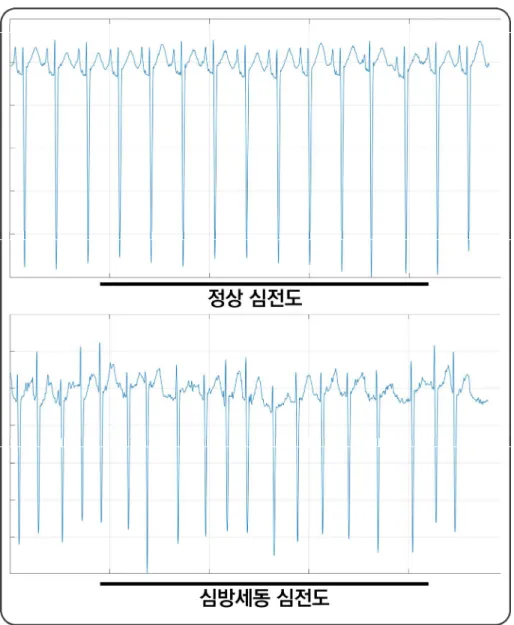
딥러닝, 네트워크 기반 오토인코더 전이학습을 이용한 심방세동 검출 모델. 심방세동과 같은 심부정맥을 검출하는 분야에서는 딥러닝 기법이 많은 연구에서 적용되어 왔다.
연구배경
그러나 부정맥을 진단하기 위해서는 심전도에 기록되는 방대한 양의 데이터를 임상의가 일일이 확인해야 한다는 문제가 있다. 또한, 중환자실과 같이 심전도가 24시간 기록되는 환경에서는 임상의가 모든 심전도 데이터를 검토하고 진단을 내리는 것이 어렵습니다.
Open access 데이터를 이용한 심방세동 자동검출 연구
그러나 이들 연구는 동일한 기기로 기록된 내부 데이터 세트에서만 성능을 학습하고 테스트했다는 점에서 한계가 있습니다. 이 경우, 다른 외부 데이터 세트를 이용하여 성능을 테스트하더라도 동일한 성능을 유지할 수 있는지 검증되지 않는다는 것이 문제이다.
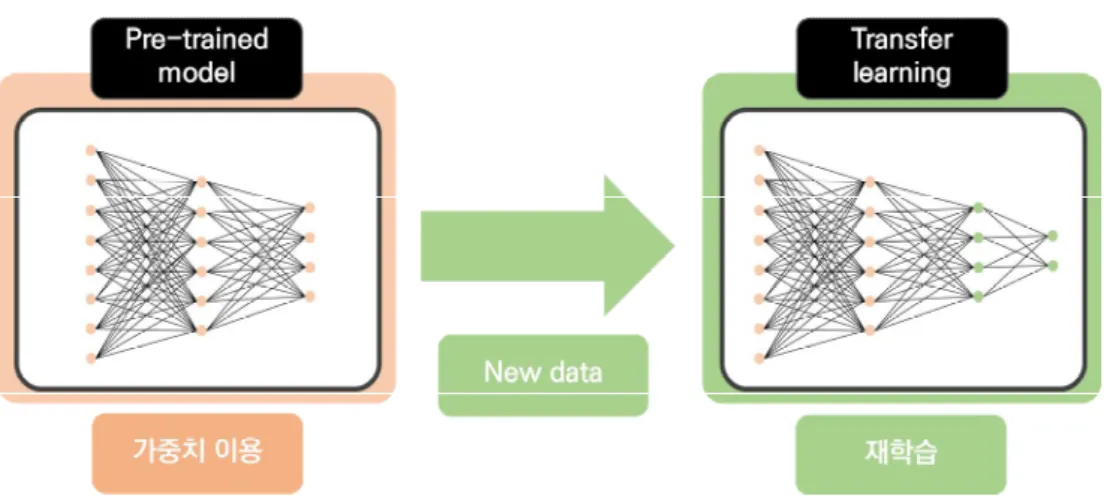
오토인코더와 전이학습을 이용한 심방세동 자동검출 연구
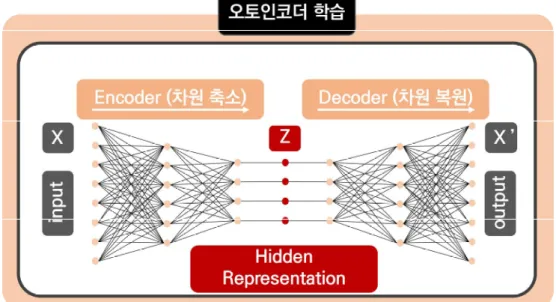
딥러닝의 오토인 인코더는 이 과정을 반복하면서 숨겨진 데이터의 특성을 학습합니다. 이러한 전이 학습은 레이블이 지정되지 않은 데이터를 사용할 수 있는 오토인코더를 적용하는 편리한 방법입니다.
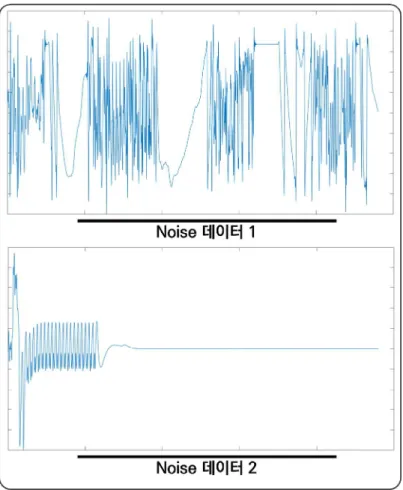
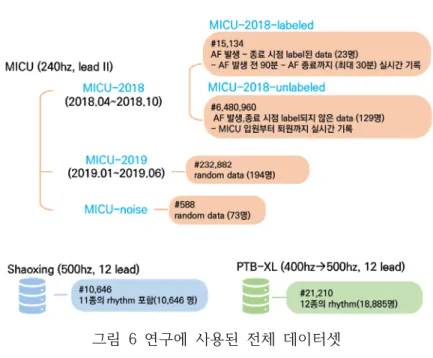
데이터셋
종말점이 있는 23명의 환자로부터 얻은 실시간 데이터가 포함되어 있습니다. MICU 사운드 데이터에는 73명의 환자로부터 녹음된 588개의 사운드 세그먼트가 포함되어 있습니다. 이 데이터세트에는 동서맥, 동리듬, 심방세동을 포함한 11개의 리듬이 포함되어 있습니다.
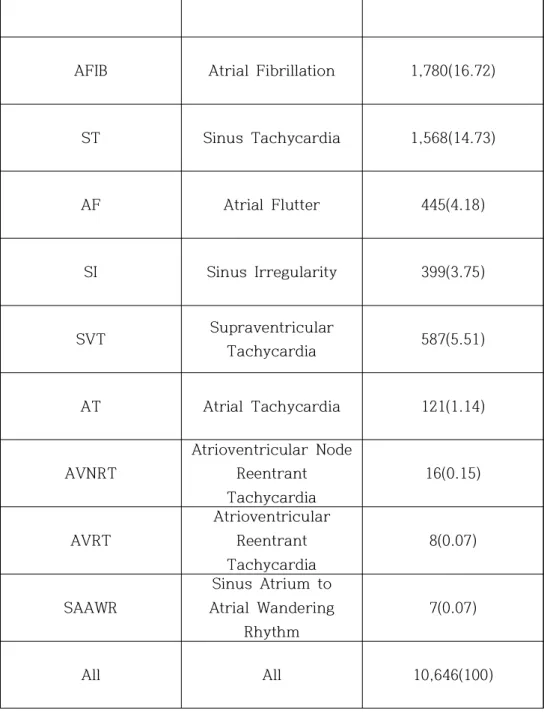
각 리듬의 세부 구성과 데이터 수는 Table 1과 같다. PTB-XL 데이터 세트는 독일 Physikalisch-Technische Bundesanstalt 연구소에서 1989년 10월부터 1996년 6월까지 기록되었다[15]. 모든 데이터 세트는 7:1:2의 비율로 학습, 검증 및 테스트 세트로 나누어졌습니다.
모델 개발의 워크플로우
오토인코더 모델 구조
전이학습 모델 구조
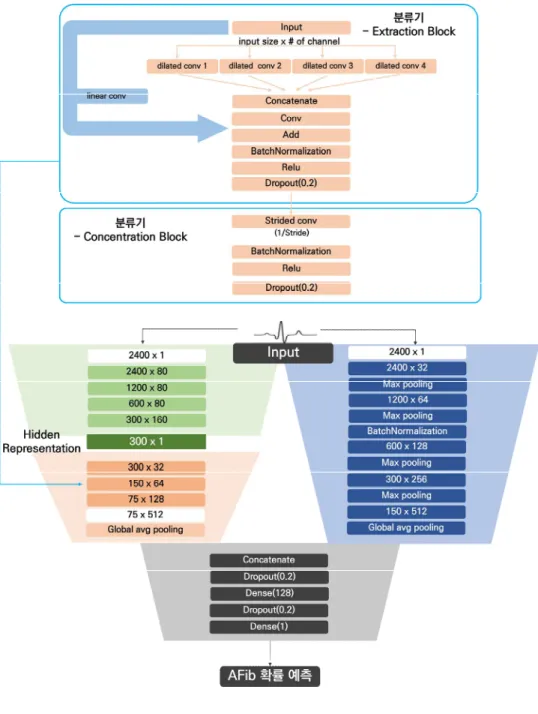
이때, 새로운 모델을 학습할 때 오토인코더의 가중치가 업데이트되지 않도록 고정된 상태에서 미세 조정을 수행했습니다. 확장된 CNN의 구조는 확장률을 변경하여 수용 필드를 늘려 입력 신호의 특징을 추출하는 추출 블록과 추출된 특징의 비선형성을 높이는 집중 블록으로 구성됩니다. 추출 블록과 집중 블록은 총 3개의 레이어로 구성되며 컨볼루션 레이어, 배치 정규화 레이어, 활성화 함수, 드롭아웃, 글로벌 평균 풀 레이어를 거쳐 일반 CNN 레이어와 연결됩니다.
다음으로 일반 CNN은 사전 학습된 모델인 Autoencoder를 거치지 않고 입력 데이터를 직접 입력받아 비선형 컨볼루션 레이어를 거치고 비선형성을 높이고 max-pooling을 통해 특징을 추출합니다. 손실 함수에는 이진 교차 엔트로피가 사용되었습니다(식 3). 분류 모델의 전체 구성은 그림 11에 나타나 있으며, 각 하이퍼파라미터의 값은 표 4에 나타나 있다.
전이학습을 이용한 분류모델 학습
4를 반올림하여 당시 심전도 데이터를 b부에 나타내었으나 모든 경우에서 AFib 발생 지점이 정확하게 검출되었음을 확인할 수 있다. 그림 19에서 볼 수 있듯이 모델이 예측한 심전도에서 심실의 수축을 나타내는 qrs 파형은 불규칙하게 나타난다.
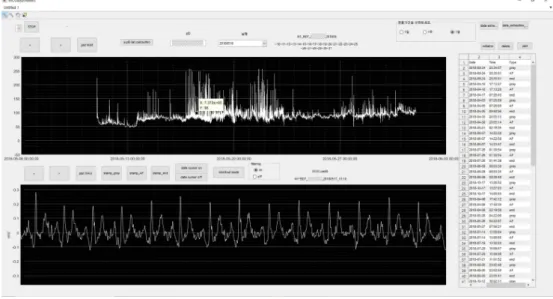
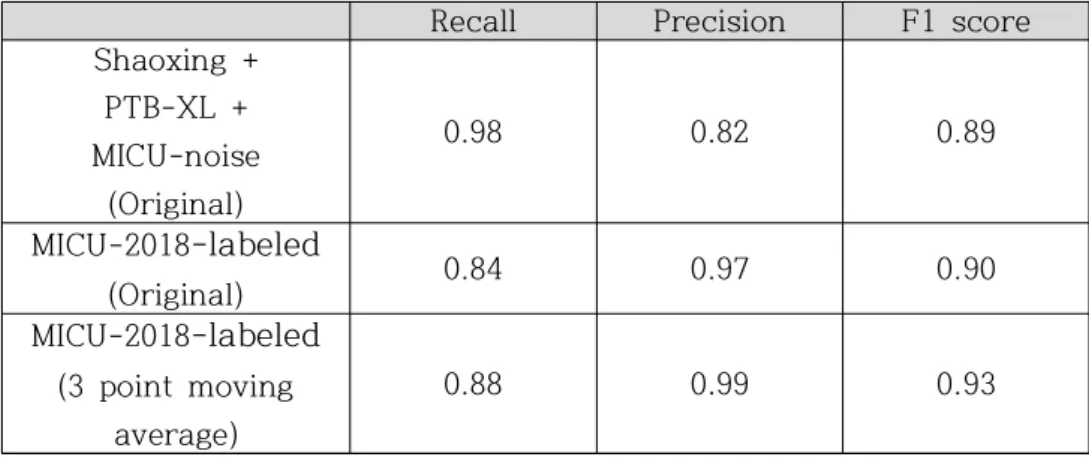
다음으로 심사 결과에 대한 검증을 실시하였다. 환자의 심전도에 안정화 기간을 주기 위해 MICU에 입장한 후 1시간 동안의 데이터에 대해서만 실시하였다. MICU-2018 unlabeled 데이터세트에 훈련된 분류 모델을 적용하고, 3점 이동평균법을 이용하여 심방세동이 30초 동안 지속되는 경우를 심방세동의 시작으로 설정하여 예측값을 얻었다.
심박수 비교
희소 부정맥에 대한 예측값
모델에 대한 인종 데이터 차이의 영향
모델을 훈련한 후 동일한 MICU-2018 레이블이 지정된 데이터를 사용하여 테스트를 수행했습니다. 결과는 Table 7과 같으며 Shaoxing 데이터 세트와 PTB-XL 데이터 세트를 모두 사용한 전이 학습 결과와 함께 표시됩니다. 이는 테스트가 수행된 MICU-2018 unlabeled 데이터에 한국인 환자의 데이터가 포함되어 있어 동일한 노란색 사람을 대상으로 훈련된 Shaoxing 모델이 백인 데이터가 포함된 단일 PTB-XL 모델보다 더 높은 F1 점수를 달성했기 때문입니다. 다음과 같이 해석될 수 있다.
따라서 동일한 품종의 데이터를 이용하여 학습하고 테스트를 함으로써 더 좋은 결과를 얻을 수 있다고 해석할 수 있다. 또한, 본 연구에서 두 데이터 세트를 모두 사용하여 제안한 모델은 중국인 환자를 포함하는 노란색 데이터와 독일인 환자를 포함하는 백인 데이터를 모두 학습할 수 있다는 장점이 있을 수 있다.
한계점
또한 본 연구에서 두 데이터 세트를 모두 활용하여 제안한 모델은 중국인 환자를 포함한 노란색 데이터와 독일인 환자를 포함한 백인 데이터를 모두 학습할 수 있다는 장점이 있을 수 있다. 정보샘플을 선택하여 학습하는 방법이다[20]. 이는 AFib가 아닌 것을 구별하고 이를 전이학습 모델의 학습 데이터로 다시 통합하는 방법으로 적용할 수 있습니다. 이를 통해 모델은 Shaoxing 및 PTB-XL 데이터에 포함되지 않은 새로운 부정맥 리듬을 학습하여 거짓양성을 줄일 수 있습니다.
모델 개발에서는 라벨링에 소요되는 시간과 비용을 최소화하기 위해 라벨이 없는 데이터와 라벨이 있는 공개 데이터를 사용했습니다. 또한 모델은 중국인 환자 데이터를 포함한 황인종의 심전도 데이터와 독일인 환자 데이터를 포함한 백인 데이터를 사용하여 훈련되었으며, 두 인종 모두에 대한 일반화 성능을 가지고 있습니다. 더욱이, 공공 기록에 포함되지 않은 부정맥 리듬의 오분류 문제는 여전히 만성적이다.