Many research groups have presented a lot of new technologies for the critical path of the conventional storage system to ensure the original performance of PM hardware. However, the performance bottleneck in the critical path has been moved from the hardware part to the software stack because media performance has increased dramatically [7-9].
Persistent Memory
Next, we review some of the recent studies that have considered PM as part of system configuration.
Making Use of Persistent Memory
This research is based on the assumption that legacy file systems are not optimal for PM storage attached to a memory bus. However, in general, we find that the main ingredient missing from older file systems than a PM storage file system is a component that can effectively exploit PM.
Analysis of File Systems
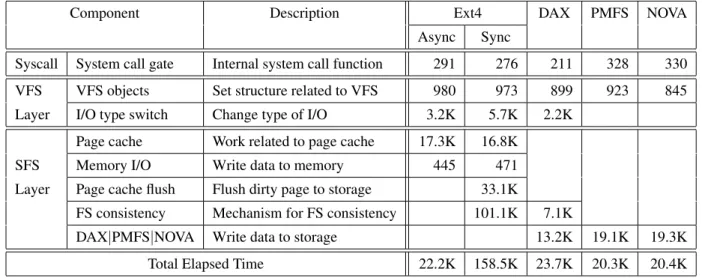
In the Ext4 implementation (as well as other Linux filesystems), we find code that clearly separates the 'Page cache flush' and 'FS consentency' components for easy manipulation. Specifically, they are the components that make up the synchronous I/O part of the write() call, namely the page cache flush and FS consistency components.
PMAL Design and Implementation
Therefore, it is virtually impossible to pull out the page cache component while keeping the file system's intrinsic features intact. Therefore, in PMAL we choose to empty data written to the page cache when it suits us.
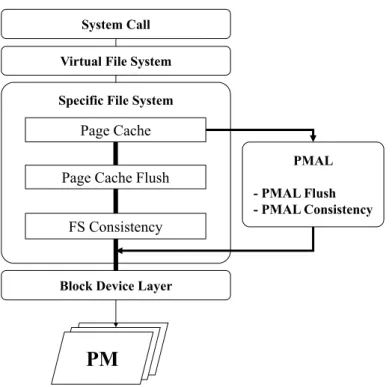
Experimental Results
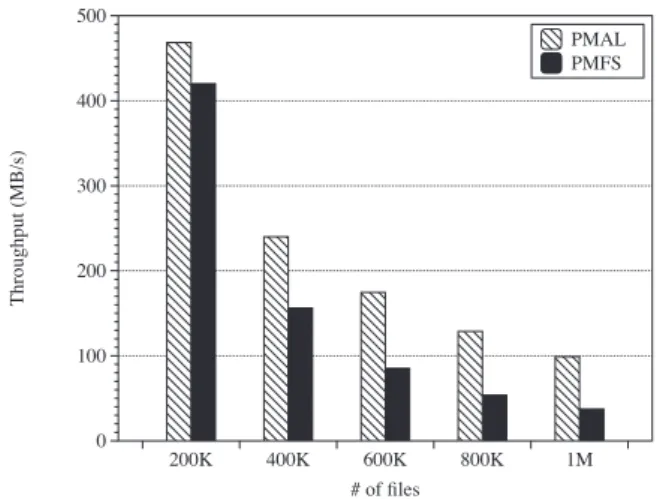
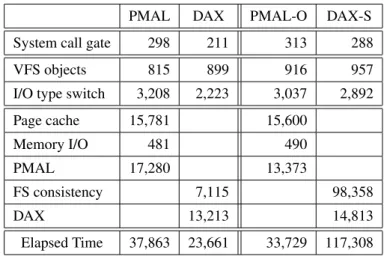
To evaluate the effectiveness of the PMAL approach, we implement PMAL and integrate it into the Ext4 file system in Linux kernel version 4.3.3. The performance of PMAL is only slightly lower than that of the ideal Ext4-A case, where all writes are written asynchronously to the page cache. The macro effect of these changes on benchmark performance is shown in Figure 7 and discussed below.
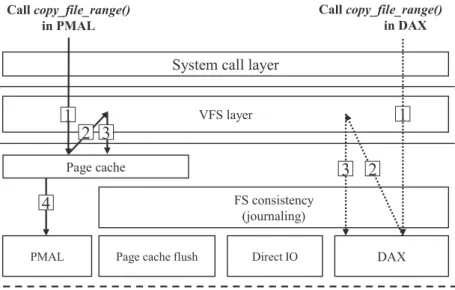
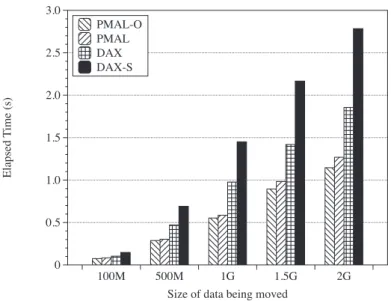
As expected, the performance of the benchmarks with PMAL-O performs better than with PMAL and DAX-S performs worse than DAX. Unlike PMAL, DAX must take a different route when maintainingcopy_file_range() because it cannot use the page cache. The results, shown in Figure 9, where the axis represents elapsed time, show that PMAL, which uses the page cache, significantly outperforms DAX.
Summary
PMAL is lightweight and consists of about 180 lines of code in total and can be easily integrated into legacy file systems. Using Filebench and key-value store benchmarks, we have shown that performance of PMAL-integrated Ext4 is in line with PM dedicated file systems. IV Improving performance of persistent memory file systems through a lightweight consistency mechanism at the VFS layer.
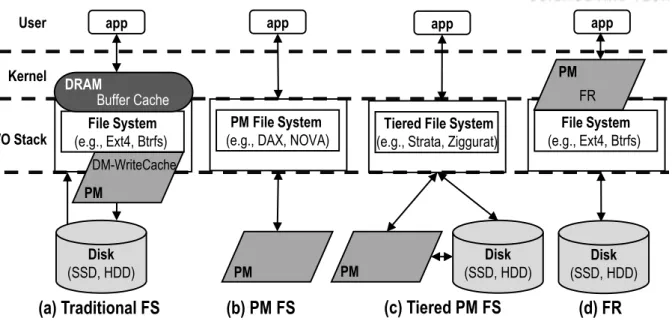
Another contribution is improving the performance of PM-targeted file systems using MeLo@V. Since MeLo@V itself provides consistency and CFP provides persistence, these aspects of PM-dedicated file systems can be removed. In Section 4.1, we provide a detailed analysis of the various file systems, breaking down the components that make up file systems in terms of functionality and performance.
File Systems and the Challenges
In Ext4 synchronous mode there are two other components, namely 'Page cache flush' and. The main tasks of these components are to flush data from the page cache to backup storage and manage the file system consistency mechanism, respectively. These PM-specific file systems do not have any components related to the page cache, as they do not use the page cache.
Our observations from Section 4.1.1 show that, apart from the writing to media that ultimately needs to be done, two components stand out, namely the 'Page cache flush' and 'FS consistency' components. So the main challenge here is to provide functionality for the 'Page cache flush' and 'FS consistency' components with negligible overhead and without making any or minimal changes to the file system. 51, 52], with the difference that we do not make any changes to the page cache mechanism.
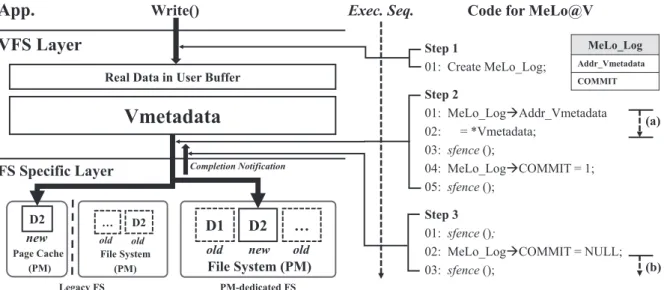
MeLo@V: Design and Implementation
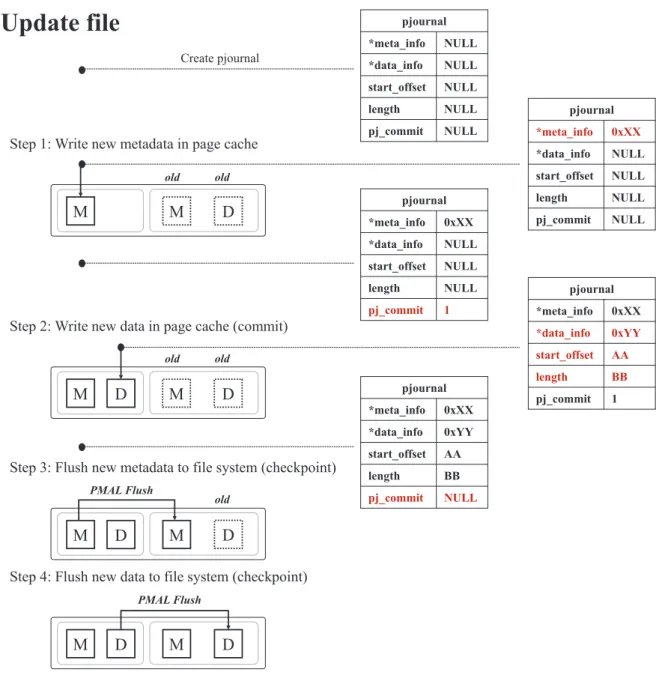
Upon a file update request, a log data structure is created at the VFS layer, which we call MeLo_Log with the Addr_Vmetadata and COMMIT elements, both initialized to NULL. Then, to indicate that MeLo_Log has been written safely, the COMMIT flag is set to 1. Note that step 3 is also performed in the VFS layer just before notifying the application.
There is actually no specific recovery mechanism and we simply rely on the replay recovery process to recover from a failed write process using MeLo_Log items. To start the recovery process using MeLo_Log, we must first find the MeLo_Log address in the file descriptor that was opened during the abnormal system termination due to the failure. When MeLo_Log is found, we consider the value of the COMMIT marker and restore as follows.
Performance Evaluation
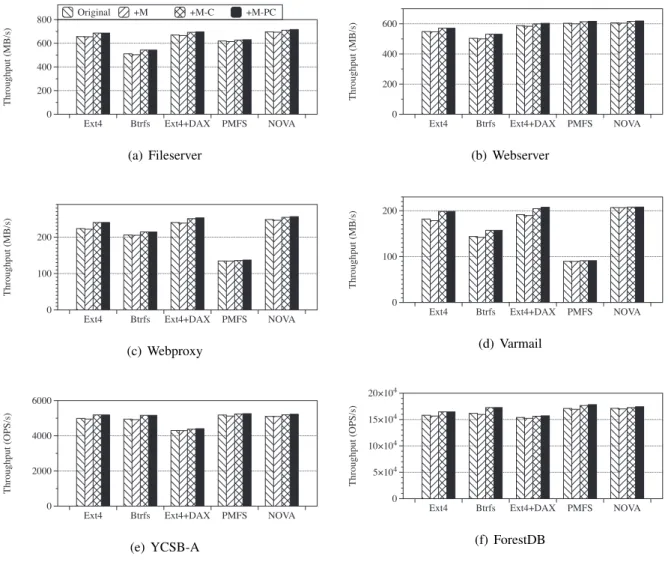
The other group of file systems are those with MeLo@V installed, but the native consistency mechanism is disabled. Even with MeLo@V installed, performance is only slightly, roughly 2%, lower than native filesystems. First, we see that removing the persistence and persistence mechanisms inherent to file systems while deploying MeLo@V makes a difference in performance.
These experiments are performed for the original Ext4 and Btrfs file systems and their variants Ext4+M−PCand Btrfs+M−PC. In contrast, PM-dedicated filesystems would need a completely different implementation since they do not use the page cache. Note that such features of legacy file systems are naturally exploited with our MeLo@V approach.
Summary
Separately, Ziggurat, proposed by Zheng et al., is a layered file system that supports a combination of devices [15]. The goal of this study is to encompass the goals of previous PM file system developments. In-order file system semantics is where all file system operations, including writes, occur in the exact order in which they are performed.
With the advent of PM, such a choice seems redundant, because providing ordered file system semantics should be natural and easy. However, to date, supporting such semantics is only possible with a total file system refresh. This allows any mature file system to reap the benefits of PM.
First Responder: The Design
FR is also a cache as the size is limited (although generally large) and eventually, it is distributed to traditional storage media via the I/O stack. In the previous section, we mentioned that FR is like a cache, but there is much more to it. The obvious answer, of course, is yes; but we argue that this is only true under the traditional assumption that cache size is a very small fraction of storage capacity.
However, apart from these, it is well known that as the cache increases, the effect of the caching policy decreases. Imagine the cache to be organized in array form with the index iandSb indicating the location and size of the cache block, respectively. Furthermore, since FR is based on the premise that PM is in the size range used by PM-based file systems such as NOVA and DAX, for example, at least 128 GB, this large enough cache size allows the accommodation of a.
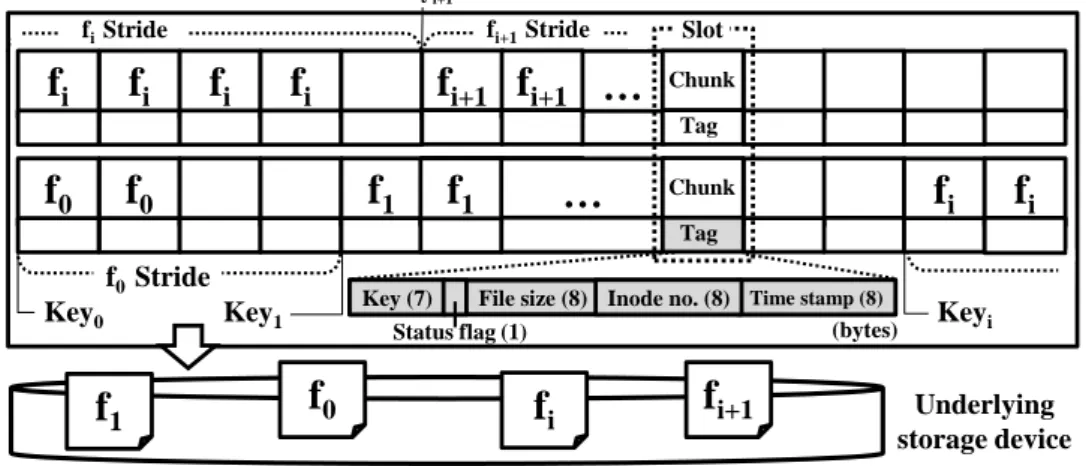
Data Consistency and Recovery Protocol
UponWrite(K')), if part of the unmodified K is found in storage, it is first read into the chunk.1Then K' is written to the chunk and continues with the clubbandfence operations. The state of the chunk pair in FR before and afterWrite(K') is shown in Figure 15(a). Note that K' cannot be written directly to the first part, but must be overwritten on a copy of the part containing K.
Since access to chunks is controlled by individual locks, we acquire locks for each of the chunks in order from the first chunk to the last. Then the subsequent chunks are written, along with the timestamp tag, where the timestamp of the first chunk is written. Thus, all pieces of the multi-piece that have been written must be reset to their pre-write state.
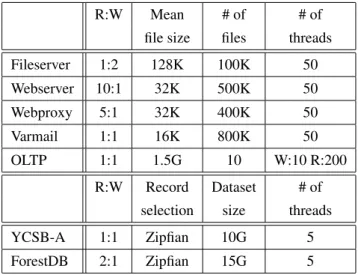
Performance Evaluation
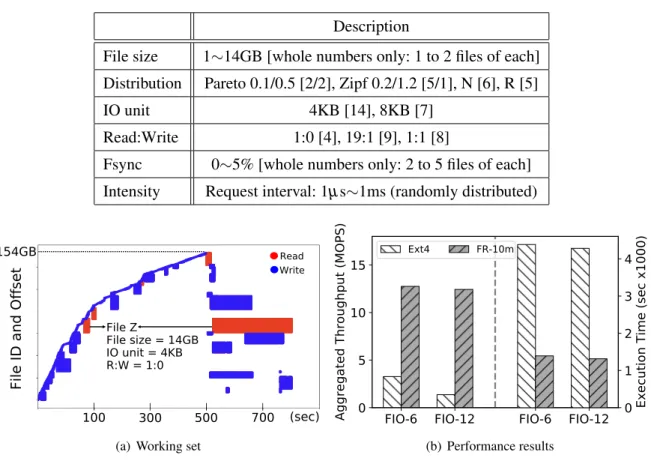
The working set for light workloads is around 50GB, while for heavy workloads it is around 100GB. However, it should be noted that DM-WC uses double the resources than other schemes, as it uses the entire DRAM as the page cache and 128 GB of PM for the DM cache. We find that most of the forced flushes for Fileserver and Varmail are due to this.
In particular, we see that Ext4 and DM-WC perform significantly well for DWOM since it makes use of the DRAM page cache, while they perform worst for DWSL due to synchronization with the storage device. Effect of Period: From now on, we will perform an analysis of the performance of FR according to the period of the Periodic Flush technique. We chose the period of the point with the same performance as the baseline as default.
FR on Distributed Storage Platform (Ceph)
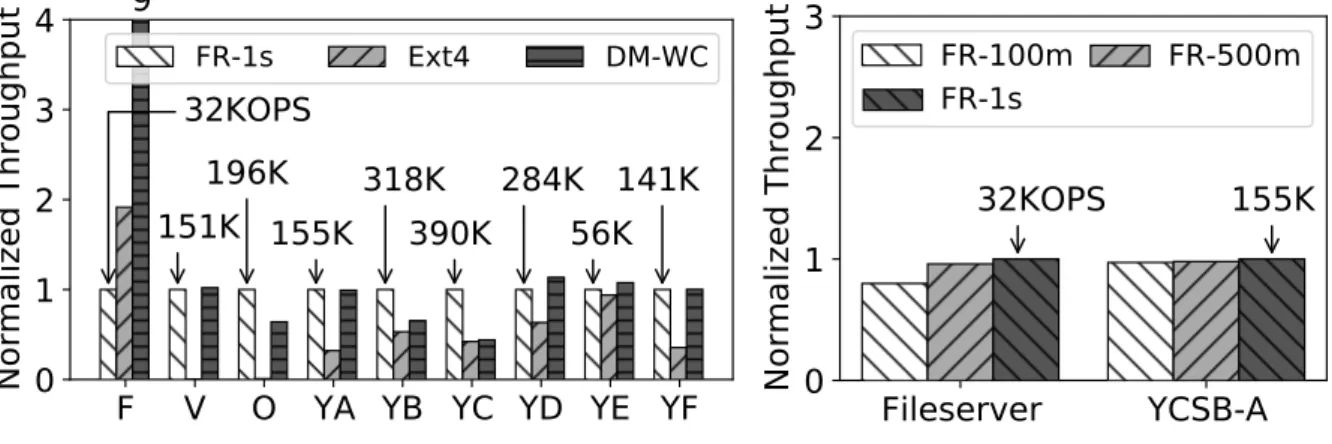
The capacity of the FR used for the admin server is 128 GB, which is the same as in the previous experiment. As shown in this figure, the overall performance benchmarks are similar to the results in Figure 24(b) when the supporting storage is HDD. As the performance of the media used as backup memory improves, we can show that the DM-WC effect disappears.
As shown in the results, the performance trend of FR by period in environments where network-attached OSDs are used as backing storage is similar to performance trends in other media. In Fileserver, the performance when the period is 100 ms decreased by about 20% compared to the performance when the period is 1 sec. We can guarantee the durability of data and metadata with the performance of PM and dramatically improve the performance degradation that can occur due to synchronization for system integrity.
Summary
Hady, “When Poll is Better Than Interrupt”, në Proceedings of Conference of USENIX on File and Storage Technologies (FAST), 2012. Software System for Persistent Memory, in Proceedings of the European Conference on Computer Systems (EuroSys), 2014. Anderson, “Strata: A Cross Media File System”, në Proceedings of the ACM Symposium on Operating Systems Principles (SOSP), 2017.
Noh, "WORT: Write Optimal Radix Tree for Persistent Memory Storage Systems," inProceedings of the USENIX Conference on File and Storage Technologies (FAST), 2017. Nam, "Write-Optimized Dynamic Hashing for Persistent Memory," inProceedings of the USENIX Conference on File and Storage Technologies (FAST), 2019. Lorch, "A Five-Year Study of File-System Metadata," i Proceedings of the USENIX Conference on File and Storage Technologies (FAST), 2007.