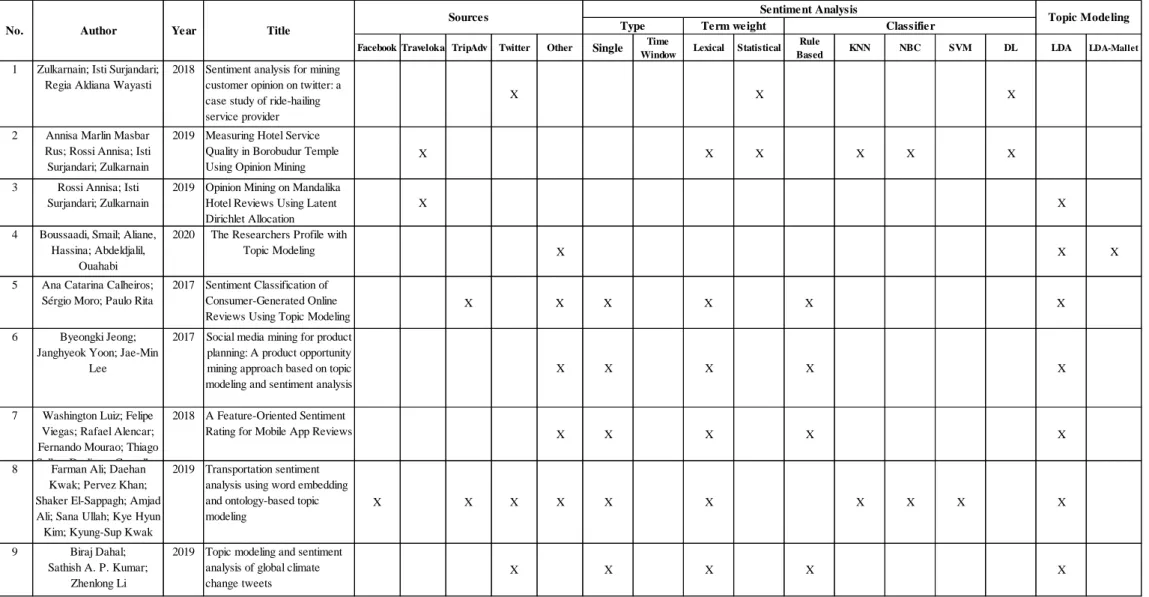
Analisis Sentimen, Analisis Sentimen Jendela Waktu, Palu Pemodelan Topik, TF-IDF SVM, Jasa Pengiriman Barang. Seperti yang telah dijelaskan di atas, penelitian ini berupaya untuk mengetahui apakah pandemi memiliki korelasi dengan tren sentimen jasa pengiriman barang di Indonesia dengan menggunakan media sosial Twitter sebagai sumber data.

PENDAHULUAN
- Latar Belakang
- Perumusan Masalah
- Tujuan Penelitian
- Manfaat Penelitian
- Batasan Penelitian
- Sistematika Penulisan
Hasil uji korelasi dan signifikansi polaritas sentimen 'Negatif' dengan pandemi Covid-19 periode pertama dapat dilihat pada Tabel 4.19 dan Tabel 4.20 sesuai data yang dicetak tebal. Tweet yang ditulis dengan model ini diklasifikasikan ke dalam kelas sentimen "Neutral" dan "Positif".
TINJAUAN PUSTAKA
Jasa Pengiriman Barang Domestik di Indonesia
Jasa pengiriman barang di Indonesia terus berkembang seiring dengan berkembangnya bisnis e-commerce seiring semakin mudahnya masyarakat mengakses internet dan semakin banyaknya pengguna bertransaksi pembelian secara online. J&T Express adalah perusahaan pengiriman barang yang relatif baru di Indonesia di bawah naungan PT.
Kebijakan Terkait Penanganan Pandemi
Sosial Media Twitter
- Pengguna Twitter di Indonesia
- Twitter Sebagai Pusat Pengaduan dan Layanan Pelanggan
Kemp (2021) menyatakan bahwa pada tahun 2021, jumlah pengguna media sosial akan mencapai 170 juta orang atau 61,8% dari total penduduk Indonesia. Bagi penyedia layanan, kehadiran media sosial memberikan keuntungan bagi Twitter dimana penyedia layanan tidak harus secara mandiri menyiapkan platform pusat pengaduan dan layanan pelanggan yang tentunya membutuhkan biaya yang tidak sedikit.
Text Mining
Analisis Teks
Perayapan web adalah proses pengambilan data dari Internet berdasarkan koneksi dan membutuhkan saluran komunikasi khusus, sedangkan web scraping adalah proses pengambilan data dari Internet berdasarkan metode penggalian konten halaman web. Pemrosesan Bahasa Alami: Analisis teks ini adalah proses sinkronisasi algoritmik yang menormalkan teks agar sesuai dengan pemahaman bahasa manusia.
Analisis Sentimen
- Analisis Sentimen Jendela Waktu
- Ekstraksi Fitur dalam Sentimen Analisis
- Data Preprocessing
- Klasifikasi
- Pengujian dan Validasi
Dalam analisis sentimen, kata-kata yang dapat dijadikan fitur dalam proses klasifikasi biasanya disebut fitur, sehingga kata-kata yang memiliki nilai sentimen dipertimbangkan dalam proses ekstraksi fitur. Hal ini dilakukan karena kata yang menggunakan huruf kapital memiliki arti yang sama dengan kata yang tidak menggunakan huruf kapital.
Pemodelan Topik
- Latent Dirichlet Allocation
- LDA-Mallet
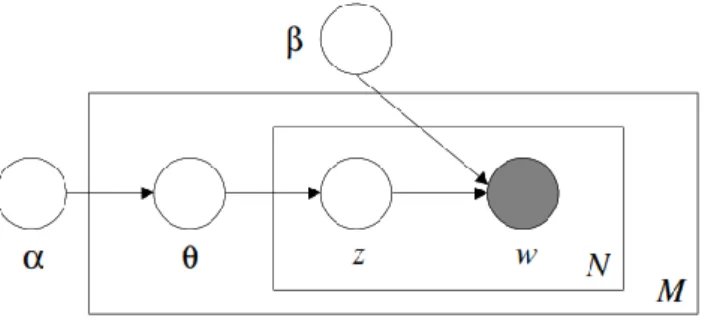
Metode LDA terdiri dari tiga level data seperti terlihat pada Gambar 2.2, dimana parameter pengumpulan data α dan β merupakan level korpus yang diambil dengan menggunakan metode probabilitas Bayesian, θ adalah Dirichlet yang terdistribusi dalam level kalimat pada total M kalimat, z dan w adalah tingkat kata yang memiliki distribusi multinomial sesuai dengan jumlah mata pelajaran yang ingin dibentuk. Parameter α menunjukkan kepadatan topik dalam dokumen, sehingga semakin besar nilainya maka akan semakin banyak topik yang terbentuk. Parameter β menunjukkan kepadatan kata dalam topik, sehingga semakin besar nilainya, semakin banyak kata yang mewakili topik yang terbentuk.
Metode LDA-Mallet atau LDA-Machine Learning for Language Toolkit adalah versi optimal dari metode LDA standar yang ditulis oleh McCallum (2002). Perbedaan mendasar antara LDA-Mallet dan LDA standar adalah penggunaan teknik pengambilan sampel, dimana metode LDA standar menggunakan varian teknik pengambilan sampel.
Penelitian Terkait
LDA-Mallet sedikit lebih lambat dalam proses komputasi, tetapi dapat memberikan hasil pembentukan topik yang lebih akurat, seperti yang ditunjukkan oleh penelitian yang dilakukan oleh Boussaadi, Aliane, dan Abdeldjalil (2020). Metode MCMC lebih cocok untuk klasifikasi data tanpa pengawasan daripada LDA, yang terkait dengan parameter inferensi sampling α dan β. Metode MCMC memiliki kelebihan dalam menentukan proporsi parameter sampel dan kemampuan menghitung data berdimensi tinggi dengan distribusi probabilitas yang kompleks, dimana metode MCMC menentukan nilai optimal dari parameter sampel berdasarkan distribusi probabilitas dari data yang digunakan (Rocca, 2019).
Meskipun menggunakan metode klasifikasi sentimen yang berbeda, pencarian sentimen adalah analisis time window seperti yang dilakukan oleh beberapa peneliti sebelumnya, seperti yang dilakukan oleh Wang, Wu, Zhang, & Zhu (2020), Rao & . Srivastava (2012) dan Yoo, Song, & Jeong (2018) memberikan gambaran bahwa analisis sentimen jendela waktu dapat digunakan secara efektif untuk kebutuhan identifikasi, deteksi, dan prediksi terkait peristiwa dengan menganalisis tren polaritas sentimen. .
Usulan Penelitian
METODE PENELITIAN
Rancangan penelitian
- Pengumpulan Data
- Data Preprocessing
- Klasifikasi Data Latih
- Klasifikasi Keseluruhan Data
- Analisis Jendela Waktu
- Pemodelan Topik
- Hasil dan Kesimpulan
Data dengan polaritas sentimen 'negatif' sebelum dan selama pandemi ditunjukkan pada Tabel 4.18 dan grafik pada Gambar 4.14. Selanjutnya hasil uji korelasi dan signifikansi polaritas sentimen 'Negatif' dengan pandemi Covid-19 periode kedua pandemi dapat dilihat pada Tabel 4.21 dan Tabel 4.22 sesuai data yang dicetak tebal. Data dengan polaritas sentimen 'netral' sebelum dan selama ditunjukkan pada Tabel 4.23 dan grafik pada Gambar 4.15.
Data dengan polaritas sentimen 'positif' sebelum dan selama ditunjukkan pada Tabel 4.29 dan secara grafis ditunjukkan pada Gambar 4.16. Hasil uji korelasi dan signifikansi polaritas sentimen 'positif' dengan pandemi Covid-19 periode pertama dapat dilihat pada Tabel 4.30 dan Tabel 4.31 sesuai data yang dicetak tebal.
HASIL DAN PEMBAHASAN
Pengumpulan Data
Penyebutan tersebut berisi informasi ke akun mana pesan tersebut ditujukan, dengan menyebutkan nama akun-akun tersebut. Reply_to berisi informasi tentang akun yang dituju oleh pesan balasan dengan menyebutkan nama akun pembuat asli pesan tersebut. Sayangnya, variabel Tempat dari data yang dikumpulkan tidak memuat informasi yang cukup lengkap, yaitu hanya berisi 109 informasi koordinat pengguna.
Data aktivitas tweet untuk akun resmi dapat dilihat pada Gambar 4.2 dimana gambar ini menunjukkan bahwa Pos Indonesia merupakan penyedia layanan yang paling aktif dengan 97,23% atau 40.879 dibandingkan dengan 42.045 tweet dari akun lain yang menyebutkan akunnya. Berdasarkan lokal yang digunakan, data yang menyebutkan akun resmi penyedia layanan memiliki ciri-ciri yang ditunjukkan pada Gambar 4.3, dimana data yang menggunakan lokal bahasa Indonesia tidak menyebutkan lokal menggunakan bahasa Inggris dan menggunakan bahasa lain.

Data Preprocessing
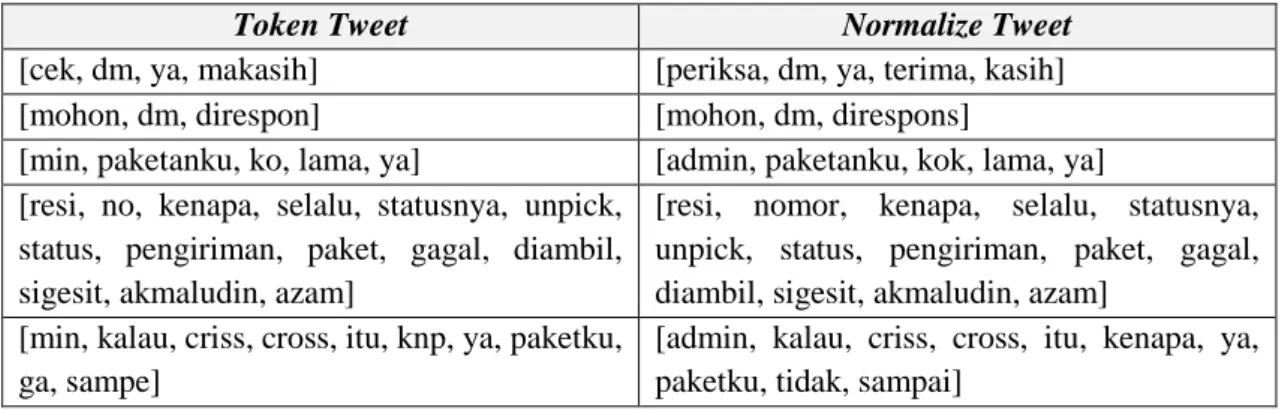
Perubahan format data dari bentuk aslinya, selama proses cleansing dan selama proses tokenisasi dapat dilihat pada Tabel 4.2. Dari Tabel 4.2 terlihat bahwa mention, tanda baca, link ke halaman web dan nomor pada kolom 'Tweet' telah dihapus dan semua huruf pada kolom telah diubah menjadi huruf kecil seperti pada kolom 'Bersihkan tweet'. Selanjutnya adalah tahap normalisasi atau tahap penyatuan data yaitu mengubah kata tidak baku menjadi kata baku.
Tahap ini menggunakan masukan kamus daerah yaitu daftar kata tidak baku menjadi kata baku yang dibuat secara manual berdasarkan data observasi. Dari Tabel 4.5 terlihat beberapa kata seperti 'reply' telah berubah menjadi kata dasarnya yaitu 'reply', 'my package' menjadi 'package', 'status' menjadi 'status'.

Klasifikasi Data Latih
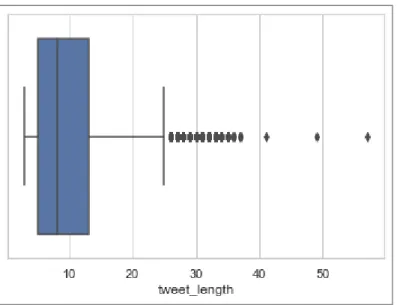
Batasan Pengambilan Sampel Data Training (Data Distribution Box Plot) Pengambilan sampel dilakukan dengan metode stratified random sampling, dengan menggunakan variabel 'origin' dan . Penelitian sebelumnya telah memvariasikan jumlah data latih saat membuat model klasifikasi, namun semakin besar jumlah data latih yang digunakan, semakin besar akurasi model yang dibuat. Misalnya kalimat 'follow up belum datang', kata sentimental pada leksikon kalimat ini adalah kata 'please' dengan skor -5 dan 'sampai' dengan skor +1, sedangkan kata ' Belum'.
Contoh proses ekstraksi ciri untuk beberapa data lain dengan pendekatan leksikon ini dapat dilihat pada Tabel 4.8. Setelah semua data latih diklasifikasikan menurut polaritas masing-masing sentimen, klasifikasi data latih dilanjutkan dengan proses evaluasi hasil secara manual dengan melihat kesesuaian metode klasifikasi dengan klasifikasi yang diharapkan.
Klasifikasi Keseluruhan Data
Dari tabel tersebut terlihat bahwa jumlah data yang diprediksi untuk setiap kelas sentimen, dimana dari total 2.002 data uji, model klasifikasi dapat memprediksi kelas sentimen secara akurat. Kelas sentimen 'netral' diprediksi dengan benar = 378 data, diprediksi pada kelas sentimen 'Negatif' = 46 data, dan. Untuk kelas sentimen 'Positif' dapat diprediksi dengan tepat = 105 data, diprediksi pada kelas sentimen 'Negatif' = 8 data, dan 'Neutral' = 23 data.
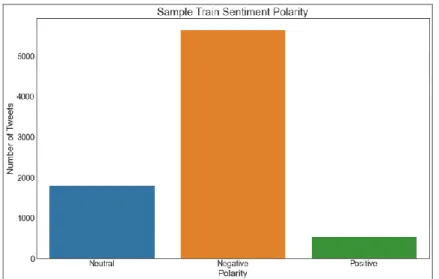
Untuk melihat akurasi klasifikasi setiap kelas sentimen, maka perlu dilakukan perhitungan nilai precision, recall dan f1 score untuk setiap kelas sentimen. Hasil klasifikasi sentimen ini mirip dengan klasifikasi polaritas data training yang digunakan, dimana kelas sentimen 'Negatif' mendominasi keseluruhan kelas sentimen dengan proporsi yang sedikit berbeda.
Analisis Sentimen Jendela Waktu
- Jumlah Tweet Sebelum dan Selama Pandemi
- Polaritas Sentimen Sebelum dan Selama Pandemi
Tabel 4.19 dan 4.20 menunjukkan bahwa jumlah tweet 'Negatif' meningkat tajam di hampir semua penyedia layanan pada periode pertama pandemi (p-value ≤ 0,05). Hasil uji korelasi dan signifikansi polaritas sentimen 'Neutral' dengan pandemi Covid-19 periode pertama dapat dilihat pada Tabel 4.24 dan Tabel 4.25 sesuai data yang dicetak tebal. Kecenderungan sentimen 'Neutral' periode kedua menunjukkan hasil uji korelasi dan signifikansi yang berbeda dibandingkan periode sebelumnya.
Konten polaritas sentimen 'netral' seperti yang terlihat pada contoh Tabel 4.28 adalah tweet yang tidak mencerminkan polarisasi sentimen pelanggan yang sebenarnya. Contoh tweet pelanggan terkait promo atau event ulang tahun salah satu provider yang tergolong memiliki polaritas sentimen “positif” dapat dilihat pada Tabel 4.34.

Pemodelan Topik
- Topik tweet “Negatif’ sebelum pandemi
- Topik tweet ‘Negatif’ periode pertama pandemi
- Topik tweet ‘Negatif’ periode kedua pandemi
PENUTUP
Kesimpulan
- Analisis Sentimen
- Pemodelan Topik
Dengan model tersebut, secara umum klasifikasi data terkait jasa pengiriman barang dalam negeri di Indonesia memiliki skor polaritas sentimen 'Negatif' = 65,32%. Selama tiga bulan pertama pandemi, analisis rentang waktu menunjukkan bahwa Covid-19 tidak hanya terkait secara positif secara signifikan dengan jumlah tweet, tetapi juga secara positif terkait dengan polaritas mood 'negatif' di hampir semua layanan. penyedia. Pada periode pra-pandemi, diperoleh jumlah optimal dari 5 topik ini, antara lain: (1) kecepatan layanan dan garansi, (2) tracking dan update informasi, (3) update progress pengiriman, (4) sinkronisasi status barang, ( 5) pengiriman konfirmasi.
Pada tiga bulan pertama pandemi, jumlah topik optimal yang diterima adalah 6 topik, yang sebagian merupakan topik baru seperti: (1) layanan pelanggan, (2) pengiriman, sedangkan sisanya topik lama, misalnya. (3) jaminan kecepatan dan layanan, (4) informasi pelacakan dan pembaruan, (5) pembaruan kemajuan pengiriman, dan (6) konfirmasi pengiriman. Terakhir, selama trimester kedua pandemi, jumlah topik optimal yang diterima adalah 6 topik tertentu.
Implikasi Penelitian
- Implikasi Teoritis
- Implikasi Praktis
Padahal, semua topik bahasan tersebut merupakan topik yang sudah ada pada periode-periode sebelumnya, yang hanya dapat dikelompokkan menjadi 4 topik utama, yaitu: (1) pelacakan dan pemutakhiran informasi, (2) konfirmasi pengiriman, (3) sinkronisasi status barang informasi, dan (4) jaminan kecepatan dan pengiriman. Dengan pendekatan leksikon, metode manual hanya diperlukan untuk mengevaluasi dan memastikan bahwa hasil klasifikasi sesuai dengan konteks. Hasil penelitian ini dapat dijadikan masukan bagi penyedia jasa pengiriman barang dalam negeri di Indonesia.
Menyajikan analisis sentimen dan pemodelan topik tidak hanya dapat digunakan untuk mengetahui sentimen saat ini, tetapi juga dapat digunakan untuk perbaikan melalui evaluasi topik sentimen 'negatif'. Topik ini meliputi: (1) jaminan kecepatan dan layanan, (2) melacak dan memperbarui informasi, dan (3) konfirmasi pengiriman.
Saran
Penambangan media sosial untuk perencanaan produk: Pendekatan penambangan peluang produk berdasarkan pemodelan topik dan analisis sentimen. Diambil dari website JNE Express: https://www.jne.co.id/en/company/profil-company#. Diambil dari situs Kompas: https://nasional.kompas.com/readbulan-pandemi-covid-19-note-about-psbb-dan-penerapan-protokol?page=all McCallum, A.
Diambil kembali dari Pos Indonesia website: https://www.posindonesia.co.id/en/content/sejarah-pos. Sentiment Analysis for Mining Customer Opinion on Twitter: A Case Study of Ride-Hailing Service Provider.
Perhitungan nilai TF-IDF
Perhitungan nilai akurasi berdasarkan confussion matrix
Contoh perhitungan nilai presisi kelas ‘Positif’
Contoh perhitungan nilai recall kelas ‘Positif’
Perhitungan nilai f1-score
Perhitungan nilai skor sentimen
Perhitungan nilai akurasi berdasarkan confussion matrix tiga elemen . 39
Perhitungan nilai presisi kelas ‘Netral’ tiga elemen
Perhitungan nilai presisi kelas ‘Negatif’ tiga elemen
Perhitungan nilai recall kelas ‘Positif’ tiga elemen tiga elemen
Perhitungan nilai recall kelas ‘Netral’ tiga elemen tiga elemen
Perhitungan nilai recall kelas ‘Negatif’ tiga elemen tiga elemen