Penerapan Representasi Emoji dan Kontraksi Serta Ekstraksi Fitur Latent Semantic Analysis Menggunakan Klasifikasi
Machine Learning Dalam Analisis Sentimen Skripsi
Oleh FAZRIANSYAH
11190910000062
PROGRAM STUDI TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS ISLAM NEGERI SYARIF HIDAYATULLAH JAKARTA
2023 M/1444 H
Penerapan Representasi Emoji dan Kontraksi Serta Ekstraksi Fitur Latent Semantic Analysis Menggunakan Klasifikasi
Machine Learning Dalam Analisis Sentimen
Skripsi
Diajukan sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer Pada Program Studi Teknik Informatika Fakultas Sains dan Teknologi
Universitas Islam Negeri UIN Syarif Hidayatullah Jakarta
Oleh FAZRIANSYAH
11190910000062
PROGRAM STUDI TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS ISLAM NEGERI SYARIF HIDAYATULLAH JAKARTA
2023 M/1444 H
KATA PENGANTAR
Puji syukur penulis ucapkan kehadirat Allah SWT yang telah memberikan rahmat dan karunia-Nya sehingga penulis dapat menyelesaikan tugas akhir atau skripsi ini.
Penulisan skripsi ini dilakukan dalam rangka memenuhi salah satu syarat untuk mencapai gelar Sarjana Komputer Program Studi Teknik Informatika Fakultas Sains dan Teknologi Universitas Islam Negeri Syarif Hidayatullah Jakarta. Dalam penyelesaian skripsi, penulis mendapatkan berbagai bantuan, dukungan, saran dan kritik dari berbagai pihak. Oleh karena itu dalam kesempatan ini penulis ingin mengucapkan terima kasih kepada:
1. Allah SWT, yang telah memberikan rahmat, nikmat, dan karunia-Nya sehingga skripsi ini dapat diselesaikan.
2. Kedua orang tua dan keluarga, yang selalu memberikan do’a terbaik serta memberikan berbagai dukungan baik moril maupun materiil.
3. Bapak Dr. Husni Teja Sukmana, S.T., M.Sc. selaku Dekan Fakultas Sains dan Teknologi
4. Ibu Dewi Khairani, M.Sc, selaku Ketua Program Studi Teknik Informatika Fakultas Sains dan Teknologi.
5. Ibu Nurhayati, Ph.D., selaku Dosen Pembimbing I dan Bapak Dr. Imam Marzuki Shofi, M.T. selaku Dosen Pembimbing II yang telah memberikan bimbingan dan arahan sehingga skripsi ini dapat diselesaikan dengan baik..
6. Seluruh Dosen, Staf Karyawan Fakultas Sains dan Teknologi, khususnya Program Studi Teknik Informatika yang telah memberikan bantuan dan kerjasama dari awal perkuliahan.
7. Kepada teman seperjuangan Teknik Informatika Angkatan 2019 dan khususnya teman-teman TI C termasuk Rebahan Grup.
8. Serta seluruh pihak yang telah membantu penulis secara langsung maupun tidak langsung yang nama nya tidak dapat disebutkan satu per satu.
Penulis menyadari bahwa dalam penyajian skripsi ini masih belum bisa disebut sempurna. Apabila terdapat kebenaran dalam penulisan ini maka kebenaran
tersebut datangnya dari Allah SWT, apabila terdapat kesalahan dalam penulisan ini maka kesalahan tersebut murni berasal dari penulis. Semoga skripsi ini dapat bermanfaat bagi pengembangan ilmu. Semoga Allah SWT membalas segala kebaikan semua pihak yang telah membantu dan meridhoi segala usaha kita
Jakarta, 18 September 2023
Fazriansyah
PERNYATAAN PERSETUJUAN PUBLIKASI SKRIPSI
Sebagai civitas akademik UIN Syarif Hidayatullah Jakarta, saya yang bertandatangan dibawah ini:
Nama : Fazriansyah NIM : 11190910000062 Program Studi : Teknik Informatika Fakultas : Sains dan Teknologi Jenis Karya : Skripsi
Demi pengembangan ilmu pengetahuan, menyetujui untuk memberikan kepada Universitas Islam Negeri Syarif Hidayatullah Jakarta Hak Bebas Royalti Non Eksklusif (Non-exclusive Royalti Free Right) atas karya ilmiah saya yang berjudul:
Penerapan Representasi Emoji dan Kontraksi Serta Ekstraksi Fitur Latent Semantic Analysis Menggunakan Klasifikasi Machine Learning Dalam Analisis Sentimen Beserta perangkat yang ada (jika diperlukan). Dengan Hak Bebas Royalti Non Eksklusif ini Universitas Islam Negeri Syarif Hidayatullah Jakarta berhak menyimpan, mengalihmedia/formatkan, megelola dalam bentuk pangkalan data (database), merawat, dan mempublikasikan tugas akhir saya selama tetap mencantumkan nama saya sebagai penulis/pencipta dan sebagai pemilik Hak Cipta.
Demikian pernyataan ini saya buat dengan sebenarnya.
Dibuat di : Jakarta
Pada tanggal : 18 September 2023 Yang menyatakan,
(Fazriansyah)
Nama : Fazriansyah
Program Studi : Teknik Informatika
Judul : Penerapan Representasi Emoji dan Kontraksi Serta Ekstraksi Fitur Latent Semantic Analysis Menggunakan Klasifikasi Machine Learning Dalam Analisis Sentimen
ABSTRAK
Analisis sentimen adalah teknik pemrosesan bahasa alami yang bertujuan untuk mengklasifikasikan dan mengekstraksi sentimen yang terkandung dalam teks. Pada penelitian ini, objek yang dijadikan sebagai sumber data teks adalah data tweet pengguna Twitter mengenai Singapore Airlines, karena Singapore Airlines terpilih sebagai maskapai penerbangan terbaik di dunia pada tahun 2023 sehingga menjadi topik yang banyak dibicarakan dalam jangkauan internasional. Penulis mengumpulkan data tweet menggunakan Tweepy dan mengumpulkan total 5359 tweet dengan kode en untuk tweet yang berupa Bahasa Inggris. Penulis menerapkan representasi emoji dan kontraksi pada praproses data, karena pada penelitian sebelumnya, emoji diabaikan atau dihapus dan belum adanya representasi kontraksi. Pemodelan Machine Learning yang dilakukan penulis terdiri dari tiga tahapan yaitu vektorisasi teks, Latent Semantic Analysis sebagai ekstraksi fitur, dan pengklasifikasi Machine Learning yang dalam penelitian ini penulis menggunakan.
algoritma yang berbeda dengan penelitian sebelumnya yaitu Logistic Regression, Naïve Bayes, Stochastic Gradient Descent dan Decision Tree untuk mengetahui algoritma klasifikasi manakah yang memiliki akurasi terbaik dalam penggunaan Latent Semantic Analysis. Hasil yang ditemukan bahwa teknik representasi emoji dan kontraksi dapat meningkatkan akurasi model dalam mengklasifikasi sentimen.
Serta hasil akurasi model dengan ekstraksi fitur Latent Semantic Analysis pada algoritma Decision Tree sebesar 94.66%, Logistic Regression 63.78%, Naïve Bayes 42.04% dan Stochastic Gradient Descent 64.66%. Disarankan dalam pencarian jumlah komponen fitur yang dipertahankan dilakukan analisis komponen utama atau metode validasi siluet agar mengetahui jumlah kompnen terbaik pada model klasifikasi Machine Learning. Model klasifikasi Machine Learning dapat diimplementasikan ke dalam suatu aplikasi yang membutuhkan fitur klasifikasi teks berupa ulasan, komentar dan sebagainya.
Kata Kunci :
Analisis Sentimen, Twitter, Machine Learning, Latent Semantic Analysis, Emoji, Kontraksi
Nama : Fazriansyah
Program Studi : Teknik Informatika
Judul : Penerapan Representasi Emoji dan Kontraksi Serta Ekstraksi Fitur Latent Semantic Analysis Menggunakan Klasifikasi Machine Learning Dalam Analisis Sentimen
ABSTRACT
Sentiment analysis is a natural language processing technique that aims to classify and extract sentiment contained in text. In this research, the object used as a text data source is Twitter user tweet data regarding Singapore Airlines, because Singapore Airlines was selected as the best airline in the world in 2023, making it a topic that is widely discussed internationally. The author collected tweet data using Tweepy and collected a total of 5359 tweets with en code for tweets in English. The author applies emoji and contraction representations in data preprocessing, because in previous research, emojis were ignored or deleted and there was no contraction representation. The Machine Learning modeling carried out by the author consists of three stages, namely text vectorization, Latent Semantic Analysis as feature extraction, and the Machine Learning classifier which in this research the author uses. Algorithms that are different from previous research are Logistic Regression, Naïve Bayes, Stochastic Gradient Descent and Decision Tree to find out the classification algorithm that has the best accuracy when using Latent Semantic Analysis. The results found that emoji and contraction representation techniques can increase the model's accuracy in classifying sentiment. As well as the accuracy results of the model using Latent Semantic Analysis feature extraction on the Decision Tree algorithm of 94.66%, Logistic Regression 63.78%, Naïve Bayes 42.04% and Stochastic Gradient Descent 64.66%.
It is recommended that in searching for the number of feature components to be retained, principal component analysis or silhouette validation methods be carried out in order to find out the best number of components in the Machine Learning classification model. Machine Learning classification models can be implemented into an application that uses text classification features in the form of reviews, comments and others.
Key words :
Sentiment Analysis, Twitter, Machine Learning, Latent Semantic Analysis, Emoticon, Contractions.
DAFTAR ISI
PERYATAAN ORISINALITAS ... iii
LEMBAR PERSETUJUAN ... iv
LEMBAR PENGESAHAN ... v
KATA PENGANTAR ... vi
PERNYATAAN PERSETUJUAN PUBLIKASI SKRIPSI ... viii
ABSTRAK ... ix
ABSTRACT ... x
DAFTAR ISI ... xi
DAFTAR GAMBAR ... xiv
DAFTAR TABEL ... xvi
BAB 1 ... 1
PENDAHULUAN ... 1
1.1. Latar Belakang ... 1
1.2. Rumusan Masalah ... 3
1.3. Batasan Masalah ... 4
1.4. Tujuan Penelitian ... 5
1.5. Manfaat Penelitian ... 5
1.6. Metode Penelitian ... 5
1.6.1. Metode Pengumpulan Data ... 5
1.6.2. Metode Klasifikasi Machine Learning... 6
1.7. Sistematika Penulisan ... 6
BAB 2 ... 8
TINJAUAN PUSTAKA DAN LANDASAN TEORI ... 8
2.1. Twitter ... 8
2.1.1. Glosarium Twitter ... 8
2.1.2. Tweepy... 9
2.2. Sumber Data dan Metode Pengumpulan Data... 10
2.3. Emoji ... 10
2.4. Kontraksi ... 10
2.5. Ekstraksi Fitur ... 11
2.6. Praproses Teks ... 11
2.7. Analisis Sentimen ... 13
2.8. Latent Semantic Analysis (LSA) ... 14
2.9. Term Frequency-Inverse Document Frequency (TF-IDF)... 14
2.6.1. TF ... 14
2.6.2. IDF ... 15
2.10. Decision Tree ... 15
2.11. Naïve Bayes ... 15
2.12. Logistic Regression ... 16
2.13. Stochastic Gradient Descent ... 16
2.14. Singular Value Decomposition (SVD) ... 17
2.15. Python ... 17
2.16. XAMPP ... 20
2.17. Literatur Sejenis ... 20
BAB 3 ... 27
METODOLOGI PENELITIAN ... 27
3.1. Desain Penelitian ... 27
3.2. Metode Penelitian ... 29
3.3. Metode Pengumpulan Data ... 30
3.3.1. Data ... 30
3.3.2. Studi Pustaka ... 32
3.4. Praproses Data ... 32
3.4.1. Case Folding ... 32
3.4.2. Representasi Emoji... 32
3.4.3. Representasi Kontraksi... 33
3.4.4. Cleaning ... 34
3.4.5. Stopwords Removal ... 35
3.4.6. POS Tagging ... 35
3.4.7. Lematisasi ... 35
3.5. Pelabelan Sentimen ... 36
3.6. Ekstraksi Fitur ... 36
3.6.1. TF-IDF ... 36
3.6.2. Latent Semantic Analysis ... 37
3.7. Klasifikasi Machine Learning ... 39
3.8. Validasi dan Evaluasi ... 41
BAB 4 ... 42
PERANCANGAN DAN PENGUJIAN ... 42
4.1. Analisis Data ... 42
4.2. Praproses Data ... 43
4.2.1. Case Folding ... 43
4.2.2. Cleaning ... 45
4.2.3. Representasi Emoji... 48
4.2.4. Representasi Kontraksi... 51
4.2.5. Stopwords Removal ... 57
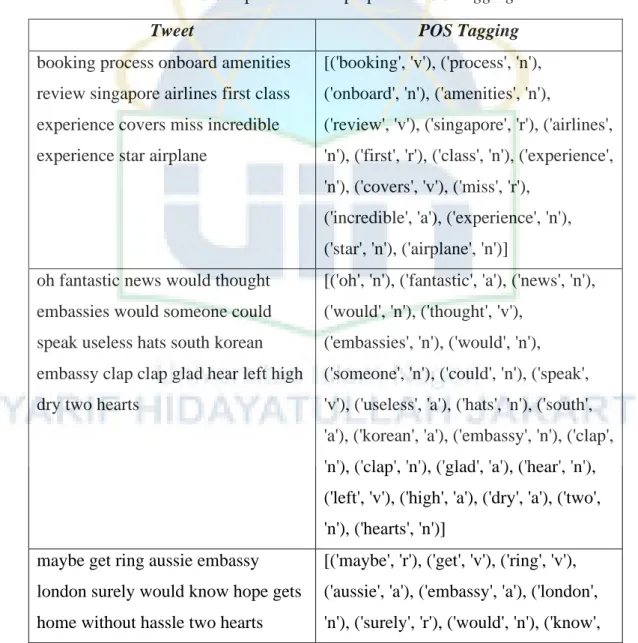
4.2.6. POS Tagging ... 59
4.2.7. Lematisasi ... 61
4.3. Pelabelan Sentimen ... 63
4.4. Analisis Sentimen dengan Model Machine Learning ... 65
4.4.1. Pemodelan Machine Learning Classifier ... 65
4.4.2. Implementasi Model Pada Program PHP ... 78
BAB 5 ... 84
HASIL DAN PEMBAHASAN ... 84
5.1. Hasil Klasifikasi Sentimen ... 84
5.1.1. Kecepatan ... 84
5.1.2. Metrik Klasifikasi... 84
5.1.3. Akurasi ... 87
5.2. Penerapan Teknik Representasi Emoji dan Kontraksi ... 88
5.3. Perbandingan Penerapan Representasi Emoji dan Kontraksi ... 88
BAB 6 ... 91
PENUTUP ... 91
6.1. Kesimpulan ... 91
6.2. Saran ... 91
DAFTAR PUSTAKA ... 93
LAMPIRAN ... 97
DAFTAR GAMBAR
Gambar 3. 1 Desain Penelitian ... 27
Gambar 3. 2 Tahapan metode klasifikasi Machine Learning ... 40
Gambar 4. 1 Sampel data mentah pencarian tweet ... 43
Gambar 4. 2 Frekuensi nilai skor polaritas dan label sentimen tweet ... 64
Gambar 4. 3 Sampel data tweet beserta sentimen skor dan labelnya... 65
Gambar 4. 4 Hasil pengujian model Decision Tree pada data uji ... 67
Gambar 4. 5 Kecepatan performa model Decision Tree ... 68
Gambar 4. 6 Hasil klasifikasi model Decision Tree pada seluruh data ... 68
Gambar 4. 7 Confusion Matrix model Decision Tree ... 68
Gambar 4. 8 Hasil pengujian model Logistic Regression pada data uji ... 70
Gambar 4. 9 Kecepatan performa model Logistic Regression ... 71
Gambar 4. 10 Hasil klasifikasi model Logistic Regression pada seluruh data ... 71
Gambar 4. 11 Confusion Matrix model Logistic Regression ... 71
Gambar 4. 12 Hasil pengujian model Naive Bayes pada data uji ... 73
Gambar 4. 13 Kecepatan performa model Naive Bayes ... 73
Gambar 4. 14 Hasil klasifikasi model Naive Bayes pada seluruh data ... 74
Gambar 4. 15 Confusion Matrix model Naive Bayes ... 74
Gambar 4. 16 pengujian model Stochastic Gradient Descent pada data uji ... 76
Gambar 4. 17 Kecepatan performa model Stochastic Gradient Descent ... 76
Gambar 4. 18 Hasil klasifikasi model SGD pada seluruh data ... 77
Gambar 4. 19 Confusion Matrix model Stochastic Gradient Descent ... 77
Gambar 4. 20 Halaman input teks model Decision Tree ... 79
Gambar 4. 21 Halaman input teks model Logistic Regression ... 79
Gambar 4. 22 Halaman input teks model Naive Bayes ... 80
Gambar 4. 23 Halaman input teks model Stochastic Gradient Descent ... 80
Gambar 4. 24 Hasil analisis sentimen model Decision Tree ... 82
Gambar 4. 25 Hasil analisis sentimen model Logistic Regression ... 82
Gambar 4. 26 Hasil analisis sentimen model Naive Bayes ... 82
Gambar 4. 27 Hasil analisis sentimen model Stochastic Gradient Descent ... 83
Gambar 5. 1 Perbandingan kecepatan model dalam klasifikasi data ... 84
Gambar 5. 2 Perbandingan nilai precision model pada setiap label ... 85
Gambar 5. 3 Perbandingan nilai recall model pada setiap label ... 86
Gambar 5. 4 Perbandingan nilai f1-score model pada setiap label ... 86
Gambar 5. 5 Perbandingan akurasi klasifikasi data setiap model ... 87
Gambar 5. 6 Perbandingan akurasi dan metrik hasil klasifikasi seluruh data ... 90
DAFTAR TABEL
Tabel 2. 1 Perbandingan Penelitian Penulis dengan Penelitian Sebelumnya... 21
Tabel 2. 2 Perbandingan penellitian penulis dengan penelitian sebelumnya ... 24
Tabel 3. 1 Sampel data tweet ... 30
Tabel 3. 2 Contoh data teks dokumen ... 36
Tabel 3. 3 Contoh data matriks TF-IDF ... 38
Tabel 3. 4 Data TF-IDF setelah dikurangi nilai mean ... 38
Tabel 3. 5 Data matriks TF-IDF terpusat dan TF-IDF kovariansi ... 38
Tabel 3. 6 Hasil reduksi dimensi matriks TF-IDF oleh TruncatedSVD ... 39
Tabel 4. 1 Sampel data hasil praproses Case Folding ... 43
Tabel 4. 2 Sampel data hasil praproses Cleaning ... 46
Tabel 4. 3 Sampel data hasil praproses representasi emoji ... 48
Tabel 4. 4 Representasi emoji dengan teks hanya emoji dan kontraksi ... 50
Tabel 4. 5 Sampel data hasil praproses representasi kontraksi ... 52
Tabel 4. 6 Representasi kontraksi dengan teks hanya emoji dan kontraksi ... 54
Tabel 4. 7 Sampel data hasil praproses Stopwords Removal... 57
Tabel 4. 8 Sampel data hasil praproses POS Tagging ... 59
Tabel 4. 9 Sampel data hasil praproses lematisasi ... 61
Tabel 4. 10 Pembagian data latih dan data uji ... 65
Tabel 5. 1 Perbandingan frekuensi data tweet hasil klasifikasi seluruh data ... 89
BAB 1
PENDAHULUAN
1.1. Latar Belakang
Pada 20 Juni 2023, Singapore Airlines telah terpilih sebagai maskapai terbaik dunia pada World Airline Awards 2023 dari hasil survei. Survei dilakukan pelanggan dengan cara online yang beroperasi dari September 2022 hingga Mei 2023 lalu. Survei pelanggan disediakan dalam Bahasa Inggris, Prancis, Spanyol, Rusia, Jepang, dan China. Lebih dari 100 negara pelanggan berpartisipasi dalam survei 2022/2023. Entri survei disaring untuk mengidentifikasi IP dan informasi pengguna, dengan semua entri duplikat, tersangka, atau tidak memenuhi syarat dihapus. Lebih dari 325 maskapai ditampilkan dalam hasil akhir penghargaan (Singapore Airlines Is the World’s Best Airline at 2023 World Airline Awards, 2023).
Dengan berkembangnya zaman, kini kita dapat mengetahui ulasan para penumpang yang sudah menggunakan layanan dari maskapai penerbangan Singapore Airlines untuk menjadikan referensi dalam pelayanan maskapai tersebut.
Salah satu contohnya dengan menggunakan media sosial Twitter kita dapat mengetahui kesan pesan para pengguna Twitter yang menyampaikan perasaannya.
Media sosial Twitter juga menyediakan pengguna fasilitas untuk mengumpulkan data tweet pengguna yang bersifat publik dengan Twitter API (Application Programming Interface). Berdasarkan penjelasan sebelumnya, penulis menggunakan Twitter sebagai sumber data yang akan digunakan dalam penelitian ini karena kemudahan dalam memproses pengumpulan data dengan menggunakan API yang sudah tersedia.
Analisis sentimen adalah teknik pemrosesan bahasa alami yang bertujuan untuk mengidentifikasi, mengklasifikasikan, dan mengekstraksi sentimen atau pendapat yang terkandung dalam teks, seperti ulasan produk, postingan media sosial, atau berita. Kemampuan untuk memahami sentimen secara otomatis dari teks memiliki banyak manfaat, seperti memantau merk atau brand, membuat
keputusan bisnis, dan menganalisis opini publik. Analisis sentimen dapat memberikan wawasan penting tentang perasaan dan pendapat pengguna tentang berbagai topik, produk, atau peristiwa. Pertumbuhan media sosial dan volume data teks yang dihasilkan oleh pengguna telah menyebabkan bidang penelitian ini berkembang pesat dalam beberapa tahun terakhir. Pada penelitian ini, objek atau target yang akan dijadikan sebagai sumber data tweet sebagai dataset adalah maskapai penerbangan Singapore Airlines, karena berdasarkan paparan sebelumnya Singapore Airlines terpilih sebagai maskapai penerbangan terbaik pada tahun 2023 sehingga menjadi topik yang banyak dibicarakan dalam jangkauan internasional.
Pada proses analisis sentimen, data teks yang digunakan sebelumnya dilakukan tahap praproses teks atau text preprocessing untuk mengolah data teks menjadi lebih berkualitas dan memiliki informasi yang penting untuk digunakan sebagai fitur klasifikasi. Namun pada tahap praproses teks pada penelitian sebelumnya yang dilakukan oleh Kashfia Sailunaz (2019) yang menggunakan data dari media sosial Twitter, belum terdapat representasi emoji dan representasi kontraksi. Emoji diabaikan atau dihapus pada tahap Cleaning teks, sehingga dapat mengurangi perasaan atau suatu emosi pada suatu teks. Lalu untuk kontraksi yang dapat berupa kata negasi, pemendekan kata dan juga termasuk kata-kata tren atau slang language, dapat direpresentasikan menjadi kata-kata yang mengandung makna atau maksud yang sebenarnya untuk dapat diketahui informasi lengkap yang terdapat pada suatu teks.
Latent Semantic Analysis (LSA) adalah salah satu teknik penting dalam Natural Language Processing (NLP) untuk mengatasi kompleksitas pemahaman teks dan analisisnya. LSA digunakan untuk menemukan hubungan semantik antara kata-kata dalam teks dan menghasilkan representasi vektor yang secara statistik menunjukkan makna teks. LSA didasarkan pada prinsip bahwa kata-kata yang sering muncul bersama dalam teks cenderung memiliki makna yang sama. Dengan menggunakan teknik reduksi dimensi, LSA mengubah ruang teks yang lebih besar menjadi lebih kecil, yang memungkinkan pemahaman yang lebih baik tentang teks.
Dalam analisis sentimen, dasar utama representasi teks secara langsung bergantung
pada karakteristik kata atau kalimat. Hal ini dapat mengabaikan keseluruhan makna dan konteks teks pada suatu kalimat. Oleh karena itu, LSA yang menampilkan representasi vektor yang mengandung makna semantik, dapat menjadi alat yang berguna dalam analisis sentimen. Hasil dari representasi LSA akan menjelaskan hubungan antara kata-kata, yang akan digunakan sebagai fitur input oleh model klasifikasi Machine Learning.
Analisis sentimen menggunakan model Klasifikasi Machine Learning memiliki keunggulan dalam mengolah volume besar data teks dan dapat mengidentifikasi sentimen dengan cepat dan akurat. Metode klasifikasi berbasis pembelajaran mesin, seperti Decision Tree, Logistic Regression, Naïve Bayes, dan Support Vector Machine, telah banyak digunakan dalam analisis sentimen. Metode ini melibatkan proses pelatihan model dengan menggunakan kumpulan data yang sudah dilabeli untuk mengenali pola dan hubungan antara fitur teks dan sentimen yang terkait. Pada penelitian sebelumnya yang dilakukan oleh Satanik Mitra (2018) yang menggunakan LSA sebagai ekstraksi fitur pada klasifikasi Machine Learning sudah dilakukan menggunakan algoritma klasifikasi Decision Tree, Random Forest dan Support Vector Machine dengan hasil akurasi terbaik yaitu Decision Tree. Oleh karena itu, pada penelitian ini penulis menggunakan Decision Tree dan tiga pengklasifikasi yang berbeda yaitu Logistic Regression, Naïve Bayes, dan Stochastic Gradient Descent untuk penggunaan LSA sebagai ekstraksi fitur.
Berdasarkan uraian pada latar belakang yang telah penulis jelaskan sebelumnya, maka penulis melakukan penelitian terkait ekstraksi fitur Latent Semantic Analysis dan penerapan representasi emoji dan kontraksi dalam analisis sentimen serta mengukur tingkat akurasi algoritma klasifikasi Machine Learning sebagai kajian yang penulis bentuk dalam skripsi dengan judul “Penerapan Representasi Emoji dan Kontraksi Serta Ekstraksi Fitur Latent Semantic Analysis Menggunakan Klasifikasi Machine Learning Dalam Analisis Sentimen”.
1.2. Rumusan Masalah
1. Manakah algoritma klasifikasi Machine Learning yang menghasilkan nilai akurasi terbaik dalam analisis sentimen menggunakan ekstraksi fitur Latent Semantic Analysis?
2. Apakah penggunaan representasi emoji, dan representasi kontraksi dalam praproses teks mempengaruhi hasil klasifikasi sentimen?
1.3. Batasan Masalah
1. Dataset tweet yang diambil menggunakan Bahasa Inggris yaitu yang memiliki kode bahasa en, agar sesuai dengan objek penelitian dan juga opini pengguna yang diambil lebih luas dalam jangkauan internasional.
2. Dataset tweet yang digunakan sesuai dengan kata kunci yang ditentukan yaitu “Singapore Airlines” sebuah tweet yang berisikan 2 kata yang berdampingan yaitu Singapore dan Airlines, “@SingaporeAir” sebuah tweet yang berisikan mention akun Twitter resmi Singapore Airlines dan
“#FlySQ” sebuah tweet yang berisikan tagar atau hashtag resmi yang ditujukan untuk para follower berkeluh kesah dan bercerita atau berbagi pengalaman terkait Singapore Airlines.
3. Dataset tweet didapatkan dengan menggunakan API Twitter yang tersedia di situs pengembang Twitter dengan menggunakan modul Python dari pustaka Tweepy.
4. Teks hasil representasi pada emoji yang digunakan yaitu happy, love, neutral, sad, sleep, sick, shock, concern, cry, tired, angry, evil, disgust, agree, hope, disagree, celebrate, pray, smile, paralyze, dan kiss.
5. Metode klasifikasi Machine Learning yang digunakan adalah Decision Tree, Logistic Regression, Naïve Bayes, dan Stochastic Gradient Descent 6. Peralatan yang digunakan yaitu Visual Studio Code, Bahasa
Pemrograman Python v3.11.4, PHP v7.4.23, dan XAMPP.
7. Perangkat (laptop) yang digunakan penulis yaitu Acer Aspire E 14 E5- 475G-38LQ dengan spesifikasi Intel® Core™ i3-6006U CPU (@ 2.0 GHz 1.99GHz, 3MB L3 Cache), NVIDIA GeForce 940MX 2GB
VRAM, 4GB DDR4 Memory, 250GB SSD & 500GB HDD, dan Sistem Operasi Windows 10 Pro Version 22H2.
1.4. Tujuan Penelitian
1. Untuk mengetahui algoritma klasifikasi Machine Learning manakah yang menghasilkan nilai akurasi terbaik menggunakan ekstraksi fitur Latent Semantic Analysis dalam analisis sentimen.
2. Untuk mengetahui pengaruh dalam penggunaan representasi emoji dan representasi kontraksi dalam praproses teks dapat mempengaruhi hasil klasifikasi sentimen.
1.5. Manfaat Penelitian
Manfaat bagi penulis sendiri adalah penulis dapat menerapkan ilmu yang diperoleh selama perkuliahan untuk penelitian ini. Dan tentunya merupakan salah satu syarat untuk memperoleh gelar Sarjana (S1) dari Program Studi Teknik Informatika, Fakultas Sains dan Teknologi, Universitas Islam Negeri Syarif Hidayatullah Jakarta. Tidak hanya bermanfaat bagi penulis, tetapi juga membantu Instansi tempat penulis menuntut ilmu. Seperti membantu penelitian mahasiswa Prodi Teknik Informatika, dalam bidang pengolahan bahasa alami atau Natural Language Processing. Kemudian juga menjadi acuan bagi perguruan tinggi untuk menentukan keberhasilan dan kemampuan penulis dalam menerapkan ilmu yang diperoleh selama menempuh pendidikan di UIN Syarif Hidayatullah Jakarta.
Tentunya pada akhirnya bermanfaat bagi peneliti ataupun pengembang aplikasi yang akan membuat suatu fitur untuk ulasan pengguna yang dapat menerapkan model klasifikasi sentimen dan teknik praproses teks yang peneliti lakukan.
1.6. Metode Penelitian
Metode yang digunakan oleh penulis dalam penelitian ini terdapat dua metode yaitu metode pengumpulan data dan metode klasifikasi Machine Learning.
1.6.1. Metode Pengumpulan Data
1. Studi Pustaka
Dalam metode ini, penulis melakukan pencarian dan mengumpulkan data-data terkait penelitian yang sejenis dari jurnal, artikel, karya ilmiah, dan situs web untuk digunakan sebagai tinjauan literatur terkait topik pada penelitian ini untuk mendapatkan informasi yang diperlukan dalam menangani masalah yang akan diteliti.
2. Pengumpulan Data Primer
Pada metode ini, penulis mengumpulkan data mentah secara real- time dengan menggunakan Twitter API. dengan modul pustaka Tweepy yang terdapat fitur search_tweets untuk mengambil data tweet dengan memasukan query beserta parameter tertentu dan kata kunci yang sudah ditentukan.
1.6.2. Metode Klasifikasi Machine Learning
Dalam metode ini, penulis mengklasifikasikan data yang berasal dari data tweet untuk mendapatkan hasil kategori sentimen dari analisis yang berupa sangat negatif, negatif, netral, positif dan sangat positif. Klasifikasi dilakukan menggunakan metode Machine Learning yaitu metode yang memasukkan data ke dalam kelas atau kategori yang telah ditentukan secara otomatis. Metode ini adalah sebuah cabang pembelajaran mesin tempat algoritma belajar dari data pelatihan berlabel untuk membuat prediksi atau penilaian tentang data baru yang belum teramati.
1.7. Sistematika Penulisan
Sistematika penulisan yang akan dilakukan dalam penelitian ini terdiri dari beberapa bagian:
BAB I PENDAHULUAN
Bab ini membahas hal umum dalam penelitian, seperti latar belakang dari dari sebuah permasalahan yang diangkat, tujuan penelitian, manfaat penelitian, rumusan masalah, batasan masalah, metodologi
penelitian, sistematika penulisan, dan jadwal penelitian.
BAB II LANDASAN TEORI
Bab ini menjelaskan beberapa materi dan teori yang dibutuhkan dalam melaksanakan penelitian ini. Serta pemaparan literatur yang penulis jadikan sebagai tinjauan pustaka dalam penelitian ini.
BAB III METODOLOGI
Bab ini menjelaskan tentang metode yang digunakan serta tahap-tahap dalam melakukan penelitian ini.
BAB IV PERANCANGAN DAN PENGUJIAN
Bab ini menjelaskan tentang proses perancangan dan pengujian sistem dari metode yang digunakan untuk menyelesaikan permasalahan penelitian yang sudah didapatkan pada rumusan masalah.
BAB V HASIL DAN PEMBAHASAN
Bab ini membahas tentang penjabaran hasil penelitian, akurasi metode yang digunakan, serta analisis hasil dari klasifikasi pada objek penelitian.
BAB VI PENUTUP
Bab ini menjelaskan kesimpulan dari hasil yang diperoleh dan menjawab semua masalah utama yang dirancang dan saran untuk penyelidikan lebih lanjut terhadap tema terkait dengan menjabarkan keterbatasan pada penelitian ini.
BAB 2
TINJAUAN PUSTAKA DAN LANDASAN TEORI
2.1. Twitter
Twitter adalah situs jejaring sosial yang memungkinkan pengguna untuk mengirim dan menerima tweet beberapa karakter. Sejak diluncurkan pada tahun 2006, Twitter telah berkembang menjadi salah satu jaringan media sosial yang paling banyak digunakan di seluruh dunia. Banyak orang mengungkapkan pendapat mereka tentang kehidupan sehari-hari mereka, masalah sosial/nasional/internasional yang berbeda, dan lain-lain. Mereka membagikan pandangan mereka dalam teks 140 karakter dan terkadang juga berbagi berkas audio/video. Istilah dalam Twitter untuk kegiatan berbagi tersebut adalah tweet yang bersifat publik. Orang lain dapat menyukai kiriman, mengomentarinya. Orang bisa saling follow atau bisa berteman satu sama lain di Twitter. Tidak seperti kebanyakan jejaring media sosial lainnya, Twitter mengizinkan satu tautan arah, yang berarti satu pengguna dapat mengikuti pengguna lain tanpa pengguna terakhir membalas komunikasi. Interaksi ini mengarah pada jaringan komunikasi (Sailunaz
& Alhajj, 2019).
Twitter juga berkontribusi secara signifikan terhadap penyebaran informasi penting, berita, tren, dan opini secara real-time. Twitter sering digunakan untuk debat publik, pemantauan merek atau produk, kampanye sosial, politik, dan inisiatif pemasaran. Twitter adalah cara lain yang cepat dan mudah bagi masyarakat dunia untuk mendapatkan berita dan informasi terkini. Twitter secara signifikan mempengaruhi politik, bisnis, dampak sosial, dan budaya populer. Pengguna dapat berinteraksi dengan orang-orang dari seluruh dunia dan mengambil bagian dalam dialog global dan acara global real-time dengan memanfaatkan kemampuannya.
2.1.1. Glosarium Twitter
Glosarium ini mencakup beberapa istilah dasar yang sering digunakan dalam konteks Twitter. Berikut beberapa istilah yang sering digunakan yang berkaitan dengan Twitter:
1. Tweet: pesan 140–280 karakter yang dikirim oleh pengguna Twitter.
2. Retweet (RT) adalah tindakan mengirimkan tweet orang lain ke pengikutnya. Retweet memungkinkan individu untuk berbagi konten dari orang lain dengan audiens pengguna sendiri.
3. Like: Tindakan menandai tweet dengan memberikan dukungan pengguna atau menyukainya. biasanya disebut "favorit" dan memiliki ikon hati untuk menunjukkannya.
4. Hashtag (#) digunakan untuk menyorot kata atau subjek tertentu dalam tweet. Akibatnya, tweet dapat ditemukan dan dikelompokkan di bawah subjek yang sama dengan tweet lain yang juga menggunakan tagar yang sama.
5. Mention (@) digunakan untuk menyebutkan pengguna Twitter lain dalam tweet dengan menyisipkan tanda "@" di depan nama pengguna mereka. Hal ini memungkinkan pengguna yang disebutkan untuk melihat tweet dan dapat pemberitahuan yang dikirim ke akun mereka.
2.1.2. Tweepy
Tweepy adalah pustaka Python yang berguna untuk ekstraksi data dari Twitter API. Tweepy memungkinkan pengambilan data yang tepat dengan mencari melalui kata kunci, hashtag, timeline, tren, atau lokasi geografis (Prakash Pokharel, 2020). Tweepy digunakan untuk berkomunikasi dengan API Twitter. Tweepy menawarkan antarmuka pemrograman sederhana untuk mendapatkan akses ke berbagai fitur dan data yang disediakan Twitter melalui API-nya. Tweepy memudahkan untuk merancang aplikasi yang menggunakan Twitter API. Library ini menawarkan fitur bawaan dan memanfaatkan autentikasi OAuth untuk melindungi akses ke API Twitter. Tweepy menawarkan berbagai fitur tambahan yang dapat digunakan untuk berinteraksi dengan Twitter API lebih lanjut, termasuk mengambil informasi pengguna, mengekstrak tweet berdasarkan kata kunci, mengirim pesan langsung (Direct Message), dan
lainnya. Pengembang cukup menggunakan fitur Twitter dalam program Python mereka dengan memanfaatkan Tweepy.
2.2. Sumber Data dan Metode Pengumpulan Data
Data primer adalah data yang didapatkan dari sumber data pertama, yang dapat berasal dari subjek penelitian (Chaudhri et al., 2021). Pengumpulan data primer melibatkan pengumpulan informasi dari sumber asli langsung oleh penulis.
Data primer adalah informasi yang belum pernah dikumpulkan sebelumnya dan langsung dikumpulkan oleh penulis untuk alasan penelitian tertentu. Penulis dapat merancang pengumpulan data primer yang terstruktur, valid, dan dapat dipercaya.
Dalam penelitian ini, penulis menggunakan API Twitter untuk memperoleh data sehingga data tweet yang diperoleh diambil secara langsung dan tidak mengubah struktur atau isi data sehingga data dapat dipercaya dan valid.
2.3. Emoji
Danesi (2017) menjelaskan bahwa emoji berasal dari istilah Jepang yang berarti "gambar" dan "huruf", dan fungsinya adalah untuk meningkatkan kualitas pesan dan menekankan makna dalam percakapan. Emoji dirancang untuk menutupi ketidakmampuan komunikasi tertulis dalam menyampaikan nada suara, ekspresi, gerak tubuh, dan postur. Dengan demikian, Emoji dapat membantu menjembatani kesenjangan antara komunikasi tertulis dan tatap muka, serta membantu pembaca memahami maksud penulis melalui penggunaan visual yang menggambarkan berbagai ekspresi wajah (Arafah & Hasyim, 2019). Rezabek dan Cochenour (1998) berpendapat bahwa emoji adalah petunjuk visual yang dibuat dari tipografi simbol yang khas untuk menyampaikan sentimen atau emosi.
2.4. Kontraksi
Kontraksi adalah kata-kata pendek yang diucapkan dan ditulis dengan lebih santai daripada tertulis yang sering kali digunakan oleh pengguna internet untuk mengurangi jumlah karakter. Dalam kontraksinya, tanda kutip digunakan sebagai pengganti satu atau lebih huruf yang hilang (Naseem et al., 2021). Karena
merupakan tanda yang sangat kuat, apostrof (‘) atau tanda kutip adalah satu-satunya tanda yang digunakan dalam Bahasa Inggris untuk kata-kata kontraksi, baik kontraksi afirmatif maupun kontraksi negatif. Sehingga menjadikannya komponen yang sangat penting dalam kalimat Bahasa Inggris (Quirk, 1989).
2.5. Ekstraksi Fitur
Ekstraksi fitur adalah teknik yang lebih luas yang tujuannya adalah untuk menciptakan transformasi subruang berdimensi rendah dari ruang masukan yang mempertahankan sebagian besar data terkait. Teknik ekstraksi dan pemilihan fitur diterapkan secara tunggal atau kombinasi untuk meningkatkan metrik kinerja termasuk perkiraan akurasi, pemahaman pengetahuan yang dipelajari, dan visualisasi. Proses pengurangan dimensi ruang fitur tanpa mengorbankan informasi aslinya disebut ekstraksi fitur, atau reduksi dimensi. Ketidakmampuan untuk menafsirkan kombinasi linier dari fitur asli dan seringnya hilangnya informasi mengenai kontribusi relatif dari fitur asli merupakan kelemahan ekstraksi fitur.
(Khalid, 2014).
2.6. Praproses Teks
Praproses teks adalah langkah pertama dalam klasifikasi teks yang menyiapkan data teks untuk digunakan pada langkah selanjutnya. Proses ini akan meningkatkan data teks untuk menyediakan teks yang berkualitas tinggi yang disiapkan untuk digunakan dalam proses selanjutnya (Khairunnisa et al., 2021a).
Untuk membuat teks mentah lebih terstruktur, lugas, dan cocok untuk analisis atau pemrosesan tambahan, praproses teks berupaya membersihkan dan mengubahnya sehingga analisis teks menjadi lebih akurat, berkualitas lebih tinggi, dan menghasilkan hasil yang lebih mendalam dari data teks yang dipelajari. Tahap- tahap praproses teks dalam penelitian ini seperti berikut:
1. Case Folding (Lowercase)
Alasan utama untuk mengubah huruf besar kecil teks menjadi huruf kecil semua adalah untuk memastikan bahwa kata-kata seperti "Halo" dan
"halo" tidak membingungkan karena merupakan kata yang sama. Hal ini
membantu menurunkan jumlah kata yang harus diproses kamus pada satu waktu (Mothe et al., 2019).
2. Representasi Emoji
Ada berbagai metode untuk menggunakan emoji dalam kalimat dan tweet. Emoji bisa muncul di awal atau akhir tweet. Mereka dapat dikelompokkan bersama dalam tweet tanpa spasi atau muncul sebagai bagian dari grup emoji yang dipisahkan oleh spasi.
Penulis menggunakan modul Emoji untuk mengubah emoji menjadi teks yang sesuai. Contohnya seperti emoji “ ” yang diubah menjadi teks
“face with tears of joy” yang kemudian direpresentasikan menjadi sebuah teks “laugh”.
3. Representasi Kontraksi
Kata-kata kontraksi negatif atau negasi seperti "don’t", "can't", dan kata- kata serupa lainnya yang muncul bersamaan untuk membentuk kalimat mengubah orientasi teks menjadi polaritas yang berbeda sangat penting untuk mengklasifikasikan sentimen. Peneliti menerapkan singkatan untuk kata kunci pendek seperti "don’t", "can’t", "n’t" menjadi "do not", "cannot",
"not". untuk mencerminkan efek negasi, yang mengubah sentimen tweet (Keerthi Kumar & Harish, 2018). Selain kata negasi, terdapat kata kontraksi afirmatif seperti “I’m”, “He’s”, “you’re” dan lainnya yang juga direpresentasikan menjadi bentuk lengkapnya menjadi “I am”, “he is”, dan
“you are”. Lalu kata-kata tren atau slang word juga direpresentasikan ke dalam maksud sebenarnya atau bentuk lengkapnya, seperti “lol” menjadi
“laughing out loud”.
4. Cleaning
Cleaning adalah proses menghilangkan tanda baca, angka, simbol, tautan URL, dan nama pengguna dari teks (Khairunnisa et al., 2021b). Selain itu penulis juga menghilangkan tanda retweet yang biasanya terdapat dalam sebuah tweet hasil dari memposting kembali tweet dari orang lain yang terdapat di awal teks, seperti “RT @Nimitiwari” menjadi “@Nimitiwari”.
5. Stopword Removal
Stopwords adalah kata-kata yang paling sering terlihat di tweet, seperti
"a", "all", "am", "an", "and", "any", "are", dan sebagainya. Kami menghapus istilah bahasa Inggris ini karena tidak benar-benar menambahkan apapun ke sentimen tweet (Keerthi Kumar & Harish, 2018).
6. POS Tagging
Untuk menghindari kesalahan terkait stemming dan lematisasi, POS Tagging melibatkan penandaan token atau kata-kata sesuai dengan bagian ucapannya (Anandarajan et al., 2019).
Menetapkan label tata bahasa untuk setiap kata dalam dokumen menggunakan Part-of-Speech (POS) Tagging adalah teknik pemrosesan bahasa alami. Label atau tag ini mengidentifikasi bagian dari kata tersebut, seperti fungsinya sebagai kata benda, kata kerja, kata sifat, atau kata keterangan.
7. Lematisasi
Mirip dengan proses stemming, lematisasi menghasilkan akar kata atau bentuk kamus (Mothe et al., 2019). Lematisasi adalah teknik yang digunakan dalam pemrosesan bahasa alami yang berupaya mereduksi kata menjadi tenses atau bentuk yang paling mendasar, yang sering dikenal sebagai "lemma". Lematisasi, yang mereduksi kata menjadi bentuk paling dasar, digunakan dalam analisis sentimen untuk meningkatkan konsistensi dan akurasi hasil.
2.7. Analisis Sentimen
Analisis sentimen mengotomatiskan ekstraksi atau klasifikasi sentimen dari ulasan menggunakan analisis teks, Natural Language Processing (NLP), dan pendekatan komputasi. Beberapa industri, termasuk informasi konsumen, pemasaran, publikasi, aplikasi, situs web, dan media sosial, telah menerbitkan analisis pemikiran dan sikap ini (Hussein, 2018).
Data yang disimpan dalam format teks dianalisis menggunakan analisis sentimen. Informasi tekstual dapat berbentuk ulasan konsumen, keluhan, komentar, percakapan, dan tweet media sosial. Dengan meningkatnya koneksi online yang
dibawa oleh media sosial, sejumlah besar data dihasilkan setiap hari (Satuluri Vanaja & Meena Belwal, 2018).
2.8. Latent Semantic Analysis (LSA)
Latent Semantic Analysis (LSA) yang diusulkan oleh Landauer (1998).
adalah salah satu model penyisipan kata pertama yang diperkenalkan dan menghasilkan hasil yang memuaskan dalam tugas kesamaan makna kata. Model penyematan kata yang lebih baru termasuk Word2vec, GloVe dan fastText (Agarwal et al., 2020). Latent Semantic Analysis (LSA), juga disebut sebagai Latent Semantic Index, mempertahankan metode penentuan kesamaan antara istilah dan dokumen yang ditunjukkan oleh vektor ruang dengan menggunakan sudut antara vektor ruang dalam model ruang vektor konvensional. Selain itu, kata-kata dan teks dipetakan lebih lanjut ke dalam ruang semantik laten, ditambah dengan penambangan semantik yang mendasarinya dan subjek laten di bawah permukaan teks dan dokumen, meningkatkan efektivitas pencarian informasi (Han et al., 2020).
Latent Semantic Analysis (LSA) adalah metode untuk pengurangan dimensi dan menangkap struktur semantik laten (tersembunyi) dalam kumpulan teks besar yang digunakan dalam pemrosesan bahasa alami. Dalam penelitian ini, LSA digunakan untuk mendapatkan wawasan tentang organisasi semantik dari data teks berupa vektor semantik laten yang ditampilkan dalam ruang dimensi yang lebih rendah.
2.9. Term Frequency-Inverse Document Frequency (TF-IDF)
Term frequency-inverse document frequency, sering dikenal sebagai TF- IDF, adalah teknik yang banyak digunakan untuk menentukan signifikansi kata dalam teks. Rasio kemunculan istilah dalam teks terhadap jumlah kata keseluruhannya digunakan untuk menentukan frekuensi frasa (Ahuja et al., 2019).
2.6.1. TF
(Avinash & Sivasankar, 2019) Term frequency menghitung berapa kali frasa tertentu (t) muncul dalam suatu dokumen (d). Dengan membagi
frekuensi frasa (t) dalam sebuah dokumen dengan jumlah total istilah dalam dokumen tersebut, Term frequency ditentukan. Berikut formula TF:
TF(t, d) = Jumlah frasa t muncul dalam dokumen d (2.1) 2.6.2. IDF
TF hanya menghitung frekuensi frasa. Terminologi tertentu, seperti stopword, sering digunakan tetapi mungkin tidak membantu. Untuk mengukur signifikansi frasa, Inverse Document Frequency (IDF) digunakan. IDF lebih menekankan pada istilah yang jarang muncul dalam dokumen d. Rumus IDF adalah:
IDF(t) = log Jumlah total keseluruhan dokumen
Jumlah total dokumen dengan frasa 𝑡 di dalamnya
(2.2) Nilai akhir fras dalam dokumen d ditentukan sebagai berikut:
TF – IDF(t, d) = TF(t, d) × IDF(t) (2.3)
2.10. Decision Tree
Karena kemudahan penggunaan, interpretasi, dan efisiensi dalam tugas klasifikasi, Decision Tree (DT) adalah metode Machine Learning yang umum digunakan dalam penelitian analisis sentimen. DT dapat digunakan dalam analisis sentimen untuk mengkategorikan data teks ke dalam kategori dengan sentimen positif, negatif, atau netral tergantung pada fitur yang diekstraksi dari teks. DT adalah algoritma yang menggunakan pohon untuk meramalkan hasil instance. Pada intinya, sebuah node tes yang menghitung hasil tergantung pada nilai atribut dari sebuah instance, dimana setiap hasil potensial terhubung ke subpohon tertentu.
Mulai dari simpul akar pohon, proses klasifikasi untuk sebuah instans dimulai. Jika simpul akar adalah pengujian, hasil dari contoh diprediksi ke salah satu subpohon, dan proses berlanjut hingga simpul daun ditemukan; dalam hal ini, label dari node daun memberikan prediksi kelas dari instance (Guia et al., 2019).
2.11. Naïve Bayes
Naive Bayes adalah jenis Machine Learning yang melakukan perhitungan probabilitas menggunakan ide metode Bayesian. Algoritma Naive Bayes menerapkan teorema Bayes dengan menggabungkan probabilitas sebelumnya dan
probabilitas bersyarat dalam sebuah formula yang dapat digunakan untuk menentukan kemungkinan dari setiap kemungkinan kategorisasi (Bayhaqy et al., 2018). Metode ini adalah pengklasifikasi probabilistik yang dibangun di atas teori Bayes yang unggul dalam tugas klasifikasi teks seperti analisis sentimen. Istilah
"naive" mengacu pada asumsi yang dibuat oleh Naïve Bayes bahwa fitur (kata atau token) dalam input data adalah kondisional independen yang diberi label kelas.
2.12. Logistic Regression
Logistic Regression adalah algoritma klasifikasi Machine Learning yang digunakan untuk memprediksi probabilitas variabel dependen kategori. Dalam Logistic Regression, variabel dependen adalah variabel biner yang berisi data berkode 1 (ya) atau 0 (tidak). Metode ini adalah metode regresi linier umum untuk mempelajari pemetaan dari sejumlah variabel numerik ke variabel biner atau probabilistik (Hasanli & Rustamov, 2019).
Metode analisis prediktif yang digunakan untuk masalah kategorisasi adalah Logistic Regression. Metode ini didasarkan pada gagasan probabilitas. "Fungsi Sigmoid" yaitu fungsi biaya yang lebih rumit yang digunakan dalam Logistic Regression. Fungsi biaya sering dibatasi pada kisaran 0 dan 1 sesuai dengan hipotesis Logistic Regression. Dengan input vektor bilangan bulat frekuensi kata, fungsi LogisticRegression() memperkirakan ketepatan kategorisasi sentimen (Poornima. A & K. Sathiya Priya, 2020).
2.13. Stochastic Gradient Descent
Stochastic Gradient Descent (SGD) adalah algoritma pengoptimalan tidak adaptif klasik yang digunakan untuk mengoptimalkan jaringan pembelajaran mendalam yang menggunakan laju pembelajaran tunggal yang tidak berubah selama pelatihan (Rhanoui et al., 2019).
Metode Stochastic Gradient Descent digunakan untuk menghitung kesalahan pada setiap node untuk memperbarui bobot dan bias dalam jaringan untuk mengurangi kesalahan pelatihan. Pengulangan proses ini berlanjut hingga
keluaran akhir sesuai dengan hasil yang diharapkan, dan kesalahan pelatihan diminimalkan ke tingkat yang memadai (Kaur et al., 2021).
2.14. Singular Value Decomposition (SVD)
Singular Value Decomposition (SVD), adalah metode reduksi dimensi ampuh yang digunakan untuk ekstraksi fitur dalam berbagai tugas Machine Learning, termasuk analisis sentimen. SVD dapat digunakan dalam konteks penelitian analisis sentimen untuk mengubah ruang fitur berdimensi tinggi dari data teks menjadi representasi berdimensi lebih rendah dengan tetap mempertahankan detail dan pola yang paling penting.
SVD adalah salah satu teknik ekstraksi fitur yang cocok untuk ruang fitur berdimensi tinggi (Orkphol & Yang, 2019). SVD mengekstrak fitur paling penting yang berkorelasi kuat dengan data. SVD menguraikan matriks M menjadi produk dari tiga matriks. M adalah matriks n × m, U adalah matriks kotak n, ∑ adalah matriks diagonal n × matriks kesatuan m, dan V* adalah matriks kotak m × matriks kesatuan m. Matriks U mengukur korelasi antar kolom matriks M. Matriks V mengukur korelasi antar baris matriks M. U dan V keduanya memberikan urutan korelasi penting menurut matriks M:
M = U∑V* (2.4)
Nilai-nilai sepanjang matriks diagonal ∑ disebut nilai singular (σ). Nilai singular ini dalam urutan menurun dari faktor-faktor penting yang berkontribusi pada matriks M, σ1 ≥ σ2 ≥ … ≥ σm ≥ 0. Perkalian U∑V* akan sama dengan penjumlahan matriks peringkat-1 m, σ1𝑢1
𝑣
1∗ + σ2𝑢2𝑣
2∗ + … + σ𝑚𝑢𝑚𝑣
𝑚∗ . M dapat didekati dengan memilih suku k pertama dari penjumlahan sebelumnya, ukuran matriks yang didekati M adalah n × k. Matriks M sekarang terpotong menjadi ruang fitur berdimensi lebih rendah yang siap untuk pengelompokan. Normalisasi matriks M akan mengubah perilaku jarak Euclidean menjadi mirip dengan jarak kosinus secara otomatis.2.15. Python
Python adalah bahasa komputer tingkat tinggi yang memungkinkan pemrograman berorientasi objek. Python berbeda dengan bahasa pemrograman lain terutama dalam penulisan sintaksisnya (Duei Putri et al., 2022). Python memiliki sintaks yang mudah dipahami. Oleh karena itu, Python adalah bahasa pemrograman tingkat tinggi yang mudah digunakan (Pasek et al., 2022). Dalam bahasa pemrograman terdapat library atau pustaka modul yang digunakan untuk melakukan analisis data. Berikut library yang digunakan dalam penelitian ini:
1. Tweepy
Pustaka Python bernama Tweepy digunakan untuk mengakses API Twitter. Tweepy memiliki akses ke Twitter API dan dapat menggunakan skrip Python untuk mengambil data dari Twitter (Duei Putri et al., 2022).
2. Pandas
Pustaka pandas adalah perangkat analisis dan manipulasi data yang populer untuk Python yang menawarkan struktur dan fungsi data untuk bekerja dengan data terstruktur.
3. NLTK
Natural Language Toolkit (NLTK) adalah pustaka Python yang menawarkan sumber daya, alat, dan modul untuk bekerja dengan data bahasa manusia (teks dan ucapan). NLTK adalah perpustakaan yang luas dan kuat untuk analisis teks dan operasi Natural Language Processing (NLP).
4. RE (Regular Expression)
Pustaka re (regular expression) Python adalah modul yang kuat untuk bekerja dengan ekspresi reguler. Ekspresi reguler (regex atau regexp) adalah rangkaian karakter yang menentukan pola pencarian. Modul ini digunakan untuk manipulasi teks, ekstraksi data, dan pencocokan pola di dalam string.
5. Contractions
Pustaka contractioins Python adalah pustaka utilitas ringkas yang menawarkan metode sederhana untuk memperluas kontraksi dalam teks Bahasa Inggris. Kontraksi adalah versi singkatan kata atau frasa yang dibuat dengan menggabungkan dua kata dan menambahkan apostrof pada
beberapa huruf. Kontraksi "can’t" dari "cannot", "won't" dari "will not", dan
"I'll" adalah contoh umum dari "I will". Mengubah versi yang disingkat ini kembali ke kata atau kalimat aslinya yang utuh dikenal sebagai kontraksi yang meluas.
6. Emoji
Pustaka emoji Python adalah modul yang menawarkan metode mudah dan praktis untuk mengintegrasikan emoji ke dalam program Python. Emoji adalah gambar atau simbol visual kecil yang digunakan dalam pesan teks untuk mewakili perasaan, objek, atau ide. Emoji kini menjadi komponen penting dari media sosial, SMS di perangkat seluler, pesan online, dan bentuk komunikasi digital lainnya.
7. Matplotlib
Pustaka Python Matplotlib digunakan untuk menghasilkan visualisasi statis, animasi, dan interaktif dalam berbagai bentuk. Modul ini berfungsi sebagai alat penting untuk analisis data, penelitian ilmiah, dan presentasi data karena menawarkan perangkat serbaguna dan ekstensif untuk visualisasi data.
8. Scikit-learn
Pustaka scikit-learn Python populer dalam hal pembelajaran mesin (Machine Learing) dan aktivitas ilmu data, biasa disebut juga dengan sklearn. Modul ini menawarkan perangkat yang mudah dan efektif untuk berbagai aplikasi pembelajaran mesin, seperti klasifikasi, regresi, pengelompokan, pengurangan dimensi, pemilihan model, dan prapemrosesan data.
9. Pickle
Objek Python dapat dibuat serial dan deserialized menggunakan pustaka pickle. Objek Python diubah menjadi aliran byte melalui proses serialisasi, yang kemudian dapat disimpan ke file atau berkas, dikirimkan melalui jaringan, atau disimpan dalam database. Prosedur sebaliknya, yang dikenal sebagai deserialisasi, mengubah aliran byte kembali menjadi objek Python.
Fungsi utama Pickle adalah menyimpan objek Python dan memuatnya nanti sambil mempertahankan struktur dan statusnya.
10. Seaborn
Perangkat visualisasi data Python Seaborn, yang didasarkan pada Matplotlib, menawarkan antarmuka tingkat tinggi untuk menghasilkan visual statistik yang berguna dan menarik. Hal ini sangat berguna untuk memeriksa korelasi dalam kumpulan data besar dan memvisualisasikan kumpulan data yang kompleks. Pembuatan plot statistik umum menjadi lebih mudah dengan Seaborn, yang juga memberikan kemungkinan penyesuaian tingkat lanjut.
2.16. XAMPP
XAMPP merupakan paket PHP yang dibangun berbasis open source.
XAMPP adalah rangkaian perangkat lunak yang mengintegrasikan sejumlah program terpisah menjadi satu. Beberapa program yang terdapat dalam paket tersebut adalah Apache, MySQL, PHP, FileZilla FTP Server, phpMyAdmin, dan program lainnya (Safitri, 2018).
Berikut program yang digunakan dalam penelitian ini:
1. Apache
Apache adalah salah satu server web yang paling banyak digunakan secara global. Program ini berfungsi untuk menyajikan halaman web dan konten lainnya ke sisi klien (biasanya browser web) melalui protokol HTTP dan HTTPS.
2. PHP
PHP adalah bahasa pemrograman web yang biasanya digunakan untuk mengolah data di internet. PHP juga dapat diartikan sebagai bahasa pemrograman yang berjalan di sisi server web yang open source dan gratis.
PHP adalah skrip sisi server yang digabungkan dengan HTML (Sari et al., 2022).
2.17. Literatur Sejenis
Penulis melakukan studi literatur sejenis untuk digunakan sebagai referensi dan pembekalan dalam penelitian yang akan dilakukan. Dan juga sebagai perbandingan perbedaan penelitian yang dilakukan oleh peneliti sebelumnya dengan yang akan dilakukan oleh penulis. Literatur yang digunakan oleh penulis berasal dari beberapa jurnal, paper, karya ilmiah dan karya publikasi lainnya dalam.
Berikut tabel perbandingan penelitian penulis dengan beberapa penelitian sebelumnya yang sejenis.
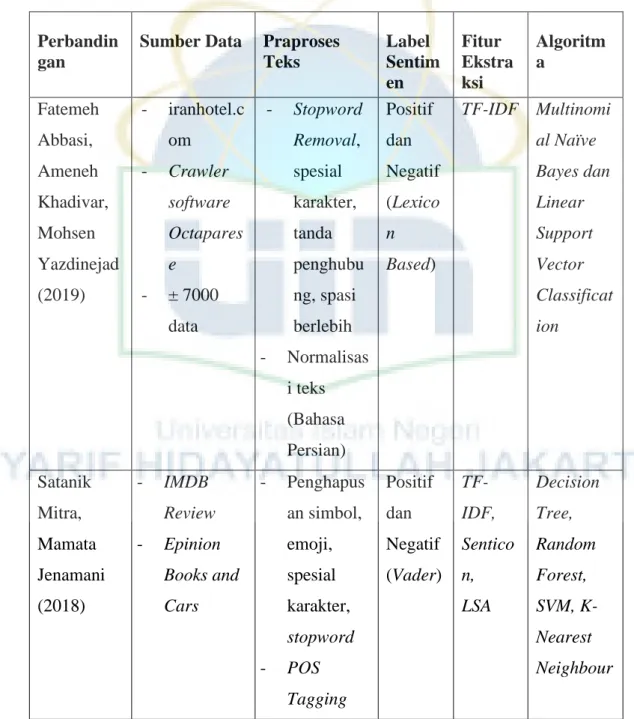
Tabel 2. 1 Perbandingan Penelitian Penulis dengan Penelitian Sebelumnya Perbandin
gan
Sumber Data Praproses Teks
Label Sentim en
Fitur Ekstra ksi
Algoritm a
Fatemeh Abbasi, Ameneh Khadivar, Mohsen Yazdinejad (2019)
- iranhotel.c om - Crawler
software Octapares e
- ± 7000 data
- Stopword Removal, spesial karakter, tanda penghubu ng, spasi berlebih - Normalisas
i teks (Bahasa Persian)
Positif dan Negatif (Lexico n Based)
TF-IDF Multinomi al Naïve Bayes dan Linear Support Vector Classificat ion
Satanik Mitra, Mamata Jenamani (2018)
- IMDB Review - Epinion
Books and Cars
- Penghapus an simbol, emoji, spesial karakter, stopword - POS
Tagging
Positif dan Negatif (Vader)
TF- IDF, Sentico n, LSA
Decision Tree, Random Forest, SVM, K- Nearest Neighbour
Kashfia Sailunaz, Reda Alhajj (2019)
- Twitter (API Twitter) - 7246 tweet
- Hapus emoji, URL, pengulanga n karakter, non- alfanumeri k
- Tokenisasi - Stopword
Removal - POS
Tagging
Positif, Negatif, Netral
- Naïve
Bayes, SVM, Random Forest
M.
Avinash, E.
Sivasankar (2019)
- Movie review (1500 data)
- UCI repository (2000 data) -
cs.cornell.edu -
ai.stanford.edu
- Tokenisasi - Stopword
Removal
Positif dan Negatif
TF- IDF, Doc2Ve c
Logistic Regressio n, SVM- rbf, SVM- linear, KNN, Decision Tree, Naïve Bayes- Bernoulli
Saurav Pradha, Malka N.
Halgamuge , Nguyen
- Twitter - GetOldTwe
ets3 (API Twitter)
- Case Folding - Hapus
mention, URL, tanda
Positif, Negatif dan Netral
- Deep
Learning, Naïve Bayes, Support
Tran Quoc Vinh (2019)
hubung, hashtag, spasi berlebih - Tokenisasi - Hapus kata
berformat yang tidak bermakna - Stopword Removal - Stemming,
Lemmatiza tion, Spelling Correction
(Textbl ob)
Vector Machine
Fazriansya h (2023)
- Twitter - 5359 tweet - Tweepy
(API Twitter)
- Case Folding - Representa
si emoji - Representa
si
kontraksi - Cleaning
(hapus retweet, URL, hashtag, mention, angka, spesial
Sangat negatif, negatif, netral, positif dan sangat positif (Vader)
TF- IDF, LSA (SVD)
Decision Tree, Logistic Regressio n, Naïve Bayes, Stochastic Gradient Descent
karakter, tanda hubung, ruang kosong, dan karakter berulang pada akhir kata - Tokenisasi - Stopword
Removal - POS
Tagging dan
Lematisasi
Berdasarkan perbandingan pada Tabel 2.1, penulis melakukan analisis studi literatur dari beberapa perbandingan penelitian sebelumnya dengan penelitian yang penulis akan lakukan. Penulis merangkum perbandingan tersebut seperti dalam Gambar 2.1.
Tabel 2. 2 Perbandingan penellitian penulis dengan penelitian sebelumnya
Untuk lebih rincinya, berikut penjelasan dari Tabel 2.2:
1. Dari kelima penelitian sebelumnya, terdapat dua penelitian yang menggunakan data yang berasal dari Twitter yaitu penelitian Saurav Pradha dan Kashfia Sailunaz. Dari kedua penelitian tersebut, penelitian Kashfia Sailunaz menggunakan web scraper sedangkan Saurav Pradha menggunakan tool Getoldtweets3. Penulis menggunakan data dari Twitter dengan tool tweepy karena dapat mengambil data secara real- time serta dengan fitur filter dalam query pencarian tweet penulis dapat mengambil data yang lebih fleksibel dan spesifik.
2. Dari kelima penelitian sebelumnya, terdapat berbagai macam praproses teks yang dilakukan namun terdapat beberapa perbedaan dengan yang dilakukan oleh penulis, yaitu representasi emoji dan representasi kontraksi. Penelitian sebelumnya hanya menghilangkan emoji yang terdapat dalam teks, sedangkan penulis melakukan representasi emoji ke bentuk teks seperti “ ” menjadi laugh yang berarti tertawa dan
sebagainya. Juga merepresentasi negasi atau kontraksi seperti “don’t”
menjadi “do not”, “haven’t” menjadi “have not” dan sebagainya.
3. Dari kelima penelitian sebelumnya, hampir semuanya menggunakan 3 kelas atau label yaitu positif, negatif, dan netral. Sedangkan penulis membagi ke dalam 5 kelas yaitu sangat negatif, negatif, netral, positif dan sangat positif.
4. Dari kelima penelitian sebelumnya, hanya satu penelitian yang menggunakan ekstraksi fitur dengan TF-IDF dan LSA yaitu penelitian Satanik Mitra. Namun dalam penelitiannya hanya menggunakan algoritma Decision Tree, Random Forest, Support Vector Machine dan K-NN. Penulis menggunakan Decision Tree karena berdasarkan penelitian yang dilakukan menghasilkan akurasi tertinggi dibanding Random Forest, SVM dan K-NN yaitu sebesar 80.32%, lalu penulis menambahkan algoritma machine learning yang lain seperti Naïve Bayes, Logistic Regression, Stochastic Gradient Descent untuk digunakan sebagai klasifikasi sentimen dalam menggunakan fitur ekstraksi LSA.
BAB 3
METODOLOGI PENELITIAN
3.1. Desain Penelitian
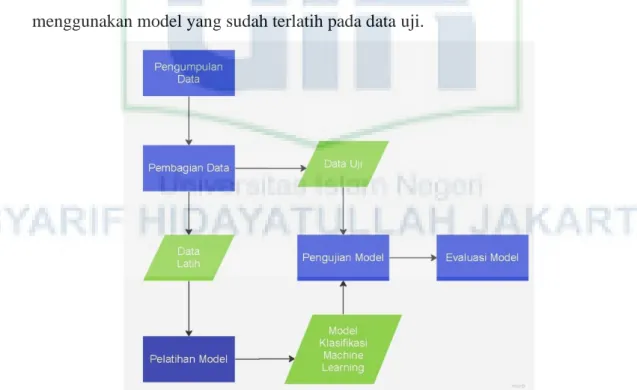
Gambar 3. 1 Desain Penelitian
Desain penelitian merupakan tahap-tahap yang akan dilakukan penulis dalam penelitian. Tahapan penelitian dijabarkan dalam bentuk Gambar 3.1. Berikut penjelasannya:
1. Mengumpulkan data menggunakan API Twitter membutuhkan autentikasi agar dapat mengakses API tersebut. Penulis melakukan pendaftaran akun Twitter ke halaman situs web https://developer.twitter.com/ sebagai akun pengembang untuk mendapatkan consumer_key, consumer_secret, access_token, dan access_token_secret lalu memasukan data itu untuk dapat mengakses API Twitter dengan modul Tweepy Library.
2. Menentukan keyword atau kata kunci yang berkaitan dengan objek penelitian yang di dalam penelitian ini adalah Singapore Airlines. Kata kunci yang sudah ditentukan yaitu “Singapore Airlines”,
@SingaporeAir, dan #FlySQ.
3. Mencari tweet dengan kata kunci sebagai input query. pencarian tweet menggunakan search_tweets dan beberapa parameter tertentu untuk menyesuaikan data agar lebik spesifik.
4. Melakukan praproses teks pada tweet untuk membuat teks menjadi lebih terstruktur dan berkualitas tinggi dalam melakukan proses selanjutnya.
5. Pelabelan kelas sentimen setiap tweet dilakukan dengan berbasis aturan (Rule-Based) menggunakan sentiment analyzer pada library Vader.
Lalu tweet dianalisis dan menghasilkan nilai polaritas yang kemudian diklasifikasikan menjadi lima kelas yaitu sangat negatif, negatif, netral, positif, dan sangat positif dengan rentang nilai polaritas -1 sampai 1 dengan jarak skor polaritas tiap kelas 0.4.
6. Data kemudian dibagi menjadi dua untuk proses selanjutnya dengan pembagian 80% data latih dan 20% data uji.
7. Pelatihan model algoritma Machine Learnimg menggunakan data latih sebagai input yang dilakukan ekstraksi fitur menggunakan TF-IDF dan LSA sebagai konversi teks ke bentuk numerik matriks. Kemudian
dilakukan pengujian atau testing model dengan data uji sebagai input.
Hasil pengujian model kemudian dievaluasi lalu model klasifikasi sentimen disimpan untuk dilakukan analisis selanjutnya.
8. Klasifikasi sentimen data praproses tweet dengan sentimen asli menggunakan model yang telah disimpan sebeumnya. Mengevaluasi kinerja model dalam mengklasifikasi seluruh data dengan mengukur nilai akurasi, recall, precision, dan f1-score. Kemudian memvalidasi hasil klasifikasi dengan confusion matrix untuk mengetahui jumlah kesalahan klasifikasi sentimen tweet hasil klasifikasi menggunakan model dengan sentimen yang asli.
3.2. Metode Penelitian
Metode penelitian yang digunakan oleh penulis dalam penelitian ini adalah metode klasifikasi dengan model Machine Learning dengan penggunaan Latent Semantic Analysis (LSA) sebagai ekstraksi fitur. Penelitian sebelumnya oleh Satanik Mitra dan Mamata Jenamani pada tahun 2018 yang menggunakan metode Decision Tree, Random Forest, Support Vector Machine (SVM), dan K-Nearest Nighbour (K-NN) yang mana hasil dari penelitian tersebut membuktikan bahwa penggunaan LSA sebagai ekstraksi fitur pada algoritma Decision Tree lebih unggul dengan nilai akurasi sebesar 77.04% dibandingkan dengan algoritma Random Forest sebesar 60.65%, SVM sebesar 70.49%, dan K-NN sebesar 65.57%.
Berdasarkan penelitian yang dilakukan oleh Huseyn Hasanli dan Samir Rustamov pada tahun 2020 yang menggunakan Metode Logistic Regression, SVM dan Naïve Bayes dengan ekstraksi fitur Bag-of-Words (BoW) menghasilkan akurasi yang tinggi yaitu masing-masing sebesar 93% untuk Logistic Regression, SVM sebesar 93% dan Naïve Bayes sebesar 94%. Pada penelitian yang dilakukan oleh Sara Ashour Aljuhani dan Norah Saleh Alghamdi pada tahun 2019 yang membandingkan metode Naïve Bayes, Logistic Regression dan Stochastic Gradient Descent (SGD) untuk analisis sentimen menggunakan ekstraksi fitur BoW menghasilkan akurasi masing-masing Logistic Regression sebesar 77.47%, Naïve Bayes sebesar 74.9% dan SGD sebesar 76.05%. Oleh karena itu penulis