVM tersebut digunakan untuk memprediksi data testing untuk mendapatkan generalisasi tingkat akurasi model (Naufal, 2017).
2.6 K-fold Cross Validation
Salah satu pendekatan alternatif untuk “training dan testing” yang sering di adopsi dalam beberapa kasus (dan beberapa lainnya terlepas dari ukurannya) yang di sebut dengan k-fold cross validation, dengan cara menguji besarnya error pada data testing (Santosa, 2007). Pada penelitian ini digunakan k-1 sampel untuk training dan 1 sampel sisanya untuk testing. Misalnya ada 10 subset data, kita menggunakan 9 subset untuk training dan 1 subset sisanya untuk testing. Ada 10 kali training dimana pada masingmasing training ada 9 subset data untuk training dan 1 subset digunakan untuk testing. Kemudian di hitung rata-rata error dan standar deviasi error (Santosa, 2007). Setiap bagian k pada gilirannya digunakan sebagai ujian menetapkan dan k lainnya dan 1 bagian digunakan sebagai training set (Enri, 2018).
METODE PENELITIAN
3.1 Studi Literatur
Studi literatur merupakan proses pengumpulan teori, informasi, dan data pendukung yang dibutuhkan untuk melakukan penilitan ini. Dilakukan dengan mempelajari jurnal, karya ilmiah, atau buku yang berkaitan dengan penelitian ini seperti informasi tentang klasifikasi, SVM, dan Grid Search.
3.2 Analisa dan Perancangan Sistem
Pada tahap ini, dilakukan proses analisa terhadap informasi dan teori yang telah diperoleh. Dan hasil dari analisa informasi tersebut akan dituangkan ke dalam rancangan sistem klasifikasi. Rancangan sistem yang diusulkan dalam penelitian ini dapat dilihat pada Gambar 3.1.
Gambar 3.1 Rancangan Sistem
Gambar 3.1 adalah rancangan tahapan proses yang akan dilakukan untuk melakukan klasifikasi berita hoax tentang covid-19. Tahapan-tahapan yang akan dilakukan, diantaranya :
18
3.3 Pengumpulan Data
Dalam penelitian ini, data yang didapatkan bersumber dari crawling data dari portal berita Detik.com. Dataset diambil dengan melakukan crawling data pada Detik sejak tanggal 13 juni 2023. Data tersebut diambil dengan menggunakan kata kunci “covid”. Data yang telah berhasil diambil akan disimpan dengan format .csv. Hasil pengambilan data yang didapat dapat dilihat pada Tabel 3.1.
Tabel 3.1 Contoh hasil data di Detik dan Turnbackhoax
Judul Label
Tertinggi! Ini Sebaran 8.662 Kasus Sembuh COVID-19 RI
Per 16 Januari Detik
[SALAH] Polisi Membubarkan Massa Aksi Bela Palestina di
Solo dengan Tembakan Turnbackhoax
Data berupa teks yang didapat masih berupa teks tidak terstruktur. Oleh karena itu, dilakukan tahap preprocessing yang akan membuat data teks menjadi lebih bersih dan terstruktur. Hasil yang diharapkan setelah melewati tahap processing adalah teks yang terstruktur sehingga polaritas dari teks dapat ditentukan. Seperti yang ditunjukkan pada Tabel 3.2.
Tabel 3.2 Contoh hasil yang diharapkan setelah tahap preprocessing
Judul Label
['sebar', 'sembuh', 'covid', 'januari'] Detik
['polisi', 'bubar', 'massa', 'aksi', 'bela', 'palestina', 'solo',
'tembak'] Turnbackhoax
3.2.1 Preprocessing
Tahapan prepocessing adalah proses penyederhanaan tanggapan agar lebih mudah saat melakukan proses selanjutnya. Tahapan ini terbagi lagi menjadi 5 tahap, yaitu :
1. Case Folding
Dalam dokumen teks yang didapat, tidak semuanya menggunakan penggunaan huruf yang konsisten. Oleh karena itu case folding diperlukan untuk mengubah karakter huruf pada tanggapan menjadi karakter huruf kecil seluruhnya. Hasil dari proses ini dapat dilihat pada Tabel 3.3.
Tabel 3.3 Contoh proses case folding
Input Output
Tertinggi! Ini Sebaran 8.662 Kasus Sembuh COVID-19 RI Per 16 Januari
tertinggi! ini sebaran 8.662 kasus sembuh covid-19 ri per 16 januari
2. Normalisasi
Tahap ini merupakan tahapan dimana karakter khusus seperti tanda baca (titik(.), koma(,), tanda tanya(?), tanda seru(!), tanda petik(‘), dan sebagaimnya), angka numerik (0-9), dan simbol lainnya (*,#,%, dan sebagainya) dihilangkan. Hal ini bertujuan agar proses klasifikasi lebih akurat. Hasil dari proses ini dapat dilihat dari Tabel 3.4.
Tabel 3.4 Contoh proses normalisasi fitur
Input Output
tertinggi! ini sebaran 8.662 kasus sembuh covid-19 ri per 16 januari
tertinggi ini sebaran kasus sembuh covid ri per januari 3. Tokenisasi
Tahapan ini bertujuan untuk memecah tanggapan menjadi satuan kata.
Proses ini dilakukan dengan melihat spasi antar kalimat, berdasarkan spasi tersebut setiap kata akan dipecah (Nurrohmat and SN, 2019). Hasil dari proses ini dapat dilihat pada Tabel 3.5.
20
Tabel 3.5 Contoh proses tokenisasi
Input Output
tertinggi ini sebaran kasus sembuh covid ri per januari
['tertinggi', 'ini', 'sebaran', 'kasus', 'sembuh', 'covid', 'ri', 'per', 'januari']
4. Slangword
Pada tahap ini, kata yang termasuk slangword atau kata tidak baku (bahasa gaul) diubah ke dalam bentuk baku sesuai KBBI. Yang termasuk dalam kategori slangword adalah kata tidak baku, singkatan-singkatan, atau salah penulisannya (Isnain, Sihabuddin and Suyanto, 2020). Hasil dari proses ini dapat dilihat pada Tabel 3.6.
Tabel 3.6 Contoh proses slangword
Input Output
['tertinggi', 'ini', 'sebaran', 'kasus', 'sembuh', 'covid', 'ri', 'per', 'januari']
['tinggi', 'ini', 'sebar', 'kasus', 'sembuh', 'covid', 'ri', 'per', 'januari']
5. Stopword
Tahapan ini bertujuan untuk menghapus kata-kata yang tidak deskriptif atau tidak berpengaruh seperti yang, ke, dari, atau, dan sebagainya agar klasifikasi lebih akurat (Isnain, Sihabuddin and Suyanto, 2020). Hasil dari proses ini dapat dilihat pada Tabel 3.7.
Tabel 3.7 Contoh proses stopword
Input Output
['tinggi', 'ini', 'sebar', 'kasus', 'sembuh', 'covid', 'ri', 'per', 'januari']
['sebar', 'sembuh', 'covid', 'januari']
3.2.2 Penerapan Metode SVM
Pada penelitian ini akan diterapkan metode SVM-Grid Search dengan rancangan arsitektur seperti pada Gambar 3.2.
Gambar 3.2 Proses Penerapan SVM-Grid Search
Proses optimasi Grid Search diawali dengan penginputan parameter SVM (Kernel, C, Gamma, dan sebagainya) pada tahap input, dengan menggunakan teknik cross validation (CV) sebagai matriks performa.
Bertujuan untuk mengidentifikasi hyper-parameter kombinasi terbaik sehingga classifier dapat memprediksi data secara akurat. Teknik cross validation (CV) dapat mencegah masalah over-fitting (Lin et al., 2008).
Untuk memilih nilai C dan Gamma menggunakan k-fold CV, pertama kita harus membagi dataset kedalam k subset. Satu subset digunakan sebagai data testing, kemudian dievaluasi menggunakan subset testing k-1 tersisa.
Kemudian menghitung CV error menggunakan spilt error untuk pengklasifikasian SVM menggunakan nilai C, Gamma dan parameter lain yang
22
berbeda. Berbagai kombinasi nilai hyper-parameter dimasukkan dan bagi yang memiliki nilai cross validation terbaik atau CV error terendah dipilih dan digunakan untuk train SVM diseluruh dataset.
Salah satu masalah terbesar dalam optimasi parameter SVM adalah tidak ada rentang nilai C dan Gamma. Semakin luas rentang nilai parameter, maka semakin banyak kemungkinan metode grid search dapat menemukan parameter terbaik (Syarif, Prugel-Bennett and Wills, 2016).
3.4 Pengujian
Untuk mengetahui performa dari sistem yang telah dibuat, maka sistem tersebut perlu dievaluasi. Disini peneliti menggunakan metode confussion matrix. Metode ini dapat digunakan untuk mengukur performa klasifikasi dari dokumen dengan lebih dari satu kelas. Parameter yang diukur adalah akurasi, presisi, recall, dan f-measure. Akurasi adalah nilai kemiripan antara nilai prediksi dan nilai sebenarnya. Presisi adalah tingkat kebenaran antara informasi yang diminta pengguna dan yang diberikan sistem. Recall adalah tingkat keberhasilan dari sistem dalam menemukan kembali suatu informasi. F- measure merupakan bentuk parameter gabungan dari recall dan presisi untuk ukuran keberhasilan retrival.
Akurasi : TP+TN
TP+TN+FP+FN (3.1)
Presisi : TP
TP+FN (3.2)
Recall : TP
TP+FP (3.3)
F-measur : 2 ∗ Presisi∗Recall
Presisi+Recall (3.4) TP : True Positive
TN : True Negative FP : False Positive FN : False Negative
BAB IV IMPLEMENTASI
4.1 Deskripsi Implementasi
Dalam penelitian ini, pembangunan sistem dilakukan dengan menggunakan bahasa pemrograman python. Python memiliki banyak sekali library siap pakai yang akan membantu mengatasi setiap kasus yang dihadapi dalam penelitian ini. Berikut adalah kebutuhan yang diperlukan dalam penelitian ini, diantaranya :
1. Hardware :
a. Komputer dengan processor Intel Core i7-3770, 3.40Ghz b. RAM 8Gb
c. GPU Nvidia GTX 660 2. Software :
a. Sistem Operasi Windows 10 b. Phython v 3.9.13
c. Library requests d. Library csv
e. Library BeautifulSoup f. Library pandas
g. Library numpy h. Library string i. Library re j. Library nltk
k. Library Sastrawi l. Library ast m. Library sklearn n. Library svm
o. Library TfidfVectorizer p. Library classification report q. Library cross val score r. Library GridSearchCV
s. Library ConfusionMatrixDisplay t. Library SVC
4.2 Implementasi Pengumpulan Data
Data yang digunakan adalah dataset yang didapat dari portal berita Detik.com dan turnbackhoax. Dataset diambil dengan melakukan crawling data menggunakan library BeautifulSoup pada portal berita sejak tanggal 13 juni
24
2023. Data tersebut diambil dengan menggunakan kata kunci “covid”.
Kode program dapat dilihat pada gambar berikut.
Gambar 4.1 Implementasi kode pada crawling data portal Detik.com
Gambar 4.2 Implementasi kode pada crawling data portal turnbackhoax
4.3 Implementasi Preprocessing
Data yang didapatkan pada proses pengumpulan data merupakan data yang tidak terstruktur. Untuk membersihkan data dari bagian-bagian yang tidak diperlukan, dilakukan proses preprocessing guna membersihkan data agar hasil yang didapat lebih akurat. Tahap preprocessing memiliki beberapa tahapan diantaranya case folding, normalisasi fitur, tokenisasi, konversi slangword, dan penghapusan stopword. Implementasi tahap preprocessing pada penelitian ini menggunakan bahasa pemrograman python, dimana data yang telah dicrawling disimpan dalam format csv, setelah program dijalankan data csv diubah menggunakan library pandas menjadi dataframe. Dataframe yang digunakan
26
hanya pada kolom “Judul”. Berikut adalah tahapan dari proses preprocessing beserta baris kode program :
1. Case Folding
Pada pemrosesan kata, tahap case folding merupakan tahapan dimana data teks yang memiliki huruf kapital diubah kedalam huruf kecil (lower case) dan disimpan dalam dataframe kolom “Case_Folding”. Kode dapat dilihat pada Gambar 4.3.
Gambar 4.3 Implementasi Case Folding 2. Normalisasi Fitur
Tahapan ini merupakan tahapan pemrosesan kata dimana tanda baca, angka numerik, dan simbol-simbol unik lainnya dihilangkan serta disimpan dalam dataframe kolom “Normalisasi”. Kode dapat dilihat pada Gambar 4.4.
Gambar 4.4 Implementasi Normalisasi Fitur
3. Tokenisasi
Pada tahap ini, data teks akan dipisahkan per kata berdasarkan spasi.
Pemisahan ini dilakukan agar tiap kata dapat dianalisis dengan mudah serta disimpan dalam dataframe kolom “Tokenisasi”. Kode dapat dilihat pada Gambar 4.5.
Gambar 4.5 Implementasi Case Folding 4. Konversi Slangword
Kata yang tidak baku pada data teks akan diubah ke bentuk baku sesuai dengan Kamus Besar Bahasa Indonesia (KBBI) dan disimpan dalam dataframe kolom “Slangword”. Kode dapat dilihat pada Gambar 4.6.
Gambar 4.6 Implementasi Slangword 5. Penghapusan Stopword
Pada tahap ini, kata-kata yang muncul dalam jumlah besar dan tidak deskriptif atau tidak berpengaruh seperti yang, ke, dari, atau, dan sebagainya akan dihapus serta disimpan dalam dataframe kolom “Stopword”. Kode dapat dilihat pada Gambar 4.7.
28
Gambar 4.7 Implementasi Stopword
4.4 Implementasi TF-IDF
Setelah dataset diolah melalui proses prescessing maka data akan diubah menjadi dataframe. Dataframe ini akan melalui proses pembobotan dimana pada tahap ini penulis menggunakan TF-IDF (Term Frequency-Inverse Document Frequency). Sebelum itu dataframe akan diubah menjadi file csv, lalu baca file tersebut menggunakan Pandas, dimana kita hanya membutuhkan kolom “Label” dan “Stopword”. Kode dapat dilihat pada Gambar 4.8.
Gambar 4.8 Implementasi pembacaan data csv
Pada kolom “Stopword” memiliki tipe data <class str> , tipe data ini harus diubah menjadi list dan disimpan pada Pandas Series. Kode dapat dilihat pada Gambar 4.9.
Gambar 4.9 Implementasi pengubahan data string
Setelah data list disimpan pada Pandas Series, kita dapat menghitung TF-IDF menggunakan library Scikit-Learn. Method TfidfVectorizer() ketika diterapkan pada documents/corpus dengan fungsi .fit_transform() , akan menghasilkan matrix dari data list “df2”, sedangkan data list “y” berisi data yang bernilai 0 atau 1 dari setiap kolom, data ini didapat dari TWEET_DATA["Label"] yang diubah tipenya menjadi int. Kode dapat dilihat pada Gambar 4.10.
Gambar 4.10 Implementasi TF-IDF
Selanjutnya menentukan data training dan data test dengan ketentuan 80% data sampel. Kode dapat dilihat pada Gambar 4.11.
Gambar 4.11 Implementasi pembagian data training dan data set
30
4.5 Implementasi SVM
Dalam implementasi SVM penulis menggunakan menggunakan data sampel dari data train dan data test yang sudah dibagi, serta Library Scikit-Learn dengan ketentuan parameter kernel linear, C = 0.5, α = scale. Kode dapat dilihat pada Gambar 4.12.
Gambar 4.12 Implementasi SVM kernel Linear
4.6 Implementasi SVM yang Dioptimasi Grid Search
Dalam implementasi SVM penulis menggunakan menggunakan data sampel dari data train dan data test yang sudah dibagi, serta Library Scikit-Learn dan penentuan parameter dilakukan oleh Library GridSearchCV, dalam proses ini juga melibatkan cross validation sebanyak 5-fold untuk menentukan nilai parameter terbaik dari setiap kernel, nilai C, dan α. Kode dapat dilihat pada Gambar 4.13.
Gambar 4.13 Implementasi SVM-Grid Search
4.7 Implementasi Confusion Matrix
Pada proses ini hasil dari implementasi SVM dan hasil dari implementasi SVM-Grid Search akan diolah menggunakan Library ConfusionMatrixDisplay yang berfokus pada parameter akurasi, presisi, recall, dan f-measure. Kode dapat dilihat pada Gambar 4.14.
Gambar 4.14 Implementasi Confusion Matrix
BAB V
HASIL DAN PEMBAHASAN
Pada tahap ini dilakukan pengujian untuk mengetahui performa dari sistem yang dibuat guna mendapatkan hasil yang terbaik. Hasil dari implementasi SVM-Grid Search yang dibuat akan diukur untuk mengetahui nilai akurasi, presisi, recall, dan f-measure agar dapat menemukan parameter terbaik. Akurasi merupakan nilai tingkat kemiripan antara nilai prediksi dan nilai sebenarnya. Presisi adalah tingkat kebenaran antara informasi yang diminta pengguna dan yang diberikan sistem. Recall adalah tingkat keberhasilan dari sistem dalam menemukan kembali suatu informasi. F- measure merupakan bentuk parameter gabungan dari recall dan presisi. Lalu hasil dari SVM-Grid Search akan dibandingkan dengan hasil yang didapatkan oleh SVM kernel Linear. Klasifikasi SVM kernel Linear diimplementasikan dengan bantuan library sklearn pada python.
5.1 Data
Dataset diambil dengan melakukan crawling data pada portal berita sejak tanggal 1 Januari 2021. Data tersebut diambil dengan menggunakan kata kunci “covid”. Setelah melewati tahap preprocessing, terkumpulah data sebanyak 324 data. Yang kemudian data tersebut diberi label dengan nilai 1 sebagai kelas positif dan nilai 0 sebagai kelas negative. Dari proses pelabelan tersebut didapatlah data kelas positif sebanyak 162 dan data kelas negatif sebanyak 162 data. Keseimbangan antara kelas positif dan negatif sangat berpengaruh terhadap akurasi yang didapatkan (Muhammad Hafiz Azhar, Putra Pandu Adikara and Yuita Arum Sari, 2018). Total dataset yang digunakan pada akhirnya berjumlah 324 data.
5.2 Pengujian SVM-Grid Search dan SVM kernel linear
Pengujian SVM-Grid Search dan SVM kernel linear dilakukan untuk menemukan model terbaik dari beberapa parameter. Akan diujikan beberapa parameter guna mendapatkan nilai akurasi, presisi, recall, dan f-measure yang
terbaik. Dalam penelitian ini, penulis akan melakukan uji coba pada program yang telah dibuat dengan 4 skenario pembagian data untuk mendapatkan performa dari setiap parameter yang digunakan agar pengolahan klasifikasi akan menghasilkan nilai tingkat akurasi, precision, recall, f-measure dan error rate. Pembagian data training dan data testing dapat dilihat pada Tabel 5.1.
Tabel 5.1 Skenario Pembagian Data Training dan Data Testing Skenario 1 Data Training (60%) Data Testing (40%) Skenario 2 Data Training (70%) Data Testing (30%) Skenario 3 Data Training (80%) Data Testing (20%) Skenario 4 Data Training (90%) Data Testing (10%) Kemudian dilakukan pengujian terhadap tiap skenario dengan menggunakan SVM-Grid Search dan SVM kernel linear.
1. Skenario 1 (60:40) : hasil dari pengujian pada pemodelan klasifikasi berita hoax dan berita bukan hoax dengan skenario 1 adalah sebagai berikut.
• Pengujian dengan SVM-Grid Search
Gambar 5.1 Hasil Pengujian dengan SVM-Grid Search Skenario 1
Tabel 5.2 Hasil Prediksi SVM-Grid Search Nilai
True Positive 47
True Negative 49
False Positive 25
False Negative 9
34
• Pengujian dengan SVM kernel linear
Gambar 5.2 Hasil Pengujian dengan SVM kernel linear Skenario 1 Tabel 5.3 Hasil Prediksi SVM kernel linear
Nilai
True Positive 52
True Negative 47
False Positive 20
False Negative 11
2. Skenario 2 (70:30) : hasil dari pengujian pada pemodelan klasifikasi berita hoax dan berita bukan hoax dengan skenario 2 adalah sebagai berikut.
• Pengujian dengan SVM-Grid Search
Gambar 5.3 Hasil Pengujian dengan SVM-Grid Search Skenario 2
Tabel 5.4 Hasil Prediksi SVM-Grid Search Nilai
True Positive 34
True Negative 33
False Positive 24
False Negative 6
• Pengujian dengan SVM kernel linear
Gambar 5.4 Hasil Pengujian dengan SVM kernel linear Skenario 2 Tabel 5.5 Hasil Prediksi SVM kernel linear
Nilai
True Positive 41
True Negative 32
False Positive 17
False Negative 7
3. Skenario 3 (80:20) : hasil dari pengujian pada pemodelan klasifikasi berita hoax dan berita bukan hoax dengan skenario 3 adalah sebagai berikut.
• Pengujian dengan SVM-Grid Search
Gambar 5.5 Hasil Pengujian dengan SVM-Grid Search Skenario 3
36
Tabel 5.6 Hasil Prediksi SVM-Grid Search Nilai
True Positive 35
True Negative 19
False Positive 6
False Negative 5
• Pengujian dengan SVM kernel linear
Gambar 5.6 Hasil Pengujian dengan SVM kernel linear Skenario 3
Tabel 5.7 Hasil Prediksi SVM kernel linear Nilai
True Positive 33
True Negative 17
False Positive 8
False Negative 7
4. Skenario 4 (90:10) : hasil dari pengujian pada pemodelan klasifikasi berita hoax dan berita bukan hoax dengan skenario 3 adalah sebagai berikut.
• Pengujian dengan SVM-Grid Search
Gambar 5.7 Hasil Pengujian dengan SVM-Grid Search Skenario 4
Tabel 5.8 Hasil Prediksi SVM-Grid Search Nilai
True Positive 19
True Negative 9
False Positive 2
False Negative 2
• Pengujian dengan SVM kernel linear
Gambar 5.8 Hasil Pengujian dengan SVM kernel linear Skenario 4 Tabel 5. 9 Hasil Prediksi SVM kernel linear
Nilai
True Positive 19
True Negative 8
False Positive 2
False Negative 3
38
5.3 Perbandingan Hasil Pengujian
Hasil yang diperoleh dari seluruh pengujian dengan model SVM akan dibandingkan untuk mengetahui model terbaik dalam proses klasifikasi. Hasil perbandingan evaluasi menggunakan 4 skenario dapat dilihat pada Tabel 5.10.
Tabel 5.10 Perbandingan Evaluasi Model
Berdasarkan tabel di atas, dapat dilihat hasil akurasi menggunakan SVM-Grid Search mendapatkan nilai akurasi terbesar pada skenario 3 (80:20) sebesar 90%. Sedangkan SVM dengan kernel linear mendapatkan nilai akurasi terbesar pada skenario 1 (60:40) sebesar 87%. Namun hasil dari nilai akurasi saja tidak cukup untuk menentukan model terbaik pada penelitian ini. Dapat dilihat juga hasil prediksi dari masing-masing kernel dengan 4 skenario pada tabel. Skenario 3 (80:20) dengan kernel sigmoid mendapatkan hasil yang baik karena model dapat meng-klasifikasikan data berita hoax dan berita bukan hoax dengan baik. Hasil yang didapat yaitu ada 204 data hoax yang diprediksi hoax, ada 28 data hoax yang diprediksi bukan hoax. Sedangkan data bukan hoax yang diprediksi hoax ada 19 dan data bukan hoax yang diprediksi bukan hoax ada 229. ditunjukan pada Tabel 5.11.
Tabel 5.11 Hasil Prediksi SVM-Grid Search dan SVM kernel linear Pada 4 Skenario
40
Tabel 5.11 Hasil Prediksi SVM-Grid Search dan SVM kernel linear Pada 4 Skenario (Lanjutan)
BAB VI
KESIMPULAN DAN SARAN 6.1 Kesimpulan
Berdasarkan penelitian yang telah dilakukan, maka diperoleh kesimpulan sebagai berikut :
1. Metode Support Vector Machine yang dioptimasi oleh Grid Search menghasilkan nilai akurasi yang lebih baik dibanding metode Support Vector Machine kernel linear dengan nilai akurasi 88% dibandingkan hasil akurasi dari metode Support Vector Machine kernel linear dengan nilai akurasi 84%.
2. Model terbaik dalam 4 skenario prediksi adalah metode Support Vector Machine yang dioptimasi oleh Grid Search pada skenario 4 (90:10) dengan kernel rbf mendapatkan hasil yaitu ada 19 data hoax yang diprediksi hoax, ada 2 data hoax yang diprediksi bukan hoax dan data bukan hoax yang diprediksi hoax ada 2 serta data bukan hoax yang diprediksi bukan hoax ada 9 sedangkan model yang kurang baik didapat pada metode Support Vector Machine yang dioptimasi oleh Grid Search kernel sigmoid dengan skenario 2 (70:30) mendapatkan hasil yaitu ada 34 data hoax yang diprediksi hoax, ada 24 data hoax yang diprediksi bukan hoax dan data bukan hoax yang diprediksi hoax ada 6 serta data bukan hoax yang diprediksi bukan hoax ada 33.
6.2 Saran
Penelitian ini masih memiliki kekurangan yang kedepannya masih dapat ditingkatkan kembali guna mencapai hasil yang optimal. Beberapa saran untuk penelitian selanjutnya, diantaranya :
1. Menggunakan metode Hypertuning selain Grid Search, seperti Random Search.
2. Pada crawling data website detik.com diharapkan bisa menggunakan code dengan maksimal, dimana website detik.com hanya dapat menampilkan maksimal halaman 1.111 hal ini mengakibatkan penggunaan code yang kurang maksimal saat pengambilan data
42
DAFTAR PUSTAKA
Aji, R.P. and Sarmini (2019) ‘Pelatihan Identifikasi dan Pelaporan Berita Hoax melalui portal “turnbeckhoax.id” kepada Masyarakat Desa Kedungwringin Pelatihan Identifikasi dan Pelaporan Berita Hoax melalui portal “turnbackhoax.id” kepada Masyarakat Desa Kedungwringin’, Jurnal Pengabdian Mitra Masyarakat (JPMM), 1(2), pp. 120–127.
Cortes, C. and Vapnik, V. (1995) ‘Support Vector Machine’, in. Mach. Learn, pp.
1303–1308.
Deolika, A., Kusrini and Luthfi, E.T. (2019) ‘Analisis Pembobotan Kata Pada Klasifikasi Text Mining’, Jurnal Teknologi Informasi, 3(2), p. 179.
Available at: https://doi.org/10.36294/jurti.v3i2.1077.
Dewan Pers (2019) Data Perusahaan Pers, Dewan Pers. Available at:
https://dewanpers.or.id/data/perusahaanpers.
Enri, U. (2018) ‘Optimasi Parameter Support Vector Machins untuk Prediksi Nilai Tukar Rupiah Terhadap Dollar Amerika Serikat’, Jurnal gerbang, 8(1), pp. 65–72.
Feldman, R. and Sanger, J. (2007) The Text Mining Handbook : Advanced Approaches in Analyzing Unstructured Data. Cambridge University Press.
Available at:
https://books.google.co.id/books?hl=id&lr=&id=U3EA_zX3ZwEC&oi=f nd&pg=PR1&dq=Feldman,+R.,+%26+Sanger,+J.+(2007)+The+text+mi ning+handbook:+advanced+approaches+in+analyzing+unstructured+dat a,+Cambridge+university+press&ots=2OBKObIwKH&sig=8q7FEoUq3 YR7-7P-Zoqh.
Feriyawan, C.Y. and Danoedoro, P. (2012) ‘Kajian Kemampuan Jaringan Syaraf Tiruan Algoritma Backpropagation untuk Klasifikasi Penggunaan Lahan Menggunakan Citra ALOS AVNIR-2’, Jurnal Bumi Indonesia, pp. 101–
110. Available at: https://core.ac.uk/download/pdf/295175909.pdf.
Fitrani, A.S. and Novarika, W. (2019) ‘Implementation of Data Mining Using Naïve Bayes Classification Method To Predict Participation of Governor And Vocational Governor Selection in Jemirahan Village , Jabon District’,
International Journal of Informatics and Computer Science, 3(2), pp. 66–
79. Available at: https://doi.org/10.30865/ijics.v3i2.1391.
Hutter, F., Kotthoff, L. and Vanschoren, J. (2019) Automated Machine Learning, Data Science in Chemistry. The Springer Series. Available at:
https://doi.org/10.1515/9783110629453-084.
Isnain, A.R., Sihabuddin, A. and Suyanto, Y. (2020) ‘Bidirectional Long Short Term Memory Method and Word2vec Extraction Approach for Hate Speech Detection’, IJCCS (Indonesian Journal of Computing and Cybernetics Systems), 14(2), p. 169. Available at:
https://doi.org/10.22146/ijccs.51743.
Juditha, C. (2019) ‘Literasi Informasi Melawan Hoaks Bidang Kesehatan di Komunitas Online’, Jurnal ILMU KOMUNIKASI, 16(1), pp. 77–90.
Available at: https://doi.org/10.24002/jik.v16i1.1857.
Juditha, C. (2020) ‘People Behavior Related To The Spread Of Covid-19’s Hoax’, Journal Pekommas, 5(2), p. 105. Available at:
https://doi.org/10.30818/jpkm.2020.2050201.
Kemdikbud (2016) Arti kata Berita, Kamus Besar Bahasa Indonesia. Available at:
https://kbbi.kemdikbud.go.id/entri/berita.
Kemp, S. (2019) DIGITAL 2019: INDONESIA, Data Reportal. Available at:
https://datareportal.com/reports/digital-2019-indonesia.
Kemp, S. (2020) DIGITAL 2020: INDONESIA, Data Reportal. Available at:
https://datareportal.com/reports/digital-2020-indonesia.
Kominfo (2020) Kominfo Mencatat Sebanyak 1.028 Hoaks Tersebar terkait COVID-19, Kementerian Komunikasi dan Informatika RI. Available at:
https://kominfo.go.id/content/detail/28536/kominfo-mencatat-sebanyak- 1028-hoaks-tersebar-terkait-covid-19/0/sorotan_media.
Lin, S.W. et al. (2008) ‘Particle swarm optimization for parameter determination and feature selection of support vector machines’, Expert Systems with Applications, 35(4), pp. 1817–1824. Available at:
https://doi.org/10.1016/j.eswa.2007.08.088.
Moreno, G.A.L. et al. (2018) ‘Design of experiments and response surface methodology to tune machine learning hyperparameters, with a random
44
forest case-study’, in Expert Systems with Applications. ELSEVIER, pp.
195–205. Available at:
https://www.sciencedirect.com/science/article/abs/pii/S09574174183031 78.
Muhammad Hafiz Azhar, Putra Pandu Adikara and Yuita Arum Sari (2018)
‘Analisis Sentimen pada Ulasan Hotel dengan Fitur Score Representation dan Identifikasi Aspek pada Ulasan Menggunakan K-Modes’, Jurnal Pengembangan Teknologi Informasi dan Ilmu Komputer, 2(9), pp. 2777–
2782.
Nasution, M.R.A. and Hayaty, M. (2019) ‘Perbandingan Akurasi dan Waktu Proses Algoritma K-NN dan SVM dalam Analisis Sentimen Twitter’, Jurnal Informatika, 6(2), pp. 226–235. Available at:
https://doi.org/10.31311/ji.v6i2.5129.
Naufal, M.F. (2017) ‘Peramalan Jumlah Wisatawan Mancanegara Yang Datang Ke Indonesia Berdasarkan Pintu Masuk Menggunakan Metode Support Vector Machine (SVM)’, DEPARTEMEN SISTEM INFORMASI [Preprint]. Available at: https://core.ac.uk/download/pdf/291462998.pdf.
Nugraha, W. and Sasongko, A. (2022) ‘Hyperparameter Tuning pada Algoritma Klasifikasi dengan Grid Search’, Jurnal Sistem Informasi, 11(2), pp. 391–
401.
Nurrohmat, M.A. and SN, A. (2019) ‘Sentiment Analysis of Novel Review Using Long Short-Term Memory Method’, IJCCS (Indonesian Journal of Computing and Cybernetics Systems), 13(3), p. 209. Available at:
https://doi.org/10.22146/ijccs.41236.
Oxford University (2022) Oxford Learners Dictionaries, Oxford University Press.
Available at:
https://www.oxfordlearnersdictionaries.com/definition/english/hoax_1?q
=hoax.
Pratama, E.E. and Atmi, R.L. (2020) ‘A Text Mining Implementation Based on Twitter Data to Analyse Information Regarding Corona Virus in Indonesia’, Journal of Computers for Society, 1(1), pp. 91–100. Available at: https://ejournal.upi.edu/index.php/JCS/article/view/25502.
Purba, A.H. and Situmorang, Z. (2017) ‘Analisis Perbandingan Algoritma Rabin- Karp Dan Levenshtein Distance Dalam Menghitung Kemiripan Teks’, 02, pp. 24–32.
Rahmawati, D.B. et al. (2020) ‘Text Mining To Detect Plagiarism In E-Learning System Using Rabin Karp Algorithm’, Ire 1701953 Iconic Research and Engineering Journals, 3(8), pp. 183–191. Available at:
https://ejournal.upi.edu/index.php/JCS/article/view/25502.
Ropikoh, I.A. et al. (2021) ‘Penerapan Algoritma Support Vector Machine (SVM) untuk Klasifikasi Berita Hoax Covid-19’, Journal of Applied Informatics and Computing, 5(1), pp. 64–73. Available at:
https://doi.org/10.30871/jaic.v5i1.3167.
Santosa, B. (2007) ‘Data Mining : Teknik Pemanfaatan Data untuk Keperluan Bisnis’, Graha Ilmu [Preprint].
Susilowati, E., Sabariah, M.K. and Gozali, A.A. (2015) ‘Implementasi Metode Support Vector Machine untuk Melakukan Klasifikasi Kemacetan Lalu Lintas Pada Twitter’, E-Proceeding of Engineering, 2(1), pp. 1478–1484.
Syarif, I., Prugel-Bennett, A. and Wills, G. (2016) ‘SVM Parameter Optimization using Grid Search and Genetic Algorithm to Improve Classification Performance’, TELKOMNIKA (Telecommunication Computing Electronics and Control), 14(4), p. 1502. Available at:
https://doi.org/10.12928/telkomnika.v14i4.3956.
Wibawa, A.P. et al. (2018) ‘Metode-metode Klasifikasi’, Prosiding Seminar Ilmu Komputer dan Teknologi Informasi, 3(1), p. 134.
46
LAMPIRAN
Kode Program
1. Class CrawlingDetik
2. Class CrawlingTurnbackhoax
48
3. Class CombineAndRandomizer
4. Class Preprocessing
50
52
5. Class SVM-Grid
54
6. Class SVM
56