In this dissertation, we present new techniques to improve the performance of Apache Hadoop and NVMM-based LSM-trees by adapting task fragmentation and I/O. We propose ZipperDB - a key-value store that transforms the LSM tree for byte-address persistent storage.
Apache Hadoop YARN
Non-Volatile Main Memory
Using NVMM for Key-Value Stores
NVMM-Resident Index
To take advantage of the high performance and byte-addressability of DCPM, several indexing structures have been proposed recently[15–22]. While NVMM-resident indexing structures such as FAST and FAIR B+tree [17],WORT [18],CCEH [19], etc., provide orders of magnitude higher performance than disk-based indexing structures, NVMM-resident indexing structures suffer from i) latencies higher than DRAM , ii) bandwidth lower than DRAM, iii) expensive cache line flush instructions that accompany store instructions, and iv) a higher NVMM access granularity due to 256 bytes of internal buffer, which is often referred to as XPline. Moreover, v)NVMM-resident indexes are more sensitive to the NUMA effect compared to DRAM-resident indexing structures[23–25]. Furthermore, byte-addressable persistence complicates failure atomicity (i.e., reusability after a system crash) because the CPU cache replacement mechanism can evict dirty cache lines that are not ready to be persisted. To ensure failure atomicity despite such unexpected cacheline flushes, NVMM-only data structures carefully order machine instructions using memory fence instructions and frequently call expensive clflush instructions to persist dirty cachelines, incurring significant overhead bring in NVMM[17,21,26].
Hybrid DRAM+NVMM Key-Value Store
Asynchronous Incremental Checkpointing
Log-Structured Merge-Tree (LSM-Tree)
- Write in LSM-Tree
- Write Amplification Problem
- Search in LSM-Tree
- Side Effect of Write Buffer: Write Stall
Most LSM tree-based key-value stores block clients from inserting new objects into the MemTable until compaction finishes and makes room for a new MemTable. This write stall problem occurs frequently in disk-based LSM tree-based key-value stores due to the high latency of the disk.
NUMA Effects of NVMM
For a read query, an LSM tree looks up a mutable MemTable, immutable MemTables and then SSTables from level 0 to the higher levels, that is, the recently saved objects are searched first. 13]reported that most jobs in real-world MapReduce deployments process datasets that are less than 100 GB in size, for example the average job size is 14 GB in a Microsoft data center.
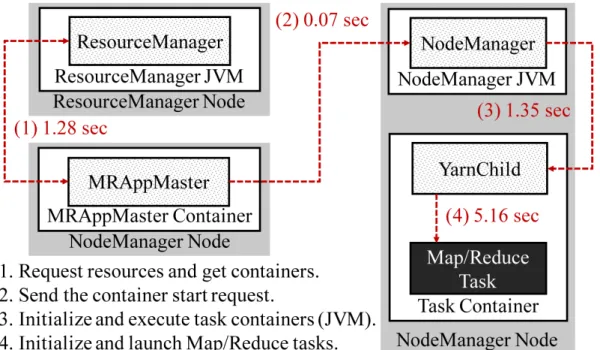
Anatomy of YARN Container Overhead
After startup, MRAppMaster i) spends 1.28 seconds communicating with the ResourceManager to determine where to start the map and reduce tasks (Figure 1, step 1). When the MRAppMaster receives information about the available slots, ii) it sends a request to start the container for each worker node where the tasks should be executed (Figure 1, step 2). iii) It takes 1.35s for the node manager of each worker node to write the container credentials and launch the scheduled containers as Java applications - YarnChild (Figure 1, step 3). iv) YarnChild loads the task configuration, configures resource limits, initializes the user pool mechanism for authentication in YARN and its related classes, initializes performance metrics to monitor Java Virtual Machine (JVM) status, and loads credentials from the usergroup information instance. Then, vi) initializes JVM metrics, creates user group information for JvmTask, and adds delegation tokens to the user group information instance that provides access to HDFS blocks.
Enabling Single Map Wave with Input Splits
Input Split
When submitting a grep application for a 250GB file, it takes about 1.51s to start the MRAppMaster. Steps iv–vii correspond to step 4 in Figure 1, which takes 5.16s to complete in our testbed cluster.
Enabling Single Map Wave
Evaluation
Experimental Setup
Experimental Results
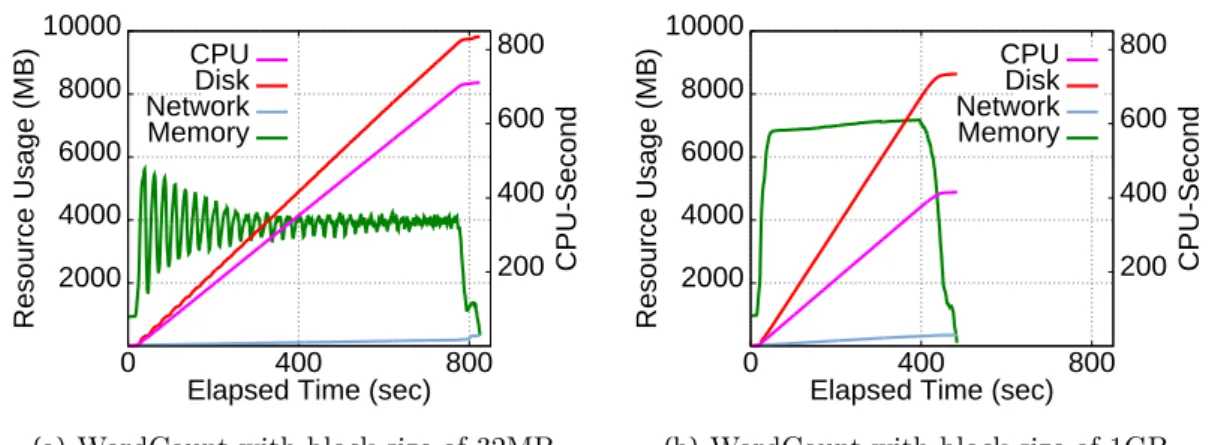
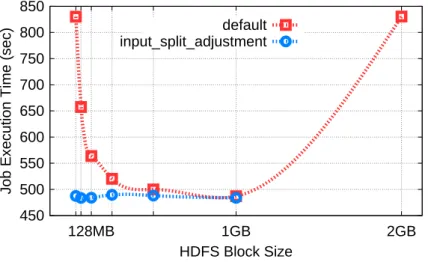
When the HDFS block size is 1 GB, each slot runs a single map wave, reducing container initialization overhead. Therefore, WordCount runs 1.7x and 1.16x faster compared to when the HDFS block size is 32 MB and 128 MB, respectively.
Summary
Our experimental results show that setting the right input split size can significantly reduce the cost of the container. Enabling a single map wave by setting the right input split size can significantly reduce the cost of a YARN container.
Problems of Coarse-Grained Task Scheduling
In this section, we first analyze the maximum input split size problems for a single short wave. That is, increasing the input split size results in long-running jobs, and the long-running jobs will make waiting jobs longer, and it will harm the fairness of job scheduling.
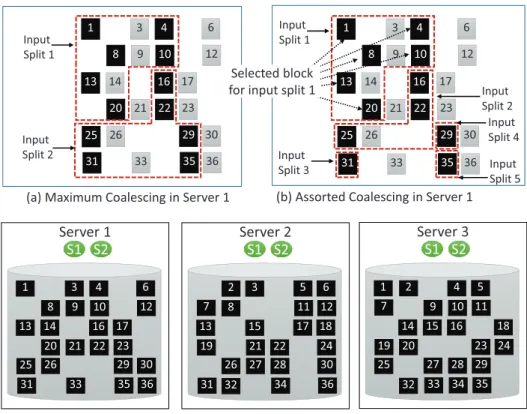
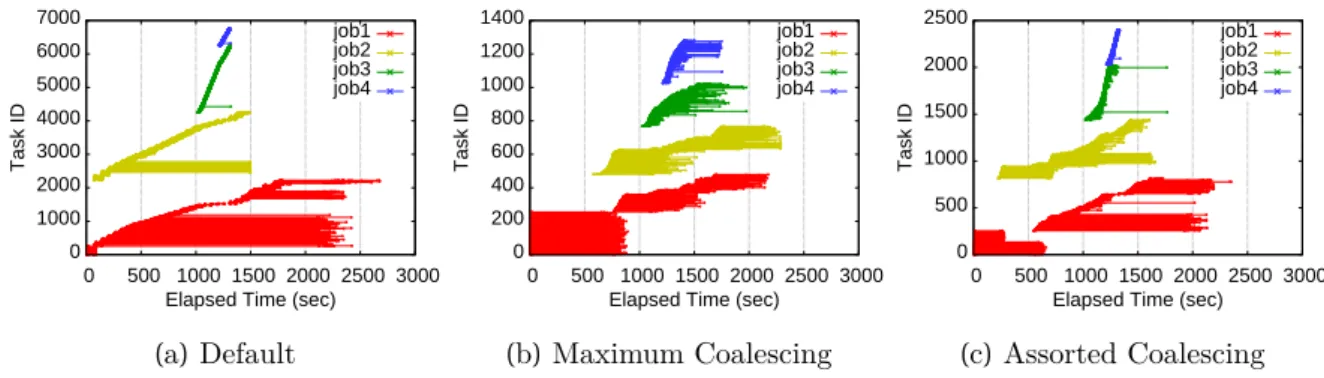
Assorted Coalescing for Fine-Grained Task Scheduling
But the number of slots used for each input partition size can be configured based on the workload and application type. Note that it is undesirable to create a large input partition if the data node does not have a sufficient number of local blocks for the current input partition size. In the for loop shown in lines 8-23, each data node selects the next merge candidate block for its current input split size.
Performance Evaluation of Assorted Coalescing
- Load Balance
- MapReduce Pipelining
- Job Scheduling Fairness
- Performance of Assorted Coalescing
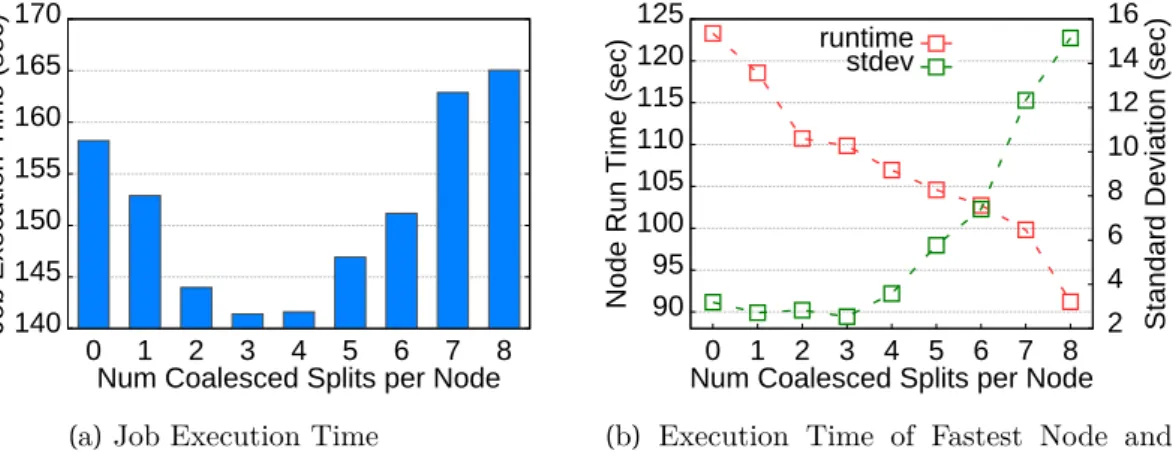
When we create the maximum size input splits for only half of the slots, that is, when the number of merged input splits in the example is 3 or 4, we may compromise the container overhead reduction and load balance. We measure the task execution time and cumulative network usage while varying the number of maximum input splits per node. However, as we increase the number of maximum input splits, the job execution time increases slightly, but it is still faster than the standard HDFS block size unless the number of large input splits is greater than 5.
Summary
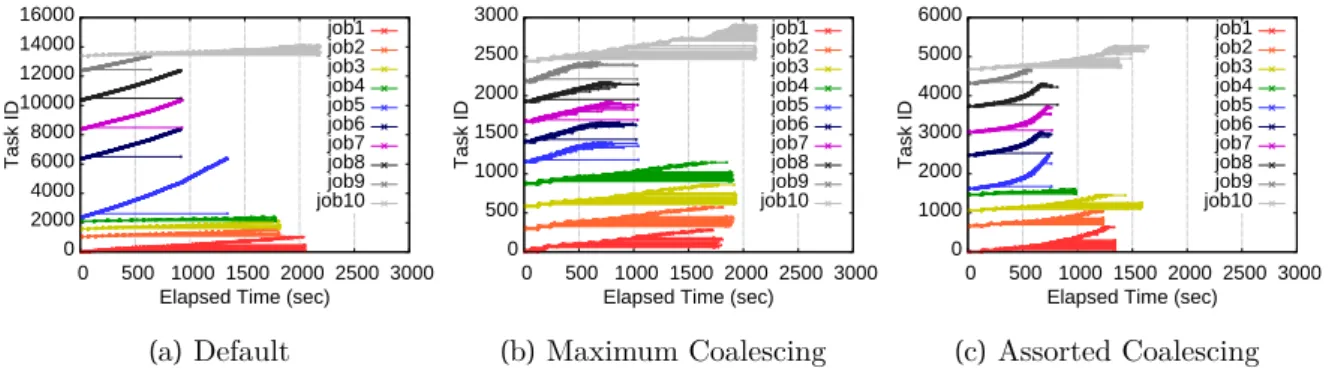
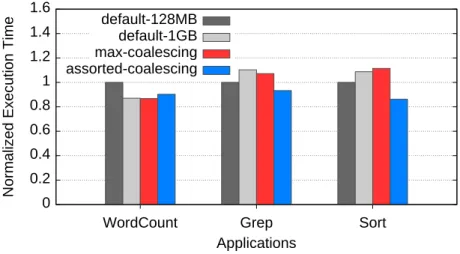
For WordCount, the maximum coalescence scheme shows the fastest performance, and standard Hadoop with 1 GB blocks shows comparable performance. However, the assorted coalescing scheme reduces container overhead while achieving good load balancing, which explains a 7% improvement over standard Hadoop. The results show that the assorted coalescing scheme has better fairness than the maximum coalescing scheme.
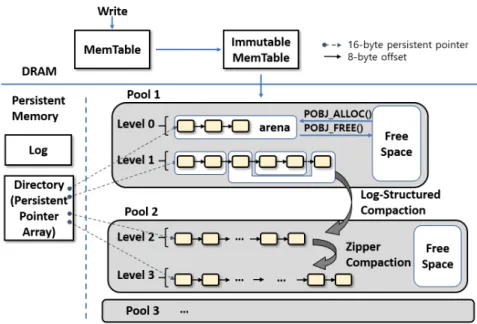
ZipperDB: Design and Implementation
- Failure-Atomic Insertion into SkipList
- Zipper Compaction: In-Place Merge
- Log-Structured Compaction
- Lock-Free Search and Crash Consistency
Various lock-free SkipLists have been studied in the literature[61,62] and the Java TM class SEConcurrentSkipListMap has been proven to work well in practice [60]. In the scan phase, we scan the low-level SkipList (LK−1) following its lower-layer pointers. In the next step, we update the next pointers of the rightmost node in each layer (line 32), as shown in Figure 13f.
Evaluation
Experimental Setup
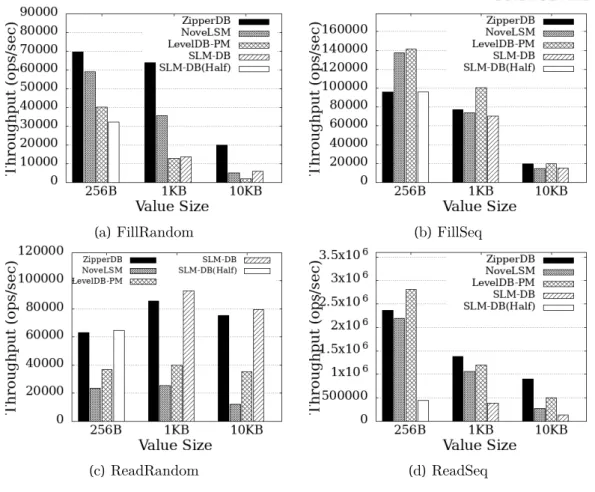
For LevelDB and NoveLSM we use the defaulttable cache and block cachesize so that they can cache up to 32 GB of SSTables in DRAM. However, because ZipperDB replaced SSTables with persistent SkipLists, ZipperDB does not use the DRAM-based table cache and block cache. For the experiments, we set the default values to all governors for LevelDB-PM, NoveLSM, and ZipperDB.
Experimental Results
As a result, NoveLSM takes advantage of the large variable persistent MemTable achieving a 57% higher throughput than LevelDB-PM. LevelDB-PM and NoveLSM support this governor because if the number of overlapping L0 SSTables increases, the read performance deteriorates. As a result, the throughput of LevelDB-PM does not increase as we increase the number of concurrent clients.
Summary
In Section V, we showed that ZipperDB helps reduce the write amplification through its persistent SkipList and the zipper compaction, an in-place merge-sort algorithm. If the so-called write-stall problem occurs, the insert throughput is limited by NVMM performance, not by DRAM performance; that is, the writeback buffer cache becomes useless. Therefore, it makes the MemTable flush throughput higher than the write throughput of the DRAM index, thus solving the write stall problem.
Write Amplification in LSM-Trees
Multi-Level vs. Two-Level Compaction
Fast compression with in-place merge sort: A zip merge sorts two SkipLists in-place without blocking read operations. By avoiding copying, zip hashing alleviates the problem of write scaling [32–34] and quickly and efficiently reduces the number of SkipLists to improve read and recovery performance.
Decoupling Merge-Sort from Flush
Design of ListDB
Three-Level Architecture
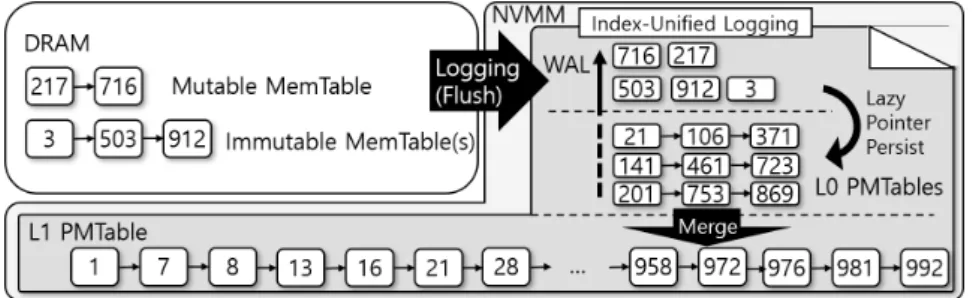
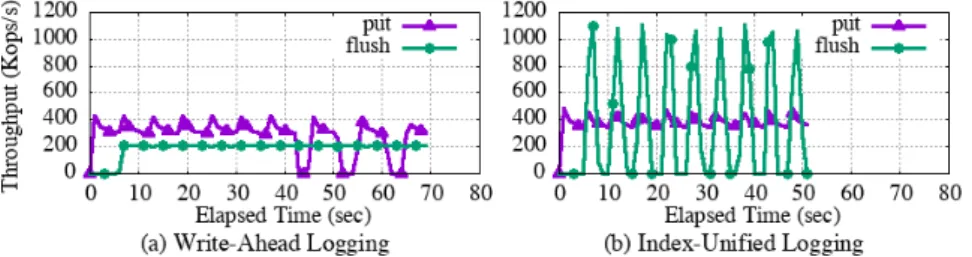
Index-Unified Logging
- Conversion of IUL into SkipList
- MemTable Flush without clflush
- Walk-Through Example
- Checkpointing L0 PMTable
Although the log data has now been converted to L0 PMTable elements, the boundary between the log space and the L0 PMTable space (indicated as a thick dotted line in Figure 26a) has not been moved because the pointers of the new L0 PMTable are not guaranteed to be the same are. persistent. Even if L0 PMTables are not saved at all, this will not affect crash consistency, because all elements in allL0PMTables are treated as log data if the system crashes, and the key order of L0 PMTable elements can be reconstructed from the log file. That is, even if IUL does not maintain any L0 PMTable, the Zip compaction persists quickly when merging an L0 PMTable into the L1PMTable, and IUL's recovery time is much shorter than synchronous checkpoints, as will be shown in Section 6.8.
NUMA Effects for SkipList
NUMA-aware Braided SkipList
In contrast, if checkpoint frequency is high, recovery will be fast but sink throughput degrades. Zip compaction, which will be described in Section 6.5, persists pointers fast enough to prevent the number of L0PMTables from growing. Since 7 is greater than 5, the wire moves down again and follows the bottom layer pointer to element 4.
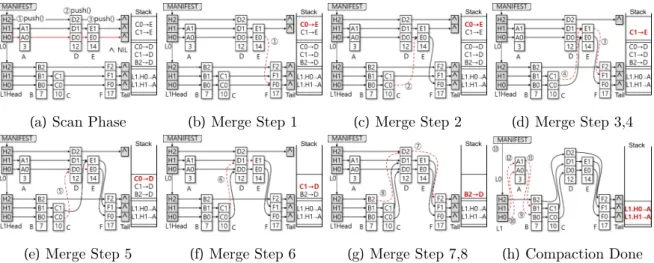
Braided Zipper Compaction
- Scan Phase
- Merge Phase
- Updates and Deletes
- Fragmentation and Garbage Collection
- Linearizability
34: // Extract and apply updates without worrying about NUMA IDs 35: L0_element.next[layer]←rightmost2update[layer].next[layer];. In the next step, shown in Figure 28c, the compression thread sets C0 to the address of E. In the next step, shown in Figure 28d, the compression thread popsC1→E, setsE1toF, and makesC1point toE.
Look-up Cache
There are two linearization points e.search_L0 and e.search_L1 for a reader as it searches L0 and then L1 PMTable in sequence. Since all three cases succeed in finding e, Zipper compression is linearizable, meaning that a read always succeeds in finding an element if the element was inserted by a committed write transaction, regardless of whether the element is in the L0 or L1 PMTable.
Recovery
Evaluation
- Experimental Setup
- Evaluation of Index-Unified Logging
- Evaluation of Braided SkipList
- Putting It All Together
- Recovery Performance
- Comparison with Other Designs
- Comparison with NoveLSM and SLM-DB
- Comparison with Pmem-RocksDB
To mitigate the problem, checkpointing can be performed less frequently, but this increases recovery time (ie, the time to rebuild the checkpointed index and insert log entries into it) as more log entries accumulate. The experiments shown in Figure 37 run on 80 client threads and use the benchmark's default key and value sizes (48-byte string keys and variable-length values ranging from 16 bytes to 10 KB). The workload submits queries according to query arrival. velocity (QPS parameter), which follows a sinusoidal distribution with a noise factor of 0.5. In contrast, Figure 37b shows that the throughput of ListDB follows a sinusoidal distribution, i.e. rate of arrival of queries, without blocking queries.
Summary
Leung, "The Google File System,"in Proceedings of the 19th ACM Symposium on Operating Systems Principles (SOSP), 2003. Better I/O through Byte-adresserable, Persistent Memory,"i Proceedings of the 22nd ACM Symposium on Operating Systems Principles ( SOSP), 2009. Wenisch, "Memory Persistency," i Proceedings of the 41st International Symposium on Computer Architecture (ISCA), 2014, pp.