KLASIFIKASI PASIEN COVID - 19 YANG MEMBUTUHKAN INTENSIVE CARE UNIT MENGGUNAKAN SUPPORT VECTOR
MACHINE SKRIPSI
Diajukan untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Komputer Program Studi Informatika
Disusun Oleh:
Fransiska Annalisa Christiana Holly 175314095
PROGRAM STUDI INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA
ii
CLASSIFICATION OF COVID - 19 PATIENTS NEEDING INTENSIVE CARE UNIT USING SUPPORT VECTOR MACHINE
THESIS
Presented as Partial Fulfillment of The Requirements
To Obtain the Sarjana Komputer Degree in Informatics Study Program
by:
Fransiska Annalisa Christiana Holly 175314095
INFORMATICS STUDY PROGRAM FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY YOGYAKARTA
v
HALAMAN PERSEMBAHAN
“Success is the sum of small efforts repeated day in day out.”
“Lihat, saatnya datang, bahkan sudah datang, bahwa kamu dicerai – beraikan masing – masing ketempatnya sendiri dan kamu meninggalkan Aku seorang diri.
Namun Aku tidak seorang diri, sebab Bapa Menyertai Aku. Semuanya itu Kukatakan kepadamu, supaya kamu beroleh damai sejahtera dalam Aku. Dalam dunia kamu menderita, tetapi kuatkanlah hatimu, Aku telah mengalahkan dunia.”
Yohanes 16 : 32
Dengan segala puji dan syukur kupersembahkan skripsi ini kepada : Tuhan Yesus Kristus dan Bunda Maria
Mami, Papi dan Imel Keluarga dan kerabat, dan
viii ABSTRAK
Severe Acute Respiratory Syndrome Coronavirus 2 (SARS – Cov2) atau yang dikenal dengan Covid - 19 (Pane, 2020). Coronavirus adalah kumpulan virus yang bisa menginfeksi sistem pernapasan. Pasien Covid – 19 adalah pasien yang paling rentan dan paling membutuhkan perawatan di rumah sakit. Sebab, beberapa riset menemukan bahwa mereka yang memiliki risiko dirawat di ICU atau meninggal adalah populasi-populasi rentan. Selain itu perlu kriteria pasien Covid - 19, agar penggunaan ICU optimal bagi pasien yang sangat membutuhkan perawatan intensif (Sumartiningtyas, 2020). Mengingat banyaknya data pasien Covid - 19, dibutuhkan klasifikasi untuk pasien yang membutuhkan ruang ICU agar nyawa pasien Covid - 19 terselamatkan. Pada penelitian ini melakukan klasifikasi dengan data pasien Covid - 19 yang membutuhkan ruang ICU menggunakan data Covid - 19 di Mexico sebanyak 566.602 data menggunakan algoritma Support Vector Machine (SVM). Teknik pengujian menggunakan 3 fold cross validation dan 5 fold cross validation. Berdasarkan pengujian tersebut akurasi yang dihasilkan oleh sistem memilki akurasi optimal sebesar 87,1055% dengan menggunakan kernel Linear, kernel Polynominal dan kernel Gaussian RBF dengan tidak dikenai balancing.
ix ABSTRACT
Severe Acute Respiratory Syndrome Coronavirus 2 (SARS – Cov2) or better known as Covid - 19 (Pane, 2020). Coronavirus is a collection of viruses that can infect the respiratory system. Covid-19 patients are the most vulnerable patients and most need treatment in hospitals. This is because several studies have found that those at risk of being admitted to the ICU or dying are vulnerable populations. In addition, the criteria for Covid - 19 patients are needed, so that the use of the ICU is optimal for patients who really need intensive care (Sumartiningtyas, 2020). Given the large number of data on Covid - 19 patients, classification is needed for patients who need the ICU room so that the lives of Covid - 19 patients are saved. In this study, classification was carried out with data on Covid - 19 patients who needed the ICU room using Covid - 19 data in Mexico as many as 566,602 data using the Support Vector Machine (SVM) algorithm. The testing technique uses 3 fold cross validation and 5 fold cross validation. Based on these tests, the accuracy produced by the system has an optimal accuracy of 87,1055% using the Linear kernel, Polynominal kernel and Gaussian RBF kernel without balancing.
x
KATA PENGANTAR
Puji syukur kepada Tuhan Yang Maha Esa, karena pada akhirnya penulis menyelesaikan penelitian tugas akhir ini yang berjudul “KLASIFIKASI PASIEN COVID - 19 YANG MEMBUTUHKAN INTENSIVE CARE UNIT
MENGGUNAKAN SUPPORT VECTOR MACHINE”
Penulisan skripsi ini tidak lepas dari peran pentingnya berbagai pihak, sehingga dalam kesempatan ini penulis dengan kerendahan hati mengucapkan terimakasih kepada semua pihak yang telah memberikan dukungan baik secara langsung maupun tidak langsung kepada penulis dalam penyelesaian skripsi hingga selesai. Oleh karena itu penulis mengucapkan terimakasih kepada :
1. Tuhan Yesus Kristus dan Bunda Maria yang selalu menyertai, memberikan kekuatan, kesabaran dan memberikan kelancaran sehingga penulis dapat menyelesaikan tugas akhir.
2. Ibu Paulina Heruningsih Prima Rosa S.Si., M.Sc. selaku dosen pembimbing yang selalu membimbing, mengarahkan dan memberi semangat selama penyusunan skripsi.
3. Bapak Robertus Adi Nugroho S.T., M.Eng selaku Ketua Program Studi Informatika yang selalu memberikan dukungan dan saran dalam perkuliahan.
4. Kedua orangtua penulis Arnoldus Janssen Subiakto dan Anastasia Lily beserta adik penulis Vincencia Imelda Holly yang selalu memberi dukungan, doa dan perhatian kepada penulis selama perjalanan perkuliahan. 5. Romo Petrus Hamonangan Sidabalok OMI yang selalu memberi doa,
dukungan dan semangat dalam perjalanan di perkuliahan.
6. Agustinus Handaya Ajitama teman pertama awal memasuki Universitas Sanata Dharma yang selalu menemani, berjuang, berkelompok bersama dan membantu sampai peulisan tugas akhir selesai.
7. Aloysius Yossy Praditya dan Maria Yuniar yang selalu menemani awal perkuliahan dan memberi dukungan semangat sampai tugas akhir selesai. 8. Tim Hore yang selalu memberi semangat dalam perjalanan lika - liku
xi
9. Laurensius Setiawan, Gregorius Setiadi dan Syelen Krisnanda yang telah memberi semangat dan motivasi dalam perjalanan perkuliahan.
10. Teman sekelas teruz atau Generasi Penerus Bangswag yang selalu bersama, memberikan semangat dan membantu satu sama lain dalam perjalanan perkuliahan penulis.
11. Teman – teman angkatan 17 yang memberikan semangat dan motivasi secara langsung atau tidak langsung dalam perjuangan kuliah di Universitas Sanata Dharma.
12. Semua pihak yang tidak dapat disebutkan satu persatu yang telah memberikan dalam hal materi maupun segala hal dalam membantu penulis menyelesaikan tugas akhir ini.
Penulis menyadari bahwa skripsi ini jauh dari kata sempurna, maka kritik dan saran yang berisfat membangun dari berbagai pihak sangat diharapkan. Akhir kata penulis berharap semoga skripsi ini bermanfaat bagi semua pihak.
Yogyakarta, 6 Juli 2021 Penulis,
xii DAFTAR ISI HALAMAN JUDUL………...…i HALAMAN PERSETUJUAN………...iii HALAMAN PENGESAHAN………...iv HALAMAN PERSEMBAHAN ... v
PERNYATAAN KEASLIAN KARYA………...vi
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI………vii
ABSTRAK ... viii
ABSTRACT ... ix
KATA PENGANTAR ... x
DAFTAR ISI ... xii
DAFTAR GAMBAR ... xiv
DAFTAR TABEL ... xv BAB I PENDAHULUAN ... 1 1.1 Latar Belakang ... 1 1.2 Rumusan Masalah ... 4 1.3 Tujuan ... 4 1.4 Batasan Masalah ... 5 1.5 Sistematika Penulisan ... 5
BAB II LANDASAN TEORI ... 7
2.1 Covid - 19 ... 7
2.2 Data Mining (Penambangan Data) ... 8
2.3 Algoritma Support Vector Machine (SVM) ... 10
2.4 Model Evaluasi ... 15
2.4.1 Information Gain ... 15
2.4.2 Cross Validation ... 17
2.4.3 Confusion Matrix ... 18
2.4.4 Normalisasi min - max ... 19
2.4.5 Synthetic Minority Oversampling Technique ... 21
BAB III METODOLOGI PENELITIAN ... 24
3.1 Data ... 24
xiii
3.3 Desain Eksperimen ... 29
3.4 Tahapan Penelitian ... 30
3.3.1 Pengumpulan Data ... 30
3.3.2 Tahap Preprocessing ... 30
3.3.3 K-Fold Cross Validation ... 35
3.3.4 Tahap Klasifikasi ... 36
3.5 Desain Pengujian ... 39
3.6 Desain Sistem ... 40
3.7 Kebutuhan Sistem ... 40
BAB IV IMPLEMENTASI DAN ANALISIS HASIL ... 42
4.1 Preprocessing ... 42 4.1.1 Data Cleaning ... 43 4.1.2 Data Selection ... 44 4.3.1 Data Balancing ... 47 4.3.2 Data Tranformation ... 47 4.2 Klasifikasi ... 48
4.3 Pelatihan dan Pengujian ... 49
4.3.1 Uji Performa Fungsi Kernel dan KFold tanpa Balancing ... 49
4.3.3 Uji Performa Fungsi Kernel dan KFold dengan Balancing ... 57
4.4 Analisa Hasil ... 65
BAB V KESIMPULAN DAN SARAN ... 68
5.1 Kesimpulan ... 68
5.2 Saran ... 69
xiv
DAFTAR GAMBAR
Gambar 2.1 Contoh skema pembagian data 3 fold cross validation……...…...17
Gambar 3.1 Desain alat uji ………27
Gambar 3.2 Desain variasi eksperimen ……….29
Gambar 3.3 Hasil perankingan atribut ………..………33
Gambar 3.4 Distribusi data imbalance ……….34
Gambar 3.5 Distribusi data setelah balancing ………...……...35
Gambar 3.6 Desain sistem ………40
Gambar 4.1 Grafik 3 fold cross validation tanpa balancing ……….53
Gambar 4.2 Grafik 5 fold cross validation tanpa balancing ……….57
Gambar 4.3 Grafik 3 fold cross validation dengan balancing ………..60
Gambar 4.4 Grafik 5 fold cross validation dengan balancing ………..64
xv
DAFTAR TABEL
Tabel 2.1 Ukuran evaluasi model klasifikasi ………18
Tabel 2.2 Confusion matrix ………...19
Tabel 2.3 Sample data sebelum di normalisasi ……….20
Tabel 2.4 Sample data sesudah di normalisasi min-max ………..21
Tabel 3.1 Penjelasan atribut Covid - 19 ……….…..24
Tabel 3.2 Sample 4 data asli ……….31
Tabel 3.3 Data yang sudah di cleaning ………32
Tabel 3.4 Data selection ……….34
Tabel 3.5 Pembagian data ……….36
Tabel 3.6 Data sample model klasifikasi ………..36
Tabel 3.7 Data sample baru ………...38
Tabel 3.8 Confusion matrix pengujian ………..39
Tabel 3.9 Spesifikasi PC ………...40
Tabel 4.1 Implementasi library python ……….42
Tabel 4.2 Akurasi 16 atibut pengujian 3 fold cross validation ………45
Tabel 4.3 Implementasi kernel ………..48
Tabel 4.4 Hasil akurasi kernel 3 fold cross validation tanpa balancing ……50
Tabel 4.5 Hasil akurasi kernel 5 fold cross validation tanpa balancing ……54
Tabel 4.6 Hasil akurasi kernel 3 fold cross validation balancing …………...55
Tabel 4.7 Hasil akurasi kernel 5 fold cross validation balancing …………...58
Tabel 4.8 Confusion matrix kernel linear data uji ke – 1 ………..65
Tabel 4.9 Confusion matrix kernel linear data uji ke – 2 ………..65
xvi
Tabel 4.11 Confusion matrix kernel RBF data uji ke – 1 ………66
Tabel 4.12 Confusion matrix kernel RBF data uji ke – 2 ………66
Tabel 4.13 Confusion matrix kernel RBF data uji ke – 3 ………....66
Tabel 4.14 Confusion matrix kernel polynominal data uji ke – 1 ………66
Tabel 4.15 Confusion matrix kernel polynominal data uji ke – 2 …………...66
Tabel 4.16 Confusion matrix kernel polynominal data uji ke – 3 ………66
Tabel 4.17 Confusion matrix balancing kernel RBF data uji ke – 1 ………...67
Tabel 4.18 Confusion matrix balancing kernel RBF data uji ke – 2 ………...67
Tabel 4.19 Confusion matrix balancing kernel RBF data uji ke – 3 ………...67
Tabel 4.20 Confusion matrix balancing kernel RBF data uji ke – 4 ………...67
1 BAB I PENDAHULUAN
Pada bab ini terdapat latar belakang, rumusan masalah, tujuan, batasan masalah dan sistematika penulisan dalam mendukung penelitian ini.
1.1 Latar Belakang
Dunia sedang berduka, terdapat jenis virus baru yang menyebabkan jumlah korban meninggal sangat banyak. Virus tersebut muncul di akhir tahun 2019, pertama kali di Wuhan, China. Severe Acute Respiratory Syndrome Coronavirus 2 (SARS – Cov2) atau yang dikenal dengan Covid - 19 (Pane, 2020). Virus ini dapat menyerang anak – anak, orang dewasa dan lansia. Coronavirus adalah kumpulan virus yang bisa menginfeksi sitem pernapasan. Namun Covid - 19 menyebar karena tidak dapat terdeteksi waktu itu sehingga menyebar hampir seluruh negara. Virus ini menyebabkan sistem pernapasan menjadi berat seperti infeksi paru – paru (pnuemonia). Gejala lain yang ditimbulkan seperti demam tinggi (suhu tubuh diatas 380C), batuk kering, flu, hidung berair, nyeri tenggorokan, dan sesak napas. Penyebaran virus bekerja dalam waktu 2 minggu terakhir kontak didaerah rawan Covid - 19, maka dianjurkan untuk karantina mandiri. Terdapat 3 kategori pasien Covid - 19 yaitu ODP (Orang Dalam Pantauan), PDP (Pasien Dalam Pengawasan) dan OTG (Orang Tanpa Gejala).
Terdapat 3 total data kematian pasien Covid - 19 tertinggi pada tanggal 17 Maret 2021 yaitu Amerika Serikat sebanyak 531.855 orang, Brazil sebanyak 282.127 orang, dan Mexico sebanyak 195.119 orang (Sumber World Health Organization). Kematian Covid - 19 di Indonesia dengan total data yaitu 38.195 orang diambil pada 17 Maret 2021 (Sumber World Health Organization). Beberapa negara menerapkan kebijakan untuk melakukan lockdown dalam mencegah penyebaran virus. Selain itu wajib memakai masker, rajin mencuci tangan setelah menyentuh benda dan menjaga jarak satu dengan lain. Menentukan pasien terinfeksi Covid - 19 dengan melihat gejala terjadi dan melakukan pemeriksaan rapid test atau swab test atau PCR. Bila hasil positif maka kemungkinan terjangkit Covid - 19, namun bila negatif belum tentu terbebas Covid - 19. Hingga saat ini belum ada obat atau terapi yang tebukti efektif mengatasi Covid - 19 ini.
Pengobatan sementara dengan meringankan kondisi pasien yang dialami berdasarkan tingkat keparahannya.
Menurut Prof Irwandy yang merupakan Ketua Departemen Manajemen Rumah Sakit, Fakultas Kesehatan Masyarakat Universitas Hasanuddin, kriteria pasien yang memerlukan perawatan ICU harus dipertegas yang betul - betul membutuhkan (Sumartiningtyas, 2020). Pasien Covid – 19 adalah pasien yang paling rentan dan paling membutuhkan perawatan di rumah sakit. Sebab, beberapa riset menemukan bahwa mereka yang memiliki risiko dirawat di ICU atau meninggal adalah populasi-populasi rentan. Selain itu perlu kriteria pasien Covid - 19, agar penggunaan ICU optimal bagi pasien yang sangat membutuhkan perawatan intensif (Sumartiningtyas, 2020). SARS-RAS Italian Society of Hypertension, melakukan penelitian pada pasien Covid - 19 di Italia, pasien rata - rata datang dengan penyakit hipertensi, penyakit diabetes, penyakit paru obstruktif kronik, penyakit arteri koroner, penyakit gagal jantung, penyakit obesitas, dan penyakit ginjal kronis (Laccarino, et al., 2020). Lalu SARS-RAS Italian Society of Hypertension, melakukan survei nasional multicenter observasional cross-sectional, terdapat revalensi penyakit diabetes, penyakit arteri koroner, dan penyakit ginjal kronis lebih rendah pada wanita daripada pria. Selain itu survei tersebut untuk memahami prediksi klinis terkait jenis kelamin dari penerimaan ICU pada pasien Covid – 19. Dari total populasi penelitian tersebut, terdapat 395 pasien di Italia yang masuk ICU. Pasien ini lebih sering pria, penderita lebih tinggi dengan kriteria obesitas, hipertensi, diabetes, ginjal kronis, dan gagal jantung. Sehingga dominasi penerima ICU yaitu pasien berjenis kelamin pria sebanyak 291 dan pasien wanita 104 (Laccarino, et al., 2020).
Mengingat banyaknya data pasien Covid - 19, dibutuhkan klasifikasi untuk pasien yang membutuhkan ruang ICU agar nyawa pasien Covid - 19 terselamatkan. Karena masih belum ditemukan atribut yang menunjang klasifikasi, perlu diteliti atribut penunjang untuk pasien Covid - 19 yang sangat membutuhkan ICU. Klasifikasi merupakan sebuah proses untuk menemukan model atau fungsi yang membedakan sebuah kelas data untuk memprediksi suatu obyek dan tidak diketahui. Menurut KBBI, klasifikasi adalah penyusunan bersistem dalam kelompok atau golongan menurut kaidah atau standar yang ditetapkan. Klasifikasi
merupakan teknik data mining untuk mengelompokkan data (Oktanisa & Supianto, 2014).
Salah satu algoritma yang dapat dipergunakan untuk klasifkasi adalah Support Vector Machine (SVM). Terdapat berbagai penelitian tentang menggunakan SVM. Diantaranya adalah penerapan metode support vector machine (SVM) dalam klasifikasi kualitas pengelasan SMAW (shield metal arc welding) menggunakan kernel fungsi quadratik menghasilkan akurasi 96,2 % dan pengujian menggunakan data uji menghasilkan akurasi 98% (Ritonga & Purwaningsih, 2018). Ada pula peneltian tentang klasifikasi varietas kopi arabika menggunakan metode support vector machine (SVM) dengan pemodelan one againts one dengan teknik pengujian 3 fold cross validation dihasilkan akurasi 48,33% (Windrawati, 2020). Jurnal lain tentang implementasi algoritme support vector machine (SVM) untuk memprediksi ketepatan waktu kelulusan mahasiswa dengan menggunakan kernel gaussian RBF menghasilkan akurasi 80,55% (Pratama., dkk, 2018). Penelitian tentang klasifikasi pola mirkovaskuler retina untuk deteksi dini retinopati diabetik menggunakan support vector machine (SVM) menggunakan kernel polynominal orde 3 menghasilkan akurasi 99% (Hermawati, 2015). Penelitian tentang metode decision tree, dalam klasifikasi kelayakan calon pendonor darah studi kasus PMI kota Yogyakarta, menggunakan pengujian data training dan data testing sebesar 60 : 40 dengan metode C4.5 menghasilkan akurasi tertinggi 98.81% (Alfian, 2018). Penelitian lain tentang klasifikasi data nasabah berpotensi terkena kredit macet dengan menggunakan naïve bayes, menggunakan pengujian 15393 data menggunakan fold 3 dan dilakukan sebanyak 23 kali dengan akurasi tertinggi 77,2819% (Putri, 2019). Penelitian lain perbandingan algoritma support vector machine dan C.45 untuk analisa resiko kredit kendaraan bermotor, dengan algoritma C.45 menghasilkan akurasi 85% dan algoritma support vector machine menghasilkan akurasi 77,5% (Muttaqi, 2018). Jurnal tentang penerapan metode klasifikasi support vector machine (SVM) pada data akreditasi sekolah dasar (SD) di kabupaten Magelang, menghasilkan akurasi 93,902% menggunakan kernel gaussian radial basic function (RBF) (Octaviani., dkk, 2014).
Dari berbagai hasil penelitian dan permasalahan diatas, penulis tertarik melakukan klasifikasi pasien Covid - 19 yang membutuhkan ruang ICU dengan
menggunakan data Covid - 19 di Mexico dengan menggunakan algoritma Support Vector Machine (SVM) pada penelitian ini. Support Vector Machine (SVM) adalah salah satu algoritma klasifikasi untuk menemukan hyperplane yang bisa memisahkan dua set data dari dua kelas yang berbeda (Cortes & Vapnik, 1995). Konsep klasifikasi SVM bermula dari masalah klasifikasi dua kelas sehingga membutuhkan training set positif dan negatif (Pratama.,dkk, 2018). Algoritma tersebut dapat menangani data jumlah besar dan memisahkan dua set data dari dua kelas yang berbeda.
1.2 Rumusan Masalah
Berdasarkan penerapan latar belakang diatas, terdapat rumusan masalah yang akan dihasilkan dalam penelitian ini adalah :
a. Bagaimana menerapkan algoritma support vector machine (SVM) untuk mengklasifkasi pasien Covid - 19 yang membutuhkan ICU? b. Berapa akurasi terbaik yang dihasilkan oleh algoritma SVM dalam
kasus klasifikasi data pasien yang membutuhkan ICU?
c. Kernel mana yang menghasilkan akurasi terbaik dalam kasus klasifikasi data pasien yang membtuhkan ICU?
d. Apa dampak penerapan balancing terhadap akurasi untuk klasifikasi data pasien yang membutuhkan ICU?
e. Kriteria apa saja yang dapat dipergunakan untuk mengklasifikasikan pasien Covid - 19 yang membutuhkan ICU?
1.3 Tujuan
Tujuan penelitian ini adalah :
a. Membangun dan menerapkan sistem klasifikasi pasien Covid - 19 yang membutuhkan ICU dengan algoritma support vector machine (SVM). b. Mengetahui hasil akurasi klasifikasi pasien Covid - 19 yang
membutuhkan ICU dari penerapan algoritma support vector machine (SVM).
c. Mengetahui kernel yang menghasilkan akurasi terbaik dalam klasifkasi data pasien yang membutuhkan ICU.
d. Mengetahui dampak penerapan balancing terhadap akurasi untuk klasifikasi data pasien yang membutuhkan ICU.
e. Mengidentifikasi atribut yang dapat dipergunakan untuk
mengklasifikasikan pasien Covid – 19 yang membutuhkan ICU. 1.4 Batasan Masalah
Beberapa batasan masalah pada penelitian ini :
a. Data penelitian adalah data prakondisi Covid – 19.
b. Data diperoleh dari website Kaggle tentang data Covid - 19 di Mexico. https://www.kaggle.com/tanmoyx/covid19-patient-precondition-dataset
c. Klasifikasi menggunakan algoritma support vector machine (SVM). d. Sistem dibuat menggunakan bahasa pemrograman python.
1.5 Sistematika Penulisan
Untuk mencapai tujuan yang diharapkan, sistematika penulisan disusun sebagai berikut :
a. BAB I PENDAHULUAN
Bab ini berisi mengenai Latar Belakang, Rumusan Masalah, Tujuan, Batasan Masalah, dan Sistematika Penulisan dalam penelitian ini. b. BAB II LANDASAN TEORI
Bab ini mengenai teori berkaitan dengan Covid - 19, data mining, algoritma support vector machine (SVM), perhitungan algoritma dan model evaluasi.
c. BAB III METODOLOGI PENELITIAN
Bab ini memuat data, langkah – langkah penelitian, algoritma yang dipakai, perangkat keras dan perangkat lunak serta desain rancangan sistem.
d. BAB IV IMPLEMENTASI DAN ANALISIS HASIL
Bab ini berisi tentang implementasi perangkat lunak berdasarkan hasil perancangan antamuka dan analisa tentang hasil pengujian yang dilakukan pada sistem.
e. BAB V KESIMPULAN DAN SARAN
Bab ini berisi simpulan, saran dan daftar pustaka disertai hasil akhir penelitian.
7 BAB II
LANDASAN TEORI
Pada bab ini digunakan untuk mendukung penelitian tentang teori Covid - 19, data mining, algoritma support vector machine (SVM) dan model evaluasi.
2.1 Covid - 19
Severe Acute Respiratory Syndrome Coronavirus 2 (SARS – Cov2) lebih dikenal dengan virus corona. Virus corona pertama kali menyerang Wuhan, China bulan Desember tahun 2019. Virus ini menular dengan sangat cepat dan menyebar hampir seluruh negara termasuk Indonesia. Virus ini termasuk dalam kelompok virus Severe Acute Respiratory Syndrome (SARS) dan virus penyebab Middle-East Respiratory Syndrome (MERS) (Pane, 2020). Seseorang dapat tertular Covid - 19 yaitu tidak sengaja menghirup atau menyentuh percikan air liur yang keluar dari penderita. Gejala yang terjadi seperti hidung berair, sakit kepala, demam tinggi, batuk, sakit tenggorokan, sesak napas dan nyeri dada. Bila setelah 2 – 14 hari dari kontak dengan penderita Covid - 19 atau masuk virus ke dalam tubuh kemungkinan positif Covid - 19 (Fadli, 2020). Terdapat diagnosis tentang Covid - 19 untuk menentukan pasien terinfeksi yaitu :
1. Rapid Test
Mendeteksi antibodi (IgM dan IgG) yang diproduksi oleh tubuh. 2. Swab Test atau PCR Test
Mendeteksi Covid - 19 dalam tubuh yang di dalam tenggorokan atau berupa cek dahak.
Terdapat kategori pasien yang terinfeksi Covid - 19 yaitu :
1. Suspek atau PDP (Pasien Dalam Pengawasan) memiliki kriteria : a. Orang dengan infeksi saluran pernapasan akut (ISPA) yang pada 14
hari terakhir sebelum timbul gejala memilki riwayat perjalanan atau tinggal di negara wilayah Indonesia yang melaporkan transmisi lokal.
b. Orang dengan salah satu gejala dan pada 14 hari terakhir sebelum timbul gejala memiliki riwayat kontak dengan pasien kasus konfirmasi.
2. Kontak Erat ODP (Orang Dalam Pengawasan) memiliki kriteria : a. Kontak tatap muka atau berdekatan dengan kasus probable atau
kasus konfirmasi Covid - 19 dalam jarak 1 m dan dalam jangka waktu 15 menit atau lebih.
b. Bersentuhan secara fisik dengan kasus probable atau konfirmasi Covid - 19.
c. Orang yang memberikan perawatan langsung terhadap kasus probable atau konfirmasi tanpa menggunakan APD sesuai standar. d. Situasi lainnya yang mengindikasikan adanya kontak berdasarkan
penilaian risiko lokal yang yang ditetapkan oleh tim penyelidik epidemiologi setempat.
3. Kasus Konfirmasi memiliki kriteria : a. Kasus konfirmasi dengan gejala
b. Kasus konfirmasi tanpa gejala atau OTG (Orang Tanpa Gejala) c. Kasus Probable
Kasus suspek dengan ISPA berat atau meninggal dengan gambaran klinis yang meyakinkan Covid - 19 dan belum ada hasil pemeriksaan laboratorium RT-PCR.
2.2 Data Mining (Penambangan Data)
Data mining adalah penambangan atau penemuan informasi baru dengan mencari pola atau aturan tertentu dari sejumlah data yang sangat besar (Davies & Paul, 2004). Terdapat beberapa istilah dalam data mining yaitu
Knowledge Discovery Database (KDD), Knowledge Extraction, Data / Pattern Analysis, Business Intelligience, Data Archaeology Data Dredging (Larose, 2015).
Terdapat metode untuk menentukan Knowledge Discovery Database (KDD) sebagai berikut (Han et al., 2012) :
1. Data Cleaning
Proses dimana data yang tidak lengkap, mengandung eror dan tidak konsisten akan dibuang dari koleksi data.
2. Data Integration
Melakukan kombinasi data jika memiliki lebih dari satu dataset. 3. Data Selection
Pemilihan data yang relevan terhadap analisis untuk diterima dari database.
4. Data Tranformation
Perubahan bentuk data ke dalam bentuk yang sesuai dengan cara penjumlahan atau agregasi.
5. Data Mining
Proses terpenting dalam menerapkan metode untuk mencari pola data. 6. Pattren Evolution
Sebuah proses untuk menemukan pola yang menarik yang sebelumnya sudah ditemukan dengan identifikasi.
7. Knowledge Presentation
Tahap akhir yang biasanya berupa teknik visualiasasi.
Data mining dibagi menjadi beberapa bagian berdasarkan tugas yang dilakukan (Kusrini.,dkk, 2009) :
1. Deskripsi
Mencari pola atau kecendurungan dalam suatu data. 2. Estimasi
Estimasi hampir sama dengan klasifikasi, namun target estimasi merupakan numerik.
3. Prediksi
Memprediksi nilai hasil dimasa mendatang. 4. Classification
Mempunyai target kategori yang proses penemuan model atau fungsi untuk membedakan konsep atau kelas data. Tujuannya membedakan suatu obyek yang tidak diketahuikelas labelnya.
5. Clustering
Pengelompokan record, pengamatan atau memperhaitkan dan membentuk kelas obyek yang memiliki kemiripan.
6. Asosiasi
Menemukan atribut yang muncul dalam satu waktu. Dalam bisnis lebih dikenal analiisis keranjang belanja
2.3 Algoritma Support Vector Machine (SVM)
Support Vector Machine (SVM) adalah salah satu metode terbaik yang bisa dipakai dalam permasalahan klasifikasi (Pratama., dkk, 2018). SVM memiliki prinsip dasar linier classifier yaitu kasus klasifikasi yang secara linier dapat dipisahkan, namun SVM telah dikembangkan agar dapat bekerja pada problem non-linier dengan memasukkan konsep kernel pada ruang kerja berdimensi tinggi. Pada ruang berdimensi tinggi, akan dicari hyperplane yang dapat memaksimalkan jarak (margin) antara kelas data (Octaviani.,dkk , 2014). Support Vector Machine adalah algoritma untuk klasifikasi linier dan data nonlinier. Ini mengubah data asli menjadi dimensi yang lebih tinggi, dimana dapat menemukan hyperplane untuk pemisahan data menggunakan tupel training penting yang disebut support vectors (Han et al., 2012). Terdapat point dalam data (Srivastava & Bhambhu, 2009) : {(𝑥1, 𝑦1), (𝑥2, 𝑦2), (𝑥3, 𝑦3), (𝑥4, 𝑦4) … … … . , (𝑥𝑛, 𝑦𝑛)} (2.1)
Keterangan :
𝑦𝑛 = 1 / -1 ( konstanta menuju titik xn) 𝑛 = jumlah sampel
SVM bekerja untuk menemukan hyperplane dengan margin yang maksimal. Hyperplane klasifikasi linear memisahkan kedua kelas dengan persamaan (Windrawati, 2020) :
𝑤. 𝑥 + 𝑏 = 0 (2.2)
Keterangan : 𝑤 = vektor bobot
𝑥 = nilai masukan atribut 𝑏 = bias
Sehingga menurut Vapink dan Cortes (1995) diperoleh persamaan : [ (𝑤. 𝑥𝑖) + 𝑏] ≥ 1 𝑗𝑖𝑘𝑎 𝑦𝑖 = 1 (2.3) [ (𝑤. 𝑥𝑖) + 𝑏] ≤ 1 𝑗𝑖𝑘𝑎 𝑦𝑖 = −1 (2.4) Keterangan : 𝑤 = vektor bobot 𝑥𝑖 = nilai atribut ke i 𝑏 = bias 𝑦𝑖= label atribut ke i
Untuk mendapatkan hyperplane terbaik adalah dengan mencari hyperplane yang terletak di tengah-tengah antara dua bidang pembatas kelas dan untuk mendapatkan hyperplane terbaik itu, sama dengan memaksimalkan margin atau jarak antara dua set objek dari kelas yang berbeda (Santosa, 2007). Sampel di sepanjang hyperplane disebut support vector (SV). Hyperplane pemisah dengan margin terbesar ditentukan (Srivastava & Bhambhu, 2009):
M = 2
|| 𝑤 || (2.5)
Mencari hyperplane terbaik dapat digunakan metode Quadratic Progamming (QP) Problem yaitu meminimalkan untuk mencari titik minimal persamaan
min 𝑤 → 𝑇(𝑤) = 1 2 ||𝑤|| 2 (2.6) Dengan syarat yi (wi . xi + b ) - 1 > 0 (2.7)
Solusi untuk mengoptimasi oleh Cortes dan Vapnik (1995) diselesaikan dengan menggunakan fungsi Lagrange sebagai berikut:
( 1 ) L (w,b,a) = 1 2 𝑤 𝑇 𝑤 - ∑ 𝛼 𝑖 𝑛 𝑖=1 { (𝑤𝑇. 𝑥𝑖) + 𝑏 ] – 1 } (2.8) Keterangan : 𝑤 = vektor bobot
𝑤𝑇= vektor bobot transformasi 𝑥𝑖 = nilai atribut ke i
𝑏 = bias
𝑦𝑖= label atribut ke i
𝛼𝑖 = pengganda fungsi Langrange
𝑖 = nilai 1,2,…….,n
Nilai optimal dapat dihitung dengan memaksiimalkan L terhadap 𝛼𝑏 dan
meminimalkan L terhadap w dan b. hal ini seperti kasus dua problem (Octaviani.,dkk , 2014) :
𝑚𝑎𝑥𝛼 𝑊 (𝛼) = 𝑚𝑎𝑥𝛼 (𝑚𝑖𝑛𝑤 𝑏𝐿 (𝑤, 𝑏, 𝛼)) (2.9)
Nilai minimum dari fungsi Lagrange tersebut diberikan oleh :
𝜕 𝐿 𝜕𝑏 = 0 ⇒ ∑ 𝛼𝑖 𝑦𝑖 = 0 𝑛 𝑖=1 (2.10) ( 2 ) 𝜕 𝐿 𝜕𝑤= 0 ⇒ 𝑤 = ∑ 𝛼𝑖 𝑥𝑖𝑦𝑖 𝑛 𝑖=1 (2.11) Keterangan :
𝜕 𝐿 = Turunan parsial Lagrange 𝜕 𝑤 = Turunan parsial vektor bobot
𝑤 = vektor bobot 𝑥𝑖 = nilai atribut ke i 𝑦𝑖= label atribut ke i
𝛼𝑖 = pengganda fungsi Langrange
𝑖 = nilai 1,2,…….,n
Untuk menyederhanakannya persamaan (1) harus ditransformasikan ke dalam fungsi Lagrange Multiplier itu sendiri, Menurut Santosa (2007) persamaan (1) menjadi : (3) L (w,b,a) = 1 2 𝑤 𝑇 𝑤 − ∑ 𝛼 𝑖 𝑦𝑖 ( 𝑛 𝑖=1 𝑤𝑇 . 𝑥𝑖) − 𝑏 ∑𝑛𝑖=1𝛼𝑖 𝑦𝑖+ ∑𝑛𝑖=1𝛼𝑖 (2.12)
Dengan batasan 𝛼𝑖 > 0 adalah lagrange multipliers, nilai optimal dari persamaan tersebut dapat dihitung dengan meminimalkan L terhadap w dan b sekaligus memaksimalkan L terhadap 𝛼𝑖. Dengan diketahui titik optimal
gradient L = 0 maka persamaan (2.12). Berdasarkan persamaan (2), maka persamaan (3) menjadi sebagai berikut (Hastie., et al, 2001):
∑ 𝛼𝑖 − 1 2 ∑ ∑ 𝛼𝑖 𝛼𝑗 𝑦𝑖 𝑦𝑗 𝑛 𝑗=1 𝑛 𝑖=1 𝑛 𝑖=1 𝑥𝑖𝑥𝑗 (2.13) 𝛼𝑖 ≥ 0 (𝑖 = 1,2 … . 𝑛) ∑𝑛𝑖=1𝛼𝑖 𝑦𝑖 = 0 (2.14) Maksimalisasi ini menghasilkan sejumlah 𝛼𝑖yang bernilai positif. Data data yang berhubungan dengan 𝛼𝑖positif inilah yang disebut sebagai support vector. Fungsi pemisah dapat didefinisikan sebagai berikut (Windrawati, 2020) :
𝑔 (𝑥) = 𝑠𝑔𝑛(𝑓(𝑥)) (2.15)
dengan 𝑓(𝑥) = 𝑤𝑇𝑥 + 𝑏 (2.16)
Keterangan :
𝑤𝑇 = vektor bobot transformasi 𝑥 = nilai atribut ke i
𝑏 = bias
Pembelajaran SVM mudah untuk menyelesaikan masalah secara linear dengan rumus pemecahan masalah SVM dengan Linear Kernel (Srivastava & Bhambhu, 2009) :
𝐾 (𝑥𝑖 , 𝑥𝑗) = 𝑥𝑖𝑇 𝑥𝑗 (2.17)
Sehingga SVM dimodifikasikan sedemikian rupa dengan memasukan fungsi kernel (Windrawati, 2020). Dalam fungsi non linear training vektor xi dipetakan ke yang lebih tinggi (mungkin tak terhingga) dimensi ruang oleh fungsi Ф. Kemudian SVM menemukan pemisah linier hyperplane dengan margin maksimal di yang lebih tinggi ini ruang dimensi. C > 0 adalah parameter penality dari eror term. Fungsi kernel non linear (Srivastava & Bhambhu, 2009) :
𝐾 (𝑥𝑖 , 𝑥𝑗) ≡ Ф (𝑥𝑖) . Ф (𝑥𝑗) (2.18) Selain itu fungsi kernel non linear lain yang dapat digunakan dalam
meningkatkan hyperplane pemisah maksmimal (Han et al., 2012) : a. Polynomial Kernel :
𝐾 (𝑥𝑖 , 𝑥𝑗) = (𝑥𝑖 , 𝑥𝑗 + 1)ℎ (2.19)
b. Gaussian RBF(Radial Basis Function) Kernel :
𝐾 (𝑥𝑖 , 𝑥𝑗) = e − || 𝑥𝑖− 𝑥𝑗 ||2 / 2𝜎2 (2.20) c. Sigmoid Kernel : 𝐾 (𝑥𝑖 , 𝑥𝑗) = tanh(k 𝑥𝑖 . 𝑥𝑗 + 𝛿) (2.21) Keterangan : 𝑥𝑖 = data training 𝑥𝑗 = data testing
2.4 Model Evaluasi
Terdapat beberapa model evaluasi dalam klasifkasi yaitu information gain, corss validation, confusion matrix, normalisasi min – max dan Synthetic Minority Oversampling Technique.
2.4.1 Information Gain
Information gain merupakan salah satu metode seleksi firtur yang banyak dipakai untuk menentukan batas sebuah atribut. Nilai information gain diperoleh dari nilai entropy sebelum pemisahan dikurangi dengan nilai entropy setelah pemisahan. Pengukuran nilai hanya dgunakan di tahap awal penentuan atribut yang nantinya akan dibuang atau digunakan (Windrawati, 2020). Atribut yang memenuhi kriteria pembobotan yang nantinya akan digunakan dalam proses klasifikasi sebuah algoritma. Pemilihan fitur dengan information gain dilakukan dalam 3 tahapan (Maulana & Al Karomi, 2015) :
i. Menghitung nilai information gain untuk setiap atribut dalam dataset original.
ii. Tentukan batas (treshold) yang diinginkan. Hal ini akan memungkinkan atribut yang berbobot sama dengan batas atau lebih besar akan dipertahankan serta membuang atribut yang berada dibawah batas.
iii. Dataset diperbaiki dengan pengurangan atribut.
Pengukuran atribut ini pertama kali dipelopori oleh Claude Shannon didalam teori informasi oleh Gallager dan Fellow dituliskan sebagai :
𝑖𝑛𝑓𝑜 𝐷 = ∑𝑚𝑖=1𝑝𝑖 log2(𝑝𝑖) (2.22) Keterangan :
D : Himpunan kasus M : Jumlah partisi D
Sedangkan pi merupakan probabilitas sebuah tuple pada D yang masuk kedalam kelas Ci dan diestimasi dengan |𝐶𝑖, 𝐷| / |𝐷| . Fungsi log dalam hal ini digunakan log berbasis 2 karena informasi dikodekan berbasis bit. Perhitungan nilai entropy setelah pemisahan dapat dilakukan dengan menggunakan rumus :
𝑖𝑛𝑓𝑜 𝐷 = ∑ |𝐷𝑗| |𝐷| 𝑥 𝑖𝑛𝑓𝑜(𝐷𝑖 𝑣 𝑗=1 ) (2.23) Keterangan : 𝐷: Himpunan kasus 𝐴: Atribut
𝑣: Jumlah partisi atribut A |𝐷𝑗|: Jumlah kasus dalam D |𝐷|: Jumlah kasus dalam D
𝐼 (|𝐷𝑗): Total entropy dalam partisi
Sedangkan untuk mencari information gain atribut A dapat digunakan rumus : 𝐺𝑎𝑖𝑛(𝐴) = 𝐼(𝐷) − 𝐼(𝐴) (2.24) Keterangan : 𝐺𝑎𝑖𝑛 (𝐴): Information atribut A 𝐼 (𝐷) : Total Entropy 𝐼 (𝐴) : Entropy A
Gain (A) merupakan reduksi yang diharapkan didalam entropy yang disebabkan oleh pengenalan nlai atribut dari A. Atribut yang memiliki nilai information gain terbesar selanjutnya dipilih sebagai uji atribut himpunan S.
2.4.2 Cross Validation
Cross Valdiation adalah meode statistik yang dapat digunakan untuk mengevaluasi kinerja model atau algoritma dimana data dipisahkan menjadi dua subset (Wibowo). Sedangkan k - fold cross validation merupakan salah satu metode cross vaidation dengan melipat data sebanyak K dan mengulangi (meniterasi) ekperimennya sebanyak K. Himpunan data D dipartisi secara acak menjadi k fold (sub himpunan) yang saling bebas : 𝑓1, 𝑓2, … . . , 𝑓𝑘 sehingga masing masing fold berisi 1
𝑘 bagian data. Sebagai contoh dengan
menggunakan k = 5 maka akan didapatkan himpunan data D1 berisi empat fold : 𝑓2, 𝑓3, 𝑓4 𝑑𝑎𝑛 𝑓5 untuk data latih serta satu fold f1 untuk data uji. Himpunan D2 berisi fold : 𝑓1, 𝑓3, 𝑓4 𝑑𝑎𝑛 𝑓5 begitu pula seterusnya untuk himpunan data D3, D4 dan D5 (Windrawati, 2020). Bila penggunaan 𝑘 semakin banyak maka akan mendapatkan akurasi dengan bias dan variasi yang lebih relatif rendah. Dengan menggunakan metode k - fold cross validation, dapat dipergunakan untuk mengukur kualitas dari model klasifikasi yang dibangun (Suryanto, 2019).
Berikut contoh ilustrasi pembagian data menggunakan 3 fold cross
validation dengan membagi data testing 1
3 dan data training 2 3.
Gambar 2.1 Contoh skema pembagian data 3 fold cross validation Keterangan :
2.4.3 Confusion Matrix
Confusion matrix merupakan ukuran evaluasi untuk menilai kualitas classifier. Confusion matrix menyatakan jumlah data uji yang benar diklasifikasikan dan jumlah data uji yang salah di klasifikasikan (Windrawati, 2020). Terdapat beberapa ukuran yang dapat digunakan dalam menilai data mengevaluasi model klasfikasi seperti accuracy atau tingkat pengenalan, eror rate atau tingkat kesalahan, recall atau sensitivy atau true positive rate, sepcificity atau true negative rate, precision, F meansure atau F1 atau F-score atau rata – rata harmonik dari precision dan recall, serta 𝐹𝛽(Han et al., 2012).
Tabel 2.1 Ukuran evaluasi model klasifikasi
No Ukuran Rumus
1 Accuracy atau tingkat
pengenalan
𝑇𝑃 + 𝑇𝑁 𝑃 + 𝑁
2 Eror rate atau tingkat
kesalahan
𝐹𝑃 + 𝐹𝑁 𝑃 + 𝑁
3 Recall atau true positive
rate
𝑇𝑃 𝑃
4 Specificity attau true
negative 𝑇𝑁 𝑁 5 Precision 𝑇𝑃 𝑇𝑃 + 𝐹𝑃 6 𝐹 atau 𝐹1 2 𝑥 𝑝𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 𝑥 𝑟𝑒𝑐𝑎𝑙𝑙 𝑝𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 + 𝑟𝑒𝑐𝑎𝑙𝑙 7 𝐹𝛽 dimana adalah 𝛽
sebuah bilangan rill non negatif
(1 + 𝛽2)𝑥 𝑝𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 𝑥 𝑟𝑒𝑐𝑎𝑙𝑙 𝛽2 𝑥 𝑝𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 + 𝑟𝑒𝑐𝑎𝑙𝑙
Pada tabel 2.1 terdapat beberapa istilah penting dalam memahami ukuran evaluasi di atas (Windrawati, 2020) :
a. TP atau True Positivies adalah jumlah tuple positif yang dilabeli dengan benar oleh classifier.
b. TN atau True Negative adalah julah tuple negatif yang dilabeli dengan benar oleh classifier.
c. FP atau False Positives adalah jumlah tuple negatif yang salah dilabeli oleh classifier.
d. FN atau False Negative adalah adalah jumlah tuple positif yang salah dilabeli benar oleh classifier.
Istilah tersebut dapat digambarkan sebagai confusion matrix seperti dalam tabel 2.2.
Tabel 2.2 Confusion matrix Kelas hasil prediksi
Ya Tidak Jumlah
Kelas aktual Ya TP FN P
Tidak FP TN N
Jumlah P N’ P + N
𝑇𝑃 dan 𝑇𝑁 menyatakan bahwa classifier mengenali tuple dengan benar, yang berarti tuple positif dikenali sebagai positif dan tuple megatif dikenali sebagai negatif. Sebaliknya 𝐹𝑃 dan 𝐹𝑁 menyatakan bahwa classifier salah dalam mengenali tuple negatif dikenali sebagai positif dan tuple negatif dikenali sebagai positif. 𝑃’ adalah jumlah tuple yang diberi label positif (𝑇𝑃 + 𝐹𝑃) sedangkan 𝑁’ adalah jumlah tuple yang diberi label negatif (𝑇𝑁 + 𝐹𝑁). Sementara itu, jumlah keseluruhan tuple dapat dinyatakan sebagai (𝑇𝑃 + 𝑇𝑁 + 𝐹𝑃 + 𝐹𝑁) atau (𝑃 + 𝑁) atau (𝑃’ + 𝑁’) (Suryanto, 2019).
2.4.4 Normalisasi min - max
Normalisasi data mencoba memberikan bobot yang sama pada semua atribut. Normalisasi sangat berguna untuk algoritma klasifikasi yang melibatkan neural network atau pengukuran jarak seperti klasifikasi, nearest neighbor dan clustering. Ada banyak metode untuk normalisasi data. Kami mempelajari normalisasi min - max, normalisasi z - score, dan normalisasi dengan penskalaan desimal (Han et al., 2012). Normalisasi min - max melakukan transformasi linier pada data asli. Seharusnya bahwa minA dan
maxA adalah nilai minimum dan maksimum dari sebuah atribut A. Normalisasi min - max memetakan nilai (Han et al., 2012) :
𝑣𝑖′= 𝑣𝑖 −𝑚𝑖𝑛𝐴
𝑚𝑎𝑥𝐴− 𝑚𝑖𝑛𝐴 (𝑛𝑒𝑤𝑚𝑎𝑥𝐴− 𝑛𝑒𝑤𝑚𝑖𝑛𝐴) + 𝑛𝑒𝑤𝑚𝑖𝑛𝐴 (2.25)
Keterangan :
𝑣 : value (data asli)
𝑣’ : nilai value baru
𝐴 : atribut
𝑚𝑎𝑥𝐴 , 𝑚𝑖𝑛𝐴 : nilai value maksimum dan minimum dalam data asli
𝑛𝑒𝑤_𝑚𝑎𝑥𝐴, 𝑛𝑒𝑤_𝑚𝑖𝑛𝐴 : Rentang nilai value dalam data asli yang sudah dinormalisasi contoh (1,0).
Tabel 2.3 Sample data sebelum dinormalisasi
Data X1 X2 1 5 3 2 4 1 3 6 4 4 7 0 5 8 2
Pada tabel 2.3 terdapat sample data sebeluim dinormalisasi sehingga implementasi dari perhitungan normalisasi min – max sebagai berikut :
Normalisasi atribut 𝑥1 data ke 1:
5 −4
8 −4(1 − 0) + 0 = 0.25
Normalisasi atribut 𝑥2 data ke 1:
3 −0
Tabel 2.4 Sampel data sesudah dinormalisasi min - max
Pada Tabel 2.4 adalah hasil perhitungan normalisasi min – max yang sudah dinormalisasi dengan menggunakan sample data Tabel 2.3.
2.4.5 Synthetic Minority Oversampling Technique
Synthetic Minority Oversampling Technique (SMOTE) yaitu pendekatan menangani ketidakseimbangan kelas, sebagai perbaikan metode sampling. SMOTE menggunakan pendekatan sampling pada kelas minoritas. Kelas minoritas dilakukan over-sampling dengan mengambil sample pada kelas minoritas kemudian membuat sample sintesis sepanjang garis segmen dimana melibatkan beberapa atau keseluruhan k-nighbour (sample yang berterdekat). Nilai 𝑘 disesuaikan dengan kebutuhan tingkat over-sampling, sebanyak tetangga yang akan diolah secara acak (Kurniawati, 2019).
Pada pembelajaran mesin, data yang memiliki kelas tidak seimbang (imbalance) membuat pengklasifikasian berkinerja buruk karena klasifikasi hanya berjalan di kelas moyoritas. Alasannya bahwa klasifikasi berusaha mengurangi tingkat kesalahan dan tidak mempertimbangkan distribusi data. Hal ini mengakibat sample kelas mayoritas tergolong baik, sedangkan sample dari kelas minoritas cenderung salah. diabaikan atau diasumsikan sebagai noise (Poolsawad, dkk. 2014). Metode SMOTE pertama kali dikenalkan
Data x1 x2 1 0,25 0,75 2 0 0,25 3 0,5 1 4 0,75 0 5 1 0,5
oleh Chawla, dkk pada tahun 2002. Metode SMOTE menambahkan jumlah data kelas minor dengan cara membangkitkan data buatan. Data buatan tersebut dibuat berdasarkan k - neighbour terdekat. Jumlah k - neighbour terdekat ditentukan dengan mempertimbangkan kemudahan dalam melaksanakannya. Data numerik diukur jarak kedekatanya dengan jarak Euclidean, sedangkan data kategorik lebih sederhana, yaitu dengan nilai modus. Perhitungan jarak antara contoh kelas minor yang perubahannya berskala kategorik dilakukan dengan rumus value difference metric (VDM) yaitu sebagai berikut (Ardiningtyas, 2020) :
∆ (𝑋, 𝑌) = 𝑊𝑥𝑌𝑦∑𝑁𝑖=1𝛿(𝑋𝑖 , 𝑌𝑖)𝑟 (2.26) Dengan :
∆ (𝑋, 𝑌) : jarak antara amatan A dengan Y 𝑊𝑥𝑌𝑦 : bobat amatan (dapat diabaikan)
𝑁 : banyaknya peubah penjelas
𝑅 : benrilai 1 (jarak manhattan) atau 2 (jarak euclidean)
𝛿 (𝑋𝑖 , 𝑌𝑖)𝑟 : jarak antara kategori, dengan rumus : 𝛿 (𝑉1𝑉2) = ∑ | 𝐶1𝑖 𝐶1 − 𝐶2𝑖 𝐶2 | 𝑘 𝑛 𝑖=1 (2.27) Dimana :
𝛿 (𝑉1𝑉2) : jarak antara nilai V1 dan V2
𝐶1𝑖 : banyaknya V1 yang termasuk kelas i
𝐶2𝑖 : banyaknya V2 yang termasuk kelas i
I : banyaknya kelas i = 1,2,..., m 𝐶1 : banyaknya nilai 1 terjadi 𝐶2 : banyaknya nilai 2 terjadi
N : banyaknya kategori K : kostanta (biasanya 1
24 BAB III
METODOLOGI PENELITIAN
Bab ini berisi data yang akan digunakan dalam penelitian, tahapan penelitian, menampilkan desain alat uji, desain eksperimen, desain pengujian, desain sistem, dan kebutuhan sistem yang digunakan.
3.1 Data
Data yang digunakan dalam penelitian ini merupakan data Covid - 19 patient pre-condition dataset (data COVID-19 dari pemerintah Mexico) yang diperoleh dari website kaggle.
Data tersebut memiliki 566.602 baris data dan 23 kolom atribut namun akan dipilih beberapa data aribut dalam penelitian. Data ini diunggah di Kaggle pada 19 Juli 2020 dan diperbaharui pada 22 Juli 2020 oleh Tanmoy Mukherjee. Data teresbut merupakan data precondition maka peneliti mengambil data pada tanggal 24 November 2020. Penelitian akan dilakukan dengan mengklasfikiasi atribut ICU menggunakan algoritma SVM. Atribut ICU memiliki dua kelas klasifikasi yaitu 1 (yes) yaitu membutuhkan ICU dan 2 (no) tidak membutuhkan ICU. Dalam penelitian ini data digunakan adalah data Covid - 19 di Mexico. Berikut tabel 3.1 data mentah yang akan diproses.
Tabel 3.1 Penjelasan atribut Covid - 19
No Atribut Keterangan Atribut Keterangan Variabel
1 id Nomor ID pasien Contoh “11ea2f”
2 sex Jenis kelamin 1 – Female (Wanita) , 2 –
No Atribut Keterangan Atribut Keterangan Variabel 3 patient_type Tipe rawat pasien
1 – Outpatient (Rawat jalan) , 2 – Inpatient
(Rawat inap) 4 entry_date Tanggal masuk rumah
sakit Contoh “25/04/2020”
5 date_symptoms Tanggal gejala pertama Contoh “11/04/2020” 6 date_died Tanggal kematian Contoh “27/04/2020”
7 intubed Pasien pernah menggunakan bantuan alat pernafasan 1 – Yes (Ya), 2 – No (Tidak) dan 97,98,99 – NA (Tidak diketahui) 8 pneumonia Memiliki riwayat radang
paru paru
1 – Yes (Ya), 2 – No (Tidak) dan 97,98,99 –
NA (Tidak diketahui)
9 age Umur Contoh “45”
10 pregnancy Sedang Mengandung
1 – Yes (Ya), 2 – No (Tidak) dan 97,98,99 –
NA (Tidak diketahui)
11 diabetes Memiliki riyawat
kencing manis
1 – Yes (Ya), 2 – No (Tidak) dan 97,98,99 –
NA (Tidak diketahui)
12 copd Memiliki riwayat paru
obstruktif kronik
1 – Yes (Ya), 2 – No (Tidak) dan 97,98,99 –
NA (Tidak diketahui) 13 asthma Memiliki riwayat asma
1 – Yes (Ya), 2 – No (Tidak) dan 97,98,99 –
NA (Tidak diketahui) 14 inmsupr Kekurangan imun dalam
tubuh
1 – Yes (Ya), 2 – No (Tidak) dan 97,98,99 –
NA (Tidak diketahui) 15 hypertension Memiliki riwayat
hipertensi
1 – Yes (Ya), 2 – No (Tidak) dan 97,98,99 –
NA (Tidak diketahui) 16 other_disease Memiliki riwayat
penyakit lain
1 – Yes (Ya), 2 – No (Tidak) dan 97,98,99 –
NA (Tidak diketahui) 17 cardiovascular Memiliki riwayat
penyakit jantung
1 – Yes (Ya), 2 – No (Tidak) dan 97,98,99 –
No Atribut Keterangan Atribut Keterangan Variabel
18 obesity Mengalami obesitas
1 – Yes (Ya), 2 – No (Tidak) dan 97,98,99 –
NA (Tidak diketahui) 19 renal_chronic Memiliki riyawat
ginjal kronis 1 – Yes (Ya), 2 – No (Tidak) dan 97,98,99 – NA (Tidak diketahui) 20 tobacco Perokok 1 – Yes (Ya), 2 – No (Tidak) dan 97,98,99 – NA (Tidak diketahui) 21 contact_other_covid Kontak dengan pasien
covid
1 – Yes (Ya), 2 – No (Tidak) dan 97,98,99 –
NA (Tidak diketahui) 22 covid_res Status covid 1 – Positif, 2 – Negatif, 3 – Menunggu Hasil
23 icu Masuk unit perawatan
intensif
1 – Yes (Ya), 2 – No (Tidak) dan 97,98,99 –
3.2 Desain Alat Uji
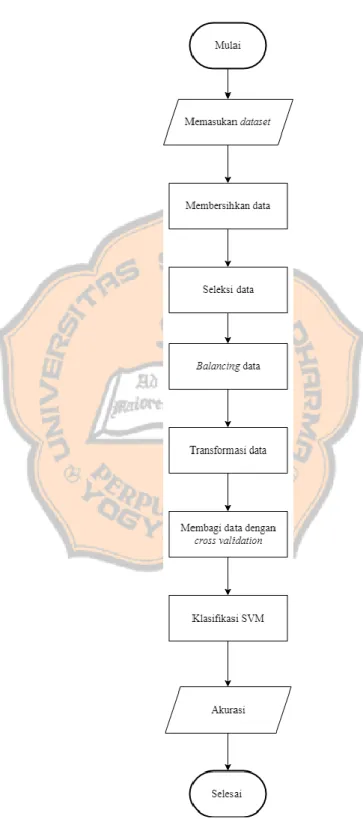
Sub bab ini berisikan tentang perancangan sistem yang akan dibangun. Berikut gambar 3.1 merupakan desain alat uji dari tahapan penelitian yang dilakukan penulis.
Pada Gambar 3.1 menunjukan sistem akan melakukan memasukan dataset Covid - 19 yang kemudian dilakukan tahap preprocessing data untuk mengolah data ke dalam bentuk yang siap diproses oleh sistem. Pada tahap preprocessing dilakukan beberapa tahapan seperti membersihkan data, seleksi data, balancing data, dan transformasi data. Membersihkan data untuk menghapus nilai NaN atau 97,98,99 yang merupakan nilai missing value. Pada seleksi data akan menyeleksi data atribut untuk memilih atribut penunjang yang berpengaruh dengan atribut ICU. Transformasi data yaitu melakukan normalisasi data dengan normalisasi min-max. Selanjutnya membagi data dengan cross validation. Sebagai contoh bila menggunakan
3 fold cross validation dengan 2
3 data akan digunakan sebagai data training.
Selanjutnya data training untuk menghasilkan model SVM dengan kernel linear, kernel gaussian RBF, dan kernel polynominal. Pada tahap testing menggunakan 1
3 dataset akan dilakukan klasifikasi berdasarkan model SVM
yang telah dibuat. Dengan menggunakan confusion matrix yang akan membagi jumlah hasil prediksi benar dengan jumlah seluruh data. Lalu didapatkan hasil akurasi dari rata - rata confusion matrix dari k - fold cross validation.
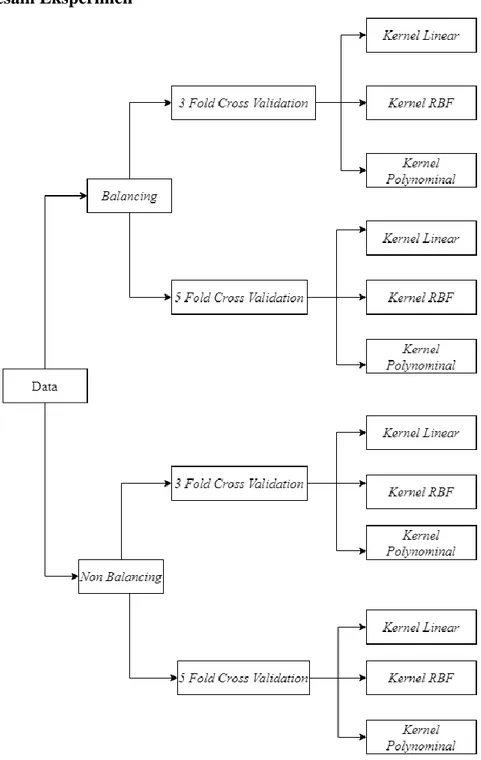
3.3 Desain Eksperimen
Gambar 3.2 Desain variasi eksperimen
Pada Gambar 3.2 variasi pengujian dilakukan dengan balancing dan tanpa balancing. Lalu menggunakan variasi 3 fold cross validation dan 5 fold cross validation. Dilakukan eksperimen kernel dengan kernel linear, kernel gaussian RBF, dan kernel polynominal. Setelah melakukan eksperimen didapatkan kesimpulan akurasi yang optimal.
3.4 Tahapan Penelitian
Pada tahapan penelitian akan dilakukan pengumpulan data, tahap preprocessing, k - fold cross validation, dan tahap klasifikasi.
3.3.1 Pengumpulan Data
Tahap awal penelitian ini adalah mengambil data yang sudah di kumpulkan. Pengumpulan data berupa data public yang diperoleh dari website Kaggle.
3.3.2 Tahap Preprocessing
Pada tahap preprocessing terdapat proses yaitu data cleaning, data selection, data balancing dan data transformation.
3.3.2.1 Data Cleaning
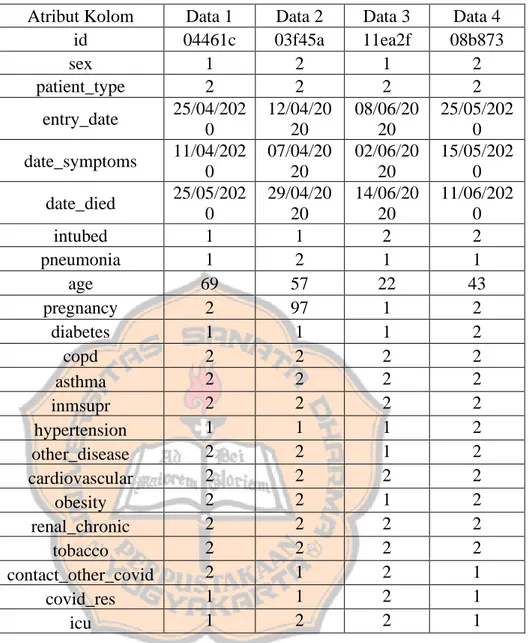
Pada tahap ini dilakukan pembersihan data yang kosong dan missing value agar tidak terjadi eror. Pada data Covid - 19 Mexico sistem akan menghapus data yang mempunyai nilai berisi “97,98,99” atau kosong (NaN) dan menghapus atribut “pregnancy”. Lalu menambah atribut baru yaitu “incubation_period” atau “masa waktu inkubasi”. Atribut “incubation_period” berisi dari selisih atribut “entry_date” atau “tanggal masuk rumah sakit” dengan atribut “date_symptoms” atau “tanggal gejala pertama Covid - 19”. Setelah itu menghapus atribut yang tidak digunakan yaitu atribut “id, intubed, entry_date, date_symptoms, date_died, age”. Tahap ini menggunakan tools PyCharm. Peneliti mencoba melakukan pengujian data dengan memilih secara manual dan memakai 4 data sampel Covid - 19 di Mexico secara acak yang terdapat pada tabel 3.2.
Tabel 3.2 Sample 4 data asli
Atribut Kolom Data 1 Data 2 Data 3 Data 4
id 04461c 03f45a 11ea2f 08b873 sex 1 2 1 2 patient_type 2 2 2 2 entry_date 25/04/202 0 12/04/20 20 08/06/20 20 25/05/202 0 date_symptoms 11/04/202 0 07/04/20 20 02/06/20 20 15/05/202 0 date_died 25/05/202 0 29/04/20 20 14/06/20 20 11/06/202 0 intubed 1 1 2 2 pneumonia 1 2 1 1 age 69 57 22 43 pregnancy 2 97 1 2 diabetes 1 1 1 2 copd 2 2 2 2 asthma 2 2 2 2 inmsupr 2 2 2 2 hypertension 1 1 1 2 other_disease 2 2 1 2 cardiovascular 2 2 2 2 obesity 2 2 1 2 renal_chronic 2 2 2 2 tobacco 2 2 2 2 contact_other_covid 2 1 2 1 covid_res 1 1 2 1 icu 1 2 2 1
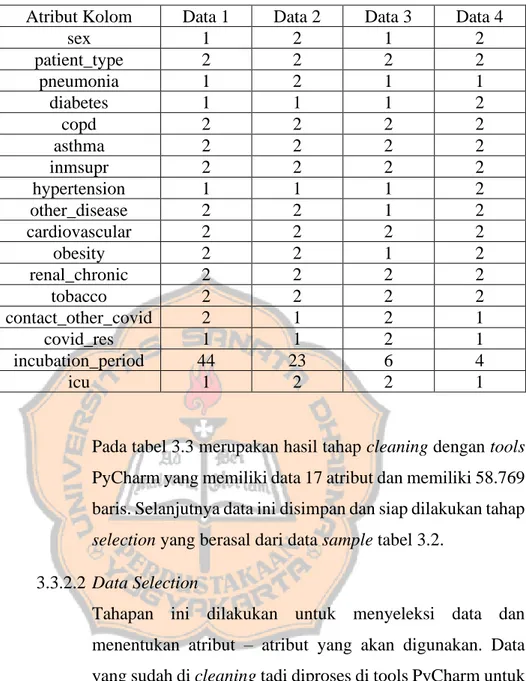
Tabel 3.3 Data yang sudah di cleaning
Atribut Kolom Data 1 Data 2 Data 3 Data 4
sex 1 2 1 2 patient_type 2 2 2 2 pneumonia 1 2 1 1 diabetes 1 1 1 2 copd 2 2 2 2 asthma 2 2 2 2 inmsupr 2 2 2 2 hypertension 1 1 1 2 other_disease 2 2 1 2 cardiovascular 2 2 2 2 obesity 2 2 1 2 renal_chronic 2 2 2 2 tobacco 2 2 2 2 contact_other_covid 2 1 2 1 covid_res 1 1 2 1 incubation_period 44 23 6 4 icu 1 2 2 1
Pada tabel 3.3 merupakan hasil tahap cleaning dengan tools PyCharm yang memiliki data 17 atribut dan memiliki 58.769 baris. Selanjutnya data ini disimpan dan siap dilakukan tahap selection yang berasal dari data sample tabel 3.2.
3.3.2.2 Data Selection
Tahapan ini dilakukan untuk menyeleksi data dan menentukan atribut – atribut yang akan digunakan. Data yang sudah di cleaning tadi diproses di tools PyCharm untuk mencari varisi atribut optimal. Menggunakan information gain dengan metode ranker dan menggunakan full training set dengan acuan atribut “ICU” terdapat pada gambar 3.3.
Gambar 3.3 Hasil perankingan atribut Tabel 3.4 Data selection
No Atribut Kolom 1. pneumonia 2. patient_type 3. cardiovascular 4. other_disease 5. inmsupr 6. tobacco 7. asthma 8. renal_chronic 9. copd 10. obesity 11. diabetes 12. contac_other_covid 13. sex 14. hypertension 15. covid_res 16. incubation_period
Hasil perangkingan atribut dengan menggunakan information gain terlihat pada gambar 3.3. Atribut pneumonia sebagai atribut yang memiliki nilai rangking tertinggi. Setelah itu seleksi data dengan atribut pada Tabel 3.4 dengan menggunakan tools microsoft excel untuk membuat file excel dengan kombinasi rangking atribut. Terdapat 16 file excel untuk mencari akurasi atribut yang optimal dalam pemilihan atribut.
3.3.2.3 Data Balancing
Tahap selanjutnya yaitu balancing data dengan membuat replika dari data minoritas. Data “icu” yang tidak seimbang yang akan ditunjukan pada Gambar 3.4 berikut :
Gambar 3.4 Distrubusi data imbalance
Pada gambar di atas terdapat data berjumlah 58769 records dan memiliki 2 kelas yang merupakan kelas ICU. Kelas tersebut terdiri dari kelas 1 atau “Yes” digambarkan warna biru dan kelas 2 atau “No” digambarkan warna hijau. Setelah itu dilakukan proses balancing data menggunakan SMOTE yang terdapat di aplikasi WEKA yang ditujukan pada Gambar 3.5. 1000 5000 9000 13000 17000 21000 25000 29000 33000 37000 41000 45000 49000 53000 ICU Re cor ds Data
Distribusi data imbalance
Gambar 3.5 Distribusi setelah data balancing
Pada gambar 3.5 ditujukan distribusi data pada kelas 1 atau “Yes” menjadi 15156 data dan kelas 2 atau “No” tetap. 3.3.2.4 Data Balancing
Pada tahap ini dilakukan normalisasi data agar setiap atribut dalam dataset memiliki bobot yang sama. Sehingga tidak ada salah satu atribut yang mendominasi. Normalisasi dilakukan dengan menggunakan normalisasi min-max. Normalisasi min-max akan mentransformasi nilai data berdasarkan nilai minimum dan maksimum pada dataset.
3.3.3 K-Fold Cross Validation
Pada penelitian ini menggunakan data sebanyak 58.769 baris yang akan dibagi menjadi dua bagian pengujian yaitu training dan testing data. Masing – masing kelompok data dibagi berdasarkan pengujian k - fold cross validation yang menentukan data training dan data testing. Berikut ini ilustrasi pembagian data yang dilakukan pada Tabel 3.5. 1000 5000 9000 13000 17000 21000 25000 29000 33000 37000 41000 45000 49000 53000 ICU Re cor ds Da ta
Distribusi setelah data balancing
Tabel 3.5 Pembagian data
Fold Data Testing Data Training
3 2/3 1/3
5 4/5 1/5
…. …. ….
3.3.4 Tahap Klasifikasi
Pada tahap ini klasifikasi support vector machine (SVM) yang menggunakan tools PyCharm. Setelah data terbagi menjadi data training dan data testing yang sudah dinormalisasi selanjutnya melatih SVM pada data training. Scikit-Learn berisi library SVM yang berisi kelas pengklasifikasi vektor dukungan yang ditulis sebagai SVC. Kerja algoritma SVM dapat menggunakan rumus persamaan 2.7 dengan sebagai contoh sample pada Tabel 3.2. Penulis mengambil beberapa sample atribut yang terdapat pada tabel 3.6.
Tabel 3.6 Data sample model klasfikasi
Berdasarkan tabel 3.6 maka atribut “sex” sebagai x1, atribut “pneumonia” sebagai x2, atribut “other_disease” sebagai x3 dan “icu” sebagai b. Dalam SVM hanya mempunyai dua kelas penentu yaitu kelas positif dan negatif. Dalam atribut ICU terdapat variable 1 sebagai kelas positif dan variable 2 sebagai kelas negatif. Setelah itu menggunakan rumus persamaan 2.7 dapat diterapkan sebagai berikut :
(1) ( 1𝑤1 + 1𝑤2+ 2𝑤3+ 1𝑏 ) ≥ 1 → ( 1𝑤1+ 1𝑤2+ 2𝑤3 + 𝑏 ) ≥ 1
Data Atribut
sex pneumonia other_disease icu
1 1 1 2 1
2 2 2 2 2
3 1 1 1 2
(2) ( 2𝑤1 + 2𝑤2+ 2𝑤3+ 2𝑏 ) ≥ 1 → (−2𝑤1− 2𝑤2− 2𝑤3 − 𝑏 ) ≥ 1 (3) ( 1𝑤1 + 1𝑤2+ 1𝑤3+ 2𝑏 ) ≥ 1 → (− 1𝑤1− 1𝑤2− 1𝑤3 − 𝑏 ) ≥ 1 (4) ( 2𝑤1 + 1𝑤2+ 2𝑤3+ 1𝑏 ) ≥ 1 → ( 2𝑤1+ 1𝑤2+ 2𝑤3 + 𝑏 ) ≥ 1
Maka dapat dituliskan sebagai matrix :
1 1 2 1 | 1
−2 −2 −2 −1 | 1
−1 −1 −1 −1 | 1
2 1 −2 1 | 1
Lalu selanjutnya menggunakan persamaan rumus
𝑅2+ 2𝑅1 → 𝑅2 ; 𝑅3 + 1𝑅1 → 𝑅3 ; 𝑅4− 2𝑅1 → 𝑅4 sebagai berikut : 1 1 2 1 | 1 0 0 2 1 | 3 0 0 1 0 | 2 0 −1 −6 −1 | −1 𝑅2 ↔ 𝑅4 sebagai berikut : 1 1 2 1 | 1 0 −1 −6 −1 | −1 0 0 1 0 | 2 0 0 2 1 | 3 𝑅2/−1 → 𝑅2 sebagai berikut : 1 1 2 1 | 1 0 1 6 1 | 1 0 0 1 0 | 2 0 0 2 1 | 3 𝑅1− 1𝑅2 → 𝑅1 sebagai berikut : 1 0 −4 0 | 0 0 1 6 1 | 1 0 0 1 0 | 2 0 0 2 1 | 3
𝑅1+ 4𝑅3 → 𝑅1 ; 𝑅2− 6𝑅3 → 𝑅2 ; 𝑅4− 2𝑅3 → 𝑅4 sebagai berikut: 1 0 0 0 | 8 0 1 0 1 | −11 0 0 1 0 | 2 0 0 0 1 | −1 𝑅2− 1𝑅4 → 𝑅2 sebagai berikut : 1 0 0 0 | 8 0 1 0 0 | −10 0 0 1 0 | 2 0 0 0 1 | −1
Jadi di dapatkan nilai variable : 𝑤1 = 8
𝑤2 = −10 𝑤3 = 2 𝑏 = −1
Lalu menerapkannya dalam data sample baru pada tabel 3.7 untuk pengujian model yang sudah didapatkan.
Tabel 3.7 Data sample baru
ID sex pneunomia other_disease
136318 1 1 2
0b5976 1 1 2
1761b2 2 2 2
03b7be 2 2 2
Dengan menggunakan rumus 2.16 maka :
f(x) = 𝑤1. 𝑥1+ 𝑤2. 𝑥2+ 𝑤3. 𝑥3+ 𝑏 Data 136318 = (8 . 1) + (-10 . 1) + (2 . 2) + ( -1)
= 8 – 10 + 4 -1
= 1
= 8 – 10 + 4 -1 = 1 Data 1761b2 = (8 . 2) + (-10 . 2) + (2 . 2) + ( -1) = 16 – 20 + 4 – 1 = -1 Data 03b7be = (8 . 2) + (-10 . 2) + (2 . 2) + (-1) = 16 – 20 + 4 -1 = -1 Keterangan : 𝑅1 : Baris ke 1 𝑅2 : Baris ke 2 𝑅3 : Baris ke 3 𝑅4 : Baris ke 4
𝑥1 : Data baru atribut “sex”
𝑥1 : Data baru atribut “pneunomia” 𝑥1 : Data baru atribut “other_disease” 3.5 Desain Pengujian
Pada penelitian ini menggunakan pengujian metode K-Fold Cross Validation yang akan membagi data yang tampak dalam Tabel 3.8.
Tabel 3.8 Confusion matrix pengujian Kelas hasil prediksi
Ya Tidak Jumlah Kelas Aktual Ya TP FN P Tidak FP TN N Jumlah P N’ P + N Akurasi = 𝑇𝑃+𝑇𝑁 𝑃+𝑁 𝑥 100%
3.6 Desain Sistem
Gambar 3.6 Desain sistem
Pada Gambar 3.6 merupakan desain dari user interface yang rencananya akan digunakan. User memasukan data dengan menekan tombol Cari. Data yang diambil merupakan data excel. Terdapat tombol hapus untuk menghapus data yang di input dan terdapat tombol lihat untuk melihat data yang di input. Lalu menginputkan jumlah fold yang diinginkan dan memasukan kode angka kernel SVM yang akan digunakan. Setelah ittu menekan tombol proses untuk mendapatkan akurasi klasifikasi.
3.7 Kebutuhan Sistem
a. Perangkat Keras (Hardware) :
Laptop dieperlukan dalam menunjang pembuatan sistem, adapun spesifikasi yang digunakan dalam pembuatan sistem ini yaitu :
Tabel 3.9 Spesifikasi PC
Model Asus X450CA
Platform Notebook PC
Hard Disk Drive 500 Gigabyte
Graphic Processing Unit Intel® HD Graphics 4000 Operating System Windows 8.1 64 bit
b. Perangkat Lunak :
Perangkat lunak yang diperlukan adalah menggunakan software Microsoft Excel 2013, WEKA versi 3.8 dan Pycharm versi 2020.1.2 untuk membuat serta menjalankan sistem yang dibuat.
42 BAB IV
IMPLEMENTASI DAN ANALISIS HASIL
Pada bab ini melakukan implementasi dengan preprocessing, klasifikasi, pelatihan dan pengujian serta menampilkan analisa hasil.
4.1 Preprocessing
Pada implementasi perangkat lunak memiliki kelas yaitu kelas proses. Selain itu, perangkat lunak ini menggunakan library python yang terdapat pada tabel 4.1.
Tabel 4.1 Implementasi library python
No Kode Deskripsi 1 import pandas Untuk menganalisis, membersihkan, mengeksplorasi. 2 import numpy
Menyediakan obyek array, menganalisis numerik,
melakukan matrix, dan operasi matematika.
3 from sklearn.feature_selection import mutual_info_classif
Menghitung nilai informasi variabel dengan fitur nilai target.
4 read_excel( ) Membaca file Excel menjadi
DataFrame pandas. 5 to_datetime( )
Mengubah data tanggal menjadi format DataFrame pandas.
6 MinMaxScaler( )
Melakukan preprocessing menggunakan normalisasi min-max.
7 from sklearn.model_selection
import KFold Membuat cross validation.
8 from sklearn import svm Membuat model klasifikasi SVM.
9 svm.SVC(kernel = 'linear') Fungsi kernel linear dalam klasifikasi SVM.
10 svm.SVC(kernel = 'rbf')
Fungsi kernel radial basic function (RBF) dalam klasifikasi SVM.
11 svm.SVC(kernel = 'poly') Fungsi kernel polynominal dalam klasifikasi SVM.
12 split() Untuk membagi data training dan data testing.
13 predict(X) Untuk memprediksi nilai
testing. 14
from sklearn.metrics import confusion_matrix, accuracy_score
Menghitung matrix dan
menghitung akurasi klasifikasi. 15 from tkinter import * Untuk membuat desain
antarmuka.
16 from tkinter import filedialog Untuk membuka file dalam system.
17 from tkinter import messagebox Untuk memberi informasi berupa pop up.
18 from pandastable import Table
Untuk membuat dan menambahkan tabel dalam DataFrame.
19 from tkinter import Label Membuat nama pada desain antarmuka.
4.1.1 Data Cleaning
Tahap cleaning ini bertujuan untuk menghapus atribut yang tidak diperlukan dan menghilangkan missing value. Proses cleaning data dilakukan di tools PyCharm. Pertama data COVID diinputkan dan dibaca, mempunyai data 23 atribut seperti pada Tabel 3.2 dan memiliki 566.602 baris. Langkah pertama menghapus atribut “pregnancy” karena sangat berpengaruh dengan atribut “sex”. Bila atribut “pergnancy” tetap digunakan maka nilai atribut “sex” hanya nilai “1” atau “Female” saja.
Setelah itu membuat atribut baru “incubation_period” berisi hasil selisih atribut “entry_date” dengan atribut “date_died”. Lalu setelah itu menghapus atribut yang tidak perlu “id”, “entry_date”, “date_symptoms”, “date_died” dan “age”. Setelah atribut bersih lalu selanjutnya menghilangkan missing value. Nilai 97,98,99 merupakan nilai missing value sehingga perlu dihilangkan. Setelah itu file disimpan kembali untuk melalukan tahap data selection. Berikut potongan program cleaning data.