The FER system is configured for multi-class facial expression classification mode using Support Vector Machine (SVM). Experiments on facial expression databases show that maximum recognition rate will be obtained for the scale in which the width is greater than the height of the operator.
Context
Deriving face image analysis by integrating face and facial expression tasks would help schizophrenics [11] and patients with dual dissociation patterns [12]. In designing an automatic face image analysis system integrating face recognition and facial expression recognition, the first subtask is to detect the face(s) in the given input image and localize the facial features (nose, eyes and mouth).
Challenges
Illumination
Variations in the strength and angle of the incident light on the face would cause significant changes in the image, as shown in Figure 1.1. An ambient light source would cause fewer intra-class variations in the image, which can be easily handled compared to point sources such as mugshot images.
Pose
Facial Expressions
Automatic Face Image Analysis
Face Recognition System (FRS)
Components of FRS
The facial recognition system is limited to faces with facial expressions inherent in most standard databases. These feature extraction techniques should be robust to the difficulties/challenges that the image analysis system would face in real-world application.
Principal Component Analysis (PCA)
Similarity Measures
This can be formalized as follows: given a new feature vector x and a database of enrolled N subject templates. Given two vectors x and ¯yi, where x denotes the face feature vector, ¯yi denotes the mean vector of the system client featuresIi, (i= 1,2. . . , N), C−1 is the inverse covariance matrix and T denotes the transposition of the vector, we can formalize each distance as similar [59, 60].
FR Performance Measures
Facial Expression Recognition System (FERS)
Types of Facial Expression
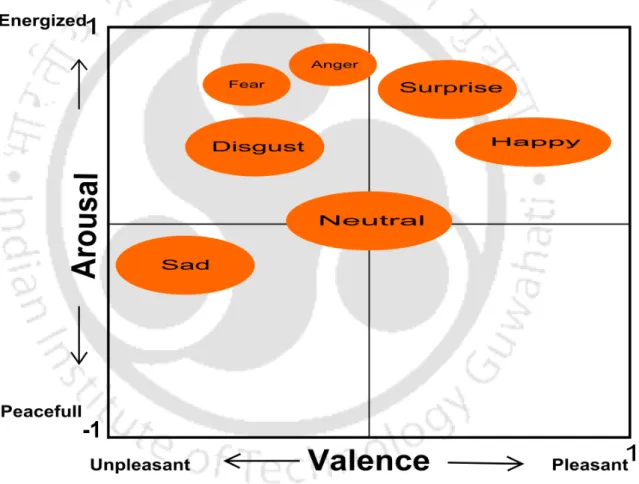
Each facial expression is represented as a combination of deformation of facial muscles called Action Units (AUs). Most of the researchers consider Valance and Arousal dimensions as shown in Figure 1.5, as they can represent most of the emotions.
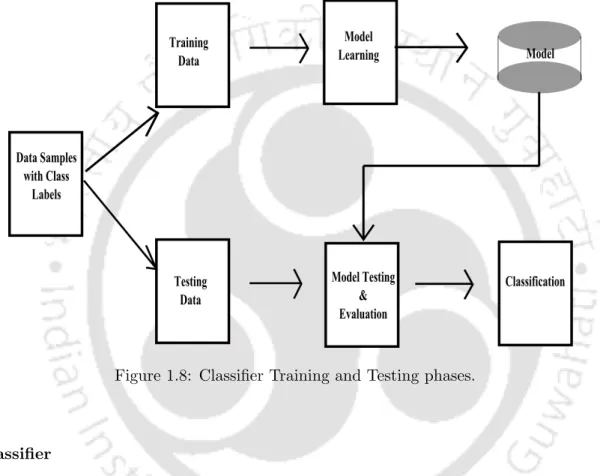
Components of FERS
Emotion recognition deals with the interpretation of facial expression with context, feeling of the subject and surrounding environment. Spatial information (location) is important as facial expressions are the result of contraction of facial muscles in specific regions of the face. The learning model should not overfit the data, that is, the model performs best on the training and test data, but performs worst on unseen data.
Intersections of the Framework
Contributions
Overview of the Thesis
Chapter Summary
It is well known that FR and FER systems can be categorized into two types depending on the type of input image processed by feature extraction methods. Furthermore, it is also known that systems incorporating local feature extraction techniques would provide better performance than holistic ones. The research illustrates local and global feature extraction methods used to derive FR and FER systems.
Face Recognition
Survey on LBP based Operators in FR
Tanet.al [91] has proposed the Local Ternary Model (LTP) to extract face representation for face recognition under difficult lighting conditions. In [92] the authors used differential LTP (DLTP) for face recognition, which is robust to noise and illumination. Wolfet.al [93] has used Three Patch (TPLBP) and Four Patch LBP (FPLBP) for face identification and verification.
![Figure 2.1: Taxonomy of local descriptors [4] used in face recognition.](https://thumb-ap.123doks.com/thumbv2/azpdfnet/10495396.0/61.892.178.742.207.690/figure-2-taxonomy-local-descriptors-used-face-recognition.webp)
Facial Expression Recognition
Survey on LBP based Operators in FER
Some of the studies applying LBP-based operators for facial expression recognition are briefly discussed below. Moore et al. used two consecutive stages to study the effect of facial pose in different facial views to classify the facial expressions. In this group, the authors considered reducing the redundancy and dimensionality of the input feature space to increase the facial expression recognition speed.
Intersection of Feature Extraction methods
Chapter Summary
The process of extracting discriminative salient features from an image is called feature extraction or feature representation. The performance of a system mainly depends on the feature extraction techniques as it decides what and how the discriminative information is extracted from the image. Recently local feature extraction methods have proven to be efficient in FR and FER systems.
Local Binary Pattern based Operators
Convolution Method
15] suggested that the constraint would reduce the influence of border pixels, thus increasing the discrimination ability of the operator. However, there is a loss in the number of available codes used in deriving the histogram from each grid. Reducing the number of LBP codes would affect the histogram and change the performance of the facial image analysis system.
Traditional Face Representation
Therefore, the size of the operator also affects the number of labeled codes per image, the size of the cropped image, and the size of the grid. However, the choice of the number of grids (and thus the size) would depend on the application and also the type of normalization applied to the image. Where R is the radius of the operator, α and β are the width and height of the image, respectively.
![Figure 3.5: LBP based face representation [6].](https://thumb-ap.123doks.com/thumbv2/azpdfnet/10495396.0/76.892.108.747.223.491/figure-3-5-lbp-based-face-representation-6.webp)
Proposed Face Representation
Modified Convolution (MC) Method
This technique maximizes the available labeled codes per image, and the size of the operator does not affect the size of the cropped image and the size of the grid, since the boundary constraint is relaxed. In this case, the average for these operator subregions is calculated considering only the overlapped pixels of that region with the image grid and the pixel (1, 1) encoded as decimal 254. The bold numbers represent the average values of the respective pixels overlapped with the operator subregions.
![Figure 3.6: Modified convolution method [8]: (a) 5 × 5 ARLBP thresholding when region of the operator is out of bound with the image boundary](https://thumb-ap.123doks.com/thumbv2/azpdfnet/10495396.0/79.892.174.800.213.642/figure-modified-convolution-method-arlbp-thresholding-operator-boundary.webp)
Asymmetric Region LBP (ARLBP)
The size of the central region is invariant to changes in subregion size and operator size. The average of each region is calculated as shown in the region with bold numbers, except for the central region for illustration. ARLBP encodes micro-patterns at smaller scales as it is similar to the LBP operator in size 3 × 3, and also encodes macro-patterns at larger scales as it is scalable without increasing the feature histogram.
Extended Asymmetric Region-LBP (EARLBP)
Robust to noise as it considers the average pixel intensity for labeling and the pixel threshold value.
Chapter Summary
Face recognition is one of the challenging areas of research regarding the problems that must be addressed by a system to deliver reasonable performance. To derive a good system, one should pay attention to the design of the components such as feature extraction and classifier that would be invariant to variation. These LBP-based face representations are sensitive to different parameters such as size of the image, size and number of belts into which a face image is divided, size of the operators, type of classifier, etc.
Why Face Verification?
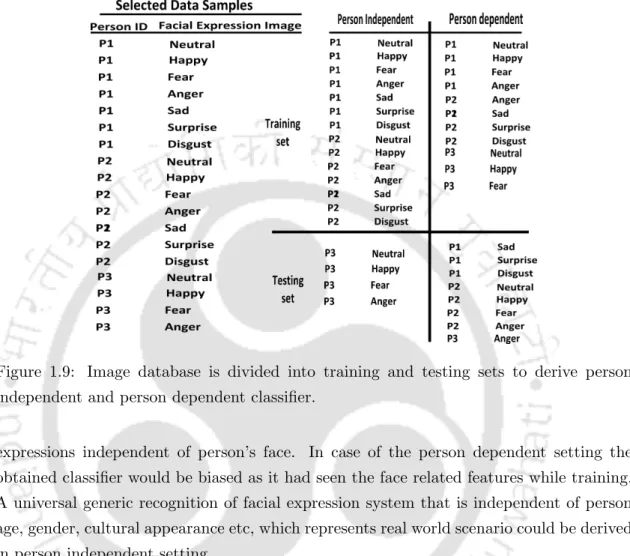
Description of the Databases used
Each subject posed 7 facial expressions (6 basic expressions and 1 neutral) photographed with constant lighting and a uniform background. The database is used to test the invariance capability of FRS with respect to the facial expressions that are part of the database. Images are captured by introducing some variations such as time, changing lighting, facial expressions (eyes open/closed, smiling/not smiling) and facial details (glasses/no glasses) but with a constant background.

Experimental Process
Experimental Design
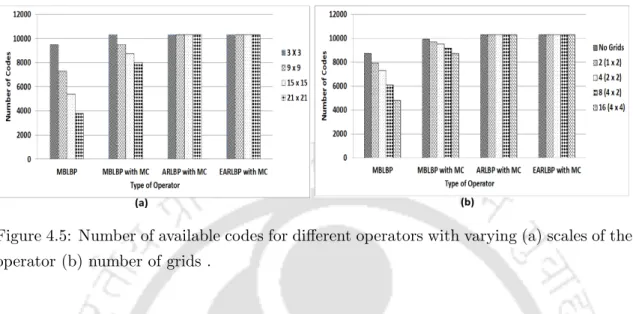
The following experiment cases are designed to investigate the effect of ignoring boundary pixels by traditional convolution technique and the suitability of proposed operators in the FR domain. This case is designed to study the effect of several parameters such as the scale of the operator, the number of grids into which an image is divided and the number of available labeled codes. Furthermore, MBLBP is used experimentally to verify the effect of MC on the number of available codes.
Experiments and Results
Case 1: Effect of Modified Convolution (MC)
This may be due to the fact that the available codes will decrease rapidly with increase in the scale of the operator and the number of grids. This is due to the fact that the available codes are still dependent on the scale of the central region. When the available codes are constant per image, the effect of number of grids and scale of the operator on FR or FER can be investigated.
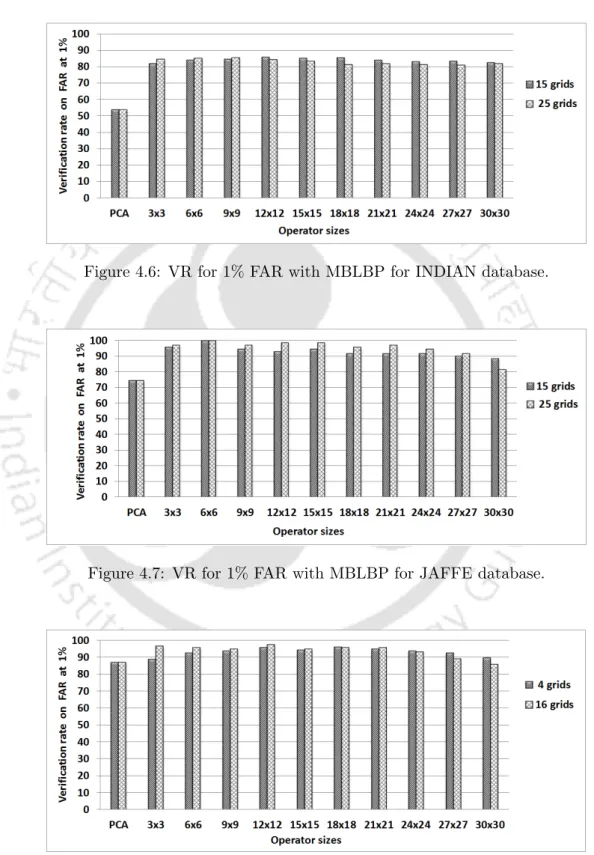
Case 2: Face Verification
This may be due to two factors such as: decrease in the available codes as the scale of the operator increases. For 15 grids, the VR increases with increase in the scale of the operator on INDIAN database. But the VR decreases as the scale of the operator further increases (observed from the scale 13×13 onwards).
Chapter Summary
Localization and Registration Errors
Facial expressions are the result of deformation of muscles in a certain part of the face. Given a constant background, low-level features such as skin color [146], edges, and motion [147] can be used to localize the face. It is one of the best and most widely used face localization methods available in face detection literature.

Face Localization Method
In the context of automatic feature extraction, face localization and image registration must be consistent in order to obtain facial expression features. Eye detectors (left and right) are used to reduce the false positive of the face detector. Of the three rectangles, one is the face rectangle Γ(xΓ, yΓ, αΓ, βΓ) and two are eye rectangles, LE (xLE, yLE, αLE, βLE) for the left eye (LE) and RE(xRE, yRE, αRE, βRE) for the right eye (RE).
Description of the Databases used
The database consists of 593 sequences with peak frame FACS (Facial Action Coding System) coded and 327 sequences out of 593 peak frames were emotion coded (neutral, happy, sad, surprise, fear, disgust, anger and contempt) using the active appearance model and Support vector machine. The FGNET [138] is a more challenging database of facial expressions as it captures facial expression as naturally as possible when people react to a movie being played. The database has a video sequence of 18 individuals (male and female) performing each facial expression three times.

Facial Expression Recognition using Asymmetric Region based LBPs
Experimental Process
For each degree (magnitude) of the ARLBP operator, the face in the images was localized using The size of the proposed operators does not affect the histogram length as in other LBP-based operators, except for the MBLBP operator. Moreover, the size of the operator does not affect or affect the number of the network.
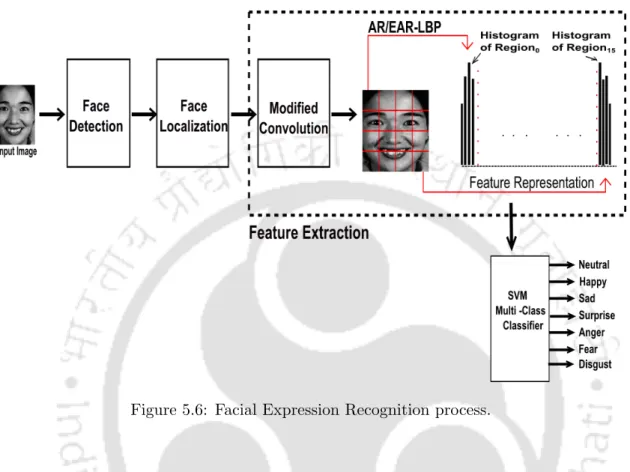
Experimental Design
Facial Expression Recognition using ARLBP
Case 1: Person dependent with registration errors
From the table it can be seen that the recognition rate tends to increase when the width is greater than the height of the operator and reaches a maximum of 95.71%. When the width and height of the operator are equal (viewed diagonally from top left to bottom right) the recognition rate does not increase. However, when the height decreases and as the width increases (observed diagonally from top right to bottom left), the recognition rate shows an increasing trend except for the 11×5 size.
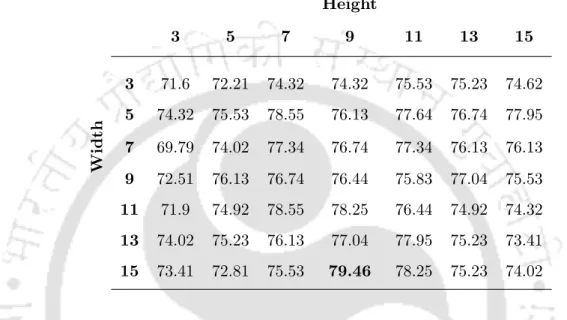
Case 2: Person independent with registration errors
In the case of CK+ database, it is clear from Table 5.5 and Table 5.6 that the maximum recognition rate is 83.19%. The performance is better for sizes where the width is greater than the height of the operator.
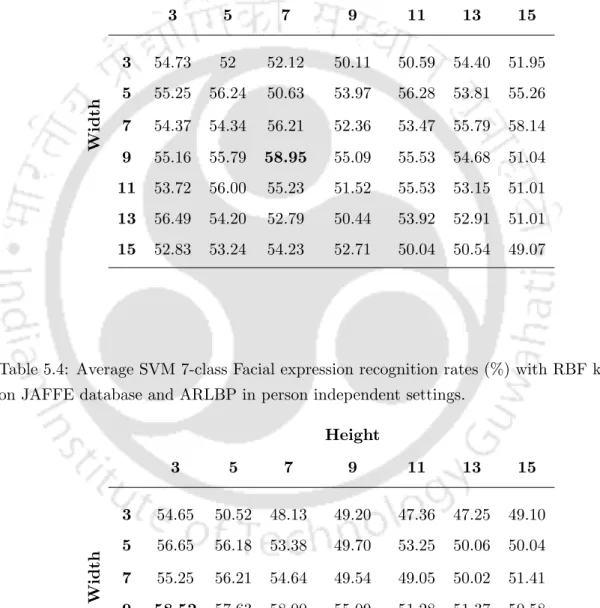
Case 3: Person independent without registration errors
Facial Expression Recognition using EARLBP
Case 2: Person independent with registration errors
One can observe that the recognition rate is significantly higher for size when the width is more than the height of the operator. From Table 5.11 and Table 5.12 similar observations can be made on CK+ database as obtained in the case of the JAFFE database. On the contrary, better performance was obtained when the width and height of the operator were less than 9 (observed 1st to 3rd columns of all tables) for both databases.
Case 3: Person independent without registration errors
It is obvious that the highest level of recognition was achieved in the case where the width of the operator is greater than his height. The linear kernel SVM achieved a higher recognition rate of 87.62% compared to the performance of 86.76% in the case of the RBF kernel. These operators perform better in the CK+ database in the case of no registration errors compared to registration errors.
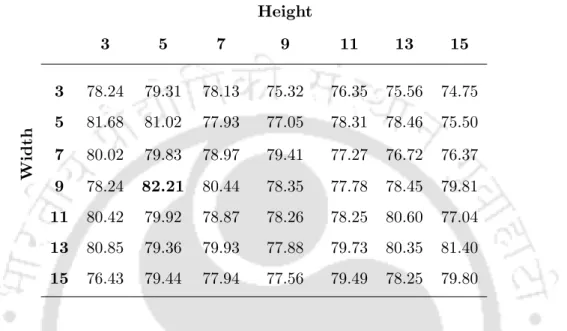
Chapter Summary
The system capacity is reduced due to the reduction of available codes, which is affected by the increase in the number of networks and the range of the operator. System operation would be maintained as long as the number of codes available was not affected. The operation of the system is highly dependent on the available codes and not on the operator's scope and number of networks.
Scope for Future Work
Huang, “Real-time facial expression recognition with adaboost,” in Proceedings of the 17th International Conference on Pattern Recognition, ICPR 2004, vol. Chae, "Facial expression recognition using local direction pattern (LDP)", in 17th IEEE International Conference on Image Processing (ICIP), September Das, "Face recognition using MB-LBP and PCA: a comparative study", in International Conference on Computer Communications and Informatics (ICCCI -2014).
![Figure 1.1: Face under fixed view with varying illumination (ambient) (adapted from [1])](https://thumb-ap.123doks.com/thumbv2/azpdfnet/10495396.0/32.892.131.736.633.794/figure-face-fixed-view-varying-illumination-ambient-adapted.webp)
![Figure 1.6: Common Action Units [3].](https://thumb-ap.123doks.com/thumbv2/azpdfnet/10495396.0/46.892.109.746.318.958/figure-1-6-common-action-units-3.webp)

![Figure 3.3: Example of MBLBP [7] with 3 × 3 sub-regions of the size 3 × 2.](https://thumb-ap.123doks.com/thumbv2/azpdfnet/10495396.0/74.892.153.728.219.557/figure-3-3-example-mblbp-sub-regions-size.webp)
![Figure 3.7: Example of 5 × 5 sized, Asymmetric Region-LBP [8]](https://thumb-ap.123doks.com/thumbv2/azpdfnet/10495396.0/80.892.109.703.218.495/figure-3-7-example-sized-asymmetric-region-lbp.webp)
