In this work, we present a new dynamic hashing technique, ScanHash, which produces fast point queries of the hash table index with sorting buckets in the natural order of keys to support scanning operations. ScanHash provides efficient point queries based on the extensible hash table structure and per-sorted bucket scan queries with natural key ordering. Although the hash table performs better than the other data structure on point query operations, the database that needs to support scan operations must use a scannable indexing structure because it does not support scan operations.
Some research suggests that indexing data structures using both hash table and secondary scannable data structure such as B-tree or Skiplist [1] [2] has the advantage of fast point query of the hash table while supporting the scan operation.
Extendible Hashing
Persistent Memory
CCEH
FAST algorithm
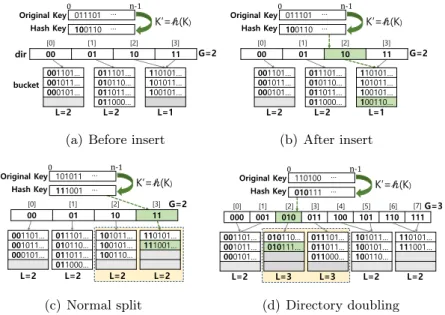
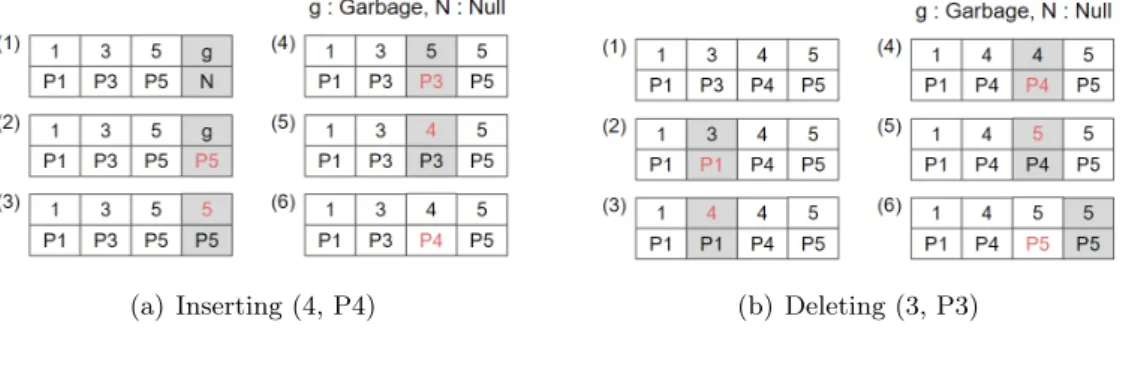
In state 4, although the read transaction searches for key 5, the left key 5 is detected as an inconsistent state because the value pointer is the same as the left pointer P3. Delete is the reverse of the insert shift key first and the value cursor after from right to left. ScanHash also uses the FAST algorithm to efficiently move the key-value-pointer pairs in the bucket.
In this section, we describe the overview of ScanHash which is a scannable dynamic hash based on extensible hashing with buckets arranged in the natural order of the raw keys using the remapping function instead of the hash function to reduce collision and overhead. rehashing.
ScanHash Structure
Key Distribution
It can be proved that the cumulative distribution function FX, which is continuous and increasing function, is uniformly distributed. However, the cost of computing the exact cumulative distribution function from the set of given discrete keys is expensive because it requires scanning from the smallest key to the specific key for each query. On the other hand, some of continuous distribution, such as normal and exponential distribution, have the formula of the cumulative distribution function using the distribution parameter.
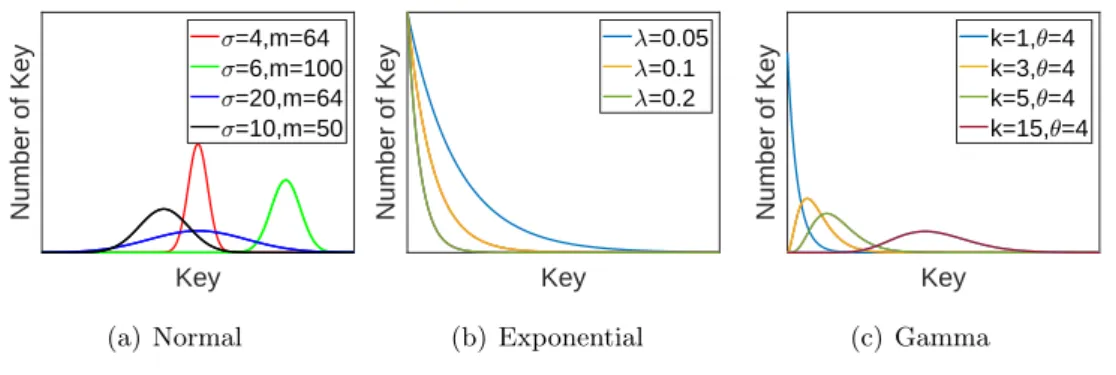
To overcome the high cost to calculate the cumulative distribution function from the discrete key, we first assume that the key distribution is one of the graded continuous distributions that the formula of the cumulative distribution function is well known, in this work, the normal distributions , exponential and gamma as shown. in Figure 4 that are commonly used and observed in the natural and social sciences, and modified the continuous cumulative distribution function calculated with the given formula of the cumulative distribution function to discrete. By doing so, it is possible for two different discrete keys to be associated with the same recovered key, as it ignores the value below the decimal point. Although it increases the chance of collision, it is acceptable because the recovered key is only used to find the directory index as a hash function returning the same hash value to the different key.
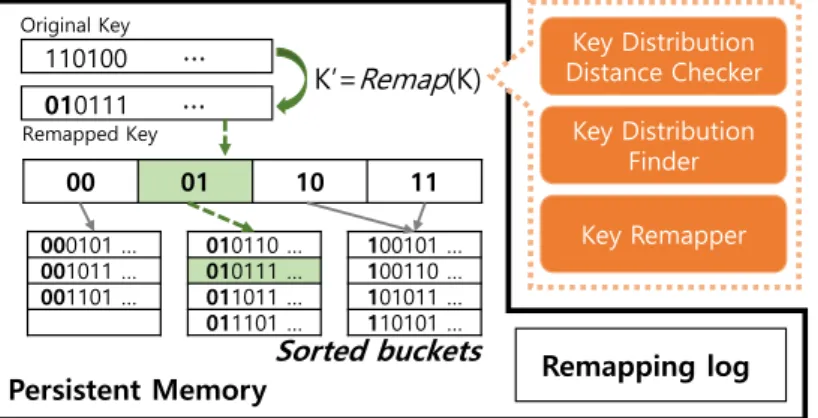
Remapping Process
Since the size of the directory is equal to 2global_depth, we need to have 261 indexes containing an 8-byte pointer, which is 16 exbibytes, which is not available now. To avoid this situation, ScanHash provides key remapping, which consists of checking the key distribution distance to check how far the current key distribution is from the uniform distribution. distribution and its parameters of the current key distribution when the distance checker has decided that the current distribution is not uniform, and mapping the keys to build a new directory using the cumulative distribution function calculated by the distribution finder. In this section, we describe basic operations and ScanHash with a sorted bucket without considering key mapping or distribution changes.
Additionally, we describe ScanHash's concurrency with lock-based insert/delete operations and lock-free search operations.
Operations with FAST algorithm
Concurrency and Consistency
In this section, we describe three non-uniform distributions we used in this work, normal, exponential and gamma distributions, and how key remapping works with three different components, key distribution distance checker, key distribution finder and key remapping. Although we only use three widespread distributions, another distribution can be added because the idea of ScanHash is to use the remapping function that increases the cumulative distribution function of key distribution instead of a hash function.
Key Distribution and cumulative distribution function
Key Distribution Distance Checker
Since the uniform distribution with a key range from 0 to 2key_bits has fixed variance, we compare the calculated variance of current key distribution and uniform to see how distribution is far from the uniform periodic. Additionally, if the key distribution is too skewed, many keys share common prefix global depth bits and are inserted into the same bucket causing too frequent directory duplication before a periodic checker is called. Considering the main purpose of remapping is to make the distribution uniform to reduce the fragmentation and large directory overhead, we activate the key distribution distance checker when the number of consecutive directory duplication is greater than some threshold.
Key Distribution Finder
Key Remapper
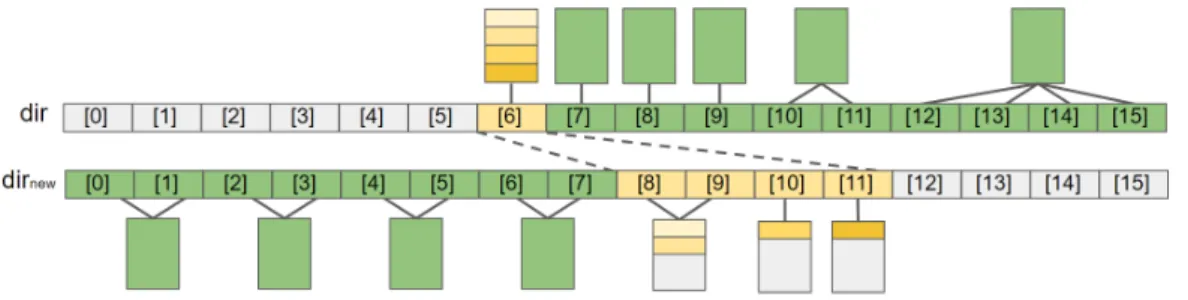
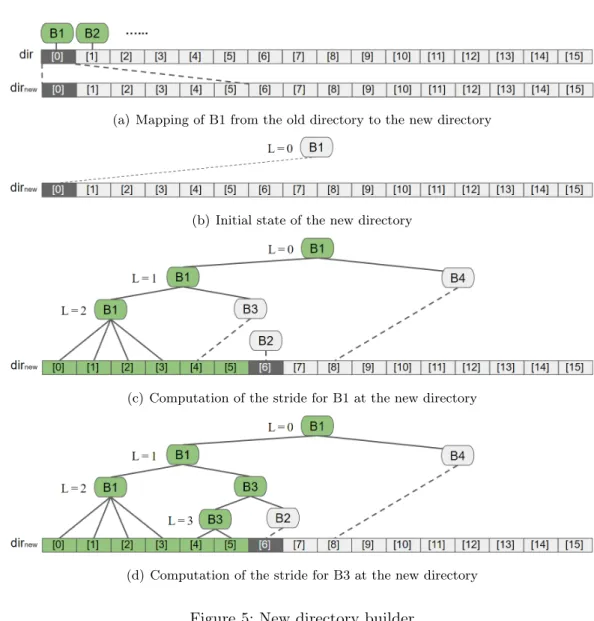
According to the split history property, building a new directory for a new mapping function is similar to building a split history from a bucket location. In the state of Figure 5(c), bucket B2 covers bucket B3 and bucket B1 does not need to be split to form bucket B2. Bucket B3 is split to form B2, and bucket B3 is attached because bucket B2 is not below bucket B3.
Bucket B2 is connected to dirnew[6] so that the step dirnew[0] is doubled twice and covers four indices. We repeat this until the parent node is root and restart from index dirnew[4] with bucket B3 unpatched. Bucket B2 is below bucket B3 and cannot be pointed to by a pointer that does not point to bucket B3.
Since we set the step limit to capacity, the step limit of bucket B2 is below the step of bucket B3 of the second level with a local depth of 2. The step of bucket B3 connected to dirnew[4] is 2 because dirnew[6] is a remapped index, so Figure 5 (d) shows the result for setting indexes with split history before the remapped index dirnew[6]. From the bucket pointed to by dir[6] , the directory editor maps the keys in the bucket with the new mapping function and inserts the key into the corresponding bucket of the new directory.
Methodology
Microbenchmarks
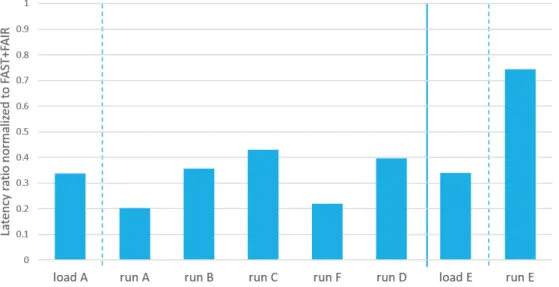
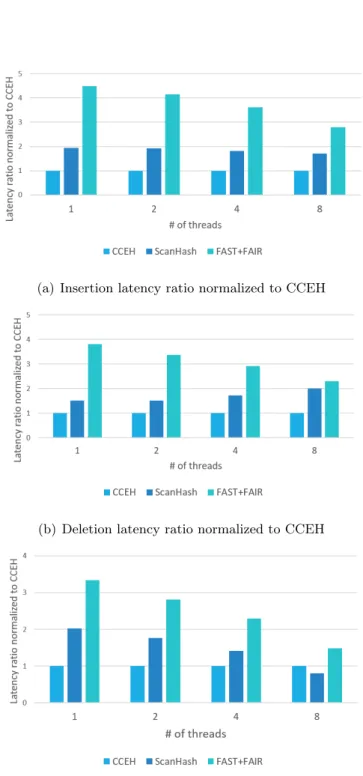
In Figure 8, we compare the performance of the range query with FFB only because CCEH does not provide the range query. We scan N keys from the given initial key or the smallest key greater than the initial key if the key does not exist in the data structure. Since FFB's range query is implemented to return the keys between the first and last key in Github, we modify the condition to end the range query to make the range query find N keys.
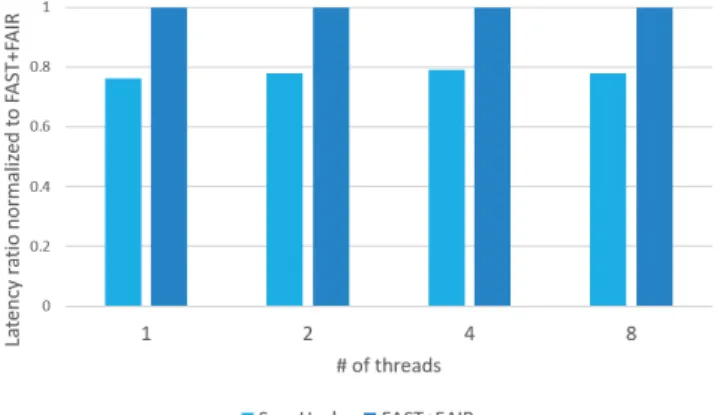
As in performing the search operation, FFB must traverse the tree to find the first node containing the first key. Both ScanHash and FFB do not have a block for search and scan, the performance of both increases, while the normalized ratio with FFB remains the same.
Performance Over Non-Uniform Key Distributions
The overall performance is reduced if the key distribution is not uniform because it calculates to get the mapped key using one of the linear functions that approximate the cumulative distribution function. As the set of linear functions is divided into subranges with the same number of keys, the first key of each subrange is dynamically determined in the key distribution finder. Although a linear function is inherently cheaper than a standard hash function, the overhead of the remapping function is similar to a standard hash function because it scans a set of linear functions to find a matching function.
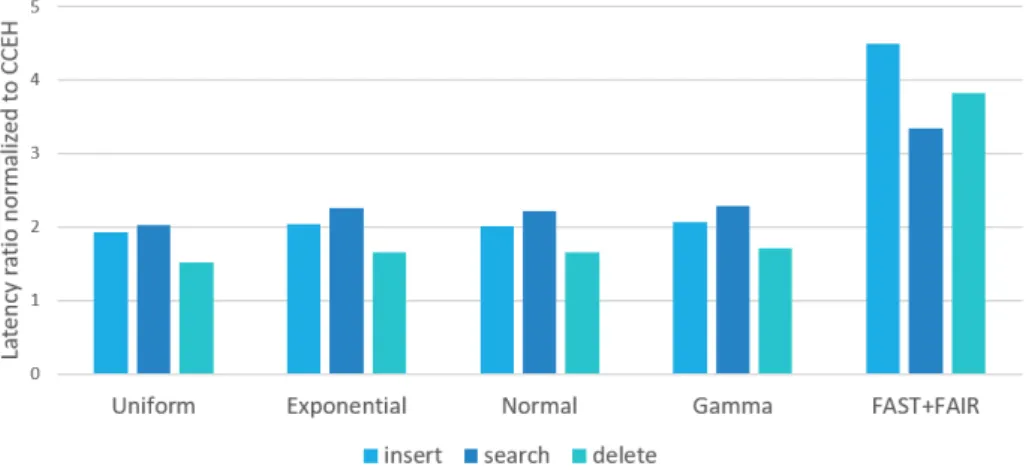
The search time is 2.02x slower than CCEH for the uniform distribution and 2.21x, 2.20x and 2.28x slower than CCEH for exponential, normal and gamma distribution respectively.
Scalability
Size of Bucket
The search time is 2.02x slower than CCEH for the uniform distribution and 2.21x, 2.20x and 2.28x slower than CCEH for exponential, normal and gamma distribution respectively. a) Add latency ratio normalized to CCEH. Since the 256 byte bucket can only hold 14 keys, it necessarily has a larger directory and more buckets to store the same amount of keys. Therefore, scan reads more buckets moving more sibling pointers making the performance slower than the FFB, 72.48% slower than the ScanHash default bucket size while FFB is 31.30% slower.
On the other hand, the 1024 byte bucket is faster to scan than the 512 byte bucket.
Yahoo! Cloud Serving Benchmarks(YCSB)
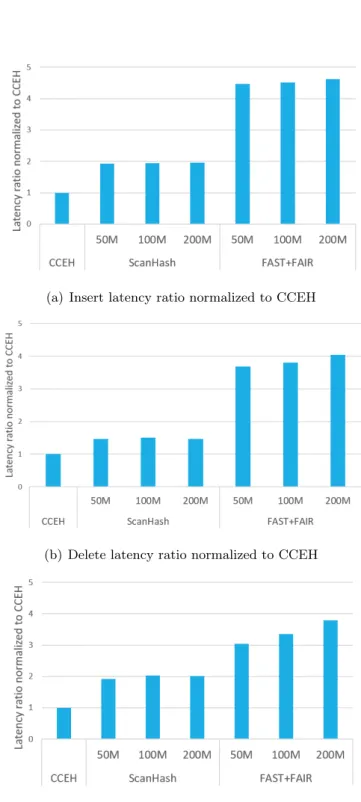
At runtime, the key distribution check does not trigger a new assignment and when we analyze the key pattern generated by YCSB, the key itself is randomly generated, which means that the key distribution is uniform. It includes the update operation which is different from the insert operation. Therefore, we set the update operation to search the key first and place the key in the bucket if the key exists. In this work, we proposed the scannable hash table, ScanHash, which provides a fast point query using the advantages of the hash table while supporting the range query.
Sun, “HiKV: A Hybrid Index Key-Value Store for DRAM-NVM Memory Systems”, në Proceedings of the 2017 USENIX Conference on Usenix Annual Technical Conference (USENIX ATC), 2017. Nam, “Endurable Transient Inconsistency in Byte- Address Persistent+ -Tree,” in Proceedings of the 16th Usenix Conference on File and Storage Technologies (FAST), 2018. Nam, “Write-Optimized Dynamic Hashing for Persistent Memory,” në Proceedings of the 17th Usenix Conference on File and Storage Technologies (FASTFAST), 2019.
Noh, “WORT: Write optimal radix tree for persistent memory storage systems,” in 15th USENIX Conference on File and Storage Technologies (FAST), 2017. Reducing Consistency Costs for NVM-based Single-Tier Systems,” in 13th USENIX Conference on File and Storage Technologies (FAST), 2015. Choi, “SLM-DB: A single-level key-value store with persistent memory,” in 17th USENIX Conference on File and Storage Technologies (FAST), 2019.