I certify that this report entitled "VOICE TO TEXT CONVERSION APP WITH SPEAKER RECOGNITION" is my own work, except as noted in the references. Mel Frequency Cepstral Coefficient is popular in this field to describe the phenomena of voice. In the first part of experiments with self-generated datasets, the total number of users tested in this article is 5.
25 voice recordings, 5 of which belong to each speaker, are used as input to the system to identify each speaker. In the second part of the experiments using the LibriSpeech datasets, the total number of users tested in this paper is 20, including myself and speakers from the LibriSpeech dataset.
INTRODUCTION
Problem Statement and Motivation
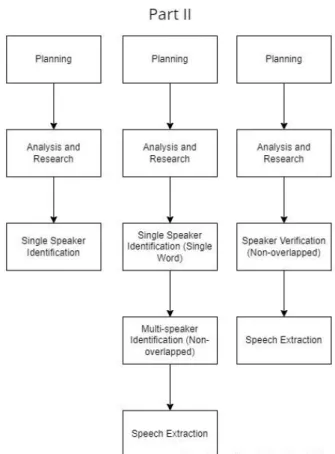
Project Scope
Project Objectives
Impact, Significance and Contribution
Background Information
Report Organization
LITERATURE REVIEW
Speaker-attributed Automatic Speech Recognition Model
There are already tons of studies regarding speaker attributed automatic speech recognition prior to this research. However, there are only some studies regarding combining all the modules for speaker-attributed automatic speech recognition. An end-to-end speaker-attributed automatic speech recognition model that unifies speaker counting, speech recognition, and speaker identification on mono overlapping speech was proposed [2].
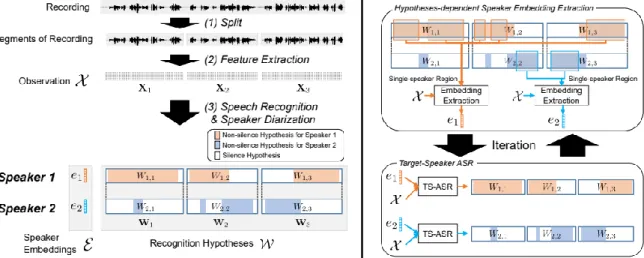
This means that in order for the speech recognition system to work as they want in an environment, the system must have registered the entire profile of the speakers that are in that environment. To overcome this limitation, application of iterative method where estimation of target-speaker embeddings and target-speaker automatic speech recognition based on the estimation is performed alternately [3] can work with unknown speakers.
Target-Speaker Automatic Speech Recognition (TS-ASR) model
In addition, there was also a VoiceFilter-Lite model developed by Wang et al. in [6]. The noisy audio to be enhanced and the reference audio from the target speaker were used as input to the VoiceFilter-Lite system. A loss function that measures the difference between the clean spectrogram and the masked spectrogram is used to train the VoiceFilter-Lite network.
If there is overlapping speech, the weight should be higher to make the VoiceFilter-Lite more useful. The strength of VoiceFilter-Lite model is that it uses the target speaker's recorded voice to improve automatic speech recognition on overlapping speech.
![Figure 2.2: Neural network topology of the VoiceFilter-Lite model. [6]](https://thumb-ap.123doks.com/thumbv2/azpdforg/10216244.0/20.892.116.774.457.713/figure-neural-network-topology-voicefilter-lite-model.webp)
Speaker Identification and Verification
Moreover, the authors in Speaker Identification in Multi-Talker Overlapping Speech Using Neural Networks [10] had tried to identify the speaker in an overlapping speech. The authors' model predicts output based on probability from features extracted from input speech, which is the unknown speech segment. Therefore, the authors artificially mix the registered individual speaker voice to form the overlapping speech for training data.
The authors tried the method using 1D convolutional neural network, multi-layer perceptron and also Gaussian mixture models. The authors' main method using 1D convolutional neural network has a flaw because deep learning is very biased towards the training data.
![Figure 2.4: Single-stage overlapping speaker identification system. [10]](https://thumb-ap.123doks.com/thumbv2/azpdforg/10216244.0/23.892.242.651.487.697/figure-single-stage-overlapping-speaker-identification-system.webp)
SYSTEM MODEL
- Development Tools
- Python
- Pycharm
- Google Cloud Speech-To-Text API
- FFmpeg
- Python Libraries
- System Specification
- Methodologies
- Speech Recognition Module
- Speaker Identification Model
- Speaker Extraction Module
- Noise Estimation Module
- General Overview of the Flow between Integrated Models
- Implementation Issues and Challenges
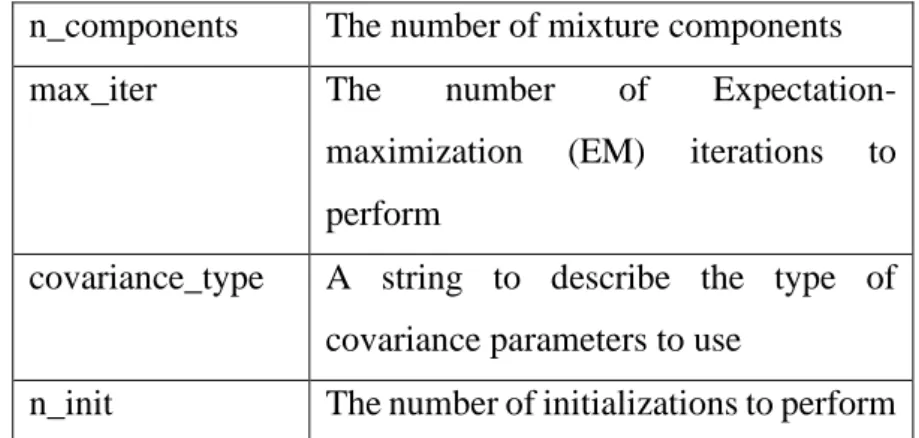
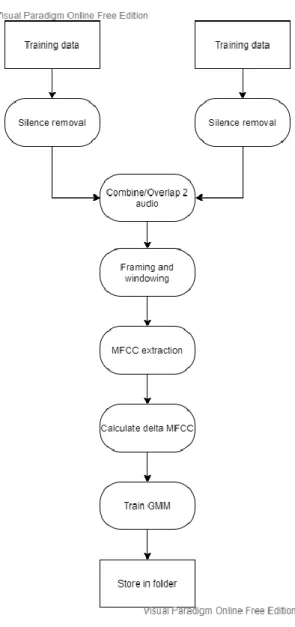
After that, the MFCCs and also the delta will be used to train a Gaussian Mixture Model and the model will be saved [17]. During the testing phase, the Gaussian Mixture Model will be used to calculate the similarity score with the test recordings and determine who the speaker is. All training audios for each user will be combined using the combination formula 𝐶2𝑁, where N = number of recorded speakers.
During the testing phase, the Gaussian mixture model will be used to calculate similarity scores with the test recordings and determine who is the two-speaker or the single-speaker. These models will be used to help identify multi-speakers in the following part by using it to guess how many speakers are present in the audio. Each word will be tested with single speaker identification using the single word model.
When testing test data, log-likelihood with both target speaker model and UBM will be calculated. Following the model in 3.2.2.4 Multi-Speaker Identification (Non-Overlapped) helps to identify the speaker that exists in a speech sound without overlapping speakers, the speech will be extracted to under each target separately using google cloud speech to text API for speaker diarization and single speaker identification model for speaker recognition. If the test data is only a single speaker, no further action is required and it will be recognized as speech directly.
However, if the test data consists of multiple speakers, it will be recognized as speech first. However, if the test data consists of an unknown voice, it will be recognized in speech first. Subsequently, one of the challenges that will be faced is the lack of research in this area.

EXPERIMENT AND EVALUATION
Experiments with Self-Generated Datasets
- Speech Recognition
- Single Speaker Identification
- Two-Speaker Identification (Overlapped)
- Discussion and Concluding Remark
The figure above shows the speech known for the test audio recordings for the speaker Ang Sea Zhe. In addition, it could also be recording issues because the recordings for the test audio are 10 seconds before unmute. In the later part of experiments with LibriSpeech datasets, the Google Cloud Speech-To-Text API is used instead of the python speech recognition library in this part.
After getting the input sound for training phase as in Figure 4.3, the model is trained by selecting option 3. 25 pre-recorded test audio are used to evaluate the model, 5 of them belong to each speaker. The shorter wav file after removing silence will cover the longer wav file so that the training data is overlapped most of the time.
The model is then trained in the same way as for the identification of a single speaker. Each test audio is compared to all GMMs in Figure 4.7 and classifies them accordingly, similar to identifying a single speaker. In this part of the experiment, identification of one speaker and identification of two speakers (overlapping) were tested with self-generated datasets.
For the identification of a single speaker, it can be seen that GMM performs quite well with an accuracy of 96.00%. For two-speaker (overlapping) identification, it performs worse with only 72.31% accuracy on the test data. Not only that, this part of the experiment faced a big challenge as even after the two speakers are identified in the overlapping speech.

Experiments with LibriSpeech Datasets
- Single Speaker Identification
- Multi-Speaker Identification (Non-Overlapped) with Training Audio Longer Than
- Multi-Speaker Identification (Non-Overlapped) with Training Audio of All Lengths
- Speaker Verification
- Voice to Text Conversion App with Speaker Recognition
- Discussion and Concluding Remark
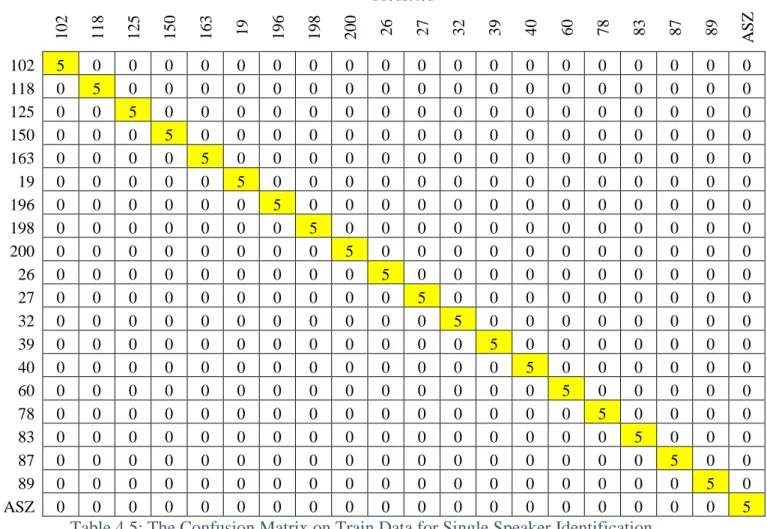
The evaluation tests performed on the single talker identification are 100 train data and 200 test data. In this experiment, the evaluation is done on the classification of speaker tag to evaluate the correctness of the speaker identification model. One of them is the models mentioned above, another one is the models built in 4.2.1 Single Speaker Identification.
Almost all the settings are the same as in the previous experiment 4.2.2 Identification of multiple speakers (non-overlapping) with a training sound longer than or equal to 0.5 s. Compared to the experiment in 4.2.2 Multi-speaker identification (non-overlapping) with a training sound longer than or equal to 0.5 s, the hypothesis of using only the longer word for identification is proven to be false, as the model using each individual word outperforms the model using only the longer word. The DER is usually 10% to 20%, so we can say that the model in this experiment performs quite well and better than the model in 4.2.2 Multi-speaker identification (non-overlapping) with training sound longer than or equal to 0.5s for the overall result.
First is single speaker identification, followed by multi-speaker identification in non-overlapping speech with speech extraction and speaker verification in non-overlapping speech. However, for the result of single speaker identification of single speaker identification in 4.1.2 Single Speaker Identification, there was a small error in the classification with an accuracy of 97.00%. As a conclusion for the single speaker identification experiments, GMM with MFCC performs quite well for single speaker identification task.
The first sub-experiment is that the single-word models mentioned in 3.2.2.3 Identification of a single speaker (one word) are built only with a word longer than 0.5s, even when the test data is transferred to the system and divided into each word, only the word longer than 0.5s is tested to identify the speaker before increasing the number. From these experiments, it can be said that the multi-speaker identification result is acceptable. An error occurs when counting words by individual speaker instead of achieving a perfect result as in normal single-speaker identification.
Therefore, safe count mentioned in 3.2.2.4 Multi-Speaker Identification (Non-Overlapped) is introduced to tackle this small error, but the safe count theory keeps the improvement of the result down. If there is a way to perfect the speaker's identification of short words, the algorithm will be improved.
Objectives Evaluation
Summarization of Finding
Novelties of Work
Concluding with Supportive Remark
For identification of one speaker out of 19 speakers from LibriSpeech datasets and myself, perfect accuracy of 100% is achieved. This has proven that GMM is good for single speaker identification with an appropriate amount of training data with a good quality microphone. For identification of multiple speakers on the non-overlapping speech, two experiments were done, the experiment that gives a better result gives an accuracy of 83% and DER of only 7.7%.
Finally, it performs for speaker verification with 98% accuracy and can avoid compromise when adjusting the threshold. Last but not least, testing the speech to text converter app with speaker recognition is finally made. Targeting speaker 19 from LibriSpeech datasets, the non-overlapping speech of another unknown speaker can be removed with optimal results.
Recommendation
Kanda et al., "Joint Speaker Counting, Speech Recognition, and Speaker Identification for Overlapped Speech of Any Number of Speakers," INTERSPEECH 2020, s. Kanda et al., "Simultaneous Speech Recognition and Speaker Diarization for Monaural Dialogue Recordings with Targettic EEn-Speaker Automatic Speech-Speaker" ition and Understanding Workshop (ASRU), 2019. Sarmiento, "Continuous Speech Recognition and Identification of the Speaker System," Proceedings of the International Conference on Information Technology & Systems (ICITS 2018), pp.
Jahangir et al., "Text-Independent Speaker Identification Through Feature Fusion and Deep Neural Network," IEEE Access Volume 8, pp. Tsai, "Speaker Identification in Multi-Talker Overlapping Speech Using Neural Networks", IEEE Access Volume 8, pp. Implemented speaker diarization with Google Cloud Speech to Text API 2. Start working more on the report.
Done evaluating most of the experiment and writing the report 2. Finalizing the report and adjusting the flow of the report. Note The Supervisor/Candidate(s) must/are required to provide the Faculty/Institute with a full copy of the complete set of originality report. Based on the above results, I declare that I am satisfied with the authenticity of the Final Year Project Report submitted by my student(s) as mentioned above.
Form Title: Supervisor's Comments on Originality Report Generated by Turnitin for Final Project Report Submission (for undergraduate programs).
Checklist
![Figure 2.3: MFCCs extraction algorithm. [8]](https://thumb-ap.123doks.com/thumbv2/azpdforg/10216244.0/22.892.193.684.388.527/figure-mfccs-extraction-algorithm.webp)