This research presents an attempt to build a neural network classifier for the Latin uncial alphabet found in Codex A, a late fourth-century manuscript held by the Archivo Capitolare in Vercelli, Italy, which is the oldest Latin gospel. I would also like to acknowledge the generous gift from the Carrier family that funded my education at the University of Mississippi. It proved to be a problematic classification task due to the irregularities present in the character classes of the alphabet.
This variability makes it very difficult to classify characters based on manually designed heuristics of the data. This presents a new difficulty for human classification of characters in manuscript, prompting us to find a computational approach.
The Codex A
Because Codex A has suffered damage and decay due to age and water exposure, the text is extremely degraded in large parts of the manuscript.
EBLearn
Developed by Pierre Sermanet and Yann LeCun at New York University's Machine Learning Lab, it also uses optimizations, tools, and cross-platform support added by Soumith Chintala.
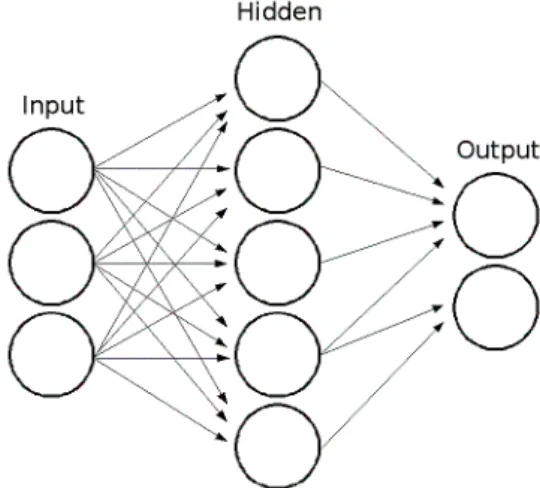
Neural Networks
- Net Topology
- Convolution
- Sigmoid Function and Bias Term
- Backpropagation Algorithm
- Success of Neural Network Application
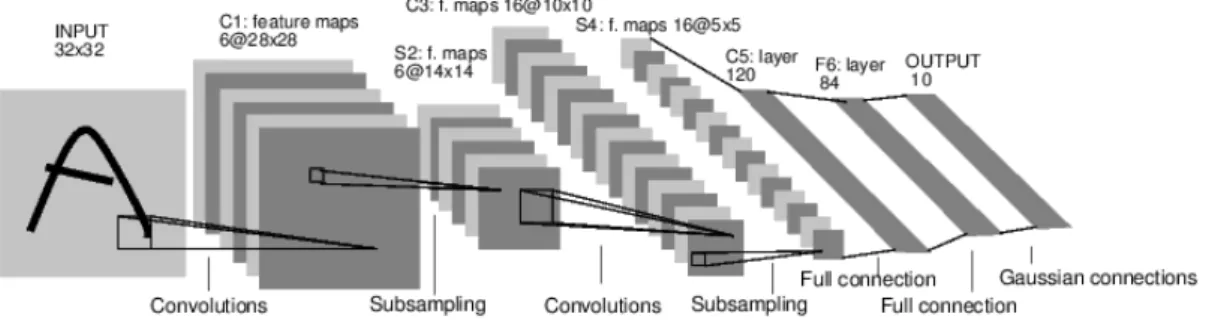
It should be noted that the dimensions of this kernel should not exceed the dimensions of the input matrix. The size of the output matrix is equal to the difference of the dimensions of the input matrix and the kernel. Returning to equation 1.1, we see that the sigmoid function is tanh; this function ensures that the sum hnij associated with each neuron is continuous and thus differentiable, a necessary condition for using the network's learning algorithm.
They are first randomly chosen by the neural net and then modified using the backpropagation algorithm to produce the desired output [7]. The backpropagation algorithm aims to find the weights that minimize this error using gradient descent, so that the partial derivatives of the error are calculated with respect to the weights. In 1989, Yann Lecun and his fellow researchers were the first to achieve state-of-the-art recognition results using a neural network.
Lecun and his team went on to achieve similar brilliant results on the SVHN (house number image dataset) dataset, achieving a point-of-recognition improvement over the prior art. It has been shown theoretically and experimentally that the gap that exists between the expected error rate of the test set, Etest, and the error rate of the training set, Etrain, is given by . Thus, there is a trade-off between reducing Etrain and increasing the gap.
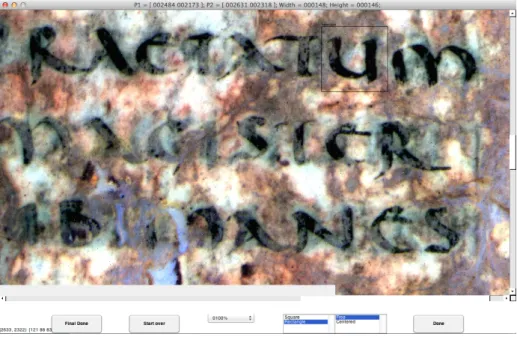
There is no compression or distortion of the image when using the GUI for data collection.
Artificial Training Data Creation
- Bilateral Filtering
- Principal Components Analysis
- Translations, Rotations, Skewing Data
- Manual Data Alterations
For the purpose of creating the training data, I chose the number of quantization levels to be 4 in order to preserve the shape of the characters while also minimizing the background noise as much as possible. I chose half the window size of the bilateral Gaussian filter to be 5, and the standard deviation of the filter for the spatial domain to be 3, and the intensity domain to be 0.1. Principal component analysis, or PCA, in its simplest form is a tool to reduce the dimensionality of a data set while preserving the important features of the data.
PCA achieves this by first computing the covariance matrix of the original set of observations, in this case a matrix of pixel values, and then finding the eigenvectors of this matrix. These eigenvectors are the key components of the set of observations, and because these eigenvectors are orthogonal to each other, they can be used to rebase the coordinate system of the data set. PCA is especially useful in creating artificial training data because it extracts the information most relevant for classification.
Each image shown consists of the original grayscale image (top row) projected onto the first-order principal components of five other images in the training set. I visually inspected the new training data and if an image appeared to be malformed, I deleted that record. In 2003, Simard, Steinkraus, and Platt managed to achieve an accuracy rate of 99.7% for the MNIST dataset using a simple neural network with two convolution-pooling layers, followed by a hidden fully connected layer of 100 neurons, by increasing the training set, introducing translations and rotations and warping of the training data.
For both of these classes, I manually modified some of the original training data I collected to make it look more visually like the prototypes shown in figure 2.2.

Pre-Processing
While the previous two methods help overcome the challenge associated with the sparing use of some letters, there is the additional problem that some character classes appear in largely degraded form throughout the manuscript. Within the field of machine learning, there are two main approaches to pattern recognition: supervised and unsupervised learning. Thus, the learning algorithm used must distinguish the characteristics of the data to group them into meaningful categories.
Because we are able to identify examples of each character class and ultimately assert how many character classes exist within the Latin alphabet, a supervised learning method is more desirable for character classification in Codex A. Supervised" refers to the labeling of input, such as that classification errors can be calculated and the system can learn from these errors [24]. We are using a neural network architecture as a classification tool, so within the system, we have labeled each character class .
Net Model
After applying the kernel, a bias is added and a sigmoid function (tanh) is applied to produce the final feature map [3]. After the first convolution layer is a sub-sampling layer that reduces the 28x28 feature maps to 14x14 using an L2 pooling method. Next comes a second convolution layer with sixteen feature maps using a 6x6 kernel, then the second sub-sampling layer which reduces the 10x10 images to 5x5.
The final layer is a fully connected layer that performs a linear combination of its input and their internal weights, adds a bias, and uses a sigmoid. The results of this layer are shown in the output by creating a vector containing the value or energy for each of the classes. The error in the expected values for each of the classes is then calculated and a backpropagation algorithm can be used to calculate the gradient of the loss function with respect to each of the weights in the network.
These gradients are used in the gradient decent optimization method to minimize the loss function, updating the weights within the system [3].
Network Parameters
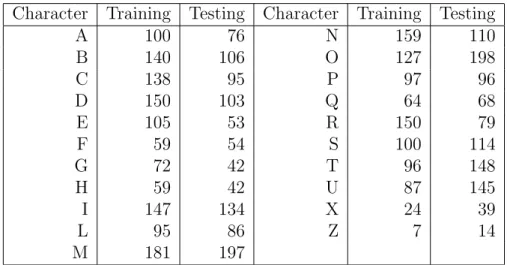
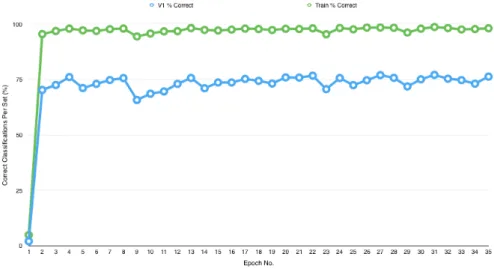
I tested each network using a validation set consisting of data selected from the manuscript that were corrupted or imperfect (these data were not subjected to any preprocessing or alteration, beyond reduction and alteration to grayscale), now marked and so on. I also tested the most successful meshes with a second validation set consisting of randomly selected images from the training set, denoted as the "V2" test set. The number of training and test images for these trials are included in Tables 4.3 and 4.4.
It should be noted that when the second validation set was used, the training set did not contain the images selected for the test set.
Epochs
Overfitting & Underfitting
Training Sets
Background Training
Results
Manuscript Testing
I found that the net recognized larger regions of the input images when I limited the size of the scales for this particular input size, although I was unable to achieve any successful classifications for these new input images. However, the net misidentified smaller portions of the images when these alternative parameter values were used. I discuss the practical limitations of the net in Chapter 5 and the potential causes of the failure to recognize new examples.
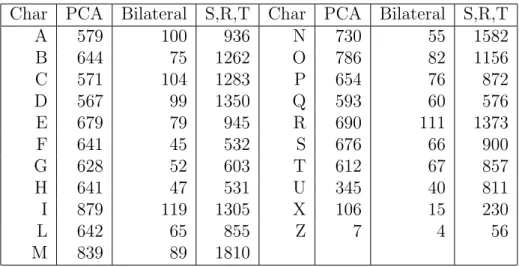
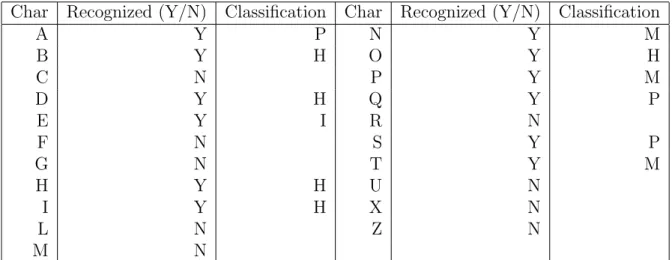
Somewhat encouragingly, the web was able to detect that there were signs in many of the images, as summarized in Table 4.4. In fact, the set of nets that do not include background data in the training data does not accurately predict the order of the most successful nets among the set trained on background data, as one might expect. It appears that the additional parameters introduced by the background class cause fluctuations in the success and relative success of the training set classes.
Furthermore, the differences in relative success of the nets based on the inclusion of the background class suggest that a greater variety of training data is useful in distinguishing character data from background, an unavoidable task inherent in the classification of real-world data. In terms of inferring which artificial training data is most useful in improving the success rates of the nets, it appears that the manual changes provided the most improvement, with an increase of 1.73 percentage points for the V1 set among the group of nets that were not trained in the background. facts. It is important to note that the V1 test set itself is an approximation of the variety of character data a net may encounter.
So understanding the relative success of each of these networks depends on the quality and variety of data captured by the V1 cluster.
Possible Means of Improvement
Computing Power
I operated under the assumption that a network that included the most training data that also gave the highest recognition rate would produce the best results for real-world data.
Training Data
Manuscript Testing Limitations
Applications
Transcriptions
Because Codex A consists of the Latin Gospels, we can consult the older Greek texts as well as the other Latin Gospels to confirm textual identities, so visual allograph identification is not an impossible task. Furthermore, an automated handwriting recognition system would be useful in saving time and resources of visual transcribers and would also serve as a means of confirming visual identifications if this visual method is still desirable to use.
Image Processing
Each language would require its own neural network, although with the extensive training data available at the monastery, in a variety of hands and styles, more powerful neural networks could be developed, such that they would not only have specific recognition skills for manuscripts.
Covariance Matrix
Eigenvector
Basic Neural Network
Matlab Training Data Collection Tool
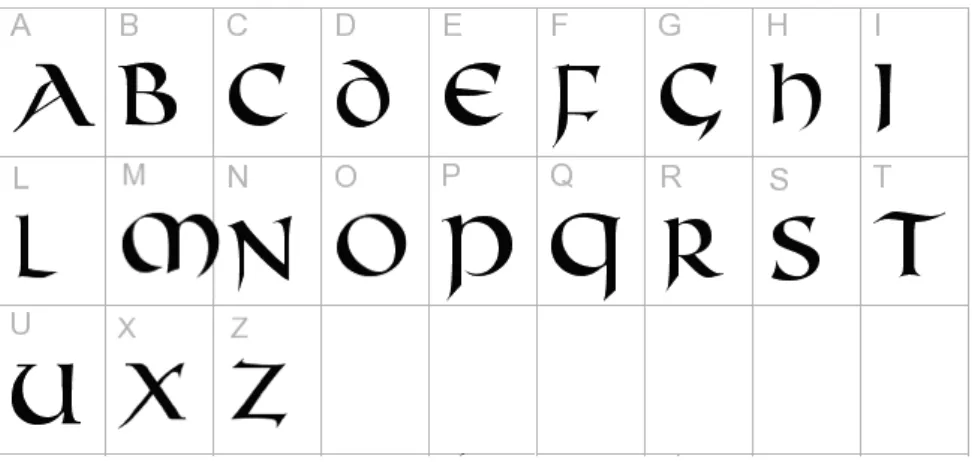
Latin Alphabet in Uncial Script
Training Data: Original, Quantized, and PCA Images
Manually Altered Training Data
Lenet 5 Architecture
V1 Testing Set Class Examples
Cartoon Net: Training and V1 Success Rates
Detect Function Results for BG PCA+Cartoon+Shift Net