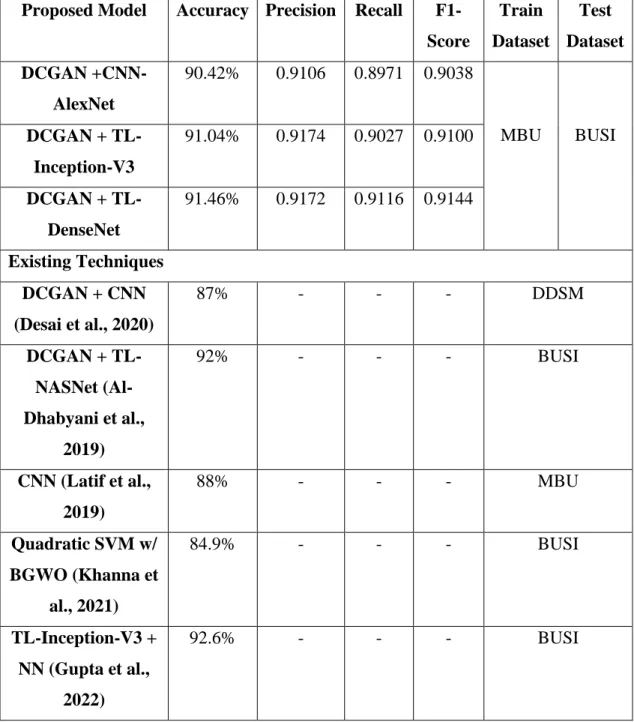
The copyright of this report belongs to the author under the terms of the Copyright Act 1987 as qualified by the Universiti Tunku Abdul Rahman Intellectual Property Policy. The proposed models, CNN-AlexNet, TL-Inception-V3 and TL-DenseNet are tuned and trained on the MBU database. Fine-tuned TL-DenseNet exhibited the best performance among all proposed models achieving an accuracy of 91.46% and F1 score of 0.9144, followed by fine-tuned TL-Inception-V3 with an accuracy of 91, 04% and F1 score of 0.9100.
Background
Furthermore, the data from Global Cancer Observatory shows that breast cancer has the highest incidence in 2020, with a number of cases of 11.7% of the total cancer incidence recorded in 2020, which means that among 19 million cancers diagnosed in 2020, there 2.26 million of the total cases are breast cancer. Moreover, since the process can be tedious, it can therefore lead to misdiagnosis from the pathologists' visual inspections. Besides, automating computer systems also benefits in reducing the subjectivity of the breast cancer classification (Zhi et al., 2017).
Problem Statements
However, ultrasound imaging technology also has some major drawbacks, such as acquisition noise generated by the ultrasound imaging device, ambient noises generated by the ultrasound imaging environment, and the presence of body fat, organs, and other tissues. can significantly affect image quality (Hiremath et al., 2013). In addition, traditional diagnostic methods of breast cancer are mostly expensive, time-consuming and based on extensive experience of diagnosticians and specialists. Furthermore, due to patient privacy, access to open access breast tumor datasets is very low.
Project Scope
Especially, because of the reasonable overall cost, the expertise of the operator and the relatively lower impact on human health. In addition, ultrasound imaging technology has been widely applied in the field of breast diagnostics.
Project Objectives
Overview
Generative Adversarial Network (GANs)
The main motivation of the generative model is to generate fake samples until it is indistinguishable from the actual training data. To improve the discriminant model, the generative model is responsible for degrading the discriminant model estimate. To summarize succinctly, the objective of the generative model is achieved when the discriminative model faces difficulties in classifying the samples.
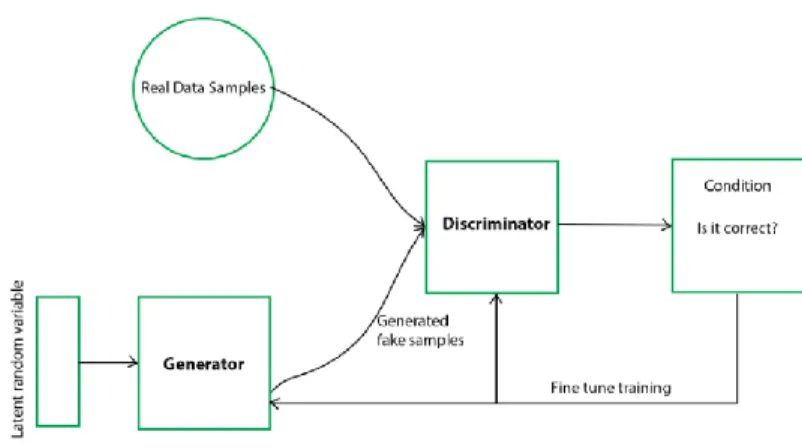
Deep Convolutional Generative Adversarial Networks (DCGANs)
The structure of the DCGAN is inspired by the Enhanced GANs proposed by Salimans, Goodfellow, Zaremba, et al. These techniques improve the diversity of the discriminator network by improving the diversity of samples created by the generative model when samples are discriminated. Thus, with the inspiration of the improved GANs, DCGAN extended GAN from multilayer perceptron (MLP) structure to convolutional neural network (CNN) structure (Fang et al., 2018).
GoogleLeNet (Inception)
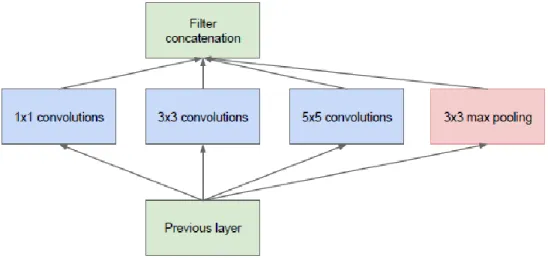
Inception-v1
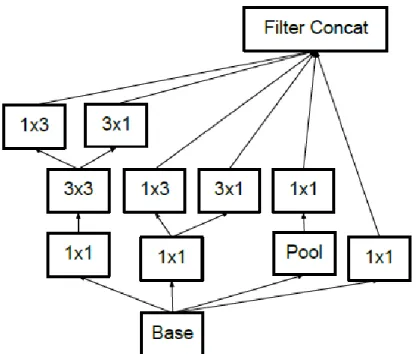
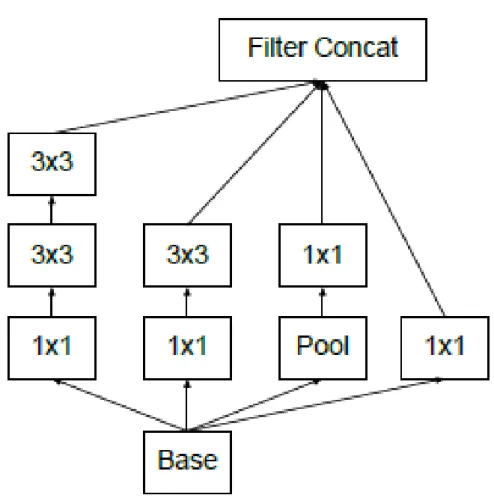
Inception-v2 & Inception-v3
Furthermore, the output of the filter banks in the Inception-v2 module was extended to eliminate the representative bottleneck (see Figure 2-8) (Szegedy et al., 2016). In Inception-v3, the network incorporated all the improvement in Inception-v2 and the following modification: .. ii) BatchNorm in Auxiliary Classifiers. iii) Label smoothing. iv) Factorized 7 x 7 windings (Raj, 2018).
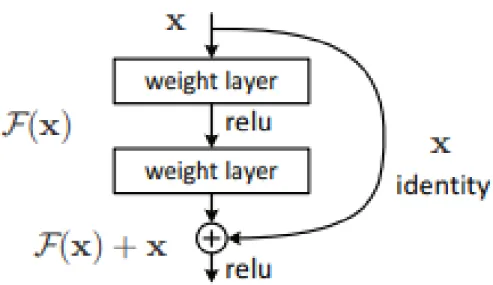
Residual Neural Network (ResNet)
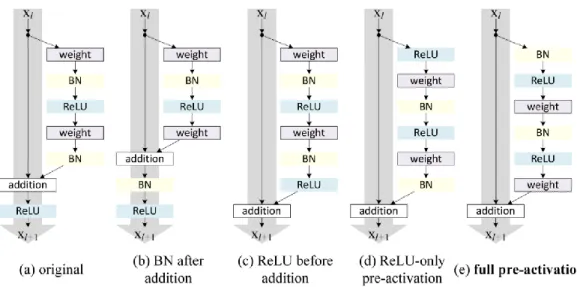
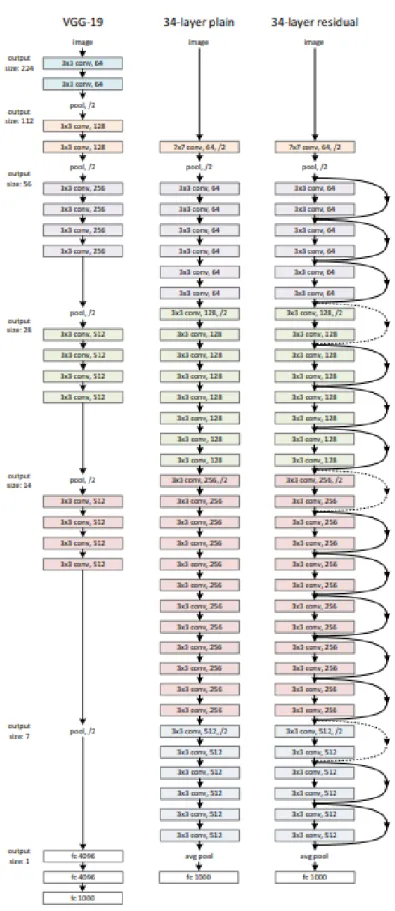
Therefore, ResNet introduced a link with a shortcut to identity, also called residual blocks, as shown in Figure 2-9. In addition, He et al further modified the residual blocks by introducing a pre-activation version of the residual block as shown in Figure 2-10. According to the paper “Deep Residual Learning for Image Recognition”, the shortcut links used in ResNet were inspired by the Highway Network proposed by Srivastava et.
Related Works
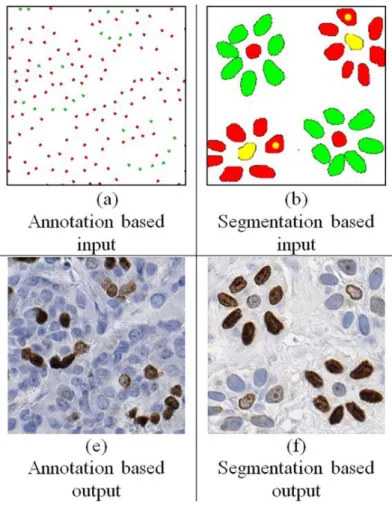
In the paper, MIGAN is applied to retinal vessel images for STARE and DRIVE public dataset. In addition, MIGAN also reduces the threshold of existing GAN techniques, smaller input samples required to generate the desired synthetic images due to MIGAN's refined loss function. 2018) introduced the Conditional Generative Adversarial Network also known as cGAN to generate realistic synthetic histopathological breast cancer images from the Ki67 datasets.
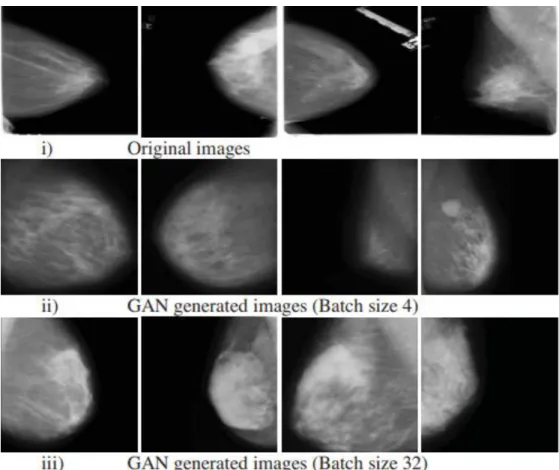
The main objective of this work is to overcome the limited available labeled data by implementing DCGANs to generate synthetic images for deep learning breast cancer classification. The author trained the DDSM dataset for batch size 4 and batch size 32, the samples of the synthetic images are shown in Figure 2-16. According to the CNN deep learning classification model, the batch size 32 outperforms the batch size 4 DCGANs configuration in terms of accuracy, F1 score, specificity and sensitivity.
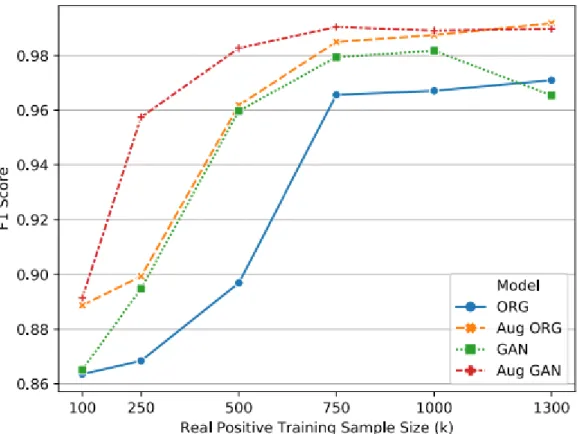
According to the paper, the author has trained the CNN model with four different approaches as shown in Figure 2-17, which are the original input (Blue), the extended original input (Orange), the GAN's input (Green) and the extended GAN's input (Red) . The results shown in Figure 2-18 illustrated that augmented GAN data as input has outperformed other inputs in terms of F1 score. The highest accuracy for this achieved for this study is the CNN classifier with the CNN denoise method at 88%.
The quadratic SVM classifier with BGWO feature selection has the highest performance in terms of accuracy at 84.9%.

Overview
Environment Setup
Hardware
Software
Data Processing
- Dataset Preparation
- Image Pre-Processing
- Image Augmentation
- Data Augmentation
- Data Segmentation
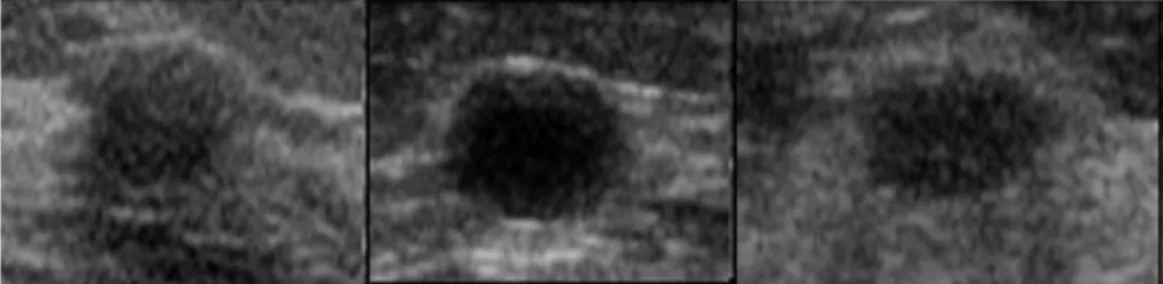
After the data sets are downloaded and analyzed, some image processing methods are applied to the data to improve the quality of the breast tumor images. In the first approach, the bilateral smoothing filter is applied to the images with a kernel size of 3x3. In the third approach, a gaussian filter with a kernel size of 5x5 is applied to the images.
In the fifth approach, a special OpenCV filter called block-matching denoise filter is applied to the image. Due to the small data set, several image enhancement methods have been implemented on the images. Furthermore, a four fractionally stepped convolution layer aka deconvolution layer with a 5x5 kernel size is added to the network.
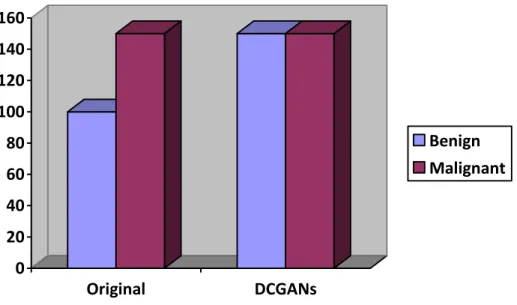
In addition, the LeakyReLU activation function is added to each layer, except the tanh activation function, which is added to the output layer. The size of the training set used for benign is 128 and 256 for malignant due to the amount of data set. Synthetic images generated by the DCGAN model were added to the dataset to increase the amount of data and balance the dataset.
Furthermore, image enlargement method such as rotation and flipping of the images were applied to the data set to increase the amount of data.
Classification Model
Dataset Cross-Validation
Breast tumor ultrasound images are divided into 5 different combinations of training and test sets.
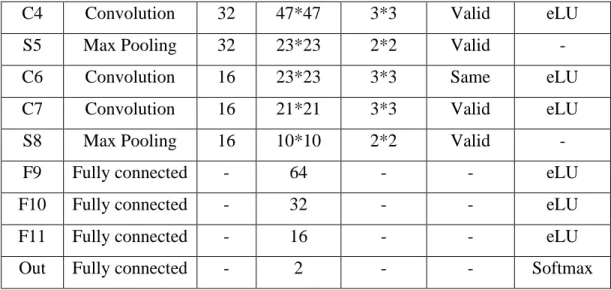
CNNs and TL Architecture Design
- CNNs-AlexNet
- TL-Inception-V3 with 3 extra hidden layers + dropout
- TL-DenseNet with 6 extra hidden layers + dropout
In addition, the algorithm uses the binary cross-entropy loss function to evaluate the performance of the model. The transfer learning technique can be applied in the project to use the improved version of the ILSVRC14 winner, Inception-V3 as a pre-trained model in this breast tumor classification project. In addition, due to the small dataset available for this project, the proposed pre-trained Inception-V3 model can be useful for the classifier.
All layers of Inception-V3 except the last fully connected one are imported into the project's classification. Four additional layers were added to the TL-InceptionV3 model, including 1 average pooling layer with 0.2 dropout, 1 flat layer, and 1 fully connected 128 size layer. Moreover, the binary cross entropy is used as the algorithm loss function due to the two target classes of output.
DenseNet is chosen for the second transfer learning model because of the simplicity in its algorithm architecture. Since most CNN architectures are nested, information from the input layer can be faded before reaching the output layer. Similar to TL-Inception-V3, all layers except the last fully connected layer of TL-DenseNet are imported into the CNN classifier.
All layers are set as non-trainable, and 6 extra hidden layers are added to the architecture, which include 1 averaging pool layer, 2 batch normalization layers with dropout of 0.5, and 3 fully connected layers.
Evaluation Method
Project Timeline
Overview
Image Pre-Processing
Image Augmentation
Data Augmentation using DCGAN
Training Results
CNN-AlexNet
- Accuracy
- Loss
- Confusion Matrix
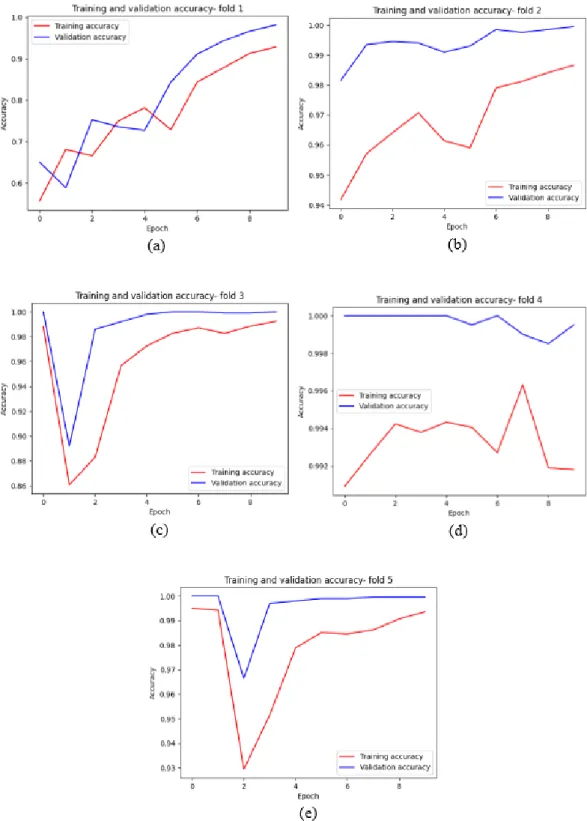
The average training time for one epoch is approximately 10 minutes, and the total training time for 10 epochs and the 5-fold cross-validation process is approximately 8.3 hours. The CNN- AlexNet architecture achieved an average validation accuracy of 95.52%; average validation loss of 0.1210; average validation accuracy of 0.9958; mean validity draws of 0.9942; average F1-Score estimate of 0.9950. The full training results of the 5-fold CNN-AlexNet model are attached in the Appendix A section below.
TL-Inception-V3 with 3 extra hidden layers + dropout
- Accuracy
- Loss
- Confusion Matrix
TL-DenseNet with 6 extra hidden layers + dropout
- Accuracy
- Loss
- Confusion Matrix
Testing Results on BUSI dataset
Comparison between Existing Techniques
On the other hand, it should be noted that the proposed models in this work use the MBU + DCGAN dataset with extension as the training dataset, while the testing results are evaluated on the BUSI dataset, which is from a completely different source, so the results are very difficult to achieve greater accuracy due to special configuration such as lighting, ultrasound device, operators, etc. Therefore, the proposed models are able to accurately classify benign and malignant tumors even on invisible data sets.
Discussion
It has been demonstrated that these strategies can overcome the obstacles of the conventional techniques used in current industrial imaging technologies. In this project, several image processing techniques are implemented on both training and testing breast tumor ultrasound images to improve the training process efficiency of the DCGANs and CNNs model. Since the deep learning algorithm requires numerous data to fine-tune the parameters of the algorithm after each iteration.
This fine-tuning process requires a huge data set to improve the performance of the neural network. Zooming methods include flipping, rotating, resizing, and cropping; thus, a deep learning classifier could be trained on different orientations of tumor images to enable the algorithm to accurately classify according to different types or perspectives of the tumor dataset. Due to the robust design of DCGAN, the model could study and train higher hierarchical features and extract useful information from the data quickly and efficiently.
The test set of MBU dataset is used to evaluate the proposed models on the unseen training set in the first evaluation phase of the project. Based on accuracy and F1 score results of the proposed CNN-AlexNet model, TL-Inception-V3 with 3 additional hidden layers + dropout model and TL-DenseNet with 6 additional hidden layers + dropout model have achieved 90% and above on training and validation sets. Undoubtedly, the performance of a medical deep learning classifier is better if the F1 score rate is higher.
The test accuracy TL-Inception-V3 model before fine-tuning is 48.13% and F1 score of 0.4191, which performance is poor and unacceptable.
Project Review
Project Findings
In addition, the last classification layer of the transfer learning model is removed and replaced with the proposed classification layer.
Recommendations for Future Improvement
Conclusion