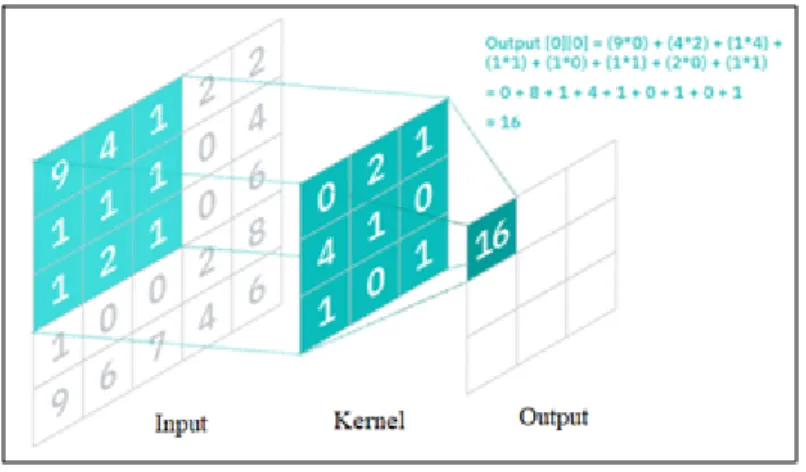
The training process gives the final results in the form of an accuracy value of 95.45% and a loss value of 0.1424. The prediction system uses an artificial neural network model generated by the learning process in the third experiment.
CONCLUSION AND SUGGESTION
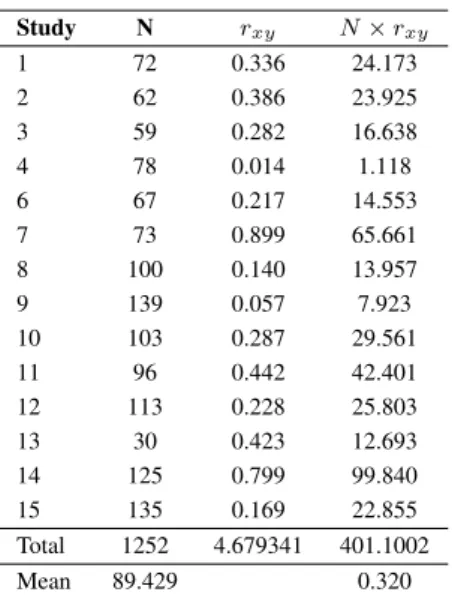
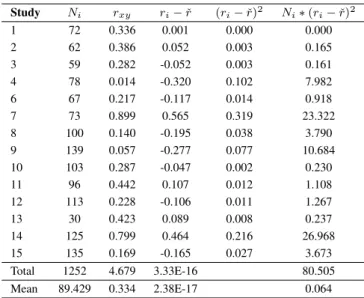
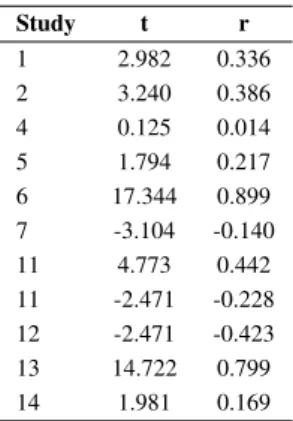
The experiment has a higher accuracy value compared to the learning process in the first and second trials. The result showed that there is a negative correlation between nurses' workload and performance, with ρ = 0.334 being in the receiving area of the 95%.
INTRODUCTION
This research was conducted to determine the effect of workload on nurses' performance with a meta-analysis approach. This research has been conducted through secondary data obtained from relevant sources related to nurses' workload and nurses in various journals.
LITERATURE REVIEW 1. Meta-Analysis
From a quantitative point of view, the large number of studies conducted on this topic increases the possibility of variations in the results or research conclusions. The nurse's workload is all activities in the nursing department performed by a nurse (Marquis and Huston, 2017).
RESEARCH METHOD
36 of 2009 states that workload is the product of the number of jobs over time and the amount of work to be dealt with by a position or organizational unit. The high workload can result in poor communication between nurses and patients, failure of collaboration between nurses and doctors, nurses leaving and dissatisfaction.
RESULTS AND DISCUSSION 1. Inclusion Criterion
Based on the results of the actual correlation variance (σ2ρxy), the size of the standard deviation (SD) =q can be calculated. Based on the problem, it is necessary to study the determinants of leprosy prevalence in Sulawesi Island.
LITERATURE REVIEW
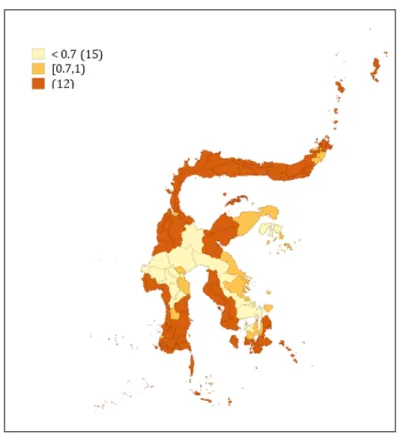
Based on the problem, it is necessary to study determinants of the leprosy incidence on Sulawesi Island in 2017. The independent variables are population density ("Dense"), the percentage of households that practice a clean and healthy lifestyle ("PHBS"), the percentage of households that have good sanitation ("Sanitation)", the percentage of households that have access to safe water ("Water )” have, and the number of MB leprosy (“LepraMB).
RESULTS AND DISCUSSION
Meanwhile, in the research of (Shovalina and Atok, 2016), population density also significantly affects the prevalence of leprosy in East Java Province. On the contrary, in a study conducted by (Sabil et al., 2018), it was found that the percentage of the population with access to proper sanitation has a significant effect on the prevalence of leprosy in South Sulawesi Province.
LITERATURE REVIEW 1. Time Series Analysis
ARCH-GARCH a. ARCH
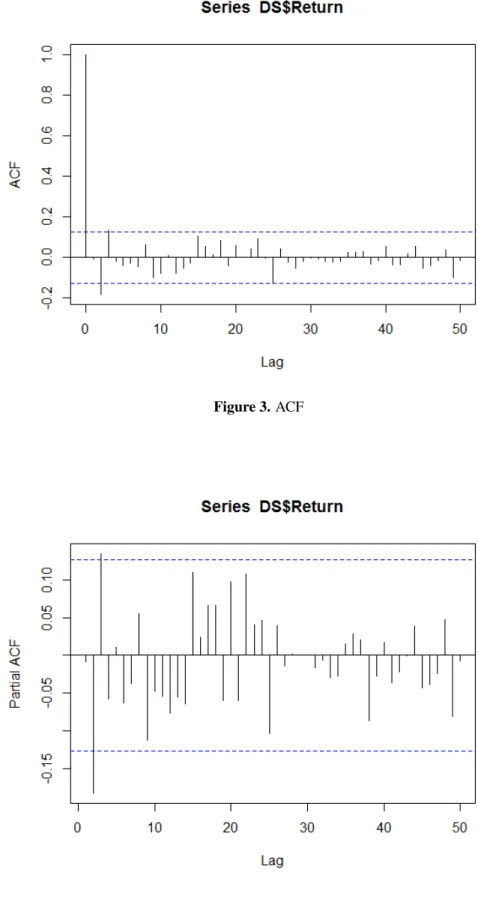
The basic concept of the ARCH model is that the residual variance depends on the square of the previous residual. Time series data cannot be separated from the stationarity test of the data under study. A model suitability study is performed to prove that the resulting model is adequate, as shown in Table 4 below.
Selection of the best model based on the lowest significance (5%) of the AIC and BIC models.
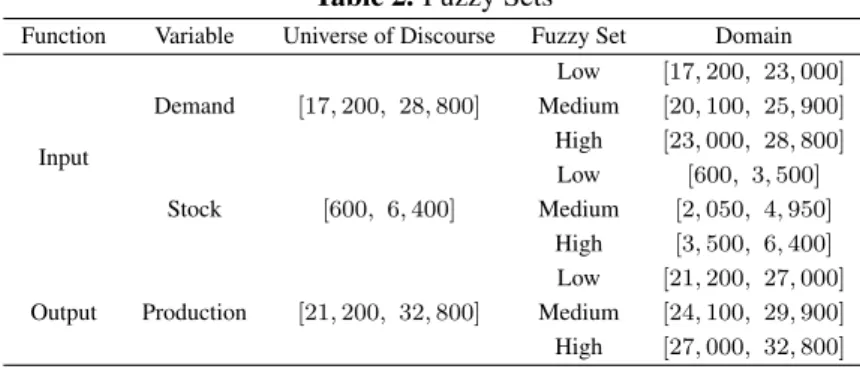
LITERATURE REVIEW 1. Fuzzy Set
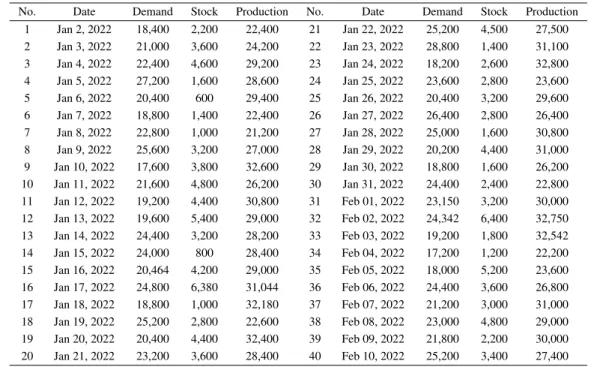
The factory needs a plan to determine the amount of production to meet market demand and maximize profits. Therefore, planning the amount of production in a company is very important to meet the market demand and in the right quantity. Subsequently (Rahakbauw et al., 2019) applied the Mamdani FIS method to predict the amount of rubber production by considering the availability of data and the requested data and an accuracy rate of 87.83%.
This research aims to compare the amount of production calculated using the five Mamdani defuzzification methods.
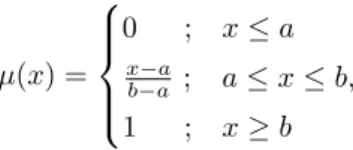
RESEARCH METHOD 1. Place and Funding Sources
In the midline method, the crisp solution is obtained by taking the domain that has a value from the number of membership values in the fuzzy area. In the MOM method, the sharp solution is obtained by taking the average value of the domain that has the maximum membership value. In the LOM method, the maximum solution is obtained by taking the largest value from the domain that has the maximum membership value.
In the SOM method, the clear solution is obtained by taking the smallest value from the domain that has the maximum membership value.
RESULT AND DISCUSSION
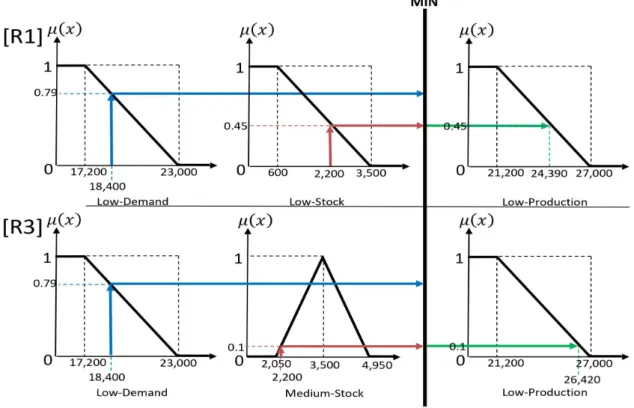
The geometric representation of the membership function of the three fuzzy sets for the question is shown in Figure 2(a). The geometric representation of the membership functions of the three fuzzy supply sets is shown in Figure 2(b). And the geometric representation of the membership functions of the three fuzzy sets for the productions is shown in Figure 2(c).
One financial instrument in the United States capital market that has price stability is a type of stock.
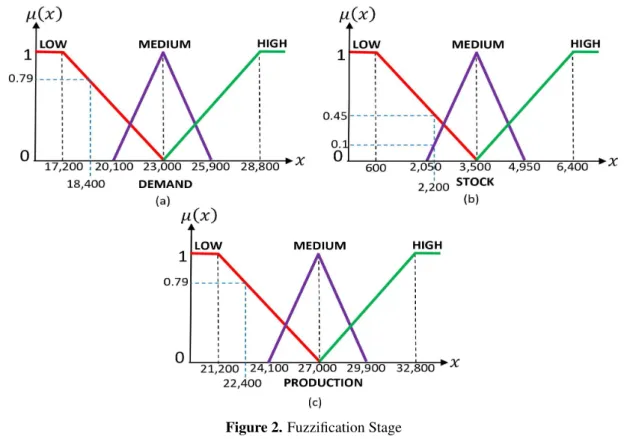
LITERATURE REVIEW 1. US Big-Cap Stocks
The study uses a real database to test the effectiveness of the proposed approach (Zheng and Chen, 2013). Conditional value at risk (CVaR), another name for ETL, is used by Arif and Sohail (Arif and Sohail, 2020) to estimate the risk of the Pakistan stock market with an optimal investment ETL value of 7.52%. In parallel, the ARCH model assumes that the unconditional variance of the error process is constant over time, but allows the conditional variance of ofat to vary as a function of the past squared error.
Suppose the simulation in this study aims to estimate an unknown quantity based on the blestimulator, which is a function of the data generated by the simulation.
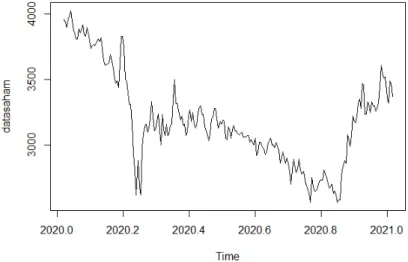
RESULTS AND DISCUSSION 1. Data Characteristics
The movement of the results of calculating the weight of each stock in the optimized portfolio based on the risk aversion value is shown in Figure 2. From these results it can be concluded that the ETL value of the optimized portfolio is 2.9%. Based on the illustration in the figure, it can be seen that the optimized portfolio has the lowest ETL value.
The Monte Carlo simulation on the ETL calculation yields a value of 2.9% for the optimized portfolio.
LITERATURE REVIEW 1. Earlier Research
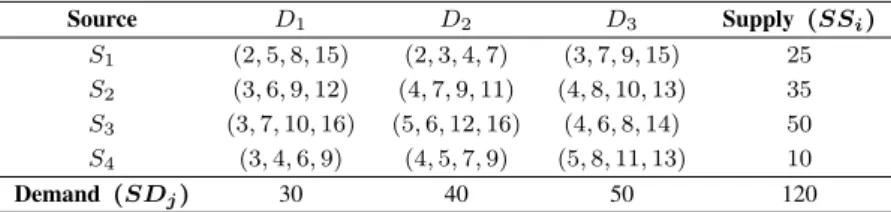
This paper proposes a new approach to solve the fuzzy transportation problem in an optimization phase. A fuzzy transportation problem with the number of sources distinct from the number of destinations is presented in Table 1. The method used in this research is the analysis of relevant theories for fuzzy transportation problems with the number of sources not equal to the number of destinations.
Furthermore, a new approach was developed to solve the fuzzy transportation problem in one optimization stage.
RESULTS AND DISCUSSION 1. Algorithm
In the non-hierarchical method, the number of clusters is determined first, then cluster members are searched based on distance, which has the same characteristics (Xie et al., 2019). In economics, a k-means algorithm was used to partition the open rate of unemployment in South Sulawesi Province (Akramunnisa and Fajriani, 2020). The comprehensive economic development index is one of the benchmarks for a region's success in the well-being of its population.
The silhouette coefficient is used in the clustering optimization process to get the best number and members of the cluster (Naghizadeh and Metaxas, 2020).
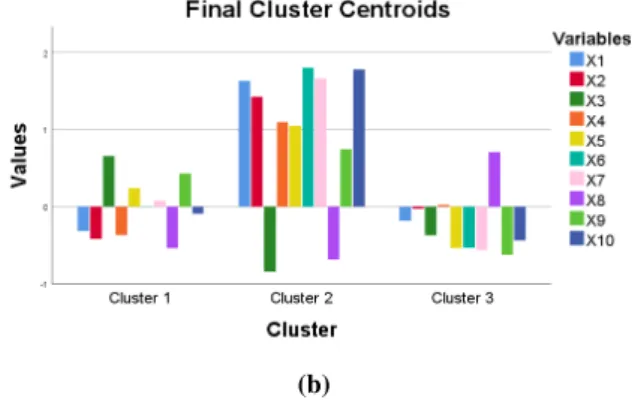
RESULTS AND DISCUSSION 1. The Results K-means Algorithm
Determination of the best scenario of k-means clustering in the clustering of districts/cities in East Java Province based on 10 indicators of inclusive economic development, the silhouette. Of the three scenarios, scenario 2 is the best k-means clustering analysis on the clustering of districts/cities in East Java based on an inclusive economic development index. Based on the results listed in Table 5, the k-means cluster analysis on the clustering of the inclusive economic development index in East Java uses 2 clusters.
Based on the description in the paragraph above, cluster 1 in scenario 1 is a group where the average inclusive economic development index of the 10 categories used is below the overall average.
LITERATURE REVIEW 1. Mask Use Compliance
The survey showed that 39% of the population did not implement the health protocol because no cases of COVID-19 occurred (National Statistical Office, 2020). This study aims to model the effect of reaching a second vaccine dose and total number of COVID-19 cases on public compliance with mask use as a measure of government policy based on nonparametric regression. Sλ : is a matrix of size nn with the equation Sλ= (I+λK)−1 z. 7) The minimum value of MSE from the calculation of Equation 7 indicates that the estimated value is close to the true value (Maharani and Saputro, 2021).
The steps for data analysis in the study, the effect of the second vaccine dose and the total number of COVID-19 cases on public compliance with mask use as a measure of public policy are as follows:
RESULTS AND DISCUSSION 1. Descriptive Statistics
So, based on the best nonparametric spline regression model using three nodes, the determination of the coefficient of the model is 69.952%, which means that the variable coverage of the second vaccination dose and the total number of cases of COVID-19 affect the level of Compatibility of masks up to 69,952% and other factors affect the rest. This model can be used to represent the effect of the second dose of vaccination and total cases of COVID-19 on mask compliance because it has an R-sq of 69.952%, which means that the second dose of vaccination and total cases of COVID-19 cases affect the level of mask compliance up to 69.952% and other factors affect the rest. Based on the results of the analysis, it can be seen that total cases of COVID-19 have a significant effect on compliance with public masks.
Compliance with public masking is significantly affected by the achievement of the second vaccination dose and the total number of COVID-19 cases.
Prototypes Algorithm For Clustering The Tectonic Earthquake In Sulawesi Island
Thek prototypes algorithm is one of the clustering methods based on partitioning (Pham et al., 2011) (Iriawan et al., 2018). This algorithm is the result of the development of the k-means algorithm (Mau and Huynh, 2021) (Ahmad and Dey, 2011) to handle clustering on data with mixed numerical and categorical type characteristics (Dinh et al., 2021). In general, the k-prototypes algorithm is divided into three main stages, (Sulastri et al.,2021), as follows: First, initialization of the prototype.
At this point, the k-prototype algorithm assigns all objects in the data set to the group where the prototype of the group has the closest distance to the data object.
RESULTS AND DISCUSSION 1. Data Description
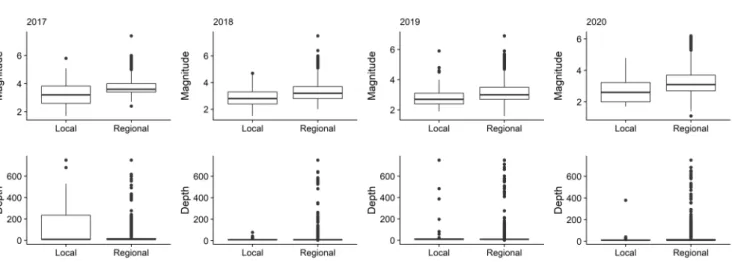
We can see that cluster 1 and cluster 2 contain larger earthquakes than others, and cluster 4 contains the smallest earthquake in 2017. In 2018, cluster 2 and cluster 4 contain larger earthquakes than the others, with the smallest earthquake being Cluster 3. In 2019 contains Cluster 1 and Cluster 4 larger earthquakes than the others, with the smallest earthquake being Cluster 2.
Finally, in 2020, cluster 1 and cluster 6 contain a larger earthquake than the others, with the lowest magnitude earthquake being Cluster 5.