TESIS – KS185411
PERAMALAN HARGA MINYAK MENTAH INDONESIA MENGGUNAKAN ENSEMBLE EMPIRICAL MODE
DECOMPOSITION (EEMD) DAN LONG SHORT TERM MEMORY (LSTM)
NUCHAILA AINIYAH NRP.6003211017
Dosen Pembimbing:
Prof. Dr.rer.pol. Heri Kuswanto, M.Si Dr. Dra. Kartika Fithriasari, M.Si
Program Magister Departemen Statistika
Fakultas Sains Dan Analitika Data Institut Teknologi Sepuluh Nopember 2023
TESIS – KS185411
DPERAMALAN HARGA MINYAK MENTAH INDONESIA MENGGUNAKAN ENSEMBLE EMPIRICAL MODE
DECOMPOSITION (EEMD) DAN LONG SHORT TERM MEMORY (LSTM)
NUCHAILA AINIYAH NRP.6003211017
Dosen Pembimbing:
Prof. Dr.rer.pol. Heri Kuswanto, M.Si Dr. Dra. Kartika Fithriasari, M.Si
Program Magister Departemen Statistika
Fakultas Sains Dan Analitika Data Institut Teknologi Sepuluh Nopember 2023
THESIS – KS185411
FORECASTING OF INDONESIAN CRUDE OIL PRICE USING ENSEMBLE EMPIRICAL MODE
DECOMPOSITION (EEMD) AND LONG SHORT TERM MEMORY (LSTM)
NUCHAILA AINIYAH NRP.6003211017
Supervisors:
Prof. Dr.rer.pol. Heri Kuswanto, M.Si Dr. Dra. Kartika Fithriasari, M.Si
Master Program
Department of Statistics
Faculty of Science and Data Analytics Institut Teknologi Sepuluh Nopember 2023
i
PERAMALAN HARGA MINYAK MENTAH INDONESIA MENGGUNAKAN ENSEMBLE EMPIRICAL MODE DECOMPOSITION (EEMD) DAN LONG SHORT TERM
MEMORY (LSTM)
Nama : Nuchaila Ainiyah
NRP : 6003211017
Pembimbing : Prof. Dr.rer.pol. Heri Kuswanto, M.Si Co-Pembimbing : Dr. Dra. Kartika Fithriasari, M.Si
ABSTRAK
Minyak mentah merupakan salah satu komoditas yang memegang peranan sangat penting dalam semua perekonomian. Dampak langsung dari naik turunnya harga minyak mentah adalah perubahan biaya-biaya operasional. Perkembangan harga minyak mentah Indonesia akhir-akhir ini mengalami tren sepanjang awal Mei 2020, maka hal tersebut menyebabkan grafik harga minyak mentah mengalami fluktuatif. Tujuan penelitian ini adalah melakukan peramalan harga minyak mentah Indonesia dengan menggunakan Ensemble Empirical Mode Decompostion (EEMD) dan Long Short Term Memory (LSTM). Metode tersebut digunakan untuk mengurangi kesulitan pada peramalan dan meningkat nilai akurasi pada prediksi.
Data harga minyak mentah Indonesia didekomposisikan menjadi beberapa Intrinsic Mode Function (IMF) menggunakan metode EEMD. Hasil IMF kemudian dilakukan peramalan menggunakan LSTM dan menjumlahkan hasil peramalan setiap komponen IMF. Penelitian ini menunjukkan hasil peramalan menggunakan metode EEMD-LSTM mendapatkan hasil yang lebih baik dibandingkan dengan metode LSTM tanpa menggunakan EEMD dengan hasil nilai MAPE dan RMSE terkecil.
Kata kunci : EEMD, Harga Minyak Mentah, IMF, LSTM.
ii
iii
FORECATING OF INDONESIAN CRUDE OIL PRICE USING ENSEMBLE EMPIRICAL MODE DECOMPOSITION (EEMD)
AND LONG SHORT TERM MEMORY (LSTM)
Name : Nuchaila Ainiyah
NRP : 6003211017
Supervisor : Prof. Dr.rer.pol. Heri Kuswanto, M.Si Co- supervisor : Dr. Dra. Kartika Fithriasari M.Si.
ABSTRACT
The Crude oil is one of the commodities that play a very important role in all economies. The direct impact of rising crude oil prices is a change in operating costs. The development of Indonesian crude oil prices recently experienced a trend throughout the beginning of 1 May 2020, which caused the crude price chart to fluctuate. This research aims to make predictions of Indonesian crude oil prices using Ensemble Empirical Mode Decomposition (EEMD) and Long Short Term Memory. (LSTM). These methods are used to reduce the difficulty of predicting and increase the accuracy of predictions. Indonesia’s crude oil price data is compounded into several Intrinsic Mode Functions (IMF) using the EEMD method.
The IMF results were then predicted using the LSTM and summarized the forecast heights of each IMF component. This study showed that predictions using the EEMD-LSTM method obtained better results compared to the LSTM without using the MAPE and RMSE results.
Keywords : EEMD, Crude Price Oil, IMF, LSTM.
iv
v
KATA PENGANTAR
Puji syukur penulis panjatkan kehadirat Allah SWT yang telah melimpahkan segala rahmat dan hidayah-Nya, sehingga penulis dapat menyelesaikan Tesis yang berjudul : “Peramalan Harga Minyak Mentah Indonesia Menggunakan Ensemble Empirical Mode Decompostion (EEMD) – Long Short Term Memory (LSTM)”.
Selama proses penyusunan Tesis ini, penulis dapat menyelesaikan dengan baik dan lancar tidak lepas dari adanya bantuan berbagai pihak. Oleh karena itu, dengan penuh hormat, ketulusan, dan rendah hati, penulis ingin mengucapkan terima kasih kepada :
1. Ibu Dr. Dra. Kartika Fithriasari, M.Si. selaku Kepala Departemen Statistika FSAD, Bapak Dr.rer.pol. Dedy D Prastyo, M.Si Selaku Kepala Program Studi Pasca Sarjana Statistika, Ibu Santi Wulan Purnami, M.Si., Ph.D. selaku Sekretaris Departemen I (Bidang Akademik, Kemahasiswaan, Penelitian dan Pengabdian Kepada Masyarakat) dan Ibu Dr. Vita Ratnasari, M.Si. selaku Sekretaris Departemen II (Bidang Sumber Daya Keuangan, Sumber Daya Manusia, dan Sarana Prasarana) yang telah menyediakan fasilitas untuk menyelesaikan Tesis ini.
2. Bapak Prof. Dr.rer.pol. Heri Kuswanto, M.Si selaku dosen pembimbing I dan Ibu Dr. Kartika Fithriasari, M.Si. selaku dosen pembimbing II yang telah meluangkan waktu, mengarahkan, membimbing dengan sabar dan memberikan dukungan yang sangat besar bagi penulis dalam menyelesaikan Tesis.
3. Bapak Prof. Nur Iriawan, M.Ikom, Ph.D. dan Bapak Dr. Muhammad Ahsan, S.Si. selaku dosen penguji yang telah memberikan masukan dan saran untuk kesempurnaan Tesis.
4. Bapak Prof. Dr.rer.pol. Heri Kuswanto, M.Si. selaku dosen wali yang telah memberikan nasehat, motivasi dan bimbingan selama ini.
5. Seluruh dosen Statistika ITS yang telah memberikan ilmu dan pengetahuan selama belajar di Departemen Statistika ITS.
6. Kedua Orangtua dan saudara penulis yang selalu memberikan doa, kasih sayang, serta dukungan dalam menyelesaikan Tesis.
vi
7. Semua pihak yang turut memberikan dukungan dan penulis baik secara langsung maupun tidak langsung yang tidak dapat penulis sebutkan satu persatu.
Semoga tesis yang penulis susun dapat bermanfaat dan mampu digunakan sebagaimana mestinya. Penulis menyadari apabila pembuatan tesis ini masih jauh dari kesempurnaan, besar harapan dari penulis untuk menerima kritik dan saran yang berguna untuk perbaikan di masa mendatang. Serta tidak lupa penulis memohon maaf apabila terdapat banyak kekurangan dalam tesis yang telah penulis susun. Atas perhatian dan dukungannya penulis sampaikan ucapan terima kasih.
Surabaya, Januari 2023
Penulis
vii
DAFTAR ISI
LEMBAR PENGESAHAN TESIS ... i
ABSTRAK ... i
ABSTRACT ... iii
KATA PENGANTAR ... v
DAFTAR ISI ... vii
DAFTAR TABEL ... ix
DAFTAR GAMBAR ... xi
DAFTAR LAMPIRAN ... xiii
BAB I PENDAHULUAN ... 1
1.1 Latar Belakang ... 1
1.2 Rumusan Masalah ... 5
1.3 Tujuan Penelitian... 5
1.4 Manfaat Penelitian... 5
1.5 Batasan Masalah ... 6
BAB II TINJAUAN PUSTAKA ... 7
2.1 Time Series ... 7
2.2 Forecasting ... 7
2.3 Empirical Mode Decomposition... 8
2.4 Ensemble Empirical Mode Decomposition ... 10
2.5 Recurrent Neural Network ... 11
2.6 Long Short Term Memory ... 12
2.7 Uji Linieritas Terasvirta ... 19
2.8 Pengukuran Nilai Error ... 20
2.9 Minyak Mentah ... 21
BAB III METODOLOGI PENELITIAN ... 23
3.1 Sumber Data ... 23
3.2 Analisis Model EEMD-LSTM ... 23
3.3 Analisis Model LSTM ... 25
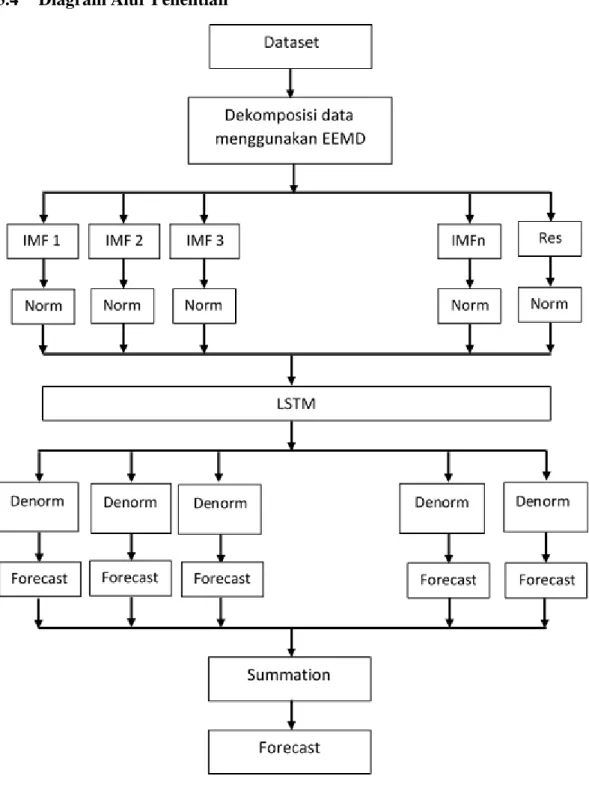
3.4 Diagram Alur Penelitian... 27
BAB IV ANALISIS DAN PEMBAHASAN ... 31
viii
4.1. Karakteristik Data ... 31
4.2. Uji Stasioneritas Data ... 32
4.3. Dekomposisi Data dengan EEMD ... 33
4.4. Peramalan dengan LSTM ... 40
4.5. Perbandingan Kebaikan Model... 42
BAB V KESIMPULAN DAN SARAN ... 43
5.1 Kesimpulan ... 43
5.2 Saran ... 43
DAFTAR PUSTAKA ... 45
BIODATA PENULIS ... 47
LAMPIRAN ... 49
ix
DAFTAR TABEL
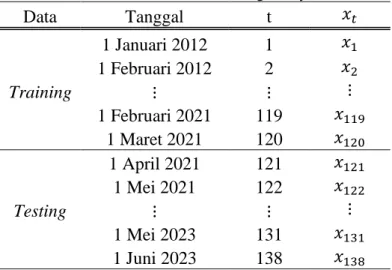
Tabel 3.1 Struktur Data Penelitian Harga Minyak Mentah ... 23
Tabel 4.1 Uji ADF Data Harga Minyak Mentah ... 32
Tabel 4.2 Uji Terasvirta Data Harga Minyak Mentah ... 32
Tabel 4.3 Hasil Pelatihan LSTM Tiap IMF ... 37
Tabel 4.4 Deskriptif Komponen IMF ... 39
Tabel 4.5 Perbandingan Nilai Akurasi Model ... 42
x
(Halaman ini sengaja dikosongkan)
xi
DAFTAR GAMBAR
Gambar 2.1 Ilustrasi Sifting Processes ………...8
Gambar 2.2 Arsitektur RNN ... 11
Gambar 2.3 Perbedaan Arsitektur RNN dan LSTM ... 12
Gambar 2.4 Arsitektur LSTM ... 13
Gambar 2.5 Bagian – bagian LSTM ... 14
Gambar 2.6 Forget Gate LSTM ... 14
Gambar 2.7 Input Gate LSTM ... 15
Gambar 2.8 Cell State LSTM ... 16
Gambar 2.9 Output Gate LSTM... 17
Gambar 3.1 Diagram Alir EEMD-LSTM ... 27
Gambar 3.2 Diagram Alir LSTM ... 28
Gambar 3.3 Diagram Alir Perbandingan EEMD-LSTM dan LSTM ... 29
Gambar 4.1 Time Series Plot Harga Minyak Mentah Indonesia ... 31
Gambar 4.2 Dekomposisi Harga Minyak Mentah Periode Bulanan ... 33
Gambar 4.3 Plot IMF 1 dan IMF 1 yang dinormalisasi ... 34
Gambar 4.4 Plot IMF 2 dan IMF 2 yang dinormalisasi ... 34
Gambar 4.5 Plot IMF 3 dan IMF 3 yang dinormalisasi ... 35
Gambar 4.6 Plot IMF 4 dan IMF 4 yang dinormalisasi ... 35
Gambar 4.7 Plot IMF 5 dan IMF 5 yang dinormalisasi ... 35
Gambar 4.8 Plot IMF 6 dan IMF 6 yang dinormalisasi ... 35
Gambar 4.9 Plot IMF 7 dan IMF 7 yang dinormalisasi ... 36
Gambar 4.10 Plot Residual dan Residual yang dinormalisasi ... 36
Gambar 4.11 Perbandingan Data Testing dan Data Training ... 38
Gambar 4.12 Hasil Peramalan dengan EEMD-LSTM ... 39
Gambar 4.13 Plot Data Asli dan Data dinormalisasi... 40
Gambar 4.14 Plot Hasil Peramalan Training dengan LSTM ... 41
Gambar 4.15 Plot Hasil Peramalan Testing dengan LSTM ... 41
xii
(Halaman ini sengaja dikosongkan)
xiii
DAFTAR LAMPIRAN
Lampiran 1. Data Penelitian ... 49
Lampiran 2. Augmented Dickey Fuller (ADF) Test ... 51
Lampiran 3. Hasil Output Parameter Bobot EEMD-LSTM ... 52
Lampiran 4. Syntax EEMD-LSTM ... 61
Lampiran 5. Syntax EEMD_LSTM IMF ... 63
Lampiran 6. Syntax LSTM ... 76
xiv
(Halaman ini sengaja dikosongkan)
1
BAB I
PENDAHULUAN
1.1 Latar Belakang
Indonesia memiliki sumber daya alam yang begitu banyak dalam bidang perkebunan atau pertanian dan salah satu yang menjadi sumber daya alam yang tidak dapat diperbarui adalah minyak. Minyak di Indonesia paling banyak komoditasnya adalah minyak yang berasal dari kelapa sawit . Indonesia adalah salah satu negara yang berperan sebagai penghasil minyak mentah di dunia walaupun tidak sebesar peran dari negara – negara yang berasal dari Timur Tengah.
Di dunia perdagangan minyak mentah adalah hal yang setiap negara selalu melakukannya karena minyak adalah komoditas penting di dunia ini. Untuk menjaga keseimbangan harga minyak dan suplai minyak untuk negara – negara di dunia dibentuklah OPEC. Organization of the Petroleum Exporting Countries (OPEC) adalah organisasi yang berisi negara – negara anggota yang membuat kebijakan untuk melakukan suplai dalam perdagangan minyak mentah dunia hal ini membuat harga minyak dunia menjadi tidak stabil dan cenderung semakin tinggi. Kenaikan harga minyak mentah dapat dipengaruhi oleh tiga hal yaitu faktor fundamental, faktor non fundamental dan pengaruh dari kebijakan OPEC.
Minyak mentah adalah sumber energi yang paling banyak digunakan baik dalam industri maupun ekonomi, memberikan sekitar 33% dari total konsumsi energi dunia pada tahun 2019, menurut International Energy Agency (IEA) (Haque, 2021). Meskipun energi terbarukan menjadi fokus di bidang industri dan teknologi saat ini, ada biaya yang harus dikeluarkan masih cukup tinggi. Hal ini disebabkan keterbatasan ketersediaan teknologi yang mendukung energi terbarukan. Apalagi mesin dan peralatan yang menggunakan energi terbarukan masih dalam skala kecil sehingga membatasi penggunaannya energi terbarukan, dan efisiensi energi terbarukan masih kurang karena masih belum mampu transportasi, penyimpanan, dan teknologi untuk mencapainya. Hingga saat ini, minyak mentah masih memiliki pangsa terbesar konsumsi sumber energi utama dunia (Cherief dkk, 2021).
2
Sebagai sumber energi utama, minyak mentah sangat penting karena hampir semua bidang industri di setiap negara memiliki ketergantungan terhadap minyak mentah dalam menjalankan kegiatan produksi dan transportasinya (Singhal dkk, 2019). Kenaikan harga minyak mentah yang tiba-tiba dapat berdampak langsung atau tidak langsung terhadap pertumbuhan ekonomi, ketika harga sumber energi meningkat, permintaan akan turun, ini akan menyebabkan lapangan kerja dan PDB (Produk Domestik Bruto) pertumbuhan menjadi menurun, sehingga meningkatkan tingkat inflasi (Charfeddine dkk, 2020). Berbagai faktor mempengaruhi ketidakstabilan di harga minyak mentah. Dalam tren jangka panjang, harga dipengaruhi oleh penawaran dan permintaan, dan tren jangka pendek dipengaruhi oleh faktor ekonomi (Peng dkk, 2020). Oleh karena itu, prediksi harga minyak mentah yang akurat adalah besar dan tantangan penting karena dapat membantu membuat penganggaran dan perencanaan ekonomi yang lebih baik, terutama selama Pandemi COVID-19. Harga minyak mentah selama wabah COVID-19 mengalami penurunan yang signifikan penurunan yang membuat pasar minyak sangat fluktuatif. Hal ini membuat prediksi harga minyak menjadi sangat penting, yang mana dapat membantu memantau pergerakan pasar untuk menghindari kerugian besar (Sa’adah dkk, 2020).
Dengan mengenali karakteristik yang nonlinier dan kompleks dari sistem harga minyak mentah Indonesia, maka dibutuhkan metode peramalan yang sesuai, salah satunya adalah metode dekomposisi. Metode dekomposisi dapat membedakan atau memisahkan masing-masing komponen dari pola dasar yang ada. Pemisahan seperti itu seringkali dapat membantu meningkatkan ketepatan peramalan dan membantu pemahaman atas perilaku deret data secara lebih baik.
Metode dekomposisi biasanya mencoba memisahkan ketiga komponen terpisah dari pola dasar yang cederung mencirikan deret data ekonomi dan bisnis.
Komonen tersebut adalah faktor trend (kecenderungan), siklus, dan musiman (Makridakis dkk., 1999).
Banyak dipertimbangkan faktor-faktor yang mempengaruhi harga minyak mentah. Terlepas dari permintaan dan penawarannya, harga minyak mentah sangat dipengaruhi oleh peristiwa politik, efek subsitusi energi baru, tingkat indeks saham
3
nilai tukar terutama impor minyak atau negara pengekspor dan banyak hal(Basher dkk, 2018) Semua faktor di atas menyebabkan kompleksitas dan ketidakteraturan pasar minyak mentah. Jadi, beberapa penelitian mencari metode peramalan yang lebih baik untuk meningkatkan akurasi.
Berbagai model peramalan telah banyak dieksplorasi untuk meramalkan perubahan harga minyak mentah dari model statistik hingga model yang memanfaatkan algoritma pembelajaran. Algoritma pembelajaran yang mampu membangun model optimal dan memiliki performa yang handal adalah Deep learning. Deep Learning adalah salah satu bagian dari machine learning. Yang dalam penerapannya deep learning memiliki beberapa layer informasi yang jenisnya non-linier. Algoritma deep learning yang dapat digunakan salah satunya yaitu Long Short Term Memory (LSTM). LSTM merupakan turunan dari Recurrent Neural Network (RNN) yang terbukti berhasil digunakan untuk prediksi data time series (Wiranda & Sadikin, 2019). Peramalan harga minyak mentah telah dilakukan sebelumnya oleh (Lee, Shuhaida, Aida, dan Mohd, 2020) dengan menggunakan model yang mempetimbangkan metode Support Vector Machine (SVM), Artificial Neural Network (ANN) dan EMD-SVM. Hasil analis diketahui bahwa kinerja EMD-SVM lebih unggul daripada metode (ANN) dan SVM. Selain itu (Lihong dan Jun, 2020) telah melakukan peramalan dengan model hybird Ensemble Empirical Mode Decomposition (EEMD) dengan E-STERNN, ST-ERNN dan ERNN. Hasil yang didapatkan E-STERNN lebih baik dibandingkan dengan yang lain. (Hou, dkk.
2012) melakukan penelitian dengan generalized autoregressive conditional heteroscedasticity (GARCH) untuk meramalkan haga minyak mentah. (Murat dkk, 2009) telah melakukan penelitian peramalan pergerakan harga minyak dengan crack spread futures, dan model Vector Autoregressive (VAR) untuk peramalakan harga minyaktelah dilakukan (Lanza dkk, 2005), banyak diterapkan pada peramalan harga minyak mentah, peramalan produksi minyak menggunakan EEMD-LSTM yang telah dilakukan oleh (Wei dkk, 2020) telah diterapkan pada penelitiannya dengan menggunakan ANN, SVM dan LSTM. Dimana hasil yang lebih optimal dengan nilai MAPE yang terkecil menggunakan LSTM.
Beberapa Beberapa metode berbasis data mengandalkan data observasi historis untuk memprediksi karakteristik data dan hubungan antara input dan output
4
model. Metode berbasis data telah banyak digunakan dan telah mencapai hasil yang sangat baik. Wu dkk. (2005) mengembangkan model jaringan syaraf tiruan (JST) dan berhasil menerapkannya pada peramalan arus jangka pendek. Nanda dkk.
(2016) menggunakan model linear autoregressive moving average untuk meramalkan banjir dengan periode ramalan 1–3 hari (Ahmadi et al., 2019) menggunakan model ANN secara harian, bulanan, dan tahunan di DAS Kan yang terletak di Teheran barat, Iran. Metode peramalan berbasis data tertentu, seperti JST, sistem inferensi fuzzy berbasis jaringan adaptif, dan metode mesin vektor pendukung mengasumsikan bahwa deret aliran aliran stabil, yang bertentangan dengan kenyataan dan menyebabkan nilai yang disimulasikan menyimpang dari yang diamati (Adamowski et al. , 2014).
Untuk mengatasi masalah ketidakstabilan deret limpasan dan meningkatkan akurasi simulasi model, banyak penelitian menggunakan Ensemble Empirical Mode Decomposition (EEMD) untuk memproses deret limpasan dan mendekomposisi deret asli yang tidak stasioner menjadi tren dengan beberapa sub deret yang stabil.
Metode ini telah banyak digunakan dalam kombinasi dengan metode berbasis data dalam beberapa tahun terakhir. Tan dkk. (2018) menggunakan model EEMD-ANN untuk meramalkan limpasan bulanan di tiga stasiun di Ertan, Cuntan, dan Yichang.
Wang dkk. (2020) menggunakan ANN dan SVR untuk meregresi rangkaian aliran bulanan yang diuraikan oleh EEMD menurut indeks iklim. Metode EMD secara inovatif memperkenalkan “fungsi mode intrinsik” berdasarkan karakteristik lokal dari sinyal, yang membuat frekuensi seketika bermakna. Ini membuatnya cocok untuk proses stasioner nonlinier dan linier (Huang et al., 1998). Zhao dkk. (2017) menggunakan metode EMD untuk menguraikan limpasan tahunan; mereka secara efektif meningkatkan akurasi simulasi model Chaotic Least Squares Support Vector Machine. Berdasarkan EMD, metode EEMD memperbaiki fenomena aliasing modal EMD dengan menambahkan white noise. Yu dkk. (2018) menggabungkan metode EEMD dengan jaringan syaraf radial basis function (RBF) dan model autoregression (AR) untuk meramalkan limpasan tahunan, yang secara efektif meningkatkan akurasi simulasi kedua model tersebut.
Menggabungkan EEMD dan metode berbasis data untuk prediksi rangkaian data telah dipelajari secara ekstensif di berbagai bidang, tetapi hanya sedikit
5
penelitian yang menggabungkan metode EEMD dan Long Short Term Memory (LSTM) atau menggunakan metode gabungan ini untuk melakukan prediksi.
Peramalan harga minyak mentah Indonesia merupakan salah satu cara yang berguna untuk memprediksi harga minyak mentah Indonesia dimasa mendatang.
Peramalan harga minyak mentah Indonesia yang dapat dilakukan dengan menentukan metode peramalan yang efektif untuk dapat mengetahui pola harga minyak mentah Indonesia yang akan datang. Penelitian ini dilakukan dengan tujuan mengkaji penerapan metode dekomposisi lainnya yaitu Ensemble Empirical Mode Decomposition (EEMD) yang diintegrasikan dengan Long short Term Memory (LSTM) untuk peramalan data runtun waktu harga emas dunia dan membandingkan ketepatan peramalannya dengan menggunakan model EEMD-LSTM dan LSTM.
1.2 Rumusan Masalah
Diagram Berdasarkan latar belakang penelitian yang telah dijelaskan sebelumnya, maka peramalan harga minyak mentah Indonesia dapat menggunakan model EEMD-LSTM dan LSTM untuk mengurangi kesulitan dalam pemodelan dan untuk meningkatkan akurasi prediksi. Oleh karena itu, dalam penelitian ini dapat dirumuskan suatu permasalahan yaitu bagaimana karakteristik pergerakan harga minyak mentah Indonesia dan bagaimana perbandingan hasil model peramalan menggunakan metode EEMD-LSTM dan LSTM.
1.3 Tujuan Penelitian
Berdasarkan rumusan masalah yang telah diuraikan, tujuan yang ingin dicapai dalam penelitian ini adalah sebagai berikut.
1. Memperoleh hasil peramalan pada data harga minyak mentah periode bulanan dengan model peramalan EEMD-LSTM dan LSTM.
2. Memperoleh perbandingan hasil akurasi dari peramalan data harga minyak mentah Indonesia dengan model peramalan EEMD-LSTM dan LSTM.
1.4 Manfaat Penelitian
Manfaat yang ingin dicapai dari hasil penelitian ini adalah sebagai berikut.
1. Bagi Investor
6
Membantu dalam pengambilan keputusan investasi dengan memiliki informasi yang akurat tentang peramalan harga minyak mentah, investor dapat membuat keputusan investasi yang lebih baik. Investor dapat menggunakan peramalan harga minyak mentah untuk menentukan kapan harus membeli atau menjual saham perusahaan energi atau perusahaan yang terkait dengan industri minyak dan gas.
2. Bagi Akademisi
Meningkatkan pengetahuan tentang metode peramalan melalui proses peramalan, akademisi dapat mempelajari metode-metode peramalan yang digunakan dan menguji keakuratan dari setiap metode tersebut. Hal ini dapat meningkatkan pemahaman tentang kelebihan dan kekurangan dari masing- masing metode peramalan.
3. Bagi Masyarakat Umum
Mengetahui perkiraan harga minyak mentah: Dengan melakukan peramalan harga minyak mentah Indonesia, masyarakat umum dapat mengetahui perkiraan harga minyak mentah di masa depan. Hal ini dapat membantu mereka dalam merencanakan keuangan dan mengambil keputusan yang tepat dalam hal investasi atau pengeluaran.
1.5 Batasan Masalah
Batasan masalah diperlukan agar permasalahan pada penelitian tidak meluas.
Batasan masalah dari peramalan harga minyak mentah Indonesia yang akan dibuat adalah data harga emas dunia yang diambil dari website Kementrian Energi dan Sumber Daya Mineral dan data yang digunakan dalam penelitian ini adalah harga minyak mentah Indonesia periode bulanan dari 1 Januari 2012 hingga 31 Desember 2022.
7
BAB II
TINJAUAN PUSTAKA
2.1 Time Series
Time series merupakan salah satu tipe dalam metode peramalan kualitatif.
Time series merupakan serangkaian pengamatan terhadap suatu peristiwa, atau kejadian yang terjadi dari waktu ke waktu dengan interval yang sama. Waktu yang digunakan dapat berupa hari, bulan, dan tahun (Pandji et al., 2019). Hasil dari pengamatan yang dikumpulkan secara berkala pada sebuah variabel waktu tertentu menghasilkan relasi antara waktu dan kebutuhan yang dapat digunakan untuk memprediksi kebutuhan di masa yang akan datang yaitu dengan mempelajari dan melihat bagaimana variabel dapat berubah dari waktu kewaktu (Pangestu et al., 2018). Oleh karena itu untuk memilih suatu metode time series yang tepat harus mempertimbangkan pola data, agar metode yang digunakan dengan pola tersebut dapat diuji.
2.2 Forecasting
Forecasting atau peramalan merupakan sebuah teknik yang digunakan untuk melakukan perkiraan apa yang akan terjadi dimasa depan. Teknik ini memerlukan histori data kebelakang untuk diolah dan memproyeksikannya menjadi data yang akan terjadi dimasa depan menggunakan model matematika (A. Nasution, 2019).
Dapat disimpulkan bahwa dengan menggunakan metode atau teknik ini kita bisa mengetahui kira-kira apa yang akan terjadi di masa akan datang.
Pada metode forecasting terdapat 2 tipe pendekatan yaitu pendekatan kualitatif dan pendekatan kuantitatif.
1. Metode pendekatan kualitatif merupakan metode yang subjektif. Metode ini didasari atas data kualitatif pada masa lampau. Hasil yang didapatkan dalam pendekatan ini sangat tergantung pada pemikiran atau pola pikir orang yang menysun metode tersebut. Pemikiran ini biasanya didasari oleh hasil penelitian sebelumnya (Krisma et al., 2019).
2. Metode peramalan kuantitatif ini dibagi menjadi 2 jenis, yaitu kausal dan time series. Untuk kuantitatif, tipe kausal berhubungan dengan variabel dalam membuat prediksi seperti analisis regresi. Sedangkan untuk tipe time series
8
ini menggunakan kuantitatif, yang mana metode dengan tipe ini dipergunakan untuk menganalisis data histori masa lampau yang telah dikumpulkan secara urut berdasarkan tanggal atau waktu menggunakan teknik yang tepat.
Pengguanaan dan pemilihan metode yang berbeda menyebabkan hasil akhir yang berbeda. Hasil yang didapat juga bisa digunakan sebagai acuan untuk prediksi kejaian dimasa yang akan datang (Rahmad dkk., 2019).
2.3 Empirical Mode Decomposition
Empirical Mode Decomposition (EMD) merupakan metode untuk menguraikan serangkaian waktu menjadi sejumlah Intrinsic Mode Functions (IMFs) dan residu berdasarkan pemisahan skala (Huang, 1998). Skala didefinisikan sebagai jarak antara dua ekstrem lokal minimum atau maksimum yang berurutan.
EMD telah terbukti cukup fleksibel mengekstraksi sinyal dari data yang mempunyai karakteristik nonlinier dan nonstasioner. Trnka & Hofreiter (2011) menggunakan EMD ini untuk analisis data runtun waktu dengan hasil yang baik.
Gambar 2. 1 Ilustrasi sifting processes:(a) data asli (b) data dalam garis pada tipis, dengan upper envelop dan lower envelope dalam garis putus-putus dan rata-rata
dalam garis padat.
Algoritma EMD adalah sebagai berikut:
1. Identifikasi semua nilai lokal maksimum dan minimum dari data historis.
( a )
( b )
9
2. Tentukan upper envelope (E𝑢𝑝(𝑡)) dan lower envelope (E𝑙𝑜𝑤(𝑡)). Berdasarkan definsi IMF, metode dekomposisi dapat menggunakan envelopes yang ditentukan oleh lokal maksimum dan minimum secara terpisah. Setelah extrema diidentifikasi, semua lokal maksimum dihubungkan oleh garis cubic spline sebagai bagian upper envelope. Ulangi prosedur untuk lokal minimum untuk menghasilkan lower envelope. Upper dan lower envelope harus mencakup semua data.
3. Menghitung rata-rata dari upper envelope dan lower envelope dengan persamaan
𝑚1(𝑡) =𝐸𝑢𝑝(𝑡)+𝐸𝑙𝑜𝑤(𝑡)
2 (2.1) 4. Mengekstrak ℎ1(𝑡) sebagai proses pembentukan IMF antara data input deret
waktu 𝑥(𝑡) dan nilai rataan 𝑚1(𝑡)
ℎ1(𝑡) = 𝑥(𝑡) − 𝑚1(𝑡) (2.2) 5. Cek nilai ℎ1(𝑡) menggunakan kondisi berikut:
Pada seluruh deret data, jumlah extrema (penjumlahan maksimum dan minimum) dan jumlah deret data yang sama dengan nol (zero crossing) harus sama atau berbeda paling banyak 1.
Nilai mean untuk envelope yang diperoleh dari lokal maksimum dan minimum harus sama dengan nol pada setiap titik.
6. Apabila ℎ1(𝑡) bukan merupakan IMF, maka dilakukan sebanyak 𝑘 iterasi pada langkah 1-5 dengan menetapkan ℎ1(𝑡) sebagai data input 𝑥(𝑡) yang baru pada iterasi selanjutnya,
ℎ11(𝑡) = ℎ1(𝑡) − 𝑚11(𝑡) (2.4) Proses ini terus dilakukan hingga memenuhi kriteria pembentukan suatu IMF.
Apabila ℎ11(𝑡) merupakan suatu IMF setelah 𝑘 iterasi
ℎ1𝑘(𝑡) = ℎ1(𝑘−1)(𝑡) − 𝑚1𝑘(𝑡) (2.5) Maka IMF pertama tersebut ditetapkan sebagai.
ℎ1𝑘(𝑡) = 𝑐1(𝑡) (2.6)
7. Mengekstrak sisaan IMF
𝑟1(𝑡) = 𝑥(𝑡) − 𝑐1(𝑡) (2.7)
10
8. Memeriksa sisaan IMF sebagai suatu fungsi monoton (tidak memiliki nilai ekstrim). Jika sisaan IMF bukan fungsi monoton maka ulangi langkah 1-7 (sifting process) sebanyak i iterasi. Jika sisaan IMF termasuk fungsi monoton maka proses sifting dihentikan.
9. Sehingga didapatkan
𝑥(𝑡) = ∑ 𝑐𝑖(𝑡) + 𝑟𝑛 (2.8)
𝑛
𝑖=1
𝑟𝑖(𝑡) = 𝑟𝑖−1(𝑡) − 𝑐𝑖(𝑡)
Dimana 𝑟𝑛 adalah sisaan IMF. Dengan demikian, apabila nilai IMF 𝑐𝑖(𝑡) ditambahkan bersama-sama, maka data input deret waktu yang asli 𝑥𝑖(𝑡) akan terkontruksi kembali. IMF pada 𝑐1(𝑡), 𝑐2(𝑡), ⋯ , 𝑐𝑛(𝑡) sudah mencakup pita frekuensi yang berbeda mulai dari tinggi sampai rendah.
2.4 Ensemble Empirical Mode Decomposition
Ensemble Empirical Mode Decomposition (EEMD) adalah adalah metode analisis data deret waktu yang dilakukan dengan menambahkan sinyal white noise.
Dalam metode analisis data deret waktu EEMD, white noise ditambahkan untuk memungkinkan pemisahan skala deret waktu yang kontras, yang pada gilirannya, mengarah pada peningkatan efisiensi dekomposisi metode EMD. White noise yang dikenalkan terdiri dari komponen skala berbeda yang secara sistematis akan mengisi seluruh ruang frekuensi waktu. Komponen skala yang berbeda dari sinyal secara spontan diproyeksikan ke skala referensi yang tepat yang dibentuk oleh white-noise Gaussian, karena white noise yang didistribusikan secara sistematis diperkenalkan ke sinyal. karena semua komponen terdekomposisi dari white noise Gaussian yang diperkenalkan terdiri dari sinya dan white noise yang diperkenalkan, semua percobaan individu biasanya berakhir dengan hasil yang noise. Namun, white noise hampir sepenuhnya dapat dihilangkan dengan bantuan ensemble rata- rata dari keseluruhan percobaan, karena white noise di setiap percobaan adalah unik dalam percobaan yang berbeda (Wu dkk, 2009).
Algoritma EEMD adalah sebagai berikut:
1. Menambahkan ensembles white Gaussian noise 𝑤𝑛(𝑡) untuk input data 𝑓(𝑡) 𝑓𝑛(𝑡) = 𝑓(𝑡) + 𝑤𝑛(𝑡) (2.9)
11
2. Dekomposisi data noise 𝑓𝑛(𝑡) dengan standar EMD. Prosedur ini diulang beberapa kali dengan random noise yang dihasilkan untuk setiap percobaan.
3. Mengambil ensemble mean dari semua IMF yang dihasilkan.
𝑖𝑚𝑓(𝑡) = 1
𝑁∑ 𝑖𝑚𝑓𝑛(𝑡)
𝑁
𝑛=1
(2.10)
2.5 Recurrent Neural Network
Recurrent Neural Network (RNN) adalah salah satu jenis arsitektur jaringan saraf tiruan (JST) yang dalam prosesnya dipanggil berulang kali untuk memproses input data sekuensial (Firmansyah et al., 2020). RNN termasuk dalam salah satu kategori Deep Learning karena data yang diproses harus melalui banyak lapisan.
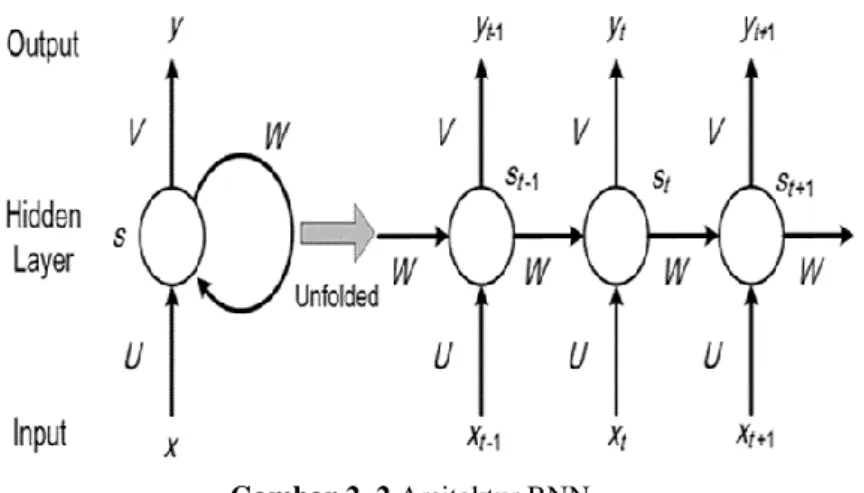
RNN telah mengalami kemjuan yang cukup pesat dan telah merevolusi bidang – bidang seperti NLP (Liu et al., 2016). Dalam setiap proses, output yang dihasilkan tidak hanya merupakan fungsi dari satu sampel itu saja, tetapi output yang dihasilkan juga berdasarkan state internal yang merupakan hasil dari pemrosesan sampel – sampel sebelumnya (Yogatama et al., 2017). Pemodelan RNN dapat menyelesaikan berbagai tugas kategorisasi kalimat dan dapat melakukan klasifikasi (Xia et al., 2018). Pada intinya RNN adalah jaringan syaraf tiruan yang menggunakan rekurensi dengan memanfaatkan data masa lalu.
Gambar 2. 2 Arsitektur RNN
Pada gambar 2.2 di atas, pada bagian arsitektur sebelah kiri menunjukkan bahwa RNN berada pada posisi yang tidak terbuka ke jaringan penuh. Sedangkan untuk arsitektur yang berada disebelah kanan menunjukkan bagian RNN yang telah
12
dibuka menjadi full network. Contohnya jika data yang dimasukkan berupa 1 kalimat dengan 3 kata, maka akan terdapat 3 layer Neural Network, satu layer untuk setiap kata. Berikut ini ialah keterangan simbol formula dari gambar di atas:
1. 𝑥𝑡 adalah input pada time step. Misalnya, 𝑥1 dapat menjadi one-hot vector yang sesuai dengan kata kedua dari sebuah kalimat yang sedang diproses.
2. 𝑠𝑡 adalah hidden state pada setiap time step t. Hidden state bisa disebut sebagai
“memory” dari sebuah network yang berfungsi menyimpan hasil perhitungan dan rekaman yang telah dilakukan. 𝑠𝑡 dihitung berdasarkan hidden state sebelumnya dan berdasarkan input pada current state (keadaan saat ini)
𝑠𝑡= 𝑓(𝑈𝑥𝑡+ 𝑊𝑠𝑡−1) (2.11) Fungsi f biasanya adalah non-linear seperti tanh atau ReLU. 𝑠𝑡−1 digunakan untuk menghitung hidden state yang pertama, biasanya pada inisialisasi selalu diawali dengan 0 (nol).
3. 𝑦𝑡 adalah output pada step t. Misalnya, jika kita ingin memprediksi “kata selanjutnya” pada sebuah kalimat, maka yt merupakan vektor probabilitas di seluruh kosakata dalam database yang kita miliki.
𝑦𝑡 = 𝑠𝑜𝑓𝑡𝑚𝑎𝑥(𝑉𝑠𝑡) (2.12) Satu permasalahan yang terdapat dalam arsitektur RNN adalah masalah hilangnya gradien (vanishing problem) pada proses backward pass. Cara yang cukup populer untuk mengatasi permasalahan ini ialah menggunakan unit RNN yaitu LSTM. LSTM diusulkan sebagai solusi untuk mengatasi terjadinya vanishing gradient pada RNN saat memproses data sequential yang panjang. Permasalahan vanishing gradient ini mengakibatkan RNN gagal dalam menangkap long term dependencies, sehingga mengurangi akurasi dari suatu prediksi pada RNN.
2.6 Long Short Term Memory
Long Short Term Memory (LSTM) merupakan salah satu jenis dari RNN dimana dilakukan modifikasi pada RNN dengan menambahkan memory cell yang dapat menyimpan informasi untuk jangka waktu yang lama (Aprian et al., 2020).
Metode ini diajukan oleh Sepp Hochreiter dan Jurgen Schimidhuber pada tahun 1927. RNN tidak dapat untuk belajar menghubungkan informasi karena memori lama yang tersimpan akan semakin banyak dan tidak berguna dengan seiring
13
berjalan waktu karena tertimpa atau tergantikan dengan memori yang baru, permasalahan ini ditemukan oleh Bengio, et al. (1994) (Arfan & ETP, 2019).
Gambar 2. 3 Perbedaan Arsitektur RNN dan LSTM
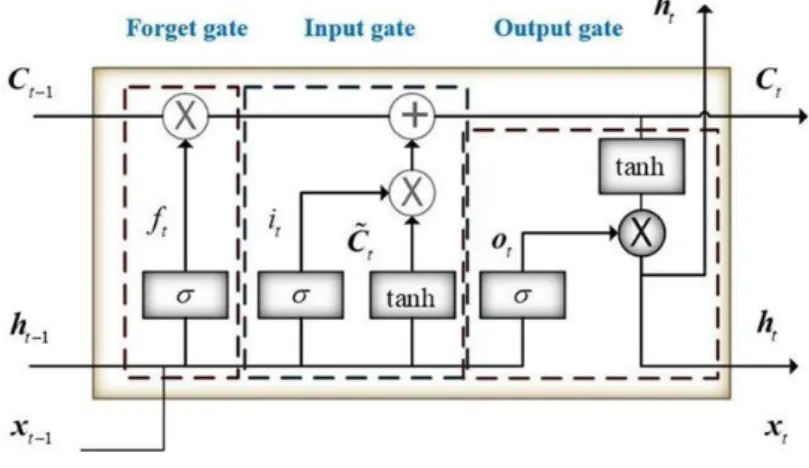
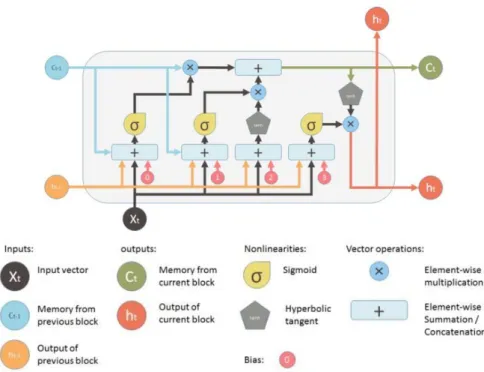
LSTM dapat mempelajari data mana yang dibutuhkan untuk diproses dan data mana yang tidak karena memiliki sistem gates di dalam nya. LSTM sendiri cocok digunakan pada teknologi pemrosesan video maupun teks, dan data time series (Wildan et al., 2018). Sebuah penelitian A New Method for Semantic Consistency Verification of Aviation Radiotelephony Communication Based on LSTM-RNN mengatakan bahwa LSTM berhasil diterapkan pada berbagai tugas sekuensial dan bahasa pemodelan (Wiranda & Sadikin, 2019). Arsitektur LSTM seperti gambar 2.2 dibawah memiliki gate seperti filter yang berfungsi untuk menghapus maupun menambahkan informasi.
Gambar 2. 4 Arsitektur LSTM
Pada gambar 2.4 diatas tergambar bentuk dari LSTM, pada gambar tersebut terdapat input gate, forget gate dan output gate. Dan pada gambar 2.5 merupakan
14
bagian dari masing – masing filter dari LSTM. Untuk memperjelas dalam pemahaman mengenai LSTM dapat dilihat pada gambar dibawah ini.
Gambar 2. 5 Bagian-bagian LSTM
Perhitungan dan penjelasan proses LSTM seperti penjelasan berikut:
a. Forget gate (𝑓𝑡)
Gerbang ini memutuskan apakah suatu informasi harus dibuang atau tidak dari cell state. Hasil output dari gerbang ini adalah angka antara 0 dan 1. Angka 1 menggambarkan bahwa informasi harus disimpan, sedangkan angka 0 sebaliknya, yaitu informasi sudah tidak dibutuhkan sehingga boleh dihapus.
Gambar 2. 6 Forget Gate LSTM
15
𝑓𝑡 = 𝜎(𝑊𝑓𝑥 ∙ 𝑥𝑡+ 𝑊𝑓ℎ∙ ℎ𝑡−1+ 𝑏𝑓) (2.13) Keterangan:
𝑓𝑡 : forget gate 𝜎 : Fungsi sigmoid
𝑊𝑓 : Bobot untuk nilai input pada waktu ke t 𝑥𝑡 :Input pada waktu ke t
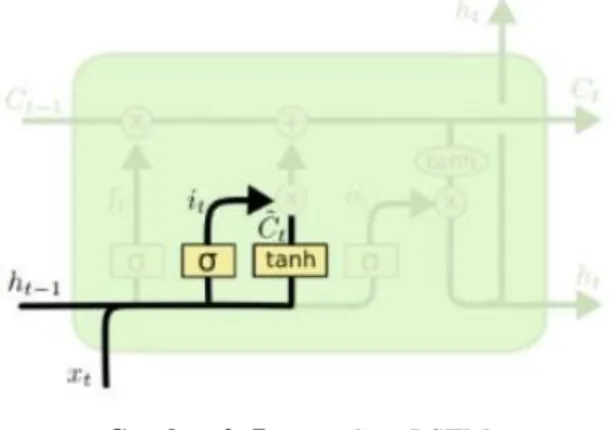
ℎ𝑡−1 : Output dari waktu ke t-1 𝑏𝑓 : bias pada forget gate b. Input gate (𝑖𝑡)
Secara kondisional, gerbang ini digunakan untuk menentukan sebuah masukan baru yang akan ditambahkan ke dalam memori cell state saat itu atau tidak (Zaman et al., 2019). Fungsi aktivasi sigmoid pertama, memutuskan nilai mana yang akan diupdate. Kemudian fungsi tanh, membuat vektor dari kandidat nilai yang baru, Ct, yang akan ditambahkan ke state. Kedua nilai dari fungsi aktivasi ini kemudian akan dikombinasikan menjadi nilai tambahan.
Gambar 2. 7 Input Gate LSTM
𝑖𝑡= 𝜎(𝑊𝑖𝑥∙ 𝑥𝑡+ 𝑊𝑖ℎ∙ ℎ𝑡−1+ 𝑏𝑖) (2.14) 𝐶̃𝑡 = tanh(𝑊𝑐𝑥∙ 𝑥𝑡+ 𝑊𝑐ℎ∙ ℎ𝑡−1+ 𝑏𝑐) (2.15) Keterangan:
𝑖𝑡 : Nilai input gate
16
𝜎 : Fungsi Sigmoid
𝑊𝑖 : Bobot untuk nilai input pada waktu ke t ℎ𝑡−1 : Nilai output dari waktu ke t-1
𝑥𝑡 : Nilai input pada waktu ke t 𝑏𝑖 : Bias pada input gate 𝐶𝑡 : Kandidat cell state
𝑡𝑎𝑛ℎ : Fungsi Hyperbolic tangent
𝑊𝑐 : Bobot untuk nilai input pada cell ke c 𝑏𝑐 : Bias pada cell ke c
c. Cell State (𝐶𝑡)
Jalur ini berfungsi sebagai memori atau ingatan pada layer LSTM. Pada akhir tahap ini, nilai pada cell state diupdate dari 𝐶𝑡−1 menjadi 𝐶𝑡. Nilai dari state yang lama, dikalikan dengan nilai dari forget gete (𝑓𝑡) yang mana bisa merupakan nilai anatar 0 sampai 1. Kemudian ditambahkan nilai dari hasil input gate yaitu 𝑖𝑡∗ 𝐶𝑡. Pada akhirnya didapatkan nilai baru dari cell state 𝐶𝑡.
Gambar 2. 8 Cell State LSTM
𝐶𝑡 = 𝑓𝑡∗ 𝐶𝑡−1+ 𝑖𝑡∗ 𝜍̃ (2.16) d. Output gate (𝑂𝑡)
Gate ini memutuskan apa yang akan dihasilkan berdasarkan nilai dari input dan cell state. Pada tahap akhir ini, output berdasarkan pada cell state saat ini, tapi akan melalui tahap filter terlebih dahulu. Pertama layer sigmoid yang
17
memutuskan nilai mana yang akan dipertahankan menuju output. Kemudian cell state akan melewati fungsi tanh (yang mengubah nilai menjadi rentang antara -1 dan 1) dan mengalikan dengan output dari gerbang sigmoid (Moghar
& Hamiche, 2020).
Gambar 2. 9 Output Gate LSTM
𝑜𝑡 = 𝜎(𝑊𝑜∙ [ℎ𝑡−1, 𝑥𝑡] + 𝑏𝑜) (2.17) ℎ𝑡 = 𝑜𝑡∗ tanh 𝐶𝑡 (2.18) Keterangan:
𝑜𝑡 : Ouput gate 𝜎 : Fungsi sigmoid
𝑊𝑜 : Bobot untuk nilai input pada waktu ke t ℎ𝑡−1 : Nilai output dari waktu ke t-1
𝑥𝑡 : Nilai input pada waktu ke t 𝑏𝑜 : Bias pada output gate ℎ𝑡 : Hasil output final 𝑜𝑡 : Nilai output gate
𝑡𝑎𝑛ℎ : Fungsi hyperbolic tangent
𝐶𝑡 : Nilai memori cell state yang baru
Estimasi bobot pada LSTM dilakukan dengan menggunakan algoritma Backpropagation Through Time (BPTT). Hal ini dilakukan karena model LSTM melakukan proses perulangan dalam hidden neuron. Pada algoritma BPTT digunakan untuk mengevaluasi turunan parsial dari nilai loss function terhadap semua bobot network. Proses perhitungan algoritma BPTT ada bobot LSTM dapat dilakukan sebagai berikut:
18
𝑊𝑓 = 𝑊𝑓− 𝜂Δ𝑊𝑓 (2.19) 𝑊𝑖 = 𝑊𝑖− 𝜂Δ𝑊𝑖 (2.20) 𝑊𝑐 = 𝑊𝑐 − 𝜂Δ𝑊𝑐 (2.21) 𝑊𝑜 = 𝑊𝑜− 𝜂Δ𝑊𝑜 (2.22) 𝜂 adalah sebuah konstanta yang menentukan seberapa cepat proses pembelajaran model LSTM dilakukan biasanya memiliki interval dari 0 hingga 1.
Misalnya loss function yang digunakan adalah sebagai berikut:
𝐸 = ∑(𝑟𝑡− 𝑟̂𝑡)2
𝑛
𝑡=1
(2.23)
maka
∆𝑊𝑓 = 𝜕𝐸
𝜕𝑊𝑓 = 𝜕𝐸
𝜕𝑓𝑡∙ 𝜕𝑓𝑡
𝜕𝑊𝑓 = 𝜕𝐸
𝜕𝑐𝑡∙𝜕𝑐𝑡
𝜕𝑓𝑡∙ 𝜕𝑓𝑡
𝜕𝑊𝑓= ∆𝑐𝑡𝑐𝑡−1 𝑥𝑡 𝑓𝑡 (1 − 𝑓𝑡) (2.23)
∆𝑊𝑖 = 𝜕𝐸
𝜕𝑊𝑖 =𝜕𝐸
𝜕𝑖𝑡∙ 𝜕𝑖𝑡
𝜕𝑊𝑖 = 𝜕𝐸
𝜕𝑐𝑡∙𝜕𝑐𝑡
𝜕𝑖𝑡 ∙ 𝜕𝑖𝑡
𝜕𝑊𝑖 = ∆𝑐𝑡𝑐̃𝑡 𝑥𝑡 𝑖𝑡 (1 − 𝑖𝑡) (2.24)
∆𝑊𝑐 = 𝜕𝐸
𝜕𝑊𝑐 = 𝜕𝐸
𝜕𝑐̃𝑡∙ 𝜕𝑐̃𝑡
𝜕𝑊𝑐 = 𝜕𝐸
𝜕𝑐𝑡∙𝜕𝑐𝑡
𝜕𝑐̃𝑡∙ 𝜕𝑐̃𝑡
𝜕𝑊𝑐 = ∆𝑐𝑡𝑖𝑡 𝑥𝑡 𝑐̃𝑡 (1 − 𝑐̃𝑡2) (2.25)
∆𝑊𝑜= 𝜕𝐸
𝜕𝑊𝑜= 𝜕𝐸
𝜕𝑜𝑡∙ 𝜕𝑜𝑡
𝜕𝑊𝑜= 𝜕𝐸
𝜕ℎ𝑡∙𝜕ℎ𝑡
𝜕𝑜𝑡 ∙ 𝜕𝑜𝑡
𝜕𝑊𝑜= ∆ℎ𝑡tanh(𝑐𝑡) 𝑥𝑡 𝑜𝑡 (1 − 𝑜𝑡) (2.24) Dengan ∆𝑐𝑡 dan ∆ℎ𝑡 dapat didapatkan dari persamaan berikut :
∆𝑐𝑡 = 𝜕𝐸
𝜕𝑐𝑡= 𝜕𝐸
𝜕ℎ𝑡∙𝜕ℎ𝑡
𝜕𝑐𝑡 = ∆ℎ𝑡 𝑜𝑡(1 − 𝑡𝑎𝑛ℎ2(𝑐𝑡)) (2.25)
∆ℎ𝑡= 𝜕𝐸
𝜕ℎ𝑡 (2.26) Penggunaan algoritma BPTT pada model LSTM membutuhkan penyimpanan internal dari inti jaringan pada setiap timestep. Oleh karena itu, untuk mengevaluasi bobot turunan parsial secara benar perlu dilakukan komputasi agar lebih efisien.
19
2.7 Uji Linieritas Terasvirta
Uji linieritas Terasvirta merupakan uji linieritas yang dikembangkan dari model neural network dengan ekspansi Taylor (Subhanar & Suhartono, 2000).
Ekspansi tersebut dapat dinotasikan dalam persamaan berikut:
𝑦𝑡 = 𝛽′𝑤𝑡 + ∑ 𝜃0𝑗{𝑠𝑖𝑔(𝛾′𝑤𝑡) −1 2} + 𝑢𝑡
𝑞
𝑗=1
(2.27)
Keterangan:
𝛽′𝑤𝑡 : komponen linear
𝑠𝑖𝑔(𝛾′𝑤𝑡) : komponen non linear yang memiliki fungsi aktivasi sigmoid 𝜃0𝑗 : bobot neural network dari hidden layer ke output layer non linear Hipotesis uji liniaritas terasvirta dapat dituliskan sebagai berikut:
Hipostesi
𝐻0 ∶ 𝜃01 = 𝜃02= ⋯ = 𝜃0𝑞 = 0 (Data time series bersifat linear) 𝐻1 ∶ 𝜃01= 𝜃02 = ⋯ = 𝜃0𝑞 ≠ 0 (Data time series bersifat tidak linear)
Berdasarkan (T. Terasvirta, C. F. Lin & C. W. J. Granger. 1993), langkah-langkah uji linearitas Terasvirta dilakukan dengan menggunakan distribusi chi-square sebagai berikut:
1. melakukan pemodelan regresi 𝑟𝑡 pada 𝑟𝑡−1, 𝑟𝑡−2, ⋯ , 𝑟𝑡−𝑝 dengan nilai konstanta sebesar 1 dan menghitung nilai residual 𝑢̂𝑡 = 𝑟𝑡− 𝑟̂𝑡.
2. Melakukan pemodelan regresi 𝑢̂𝑡 pada 𝑟𝑡−1, 𝑟𝑡−2, ⋯ , 𝑟𝑡−𝑝 dengan nilai konstanta sebesar 1 dan 𝑣 tambahan suku kuadratik dan kubik yang merupakan hasil pendekatan dari deret taylor.
3. Menghitung koefisien determinasi (𝑅2) dari pemodelan regresi pada langkah sebelumnya.
Statsitik uji
𝜒ℎ𝑖𝑡𝑢𝑛𝑔2 = 𝑛𝑅2 (2.28) Keterangan:
𝑛 : jumlah pengamatan 𝑅2 : koefisien determinasi Kriteria pengujian
20
Menolak 𝐻0 jika 𝜒ℎ𝑖𝑡𝑢𝑛𝑔2 > 𝜒𝑎,𝑣2 dengan derajat kebebasan 𝑣 atau p-value < 𝛼 yang artinya data time series tidak linear.
2.8 Pengukuran Nilai Error
Setelah mendapatkan hasil prediksi dari proses yang telah dijalankan maka langkah selanjutnya adalah melakukan pengecekan atau pengukuran nilai error dari hasil prediksi tersebut. Seperti yang diketahui bahwa harga yang terjadi atau terbentuk dimasa depan tidak ada yang tahu pasti akan tetapi dengan menggunakan metode forecasting atau peramalan maka masa depan dapat terprediksi mendekati realita. Walaupun tidak sama persis dengan realita, akan tetapi ini hasil ini bisa dijadikan salah satu pertimbangan untuk membuat keputusan dimasa depan. Hasil peramalan sampai saat ini belum ada yang bisa dipastikan benar seluruhnya, pasti ada perbedaan antara nilai aktual dengan nilai prediksi. Berikut ini beberapa jenis evaluasi yang sering digunakan:
a. Root Mean Square Error
RMSE (Root Mean Square Error) adalah metode atau cara umum yang sering dipergunakan untuk mengukur kesalahan model dari prediksi data yang bersifat kuantitatif (Karno, 2020). RSME menghitung kesalahan berdasarkan nilai standart deviasi. Hasil akhir diberikan dalam standart deviasi dari besarnya kesalahan.
Rumus RMSE:
𝑅𝑀𝑆𝐸 =√∑𝑛𝑡=1(𝑥𝑡− 𝑓𝑡)2
𝑛 (2.20) Keterangan :
𝑥𝑡 : nilai aktual pada waktu ke- 𝑡
𝑓𝑡 : nilai dugaan (hasil prediksi) pada waktu ke- 𝑡 𝑛 : jumlah data yang diprediksi
b. Mean Absolute Percentage Error (MAPE)
Mean Absolute Percentage Error (MAPE) adalah nilai rata – rata perbedaan absolut yang ada diantara nilai dari prediksi dan nilai realisasi yang disebutkan sebagai hasil persenan dari nilai realisasi. Penggunaan Mean Absolute Percentage Error (MAPE) pada evaluasi dari hasil peramalan dapat melihat tingkat akurasi terhadap angka
21
peramalan dan angka realisasi (Nabillah & Ranggadara, 2020). Nilai MAPE dapat dihitung dengan menggunakan persamaan berikut:
𝑀𝐴𝑃𝐸 = 1
𝑛∑|𝑥(𝑡) − 𝑦̂𝑘(𝑡)|
𝑥(𝑡) ∙ 100
𝑛
𝑡=1
(2.21)
Keterangan :
𝑥(𝑡) : nilai aktual pada waktu ke- 𝑡
𝑦̂𝑘(𝑡) : nilai dugaan (hasil prediksi) pada waktu ke- 𝑡 𝑛 : jumlah data yang diprediksi
2.9 Minyak Mentah
Minyak mentah (Crude Oil) yang baru keluar dari sumur eksplorasi mengandung bermacam-macam zat kimia yang berbeda baik dalam bentuk gas, cair maupun padatan. Lebih dari separuh (50-98%) dari zat-zat tersebut adalah merupakan hidrokarbon. Senyawa utama yang terkandung di dalam minyak bumi adalah alifatik, alisiklik dan aromatik (Supriharyono, 2000). Minyak bumi ditemukan bersama-sama dengan gas alam. Minyak bumi yang telah dipisahkan dari gas alam disebut juga minyak mentah (crude oil). Minyak mentah dapat dibedakan atas:
a. Minyak mentah ringan (light crude oil), mengandung kadar logam dan belerang rendah, berwarna terang dan bersifat encer (viskositas rendah).
b. Minyak mentah berat (heavy crude oil), mengandung kadar logam dan belerang tinggi, memiliki viskositas tinggi sehingga harus dipanaskan agar meleleh.
Minyak mentah merupakan campuran yang kompleks dengan komponen utama alkana dan sebagian kecil alkena, alkuna, siklo-alkana, aromatik dan senyawa anorganik. Minyak mentah mengandung senyawa hidrokarbon dan sisanya merupakan senyawa non-hidrokarbon (Sulfur, Nitrogen, Oksigen dan beberapa logam berat seperti Pb, V, Ni dan Cu). Air dan garam hampir selalu terdapat dalam minyak bumi dalam keadaan terdispersi. Bahan-bahan bukan hidrokarbon ini biasanya dianggap sebagai kotoran karena pada umumnya akan memberikan gangguan dalam proses pengolahan minyak dalam kilang dan mempengaruhi kualitas minyak yang dihasilkan.
22
(Halaman ini sengaja dikosongkan)
23
BAB III
METODOLOGI PENELITIAN
3.1 Sumber Data
Sumber Data harga minyak mentah Indonesia dalam penelitian ini berasal dari database harga histori harga minyak mentah Indonesia periode bulanan yang dipublikasikan pada website Kementrian Energi dan Sumber Daya Mineral dari 1 Januari 2012 – 1 Juni 2023. Jumlah data yang digunakan untuk peramalan harga minyak mentah Indonesia ini sebesar 138 data. Data penelitian tersebut dibagi menjadi data training dari 1 Januari 2012 – 1 Maret 2021, sedangkan data testing yang digunakan terdiri dari 1 April 2021 – 1 Juni 2023. Satuan data harga minyak mentah Indonesia adalah US$.
Tabel 3. 1 Struktur Data Penelitian Harga Minyak Mentah
Data Tanggal t 𝑥𝑡
1 Januari 2012 1 𝑥1
1 Februari 2012 2 𝑥2
Training ⋮ ⋮ ⋮
1 Februari 2021 119 𝑥119
1 Maret 2021 120 𝑥120
1 April 2021 121 𝑥121
1 Mei 2021 122 𝑥122
Testing ⋮ ⋮ ⋮
1 Mei 2023 131 𝑥131
1 Juni 2023 138 𝑥138
3.2 Analisis Model EEMD-LSTM
Langkah-langkah yang dilakukan dalam penelitian ini adalah sebagai berikut:
1. Mendeskripsi karakteristik data harga minyak mentah Indonesia periode bulanan dengan menyajikan data dalam bentuk time series plot.
2. Melakukan dekomposisi data harga minyak mentah Indonesia periode bulanan 𝑥𝑖(𝑡) dengan metode EEMD dengan langkah-langkah sebagai berikut:
a. Mendapatkan sejumlah komponen IMF dan residual dengan menggunakan algoritma EMD dengan penambahan white noise yang memiliki rata-rata sebesar nol dan simpangan baku sebesar 0,1 dengan sebanyak iterasi
24
sebesar 100 kali. Pada umumnya Huang dan Wu (2008) menyarankan untuk menambahkan noise dengan standar deviasi sekitar 0,2 dari rata-rata yang akan diteliti. Namun, ketika data didominasi oleh signal dengan frekuensi tinggi, dapat ditambahkan amplitude noise yang lebih kecil, ketika data didominasi oleh frekuensi rendah, maka amplitude noise dapat ditingkatkan.
b. Mendeskripsikan karakteristik sejumlah komponen IMF dan residual yang didapat dengan metode EEMD
4. Melakukan peramalan dengan metode EEMD-LSTM dengan langka-langkah sebagai berikut:
a. Melakukan proses dekomposisi terhadap data harga minyak mentah Indonesia dengan menggunakan metode EEMD sehingga didapatkan sejumlah komponen IMF dan residual.
b. Melakukan preprocessing dengan teknik normalisasi pada setiap komponen IMF dan residual. Normalisasi adalah proses transformasi nilai menjadi kisaran 0 dan 1 yang bertujuan untuk mendapatkan data dengan ukuran lebih kecil untuk mewakili data asli tanpa kehilangan karakteristik data tersebut. Normalisasi data merupakan proses penskalaan nilai atribut data sehingga sesuai pada range tertentu. Tujuan dari normalisasi pada data adalah untuk mempercepat proses konvergensi dan meningkatkan akurasi (Ariani, 2015). Persamaan yang digunakan untuk proses normalisasi data adalah sebagai berikut:
𝑥∗(𝑡) = 𝑥(𝑡) − 𝑚𝑖𝑛(𝑥(𝑡)) 𝑚𝑎𝑥(𝑥(𝑡)) − 𝑚𝑖𝑛(𝑥(𝑡)) Keterangan :
𝑥∗(𝑡) : data yang dinormalisasi
𝑥(𝑡) : data yang belum dinormalisasi
𝑚𝑖𝑛(𝑥(𝑡)) : nilai minimum dari keseluruhan data asli 𝑚𝑎𝑥(𝑥(𝑡)) : nilai maksimum dari keseluruhan data asli c. Membagi data menjadi data training dan data testing
25
d. Membentuk model LSTM pada setiap komponen pada setiap komponen IMF dan residual
e. Melakukan peramalan harga minyak menggunakan LSTM yang terbentuk pada setiap komponen IMF dan residual
f. Melakukan post processing data hasil ramalan dengan cara denormalisasi pada setiap komponen IMF dan residual.
g. Data hasil ramalan pada setiap komponen IMF dan residual direkontruksi kembali dengan cara menjumlahkan sehingga menjadi data hasil ramalan akhir.
h. Melakukan evaluasi hasil kebaikan model dengan mencari nilai MAPE dan nilai RMSE dari hasil ramalan terhadap data testing.
i. Mencari model terbaik berdasarkan model EEMD-LSTM dengan menggunakan kriteria nilai MAPE.
3.3 Analisis Model LSTM
Adapun langkah-langkah analisis LSTM
1. Menampilkan visualisasi data melalui grafik time series data untuk melihat pola data.
2. Lakukan preprocesing data yang meliputi, normalisasi dimana pada tahap ini terjadi proses penskalaan dan segmentasi merupakan proses pemisahan dan pengelompokkan data dari data asli menjadi data yang dibutuhkan sistem.
3. Pembagian data, pada tahap ini data kan dibagi menjadi dua bagian yaitu data latih dan data uji.
4. Melakukan kontruksi model dengan LSTM berdasarkan masing-masing pembagian data menggunakan data latih dengan menentukan inisialisasi parameter-parameter yang dibutuhkan yaitu jumlah epoch, neuron hidden dan jumlah batch size.
5. Menguji model training dengan data uji
6. Melakukan prediksi untuk melihat prediksi harga minyak mentah Indonesia.
7. Melakukan evaluasi model menggunakan MAPE
26
8. Melakukan forecasting dengan data testing dan melihat visualisasi yang dihasilkan dari data yang diramalkan.
27
3.4 Diagram Alur Penelitian
Gambar 3. 1 Diagram Alir EEMD-LSTM
28
Gambar 3. 2 Diagram Alir LSTM
29
Gambar 3. 3 Diagram Alir perbandingan EEMD-LSTM dan LSTM
30
(Halaman ini sengaja dikosongkan)
31
BAB IV
ANALISIS DAN PEMBAHASAN
Pada bab ini membahas mengenai model hybrid EEMD-LSTM dan LSTM pada data harga minyak mentah di Indonesia. Pertama dilakukan dekomposisi data harga minyak mentah periode bulanan dengan menggunakan metode EEMD. Hasil dari dekomposisi kemudian diprediksi dengan metode yang digunakan yaitu EEMD-LSTM. Evaluasi model yang dilakukan dengan melihat nilai MAPE pada data testing. Selanjutnya dilakukan perbandingan pada model EEMD-LSTM dan model LSTM yang tanpa melalui proses dekomposisi.
4.1. Karakteristik Data
Data yang digunakan adalah data harga minyak mentah Indonesia periode bulanan dengan total data sebanyak 138 data harga minyak mentah di Indonesia.
Gambar 4. 1 Time Series Plot Harga Minyak Mentah Indonesia
Berdasarkan pada Gambar 4.1 menunjukkan bahwa harga minyak mentah Indonesia periode bulanan mengalami penurunan mulai Juli 2014, meskipun pada Februari 2016 harga minyak mentah Indonesia sudah mulai naik, namun setelah itu harga minya mentah Indonesia turun kembali dan naik kebali pada Mei 2020 hingga tahun 2022. Dapat dilihat pada tahun 2020, harga minyak mentah Indonesia mengalami penurunan, hal ini terjadi diduga akibat adanya pandemic COVID-19.
32
4.2. Uji Stasioneritas Data
Pada analisis data time series, tahap awal untuk identifikasi stasioneritas dengan menggunakan uji Augmented Dickey-Fuller (ADF).
Tabel 4. 1 Uji ADF Data Harga Minyak Mentah
Data p-Value t-Value Critical Value ICP 0.3475 -18,673 -2,886
Pada pengujian stasioneritas menggunakan uji Augmented Dickey-Fuller diperoleh nilai p-value sebesar 0,123 dan nilai t-value sebesar -2,466. hasil tersebut menunjukkan bahwa data harga minyak mentah Indonesia tidak stasioner karena memiliki nilai p-value yang lebih besar dibandingkan tingkat signifikansi 0,05 dan nilai t-value yang lebih besar daripada nilai critical value.
Pada pemodelan LSTM, unit memori jangka panjang dan gerbang kontrol memungkinkan mengingat informasi masa lalu yang relevan dalam urutan waktu dan menyesuaikan bobotnya secara adaptif. Kemampuan ini memungkinkan LSTM untuk menangkap pola yang tidak linear dalam data sekuensial. LSTM dirancang khusus untuk memodelkan dependensi jangka panang dan mengenali pola yang kompleks dalam data sekuensial, termasuk data yang bersifat tidak linear. Oleh karena itu, sebelum dilakukan pemodelan perlu dilakukan uji linearitas terlebih dahulu untuk mengetahui apakah data yang digunakan memiliki sifat linearitas atau tidak. Pada penelitian ini dilakukan uji linearitas Terasvirta dengan hasil sebagai berikut.
Tabel 4. 2 Uji Linearitas Terasvirta Harga Minyak Mentah
𝝌𝒉𝒊𝒕𝒖𝒏𝒈𝟐 p – value
ICP 1402,2 0,000
Berdasarkan hasil pengujian linearitas Terasvirta, didapatkan nilai p-value yang kurang dari taraf signifikansi 0,05. Hal ini berarti harga minyak mentah Indonesia memiliki sifat yang tidak linear. Suatu data yang tidak linear mengindikasikan bahwa hubungan antara variabel-variabelnya yang tidak dapat dijelaskan dengan model linear.
33
4.3. Dekomposisi Data dengan EEMD
Harga minyak mentah Indonesia memiliki karakteristik data yang tidak linier dan tidak stasioner baik dalam rataan maupun ragam, sehingga dekomposisi dengan metode Ensemble Empirical Mode Decomposition (EEMD). Pada penelitian ini, jumlah anggota ensemble menggunakan 100 iterasi dan standar deviasi dari white noise sebesar 0,1. Hasil dekomposisi dapat disajikan pada Gambar
Gambar 4. 2 Dekomposisi Harga Minyak Mentah Indonesia Periode Bulanan
Dekomposisi data harga minyak mentah Indonesia periode bulanan metode EEMD menguraikan data menjadi 7 IMF dan residual. Pembentukan IMF dilakukan secara bertahap dimulai dari dekomposisi data dengan frekuensi tertinggi hingga terendah. Gambar 4.2 menunjukkan variasi waktu pada pergerakan harga minyak mentah Indonesia, misalkan IMF 1 dan IMF 2 menunjukkan pergerakan harga minyak mentah Indonesia jangka pendek yaitu masing-masing periode.
34
Sedangkan pergerakan harga minyak mentah Indonesia jangka panjang dapat dilihat pada IMF 6 dan IMF 7 dengan masing-masing periode hari. Residual pada hasil dekomposisi EEMD menunjukkan trend pada pergerakan harga minyak mentah.
Peramalan dengan EEMD-LSTM
Setelah dilakukan dekomposisi dengan metode EEMD, langkah selanjutnya adalah noemalisasi data dimana, transformasi nilai menjadi kisaran 0 dan 1 yang bertujuan untuk mendapatkan data dengan ukuran lebih kecil untuk mewakili data asli tanpa kehilangan karakteristik data tersebut. Normalisasi data merupakan proses penskalaan nilai atribut data sehingga sesuai pada range tertentu. Tujuan dari normalisasi pada data adalah untuk mempercepat proses konvergensi dan meningkatkan akurasi.
Gambar 4. 3 Plot IMF 1 dan IMF 1 yang dinormalisasi
Gambar 4. 4 Plot IMF 2 dan IMF 2 yang dinormalisasi